1. Introduction
Vehicle hijacking is a problem in South Africa, as shown by the yearly crime statistics. In 2018/19 there were roughly 32,000 incidences of hijacking of motor vehicles. About 0.08% of individuals aged 16 and older were hijacked [
1]. In 2019, an average of 2600 vehicles were hijacked per month. Many attempts have been made to reduce this on-road crime. These have been inadequate because a vehicle is mobile and a hijacking can take place anywhere. A vehicle is usually followed to a quiet location and then hijacked, which makes this particular type of crime difficult to combat by traditional crime-fighting strategies. Technology is an improved alternative to combating such on-road hijackings.
To this end, automatic licence-plate recognition (ALPR) is utilized as a way of identifying suspicious vehicles on the road which follow the ego vehicle with the intent of hijacking it. ALPR is a process of identifying information in licence-plate images.
Automatic licence-plate recognition is normally performed by first extracting the licence-plate, followed by character segmentation on the extracted licence-plate to separate characters. Finally, character recognition is performed, in which the isolated characters are detected to identify the letters and numbers on the licence-plate. Refs. [
2,
3,
4] presents licence-plate recognition using edge features and [
5] binary character processing. These methods use convolution neural network (CNN) and artificial neural network (ANN)-based character recognition that has efficient character classification. However, the methods have a high computational cost because of the neural network. Refs. [
6,
7,
8] presents edge-based licence-plate extraction and recognition methods, while [
9] presents a zone-based licence-plate recognition method. These methods have a high computational cost because of the character segmentation and recognition steps, with a possible added drawback of misclassification of characters in the recognition stage.
This paper overcomes the above challenges by using a modified pipeline that replaces character segmentation and recognition stages with licence-plate template matching. This method utilises extracted licence-plates as whole image templates without any further processing steps. It has improved computational cost and no misclassification of characters. A method of line-ratio computation is also presented for licence-plate locating and extraction on an edge map. Ratio computation calculates the width and height of two horizontal edges at a time, to find a ratio that equals that of a licence-plate. The extracted licence-plate templates are then used for comparison to identify similar licence-plates.
The rest of the paper is organized as follows:
Section 2 presents the related work;
Section 3 sets out the proposed method;
Section 4 gives the experiment and results;
Section 5 comprises the results discussion; and
Section 6 is the conclusion.
2. Related Work
The review of licence-plate methods is carried out to search for a method that extracts licence-plates from a vehicle. The method should have a low computational cost and a high detection rate, because failing to capture licence-plates could result in reduced efficiency.
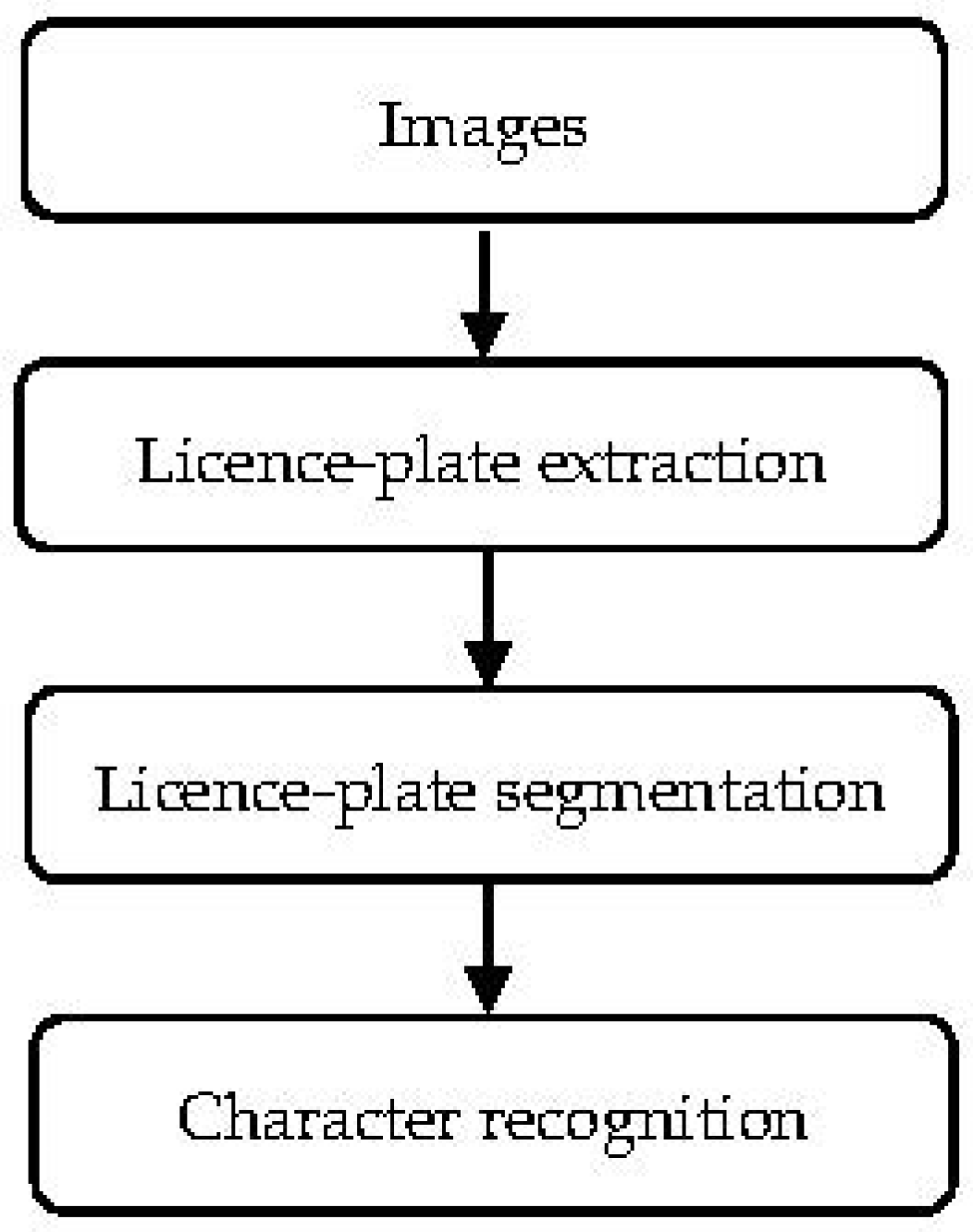
Automatic licence-plate recognition (ALPR) generally consists of four stages, as shown in
Figure 1.
ALPR takes input as an RGB vehicle image that usually originates from a camera mounted on a vehicle or structure.
The RGB image acquisition is followed by licence-plate extraction, which detects a licence-plate in a vehicle image. Licence-plates come with varying characteristics [
10] such as different licence-plate locations, different sizes, different colours, different languages and fonts, different backgrounds, and letter colours, although most licence-plates are rectangular. These characteristics are used in licence-plate extraction.
Licence-plate extraction is then followed by character segmentation, in which the individual licence-plate characters are isolated. This is to prepare for the classification of the characters by obtaining the symbol and leaving out irrelevant pixels. The segmentation methods are generally divided based on the features focused on, such as character contour, vertical and horizontal projection attributes, implementing classifiers, connectivity of pixels, prior knowledge of characters, and mathematical morphology attributes [
11]. Region props, optical character recognition, and template matching [
12] are also used in some segmentation methods. The drawback to these methods is the processing time.
The character recognition stage depends on the accuracy of the previous two stages. This is where the characters are identified and displayed. Deploying extracted attributes, the methods used for this stage are categorized as artificial neural networks, pattern-matching attributes, template matching, deploying classifiers, optical character recognition, and statistical classifiers.
The drawback of character recognition is the high computational cost. Additionally, the characters recognized from the image at times differ from those on the licence-plate. This misclassification and identification of characters may occur because characters in the database are of different shapes, fonts, and sizes [
11].
The front-vehicle licence-plate recognition is commonly used to identify licence-plates, in which features of an image are extracted from the licence-plate, allowing for character recognition. In the literature [
13], licence-plates are recognized from the front of vehicles using colour information, i.e., character colour combination. Licence-plate detection is performed by means of a geometric template with connected component and support vector machines for segmentation and recognition, respectively.
An algorithm was presented based on background subtraction for vehicle detection and front licence-plate extraction, using texture and colour features [
14]. The aspect ratio was used to extract the licence-plate. The drawback of colour features is that it has difficulty with licence-plate extraction when the licence-plate and vehicle have a similar colour. The computational expense is a disadvantage of this method. A support vector machine method [
15] was used to determine whether an area is a licence-plate; dilation and erosion contours were used to locate candidate front licence-plates. Modified connected component analysis [
16] was used to extract characters on a front vehicle licence-plate. The last stage was character-component identification. The drawback is that this method can label one object as two distinct objects. In [
17], a character-based vehicle front licence-plate extraction algorithm was suggested. A candidate licence-plate was located by finding the centroid of connected components, i.e., characters. A window approach, having the highest number of transitions, was then used to extract the licence-plate.
Edge feature extraction is a simple and fast feature extraction technique with binary pixels that can be used to extract and analyse shapes, and to detect objects such as licence-plates. In [
6], an edge-based licence-plate recognition was presented for the front image of vehicles. In this method, licence-plate extraction was performed by edge detection using Canny edge. Letters were segmented and identified by template matching techniques. However, the use of Canny edge can create unnecessary edges. In [
2], a front licence-plate detection method was proposed using Prewitt edges and a convolution neural network for character recognition. It should be noted that the neural network is computationally expensive.
In the literature [
18], a vertical-edge detection method was offered for front licence-plate extraction. Candidate region extraction was performed by selecting either the upper or lower part of the image with a licence-plate region.
Most of the methods for licence-plate recognition make use of plate extraction, segmentation, and recognition; this addition of character segmentation and recognition increases computational cost. The character-recognition step also tends to misclassify characters. Edges have the lowest computational cost. However, edges are usually followed by additional methods after edge detection, and this results in increased computational cost.
3. Proposed Approach
For the proposed approach, a monocular camera is used to capture images with camera intrinsic parameters that include the focal length of [974.1667, 979.1361] pixels; the principal point of [950.8207, 559.9735] pixels; and an image resolution of 1080 × 1920. The camera extrinsic parameters include a pitch of 5 degrees, and a height of 1.1798 m above ground.
The proposed approach begins with licence-plate extraction in which the edge map of the licence-plate is generated with the vertical line ratio computed to locate the licence-plate. Licence-plate extraction is then followed by licence-plate template-matching, using normalized cross-correlation to match the plates.
3.1. Licence-Plate Extraction and Matching
Feature-based licence-plate extraction saves processing time and is robust. The edge-based method is the simplest and fastest of the feature-based extraction methods. In the literature [
6], Canny edge was used for licence-plate extraction. The drawback was the higher computational cost compared to the Sobel edge detection. Canny edge detection also produces many unwanted edges. Literature [
6] also performed licence-plate segmentation and character recognition which increases computational cost after licence-plate extraction. Character recognition has the further drawback of interpreting characters wrongly. This can cause the same licence-plate to be seen as different, thus failing to identify the vehicle as the same. The traditional licence-plate pipeline is shown in
Figure 1, which includes character segmentation and recognition.
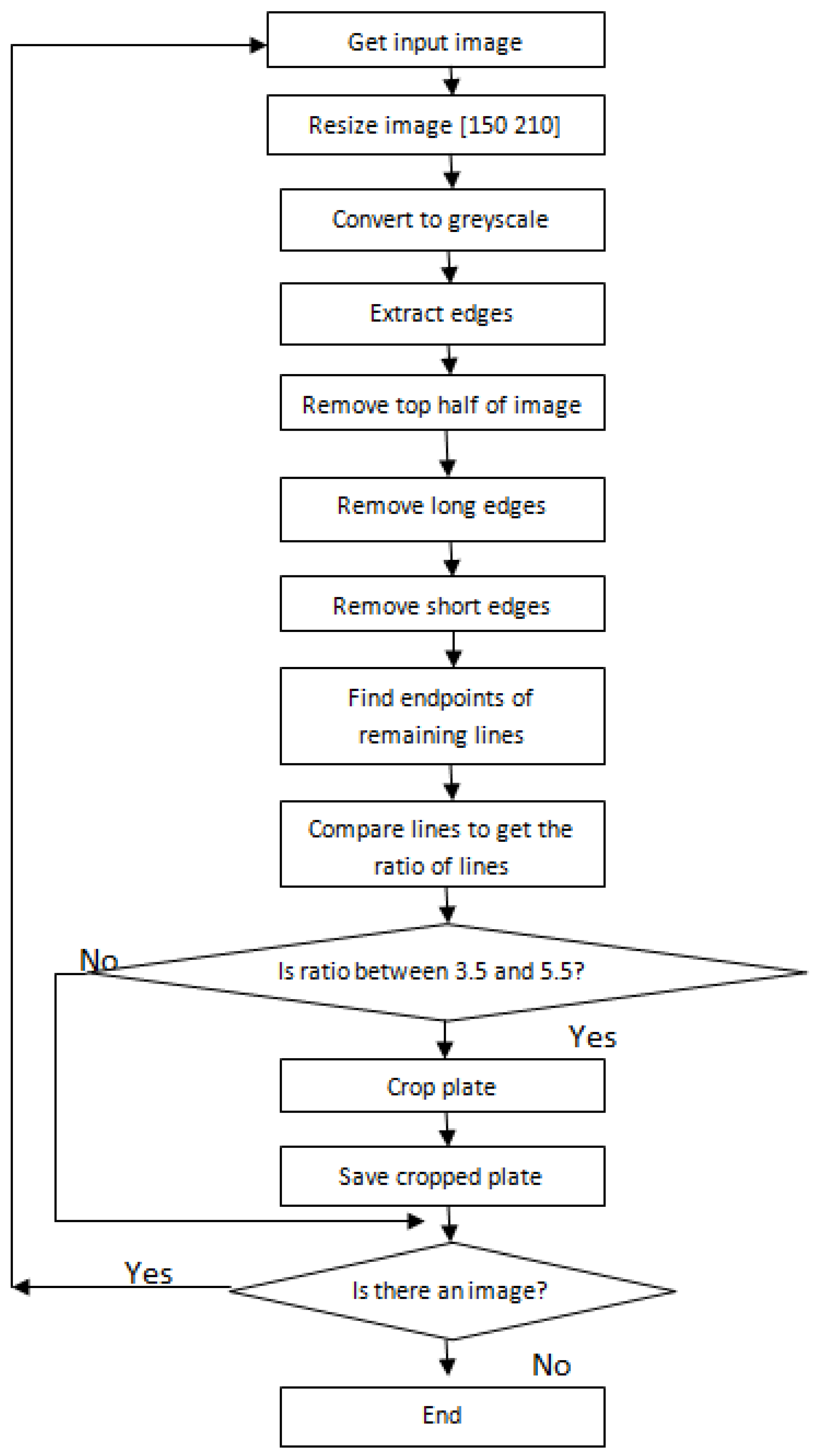
To solve the problem of high computational cost and the misclassification of characters in the traditional licence-plate pipeline, we propose the elimination of the character segmentation and the character recognition steps. These two steps will be replaced by the licence-plate template-matching, which will tackle high computational cost and the problem of misclassified characters. The pipeline of the proposed method is shown in
Figure 2.
Licence-plate segmentation and character recognition isolates characters of the extracted licence-plate from the background licence-plate using optical character recognition (OCR) or similar methods. After these characters are isolated, each character is identified to find a match or to record the licence-plate. The proposed licence-plate matching method does not perform these steps; it merely takes the extracted licence-plate to find a match with the saved licence-plates.
In this way, a solution to the problem of high computational cost is presented that takes two complex steps and replaces them with a single simple step. The proposed method identifies the licence-plate as a whole to check for similarity and does not make use of individual characters. The extracted licence-plate templates, such as shown in
Figure 3, can then be compared to check for similarity, and to identify vehicles as identical.
To avoid detecting different licence-plates as similar, after a licence-plate is matched as similar, matching is repeated several times at different distances (this verification process is repeated 3 times).
3.2. Licence-Plate Template-Matching
Licence-plate template-matching is used to compare licence plates to check whether the current vehicle licence-plate is identical with a previous one. This is performed without character segmentation and character recognition to improve the cost of computation. The method that is used for licence-plate template-matching is normalized cross-correlation.
Cross-correlation for template matching is based on squared Euclidean distance measure, Equation (10):
where
is the extracted licence-plate, the sum is over
under the window containing the template
positioned at
.
gives the below result. From Equation (10) is found
The term
is constant. If the term
is approximately constant, the remaining cross-correlation term, Equation (12) is a measure of the similarity between the extracted licence-plate and the template:
The normalized cross-correlation is achieved by normalizing the extracted licence-plate and the template vectors to unit length, producing Equation (13):
where
is the mean of the template and
is the mean of
in the region under the template.
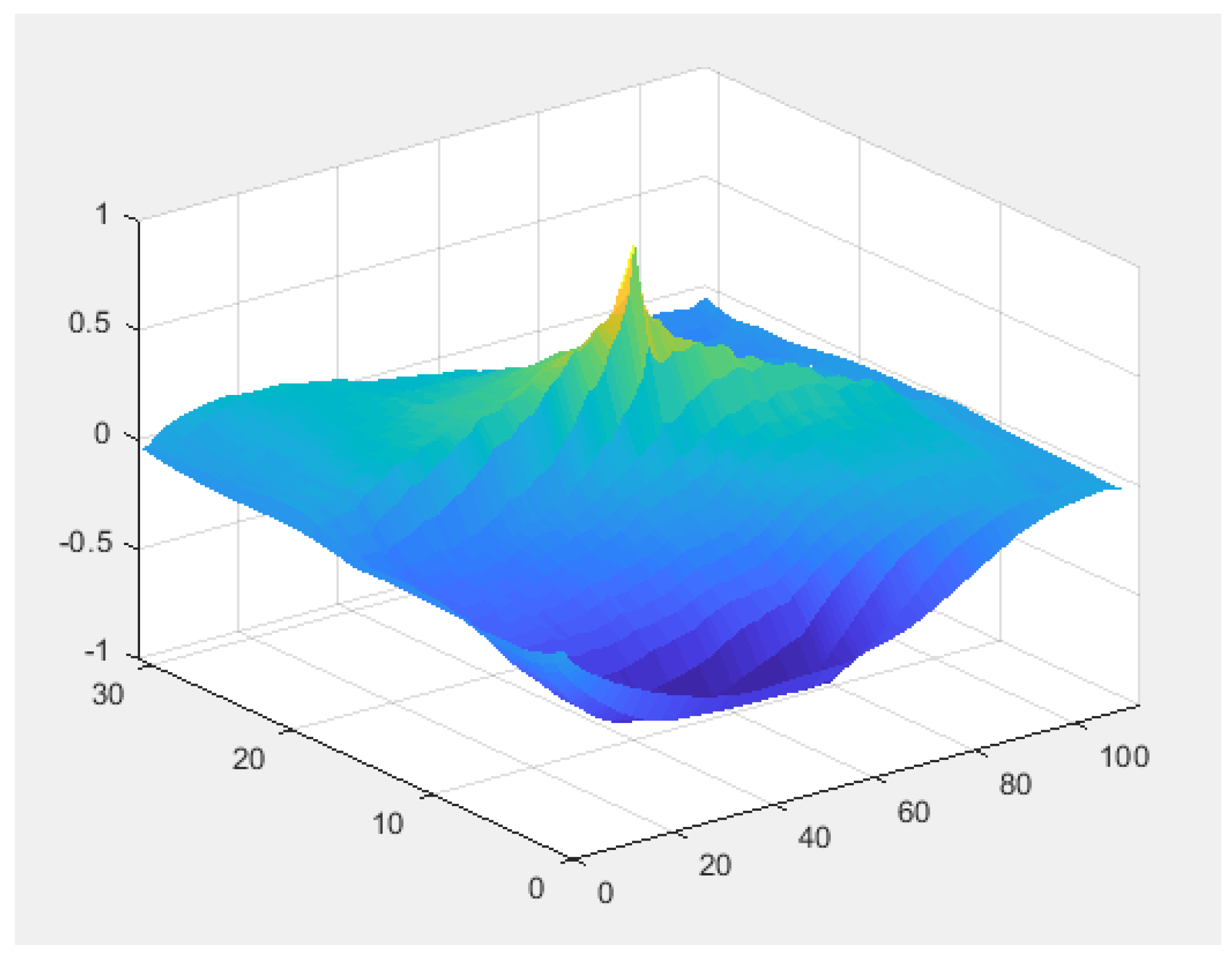
The normalized cross-correlation for two matching licence-plates displayed as a surface is shown in
Figure 9.
5. Results Discussion
The proposed method provides a licence-plate detection accuracy of 92% on a dataset captured on a South African road. The proposed method also shows a licence-plate extraction accuracy of 82% on the literature [
19] dataset, and 66% on the Kaggle dataset. The accuracy on Kaggle is negatively impacted by vehicle images that are at a distance, in which edges are short and are eliminated in the processing steps. The proposed method achieved a lower plate-extraction computational cost than the existing method [
19] on the Kaggle dataset. Better computation can also be achieved by an image with fewer edges. This validated the effectiveness of the proposed method under different circumstances and conditions.
The vehicle licence-plate template matching provides further validation of the proposed method. The matching of similar licence-plates gives high accuracy. A threshold of 80% was observed based on experiments, to determine whether a vehicle in the current frame is the same vehicle in previous frames, even when they have a similar appearance, such as being the same model and colour.
Licence-plate matching has a faster processing time than methods [
19,
21]. This validated the proposed modified licence-plate pipeline without character segmentation and recognition as saving computational cost over the traditional pipeline.
6. Conclusions
This paper aimed to develop a vehicle following behaviour detection method by matching the extracted vehicle licence-plate with the plates detected earlier. A robust and cost-effective licence-plate recognition method was achieved, which uses edges and licence-plate ratio to extract licence-plates. This method was shown to be reliable, as it produced better licence-plate detection results on tested datasets. It was also more computationally cost-effective than semantic segmentation methods.
The proposed licence-plate matching method was also shown to have a lower computational cost than methods using character segmentation and recognition. This validated the proposed licence-plate recognition pipeline, which replaces character segmentation and recognition with licence-plate template matching.
The edge-based method can miss certain licence-plate extractions because of the processing steps removing the edges of the licence-plate in smaller sized vehicle images. This filtering of edges is performed to reduce the computational cost of locating the licence-plate by the line ratio computation method. Future research will propose a method for the line ratio calculation that is less dependent on the number of edges in the image. The new method will improve licence-plate extraction accuracy without compromising the computational cost of the method.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}