
Utilizing LLMs and ML Algorithms in Disaster-Related Social Media Content


Abstract
1. Introduction
2. Literature Review
2.1. Utilization of the Social Media Datasets for Disaster Management
- CrisisNLP: CrisisNLP provides resources for crisis informatics research, including annotated datasets of tweets and images from disasters, labeled for various attributes. It also offers tools for tweet downloading, pre-trained models, benchmarked datasets for classification, and large COVID-19 tweet datasets, all aimed at developing computational tools for humanitarian aid [17].
- HumAID: A dataset of human-annotated disaster incidents from Twitter, covering 19 major natural disasters from 2016 to 2019. This dataset focuses specifically on identifying and classifying different types of disaster incidents, providing valuable training data for machine learning models used in emergency response [18].
- CrisisBench: A consolidated dataset combining eight publicly available disaster-related datasets, providing over 166,000 tweets for informativeness classification and over 141,000 tweets for humanitarian classification tasks. By consolidating multiple datasets, CrisisBench offers a larger and more diverse dataset for training and evaluating machine learning models in disaster management [19].
- GeoCoV19: A dataset of over 500 million multilingual tweets related to the COVID-19 pandemic, spanning 218 countries and 47,000 cities. This dataset captures the global impact of the pandemic and provides valuable insights into how social media is used during public health emergencies [20].
- TBCOV: A dataset comprising over two billion multilingual tweets related to the COVID-19 pandemic, with sentiment, named entities, geo, and gender labels. The inclusion of these labels allows for a more nuanced analysis of social media content and enables researchers to study the social and emotional impact of the pandemic [21].
2.2. Challenges and Limitations
2.3. Utilization of LLMs and GenAI
2.4. LLMs and Generative AI for Disaster Management
3. Methodology
3.1. Ground Truth Labeling
- main disaster type: Categorizing the primary type of disaster being discussed from the following list:
- ○
- Earthquake
- ○
- Tsunami
- ○
- Flood
- ○
- Hurricane
- ○
- Wildfire
- ○
- Drought
- ○
- Heatwave
- ○
- Landslide
- ○
- Volcano
- ○
- Tornado
- ○
- Pandemic
- ○
- Famine
- ○
- Conflict
- ○
- Cyberattack
- ○
- Blackout
- ○
- Chemical Spill
- ○
- Nuclear Accident
- ○
- Industrial Accident
- ○
- Mass Shooting
- ○
- Explosion
- ○
- Other
- ○
- N/A
- severity: Assessing the perceived severity of the disaster from the following list:
- ○
- Severe damage
- ○
- Mild damage
- ○
- Little or no damage
- ○
- Do not know or cannot judge
- informative: Indicating whether the tweet contains informative content related to the disaster. Boolean value.
- impact: Describing the type of impact mentioned in the tweet from the following list:
- ○
- Affected individuals
- ○
- Infrastructure and utility damage
- ○
- Injured or dead people
- ○
- Missing or found people
- ○
- Rescue, volunteering, or donation effort
- ○
- Vehicle damage
- ○
- Other relevant information
- ○
- Not relevant
- location mentioned: Identifying if a specific location (country or city) is mentioned in the tweet as free text.
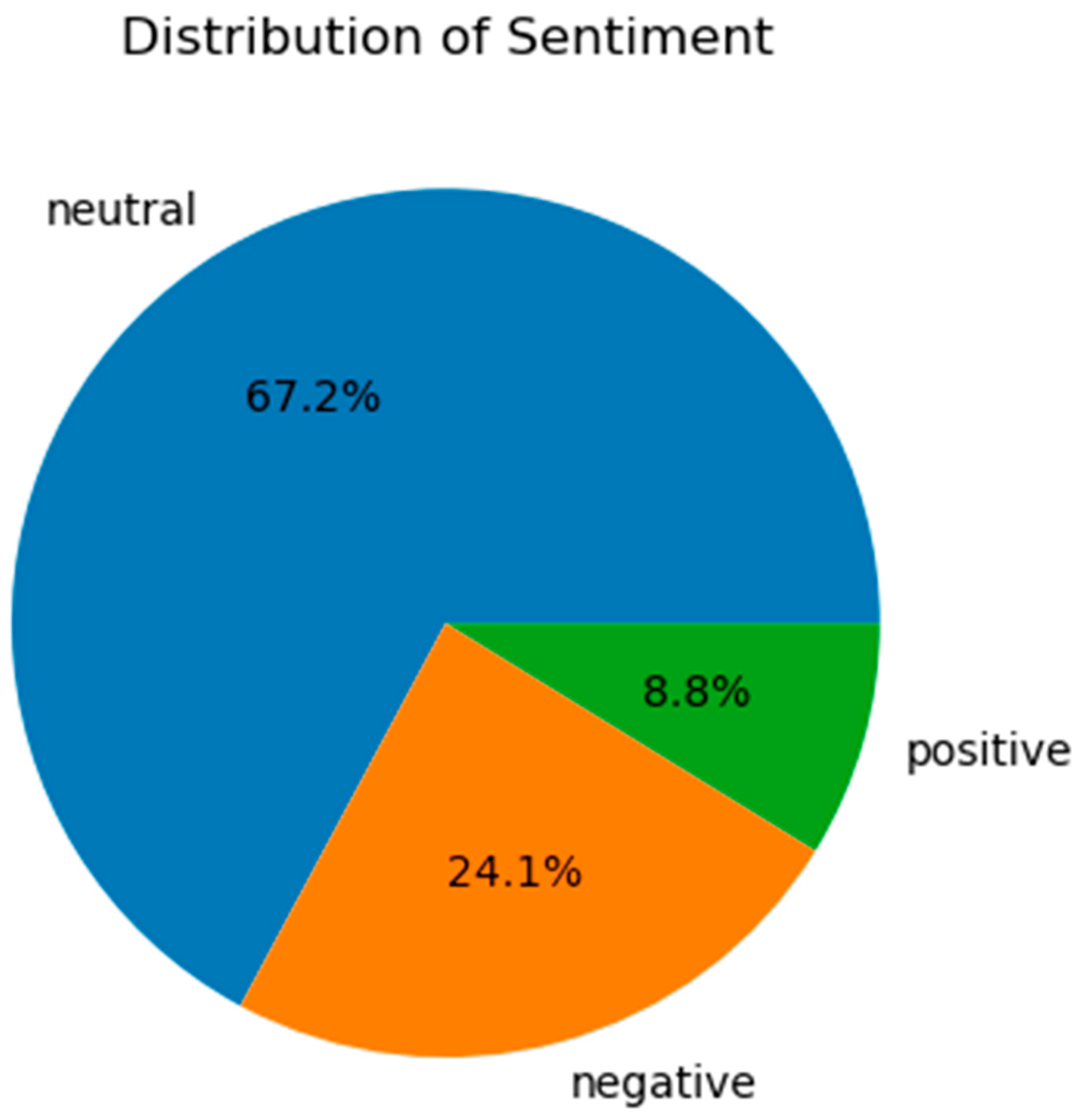
- sentiment: Classifying the overall sentiment expressed in the tweet as positive, negative, or neutral.
3.2. Automated LLM Labeling
3.2.1. Data Preprocessing
3.2.2. LLM Prompting
3.2.3. Output Structuring
3.2.4. Prompt Development and Model Configuration
3.3. Evaluation Methodology
- Accuracy: The proportion of correctly classified instances.
- Precision: The proportion of predicted positive instances that were actually positive.
- Recall: The proportion of actual positive instances that were correctly identified.
- F1-score: The harmonic mean of precision and recall, providing a balanced measure of performance.
3.4. Evaluation Results
4. Dataset Analysis
4.1. Descriptive Analysis of Disaster-Related Tweets
4.2. Unsupervised Text Analysis
4.2.1. Word Cloud Visualization
4.2.2. K-Means Clustering
- Cluster 1: health, public, amp, new
- Cluster 2: damage, property, accident, reported
- Cluster 3: emergency, response, management, environmental
- Cluster 4: disaster, natural, relief, help
4.2.3. Principal Component Analysis (PCA)
4.2.4. Limitations of Unsupervised Techniques for Short-Text Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Centre for Research on the Epidemiology of Disasters (CRED) Institute Health and Society—UCLouvain. 2023 Disasters in Numbers: A Significant Year of Disaster Impact. CRED. 2024. Available online: https://files.emdat.be/reports/2023_EMDAT_report.pdf (accessed on 10 December 2024).
- Imran, M.; Castillo, C.; Diaz, F.; Vieweg, S. Processing Social Media Messages in Mass Emergency: A Survey. ACM Comput. Surv. 2015, 47, 1–38. [Google Scholar] [CrossRef]
- Liu, S.; Brewster, C.; Shaw, D. Ontologies for Crisis Management: A Review of State of the Art in Ontology Design and Usability. In Proceedings of the 10th International ISCRAM Conference, Baden-Baden, Germany, 12–15 May 2013; pp. 349–359. [Google Scholar]
- Linardos, V.; Drakaki, M.; Tzionas, P.; Karnavas, Y. Machine Learning in Disaster Management: Recent Developments in Methods and Applications. Mach. Learn. Know. Extr. 2022, 4, 446–473. [Google Scholar] [CrossRef]
- Wang, Z.; Ye, X.; Tsou, M.H. Spatial, temporal, and content analysis of Twitter for wildfire hazards. Nat. Hazards 2016, 83, 523–540. [Google Scholar] [CrossRef]
- Jongman, B.; Wagemaker, J.; Romero, B.R.; De Perez, E.C. Early Flood Detection for Rapid Humanitarian Response: Harnessing Near Real-Time Satellite and Twitter Signals. ISPRS Int. J. Geo-Inf. 2015, 4, 2246–2266. [Google Scholar] [CrossRef]
- Avvenuti, M.; Cresci, S.; Marchetti, A.; Meletti, C.; Tesconi, M. EARS (Earthquake Alert and Report System): A Real Time Decision Support System for Earthquake Crisis Management. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1749–1758. [Google Scholar]
- Wang, Z.; Ye, X. Social Media Analytics for Natural Disaster Management. Int. J. Gegr. Inf. Sci. 2018, 32, 49–72. [Google Scholar] [CrossRef]
- Alam, F.; Ofli, F.; Imran, M. CrisisMMD: Multimodal Twitter Datasets from Natural Disasters. In Proceedings of the 12th International AAAI Conference on Web and Social Media, Stanford, CA, USA, 25–28 June 2018; pp. 465–473. [Google Scholar]
- Linardos, V.; Drakaki, M.; Tzionas, P. A transformers-based approach on industrial disaster consequence identification from accident narratives. Procedia Comput. Sci. 2023, 217, 1446–1451. [Google Scholar] [CrossRef]
- Houston, J.B.; Hawthorne, J.; Perreault, M.F.; Park, E.H.; Goldstein Hode, M.; Halliwell, M.R.; McElderry, J.A.; Griffith, S.A. Social Media and Disasters: A Functional Framework for Social Media Use in Disaster Planning, Response, and Research. Disasters 2015, 39, 1–22. [Google Scholar] [CrossRef]
- Alam, F.; Ofli, F.; Imran, M.; Aupetit, M. A Twitter Tale of Three Hurricanes: Harvey, Irma, and Maria. In Proceedings of the 15th International ISCRAM Conference, Rochester, NY, USA, 20–23 May 2018; pp. 553–562. [Google Scholar]
- Zou, L.; Lam, N.S.N.; Cai, H.; Qiang, Y. Mining Twitter Data for Improved Understanding of Disaster Resilience. Ann. Am. Assoc. Geogr. 2018, 108, 1422–1441. [Google Scholar] [CrossRef]
- Gruebner, O.; Lowe, S.R.; Sykora, M.; Galea, S.; Subramanian, S.V.; Shankardass, K. A Novel Surveillance Approach for Disaster Mental Health. PLoS ONE 2017, 12, e0181233. [Google Scholar] [CrossRef]
- Weber, E.; Papadopoulos, D.; Lapedriza, À.; Ofli, F.; Imran, M.; Torralba, A. Incidents1M: A large-scale dataset of images with natural disasters, damage, and incidents. Trans. Pattern Anal. Mach. Intell. 2023, 45, 4768–4781. [Google Scholar] [CrossRef]
- Linardos, V.; Drakaki, M. Assessing the Impact of the 2021 Evia Wildfires through Social Media Analysis. In Proceedings of the International Conference on Humanitarian Crisis Management (KRISIS 2023); Drakaki, M., Vega, D., Eds.; Institute for the Management of Refugee Flows and Crises, University Research Center, International Hellenic University: Thessaloniki, Greece, 2023; ISBN 978-618-5630-17-1. Available online: https://www.ihu.gr/ucips/wp-content/uploads/sites/4/2023/12/KRISIS_2023_paper_14_Linardos_-et-al.pdf (accessed on 1 October 2024).
- Imran, M.; Mitra, P.; Castillo, C. Twitter as a Lifeline: Human-annotated Twitter Corpora for NLP of Crisis-related Messages. In Proceedings of the 10th International Conference on Language Resources and Evaluation, Portorož, Slovenia, 23–28 May 2016; pp. 1638–1643. [Google Scholar]
- Alam, F.; Ofli, F.; Imran, M. HumAID: Human-Annotated Disaster Incidents Data from Twitter with Deep Learning Benchmarks. In Proceedings of the 14th International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 8–11 June 2020; pp. 15–25. [Google Scholar]
- Alam, F.; Sajjad, H.; Imran, M.; Ofli, F. CrisisBench: Benchmarking Crisis-related Social Media Datasets for Humanitarian Information Processing. In Proceedings of the 15th International AAAI Conference on Web and Social Media, Virtual Event, 7–10 June 2021; pp. 923–932. [Google Scholar]
- Qazi, U.; Imran, M.; Ofli, F. GeoCoV19: A Dataset of Hundreds of Millions of Multilingual COVID-19 Tweets with Location Information. SIGSPATIAL Spec. 2020, 12, 6–15. [Google Scholar] [CrossRef]
- Banda, J.M.; Tekumalla, R.; Wang, G.; Yu, J.; Liu, T.; Ding, Y.; Artemova, E.; Tutubalina, E.; Chowell, G. A Large-scale COVID-19 Twitter Chatter Dataset for Open Scientific Research—An International Collaboration. Epidemiologia 2021, 2, 315–324. [Google Scholar] [CrossRef] [PubMed]
- Starbird, K.; Maddock, J.; Orand, M.; Achterman, P.; Mason, R.M. Rumors, False Flags, and Digital Vigilantes: Misinformation on Twitter after the 2013 Boston Marathon Bombing. In Proceedings of the 8th International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; pp. 654–657. [Google Scholar]
- Shen, H.; Ju, Y.; Zhu, Z. Extracting Useful Emergency Information from Social Media: A Method Integrating Machine Learning and Rule-Based Classification. Int. J. Environ. Res. Public Health 2023, 20, 1862. [Google Scholar] [CrossRef]
- Palen, L.; Anderson, K.M. Crisis Informatics—New Data for Extraordinary Times. Science 2016, 353, 224–225. [Google Scholar] [CrossRef]
- Crawford, K.; Finn, M. The Limits of Crisis Data: Analytical and Ethical Challenges of Using Social and Mobile Data to Understand Disasters. GeoJournal 2015, 80, 491–502. [Google Scholar] [CrossRef]
- Hughes, A.L.; Palen, L. Twitter Adoption and Use in Mass Convergence and Emergency Events. Int. J. Emerg. Manag. 2009, 6, 248–260. [Google Scholar] [CrossRef]
- Otal, H.T.; Stern, E.; Canbaz, M.A. LLM-Assisted Crisis Management: Building Advanced LLM Platforms for Effective Emergency Response and Public Collaboration. In Proceedings of the 2024 IEEE Conference on Artificial Intelligence (CAI), Singapore, 25–27 June 2024. [Google Scholar]
- Chamola, V.; Hassija, V.; Gupta, S.; Goyal, A.; Guizani, M.; Sikdar, B. Disaster and Pandemic Management Using Machine Learning: A Survey. IEEE Internet Things J. 2021, 8, 13749–13768. [Google Scholar] [CrossRef]
- CIMA Research Foundation. The Large Language Model for Disaster Risk Reduction. CIMA Research Foundation, 2024. Available online: https://www.cimafoundation.org/en/news/the-large-language-model-for-disaster-risk-reduction/ (accessed on 10 March 2025).
- Deparday, V.; Gevaert, C.M.; Molinario, G.M.; Soden, R.J.; Balog-Way, S.; Andrea, B. Machine Learning for Disaster Risk Management (English); World Bank Group: Washington, DC, USA, 2019; Available online: http://documents.worldbank.org/curated/en/503591547666118137 (accessed on 12 December 2024).
- Federal Emergency Management Agency. Planning Assistance Resource Center (PARC): Leveraging AI for Community Resilience; FEMA Technical Report; Federal Emergency Management Agency: Washington, DC, USA, 2023.
- United Nations Office for Disaster Risk Reduction. 2023 Global Assessment Report on Disaster Risk Reduction; UNDRR: Geneva, Switzerland, 2023. [Google Scholar]
- Smith, A.B.; Brown, C.D.; Jones, E.F. Assessing the utility of social media as a data source for flood risk management using a real-time modelling framework. J. Flood Risk Manag. 2015, 10, 370–380. [Google Scholar] [CrossRef]
- Moody’s Analytics. “Disruption” Doesn’t Cover It: 3 Ways GenAI is Upending Commercial Real Estate. Available online: https://www.moodyscre.com/insights/cre-news/disruption-doesnt-cover-it-3-ways-genai-is-upending-commercial-real-estate (accessed on 10 January 2025).
- Benigni, M.C.; Joseph, K.; Carley, K.M. Online Extremism and the Communities That Sustain It: Detecting the ISIS Supporting Community on Twitter. PLoS ONE 2017, 12, e0181405. [Google Scholar] [CrossRef]
- World Food Programme. The Benefits of Machine Learning in Emergencies from River DEEP to Mountain SKAI. WFP Drones. 2022. Available online: https://drones.wfp.org/updates/benefits-machine-learning-emergencies-river-deep-mountain-skai (accessed on 20 September 2024).
- Prevention Web. Machine Learning Model Uses Social Media for More Accurate Wildfire Monitoring. Prevention Web, 2022. Available online: https://www.preventionweb.net/news/machine-learning-model-uses-social-media-more-accurate-wildfire-monitoring (accessed on 12 September 2024).
- Illinois Institute of Technology. Tapping Social Media and AI for Faster Disaster Response. IIT News. 2023. Available online: https://www.iit.edu/news/tapping-social-media-and-ai-faster-disaster-response (accessed on 18 November 2024).
- Dikmener, G.; Nothnagel, R.; Akylbekova, D.; Szigeti, M.; Jung, Y.; Turunen, T.; Huihua, H.; Radjy, S. Innovation in Disaster Management: Leveraging Technology to Save More Lives. UNDP and OCHA 2023. 2023. Available online: https://www.undp.org/policy-centre/istanbul/publications/innovation-disaster-management-leveraging-technology-save-more-lives (accessed on 10 February 2025).
- Caragea, C.; Silvescu, A.; Tapia, A.H. Identifying Informative Messages in Disaster Events using Convolutional Neural Networks. In Proceedings of the 13th International ISCRAM Conference, Rio de Janeiro, Brazil, 22–25 May 2016. [Google Scholar]
- Li, X.; Caragea, D.; Zhang, H.; Imran, M. Visual and Textual Analysis of Social Media and Satellite Images for Disaster Type Detection. In Proceedings of the 16th International ISCRAM Conference, Valencia, Spain, 19–22 May 2019; pp. 752–764. [Google Scholar]
- Xu, L.; Li, X.; Zhang, H.; Caragea, D. Disaster Image Classification by Fusing Multimodal Social Media Data. ISPRS Int. J. Geo-Inf. 2021, 10, 636. [Google Scholar]
- Petersen, K.; Büscher, M.; Kuhnert, M. Designing with Users: Co-Design for Innovation in Emergency Technologies. In Proceedings of the 10th International ISCRAM Conference, Baden-Baden, Germany, 12–15 May 2013; pp. 319–328. [Google Scholar]
- Homeland Security. Federal Emergency Management Agency—AI Use Cases. Available online: https://www.dhs.gov/ai/use-case-inventory/fema (accessed on 8 April 2025).
- Google. Wildfire Boundary Tracking. Available online: https://sites.research.google/gr/wildfires/boundary-tracking (accessed on 28 March 2025).
- European Centre for Medium-Range Weather Forecasts. AI Forecasting Systems Outperform Traditional Models in Hurricane Tracking; ECMWF: Reading, UK, 2023. [Google Scholar]
- Zade, H.; Shah, K.; Rangarajan, V.; Kuwajima, H.; Crooks, A.; Tandon, P.; Palen, L.; Starbird, K. From Situational Awareness to Actionability: Towards Improving the Utility of Social Media Data for Crisis Response. Proc. ACM Hum. Comput. Interact. 2018, 2, 1–18. [Google Scholar] [CrossRef]
- Yin, K.; Liu, C.; Mostafavi, A.; Hu, X. CrisisSense-LLM: Instruction Fine-Tuned Large Language Model for Multi-label Social Media Text Classification in Disaster Informatics. arXiv 2024, arXiv:2406.15477. [Google Scholar]
- Zhang, Z. A Global Multimodal Flood Event Dataset with Heterogeneous Text and Multi-Source Remote Sensing Images. Big Earth Data 2024, 8, 2358615. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Stogaitis, M.; Gadh, T.; Allen, R.M.; Barski, A.; Bosch, R.; Robertson, P.; Cho, Y.; Thiruverahan, N.; Raj, A. Gemini and Physical World: Large Language Models Can Estimate the Intensity of Earthquake Shaking from Multimodal Social Media Posts. Geophys. J. Int. 2024, 240, 1281–1294. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| main disaster type | 0.7204 | 0.7275 | 0.7204 | 0.7025 |
| severity | 0.7087 | 0.6741 | 0.7087 | 0.6601 |
| informative | 0.8085 | 0.8200 | 0.8085 | 0.8098 |
| impact | 0.7172 | 0.7004 | 0.7172 | 0.6869 |
| location mentioned | 0.8360 | 0.8768 | 0.8360 | 0.8464 |
| sentiment | 0.8561 | 0.9052 | 0.8561 | 0.8700 |
| overall | 0.2896 | 0.7840 | 0.7745 | 0.7626 |
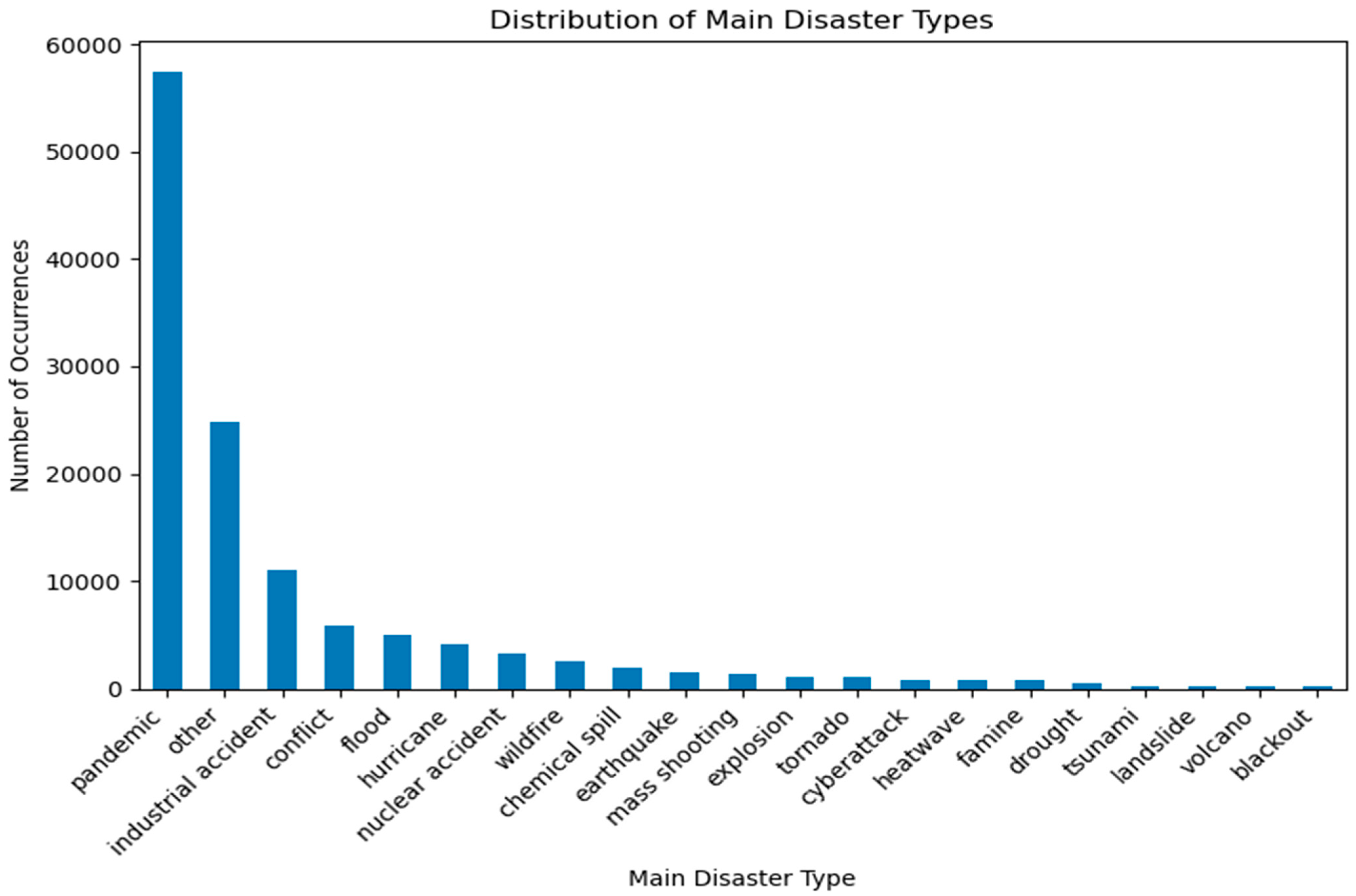
| Disaster Type | Count (No. of Tweets) | Percentage |
|---|---|---|
| Pandemic | 57,384 | 45.74% |
| Other | 24,792 | 19.76% |
| Industrial Accident | 11,060 | 8.82% |
| Conflict | 5832 | 4.65% |
| Flood | 5007 | 3.99% |
| Hurricane | 4197 | 3.35% |
| Nuclear Accident | 3328 | 2.65% |
| Wildfire | 2498 | 1.99% |
| Chemical Spill | 1942 | 1.55% |
| Earthquake | 1586 | 1.26% |
| Mass Shooting | 1448 | 1.15% |
| Explosion | 1167 | 0.93% |
| Tornado | 1084 | 0.86% |
| Cyberattack | 880 | 0.70% |
| Heatwave | 870 | 0.69% |
| Famine | 862 | 0.69% |
| Drought | 479 | 0.38% |
| Tsunami | 292 | 0.23% |
| Landslide | 282 | 0.22% |
| Volcano | 260 | 0.21% |
| Blackout | 210 | 0.17% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Linardos, V.; Drakaki, M.; Tzionas, P. Utilizing LLMs and ML Algorithms in Disaster-Related Social Media Content. GeoHazards 2025, 6, 33. https://doi.org/10.3390/geohazards6030033
Linardos V, Drakaki M, Tzionas P. Utilizing LLMs and ML Algorithms in Disaster-Related Social Media Content. GeoHazards. 2025; 6(3):33. https://doi.org/10.3390/geohazards6030033
Chicago/Turabian StyleLinardos, Vasileios, Maria Drakaki, and Panagiotis Tzionas. 2025. "Utilizing LLMs and ML Algorithms in Disaster-Related Social Media Content" GeoHazards 6, no. 3: 33. https://doi.org/10.3390/geohazards6030033
APA StyleLinardos, V., Drakaki, M., & Tzionas, P. (2025). Utilizing LLMs and ML Algorithms in Disaster-Related Social Media Content. GeoHazards, 6(3), 33. https://doi.org/10.3390/geohazards6030033