
Qualitative Methods with Nvivo Software: A Practical Guide for Analyzing Qualitative Data

 ,
,  and
and
Abstract
:1. Introduction
2. Data Preparation
2.1. Key Terms
- Code—A meaningful word or phrase which represents and conveys the messages and meanings of participant words.
- Coding—The process of looking through data to find, and additionally assign, codes to participant words.
- Node—A feature in NVivo which provides “Containers for your coding—they let you gather [data which has been assigned a code] in one place” [11] (p. 7).
- SC—Single-Click; one left click with a mouse.
- DC—Double-Click; two left clicks in quick succession with a mouse.
- RC—Right-Click; one right click with a mouse.
- SC-HD—Single-Click and Hold-Down; one left click with a mouse, keeping the pressure of the clicking finger held down.
- R-SC—Release-Single-Slick; release the pressure of the finger holding a single-click down.
2.2. Preparing Data for Analysis
- Open Nvivo and create a new, empty Nvivo file;
- SC “Import” on the ribbon;
- SC “Files”;
- Navigate to the files of interest;
- Select the desired file(s) to import into Nvivo;
- SC “Open”;
- SC “Import”;
- SC “OK”;
- Save.
3. Performing Open Coding
3.1. Open Coding through the Entire Interview Method
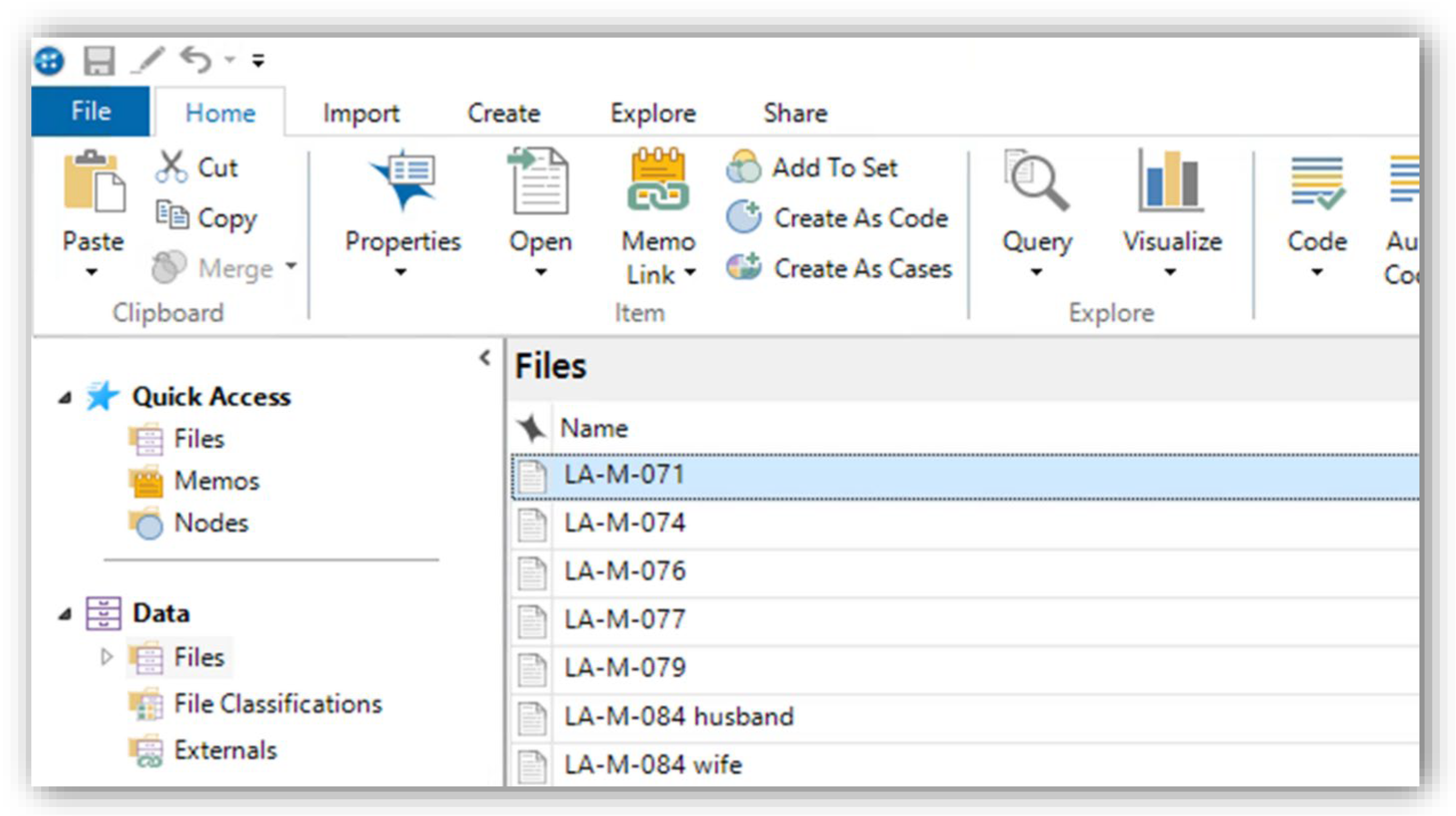
- SC “Files” in the left navigation menu to display a list of files (transcripts);
- Open the transcript by performing a DC on the file name. Alternatively, RC the file name then SC the “open document” option;
- SC inside the window with the text of the transcript so that “document tools” appears on the ribbon. Under “document tools”, (1) SC coding stripes > SC “all coding” and (2) SC “highlight” > SC “all coding”;
- a.
- Note—coding stripes make it easy to view and track coding conducted by researchers
- SC “nodes” in the left navigation menu. The node navigation pane will appear (which should be empty at this point);
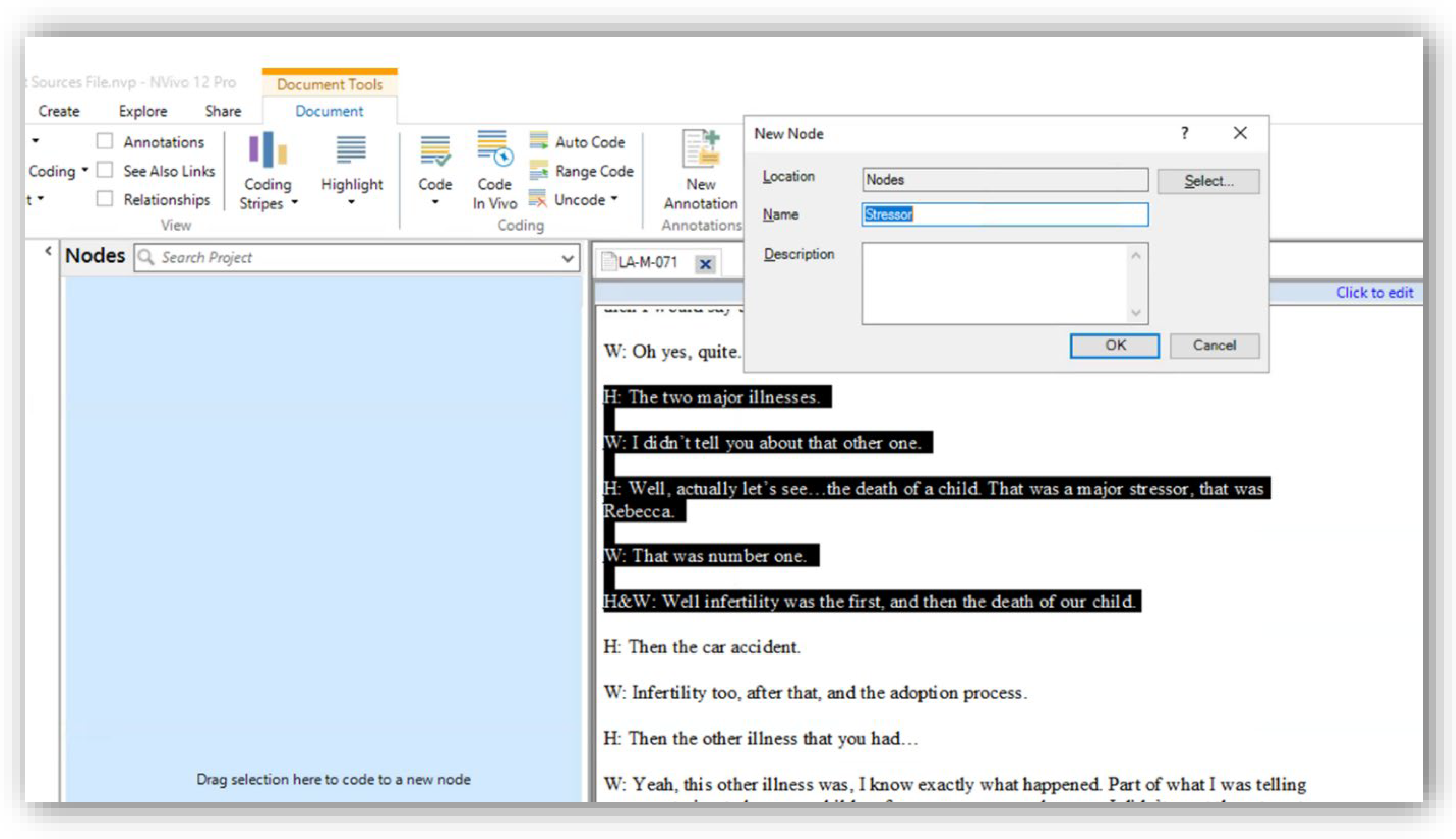
- Read through a section of text (about a paragraph) and determine a “code” that fits it adequately;
- Once a code is decided upon, highlight the text and SC-HD at the start of the code > drag to the end of the code > R-SC;
- SC-HD the highlighted text > drag mouse to empty space in the nodes pane > R-SC;
- a.
- Note—there are additional ways to assign a text to a node—see [11] (p. 25)
- In the new window that popped up type in the name of the code decided in step 4;
- SC “okay”. A new node appears in the nodes pane with the name of the code;
- Continue the process until the end of interview:
- a.
- If the same code is present more than once (as it likely will be), repeat steps 5–6, but at step six drag the mouse to the re-occurring node and then R-SC.
- b.
- If a new code becomes present (as it likely will), repeat steps 5–9.
- Once you have finished coding the interview, go through it quickly one more time to ensure that no codes were missed. If necessary, repeat the steps 10a or 10b;
- Save, open the next interview to be coded, and perform steps 10a or 10b. Do not delete the nodes in the nodes pane;
- Perform step 12 until all interviews are coded.
3.2. Open Coding through the Deep Dive Method
- SC “Nodes” in the left navigation menu to display a list of nodes;
- Open the node corresponding to the code you are performing a “deep dive” on by performing a DC on the node name. Alternatively, RC the node name then SC the “open node” option;
- SC inside the window with the text of the transcript so that “document tools” appears on the ribbon. Under “document tools”, (1) SC coding stripes > SC “all coding” and (2) SC “highlight” > SC “all coding”;
- SC “nodes” in the left navigation menu. The node navigation pane will appear (which should be empty at this point);
- Read through a section of text (about a paragraph) and determine a “code” that fits it adequately. Ensure you only look for new codes (do not code at the node you are doing the deep dive on);
- Once a code is decided upon, highlight the text and SC-HD at the start of the code > drag to the end of the code > R-SC;
- SC-HD the highlighted text > drag mouse to empty space in the nodes pane > R-SC;
- In the new window that popped up type in the name of the code decided in step 4;
- SC “okay”. A new node appears in the nodes pane with the name of the code;
- Continue the process until the end of node:
- a.
- If the same code is present more than once (as it likely will be), repeat steps 5–6 but at step six drag the mouse to the re-occurring node and then R-SC.
- b.
- If a new code becomes present (as it likely will), repeat steps 5–9.
- Save.
3.3. Open Coding through the Keyword Method
- SC “Explore” on the ribbon to display the query command group;
- SC “Text Search”;
- SC inside the “search for” box;
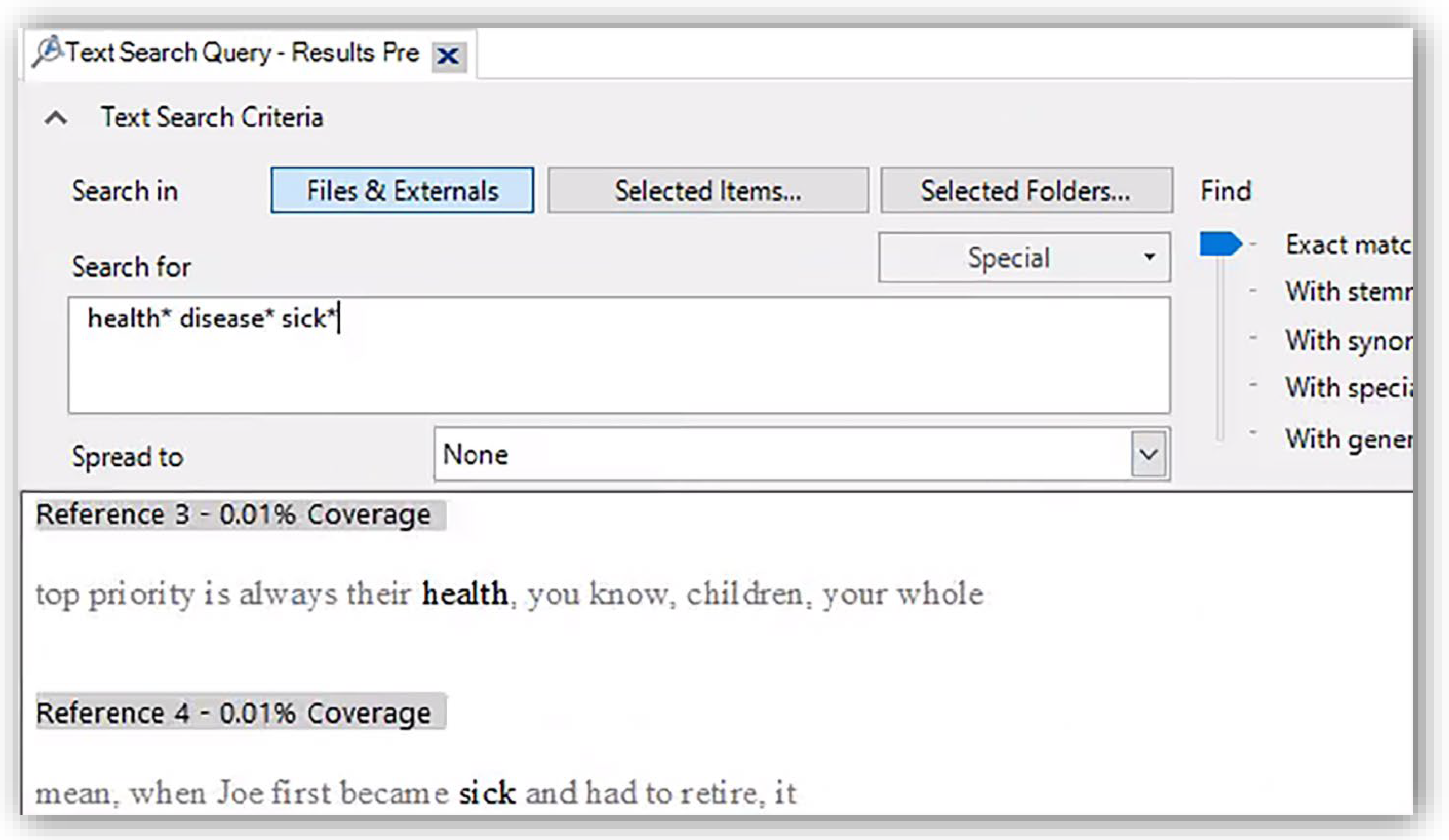
- Ensuring that the “find” slider is set at “exact matches” and the “spread to” drop down box is set to “none”, enter keywords into the “search for” box utilizing the wildcard “*” after (and potentially before) keywords;
- a.
- Note—the wildcard “*” enables stems of words to be found instead of only the exact word itself. There is an option on the slider to utilize “with stemmed words”. However, utilizing the wildcard “*” instead of the “with stemmed words” option on the slider yields more search hits. For instance, searching one of our datasets with the criteria “health* disease* sick*” and the slider set on “exact matches” yielded 140 matching files and 507 matching references. However, searching our dataset with the criteria “health disease sick” with the slider on “stemmed words” yielded 121 files and 389 references. Accordingly, we recommend using wildcards and setting the find slider set to “exact matches”
- b.
- Note—there is an option on the “find” slider to include synonyms by selecting “with synonyms”. We recommend not using this option and rather finding synonyms beforehand and using the “exact matches” option. Our reasoning is (1) the researcher knows exactly what words Nvivo used in the search and (2) the researcher has the exact words used for searching available to report
- SC “Run Query”;
- Review search results by SC on either “reference” or “word tree” on the right-hand ribbon next to the search results (“reference” shown in Figure 3) and adjust search terms as necessary;
- a.
- Note—finalizing the search iterative process and adding and subtracting words through trial and error is helpful
- b.
- Note—Word trees are helpful for visualizing the search and are one aesthetic way to display search terms for reports, posters, presentations and other publications (for more information on word trees, see http://help-nv11.qsrinternational.com/desktop/procedures/run_a_text_search_query.htm; accessed 17 March 2022)
- If desired, save word tree by RC in the window with the word tree > SC “Export Word Tree” > Select File Location > SC “Save” (Word trees cannot be saved when coding is spread as is performed in step 8);
- In the “Spread To” drop down menu, SC custom context > SC the “Number of Words” bubble > enter “30” in the “Number of Words” box > SC “OK”
- a.
- Note—Our recommendation for the minimum number of words is 30; more can be added if desired
- SC “Run Query”;
- In Nvivo (or a separate program), record the keywords utilized in the search for reference and later reporting;
- SC “Save Results”;
- SC “Select” next to the “location” box > SC “nodes” > SC “OK”;
- a.
- Note—Another option would be to save it in the “query results” location. The downside of this approach is that you cannot uncode irrelevant search hits)
- Enter the name of the search results (e.g., Health Project Search Hits);
- SC “OK”. A new node is created, opened, and is accessible under “codes” on the left navigation pane in “nodes”;
- Save;
- Share the file with each team member performing open coding.
- 17.
- SC inside the window with the text of the transcript so that “document tools” appears on the ribbon. Under “document tools”, (1) SC coding stripes > SC “all coding” and (2) SC “highlight” > SC “all coding”;
- 18.
- SC “nodes” in the left navigation menu. The node navigation pane will appear (which should be empty at this point);
- 19.
- Read through a section of text (about a paragraph) and determine a “code” that fits it adequately. Ensure you only look for new codes (do not code at the keyword node);
- 20.
- Once a code is decided upon, highlight the text and SC-HD at the start of the code > drag to the end of the code > R-SC;
- 21.
- SC-HD the highlighted text > drag mouse to empty space in the nodes pane > R-SC;
- 22.
- In the new window that popped up type in the name of the code decided in step 4;
- 23.
- SC “okay”. A new node appears in the nodes pane with the name of the code;
- 24.
- Continue the process until the end of node:
- a.
- If the same code is present more than once (as it likely will be), repeat steps 19–20 but at step 20 drag the mouse to the re-occurring node and then R-SC.
- b.
- If a new code becomes present (as it likely will), repeat steps 19–23.
- 25.
- Save.
3.4. A Tip for Speeding Up Open Coding … and a Caution
4. Consolidating Open Codes in Preparation for Systematic Coding
5. Dividing Team Members into Pairs When Coding Teams Are Larger than Two
- Researcher one could review interviews 1–15 of researcher two and interviews 16–30 of researcher three.
- Researcher two could review interviews 1–15 of researcher three and interviews 16–30 of researcher one
- Researcher three could review interviews 1–15 of researcher one and interviews 16–30 of researcher two
6. Systematic Coding
6.1. Preparing a File for Systematic Coding
6.2. The Process of Systematic Coding
6.3. Common Questions When Conducting Systematic Coding
7. Reviewing Partner Work
7.1. Individual Review of a Partner’s Work
- Review the core themes and the definitions of the core themes;
- Open (or create and then open) the memo or document used for recording partner review notes (see proceeding section in this manuscript “Effective partner memos and audit trails” for more on memos);
- Depending on the method, either open the first interview or the overarching node or keyword node and turn on highlighting and coding stripes;
- Beginning at the first interview or the beginning of the overarching or keyword node, read through the paragraph/section and decide if you agree or disagree with the decision made by a partner to either assign or not assign this paragraph/section of text to a particular node. Evaluate partner decisions based if one believes a partner:
- a.
- Correctly coded something that should be coded (their code is correct).
- b.
- Incorrectly coded something that should not be coded (their code needs to be removed).
- c.
- Correctly did not code something that should not have been coded (their decision to not code was correct).
- d.
- Incorrectly did not code something that should have been coded (a code they missed should be added).
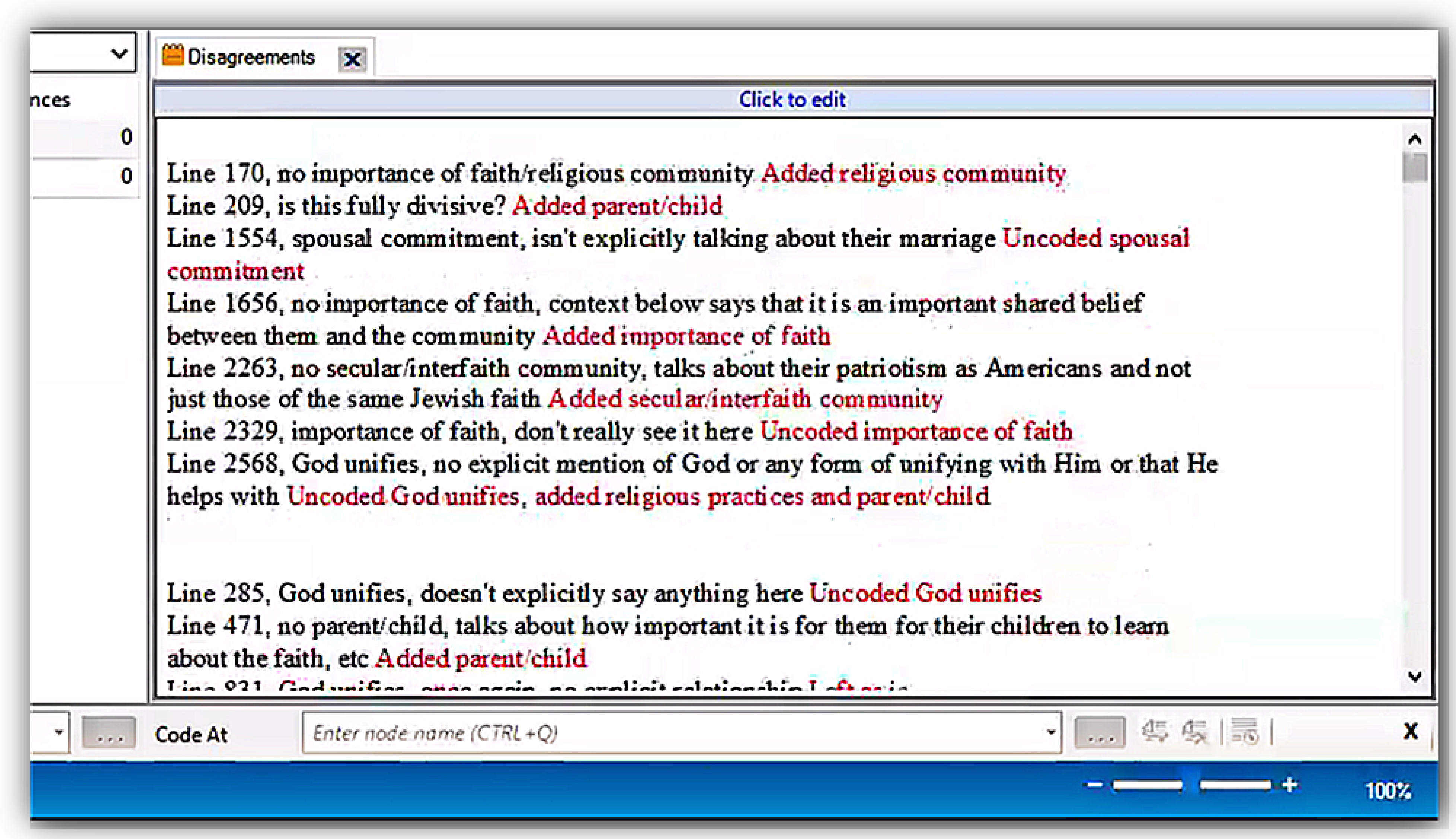
- If you agree, note it on your partner review memo. If you disagree, similarly note it, and additionally record a brief sentence indicating why you disagree;
- Repeat Steps 4–5 until all text is reviewed, saving often.
7.2. Meeting Together to Discuss Partner Work
- Both partners sit side by side with their own individual computer in front of them and (a) open Nvivo, (b) open their partner’s coded file and the relevant nodes or interviews depending on the method, and (c) open the memo or document used for recording partner review notes;
- a.
- Note—even in a trio, this process is conducted with a partner—so that only two members of the trio perform this process at a time together
- The reviewer, looking at their reviewee’s coded file open in Nvivo and their own memo or review document, and beginning at the first interview, shares the first instance where they disagreed or thought a code was missed by the reviewee. If there are no disagreements, move directly to step 10;
- a.
- Note—the reviewer is the partner providing feedback and suggestion and the reviewee is the partner the reviewer is evaluating
- b.
- Note—all methods, including the deep dive and keyword methods, are grouped by interviews when displayed in Nvivo. Accordingly, we suggest going interview by interview during a partner review session
- The reviewer waits for the reviewee to identify the spot the reviewer is referring to;
- The reviewer shares (a) what they disagreed with, or thought should be added, (b) why they disagreed or thought a code should be added and (c) what action they recommend taking (with the possible actions being removal of a code or addition of a code that was missed);
- The reviewee responds, sharing their rational as to why they did (in the case of a removal disagreement) or did not (in the case of a code addition disagreement) code a section as they did, potentially rebutting the suggestion of the reviewer;
- Partners continue to discuss the disagreement until agreeing, accepting, or conceding occurs. Agreeing, accepting, and conceding are defined below:
- a.
- Agreeing: The act of the reviewee wholeheartedly and enthusiastically viewing a suggested change by the reviewer as correct.
- b.
- Accepting: The act of the reviewee viewing a suggested change by the reviewer as incorrect but reservedly and reluctantly accepting the suggested change.
- c.
- Conceding: The act of the reviewer viewing the rebuttal from the reviewee about their suggested change to the reviewee as incorrect, but reservedly and reluctantly dismissing the change they (the reviewer) suggested.
- Partners tally the results of the disagreement for later counting, with agreeing counting towards agreements and accepting and conceding counting towards unresolvable disagreements;
- Partners make the necessary change to the reviewee’s file, either removing or adding code(s). To remove, RC the coding stripe corresponding to the relevant node > SC “uncode”. To add a code, SC-HD at the start of the code > drag to the end of the code > R-SC. Then, SC-HD the highlighted text > drag mouse to corresponding node > R-SC;
- Keeping the same roles as reviewer or reviewee respectively, repeat steps 2–8, for the rest of the disagreements in the first interview;
- Switch roles as reviewer and reviewee and repeat steps 2–9 for the text in the first interview;
- Count up the number of agreements and unresolvable disagreements. Include in the count of agreements the number of times the reviewer agreed with the reviewee’s codes, but which were not already discussed (because there was no disagreement);
- Record on the inter-rater reliability spreadsheet the count of agreements and unresolvable disagreements;
- Save both partners Nvivo files as well as the inter-rater reliability spreadsheet;
- Repeat steps 2–13 for the rest of the interviews where partners reviewed one another.
7.3. Effective Partner Memos and Audit Trails
8. Preparing Work for Publication
8.1. Merging Partner Files
- Open one member of the coding pairs files in Nvivo;
- Save a copy, ensuring the name of the new file designates a merge and which partnership (e.g., healthcoding-Alexa-Joseph-merge.nvp);
- Opening and using the new, copied file, SC “import” on the ribbon > SC “project” > browse to the other partner’s file location > select the file to be imported > SC “open”;
- Ensuring that the defaults, “all (including content)” and “merge into existing item” are selected, SC “import”:
- a.
- At this point, the nodes are merged; however, for the purposes of Marks’ [4] method, the reference counts are not accurate—Nvivo is double counting overlap between coders (where they both coded the same section of text) as multiple nodes when in reality they only should count as one. The following steps remedy this.
- Create a new node by RC in a blank area of the nodes window (or use the shortcut CTRL + Shift + N) and name it (e.g., “correct count”);
- RC one of the nodes > SC “create as” > SC “create as code”;
- In the “select location” window that appears, SC the plus sign under nodes > SC the recently created code (e.g., SC “correct count”) > SC “ok”;
- In the “new node” window that appears, provide a name for the node (the name of the old node will suffice) > SC “ok”:
- a.
- Note how the reference count for the new node is less as compared to the old node it was created from. This is correct and will happen in nearly every case.
- Repeat this step for each node (including the overarching deep dive or keyword node). If necessary (i.e., using the deep dive or keyword methods), organize nodes under the overarching deep dive or keyword node (hold ctrl on the keyboard down > SC all nodes except overarching node > on the last node, SCHD > drag mouse to the overarching node > R-SC. To display the nodes now organized under the overarching node, SC the small box with the “+” sign next to the overarching nodes name);
- Delete the nodes with the incorrect counts (e.g., not part of the “correct count node”) by selecting the appropriate nodes > press the delete key (alternatively RC > SC “delete”) > SC “yes” in the delete confirmation window that appears;
- Save the file;
- Repeat steps 1–11 for each coding pair’s files.
8.2. Our Perspective on Numbers and How to Prepare a Numerical Content Analysis
- Select all nodes desire for export (so that all nodes a highlighted);
- RC one of the highlighted nodes > SC “export” > SC “export list”;
- In the save as dialog box which appears, navigate to the desired folder to save the file in (if necessary), change the file name (if desired), and change the file type if desired (e.g., .xlsx, .docx, .rtf, .txt, etc.);
- SC “save”. Use the information in the saved file to create an NCA table.
8.3. Preparing and Trimming Gems
9. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Tips for Transcribing
Appendix A.2. Outsourcing Benefits and Cautions
References
- Marks, L.D.; Kelley, H.H.; Galbraith, Q. Explosion or much ado about little? A quantitative examination of qualitative publications from 1995–2017. Qual. Res. Psychol. 2021, 1–19. [Google Scholar] [CrossRef]
- Gergen, K.J.; Josselson, R.; Freeman, M. The promises of qualitative inquiry. Am. Psychol. 2015, 70, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Morison, T.; Gibson, A.F.; Wigginton, B.; Crabb, S. Online Research Methods in Psychology: Methodological Opportunities for Critical Qualitative Research. Qual. Res. Psychol. 2015, 12, 223–232. [Google Scholar] [CrossRef]
- Marks, L.D. A Pragmatic, Step-by-Step Guide for Qualitative Methods: Capturing the Disaster and Long-Term Recovery Stories of Katrina and Rita. Curr. Psychol. 2015, 34, 494–505. [Google Scholar] [CrossRef]
- Levitt, H.M.; Bamberg, M.; Creswell, J.W.; Frost, D.M.; Josselson, R.; Suárez-Orozco, C. Journal article reporting standards for qualitative primary, qualitative meta-analytic, and mixed methods research in psychology: The APA Publications and Communications Board task force report. Am. Psychol. 2018, 73, 26–46. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mitchell, T.; Friesen, M.; Friesen, D.; Rose, R. Learning Against the Grain: Reflections on the Challenges and Revelations of Studying Qualitative Research Methods in an Undergraduate Psychology Course. Qual. Res. Psychol. 2007, 4, 227–240. [Google Scholar] [CrossRef]
- Ponterotto, J.G. Integrating qualitative research requirements into professional psychology training programs in North America: Rationale and curriculum model. Qual. Res. Psychol. 2005, 2, 97–116. [Google Scholar] [CrossRef]
- Parker, I. Criteria for qualitative research in psychology. Qual. Res. Psychol. 2004, 1, 95–106. [Google Scholar] [CrossRef]
- Fielding, N.G.; Lee, R.M. Computer Analysis and Qualitative Research; SAGE Publications: Thousand Oaks, CA, USA, 1999. [Google Scholar]
- Zamawe, F.C. The Implication of Using NVivo Software in Qualitative Data Analysis: Evidence-Based Reflections. Malawi Med. J. 2015, 27, 13–15. [Google Scholar] [CrossRef] [Green Version]
- QSR International. NVivo 10 for Windows: Getting Started. 2014. Available online: http://download.qsrinternational.com/Document/NVivo10/NVivo10-Getting-Started-Guide.pdf (accessed on 17 March 2022).
- LeBaron, A.B.; Hill, E.J.; Rosa, C.M.; Marks, L.D. Whats and Hows of Family Financial Socialization: Retrospective Reports of Emerging Adults, Parents, and Grandparents. Fam. Relat. 2018, 67, 497–509. [Google Scholar] [CrossRef]
- Jorgensen, B.L.; Allsop, D.B.; Runyan, S.D.; Wheeler, B.E.; Evans, D.A.; Marks, L.D. Forming Financial Vision: How Parents Prepare Young Adults for Financial Success. J. Fam. Econ. Issues 2019, 40, 553–563. [Google Scholar] [CrossRef]
- Allsop, D.B.; Leavitt, C.E.; Clarke, R.W.; Driggs, S.M.; Gurr, J.B.; Marks, L.D.; Dollahite, D.C. Perspectives from Highly Religious Families on Boundaries and Rules About Sex. J. Relig. Health 2021, 60, 1576–1599. [Google Scholar] [CrossRef] [PubMed]
- Ando, H.; Cousins, R.; Young, C. Achieving Saturation in Thematic Analysis: Development and Refinement of a Codebook. Compr. Psychol. 2014, 3, 03-CP. [Google Scholar] [CrossRef] [Green Version]
- Hennink, M.M.; Kaiser, B.N.; Marconi, V.C. Code Saturation Versus Meaning Saturation. Qual. Health Res. 2017, 27, 591–608. [Google Scholar] [CrossRef] [PubMed]
- Saunders, B.; Sim, J.; Kingstone, T.; Baker, S.; Waterfield, J.; Bartlam, B.; Burroughs, H.; Jinks, C. Saturation in qualitative research: Exploring its conceptualization and operationalization. Qual. Quant. 2018, 52, 1893–1907. [Google Scholar] [CrossRef] [PubMed]
- Robb, M.P.; Maclagan, M.A.; Chen, Y. Speaking rates of American and New Zealand varieties of English. Clin. Linguist. Phon. 2004, 18, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Johnson, W.; Darley, F.L.; Spriesterbach, D.C. Diagnostic Methods in Speech Pathology; Harper & Row: Oxford, UK, 1963; p. xv, 347. [Google Scholar]
- James, W. The Varieties of Religious Experience: A Study in Human Nature; Longmans, Green and Co.: New York, NY, USA, 1902. [Google Scholar]
- Thomas, W.I. The Unadjusted Girl: With Cases and Standpoint for Behavior Analysis; Little, Brown, and Co.: Boston, MA, USA, 1923. [Google Scholar]
- Matheson, J. The Voice Transcription Technique: Use of Voice Recognition Software to Transcribe Digital Interview Data in Qualitative Research. Qual. Rep. 2015, 12, 547–560. [Google Scholar] [CrossRef]
- Tilley, S.A. “Challenging” Research Practices: Turning a Critical Lens on the Work of Transcription. Qual. Inq. 2003, 9, 750–773. [Google Scholar] [CrossRef]
- Bird, C.M. How I Stopped Dreading and Learned to Love Transcription. Qual. Inq. 2005, 11, 226–248. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Question and Decision |
|---|---|
| Entire interview method | -- |
| 1a | Are there more than 20 interviews? No: Open code all interviews Yes: Proceed to Step 2a |
| 2a | Does the word count of all interviews exceed or equal 200,000? a No: Open code all interviews Yes: Proceed to Step 3a |
| 3a | Do you wish to limit data coded in order to speed up open coding? No: Open Code all interviews Yes: Cautiously decide which of the 20 interviews will be open coded. Record decision rationale for later reporting |
| Deep dive or keyword methods | -- |
| 1b | Does the word count of all text in the deep dive node or keyword node exceed or equal 200,000? a No: Open code the entire deep dive or keyword node Yes: Proceed to Step 2b |
| 2b | Do you wish to limit data coded in order to speed up open coding? No: Open Code all interviews Yes: Cautiously decide how to limit coding, aiming to open code at least 200,000 words or more. Record decision rationale for later reporting |
| Step | Description | |
|---|---|---|
| 1 | Have the list of codes and definitions (from the consolidation meeting) nearby. | |
| -- | Steps to take if a clean copy a is not available. | |
| 2 | Create a copy of one of the researchers’ Nvivo files being utilized for the project (preferably designating in the file name that the file is a master, un-coded copy). If conducting the deep dive or keyword methods, ensure that the copied file contains the overarching node. | |
| 3 | SC “nodes” in the left navigation menu. The node navigation pane will appear. | |
| 4 | If performing the entire interview method: Delete all nodes (SC a node > on the keyboard press delete key; alternatively RC on the node > SC “delete”). | If performing the deep dive or keyword methods: Delete all nodes except the overarching node guiding the project (SC a node > on the keyboard press delete key; alternatively, RC on the node > SC “delete”). |
| -- | Steps once a clean copy is made. | |
| 5 | Create new nodes which correspond to the names of the core themes (RC in the nodes navigation pane > SC “new node” > type name of node > SC “okay”; alternatively, use keyboard shortcut ctrl + shift + n > type name of node > SC “okay”). Double check spelling. | |
| 6 | If performing the entire interview method: Proceed to step 7. | If performing the deep dive or keyword methods: Select all nodes except the overarching node and organize them under the overarching node (hold ctrl on the keyboard down > SC all nodes except overarching node > on the last node, SCHD > drag mouse to the overarching node > R-SC. To display the nodes now organized under the overarching node, SC the small box with the “+” sign next to the overarching nodes name). |
| 7 | Save the file. | |
| 8 | Create copies of the file for each team member (preferably designating each team members name in their copy of the file). | |
| 9 | Distribute copies of the files to team members. | |
| Step | Description | |
|---|---|---|
| 1 | Depending on the method, either open the first interview a or the overarching node or keyword node b and optionally turn on highlighting and coding stripes. | |
| 2 | Read through a section of text (about a paragraph) and determine if it adequately fits the codes (nodes) listed in the node navigation pane. | |
| 3 | If the section of text adequately fits the codes (nodes) listed in the navigation pane, highlight the text by SC-HD at the start of the code > drag to the end of the code > R-SC. Then, SC-HD the highlighted text > drag mouse to corresponding node > R-SC. If the section of text matches multiple codes, repeat this step accordingly. | |
| 4 | If the section of text does not adequately fit the code, proceed to the next section of text. | |
| 5 | Entire interview method: follow steps 2–4 until the end of the interview. Save often. | Deep dive or keyword methods: follow steps 2–4 on until the end of the text contained in the deep dive node or keyword node. Save often. |
| 6 | Open the next interview to be coded and repeat steps 1–5 until all interviews are coded. | -- |
| Step | Example Conversation | |||||
|---|---|---|---|---|---|---|
| 1 | -- | |||||
| 2 | Reviewer: “My first disagreement is at line 55 where the husband said, ‘I had to take a little more than a week off my job due to the illness. It was disheartening not just for me, but for my whole family’. Do you see that spot?”. | |||||
| 3 | Reviewee: “Okay, I see it”. | |||||
| Example of Code Removal Disagreement | Example of Code Addition Disagreement | |||||
| 4 | Reviewer: “From line 55 to line 56 you coded this section as ‘debilitating illness.’ However, I do not feel it matches up with that code. I think we should remove it”. | Reviewer: “From line 55 to line 70 I think we should add the code ‘depression’. The husband references how it was ‘disheartening,’’ and is conveying how it was depressing to have to be sick and take off work. Subsequently, we should code that section as ‘depression’”. | ||||
| 5 | Reviewee: “I see. At line 55 he mentions how he had to take work of for about a week. To me, that matches our definition of ‘debilitating illness’. | Reviewee: “I see. I did not initially feel that spot fit the ‘depression’ code—making it fit seemed like too big of a stretch”. | ||||
| Ex. of Agreeing | Ex. of Accepting | Ex. of Conceding | Ex. of Agreeing | Ex. of Accepting | Ex. of Conceding | |
| 6 | Reviewee: “But, now that I think about it more, I do not think it fits like you suggest. Let’s remove it”. | Reviewee: “But, I see your point though. I still think that code belongs there, but we can remove it as you suggest”. | Reviewee: “Based on that point I shared, I think we should keep it”. Reviewer: “I’m still not on board, but I see what you mean and we don’t need to remove it”. | Reviewee: “But, now that I think about it more, I do think it fits like you suggest. Let’s add it”. | Reviewee: “But, I see your point though. I still think that code doesn’t belong, but we can add it as you suggest”. | Reviewee: “Based on that point I shared, I think we should not add it”. Reviewer: “I’m still not on board, but I see what you mean and we don’t need to add it”. |
| 7 | Agree/Disagree Count | Agree/Disagree Count | Agree/Disagree Count | Agree/Disagree Count | Agree/Disagree Count | Agree/Disagree Count |
| “1 Agreement” | “1 Unresolvable Disagreement” | “1 Unresolvable Disagreement” | “1 Agreement” | “1 Unresolvable Disagreement” | “1 Unresolvable Disagreement” | |
| 8 | Action Taken | Action Taken | Action Taken | Action Taken | Action Taken | Action Taken |
| Uncode ‘debilitating illness’ at lines 55–56 in the Reviewee’s file | Uncode ‘debilitating illness’ from at 55–56 in the Reviewee’s file | No changes necessary | Code ‘depression’ at lines 55–56 in the Reviewee’s file | Code ‘depression’ at lines 55–56 in the Reviewee’s file | No changes necessary | |
| 9 | -- | |||||
| 10 | Reviewer: “Ok, now it’s your turn to be the reviewer and share your review of my coding”. | |||||
| 11 | Reviewee: “Let’s see …so we had 1 agreement where you suggested I remove something and I agreed, 1 unresolvable disagreement where you suggested we add something and I only accepted, and 1 unresolvable disagreement where you suggested we add something and you conceded”. Reviewer: “That’s what I counted too. You also had 3 codes that I agreed with that we did not need to discuss”. Reviewee: “So …in total that makes for 4 agreements and 2 unresolvable disagreements”. Reviewer: “That’s what I count too”. | |||||
| 12 | Reviewee: “Alright, on our spreadsheet, for the interview ‘Hernández’ with Alexa as the reviewee and Joseph as the reviewer, we’ll put 4 under agreements in cell ‘e7’ and 2 under unresolvable disagreements in cell ‘f7’. | |||||
| 13 | -- | |||||
| 14 | -- | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Allsop, D.B.; Chelladurai, J.M.; Kimball, E.R.; Marks, L.D.; Hendricks, J.J. Qualitative Methods with Nvivo Software: A Practical Guide for Analyzing Qualitative Data. Psych 2022, 4, 142-159. https://doi.org/10.3390/psych4020013
Allsop DB, Chelladurai JM, Kimball ER, Marks LD, Hendricks JJ. Qualitative Methods with Nvivo Software: A Practical Guide for Analyzing Qualitative Data. Psych. 2022; 4(2):142-159. https://doi.org/10.3390/psych4020013
Chicago/Turabian StyleAllsop, David B., Joe M. Chelladurai, Elisabeth R. Kimball, Loren D. Marks, and Justin J. Hendricks. 2022. "Qualitative Methods with Nvivo Software: A Practical Guide for Analyzing Qualitative Data" Psych 4, no. 2: 142-159. https://doi.org/10.3390/psych4020013
APA StyleAllsop, D. B., Chelladurai, J. M., Kimball, E. R., Marks, L. D., & Hendricks, J. J. (2022). Qualitative Methods with Nvivo Software: A Practical Guide for Analyzing Qualitative Data. Psych, 4(2), 142-159. https://doi.org/10.3390/psych4020013