1. Introduction
Access control is a critical part of the metadata of any file. Be it Linux’s iconic 777-style permissions [
1] or Windows’s read-only checkboxes, each operating system needs some method of determining who can perform operations on a file. To ensure that the metadata can work correctly for controlling access of system resources, an implied assumption is that the OS should not be compromised. This assumption however, does not always hold. Major commodity operating systems use large monolithic kernels which are prone to attacks [
2,
3,
4]. Once the OS is compromised, the adversary may arbitrarily change the file permissions by modifying desired metadata through commands like chmod [
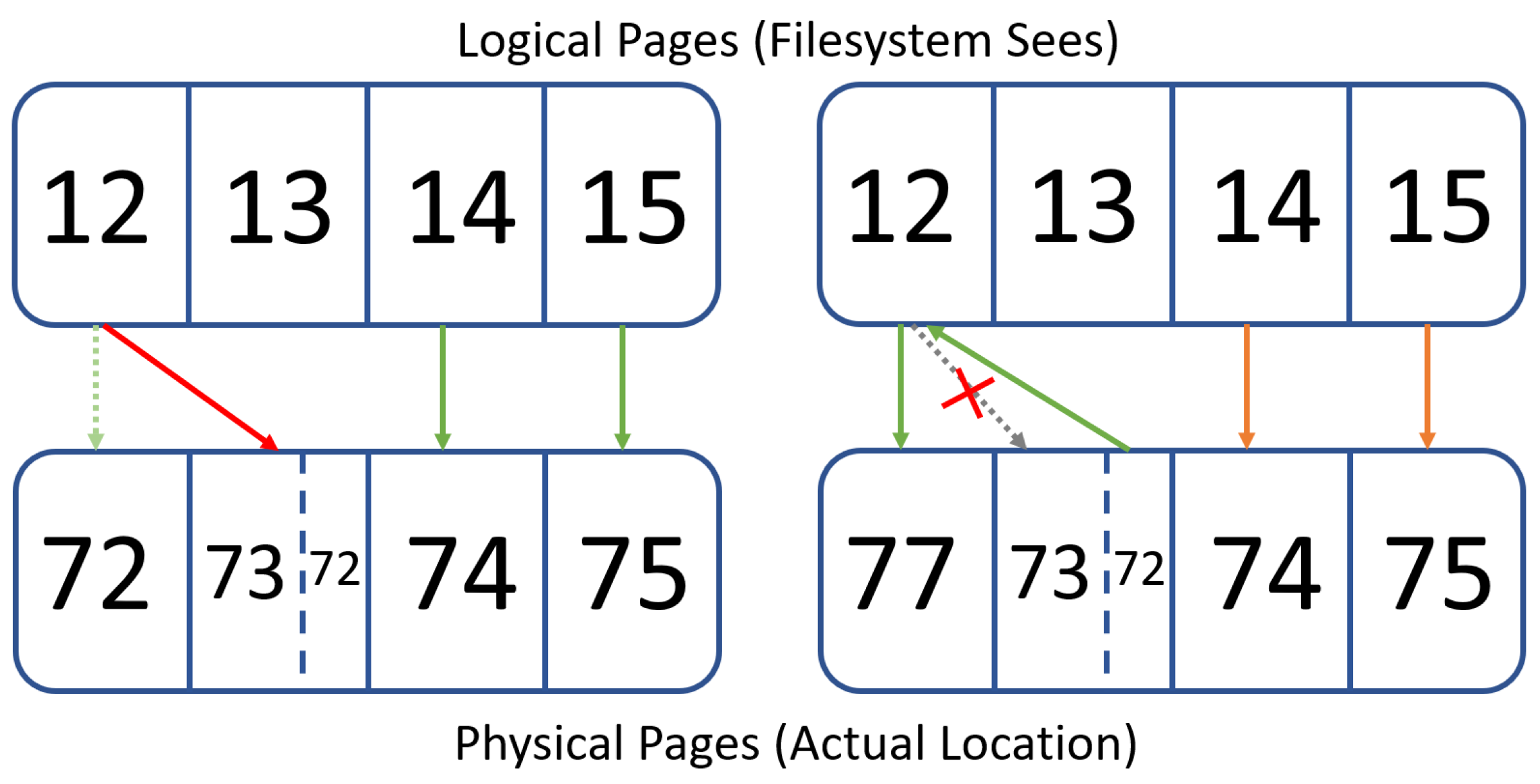
5]. This allows for easy creation of backdoor and leaked data, both of which are major threats to the security of any organization. After the adversary is detected and evicted, efficiently restoring file permissions is a crucial task in timely returning the system to its normal state. However, the malicious changes to the metadata could be wide-scale and efficiently restoring the state of files is a non-trivial problem. The core of the issue is a lack of ability to track and restore metadata across a drive, specifically metadata pertaining to access control/file restrictions. In the scenario of an attacker compromising the OS, a backdoor created by changing file permissions could persist past the removal of the attacker themselves. In order to remove this type of backdoor, changes to access control data need to be reverted. In this work, we aim to design such a system, capable of identifying generalized changes to the access control metadata and reversing them accordingly. Our design takes advantage of the out-of-place update strategy, which is implemented internally in flash memory storage media that has become dominant in the modern computer storage market.
There are several key aspects of filesystems and flash memory which our design relies on: (1) Filesystems must write all metadata to the drive somehow, a command that must be handled by a lower layer. This means that if we were able to write a program that uses that lower layer, we would be able to track metadata writes. (2) Most flash storage drives like SSDs introduce a flash translation layer (FTL), a firmware layer staying between the OS and the underlying NAND flash, which can transparently manage the unique hardware nature of raw flash, exposing a block access interface externally. This firmware layer yields a solution to the problem posed previously, giving us an area below the native operating system which can run our customized programs. (3) Part of the standard kit of flash memory is a set of small “out of bounds” (OOB) areas which can be used to store miscellaneous data [
6]. This may be usable in order to prevent large-scale memory use in sections of code which must be fast in order to properly write data. (4) FTL utilizes a strategy called out-of-place updates to perform write operations which leaves old copies of data on the drive [
7]. These copies of data can linger for extended periods of time, and this time can also be extended by modifying the code used for the update procedure. This allows us to keep older versions of data on the drive for an extended period of time.
These areas combine to allow for a system which tracks metadata writes and stores the previous location in an OOB area. After this is stored, the user can press some kind of manual override switch upon detection of an intrusion and reset any recent changes to access control metadata that they may wish to. There are, however, technical difficulties. Filesystem forensics must be conducted within the FTL, necessitating strategies to minimize memory usage. In addition, performing the forensics can be difficult due to the lack of OS support. We need to manually decode the raw binary data on the drive without relying on any built-in OS functions designed for this purpose. There is documentation for this, but navigation must still be done manually by interpreting the data. We accomplish this by following relevant chains of binary data and only saving the starts and lengths of groups of data which we want to track. This allows us to make a memory efficient system without sacrificing significant amounts of performance.
Contributions. Major contributions of this work are listed below:
We have developed , the pioneering access control recovery scheme capable of restoring access control metadata after the eviction of an adversary that has compromised the operating system.
ensures recoverability of the access control metadata in the OS by (1) leveraging the out-of-place update implementation in the FTL, and (2) performing low-level disk forensics over the raw NAND flash.
We have implemented a prototype of when deploying EXT2/EXT3 as the filesystem. Experimental evaluation demonstrates that can efficiently roll back the access control metadata, with a small impact on the performance of the equipped flash memory storage.
3. Related Work
Leveraging the FTL’s out-of-place update implementation to restore the data compromised by either the ransomware or the malware has been studied extensively in the literature. However, none of them has been specifically designed for access control and cannot be used to restore the access control metadata.
Flash-based data recovery from ransomware attacks. There were various ransomware defending designs such as FlashGuard [
23], MimosaFTL [
24], and SSD-insider [
25,
26] which can restore the data compromised by the ransomware. A common technique used in those designs is to roll-back the entire invalidated raw flash memory data after the ransomware attacks, utilizing the FTL’s out-of-place update strategy. Having observed that restoring the entire storage is time-consuming and may not be necessary, FFRecovery [
27] allows the user to restore individual files compromised by the ransomware. This is achieved by additionally incorporating the filesystem forensics which can restore the filesystem metadata. By linking the restored filesystem metadata and the corresponding file data (restored by extracting the corresponding raw flash memory data guided by the filesystem metadata), a fine-grained recovery of user files is possible. Amoeba [
28,
29] is a method for backing up full hard-drives based on scanning the content and detecting similarities within the pages. If a page is different enough, it is backed up and rolled back in the event that a ransomware attack plays out. However, it does not cover situations outside of ransomware, and its history is extremely short, only storing a single backup per page. RansomBlocker [
30] is a separate system which detects malware by looking at write patterns and sends signals to other recovery tools which can reinstate the hard drive. As it lacks its own recovery option, it is reliant on systems like ours.
Flash-based data recovery from malware attacks. Data restoration from the general malware could be more challenging compared to the ransomware. This is due to the heterogeneous nature of the malware. Bolt [
21] enabled the system restoration after the bare-metal malware analysis in a strictly controlled environment. System restoration turns easier as Bolt clearly knows when the malware starts to function. MobiDOM [
31] was developed to address malware threats in everyday scenarios where the defender lacks prior knowledge of when the malware might appear. A key design of MobiDOM is incorporating a secure malware detector which can function correctly even if the OS is compromised, by utilizing the isolated nature of trusted execution environment and the flash translation layer. The malware detector will securely collaborate with the FTL to enable data restoration after the malware is detected. MobiDR [
32] can ensure accurate restoration of the data at the point of time right before the malware starts to corrupt the data, by integrating both the FTL-based recovery and the remote version control system. Huang, et al. [
33] uses a similar system to ours, leveraging out-of-place updates to roll back data, but lacks any discussion of preserving pages. In addition, it brings no discussion of detection to the table, and has a higher impact on storage volumes due to its lack of specificity regarding data. This leaves a system which has much worse performance overhead and a much shorter cache life for rolling back data. Ref. [
34] Makes use of out-of-place updates in order to make backing up an SSD more efficient, allowing for faster recovery from malware. This system is a collaborative effort between the OS, the FTL, and a Cloud service, all of which work towards database system recovery in an efficient manner.
Flash-based data recovery in critical systems. The existing data recovery designs based on flash memory storage were mostly for computing devices used in non-critical systems. System restoration in critical systems such as cyber-physical systems turned to be even more challenging due to additional considerations such as real-time and safety requirements. Dafoe et al. [
35] designed a new framework which can restore the ECU (electronic control unit) firmware in connected and autonomous vehicles. In their design, the repair coordinator running in the secure world of Arm TrustZone was notified by a detector ECU that the ECU it resided had been compromised. This notification was sent stealthily to the TrustZone via the CAN bus. The repair coordinator then worked with the local FTL to restore the mapping data, which are small in size and can be restored efficiently in real time. Note that all the communications remain transparent to the compromised OS by leveraging steganography. After recovering the mapping data, the ECU firmware is restored to its healthy state prior to the compromise. Ref. [
36] describes a system which can recover from power failures (and other associated catastrophic failures of an SSD) by leveraging the out-of-bounds area described in
Section 2.5 in order to store extra metadata. This increases the reliability of the OS and also allows the flash to use error-correcting codes to work around complete failures. However, it assumes that these are not malware related and rolls back data indiscriminately.
is different from all the aforementioned data recovery designs as it mainly concerns on restoring the access control related metadata, which are hidden among the giant raw data in the flash memory and require careful disk forensic analysis in order to be extracted. Mostly importantly, as the OS is compromised, needs to purely rely on analyzing the raw flash memory data to distill the access control permission data created by the OS, which brings extra technical challenges. In addition, uses the specificity of its target to its advantage, allowing for smaller memory overhead than other systems designed for this type of use.
4. Models and Assumptions
System model. We consider a computing device using flash memory as external storage. This includes servers and personal computers which use solid-state drives (SSD), and mobile/IoT devices which use SD/miniSD/microSD cards, MMC/eMMC cards, or UFS cards.
Adversarial model. The adversary, e.g., a piece of malware, is able to compromise the OS of the victim device, obtaining root access. Abusing this high system privilege, the adversary is motivated to arbitrarily modify the access control for files across this device. For example, it may create a hidden user and grant this user arbitrary permissions of files, or it can delete or modify the existing file permissions of legitimate users. The device owner will be aware of this misbehavior over time (e.g., utilizing a low-level malware detection solution [
31]). After having removing the malware, the user then needs to recover changes made by the adversary to the access control metadata. This seems impossible conventionally, because the adversary has compromised the OS before and tried to eliminate any traces accessible to the OS which may be relied on to get the access control metadata restored.
Assumptions. Our design is based on a few assumptions: (1) The structure of the file system is intact. This assumption is reasonable as it would require the adversary with very high levels of knowledge about the operating system to compromise the file system’s structure without completely destroying the victim device. (2) The flash translation layer (FTL) is secure. The FTL stays between the OS and the flash memory chips and it is typically isolated by the storage hardware from the OS. This hardware-level isolation ensures the security of the FTL. Re-flashing the flash memory firmware may disrupt this assumption, which however is destructive in nature and would result in a wipe of the drive.
7. Discussion
Naturally, our implementation does not cover every possibility and permutation. There are several future directions and improvements that can be made to the system. We cover several such improvements and challenges here in detail, and anticipate that even more can be made in the future to improve on the work.
Danger and abuse of power. Naturally, a system with the power to undo user actions should be heavily restricted due to its potentially compromising nature. We propose use of a manual hardware switch which can trigger rollback, as the only way to completely guarantee that a command cannot be executed without physical access to the machine is to hard-wire it in. Of course, this comes with its own set of issues. Bringing a physical device relies on the user not forgetting to do so, and needing to retrieve an object increases the time between a rollback being requested and actually carried out. However, since the actions this program is capable of are so powerful, it is necessary to take adequate precautions.
OS write caches. One issue that came up during testing is the fact that Linux commands often cache writes rather than committing them immediately upon instruction [
41]. For example, if a file is copied and then permissions are immediately changed, the original version with unchanged permissions is never written to the drive and thus never cached. Notably, re-mounting the drive commits all pending writes, allowing us to work around this problem in testing. This feature has both upsides and downsides for our work. Favorably, this means that repeating a singular command to change the permissions data will likely only commit one change to the drive, thus preventing one potential strategy to clear the cache. However, as mentioned, an attack that targets a file immediately after creation may not be reversible due to file creation.
Partitions. The algorithm given in
Section 5.1 for locating the partition on the drive is configured to find the first partition. However, future partitions can also be found by changing the following addresses:
System type: 0x1c2 - > 0x1d2 (2nd partition), 1e2 (3rd partition), or 1f2 (4th partition) [
13]
LBA start: 0x1c6 - > 0x1d6 (2nd partition), 1e6 (3rd partition), or 1f6 (4th partition) [
13]
This allows users to select which partition on the drive is protected in case of situations such as dual booting for multiple OSes.
NTFS. New Technology File System [
42] was designed for use in Windows NT and is currently used as its primary filesystem after phasing out FAT in the 1990s. NTFS is stored as a series of files on the drive, with even important data such as boot records and metadata stored in the same format. The latest version is NTFS 3.1, released in 2001. This system features a boot record, followed by a list of files and their data. This list is known as the Master File Table, or
$MFT, and is stored as the second file on the drive. The file preceding the MFT,
$Boot, contains diagnostic information for the drive. NTFS uses a system of “clusters” of “sectors” of bytes, which are used to catalogue files. It is worth noting that these clusters are usually larger than one page of flash storage. Each file is given a certain number of clusters which it has control of and manages. Access control data is stored in two categories: A “read-only” and “hidden” bit, stored in two places across a file’s record, and the security entry, stored in a file called
$Secure. The former category means that a system which handles NTFS must track the data in
$MFT, while the latter means we must track the contents of
$Secure. This is doable, as this data is stored in contiguous sections, but some aspects of NTFS are undocumented due to its nature of being designed for Windows. As such, systems which handle NTFS would need some expertise from Windows programmers.
FAT. File Allocation Table based filesystems (FAT) [
43,
44] are the third most popular filesystem for drive use, mostly utilized by older Windows computers. They are formatted as a boot record, followed by a table listing the clusters on the drive and which files occupy them. Directories are stored as a special type of file on the drive, specifically a table of entries which describe files and metadata, and are stored in the standard data section of the drive. This data section begins with a root directory entry, which contains pointers to both its files and any subdirectories. These are 32-byte entries which contain both the location of the actual relevant data and any contained metadata, such as read-only nature, creation time, etc. These subdirectories each have their own file and subdirectory entries, leaving the directory structure as a tree. When a new directory is to be loaded, the tree is traversed using a path provided. Any metadata related to a file is stored with that file’s directory entry, which means that for a particular file to be checked, it must be checked in the tree [
45]. We now provide a summary of FAT’s challenges and how the phases for it might be implemented:
Page saving. There are a variety of options which can be used to keep pages from being erased, and we need to utilize one in order to prevent data we are tracking from being removed. Dafoe, et al. [
35] keeps a cache of pages which are currently in use by the system, preventing them from being erased at all during the time where pages are stored. Our test design used a system where the number of dirty pages in a block is only incremented when permissions are not being written, which dramatically decreases the odds that the old blocks are erased. Our application uses a differing method which attempts to use less memory. We instead insert a small boolean check into the PMT_Update function which does not increment the unused block counter for early pages, which should lower the chance that an old page is selected. This saves time and memory, but comes with a potential risk of increased wear leveling inequality.
Boot proofing. Given that we need to use a cache to track pages which have been changed, there needs to be a method of boot-proofing the system so that a shutdown of the drive does not cause us to lose progress. Dafoe, et al. [
35] uses an extra page on the flash device to write down the cache in the event that the drive is shut down, an option that we can take as well in order to keep our data safe. We would need to store both the current cache of pages which have been written and any data needed for overwrite prevention. This page can be read to recover the state of the tracking at any given point. We could also add the setup phase data, but it is not strictly necessary as all of the setup phase is doable at any point after the partition is created. In addition, if boot-proofing can be made more efficient, it is hypothetically possible to design a system that fully recovers the entire filesystem from complete corruption. This is possible owing to the fact that we are already recovering filesystem data, and could simply remove some filters during rollback and expanding the range which the cache searches. EXT in particular is susceptible to this, as inodes make up the majority of the filesystem’s data.
GPT Partition handling. Some modern drive setups will use a system called the GUID partition table (GPT) rather than the MBR for drive partitions. This system has an initial MBR entry whose partition type is 0xEE, allowing for to adjust accordingly. The GPT system does not have an OS Type header, but does still contain the location of the partition. As such, a GPT-compatible implementation would need to check the partitions for magic numbers to determine OS type rather than using the MBR entries. This is doable, however our test machines did not use GPT and such a system was not implemented.
EXT4. EXT4 is the newest version of the EXT filesystem. This added several features, including an extended superblock, dynamic groups, and more. One feature added to EXT4 is metadata checksums for all applicable inodes. This uses a crc32c algorithm to ensure the integrity of metadata across the filesystem. While good for integrity, this makes our system much more difficult to implement, especially when taking write caching (
Section 7) into account [
11]. Since crc32c is seeded, we are unable to generate new checksums for the system. In the event that a write changes both the permissions of a file and some other piece of its metadata, a system like ours must either undo all of the applicable changes or none of them due to the checksum. As such, any implementation of our system for EXT4 must be limited, though some semblance of the system can still be implemented. During rollback, a page would need to be checked for significant changes outside of permissions (minor changes like the last time modified can be safely reverted without major issue). If no significant changes are detected, the page can then be rolled back. However, if other changes (for instance, the size of the file) are made, the user may need to be informed and perform the changes manually.
Detection in the FTL. Given that the OS is compromised, it may be impossible for the user to deduce that their system is infected at all. Since we assume that the malware is removed in our system, it is worth acknowledging possible detection methods in the FTL. Chen et al. [
31], as well as several other works [
24,
25,
28], do this for mobile devices by scanning for noticeable access patterns across the FTL which lead to malware attacks. It is theoretically possible to transfer a system such as this into the FTL from the trusted app layer by downscaling the application to fit the limited processor space available. More work needs to be done in this area, but it should still be well within possibility to perform this detection automatically in the future without trusting the OS at all. This would enable users to be secure without even having to think about it in most scenarios.
Future work. Several current weaknesses in the system need to be adjusted for future iterations of the work. These include:
Boot-proofing. As discussed in the previous section, we must boot proof the system. Once this has been done, several attacks on our work become invalid as we can simply recover the state of the system after a reboot. Until then, a reboot clears the cache, possibly preventing some changes from being rolled back.
Byte-specific monitoring. While our current system leaves byte-specific checks for the rollback phase, it is hypothetically possible to do so during monitoring. This would save a large amount of cache space as false positives become impossible. However, a method for doing so efficiently has yet to be found.
Automatic Setup. Right now, the setup operation is performed by a command sent from the user. However, it may be possible for the FTL to detect a specific write pattern which corresponds to the completion of a partition on the drive. More work will need to be done in this area to confirm or deny this possibility.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}