A Multi-Feature Semantic Fusion Machine Learning Architecture for Detecting Encrypted Malicious Traffic


Abstract
1. Introduction
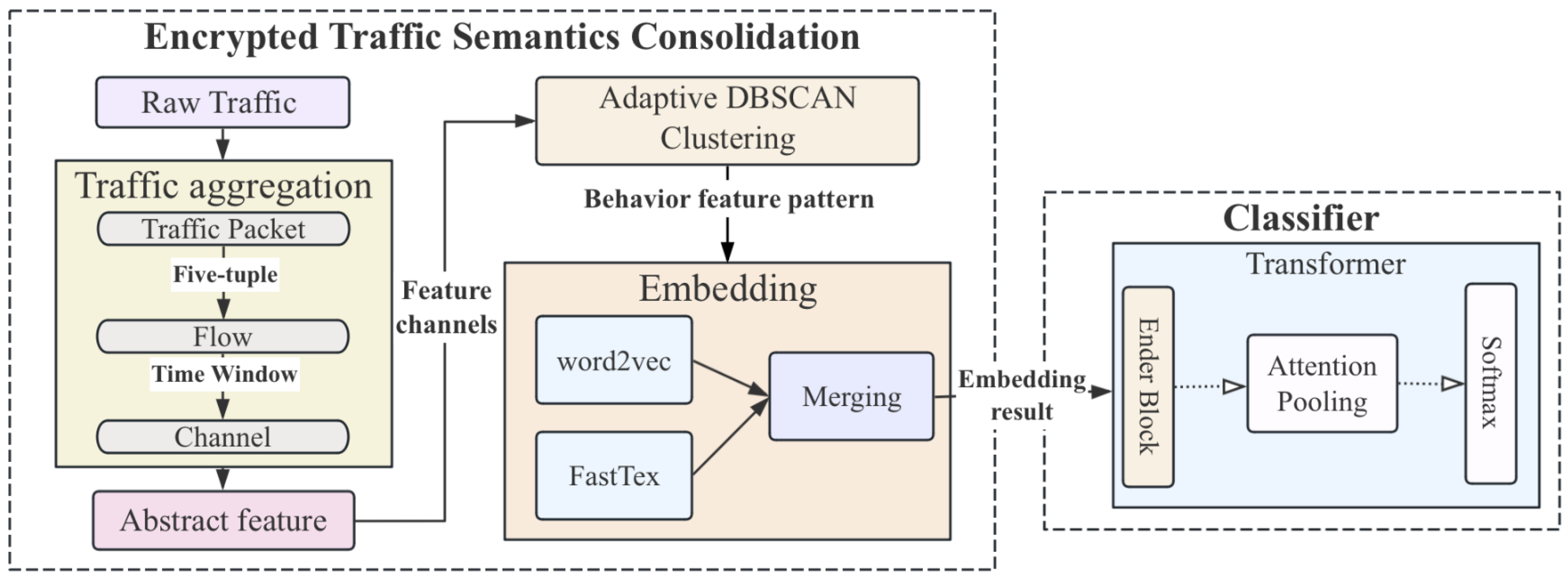
- By using quintuples, we propose a traffic aggregation extraction framework to quantify network flow activity, characterize traffic temporal patterns, and identify service types and communication features.
- The adaptive density-based spatial clustering of applications with noise (DBSCN) clustering algorithm is improved, and a noise reallocation mechanism to enhance the model’s tolerance for noise is designed, avoiding issues such as simply eliminating noise points and losing valuable information.
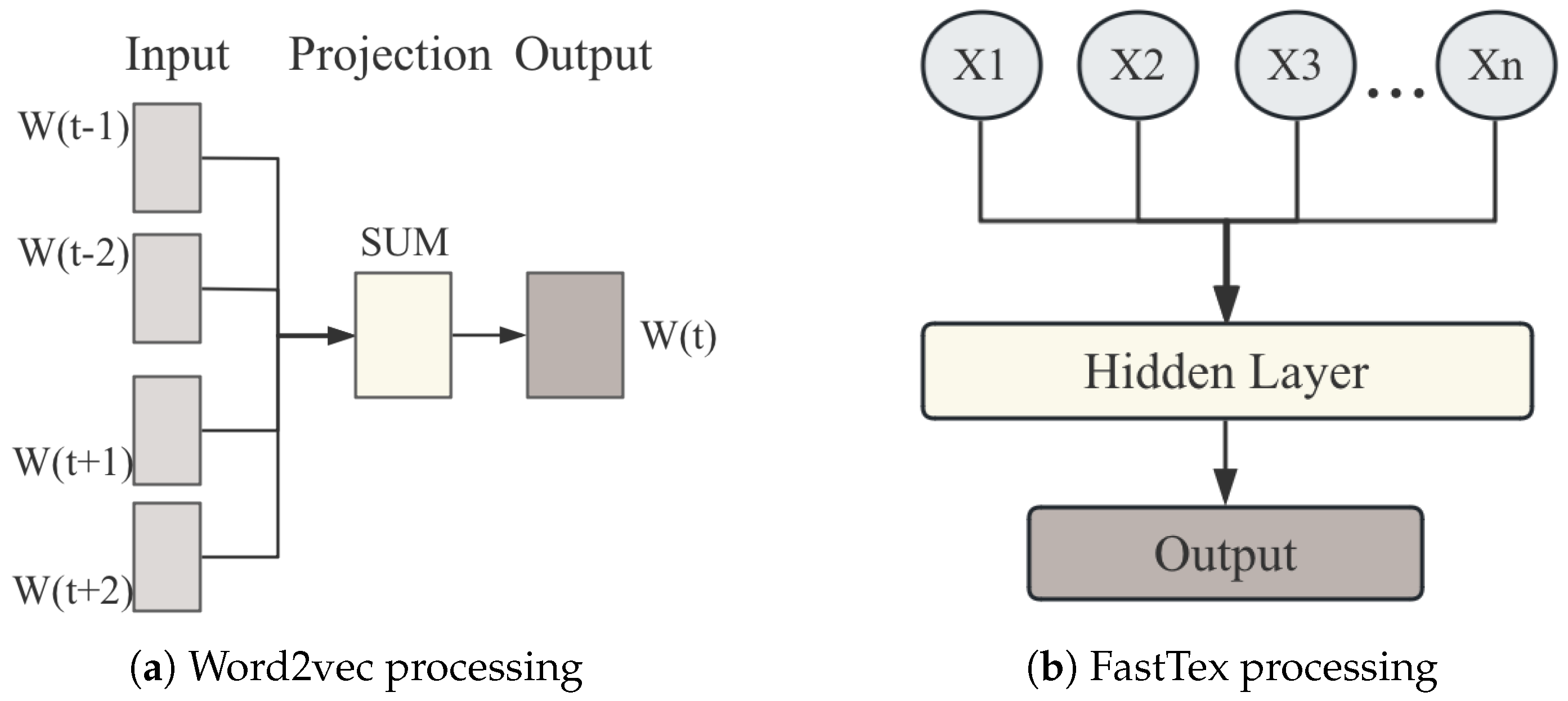
- A dual-channel embedding method based on Word2Vec and FastText is introduced to enhance generalization ability. Additionally, an embedding enhancement strategy is adopted to construct a 384-dimensional joint embedding space.
- A Transformer classifier for multi-scale feature fusion is designed. By using an attention pooling fusion mechanism, the model dynamically evaluates feature importance through a learned weight matrix, reducing false rates and computational overhead.
2. Related Work
2.1. Signature-Based Detection for Encrypted Malicious Traffic
2.2. Statistical Analysis-Based Detection for Encrypted Malicious Traffic
2.3. Machine Learning-Based Detection for Encrypted Malicious Traffic
2.4. Large Language Model-Based Detection for Encrypted Malicious Traffic
3. Materials and Methods
| Algorithm 1 EFTransformer progress |
| Require: Raw packet stream , time window , DBSCAN params |
| Ensure: Predicted labels |
|
3.1. Traffic Aggregation
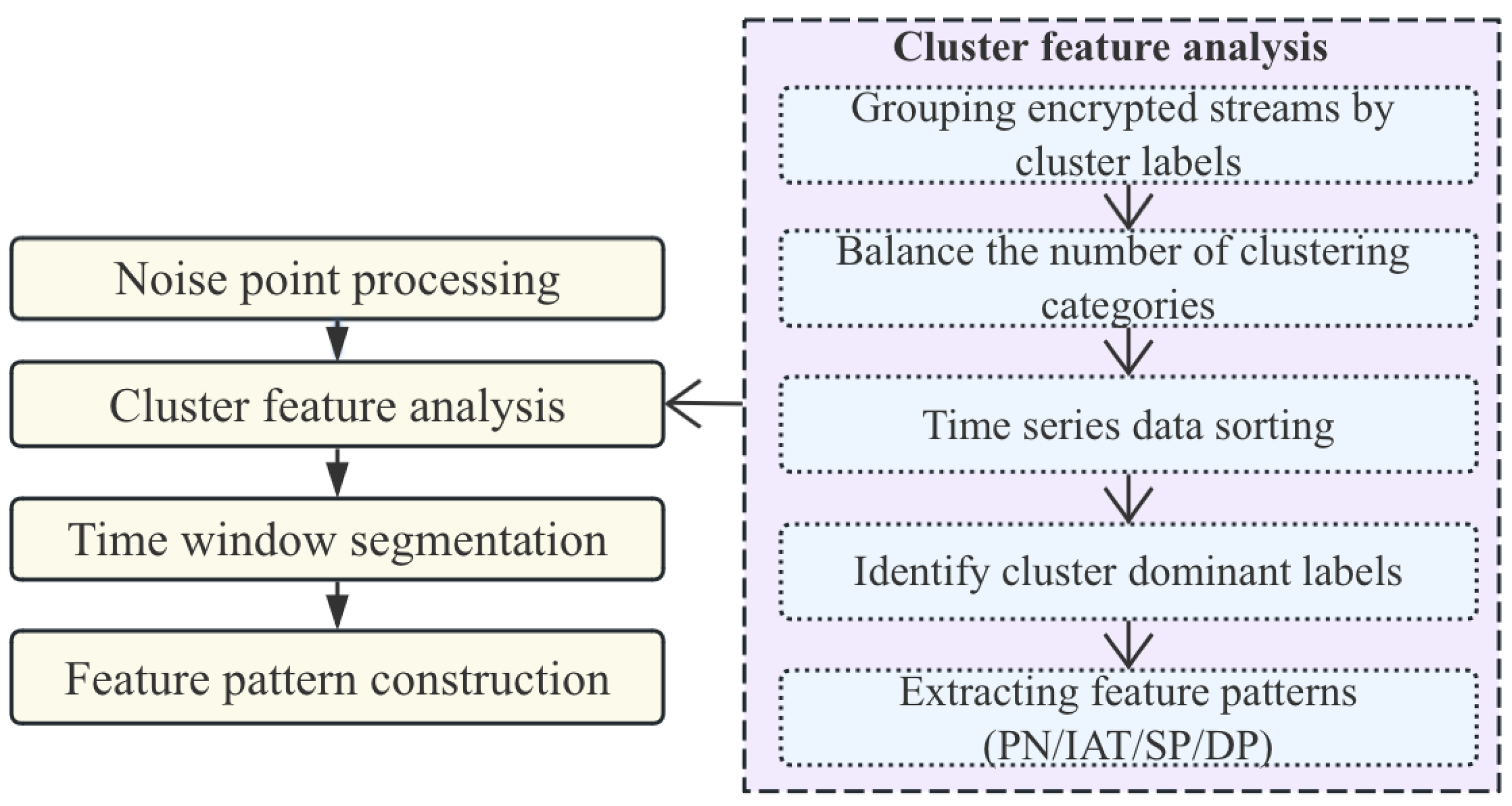
3.2. Clustering
| Algorithm 2 Adaptive clustering for encrypted traffic |
| Require: Input traffic T, window size W, neighborhood radius (Eps) |
| Ensure: Structured feature pattern channel P |
|
3.3. Embedding
- Packets Differentiation: The number of packets in different traffic channels may differ by several orders of magnitude. Excessive differences may have a significant impact on the detection results of the model. Although this problem can be solved by normalization, since there is no theoretical upper limit to the number of traffic packets and the distribution of actual traffic has large fluctuations, the normalized data may still not accurately represent the traffic characteristics, thereby affecting the stability of the model.
- Semantic Perception Error: Port numbers are essentially discrete identifiers rather than continuous variables, and adjacent digital port numbers do not always directly correspond to semantic similarities. For example, although port 80 and port 8080 have a large gap, they both point to the same web service, while port 22 and port 23 correspond to SSH and Telnet protocols respectively. Although they have small differences, they belong to different protocol types. Therefore, directly using raw numerical modeling may not accurately learn the correct semantic relationship, reducing the ability to identify malicious traffic.
3.4. Classifier
- Input layer: The output after dual-channel semantic embedding processing is used as the input of Transformer. In this work, the feature pattern is the semantic information extracted based on the channel level, which is mainly used to characterize the attack intention. The model processes different features of network traffic through four parallel encoders: packet number timing pattern (pn_encoder), flow interval time distribution (iat_encoder), source port access topology (sp_encoder), destination port service feature (dp_encoder). The 8-head attention mechanism is used to capture the long-distance dependencies in the feature sequence, so the model can effectively extract the traffic features in depth and form a multi-modal embedding representation.
- Encoding layer: Each encoder block consists of two main sub-layers: Multi-Head Attention and Feed-Forward Network. First, the importance score of the feature is calculated through a learnable weight matrix, and the normalized attention weight is generated. This mechanism can help the model adaptively focus on the feature channels that are most relevant to the current feature pattern. Secondly, the feature interaction method is used in the encoding layer to establish nonlinear associations between four-dimensional features through matrix multiplication operations, which effectively solves the problem of spatial heterogeneity. Finally, in order to suppress noise, the model introduces Dropout layer and L2 regularization in feature weighting to achieve dual noise suppression function.The self attention mechanism is a special attention mechanism in Formula (5), Where Q is the query, K is the key, and V is the value matrix, which are calculated from the input matrix X through the weight matrices , , and .The core of multi-head attention is to calculate multiple attention heads in parallel as shown in Formula (6). Each head focuses on different semantic information of the input feature sequence, and finally all the heads are fused. Different attention heads can focus on different position information and semantics, which can also enhance the robustness of the model as shown in Formula (7) and avoid overfitting or information bias caused by a single attention head. In order to improve the expression ability, multi-perspective modeling can be used to enrich feature expression.
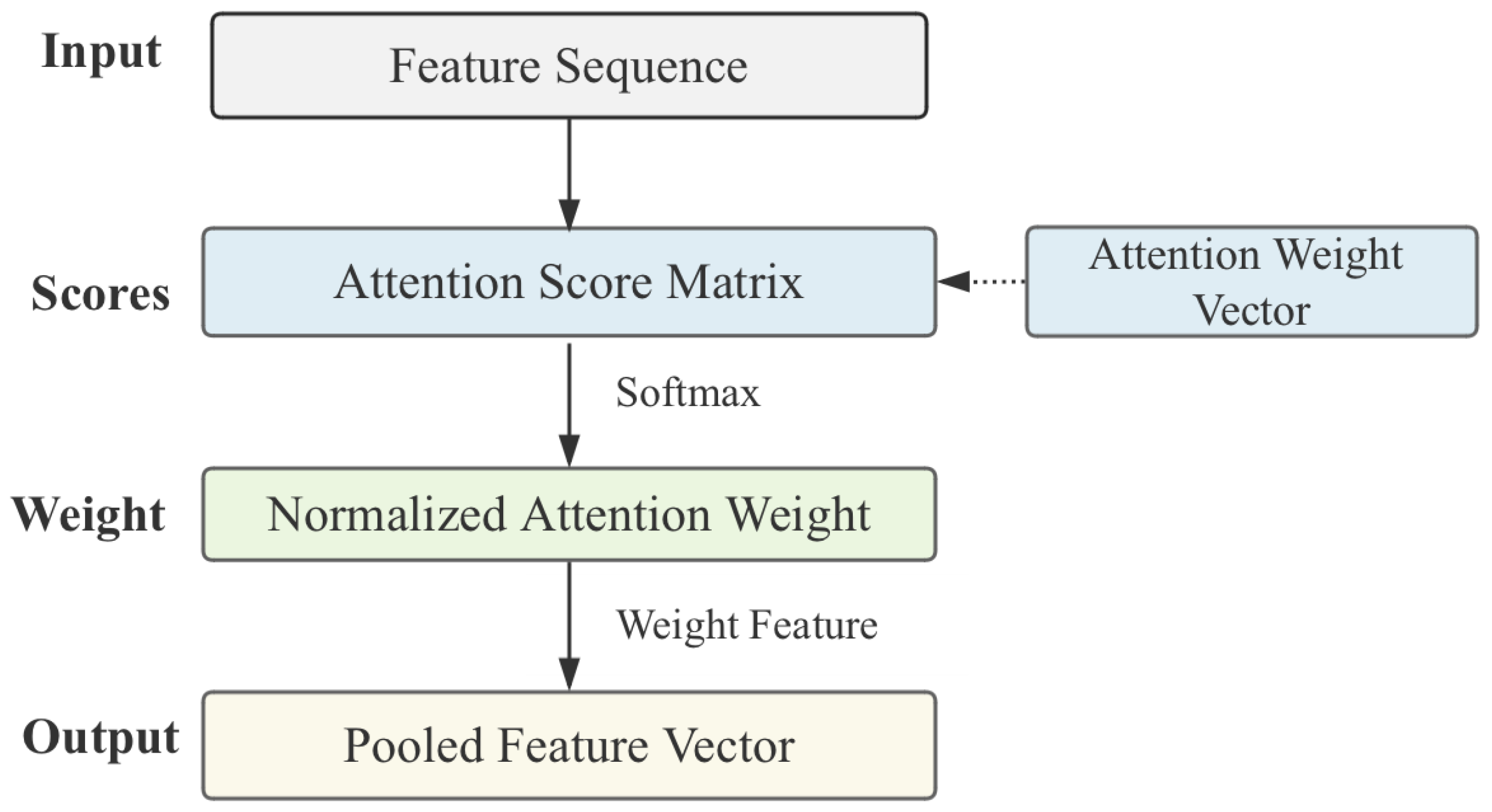
- Output layer: The classification layer will process the output of the encoder and give a dynamic weighted summation mechanism of attention pooling. The model trains the optimal feature combination in different scenarios end-to-end, and uses the pooled feature vector to map into a two-dimensional vector through nonlinear changes to capture deeper nonlinear relationships between semantic features. Finally, the model sums the vectors from four different feature modes to generate a comprehensive representation. The Softmax function is used to process the vector and calculate the final detection probability of whether the traffic is malicious or benign, thereby completing the classification task.As shown in Figure 4, a multi-scale attention pooling fusion framework through multi feature fusion and dynamic attention mechanism is described. Compared with traditional pooling, attention pooling is data-dependent and learnable, which can adaptively adjust information aggregation strategies. The weights are dynamically allocated, and the attention weight of each element is calculated based on the input feature sequence itself, rather than based on fixed rules, so as to achieve the function of content-aware aggregation. Specifically, the attention module computes importance weights across different time steps in the traffic sequence, enabling dynamic aggregation of temporal features. Important information will receive more weight, and irrelevant information will be suppressed, avoiding information loss in maximum pooling or blurring in average pooling, and retaining fine-grained features. In this way, attention pooling highlights semantically rich segments of traffic patterns and provides the model with more discriminative input representations than traditional pooling methods.The attention score of each element is calculated using a learnable function, as shown in Formula (8), where each denotes the importance score of the i-th time step in the input feature sequence . The normalized weights enable the model to perform dynamic temporal aggregation by focusing on key segments and down-weighting uninformative or noisy inputs. The aggregated representation is computed as a weighted sum of input features, which preserves fine-grained discriminative cues. The weight matrix , bias term , and scoring vector are learnable parameters, enabling the model to adaptively optimize the feature weighting scheme based on the content of the input.
4. Implementation
4.1. Implementation Setup
4.2. Dataset Description
4.3. Experimental Evaluation Index Setting
4.4. Baseline Algorithms
5. Experimental Results
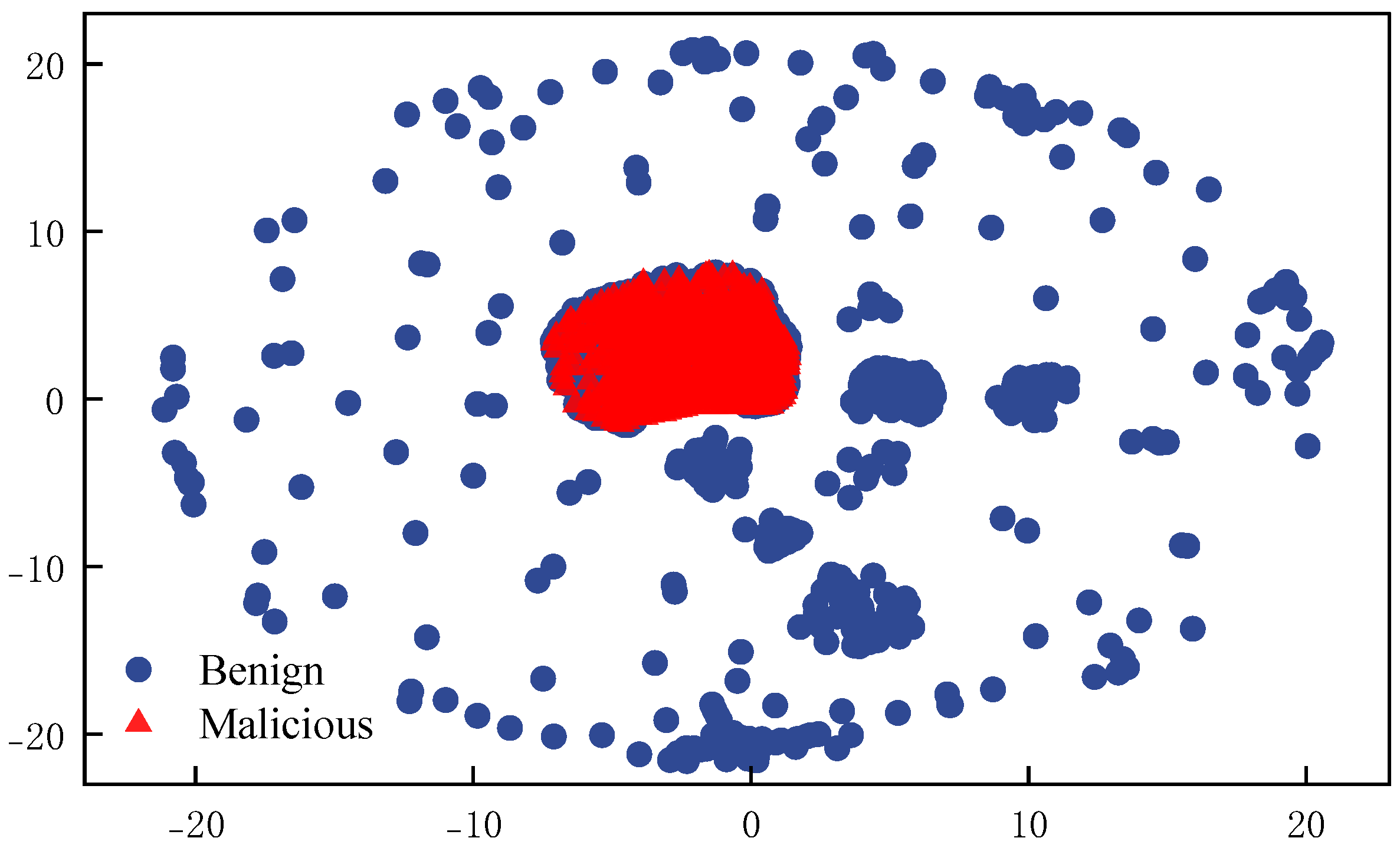
5.1. Dataset Analysis
5.2. Parameter Selection Strategy
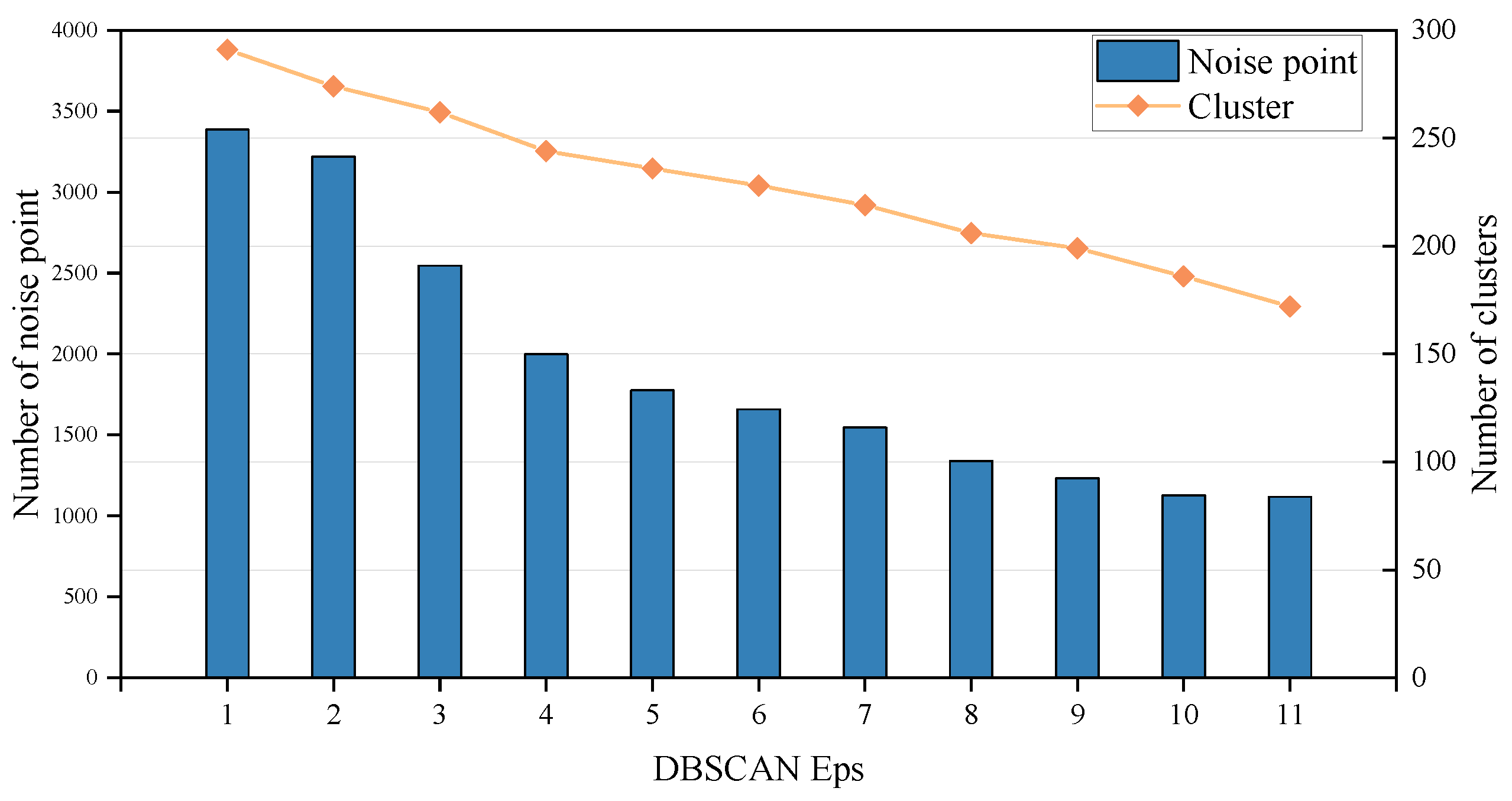
5.2.1. Clustering Parameters
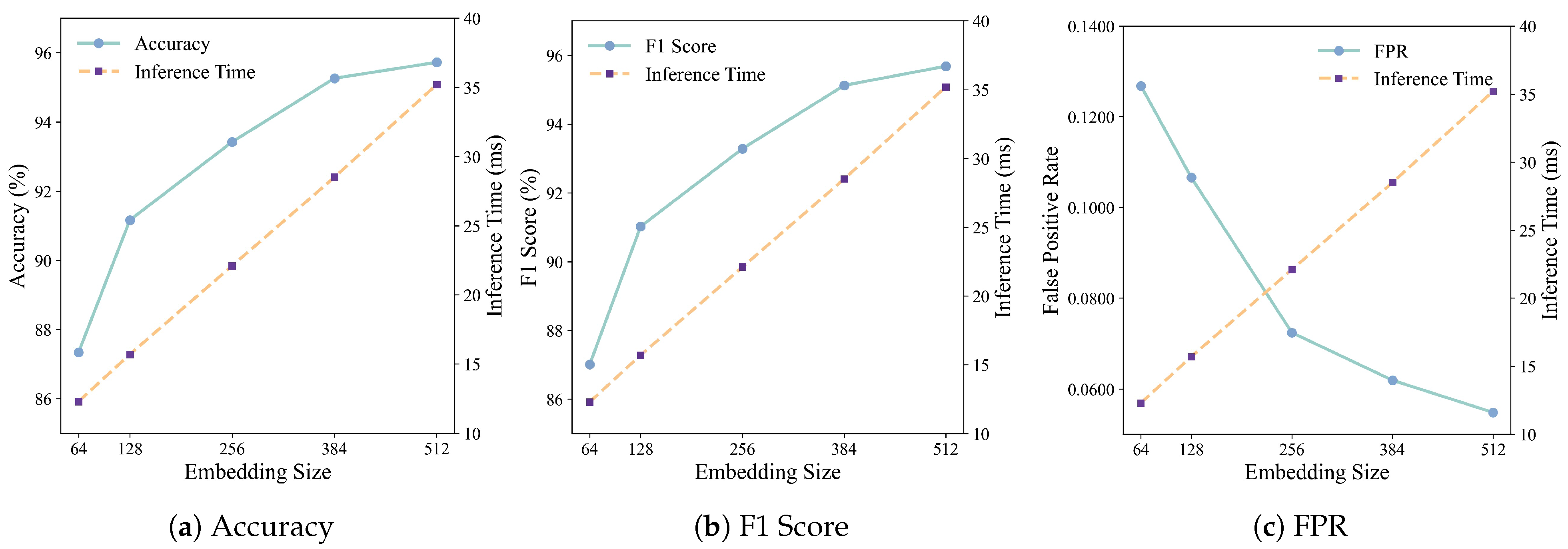
5.2.2. Embedding Size
5.3. Ablation Experiment
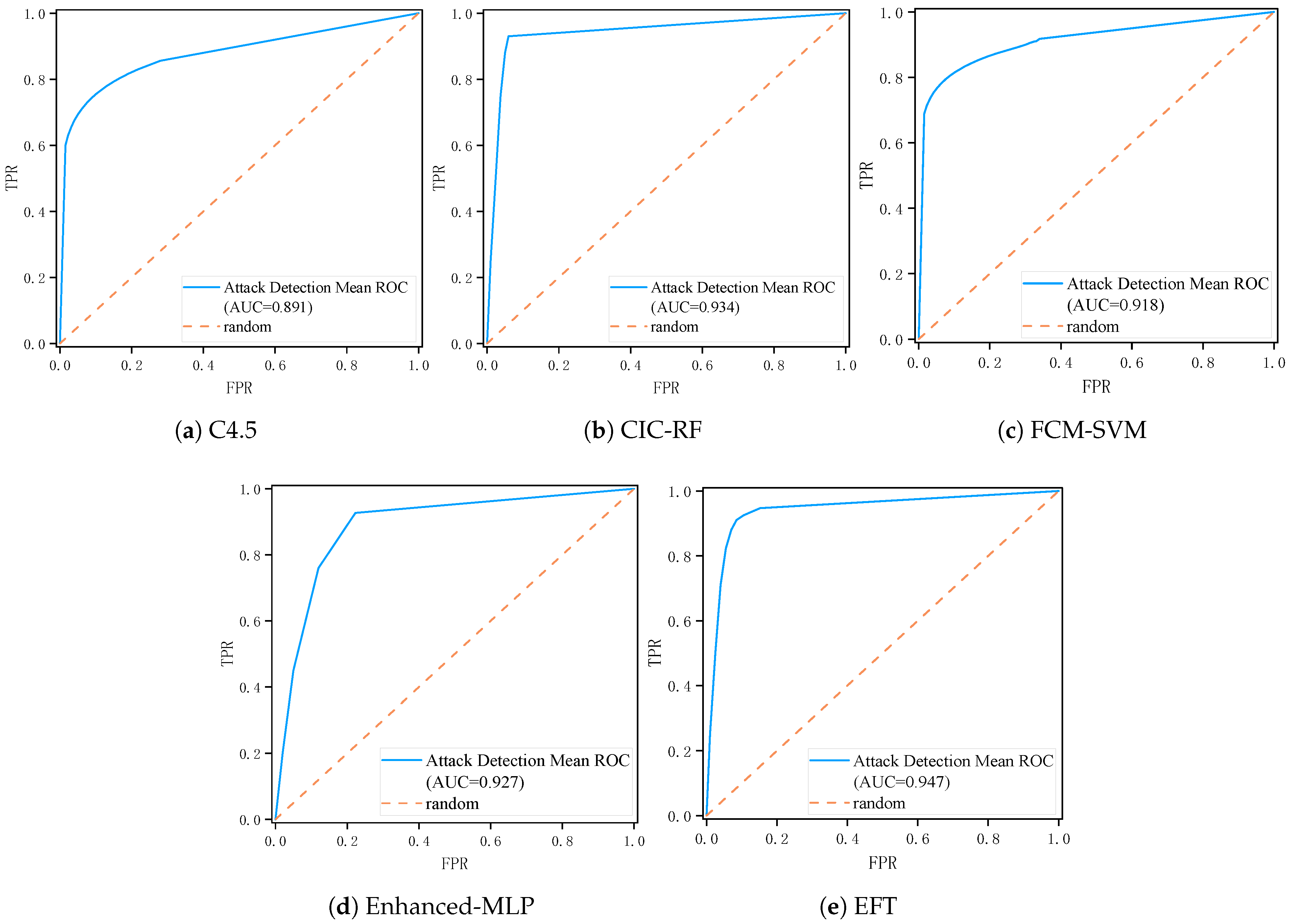
5.4. Baseline Experiment Comparison
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Aas, J.; Barnes, R.; Case, B.; Durumeric, Z.; Eckersley, P.; Flores-López, A.; Halderman, J.A.; Hoffman-Andrews, J.; Kasten, J.; Rescorla, E.; et al. Let’s Encrypt: An automated certificate authority to encrypt the entire web. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2473–2487. [Google Scholar]
- Papadogiannaki, E.; Ioannidis, S. A survey on encrypted network traffic analysis applications, techniques, and countermeasures. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- de Carné de Carnavalet, X.; van Oorschot, P.C. A Survey and Analysis of TLS Interception Mechanisms and Motivations: Exploring how end-to-end TLS is made “end-to-me” for web traffic. ACM Comput. Surv. 2023, 55, 1–40. [Google Scholar] [CrossRef]
- Alwhbi, I.A.; Zou, C.C.; Alharbi, R.N. Encrypted network traffic analysis and classification utilizing machine learning. Sensors 2024, 24, 3509. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Zhang, Z.; Guo, M. A Survey of TLS Traffic Analysis and Detection Techniques. ACM Comput. Surv. (CSUR) 2020, 53, 1–36. [Google Scholar]
- Fernandes, S.; Antonello, R.; Lacerda, T.; Santos, A.; Sadok, D.; Westholm, T. Slimming down deep packet inspection systems. In Proceedings of the IEEE INFOCOM Workshops 2009, Rio De Janeiro, Brazil, 19–25 April 2009; pp. 1–6. [Google Scholar]
- Hubballi, N.; Swarnkar, M. Bitcoding: Network traffic classification through encoded bit level signatures. IEEE/ACM Trans. Netw. 2018, 26, 2334–2346. [Google Scholar] [CrossRef]
- Liu, J.; Fan, W.; Dai, Y.; Lim, E.G.; Pan, Z.; Lisitsa, A. Leveraging semi-supervised learning for enhancing anomaly-based ids in automotive ethernet. In Proceedings of the IEEE 23rd International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Sanya, China, 17–21 December 2024; pp. 1563–1571. [Google Scholar]
- Liu, J.; Fan, W.; Dai, Y.; Lim, E.G.; Lisitsa, A. A lightweight and responsive on-line ids towards intelligent connected vehicles system. In Proceedings of the 43rd International Conference on Computer Safety, Reliability, and Security, Florence, Italy, 17–20 September 2024; pp. 184–199. [Google Scholar]
- Azab, A.; Khasawneh, M.; Alrabaee, S.; Choo, K.K.R.; Sarsour, M. Network traffic classification: Techniques, datasets, and challenges. Digit. Commun. Netw. 2024, 10, 676–692. [Google Scholar] [CrossRef]
- Anderson, B.; McGrew, D. Machine learning for encrypted malware traffic classification: Accounting for noisy labels and non-stationarity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1723–1732. [Google Scholar]
- Hwang, R.H.; Peng, M.C.; Huang, C.W.; Lin, P.C.; Nguyen, V.L. An unsupervised deep learning model for early network traffic anomaly detection. IEEE Access 2020, 8, 30387–30399. [Google Scholar] [CrossRef]
- Black, V.C. The Value of Threat Visibility in the Age of Encryption; Technical Report; White Paper; VMware: Palo Alto, CA, USA, 2020. [Google Scholar]
- Benabderrahmane, S.; Valtchev, P.; Cheney, J.; Rahwan, T. APT-LLM: Embedding-Based Anomaly Detection of Cyber Advanced Persistent Threats Using Large Language Models. arXiv 2025, arXiv:2502.09385. [Google Scholar]
- Zhang, H.; Sediq, A.B.; Afana, A.; Erol-Kantarci, M. Generative ai-in-the-loop: Integrating llms and gpts into the next generation networks. arXiv 2024, arXiv:2406.04276. [Google Scholar]
- Javadpour, A.; Ja’fari, F.; Taleb, T.; Shojafar, M.; Benzaïd, C. A Comprehensive Survey on Cyber Deception Techniques to Improve Honeypot Performance. Comput. Secur. 2024, 140, 103792. [Google Scholar] [CrossRef]
- Evangelou, M.; Adams, N.M. An anomaly detection framework for cyber-security data. Comput. Secur. 2020, 97, 101941. [Google Scholar] [CrossRef]
- Rezaei, S.; Liu, X. Deep learning for encrypted traffic classification: An overview. IEEE Commun. Mag. 2019, 57, 76–81. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. A survey on intrusion detection system: Feature selection, model, performance measures, application perspective, challenges, and future research directions. Artif. Intell. Rev. 2022, 55, 453–563. [Google Scholar] [CrossRef]
- Cui, S.; Dong, C.; Shen, M.; Liu, Y.; Jiang, B.; Lu, Z. CBSeq: A channel-level behavior sequence for encrypted malware traffic detection. IEEE Trans. Inf. Forensics Secur. 2023, 18, 5011–5025. [Google Scholar] [CrossRef]
- Sharma, A.; Lashkari, A.H. A survey on encrypted network traffic: A comprehensive survey of identification/classification techniques, challenges, and future directions. Comput. Netw. 2025, 257, 110984. [Google Scholar] [CrossRef]
- Otoum, Y.; Nayak, A. As-ids: Anomaly and signature based ids for the internet of things. J. Netw. Syst. Manag. 2021, 29, 23. [Google Scholar] [CrossRef]
- Chen, Y.; Cui, M.; Wang, D.; Cao, Y.; Yang, P.; Jiang, B.; Lu, Z.; Liu, B. A survey of large language models for cyber threat detection. Comput. Secur. 2024, 145, 104016. [Google Scholar] [CrossRef]
- Misbha, J.C.; Raj, T.A.B.; Jiji, G. Security Assessment Framework for DDoS Attack Detection via Deep Learning. IETE J. Res. 2024, 70, 8462–8475. [Google Scholar] [CrossRef]
- Abdulganiyu, O.H.; Ait Tchakoucht, T.; Saheed, Y.K. A systematic literature review for network intrusion detection system (IDS). Int. J. Inf. Secur. 2023, 22, 1125–1162. [Google Scholar] [CrossRef]
- Fu, C.; Li, Q.; Xu, K.; Wu, J. Point cloud analysis for ML-based malicious traffic detection: Reducing majorities of false positive alarms. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, Copenhagen, Denmark, 26–30 November 2023; pp. 1005–1019. [Google Scholar]
- Ahmed, M.; Mahmood, A.N.; Hu, J. A survey of network anomaly detection techniques. J. Netw. Comput. Appl. 2016, 60, 19–31. [Google Scholar] [CrossRef]
- Aghaei, E.; Niu, X.; Shadid, W.; Al-Shaer, E. Securebert: A domain-specific language model for cybersecurity. In Proceedings of the 18th EAI International Conference on Security and Privacy in Communication Networks, Kansas City, MO, USA, 17–19 October 2022; pp. 39–56. [Google Scholar]
- Khan, L.U. Visible light communication: Applications, architecture, standardization and research challenges. Digit. Commun. Netw. 2017, 3, 78–88. [Google Scholar] [CrossRef]
- Liu, L.; Wang, P.; Lin, J.; Liu, L. Intrusion detection of imbalanced network traffic based on machine learning and deep learning. IEEE Access 2020, 9, 7550–7563. [Google Scholar] [CrossRef]
- Fu, C.; Li, Q.; Shen, M.; Xu, K. Realtime robust malicious traffic detection via frequency domain analysis. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 15–19 November 2021; pp. 3431–3446. [Google Scholar]
- Ji, I.H.; Lee, J.H.; Kang, M.J.; Park, W.J.; Jeon, S.H.; Seo, J.T. Artificial intelligence-based anomaly detection technology over encrypted traffic: A systematic literature review. Sensors 2024, 24, 898. [Google Scholar] [CrossRef] [PubMed]
- Albasheer, H.; Md Siraj, M.; Mubarakali, A.; Elsier Tayfour, O.; Salih, S.; Hamdan, M.; Khan, S.; Zainal, A.; Kamarudeen, S. Cyber-attack prediction based on network intrusion detection systems for alert correlation techniques: A survey. Sensors 2022, 22, 1494. [Google Scholar] [CrossRef] [PubMed]
- Shiravi, A.; Shiravi, H.; Tavallaee, M.; Ghorbani, A.A. Intrusion Detection Evaluation Dataset (ISCXIDS2012). 2012. Available online: https://www.unb.ca/cic/datasets/ids.html (accessed on 27 April 2025).
- Lashkari, A.H.; Draper-Gil, G.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of Tor Traffic Using Time Based Features. In Proceedings of the 3rd International Conference on Information Systems Security and Privacy (ICISSP), Porto, Portugal, 19–21 February 2017; pp. 253–262. [Google Scholar]
- Chandrasekhar, A.M.; Raghuveer, K. An Effective Technique for Intrusion Detection Using Neuro-Fuzzy and Radial SVM Classifier. In Computer Networks & Communications (NetCom); Lecture Notes in Electrical Engineering; Springer: New York, NY, USA, 2013; Volume 131, pp. 499–507. [Google Scholar] [CrossRef]
- Yin, Y.; Jang-Jaccard, J.; Sabrina, F.; Kwak, J. Improving Multilayer-Perceptron (MLP)-based Network Anomaly Detection with Birch Clustering on CICIDS-2017 Dataset. In Proceedings of the IEEE 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Rio de Janeiro, Brazil, 24–26 May 2023; pp. 423–431. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Component | Specification |
|---|---|---|
| Hardware | CPU | 8-core Intel Xeon E5-2680 v4 @ 2.40 GHz |
| GPU | NVIDIA Tesla T4 (16 GB VRAM) | |
| Memory | 8 GB RAM | |
| Storage | 110 GB (30 GB system + 80 GB data) | |
| Network Interface Card | 1000 Gbps bandwidth | |
| Software | Operating System | CentOS 7.6.1810-x64 |
| Development Environment | PyTorch 1.12.1 | |
| Programming Language | Python 3.9 |
| Traffic Category | Subtype | Description |
|---|---|---|
| Normal Traffic | - | HTTP, email, video streaming, and P2P |
| Attack Traffic | Brute Force SSH | Brute-force SSH login attempts |
| DDoS | HTTP-based DDoS attacks | |
| Penetration | Exploiting vulnerabilities to access systems | |
| Web Attacks | SQL injection and XSS attacks |
| Embedding Size | Accuracy | Precision | Recall | F1 Score | FPR | FNR |
|---|---|---|---|---|---|---|
| 64 | 87.34% | 85.70% | 88.34% | 87.01% | 12.68% | 11.66% |
| 128 | 91.16% | 89.40% | 92.66% | 91.02% | 10.66% | 7.34% |
| 256 | 93.42% | 92.90% | 93.66% | 93.28% | 7.24% | 6.34% |
| 384 | 95.26% | 92.30% | 94.15% | 95.12% | 6.19% | 5.85% |
| 512 | 95.72% | 94.10% | 97.29% | 95.68% | 5.48% | 2.71% |
| Model Variant | Accuracy | Precision | Recall | F1 Score | FPR | FNR |
|---|---|---|---|---|---|---|
| EFTransformer (Ours) | 95.26% | 92.30% | 94.15% | 95.12% | 6.19% | 5.85% |
| Remove Multi-Head Attention | 89.43% | 88.00% | 90.46% | 89.21% | 10.57% | 9.54% |
| Remove Feature Fusion Layer | 91.28% | 89.50% | 92.77% | 91.12% | 8.72% | 7.23% |
| Remove Attention Pooling | 93.12% | 91.80% | 94.18% | 92.98% | 7.88% | 5.82% |
| Single Feature Encoder | 87.56% | 86.10% | 88.61% | 87.34% | 12.44% | 11.39% |
| No Residual Connection | 90.42% | 88.90% | 91.69% | 90.28% | 9.78% | 8.31% |
| Model | Accuracy | Precision | Recall | F1 Score | FPR | FNR |
|---|---|---|---|---|---|---|
| C4.5 Decision Tree | 90.13% | 89.48% | 84.16% | 87.21% | 12.03% | 15.84% |
| CIC-RF | 93.48% | 91.42% | 88.47% | 91.65% | 10.26% | 11.60% |
| FCM-SVM | 92.83% | 91.77% | 86.82% | 10.58% | 11.08% | 13.18% |
| Enhanced-MLP | 93.71% | 91.19% | 87.74% | 91.78% | 10.52% | 12.26% |
| EFTransformer (Ours) | 95.26% | 92.30% | 94.15% | 95.12% | 6.19% | 5.85% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, S.; Du, F.; Diao, Z.; Fan, W. A Multi-Feature Semantic Fusion Machine Learning Architecture for Detecting Encrypted Malicious Traffic. J. Cybersecur. Priv. 2025, 5, 47. https://doi.org/10.3390/jcp5030047
Tang S, Du F, Diao Z, Fan W. A Multi-Feature Semantic Fusion Machine Learning Architecture for Detecting Encrypted Malicious Traffic. Journal of Cybersecurity and Privacy. 2025; 5(3):47. https://doi.org/10.3390/jcp5030047
Chicago/Turabian StyleTang, Shiyu, Fei Du, Zulong Diao, and Wenjun Fan. 2025. "A Multi-Feature Semantic Fusion Machine Learning Architecture for Detecting Encrypted Malicious Traffic" Journal of Cybersecurity and Privacy 5, no. 3: 47. https://doi.org/10.3390/jcp5030047
APA StyleTang, S., Du, F., Diao, Z., & Fan, W. (2025). A Multi-Feature Semantic Fusion Machine Learning Architecture for Detecting Encrypted Malicious Traffic. Journal of Cybersecurity and Privacy, 5(3), 47. https://doi.org/10.3390/jcp5030047