
Can Sequential Images from the Same Object Be Used for Training Machine Learning Models? A Case Study for Detecting Liver Disease by Ultrasound Radiomics

 ,
, 
Abstract
:1. Introduction
2. Methods
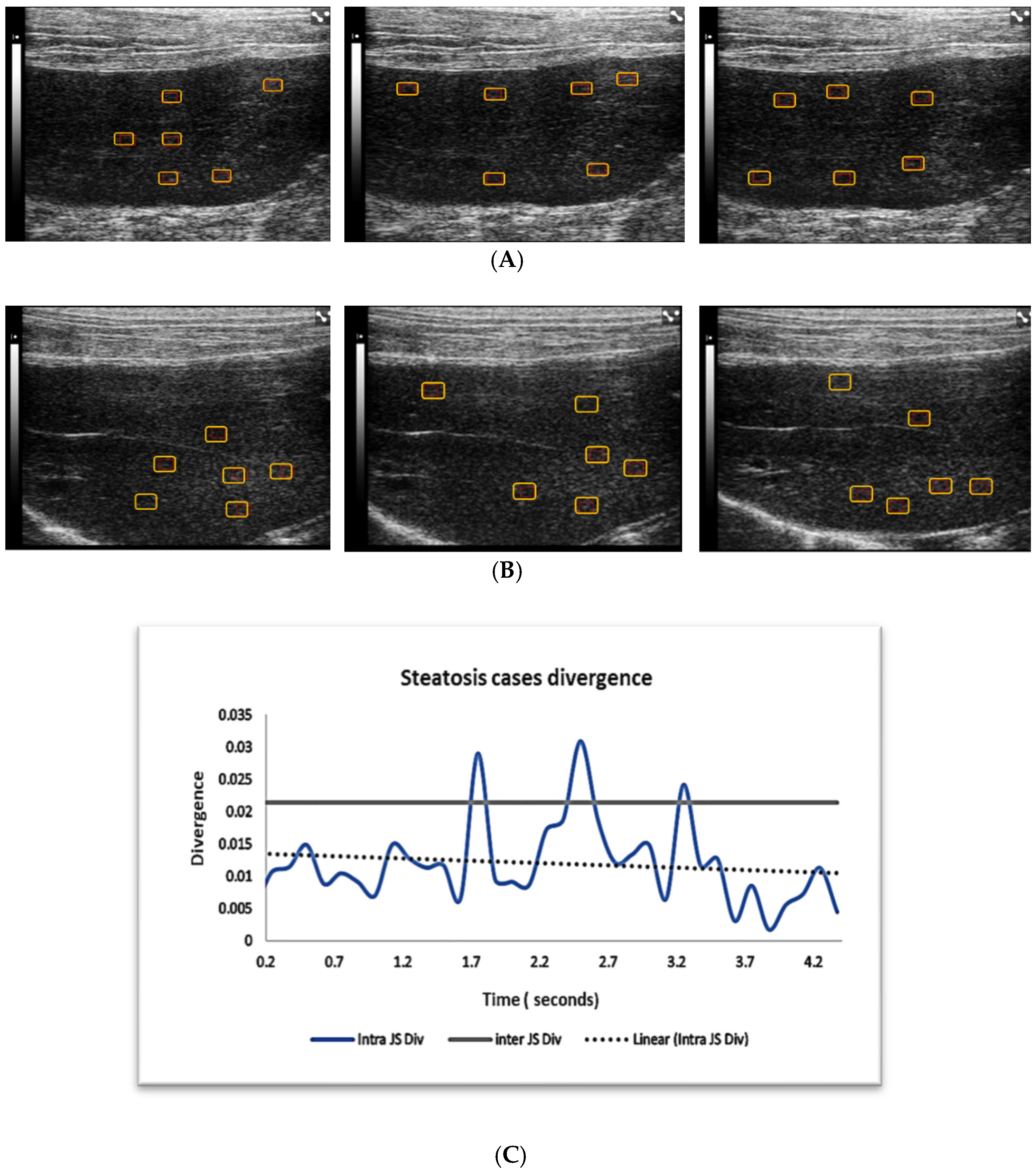
2.1. Image Acquisition and Computerized Analysis
- First order histogram features: including echo intensity, heterogeneity (regional variance between ROIs, internal heterogeneity (local variance within ROIs) [20]. Echo intensity and heterogeneity represent the mean and standard deviation of intensity within an ROI. Heterogeneity is the standard deviation of the echo intensity between the ROIs in all the planes measured throughout the liver.
- Run length features include gray-level nonuniformity (GLNU) and run length nonuniformity (RLNU). These features represent the length of the run, usually the number of pixels for the horizontal or vertical scan direction, or the number of pixels multiplied by a diagonal direction [21].
- Entropy: a gray level connectivity texture feature was also studied [21].
2.2. Feature Statistics and Machine Learning Diagnostic Models
2.3. Intra- and Inter-Case Divergence Analysis
3. Histopathologic Validation
4. Results
4.1. The Classification Performance of Ultrasound Features
4.2. Divergence Testing for Image Independence
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brattain, L.J.; Telfer, B.A.; Dhyani, M.; Grajo, J.R.; Samir, A.E. Machine learning for medical ultrasound: Status, methods, and future opportunities. Abdom. Radiol. 2018, 43, 786–799. [Google Scholar] [CrossRef] [PubMed]
- Aung, Y.Y.M.; Wong, D.C.S.; Ting, D.S.W. The promise of artificial intelligence: A review of the opportunities and challenges of artificial intelligence in healthcare. Br. Med. Bull. 2021, 139, ldab016. [Google Scholar] [CrossRef]
- Willemink, M.J.; Koszek, W.A.; Hardell, C.; Wu, J.; Fleischmann, D.; Harvey, H.; Folio, L.R.; Summers, R.M.; Rubin, D.L.; Lungren, M.P. Preparing Medical Imaging Data for Machine Learning. Radiology 2020, 295, 4–15. [Google Scholar] [CrossRef] [PubMed]
- Vabalas, A.; Gowen, E.; Poliakoff, E.; Casson, A.J. Machine learning algorithm validation with a limited sample size. PLoS ONE 2019, 14, e0224365. [Google Scholar] [CrossRef] [PubMed]
- Teng, D.; Li, F.; Zhang, W. Using comprehensive machine-learning models to classify complex morphological characters. Ecol. Evol. 2021, 11, 10421–10431. [Google Scholar] [CrossRef]
- An, C.; Park, Y.W.; Ahn, S.S.; Han, K.; Kim, H.; Lee, S.K. Radiomics machine learning study with a small sample size: Single random training-test set split may lead to unreliable results. PLoS ONE 2021, 16, e0256152. [Google Scholar] [CrossRef]
- Lehne, M.; Sass, J.; Essenwanger, A.; Schepers, J.; Thun, S. Why digital medicine depends on interoperability. NPJ Digit. Med. 2019, 2, 79. [Google Scholar] [CrossRef]
- Undar, M.; Krishnapuram, B.; Bi, J.; Rao, R.B. Learning Classifiers When the Training Data Is Not IID. IJCAI Int. Jt. 2007, 2007, 756–761. [Google Scholar]
- Darrell, T.; Kloft, M.; Pontil, M.; Rätsch, G.; Rodner, E. Machine Learning with Interdependent and Non-identically Distributed Data (Dagstuhl Seminar 15152). Schloss Dagstuhl-Leibniz-Zent. Fuer Inform. 2015, 5, 4. [Google Scholar] [CrossRef]
- Tillman, R. Structure learning with independent non-identically distributed data. ACM Int. Conf. Proceeding Ser. 2009, 382, 131. [Google Scholar] [CrossRef]
- Kagadis, G.C.; Drazinos, P.; Gatos, I.; Tsantis, S.; Papadimitroulas, P.; Spiliopoulos, S.; Karnabatidis, D.; Theotokas, I.; Zoumpoulis, P.; Hazle, J.D. Deep learning networks on chronic liver disease assessment with fine-tuning of shear wave elastography image sequences. Phys. Med. Biol. 2020, 65, 215027. [Google Scholar] [CrossRef] [PubMed]
- Carrer, L.; Donini, E.; Marinelli, D.; Zanetti, M.; Mento, F.; Torri, E.; Smargiassi, A.; Inchingolo, R.; Soldati, G.; Demi, L.; et al. Automatic Pleural Line Extraction and COVID-19 Scoring From Lung Ultrasound Data. IEEE Trans. Ultrason. Ferroelectr. Freq. Control. 2020, 67, 2207–2217. [Google Scholar] [CrossRef] [PubMed]
- Faes, L.; Wagner, S.K.; Fu, D.J.; Liu, X.; Korot, E.; Ledsam, J.R.; Back, T.; Chopra, R.; Pontikos, N.; Kern, C.; et al. Automated deep learning design for medical image classification by health-care professionals with no coding experience: A feasibility study. Lancet Digit. Health 2019, 1, e232–e242. [Google Scholar] [CrossRef]
- Nirschl, J.J.; Janowczyk, A.; Peyster, E.G.; Frank, R.; Margulies, K.B.; Feldman, M.D.; Madabhushi, A. A deep-learning classifier identifies patients with clinical heart failure using whole-slide images of H&E tissue. PLoS ONE 2018, 13, e0192726. [Google Scholar] [CrossRef]
- Qu, W.; Balki, I.; Mendez, M.; Valen, J.; Levman, J.; Tyrrell, P.N. Assessing and mitigating the effects of class imbalance in machine learning with application to X-ray imaging. Int. J. Comput. Assist. Radiol. Surg. 2020, 15, 2041–2048. [Google Scholar] [CrossRef]
- Pheng, H.S.; Shamsuddin, S.M.; Leng, W.Y. Kullback Leibler divergence for image quantitative evaluation. AIP Conf. Proc. 2016, 1750, 020003. [Google Scholar] [CrossRef]
- Nielsen, F. On the Jensen-Shannon Symmetrization of Distances Relying on Abstract Means. Entropy 2019, 21, 485. [Google Scholar] [CrossRef]
- Okada, K.; Periaswamy, S.; Bi, J. Stratified regularity measures with Jensen-Shannon divergence. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Ré, M.A.; Azad, R.K. Generalization of entropy based divergence measures for symbolic sequence analysis. PLoS ONE 2014, 9, e93532. [Google Scholar] [CrossRef]
- D’Souza, J.C.; Sultan, L.R.; Hunt, S.J.; Schultz, S.M.; Brice, A.K.; Wood, A.K.W.; Sehgal, C.M. B-mode ultrasound for the assessment of hepatic fibrosis: A quantitative multiparametric analysis for a radiomics approach. Sci. Rep. 2019, 9, 8708. [Google Scholar] [CrossRef]
- Sultan, L.R.; Chen, Y.T.; Cary, T.W.; Ashi, K.; Sehgal, C.M. Quantitative pleural line characterization outperforms traditional lung texture ultrasound features in detection of COVID-19. J. Am. Coll Emerg. Physicians Open. 2021, 2, e12418. [Google Scholar] [CrossRef]
- Tripathi, A.; Goswami, T.; Trivedi, S.K.; Sharma, R.D. A multi class random forest (MCRF) model for classification of small plant peptides. Int. J. Inf. Manag. Data Insights 2021, 1, 100029. [Google Scholar] [CrossRef]
- Frank, E.; Hall, M.A.; Witten, I.H. The WEKA Workbench. In Online Appendix for “Data Mining: Practical Machine Learning Tools and Techniques”, 4th ed.; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Streiner, D.L. Unicorns Do Exist: A Tutorial on ‘Proving’ the Null Hypothesis. Can. J. Psychiatry 2003, 48, 756–761. [Google Scholar] [CrossRef] [PubMed]
- Chauhan, A.; Sultan, L.R.; Furth, E.E.; Jones, L.P.; Khungar, V.; Sehgal, C.M. Diagnostic accuracy of hepatorenal index in the detection and grading of hepatic steatosis. J. Clin. Ultrasound. 2016, 44, 580–586. [Google Scholar] [CrossRef] [PubMed]
- Layer, G.; Zuna, I.; Lorenz, A.; Zerban, H.; Haberkorn, U.; Bannasch, P.; van Kaick, G.; Räth, U. Computerized ultrasound B-scan texture analysis of experimental diffuse parenchymal liver disease: Correlation with histopathology and tissue composition. J. Clin. Ultrasound. 1991, 19, 193–201. [Google Scholar] [CrossRef] [PubMed]
- Meszlenyi, R.J.; Hermann, P.; Buza, K.; Gal, V.; Vidnyanszky, Z. Resting state fMRI functional connectivity analysis using dynamic time warping. Front. Neurosci. 2017, 11, 75. [Google Scholar] [CrossRef]
- Salvador, S.; Chan, P. FastDTW: Toward Accurate Dynamic Time Warping in Linear Time and Space. Intell. Data Anal. 2007, 11, 561–580. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quantitative Ultrasound Features | Steatosis | Fibrosis | Normal | p-Value: Fibrosis vs. Steatosis | p-Value: Fibrosis vs. Normal | p-Value: Steatosis vs. Normal |
|---|---|---|---|---|---|---|
| Echo intensity | 34.7 ± 12.0 | 55.9 ± 16.3 | 25.4 ± 13.6 | 0.00 | 0.00 | 0.00 |
| Heterogeneity | 14.6 ± 3.7 | 20.5 ± 3.9 | 12.7 ± 4.7 | 0.00 | 0.00 | 0.0 |
| Internal Heterogeneity | 12.0 ± 1.2 | 16.3 ± 2.4 | 13.2 ± 1.8 | 0.00 | 0.00 | 00 |
| GLNU | 0.3 ± 0.1 | 0.3 ± 0.0 | 0.4 ± 0.2 | 0.00 | 4.37 × 10−52 | 0.00 |
| RLNU | 0.2 ± 0.0 | 0.2 ± 0.0 | 0.3 ± 0.1 | 0.00 | 1.7 × 10−68 | 2.914 × 10−72 |
| Entropy | 3.5 ± 0.2 | 4.5 ± 0.18 | 3.1 ± 0.5 | 0.00 | 2.4 × 10−116 | 2.64 × 10−123 |
| JS Divergence | Normal | Fibrosis | Steatosis |
|---|---|---|---|
| Intra | 0.01 ± 0.03 | 0.05 ± 0.05 | 0.01 ± 0.05 |
| Inter | 0.01 ± 0.03 | 0.07 ± 0.08 | 0.03 ± 0.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sultan, L.R.; Cary, T.W.; Al-Hasani, M.; Karmacharya, M.B.; Venkatesh, S.S.; Assenmacher, C.-A.; Radaelli, E.; Sehgal, C.M. Can Sequential Images from the Same Object Be Used for Training Machine Learning Models? A Case Study for Detecting Liver Disease by Ultrasound Radiomics. AI 2022, 3, 739-750. https://doi.org/10.3390/ai3030043
Sultan LR, Cary TW, Al-Hasani M, Karmacharya MB, Venkatesh SS, Assenmacher C-A, Radaelli E, Sehgal CM. Can Sequential Images from the Same Object Be Used for Training Machine Learning Models? A Case Study for Detecting Liver Disease by Ultrasound Radiomics. AI. 2022; 3(3):739-750. https://doi.org/10.3390/ai3030043
Chicago/Turabian StyleSultan, Laith R., Theodore W. Cary, Maryam Al-Hasani, Mrigendra B. Karmacharya, Santosh S. Venkatesh, Charles-Antoine Assenmacher, Enrico Radaelli, and Chandra M. Sehgal. 2022. "Can Sequential Images from the Same Object Be Used for Training Machine Learning Models? A Case Study for Detecting Liver Disease by Ultrasound Radiomics" AI 3, no. 3: 739-750. https://doi.org/10.3390/ai3030043
APA StyleSultan, L. R., Cary, T. W., Al-Hasani, M., Karmacharya, M. B., Venkatesh, S. S., Assenmacher, C.-A., Radaelli, E., & Sehgal, C. M. (2022). Can Sequential Images from the Same Object Be Used for Training Machine Learning Models? A Case Study for Detecting Liver Disease by Ultrasound Radiomics. AI, 3(3), 739-750. https://doi.org/10.3390/ai3030043