
Arabic Spam Tweets Classification: A Comprehensive Machine Learning Approach



Abstract
1. Introduction
2. Literature Review
2.1. Related Studies in English Tweet Spam Detection
2.2. Related Studies in Arabic Tweet Spam Detection
3. Materials and Methods
3.1. Ensemble Machine Learning Techniques and Algorithms
3.2. Deep Learning Techniques
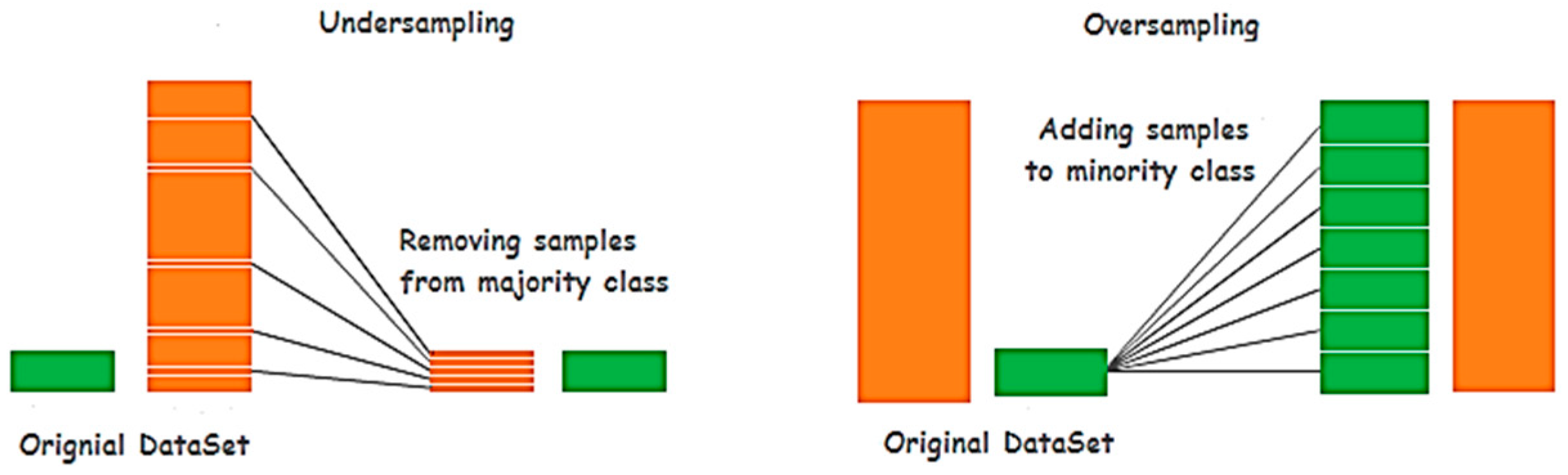
3.3. Synthetic Minority Over-Sampling Technique (SMOTE)
3.4. Natural Language Processing (NLP)
3.5. Dataset
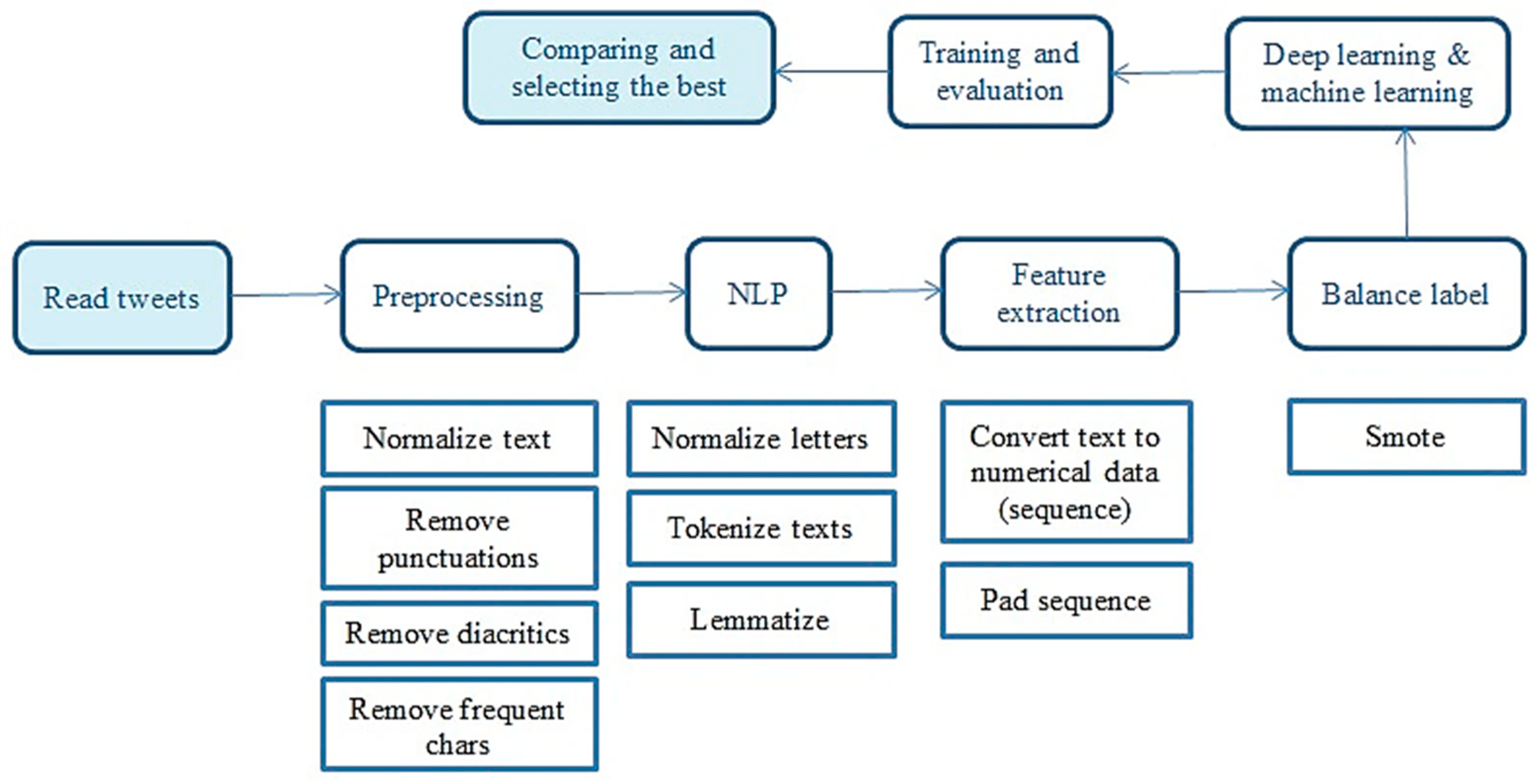
4. Proposed Approach
- Read data from Twitter using Panda’s library of Python language and extract the data frame.
- Preprocessing: This step is crucial when applying AI algorithms because algorithms are only sometimes compatible with it.
- NLP: This step is essential to converting data to a form to which can AI be applied. It contains normalizing letters, to convert letters with multiple forms to a single form. Tokenize text or convert each word to a token for initializing data to the next. Lemmatizing means converting each word to the root.
- Feature extraction means converting each word to a number and replacing each word with its number. This step is essential to convert non-numerical data to numerical data suitable for AI.
- Balancing: when the first class has more samples than the second class, the performance will not be good, so balancing means generating samples for the class that has fewer samples to be balanced with another class.
- ML and deep learning: This step builds and trains ensemble ML and DL models on ready data.
- Evaluation: comparing accuracy and other metrics to evaluate two or more models to select the best.
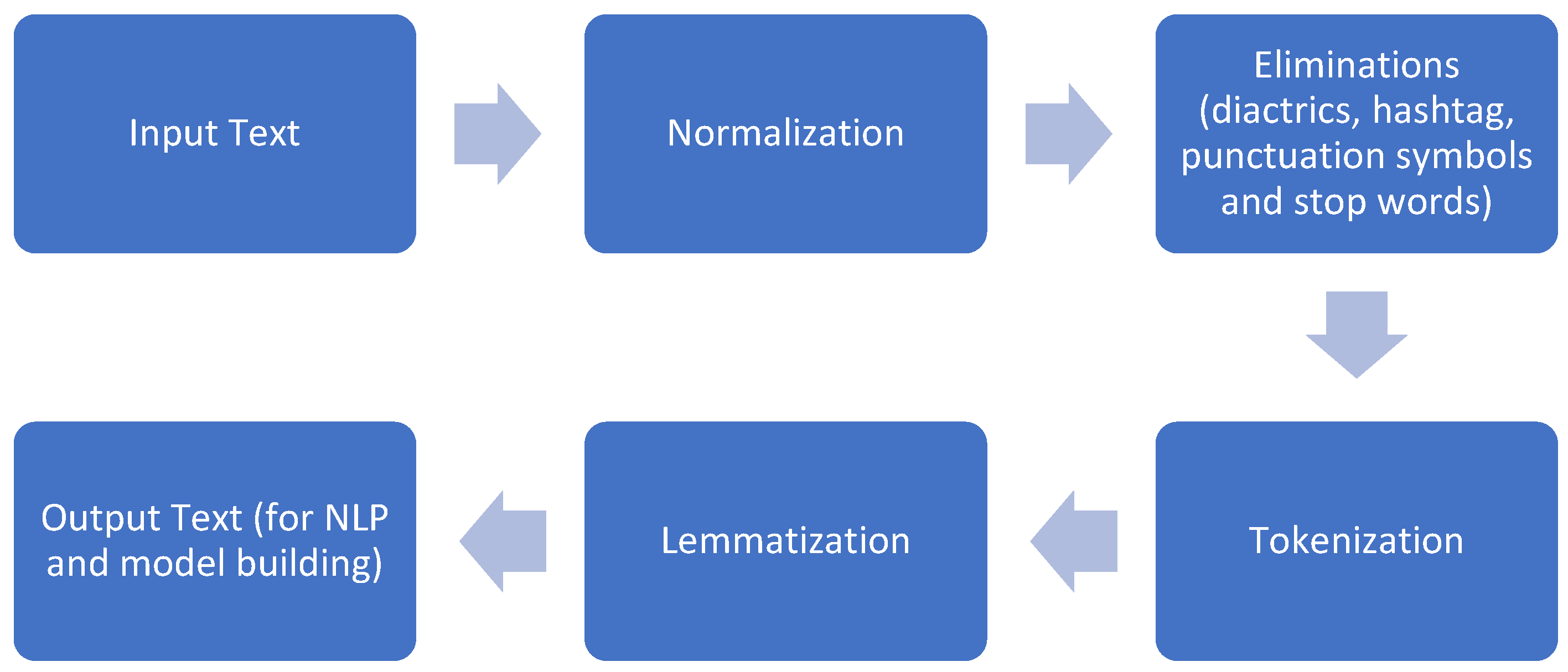
4.1. Data Preprocessing
- (a)
- Text Normalization: Normalization is the process of reducing letters to their basic form. As the Arabic language is rich morphologically, it requires normalization. For instance, Tatweel (like: “كتــــــــــــــــــــــــــــــــــــــــــــــاب” to “كتاب”). Table 3 presents the normalization form for certain Arabic letters.
- (b)
- Removing diacritics (
![Ai 05 00052 i001]() ), punctuation (‘+*/….), and repeating chars: removing diacritics, punctuation, and repeating characters to clean and standardize the text data for further analysis. For instance, “أَكَلَ مُحَمَّد تُفَاحَة” to “أكل محمد تفاحة”; this is shown in Table 4, taken from our previous work [44].
), punctuation (‘+*/….), and repeating chars: removing diacritics, punctuation, and repeating characters to clean and standardize the text data for further analysis. For instance, “أَكَلَ مُحَمَّد تُفَاحَة” to “أكل محمد تفاحة”; this is shown in Table 4, taken from our previous work [44].
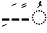
- (c)
- Eliminating hashtags, user references or indications, and URLs.
- (d)
- Eliminating punctuation symbols, for instance, full stops and commas, because they do not play any significant role in spam detection.
- (e)
- Eliminating stop words: Stop words are applied to formation of the language but usually do not contribute to its subjects. For instance, الذي, هذا, من are a few Arabic stop words. The Arabic stop words are collected from various Arabic sources [44]. A few examples of stop words are given in Table 5.
- (f)
- Tokenization: Convert the text into tokens, individual words, or meaningful units to facilitate further analysis. After the tokenization step, the data becomes separable and more adequate for the analysis.
- (g)
- Lemmatization: Convert each word to its base or root form to reduce inflectional variations and ensure consistency. In the existing studies, stemming was used in this regard, though that is vulnerable to over-stemming and under-stemming phenomenon. Though a bit computationally expensive, lemmatization is way better in terms of accuracy, since it keeps the context intact while returning the word base form, aka lemma, from the dictionary. It efficiently handles grammar and delivers the accurate language representation.
4.2. Split, Training and Testing Dataset
4.3. Feature Extraction
4.3.1. Term Frequency–Inverse Document Frequency (TF-IDF)
4.3.2. Sequence of N Words (N-Gram)
4.4. Dataset Balancing
4.5. Model Evaluation
- Accuracy is the ratio of true classified (TP and TN) outcomes to the total number of classified instances (TP, TN, FP and FN). It can be calculated as the following equation:
- The recall is calculated as the percentage of positive tweets (TP) correctly identified by the model in the dataset. It can be calculated using the following equation:
- The precision measure represents the proportion of true positive (TP) tweets among all forecasted positive tweets (TP and FP), and is calculated using the following equation:
- The F1-score is a measure that combines precision and recall in a harmonic mean. The equation to calculate the F1-score is as follows:
5. Results and Discussion
5.1. Results
5.2. Comparison with State-of-the-Art Approaches
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Atta-ur-Rahman; Dash, S.; Luhach, A.K.; Chilamkurti, N.; Baek, S.; Nam, Y. A Neuro-fuzzy approach for user behaviour classification and prediction. J. Cloud Comp. 2019, 8, 1–15. [Google Scholar] [CrossRef]
- Alqahtani, A.; Alhaidari, F.; Rahman, A.; Mahmud, M.; Sultan, K. Decision Support System Assisted E-Recruiting System. J. Comput. Theor.Nanosci. 2019, 16, 335–340. [Google Scholar]
- Sajid, N.A.; Rahman, A.; Ahmad, M.; Musleh, D.; Basheer Ahmed, M.I.; Alassaf, R.; Chabani, S.; Ahmed, M.S.; Salam, A.A.; AlKhulaifi, D. Single vs. Multi-Label: The Issues, Challenges and Insights of Contemporary Classification Schemes. Appl. Sci. 2023, 13, 6804. [Google Scholar] [CrossRef]
- Rahman, A.; Alrashed, S.A.; Abraham, A. User Behaviour Classification and Prediction Using Fuzzy Rule Based System and Linear Regression. J. Inf. Assur. Secur. 2017, 12, 86–93. [Google Scholar]
- Aljabri, M.; Mohammad, R.M.A. Click fraud detection for online advertising using machine learning. Egypt. Inform. J. 2023, 24, 341–350. [Google Scholar] [CrossRef]
- Al-Azani, S.; El-Alfy, E.-S.M. Detection of Arabic spam tweets using word embedding and machine learning. In Proceedings of the 2018 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakhier, Bahrain, 18–20 November 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Dasarathy, B.; Sheela, B. A composite classifier system design: Concepts and methodology. Proc. IEEE 1979, 67, 708–713. [Google Scholar] [CrossRef]
- Hansen, L.K.; Salamon, P. Neural network ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 993–1001. [Google Scholar] [CrossRef]
- Schapire, R.E. The strength of weak learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef]
- Polikar, R. Ensemble Learning in Ensemble Machine Learning: Methods and Applications; Springer: Boston, MA, USA, 2012; pp. 1–34. [Google Scholar]
- Modi, J.H. Detection of Web Spam using Different Classification Algorithms. Int. J. Eng. Res. Technol. IJERT 2014, 3, 718–720. [Google Scholar]
- Bahnsen, A.C.; Bohorquez, E.C.; Villegas, S.; Vargas, J.; Gonzalez, F.A. Classifying phishing URLs using recurrent neural networks. In Proceedings of the 2017 APWG Symposium on Electronic Crime Research (eCrime), Scottsdale, AZ, USA, 25–27 April 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Preethi, V.; Velmayil, G. Automatic phishing website detection using URL features and machine learning technique. Int. J. Eng. Tech. 2016, 2, 107–115. Available online: http://www.ijetjournal.org (accessed on 1 December 2019).
- Nagaraj, K.; Bhattacharjee, B.; Sridhar, A.; Gs, S. Detection of phishing websites using a novel twofold ensemble model. J. Syst. Inf. Technol. 2018, 20, 1328–7265. [Google Scholar] [CrossRef]
- Ubing, A.A.; Kamilia, S.; Abdullah, A.; Jhanjhi, N.; Supramaniam, M. Phishing website detection: An improved accuracy through feature selection and ensemble learning. Int. J. Adv. Comput. Sci. Appl. IJACSA 2019, 10, 252–257. [Google Scholar] [CrossRef]
- Hassan, R.; Islam, R. Detection of fake online reviews using semi-supervised and supervised learning. In Proceedings of the International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Jain, N.; Kumar, A.; Singh, S.; Singh, C.; Tripathi, S. Deceptive Reviews Detection Using Deep Learning Techniques; Springer Nature: Cham, Switzerland, 2019. [Google Scholar]
- Mani, S.; Kumari, S.; Jain, A.; Kumar, P. Spam review detection using ensemble machine learning. In Proceedings of the Machine Learning and Data Mining in Pattern Recognition: 14th International Conference, MLDM 2018, New York, NY, USA, 15–19 July 2018; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Bin Siddique, Z.; Khan, M.A.; Din, I.U.; Almogren, A.; Mohiuddin, I.; Nazir, S. Machine Learning-Based Detection of Spam Emails. Sci. Program. 2021, 2021, 6508784. [Google Scholar] [CrossRef]
- Dewis, M.; Viana, T. Cyber and Phish Responder: A Hybrid Machine Learning Approach to Detect Phishing and Spam Emails. Appl. Syst. Innov. 2022, 5, 73. [Google Scholar] [CrossRef]
- Alzaqebah, M.; Jawarneh, S.; Mohammad, R.M.A.; Alsmadi, M.K.; Almarashdeh, I. Improved Multi-Verse Optimizer Feature Selection Technique with Application to Phishing, Spam, and Denial of Service Attacks. Int. J. Commun. Netw. Inf. Secur. IJCNIS 2021, 13, 76–81. [Google Scholar] [CrossRef]
- AbdulNabi, I.; Yaseen, Q. Spam Email Detection Using Deep Learning Techniques. Procedia Comput. Sci. 2021, 184, 853–858. [Google Scholar] [CrossRef]
- Al-Kabi, M.N.; Wahsheh, H.A.; Alsmadi, I.M. OLAWSDS: An Online Arabic Web Spam Detection System. Int. J. Adv. Comput. Sci. Appl. 2014, 5, 105–110. [Google Scholar]
- Ghourabi, A.; Mahmood, M.A.; Alzubi, Q.M. A Hybrid CNN-LSTM Model for SMS Spam Detection in Arabic and English Messages. Future Internet 2020, 12, 156. [Google Scholar] [CrossRef]
- Mohammed, M.A.; Ibrahim, D.A.; Salman, A.O. Adaptive intelligent learning approach based on visual anti-spam email model for multi-natural language. J. Intell. Syst. 2021, 30, 774–792. [Google Scholar] [CrossRef]
- Alkadri, A.M.; Elkorany, A.; Ahmed, C. Enhancing Detection of Arabic Social Spam Using Data Augmentation and Machine Learning. Appl. Sci. 2022, 12, 11388. [Google Scholar] [CrossRef]
- Saeed, R.M.; Rady, S.; Gharib, T.F. An ensemble approach for spam detection in Arabic opinion texts. J. King SaudUniv.-Comput. Inf. Sci. 2022, 34, 1407–1416. [Google Scholar] [CrossRef]
- Alzanin, S.M.; Azmi, A.M. Rumor detection in Arabic tweets using semi-supervised and unsupervised expectation-maximization. Knowl. Based Syst. 2019, 185, 104945. [Google Scholar] [CrossRef]
- Dakalbab, F.; Abu Talib, M.; Abu Waraga, O.; Nassif, A.B.; Abbas, S.; Nasir, Q. Artificial intelligence & crime prediction: A systematic literature review. Soc. Sci. Humanit. Open 2022, 6, 100342. [Google Scholar]
- Alotaibi, A.; Rahman, A.-U.; Alhaza, R.; Alkhalifa, W.; Alhajjaj, N.; Alharthi, A.; Abushoumi, D.; Alqahtani, M.; Alkhulaifi, D. Spam and sentiment detection in Arabic tweets using MARBERT model. Math. Model. Eng. Probl. 2022, 9, 1574–1582. [Google Scholar] [CrossRef]
- Alorini, D.; Rawat, D.B. Bayesian reasoning based malicious data discovery on gulf-dialectical arabic tweets. In Proceedings of the 2018 IEEE International Symposium on Technology and Society (ISTAS), Washington, DC, USA, 13–14 November 2018; pp. 133–138. [Google Scholar] [CrossRef]
- AlGhamdi, M.A.; Khan, M.A. Intelligent Analysis of Arabic Tweets for Detection of Suspicious Messages. Arab. J. Sci. Eng. 2020, 45, 6021–6032. [Google Scholar] [CrossRef]
- Alhassun, A.S.; Rassam, M.A. A Combined Text-Based and Metadata-Based Deep-Learning Framework for the Detection of Spam Accounts on the Social Media Platform Twitter. Processes 2022, 10, 439. [Google Scholar] [CrossRef]
- Kaddoura, S.; Alex, S.A.; Itani, M.; Henno, S.; AlNashash, A.; Hemanth, D.J. Arabic spam tweets classification using deep learning. Neural Comput. Appl. 2023, 35, 17233–17246. [Google Scholar] [CrossRef]
- Kaddoura, S.; Henno, S. Dataset of Arabic spam and ham tweets. Data Brief 2024, 52, 109904. [Google Scholar] [CrossRef]
- Hassan, S.I.; Elrefaei, L.; Andraws, M. Arabic Tweets Spam Detection Based on Various Supervised Machine Learning and Deep Learning Classifiers. MSA Eng. J. 2023, 2, 1099–1119. [Google Scholar] [CrossRef]
- Thomas, R.N.; Gupta, R. A survey on machine learning approaches and its techniques. In Proceedings of the 2020 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS), Bhopal, India, 22–23 February 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Alabbad, D.A.; Ajibi, S.Y.; Alotaibi, R.B.; Alsqer, N.K.; Alqahtani, R.A.; Felemban, N.M.; Rahman, A.; Aljameel, S.S.; Ahmed, M.I.B.; Youldash, M.M. Birthweight Range Prediction and Classification: A Machine Learning-Based Sustainable Approach. Mach. Learn. Knowl. Extr. 2024, 6, 770–788. [Google Scholar] [CrossRef]
- Musleh, D.A.; Alkhwaja, I.; Alkhwaja, A.; Alghamdi, M.; Abahussain, H.; Alfawaz, F.; Min-Allah, N.; Abdulqader, M.M. Arabic Sentiment Analysis of YouTube Comments: NLP-Based Machine Learning Approaches for Content Evaluation. Big Data Cogn. Comput. 2023, 7, 127. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.-L.; Chen, S.-C.; Iyengar, S.S. A survey on deep learning. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Lindemann, B.; Müller, T.; Vietz, H.; Jazdi, N.; Weyrich, M. A survey on long short-term memory networks for time series prediction. Procedia CIRP 2021, 99, 650–655. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Qureshi, M.A.; Asif, M.; Anwar, S.; Shaukat, U.; Rahman, A.; Khan, M.A.; Mosavi, A. Aspect level songs rating based upon reviews in English. Comput. Mater. Contin. 2023, 74, 2589–2605. [Google Scholar]
- Alqarni, A.; Rahman, A. Arabic Tweets-Based Sentiment Analysis to Investigate the Impact of COVID-19 in KSA: A Deep Learning Approach. Big Data Cogn. Comput. 2023, 7, 16. [Google Scholar] [CrossRef]
- Musleh, D.A.; Alkhales, T.A.; Almakki, R.A.; Alnajim, S.E.; Almarshad, S.K.; Alhasaniah, R.S.; Aljameel, S.S.; Almuqhim, A.A. Twitter Arabic sentiment analysis to detect depression using machine learning. Comput. Mater. Contin. 2022, 71, 3463–3477. [Google Scholar]
- Jan, F.; Rahman, A.; Busaleh, R.; Alwarthan, H.; Aljaser, S.; Al-Towailib, S.; Alshammari, S.; Alhindi, K.R.; Almogbil, A.; Bubshait, D.A.; et al. Assessing Acetabular Index Angle in Infants: A Deep Learning-Based Novel Approach. J. Imaging 2023, 9, 242. [Google Scholar] [CrossRef]
- Ahmed, M.I.B.; Saraireh, L.; Rahman, A.; Al-Qarawi, S.; Mhran, A.; Al-Jalaoud, J.; Al-Mudaifer, D.; Al-Haidar, F.; AlKhulaifi, D.; Youldash, M.; et al. Personal Protective Equipment Detection: A Deep-Learning-Based Sustainable Approach. Sustainability 2023, 15, 13990. [Google Scholar] [CrossRef]
- Ahmed, M.I.B.; Alabdulkarem, H.; Alomair, F.; Aldossary, D.; Alahmari, M.; Alhumaidan, M.; Alrassan, S.; Rahman, A.; Youldash, M.; Zaman, G. A Deep-Learning Approach to Driver Drowsiness Detection. Safety 2023, 9, 65. [Google Scholar] [CrossRef]
- Ahmed, M.S.; Rahman, A.; AlGhamdi, F.; AlDakheel, S.; Hakami, H.; AlJumah, A.; AlIbrahim, Z.; Youldash, M.; Alam Khan, M.A.; Basheer Ahmed, M.I. Joint Diagnosis of Pneumonia, COVID-19, and Tuberculosis from Chest X-ray Images: A Deep Learning Approach. Diagnostics 2023, 13, 2562. [Google Scholar] [CrossRef]
- Musleh, D.; Rahman, A.; Alkherallah, M.A.; AlBo-Hassan, M.K.; Alawami, M.M.; Alsebaa, H.A.; Alnemer, J.A.; Al-Mutairi, G.F.; Aldossary, M.I.; Aldowaihi, D.A.; et al. Machine Learning Approach to Cyberbullying Detection in Arabic Tweets. Comput. Mater. Contin. 2024, 80, 1–21. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Method/Classifier | Dataset | Evaluation |
|---|---|---|---|---|
| [11] | 2023 | LADTree, Naïve Bayes and SVM using WEKA. | The dataset collects both feature and link content. | Precision 83.1% and Recall 81.8% |
| [12] | 2017 | RF and RNN | The database comprised of one million legitimate URLs | Accuracy of 98.7% |
| [15] | 2019 | Logistic Regression (LR), RF, Prediction model | A dataset of phishing websites from the university repository | Accuracy of 95% |
| [16] | 2019 | NB | A dataset comprising around 1600 reviews in textual form from twenty hotels in USA. | Accuracy of 86.32% |
| [18] | 2018 | NB, RF, and SVM. | The dataset contains 10-fold cross-validation. | Accuracy of 87.68%. |
| [19] | 2021 | CNN, NB, LSTM, and SVM | Spam emails from Kaggle | The highest accuracy achieved by the LSTM model was 98.4% |
| [20] | 2023 | LSTM, MLP and Phish Responder | Spam base (Numeric), PhishingEmail Collection (Numerical), Spam Email Dataset (Text), Spam Email (Text), Spam Classification for Basic NLP (Text), Spam Email (Numerical) | LSTM with textual dataset accuracy 99%. MLP with numerical datasets accuracy 94%. |
| [22] | 2021 | DNN (Deep Neural Network) | Two open-source datasets were used for email spam | Accuracy of 98.67% and F1 98.66%. |
| Ref. | Year | Method/Classifier | Dataset | Evaluation |
|---|---|---|---|---|
| [6] | 2019 | Word Embedding with machine learning (DT, NB and SVM) | Publicly available dataset of 3503 tweets | Accuracy 87.33% for word2vec with SVM |
| [26] | 2022 | SVM, NB, and LR | Arabic tweets dataset of a size of 1.6 million instances collected over a span of five months | The proposed approach indicated a 58% to 89% improvement in F1-score. A total accuracy of 92% with a small and selected dataset. |
| [28] | 2019 | Semi-supervised expectation–maximization (E-M) and supervised Gaussian NB | Self-collected 271,000 Arabic tweets, consisting of 89 rumors and 88 non-rumor events. | Semi-supervised learning model accuracy 78.6%. |
| [30] | 2023 | BERT, MARBERT | Arabic tweets dataset with 24,513 instances. | F1-score 75% |
| [31] | 2019 | Bayesian Reasoning | Over 2000 Arabic tweets (translated in English) from Gulf dialects: Saudi, Kuwaiti, Emirati, Bahraini, Qatari, and Omani. | Accuracy 91% |
| [32] | 2020 | DT, KNN, Linear Discriminant Algorithm (LAD), SVM, ANN, and LSTM. | Arabic tweets collected using API. | SVM with the highest accuracy of 86.72% |
| [33] | 2022 | CNN | The dataset was obtained to detect spam accounts. | CNN alone accuracy: 80%. The combined model accuracy: 94.27%. |
| [34] | 2023 | SVM, NN, LR, and NB. GloVe and FastText models with DL | Self-collected and labelled Arabic tweets dataset [35] | FastText with DL outperformed rest of the models |
| [36] | 2023 | SVM, CNN-LSTM | Automatically generated Arabic tweets | SVM with unigram: Accuracy 83.11%. CNN-LSTM: 82.65% |
| Letter | Normalized Form |
|---|---|
| إ,أ,آ,ا | ا |
| ى | ي |
| ئ | ء |
| ؤ | ء |
| ة | ه |
| كـ | ك |
| Diacritic Marks | Characters |
|---|---|
| Fatha | 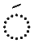 |
| Tashdeed | 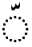 |
| Tanwin Fath |  |
| Damma | 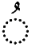 |
| Tanwin Damm | 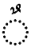 |
| Kasra | 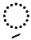 |
| Tanwin Kasr | 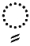 |
| Sukun | 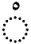 |
| # | Word |
|---|---|
| 1 | انها |
| 2 | اثناء |
| 3 | اجل |
| 4 | في |
| 5 | احيانا |
| 6 | اذا |
| 7 | ايضا |
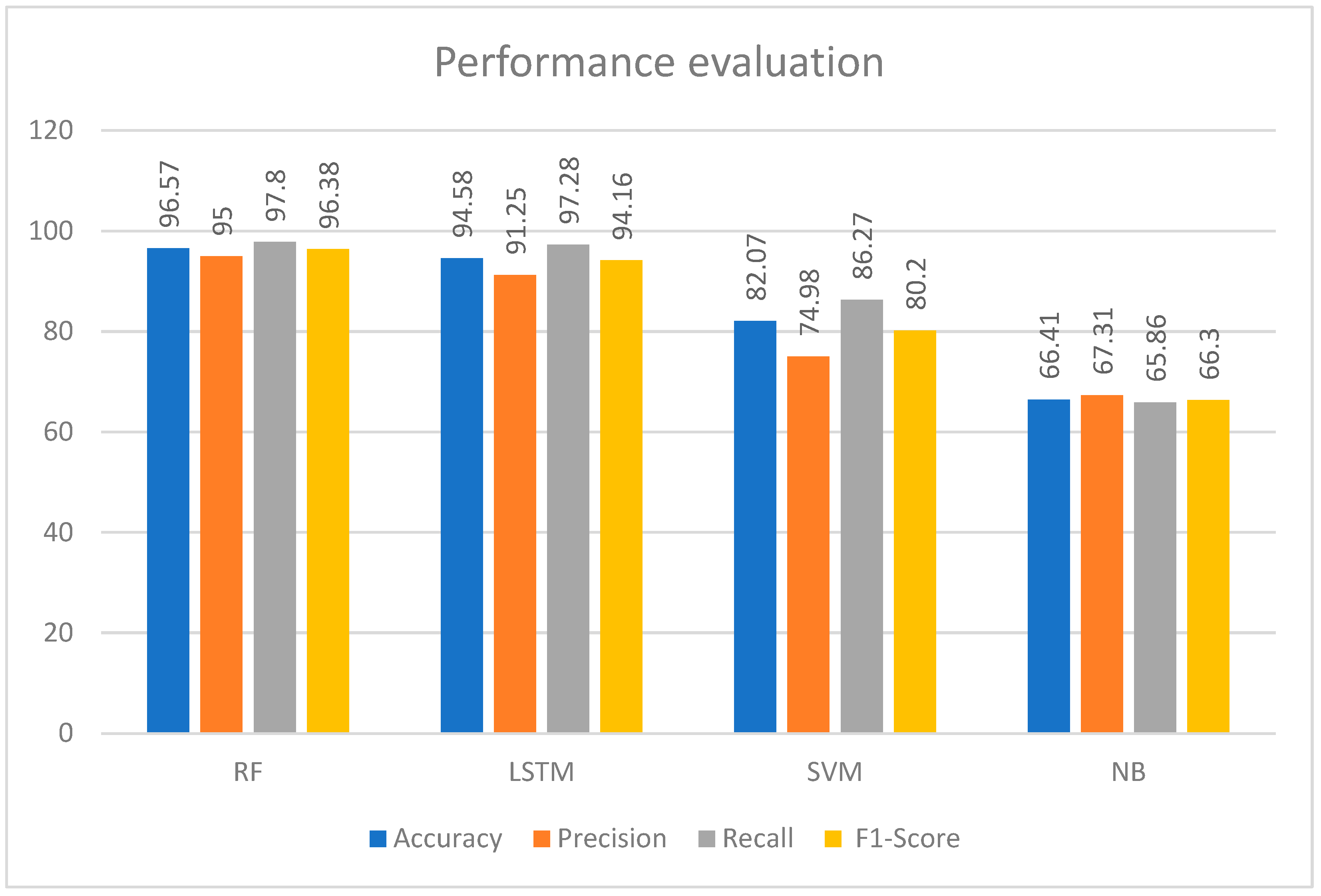
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| RF | 96.57 | 95 | 97.8 | 96.38 |
| LSTM | 94.58 | 91.25 | 97.28 | 94.16 |
| SVM | 82.07 | 74.98 | 86.27 | 80.2 |
| NB | 66.41 | 67.31 | 65.86 | 66.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hantom, W.H.; Rahman, A. Arabic Spam Tweets Classification: A Comprehensive Machine Learning Approach. AI 2024, 5, 1049-1065. https://doi.org/10.3390/ai5030052
Hantom WH, Rahman A. Arabic Spam Tweets Classification: A Comprehensive Machine Learning Approach. AI. 2024; 5(3):1049-1065. https://doi.org/10.3390/ai5030052
Chicago/Turabian StyleHantom, Wafa Hussain, and Atta Rahman. 2024. "Arabic Spam Tweets Classification: A Comprehensive Machine Learning Approach" AI 5, no. 3: 1049-1065. https://doi.org/10.3390/ai5030052
APA StyleHantom, W. H., & Rahman, A. (2024). Arabic Spam Tweets Classification: A Comprehensive Machine Learning Approach. AI, 5(3), 1049-1065. https://doi.org/10.3390/ai5030052