


Who Is to Blame for the Bias in Visualizations, ChatGPT or DALL-E?


Abstract
1. Introduction
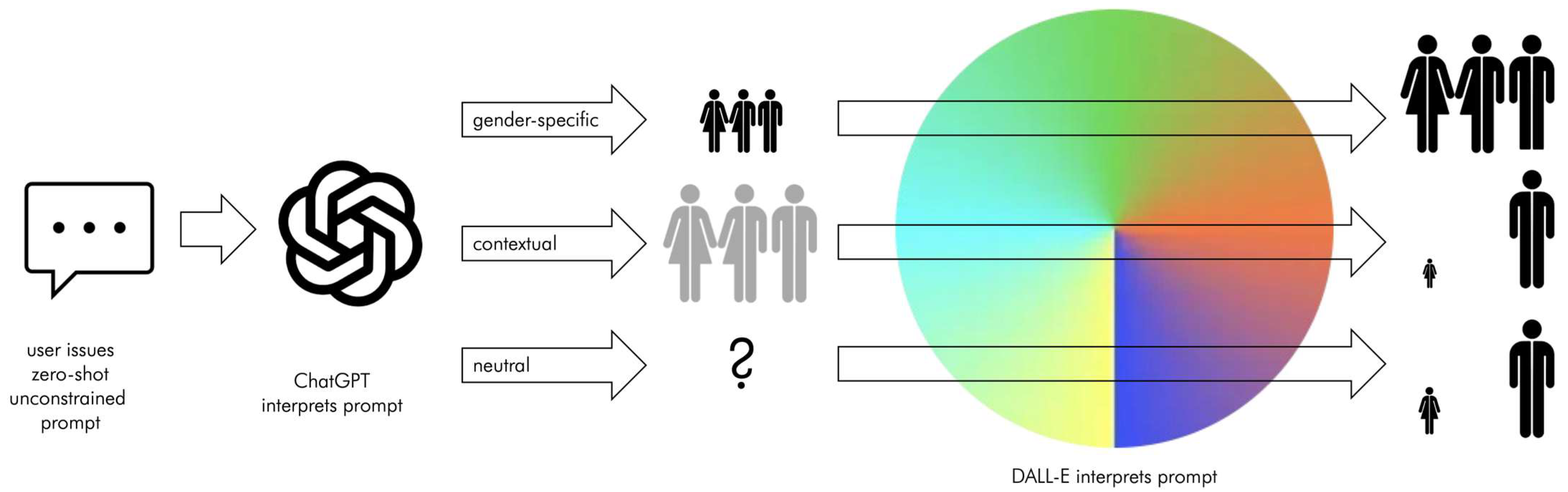
2. Methodology
2.1. The Data
“Think about [type of library] and the librarians working in these. Provide me with a visualization that shows a typical librarian against the background of the interior of the library.”
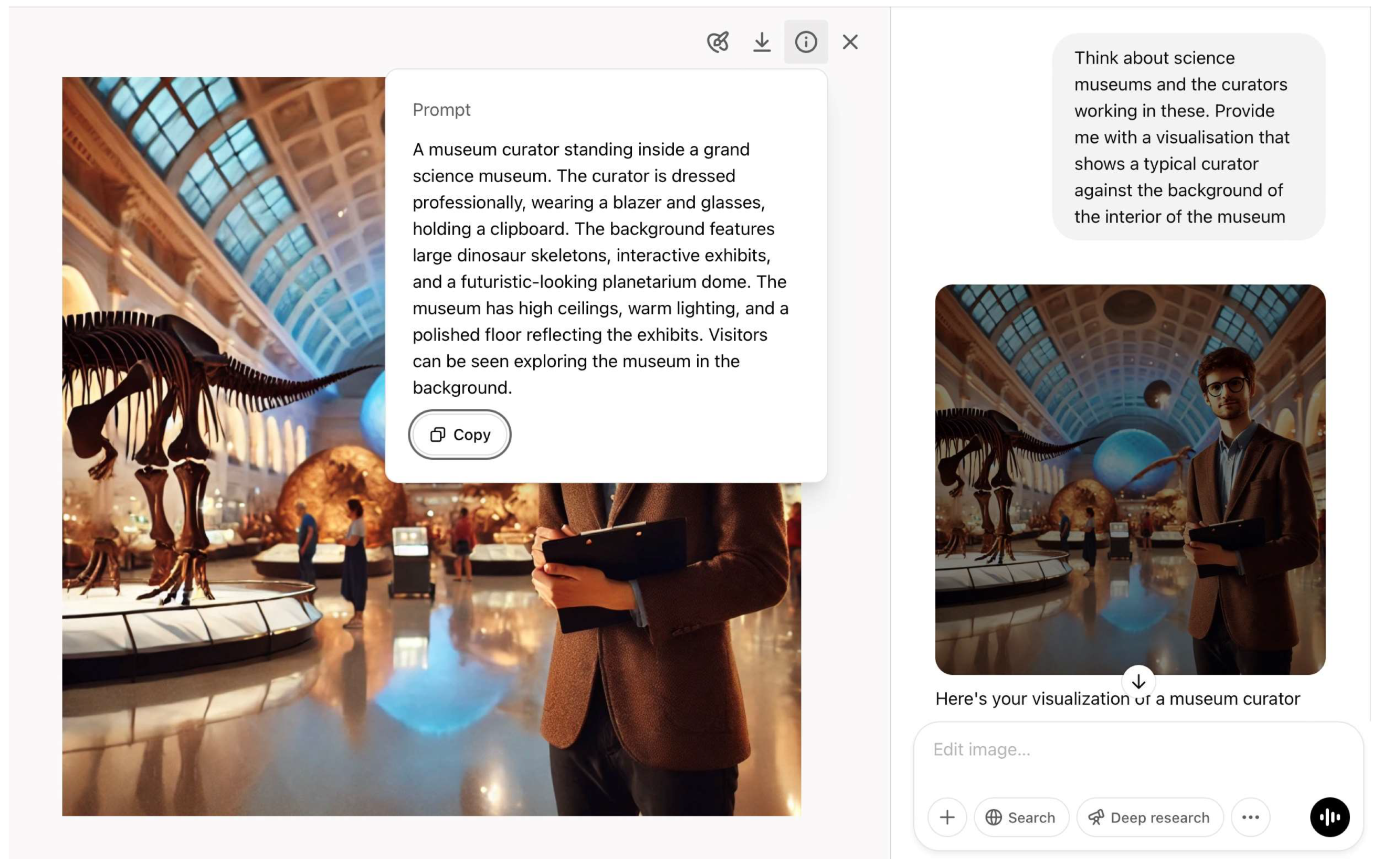
“Think about [type of museum] and the curators working in these. Provide me with a visualization that shows a typical curator against the background of the interior of the museum.”
2.2. Data Transparency
2.3. Scoring
2.4. Statistics
2.5. Limitations
3. Results
3.1. Gender

{kind=link}
{kind=link}
{kind=link}
| Apparent Gender as Rendered | ||||
|---|---|---|---|---|
| Female | Male | Total | ||
| gender specified | female | 37 | 3 | 40 |
| male or female | 24 | 28 | 52 | |
| male | 2 | 37 | 39 | |
| gender inferred via context | male (tailored suit) | 7 | 7 | |
| possibly male (blazer) | 5 | 99 | 104 | |
| dual gender (cardigan etc.) | 15 | 11 | 26 | |
| no gender prescription | 104 | 308 | 412 | |
| Total | 187 | 493 | 680 | |

3.2. Age
3.3. Ethnicity
3.4. Glasses
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Snyder, M. On the self-perpetuating nature of social stereotypes. In Cognitive Processes in Stereotyping and Intergroup Behavior; Psychology Press: London, UK, 2015; pp. 183–212. [Google Scholar]
- Shih, M.; Bonam, C.; Sanchez, D.; Peck, C. The social construction of race: Biracial identity and vulnerability to stereotypes. Cult. Divers. Ethn. Minor. Psychol. 2007, 13, 125. [Google Scholar] [CrossRef] [PubMed]
- Greenwald, A.G.; Banaji, M.R.; Rudman, L.A.; Farnham, S.D.; Nosek, B.A.; Mellott, D.S. A unified theory of implicit attitudes, stereotypes, self-esteem, and self-concept. Psychol. Rev. 2002, 109, 3. [Google Scholar] [CrossRef] [PubMed]
- Heilman, M.E. Gender stereotypes and workplace bias. Res. Organ. Behav. 2012, 32, 113–135. [Google Scholar]
- Ellemers, N. Gender stereotypes. Annu. Rev. Psychol. 2018, 69, 275–298. [Google Scholar] [CrossRef] [PubMed]
- Spennemann, D.H.R. Non-responsiveness of DALL-E to exclusion prompts suggests underlying bias towards Bitcoin. SSRN Prepr. 2025. [Google Scholar]
- Choudhary, T. Political Bias in AI-Language Models: A Comparative Analysis of ChatGPT-4,Perplexity, Google Gemini, and Claude. IEEE Access 2025, 13, 11341–11365. [Google Scholar] [CrossRef]
- Spennemann, D.H.R. The origins and veracity of references ‘cited’ by generative artificial intelligence applications. Publications 2025, 13, 12. [Google Scholar] [CrossRef]
- Tao, Y.; Viberg, O.; Baker, R.S.; Kizilcec, R.F. Cultural bias and cultural alignment of large language models. PNAS Nexus 2024, 3, 346. [Google Scholar] [CrossRef]
- Kaplan, D.M.; Palitsky, R.; Arconada Alvarez, S.J.; Pozzo, N.S.; Greenleaf, M.N.; Atkinson, C.A.; Lam, W.A. What’s in a name? Experimental evidence of gender bias in recommendation letters generated by ChatGPT. J. Med. Internet Res. 2024, 26, e51837. [Google Scholar] [CrossRef]
- Duan, W.; McNeese, N.; Li, L. Gender Stereotypes toward Non-gendered Generative AI: The Role of Gendered Expertise and Gendered Linguistic Cues. Proc. ACM Hum.-Comput. Interact. 2025, 9, 1–35. [Google Scholar]
- Gillespie, T. Generative AI and the politics of visibility. Big Data Soc. 2024, 11, 20539517241252131. [Google Scholar] [CrossRef]
- Gross, N. What ChatGPT tells us about gender: A cautionary tale about performativity and gender biases in AI. Soc. Sci. 2023, 12, 435. [Google Scholar] [CrossRef]
- Desai, P.; Wang, H.; Davis, L.; Ullmann, T.M.; DiBrito, S.R. Bias Perpetuates Bias: ChatGPT Learns Gender Inequities in Academic Surgery Promotions. J. Surg. Educ. 2024, 81, 1553–1557. [Google Scholar] [CrossRef] [PubMed]
- Farlow, J.L.; Abouyared, M.; Rettig, E.M.; Kejner, A.; Patel, R.; Edwards, H.A. Gender Bias in Artificial Intelligence-Written Letters of Reference. Otolaryngol.-Head Neck Surg. 2024, 171, 1027–1032. [Google Scholar] [CrossRef]
- Urchs, S.; Thurner, V.; Aßenmacher, M.; Heumann, C.; Thiemichen, S. How Prevalent is Gender Bias in ChatGPT?—Exploring German and English ChatGPT Responses. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Turin, Italy, 18–22 September 2023; pp. 293–309. [Google Scholar]
- Melero Lázaro, M.; García Ull, F.J. Gender stereotypes in AI-generated images. El Prof. De La Inf. 2023, 32, e320505. [Google Scholar] [CrossRef]
- Saumure, R.; De Freitas, J.; Puntoni, S. Humor as a window into generative AI bias. Sci. Rep. 2025, 15, 1326. [Google Scholar] [CrossRef]
- Hacker, P.; Mittelstadt, B.; Borgesius, F.Z.; Wachter, S. Generative discrimination: What happens when generative AI exhibits bias, and what can be done about it. arXiv 2024, arXiv:2407.10329. [Google Scholar]
- Spennemann, D.H.R.; Oddone, K. What Do Librarians Look Like? Stereotyping of a Profession by Generative Ai. J. Librariansh. Inf. Sci. Subm. 2025; (under review). [Google Scholar]
- Spennemann, D.H.R. Draw Me a Curator: Stereotyping of a Profession by Generative Ai. Curator Mus. J. Subm. (under review).
- Abdulwadood, I.; Mehta, M.; Carrion, K.; Miao, X.; Rai, P.; Kumar, S.; Lazar, S.; Patel, H.; Gangopadhyay, N.; Chen, W. AI Text-to-Image Generators and the Lack of Diversity in Hand Surgeon Demographic Representation. Plast. Reconstr. Surg.–Glob. Open 2024, 12, 4–5. [Google Scholar] [CrossRef]
- Currie, G.; Chandra, C.; Kiat, H. Gender Bias in Text-to-Image Generative Artificial Intelligence When Representing Cardiologists. Information 2024, 15, 594. [Google Scholar] [CrossRef]
- Currie, G.; John, G.; Hewis, J. Gender and ethnicity bias in generative artificial intelligence text-to-image depiction of pharmacists. Int. J. Pharm. Pract. 2024, 32, 524–531. [Google Scholar] [CrossRef]
- Morcos, M.; Duggan, J.; Young, J.; Lipa, S.A. Artificial Intelligence Portrayals in Orthopaedic Surgery: An Analysis of Gender and Racial Diversity Using Text-to-Image Generators. J. Bone Jt. Surg. 2024, 106, 2278–2285. [Google Scholar] [CrossRef] [PubMed]
- Ali, R.; Tang, O.Y.; Connolly, I.D.; Abdulrazeq, H.F.; Mirza, F.N.; Lim, R.K.; Johnston, B.R.; Groff, M.W.; Williamson, T.; Svokos, K. Demographic representation in 3 leading artificial intelligence text-to-image generators. JAMA Surg. 2024, 159, 87–95. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.W.; Morcos, M.; Lee, D.W.; Young, J. Demographic representation of generative artificial intelligence images of physicians. JAMA Netw. Open 2024, 7, e2425993. [Google Scholar] [CrossRef] [PubMed]
- Gisselbaek, M.; Suppan, M.; Minsart, L.; Köselerli, E.; Nainan Myatra, S.; Matot, I.; Barreto Chang, O.L.; Saxena, S.; Berger-Estilita, J. Representation of intensivists’ race/ethnicity, sex, and age by artificial intelligence: A cross-sectional study of two text-to-image models. Crit. Care 2024, 28, 363. [Google Scholar] [CrossRef]
- Zhou, M.; Abhishek, V.; Derdenger, T.; Kim, J.; Srinivasan, K. Bias in generative AI. arXiv 2024, arXiv:2403.02726. [Google Scholar]
- York, E.J.; Brumberger, E.; Harris, L.V.A. Prompting Bias: Assessing representation and accuracy in AI-generated images. In Proceedings of the 42nd ACM International Conference on Design of Communication, Fairfax, VA, USA, 20–22 October 2024; pp. 106–115. [Google Scholar]
- Sandoval-Martin, T.; Martínez-Sanzo, E. Perpetuation of Gender Bias in Visual Representation of Professions in the Generative AI Tools DALL·E and Bing Image Creator. Soc. Sci. 2024, 13, 250. [Google Scholar] [CrossRef]
- Wiegand, T.; Jung, L.; Schuhmacher, L.; Gudera, J.; Moehrle, P.; Rischewski, J.; Velezmoro, L.; Kruk, L.; Dimitriadis, K.; Koerte, I. Demographic Inaccuracies and Biases in the Depiction of Patients by Artificial Intelligence Text-to-Image Generators. Preprints 2024. [Google Scholar] [CrossRef]
- Hosseini, D.D. Generative AI: A problematic illustration of the intersections of racialized gender, race, ethnicity. OSF Prepr. 2024. [Google Scholar] [CrossRef]
- Amin, K.S.; Forman, H.P.; Davis, M.A. Even with ChatGPT, race matters. Clin. Imaging 2024, 109, 110113. [Google Scholar] [CrossRef]
- Hofmann, V.; Kalluri, P.R.; Jurafsky, D.; King, S. Dialect prejudice predicts AI decisions about people’s character, employability, and criminality. arXiv 2024, arXiv:2403.00742. [Google Scholar] [CrossRef]
- Lio, P.; Ahuja, K. Beautiful Bias from ChatGPT. J. Clin. Aesthetic Dermatol. 2024, 17, 10. [Google Scholar]
- Spennemann, D.H.R. Two Hundred Women Working in Cultural and Creative Industries: A Structured Data Set of Generative Ai-Created Images; School of Agricultural, Environmental and Veterinary Sciences, Charles Sturt University: Albury, NSW, Australia, 2025. [Google Scholar] [CrossRef]
- Spennemann, D.H.R. Children of AI: A protocol for managing the born-digital ephemera spawned by Generative AI Language Models. Publications 2023, 11, 45. [Google Scholar] [CrossRef]
- Spennemann, D.H.R.; Oddone, K. What Do Librarians Look Like? Stereotyping of a Profession by Generative Ai—Supplementary Data; School of Agricultural, Environmental and Veterinary Sciences, Charles Sturt University: Albury NSW, Australia, 2025. [Google Scholar] [CrossRef]
- Spennemann, D.H.R. What Do Curators Look Like? Stereotyping of a Profession by Generative Ai—Supplementary Data; School of Agricultural, Environmental and Veterinary Sciences, Charles Sturt University: Albury, NSW, Australia, 2025. [Google Scholar] [CrossRef]
- Moore, M.M.; Williams, G.I. No jacket required: Academic women and the problem of the blazer. Fash. Style Pop. Cult. 2014, 1, 359–376. [Google Scholar] [CrossRef] [PubMed]
- Kwantes, C.T.; Lin, I.Y.; Gidak, N.; Schmidt, K. The effect of attire on expected occupational outcomes for male employees. Psychol. Men Masculinity 2011, 12, 166. [Google Scholar] [CrossRef]
- Data USA Librarians. Available online: https://datausa.io/profile/soc/librarians (accessed on 12 March 2025).
- Western Australia. 6273.0 Employment in Culture, 2016; Cultural and Creative Statitics Working Group, Office for the Arts: Perth, WA, Australia, 2021. [Google Scholar]
- Reddington, M.; Kinetiq. A Study of the UK’s Information Workforce 2023; Kinetiq: New York, NY, USA, 2024. [Google Scholar]
- Statistics Canada. Table 98-10-0449-01 Occupation Unit Group by Labour Force Status, Highest Level of Education, Age and Gender: Canada, Provinces and Territories, Census Metropolitan Areas and Census Agglomerations with Parts. Available online: https://www150.statcan.gc.ca/t1/tbl1/en/tv.action?pid=9810044901 (accessed on 11 March 2025).
- Data USA Archivists, Curators, & Museum Technicians. Available online: https://datausa.io/profile/soc/archivists-curators-museum-technicians (accessed on 12 March 2025).
- Chan, J. Beyond tokenism: The importance of staff diversity in libraries. Br. Columbia Libr. Assoc. Perspect. 2020, 12. [Google Scholar]
- Luthmann, A. Librarians, professionalism and image: Stereotype and reality. Libr. Rev. 2007, 56, 773–780. [Google Scholar] [CrossRef]
- White, A. Not Your Ordinary Librarian: Debunking the Popular Perceptions of Librarians; Chandos Publishing: Oxford, UK, 2012. [Google Scholar]
- Robinson, L.T. Curmudgeons and dragons? A content analysis of the Australian print media’s portrayal of the information profession 2000 to 2004. Libr. Inf. Sci. Res. E-J. 2006, 16, 1–19. [Google Scholar] [CrossRef]
- Lawther, K. Who Are Museum Curators According To Pop Culture? AcidFree 2020, 2025. Available online: http://acidfreeblog.com/curation/who-are-museum-curators-according-to-pop-culture/ (accessed on 12 March 2025).
- Brundage, M.; Avin, S.; Wang, J.; Belfield, H.; Krueger, G.; Hadfield, G.; Khlaaf, H.; Yang, J.; Toner, H.; Fong, R.; et al. Toward Trustworthy AI Development: Mechanisms for Supporting Verifiable Claims. arXiv 2020, arXiv:2004.07213. [Google Scholar] [CrossRef]
- OpenAI. GPT-4o System Card; OpenAi: San Francisco, CA, USA, 2024. [Google Scholar]
- OpenAI. GPT-4 System Card; OpenAi: San Francisco, CA, USA, 2024. [Google Scholar]
- OpenAI. GPT-4V(ision) System Card; OpenAi: San Francisco, CA, USA, 2024. [Google Scholar]
- OpenAI. GPT-4.5 System Card; OpenAi: San Francisco CA, USA, 2025. [Google Scholar]
- Van Den Oord, A.; Vinyals, O. Neural discrete representation learning. In Advances in Neural Information Processing Systems 30, Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Von Luxburg, U., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Neural Information Processing Systems Foundation, Inc.: South Lake Tahoe, NV, USA, 2017; Volume 30, pp. 1–10. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Dayma, B.; Patil, S.; Cuenca, P.; Saifullah, K.; Abraham, T.; Lê Khac, P.; Melas, L.; Ghosh, R. DALL-E Mini Explained. Available online: https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mini-Explained-with-Demo--Vmlldzo4NjIxODA (accessed on 12 March 2025).
- OpenAI. DALL-E2 System Card. Available online: https://github.com/openai/dalle-2-preview/blob/main/system-card.md (accessed on 12 March 2025).
- OpenAI. DALL-E3 System Card; OpenAi: San Francisco, CA, USA, 2023. [Google Scholar]
- Currie, G.; Hewis, J.; Hawk, E.; Rohren, E. Gender and ethnicity bias of text-to-image generative artificial intelligence in medical imaging, part 2: Analysis of DALL-E 3. J. Nucl. Med. Technol. 2024, 52, 356–359. [Google Scholar] [CrossRef]
- Liu, S.; Maturi, T.; Yi, B.; Shen, S.; Mihalcea, R. The Generation Gap: Exploring Age Bias in the Value Systems of Large Language Models. arXiv 2024, arXiv:2404.08760. [Google Scholar]
- Choudhary, T. Reducing racial and ethnic bias in AI models: A comparative analysis of ChatGPT and Google Bard. In Proceedings of the 36th International RAIS Conference on Social Sciences and Humanities, Princeton, NJ, USA, 6–7 June 2024; pp. 115–124. [Google Scholar]
- Shin, P.W.; Ahn, J.J.; Yin, W.; Sampson, J.; Narayanan, V. Can Prompt Modifiers Control Bias? A Comparative Analysis of Text-to-Image Generative Models. arXiv 2024, arXiv:2406.05602. [Google Scholar] [CrossRef]
| Apparent Age as Rendered | |||||
|---|---|---|---|---|---|
| Young | Middle Age | Old | Total | ||
| age specified | young | 19 | 10 | 4 | 33 |
| middle aged | 16 | 65 | 15 | 96 | |
| old | 1 | 1 | 23 | 25 | |
| no age prescription | neutral | 312 | 179 | 35 | 526 |
| total | 348 | 255 | 77 | 680 | |
| Age as Rendered | |||||
|---|---|---|---|---|---|
| Young | Middle-Aged | Older | Total | ||
| age specified (ChatGPT terms) | young | 1 | 1 | ||
| late 20s or early 30s | 1 | 1 | |||
| mid-30s | 4 | 2 | 6 | ||
| late 30s or early 40s | 1 | 1 | |||
| mid-40s | 2 | 2 | |||
| middle-aged | 1 | 4 | 5 | ||
| no age prescription | neutral | 162 | 21 | 1 | 184 |
| total | 169 | 30 | 1 | 200 | |
| Age as Rendered | |||||
|---|---|---|---|---|---|
| Young | Middle-Aged | Older | Total | ||
| age cohort as identified by ChatGPT4o | 10–20 | 2 | 2 | ||
| 20–30 | 161 | 15 | 176 | ||
| 30–40 | 6 | 13 | 19 | ||
| 40–50 | 2 | 2 | |||
| 50–60 | 1 | 1 | |||
| total | 169 | 30 | 1 | 200 | |
| Gender as Rendered | ||||
|---|---|---|---|---|
| Female | Male | Total | ||
| gender specified | Male | — | 100.0 | 16 |
| bigender | 20.0 | 80.0 | 5 | |
| female | 91.3 | 8.7 | 23 | |
| no age prescription | neutral | 18.2 | 81.8 | 33 |
| total | 36.4 | 63.6 | 77 | |
| Age as Rendered | |||||
|---|---|---|---|---|---|
| Young | Middle Aged | Old | Total | ||
| age specified | young | 40.0 | 30.0 | 30.0 | 10 |
| middle aged | 9.1 | 45.5 | 45.5 | 11 | |
| old | — | 5.0 | 95.0 | 20 | |
| no age prescription | neutral | 22.2 | 52.8 | 25.0 | 36 |
| total | 16.9 | 36.4 | 46.8 | 77 | |
| Age as Rendered | |||||
|---|---|---|---|---|---|
| Young | Middle Aged | Old | Total | ||
| age specified | young | 62.5 | 12.5 | — | 8 |
| middle aged | 12.5 | 87.5 | — | 8 | |
| old | — | — | — | 0 | |
| no age prescription | neutral | 89.7 | 9.0 | 1.3 | 78 |
| total | 82.6 | 16.3 | 1.1 | 92 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Spennemann, D.H.R. Who Is to Blame for the Bias in Visualizations, ChatGPT or DALL-E? AI 2025, 6, 92. https://doi.org/10.3390/ai6050092
Spennemann DHR. Who Is to Blame for the Bias in Visualizations, ChatGPT or DALL-E? AI. 2025; 6(5):92. https://doi.org/10.3390/ai6050092
Chicago/Turabian StyleSpennemann, Dirk H. R. 2025. "Who Is to Blame for the Bias in Visualizations, ChatGPT or DALL-E?" AI 6, no. 5: 92. https://doi.org/10.3390/ai6050092
APA StyleSpennemann, D. H. R. (2025). Who Is to Blame for the Bias in Visualizations, ChatGPT or DALL-E? AI, 6(5), 92. https://doi.org/10.3390/ai6050092