
A Spatial AI-Based Agricultural Robotic Platform for Wheat Detection and Collision Avoidance



Abstract
:1. Introduction and Motivation
- Design of an agricultural robotic platform for autonomous navigation in crops while avoiding collisions. The platform uses spatial AI and deep learning models for collision avoidance and crop (wheat) detection.
- Training of different state-of-the-art deep learning models, such as MobileNet single shot detector (SSD), YOLO, and Faster region-based convolutional neural network (R-CNN) with ResNet-50 feature pyramid network (FPN) backbone, for object (wheat) detection.
- Performance comparison of the state-of-the-art deep learning models for wheat detection on different computing platforms.
- Evaluation of the trained deep learning models for wheat detection through various metrics, such as accuracy, precision, and recall.
2. Related Work
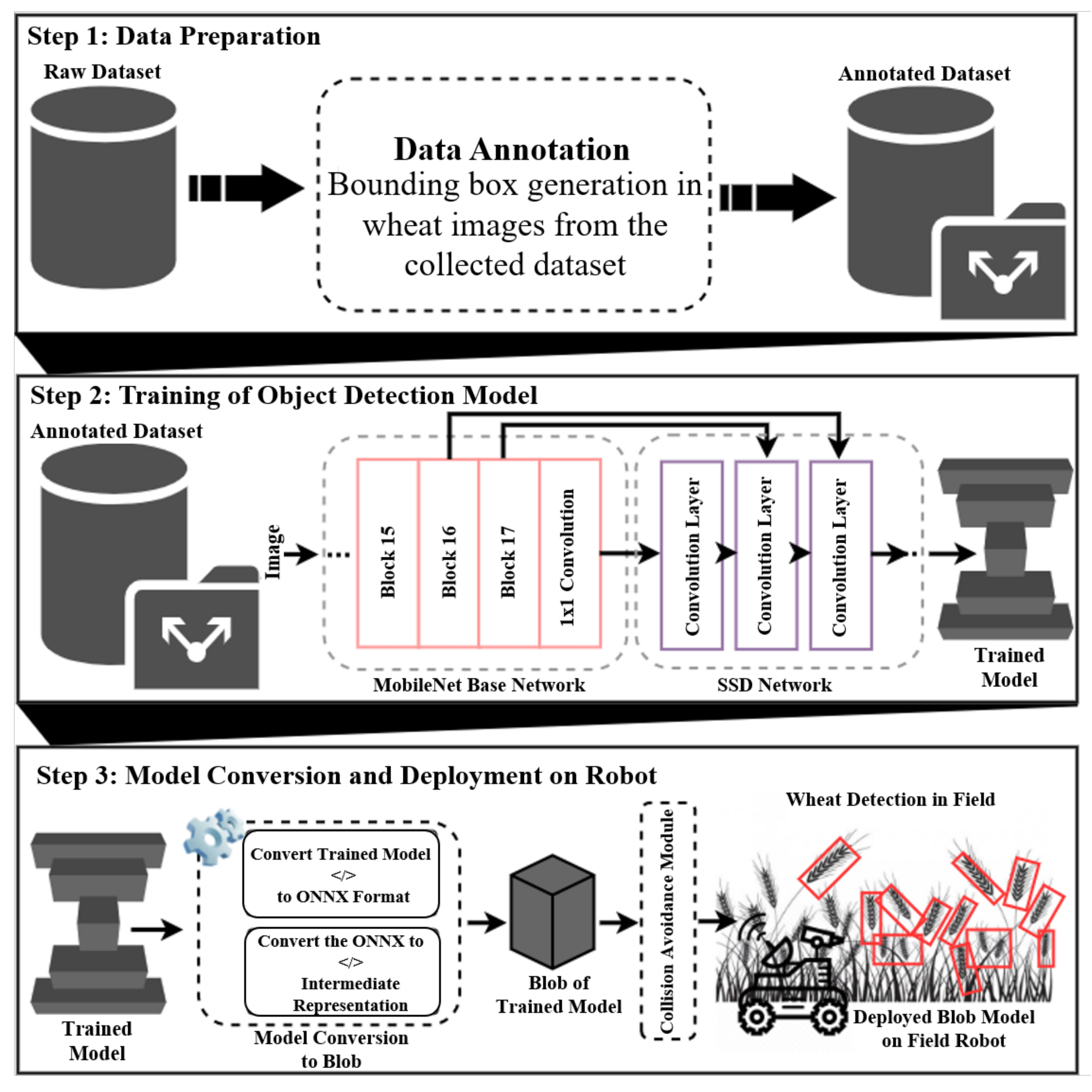
3. Proposed Spatial AI System for Collision Avoidance in Wheat Fields
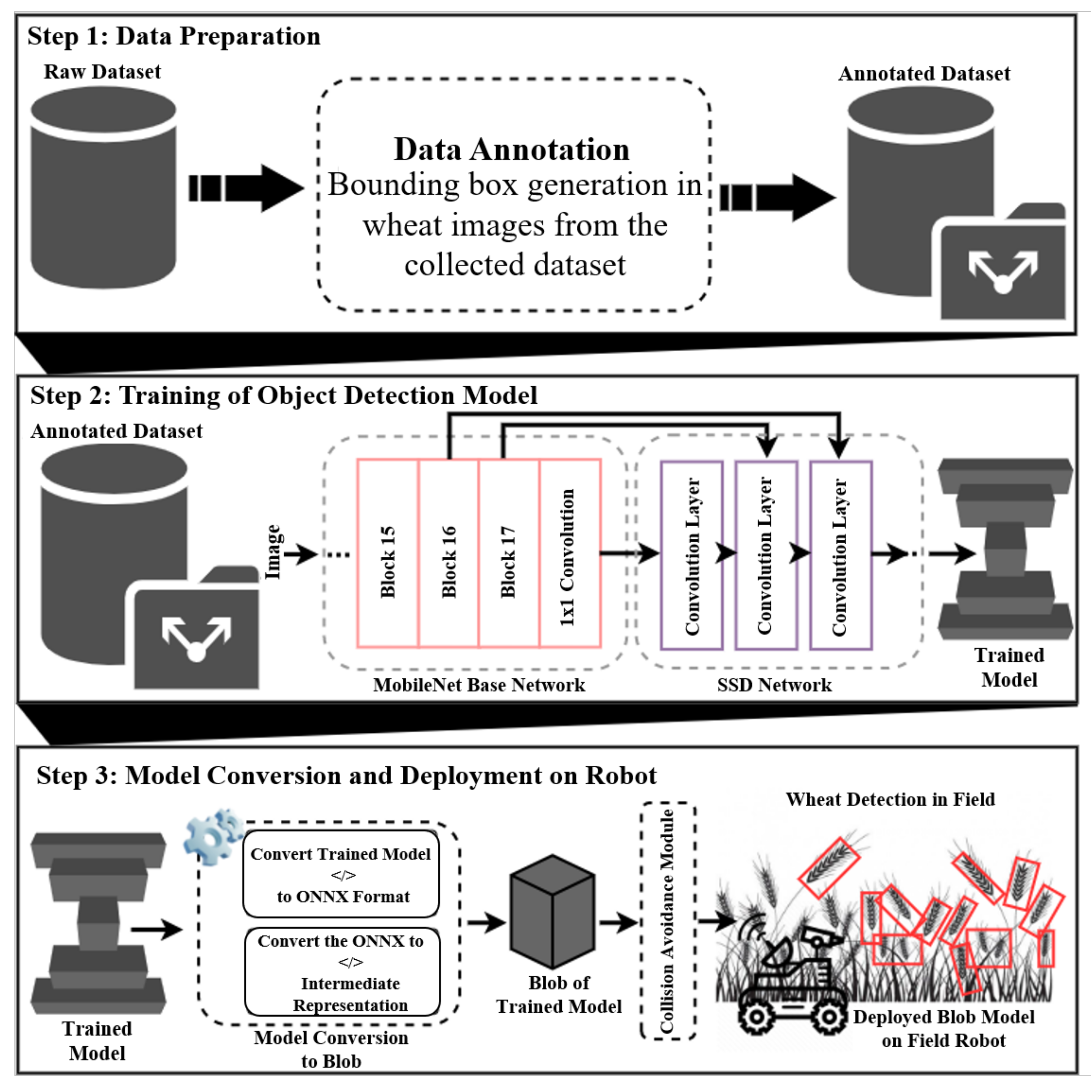
3.1. Data Preparation
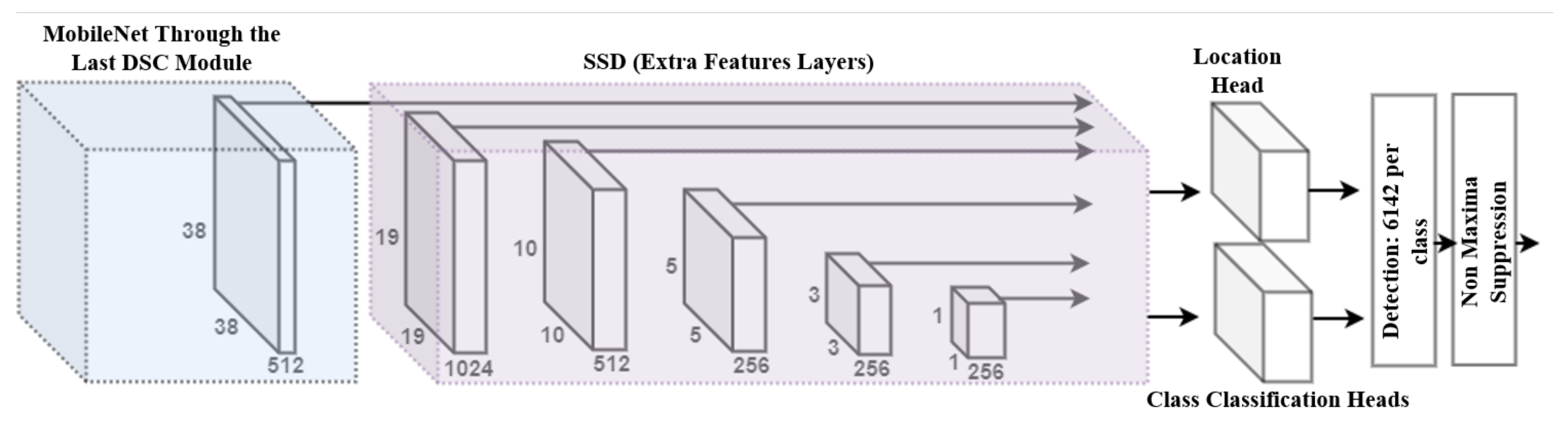
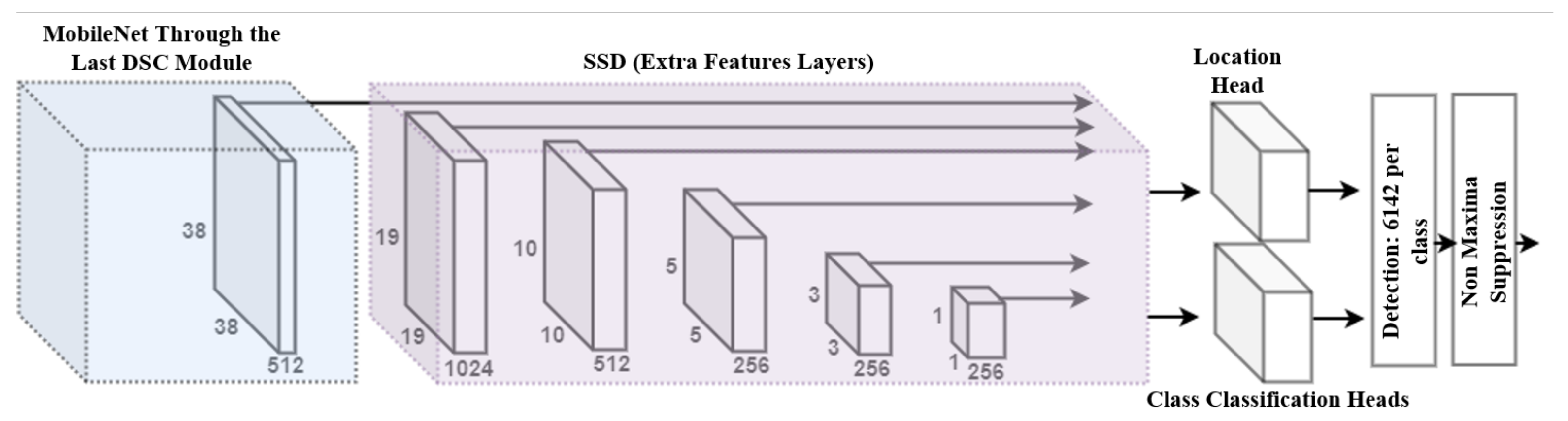
3.2. MobileNet SSD Architecture for Wheat Detection
3.2.1. Architectural Details of MobileNet SSD
3.2.2. Motivation of Using MobileNet SSD for Wheat Detection
3.3. Model Conversion and Deployment on Field Robot
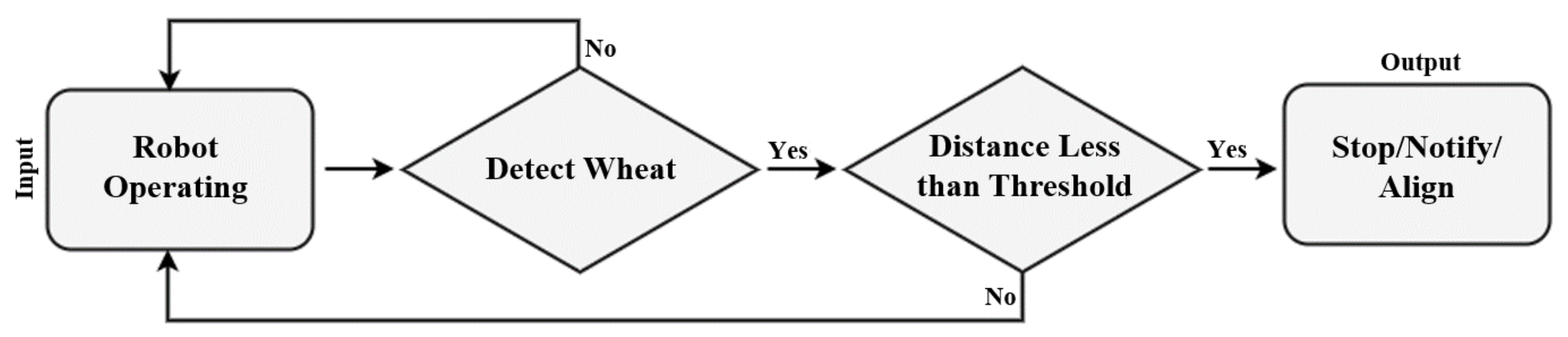
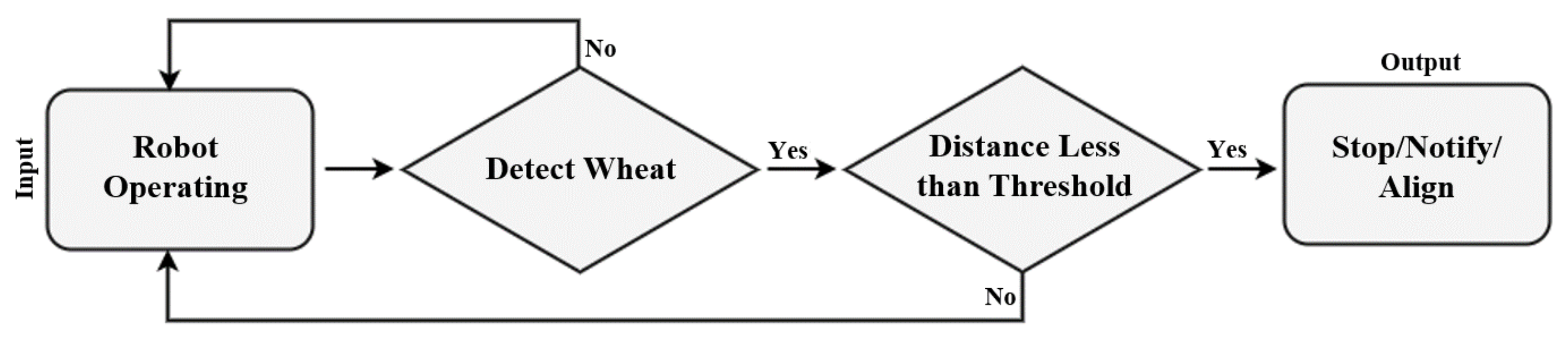
3.4. Workflow for Robot Operation and Collision Avoidance
3.4.1. Collision Avoidance via Depth Sensing
3.4.2. Communicating with the Robot Using PySerial
4. Training Evaluation and Experimental Results
4.1. Data Augmentation
4.2. Embedded Computing Platforms
4.2.1. LattePanda
4.2.2. Intel Neural Compute Stick
4.2.3. OpenCV AI Kit
4.3. Evaluation Metrics
4.3.1. Precision
4.3.2. Recall
4.3.3. Intersection over Union (IoU)
4.3.4. Mean Average Precision (mAP)
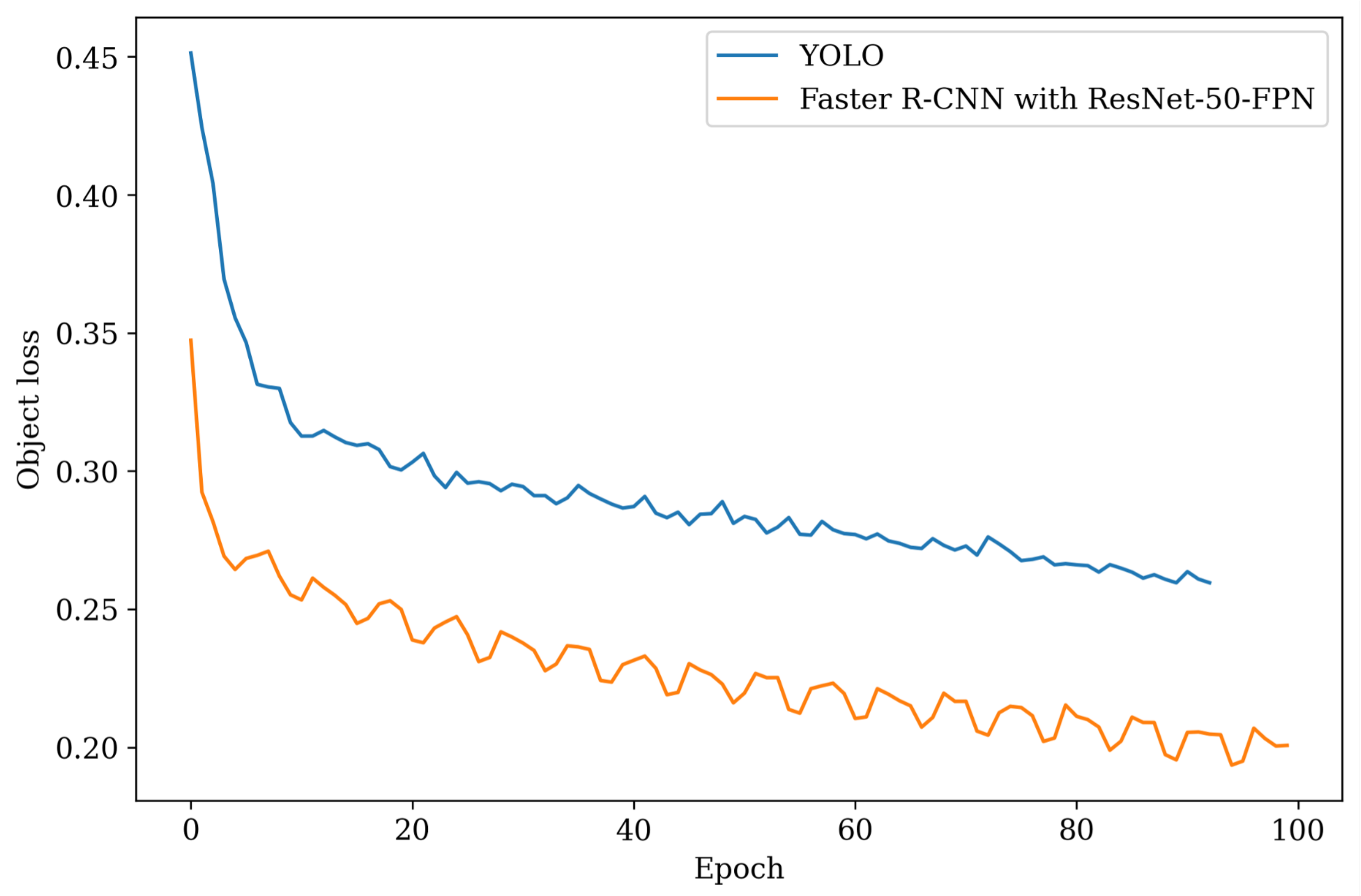
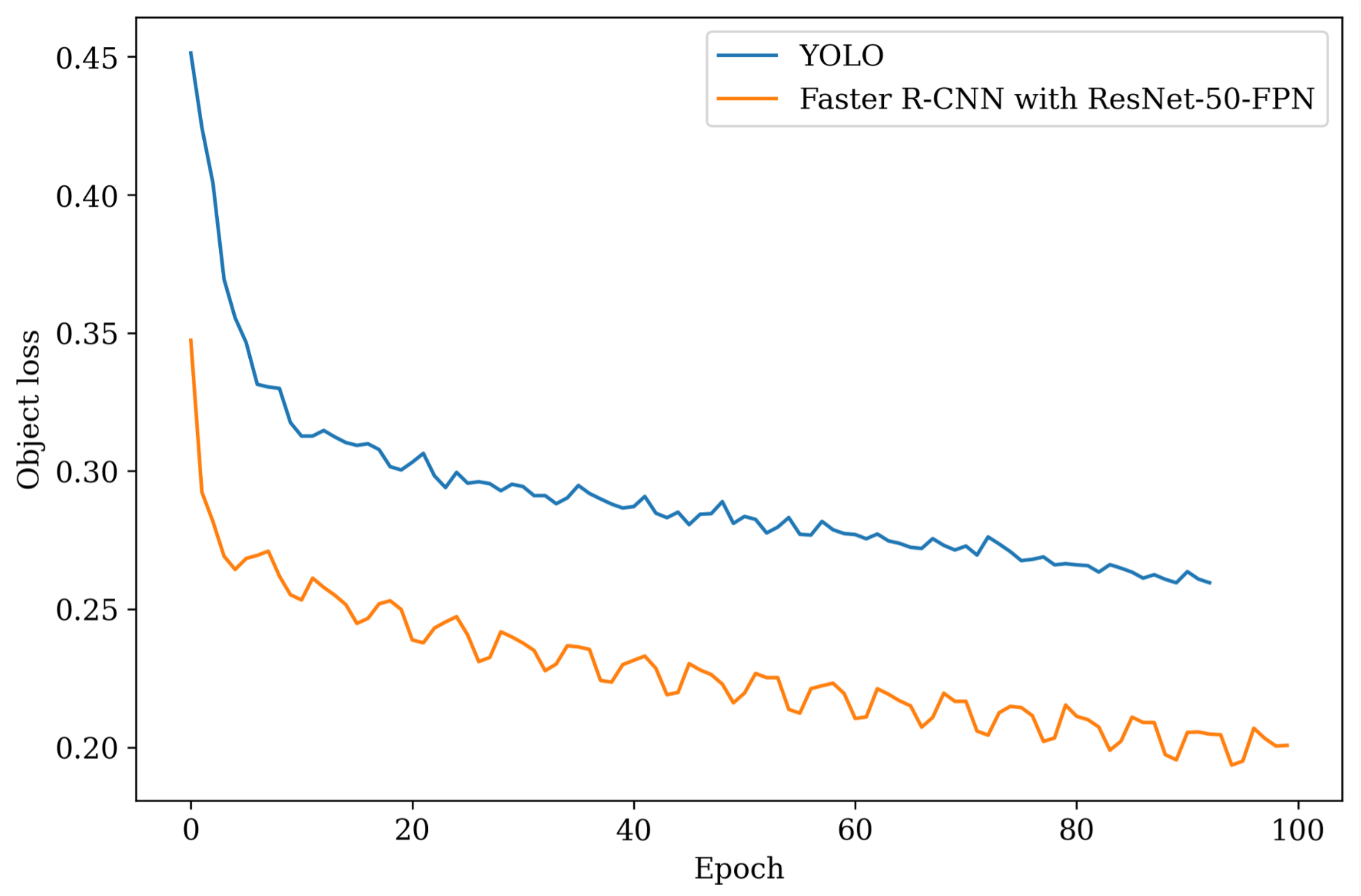
4.4. Training YOLO
4.5. Training Faster R-CNN with ResNet-50-FPN
4.6. Training MobileNet SSD
4.7. Testing YOLO
4.8. Testing Faster R-CNN with ResNet-50-FPN
4.9. Testing MobileNet SSD
4.10. Comparing YOLO, Faster-R-CNN, and MobileNet SSD
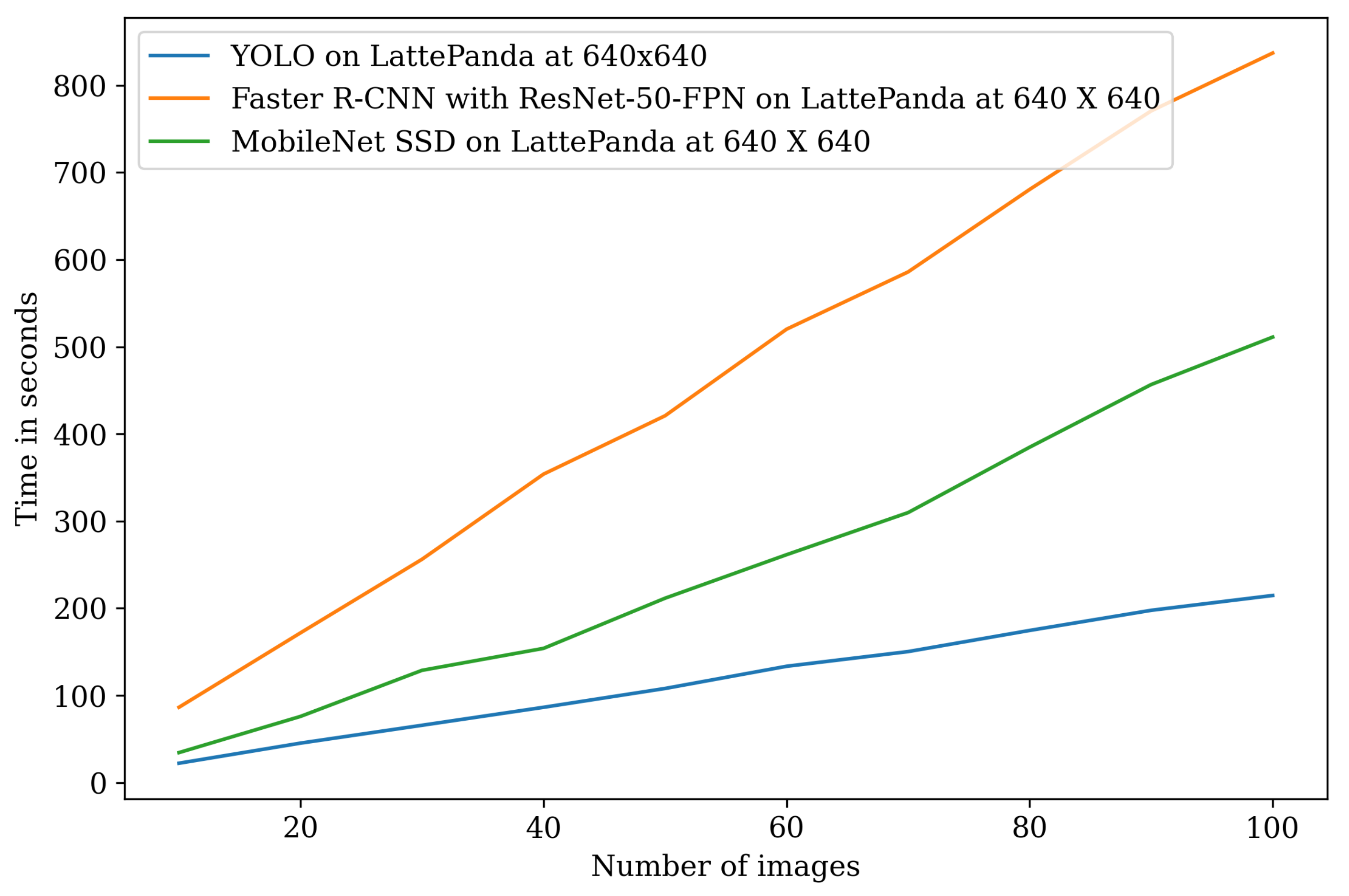
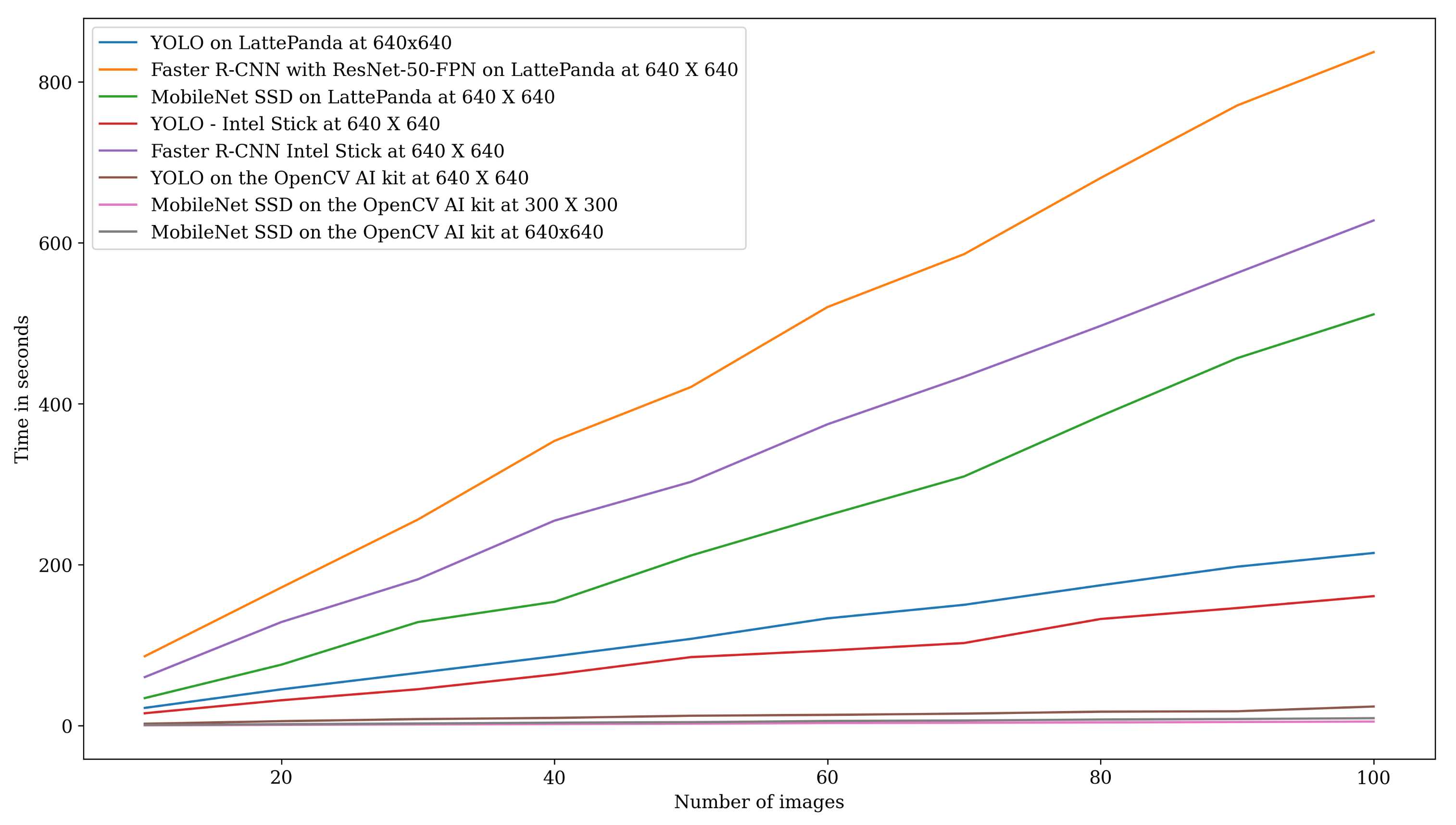
4.11. Benchmarking Deep Learning Models on Various Embedded Computing Platforms
4.12. In-Field Real-Time Object Detection and Depth Sensing
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Asseng, S.; Ewert, F.; Martre, P.; Rötter, R.P.; Lobell, D.B.; Cammarano, D.; Kimball, B.A.; Ottman, M.J.; Wall, G.; White, J.W.; et al. Rising temperatures reduce global wheat production. Nat. Clim. Chang. 2015, 5, 143–147. [Google Scholar] [CrossRef]
- Tack, J.; Barkley, A.; Nalley, L.L. Effect of warming temperatures on US wheat yields. Proc. Natl. Acad. Sci. USA 2015, 112, 6931–6936. [Google Scholar] [CrossRef] [PubMed]
- Ihsan, M.Z.; El-Nakhlawy, F.S.; Ismail, S.M.; Fahad, S.; Daur, I. Wheat phenological development and growth studies as affected by drought and late season high temperature stress under arid environment. Front. Plant Sci. 2016, 7, 795. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Srivastava, S.; Divekar, A.V.; Anilkumar, C.; Naik, I.; Kulkarni, V.; Pattabiraman, V. Comparative analysis of deep learning image detection algorithms. J. Big Data 2021, 8, 1–27. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switerland, 2014; pp. 740–755. [Google Scholar]
- ImageNet Large Scale Visual Recognition Challenge 2015 (ILSVRC2015). Available online: https://www.image-net.org/challenges/LSVRC/ (accessed on 16 August 2022).
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; ML Research Press: Maastricht, The Netherlands, 2019; pp. 6105–6114. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016; Springer: Cham, Switerland, 2016; pp. 21–37. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Mosley, L.; Pham, H.; Bansal, Y.; Hare, E. Image-based sorghum head counting when you only look once. arXiv 2020, arXiv:2009.11929. [Google Scholar]
- Ghosal, S.; Zheng, B.; Chapman, S.C.; Potgieter, A.B.; Jordan, D.R.; Wang, X.; Singh, A.K.; Singh, A.; Hirafuji, M.; Ninomiya, S.; et al. A weakly supervised deep learning framework for sorghum head detection and counting. Plant Phenomics 2019, 2019, 1525874. [Google Scholar] [CrossRef] [PubMed]
- Velumani, K.; Lopez-Lozano, R.; Madec, S.; Guo, W.; Gillet, J.; Comar, A.; Baret, F. Estimates of maize plant density from UAV RGB images using Faster-RCNN detection model: Impact of the spatial resolution. arXiv 2021, arXiv:2105.11857. [Google Scholar] [CrossRef] [PubMed]
- Gonzalo-Martín, C.; García-Pedrero, A.; Lillo-Saavedra, M. Improving deep learning sorghum head detection through test time augmentation. Comput. Electron. Agric. 2021, 186, 106179. [Google Scholar] [CrossRef]
- Xue, J.; Xia, C.; Zou, J. A velocity control strategy for collision avoidance of autonomous agricultural vehicles. Auton. Robot. 2020, 44, 1047–1063. [Google Scholar] [CrossRef]
- Shutske, J.M.; Gilbert, W.; Morgan, S.; Chaplin, J. Collision avoidance sensing for slow moving agricultural vehicles. Pap.-Am. Soc. Agric. Eng. 1997, 3. Available online: https://www.researchgate.net/publication/317729198_Collision_avoidance_sensing_for_slow_moving_agricultural_vehicles (accessed on 16 August 2022).
- Luxonis. DepthAI’s Documentation. 2022. Available online: https://docs.luxonis.com/en/latest/ (accessed on 4 August 2022).
- Luxonis. Luxonis-Simplifying Spatial AI. 2021. Available online: https://www.luxonis.com/ (accessed on 4 August 2022).
- OpenCV. OpenCV AI Kit: OAK-D. 2021. Available online: https://store.opencv.ai/products/oak-d (accessed on 4 August 2022).
- LattePanda. LattePanda Alpha 864s. 2021. Available online: https://www.lattepanda.com/products/lattepanda-alpha-864s.html (accessed on 4 August 2022).
- Intel. Intel Neural Compute Stick. 2021. Available online: https://www.intel.com/content/www/us/en/developer/tools/neural-compute-stick/overview.html (accessed on 4 August 2022).
- Naushad, R. Introduction to OpenCV AI Kits (OAK-1 and OAK-D). 2021. Available online: https://medium.com/swlh/introduction-to-opencv-ai-kits-oak-1-and-oak-d-6cdf8624517 (accessed on 4 August 2022).
- Yohanandan, S. mAP (mean Average Precision) Might Confuse You! 2020. Available online: https://towardsdatascience.com/map-mean-average-precision-might-confuse-you-5956f1bfa9e2 (accessed on 7 December 2021).
- LattePanda Alpha 864s (Win10 Pro activated)—Tiny Ultimate Windows/Linux Device. Available online: https://www.dfrobot.com/product-1729.html (accessed on 16 August 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Source | Training | Validation | Testing |
|---|---|---|---|
| Kaggle | 80 | 10 | 10 |
| Google Images | 80 | 10 | 10 |
| KSU Agronomy Farm | 70 | 10 | 20 |
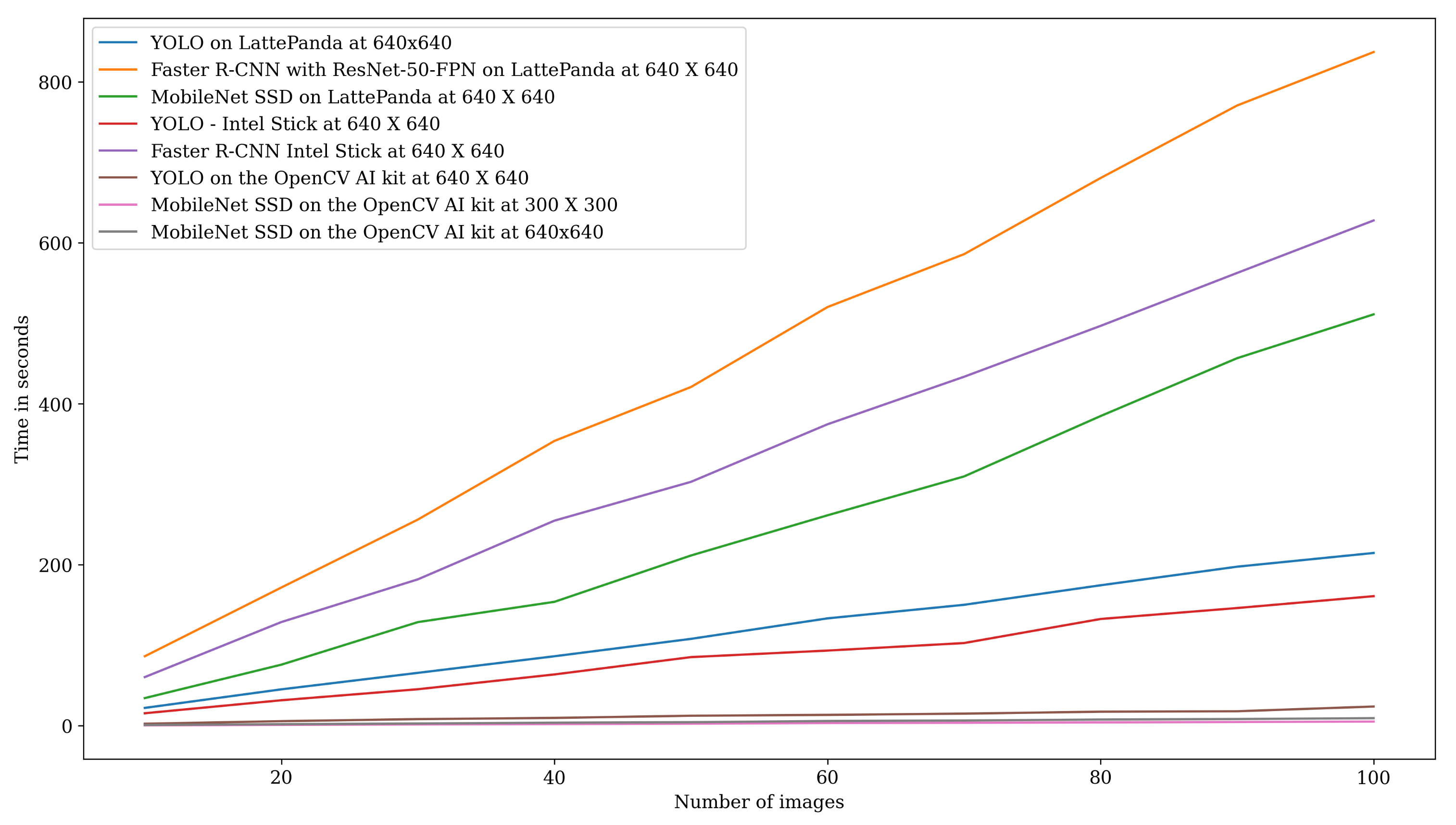
| Images | YOLO on LattePanda at 640 × 640 | Faster R-CNN on LattePanda at 640 × 640 | MobileNet SSD on LattePanda 640 × 640 | YOLO on Intel Stick 640 × 640 | Faster R-CNN on Intel Stick 640 × 640 | YOLO on OpenCV AI Kit at 640 × 640 | MobileNet SSD on OpenCV AI Kit at 640 × 640 | MobileNet SSD on OpeCV AI Kit at 300 × 300 |
|---|---|---|---|---|---|---|---|---|
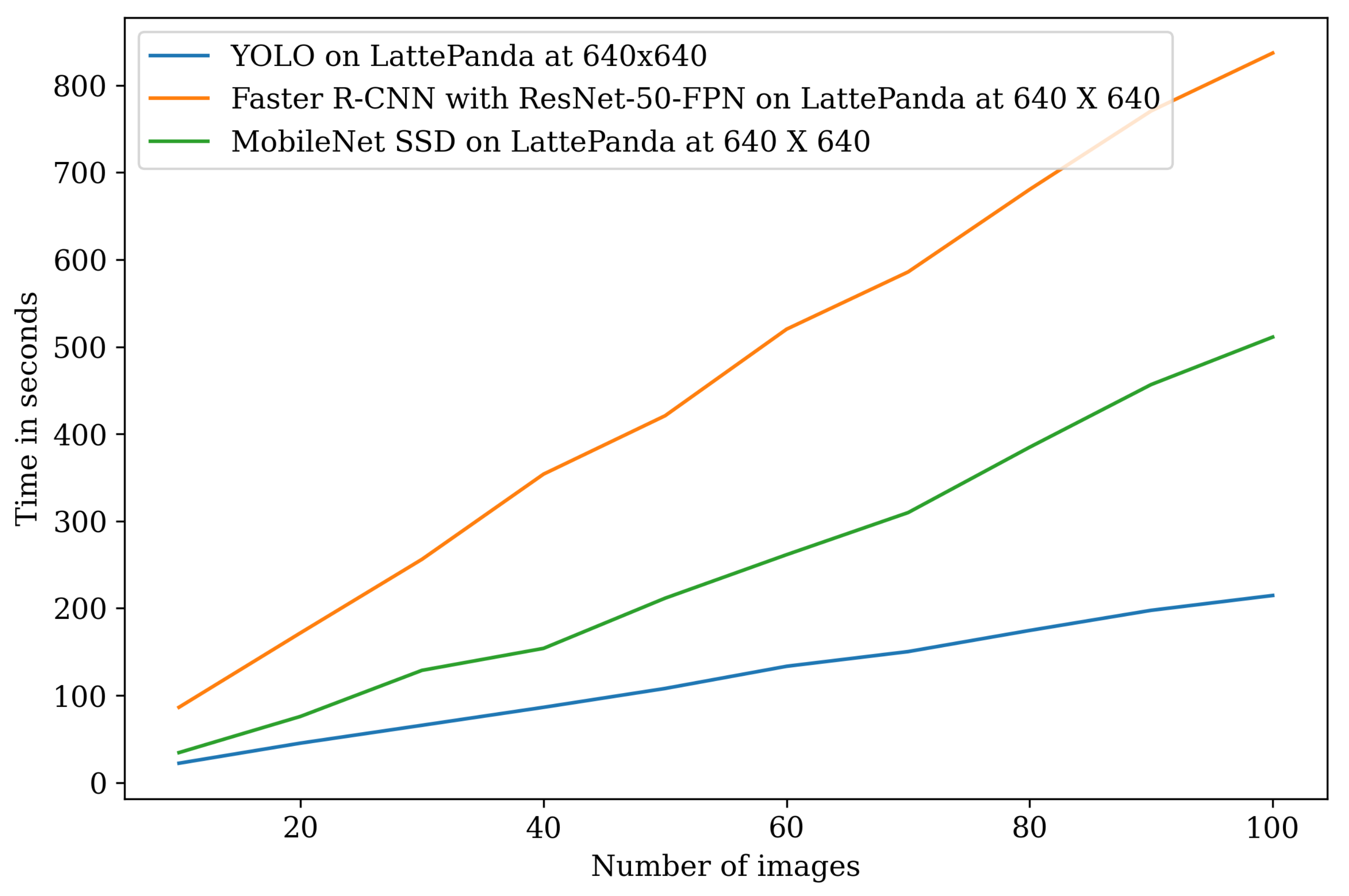
| 10 | 22.13 | 86.33 | 34.33 | 15.49 | 60.43 | 2.4 | 0.93 | 0.52 |
| 20 | 45.19 | 171.74 | 75.85 | 31.63 | 128.80 | 5.64 | 1.88 | 0.52 |
| 30 | 65.68 | 256.17 | 128.74 | 45.32 | 181.88 | 8.21 | 2.77 | 1.55 |
| 40 | 86.31 | 353.87 | 153.94 | 63.71 | 254.79 | 9.69 | 3.76 | 2.06 |
| 50 | 107.91 | 420.85 | 211.5 | 84.24 | 303.01 | 12.40 | 4.38 | 2.56 |
| 60 | 133.38 | 520.19 | 261.43 | 93.36 | 374.53 | 13.47 | 5.85 | 3.31 |
| 70 | 150.23 | 585.90 | 309.73 | 102.70 | 433.56 | 15.02 | 6.48 | 3.64 |
| 80 | 174.49 | 680.53 | 384.76 | 132.62 | 496.79 | 17.44 | 7.65 | 4.14 |
| 90 | 197.60 | 770.64 | 456.66 | 146.22 | 562.57 | 17.96 | 8.35 | 4.63 |
| 100 | 214.36 | 837.08 | 511.13 | 160.97 | 627.81 | 23.84 | 9.37 | 5.15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gunturu, S.; Munir, A.; Ullah, H.; Welch, S.; Flippo, D. A Spatial AI-Based Agricultural Robotic Platform for Wheat Detection and Collision Avoidance. AI 2022, 3, 719-738. https://doi.org/10.3390/ai3030042
Gunturu S, Munir A, Ullah H, Welch S, Flippo D. A Spatial AI-Based Agricultural Robotic Platform for Wheat Detection and Collision Avoidance. AI. 2022; 3(3):719-738. https://doi.org/10.3390/ai3030042
Chicago/Turabian StyleGunturu, Sujith, Arslan Munir, Hayat Ullah, Stephen Welch, and Daniel Flippo. 2022. "A Spatial AI-Based Agricultural Robotic Platform for Wheat Detection and Collision Avoidance" AI 3, no. 3: 719-738. https://doi.org/10.3390/ai3030042
APA StyleGunturu, S., Munir, A., Ullah, H., Welch, S., & Flippo, D. (2022). A Spatial AI-Based Agricultural Robotic Platform for Wheat Detection and Collision Avoidance. AI, 3(3), 719-738. https://doi.org/10.3390/ai3030042