3.1. Construction of DP-BCD
If an attacker knows what function or (deterministic) computation has been performed on a data set, he may derive information about this data from the outcome. This may allow him to exclude certain data points from the data set, include other specific points or deduce relations that the data set fulfils. One of the options to limit this possibility is to hide precisely which computation has been performed. In objective perturbation [
8,
22,
23,
24], it is the loss function that is perturbed, preventing the attacker from knowing what computation was performed.
The algorithm presented here consists of two phases. In the first phase, all parties train a linear model on their local data set. The labels they use for this are the parts missing from the joint prediction. In the second phase, the linear models are put together to form a linear model in the federated setting. This linear model can then be published. There are two potential groups of attackers possible in this setting. During the first phase, it is the group of all other participants. At publication, it is the outside world that receives the jointly trained model. Since the group of all other participants is also part of the outside world, we will only be considering the first group when proving our privacy guarantees.
In this study, we use locally sensitive differential privacy (LSDP), as defined in Definition 2. Based on this, only data sets at distance 1 of a party’s own data set are considered. Besides that, we use a small universe of possible data sets . It consists only of the actual data set and all data sets obtained by removing one record. We do not include possible data sets with one record more than our data set. In fact, for such a small universe, the conditions of Definitions 1 and 2 coincide.
One may argue that using the small universe based on local sensitivity to reduce the amount of noise needed while lowering the privacy budget, is in vain. This is not the case. In the transition, the privacy guarantee is shifted from absent data points with a high privacy budget to the actual data with a low privacy budget. The privacy budget is the explicit security guarantee that (LS)DP offers and as such is what users look at.
The ambition is to minimize the following 2-party loss function in both an iterative and a federated manner
This is the 2-party form of (
2) with a perturbation term added. A ridge regression term is omitted to perform a cleaner comparison to the original BCD algorithm. However, nothing prevents such a term. In (
7), each party’s loss function is perturbed by the dot product of the prediction and a secret vector
, known only by party
i.
For each party, we write that , so there are N observations of attributes in this party’s data. It follows from our data assumption that .
If the vectors
would be sampled from a normal distribution such as (
8), the perturbation term would have the added benefit that the local and federated perturbation term are of the same form. This would provide a similar perturbation term in the federated and local objective function. To avoid dimensionality problems, a different distribution is used, as explained in Remark 1.
Remark 1. The vector could be sampled from a normal distribution with densityIt is clear that the direction of the vector is uniformly sampled from the surface of the N-dimensional sphere. For its length, we want to solve for Rwhich transforms intoand is solved by the inverse lower incomplete gamma function. This is problematic. The high dimension pushes the vector outwards, so that the noise vectors tend to get bigger with increasing number of observations. This leads to noise vectors overwhelming the data and a remainder that is larger than the input label. As explained before, only the first party needs to know the labels. Afterwards, during iteration
t, party
j obtains the remainder
of the label that is not yet explained by party
. From now on we will suppress the sub- and superscripts when possible. The local solution is given by
There are two algorithms in use in the protocol. The first is used during the learning phase to communicate the missing part of the labels. It is given by
The second is used in the revealing phase and is defined by
where
is in both cases defined in (
9). In the special case of unperturbed learning, i.e.,
, we call this solution
.
We start with the privacy of the learning algorithm
. We sample
with
uniformly and
l with density
, so that
Thus, the length of the perturbation vector is normally distributed and its direction is uniformly distributed. This ensures that the length of the perturbation vector is independent of the number of observations. The parameter
is the largest allowed value of
for a successful protocol run.
The standard deviation of the length of the perturbation vector is given by
, where
is the privacy budget for the round and
The parameter
gives the maximally allowable deterioration in performance compared to the unperturbed case. It is a new parameter introduced here. It must be chosen big enough to satisfy in every iteration
tThis implies that in each iteration of the protocol, the loss scaling parameter must satisfy
Thus,
represents the cost per round of adding differential privacy to the learning algorithm. It is the multiplier of the loss with respect to the unperturbed case, where
.
The probability that two databases
of full rank at a distance 1 of each other yield the same output vector
is, according to (
9), given by
Here, we have decomposed
into parts inside the kernel and perpendicular to it. Note that the decomposition for
is different from that for
. For the probabilities, it suffices that
where
is an orthonormal basis for the kernel. Note that the parts inside the kernel can only stem from
Since both matrices are of full rank, their kernels have the same dimensions and selecting a vector out of them is equally likely. For the perpendicular parts, a standard argument can be used. Using (
13), the final inequality follows from
For the revealing phase, a very similar argument works. Instead of the missing labels, it is now the weights that are communicated. The privacy loss for revealing a single
is computed by
From simple composition, Lemma 1, it follows that revealing the weights
consumes at most a privacy budget of
.
To demand that observations should generate a full rank matrix is a minor demand. If it were not the case, a certain attribute could be predicted perfectly by the other attributes. Hence, it could be removed from the database to generate a full rank matrix again. Furthermore, it is not necessary for the proof to work with full rank matrices. They should only be of equal rank.
The complete 2-party algorithm DP-BCD is shown in Algorithm 2. A generalization to more parties is straightforward.
| Algorithm 2 Differentially private 2-party block coordinate descent algorithm |
- 1:
, and - 2:
Alice and Bob initiate and , respectively. - 3:
Alice initiates - 4:
fordo - 5:
player Alice do - 6:
- 7:
- 8:
- 9:
- 10:
- 11:
if then - 12:
send to Bob - 13:
else - 14:
abort - 15:
end if - 16:
end player - 17:
player Bob do - 18:
- 19:
- 20:
- 21:
- 22:
- 23:
if then - 24:
send to Alice - 25:
else - 26:
abort - 27:
end if - 28:
end player - 29:
end for - 30:
Alice sends to Bob. - 31:
Bob sends to Alice. - 32:
Alice and Bob publish .
|
Utility Bound
During the protocol run, the participants must check in every iteration whether the loss increase is less that a factor
, as demanded in (
13). If this is not the case, the protocol will be aborted by the participants, because a model with sufficient utility cannot be trained. Hence, at every single iteration the sum of squared errors, which is the unperturbed loss, is bounded by
This information can be used in another way. It is directly related to the utility loss and provides an upper bound for the utility loss. In a protocol run with
parties and
T iterations, the sum of squared errors is at most a factor
larger than in the unperturbed case. If we denote with
the differentially private predictions and with
those without DP, then we observe that the utility measure
This shows that we obtain a utility guarantee along with the privacy guarantee. The additional utility loss is bounded by parameters that can be set before the start of the protocol.
This proves the following theorem.
Theorem 1. The linear regression of , held by Alice, against the data can be approximated by Algorithm 2, provided that and are of full column rank and contain N data points, where and . For , and it is an -differentially private algorithm. Furthermore, the utility is bounded from below bywhere is the utility of the block coordinate algorithm without differential privacy (Algorithm 1). 3.2. Experiments on Synthetic Data
In order to quantify the performance of DP-BCD simulations with synthetic data are performed. We use standard normally distributed data and normally distributed parameters (, ). In the baseline scenario, there are nine predictors, with a correlation of , , , , and with two parties. Because preliminary analyses have indicated that five iterations is a favourable cut-off in the trade-off between privacy and noise-accumulation, this is the number of iterations used.
For comparison with this baseline scenario, each of the following factors are varied separately: the sample size , the correlation between predictors , , , and . The values are chosen big enough to avoid an abortion of the protocol run with high probability. For low values of , the algorithm may terminate (see Algorithm 1, because is too low. This could lead to an unbalanced comparison between scenarios where the is sufficiently high and those where the algorithm could not carry out all iterations for each repetition. Each of the variations is repeated 500 times with the exception of the sample size experiment, which is repeated 100 times per variation. At every iteration, a different data set ( and y) is generated. In experiments where the privacy parameters and are varied, different parameters are generated for every iteration.
To evaluate the utility, two results are considered. These are the
and the
estimates. These outcomes are also generated in the centralized setting and using BCD without differential privacy. Because the results for these two algorithms are practically identical, we only compare it to the centralized results. For several scenarios, we compute the average absolute proportional distance (AAPD) for these
estimates. For
r repetitions of a scenario with
m predictors, the corresponding AAPD is defined as
3.2.1. Impact of Privacy Parameters
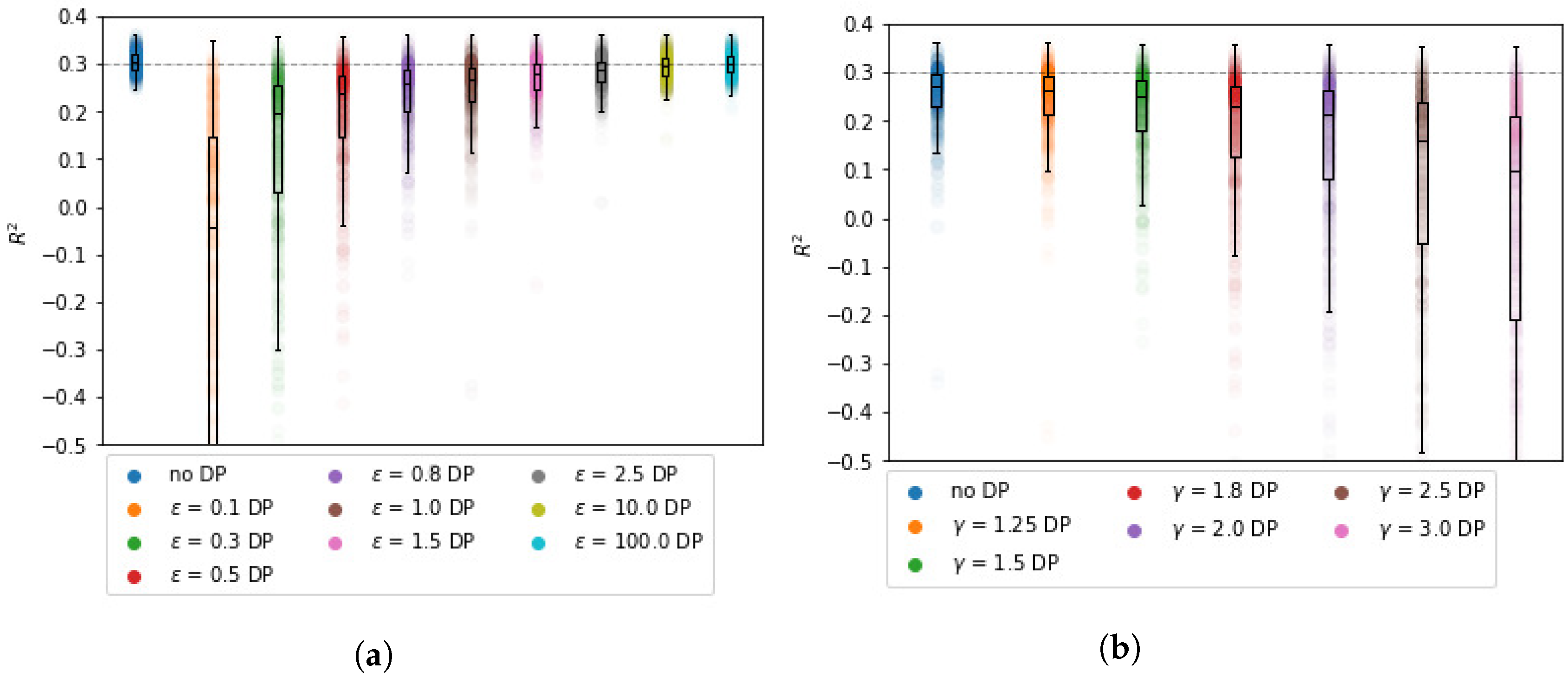
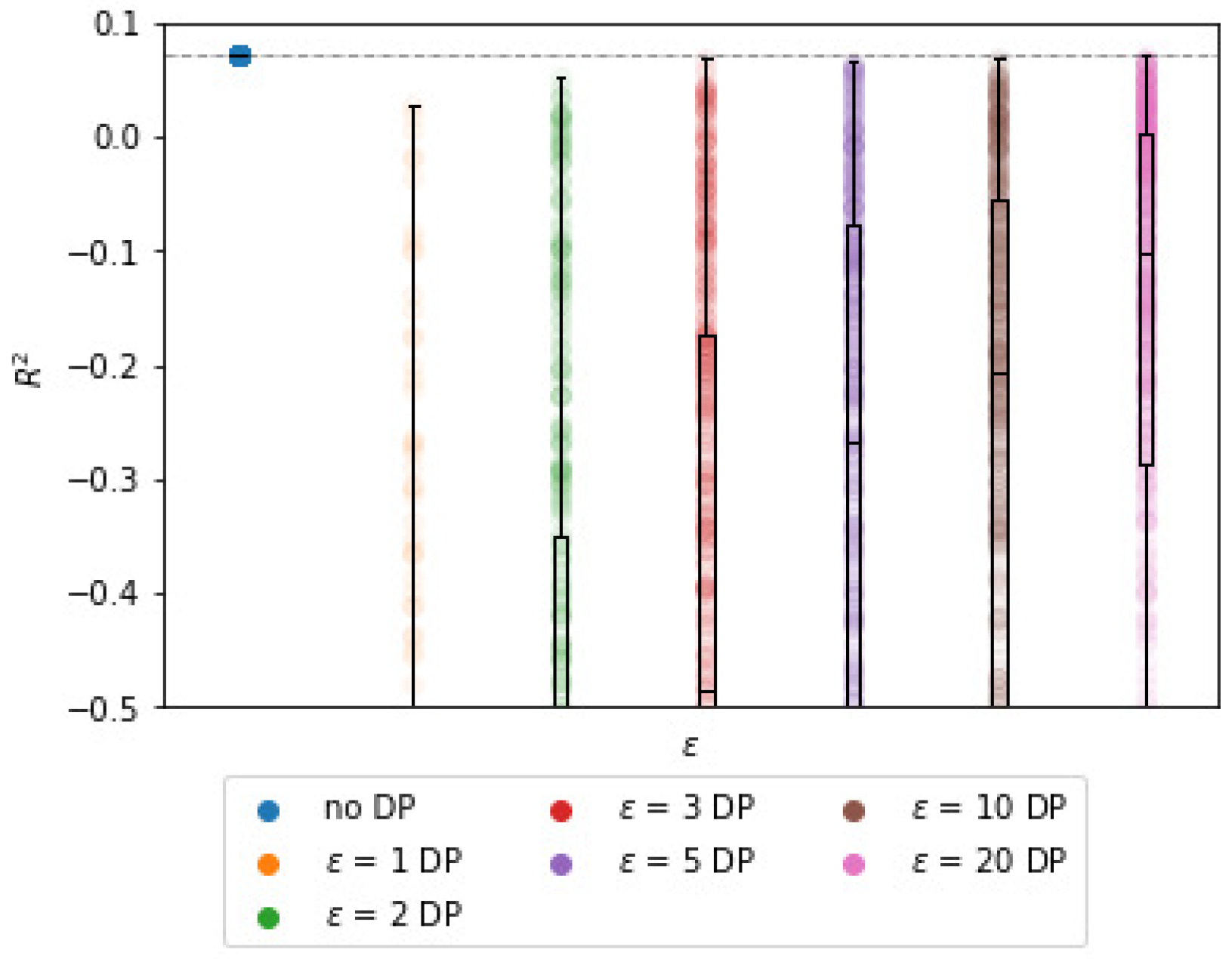
The impact of
and
on the
and
estimates is non-linear. We find that
has a stronger impact on
than
. From
Figure 1b, it can be observed that the bound for
decreases significantly with
. However, for the synthetic data, the expected decrease is not nearly as steep as its bound. For example, for
, the average
is approximately
, whereas it is bounded by
. Although the results are in line with Theorem 1, the bound can be almost meaningless for large values of
.
The
estimates grow closer to the BCD results as
increases, which is in line with the expectation.
Table 1 shows that for
= 1, the
estimates deviate 47% from the centralized
parameters on average. For
(the lowest tested value), the
estimates deviate 295% from the centralized setting, but note that this is for
, see
Table 2. For higher values of
, the estimates are closer to the centralized
parameters, though still differing by up to 47%. As a reference, the average and median deviation after five iterations for BCD without DP are practically zero.
3.2.2. Impact of
As
increases in the data-generating model, more predictive power is preserved with DP-BCD as well, see
Figure 2. The precision and bias with which the
parameters can be estimated are also significantly impacted by
in the data generating model, see
Table 3.
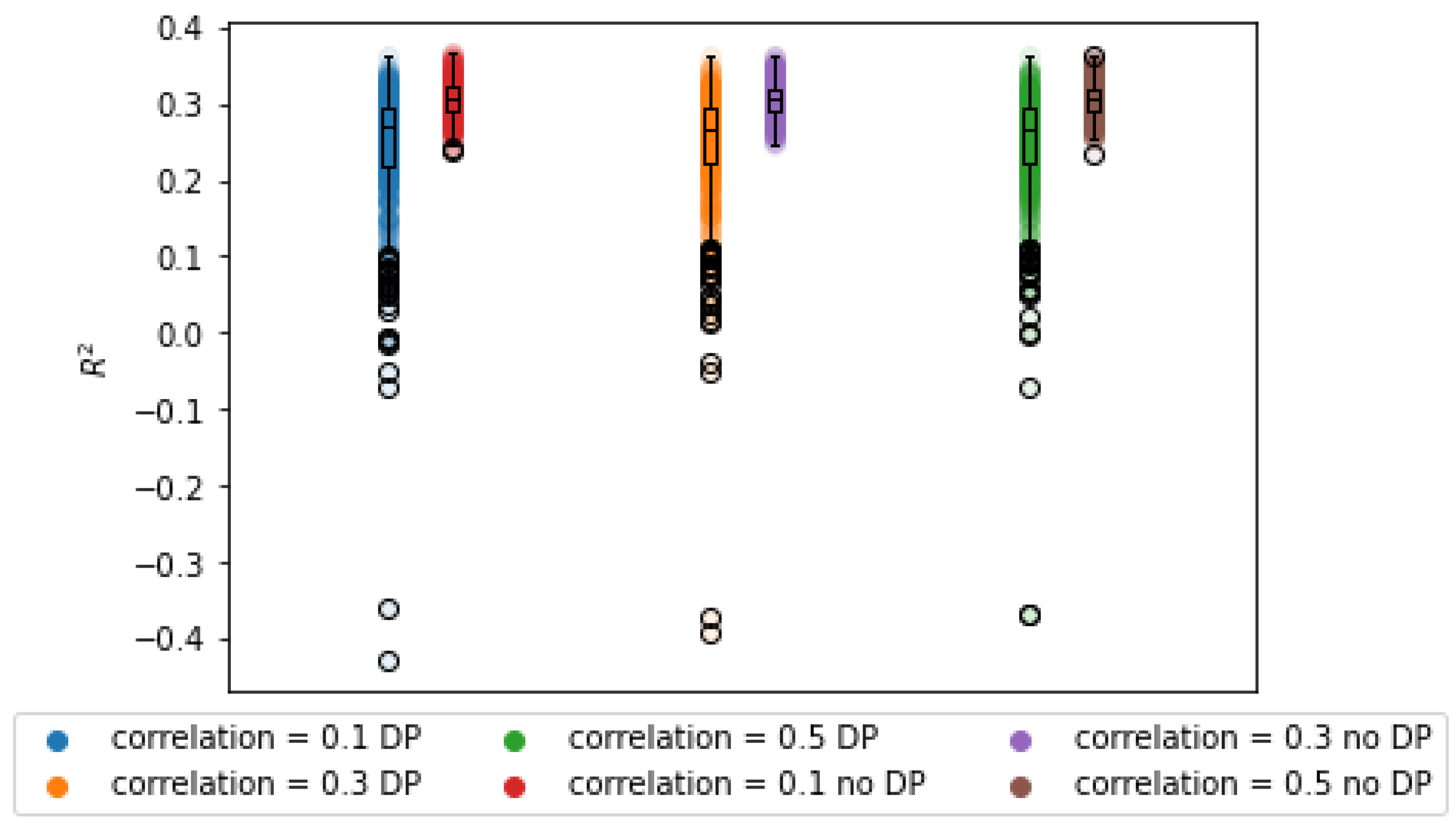
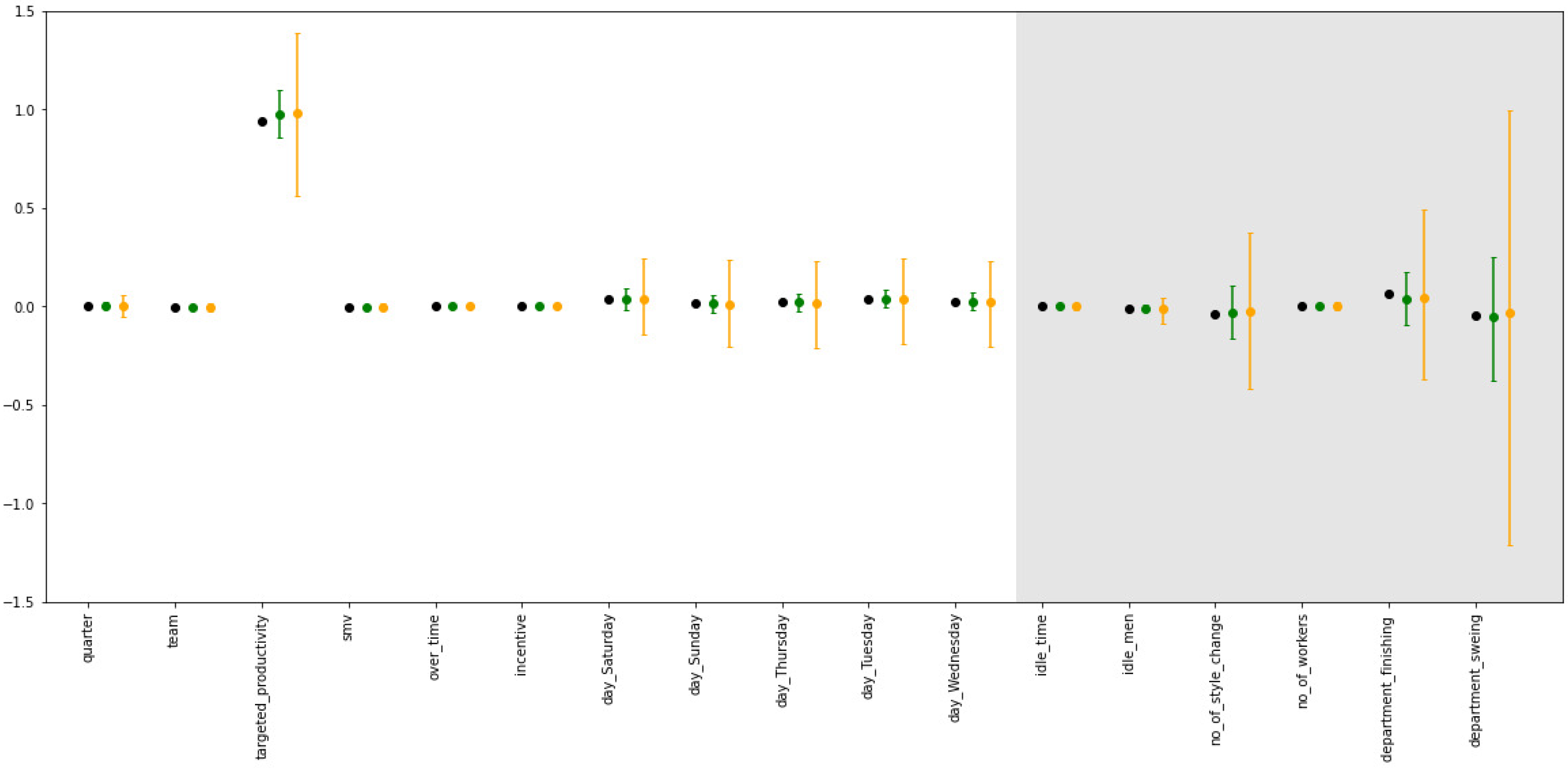
3.2.3. Impact of Correlation
The impact of the correlation on the utility of the learned model can be seen in
Figure 3. As expected, the average
error increases with the correlation between predictors. This can be observed in the wider sampling distribution in
Table 4. This is to be expected for an implementation of DP, since more noise must be added to hide the outliers in the data. For very high correlations, the average
parameters differ as well, which means that the estimates are biased. The
, however, remains unaffected by this parameter, though it is lower than with the BCD algorithm.
As studied by [
4], strongly correlated data require more iterations for accurate parameter estimation. In fact, for highly correlated data with over 25 variables, hundreds of iterations can be required for convergence of the weights. In a differential privacy setting, this may consume vast privacy budgets or yield poor results due to noise accumulation.
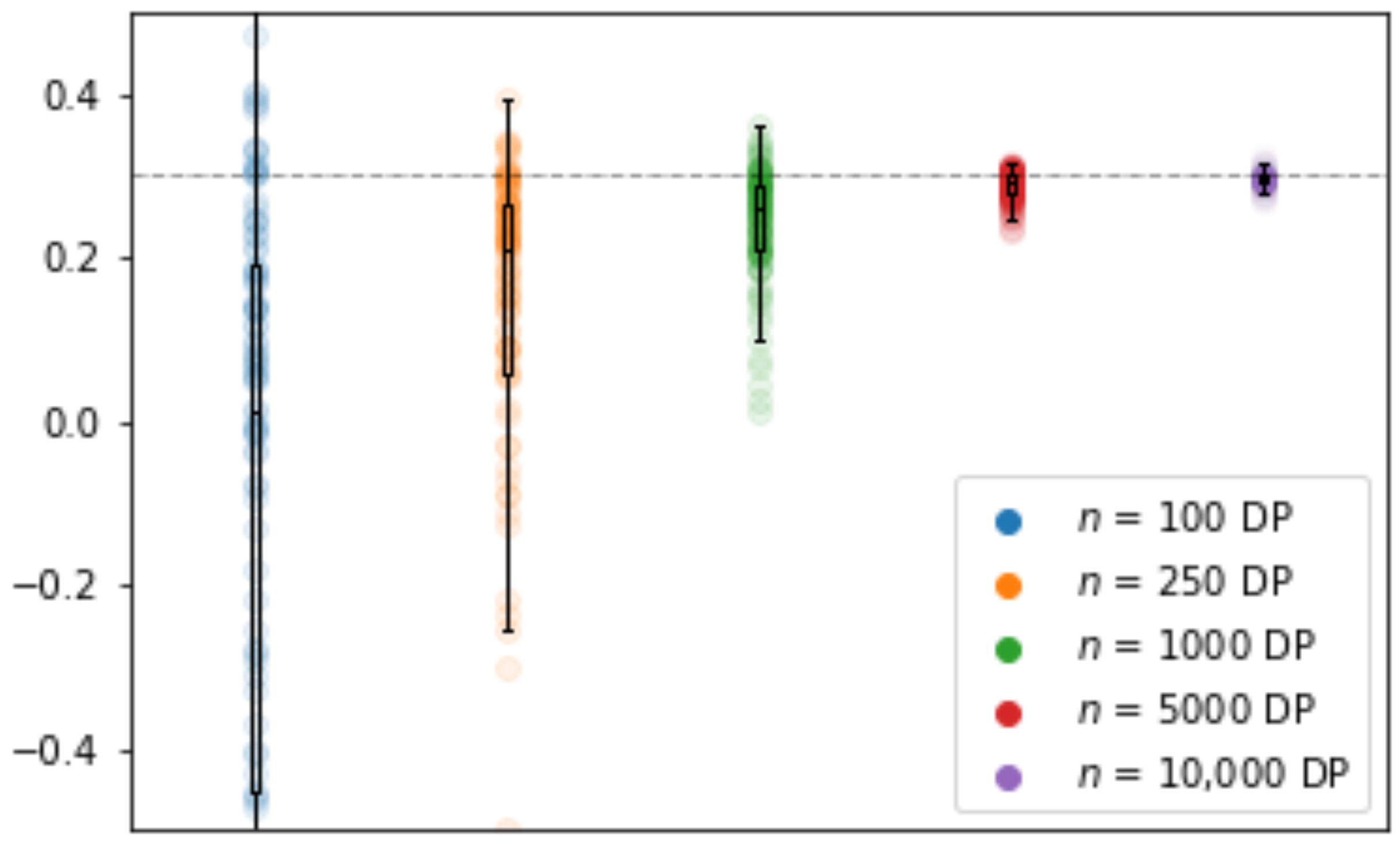
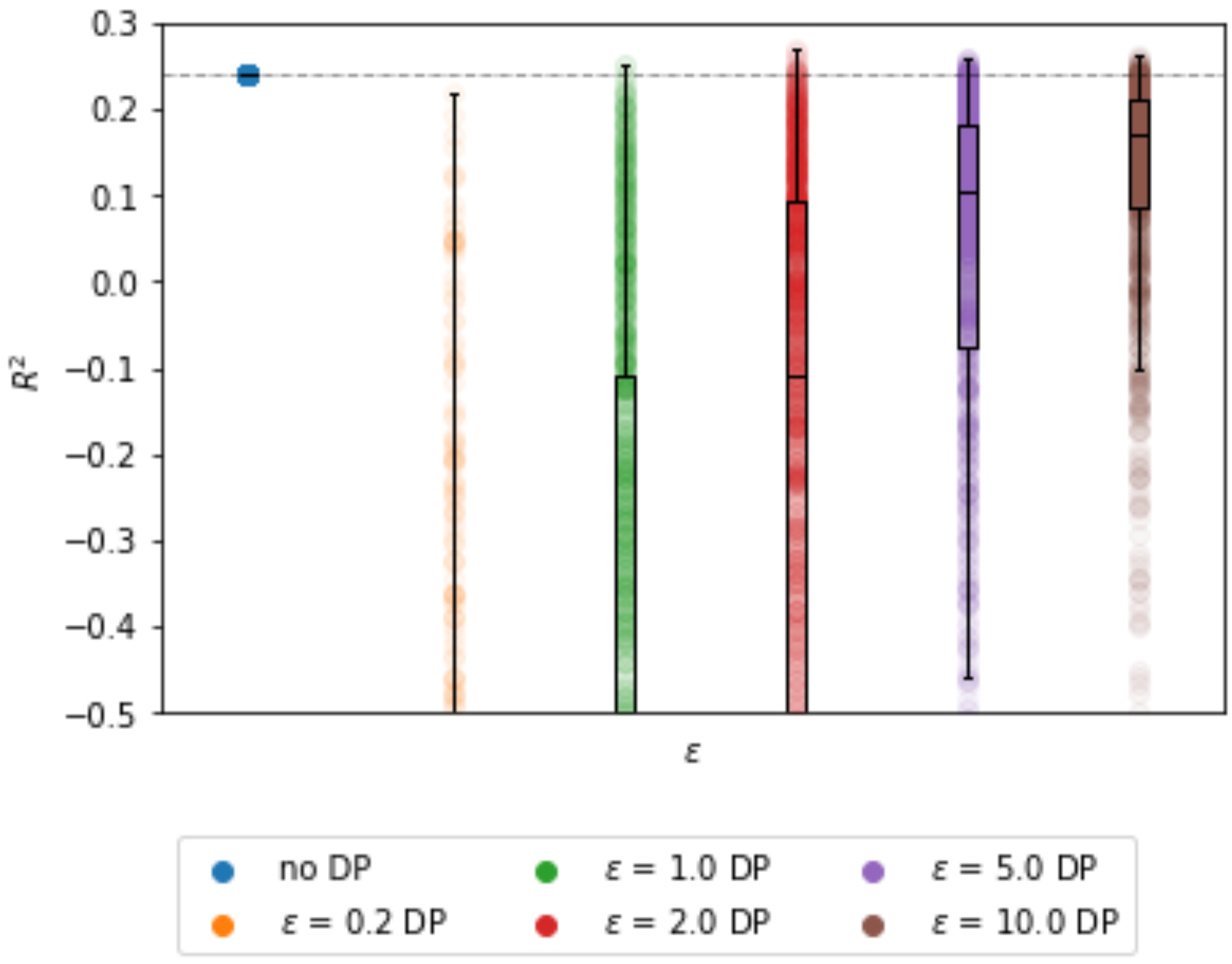
3.2.4. Impact of Sample Size
Sample size is well known to have a large impact on the performance of differentially private model, see
Figure 4. As can be observed from
Table 5, the
error steadily decreases with the sample size. Furthermore, the
distribution grows closer to the centralized results.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}