


From Play to Understanding: Large Language Models in Logic and Spatial Reasoning Coloring Activities for Children


Abstract
1. Introduction
- To what extent can GPT-4o accurately assess and correct coloring activities completed by elementary school students, given instructions involving multiple logical quantifiers and spatial relationships?
- What are the visual, logical, and correction capabilities of GPT-4o, and what type of prompts are most effective for obtaining accurate and detailed GPT-4o corrections when assessing coloring activities involving logical quantifiers and spatial relationships?
- Can GPT-4o be effectively utilized as a teaching assistant to provide immediate feedback for class discussions on these exercises?
2. Related Work
3. Methodology
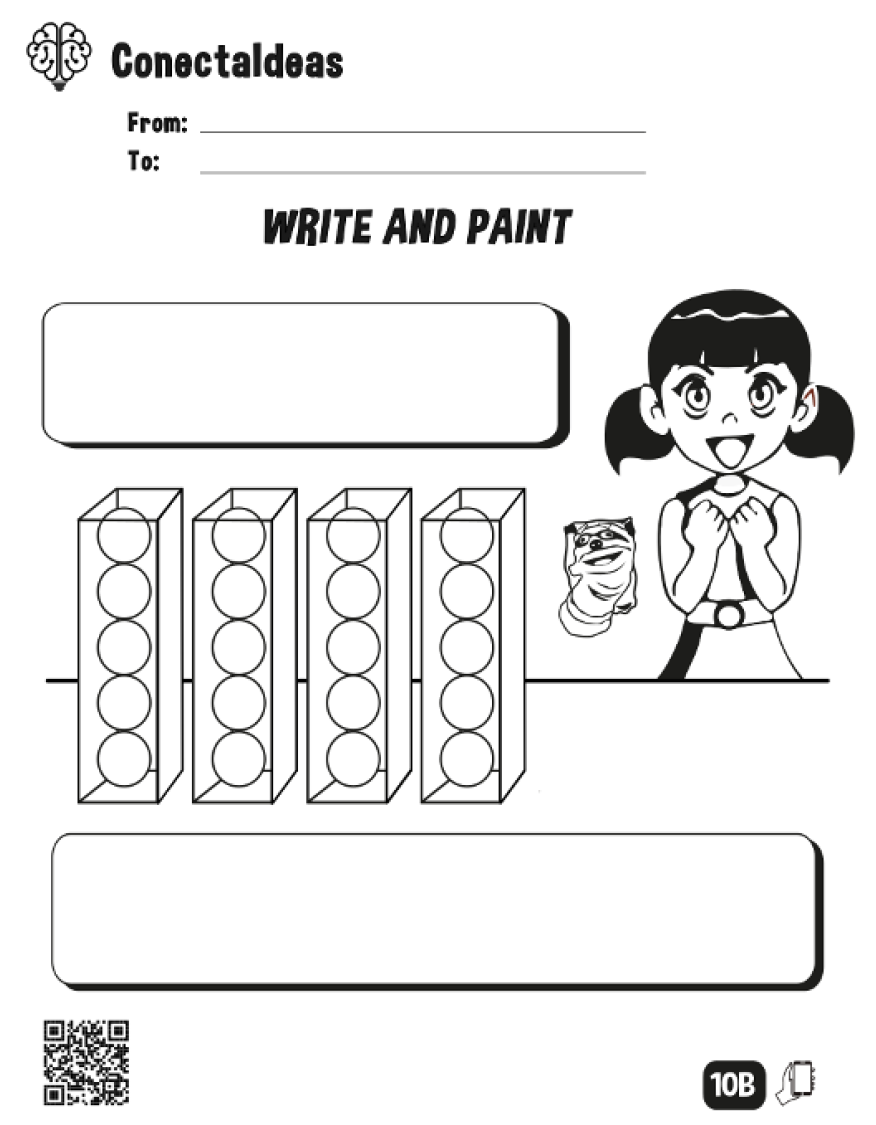
3.1. Box-and-Ball Coloring Activities
- 1.
- Choose a color and in each box paint at least two balls of that color.
- 2.
- In each box, choose a color and paint at least two balls of that color.
- 3.
- In at least two boxes, choose a color and paint each ball of that color.
- 4.
- Paint each box only if the adjacent boxes are not painted. Choose two other colors and in each box paint every ball such that each ball has a different color with the adjacent balls inside the box and the ball in the same position but in the adjacent boxes.
- 5.
- Choose a color and paint each ball with the ball’s color that is just above in the left adjacent box. If there is no ball above in the left adjacent box, paint with the ball’s color at the bottom of the left adjacent box.
3.2. Prompting Techniques
3.2.1. Zero-Shot, Few-Shot, and Chain of Thought
- Your job is to verify if the proposed solution satisfies the instruction verbatim.
- Consider that there could be many possible solutions to the instruction.
- Conclude only at the end of your answer”.
3.2.2. Visualization of Thought
3.2.3. Logic Prompting and Self-Consistency
3.2.4. Emotional Prompting
- “Write the instruction using math quantifiers and then solve the problem”, which implements the use of logic;
- “Be careful to identify colors. It is different if a color is applied for all the balls in all boxes or each box has its own color for all its balls”, preventing errors when interchanging quantifier positions;
- “Visualize each logical step”, which implements the visualization of the steps;
- “If the proposed solution is incorrect, don’t propose a correct solution”, which prevents unnecessarily long responses;
- “Unless the instruction says otherwise, you have to check all balls in all boxes whether or not the boxes are painted or not”, which prevents errors by not considering uncolored boxes.
3.3. Experiments and Analysis
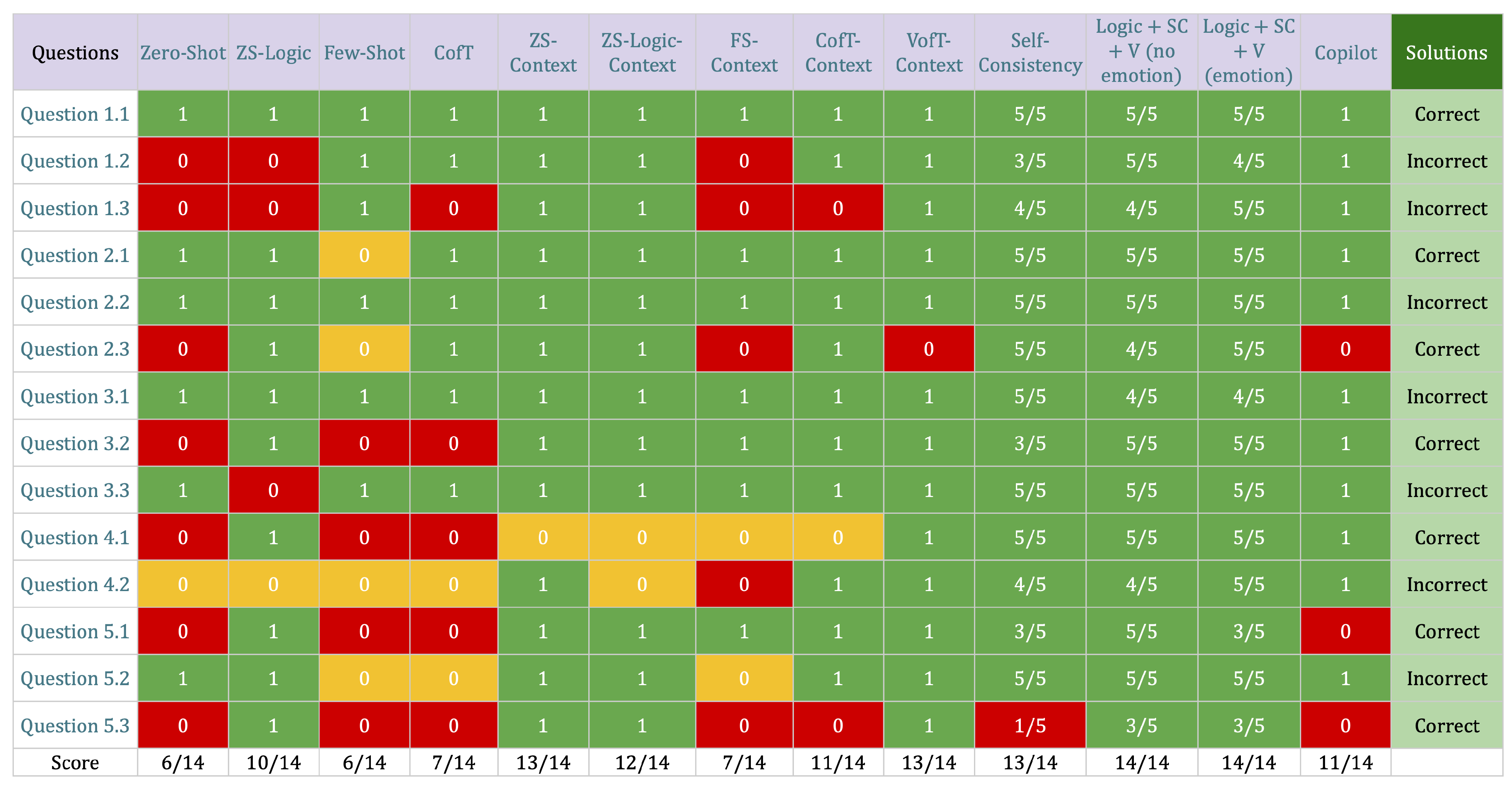
4. Results
4.1. Performance in Correcting Coloring Activities
4.2. Common Errors
4.2.1. Logic Errors
4.2.2. Spatial Errors
4.2.3. Other
5. Discussion
5.1. Limitations
5.2. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Tested Problems
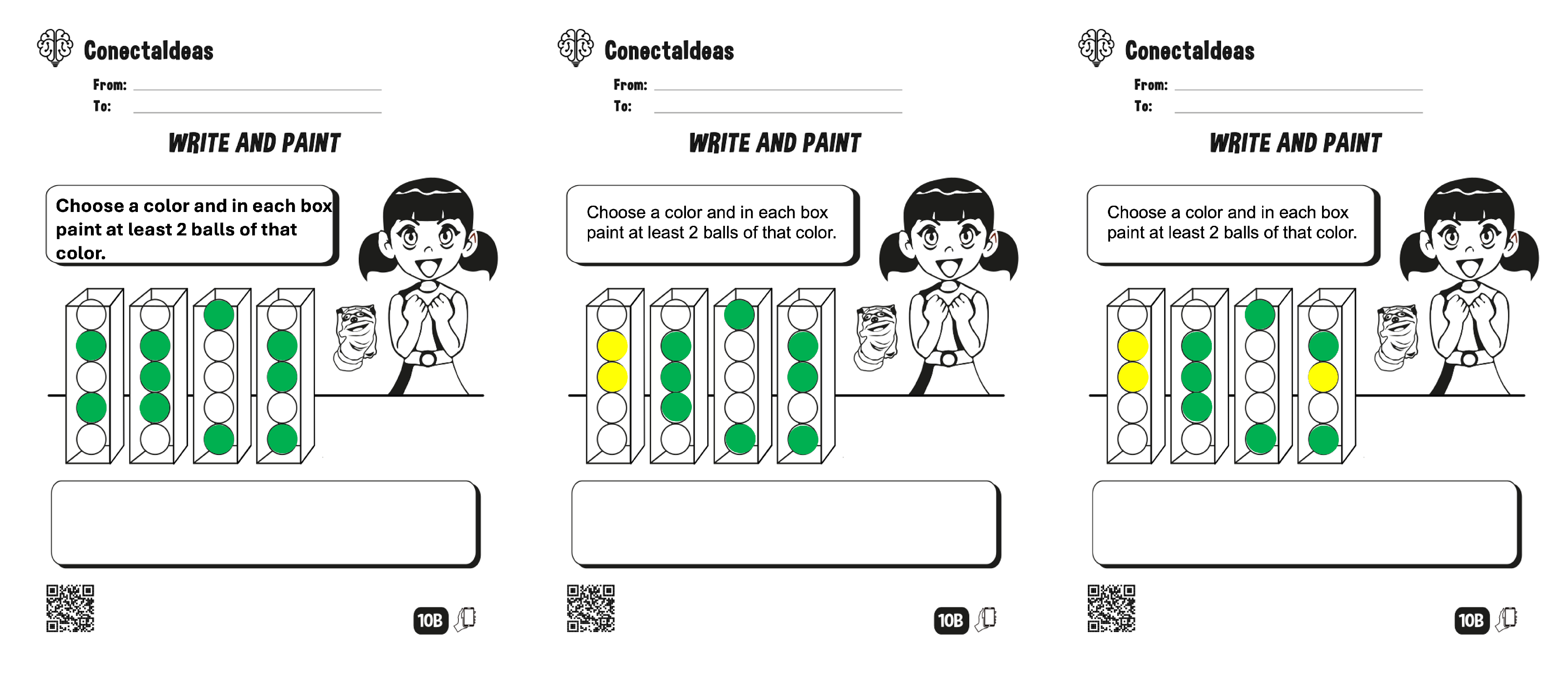
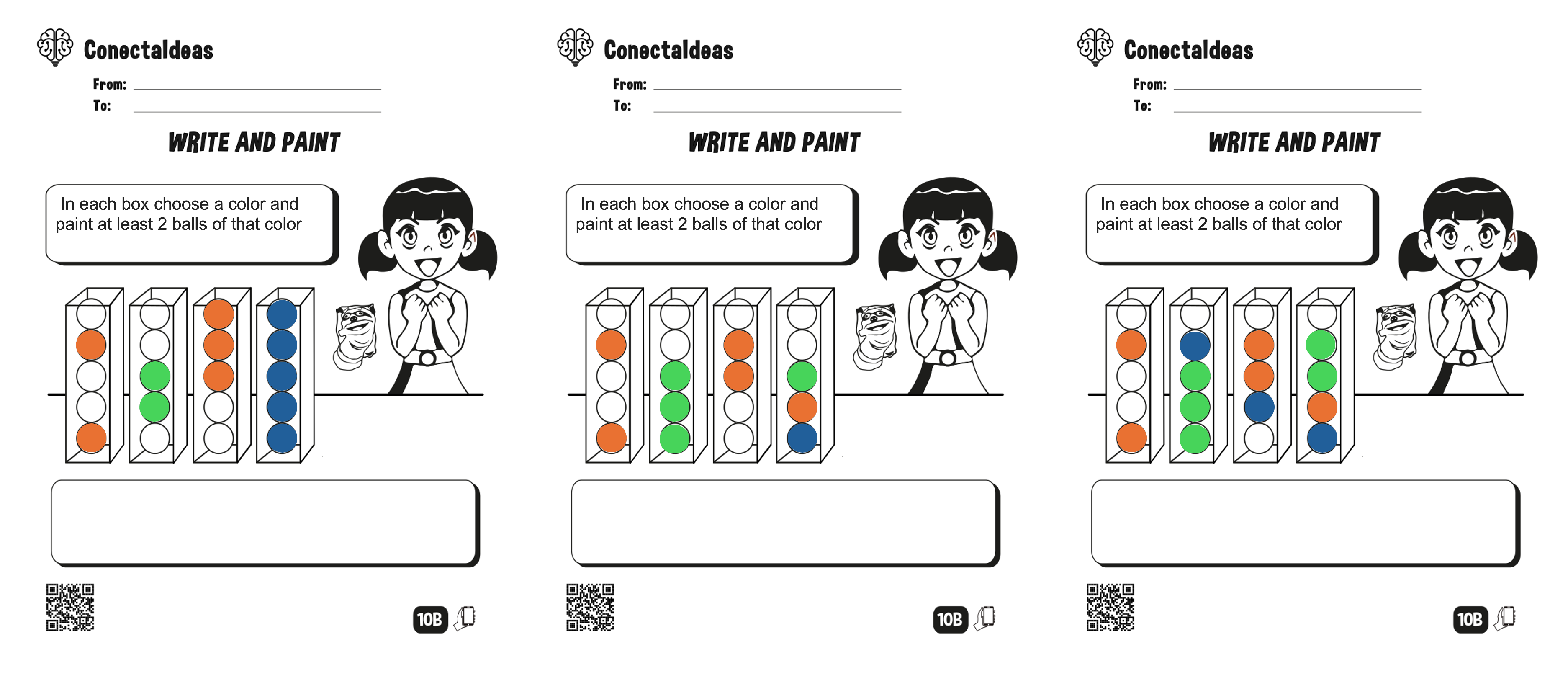
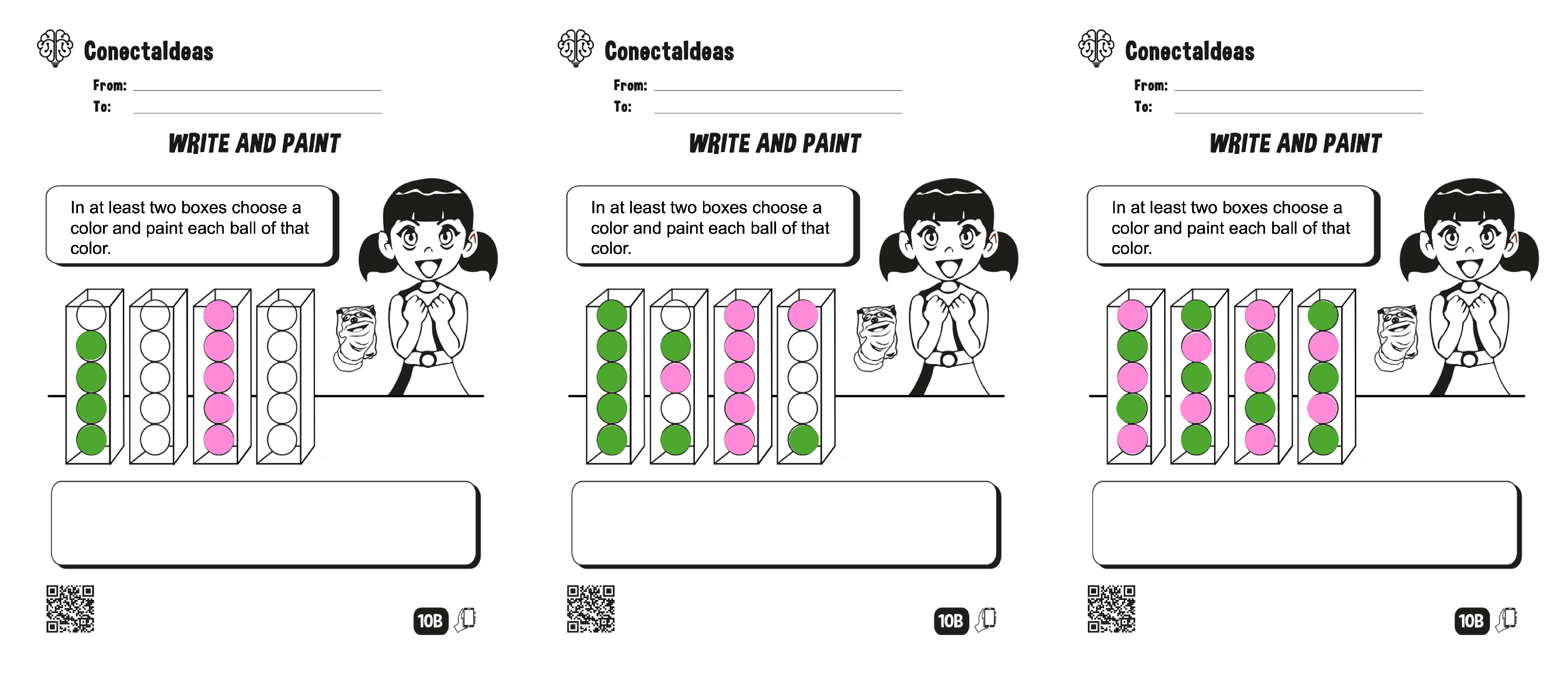

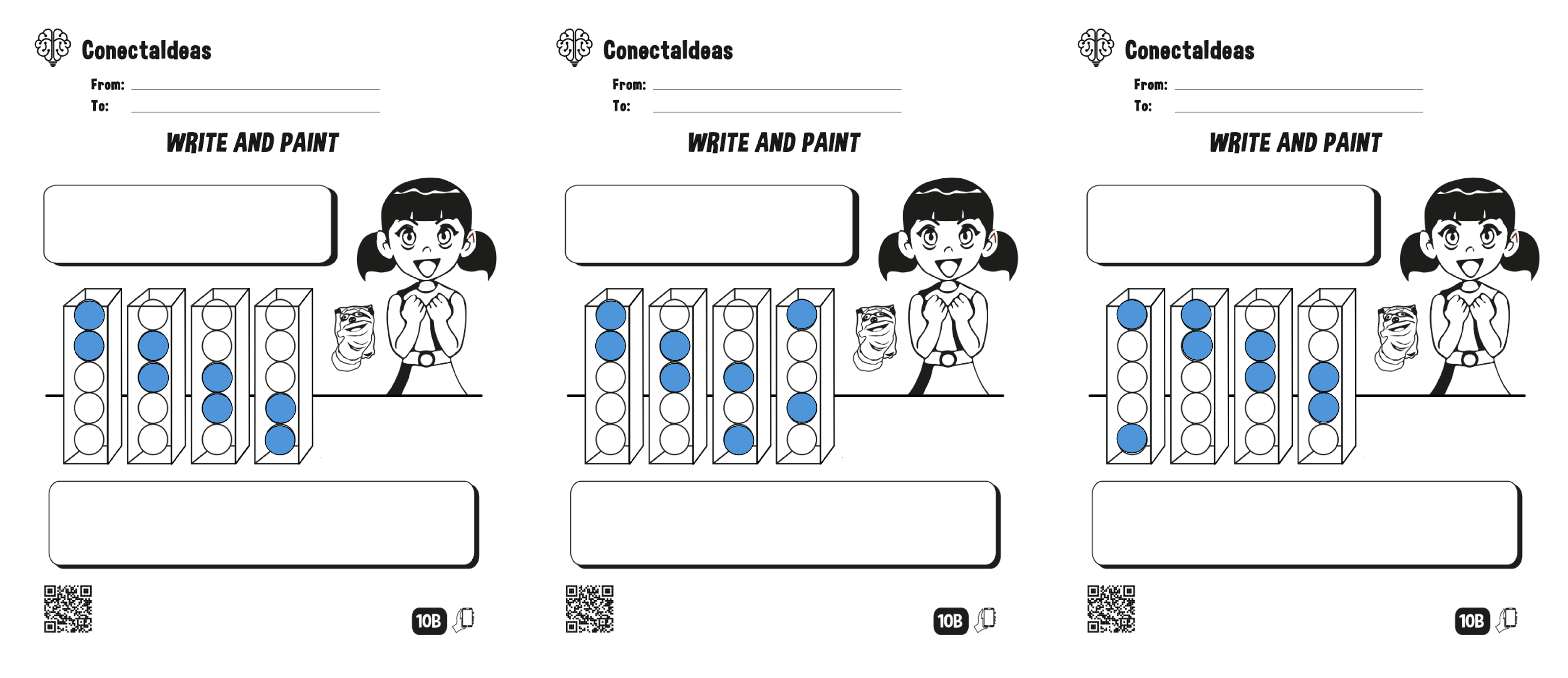
References
- Tversky, B. Visualizing thought. Top. Cogn. Sci. 2011, 3, 499–535. [Google Scholar] [CrossRef] [PubMed]
- Franconeri, S.L.; Padilla, L.M.; Shah, P.; Zacks, J.M.; Hullman, J. The Science of Visual Data Communication: What Works. Psychol. Sci. Public Interest 2021, 22, 110–161. [Google Scholar] [CrossRef] [PubMed]
- Fan, J.E.; Bainbridge, W.A.; Chamberlain, R.; Wammes, J.D. Drawing as a versatile cognitive tool. Nat. Rev. Psychol. 2023, 2, 556–568. [Google Scholar] [CrossRef]
- OECD. New PISA Results on Creative Thinking; OECD: Paris, France, 2024. [Google Scholar] [CrossRef]
- Lee, J.; Hammer, J. Gamification in Education: What, How, Why Bother? Acad. Exch. Q. 2011, 15, 1–5. [Google Scholar]
- Susannah Cahalan, N. Hottest Trend in Publishing Is Adult Coloring Books; TAPPI Corporate Headquarters: Peachtree Corners, GA, USA, 2015. [Google Scholar]
- Inharjanto, A. Developing Coloring Books to Enhance Reading Comprehension Competence and Creativity. In Proceedings of the 3rd International Conference on Innovative Research Across Disciplines (ICIRAD 2019), Grand Inna Bali Beach Sanur Bali, Indonesia, 20–21 September 2019; Atlantis Press: Amsterdam, The Netherlands, 2020; pp. 7–12. [Google Scholar] [CrossRef]
- Kaufman, R.E. A FORTRAN Coloring Book; MIT Press: Cambridge, MA, USA, 1978. [Google Scholar]
- Sandor, G. A Fortran coloring book: Roger Emanuel Kaufman, The MIT Press, Cambridge Massachusetts and London, England, 1978, 285 pp. Comput. Struct. 1979, 10, 931–932. [Google Scholar] [CrossRef]
- Araya, R. Gamification Strategies to Teach Algorithmic Thinking to First Graders. In Proceedings of the Advances in Human Factors in Training, Education, and Learning Sciences; Nazir, S., Ahram, T.Z., Karwowski, W., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 133–141. [Google Scholar]
- Somsaman, K.; Isoda, M.; Araya, R. (Eds.) Guidebook for Unplugged Computational Thinking; SEAMEO STEM-ED: Bangkok, Thailand, 2024; pp. 1–9. [Google Scholar]
- Araya, R.; Isoda, M. Unplugged Computational Thinking with Colouring Books. J. Southeast Asian Educ. 2023, 1, 72–91. [Google Scholar]
- Araya, R. What mathematical thinking skills will our citizens need in 20 more years to function effectively in a super smart society. In Proceedings of the 44th Conference of the International Group for the Psychology of Mathematics Education, Khon Kaen, Thailand, 19–22 July 2021; Volume 1, pp. 48–65. [Google Scholar]
- Lockwood, J.; Mooney, A. Computational Thinking in Education: Where does it Fit? A systematic literary review. arXiv 2017, arXiv:1703.07659. [Google Scholar] [CrossRef]
- Feldon, D. Cognitive Load and Classroom Teaching: The Double-Edged Sword of Automaticity. Educ. Psychol. 2007, 42, 123–137. [Google Scholar] [CrossRef]
- Ravi, P.; Broski, A.; Stump, G.; Abelson, H.; Klopfer, E.; Breazeal, C. Understanding Teacher Perspectives and Experiences after Deployment of AI Literacy Curriculum in Middle-School Classrooms. In Proceedings of the ICERI2023 Proceedings. IATED, 11 2023, ICERI2023, Seville, Spain, 13–15 November 2023. [Google Scholar] [CrossRef]
- Arkoudas, K. GPT-4 Can’t Reason. arXiv 2023, arXiv:2308.03762. [Google Scholar]
- Kraaijveld, K.; Jiang, Y.; Ma, K.; Ilievski, F. COLUMBUS: Evaluating COgnitive Lateral Understanding through Multiple-choice reBUSes. arXiv 2024, arXiv:2409.04053. [Google Scholar]
- Jones, C.R.; Bergen, B.K. People cannot distinguish GPT-4 from a human in a Turing test. arXiv 2024, arXiv:2405.08007. [Google Scholar]
- Urrutia, F.; Araya, R. Who’s the Best Detective? LLMs vs. MLs in Detecting Incoherent Fourth Grade Math Answers. arXiv 2023, arXiv:2304.11257. [Google Scholar]
- Yan, L.; Sha, L.; Zhao, L.; Li, Y.; Martinez-Maldonado, R.; Chen, G.; Li, X.; Jin, Y.; Gašević, D. Practical and ethical challenges of large language models in education: A systematic scoping review. Br. J. Educ. Technol. 2024, 55, 90–112. [Google Scholar] [CrossRef]
- Anderson, N.; McGowan, A.; Galway, L.; Hanna, P.; Collins, M.; Cutting, D. Implementing Generative AI and Large Language Models in Education. In Proceedings of the ISAS 2023—7th International Symposium on Innovative Approaches in Smart Technologies, Proceedings, Istanbul, Turkiye, 23–25 November 2023; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- Jeon, J.; Lee, S. Large language models in education: A focus on the complementary relationship between human teachers and ChatGPT. Educ. Inf. Technol. 2023, 28, 15873–15892. [Google Scholar] [CrossRef]
- Pinto, G.; Cardoso-Pereira, I.; Ribeiro, D.M.; Lucena, D.; de Souza, A.; Gama, K. Large Language Models for Education: Grading Open-Ended Questions Using ChatGPT. arXiv 2023, arXiv:2307.16696. [Google Scholar]
- Rahman, M.M.; Watanobe, Y. ChatGPT for Education and Research: Opportunities, Threats, and Strategies. Appl. Sci. 2023, 13, 5783. [Google Scholar] [CrossRef]
- Wang, K.D.; Burkholder, E.; Wieman, C.; Salehi, S.; Haber, N. Examining the potential and pitfalls of ChatGPT in science and engineering problem-solving. Front. Educ. 2023, 8, 1330486. [Google Scholar] [CrossRef]
- Orrù, G.; Piarulli, A.; Conversano, C.; Gemignani, A. Human-like problem-solving abilities in large language models using ChatGPT. Front. Artif. Intell. 2023, 6, 1199350. [Google Scholar] [CrossRef]
- Pan, L.; Albalak, A.; Wang, X.; Wang, W.Y. Logic-LM: Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning. arXiv 2023, arXiv:2305.12295. [Google Scholar]
- Plevris, V.; Papazafeiropoulos, G.; Rios, A.J. Chatbots Put to the Test in Math and Logic Problems: A Comparison and Assessment of ChatGPT-3.5, ChatGPT-4, and Google Bard. AI 2023, 4, 949–969. [Google Scholar] [CrossRef]
- Drori, I.; Zhang, S.; Shuttleworth, R.; Tang, L.; Lu, A.; Ke, E.; Liu, K.; Chen, L.; Tran, S.; Cheng, N.; et al. A neural network solves, explains, and generates university math problems by program synthesis and few-shot learning at human level. Proc. Natl. Acad. Sci. USA 2022, 119, e2123433119. [Google Scholar] [CrossRef] [PubMed]
- Collins, K.M.; Jiang, A.Q.; Frieder, S.; Wong, L.; Zilka, M.; Bhatt, U.; Lukasiewicz, T.; Wu, Y.; Tenenbaum, J.B.; Hart, W.; et al. Evaluating Language Models for Mathematics through Interactions. arXiv 2023, arXiv:2306.01694. [Google Scholar] [CrossRef] [PubMed]
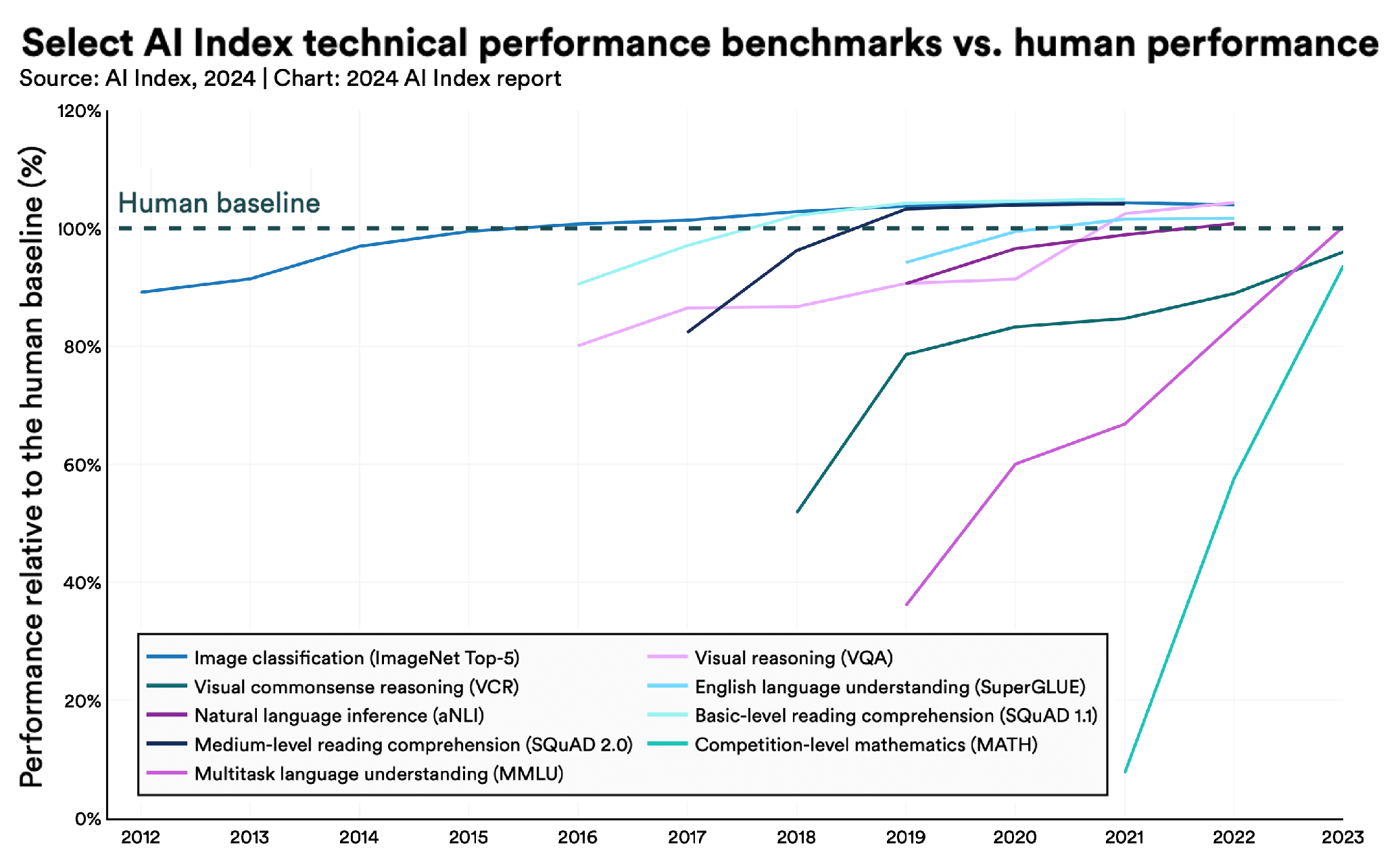
- Maslej, N.; Fattorini, L.; Perrault, R.; Parli, V.; Reuel, A.; Brynjolfsson, E.; Etchemendy, J.; Ligett, K.; Lyons, T.; Manyika, J.; et al. The AI Index 2024 Annual Report. arXiv 2024, arXiv:2405.19522. [Google Scholar]
- Wang, B.; Yue, X.; Sun, H. Can ChatGPT Defend its Belief in Truth? Evaluating LLM Reasoning via Debate. arXiv 2023, arXiv:2305.13160. [Google Scholar]
- Yan, H.; Hu, X.; Wan, X.; Huang, C.; Zou, K.; Xu, S. Inherent limitations of LLMs regarding spatial information. arXiv 2023, arXiv:2312.03042. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2023, arXiv:2201.11903. [Google Scholar]
- Wu, W.; Mao, S.; Zhang, Y.; Xia, Y.; Dong, L.; Cui, L.; Wei, F. Mind’s Eye of LLMs: Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models. arXiv 2024, arXiv:2404.03622. [Google Scholar]
- Singh, K.; Khanna, M.; Biswas, A.; Moturi, P.; Shivam. Visual Prompting Methods for GPT-4V Based Zero-Shot Graphic Layout Design Generation. In Proceedings of the The Second Tiny Papers Track at ICLR 2024, Vienna, Austria, 11 May 2024. [Google Scholar]
- Sharma, P.; Shaham, T.R.; Baradad, M.; Fu, S.; Rodriguez-Munoz, A.; Duggal, S.; Isola, P.; Torralba, A. A Vision Check-up for Language Models. arXiv 2024, arXiv:2401.01862. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Narang, S.; Chowdhery, A.; Zhou, D. Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv 2023, arXiv:2203.11171. [Google Scholar]
- Araya, R. AI as a Co-Teacher: Enhancing Creative Thinking in Underserved Areas. In Proceedings of the 32nd International Conference on Computers in Education (ICCE 2024), Quezon City, Philippines, 25–29 November 2024; Asia-Pacific Society for Computers in Education: Manila, Philippines, 2024. [Google Scholar]
- Musielak, Z.E.; Quarles, B. The three-body problem. Rep. Prog. Phys. 2014, 77, 065901. [Google Scholar] [CrossRef]
- Conway, J.H.; Guy, R. The Book of Numbers. Springer New York: New York, NY, USA, 1998. [Google Scholar]
- Yang, Z.; Li, L.; Lin, K.; Wang, J.; Lin, C.C.; Liu, Z.; Wang, L. The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision). arXiv 2023, arXiv:2309.17421. [Google Scholar]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. arXiv 2023, arXiv:2311.05232. [Google Scholar]
- DAIR.AI. Prompt Engineering Guide: Elements of a Prompt. 2024. Available online: https://www.promptingguide.ai/introduction/elements (accessed on 17 August 2024).
- Photonics, M.Q.; Group, A. ChatTutor. Available online: https://github.com/ChatTutor/chattutor.git (accessed on 18 July 2023).
- Li, C.; Wang, J.; Zhang, Y.; Zhu, K.; Hou, W.; Lian, J.; Luo, F.; Yang, Q.; Xie, X. Large Language Models Understand and Can be Enhanced by Emotional Stimuli. arXiv 2023, arXiv:2307.11760. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quantifiers | Explanation |
|---|---|
| 1. color box: | The color C is applied for all the boxes. |
| 2. box color: | Each box has its own color to apply. |
| 3. boxes: color | In two or more boxes, a color is chosen and applied for every ball. |
| 4*. (∃C color(Bi) = C ∧ ∄, color(Bi−1) = , color(Bi+1) = ) ∧(∀∈Bi, color() ≠ color() ∧ color() ≠ color()) | A box must be painted if the left and right boxes are not. Each ball has a different color than the ball below and the ball in the right box. |
| 5*. (j ≠ 1 ∧ color() = color()) ∨ (color() = color()) | A ball is painted with the color of the top-left ball or the bottom ball in the left box if the ball to be painted is the first one. |
| Instruction | Probability % |
|---|---|
| 1. Choose a color and in each box paint at least two balls of that color. | |
| 2. In each box, choose a color and paint at least two balls of that color. | |
| 3. In at least two boxes, choose a color and paint each ball of that color. | |
| 4. Paint each box only if the adjacent boxes are not painted. Choose two other colors and in each box, paint every ball such that each ball has a different color with the adjacent balls inside the box and the ball in the same position but in the adjacent boxes. | |
| 5. Choose a color and paint each ball with the ball’s color that is just above in the left adjacent box. If there is no ball above in the left adjacent box, paint with the ball’s color at the bottom of the left adjacent box. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tapia-Mandiola, S.; Araya, R. From Play to Understanding: Large Language Models in Logic and Spatial Reasoning Coloring Activities for Children. AI 2024, 5, 1870-1892. https://doi.org/10.3390/ai5040093
Tapia-Mandiola S, Araya R. From Play to Understanding: Large Language Models in Logic and Spatial Reasoning Coloring Activities for Children. AI. 2024; 5(4):1870-1892. https://doi.org/10.3390/ai5040093
Chicago/Turabian StyleTapia-Mandiola, Sebastián, and Roberto Araya. 2024. "From Play to Understanding: Large Language Models in Logic and Spatial Reasoning Coloring Activities for Children" AI 5, no. 4: 1870-1892. https://doi.org/10.3390/ai5040093
APA StyleTapia-Mandiola, S., & Araya, R. (2024). From Play to Understanding: Large Language Models in Logic and Spatial Reasoning Coloring Activities for Children. AI, 5(4), 1870-1892. https://doi.org/10.3390/ai5040093