
Classification of Exoplanetary Light Curves Using Artificial Intelligence

 ,
,  ,
,  and
and
Abstract
1. Introduction
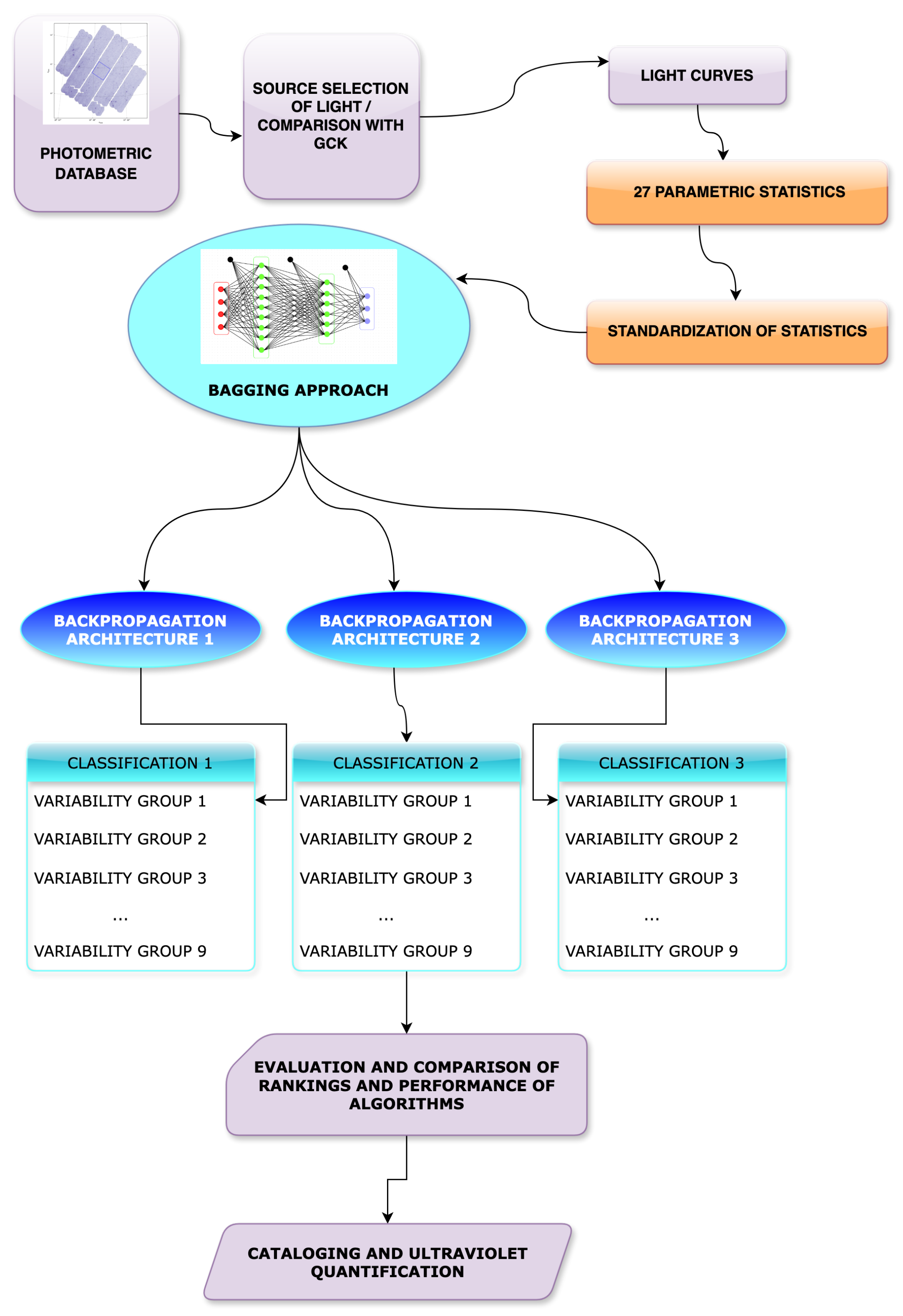
2. Methodology for Classifying Kepler Light Curves Using Artificial Intelligence
- Group 1 ECLIPSE: Eclipsing Binaries and Transit Events.
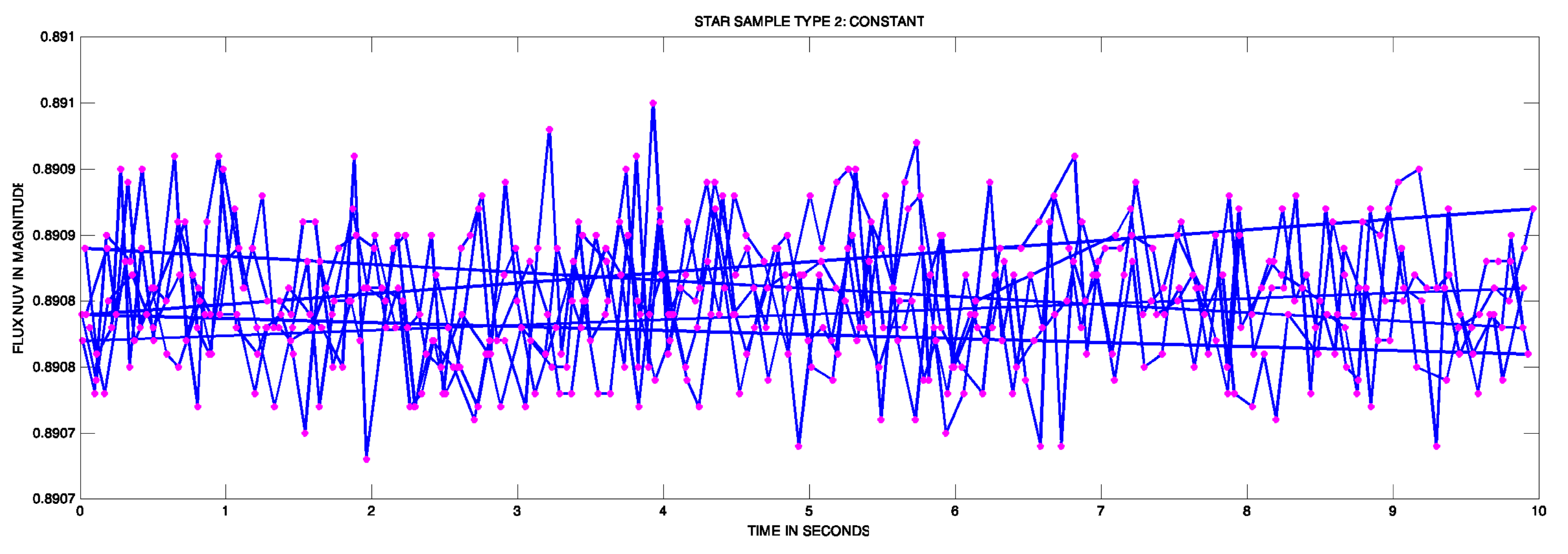
- Group 2 CONSTANT: Constant.
- Group 3 APERIODIC: Aperiodic and Long Period.
- Group 4 CONTACT-ROT (Rotational): Rotational and Binary Contact, including Chemically Peculiar.
- Group 5 DSCT-BCEP: Delta Scuti (DSCT) and Cepheids (BCEP).
- Group 6 FLARE: Stars with Transient Outbursts or Flares.
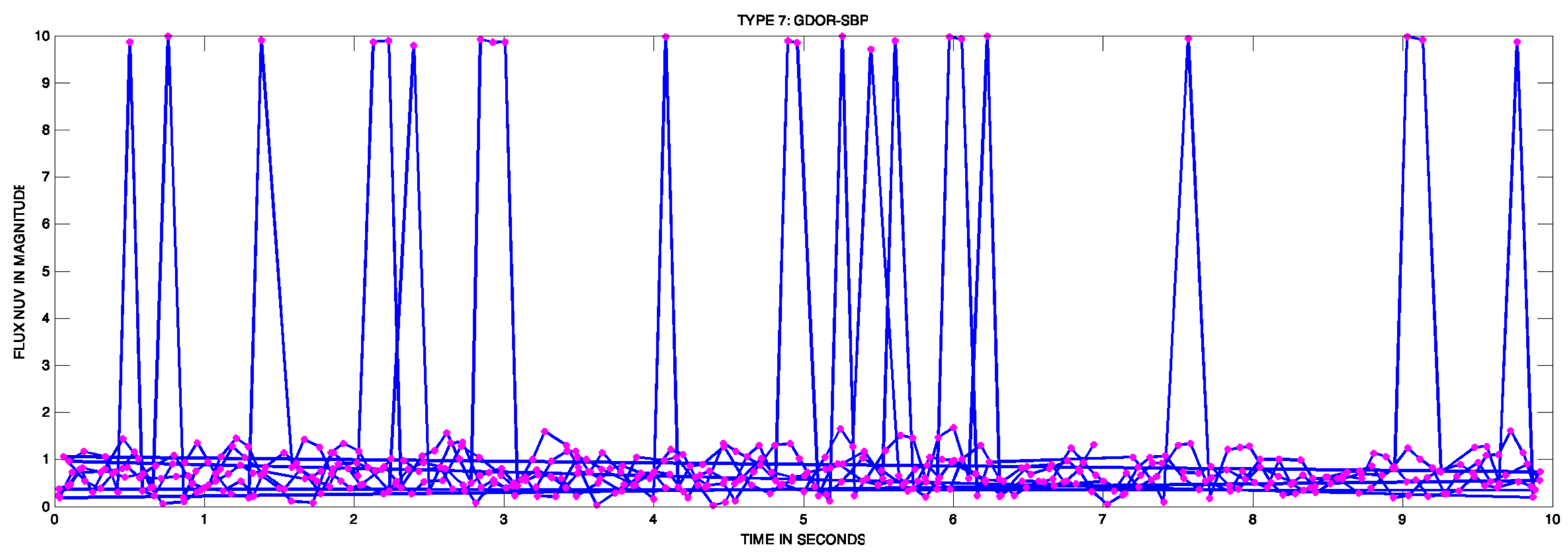
- Group 7 GDOR-SPB: Gamma Doradus (GDOR) and Slowly Pulsating B-type (SPB) stars.
- Group 8 RRLYR-CEPHEID: RRLyrae (RRLYR) stars and Cepheid Variables (CEPHEID).
- Group 9 SOLAR-LIKE: Solar-like stars.
- 1.
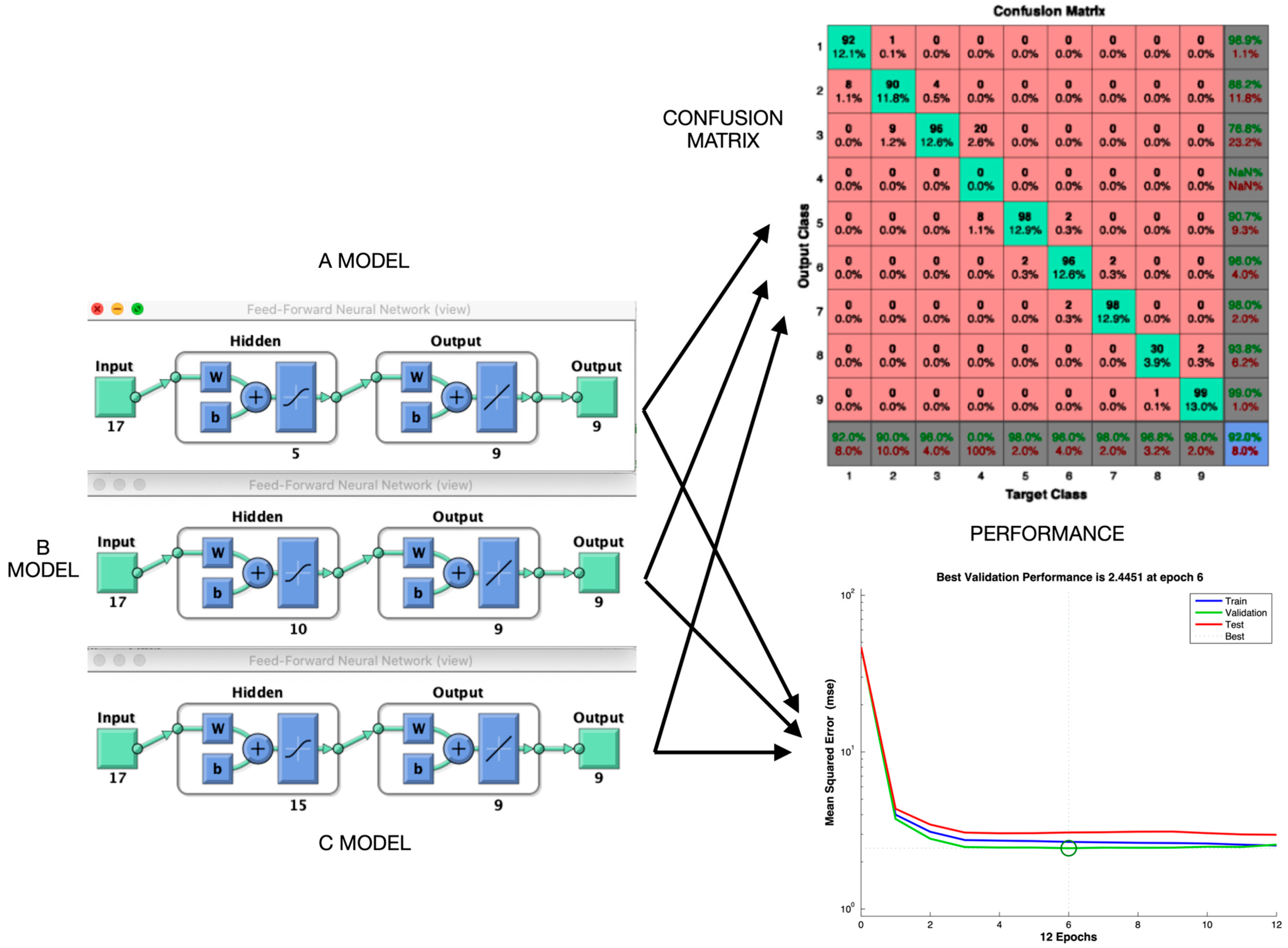
- Applying a backpropagation neural network algorithm with pre-labeled samples under a multilayer perceptron architecture with supervised learning, consisting of 17 input nodes, five hidden nodes, and nine output nodes [10].
- 2.
- Applying a backpropagation neural network algorithm with pre-labeled samples under a multilayer perceptron architecture with supervised learning, consisting of 17 input nodes, 10 hidden nodes, and nine output nodes [10].
- 3.
3. Experiments
3.1. Kepler Data Collection
3.2. Stellar Variability Categories
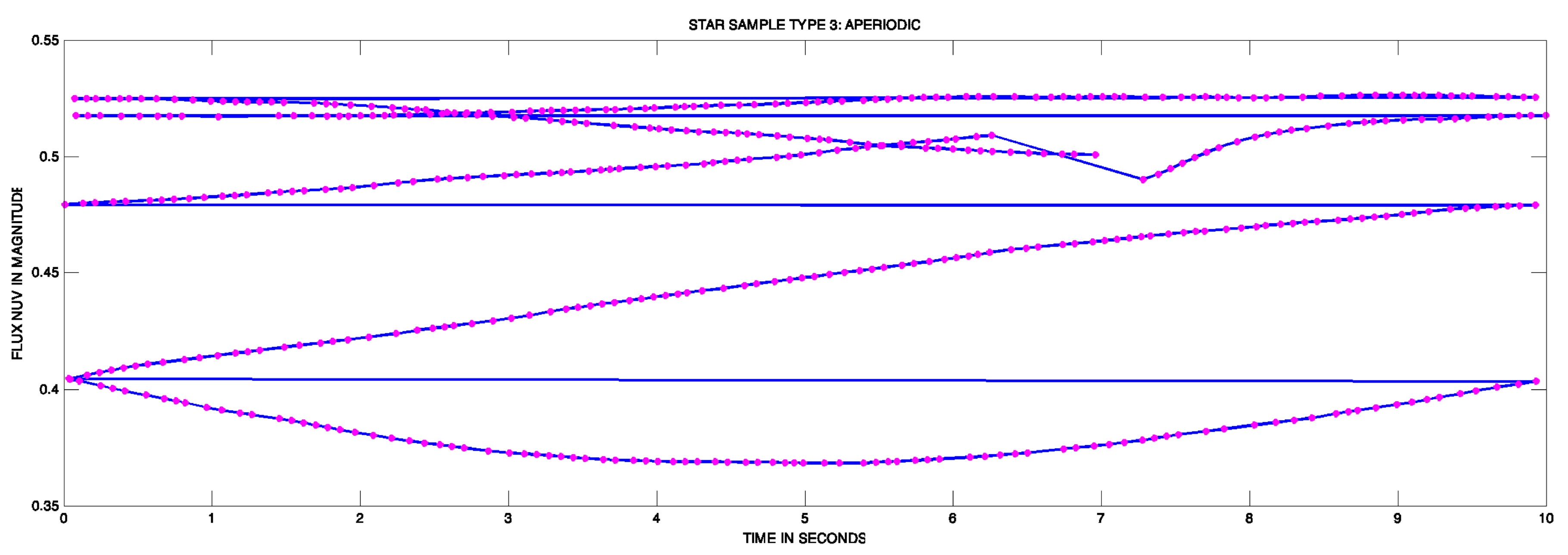
- Group 3 APERIODIC—Aperiodic and Long Period: aperiodic variable stars refer to stars that do not exhibit any regular or repeating pattern in their brightness changes over time as Mira and Semiregular (Concepts according to the American Association of Variable Star Observers (AAVSO) An example of the light curve can be seen in the Figure 5.
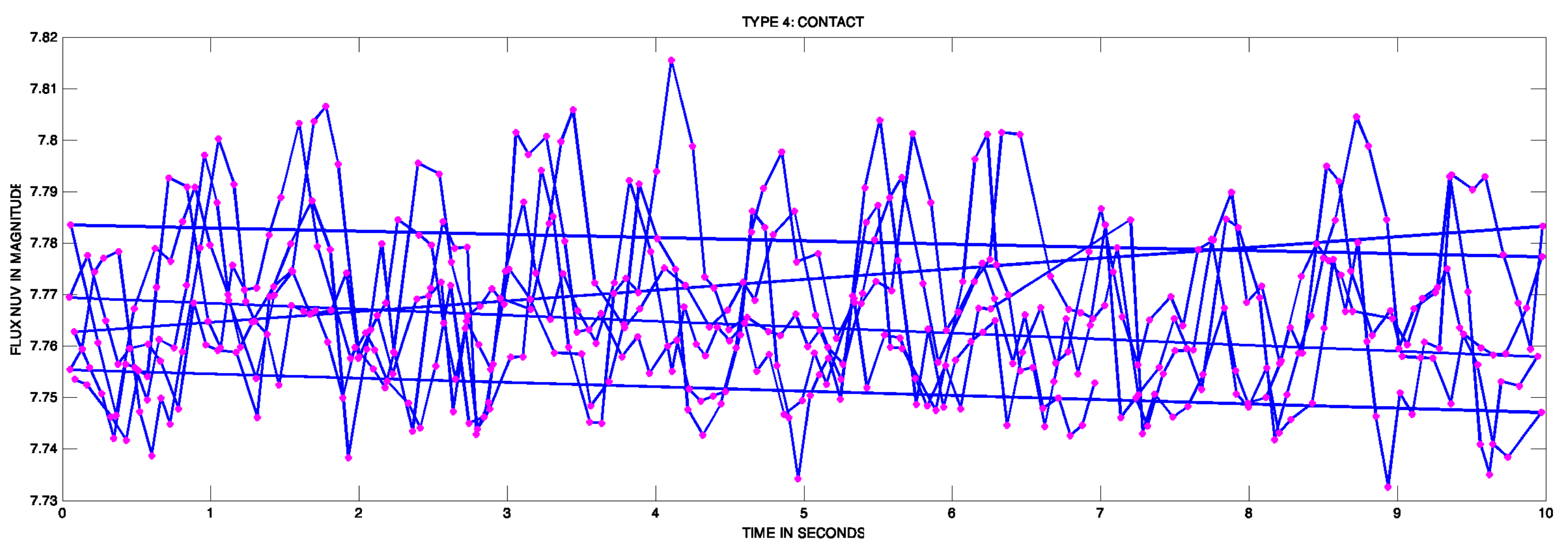
- Group 4 CONTACT-ROT—Rotational and Binary Contact: Another geometric variability is caused by the star’s rotation. Rotating or rotational variables are stars that dim by a few percent as they rotate due to starspots [13] where 450 dots in 10 months were taked, and the value in flux of near ultraviolet band is meassured in axes x and y respectively.
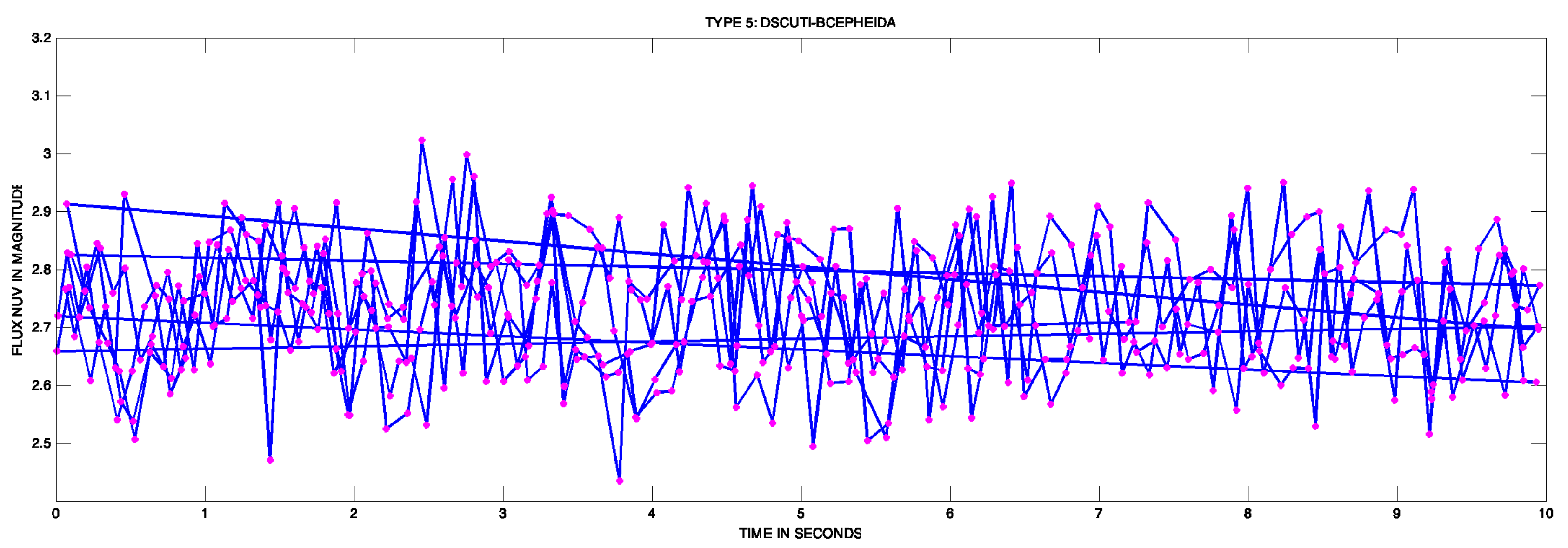
- Group 5 DSCT-BCEP—Delta () Scuti and () Cepheids: The stars Cepheids (Delta Scuti/ Cepheids) are two pulsating variables in modes of radial and non-radial pressure of low order and gravity that are excited mainly through the mechanism that acts in the zone of partial ionization of helium (Delta Scuti stars) and the iron group. Beta Cep stars have masses between 8 and 25 Me, and their pulsation periods range from 2 to 8 h. The less massive Delta Sct stars cover the 1.5 to 2.5 Me mass range and have periods of about 15 min to about 8 h. Therefore, there is a significant overlap between the two in terms of pulsation periods [5]. A sample of this type of star, in its curve light, is the Figure 7.
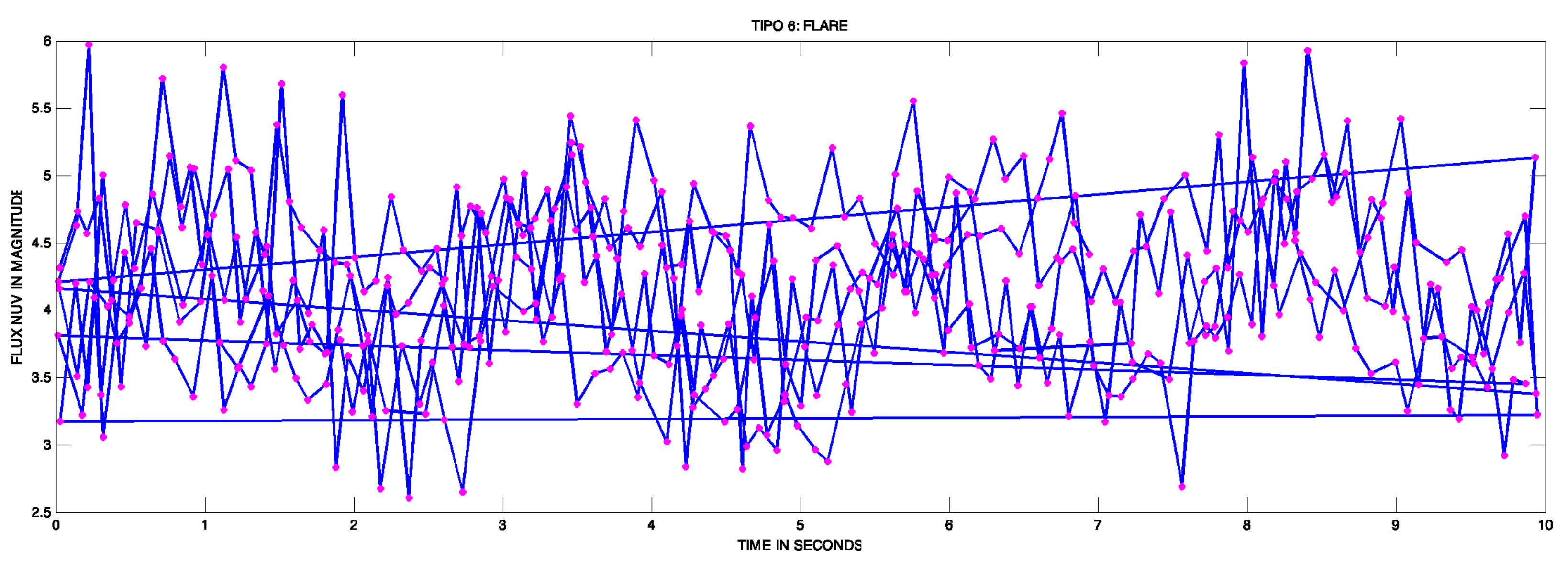
- Group 6 FLARE—Transient or Flare Stars: The flares are believed to occur due to a magnetic reconnection event that creates a beam of charged particles that impacts the stellar photosphere, generating rapid heating and emission at almost all wavelengths. Although the initial heating produces a very hot gas, the flare is more pronounced in short wavelengths: ultraviolet and X-rays [14]. One sample of how looks a curve light of this type is Figure 8.
- Group 8 RRLYR-CEPHEID—RRLyras and Cepheid Stars: Classical pulsators (class RRLyr—Ceph) are low to intermediate mass evolved stars whose intrinsic pulsation variability is driven by the opacity mechanism acting in the zone partial ionization of helium [5]. An example of the light curve can be observed in Figure 10.
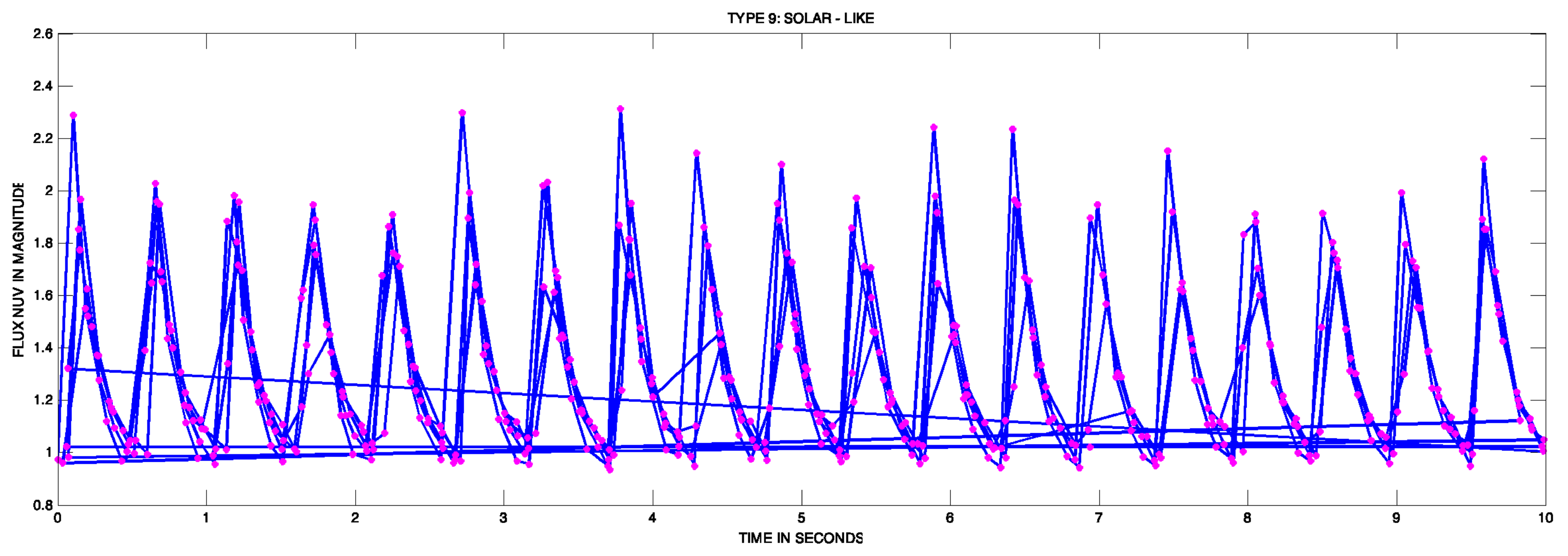
- Group 9 SOLAR LIKE—Solar Like Stars: Solar-like pulsators (solar class) are intrinsically variable stars showing oscillations driven by turbulent convective motions near their surfaces. Any star with an outer convective zone is expected to show such stochastically excited oscillations [5]. An example of a light curve can be observed in Figure 11.
4. Results
- (a)
- BAPANN configuration 1: Containing 17 input nodes, five hidden nodes, and nine output nodes (17-5-9 configuration).
- (b)
- BAPANN configuration 2: Containing 17 input nodes, 10 hidden nodes, and nine output nodes (17-10-9 configuration).
- (c)
- BAPANN configuration 3: Containing 17 input nodes, 15 hidden nodes, and nine output nodes (17-15-9 configuration).
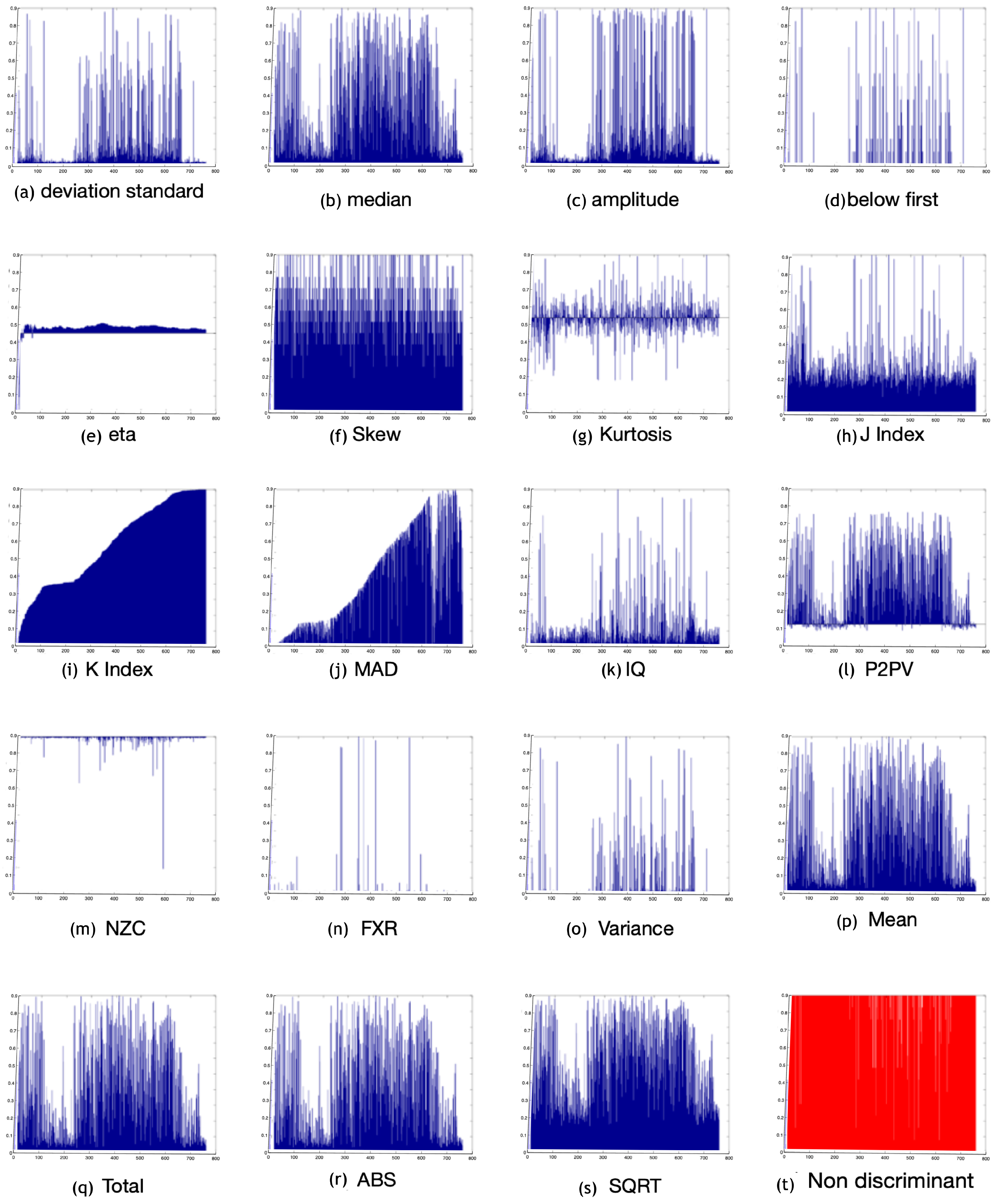
4.1. Initial Setup to Choose Discriminant Features
4.2. Second Configuration in Parametric Statistics
4.3. Test of Training Process
4.4. Analysis of Confusion Matrices
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BAPANN | Bagging-Performance Approach Neural Network |
| MGaussianM | Mixture Gaussian Model |
| BNC | Bayesian networks classifier |
| ANNC | Artificial neural networks classifier |
| SVM | Support Vector Machine |
| GALEX UV | Galaxy Evolution Explorer space telescope |
| NUV | Near deep UltraViolet band |
| TFD | TrES Lyr1 (which includes the Kepler field) light curves, parameterization through a Discrete Fourier analysis |
| SAX | Symbolic Aggregate Approximation |
| SMOTE | Synthetic Minority Over Sampling Technique |
| BN | Bayesian Network |
| RFGC | Random Forest Method |
| TESS | NASA Transiting Exoplanet Survey Satellite |
| SHORTING HAT | Hat sorting method |
| GBGC | Gradient Boosting |
| T’DA | TESS Data for Asteroseismology |
| Q9 | Is a specific number of a Kepler Field |
| UV | UltraViolet band |
| DOTS | Dots per light curve of the star |
| SNR | Signal to Noise error |
References
- Debosscher, J.; Sarro, L.M.; Aerts, C.; Cuypers, J.; Vandenbussche, B.; Garrido, R.; Solano, E. Automated supervised classification of variable stars-I. methodology. Astron. Astrophys. 2007, 475, 1159–1183. [Google Scholar] [CrossRef]
- Olmedo, M.; Lloyd, J.; Mamajek, E.E.; Chávez, M.; Bertone, E.; Martin, D.C.; Neill, J.D. Deep GALEX UV Survey of the Kepler Field. I. Point Source Catalog. Astrophys. J. 2015, 813, 100. [Google Scholar] [CrossRef]
- Bass, G.; Borne, K. Supervised ensemble classification of Kepler variable stars. Mon. Not. R. Astron. Soc. 2016, 459, 3721–3737. [Google Scholar] [CrossRef]
- Olmedo Aguilar, N.D. Fuentes Variables Ultravioleta en el campo de Kepler. PhD Thesis, INAOE, San Andrés Cholula, Mexico, 2017. [Google Scholar]
- Audenaert, J.; Kuszlewicz, J.S.; Handberg, R.; Tkachenko, A.; Armstrong, D.J.; Hon, M.; Kgoadi, R.; Lund, M.N.; Bell, K.J.; Bugnet, L.; et al. TESS data for asteroseismology (T’DA) stellar variability classification pipeline: Setup and application to the Kepler Q9 data. Astron. J. 2021, 162, 209. [Google Scholar] [CrossRef]
- Barbara, N.H.; Bedding, T.R.; Fulcher, B.D.; Murphy, S.J.; Reeth, T.V. Classifying Kepler light curves for 12,000 A and F stars using supervised feature-based machine learning. Mon. Not. R. Astron. Soc. 2022, 514, 2793–2804. [Google Scholar] [CrossRef]
- Miles, B.E.; Shkolnik, E.L. HAZMAT. II. Ultraviolet variability of low-mass stars in the GALEX Archive. Astron. J. 2017, 154, 67. [Google Scholar] [CrossRef]
- Kim, S.T.; Cai, W.; Jin, F.F.; Yu, J.Y. ENSO stability in coupled climate models and its association with mean state. Clim. Dyn. 2014, 42, 3313–3321. [Google Scholar] [CrossRef]
- Wittenmyer, R.A.; Butler, R.P.; Tinney, C.G.; Horner, J.; Carter, B.D.; Wright, D.J.; Jones, H.R.; Bailey, J.; O’Toole, S.J. The Anglo-Australian planet search XXIV: The frequency of Jupiter analogs. Astrophys. J. 2016, 819, 28. [Google Scholar] [CrossRef]
- Fausett, L.V. Fundamentals of Neural Networks: Architectures, Algorithms, and Applications; Prentice-Hall: Hoboken, NJ, USA, 1994. [Google Scholar]
- Rokach, L. Pattern classification using ensemble methods. Ser. Mach. Percept. Artif. Intell. 2010, 75, 225. [Google Scholar]
- Sewell, M. Ensemble learning. Res Note 2008, 11, 1–34. [Google Scholar]
- Preston, G.W. The chemically peculiar stars of the upper main sequence. Annu. Rev. Astron. Astrophys. 1974, 12, 257–277. [Google Scholar] [CrossRef]
- Segura, A.; Walkowicz, L.M.; Meadows, V.; Kasting, J.; Hawley, S. The effect of a strong stellar flare on the atmospheric chemistry of an Earth-like planet orbiting an M dwarf. Astrobiology 2010, 10, 751–771. [Google Scholar] [CrossRef] [PubMed]
- Antoci, V.; Cunha, M.S.; Bowman, D.M.; Murphy, S.J.; Kurtz, D.W.; Bedding, T.R.; Borre, C.C.; Christophe, S.; Daszyńska-Daszkiewicz, J.; Fox-Machado, L. The first view of δ Scuti and γ Doradus stars with the TESS mission. Mon. Not. R. Astron. Soc. 2019, 490, 4040–4059. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Title | Features | AI Method | Stars Number or %’s |
|---|---|---|---|---|
| Debosscher et al., (2007) [1] | Automated supervised classification of variable stars | 28 statistics, of the TFD of the light curve, 35 categories and 14 categories | MGaussianM Mehalanobis BNC, ANNC SVM | 60,000 stars BNC: 66% RNPB: 70% MSV: 50% MMG: 92% |
| Olmedo et al., (2015) [2] | Deep GALEX UV survey of the, Kepler Field | 28 attributes | NUV | 596,556 stars |
| Bass & Borne (2016) [3] | Supervised ensemble classification of Kepler variable stars | 165 attributes of the light curve. 14 y 8 categories, | TFD-SAX SMOTE BN RFGC | 150,000 stars BN: 64% |
| Olmedo et al., (2017) [4] | Ultraviolet variable sources in the Kepler field | 10 attributes | NUV | 6,818,181 stars |
| Audenaert et al., (2021) [5] | TESS Data for Asteroseismology (TDA) Stellar Variability Classification Pipeline: Setup and Application to the Kepler Q9 Data | 26 statistics, 30 pointsof the light curve, 289 points of the TFD | SHORTING HAT GBGC Metodos no Supervised Meta assembly | 167,243 stars Meta: 94.9% |
| Barbara et al., (2022) [6] | Light curves Classification for Kepler stars A and F by automatic learning based on features | 7000 statistics, 2000 points of the light curve of the TFD, 7 groups | Library hctsa de Matlab | from 80.8–90% 1319 stars |
| Our work | Variability studies UV of stars with planets in the Kepler field by artificial intelligence codes | 17 statistics, 50 points of the light curve 9 groups | BAPANN | 760 stars 97.8% |
| Data Set | No. Data | No. Points | Error Value | File Name |
|---|---|---|---|---|
| 1 | 9880 | 13 | 00 | mgck_ab_n013_e00.xlsx |
| 2 | 9880 | 13 | 05 | mgck_ab_n013_e05.xlsx |
| 3 | 9880 | 13 | 10 | mgck_ab_n013_e00.xlsx |
| 4 | 15,200 | 20 | 00 | mgck_ab_n020_e00.xlsx |
| 5 | 15,200 | 20 | 05 | mgck_ab_n020_e05.xlsx |
| 6 | 15,200 | 20 | 10 | mgck_ab_n020_e10.xlsx |
| 7 | 38,000 | 50 | 00 | mgck_ab_n050_e00.xlsx |
| 8 | 38,000 | 50 | 05 | mgck_ab_n050_e05.xlsx |
| 9 | 38,000 | 50 | 10 | mgck_ab_n050_e10.xlsx |
| 10 | 114,000 | 150 | 00 | mgck_ab_n150_e00.xlsx |
| 11 | 114,000 | 150 | 05 | mgck_ab_n150_e05.xlsx |
| 12 | 114,000 | 150 | 10 | mgck_ab_n150_e10.xlsx |
| 13 | 342,000 | 450 | 00 | mgck_ab_n450_e00.xlsx |
| 14 | 342,000 | 450 | 05 | mgck_ab_n450_e05.xlsx |
| 15 | 342,000 | 450 | 10 | mgck_ab_n450_e10.xlsx |
| Group No. | Variability Type | No. Samples |
|---|---|---|
| 1 | ECLIPSE | 100 |
| 2 | CONSTANT | 100 |
| 3 | APERIODIC | 28 |
| 4 | CONTACT | 100 |
| 5 | DSCT-BCEP | 100 |
| 6 | FLARE | 100 |
| 7 | GDOR-SPB | 100 |
| 8 | RRLYR-CEPHEID | 32 |
| 9 | SOLAR-LIKE | 100 |
| TOTAL | 760 |
| Run | Epochs | Dots and SNR | Hidden Nodes | Percentage |
|---|---|---|---|---|
| 6 | 18 | 13 | 15 | 92.0% |
| 12 | 45 | 20 | 15 | 96.6% |
| 20 | 68 | 50 | 10 | 97.8% * |
| 32 | 34 | 150 | 10 | 95.1% |
| 45 | 70 | 450 | 15 | 98.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Flores-Pulido, L.; Barbosa-Santillán, L.I.; Orozco-Aguilera, M.T.; Guzman-Velázquez, B.P. Classification of Exoplanetary Light Curves Using Artificial Intelligence. AI 2025, 6, 102. https://doi.org/10.3390/ai6050102
Flores-Pulido L, Barbosa-Santillán LI, Orozco-Aguilera MT, Guzman-Velázquez BP. Classification of Exoplanetary Light Curves Using Artificial Intelligence. AI. 2025; 6(5):102. https://doi.org/10.3390/ai6050102
Chicago/Turabian StyleFlores-Pulido, Leticia, Liliana Ibeth Barbosa-Santillán, Ma. Teresa Orozco-Aguilera, and Bertha Patricia Guzman-Velázquez. 2025. "Classification of Exoplanetary Light Curves Using Artificial Intelligence" AI 6, no. 5: 102. https://doi.org/10.3390/ai6050102
APA StyleFlores-Pulido, L., Barbosa-Santillán, L. I., Orozco-Aguilera, M. T., & Guzman-Velázquez, B. P. (2025). Classification of Exoplanetary Light Curves Using Artificial Intelligence. AI, 6(5), 102. https://doi.org/10.3390/ai6050102