
A Natural Language Interface to Relational Databases Using an Online Analytic Processing Hypercube



Abstract
:1. Introduction
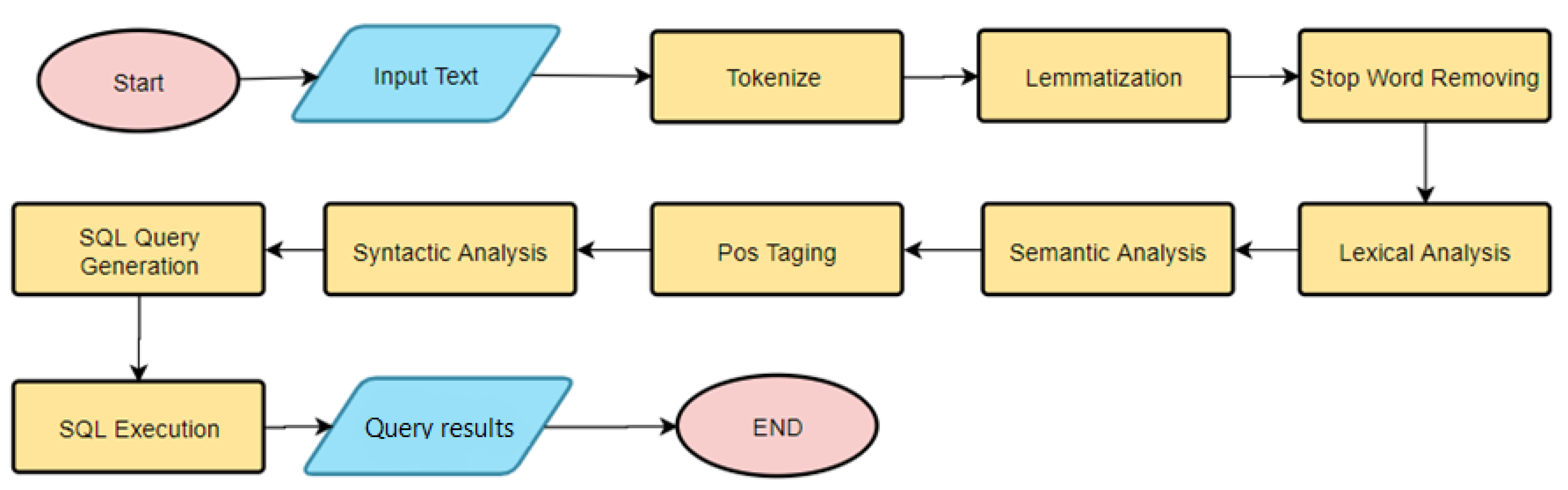
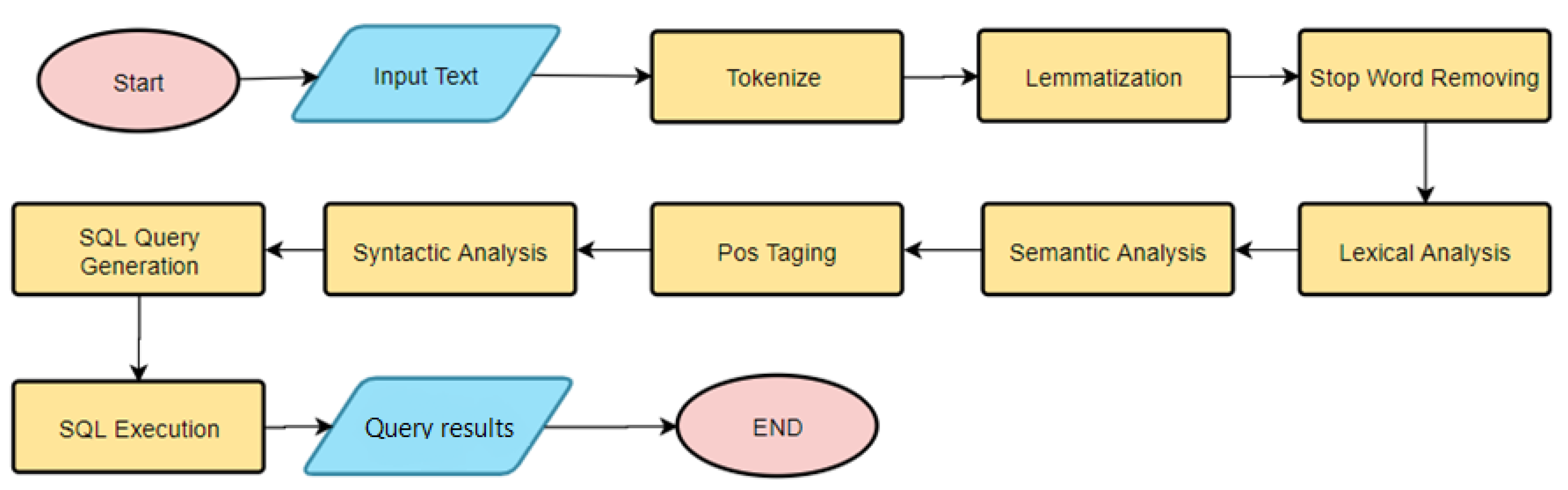
- 1.
- Tokenize module;
- 2.
- Lemmatized and Stop-Word module;
- 3.
- Lexical module;
- 4.
- Semantic module;
- 5.
- POS_tagging module;
- 6.
- Syntactic module.
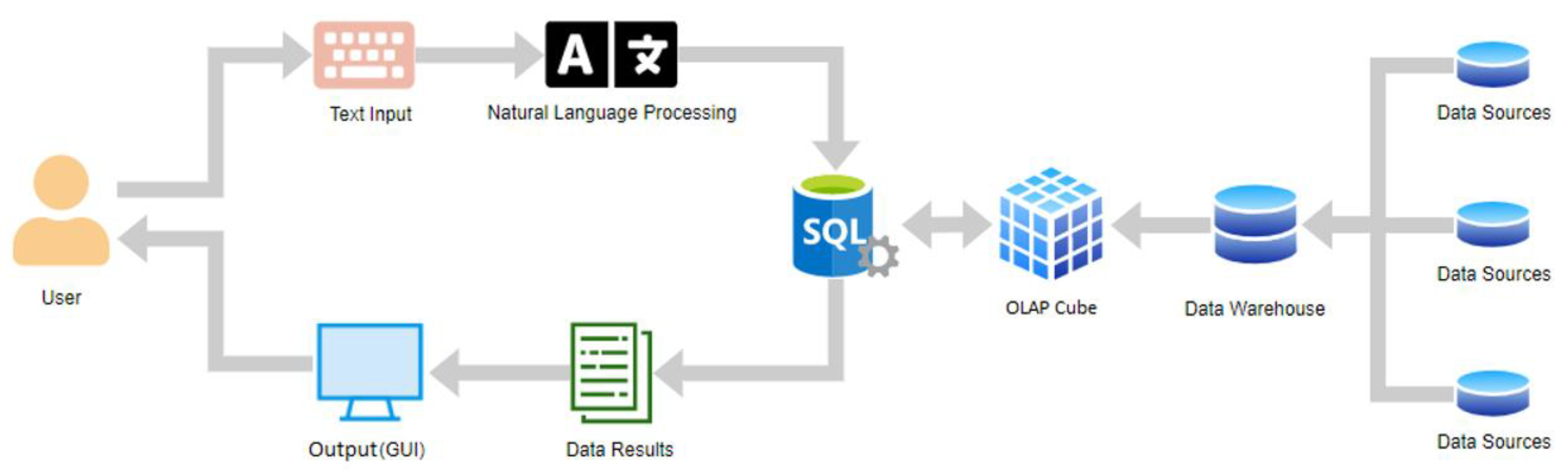
2. Online Analytical Processing (OLAP)
3. Literature Review
4. Methodology
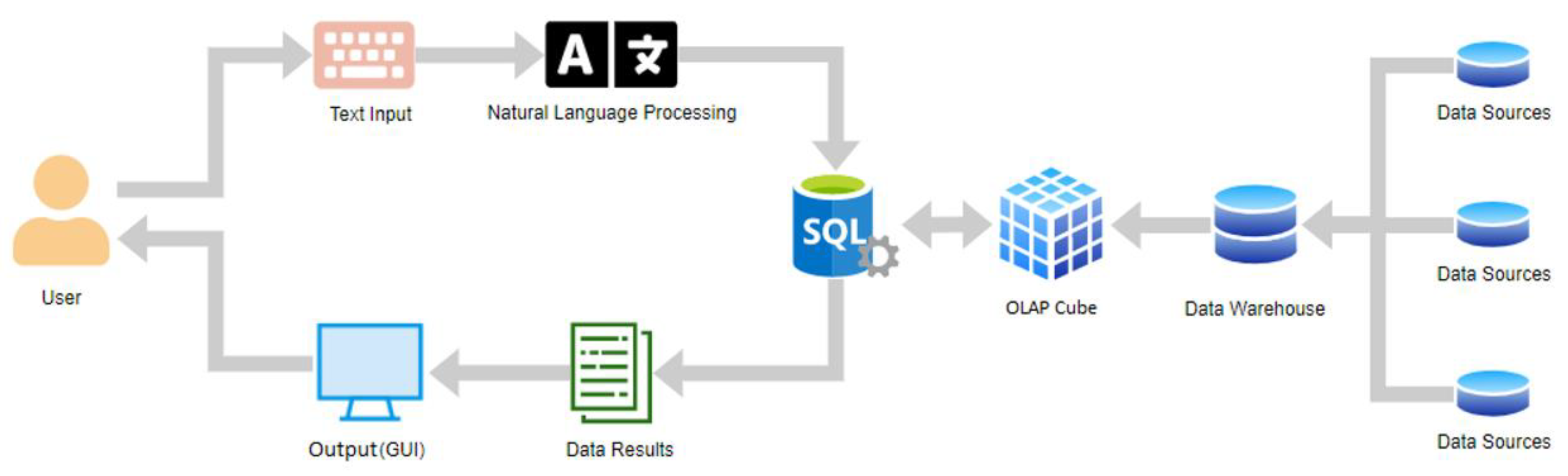
4.1. Proposed Model
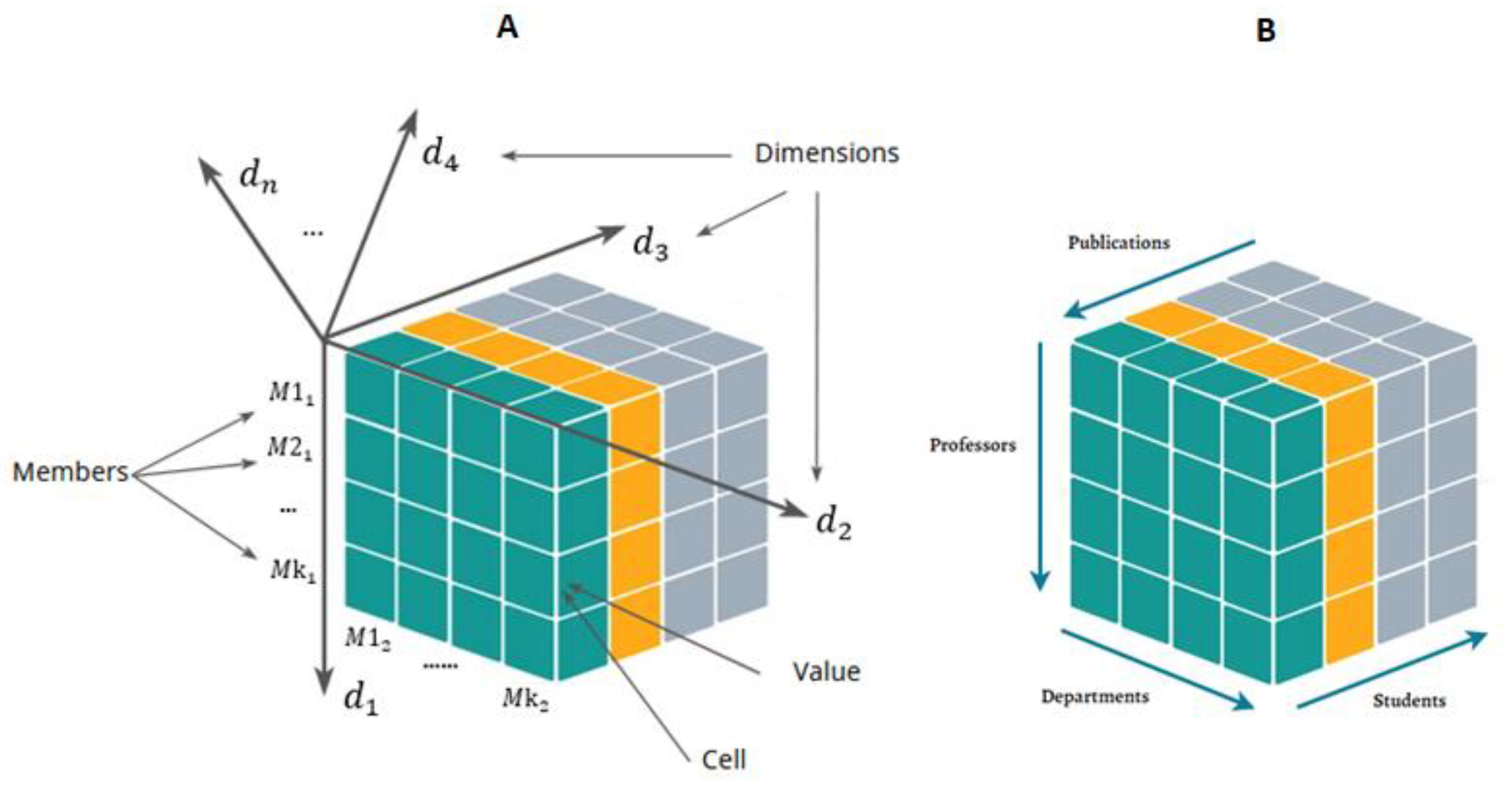
4.2. Multi-Dimensional OLAP 4D-Cube (Hypercube)
- Slicing;
- Dicing;
- Drill-Down/Up;
- Roll-Up.
- Create a cube and its dependent components including dimensions and members.
- Map the OLAP model to source data.
- Enable the materialized view rewrite to the cube.
- Load data into the dimensions and measures.
- Load and view OLAP cube data.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D1 | D2 | D3 | D4 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Department ID | Department Name | PROF. ID | PROF. NAME | JTITLE | PHONE | STUDENTID | STUNAME | PUBID | PUBTITLE |
| 1 | Mathematics and Computation | 1 | Majdi Owda | Senior Lecturer | 4401612471520 | 2 | Pei Lee | 1 | Template-Based Information Extraction System for Detection of Events on Twitter |
| 2 | Information Extraction From Big Social Data | ||||||||
| 7 | John Staven | 6 | Conversation-Based Natural Language Interface to Relational Databases | ||||||
| 5 | Crime Prevention on Social Networks Featuring Location Based Services | ||||||||
| 5 | David McLean | Senior Lecturer | 4401612471536 | 17 | Justen | 9 | An Adaptation Algorithm for an Intelligent Natural Language Tutoring System | ||
| 12 | NLP Interfaces along with OLAP | ||||||||
| 7 | Lida Nejad | Principal Lecturer | 970599255888 | 24 | Liza N. | 0 | No Publication Yet | ||
| 25 | Kojo B. | 0 | No Publication Yet | ||||||
| 2 | Digital Media Entertainment Technology | 2 | Keeley Crockett | Reader | 4401612471497 | 8 | Mohammed Kaleem | 14 | A Multi-Classifier Approach to Dialogue Act Classification Using Function Words. |
| 8 | A Multi-Classifier Approach to Dialogue Act Classification Using Function Words. | ||||||||
| 11 | An Adaptation Algorithm for an Intelligent Natural Language Tutoring System | ||||||||
| 7 | Conversation-Based Natural Language Interface to Relational Databases | ||||||||
| 0 | No Publication Yet | ||||||||
| 18 | Rania | 0 | No Publication Yet | ||||||
| 19 | Fuad | 0 | No Publication Yet | ||||||
| 26 | Nawal K. | 0 | No Publication Yet | ||||||
| 3 | James OShea | Principal Lecturer | 4401612471546 | 21 | Rani H. | 0 | No Publication Yet | ||
| 16 | Samia | 13 | A Multi-Classifier Approach to Dialogue Act Classification Using Function Words. | ||||||
| 15 | Huda | 13 | A Multi-Classifier Approach to Dialogue Act Classification Using Function Words. | ||||||
| 14 | Carolina | 13 | A Multi-Classifier Approach to Dialogue Act Classification Using Function Words. | ||||||
| 6 | Annabel Latham | Lecturer | 4401612471495 | 19 | Fuad | 10 | An Adaptation Algorithm for an Intelligent Natural Language Tutoring System | ||
| 22 | Ruti K. | 10 | An Adaptation Algorithm for an Intelligent Natural Language Tutoring System | ||||||
| 20 | Justen P. | 10 | An Adaptation Algorithm for an Intelligent Natural Language Tutoring System | ||||||
4.3. From NLP to SQL
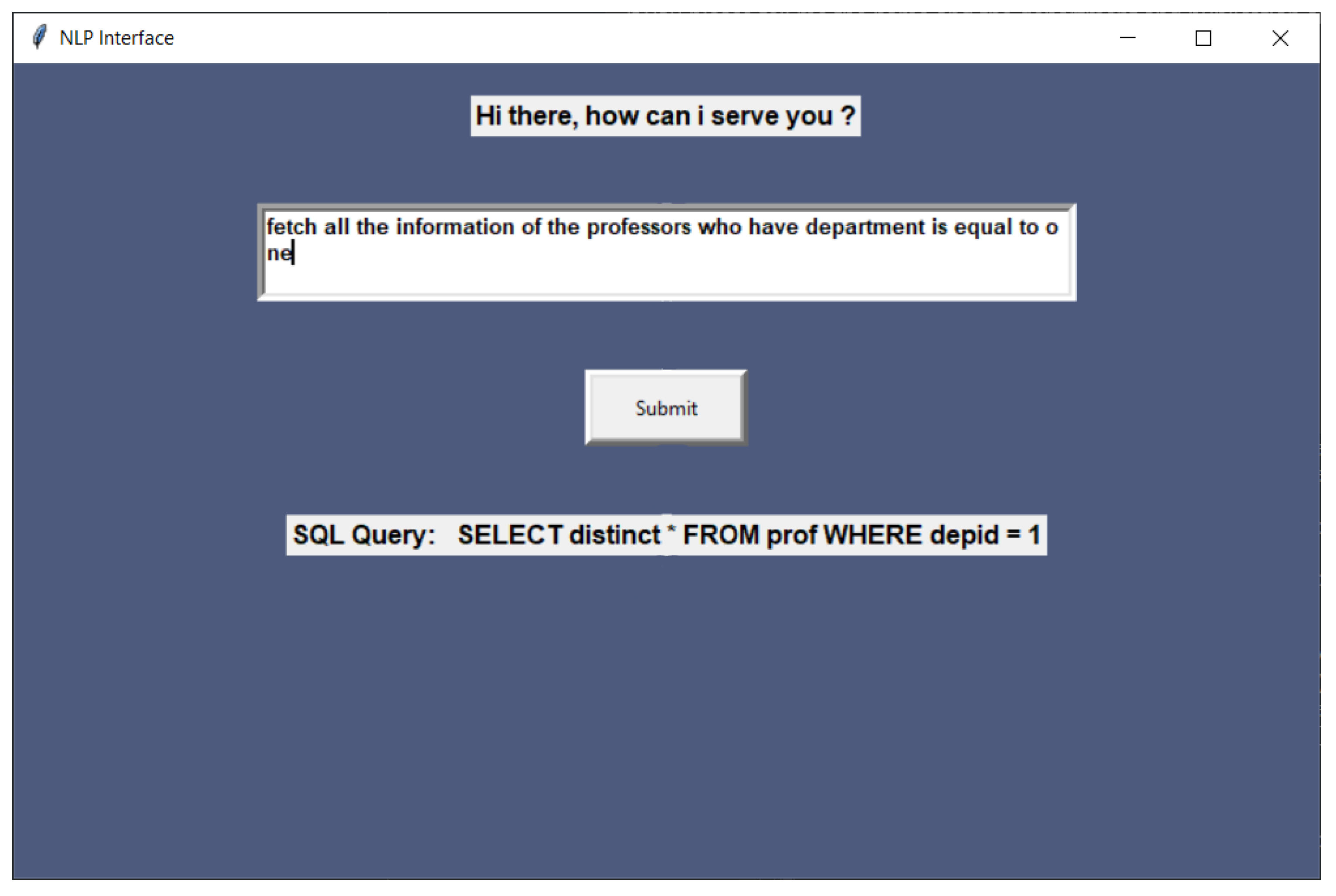
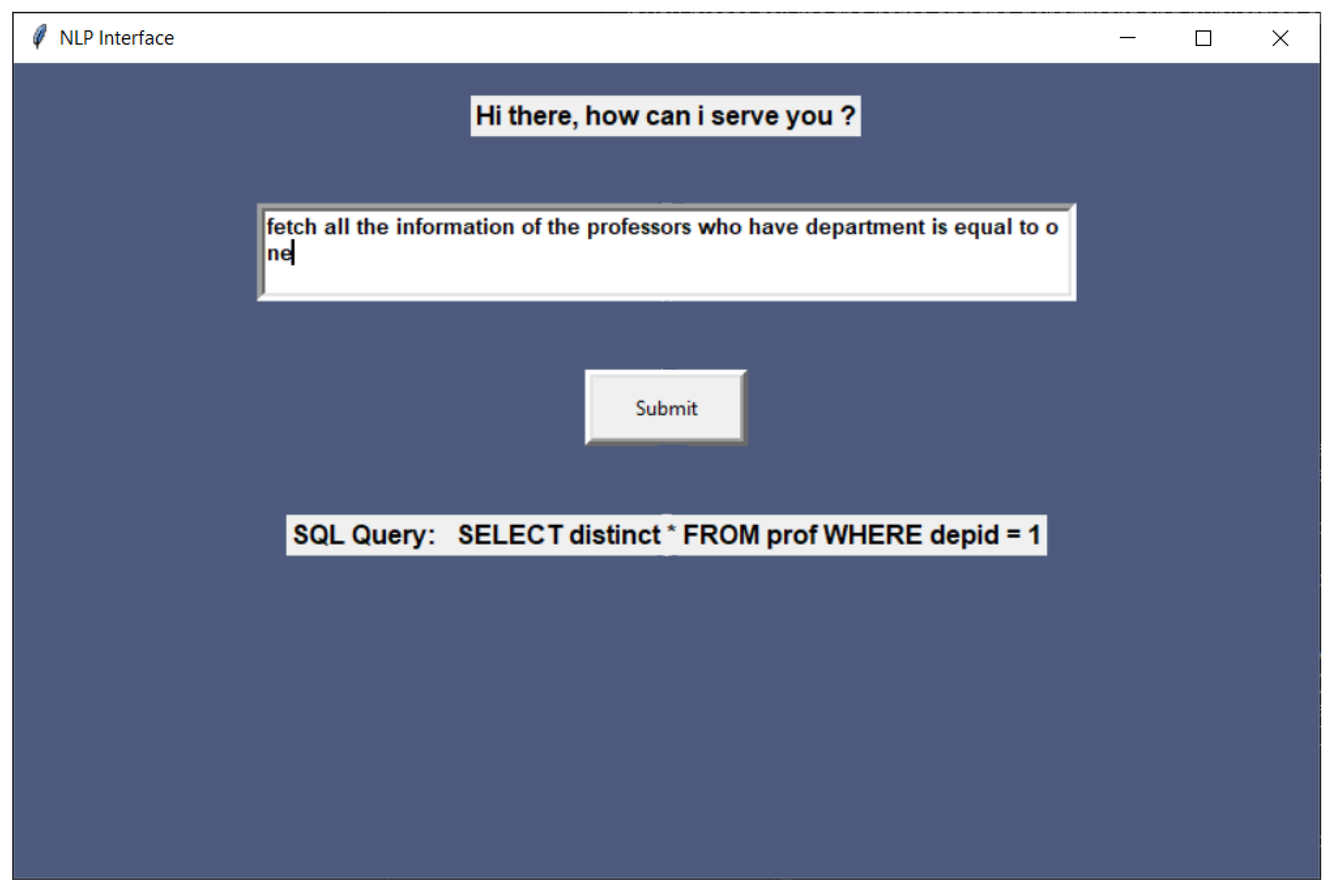
5. Walkthrough Practical Example
Model Screen Shots
6. Results and Analysis
- Calculate the time taken to process the natural language, configure the query, execute, and display the results;
- Calculate the time taken to execute SQL statements on databases.
7. Conclusions and Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SQL | Structured Query Language |
| RDBMS | Relational Database Management Systems |
| NLQ | Natural Language Query |
| OLAP | Online Analytical Processing |
| NLP | Natural Language Processing |
| AI | Artificial Intelligence |
| NLQs | Natural Language Queries |
| NL | Natural language |
| NLI | Natural Language Interface |
| RDBs | Relational Database |
| MT | Machine translation |
| ML | Machine learning |
| NLTK | Natural Language Tool Kit |
| AWM | Oracle Analytic Workspace Manager |
References
- Joshi, S.; Arindom, R.; Dikshit, T.; Anish, B.; Deep, A.G.; Pallav, P. Conceptual paper on factors affecting the attitude of senior citizens towards purchase of smartphones. Indian J. Sci. Technol. 2015, 8, 83–89. [Google Scholar] [CrossRef]
- Giordani, A.; Moschitti, A. Generating SQL queries using natural language syntactic dependencies and metadata. In International Conference on Application of Natural Language to Information Systems; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7337, pp. 164–170. [Google Scholar] [CrossRef]
- Approach, P. Conversion of Natural Language Statement into SQL Query using. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 488–491. [Google Scholar]
- Sanyal, H.; Shukla, S.; Agrawal, R. Natural Language Processing Technique for Generation of SQL Queries Dynamically. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Djahantighi, F.S.; Norouzifard, M.; Davarpanah, S.H.; Shenassa, M.H. Using natural language processing in order to create SQL queries. In Proceedings of the 2008 International Conference on Computer and Communication Engineering, Kuala Lumpur, Malaysia, 13–15 May 2008; pp. 600–604. [Google Scholar] [CrossRef]
- Bhadgale, A.M.; Gavas, S.R.; Goyal, P.R. Natural Language To Sql Conversion System. Int. J. Comput. Sci. Eng. Inf. Technol. Res. 2013, 3, 161–166. [Google Scholar]
- Kaur, S.; Bali, R.S. SQL generation and execution from natural language processing. Int. J. Comput. Bus. Res. 2012. Available online: http://researchmanuscripts.com/isociety2012/54.pdf (accessed on 19 November 2021).
- Popescu, A.-M.; Etzioni, O.; Kautz, H. Towards a theory of natural language interfaces to databases. In Proceedings of the 8th International Conference on Intelligent User Interfaces, Miami, FL, USA, 12–15 January 2003; p. 327. [Google Scholar] [CrossRef]
- Painuly, S.; Sharma, S.; Matta, P. Big Data Driven E-Commerce Application Management System. In Proceedings of the 2021 6th International Conference on Communication and Electronics Systems (ICCES), Coimbatre, India, 8–10 July 2021. [Google Scholar] [CrossRef]
- Cappa, F.; Oriani, R.; Peruffo, E.; McCarthy, I. Big Data for Creating and Capturing Value in the Digitalized Environment: Unpacking the Effects of Volume, Variety, and Veracity on Firm Performance. J. Prod. Innov. Manag. 2021, 38, 49–67. [Google Scholar] [CrossRef]
- Abourezq, M.; Idrissi, A. Database-as-a-Service for Big Data: An Overview. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 157–177. [Google Scholar] [CrossRef] [Green Version]
- Uma, M.; Sneha, V.; Sneha, G.; Bhuvana, J.; Bharathi, B. Formation of SQL from natural language query using NLP. In Proceedings of the 2019 International Conference on Computational Intelligence in Data Science (ICCIDS), Chennai, India, 21–23 February 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Singh, G.; Solanki, A. An algorithm to transform natural language into SQL queries for relational databases. Selforganizology 2016, 3, 100–116. [Google Scholar]
- Al Taleb, T.M.J.; Hasan, S.; Mahd, Y.Y. On-line analytical processing (OLAP) operation for outpatient healthcare. Iraqi J. Sci. 2021, 2021, 225–231. [Google Scholar] [CrossRef]
- Naeem, M.A.; Bajwa, I.S. Generating OLAP queries from natural language specification. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics, Chennai, India, 3–5 August 2012; pp. 768–773. [Google Scholar] [CrossRef]
- Mincheva, Z.; Vasilev, N.; Antonov, A.; Nikolov, V. NLP Using Database Context; Eurorisk Systems Ltd.: Varna, Bulgaria, 2020. [Google Scholar]
- Date, C.J.; Edgar, F. Codd: August 23rd, 1923–April 18th, 2003, A tribute and personal memoir. SIGMOD Rec. 2003, 32, 4–13. [Google Scholar] [CrossRef]
- Colliat, G. OLAP, Relational, and Multidimensional Database Systems Characteristics of On-Line Analytical Processing. Scenario 1996, 25, 64–69. [Google Scholar]
- Zaiane, O.R.; Xin, M.; Han, J. Discovering web access patterns and trends by applying OLAP and data mining technology on web logs. In Proceedings of the IEEE International Forum on Research and Technology Advances in Digital Libraries-ADL’98, Santa Barbara, CA, USA, 22–24 April 1998; pp. 19–29. [Google Scholar] [CrossRef] [Green Version]
- Joseph, S.R.; Hloman, H.; Letsholo, K.; Sedimo, K. Natural Language Processing: A Review. Int. J. Res. Eng. Appl. Sci. 2016, 6, 1–8. [Google Scholar]
- Owda, M.; Bandar, Z.; Crockett, K. Information extraction for SQL query generation in the Conversation-Based Interfaces to Relational Databases (C-BIRD). In KES International Symposium on Agent and Multi-Agent Systems: Technologies and Applications; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6682, pp. 44–53. [Google Scholar] [CrossRef]
- Owda, M.; Owda, A.Y.; Gasir, F. A Comprehensive Methodology for Evaluating Conversation-Based Interfaces to Relational Databases (C-BIRDs). Adv. Intell. Syst. Comput. 2021, 1251, 196–208. [Google Scholar] [CrossRef]
- McKeown, K.R. Discourse strategies for generating natural-language text. Artif. Intell. 1985, 27, 1–41. [Google Scholar] [CrossRef]
- Rubinoff, R. Adapting MUMBLE: Experience with Natural Language Generation TEXT’s Message Vocabulary. In Proceedings of the The Fifth National Conference on Artificial Intelligence (AAAI-86), Philadelphia, PA, USA, 11–15 August 1986; pp. 200–211. [Google Scholar]
- Grosz, B.J. Natural language processing. Artif. Intell. 1982, 19, 131–136. [Google Scholar] [CrossRef]
- Owda, M.; Bandar, Z.; Crockett, K. Conversation-Based Natural Language Interface to Relational Databases. In Proceedings of the 2007 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology, Silicon Valley, CA, USA, 5–12 November 2007; pp. 363–367. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Shi, T.; Reddy, C.K. Text-to-SQL Generation for Question Answering on Electronic Medical Records. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 350–361. [Google Scholar] [CrossRef]
- Nihalani, N.; Silakari, S.; Motwani, M. Natural language Interface for Database—A Brief review. Int. J. Comput. Sci. Issues 2011, 8, 600–608. [Google Scholar]
- Baik, C.; Jagadish, H.V.; Li, Y. Bridging the semantic gap with SQL query logs in natural language interfaces to databases. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 374–385. [Google Scholar] [CrossRef] [Green Version]
- Nagare, P.; Indhe, S.; Sabale, D.; Thorat, G.P.D.Y.; Chaturvedi, P.G.K. Automatic SQL Query Formation from Natural Language Query. Int. Res. J. Eng. Technol. 2017, 4, 1589–1591. Available online: https://www.irjet.net/archives/V4/i5/IRJET-V4I5310.pdf (accessed on 19 November 2021).
- Stoica, A.; Pu, K.Q.; Davoudi, H. NLP Relational Queries and Its Application. In Proceedings of the 2020 IEEE 21st International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 11–13 August 2020; pp. 395–398. [Google Scholar] [CrossRef]
- Osorio, J.; Beltran, A. Enhancing the Detection of Criminal Organizations in Mexico using ML and NLP. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar] [CrossRef]
- Nayyer, R.; Mishra, D. Sentiment Analysis using NLP: Survey Paper. Int. J. Res. Sci. Commun. 2021, 1, 1–4. [Google Scholar]
- Tardío, R.; Maté, A.; Trujillo, J. A new big data benchmark for olap cube design using data pre-aggregation techniques. Appl. Sci. 2020, 10, 8674. [Google Scholar] [CrossRef]
- Wisnubhadra, I.; Baharin, S.K.; Emran, N.A.; Setyohadi, D.B. Qb4mobolap: A vocabulary extension for mobility olap on the semantic web. Algorithms 2021, 14, 265. [Google Scholar] [CrossRef]
- WGraterol; Diaz-Amado, J.; Cardinale, Y.; Dongo, I.; Lopes-Silva, E.; Santos-Libarino, C. Emotion detection for social robots based on nlp transformers and an emotion ontology. Sensors 2021, 21, 1322. [Google Scholar] [CrossRef]
- Tovkach, S.S. Hypercube Architecture of Information for Aviation Engine Control System. In Proceedings of the 2020 IEEE 6th International Conference on Methods and Systems of Navigation and Motion Control (MSNMC), Kyiv, Ukraine, 20–23 October 2020; pp. 69–72. [Google Scholar] [CrossRef]
- Zykin, S.V. Formation of hypercube representation of relational database. Program. Comput. Softw. 2006, 32, 348–354. [Google Scholar] [CrossRef]
- Toce, A.; Mowshowitz, A.; Stone, P.; Bent, G.; Park, H. HyperD: A hypercube topology for dynamic distributed federated databases. In Proceedings of the 5th Annual Conference International Technology Alliance, Wrexham, North Wales, UK, 8–11 September 2011. [Google Scholar]
- Javanmard, M.M.; Ahmad, Z.; Kong, M.; Pouchet, L.N.; Chowdhury, R.; Harrison, R. Deriving parametric multi-way recursive divide-and-conquer dynamic programming algorithms using polyhedral compilers. In Proceedings of the 18th ACM/IEEE International Symposium on Code Generation and Optimization, San Diego, CA, USA, 22–26 February 2020; pp. 317–329. [Google Scholar] [CrossRef] [Green Version]
- Mowshowitz, A.; Kawaguchi, A.; Toce, A.; Nagel, A.; Bent, G.; Stone, P.; Dantressangle, P. Query Optimization in a Distributed Hypercube Database. In Proceedings of the Fourth Annual Conference of ITA, Guangzhou, China, 26–28 May 2017. [Google Scholar]
- Kasprzyk, J.P.; Devillet, G. A data cube metamodel for geographic analysis involving heterogeneous dimensions. ISPRS Int. J. Geo-Inf. 2021, 10, 87. [Google Scholar] [CrossRef]
- Al-Aiad, A.; El-Shqeirat, T. Text mining in radiology reports (Methodologies and algorithms), and how it affects on workflow and supports decision making in clinical practice (Systematic review). In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 283–287. [Google Scholar] [CrossRef]
- Uskenbayeva, R.K.; Kozhamzharova, D.K.; Kurmangaliyeva, B.K.; Bektemyssova, G.B.; Mukazhanov, N.K. Multidimensional indexing structure development for the optimal formation of aggregated indicators in OLAP hypercube. In Proceedings of the 2014 14th International Conference on Control, Automation and Systems (ICCAS 2014), Seoul, Korea, 22–25 October 2014; pp. 1466–1470. [Google Scholar]
- Owda, M.; Crockett, K.; Alghamdi, A. Natural Language Interface to Relational Database (NLI-RDB) Through Object Relational Mapping (ORM). In Advances in Computational Intelligence Systems; Springer: Berlin/Heidelberg, Germany, 2016; pp. 449–464. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, S.; Bhaskar, S.; Sarkar, A.; Debnath, N.C. A formal OLAP algebra for NoSQL based data warehouses. Ann. Emerg. Technol. Comput. 2021, 5, 154–161. [Google Scholar] [CrossRef]
- Kiruthika, S.; Umamaheswari, E. Obtaining relevant Data cubes in OLAP for Efficient Online Decision Support Systems. Ann. Rom. Soc. Cell Biol. 2021, 25, 5862–5865. [Google Scholar]
- Felber, T. Machine Learning Models for COVID-19 Fake News Detection Shared Task. Nature 2021, 388, 539–547. [Google Scholar]
- Pazos, R.R.A.; González, B.J.J.; Aguirre, L.M.A.; Martínez, F.J.A.; Fraire, H.H.J. Natural language interfaces to databases: An analysis of the state of the art. Stud. Comput. Intell. 2013, 451, 463–480. [Google Scholar] [CrossRef]
- Giordani, A.; Moschitti, A. Semantic mapping between natural language questions and SQL queries via syntactic pairing. In Proceedings of the International Conference on Applications of Natural Language to Information Systems, Saarbrücken, Germany, 24–26 June 2009; Volume 5723, pp. 207–221. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, A.T.; Dao, M.H.; Nguyen, D.Q. A Pilot Study of Text-to-SQL Semantic Parsing for Vietnamese. arXiv 2020, arXiv:2010.01891. [Google Scholar] [CrossRef]
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. arXiv 2020, arXiv:2003.07082. [Google Scholar] [CrossRef]
- Mihajlovi, S.; Kupusinac, A.; Ivetić, D.; Berković, I. The Use of Python in the field of Artifical Intelligence. In Proceedings of the International Conference on Information Technology and Development of Education (ITRO 2020), Zrenjanin, Serbia, October 2020; pp. 1–5. [Google Scholar]
- Ott, N. Aspects of the automatic generation of SQL statements in a natural language query interface. Inf. Syst. 1992, 17, 147–159. [Google Scholar] [CrossRef]
- Androutsopoulos, I.; Ritchie, G.; Thanisch, P. Masque/sql An E cient and Portable Natural Language Query Interface for Relational Databases; Database Technical Paper; Department of AI, University of Edinburgh: Edinburgh, UK, 1994; pp. 1–7. [Google Scholar]

| NAME | DEPID | PUBTITLE | JTITLE | STUNAME |
|---|---|---|---|---|
| Majdi Owda | 1 | Template-Based Information Extraction System for Detection of Events on Twitter | Senior Lecturer | Pei Lee |
| Majdi Owda | 1 | Information Extraction From Big Social Data | Senior Lecturer | Pei Lee |
| Majdi Owda | 1 | Crime Prevention on Social Networks Featuring Location Based Services | Senior Lecturer | John Staven |
| Majdi Owda | 1 | Conversation-Based Natural Language Interface to Relational Databases | Senior Lecturer | John Staven |
| ID | NAME | DEPID | JTITLE | PHONE | DEPNAME | PUBID | PUBTITLE | STUID | STUNAME |
|---|---|---|---|---|---|---|---|---|---|
| 2 | Keeley Crockett | 1 | Reader | 4401612471497 | Mathematics and Computation | 0 | No Publication Yet | 18 | Rania |
| 3 | James OShea | 1 | Principal Lecturer | 4401612471546 | Mathematics and Computation | 13 | A Multi-Classifier Approach to Dialogue Act Classification Using Function Words. | 14 | Carolina |
| 1 | Majdi Owda | 1 | Senior Lecturer | 4401612471520 | Mathematics and Computation | 6 | Conversation-Based Natural Language Interface to Relational Databases | 7 | John Staven |
| 5 | David McLean | 1 | Senior Lecturer | 4401612471536 | Mathematics and Computation | 12 | NLP Interfaces along with OLAP | 17 | Justen |
| 1 | Majdi Owda | 1 | Senior Lecturer | 4401612471520 | Mathematics and Computation | 1 | Template-Based Information Extraction System for Detection of Events on Twitter | 2 | Pei Lee |
| 1 | Majdi Owda | 1 | Senior Lecturer | 4401612471520 | Mathematics and Computation | 2 | Information Extraction From Big Social Data | 2 | Pei Lee |
| 2 | Keeley Crockett | 1 | Reader | 4401612471497 | Mathematics and Computation | 0 | No Publication Yet | 8 | Mohammed Kaleem |
| 7 | Lida Nejad | 1 | Principal Lecturer | 970599255888 | Mathematics and Computation | 0 | No Publication Yet | 24 | Liza N. |
| 7 | Lida Nejad | 1 | Principal Lecturer | 970599255888 | Mathematics and Computation | 15 | Models of Dense Cores in Translucent Regions of Low Mass Star Formation | 23 | Rand J. K. |
| 2 | Keeley Crockett | 1 | Reader | 4401612471497 | Mathematics and Computation | 0 | No Publication Yet | 26 | Nawal K. |
| 3 | James OShea | 1 | Principal Lecturer | 4401612471546 | Mathematics and Computation | 13 | A Multi-Classifier Approach to Dialogue Act Classification Using Function Words. | 15 | Huda |
| 6 | Annabel Latham | 1 | Lecturer | 4401612471495 | Mathematics and Computation | 10 | An Adaptation Algorithm for an Intelligent Natural Language Tutoring System | 22 | Ruti K. |
| 1 | Majdi Owda | 1 | Senior Lecturer | 4401612471520 | Mathematics and Computation | 5 | Crime Prevention on Social Networks Featuring Location Based Services | 7 | John Staven |
| 5 | David McLean | 1 | Senior Lecturer | 4401612471536 | Mathematics and Computation | 9 | An Adaptation Algorithm for an Intelligent Natural Language Tutoring System | 17 | Justen |
| 7 | Lida Nejad | 1 | Principal Lecturer | 970599255888 | Mathematics and Computation | 0 | No Publication Yet | 25 | Kojo B. |
| 3 | James OShea | 1 | Principal Lecturer | 4401612471546 | Mathematics and Computation | 13 | A Multi-Classifier Approach to Dialogue Act Classification Using Function Words. | 16 | Samia |
| USER QUERY ENTRIES | GENERATED SQL TEXT | NO. ROWS PROCESSED | MODULE | SQL EXEC TIME | TOTAL EXEC TIME |
|---|---|---|---|---|---|
| can you tell me prof names and title who publicationid more than 2 | SELECT distinct name, jtitle FROM prof WHERE pubid > 2 | 12 | python.exe | 0.001208 | 0.085923 |
| get all professors students and publication | SELECT distinct stuname, pubtitle FROM prof | 69 | python.exe | 0.001831 | 0.093697 |
| give me all professors students | SELECT distinct stuname FROM prof | 16 | python.exe | 0.001287 | 0.084 |
| get prof names and title who publicationid more than 2 | SELECT distinct name, jtitle FROM prof WHERE pubid > 2 | 6 | python.exe | 0.000981 | 0.089831 |
| could you please tell me the prof names and title | SELECT distinct name, jtitle FROM prof | 12 | python.exe | 0.00142 | 0.101329 |
| get prof names and title | SELECT distinct name, jtitle FROM prof | 6 | python.exe | 0.000659 | 0.087733 |
| tell me name about all professors | SELECT distinct name FROM prof | 18 | python.exe | 0.00139 | 0.071274 |
| tell me the name and publication for professors who id is equal to 1 | SELECT distinct name, pubtitle FROM prof WHERE id = 1 | 8 | python.exe | 0.001116 | 0.091737 |
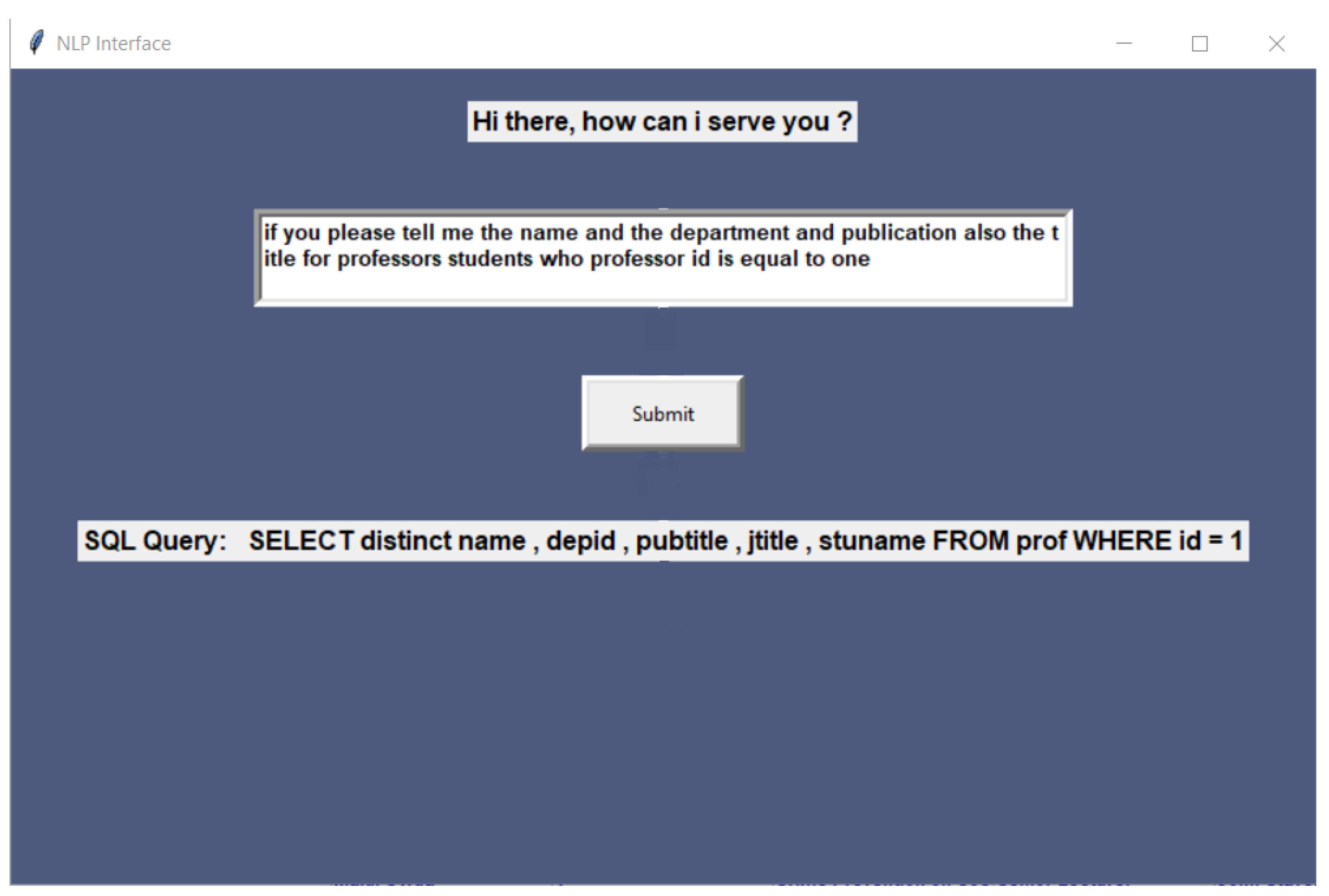
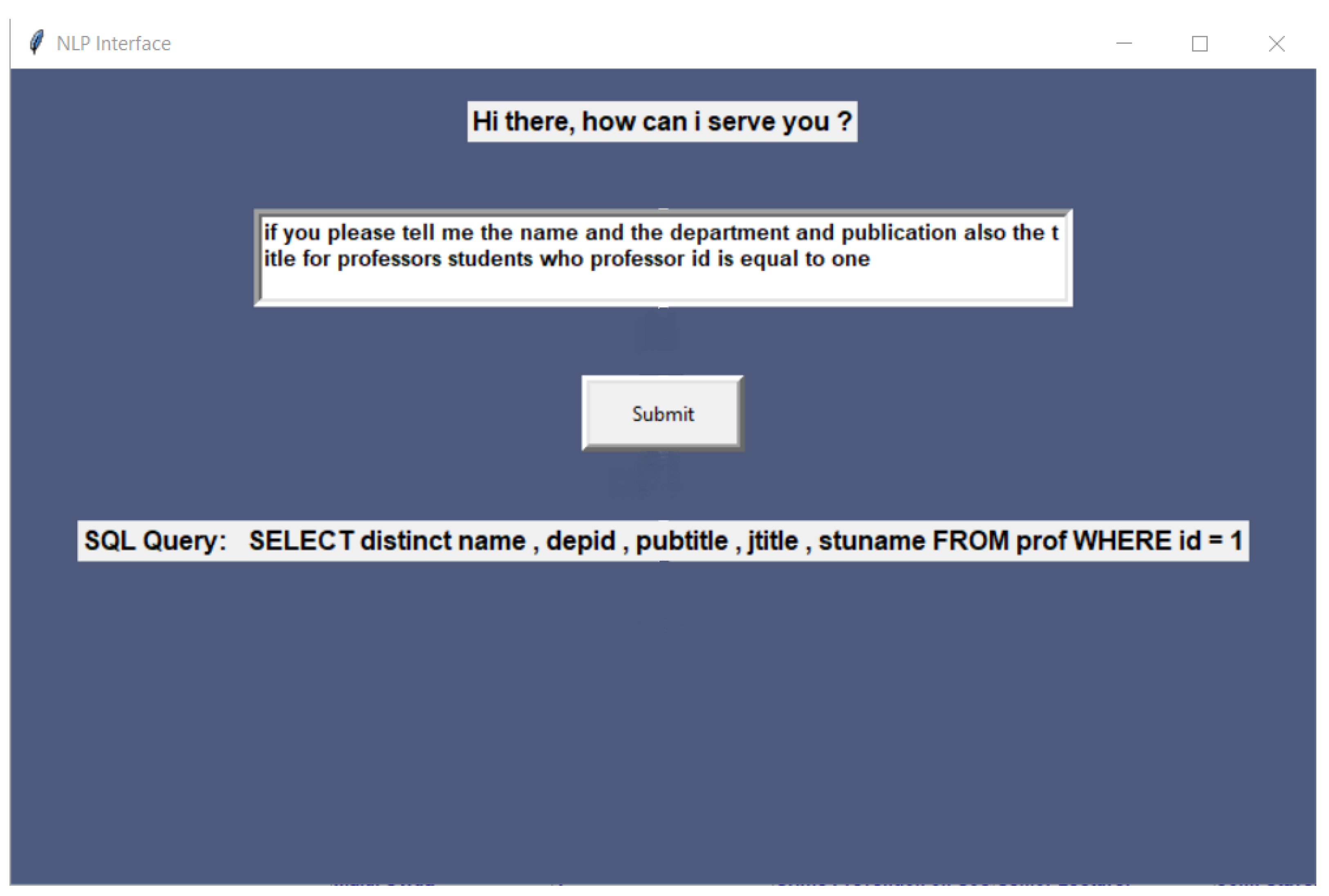
| if you please tell me the name and the department and publication also the title for professors students who professor id is equal to one | SELECT distinct name, depid, pubtitle, jtitle, stuname FROM prof WHERE id = 1 | 8 | python.exe | 0.001092 | 0.089989 |
| tell me the name and publication for professors students who professor id is equal to 1 | SELECT distinct name, pubtitle, stuname FROM prof WHERE id = 1 | 8 | python.exe | 0.001024 | 0.096109 |
| give me all professors students who professor id is more than 1 and less than nine | SELECT distinct stuname FROM prof WHERE id > 1 AND id < 9 | 56 | python.exe | 0.002042 | 0.096062 |
| tell me the name of professors who id is equal to one | SELECT distinct name FROM prof WHERE id = 1 | 1 | python.exe | 0.00072 | 0.071885 |
| Give all professors publication | SELECT distinct pubtitle FROM prof | 18 | python.exe | 0.001126 | 0.092839 |
| give me all professors informations | SELECT distinct * FROM prof | 260 | python.exe | 0.011008 | 0.141568 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hazboun, F.H.; Owda, M.; Owda, A.Y. A Natural Language Interface to Relational Databases Using an Online Analytic Processing Hypercube. AI 2021, 2, 720-737. https://doi.org/10.3390/ai2040043
Hazboun FH, Owda M, Owda AY. A Natural Language Interface to Relational Databases Using an Online Analytic Processing Hypercube. AI. 2021; 2(4):720-737. https://doi.org/10.3390/ai2040043
Chicago/Turabian StyleHazboun, Fadi H., Majdi Owda, and Amani Yousef Owda. 2021. "A Natural Language Interface to Relational Databases Using an Online Analytic Processing Hypercube" AI 2, no. 4: 720-737. https://doi.org/10.3390/ai2040043
APA StyleHazboun, F. H., Owda, M., & Owda, A. Y. (2021). A Natural Language Interface to Relational Databases Using an Online Analytic Processing Hypercube. AI, 2(4), 720-737. https://doi.org/10.3390/ai2040043