
Chinese Comma Disambiguation in Math Word Problems Using SMOTE and Random Forests


Abstract
:1. Introduction
2. Notations and Problem Statement
3. Methods
3.1. Feature Construction
- Shallow context features refer to the surface information of a text segment before or behind a comma. Given a text segment before a comma, it can be turned into a list of surface features including the position of the comma (PC), the string length (SL), the number of words (NW) and whether it contains numeric or English letters (NoE).
- Lexical features are of word level and emphasize the part-of-speech (POS) and length of the first word (WL) before or behind a comma.
- Phrasal features are derived from syntactic constituents of a text segment before or behind a comma. For each textual math word problem, a subject–predicate (SP) structure is identical to simple and unbroken discourse units that can be turned into a set of QDUs. Thus, the number of SP structures was chosen as the essential phrasal feature instead of other phrases such as noun phrase and prepositional phrase.
3.2. SMOTE
| Algorithm 1 SMOTE in Pseudo-code |
| Input: The minority class in the dataset , the percentage of synthetic minority class P, and the number of nearest neighbors K Output: The synthetic samples of minority class Syn 1: if P < 100 then 2: Randomize the minority class dataset ; 3: ; 4: P = 100; 5: end if 6: Syn is initialized to an array for the synthetic samples of minority class; 7: ; 8: ; 9: for each do 10: Compute the K-nearest neighbors for ; 11: while P ≠ 0 do 12: Randomize an integer n between 0 and ; 13: Compute the difference between d and ; 14: Randomize a number gap between 0 and 1: ; 15: Generate a synthetic minority: ; 16: ; 17: ; 18: end while 19: end for 20: return Syn; |
3.3. Random Forests
3.4. Hyperparameter Tuning
4. Experimental Setup
4.1. Dataset Description
4.2. Evaluation Measures
5. Results and Discussion
5.1. Selection of Optimal Hyperparameters
- AUC values in Table 2 imply that there is no significant variation in the performance of optimal RF classifiers under different parameter settings of SMOTE; in all cases, the hyperparameters of RF are adaptable for obtaining considerable performance, especially the values of nTrees, which range from 20 to 100, while nAttrs are of convergence in 1, 2 or 4. The optimal numbers of nTrees and nAttrs differ from their default values in many applications of RF [31]. For the convergence of nAttrs, it is in line with a thorough investigation claiming that this hyperparameter has a minor impact on the performance, though larger values may be associated with a reduction in the predictive performance [32]. While using MCC to measure performance, optimal RF classifiers achieve a completely acceptable performance.
- The hyperparameter settings of SMOTE have more influence on the variation of TPR than that of TNR. It may ascribe the flaw of SMOTE in which the synthetic samples derived from the minority samples may be of repeatability, noisy or even fuzzy boundaries between the minority and majority classes [33]. Although there is no apparent variation in TNR in all the cases, classification performance for negative samples tends to be hampered slightly. Thus, the SMOTE adds essential information to the original dataset that enhances RF classifiers’ performance on the minority samples, but is also likely to reduce the performance on classifying the majority samples.
- Comparing the TPR performance achieved by optimal RF classifiers at and , there is a statistically significant difference ( at 95% confidence). For the performance on TPR, optimal RF classifiers were improving when P was increasing from 100 to 400. TNR values, corresponding to the rise in P, are depressed, but still significantly considerable. Figure 6 shows that the best performance tradeoff between TPR and TNR occurred at . The training dataset augmented by SMOTE () was almost fully balanced and induced an optimal RF classifier, achieving the best performance on TPR. It is consistent with the experimental finding that the best oversampling rate made the enlarged dataset fully balanced in order to detect as many positive diabetes patients as possible [34].
- As shown in Figure 7, optimal RF classifiers built at achieved better performance on TPR without sacrificing the performance on TNR. In spite of parameter P values, parameter K has slightly more influence on the classification of negative samples since the number of negative samples in a training dataset has no change after conducting SMOTE with the diversity of parameter P values. This observation is not compatible with the literature recommendations in which the number of nearest neighbors for SMOTE is set to five [14].
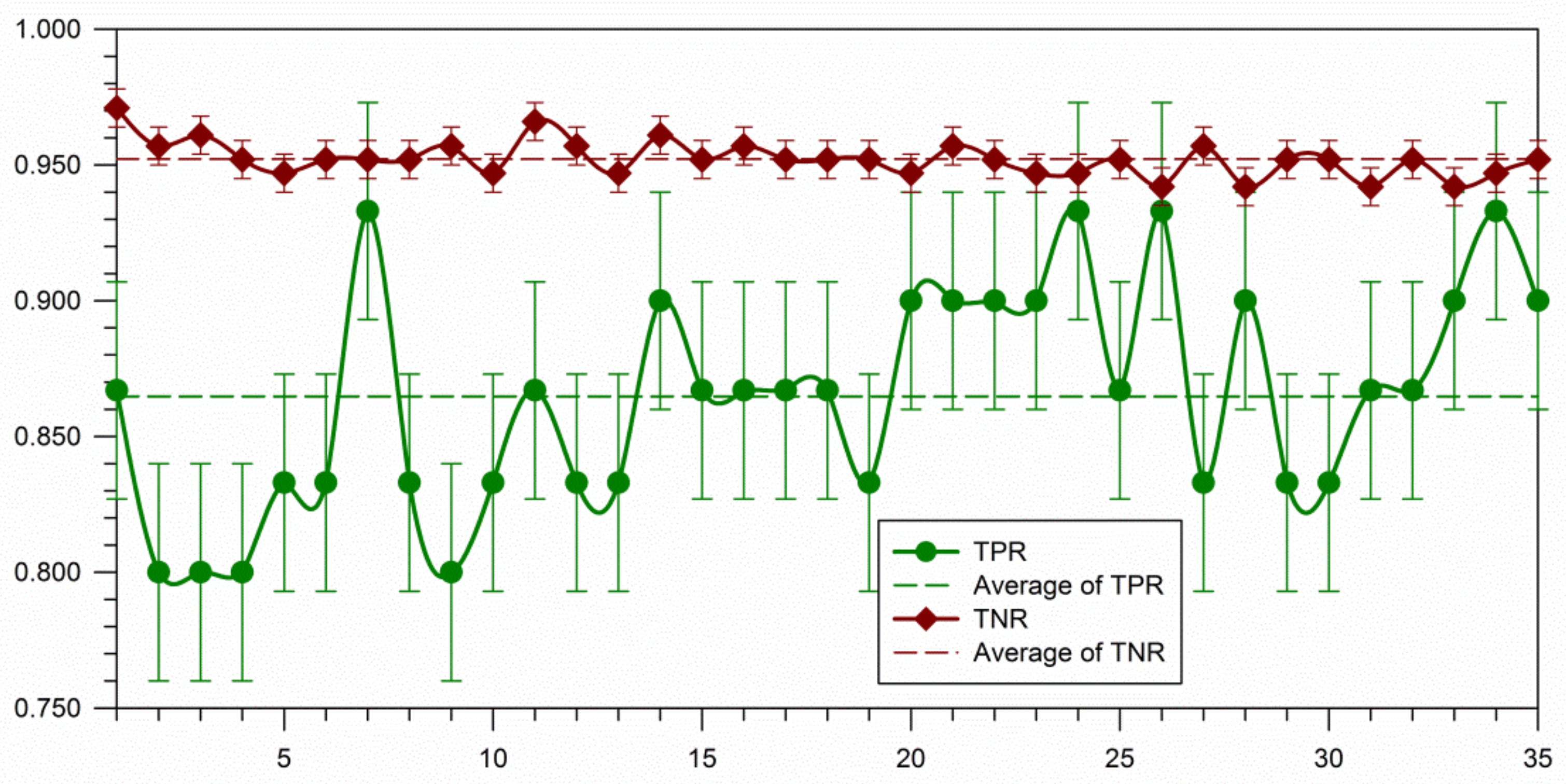
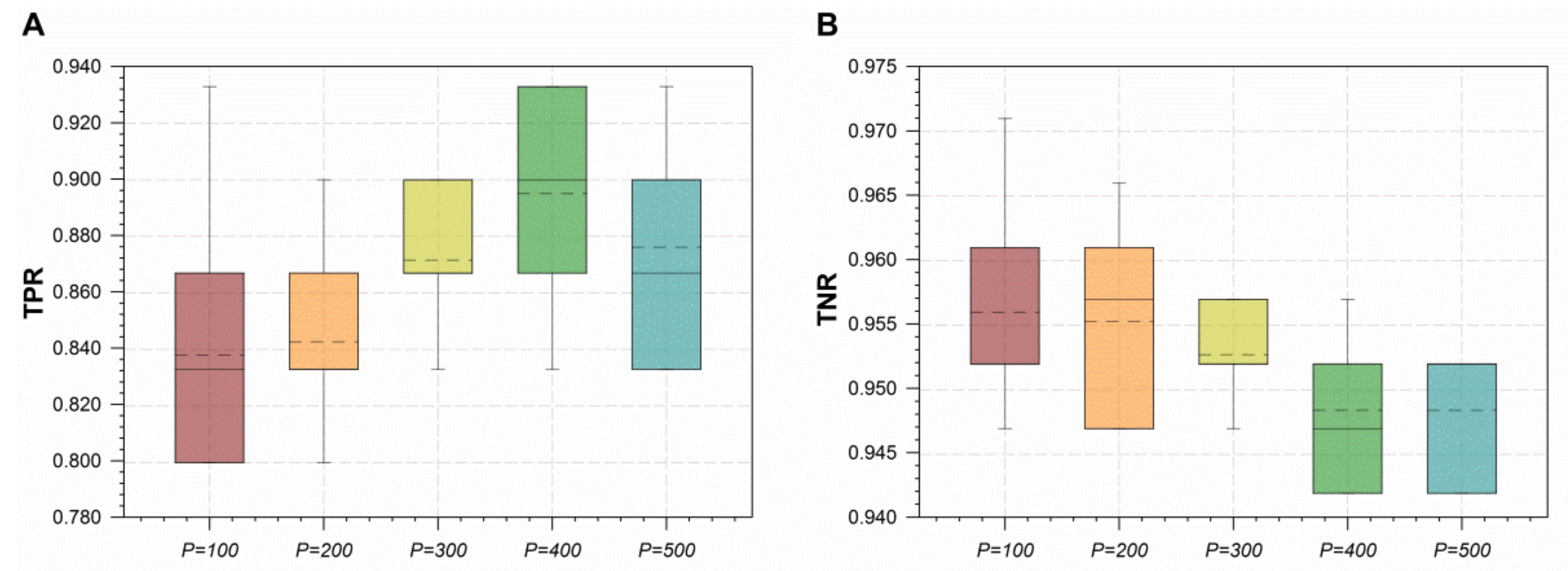
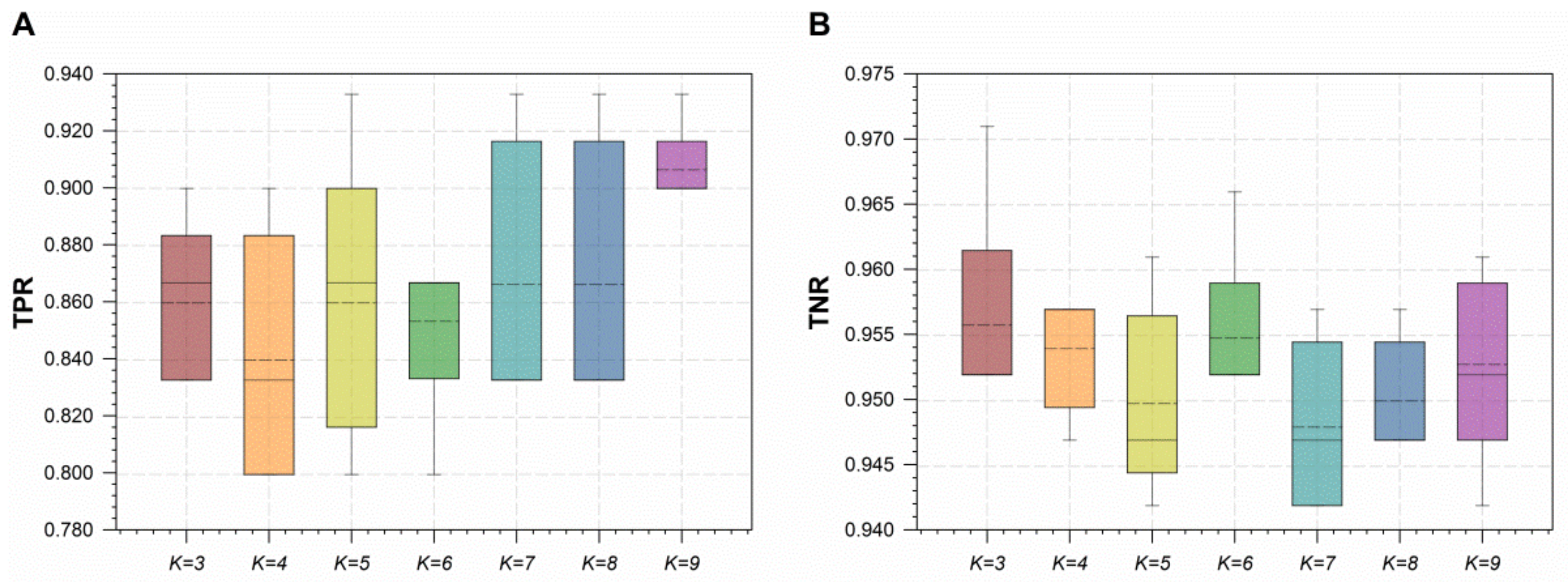
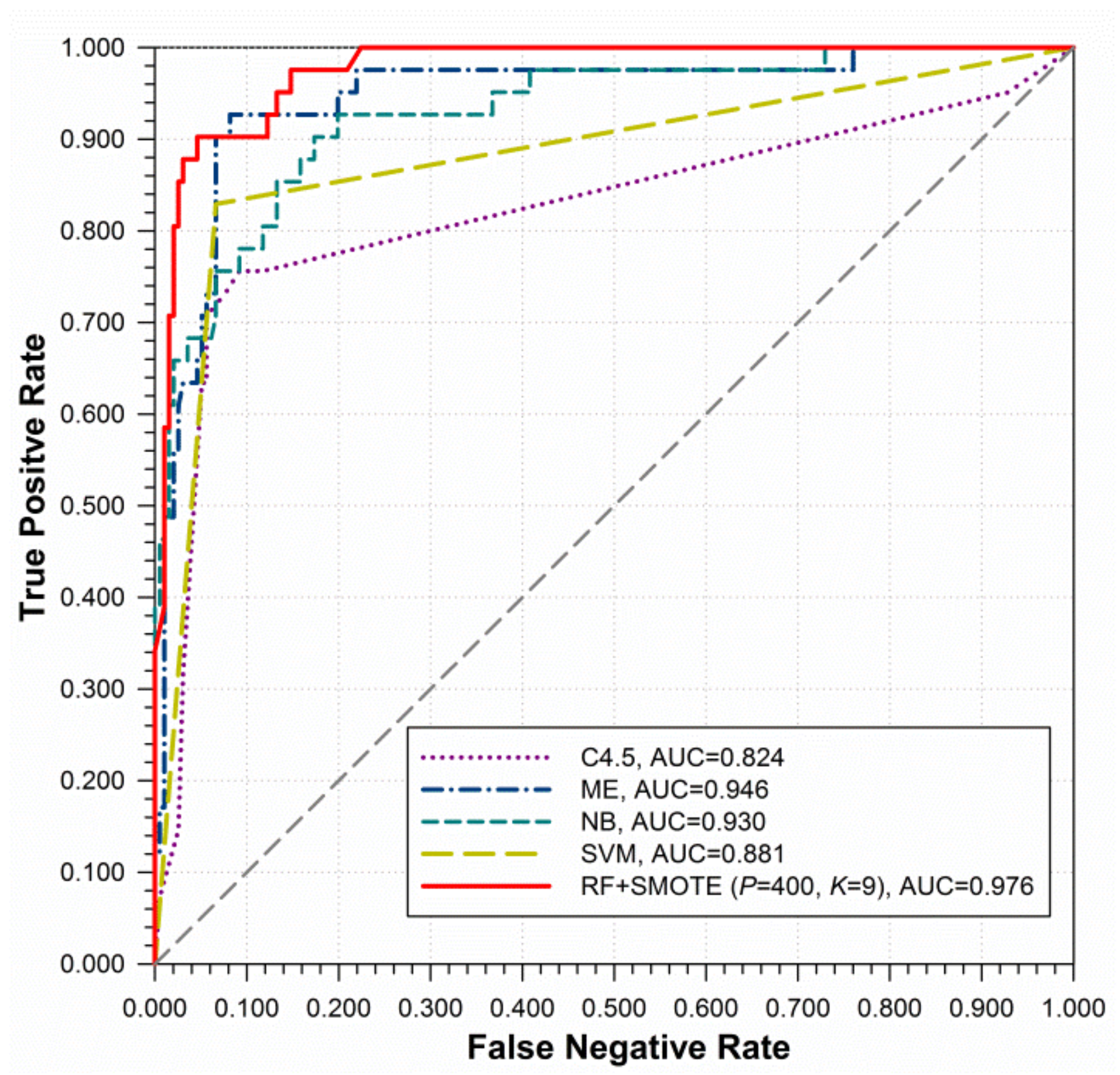
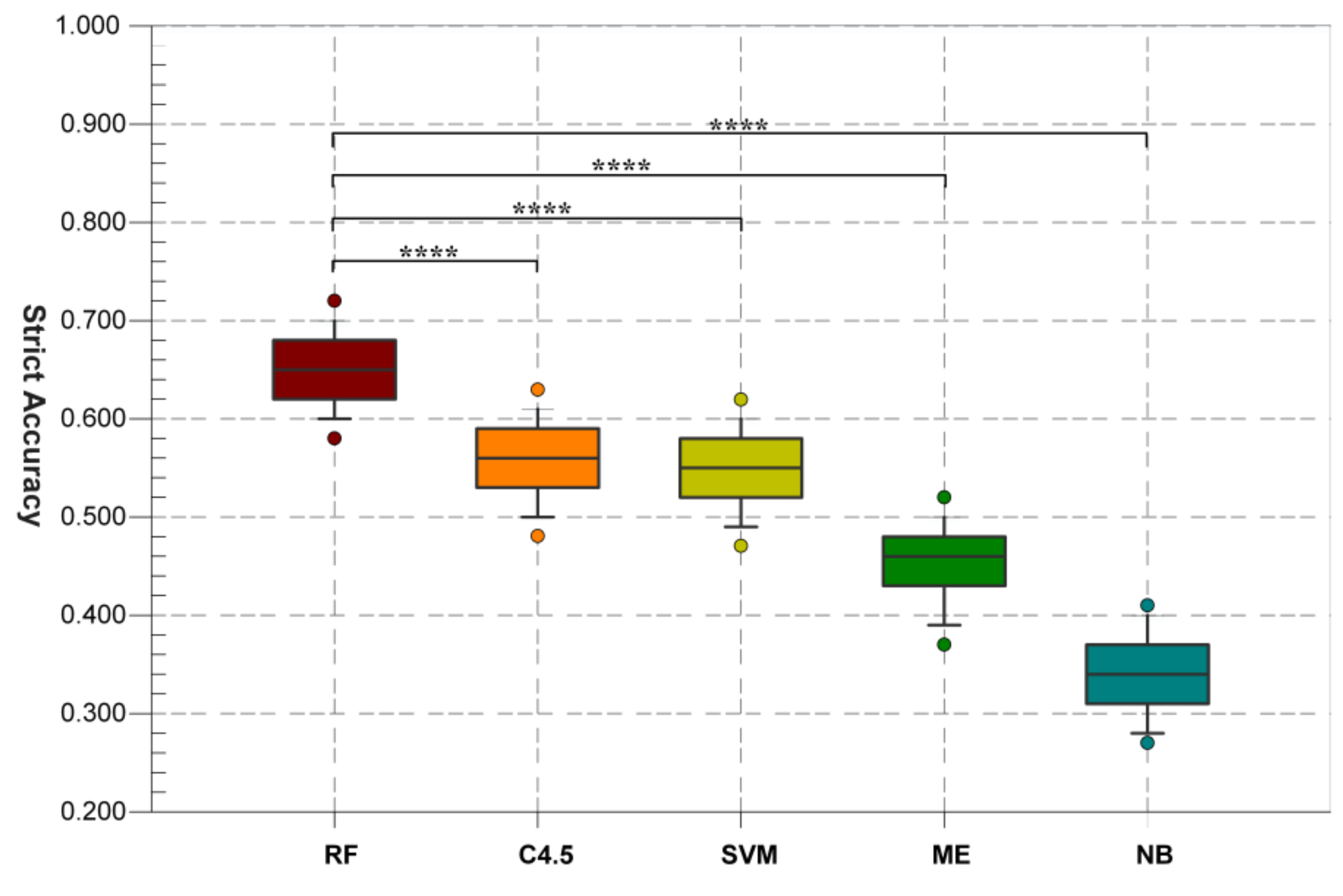
5.2. Comparison of Random Forests and Baseline Models on Comma Classification
5.3. Comparison of Deployed Models on Comma Disambiguation
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bobrow, D.G. Natural Language Input for a Computer Problem Solving System. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1964. [Google Scholar]
- Mukherjee, A.; Garain, U. A review of methods for automatic understanding of natural language mathematical problems. Artif. Intell. Rev. 2008, 29, 93–122. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, L.; Zhang, L.; Dai, B.T.; Shen, H.T. The gap of semantic parsing: A survey on automatic math word problem solvers. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2287–2305. [Google Scholar] [CrossRef] [Green Version]
- Mann, W.C.; Thompson, S.A. Rhetorical structure theory: Toward a functional theory of text organization. Text Talk 1988, 8, 243–281. [Google Scholar] [CrossRef]
- Kazawa, H.; Isozaki, H.; Maeda, E. NTT Question Answering System in TREC 2001. In Proceedings of the 10th Text Retrieval Conference, Gaithersburg, MD, USA, 13–16 November 2001. [Google Scholar]
- Arivazhagan, N.; Christodoulopoulos, C.; Roth, D. Labeling the semantic roles of commas. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 14–17 February 2016. [Google Scholar]
- Yang, Y.; Xue, N. Chinese Comma disambiguation for discourse analysis. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju, Korea, 8–14 July 2012. [Google Scholar]
- Xue, N.; Yang, Y. Chinese sentence segmentation as comma classification. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011. [Google Scholar]
- Xu, S.; Kong, F.; Li, P.; Zhu, Q. A Chinese sentence segmentation approach based on comma. In Proceedings of the 13th Chinese Lexical Semantics Workshop, Wuhan, China, 6–8 July 2012. [Google Scholar]
- Li, X.; Yang, H.; Huang, J. Maximum entropy for Chinese comma classification with rich linguistic features. In Proceedings of the 3th CIPS-SIGHAN Joint Conference on Chinese Language Processing, Wuhan, China, 20–21 October 2014. [Google Scholar]
- Li, H.; Zhu, Y. Classifying Commas for Patent Machine Translation. In Proceedings of the 12th China Workshop on Machine Translation, Urumqi, China, 25–26 August 2016. [Google Scholar]
- Kong, F.; Zhou, G. A CDT-styled end-to-end Chinese discourse parser. ACM Trans. Asian Lang. Inf. Process. 2017, 16, 1–17. [Google Scholar] [CrossRef]
- ICTPOS3.0. Available online: http://www.nlpir.org/wordpress/attachments/2011/06/ICTPOS3.0.doc (accessed on 12 October 2021).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Blagus, R.; Lusa, L. SMOTE for high-dimensional class-imbalanced data. BMC Bioinform. 2013, 14, 106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gray, K.R.; Aljabar, P.; Heckemann, R.A.; Hammers, A.; Rueckert, D. Random forest-based similarity measures for multi-modal classification of alzheimer’s disease. Neuroimage 2013, 65, 167–175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jayaraj, P.B.; Ajay, M.K.; Nufail, M.; Gopakumar, G.; Jaleel, U.C.A. GPURFSCREEN: A GPU based virtual screening tool using random forest classifier. J. Cheminform. 2016, 8, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, S.; Oehler, F.; San-Miguel-Ayanz, J.; Camia, A.; Pereira, J.M. Modeling spatial patterns of fire occurrence in Mediterranean Europe using multiple regression and random forest. For. Ecol. Manag. 2012, 275, 117–129. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Stephan, J.; Stegle, O.; Beyer, A. A random forest approach to capture genetic effects in the presence of population structure. Nat. Commun. 2015, 6, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khalilia, M.; Chakraborty, S.; Popescu, M. Predicting disease risks from highly imbalanced data using random forest. BMC Med. Inform. Decis. Mak. 2011, 11, 51. [Google Scholar] [CrossRef] [Green Version]
- Yun, J.; Ha, J.; Lee, J.S. Automatic Determination of Neighborhood Size in SMOTE. In Proceedings of the 10th International Conference on Ubiquitous Information Management and Communication, Danang, Vietnam, 4–6 January 2016. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A practical guide to support vector classification. BJU Int. 2008, 101, 1396–1400. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Elsevier: Amsterdam, The Netherlands, 2016; pp. 1–621. [Google Scholar]
- Department of Statistics. Using Random Forest to Learn Imbalanced Data. Available online: https://statistics.berkeley.edu/tech-reports/666 (accessed on 12 October 2021).
- Wu, Q.; Ye, Y.; Zhang, H.; Ng, M.K.; Ho, S.S. ForesTexter: An efficient random forest algorithm for imbalanced text categorization. Knowl.-Based Syst. 2014, 67, 105–116. [Google Scholar] [CrossRef]
- Cohen, G.; Hilario, M.; Sax, H.; Hugonnet, S.; Geissbuhler, A. Learning from imbalanced data in surveillance of nosocomial infection. Artif. Intell. Med. 2006, 37, 7–18. [Google Scholar] [CrossRef]
- Baldi, P.; Brunak, S.; Chauvin, Y.; Andersen, C.A.; Nielsen, H. Assessing the accuracy of prediction algorithms for classification: An overview. Bioinformatics 2000, 16, 412–424. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fawcett, T. ROC graphs: Notes and practical considerations for researchers. Pattern Recognit. Lett. 2004, 37, 1–38. [Google Scholar]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recognit. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- Díaz-Uriarte, R.; De Andres, S.A. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7, 3. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Fan, S. CURE-SMOTE algorithm and hybrid algorithm for feature selection and parameter optimization based on random forests. BMC Bioinform. 2017, 18, 169. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, M.; Hong, X.; Chen, S.; Harris, C.J. A combined SMOTE and PSO based RBF classifier for two-class imbalanced problems. Neurocomputing 2011, 74, 3456–3466. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 74, 1263–1284. [Google Scholar]
- Muchlinski, D.; Siroky, D.; He, J.; Kocher, M. Comparing random forest with logistic regression for predicting class-imbalanced civil war onset data. Political Anal. 2016, 24, 87–103. [Google Scholar] [CrossRef]
- Polat, K. A Hybrid Approach to Parkinson Disease Classification Using Speech Signal: The Combination of SMOTE and Random Forests. In Proceedings of the Scientific Meeting on Electrical-Electronics & Biomedical Engineering and Computer Science, Istanbul, Turkey, 24–26 April 2019. [Google Scholar]
- Mihai, D.P.; Trif, C.; Stancov, G.; Radulescu, D.; Nitulescu, G.M. Artificial Intelligence Algorithms for Discovering New Active Compounds Targeting TRPA1 Pain Receptors. AI 2020, 1, 276–285. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | non-B-QDU | B-QDU | |||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 1 | 2 | |
| PC | 5 | 8 | 32 | 44 | 60 |
| NoE | false | false | true | true | true |
| SL | 2 | 23 | 11 | 15 | 27 |
| NW | 1 | 13 | 5 | 8 | 19 |
| POS | ntc | ntc | m | n | n |
| WL | 2 | 2 | 4 | 1 | 1 |
| SP | 0 | 2 | 0 | 0 | 1 |
| Hyperparameters of SMOTE | Performance Metrics | Optimal Hyperparameter Settings of Random Forests | |||||||
|---|---|---|---|---|---|---|---|---|---|
| P | K | TPR | TNR | WA | GM | MCC | AUC | nTrees | nAttrs |
| 100 | 3 | 0.867 | 0.971 | 0.919 | 0.918 | 0.815 | 0.986 | 70 | 1 |
| 4 | 0.800 | 0.957 | 0.879 | 0.875 | 0.727 | 0.980 | 80 | 1 | |
| 5 | 0.800 | 0.961 | 0.881 | 0.877 | 0.741 | 0.981 | 80 | 1 | |
| 6 | 0.800 | 0.952 | 0.876 | 0.873 | 0.713 | 0.980 | 65 | 1 | |
| 7 | 0.833 | 0.947 | 0.890 | 0.888 | 0.723 | 0.981 | 100 | 2 | |
| 8 | 0.833 | 0.952 | 0.893 | 0.891 | 0.736 | 0.979 | 85 | 1 | |
| 9 | 0.933 | 0.952 | 0.943 | 0.942 | 0.802 | 0.982 | 30 | 4 | |
| 200 | 3 | 0.833 | 0.952 | 0.893 | 0.891 | 0.736 | 0.983 | 60 | 1 |
| 4 | 0.800 | 0.957 | 0.879 | 0.875 | 0.727 | 0.981 | 80 | 1 | |
| 5 | 0.833 | 0.947 | 0.890 | 0.888 | 0.723 | 0.981 | 85 | 1 | |
| 6 | 0.867 | 0.966 | 0.917 | 0.915 | 0.800 | 0.983 | 50 | 1 | |
| 7 | 0.833 | 0.957 | 0.895 | 0.893 | 0.749 | 0.977 | 20 | 1 | |
| 8 | 0.833 | 0.947 | 0.890 | 0.888 | 0.723 | 0.977 | 30 | 1 | |
| 9 | 0.900 | 0.961 | 0.931 | 0.930 | 0.807 | 0.982 | 30 | 1 | |
| 300 | 3 | 0.867 | 0.952 | 0.910 | 0.909 | 0.758 | 0.983 | 95 | 1 |
| 4 | 0.867 | 0.957 | 0.912 | 0.911 | 0.771 | 0.980 | 40 | 1 | |
| 5 | 0.867 | 0.952 | 0.910 | 0.909 | 0.758 | 0.982 | 100 | 1 | |
| 6 | 0.867 | 0.952 | 0.910 | 0.909 | 0.758 | 0.985 | 90 | 1 | |
| 7 | 0.833 | 0.952 | 0.893 | 0.891 | 0.736 | 0.983 | 40 | 1 | |
| 8 | 0.900 | 0.947 | 0.924 | 0.923 | 0.767 | 0.983 | 95 | 1 | |
| 9 | 0.900 | 0.957 | 0.929 | 0.928 | 0.793 | 0.984 | 75 | 1 | |
| 400 | 3 | 0.900 | 0.952 | 0.926 | 0.926 | 0.780 | 0.982 | 75 | 1 |
| 4 | 0.900 | 0.947 | 0.924 | 0.923 | 0.767 | 0.981 | 25 | 1 | |
| 5 | 0.933 | 0.947 | 0.940 | 0.940 | 0.789 | 0.979 | 25 | 4 | |
| 6 | 0.867 | 0.952 | 0.910 | 0.909 | 0.758 | 0.985 | 75 | 1 | |
| 7 | 0.933 | 0.942 | 0.938 | 0.937 | 0.777 | 0.983 | 40 | 1 | |
| 8 | 0.833 | 0.957 | 0.895 | 0.893 | 0.749 | 0.984 | 95 | 1 | |
| 9 | 0.900 | 0.942 | 0.921 | 0.921 | 0.755 | 0.980 | 40 | 1 | |
| 500 | 3 | 0.833 | 0.952 | 0.893 | 0.891 | 0.736 | 0.978 | 20 | 2 |
| 4 | 0.833 | 0.952 | 0.893 | 0.891 | 0.736 | 0.979 | 55 | 1 | |
| 5 | 0.867 | 0.942 | 0.905 | 0.904 | 0.733 | 0.981 | 75 | 1 | |
| 6 | 0.867 | 0.952 | 0.910 | 0.909 | 0.758 | 0.983 | 95 | 1 | |
| 7 | 0.900 | 0.942 | 0.921 | 0.921 | 0.755 | 0.982 | 55 | 1 | |
| 8 | 0.933 | 0.947 | 0.940 | 0.940 | 0.789 | 0.985 | 85 | 1 | |
| 9 | 0.900 | 0.952 | 0.926 | 0.926 | 0.780 | 0.983 | 95 | 1 | |
| Classification Models | Performance Metrics | ||||||
|---|---|---|---|---|---|---|---|
| R (TPR) | F | TNR | WA | GM | MCC | AUC | |
| C4.5 | 0.707 | 0.716 | 0.944 | 0.826 | 0.817 | 0.658 | 0.824 |
| ME | 0.683 | 0.709 | 0.949 | 0.816 | 0.805 | 0.651 | 0.946 |
| NB | 0.610 | 0.714 | 0.980 | 0.795 | 0.773 | 0.680 | 0.930 |
| SVM | 0.829 | 0.773 | 0.934 | 0.882 | 0.880 | 0.724 | 0.881 |
| RF | 0.780 | 0.821 | 0.974 | 0.877 | 0.872 | 0.787 | 0.978 |
| RF + Undersampling | 0.707 | 0.753 | 0.964 | 0.836 | 0.826 | 0.708 | 0.954 |
| RF+SMOTE (nTrees = 40, nAttrs = 1, P = 400, K = 9) | 0.805 | 0.825 | 0.980 | 0.893 | 0.888 | 0.817 | 0.976 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Liu, Q.; Zheng, Y.; Wu, L. Chinese Comma Disambiguation in Math Word Problems Using SMOTE and Random Forests. AI 2021, 2, 738-755. https://doi.org/10.3390/ai2040044
Huang J, Liu Q, Zheng Y, Wu L. Chinese Comma Disambiguation in Math Word Problems Using SMOTE and Random Forests. AI. 2021; 2(4):738-755. https://doi.org/10.3390/ai2040044
Chicago/Turabian StyleHuang, Jingxiu, Qingtang Liu, Yunxiang Zheng, and Linjing Wu. 2021. "Chinese Comma Disambiguation in Math Word Problems Using SMOTE and Random Forests" AI 2, no. 4: 738-755. https://doi.org/10.3390/ai2040044
APA StyleHuang, J., Liu, Q., Zheng, Y., & Wu, L. (2021). Chinese Comma Disambiguation in Math Word Problems Using SMOTE and Random Forests. AI, 2(4), 738-755. https://doi.org/10.3390/ai2040044