
Accuracy of Image-Based Automated Diagnosis in the Identification and Classification of Acute Burn Injuries. A Systematic Review


Abstract
:1. Introduction
- What is the state of evidence on the accuracy of image-based artificial intelligence for burn injury identification and severity classification?
- What is the quality of the evidence at hand, considering both the risk of bias and the applicability of the findings?
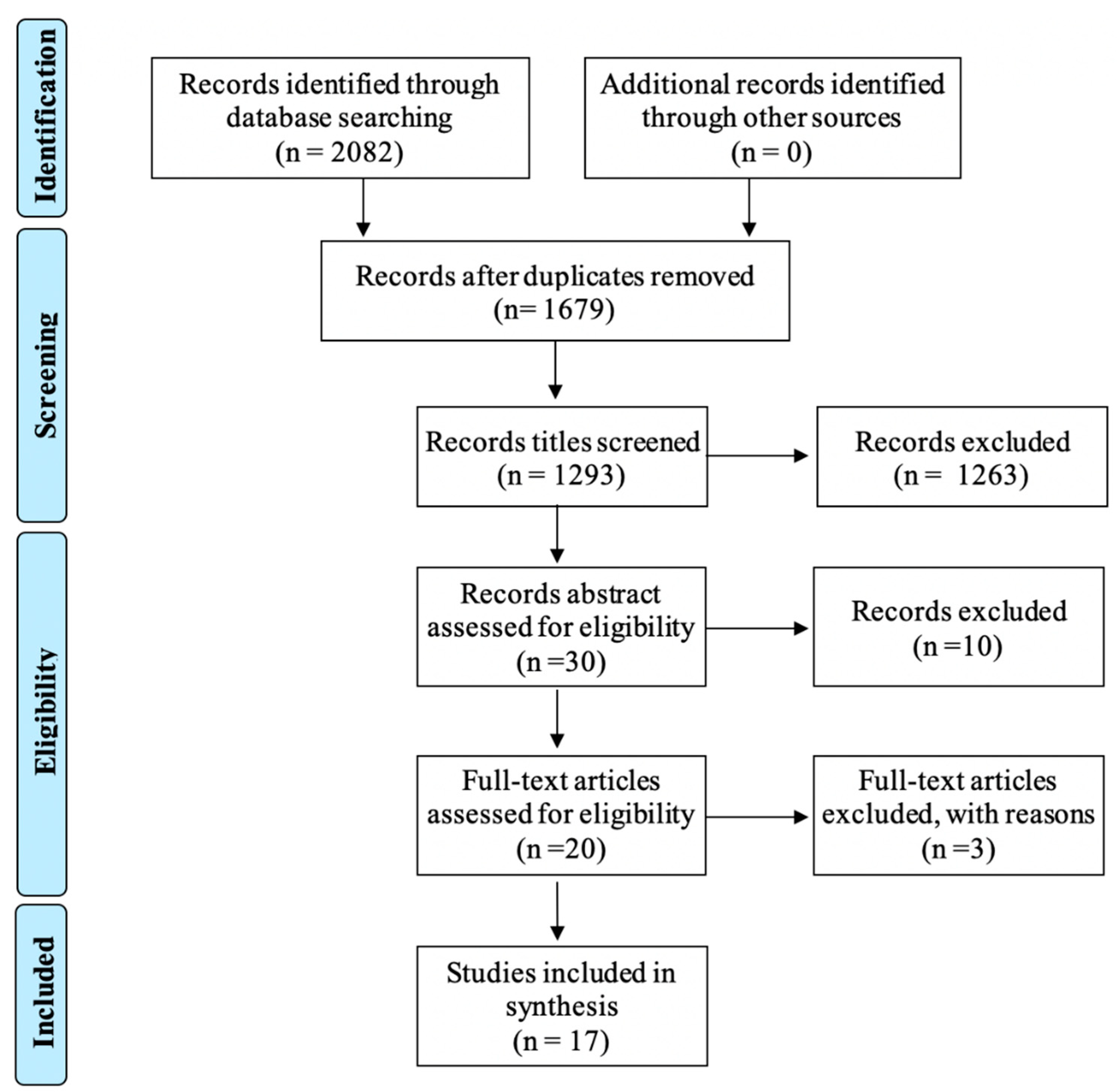
2. Methods
3. Review
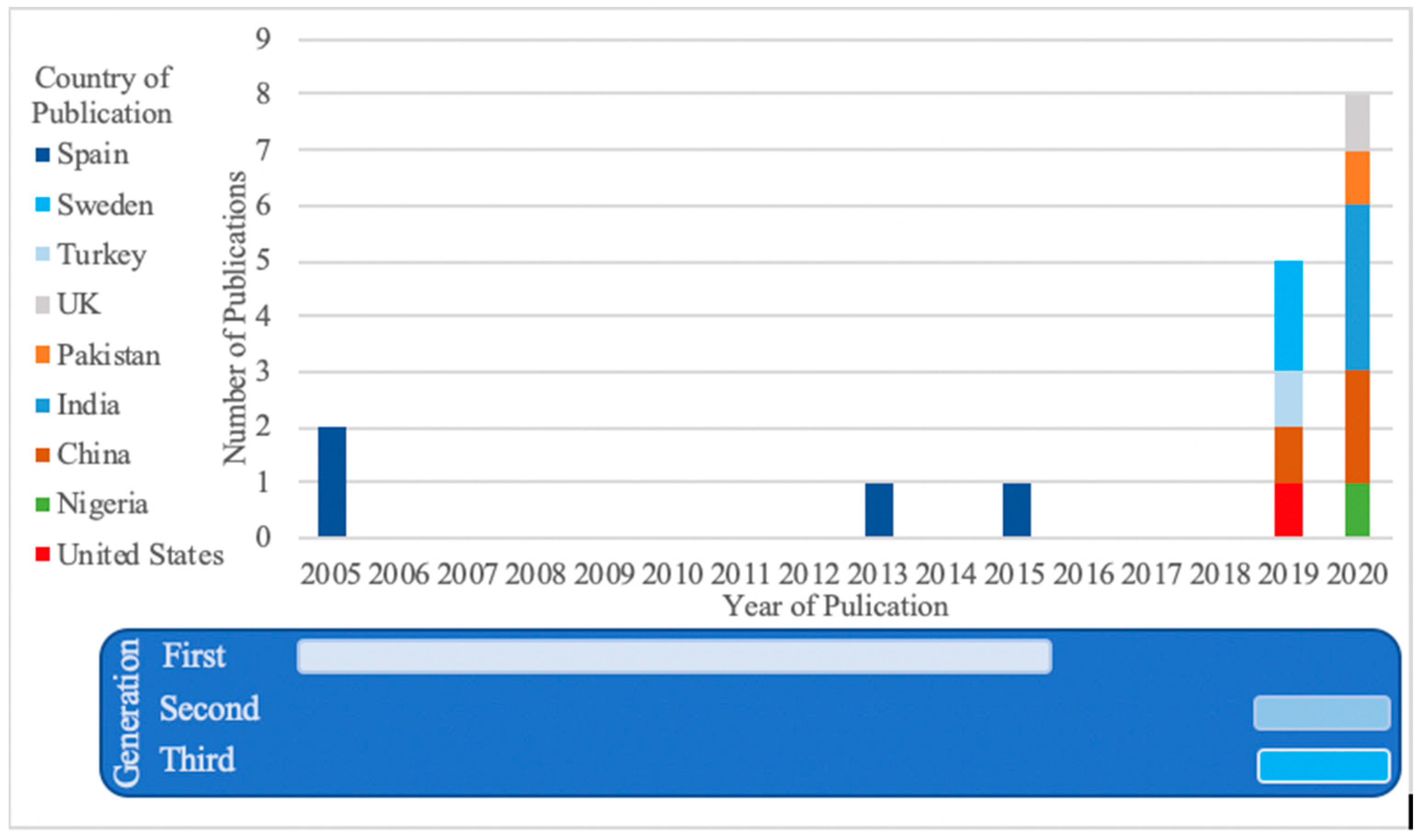
3.1. Peer-Reviewed Scientific Articles over Time and by Location
3.2. Main Features of the Selected Studies
3.3. Quality of the Evidence Published—Latest Generation of Studies
3.4. Other Considerations
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Global Health Estimates 2016: Estimated Deaths by Cause and Region, 2000 and 2016; World Health Organization: Geneva, Switzerland, 2017. [Google Scholar]
- Karim, A.S.; Shaum, K.; Gibson, A.L.F. Indeterminate-Depth Burn Injury-Exploring the Uncertainty. J. Surg. Res. 2020, 245, 183–197. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sjöberg, F. Pre-Hospital, Fluid and Early Management, Burn Wound Evaluation; Jeschke, M.G., Kamolz, L.-P., Sjöberg, F., Wolf, S.E., Eds.; Springer: NewYork, NY, USA, 2012; p. 105. [Google Scholar]
- Roa, L.; Gómez-Cía, T.; Acha, B.; Serrano, C. Digital imaging in remote diagnosis of burns. Burns 1999, 25, 617–623. [Google Scholar] [CrossRef]
- Saffle, J.R. Telemedicine for acute burn treatment: The time has come. J. Telemed. Telecare 2006, 12, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Wallis, L.A.; Fleming, J.; Hasselberg, M.; Laflamme, L.; Lundin, J. A smartphone App and cloud-based consultation system for burn injury emergency care. PLoS ONE 2016, 11, e0147253. [Google Scholar] [CrossRef] [PubMed]
- Acha, B.; Serrano, C.; Acha, J.I.; Roa, L.M. CAD tool for burn diagnosis. Inf. Process Med. Imaging 2003, 18, 294–305. [Google Scholar] [PubMed]
- Siegel, J.B.; Wachtel, T.L.; Brimm, J.E. Automated documentation and analysis of burn size. J. Trauma-Inj. Infect. Crit. Care 1986, 26, 44–46. [Google Scholar] [CrossRef]
- Martinez, R.; Rogers, A.D.; Numanoglu, A.; Rode, H. The value of WhatsApp communication in paediatric burn care. Burns 2018, 44, 947–955. [Google Scholar] [CrossRef]
- den Hollander, D.; Mars, M. Smart phones make smart referrals. Burns 2017, 43, 190–194. [Google Scholar] [CrossRef]
- Hassanipour, S.; Ghaem, H.; Arab-Zozani, M.; Seif, M.; Fararouei, M.; Abdzadeh, E.; Sabetian, G.; Paydar, S. Comparison of artificial neural network and logistic regression models for prediction of outcomes in trauma patients: A systematic review and meta-analysis. Injury 2019, 50, 244–250. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Haenssle, H.A.; Fink, C.; Schneiderbauer, R.; Toberer, F.; Buhl, T.; Blum, A.; Kalloo, A. Man against machine: Diagnostic performance of a deep learning convolutional neural network for dermoscopic melanoma recognition in comparison to 58 dermatologists Original article. Ann. Oncol. 2018, 29, 1836–1842. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. J. Am. Med. Assoc. 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Liu, N.T.; Salinas, J. Machine learning in burn care and research: A systematic review of the literature. Burns 2015, 41, 1636–1641. [Google Scholar] [CrossRef] [PubMed]
- Pabitha, C.; Vanathi, B. Densemask RCNN: A Hybrid Model for Skin Burn Image Classification and Severity Grading. Neural Process. Lett. 2021, 53, 319–337. [Google Scholar] [CrossRef]
- Abubakar, A.; Ugail, H.; Bukar, A.M. Assessment of Human Skin Burns: A Deep Transfer Learning Approach. J. Med. Biol. Eng. 2020, 40, 321–333. [Google Scholar] [CrossRef]
- Yadav, D.P.; Sharma, A.; Singh, M.; Goyal, A. Feature extraction based machine learning for human burn diagnosis from burn images. IEEE J. Transl. Eng. Health Med. 2019, 7, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Moher, D. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Dubey, K.; Srivastava, V.; Dalal, K. In vivo automated quantification of thermally damaged human tissue using polarization sensitive optical coherence tomography. Comput. Med. Imaging Graph. 2018, 64, 22–28. [Google Scholar] [CrossRef]
- Pham, T.D.; Karlsson, M.; Andersson, C.M.; Mirdell, R.; Sjoberg, F. Automated VSS-based burn scar assessment using combined texture and color features of digital images in error-correcting output coding. Sci. Rep. 2017, 7, 16744. [Google Scholar] [CrossRef] [Green Version]
- Whiting, P.F.; Rutjes, A.W.; Westwood, M.E.; Mallett, S.; Deeks, J.J.; Reitsma, J.B.; Leeflang, M.M.; Sterne, J.A.; Bossuyt, P.M.; Group, Q. QUADAS-2: A revised tool for the quality assessment of diagnostic accuracy studies. Ann. Intern. Med. 2011, 155, 529–536. [Google Scholar] [CrossRef]
- Acha, B.; Serrano, C.; Acha, J.I.; Roa, L.M. Segmentation and classification of burn images by color and texture information. J. Biomed. Opt. 2005, 10, 034014. [Google Scholar] [CrossRef] [Green Version]
- Serrano, C.; Acha, B.; Gomez-Cia, T.; Acha, J.I.; Roa, L.M. A computer assisted diagnosis tool for the classification of burns by depth of injury. Burns 2005, 31, 275–281. [Google Scholar] [CrossRef]
- Acha, B.; Serrano, C.; Fondon, I.; Gomez-Cia, T. Burn depth analysis using multidimensional scaling applied to psychophysical experiment data. IEEE Trans. Med. Imaging 2013, 32, 1111–1120. [Google Scholar] [CrossRef]
- Serrano, C.; Boloix-Tortosa, R.; Gomez-Cia, T.; Acha, B. Features identification for automatic burn classification. Burns 2015, 41, 1883–1890. [Google Scholar] [CrossRef]
- Cirillo, M.D.; Mirdell, R.; Sjöberg, F.; Pham, T.D. Tensor Decomposition for Colour Image Segmentation of Burn Wounds. Sci. Rep. 2019, 9, 3291. [Google Scholar] [CrossRef] [Green Version]
- Şevik, U.; Karakullukçu, E.; Berber, T.; Akbaş, Y.; Türkyılmaz, S. Automatic classification of skin burn colour images using texture-based feature extraction. IET Image Process. 2019, 13, 2018–2028. [Google Scholar] [CrossRef]
- Khan, F.A.; Butt, A.U.R.; Asif, M.; Ahmad, W.; Nawaz, M.; Jamjoom, M.; Alabdulkreem, E. Computer-aided diagnosis for burnt skin images using deep convolutional neural network. Multimed. Tools Appl. 2020, 79, 34545–34568. [Google Scholar] [CrossRef]
- Cirillo, M.D.; Mirdell, R.; Sjöberg, F.; Pham, T.D. Time-Independent Prediction of Burn Depth Using Deep Convolutional Neural Networks. J. Burn Care Res. 2019, 40, 857–863. [Google Scholar] [CrossRef] [PubMed]
- Jiao, C.; Su, K.; Xie, W.; Ye, Z. Burn image segmentation based on Mask Regions with Convolutional Neural Network deep learning framework: More accurate and more convenient. Burn. Trauma 2019, 7, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abubakar, A.; Ugail, H.; Smith, K.M.; Bukar, A.M.; Elhmahmudi, A. Burns Depth Assessment Using Deep Learning Features. J. Med. Biol. Eng. 2020, 40, 923–933. [Google Scholar] [CrossRef]
- Chauhan, J.; Goyal, P. BPBSAM: Body part-specific burn severity assessment model. Burns 2020, 46, 1407–1423. [Google Scholar] [CrossRef]
- Chauhan, J.; Goyal, P. Convolution neural network for effective burn region segmentation of color images. Burns 2020, 12, 12. [Google Scholar] [CrossRef]
- Dai, F.; Zhang, D.; Su, K.; Xin, N. Burn images segmentation based on Burn-GAN. J. Burn Care Res. 2020, 18, 18. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Ke, Z.; He, Z.; Chen, X.; Zhang, Y.; Xie, P.; Li, T.; Zhou, J.; Li, F.; Yang, C.; et al. Real-time burn depth assessment using artificial networks: A large-scale, multicentre study. Burns 2020, 46, 1829–1838. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Khan, F.A.; Butt, A.U.R.; Asif, M.; Aljuaid, H.; Adnan, A.; Shaheen, S.; ul Haq, I. Burnt Human Skin Segmentation and Depth Classification Using Deep Convolutional Neural Network (DCNN). J. Med. Imaging Health Inform. 2020, 10, 2421–2429. [Google Scholar] [CrossRef]
- Wong, T.Y.; Bressler, N.M. Artificial Intelligence with deep learning technology looks into diabetic retinopathy screening. JAMA 2016, 316, 2366–2367. [Google Scholar] [CrossRef]
- Lundin, J.; Dumont, G. Medical mobile technologies—What is needed for a sustainable and scalable implementation on a global scale? Glob. Health Action 2017, 10, 14–17. [Google Scholar] [CrossRef]
- Blom, L.; Boissin, C.; Allorto, N.; Wallis, L.; Hasselberg, M.; Laflamme, L. Accuracy of acute burns diagnosis made using smartphones and tablets: A questionnaire-based study among medical experts. BMC Emerg. Med. 2017, 17, 39. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schulz, K.F.; Altman, D.G.; Moher, D. CONSORT 2010 Statement: Updated guidelines for reporting parallel group randomised trials. BMC Med. 2010, 8, 18. [Google Scholar] [CrossRef] [Green Version]
- Bellemo, V.; Lim, G.; Rim, T.H.; Tan, G.S.W.; Cheung, C.Y.; Sadda, S.V.; He, M.g.; Tufail, A.; Lee, M.L.; Hsu, W.; et al. Artificial Intelligence Screening for Diabetic Retinopathy: The Real-World Emerging Application. Curr. Diabetes Rep. 2019, 19, 72. [Google Scholar] [CrossRef] [PubMed]
- Reddy, C.L.; Mitra, S.; Meara, J.G.; Atun, R.; Afshar, S. Artificial Intelligence and its role in surgical care in low-income and middle-income countries. Lancet Digit. Health 2019, 1, e384–e386. [Google Scholar] [CrossRef] [Green Version]
- Laflamme, L.; Wallis, L.A. Seven pillars for ethics in digital diagnostic assistance among clinicians: Take-homes from a multi-stakeholder and multi-country workshop. J. Glob. Health 2020, 10, 010326. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
| Domain | Patient Selection | Index Test | Reference Standard |
|---|---|---|---|
| Description | Methods of patient selection, source of the images and details of included patients (setting, previous testing, presentation) | How was the index test defined? Was a cutoff used? Was the input preprocessed or standardized? | How was the reference standard conducted and interpreted? |
| Risk of bias | Are systematic biases and exclusion avoided? | Was the input pre-processed and standardized? | Is the reference standard likely to correctly diagnose the burn? |
| Concerns about applicability | Are there concerns that the included patients and setting(s) do not represent all populations and settings? | How applicable is such an algorithm in a clinical setting? | Are there concerns that the definition of the reference standard is not ideal in all situations? |
| Author, Year | Burn Center a, Country | Source of Images | Ground Truth of the Diagnosis | Objective of the Algorithm | Total Number of Images (Burn and Non-Burn) | Training Input | Transfer Learning | Overall Accuracy | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| H-Hospital I-Internet bedside | A. Diagnostic tool B. At bedside C. Image-based D. Post-assessment of online images | Burn ident. | Severity class. | Training | Validation | A. Pre-specified features B. Identified features C. Cropped ROIs D. Whole images | Yes | No | Burn identification | Severity classification | ||||
| 2 c | >2 c | Independent | Other | PPV; S | A | |||||||||
| Acha, 2005 [23] | Seville, Spain  | H | B | X | X | 250 | 62 | A | X | PPV = 80.2% S = 83.1% | 82.3% | |||
| Serrano, 2005 [24] | Seville, Spain  | H | B | X | X | 38 | 35 | A | X | PPV = 90.2% S = 83.0% | 88.6% | |||
| Acha, 2013 [25] | Seville, Spain  | H | B | X | X | 20 | 74 | A | X | 83.8% (2 c) 66.2% (3 c) | ||||
| Serrano, 2015 [26] | Seville, Spain  | H | B | X | 20 | 74 | A | X | 79.7% | |||||
| Yadav, 2019 [18] | Texas, US  | H | B | X | 74 | 74 | A | X | 82.4% | |||||
| Cirillo, 2019a [27] | Linköping, Sweden  | H | A | X | 6 | None | B | X | PPV = 94.9% S = 95.9% | |||||
| Sevik, 2019 [28] | Turkey  | H | B | X | 105 | 5-fold CV | B C | X | PPV = 80.0% S = 81.3% | |||||
| Khan, 2020 [29] | Faisalabad, Pakistan  | H,I | B | X | X | 450 | None | D B | X | 79.4% | ||||
| Cirillo, 2019b [30] | Linköping, Sweden  | H | A | X | 2 | 10-fold CV | C | X | 81.7% | |||||
| Jiao, 2019 [31] | Wuhan, China  | H | C | X | 1000 | 150 | D | X | DC b = 84.51% | |||||
| Abubakar, 2020a [32] | Bradford, UK  | H,I | A, D | X | 743 520 b | 10-fold CV | D | X | 95.4% | |||||
| Abubakar, 2020b [17] | Bradford, UK  ; ;Gombe, Nigeria  | HX | Unspecified | X | 950 950 b | 20% | D | X | 96.4% | |||||
| Chauhan, 2020a [33] | India  | IX | D | X | 141 | 63 | D | X | 91.5% | |||||
| Chauhan, 2020b [34] | India  | IX | D | X | 316 | 42 | D | X | PPV = 82.0% S = 83.4% | |||||
| Dai, 2020 [35] | Wuhan, China  | H | C | X | 1000 | 150 | D | X | S = 90.8% DC b = 89.3% | |||||
| Pabitha, 2020 [16] | India  | H,I | Unspecified | X | X | 1200 | 100 | D | X | PPV = 85.0% S = 89.0% | No overall accuracy reported | |||
| Wang, 2020 [36] | Hunan, China  | H | B | X | 484 | 30% | C | X | No overall accuracy reported | |||||
| Patient Selection | Index Test | Reference Standard | Risk of Bias | Applicability (Generalization) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Independence of Validation Set | Sub-Analyses Performed | Resolution | Pre-Trained Model Used | Type of Output | Ground Truth (Clinical Definition) | Patient Selection a | Index Test b | Reference Standard c | Patient Selection d | Index Test e | Reference Standard f | |
| A. ResNet101 B. Inception V2 C. ResNet50 D. VCG-16 E. VCG-19 F. GoogleNet | A. Segmentation B. Classification between burn and non-burn C. Depth classification | A. Diagnostic tool B. Bedside by specialist C. Image-based D. Post-assessment of online images | ||||||||||
| [30] | Cross-validation | None | 224 × 224 | A C D F | B C | A | ☹ | ☹ | ☹ | |||
| [31] | Internal | By size and depths | 1024 × 1024 | A B | A | C | ☹ | |||||
| [32] | Cross-validation | None | 224 × 224 | C D | B C | A D | ☹ | ☹ | ||||
| [17] | Cross-validation | By racial origin | 224 × 224 | C | B | Unspecified | ☹ | ☹ | ☹ | |||
| [33] | External | By body part | 224 × 224 | C D E | C | D | ☹ | ☹ | ☹ | ☹ | ||
| [34] | Internal | None | 512 × 512 | A | A | D | ☹ | ☹ | ||||
| [16] | Internal | By size | Unspecified | A B | A C | Unspecified | ☹ | ☹ | ☹ | ☹ | ☹ | ☹ |
| [36] | Internal | None | 224 × 224 | C | C | B | ☹ | ☹ | ☹ | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boissin, C.; Laflamme, L. Accuracy of Image-Based Automated Diagnosis in the Identification and Classification of Acute Burn Injuries. A Systematic Review. Eur. Burn J. 2021, 2, 281-292. https://doi.org/10.3390/ebj2040020
Boissin C, Laflamme L. Accuracy of Image-Based Automated Diagnosis in the Identification and Classification of Acute Burn Injuries. A Systematic Review. European Burn Journal. 2021; 2(4):281-292. https://doi.org/10.3390/ebj2040020
Chicago/Turabian StyleBoissin, Constance, and Lucie Laflamme. 2021. "Accuracy of Image-Based Automated Diagnosis in the Identification and Classification of Acute Burn Injuries. A Systematic Review" European Burn Journal 2, no. 4: 281-292. https://doi.org/10.3390/ebj2040020
APA StyleBoissin, C., & Laflamme, L. (2021). Accuracy of Image-Based Automated Diagnosis in the Identification and Classification of Acute Burn Injuries. A Systematic Review. European Burn Journal, 2(4), 281-292. https://doi.org/10.3390/ebj2040020