1. Introduction
Traffic accidents have escalated into a significant global public health issue, resulting in a considerable number of fatalities and injuries annually. According to the 2018 Global Status Report on Road Safety by the World Health Organization (WHO), approximately 1.35 million individuals experience road accidents worldwide annually, with traffic-related injuries being the leading cause of death among individuals aged 5 to 29 years [
1]. Consequently, the prevention and reduction in traffic accidents on an international scale are an imperative necessity. During our investigation into the effects of urbanization on traffic accidents, it was discerned that human factors are crucial in influencing traffic accident occurrences in numerous countries and regions. Data collected from the World Health Organization (WHO) indicate that approximately 10% of road traffic deaths are related to drink driving; this corresponds to self-reported rates of 16–21% of people admitting to drink driving in a survey conducted by the European Survey Research Association (ESRA). The same self-reports reveal that nearly 50% of drivers across 48 countries report exceeding the speed limit outside built-up areas [
2]. Speeding, drink-driving, driver fatigue, distracted driving, and non-use of safety belts, child restraints and helmets are among the key behaviours contributing to road injury and death [
3]. Vulnerable road users such as pedestrians, cyclists, moped riders, and motorcyclists are particularly at high risk of severe or fatal injury when motor vehicles collide with them because of their lack of protection [
4].
In our investigation of the effects of urbanization on traffic accidents, we determined that human factors play a pivotal role in influencing traffic accident occurrences across various countries and regions. Particularly in Morocco, human factors have been identified as one of the primary reasons behind the nation’s roads being ranked among the most perilous globally. A survey conducted in Sudan revealed that individual factors were responsible for 60.6% of traffic accidents, with suboptimal road conditions (45.5%), animal-related factors (5.6%), and vehicle scarcity (1.4%) also contributing significantly [
5]. The Czech In-depth Accident Study (CzIDAS) indicates that distractions account for 40% of the analyzed accidents, highlighting the significance of this factor. Distractions may stem from a variety of causes, including attention overload (35%), distracted driving (19%), and monotonous driving (13%) [
6]. Furthermore, the likelihood of road traffic accidents is directly correlated with environmental factors such as rainfall, extreme low temperatures, fog, and hot weather conditions. The incident rates of accidents are 34%, 25%, 21%, and 20%, respectively, attributable to fog, rain, temperature variances, and additional weather-related factors [
7]. From a geographical standpoint, the proportion of fatal traffic collisions is notably higher in rural regions (66%) compared to urban areas (34%). Accidents predominantly occur on straight roads, succeeded by curved roads, intersections, and Y/T intersections, which witness the highest rates of traffic fatalities [
8]. This paragraph accentuates the impact of human factors, environmental conditions, and geographical location on the rates of traffic accidents, factors that are especially critical in the context of urbanization. Urbanization directly influences road-use patterns and traffic flow, thereby significantly impacting traffic safety.
However, challenges remain in the realm of traffic safety research. The issue of data imbalance in traffic accident studies is a persistent concern [
9,
10], as is the need for greater interpretability and transparency in traffic safety risk analysis [
11,
12,
13]. Additionally, while much research has focused on local attributes of traffic accidents, there is growing recognition of the importance of incorporating contextual information from the entire scene for a more explicit and classification [
14,
15].
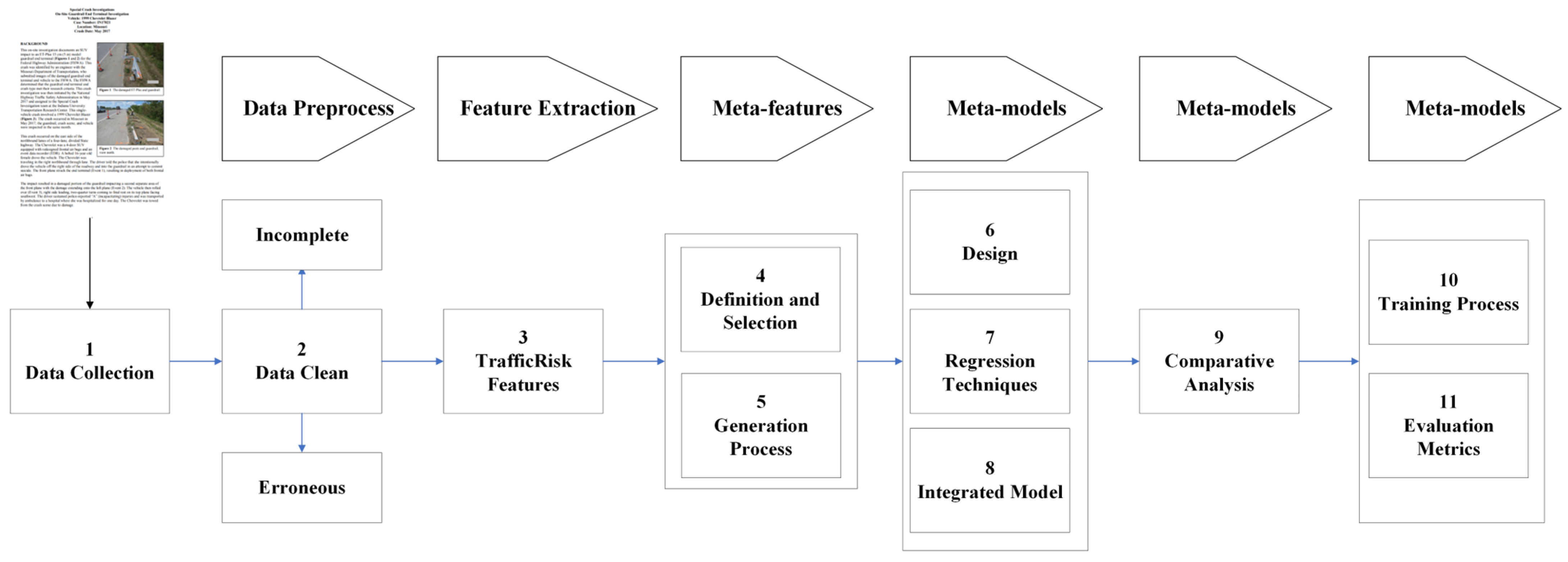
In light of these findings, there is a growing need for advanced methods to analyze and predict traffic crash risk. Traditional models, while valuable, have limitations in terms of predictive accuracy and the ability to handle complex, multifaceted data. This gap highlights the need for new methods that combine the strengths of various approaches to provide more accurate analysis. This study introduces StackTrafficRiskPrediction, a predictive model of traffic risk hazard, which is a pioneering attempt in the field of traffic safety analysis. In this study, a series of classification models are first utilized to generate meta-features, which are subsequently applied to train a regression model, i.e., a meta-model. In this way, we are able to not only capture the underlying patterns of the data using classification models, but also provide greater flexibility and accuracy in predicting continuous outputs through regression models. Our results not only provide an effective framework for predicting injury severity in traffic accidents, but also offer new perspectives on the application of machine learning in the field of traffic safety.
2. Literature Review
Within the scholarly discourse on traffic accident severity classification, accidents are typically categorized into the following three distinct types: “fatal”, “serious”, and “minor”. Fatal crashes, defined as accidents resulting in the death of one or more individuals, have a profound global impact. Research underscores this, noting that on average, 1.35 million people perish annually in traffic accidents [
16,
17]. Serious accidents refer to incidents that culminate in substantial injuries, albeit non-fatal in nature. The severity of these accidents is typically assessed based on the quantity of individuals injured and the extent of direct property damage incurred [
18]. Minor accidents are characterized by less severe injuries, and while the direct discourse on such incidents is limited, ancillary research implicitly addresses these minor injuries through the analysis of various accident types and their influence on overall accident severity [
19]. These classifications offer a foundational framework for comprehending the diverse severities of injuries sustained in traffic accidents and are pivotal in the development of tailored prevention strategies and interventions.
An exhaustive review of the literature pertaining to factors influencing traffic accidents reveals that meteorological conditions, roadway conditions, and individual factors are integral in determining the frequency and severity of traffic accidents. Meteorological conditions exert a substantial impact on traffic accidents, with varying weather conditions influencing different types of accidents in distinct manners, for instance, snowy conditions predominantly affect cycling accidents, whereas daylight glare significantly elevates the risk of multi-vehicle collisions on highways [
20,
21,
22,
23,
24]. Roadway conditions, encompassing aspects such as traffic congestion and the state of the pavement, play a pivotal role in the incidence of accidents. Research has elucidated an inverse correlation between traffic congestion and the frequency of accidents, while the condition of the road surface has also been found to significantly influence the occurrence of accidents [
25,
26]. Individual factors, particularly those encompassing driver error and fatigue, exert a profound impact on the incidence of road accidents. While existing research has delved into the relationship between personal factors and traffic accidents, a notable research gap remains regarding the precise assessment of the impact of personal factors, particularly in relation to drivers’ psychological and physiological states on accidents [
27,
28]. These studies illuminate the myriad factors influencing road accidents and underscore areas necessitating further exploration in future research endeavors to enhance overall road safety.
Conventional traffic accident data analysis methodologies have been employed to meticulously examine traffic safety issues, utilizing a spectrum of data analysis techniques including plain Bayesian classifiers, logistic regression, linear regression, K-nearest neighbours (K-NN) algorithms, K-mean clustering algorithms, auto-encoders, transfer learning, and transformer techniques. These methods are extensively utilized in road safety research, encompassing a broad spectrum of aspects ranging from road condition analysis to driving behaviour assessment and the development of collision warning systems. Plain Bayesian classifiers have gained particular prominence in applications such as pavement detection and the safety assessment of driving behaviour [
29,
30,
31]. Logistic regression has been used to analyze accident severity and driving behaviour [
32,
33,
34], whereas linear regression has played an important role in studies on the relationship between economic dynamics, road design improvements and traffic safety [
35,
36,
37]. K-NN algorithms have shown their clustering and classification capabilities in accident prediction and case retrieval [
38,
39]. K-mean clustering and auto-coders have been used to extract hidden information from traffic accident data and to performing accident hotspot identification [
40,
41,
42]. Transfer learning and transformer techniques have shown potential in traffic accident risk prediction and detection [
43,
44,
45,
46]. These research methodologies not only demonstrate the diversity and intricacy of data analytics within the realm of traffic safety, but also highlight potential limitations and chart out future research trajectories for the application of these techniques in real-world traffic scenarios.
Research in applied traffic accident analysis has focused on the following three areas: traffic accident prediction, real-time traffic behaviour analysis, and driver fatigue and distraction detection. Research in traffic accident prediction focuses on understanding the factors that lead to accidents and applying various machine learning models to make predictions, especially on motorways and high-class roads [
47,
48]. Real-time traffic behaviour analysis uses advanced techniques such as linking vehicle data for real-time assessment of traffic safety and analyzing the driving behaviour of urban bus drivers [
49]. The field of driver fatigue and distraction detection, on the other hand, focuses on the development of effective detection methods and systems, including identification using machine learning techniques [
50,
51,
52]. These studies elucidate the multifaceted nature and intricacy of road safety research, simultaneously identifying the limitations of current studies and outlining prospective avenues for future research. This includes refining the applicability of predictive models, converting research findings into actionable road safety measures, and augmenting the thoroughness and scalability of real-time assessment frameworks.
Research in contextual information analysis of traffic accidents focuses on understanding personality and behavioural traits in traffic accidents, utilizing nationwide traffic accident datasets, and applying advanced technologies such as the Internet of Vehicles (IoV) and artificial intelligence (AI) for accident prediction and prevention. Research has shown that driver personality and behavioural patterns have a significant impact on traffic safety [
53,
54,
55,
56]. In addition, the use of metadata and meta-features is becoming increasingly important in crash analysis, as these techniques can improve the accuracy and efficiency of crash detection, understand the relationship between driving behaviour and crash risk, and perform long-term trend analysis [
57,
58,
59]. Collectively, these studies underscore the significance of comprehending contextual factors in traffic accidents and exemplify the implementation of sophisticated techniques such as artificial intelligence, machine learning, and context-aware systems in exhaustive traffic accident analysis. These studies furnish the field with novel insights, methodologies, and data resources, bearing significant practical implications for the enhancement of traffic safety and the prevention of accidents.
The application and analysis of metadata are becoming important research directions in the field of traffic accident analysis. The utilization of metadata not only improves the accuracy and efficiency of traffic accident detection, but also provides insights for understanding the context and causes of accidents. For example, a traffic accident detection model developed using a metadata registry demonstrates how the accuracy of accident detection can be improved [
60]. Through meta-analysis of the relationship between traffic violations and accidents, researchers have been able to reveal biases between self-reported and archived data as well as provide insights into the link between personality traits and traffic accidents [
57]. On a technical level, the development of multidimensional design methods for spatial data warehouses and geo-decision tools demonstrates the important application of metadata in spatial analysis and road accident analysis [
59]. Long-term trend analyses using metadata, such as the analysis of road accidents in the Ugandan region, have revealed patterns and trends in accident occurrence [
61]. These studies show that metadata play a key role in improving traffic safety and preventing accidents.
Overall, these studies not only provide insights into the meta-characterization of traffic accidents, but also provide valuable references for future traffic safety management and accident prevention strategies. By integrating multiple data and models, the application of meta-characterization shows great potential in improving traffic safety.
4. Results and Discussion
After experiments, the performance of the severity prediction model of traffic accidents based on the meta-based model was obtained as follows
Table 6. This meta-model performs best in categorizing minor accidents with very high accuracy. It also showed some reliability in predicting serious and fatal accidents. And when comparing the model without meta characteristics, the accuracy rate is higher than other models.
The results of the five-fold cross-validation are shown in
Table 7, which shows the performance of the meta-model on different accident severity levels (fatal, serious, and light). For fatal accidents, the accuracy of the model averages 0.8248 and reaches a maximum of 0.9396, which indicates that the model has high accuracy and stability for predicting fatal accidents. However, it performs relatively poorly in the prediction of serious accidents, with an average accuracy of 0.7336, with the lowest accuracy dropping to 0.6094, which may point out that the model has some limitations or needs further optimization in dealing with such accidents.
For light accidents, the model performed similarly to fatal accidents, with an average accuracy of 0.7503, which shows that the model is relatively balanced but slightly less accurate in predicting light accidents than fatal accidents. In addition, there is a small difference in the minimum accuracy between the predictions of minor and fatal accidents, which suggests that there is some consistency in the model’s performance in predicting accidents of different severities. Overall, the meta-model showed some volatility in the prediction of traffic accidents at various severity levels, especially the fluctuation of accuracy on the prediction of severe accidents, which requires targeted improvement or adjustment of the model parameters to improve the accuracy and stability of the prediction in subsequent studies.
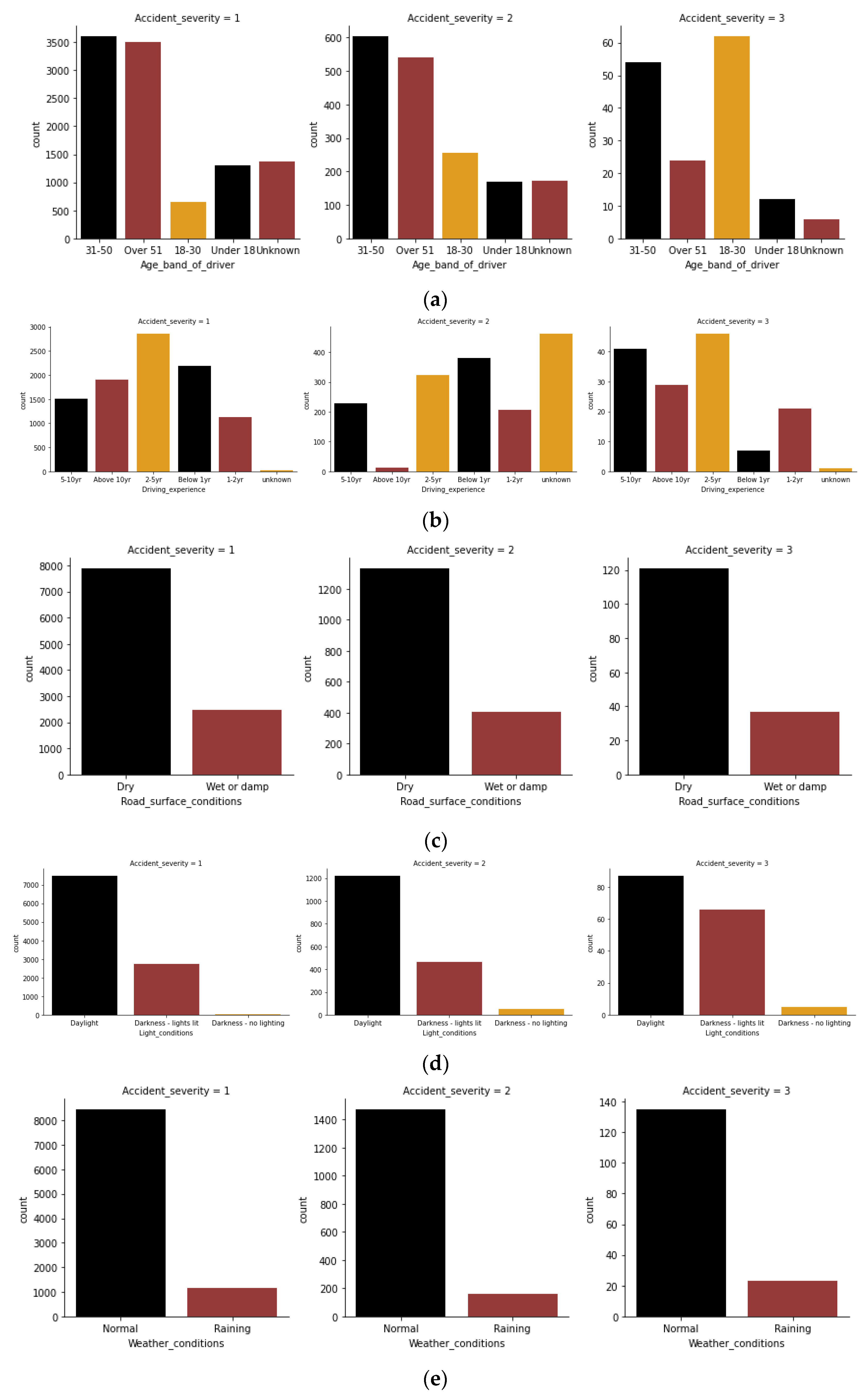
After analyzing the data from the study, as shown in
Figure 3, it was found that people between 31 and 50 years old are prone to major traffic accidents. Also, when analyzing the data on driving experience and severity of traffic risk, it was found that drivers with 2–5 years of experience were more likely to be involved in traffic accidents. Among the factors about road surface, light and weather, the study found that when drivers encounter bad road surface and weather, they instead drive more carefully and have a higher safety margin than a normal driving environment.
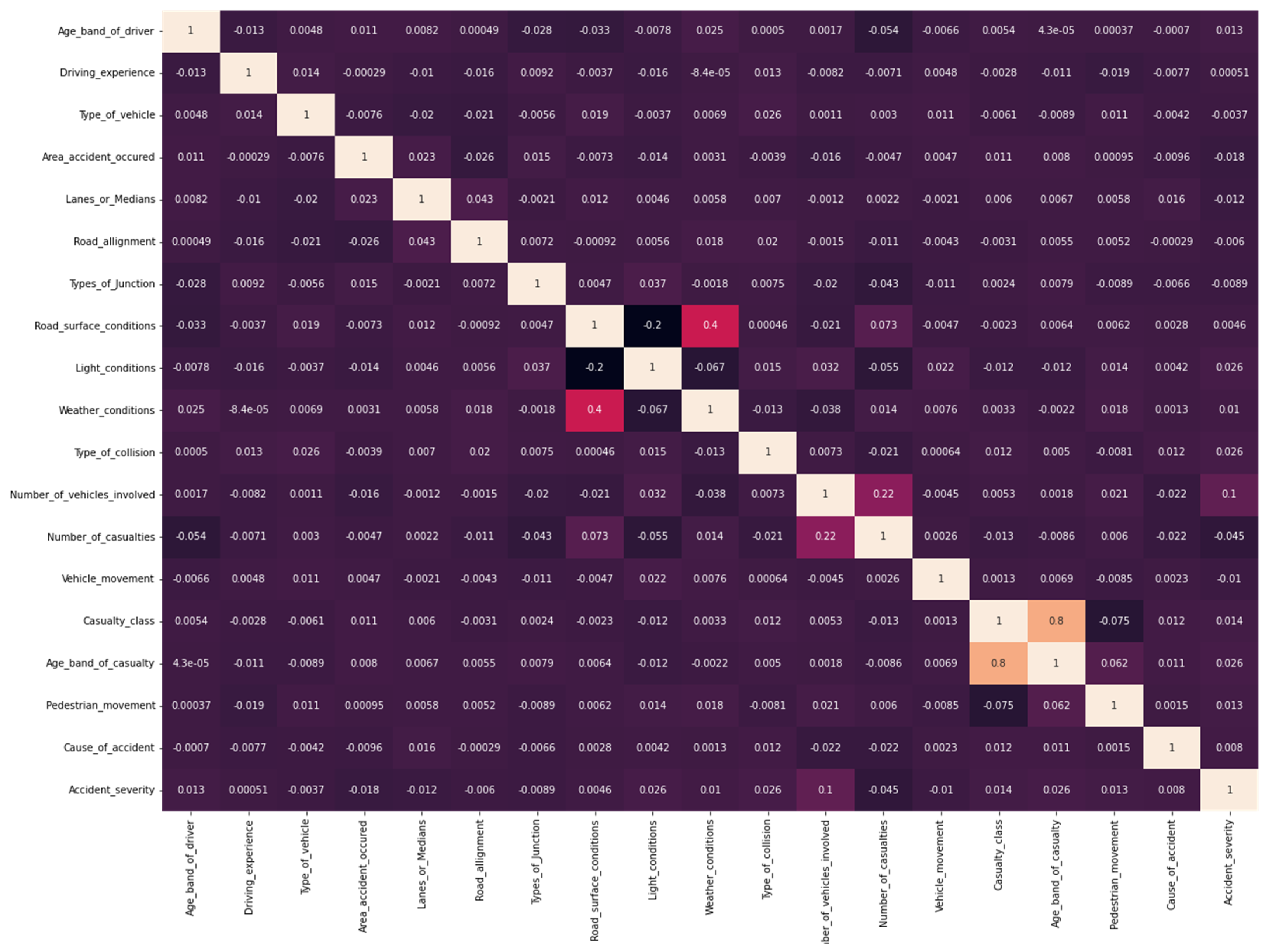
As shown in
Figure 4, without the addition of meta-features, the study found a correlation between “Accident_severity” and several factors. In particular, “Number_of_casualties” has a significant positive correlation with accident severity, meaning that as the number of casualties in an accident increase, the severity of the accident tends to increase. In addition, ‘Light_conditions’ also showed some degree of correlation with accident severity, suggesting that the severity of accidents varies under different light conditions. However, factors such as ‘Weather_conditions’, ‘Road_surface_conditions’ and ‘Type_of_collision’ were associated with the ‘Type_of_collision’. Factors such as “Accident_severity” correlate strongly with “Road_surface_conditions” and “Type_of_collision”, suggesting that they are major factors in accident severity. Therefore, the meta-feature selection in the study was performed by combining these features to form a new dataset based on the base model of the study.
The prediction results of each base model were derived after the training and evaluation of the model, as shown in
Table 8. In the performance evaluation of the different base models of the StackTrafficRiskPrediction model, we find that the GradientBoostingClassifier performs the best on all the metrics, with the highest accuracy, recall, and F1 scores, and shows optimal performance on the ROC–AUC values. RandomForestClassifier and LogisticRegression follow closely, and these two models have better F1 scores and ROC–AUC values while maintaining high accuracy and recall, showing a more balanced performance. AdaBoostClassifier (AdaBoostClassifier) also shows good performance similar to logistic regression. In contrast, Gaussian Naive Bayes and KNeighborsClassifier, while performing moderately well in terms of accuracy and recall, were slightly lacking in terms of F1 scores and ROC–AUC values. The DecisionTreeClassifier performed the worst on this dataset, especially on the ROC–AUC values, possibly due to overfitting or failing to effectively capture the complexity of the data.
In evaluating the predictive performance of the GradientBoostingClassifier model as shown in
Table 9, it can be analyzed in terms of its precision, recall, F1 score, and overall accuracy on different categories. The model performs well in terms of overall accuracy, reaching 0.77, while its weighted avg (weighted avg) precision, recall, and F1 score are 0.75, 0.77, and 0.76, respectively, which shows a high prediction efficiency taking into account the difference in the number of samples in the categories. In particular, on category 2, the model exhibits high precision (0.85), recall (0.89), and F1 score (0.87), indicating a significant advantage in prediction in this category. However, in terms of macro avg precision, recall and F1 score, the average performance of the model on different categories is only around 0.37, reflecting a more insufficient performance on small-sample categories (especially categories 0 and 1), which may be related to the insufficient number of samples and the imbalance of categories. In summary, the GradientBoostingClassifier performs well in dealing with major categories, but still needs to be improved in terms of prediction accuracy on small-sample categories to achieve a more balanced and prediction effect.
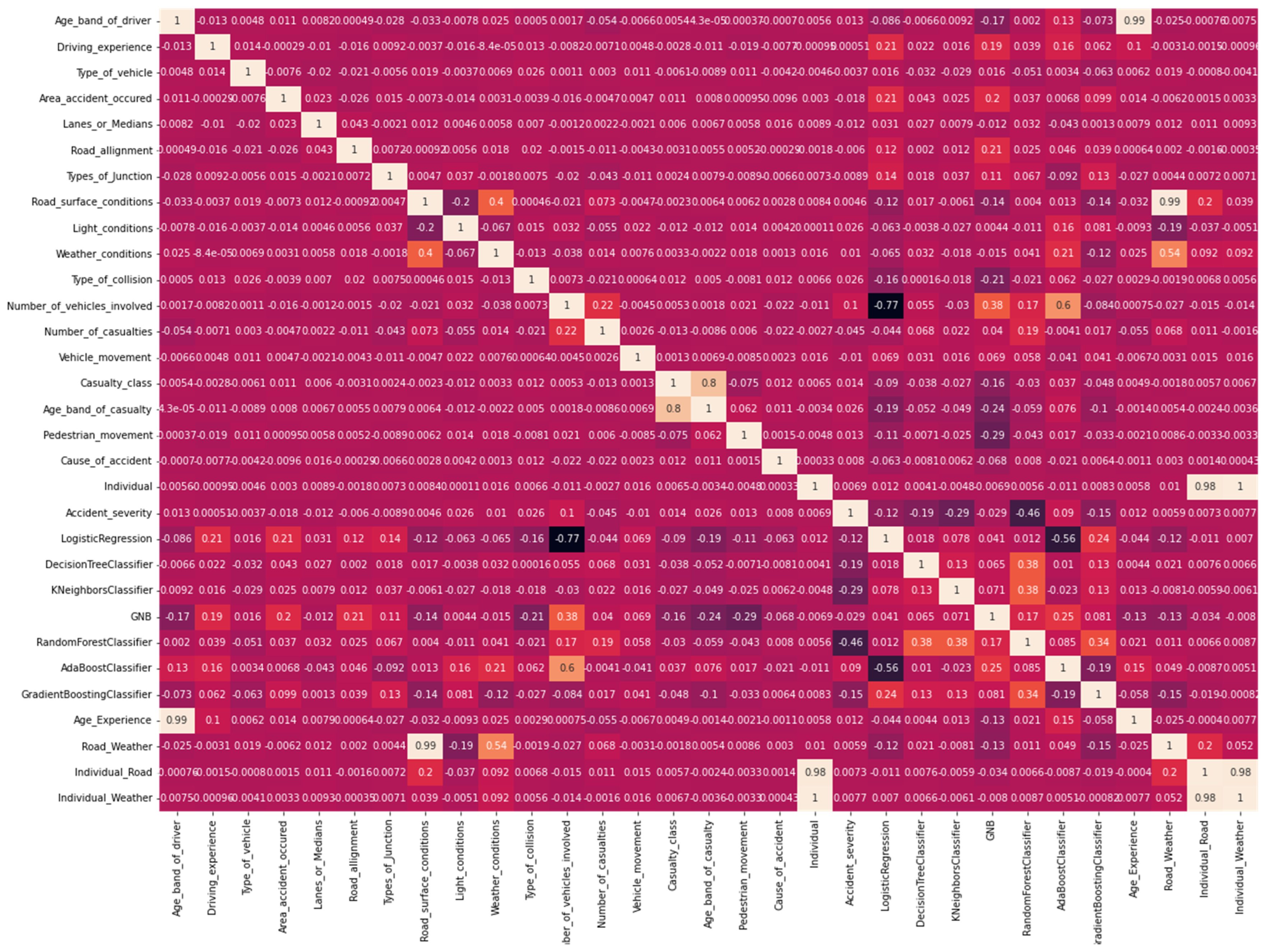
This heat map shows the correlation between various factors and accident severity in
Figure 5. The depth of the color indicates the strength of the correlation, where red represents a positive correlation and blue represents a negative correlation. Analyzing the chart reveals that no factors show a very strong positive correlation with accident severity. However, Light_conditions and Age_of_driver showed strong negative correlations with accident severity, suggesting that better lighting conditions or certain age groups of drivers may lead to lower accident severity. Weather_conditions also showed a negative correlation, but the correlation was not particularly strong.
Comparative analysis of the performance of the meta-model with several other models (including logistic regression, decision tree classifier, K nearest neighbor classifier, Gaussian Naive Bayes, random forest classifier, AdaBoost classifier and gradient boosting classifier) was carried out. Finally, we discovered some salient features of the meta-model and its advantages and disadvantages, as shown in
Table 10.
First of all, the meta-model performs outstandingly in processing “Fatal”-type events with an accuracy of 0.9613, which is much higher than the other models, showing its potential in identifying serious events. However, the performance of the meta-model in terms of precision and recall is unsatisfactory. Its precision rate is only 0.0344, the recall rate is 0.1111, and the F1 score is extremely low, only 0.0526. This shows that although the model can identify “Fatal” events well, it still needs to be greatly improved in terms of certainty and coverage.
For “Serious” and “Light”-type events, the meta-model’s performance also shows certain advantages. In the “Serious”-type event, its accuracy reached 0.9069, but it also faced problems of low precision and low recall, and its corresponding F1 score was only 0.0241. In the “Light”-type event, the meta-model showed high accuracy (0.7508), precision (0.8837) and recall (0.7524), and the F1 score reached 0.8128, showing good overall performance.
Overall, the performance of the meta-model in processing different types of events varies. Its main advantage lies in its high accuracy for “Fatal”-type events, indicating that it can effectively distinguish serious events in some cases. However, this model is generally low in precision and recall, especially when dealing with “Fatal” and “Serious”-type events, which may lead to a large number of misjudgments and missed misjudgments, thus affecting the actual application effect of the model. Therefore, future work should focus on improving the precision and recall of the meta-model to achieve more balanced and reliable performance.
In the StackTrafficRiskPrediction framework, the meta-model is an advanced regression model designed to capture the complex relationships between traffic risk factors and predict the severity of traffic accidents by integrating multiple meta-features derived from different basic classification models. This model structure includes an input layer, multiple processing layers and an output layer, which is designed to process and output the level of traffic accident risk through a deep neural network. Meta-features include combined features and base model predicted probabilities, and the choice of regression technique—first classifying severity using a random forest classifier and subsequently modeling using linear regression—is based on the properties of the meta-feature and the size and complexity of the data.
However, although the meta-model shows high accuracy in the prediction of “Fatal”-type events, it performs poorly in terms of precision and recall overall, especially when dealing with “Fatal” and “Serious”-type events. This performance may be due to problems in several aspects, i.e., the integration of meta-features may not be sufficient, the model may be too simplified and fail to simulate the complex relationships between data in detail, or the model may be overfitted on specific data, resulting in insufficient generalization ability.
In response to the above problems, there are still some methods to improve the performance of the meta-model. First, we can strengthen feature engineering, which can further analyze and integrate more diverse features, such as introducing time series analysis or data features of specific locations to enhance the model’s ability to handle complex predictive capabilities of traffic scenarios. Secondly, to optimize the model structure, we can consider adjusting the existing neural network architecture and explore the application of new deep learning technologies, such as convolutional neural networks (CNNs) or long short-term memory networks (LSTMs). These technologies can better handle time and spatially dependent data. Finally, the model training method can be strengthened, and more advanced cross-validation and regularization strategies can be adopted to avoid overfitting and ensure that the model has good prediction accuracy and adaptability to unseen data. By implementing these improvements, the meta-model will be able to more effectively assess and predict traffic accident risks and provide more accurate and reliable decision support for traffic safety management.
5. Conclusions
In this study, the research introduces the StackTrafficRiskPrediction model, which is a method for predicting the severity of traffic crashes by utilizing meta-features derived from environmental, human factors and traffic characteristics. The results show that the model is effective in identifying key factors affecting the risk of traffic crashes, such as driver age, driving experience, road surface conditions, lighting conditions, and weather conditions.
The innovative aspect of our work is the meta-modeling approach, in which we employ a stacked integrated learning strategy. This strategy utilizes the outputs of various underlying classification models as meta-features, which are subsequently used to train regression models aimed at predicting the severity of traffic accidents. A comparative performance analysis shows that the meta-model has an accuracy of 0.9613, 0.9069, and 0.7508 in predicting fatal, serious, and minor accidents, respectively, demonstrating high predictive effectiveness, and excels especially when dealing with fatal and serious accident prediction. This approach allows for a more detailed picture of complex patterns in the data, thus improving the overall predictive accuracy of the model. In contrast, traditional logistic regression models perform poorly in these areas, with accuracies of only 0.7182, 0.8669, and 0.6289 in predicting fatal, serious, and minor accidents. This further highlights the superiority of the StackTrafficRiskPrediction model.
Despite these advantages, we also observed that although the model performs well in predicting major categories such as accident severity, its accuracy is limited when dealing with categories with smaller sample sizes. In addition, our study highlights some limitations that need to be addressed. The problem of sample imbalance, especially in small categories, suggests the need for further data collection and integration to enhance the generalization ability of the model. In addition, although this study focused on specific environmental and human factors, it did not cover all potential factors that may affect the risk of traffic accidents. Future research could gain a more comprehensive understanding of crash risk by exploring other influencing factors such as vehicle technology and roadway design.
In conclusion, the StackTrafficRiskPrediction model demonstrates great potential in advancing the field of traffic accident risk prediction. By continually refining and extending the model, we aim to develop more robust tools and strategies for traffic safety management and accident prevention that can significantly reduce the incidence and severity of traffic accidents.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}