2. Related Works
A pre-trained language model refers to a model of NLP that has been trained using an unsupervised training approach on a large text corpus that represents a general domain of language. Among the most well-established pre-trained language models are Embeddings from language Models (ElMo) [
4], the Universal Language Model with Fine-Tuning (ULMFiT) [
5], Bidirectional Encoder Representations from Transformers (BERT) [
6], and the Generative Pre-Training (GPT) model [
7].
Among all mentioned language models, we chose BERT for our work because it is an open-source model with a very strong tokenizer and word-embedding matrix. In our previous work we fine-tune BERT with neural network to build cybersecurity claim sequence classifier CyBERT [
8], and show that its design (BERT+NN) improves upon the performance obtainable from other language models such as GPT2 and ULMFiT. From
Figure 1 it is readily apparent that due to its very early positioning within the overall processing workflow the overall accuracy of our vetting system is highly dependent on the accuracy obtained by the claims classifier. Any errors made during classification are propagated downstream through all subsequent processing tasks. Therefore, in this is research we focus on maximizing the claim classifier’s accuracy.
BERT uses a contextualized embedding technique that is designed to capture word semantics in a context based on its surrounding text [
9]. BERT uses the WordPiece embedding method, which divides each word into a limited set of common sub-words [
10], down to the individual letter level. This technique is very flexible and eliminates the need to deal with unfamiliar words contained within a dataset.
BERT is a multi-layer bidirectional transformer-stacked encoder based on an attention-based model architecture [
11]. Each encoder is comprised of multi-head self-attention and feed-forward neural network (FFN) sub-layers [
11]. The self-attention layer of the first encoder is initialized with the embedding matrix from each word (tokens). Subsequently, the Query, Key, and Value matrices are calculated for this embedding by the attention mechanism. Each matrix articulates a different representation of the same initial embedding. The self-attention matrix formula is given by Equation (
2):
where
Q is the Query matrix,
K is the Key matrix and
V is the Value matrix. The parameter
d represents the Key matrix’s dimension. The softmax score in the attention equation determines how much each word will be expressed at this position. Multiplying the softmax score with the Value matrix (V) produces the attention value. As a result of this multiplication, the values of the words we want to focus on are maintained, and irrelevant words are dropped out. This process is repeated eight times, with eight different randomly initiated matrices for
Q,
V and
K, as shown in [
6,
12]. The multi-head attention is then calculated by concatenating all eight self-attentions, then performing the dot product to multiply it with another random weight matrix. The multi head attention value shows which attention head is more important for the meaning of a given words. Each self-attention head focuses on a different aspect of how the tokens interact with each other, which makes BERT aware of the context of the given sentence [
6,
11].
Therefore, the attention mechanism is used to calculate the importance of any word in the sentence. In BERT, each attention layer is followed by a fully connected FFN. The FFN function consists of two linear transformations and a ReLU function, as shown in Equation (
2):
This feed-forward layer enhances the deep non-linearity in the model. The robustness of the algorithm is also enhanced by residual connections from previous states. The encoders map each input sequence to a continuous representation and then reprocesses then using the same layer structure [
11]. The output of the final encoder will be a vector that can be supplied to the NN layers of any downstream task. In the case of ClaimsBERT, this output is used by a classifier stacked on top of this BERT transformer architecture.
There are two different versions of BERT. Both models have been trained utilizing a dataset comprised of the text content of the BookCorpus and the collection of pages obtained from English Wikipedia, which combined constitute a dataset of more than 3.5 billion words [
6]. The specifics of both versions of BERT are:
BERT-Base: consists of 12 encoder layers, utilizes an embedding size of 768 dimensions, 12 multi-head attentions, and is comprised of 110M tunable parameters in total;
BERT-Large: consists of 24 encoder layers, utilizes an embedding size of 1024 dimensions, 16 multi-head attentions, and a total of 340M tunable parameters.
For completeness, we also mention the concepts of Vision Transformers (ViT) [
13], Image GPT [
14], and Multiscale Vision Transformers (MViT) [
15], which are the analogous forms of their respective NLP models, adapted specifically to Computer Vision (CV) tasks such as in the domain of autonomous vehicles. Recently, ViT models were also used to detect and extract text from images, akin to an advanced generalized form of optical character recognition (OCR), for example from image object labels, instructions and road signs, within the broader application of Scene Text Recognition (STR). An example is shown in [
16], in which a ViT model was used to find text in complex environments such as product labels, signboards, road signs and markers to help machines and agents make informed decisions. These works, however, use the transformer approach to extract text from image, not to extract meaning and context from within the text, as would be the case in NLP applications. Thus, the use of transformers in the CV domain, while in many cases a crucial technique, does not constitute natural language processing.
Another application of transformers is for so-called Vision and Language (V&L) tasks, which utilize multi-modal transformer models, comprise of separate processing streams that in one stream focus on text encoders, and in another stream on vision encoders [
17,
18,
19,
20,
21,
22,
23]. These V&L approaches focus on determining links and relationships between visual and textual content and learn their joint features [
20]. These models leverage links between text and image content, for example for navigation tasks of autonomous vision-based vehicles or robots, or for lip reading and associating visual information about facial expressions with textual information. As a result, their application domain is essentially independent of ClaimsBERT’s application domain. Therefore, they are not considered to be feasible choices for our research presented in this paper, which represents a specific application with emphasis on BERT within the NLP domain.
Recently, a new multi model for news classification was introduced in [
24]. The authors used RoBERTa to obtain text features, and separately applied a Vision Transformer for image feature extraction from news. Only after these two separate processes, the resulting features from both were concatenated together to build a fusion feature. All these features then feed into Multilayer Perceptron (MLP) layers to predict the text, image, and fusion labels separately. The fusion label is considered to be the final prediction label for the news. However, these models are not applicable to purely text-based processing, which is the focus of this paper representing aspects of the research related to our vetting framework.
In recent years the use of MLPs for text classification tasks has seen increased popularity [
25,
26,
27]. Even though the use of MLP techniques in these models is shown to achieve generally comparable performance to that of self attention-based transformers (BERT) [
28], in most applications self attention-based transformers are shown to achieve better accuracy [
29]. Therefore, the foundation of our architecture presented in this paper was chosen to be BERT.
The performance of a pre-trained language model can subsequently be further increased by adapting it to a target downstream task [
30,
31,
32,
33,
34]. Adapting a language model to domain-specific downstream tasks can be divided into the pre-training of language models and fine-tuning of language models. Pre-training essentially involves a full retraining of the model on a new corpus with randomly initialized weights, whereas fine-tuning starts with established weights and alters them to better suit the model when training on a smaller additional corpus.
Although the pre-training of BERT into domain-specific models, such as for biomedical language BioBERT [
35] or scientific text (SciBERT) [
36], improves downstream performance significantly, the process is computationally expensive and typically requires large extra corpora [
35,
37]. Therefore, we are focusing on the fine-tuning process for the ClaimsBERT model, which can achieve very similar performance improvements. To evaluate the size of the dataset required specifically for the fine-tuning of language models, Sun et al. [
33] in their work evaluated the impact that the dataset size has on the fine-tuning outcome, and showed that fine-tuning an existing language model can successfully be achieved using only a few training shots from a small dataset. This reduces or even eliminates the need to produce large-corpus datasets when fine-tuning models.
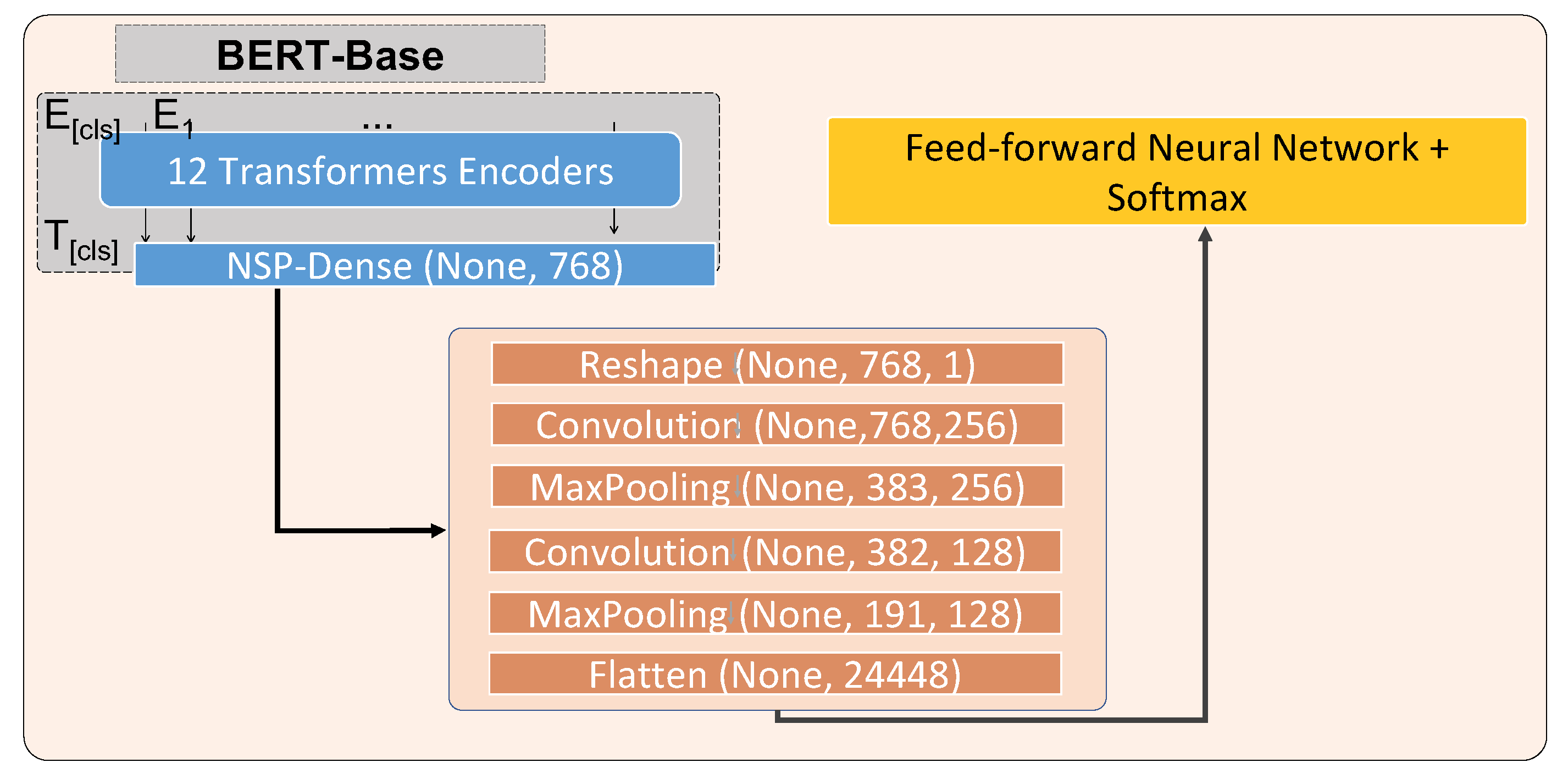
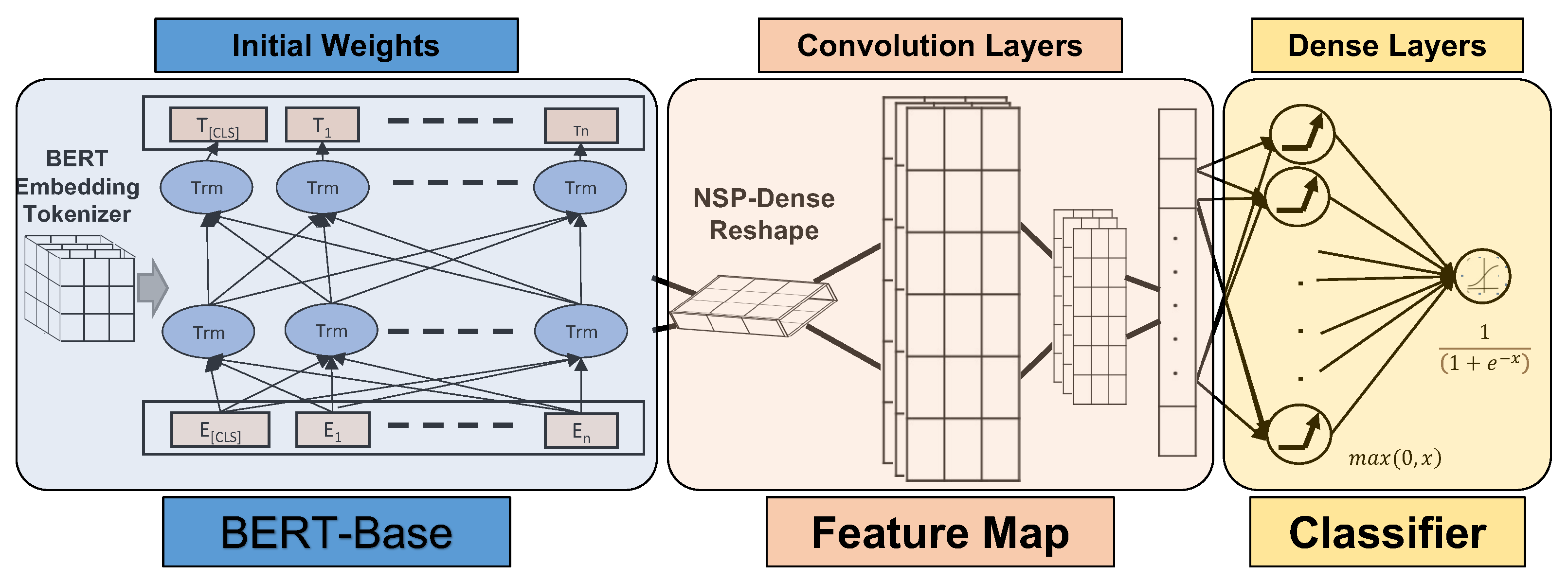
Fine-tuning enables NLP language models to be applied to many different tasks. For some NLP applications, however, a language model by itself is not sufficient for accomplishing a given downstream task, and it becomes necessary to expand the language model’s overall architecture by stacking it with another form of neural network, for example using a convolutional neural network for language models targeting classification NLP tasks. For such application scenarios, the combination of the BERT language model and deep learning models such as recurrent neural networks or convolutional neural networks were shown to be effective in recent studies for capturing meaningful features from the available data [
8,
38,
39,
40]. We utilize a similar approach for our ClaimsBERT classifier. In our approach, we train the entire pre-trained model on our dataset and use the transformer encoders stacked with neural networks to feed the output to a softmax layer for back-propagation through the entire architecture, which updates the pre-trained weights based on our dataset. Adding a feature mapping stage on top of the transformers architecture delivers useful features that can improve the performance for our downstream task. As we will show in our paper, our research showed that a CNN network provided the best results in comparison with other approaches for this feature mapping stage, specifically NN, LSTM, BiLSTM and MLP.
In this paper, we focus on maximizing the accuracy of our claim classifier without significantly impacting its efficiency. We apply our novel framework ClaimsBERT on our curated cybersecurity claim sequence database. To the best of our knowledge, no other cybersecurity-related classifier using BERT has been published in the scientific literature. Furthermore, our approach presented herein marks a significant improvement upon the original BERT classifier. The new ClaimsBERT classifier can detect claim sequences from the large dataset of vendor documents. These sequences then will be used in a vetting approach against industry standard requirements in our cybersecurity vetting engine (CYVET).
Language Models in Cybersecurity
Using language models such as BERT for cybersecurity applications is a growing research area in recent years [
8,
41,
42,
43,
44,
45,
46,
47,
48,
49]. Fine tuning language models such as BERT for cybersecurity domain tasks can provide many benefits to the cybersecurity community.
One example of using language models in this domain is the fine tuning of BERT for Name Entity Recognition (NER) applications for different languages, such as Chinese [
50], Russian [
46] and English [
42,
43,
44]. NER models provide cybersecurity professionals with an efficient way to extract specific entity information about attacks and vulnerabilities [
48]. In another study, BERT was fine tuned on Android source code applications to identify and classify existing malware [
41]. Fine-tuning BERT for classification tasks such as attack classification [
48], cybersecurity claim classification [
8], knowledge graph [
51] and vulnerability classification [
52]. ExBERT is another example of fine-tuning BERT for vulnerability exploitability prediction using sentence-level sentiment analysis [
52]. An effective evaluation of evolving risks can be accomplished with the help of semantically connected text graphs using the Construction Cybersecurity Knowledge Graph (CKG) and Graph Convolutional Network (GCN) based on BERT [
51]. Analysts who are usually required to sort through attack details to categorize various types of attack vectors may benefit from Cybersecurity Knowledge Graph (CKG) [
51].
Our review shows the benefits of fine tuning language model such as BERT for the downstream tasks in the cybersecurity domain. Therefore, we developed and present ClaimsBERT, which can accurately identify feature claims based on claim sequences from our cybersecurity domain database. The focus here is on how NLP can be leveraged for cybersecurity applications.
3. Dataset Curation
When we initiated this research effort, there was no dataset available for NLP tasks specific to cybersecurity literature [
2]. As a result, we proposed a framework for curating a large repository of device information for ICS in our previous work [
2]. Using this framework, we are able to identify ICS vendor websites, collect website-accessible documents, and identify documents relevant to the dataset using web scraping, data analytics, and natural language processing (NLP). Our framework starts by determining ICS vendor names by scraping CISA’s ICS-Cert website at
https://us-cert.cisa.gov/ics (Access on 1 March 2021). These results are combined with the vendor name results obtained utilizing predefined keyword search queries applied to different search engines, including Google, Bing, AOL, and Baidu. The framework then expands vendor names into vendor websites by conducting web searches to identify their most likely website URLs. The resulting names and websites are then classified using a web content-based scoring metric along with Latent Dirichlet Allocation (LDA) to identify vendors-of-interest. This process evaluates the home page content of each vendor’s website to determine if that vendor falls within the category of an ICS solutions vendor. Finally, our framework conducts a comprehensive web site crawl through all relevant pages to curate a list of downloadable documents, and proceeds to download each document it located. All downloaded documents are then associated with the corresponding ICS vendor. Based on our results from processing the identified vendor websites, we found that [
2]:
3% of the documents were unreadable;
5% were scanned documents;
29% where not related to ICS products;
63% of the downloaded documents are ICS product-related documents.
When analyzing the 12,581 ICS product-related documents that were found, we could determine that
25% were classified as “manuals”;
69% were classified as “brochures”;
6% were classified as “catalogs”.
Downloaded documents may contain regular paragraphs, tables, lists, and images. Text from readable documents was extracted via the
PyMuPDF python package, and we leveraged python’s
Pytesseract package for performing optical character recognition (OCR) with any scanned PDFs. With this approach, we managed to extract 2,160,517 sequences with 41,073,376 words across our curated dataset of ICS documents [
8].
In order to label the sequences in our curated dataset we developed a new mobile cross-platform application based on Xamarin that allows us to manually label sequences extracted from these ICS documents. We first identified three types of claim sequences: generic, device, and cybersecurity claims. Specifying individual claim types facilitates future investigations into claim type detection. We categorized all of these types of claims as “claim” labels in this study and removed the sequences with the “Not Sure” label from the classification dataset. For more details on this labelling process please refer to [
8].
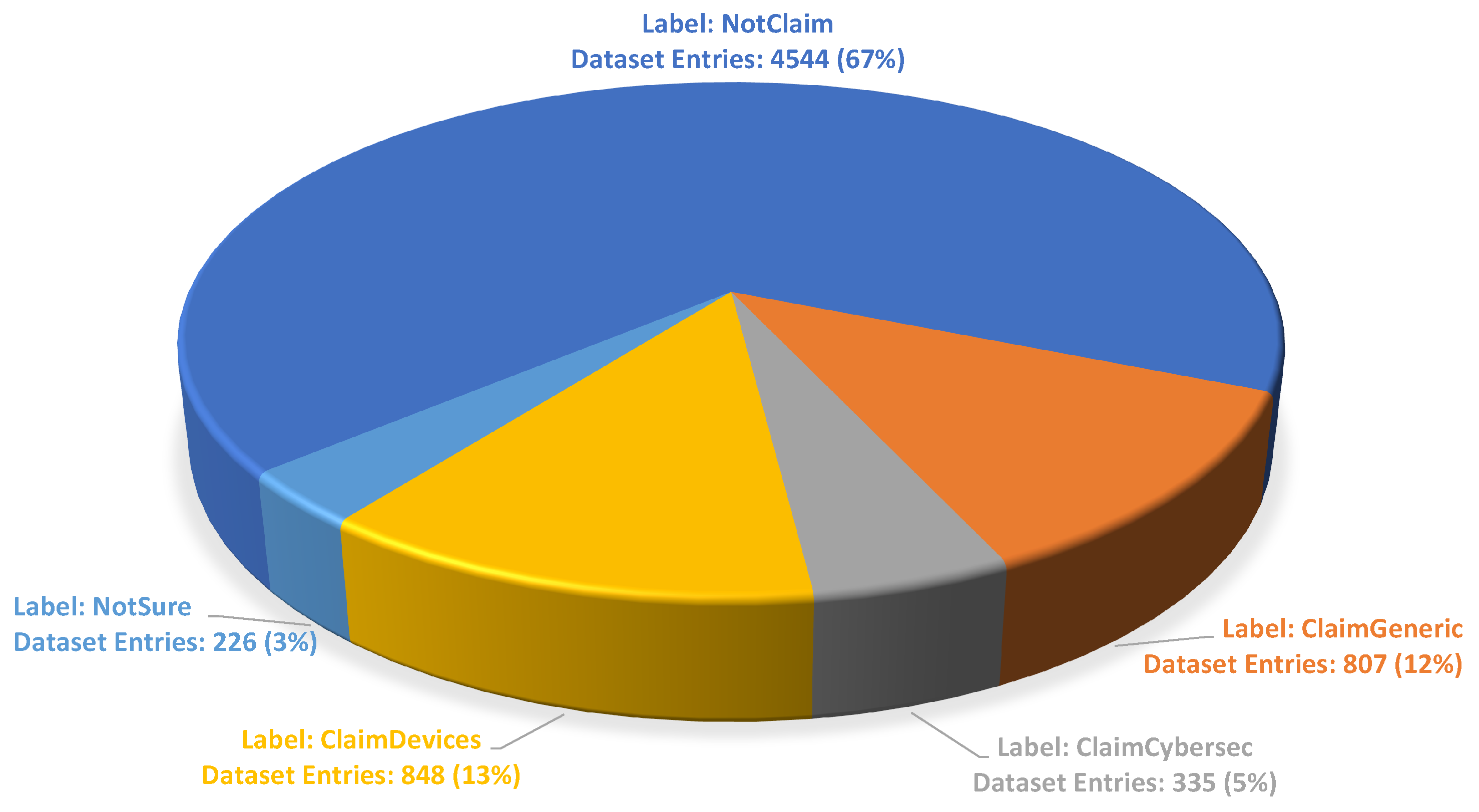
Figure 2 illustrates the labeled dataset we used to train our classifier models for the Tally-Vet project. In this paper we focus only on identifying “Claim” sequences.
Figure 3 presents the final class count and distribution of all classes.
6. Conclusions
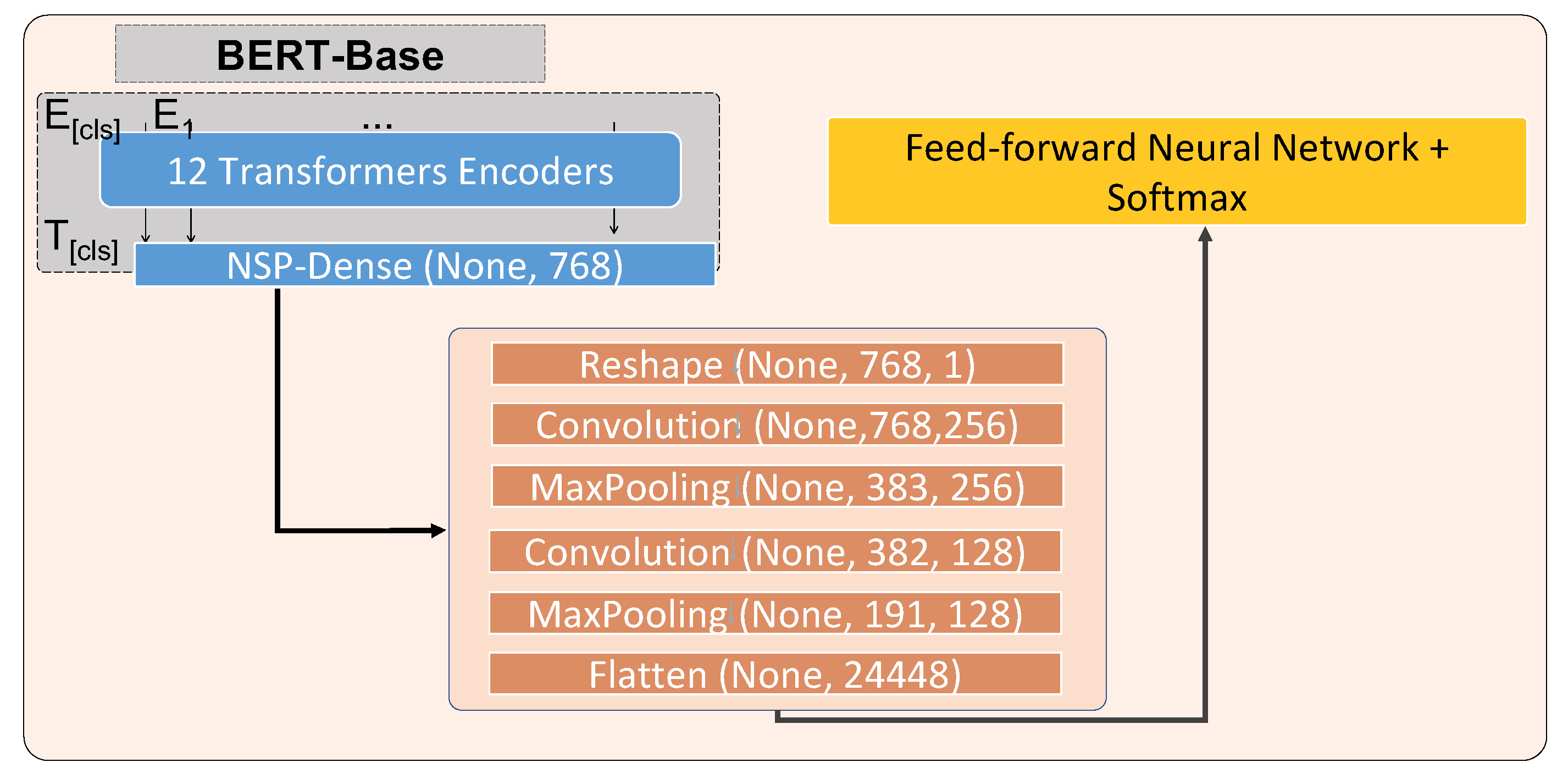
In this paper, we introduced a new concept of ClaimsBERT, a classifier model generated by incorporating feature maps via CNN into BERT, which resulted in significantly improved accuracy and performance. The proposed classifier was established by fine-tuning BERT using two convolution layers—a fully connected dense layer and a classification layer stacked on transformers.
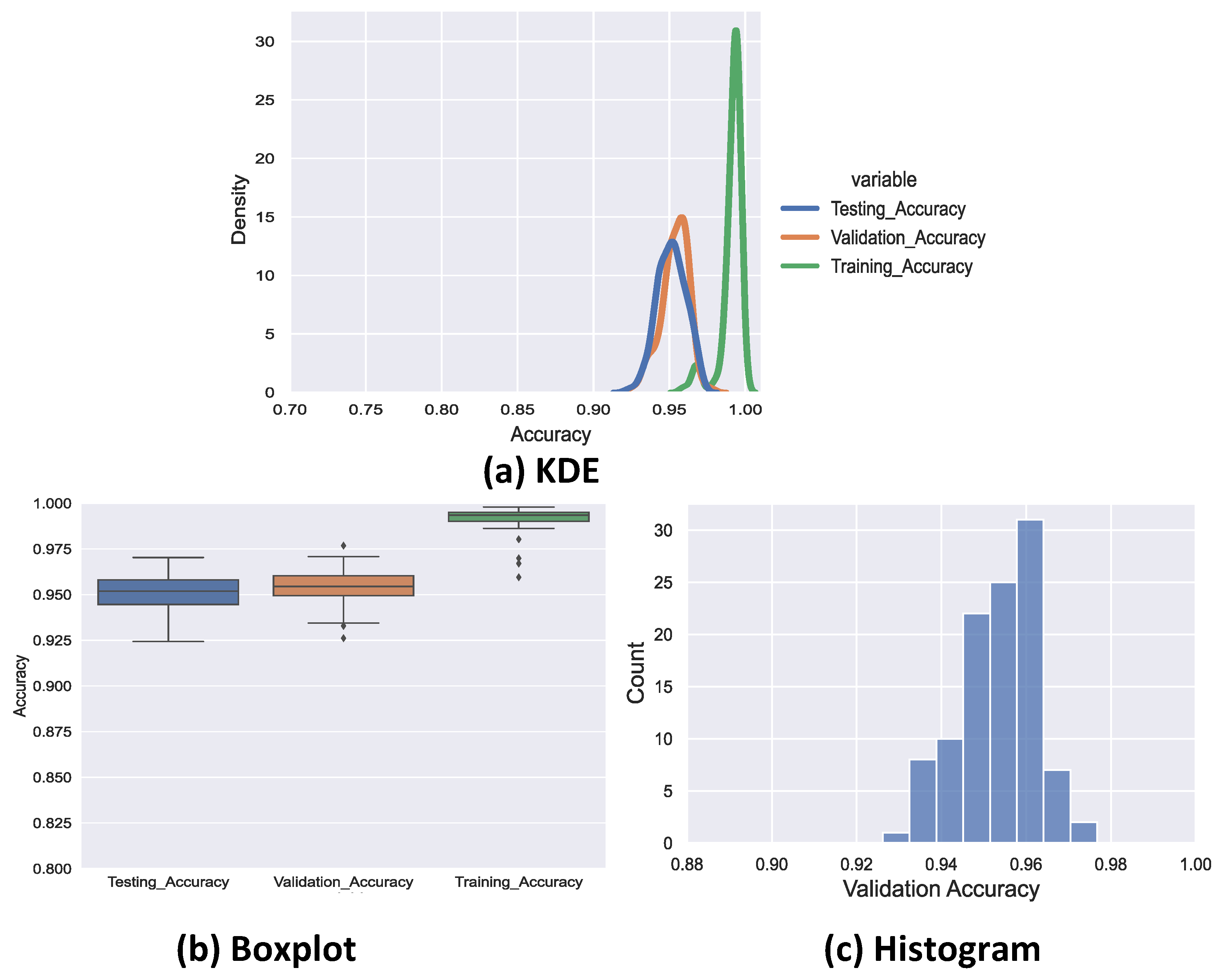
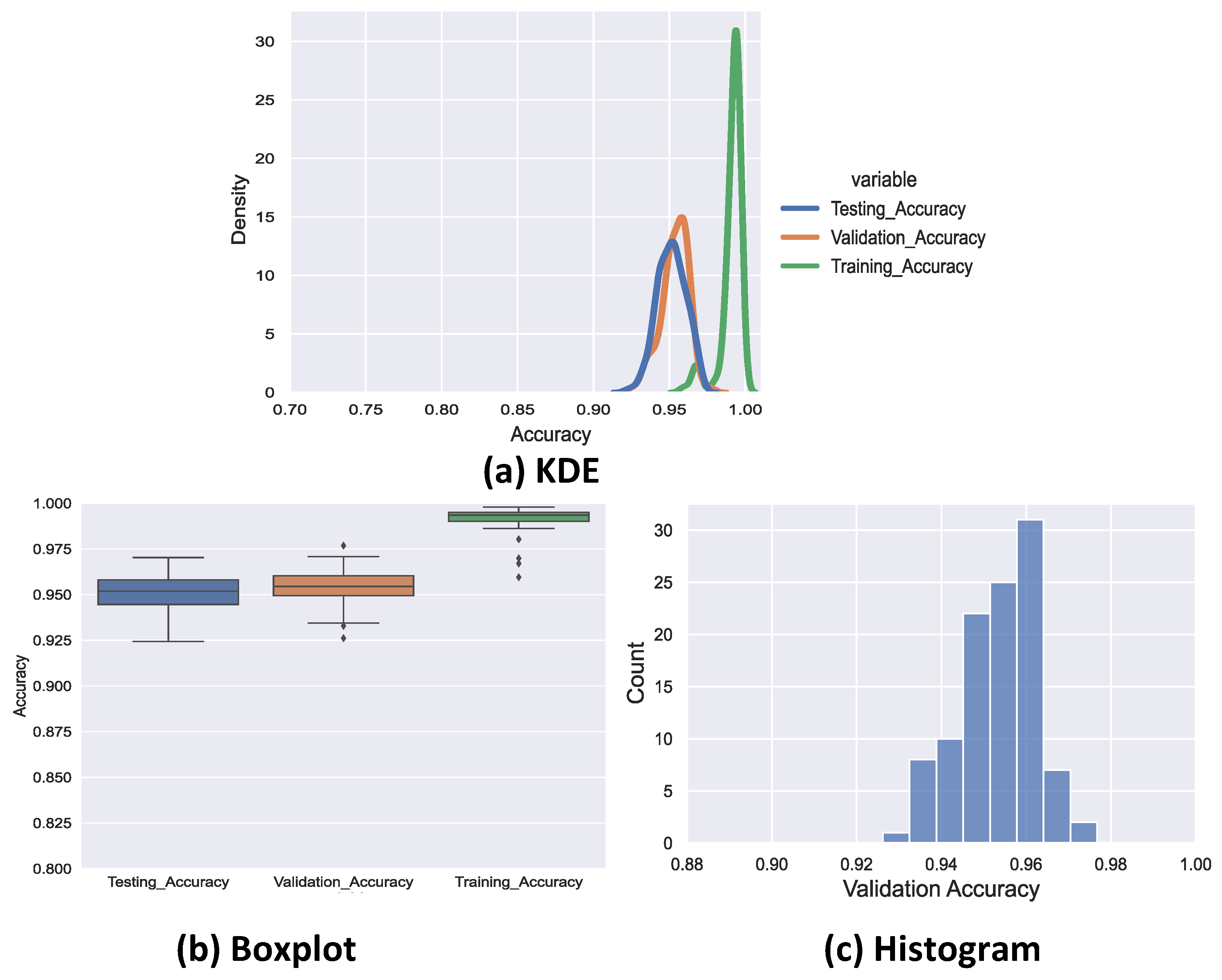
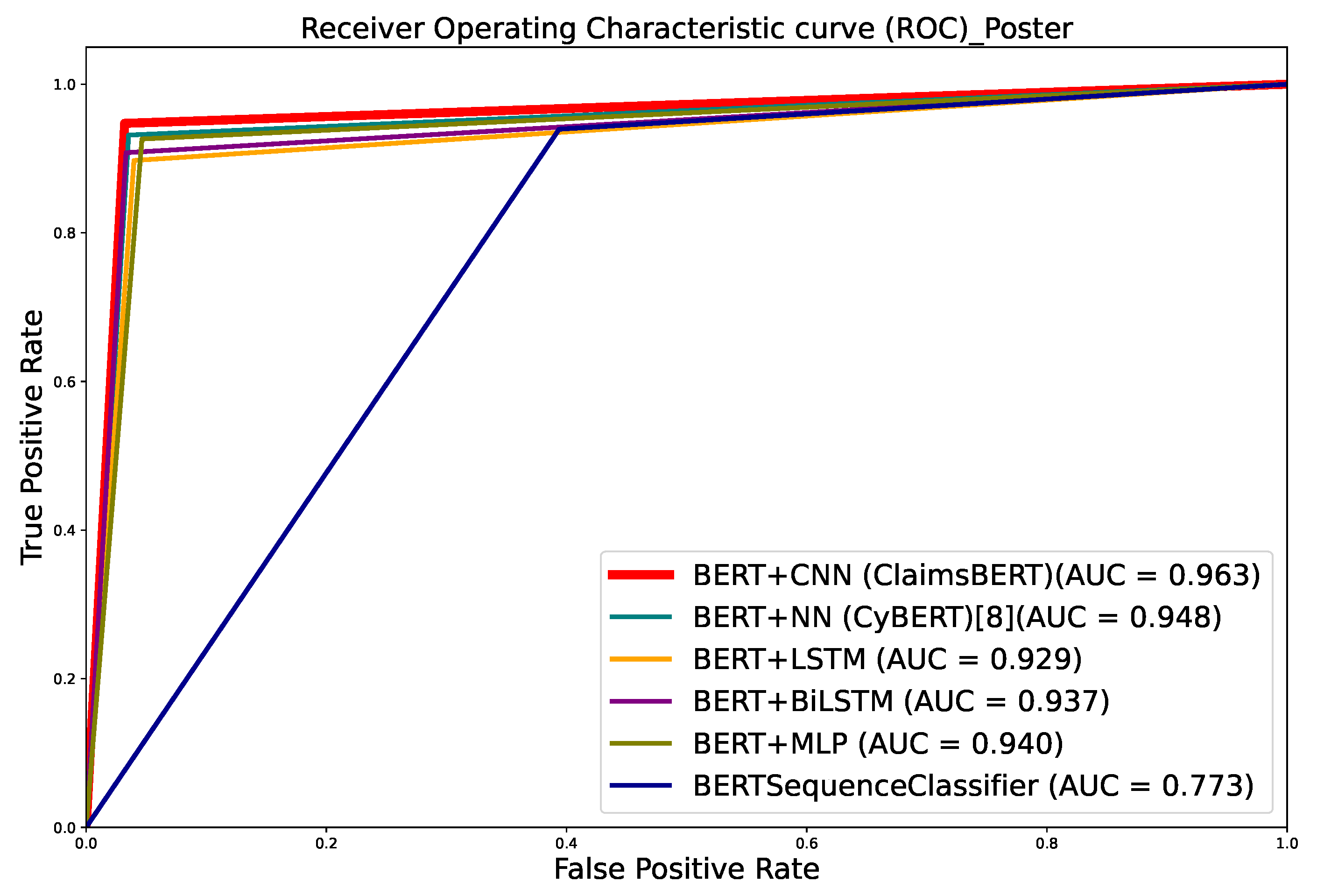
This classifier model marks a significant improvement over BertForSequenceClassification, which is a sequence classifier introduced by BERT. We use our curated cybersecurity claim sequences dataset to train our claim classifier. Our ClaimsBERT model increases the accuracy of the claim sequence classifier compared to BertForSequenceClassification, improving it from 72 to 97 percent. The ClaimsBERT model is established based on the feature map generated via CNN. These convolution layers are able to generate a feature map with smaller overall dimensionality, which helps the model understand the input features more efficiently. We also provided an in-depth comparative analysis of ClaimsBERT to show the effectiveness of our fine-tuning strategies and our hyperparameter selection method.
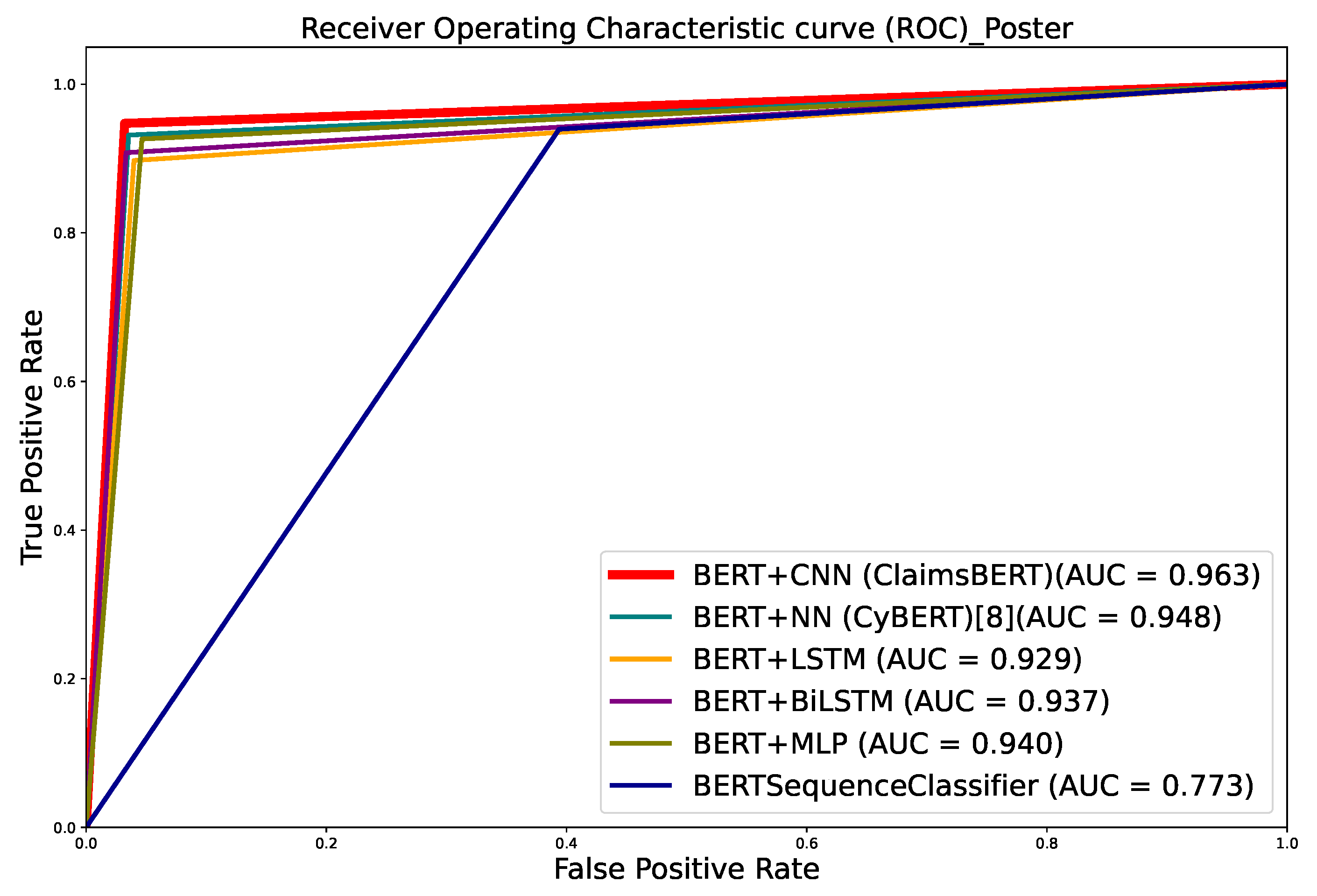
The extensive experimental results demonstrate the effectiveness, efficiency and robustness of our ClaimsBERT classifier. The results demonstrate that the performance of our ClaimsBERT is better than all other language models we tested for this paper.
The development of our novel classification model was inspired by our ongoing research activities that aim to create a new unbiased, objective, and semi-supervised cybersecurity vetting approach named CYVET that focuses on feature set claims for ICS devices, in order to obtain insights into the impact these ICS devices have on an operator’s overall cybersecurity posture. This is based on the detection and verification of vendor claims that are found in device documentation, identified using NLP. In this context, the research advancement presented here represents a fundamental cornerstone of our CYVET program for vetting cybersecurity claims in the broad domain of industrial control systems.
We wish to clarify that while our claims classifier is highly successful in identifying sequences that contain claims, it does not provide an indication of whether this is a claim of interest, or a generic claim unrelated to cybersecurity features. To accomplish this finer distinction, our research efforts are also now focusing on a claims type classifier, which requires a subsequent NLP processing step that follows the use of our ClaimsBERT classifier to detect claim sequences.
Furthermore, this classification does not provide an indication of whether the claim represents a statement in support of this feature, or expressing the lack of this feature. For this support indication, our research has contributed a sentiment analysis capability to our vetting framework that provides this indication. Nevertheless, we note that these steps require additional processing and it would be preferable for ClaimsBERT to provide all of these as an output vector.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}