1. Introduction
Gunshot wounds (GSWs) can cause severe damage to bones, organs, and surrounding tissues, often leading to infections and long-term complications [
1,
2]. The magnitude of tissue damage during bullet impacts depends on multiple elements including bullet speed and dimensions as well as bullet shape, the distance the bullet travels, and tissue vulnerability. The size of a wound caused by an embedded bullet may be smaller, larger, or equal to the actual size of the bullet. However, when X-ray imaging is used, magnification can sometimes distort the apparent size of the bullet, making accurate estimation of its caliber challenging. There are two common methods to estimate bullet caliber using X-rays. The first involves capturing two radiographs at 90-degree angles to obtain a clearer perspective. The second approach uses a micrometer device to compare the shadow of a bullet in X-ray with actual bullets of known calibers. However, the first technique is rarely practiced in clinical settings. In summary, accurately measuring a bullet’s caliber via X-ray remains largely an estimation process [
3,
4,
5].
Why X-rays Instead of Other Imaging Techniques? Various imaging techniques are available to visualize injuries caused by gunshots, including magnetic resonance imaging (MRI). However, due to the metallic nature of bullets, MRI scans pose safety risks and are generally unsuitable. This is why X-ray technology remains the primary imaging modality for assessing gunshot wounds. Gunshot wounds are a significant cause of mortality worldwide. In 2016, approximately 161,000 deaths were attributed to firearm assaults [
6]. In 2017, the U.S. alone recorded 39,773 firearm-related deaths [
6]. Countries such as Mexico, Venezuela, Colombia, the United States, Brazil, and Guatemala account for nearly half of all firearm-related fatalities worldwide [
7].
Need for AI in Radiology: The Gap in Diagnosis The interpretation of radiographs, especially those involving gunshot injuries, requires highly trained radiologists. However, manual interpretation is time-consuming—an experienced radiologist may take up to 24 h to analyze and report on a single X-ray [
8]. In contrast, deep learning models, once fully trained, can process and interpret an X-ray in just a few seconds. This has the potential to reduce the workload of radiologists while improving diagnostic efficiency. Another major concern is the shortage of radiologists worldwide. In many regions, there are only a handful of radiologists serving millions of people [
9]. Given these challenges, there is an urgent need to develop automated diagnostic techniques to support radiologists and streamline the interpretation of medical images. Deep learning models have already been successfully applied in various medical imaging tasks, a topic that is further explored in the literature review section.
Proposed Study: Automating Gunshot Wound Detection in X-rays We aimed to develop an automated deep learning-based system for diagnosing gunshot wounds in X-rays. To the best of our knowledge, this is the first study that applies deep learning to X-ray images of gunshot wounds for automated classification and localization. One of the main challenges in pursuing this research is the lack of publicly available datasets containing X-rays of gunshot wounds. To address this issue, we manually created a replicated dataset using radiographs from the National Institutes of Health (NIH) [
10]. We extracted normal chest X-rays from various NIH datasets and used augmentation techniques to generate a larger dataset, incorporating actual gunshot wound X-rays. However, some images posed challenges due to their low contrast and poor visibility, making them difficult for deep learning models to train and evaluate. Testing the model on such ambiguous cases enables us to assess its ability to handle complex and uncertain conditions, which is crucial in surgical and emergency settings where diagnostic errors are unacceptable.
Extending the Study Beyond Chest X-rays: Although the deep learning model was primarily trained on chest X-ray images of gunshot wounds, it was also tested on other anatomical regions, including the leg, neck, and abdomen, using localization techniques. This evaluation provides insights into how gunshot wounds affect different organs and how well the model generalizes across various body parts. This study aimed not only to improve radiological diagnosis and efficiency but also to pave the way for further research in utilizing AI for forensic and trauma imaging.
Neck, Chest, and Abdomen
Gunshot wounds to the neck pose a serious threat due to the high concentration of vital anatomical structures in this region. A bullet lodged in the neck can lead to severe nerve damage, uncontrolled bleeding, and life-threatening complications [
11]. Patients who experience these specific gunshot wound injuries face complex medical conditions that include expanding hematomas together with airway obstruction, neurological disabilities, and wound bubbling from air leakage as well as excessive bleeding. Medical experts decide to perform immediate surgical procedures on devastating cases to protect patients while avoiding additional harms [
12].
The combination of chest gunshot wounds creates the risk of hemothorax, pericardial tamponade, and nervous system damage, according to [
13,
14]. The placement of the heart and lungs in this area makes tiny bullet impacts carry fatal risks to the victim’s life. Surgical intervention remains necessary for chest gunshot wound patients when active bleeding fails to stop or when patients continue exposing air within the body, consequently risking their clinical state deterioration [
15].
When an individual suffers an abdominal gunshot injury, the kidneys along with the stomach, liver, pancreas, and diaphragm become endangered vital abdominal organs. The effect of abdominal gunshot injuries also generates severe bleeding, organ damage, neurological complications, and respiratory complications. Medical professionals need to diagnose and treat these complex injuries without delay because such actions are vital to ensuring patient survival.
How the Proposed Model Helps in Gunshot Wound Detection Our proposed deep learning model is designed to automatically detect and localize gunshot wounds in different regions of the body, including the chest, neck, and abdomen. By employing binary classification and object localization techniques (bounding boxes), the model can identify the presence of bullets in X-ray images with high accuracy. This technology has the potential to assist radiologists and trauma surgeons in rapidly assessing the extent of injury, reducing diagnostic time, and improving patient outcomes.
To evaluate the effectiveness of our approach, we tested the model on various real-world and augmented datasets, using multiple deep learning frameworks and tools. The results demonstrated the feasibility of AI-driven automated detection, which can significantly aid in clinical decision-making and emergency medical response.
2. Background
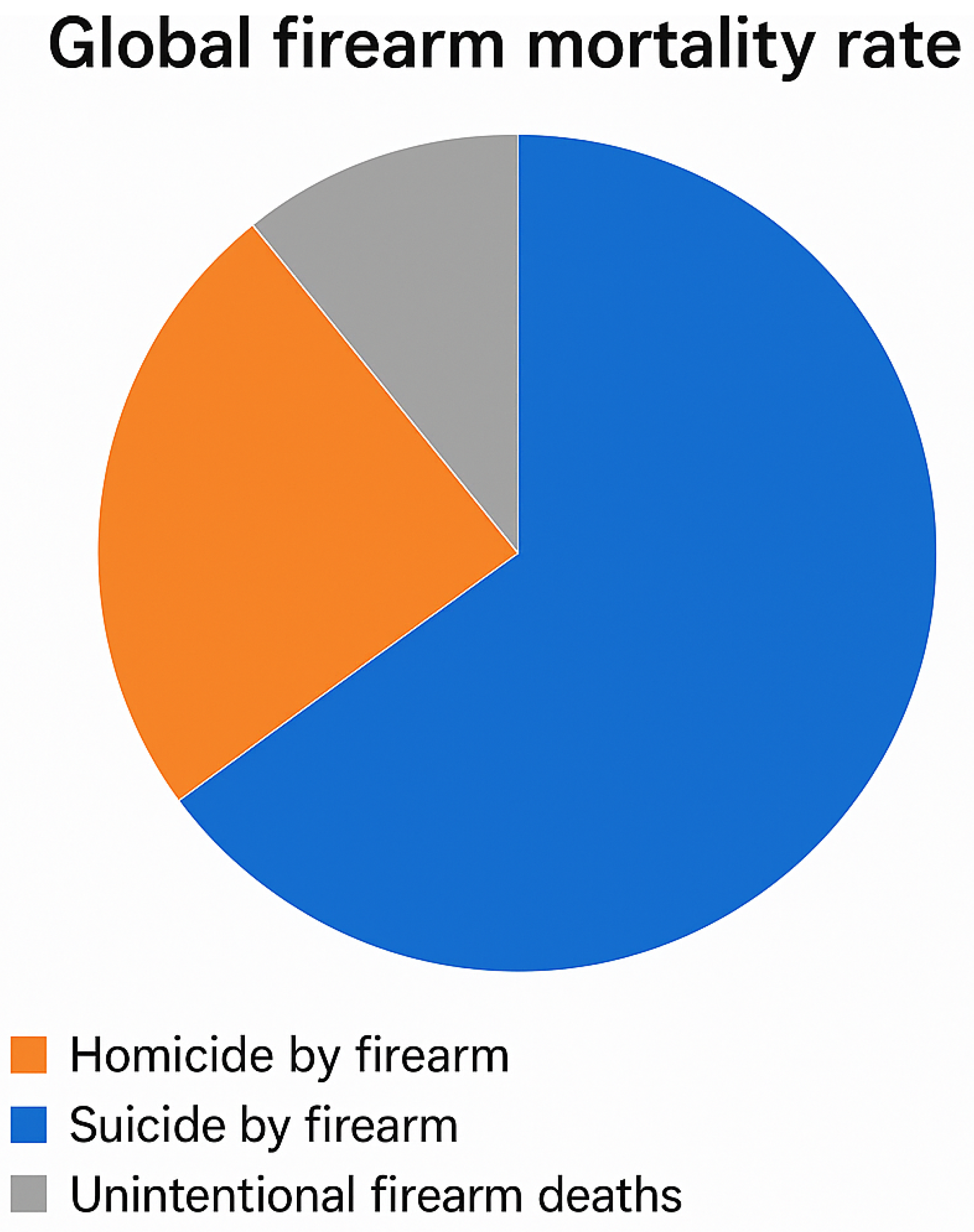
Gun violence remains a significant global concern, with nearly 1 million gunshot wounds reported worldwide in 2015 due to interpersonal violence [
16]. By 2016, firearms were responsible for 251,000 deaths globally, marking an increase from 209,000 deaths in 1990 [
7]. Among these fatalities, 64% (161,000 deaths) resulted from homicides, 27% (67,500 deaths) from suicides, and 9% (23,000 deaths) from accidental shootings [
7]. As shown in
Figure 1, homicides accounted for the majority of firearm-related deaths, followed by suicides and accidents.
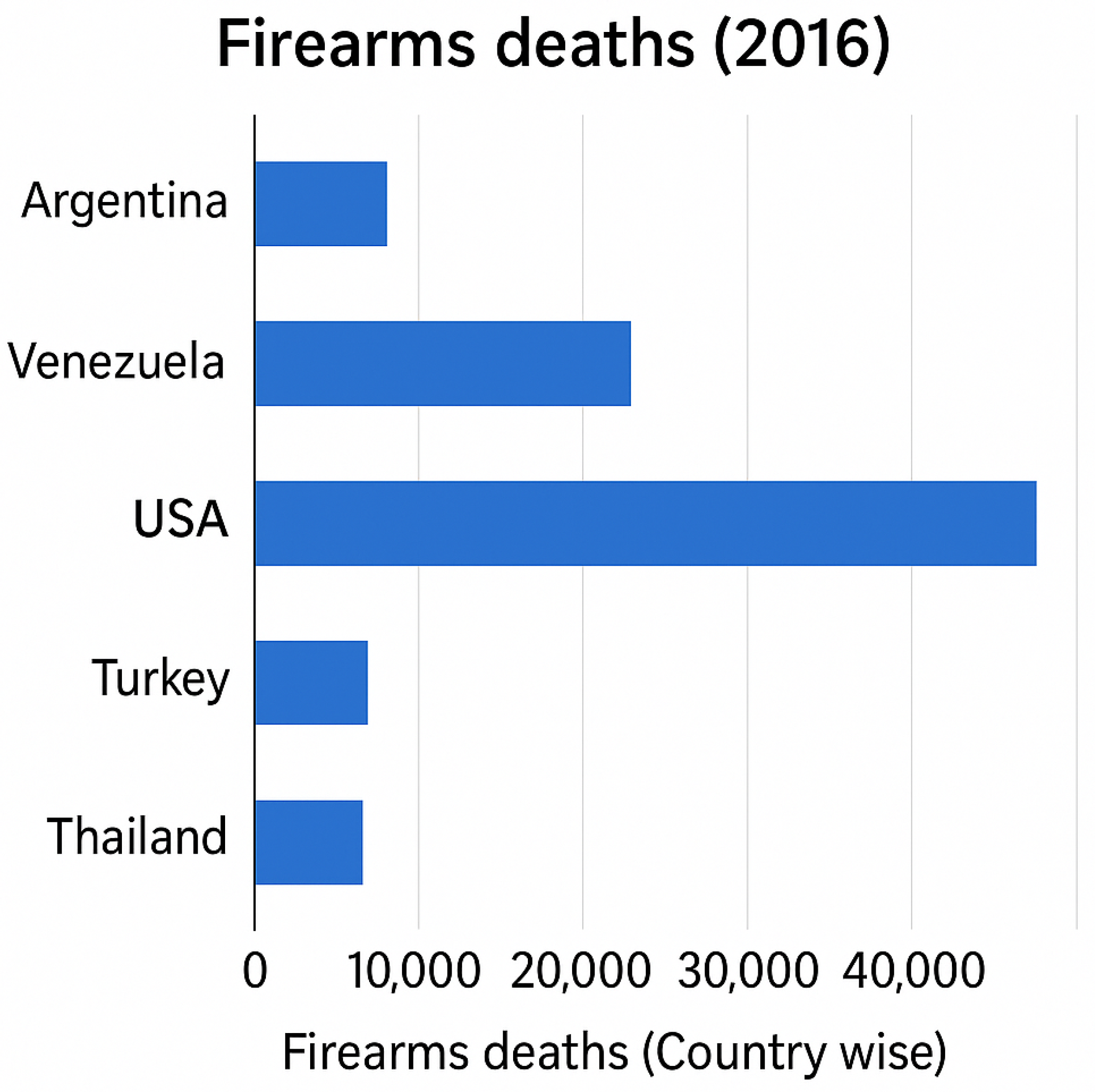
Figure 2 highlights firearm mortality rates by country, with the United States among the most affected nations, recording approximately 37,200 firearm-related deaths in 2016, one of the highest globally. Studies have also indicated that gun-related fatalities are significantly more common among men than women. In Pakistan, firearm-related deaths in 2016 were recorded at 2780, further underscoring the global impact of gun violence. These alarming statistics emphasize the urgent need for better gun control policies, enhanced trauma care, and rapid diagnostic solutions to mitigate firearm-related injuries and fatalities.
Integrating deep learning with medical imaging can significantly improve the diagnosis and treatment of gunshot wounds, potentially reducing fatalities through faster and more efficient care. In developing countries, the shortage of experienced radiologists makes accurate and timely diagnosis challenging, often delaying critical treatment. By implementing an automated system that can detect bullet-affected radiographs and accurately locate a bullet’s position, medical professionals can streamline the treatment process, reducing reliance on radiologists for initial diagnosis. This approach not only enhances efficiency in emergency care but also ensures that patients receive prompt and precise treatment, even in resource-limited healthcare settings.
3. Research Methodology
The proposed methodology consists of two key components: classification and object localization. Unlike conventional classification models, our approach not only categorizes chest X-rays but also processes them through object localization models to pinpoint the exact position of bullet wounds. The dataset used in this study was derived from the NIH ChestX-ray8 repository, which contains over 100,000 chest X-ray images from more than 30,000 patients [
10,
17].
To create a dataset specific to gunshot wounds, we extracted normal chest X-rays from the NIH database and supplemented them with actual radiographs of bullet-affected cases. We generated extra gunshot-affected X-ray images through repetition techniques because existing public gunshot wound radiograph datasets remain limited in number. Precise bullet localization served as the main objective because medical imaging requires accurate systems due to potentially severe consequences stemming from errors made by humans or machines. One hundred images were duplicated for model usage. We distributed the information into training segments that accounted for 80% of the data validation segments, composed of 10%, and testing segments that consisted of 10%. The real bullet-wound radiographs made up all examples in the test set, as the model needed to prove its worth in real-world emergency room situations. Such an organized testing method enables comprehensive model evaluation so doctors can use it reliably in clinical practice.
3.1. Classification
We applied a deep convolutional neural network (CNN) [
18] for image classification because it stands as a leading model in deep learning for medical imaging. Over the past several years, ConvNets, called CNNs, have become specialized neural networks dedicated to image processing and have produced remarkable results in numerous machine learning operations. The CNN architecture was our selection because it comes from the Visual Geometry Group at Oxford University [
19].
3.1.1. Data Preprocessing and Augmentation
The preprocessing stage of images with multiple augmentation approaches, including resizing, rescaling, shear transformation, zooming, and horizontal flipping, occurred before entering the dataset into the model. The size of our dataset was expanded by image augmentation, which enhanced model accuracy because deep learning models achieve higher accuracy with larger datasets.
3.1.2. Feature Extraction and Model Processing
Feature extraction is an essential step in deep learning-based image analysis. Instead of manually extracting patterns, CNNs automatically learn and detect key features from the dataset. This is achieved using filters (convolutional layers) that scan the images to identify important spatial information. Filters in the early layers detect simple patterns like edges, while deeper layers capture more complex structural details.
During processing, not all extracted features move forward for classification. Some are filtered out based on threshold values in the activation function. The pooling process, specifically max pooling and average pooling, helps reduce the dimensionality of image data, retaining only the most significant information.
At the final stage, dense layers (fully connected layers) refine the learned features. The model includes Global Average Pooling 2D and dropout regularization to prevent overfitting. Activation functions such as sigmoid (for binary classification) and softmax (for multi-class classification) were applied to ensure appropriate categorization.
3.1.3. Training and Optimization
To optimize model performance, we used binary cross-entropy loss for binary classification tasks and categorical cross-entropy loss for multi-class classification. The model was trained using backpropagation, where errors were computed, and weights were adjusted iteratively to improve accuracy. The stochastic gradient descent (SGD) optimizer was applied with a learning rate of 0.0001 and a momentum of 0.9, ensuring a balanced and stable training process.
3.1.4. Fine-Tuning Technique: Freeze, Pre-Train, and Fine-Tune
Our study employed the Freeze, Pre-train, and Fine-tune technique, which is particularly useful for training models on small datasets. In this approach,
The last layer of the pre-trained model is replaced with a mini-network consisting of two fully connected layers.
All pre-trained layers are frozen, and only newly added layers are trained on the dataset.
After initial training, the network’s weights are saved.
Fine-tuning is then performed using these saved weights, allowing the model to adjust and optimize for the specific dataset.
This method significantly improves accuracy, especially when working with limited datasets, as demonstrated by the results in
Figure 3.
3.2. Understanding of Object Localization
Object detection has seen significant advancements in recent years [
20,
21,
22,
23]. One key distinction between object detection and object localization is that object localization focuses on identifying a single class, while object detection involves recognizing multiple classes within an image. Since our study specifically deals with locating bullets in X-rays, we use the term object localization rather than object detection.
In image classification, a convolutional neural network (CNN) produces an output vector containing the most prominent features for all classes. However, in object localization, the model not only identifies the object but also determines its precise position. The most significant object features are used to create bounding boxes, which can either be limited to one per image or expanded to include multiple object categories. The challenge in object localization is ensuring the model accurately detects both the object’s shape and location, as these two factors are interdependent.
Bounding boxes are defined by their corner coordinates, which makes them easier to process than complex polygonal shapes. Using rectangular bounding boxes is computationally efficient, particularly for operations like convolution, which perform better with structured shapes. However, within these bounding boxes, there may be additional image regions that require classification. The model then applies machine learning algorithms to determine the correct object category within the bounding box [
20].
Unlike traditional image classification, object localization requires labeled datasets, where each object in an image is enclosed within a bounding box. To achieve this, we used LabelImg [
24], an open-source annotation tool written in Python. LabelImg allows annotations in VOC XML and YOLO formats, both commonly used in object detection tasks. In our study, we labeled training and validation datasets using the Pascal VOC XML format, which stores essential information such as image location, dimensions, object labels, and pixel coordinates of bounding boxes.
Comparing Object Localization Models: Faster R-CNN vs. SSD
We evaluated our dataset using two leading object localization models: Faster R-CNN and Single Shot MultiBox Detector (SSD). Each model has distinct characteristics and trade-offs.
Faster R-CNN: Faster R-CNN [
21] builds upon the Fast R-CNN framework by introducing a Region Proposal Network (RPN). This enhancement allows the model to automatically propose candidate regions from the extracted feature maps using a two-dimensional CNN. Instead of using external region proposal algorithms, Faster R-CNN integrates the region proposal process within the neural network, making it an end-to-end solution. This method significantly improves accuracy, but at the cost of longer execution times due to its complex architecture. The core idea of Faster R-CNN is to use convolutional layers to generate region proposals and detect objects simultaneously. The Region Proposal Network (RPN) is responsible for assigning feature maps to proposed regions, enabling efficient object localization.
SSD (Single Shot MultiBox Detector): In contrast to Faster R-CNN, SSD (Single Shot MultiBox Detector) [
22] follows a more streamlined approach. Instead of generating region proposals, SSD directly detects objects in a single forward pass of the convolutional network. Unlike segmentation-based methods, SSD does not rely on dividing images into multiple regions—it focuses on object detection in real time.
To compensate for the loss of precision that can occur due to the absence of region proposals, SSD introduces several enhancements, including default boxes and multi-scale feature maps. It processes feature maps from multiple convolutional layers, incorporating both large and small feature maps to handle objects at different scales.
SSD operates somewhat like a sliding window, beginning with a set of default bounding boxes that vary in aspect ratio and scale. The final prediction is made by applying offset adjustments to these default boxes. Elementary adjustments are made to bounding boxes, after which the model creates additional improvements to boost accuracy levels. Physical verification of default boundary boxes takes place to confirm accurate prediction placement. The unique scale values required by SSD apply to every feature map layer, while six predictive layers begin with aspect ratios that include 1, 2, 3, 1/2, and 1/3. The computation of the default box width and height starts from predefined values, which provide the following computations:
An extra default box added by SSD with scale
The Faster R-CNN model provides better precision while needing extended computation time, which works well for operations that need accurate detection over quick execution. SSD delivers quicker performance than Faster R-CNN but produces less consistent results, especially when identifying small items; thus, it proves ideal for systems that need real-time detection operations. The particular requirements of tasks determine which model, between Faster R-CNN and SSD, provides better advantages. Our research evaluates their bullet localization abilities within chest X-rays for identifying the most suitable solution for medical imaging tasks. Enhancements at the second level enable SSD to deliver Faster R-CNN-like performance on images with reduced resolution dimensions. The performance optimization in SSDs speeds up processing, which makes the storage device ideal for real-time procedures.
Unlike most object detection systems that use sliding windows to check the whole image, SSD makes this unnecessary by using a different approach. Instead, SSD sets default bounding boxes at every feature map location, and each box comes in multiple aspect ratios and scales. These set boxes support the network in spotting objects and in correcting bounding boxes at any scale. Owing to this approach, detection is much faster and does not lose accuracy on objects in various parts of the image.
4. Results and Discussion
4.1. Training and Prediction Analysis
We utilized the TensorFlow GPU library along with Google Colab’s GPU services to accelerate model execution for training purposes. We began by cloning the TensorFlow repository [
25] and installing all necessary dependencies, including those required for the COCO dataset. Next, we downloaded our dataset from Google Drive and converted all .XML annotation files into a .CSV format, which was then transformed into a TFRecord file. TFRecord, a binary format, allows the model to process data more efficiently, reducing memory usage and improving execution speed. This dataset contained both image data and corresponding labels, specifically designed for training object localization models.
Three different models required pre-trained architectures available at the TensorFlow Object Detection repository for model development. Our models underwent training and checkpoint saving before we applied them to various unseen X-ray pictures containing chest radiographs as well as X-rays of the leg, head, and abdomen. The examination used mean average precision () and average recall to evaluate how well the models detected bullet localization in their target area. This report includes performance results followed by a detailed evaluation of model performance.
The evaluation process deployed TensorBoard as a visualization tool, which monitored essential metrics from the start to the end of the training. The tool served as an essential performance evaluation platform to examine the extent to which stored weights boosted the localization precision. Increasing accuracy in this model will become possible through the optimization of hyperparameter settings, as well as training optimization and enhanced data augmentation techniques.
4.2. Mean Average Precision
The mean average precision (
) calculation extends average precision (
) through averaging scores across object classes. The common measurement used to evaluate object localization models shows their accuracy performance through a comprehensive assessment. The detection capability of a model increases when its mAP score improves because it demonstrates superior precision at finding and identifying objects in visual content.
4.3. Recall
The detection accuracy of actual image objects is measured using the recall evaluation method, which is equivalent to both sensitivity and the true positive (
) rate. The accuracy of the ground truth object detection by the model is reflected in this statistical value.
Average recall 1 determines the mean recall metric from all images by counting only detections of zero or one object per image. This scoring measurement enables model effectiveness assessments in cases where the detection of a single object should occur within each image.
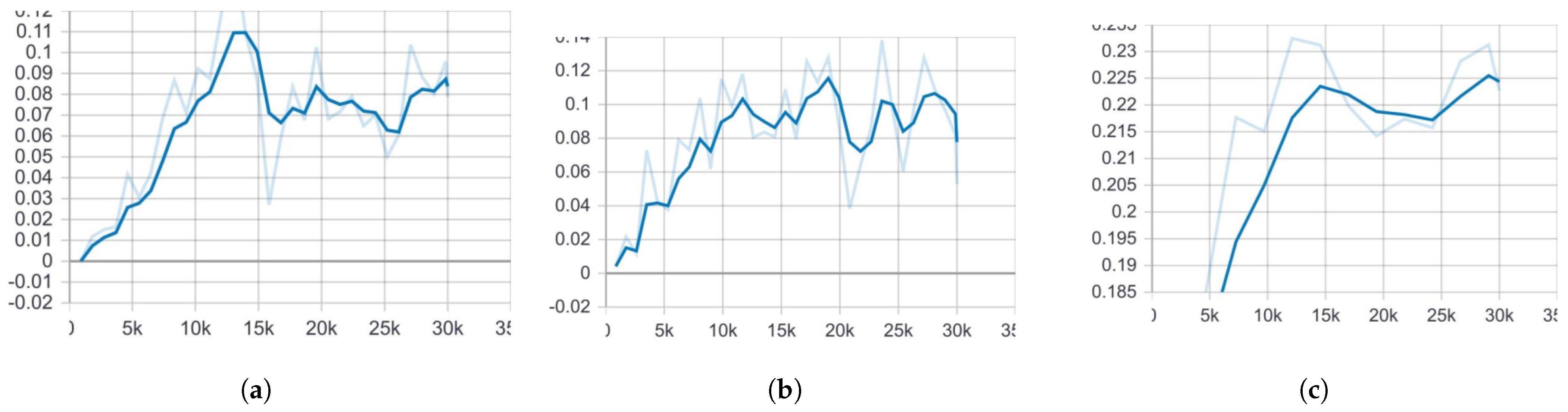
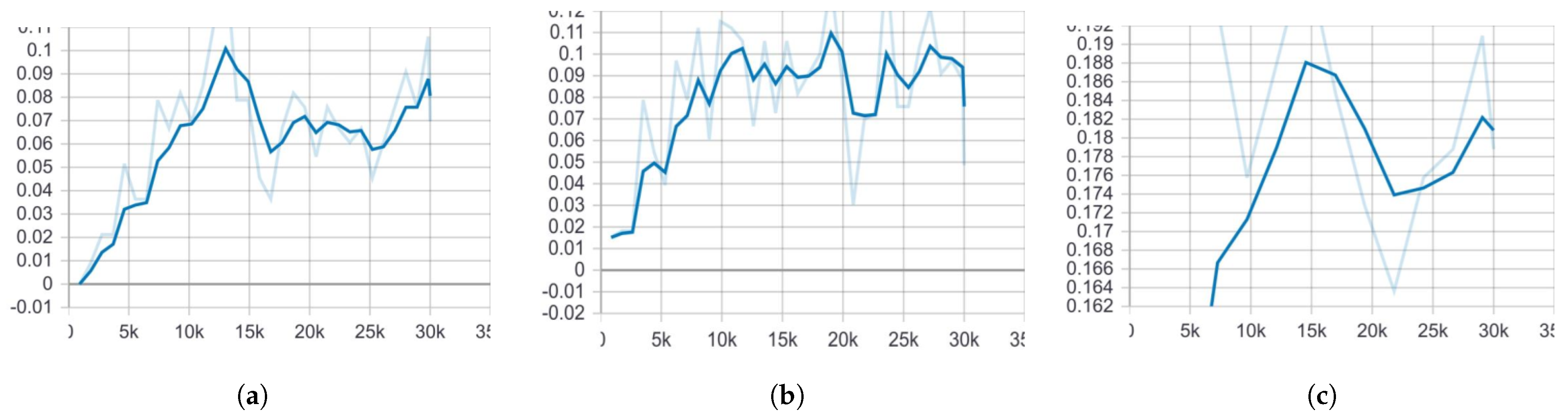
In
Figure 4, the mean average precision (
) of Faster R-CNN is noticeably higher than that of both SSD models. One key reason for this, as previously discussed, is that Faster R-CNN is more effective at detecting small objects compared to SSD. This advantage comes from its Region Proposal Network (RPN), which allows it to identify and localize smaller objects with greater accuracy.
The
values displayed in the graphs represent the final execution results of each model, ensuring a fair comparison. Similarly, in
Figure 5, the average recall of Faster R-CNN ResNet101 COCO surpasses that of the SSD models. This further demonstrates the superior detection capabilities of Faster R-CNN, particularly when dealing with small and complex objects, such as bullets in medical X-ray images.
The evaluation of three object localization models—Faster R-CNN ResNet101 COCO, SSD MobileNet V1 COCO, and SSD MobileNet V2 COCO—was conducted using a dataset of 30,000 training images and 10,000 evaluation images. Faster R-CNN ResNet101 COCO provided optimal performance based on the results, which reached 0.22 (22%) mAP and 0.18 (18%)
. The
of SSD MobileNet V1 COCO reached 0.09 (9%), while its
was 0.08 (8%), and SSD MobileNet V2 COCO performed with 0.08 (8%)
and
0.08 (8%), while the comparison of
and
is presented in
Table 1. The research demonstrates that Faster R-CNN ResNet101 COCO achieves better detection accuracy and recall than all SSD-based methods, thus making it the preferred solution for object localization in this study.
During the performance evaluation phase, we analyzed multiple object detection models to identify their behavior in different performance measurement systems. Multiple detection models used the COCO (Common Objects in Context) dataset [
26] for their pre-training purposes since this dataset serves as an industry standard for object detection, along with segmentation and image captioning tasks. As one of the most extensive benchmark datasets, COCO consists of 200,000 images accompanied by 80 object types, which establishes it as a standardized evaluation method for detection models.
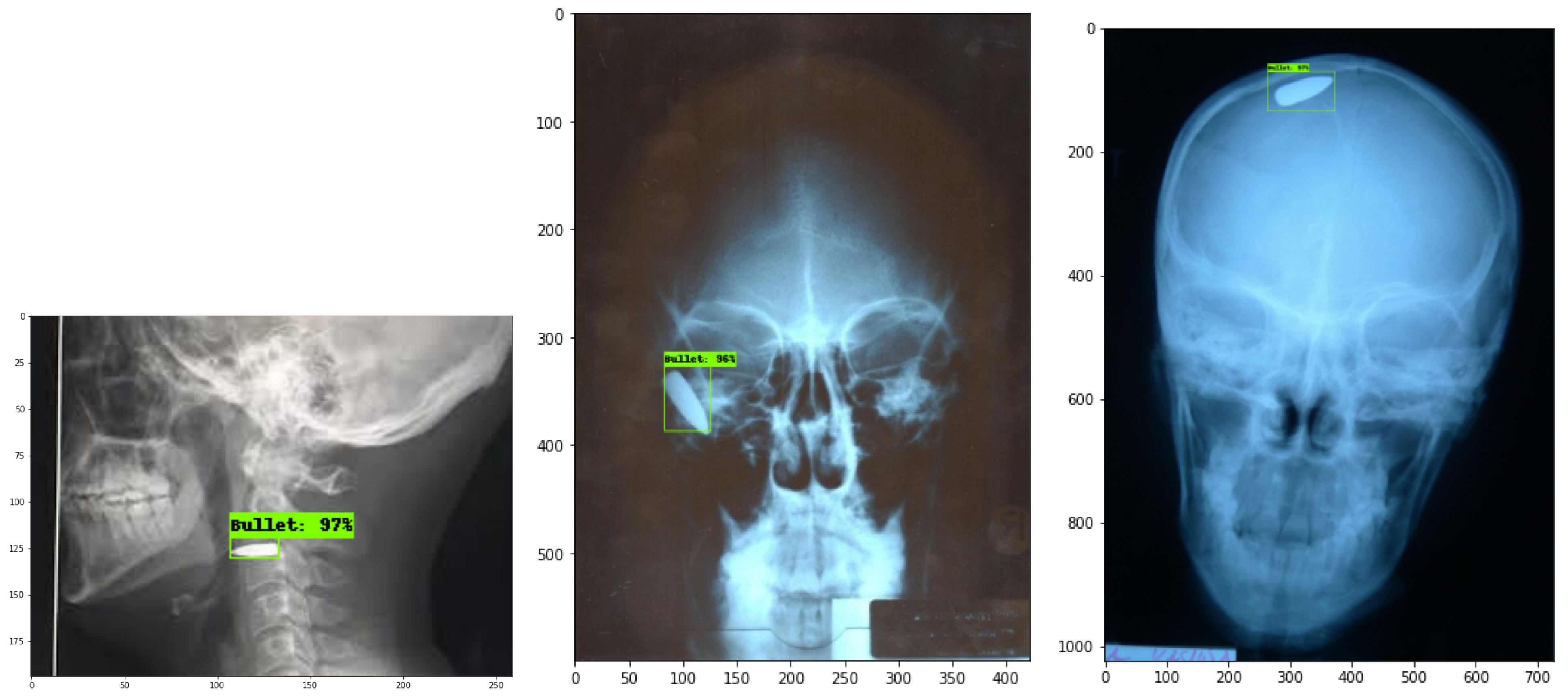
The evaluation included the testing of each model throughout chest X-ray examinations and gunshot wound (GSW) radiographs of the head, neck, leg, and abdomen region, according to
Figure 6,
Figure 7 and
Figure 8. It is important to highlight that all results are based on actual radiographs rather than synthetic or augmented data. Performance improvements can be achieved by fine-tuning hyperparameters and increasing the number of training steps per model. For evaluation, we used the Intersection over Union (IoU) metric, setting a threshold value of 50. The model will produce a bounding box only when the predicted shape overlaps with the ground truth shape by at least 50% within their boundaries.
Users adjust parameters through the pipeline configuration file, while the class labels exist in the labelmap.txt file. Small object recognition stands as a major obstacle for modern object detection software, producing mAP results that prove moderately low. The detection accuracy needs additional optimization methods to enhance detection results, particularly when dealing with small, complex medical imaging objects.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}