
_Bryant.png)




Chatbots Put to the Test in Math and Logic Problems: A Comparison and Assessment of ChatGPT-3.5, ChatGPT-4, and Google Bard




Abstract
:1. Introduction and Purpose of the Study
- Understand the problem: Chatbots must be able to accurately interpret the user’s input, recognize the type of problem being posed, and identify the relevant information needed to solve it.
- Apply appropriate algorithms or methods: Chatbots need to utilize appropriate problem-solving techniques or mathematical algorithms to tackle the given problem. This may involve arithmetic, algebra, calculus, or logical reasoning, depending on the complexity of the problem.
- Generate a coherent response and the correct answer: Once a solution is derived, chatbots should present the answer in a clear and concise manner, making sure the response is relevant and easy for the user to understand. Also, the final answer to the question should be mathematically correct.
- Performance Evaluation: How do ChatGPT-3.5, ChatGPT-4, and Google Bard perform in solving a diverse range of math and logic problems, and what understanding, problem-solving ability, and accuracy do they have?
- Comparative Analysis: What are the key differences in the performance of these chatbot systems in addressing different types of math and logic problems, and how are these differences manifested?
- Contextual Performance: How does the performance of the chatbots vary based on the complexity and nature of the problems, and what role does the context of the problem play in their capabilities?
- Comparison Across Generations: How does ChatGPT-4 compare to its predecessor, ChatGPT-3.5, in terms of improvements in accuracy, problem solving, and contextual understanding?
- External Resources Impact: What impact does Google Bard’s access to the internet and Google search have on its performance, particularly when addressing problems with publicly available solutions online?
- User Experience: How do users perceive these chatbots in an educational context, and what insights can be drawn regarding user preferences and trust in chatbot-generated responses?
2. Chatbots Used in the Study
2.1. ChatGPT-3.5 and ChatGPT-4
- Transformer architecture: The transformer model, proposed by Vaswani et al. in 2017 [19], is the backbone of ChatGPT. It uses self-attention mechanisms to process input data in parallel rather than sequentially, allowing it to efficiently handle long-range dependencies on the text.
- Pre-training: ChatGPT is pre-trained on a large corpus of text from the internet. During this unsupervised learning phase, it learns the structure and statistical properties of the language, including grammar, vocabulary, and common phrases. The objective is to predict the next word in a sentence, given the context of the preceding words.
- Fine-tuning: After the pre-training phase, ChatGPT is fine-tuned on a smaller dataset, often containing specific conversational data. This supervised learning phase involves training the model to generate appropriate responses in a conversational setting. The model learns from human-generated input–output pairs and refines its ability to provide contextually relevant and coherent responses.
- Tokenization: When ChatGPT receives input text, it tokenizes the text into smaller units, such as words or subwords. These tokens are then mapped to unique IDs, which are used as input for the model.
- Encoding and decoding: The transformer architecture consists of an encoder and a decoder. The encoder processes the input tokens, while the decoder generates the output tokens sequentially. Both the encoder and decoder rely on self-attention mechanisms and feed-forward neural networks to process and generate text.
- Attention mechanisms: Attention mechanisms enable the model to weigh the importance of different parts of the input when generating a response. This helps ChatGPT to focus on the most relevant information in the input text and generate coherent and contextually appropriate responses.
- Probability distribution: The model’s output is a probability distribution over the vocabulary for the next token in the sequence. The token with the highest probability is chosen, and this process is repeated until the model generates a complete response or reaches a predefined maximum length.
- Beam search or other decoding strategies: To generate the most likely response, ChatGPT uses decoding strategies like beam search, which maintains a set of top-k candidate sequences at each time step. These strategies help in finding a balance between fluency and coherence while minimizing the risk of generating nonsensical or overly verbose outputs.
GPT-3.5 vs. GPT-4
- Increased model size: GPT-3 has 175 billion parameters that allow it to take an input and give a text output that best matches the user request. GPT-4 has far more parameters, although the exact number is not known, leading to improved language understanding and generation capabilities. OpenAI has not given information about the size of the GPT-4 model [22].
- Enhanced context understanding: GPT-4 can handle longer text inputs and maintain context better, which allows more coherent and relevant responses.
- Improved fine-tuning: GPT-4 has been fine-tuned on more diverse and specific tasks, allowing it to perform better across a wider range of applications.
- Better handling of ambiguity: GPT-4 is better at resolving ambiguous input and providing clearer, more accurate responses.
- More robust language support: GPT-4 has been trained on a broader range of languages and can better handle multilingual tasks and code switching.
- Enhanced safety and ethical considerations: GPT-4 has been designed with more robust safety measures to prevent harmful outputs, ensuring better alignment with human values.
- Domain-specific knowledge: GPT-4 has been trained on more specific knowledge domains, allowing it to provide more accurate information and support specialized tasks.
2.2. Google Bard
- Natural language processing (NLP): NLP is a field of computer science that deals with the interaction between computers and human (natural) languages. NLP is used in Bard to understand and process the text that the user inputs.
- Machine learning (ML): ML is a field of computer science that gives computers the ability to learn without being explicitly programmed. ML is used in Bard to train the model on the massive dataset of text and code.
- Deep learning (DL): DL is a subset of ML that uses artificial neural networks to learn from data. DL is used in Bard to train the model to generate text, translate languages, write different kinds of creative content, and answer user questions in an informative way.
2.3. Differences between ChatGPT and Bard
3. Methodology of the Study
- Clarity and Unambiguity: All the questions were designed to be clear and unambiguous to ensure that the chatbots could comprehend the problem statements accurately.
- Diversity: We aimed to include a diverse set of problems to evaluate the chatbots across various mathematical and logical domains.
- Availability: The questions were divided into two sets, with Set A consisting of 15 “Original” problems that were not readily available online and Set B consisting of 15 “Published” problems that could be found online, often with solutions. This division allowed us to assess the chatbots’ ability to handle both novel and publicly available problems.
- Well-Defined Correct Answers: Each question had a unique and well-defined correct answer, which made it possible to objectively evaluate the chatbots’ responses for correctness.
4. Discussion of the Individual Answers to Each Question
4.1. Set A: “Original” Questions
- Questions A01 and A02 (Scores: 3-1-1 and 0-0-0)
A01. “Solve the following cubic equation: x^3 - 13*x^2 + 50*x - 56 = 0”;
A02. “Solve the following cubic equation: 100*x^3 - 1340*x^2 + 5389*x - 6660 = 0”.
- Question A03 (Score: 1-1-0)
“A closed club of professional engineers has 500 members. Some members are “old members” while the others are “new members” (subscribed within one year from now). An event was organized where old members had to pay $200 each for their participation while new members had to pay $140 each. The event was successful and while all new members came, only 70% of the old members attended. What is the amount of money (in $) that was collected from all members for this event?”
- Question A04 (Score: 1-3-0)
“The sum of three adults’ ages is 60. The oldest of them is 6 years older than the youngest. What is the age of each one of them? Assume that an adult is at least 18 years old.”
- Question A05 (Score: 3-3-1)
“A decade ago, the population of a city was 55,182 people. Now, it is 170% larger. What is the city’s current population?”
- Question A06 (Score: 1-3-0)
“What is the precise sum of 523,654,123 and 7,652,432,852,136?”
- Question A07 (Score: 2-3-3)
“You decide to make a road-trip with your new car. The distance between City A and City B is 120 km. When you travel from A to B, your average speed is slow, 60 km/h. When you travel from B to A, your average speed is high, 120 km/h. What is the average speed for the whole trip A to B to A (with return to City A)?”
- Question A08 (Score: 1-3-3)
“If Tom has 35 marbles and I have 12 marbles, and then Tom gives me 9 marbles, how many more marbles does Tom have than I?”
- Question A09 (Score: 3-3-3)
“Tom’s father has three children. The younger child’s name is Erica. The middle child’s name is Sam. What is the name of the older child?”
- Question A10 (Score: 3-3-1)
“A woodworker normally makes a certain number of parts in 11 days. He was able to increase his productivity by 3 parts per day, and so he not only finished the job 2 days earlier, but in addition he made 9 extra parts. How many parts does the woodworker normally make per day?”
- Question A11 (Score: 2-3-0)
“Think of a number. Add 5, double the result, then subtract 12, then take half of the result and finally subtract the initial number. What is the result?”
- Question A12 (Score: 3-2-3)
“If one and a half hens lay one and a half eggs in one and a half days, how many eggs do 9 hens lay in 9 days?”
- Question A13 (Score: 0-2-0)
“Find a 4-digit number so that the last four digits of the number squared is the number itself.”
- Question A14 (Score: 0-3-0)
“The number of water lilies on a lake doubles every two days. If there is initially one water lily on the lake, it takes exactly 50 days for the lake to be fully covered with water lilies. In how many days will the lake be fully covered with water lilies, if initially there were two water lilies (identical with the previous one) on it?”
- Question A15 (Score: 1-3-3)
“There are 25 handball teams playing in a knockout competition (i.e., if you lose a match, you are eliminated and do not continue further). What is the minimum number of matches (in total) they need to play to decide the winner?”
4.2. Set B: “Published” Questions
- Question B01 [23] (Score: 2-3-2)
“A bad guy is playing Russian roulette with a six-shooter revolver. He puts in one bullet, spins the chambers and fires at you, but no bullet comes out. He gives you the choice of whether or not he should spin the chambers again before firing a second time. Should he spin again?”
- Question B02 [23] (Score: 2-3-3)
“Five people were eating apples, A finished before B, but behind C. D finished before E, but behind B. What was the finishing order?”
- Question B03 [23] (Score: 0-0-1)
“A man has 53 socks in his drawer: 21 identical blue, 15 identical black and 17 identical red. The lights are out, and he is completely in the dark. How many socks must he take out to make 100 percent certain he has at least one pair of black socks?”
- Question B04 [23] (Score: 1-1-3)
“Susan and Lisa decided to play tennis against each other. They bet $1 on each game they played. Susan won three bets and Lisa won $5. How many games did they play?”
- Question B05 [23] (Score: 3-3-3)
“Jack is looking at Anne. Anne is looking at George. Jack is married, George is not, and we don’t know if Anne is married. Is a married person looking at an unmarried person?”
- Question B06 [23] (Score: 0-2-3)
“A girl meets a lion and unicorn in the forest. The lion lies every Monday, Tuesday and Wednesday and the other days he speaks the truth. The unicorn lies on Thursdays, Fridays and Saturdays, and the other days of the week he speaks the truth. “Yesterday I was lying,” the lion told the girl. “So was I,” said the unicorn. What day is it?”
- Question B07 [23] (Score: 0-3-1)
“Three men are lined up behind each other. The tallest man is in the back and can see the heads of the two in front of him; the middle man can see the one man in front of him; the man in front can’t see anyone. They are blindfolded and hats are placed on their heads, picked from three black hats and two white hats. The extra two hats are hidden and the blindfolds removed. The tallest man is asked if he knows what color hat he’s wearing; he doesn’t. The middle man is asked if he knows; he doesn’t. But the man in front, who can’t see anyone, says he knows. How does he know, and what color hat is he wearing?”
- Question B08 [23] (Score: 1-1-3)
“A teacher writes six words on a board: “cat dog has max dim tag.” She gives three students, Albert, Bernard and Cheryl each a piece of paper with one letter from one of the words. Then she asks, “Albert, do you know the word?” Albert immediately replies yes. She asks, “Bernard, do you know the word?” He thinks for a moment and replies yes. Then she asks Cheryl the same question. She thinks and then replies yes. What is the word?”
- Question B09 [23] (Score: 0-0-3)
“There are three people (Alex, Ben and Cody), one of whom is a knight, one a knave, and one a spy. The knight always tells the truth, the knave always lies, and the spy can either lie or tell the truth. Alex says: “Cody is a knave.” Ben says: “Alex is a knight.” Cody says: “I am the spy.” Who is the knight, who the knave, and who the spy?”
- Question B10 [24] (Score: 0-0-3)
“Kenny, Abby, and Ned got together for a round-robin pickleball tournament, where, as usual, the winner stays on after each game to play the person who sat out that game. At the end of their pickleball afternoon, Abby is exhausted, having played the last seven straight games. Kenny, who is less winded, tallies up the games played: Kenny played eight games. Abby played 12 games. Ned played 14 games. Who won the fourth game against whom?”
B11. “The distance between two towns is 380 km. At the same moment, a passenger car and a truck start moving towards each other from different towns. They meet 4 h later. If the car drives 5 km/h faster than the truck, what are their speeds?”
B12. “A biker covered half the distance between two towns in 2 h 30 min. After that he increased his speed by 2 km/h. He covered the second half of the distance in 2 h 20 min. Find the distance between the two towns.”
- Question B13 [26] (Score: 2-3-1)
“Rhonda has 12 marbles more than Douglas. Douglas has 6 marbles more than Bertha. Rhonda has twice as many marbles as Bertha has. How many marbles does Douglas have?”
- Question B14 [27] (Score: 3-3-3)
“15 workers are needed to build a wall in 12 days. How long would it take to 10 workers to build the same wall?”
- Question B15 [24] (Score: 0-0-3)
“A hen and a half lay an egg and a half in a day and a half. How many eggs does one hen lay in one day?”
5. Performance of the Chatbots
6. Discussion, Conclusions and Future Research Directions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Weizenbaum, J. ELIZA—A computer program for the study of natural language communication between man and machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Kuhail, M.A.; Alturki, N.; Alramlawi, S.; Alhejori, K. Interacting with educational chatbots: A systematic review. Educ. Inf. Technol. 2023, 28, 973–1018. [Google Scholar] [CrossRef]
- Nguyen, H.D.; Tran, D.A.; Do, H.P.; Pham, V.T. Design an Intelligent System to automatically Tutor the Method for Solving Problems. Int. J. Integr. Eng. 2020, 12, 211–223. [Google Scholar] [CrossRef]
- Tatai, G.; Csordás, A.; Kiss, Á.; Szaló, A.; Laufer, L. Happy Chatbot, Happy User. In Intelligent Virtual Agents. 4th International Workshop, IVA 2003; Rist, T., Aylett, R.S., Ballin, D., Rickel, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2792, pp. 5–12. [Google Scholar] [CrossRef]
- Hu, K. ChatGPT Sets Record for Fastest-Growing User Base—Analyst Note. 2023. Available online: https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/ (accessed on 19 May 2023).
- Bryant, A. AI Chatbots: Threat or Opportunity? Informatics 2023, 10, 49. [Google Scholar] [CrossRef]
- Cheng, H.-W. Challenges and Limitations of ChatGPT and Artificial Intelligence for Scientific Research: A Perspective from Organic Materials. AI 2023, 4, 401–405. [Google Scholar] [CrossRef]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment. JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef] [PubMed]
- Frieder, S.; Pinchetti, L.; Griffiths, R.-R.; Salvatori, T.; Lukasiewicz, T.; Petersen, P.C.; Chevalier, A.; Berner, J. Mathematical Capabilities of ChatGPT. arXiv 2023, arXiv:2301.13867. [Google Scholar] [CrossRef]
- Shakarian, P.; Koyyalamudi, A.; Ngu, N.; Mareedu, L. An Independent Evaluation of ChatGPT on Mathematical Word Problems (MWP). arXiv E-Prints 2023, arXiv:2302.13814. [Google Scholar]
- Upadhyay, S.; Chang, M.-W. Annotating Derivations: A New Evaluation Strategy and Dataset for Algebra Word Problems. arXiv 2017, arXiv:1609.07197. [Google Scholar]
- Upadhyay, S.; Chang, M.-W.; Chang, K.-W.; Yih, W.-t. Learning from Explicit and Implicit Supervision Jointly For Algebra Word Problems. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Association for Computational Linguistics: Kerrville, TX, USA, 2016; pp. 297–306. [Google Scholar]
- Lan, Y.; Wang, L.; Zhang, Q.; Lan, Y.; Dai, B.T.; Wang, Y.; Zhang, D.; Lim, E.-P. MWPToolkit: An Open-Source Framework for Deep Learning-Based Math Word Problem Solvers. Proc. AAAI Conf. Artif. Intell. 2022, 36, 13188–13190. [Google Scholar] [CrossRef]
- Zheng, S.; Huang, J.; Chang, K.C.-C. Why Does ChatGPT Fall Short in Answering Questions Faithfully? arXiv 2023, arXiv:2304.10513. [Google Scholar]
- Lai, U.H.; Wu, K.S.; Hsu, T.-Y.; Kan, J.K.C. Evaluating the performance of ChatGPT-4 on the United Kingdom Medical Licensing Assessment. Front. Med. 2023, 10, 1240915. [Google Scholar] [CrossRef] [PubMed]
- Plevris, V.; Papazafeiropoulos, G.; Jiménez Rios, A. Dataset of the study: “Chatbots put to the test in math and logic problems: A preliminary comparison and assessment of ChatGPT-3.5, ChatGPT-4, and Google Bard”. Zenodo 2023. [Google Scholar] [CrossRef]
- Plevris, V.; Papazafeiropoulos, G.; Jiménez Rios, A. Chatbots put to the test in math and logic problems: A preliminary comparison and assessment of ChatGPT-3.5, ChatGPT-4, and Google Bard. arXiv 2023, arXiv:2305.18618. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar] [CrossRef]
- Alruqi, T.N.; Alzahrani, S.M. Evaluation of an Arabic Chatbot Based on Extractive Question-Answering Transfer Learning and Language Transformers. AI 2023, 4, 667–691. [Google Scholar] [CrossRef]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of Hallucination in Natural Language Generation. ACM Comput. Surv. 2023, 55, 248. [Google Scholar] [CrossRef]
- Heaven, W.D. GPT-4 is Bigger and Better Than ChatGPT—But OpenAI Won’t Say Why. 2023. Available online: https://www.technologyreview.com/2023/03/14/1069823/gpt-4-is-bigger-and-better-chatgpt-openai/ (accessed on 19 May 2023).
- Parade. 25 Logic Puzzles That Will Totally Blow Your Mind, But Also Prove You’re Kind of a Genius. 2023. Available online: https://parade.com/970343/parade/logic-puzzles/ (accessed on 11 May 2023).
- Feiveson, L. These 20 Tough Riddles for Adults Will Have You Scratching Your Head. 2022. Available online: https://www.popularmechanics.com/science/math/a31153757/riddles-brain-teasers-logic-puzzles/ (accessed on 11 May 2023).
- math10.com. Math Word Problems and Solutions—Distance, Speed, Time. 2023. Available online: https://www.math10.com/en/algebra/word-problems.html (accessed on 11 May 2023).
- Wolfram Alpha LLC. Examples for Mathematical Word Problems. 2023. Available online: https://www.wolframalpha.com/examples/mathematics/elementary-math/mathematical-word-problems (accessed on 12 May 2023).
- 15 Workers Are Needed to Build a Wall in 12 Days. How Long Would 10 Workers Take to Build the Wall? 2023. Available online: https://www.quora.com/15-workers-are-needed-to-build-a-wall-in-12-days-how-long-would-10-workers-take-to-build-the-wall (accessed on 12 May 2023).
- Krichen, M.; Lahami, M.; Al–Haija, Q.A. Formal Methods for the Verification of Smart Contracts: A Review. In Proceedings of the 2022 15th International Conference on Security of Information and Networks (SIN), Sousse, Tunisia, 11–13 November 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Abdellatif, T.; Brousmiche, K. Formal Verification of Smart Contracts Based on Users and Blockchain Behaviors Models. In Proceedings of the 2018 9th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 26–28 February 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Krawczyk, J.; Subramanya, A. Bard Is Getting Better at Logic and Reasoning. 2023. Available online: https://blog.google/technology/ai/bard-improved-reasoning-google-sheets-export/ (accessed on 4 September 2023).

{kind=link}
{kind=link}
| Correct Calculation and Result | 523,654,123 +7,652,432,852,136 |
|---|---|
| 7,652,956,506,259 | |
| ChatGPT-3.5 Attempt #1 | ✓ 7,652,956,506,259 |
| ChatGPT-3.5 Attempt #2 | ✗ 7,653,956,506,259 |
| ChatGPT-3.5 Attempt #3 | ✗ 7,653,956,506,259 |
| Bard Attempt #1 | ✗ 7,652,956,515,259 |
| Bard Attempt #2 | ✗ 7,652,956,505,259 |
| Bard Attempt #3 | ✗ 7,652,956,505,259 |
| ChatGPT-3.5 | ChatGPT-4 | Bard | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Question | #1 | #2 | #3 | SUM | #1 | #2 | #3 | SUM | #1 | #2 | #3 | SUM |
| A01 | 1 | 1 | 1 | 3 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| A02 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| A03 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| A04 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 3 | 0 | 0 | 0 | 0 |
| A05 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 | 0 | 1 | 0 | 1 |
| A06 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 3 | 0 | 0 | 0 | 0 |
| A07 | 1 | 0 | 1 | 2 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 |
| A08 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 |
| A09 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 |
| A10 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 | 1 | 0 | 0 | 1 |
| A11 | 0 | 1 | 1 | 2 | 1 | 1 | 1 | 3 | 0 | 0 | 0 | 0 |
| A12 | 1 | 1 | 1 | 3 | 1 | 0 | 1 | 2 | 1 | 1 | 1 | 3 |
| A13 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 2 | 0 | 0 | 0 | 0 |
| A14 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 3 | 0 | 0 | 0 | 0 |
| A15 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 |
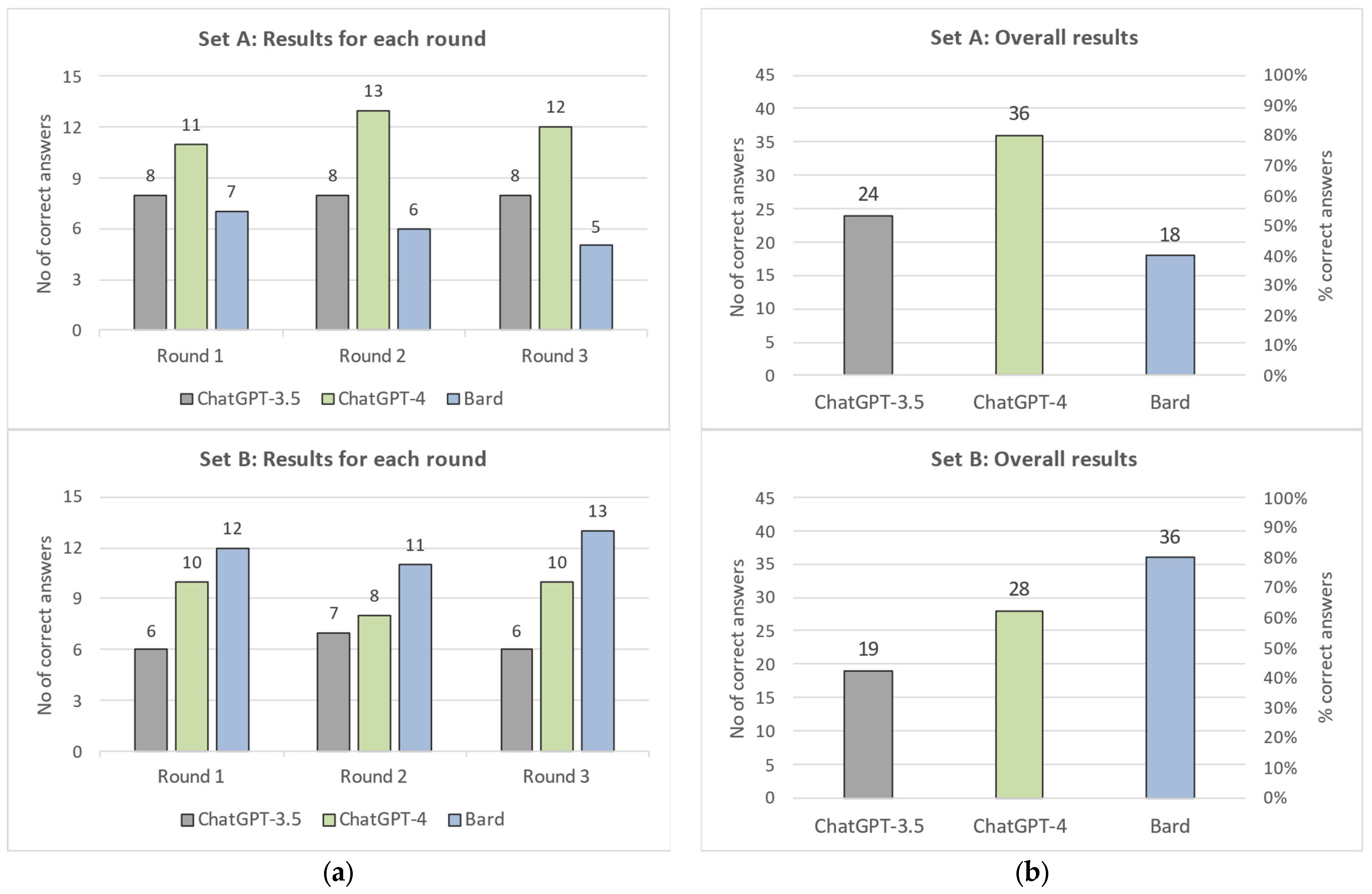
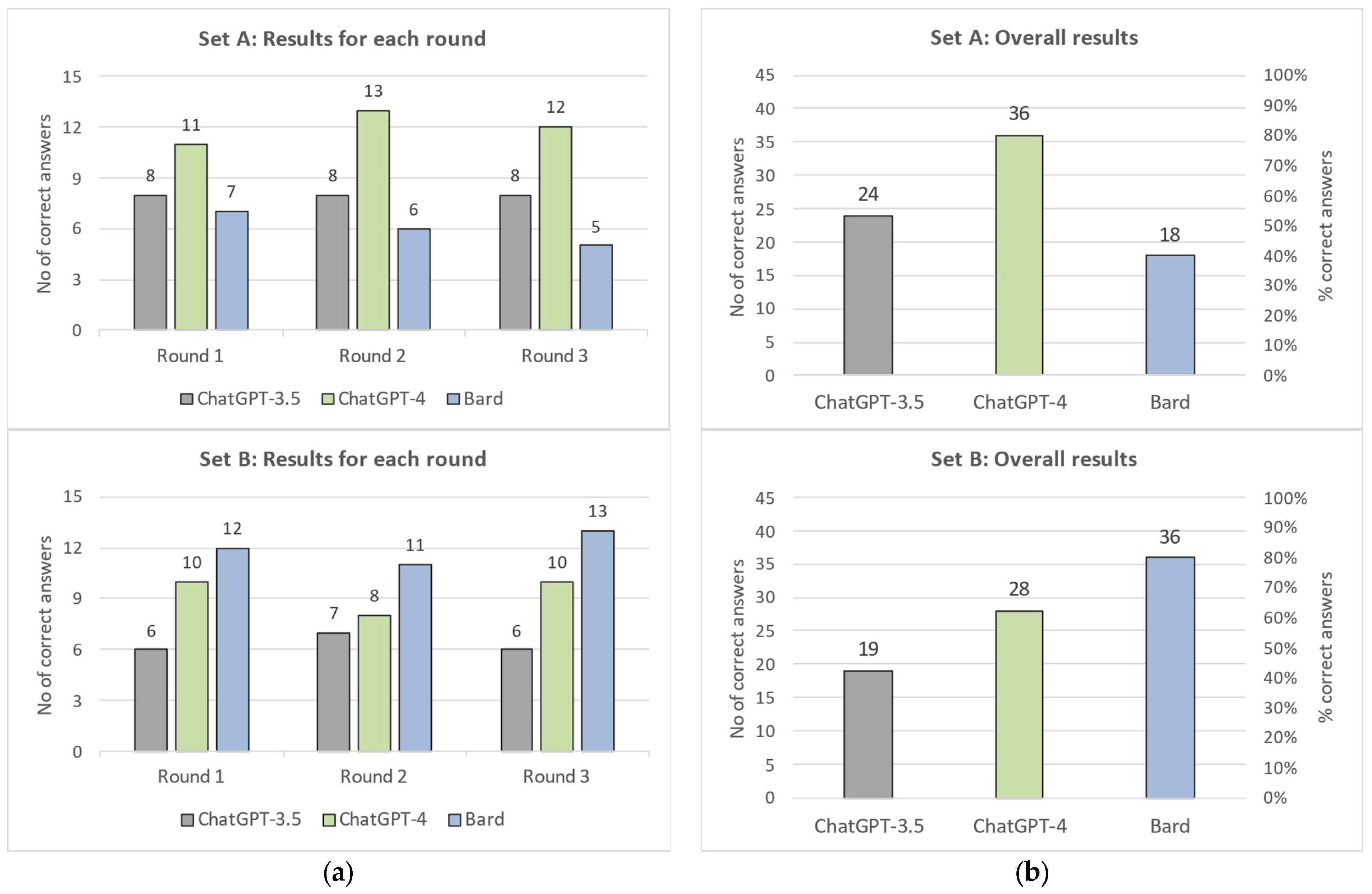
| SUM | 8 | 8 | 8 | 24 | 11 | 13 | 12 | 36 | 7 | 6 | 5 | 18 |
| Percentage | 53.3% | 53.3% | 53.3% | 53.3% | 73.3% | 86.7% | 80.0% | 80.0% | 46.7% | 40.0% | 33.3% | 40.0% |
| ChatGPT-3.5 | ChatGPT-4 | Bard | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Question | #1 | #2 | #3 | SUM | #1 | #2 | #3 | SUM | #1 | #2 | #3 | SUM |
| B01 | 1 | 1 | 0 | 2 | 1 | 1 | 1 | 3 | 0 | 1 | 1 | 2 |
| B02 | 1 | 0 | 1 | 2 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 |
| B03 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| B04 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 3 |
| B05 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 |
| B06 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 2 | 1 | 1 | 1 | 3 |
| B07 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 3 | 0 | 0 | 1 | 1 |
| B08 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 3 |
| B09 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 3 |
| B10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 3 |
| B11 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 | 1 | 0 | 1 | 2 |
| B12 | 0 | 1 | 1 | 2 | 1 | 1 | 1 | 3 | 1 | 1 | 0 | 2 |
| B13 | 1 | 1 | 0 | 2 | 1 | 1 | 1 | 3 | 0 | 0 | 1 | 1 |
| B14 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 | 1 | 1 | 1 | 3 |
| B15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 3 |
| SUM | 6 | 7 | 6 | 19 | 10 | 8 | 10 | 28 | 12 | 11 | 13 | 36 |
| Percentage | 40.0% | 46.7% | 40.0% | 42.2% | 66.7% | 53.3% | 66.7% | 62.2% | 80.0% | 73.3% | 86.7% | 80.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Plevris, V.; Papazafeiropoulos, G.; Jiménez Rios, A. Chatbots Put to the Test in Math and Logic Problems: A Comparison and Assessment of ChatGPT-3.5, ChatGPT-4, and Google Bard. AI 2023, 4, 949-969. https://doi.org/10.3390/ai4040048
Plevris V, Papazafeiropoulos G, Jiménez Rios A. Chatbots Put to the Test in Math and Logic Problems: A Comparison and Assessment of ChatGPT-3.5, ChatGPT-4, and Google Bard. AI. 2023; 4(4):949-969. https://doi.org/10.3390/ai4040048
Chicago/Turabian StylePlevris, Vagelis, George Papazafeiropoulos, and Alejandro Jiménez Rios. 2023. "Chatbots Put to the Test in Math and Logic Problems: A Comparison and Assessment of ChatGPT-3.5, ChatGPT-4, and Google Bard" AI 4, no. 4: 949-969. https://doi.org/10.3390/ai4040048
APA StylePlevris, V., Papazafeiropoulos, G., & Jiménez Rios, A. (2023). Chatbots Put to the Test in Math and Logic Problems: A Comparison and Assessment of ChatGPT-3.5, ChatGPT-4, and Google Bard. AI, 4(4), 949-969. https://doi.org/10.3390/ai4040048