
Frame-Wise Steganalysis Based on Mask-Gating Attention and Deep Residual Bilinear Interaction Mechanisms for Low-Bit-Rate Speech Streams


Abstract
1. Introduction
- By introducing a mask-gating attention mechanism, the approach overcomes the uniform weighting limitation in existing frame-wise steganalysis methods, enabling dynamic emphasis on informative codewords and effective extraction of global contextual information.
- Through the integration of bilinear feature interaction layers and a deep residual structure, the proposed method addresses the neglect of vector-level codeword correlations in existing approaches, capturing both lower- and higher-order interaction patterns for improved frame-wise detection in low-bit-rate speech streams.
2. Related Works
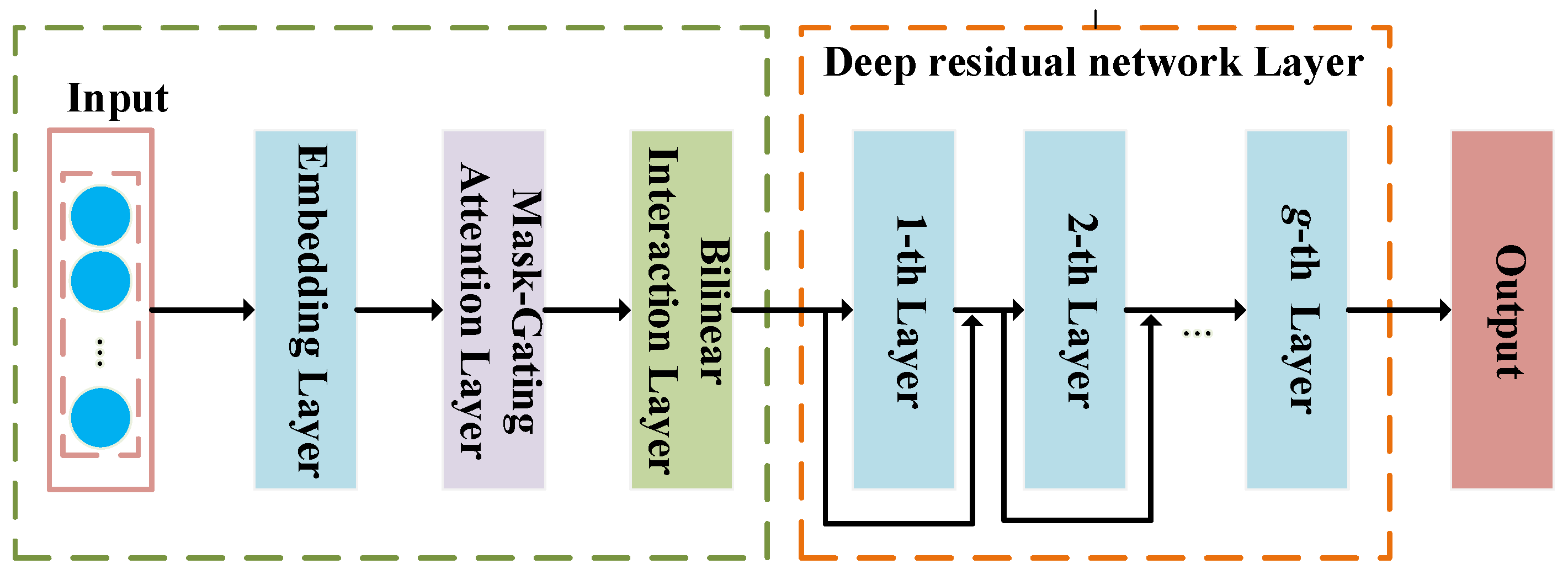
3. Proposed Method
3.1. Overview
| Algorithm 1: Overview of the proposed model |
Input: Input sequence Output: Prediction return |
3.2. Codeword Embedding Layer
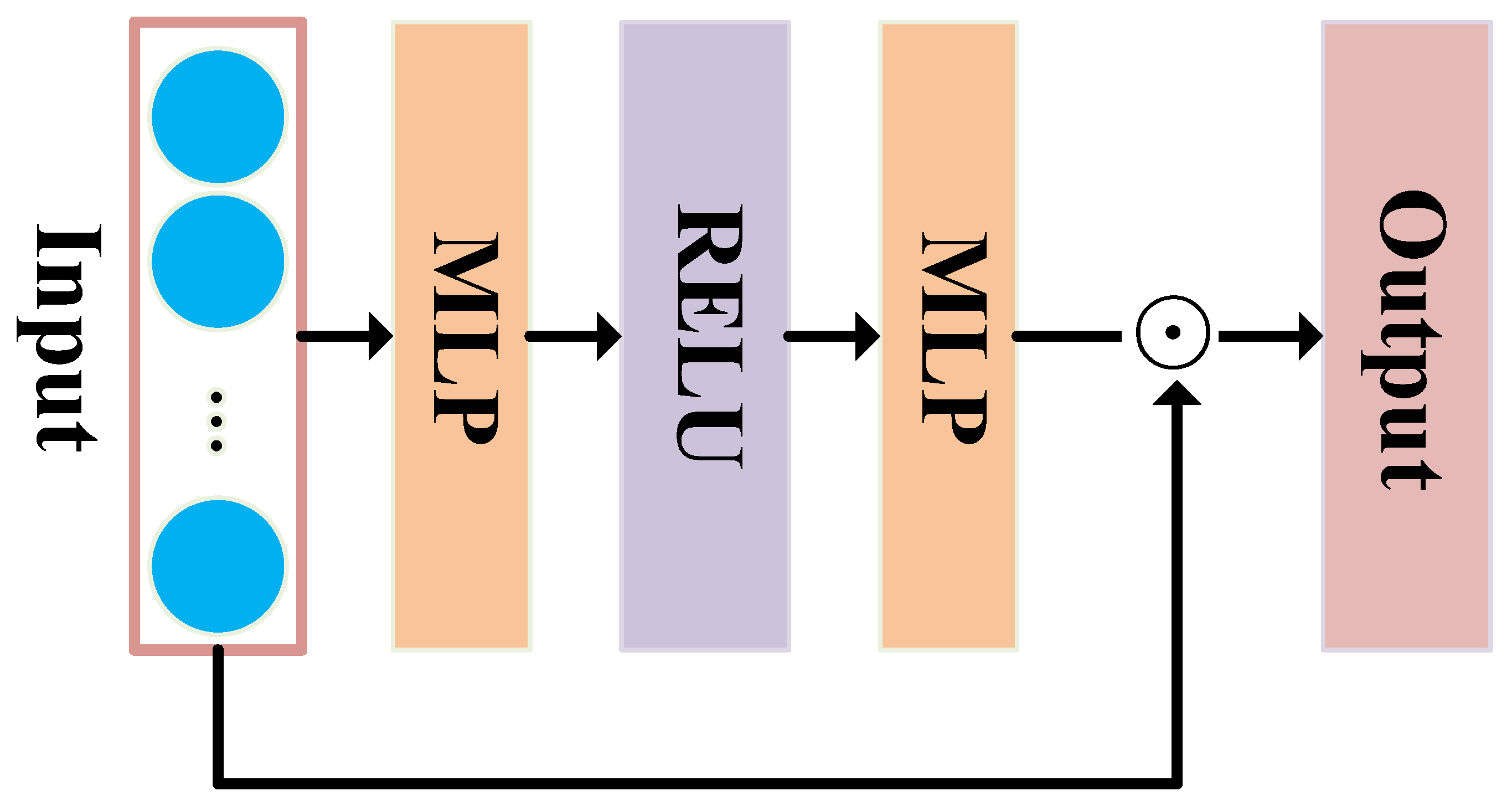
3.3. Mask-Gating Attention Layer
3.4. Bilinear Interaction Layer
3.5. Deep Residual Network Layers
4. Experimental Results and Analysis
4.1. Experimental Setup
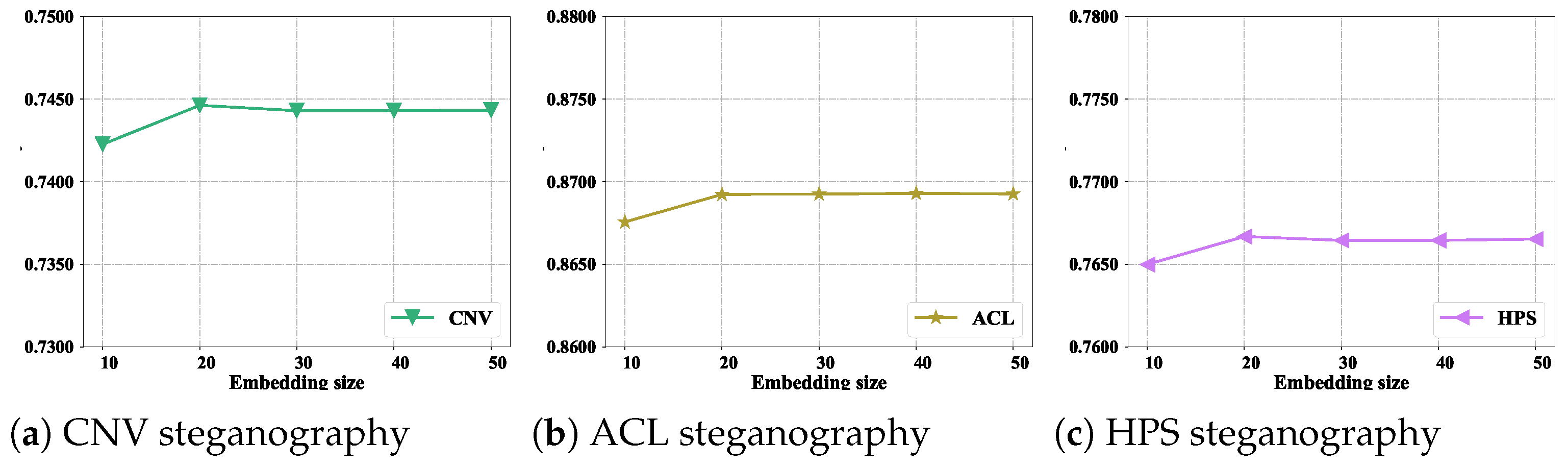
4.2. Discussion of the Dimension of the Embedding Vector
4.3. Discussion of Mask-Gating Attention Mechanism
4.4. Discussion of Codeword Interaction Types in Bilinear Interaction
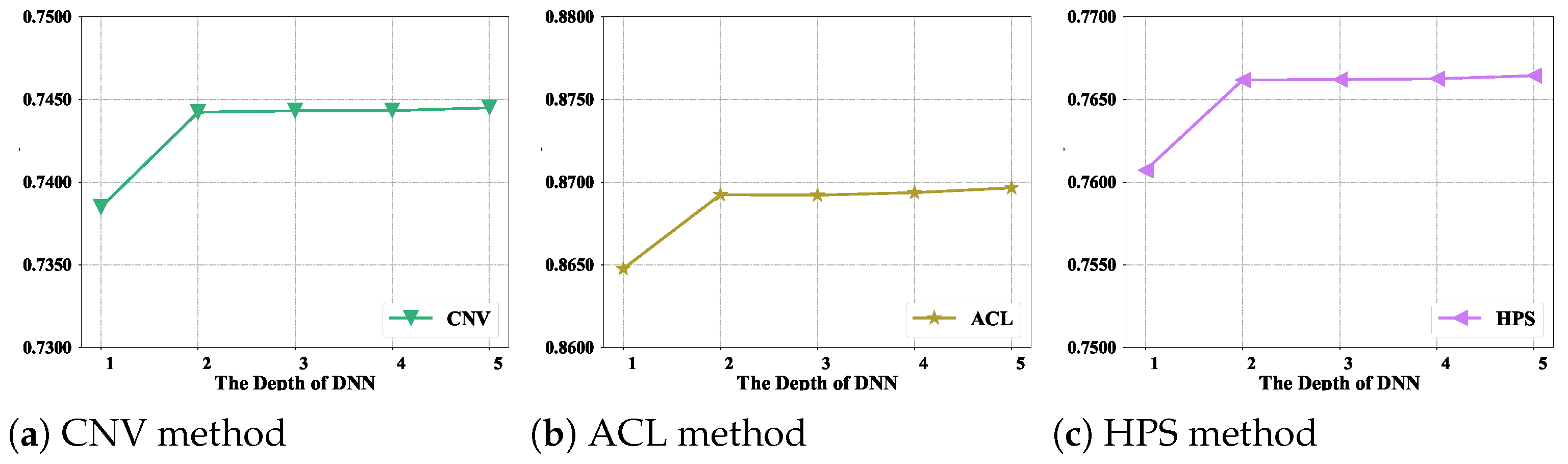
4.5. Discussion of the Depth of Deep Residual Network Layers
4.6. Performance Comparison
4.7. Comparison of Inference Times Across Methods
4.8. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zou, J.Z.; Chen, M.X.; Gong, L.H. Invisible and robust watermarking model based on hierarchical residual fusion multi-scale convolution. Neurocomputing 2025, 614, 128834. [Google Scholar] [CrossRef]
- Zhang, H.; Kone, M.M.K.; Ma, X.Q.; Zhou, N.R. Frequency-domain attention-guided adaptive robust watermarking model. J. Frankl. Inst. 2025, 362, 107511. [Google Scholar] [CrossRef]
- Roslan, N.A.; Udzir, N.I.; Mahmod, R.; Gutub, A. Systematic literature review and analysis for Arabic text steganography method practically. Egypt. Inform. J. 2022, 23, 177–191. [Google Scholar] [CrossRef]
- Alanazi, N.; Khan, E.; Gutub, A. Efficient security and capacity techniques for Arabic text steganography via engaging Unicode standard encoding. Multimed. Tools Appl. 2021, 80, 1403–1431. [Google Scholar] [CrossRef]
- Kunhoth, J.; Subramanian, N.; Al-Maadeed, S.; Bouridane, A. Video steganography: Recent advances and challenges. Multimed. Tools Appl. 2023, 82, 41943–41985. [Google Scholar] [CrossRef]
- Valandar, M.Y.; Ayubi, P.; Barani, M.J.; Irani, B.Y. A chaotic video steganography technique for carrying different types of secret messages. J. Inf. Secur. Appl. 2022, 66, 103160. [Google Scholar] [CrossRef]
- AlSabhany, A.A.; Ali, A.H.; Ridzuan, F.; Azni, A.; Mokhtar, M.R. Digital audio steganography: Systematic review, classification, and analysis of the current state of the art. Comput. Sci. Rev. 2020, 38, 100316. [Google Scholar] [CrossRef]
- Wu, J.; Chen, B.; Luo, W.; Fang, Y. Audio steganography based on iterative adversarial attacks against convolutional neural networks. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2282–2294. [Google Scholar] [CrossRef]
- Kheddar, H.; Hemis, M.; Himeur, Y.; Megias, D.; Amira, A. Deep learning for steganalysis of diverse data types: A review of methods, taxonomy, challenges and future directions. Neurocomputing 2024, 581, 127528. [Google Scholar] [CrossRef]
- Sun, C.; Tian, H.; Tian, P.; Li, H.; Qian, Z. Multi-agent deep learning for the detection of multiple speech steganography methods. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 2957–2972. [Google Scholar] [CrossRef]
- Sun, C.; Tian, H.; Mazurczyk, W.; Chang, C.C.; Quan, H.; Chen, Y. Steganalysis of adaptive multi-rate speech with unknown embedding rates using clustering and ensemble learning. Comput. Electr. Eng. 2023, 111, 108909. [Google Scholar] [CrossRef]
- Sun, C.; Tian, H.; Mazurczyk, W.; Chang, C.C.; Cai, Y.; Chen, Y. Towards blind detection of steganography in low-bit-rate speech streams. Int. J. Intell. Syst. 2022, 37, 12085–12112. [Google Scholar] [CrossRef]
- Unoki, M.; Miyauchi, R. Method of digital-audio watermarking based on cochlear delay characteristics. In Multimedia Information Hiding Technologies and Methodologies for Controlling Data; IGI Global Scientific Publishing: Hershey, PA, USA, 2013; pp. 42–70. [Google Scholar]
- Cox, I.J.; Kilian, J.; Leighton, F.T.; Shamoon, T. Secure spread spectrum watermarking for multimedia. IEEE Trans. Image Process. 1997, 6, 1673–1687. [Google Scholar] [CrossRef]
- Tian, H.; Zhou, K.; Huang, Y.; Feng, D.; Liu, J. A covert communication model based on least significant bits steganography in voice over IP. In Proceedings of the 2008 the 9th International Conference for Young Computer Scientists, Zhangjiajie, China, 18–21 November 2008; pp. 647–652. [Google Scholar]
- Tian, H.; Jiang, H.; Zhou, K.; Feng, D. Adaptive partial-matching steganography for voice over IP using triple M sequences. Comput. Commun. 2011, 34, 2236–2247. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, C.; Tang, S.; Bai, S. Steganography integration into a low-bit rate speech codec. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1865–1875. [Google Scholar] [CrossRef]
- Huang, Y.; Tao, H.; Xiao, B.; Chang, C. Steganography in low bit-rate speech streams based on quantization index modulation controlled by keys. Sci. China Technol. Sci. 2017, 60, 1585–1596. [Google Scholar] [CrossRef]
- Xiao, B.; Huang, Y.; Tang, S. An approach to information hiding in low bit-rate speech stream. In Proceedings of the IEEE GLOBECOM 2008–2008 IEEE Global Telecommunications Conference, New Orleans, LA, USA, 30 November–4 December 2008; pp. 1–5. [Google Scholar]
- Yan, S.; Tang, G.; Sun, Y.; Gao, Z.; Shen, L. A triple-layer steganography scheme for low bit-rate speech streams. Multimed. Tools Appl. 2015, 74, 11763–11782. [Google Scholar] [CrossRef]
- Hu, Y.; Huang, Y.; Yang, Z.; Huang, Y. Detection of heterogeneous parallel steganography for low bit-rate VoIP speech streams. Neurocomputing 2021, 419, 70–79. [Google Scholar] [CrossRef]
- Chen, B.; Wornell, G.W. Quantization index modulation: A class of provably good methods for digital watermarking and information embedding. IEEE Trans. Inf. Theory 2002, 47, 1423–1443. [Google Scholar] [CrossRef]
- Sun, C.; Tian, H.; Chang, C.C.; Chen, Y.; Cai, Y.; Du, Y.; Chen, Y.H.; Chen, C.C. Steganalysis of adaptive multi-rate speech based on extreme gradient boosting. Electronics 2020, 9, 522. [Google Scholar] [CrossRef]
- Tian, H.; Wu, Y.; Chang, C.C.; Huang, Y.; Chen, Y.; Wang, T.; Cai, Y.; Liu, J. Steganalysis of adaptive multi-rate speech using statistical characteristics of pulse pairs. Signal Process. 2017, 134, 9–22. [Google Scholar] [CrossRef]
- Yang, J.; Li, S. Steganalysis of joint codeword quantization index modulation steganography based on codeword Bayesian network. Neurocomputing 2018, 313, 316–323. [Google Scholar] [CrossRef]
- Li, S.; Jia, Y.; Kuo, C.C.J. Steganalysis of QIM steganography in low-bit-rate speech signals. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1011–1022. [Google Scholar] [CrossRef]
- Lin, Z.; Huang, Y.; Wang, J. RNN-SM: Fast steganalysis of VoIP streams using recurrent neural network. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1854–1868. [Google Scholar] [CrossRef]
- Yang, H.; Yang, Z.; Bao, Y.; Liu, S.; Huang, Y. Fcem: A novel fast correlation extract model for real time steganalysis of VOIP stream via multi-head attention. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2822–2826. [Google Scholar]
- Yang, H.; Yang, Z.; Bao, Y.; Huang, Y. Hierarchical representation network for steganalysis of qim steganography in low-bit-rate speech signals. In Proceedings of the International Conference on Information and Communications Security, Beijing, China, 15–17 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 783–798. [Google Scholar]
- Wang, H.; Yang, Z.; Hu, Y.; Yang, Z.; Huang, Y. Fast detection of heterogeneous parallel steganography for streaming voice. In Proceedings of the 2021 ACM Workshop on Information Hiding and Multimedia Security, Virtual, 22–25 June 2021; pp. 137–142. [Google Scholar]
- Li, S.; Wang, J.; Liu, P.; Wei, M.; Yan, Q. Detection of multiple steganography methods in compressed speech based on code element embedding, Bi-LSTM and CNN with attention mechanisms. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1556–1569. [Google Scholar] [CrossRef]
- Ren, Y.; Cai, T.; Tang, M.; Wang, L. AMR steganalysis based on the probability of same pulse position. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1801–1811. [Google Scholar] [CrossRef]
- Wei, M.; Li, S.; Liu, P.; Huang, Y.; Yan, Q.; Wang, J.; Zhang, C. Frame-level steganalysis of QIM steganography in compressed speech based on multi-dimensional perspective of codeword correlations. J. Ambient. Intell. Humaniz. Comput. 2021, 14, 8421–8431. [Google Scholar] [CrossRef]
- Li, S.; Wang, J.; Liu, P. General frame-wise steganalysis of compressed speech based on dual-domain representation and intra-frame correlation leaching. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2025–2035. [Google Scholar] [CrossRef]
- Lian, J.; Zhou, X.; Zhang, F.; Chen, Z.; Xie, X.; Sun, G. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1754–1763. [Google Scholar]
- Wang, Z.; She, Q.; Zhang, J. MaskNet: Introducing feature-wise multiplication to CTR ranking models by instance-guided mask. arXiv 2021, arXiv:2102.07619. [Google Scholar]
- Huang, T.; Zhang, Z.; Zhang, J. FiBiNET: Combining feature importance and bilinear feature interaction for click-through rate prediction. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 169–177. [Google Scholar]
- Lai, S.; Liu, K.; He, S.; Zhao, J. How to generate a good word embedding. IEEE Intell. Syst. 2016, 31, 5–14. [Google Scholar] [CrossRef]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Embedding dimension | 20 |
| Input dimension of mask-gating layer | 180 |
| Output dimension of mask-gating layer | 720 |
| Hidden dimension of mask-gating layer | 360 |
| Reduction ratio of mask-gating layer | 1 |
| Steganalysis Method | Steganography Methods | ||
|---|---|---|---|
| CNV | ACL | HPS | |
| 0.7251 | 0.8580 | 0.7460 | |
| 0.7208 | 0.8548 | 0.7404 | |
| 0.7289 | 0.8624 | 0.7501 | |
| 0.7220 | 0.8590 | 0.7421 | |
| 0.7304 | 0.8644 | 0.7522 | |
| 0.7232 | 0.8604 | 0.7454 | |
| 0.7446 | 0.8692 | 0.7664 | |
| 0.7387 | 0.8639 | 0.7616 | |
| Type of Bilinear Interaction | Steganography Methods | ||
|---|---|---|---|
| CNV | ACL | HPS | |
| Field-All | 0.7407 | 0.8654 | 0.7635 |
| Field-Each | 0.7419 | 0.8675 | 0.7651 |
| Field-Interaction | 0.7446 | 0.8692 | 0.7664 |
| Steganalysis Method | Embedding Rate | ||||
|---|---|---|---|---|---|
| 20% | 40% | 60% | 80% | 100% | |
| DMSM | 0.5231 | 0.5806 | 0.6214 | 0.6609 | 0.7208 |
| FSMDP | 0.5252 | 0.5725 | 0.6303 | 0.6649 | 0.7220 |
| Stegformer | 0.5375 | 0.5895 | 0.6426 | 0.6779 | 0.7232 |
| Our method | 0.5529 | 0.6106 | 0.6615 | 0.7052 | 0.7446 |
| Steganalysis Method | Embedding Rate | ||||
|---|---|---|---|---|---|
| 20% | 40% | 60% | 80% | 100% | |
| DMSM | 0.6094 | 0.6856 | 0.7524 | 0.8059 | 0.8548 |
| FSMDP | 0.6103 | 0.6891 | 0.7553 | 0.8082 | 0.8590 |
| Stegformer | 0.6122 | 0.6928 | 0.7568 | 0.8120 | 0.8604 |
| Our method | 0.6208 | 0.7037 | 0.7665 | 0.8226 | 0.8692 |
| Steganalysis Method | Embedding Rate | ||||
|---|---|---|---|---|---|
| 20% | 40% | 60% | 80% | 100% | |
| DMSM | 0.5451 | 0.6076 | 0.6614 | 0.6976 | 0.7404 |
| FSMDP | 0.5475 | 0.6110 | 0.6633 | 0.7013 | 0.7421 |
| Stegformer | 0.5502 | 0.6123 | 0.6680 | 0.7022 | 0.7454 |
| Our method | 0.5590 | 0.6285 | 0.6814 | 0.7178 | 0.7664 |
| Steganalysis Method | Inference Time (ms) |
|---|---|
| DMSM | 0.00073 |
| FSMDP | 0.00080 |
| Stegformer | 0.00092 |
| Our Method | 0.00098 |
| Index | Network Description | Accuracy |
|---|---|---|
| #1 | No MGA mechanism | 0.7387 |
| #2 | No BI mechanism | 0.7340 |
| #3 | No residual mechanism | 0.7412 |
| #4 | The complete proposed model | 0.7446 |
| Index | Network Description | Accuracy |
|---|---|---|
| #1 | No MGA mechanism | 0.8639 |
| #2 | No BI mechanism | 0.8585 |
| #3 | No residual mechanism | 0.8660 |
| #4 | The complete proposed model | 0.8692 |
| Index | Network Description | Accuracy |
|---|---|---|
| #1 | No MGA mechanism | 0.7616 |
| #2 | No BI mechanism | 0.7573 |
| #3 | No residual mechanism | 0.7622 |
| #4 | The complete proposed model | 0.7664 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, C.; Abdullah, A.; Samian, N.; Roslan, N.A. Frame-Wise Steganalysis Based on Mask-Gating Attention and Deep Residual Bilinear Interaction Mechanisms for Low-Bit-Rate Speech Streams. J. Cybersecur. Priv. 2025, 5, 54. https://doi.org/10.3390/jcp5030054
Sun C, Abdullah A, Samian N, Roslan NA. Frame-Wise Steganalysis Based on Mask-Gating Attention and Deep Residual Bilinear Interaction Mechanisms for Low-Bit-Rate Speech Streams. Journal of Cybersecurity and Privacy. 2025; 5(3):54. https://doi.org/10.3390/jcp5030054
Chicago/Turabian StyleSun, Congcong, Azizol Abdullah, Normalia Samian, and Nuur Alifah Roslan. 2025. "Frame-Wise Steganalysis Based on Mask-Gating Attention and Deep Residual Bilinear Interaction Mechanisms for Low-Bit-Rate Speech Streams" Journal of Cybersecurity and Privacy 5, no. 3: 54. https://doi.org/10.3390/jcp5030054
APA StyleSun, C., Abdullah, A., Samian, N., & Roslan, N. A. (2025). Frame-Wise Steganalysis Based on Mask-Gating Attention and Deep Residual Bilinear Interaction Mechanisms for Low-Bit-Rate Speech Streams. Journal of Cybersecurity and Privacy, 5(3), 54. https://doi.org/10.3390/jcp5030054