1. Introduction
In this era of artificial intelligence, machine learning algorithms are data hungry. Models require large volumes of data to generalize well to practical use cases [
1]. In reality, data are decentralized over different devices under privacy restrictions [
2]. Federated learning provides an elegant solution. It involves a global cloud model that collaborates with a federation of devices called clients that carry private local data and execute a subroutine of local refinements in each round of communication [
3]. This preserves the privacy as well as decentralizes learning to make better use of local resources while contributing to a global cloud model.
There are multiple challenges in federated learning [
4]. Data skewness is the most popular among them. In ideal cases, Independent and Identically Distributed (IID) data are desired, both in terms of features as well as classes. However, in real scenarios, non-IID data varying from moderate to strongly skewed distribution is inevitable [
5,
6]. The global class imbalance problem may prevail and adversely affect the performance of the global model [
7]. Further, communication challenges contribute towards cost and complexity of learning. The clients have limited and unequal computational power, thereby limiting the potential of learning at a local scale and affecting the global model as well [
8]. There is another challenge related to client behaviors, known as free riders. Free riders [
9] use the global model but do not contribute to learning. Free riders not only hog the limited communication resources, but also deteriorate the performance by contributing fake or low volume data in order to access the global model.
State-of-the-art federated learning algorithms include synchronous Federated Averaging (FedAvg) [
10], Federated Stochastic Variance Reduced Gradient (
FSVRG) [
11] using Stochastic Variance Reduced Gradient (
SVRG) [
12] and asynchronous Cooperative Learning (CO-OP) [
13]. These perform well on most of the real-world datasets with FedAvg outperforming FSVRG and CO-OP [
14]. Federated multi-task learning has been shown as an effective paradigm to handle real-world datasets. An effective multi-task learning algorithm is VIRTUAL, which considers the federated system of server and clients as a star-shaped Bayesian network, and learning is performed using variational inference with unbiased Monte Carlo estimation [
15]. However, the performance of all these methods depends on the important step of client selection in each round of refinement. The problem of client selection in an effective manner is the focus of this paper.
In an ideal situation, the best suited clients should be allowed to interact with the global model such that performance deterioration due to data skewness, class imbalance, and free riders can be minimized. The common approach is random client sampling. Some other approaches have also been reported. The asynchronous COOP protocol relies on age filters to allow merging of selected clients only. The age filters perform a prior verification of whether the client is active or old and if it lies in the specified age bandwidth. While age is a useful metric, it does not account for the data quality and quantity of the client. The resource-based client selection protocol FedCS [
16] actively manages the clients based on resource constraints and accelerates the performance of the global model with the aim of aggregating as many devices as possible within a pre-defined time window. In [
17], an optimal client selection strategy to update the master node is adopted based on a formula for optimal client participation. Another approach in [
18] is based on adapting an online stochastic mirror descent algorithm to minimize the variance of gradient estimation. The approach mentioned in [
19] takes into account overheads incurred on each device when designing incentive mechanisms to encourage devices with higher-quality data to participate in the learning process. However, tackling the free riders remains an open problem.
Some free riders’ attack and defense strategies were discussed in [
9]. Free riders were identified by constructing local gradients without any training on data. Gradients based on random weights and delta weights are described as a possible free rider attack strategy. Such attacks can be prevented using a deep autoencoding Gaussian mixture mode (DAGMM) and standard deviation DAGMM [
20]. More complex free riders disguising schemes based on additive stochastic perturbations and time varying noise models are discussed in [
21]. In either of these schemes, a free rider client with zero data points can participate by reporting fake gradients. Another problem is that there may be free riding clients with small data volumes but with sufficiently large gradients to adversely affect the global model. In order to counter this situation, free riders can be identified as the clients with relatively small data volumes such that they do not have anything substantial to contribute to the learning of the global model. This allows weighing down such clients irrespective of other aspects. Active federate learning (
AFL) [
22] does use a client sampling method that takes into account the data volume of clients, and therefore, it has some cushion for free riders. Furthermore, its client sampling method includes consideration of class imbalance in binary classification problems. In our own experience, AFL can support multi-class, but the performance is bad when the free rider situation is present, and non-IID conditions make it worse. It also cannot handle the issue of severe lack of data. In other words, there is an unfulfilled need for client sampling schemes that handle the real-world situation where the issues of free riders, multi-class imbalance, non-IID, and extreme data skew coexist. To solve these issues and design a versatile and robust sampling approach, we propose:
A novel single floating point score, namely the irrelevance score, which is sufficient for scoring the clients based on data volume, local class imbalance, as well as IID and non-IID conditions. The score is further scalable in the future to include other considerations.
A novel client sampling method, namely irrelevance sampling, which uses the irrelevance score in an effective manner in order to enable a selection of optimal subset of clients for subsequent learning even in challenging imbalanced and free-rider ridden environments.
We validate the utility of our irrelevance score and the performance of our client sampling approach extensively using various numerical experiments, which include non-IID conditions, highly imbalanced federated environments, and moderate-to-severe free-riders’ repleted environments. We show the integrability and robust performance of the proposed sampling approach in diverse learning schemes and illustrate the superior performance over state-of-the-art sampling methods across three well-established simulated datasets and two real-world practical application datasets.
3. Experimental Evaluation
In this section, we report extensive performance evaluation of our client sampling method for both IID and non-IID conditions for 5 datasets and also compare this with the contemporary state-of-the-art sampling methods.
3.1. Experimental Settings
In our experimental evaluation, we not only consider 3 simulated and 2 practical datasets (see
Table 1), we also simulate different challenging environments and include the consideration of learning algorithms as well (see
Table 2). All the datasets represent classification problems and the classification accuracy is used as a performance indicator.
3.1.1. Balanced and Imbalanced
We performed our experiments based on different federated environments under both balanced and imbalanced conditions. Here, balanced conditions mean that all of the classes of the classification problem being solved have equal amount of training and validation samples, while in the case of the imbalanced scenario, a certain number of classes have significantly less training and validation samples. More specifically, four, four, eighteen, one and two classes are imbalanced in the MNIST, KMNIST, FEMNIST, VSN and HAR datasets, respectively.
3.1.2. IID and Non-IID Conditions
IID stands for independent and identically distributed data, while Non-IID stands for non-independent and non-identically distributed data. The distribution of data among clients can be described in terms of feature distribution as well as class distribution. MNIST, KMNIST and EMNIST-47 describe the IID features across the data points while VSN strongly describes non-IID feature distribution. In the real-world, Non-IID data on clients both in terms of feature and class distribution is inevitable and hampers the performance of the global model. We simulate the label wise Non-IID distribution of the mentioned datasets in the experiments.
For IID conditions, all clients have all categories present in their local data, while in the Non-IID condition, a variable number of categories ranging from a single category to 70% of total categories are present on the clients. More specifically, an equal number of four types of clients with 70%, 50%, 30% and 10% classes in case of MNIST, KMNIST, FEMNIST and Cardiotocography(CTG) are simulated. In the case of the VSN dataset, clients equal number of one and two classes are simulated, and in the HAR dataset, clients with an equal number of two, three and four classes are simulated. Depending on the type of environments (E1-E6), the volume of datasets on each client also varies, as mentioned in
Table 3.
3.1.3. Federated Environments
In all of our experiments we use a federated system of 100 clients and sample 10 clients in each round of training unless stated otherwise. We create clients of six types and use different proportions of these types of clients to create different environments. The environments and types are presented in
Table 4. We note that Type V and VI demonstrate the behavior of a free rider in terms of lack of data and contributing significantly less towards the global model. E1 to E4 are used for generating results for individual datasets. Further, E5-E6 are used in ablation and convergence studies.
3.1.4. Architectures
In the experiments, multilayer perceptrons (MLP) are employed. In the case of MNIST and VSN datasets, two hidden dense flipout layers each of 100 units and an ReLU activation function with a final layer of 10 and 2 units, respectively, were used. In the case of KMNIST, FEMNIST and HAR datasets single hidden dense flipout layer of 512 units and ReLU activate function with final layer of 10, 47 and 6 units respectively were used. In the Cardiotocography dataset, 5 hidden layers of 21 units each are used with the final output layer of 10 units. In all cases, softmax activation is applied on the final layer.
3.1.5. Learning Parameters
The learning rate is kept at 0.003 for all cases. We perform 50 rounds of refinement in the global model and in each round of training, 10 clients are used to update the global model based on the sampling method with a single refinement per client. Some relevant details of the learning algorithms are presented here. We have used the naive Federated SVRG (FSVRG) as described in Algorithm 3 of [
11]. The step size parameter
h is set as 1.0. The CO-OP algorithm, as described in Algorithm 3.1 of [
13], is used with age filter parameters
a and
b as 7 and 21, respectively.
3.1.6. Parameters of the Proposed Irrelevance Sampling Method
The parameters of the proposed algorithm are set as , and for IID and , and for non-IID settings unless stated otherwise.
3.2. Results for Individual Datasets
Results for MNIST dataset: It comprises gray scale images of handwritten single digits between 0 and 9, each of size
pixels. The problem is to classify the image as belonging to the class of the digit [
24]. The results for this dataset are presented in
Table 5.
We notice that the environment E3 (free riders replete) is generally quite challenging for the AFL sampling, where it performs the poorest irrespective of the algorithm. The random sampling approach finds the imbalanced environment (E2) the most challenging for the IID condition and the free-riders repleted environment (E3) for the Non-IID conditions. Generally, both random and AFL sampling perform poorer when used in a COOP learning scheme while provide comparable performance for FedAvg and FSVRG learning schemes. We do notice the better performance of FedAvg than FSVRG for the Non-IID condition. As compared to random and AFL sampling, the proposed ’irrelevance’-based sampling approach performs the best among the three sampling methods irrespective of the environment, learning scheme, or the conditions (IID versus Non-IID). It provides the most balanced performance with small variations over different environments as well as different learning schemes. This demonstrates the robustness and versatility of the proposed sampling method. In the realistic environment E4, the clear edge of the proposed ‘irrelevance’-based sampling is evident, with at least 3% better classification accuracy than its contemporary in any environment, any condition, and with any learning scheme.
The poor performance of COOP and Virtual MTL for both AFL and random sampling is consistent through all the datasets. At the same time, there is no new insight about the proposed method specific for these schemes except that the performance of the proposed method is superior to that of the other sampling methods. Therefore, the results of these learning methods for the other datasets are not shown hereon.
3.2.1. Results for KMNIST Dataset
It is similar to MNIST, except that instead of digits, it represents hand-written Japanese characters of Hiragana [
25]. The results for this dataset are presented in
Table 6. The KMNIST dataset is generally more challenging than the MNIST dataset, as witnessed in the poorer performance for any experiment. Nonetheless, the well-balanced environment (E1) is a relatively simpler environment and all sampling methods perform similarly to each other, although the proposed ‘irrelevance’ sampling method has a slight nominal edge. Further, for the imbalanced environment (E2), AFL sampling shows a clear advantage over random sampling, and the proposed sampling method provides a further better performance by a small margin. On the other hand, the advantage of the proposed ‘irrelevance’-based sampling is clearly evident in E3 and E4, where a performance superior by an average of 5% is observed over its contemporaries across all the cases.
3.2.2. Results for FEMNIST Dataset
The FEMNIST dataset is a federated version of the EMNIST dataset, containing both characters and digits. We used the balanced version with 10 single digit classes between 0 and 9 inclusive, 26 uppercase alphabets and 11 lowercase alphabets [
26]. The results for this dataset are presented in
Table 7. With a significantly larger number of classes, this is a significantly challenging dataset and an ideal simulated scenario to investigate the performance of federated learning. The effect is observed in the poorer performance of all the sampling methods for this dataset in comparison to MNIST and KMNIST datasets. Further, in general, the proposed irrelevance sampling method provides a significant advantage (7% to 14%) for the challenging E3 and E4 environments.
3.2.3. Results for the Vehicle Sensor Network (VSN) Dataset
A network of 23 different sensors (including seismic, acoustic and passive infra-red sensors) are placed around a road segment in order to classify vehicles driving past them [
27]. The raw signal is processed into 50 acoustic and 50 seismic features. We consider every sensor as a client and perform binary classification of amphibious assault vehicles and dragon wagon vehicles. Being a real dataset for a practical application, it provides the challenges of real measurements. However, the problem involves only two classes and features a large dataset and, therefore, a relatively simpler situation than the three previous datasets. This dataset provides the performance of the proposed sampling method in the use cases where the number of categories is much less. The results for this dataset are presented in
Table 8. In general, the proposed irrelevance sampling either performs on par with or better than the other two sampling methods. Its clear advantage is evident for E2, E3 and E4 environments irrespective of the IID or Non-IID conditions or the learning scheme.
3.2.4. Results for Human Activity Recognition (HAR) Dataset
Recordings of 30 subjects performing daily activities are collected using smartphones with inertial sensors. The raw signal is divided into windows and processed into a 561-length vector [
28]. Every individual corresponds to a different client, and we perform a classification of 6 different activities (walking, walking upstairs, walking downstairs, sitting, standing, laying). With 6 classes and relatively few samples per class (see
Table 1), this dataset is quite challenging. The results are presented in
Table 9. The significant advantage of the proposed irrelevance sampling is evident in all the challenging environments (E2–E4), providing an improvement in classification accuracy of 3–18% for E2 and E3 and 1–14% for E4.
3.2.5. Results for Cardiotocography Dataset
The dataset consists of measurements of fetal heart rate (FHR) and uterine contraction (UC) features on cardiotocograms classified by expert obstetricians as described in [
29,
30]. Total 2126 fetal cardiotocograms (CTGs) were automatically processed and the respective diagnostic features measured with 21 training attributes. The CTGs were also classified by three expert obstetricians and a consensus classification label assigned to each of them. Classification was both with respect to a morphologic pattern (A, B, C. …) and to a fetal state (N, S, P). Therefore, the dataset can be used either for 10-class or 3-class experiments. This dataset has few samples per class and being a real-world problem in the medical field makes it very suitable for utilizing the proposed method under federated settings.
Table 10 shows the classification accuracies of using various sampling methods on this dataset using 10 morphological pattern categories. There is a significant advantage of using the proposed irrelevance sampling method under all challenging situations (E1–E6). The irrelevance sampling method outperforms other sampling methods by 2–10%.
3.3. Ablation Study
We perform an ablation study to validate the effectiveness of the proposed algorithm. First, we describe the affect of variation of the parameters and on validation accuracy of the global model. Second, we describe the effectiveness of the proposed algorithm under moderate to severe free rider density through environments E5 and E6, respectively.
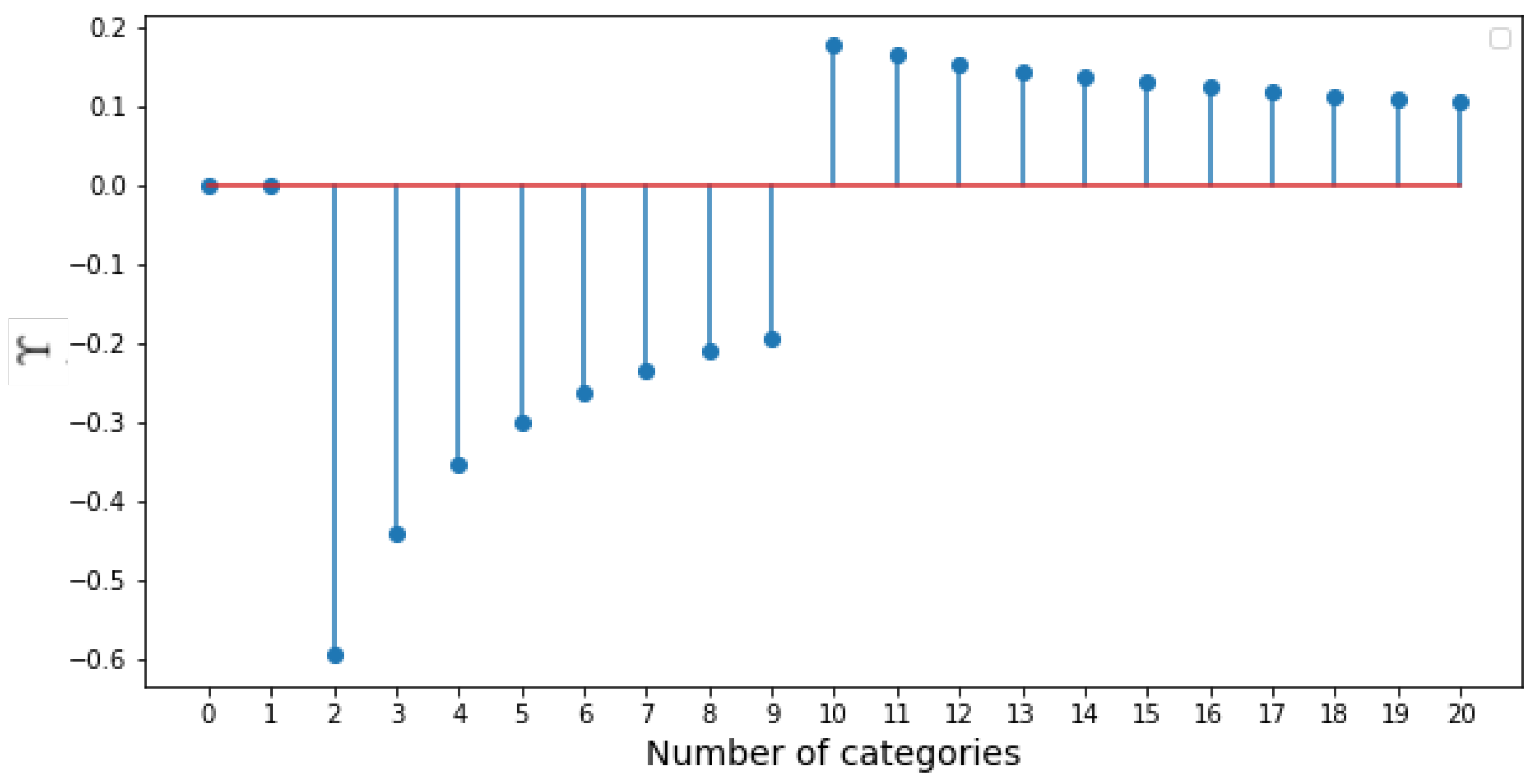
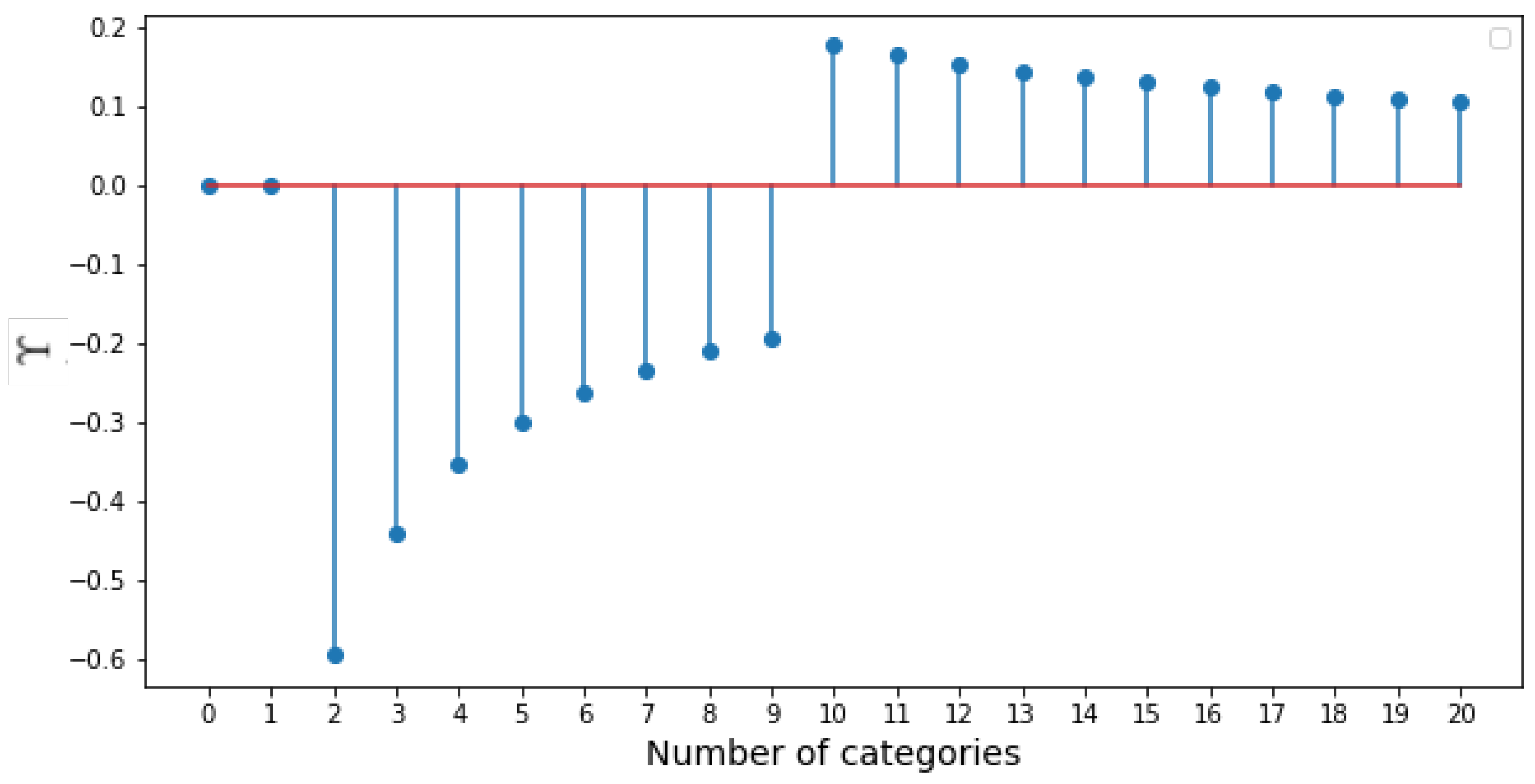
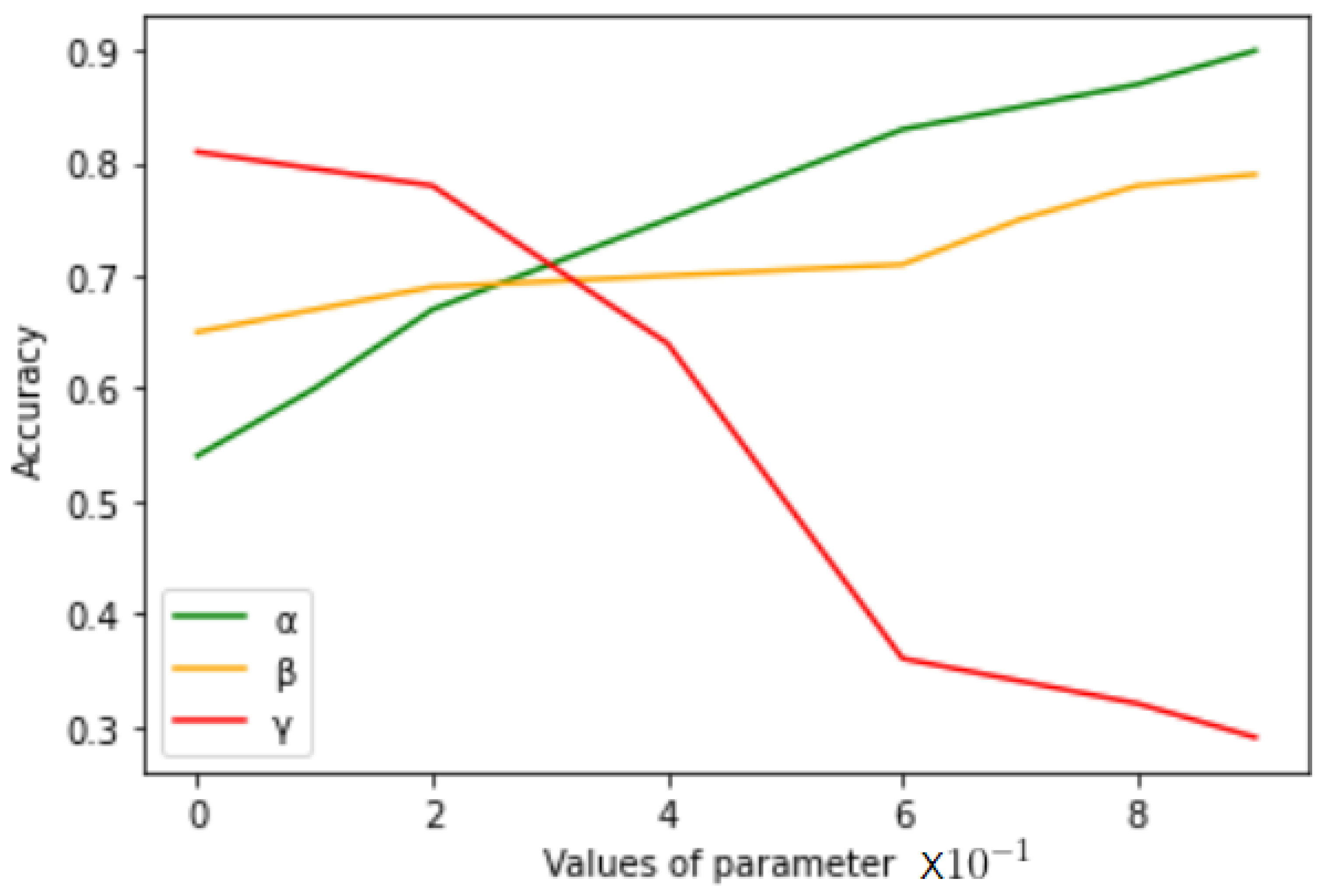
3.3.1. Variation of Parameters
As described in
Section 3.1, the parameters
and
control the distribution of selected clients. In
Table 11, we study the effect of various choices of the parameters. We clearly observe that as
is increased, the accuracy also improves rapidly. The variation of
shows a moderate increase, while the variation of
is inversely related to accuracy.
3.3.2. Free Rider Density
The performance of the proposed sampling algorithm is compared with AFL and random sampling methods under severe (E
5) and extreme (E
6) conditions of free riders. From
Table 12, it is evident that as the density of the free rider increases, there is a deterioration in the performance of all sampling methods. However, the proposed sampling method maintains the best performance in all cases.
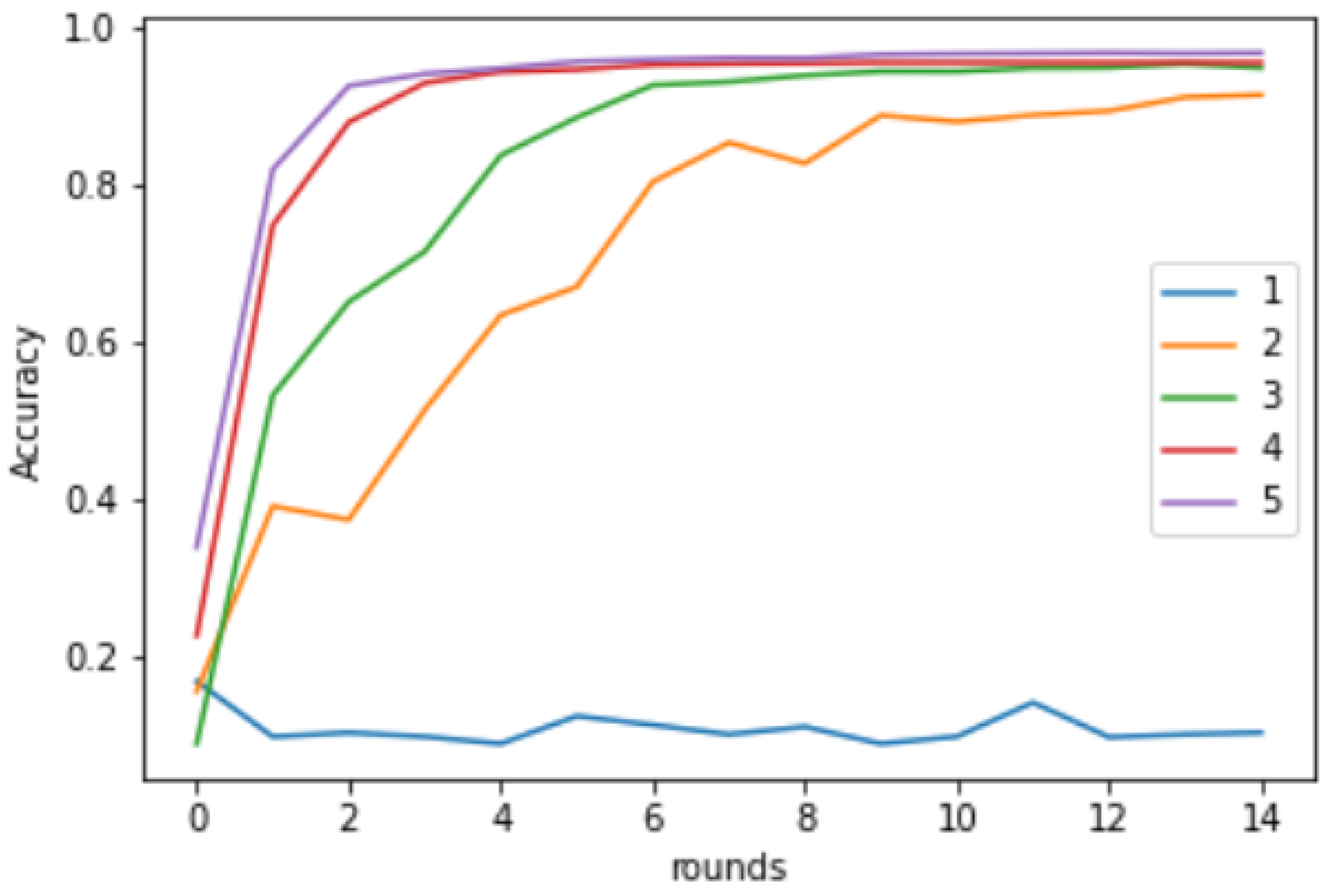
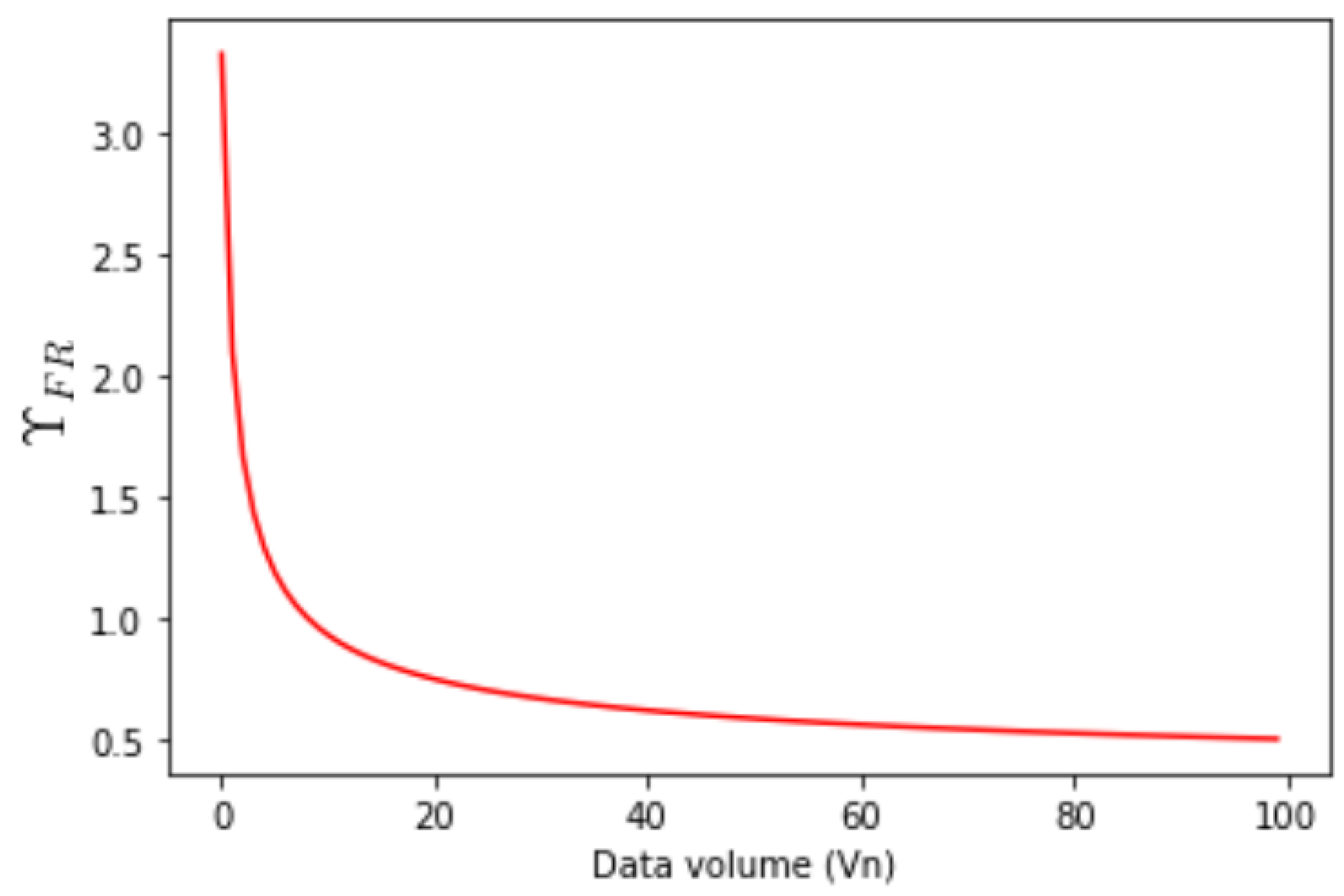
3.4. Effect of Data Volume
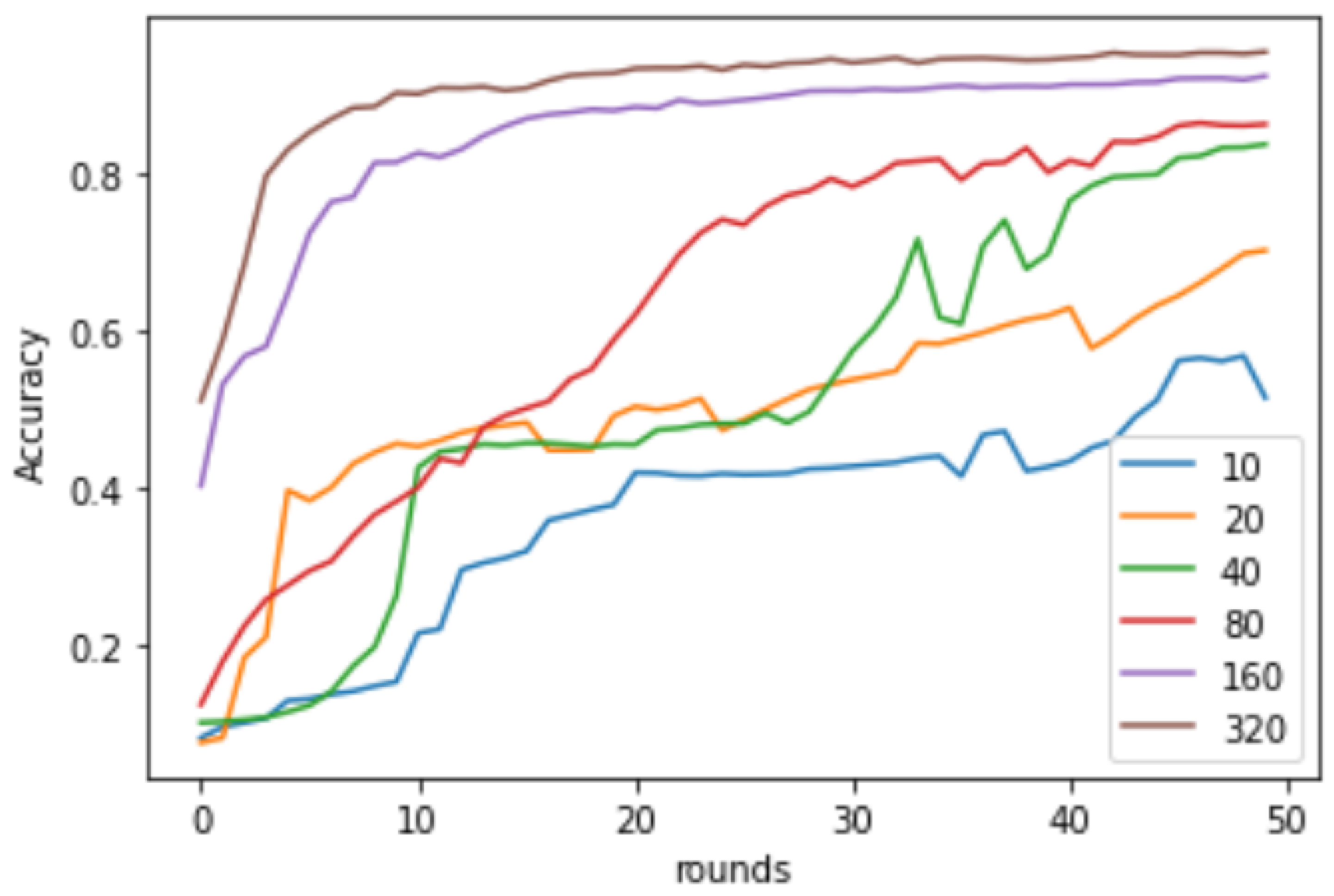
Figure 8 shows the effect of varying data volume on the performance of FedAvg using the MNIST dataset. We see that for lower volumes of data, the performance is very poor, representing the characteristics of a real-world free rider as a client participating with a very small volume of data. As the data volume is increased, the performance improves, depicting a higher relevance for clients with higher data volume.
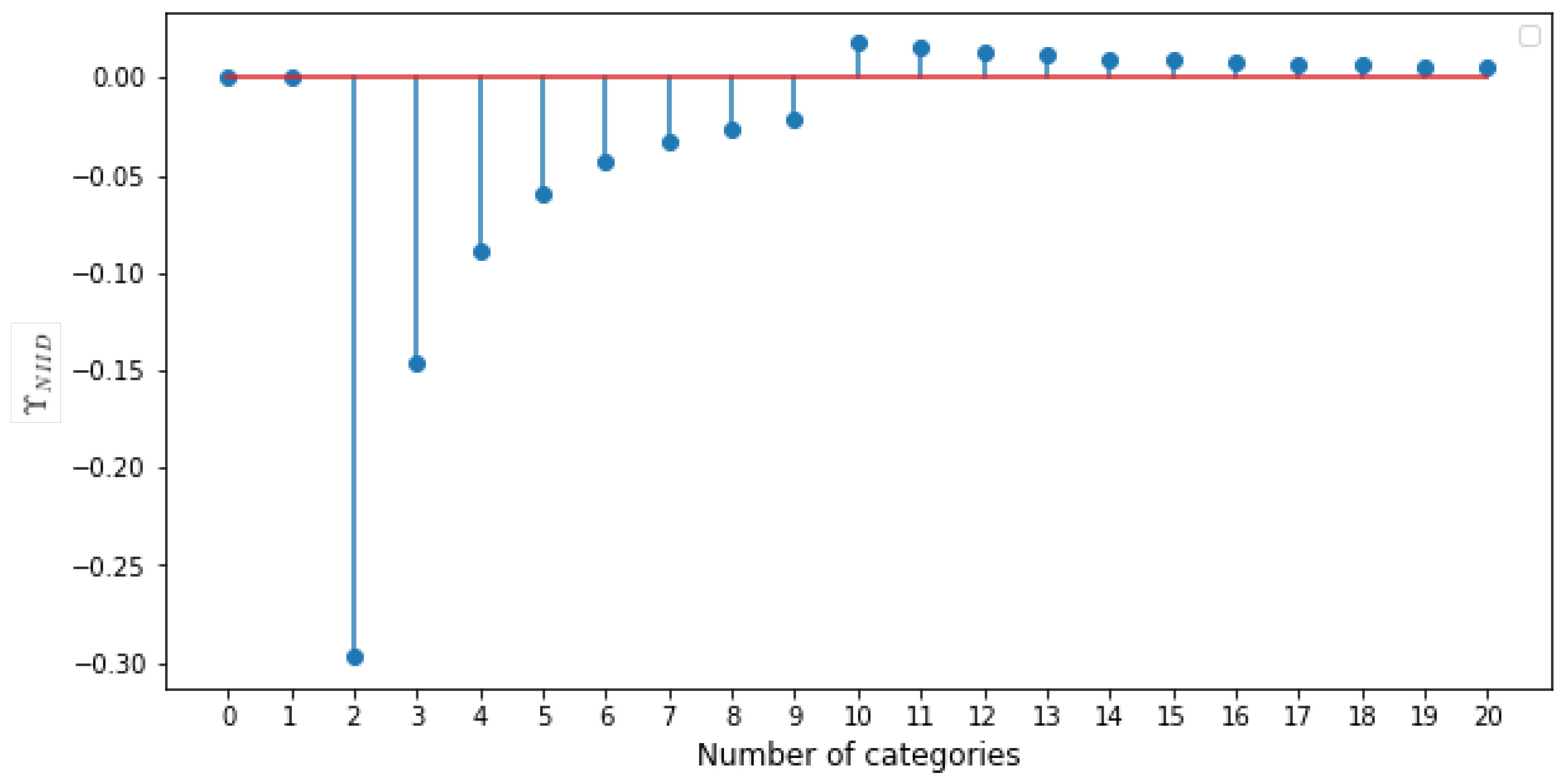
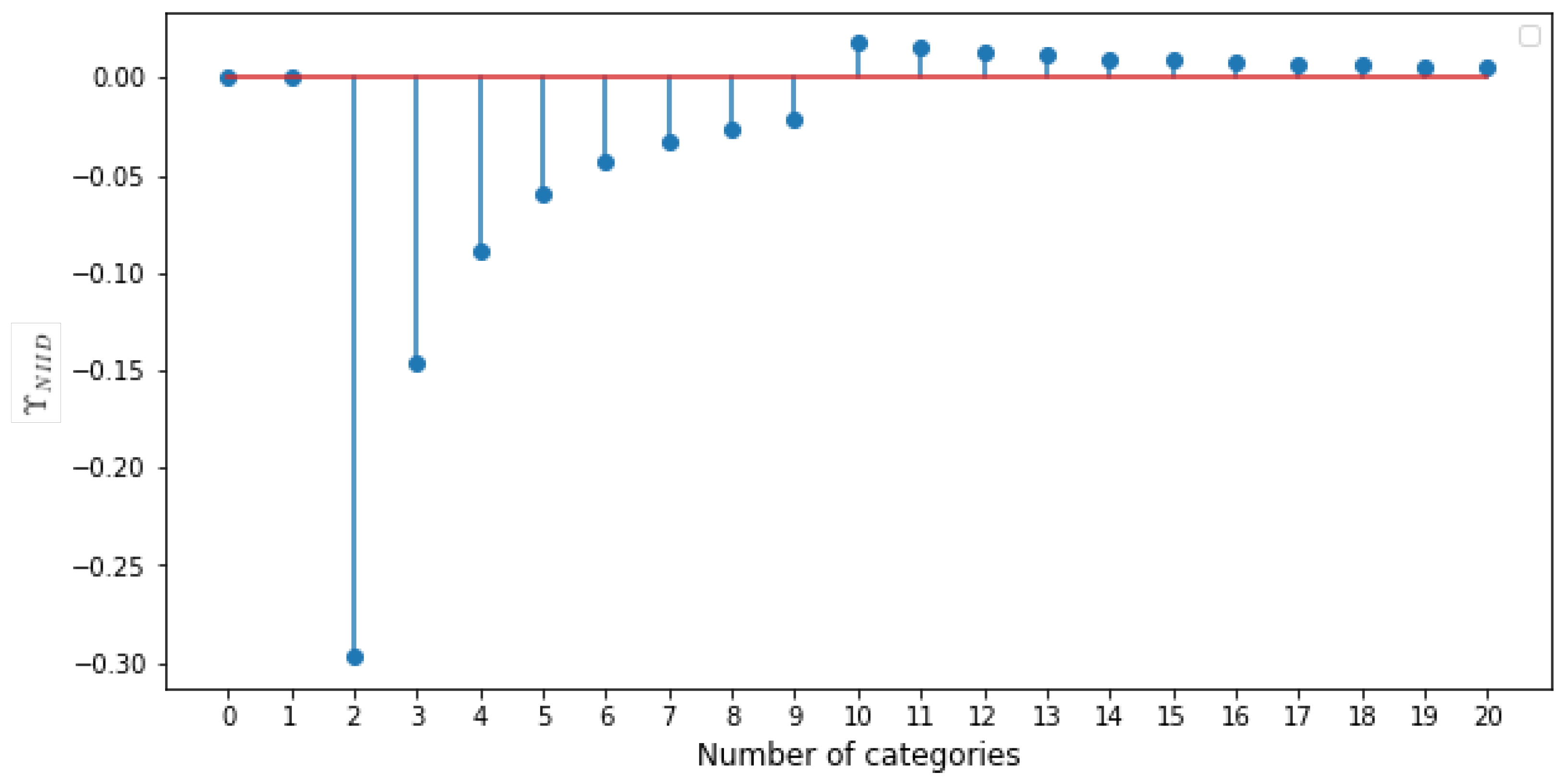
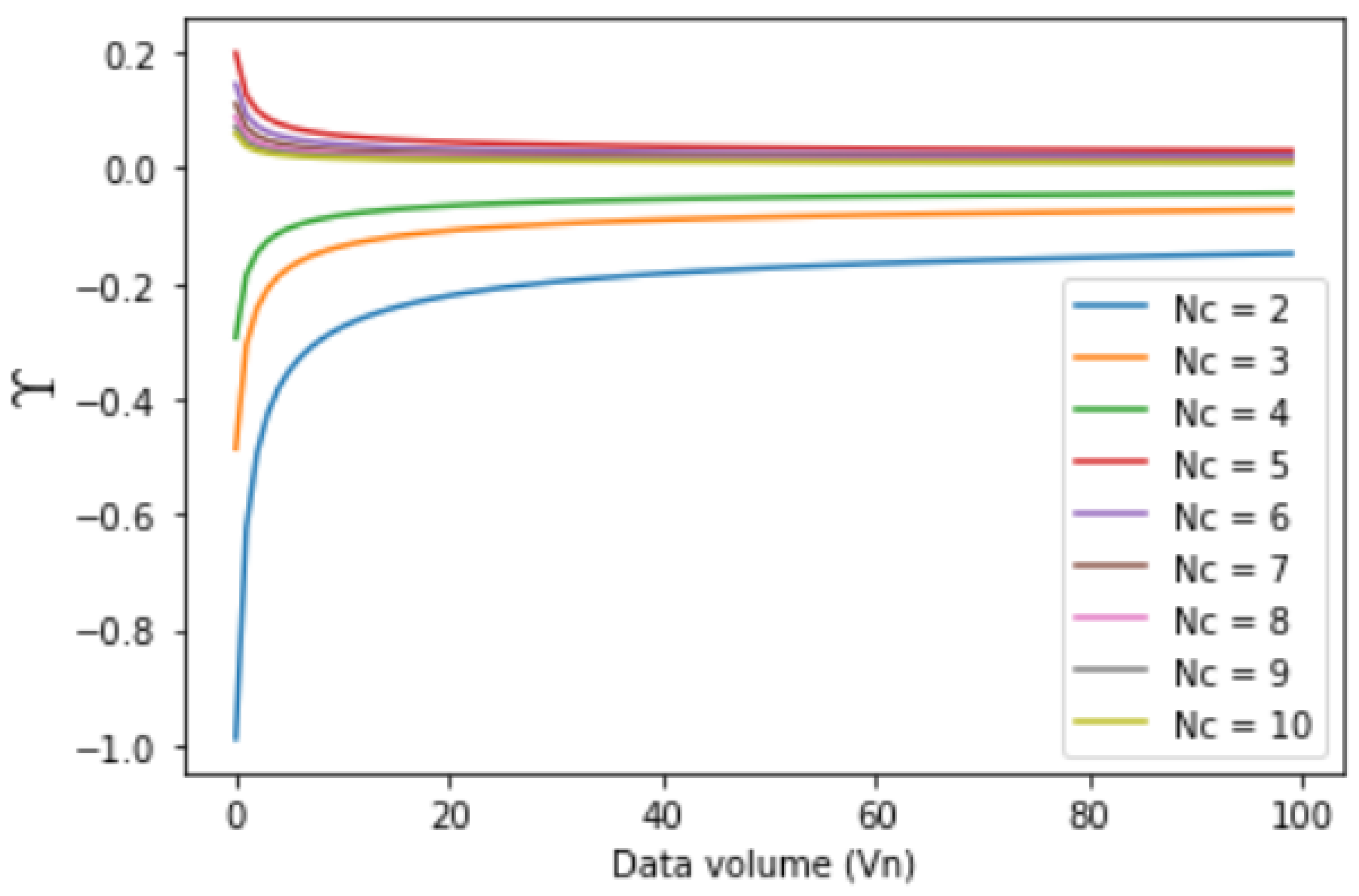
3.5. Effect of Number of Categories
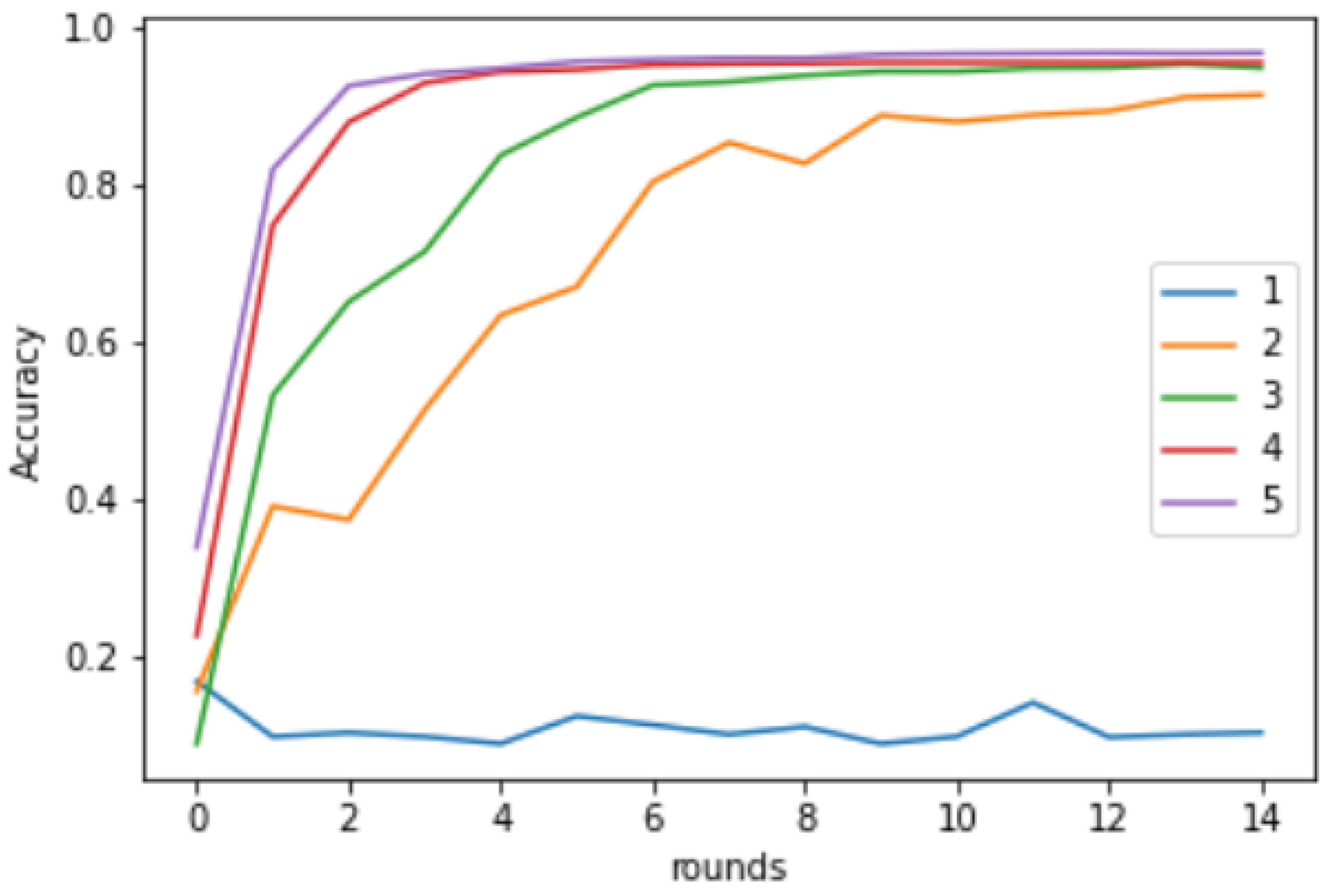
The effect of varying the number of categories on clients is shown in
Figure 9. Each of the curves correspond to using FedAvg for 15 rounds of refinement using an environment with all clients having
number of categories. We can see that clients with a single category perform the poorest and did not learn anything. This explains the
parameter variation, as shown in
Figure 7. As the number of clients increases, the performance of FedAvg improves.
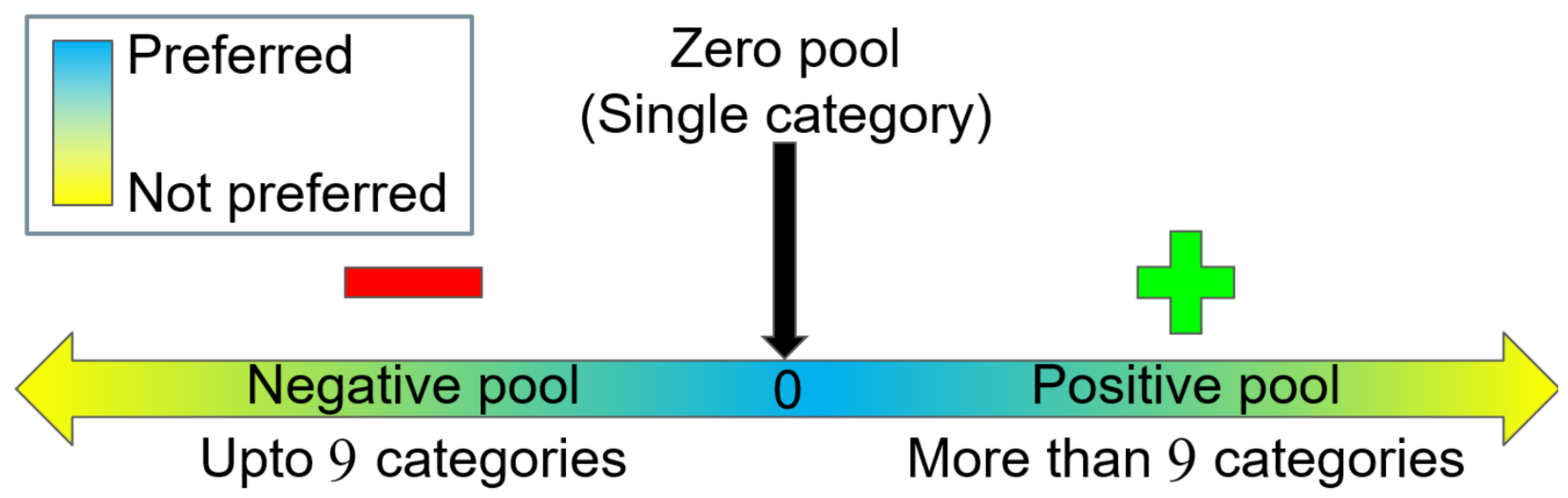
3.6. Highly Skewed Case
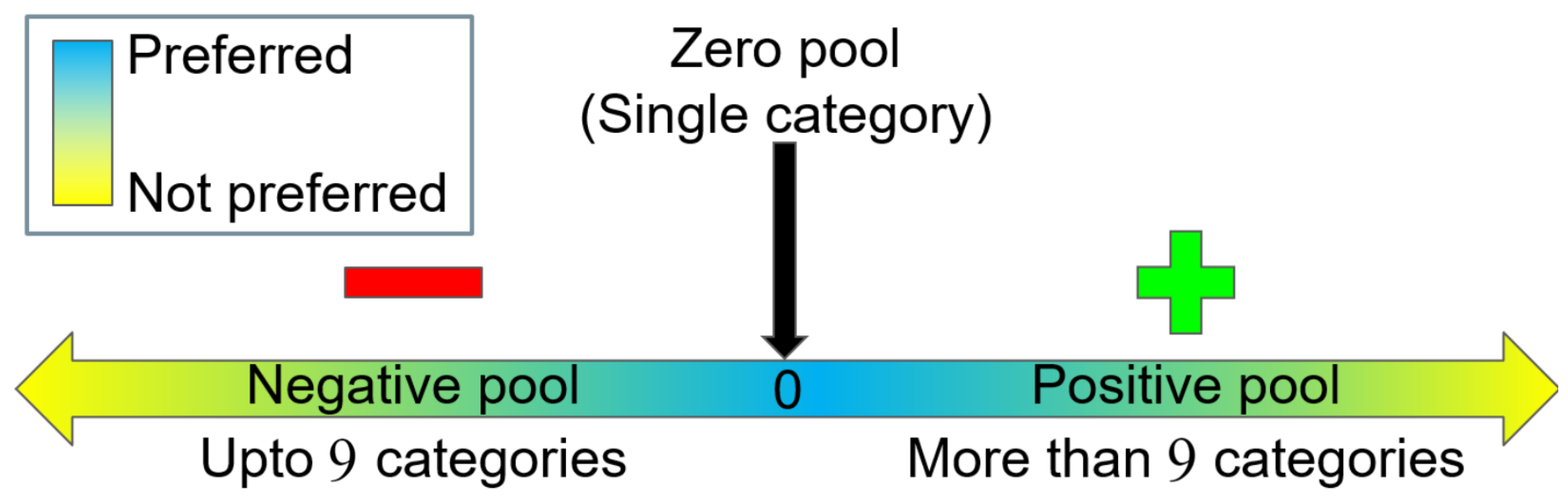
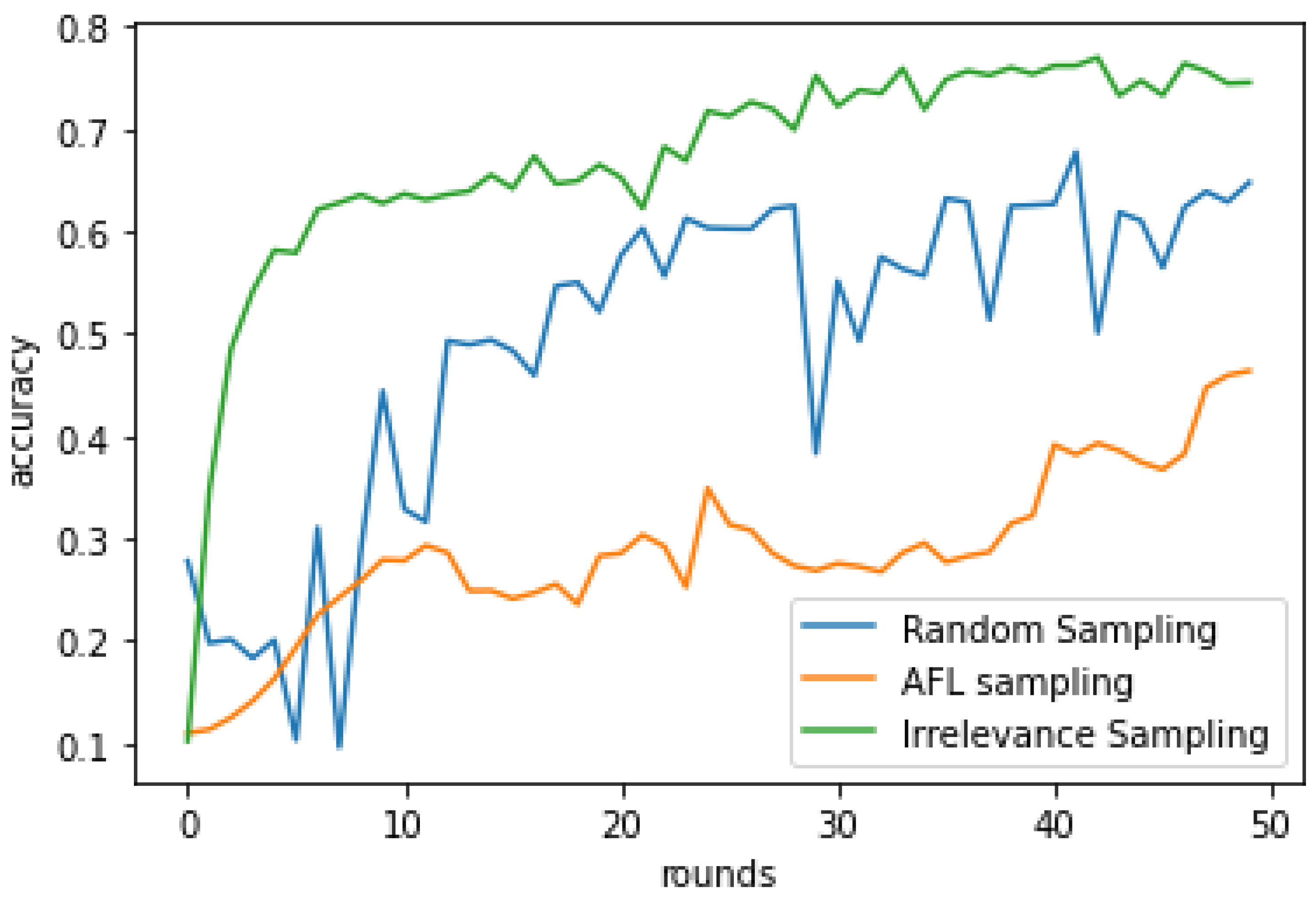
We investigated the performance of the three sampling methods on a specially created highly skewed environment using the MNIST dataset. It consists of a few clients with high class imbalance, and moderate free rider repletion is present in the environment. Moreover, three classes of digits 7, 8 and 9 are available with clients having less than three classes only (zero pool and negative pool). This environment shows the importance of the zero pool and negative pool.
Figure 10 shows the performance comparison of the three sampling methods in this environment. We can clearly see that the irrelevance sampling method is performing better than AFL and random sampling methods. The parameters used for the irrelevance sampling method are
. The smoothness of irrelevance sampling is slightly affected due to the involvement of clients from the zero pool.
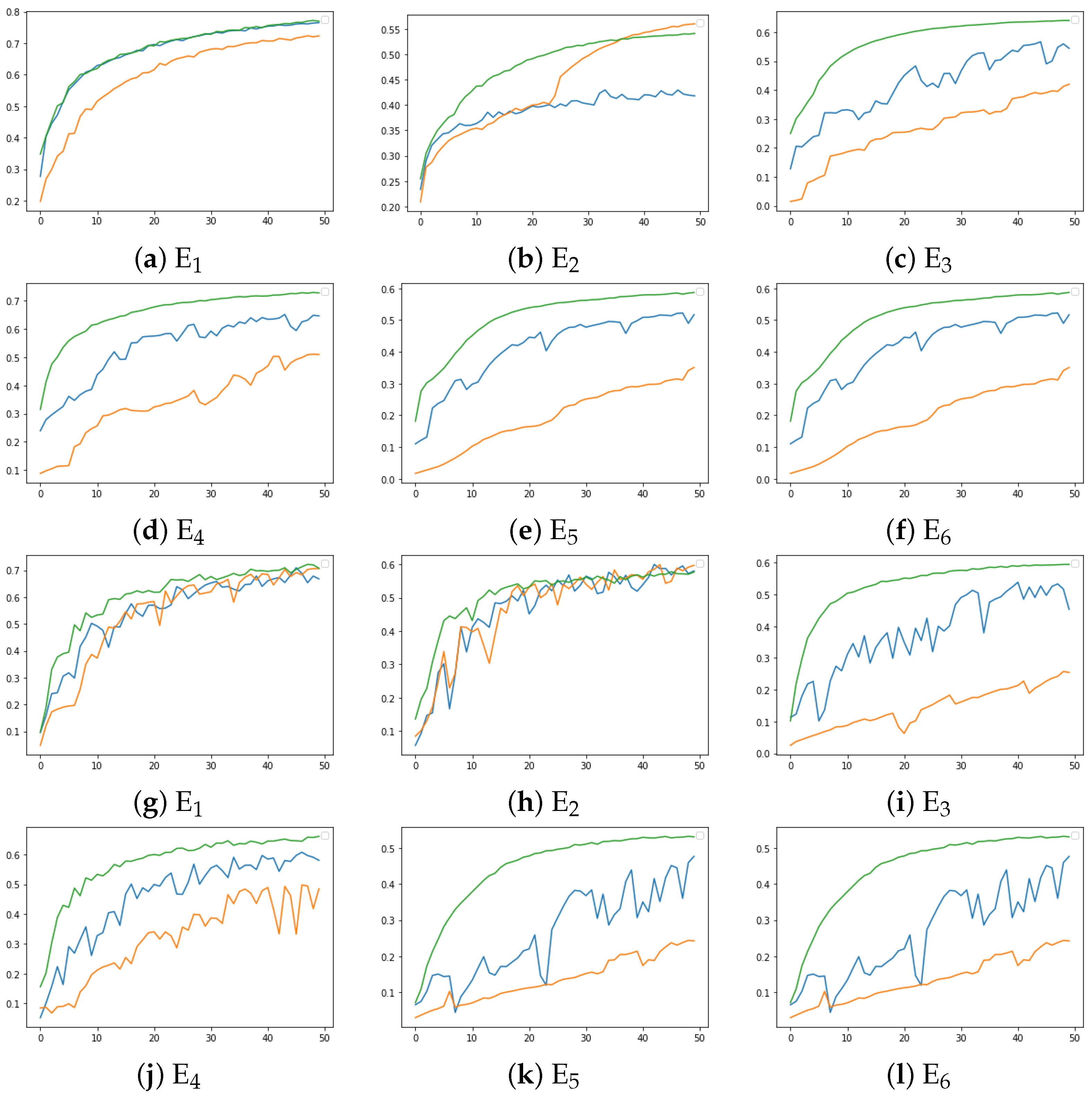
3.7. Convergence Analysis
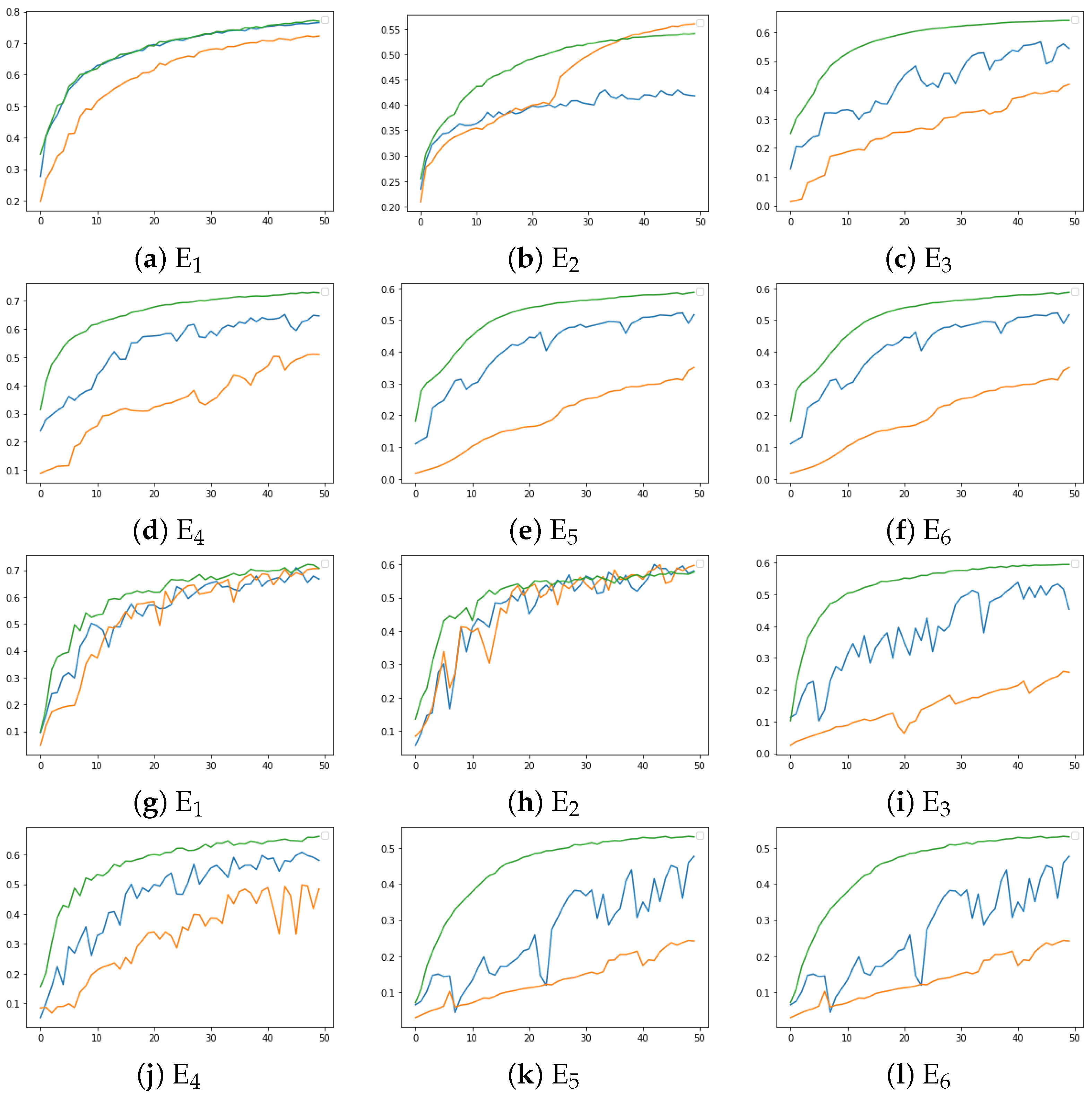
A convergence analysis is presented in
Figure 11 for the FEMNIST dataset for the three sampling methods using the FedAvg learning scheme. Smoother and quicker convergence is observed for the proposed sampling method in comparison with random and AFL sampling for all the environments and under both IID and Non-IID conditions. The results clearly indicate the effectiveness of the proposed method in selecting the optimal subset of clients to update the global model.
5. Conclusions
In conclusion, the proposed irrelevance score and the irrelevance sampling strategy is quite robust in a variety of challenging situations, including Non-IID data, a highly imbalanced federated environment and federated environment replete with free-riders. Its versatility is further demonstrated on multiple datasets with varying challenges even when different learning approaches may be employed. Further, the proposed irrelevance score is effective in preserving client privacy. Therefore, the irrelevance score and the proposed sampling method may open new doors of research.
Our experiments use simulations of possible real-world environments. Nonetheless, some specific unexplored environments may pose new challenges. One such challenge is the scenario where the irrelevance score returned by a client is invalid. Another challenge could be a rapid increase in the number of clients coming onto the server (M). Scalability could be an issue, but initially limiting the number of clients coming onto the server depending on the severity of the use case can be a solution. However, these cases are challenges faced by the AFL sampling method as well. Other disguised schemes of free riders are currently out of the scope of the proposed method and future research work is required on this to resolve issues under these scenarios. In the future, we would like to consider more challenging problems, such as clinical-record-based diagnosis using pathology labs as clients in a federated environment.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}