

An Adaptive Holt–Winters Model for Seasonal Forecasting of Internet of Things (IoT) Data Streams



Abstract
1. Introduction
2. Related Work
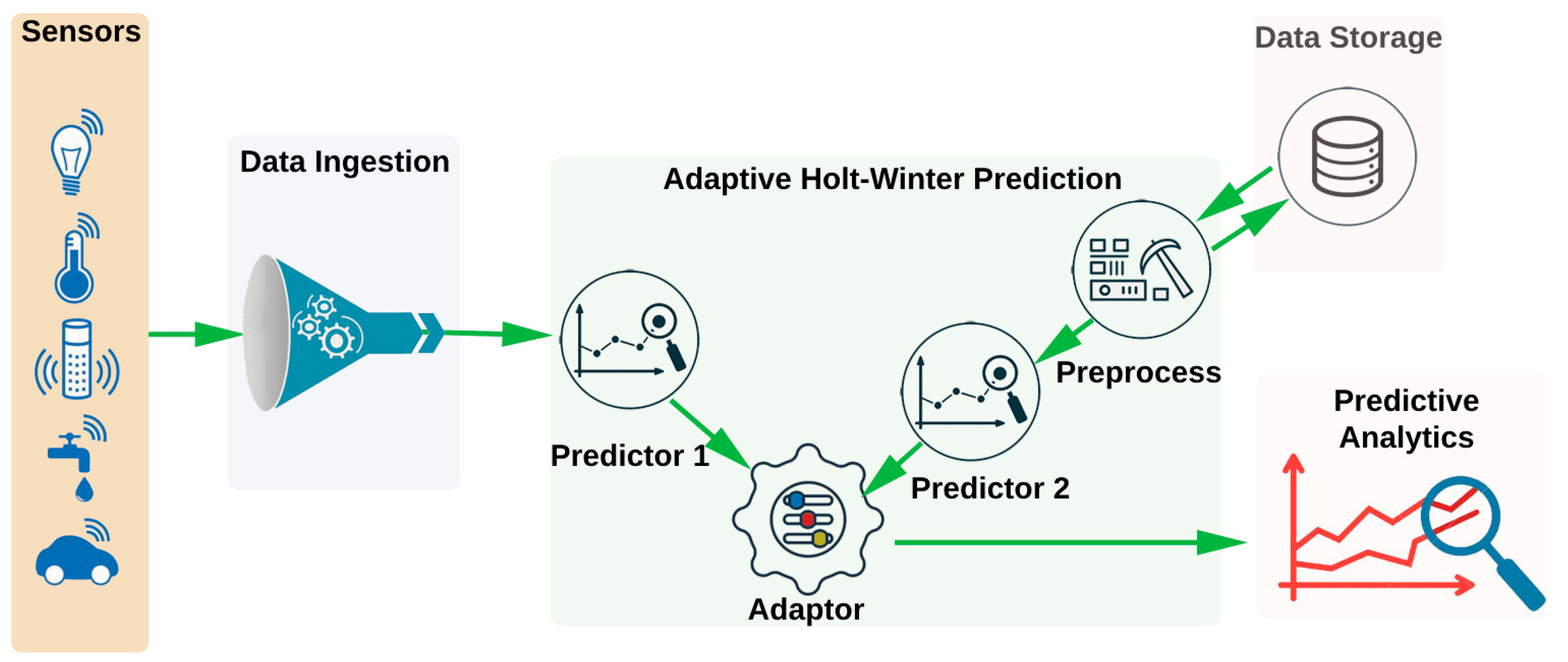
3. The Proposed AHW Forecasting Method
| Algorithm 1. Preprocess Historical Data |
| Input HistoricalData dataset WindowSize ← Select Window Size (includes at least one seasonal data) AvgWindow ← Zero Array HistoricalDataLength ← HistoricalData.length For i ← 0 to HistoricalDataLength −1 do CurrWindow ← HistoricalData[i, WindowSize] For jl ← 0 to WindowSize −1 do AvgWindow[j] ← AvgWindow[j] + CurrWindow[i] End For add WindowSize to i End For AvgLevel ← 0 For i← 0 to AvgWindow.length −1 do AvgWindow[j] ← AvgWindow[j]/(HistoricalDataLength/WindowSize) AvgWindowLevel ← AvgWindowLevel + AvgWindow[j] End For AvgWindowLevel ← AvgWindowLevel/AvgWindow.length For i ← 0 to HistoricalDataLength−1 do HistWindow ← HistoricalData[i, WindowSize] HistWindowLength ← HistWindow.length HistWindowLevel ← 0 HistWindowRMSE ← 0 For j ← 0 to HistWindowLength −1 do HistWindowLevel ← HistWindowLevel + HistWindow[j] End For HistWindowLevel ← HistWindowLevel/HistWindowLength HistWindowLevelDiff ← HistWindowLevel-AvgWindowLevel For j ← 0 to HistWindowLength −1 HistWindowRMSE ← HistWindowRMSE + SquareRoot((HistWindow[j] + HistWindowLevelDiff −AvgWindow[j])2) End For Store i, HistWindowRMSE in StoredWindowsInfo Database add WindowSize to i End For |
| Algorithm 2. Data Forecasting |
| Input LatestWindowData dataset, AvgWindow, AvgWindowLevel, HistoricalData dataset, WindowSize LatestWindowLevel ← 0 LatestWindowLength ← LatestWindowData.length For i ← 0 to LatestWindowLength −1 do LatestWindowLevel ← LatestWindowLevel + LatestWindowData [i] End For LatestWindowLevel ← LatestWindowLevel/LatestWindowLength LatestWindowLevelDiff ← LatestWindowLevel-AvgWindowLevel LatestWindowRMSE ← 0 For i ← 0 to LatestWindowLength −1 do LatestWindowRMSE ← LatestWindowRMSE + SquareRoot((LatestWindowData[i] +LatestWindowLevelDiff-AvgWindow[i])2) End For ClosestWindow ← ∞ ClosestWindowRMSEDiff ← ∞ For i ← 0 to StoredWindowsInfo.length −1 do If Absolute(StoredWindowsInfo[i].RMSE − LatestWindowRMSE) is less than ClosestWindowRMSEDiff ClosestWindow ← i ClosestWindowRMSEDiff ← Absolute(StoredWindowsInfo[i].RMSE − LatestWindowRMSE) End For ClosestWindowData ← HistoricalData[i × WindowSize, (i + 1) × WindowSize] Calculate trend, level, seasonality for LatestWindowData. LatestWindowDataTraining ← LatestWindowData [0, 0.8 × LatestWindowLength] LatestWindowDataAddapting ← LatestWindowData[0.8 × LatestWindowLength +1, LatestWindowLength] ClosestWindowDataTraining ← ClosestWindowData[0, 0.8 × ClosestWindowData.length] LatestPredict ← Use LatestWindowDataTraining to predict LatestWindowDataAddapting using Holt–Winters equation ClosestPredict ← Use ClosestWindowDataTraining to predict ClosestWindowDataAddapting using Holt–Winters equation LatestWindowDiff ← 0 TotalDiff ← 0 For i ← 0 to LatestWindowDataAddapting.length −1 do LatestWindowDiff ← LatestWindowDiff + Absolute(LatestPredict[i] − LatestWindowDataAddapting[i]) TotalDiff←TotalDiff + Absolute(LatestPredict[i] − LatestWindowDataAddapting[i]) + Absolute(ClosestPredict[i] − LatestWindowDataAddapting[i]) End For LatestPercent ← LatestWindowDiff/TotalDiff PredictNewDataLatest ← Use LatestWindowData and Holt–Winters equation PredictNewDataClosest ← Use ClosestWindowData and Holt–Winters equation For i ← 0 to PredictNewDataLatest.length −1 do FinalPredictedData[i] ← (PredictNewDataLatest × LatestPercent) + (PredictNewDataClosest × 1 − LatestPercent) End For Return FinalPredictedData |
4. Results and Discussions
4.1. Datasets
4.2. Evaluation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zeinab, K.A.M.; Elmustafa, S.A.A. Internet of Things Applications, Challenges and Related Future Technologies. World Sci. News. 2017, 67, 2. [Google Scholar]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep learning for IoT big data and streaming analytics: A survey. IEEE Commun. Surv. Tutor. 2018, 20, 2923–2960. [Google Scholar] [CrossRef]
- Xie, X.; Wu, D.; Liu, S.; Li, R. IoT data analytics using deep learning. arXiv 2017, arXiv:1708.03854. [Google Scholar]
- Hassan, S.A.; Syed, S.S.; Hussain, F. Communication Technologies in IoT Networks. In Internet of Things; Springer: Cham, Switzerland, 2017; pp. 13–26. [Google Scholar] [CrossRef]
- Kaur, N.; Sood, S.K. Efficient Resource Management System Based on 4Vs of Big Data Streams. Big Data Res. 2017, 9, 98–106. [Google Scholar] [CrossRef]
- Wazurkar, P.; Bhadoria, R.S.; Bajpai, D. Predictive analytics in data science for business intelligence solutions. In Proceedings of the 2017 7th International Conference on Communication Systems and Network Technologies (CSNT), Nagpur, India, 11–13 November 2017; pp. 367–370. [Google Scholar] [CrossRef]
- Wang, Y.; Qiu, Y.; Chen, P.; Shu, Y.; Rao, Z.; Pan, L.; Yang, B.; Guo, C. LightGTS: A Lightweight General Time Series Forecasting Model. arXiv 2025, arXiv:2506.06005. [Google Scholar] [CrossRef]
- Xu, Z.; Zeng, A.; Xu, Q. FITS: Modeling time series with 10k parameters. arXiv 2023, arXiv:2307.03756. [Google Scholar] [CrossRef]
- Huang, J.; Li, J.; Oh, J.; Kang, H. LSTM with spatiotemporal attention for IoT-based wireless sensor collected hydrological time-series forecasting. Int. J. Mach. Learn. Cybern. 2023, 14, 3337–3352. [Google Scholar] [CrossRef]
- Virmani, C.; Choudhary, T.; Pillai, A.; Rani, M. Applications of Machine Learning in Cyber Security. In Handbook of Research on Machine and Deep Learning Applications for Cyber Security; IGI Global: Hershey, PA, USA, 2020; pp. 83–103. [Google Scholar] [CrossRef]
- Marjani, M.; Nasaruddin, F.; Gani, A.; Karim, A.; Hashem, I.A.T.; Siddiqa, A.; Yaqoob, I. Big IoT data analytics: Architecture, opportunities, and open research challenges. IEEE Access 2017, 5, 5247–5261. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, Y.; Wu, F.; Fan, W.; Tang, J.; Liu, H. Multi-dimensional joint prediction model for IoT sensor data search. IEEE Access 2019, 7, 90863–90873. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Sen, P.; Roy, M.; Pal, P. Application of ARIMA for forecasting energy consumption and GHG emission: A case study of an Indian pig iron manufacturing organization. Energy 2016, 116, 1031–1038. [Google Scholar] [CrossRef]
- Calheiros, R.N.; Masoumi, E.; Ranjan, R.; Buyya, R. Workload prediction using ARIMA model and its impact on cloud applications’ QoS. IEEE Trans. Cloud Comput. 2014, 3, 449–458. [Google Scholar] [CrossRef]
- Kane, M.J.; Price, N.; Scotch, M.; Rabinowitz, P. Comparison of ARIMA and Random Forest time series models for prediction of avian influenza H5N1 outbreaks. BMC Bioinform. 2014, 15, 276. [Google Scholar] [CrossRef] [PubMed]
- Khan, I.A.; Akber, A.; Xu, Y. Sliding window regression-based short-term load forecasting of a multi-area power system. In Proceedings of the 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), Edmonton, AB, Canada, 5–8 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Zivot, E.; Wang, J. Rolling analysis of time series. In Modeling Financial Time Series with S-Plus®; Springer: New York, NY, USA, 2003; pp. 299–346. [Google Scholar] [CrossRef]
- Brownlee, J. Long Short-term Memory Networks with Python: Develop Sequence Prediction Models with Deep Learning. In Machine Learning Mastery; Jason Brownle: West Point, MS, USA, 2017. [Google Scholar]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef]
- Lee, S.I.; Yoo, S.J. A Deep Efficient Frontier Method for Optimal Investments; Department of Computer Engineering, Sejong University: Seoul, Republic of Korea, 2017. [Google Scholar] [CrossRef]
- Choi, H.K. Stock price correlation coefficient prediction with ARIMA-LSTM hybrid model. arXiv 2018, arXiv:1808.01560. [Google Scholar]
- Ghofrani, M.; Carson, D.; Ghayekhloo, M. Hybrid clustering-time series-bayesian neural network short-term load forecasting method. In Proceedings of the 2016 North American Power Symposium (NAPS), Denver, CO, USA, 18–20 September 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Rathnayaka, R.M.K.T.; Seneviratna, D.M.K.N.; Jianguo, W.; Arumawadu, H.I. A hybrid statistical approach for stock market forecasting based on artificial neural network and ARIMA time series models. In Proceedings of the 2015 International Conference on Behavioral, Economic and Socio-Cultural Computing (BESC), Nanjing, China, 30 October–1 November 2015; pp. 54–60. [Google Scholar] [CrossRef]
- Horelu, A.; Leordeanu, C.; Apostol, E.; Huru, D.; Mocanu, M.; Cristea, V. Forecasting techniques for time series from Sensor Data. In Proceedings of the 2015 17th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 21–24 September 2015; pp. 261–264. [Google Scholar] [CrossRef]
- Tan, Z.; Zhang, J.; He, Y.; Zhang, Y.; Xiong, G.; Liu, Y. Short-term load forecasting based on integration of SVR and stacking. IEEE Access 2020, 8, 227719–227728. [Google Scholar] [CrossRef]
- Khalid, A.; Sarwat, A.I. Unified univariate-neural network models for lithium-ion battery state-of-charge forecasting using minimized akaike information criterion algorithm. IEEE Access 2021, 9, 39154–39170. [Google Scholar] [CrossRef]
- Kristianto, R.P. Modeling of time series data prediction using fruit fly optimization algorithm and triple exponential smoothing. In Proceedings of the 2019 4th International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE), Yogyakarta, Indonesia, 20–21 November 2019; pp. 407–412. [Google Scholar]
- Akrami, N.; Li, Y.; Dey, P.; Dev, S. Spatial-Temporal-TES: Reanalysis Dataset Based Short-Term Temperature Forecasting System. In Proceedings of the 2023 IEEE 7th Conference on Energy Internet and Energy System Integration (EI2), Hangzhou, China, 15–18 December 2023; pp. 1763–1768. [Google Scholar]
- Guan, H.; Jiang, Q. Pattern matching of time series and its application to trend prediction. In Proceedings of the 2008 2nd International Conference on Anti-Counterfeiting, Security and Identification, Guiyang, China, 20–23 August 2008; pp. 41–44. [Google Scholar]
- Hu, Y.L. Day-Ahead Solar Power Forecasting with Pattern Analysis and State Transition. In Proceedings of the 2021 3rd Global Power, Energy and Communication Conference (GPECOM), Antalya, Turkey, 5–8 October 2021; pp. 148–153. [Google Scholar]
- Singh, N.; Swetapadma, A. Pattern Recognition and Prediction in Time Series Data Through Retrieval-Augmented Techniques. In Proceedings of the 2024 International Conference on Electrical Electronics and Computing Technologies (ICEECT), Greater Noida, India, 29–31 August 2024; pp. 1–6. [Google Scholar]
- Cao, B.; Chang, L.; Gong, X.; Barrera, J.L.C.; Levy, T.; Kilpatrick, R. Probability forecasting of wind power ramp events using a time series similarity search algorithm. In Proceedings of the 2018 IEEE Energy Conversion Congress and Exposition (ECCE), Portland, OR, USA, 23–27 September 2018; pp. 972–976. [Google Scholar]
- Saeed, F.; Rehman, A.; Shah, H.A.; Diyan, M.; Chen, J.; Kang, J.M. SmartFormer: Graph-based transformer model for energy load forecasting. Sustain. Energy Technol. Assess. 2025, 73, 104133. [Google Scholar] [CrossRef]
- Ma, A.; Luo, D.; Sha, M. MixLinear: Extreme Low Resource Multivariate Time Series Forecasting with 0.1 K Parameters. arXiv 2024, arXiv:2410.02081. [Google Scholar]
- Genet, R.; Inzirillo, H. A Temporal Linear Network for Time Series Forecasting. arXiv 2024, arXiv:2410.21448. [Google Scholar]
- Zeng, C.; Tian, Y.; Zheng, G.; Gao, Y. How Much Can Time-related Features Enhance Time Series Forecasting? arXiv 2024, arXiv:2412.01557. [Google Scholar]
- Diamond, H.J.; Karl, T.R.; Palecki, M.A.; Baker, C.B.; Bell, J.E.; Leeper, R.D.; Easterling, D.R.; Lawrimore, J.H.; Meyers, T.P.; Helfert, M.R.; et al. U.S. Climate Reference Network after one decade of operations: Status and assessment. Bull. Am. Meteor. Soc. 2013, 94, 489–498. [Google Scholar] [CrossRef]
- Meteoblue. Weather History Download Basel [Online]. Available online: https://www.meteoblue.com/en/weather/archive/export/basel_switzerland_2661604 (accessed on 5 June 2024).
- UCI. Repository of Machine Learning Database [Online]. Available online: http://archive.ics.uci.edu/ml/datasets/Individual+household+electric+power+consumption (accessed on 5 March 2024).


{kind=link}
{kind=link}
| Dataset Name | Source | Number of Rows | Data Rate | Selected Features |
|---|---|---|---|---|
| DB1: NCDC | National Centers for Environmental Information [38] | 258,212,798 | Every Five Minutes | Temperature |
| DB2: Basel City-H | NASA Meteoblue Climatology [39] | 320,664 | Every Hour | Humidity |
| DB3: Basel City-S | NASA Meteoblue Climatology [39] | 320,664 | Every Hour | Soil Moisture |
| DB4: IHEPC-GI | Household Located in Sceaux, France [40] | 2,075,259 | Every Minute | Global Intensity |
| DB5: IHEPC-GP | Household Located in Sceaux, France [40] | 2,075,259 | Every Minute | Global Reactive Power |
| Dataset | Feature | Forecasting Level | RMSE/MAE | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AHW | Holt–Winters | ARIMA | Rolling Window | SVR-RBF | LSTM | CNN | RNN | |||
| NCDC [38] | Temperature | Month | 1.9475/1.6849 | 1.9768/1.6935 | 15.5199/12.8402 | 9.3381/8.2183 | 9.3731/8.2422 | 8.7299/6.8039 | 4.7751/3.7358 | 5.8109/4.3654 |
| Day | 4.4756/3.5597 | 4.5802/3.6736 | 15.4917/12.7306 | 10.2243/8.6567 | 11.6265/9.2091 | 18.2412/15.3383 | 11.1932/9.5714 | 14.3404/11.8075 | ||
| Basel City [39] | Humidity | Month | 4.1468/3.2923 | 5.9863/5.2783 | 10.3617/9.1388 | 5.8854/4.8770 | 5.8243/4.8217 | 5.7443/4.7792 | 30.2965/28.0841 | 34.2855/32.2153 |
| Day | 8.4530/6.8796 | 12.8838/10.9986 | 13.3860/11.2767 | 9.0113/7.3990 | 8.8738/7.3050 | 10.0217/8.2478 | 8.6207/7.1614 | 13.9162/11.5179 | ||
| Soil Moisture | Month | 0.0341/0.0294 | 0.0409/0.0357 | 0.0402/0.0347 | 0.0446/0.0340 | 0.0409/0.0354 | 0.0381/0.0299 | 0.0349/0.0301 | 0.0445/0.0338 | |
| Day | 0.0335/0.0312 | 0.0460/0.0383 | 0.0386/0.0317 | 0.0481/0.0368 | 0.0440/0.0378 | 0.0889/0.0803 | 0.0714/0.0607 | 0.0479/0.0405 | ||
| IHEPC [40] | Global Intensity | Month | 0.4407/0.3797 | 0.4712/0.3824 | 1.8456/1.6420 | 0.9934/0.6929 | 2.1026/1.9031 | 4.9962/4.4495 | 1.4564/1.1902 | 2.4722/2.3042 |
| Day | 1.3022/0.9168 | 1.3204/0.9968 | 2.3290/1.9667 | 1.4283/1.0932 | 4.7298/4.3824 | 1.5365/1.1786 | 1.4132/1.0770 | 1.4738/1.1259 | ||
| Global Reactive Power | Month | 0.0218/0.0159 | 0.0218/0.0159 | 0.0224/0.0162 | 0.0277/0.0198 | 0.0218/0.0197 | 0.0219/0.0190 | 0.0282/0.0181 | 0.0353/0.0311 | |
| Day | 0.0397/0.0278 | 0.0416/0.0296 | 0.0415/0.0283 | 0.0400/0.0279 | 0.1333/0.1187 | 0.0405/0.0300 | 0.0417/0.0287 | 0.0399/0.0287 | ||
| Dataset | Feature | Forecasting Level | p Value Comparison with AHW | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Holt–Winters | ARIMA | Rolling Window | SVR-RBF | LSTM | CNN | RNN | |||
| NCDC [38] | Temperature | Month | 0.0093 | 0.0000 | 0.0000 | 0.0000 | 0.0001 | 0.0079 | 0.0000 |
| Day | 0.0203 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Basel City [39] | Humidity | Month | 0.0000 | 0.0000 | 0.0002 | 0.0002 | 0.0003 | 0.0000 | 0.0000 |
| Day | 0.0000 | 0.0000 | 0.0000 | 0.0004 | 0.0004 | 0.0000 | 0.0000 | ||
| Soil Moisture | Month | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| Day | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| IHEPC [40] | Global Intensity | Month | 0.0294 | 0.0004 | 0.1080 | 0.0003 | 0.0012 | 0.0024 | 0.0001 |
| Day | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | ||
| Global Reactive Power | Month | 0.0000 | 0.0084 | 0.0281 | 0.8722 | 0.1275 | 0.0098 | 0.1864 | |
| Day | 0.0313 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0244 | ||
| Dataset | Feature | Forecasting Level | Forecasting Time in Seconds | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AHW | Holt–Winters | ARIMA | Rolling Window | SVR-RBF | LSTM | CNN | RNN | |||
| NCDC [38] | Temperature | Month | 0.456 | 0.116 | 0.116 | 0.0002 | 0.006 | 8.086 | 7.294 | 6.785 |
| Day | 12.224 | 7.6 | 0.436 | 0.0002 | 1.452 | 122.222 | 128.627 | 115.01 | ||
| Basel City [39] | Humidity | Month | 0.866 | 0.512 | 0.623 | 0.0002 | 0.04 | 12.961 | 12.206 | 12.575 |
| Day | 9.655 | 6.783 | 1.247 | 0.0002 | 6.479 | 348.504 | 401.139 | 374.756 | ||
| Soil Moisture | Month | 0.335 | 0.127 | 0.212 | 0.0002 | 0.006 | 16.352 | 15.069 | 17.503 | |
| Day | 16.121 | 12.373 | 1.545 | 0.0002 | 0.214 | 366.774 | 322.298 | 329.069 | ||
| IHEPC [40] | Global Intensity | Month | 0.557 | 0.116 | 0.119 | 0.0003 | 0.007 | 7.821 | 4.226 | 3.398 |
| Day | 5.624 | 1.856 | 0.213 | 0.0002 | 0.134 | 33.612 | 37.186 | 34.776 | ||
| Global Reactive Power | Month | 0.447 | 0.221 | 0.089 | 0.0002 | 0.002 | 4.742 | 1.777 | 2.244 | |
| Day | 6.746 | 1.64 | 0.367 | 0.0002 | 0.007 | 27.026 | 25.497 | 30.331 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sawalha, S.; Al-Naymat, G. An Adaptive Holt–Winters Model for Seasonal Forecasting of Internet of Things (IoT) Data Streams. IoT 2025, 6, 39. https://doi.org/10.3390/iot6030039
Sawalha S, Al-Naymat G. An Adaptive Holt–Winters Model for Seasonal Forecasting of Internet of Things (IoT) Data Streams. IoT. 2025; 6(3):39. https://doi.org/10.3390/iot6030039
Chicago/Turabian StyleSawalha, Samer, and Ghazi Al-Naymat. 2025. "An Adaptive Holt–Winters Model for Seasonal Forecasting of Internet of Things (IoT) Data Streams" IoT 6, no. 3: 39. https://doi.org/10.3390/iot6030039
APA StyleSawalha, S., & Al-Naymat, G. (2025). An Adaptive Holt–Winters Model for Seasonal Forecasting of Internet of Things (IoT) Data Streams. IoT, 6(3), 39. https://doi.org/10.3390/iot6030039