
Machine-Learning-Based Hybrid Modeling for Geological Hazard Susceptibility Assessment in Wudou District, Bailong River Basin, China


Abstract
1. Introduction
2. Study Area and Data
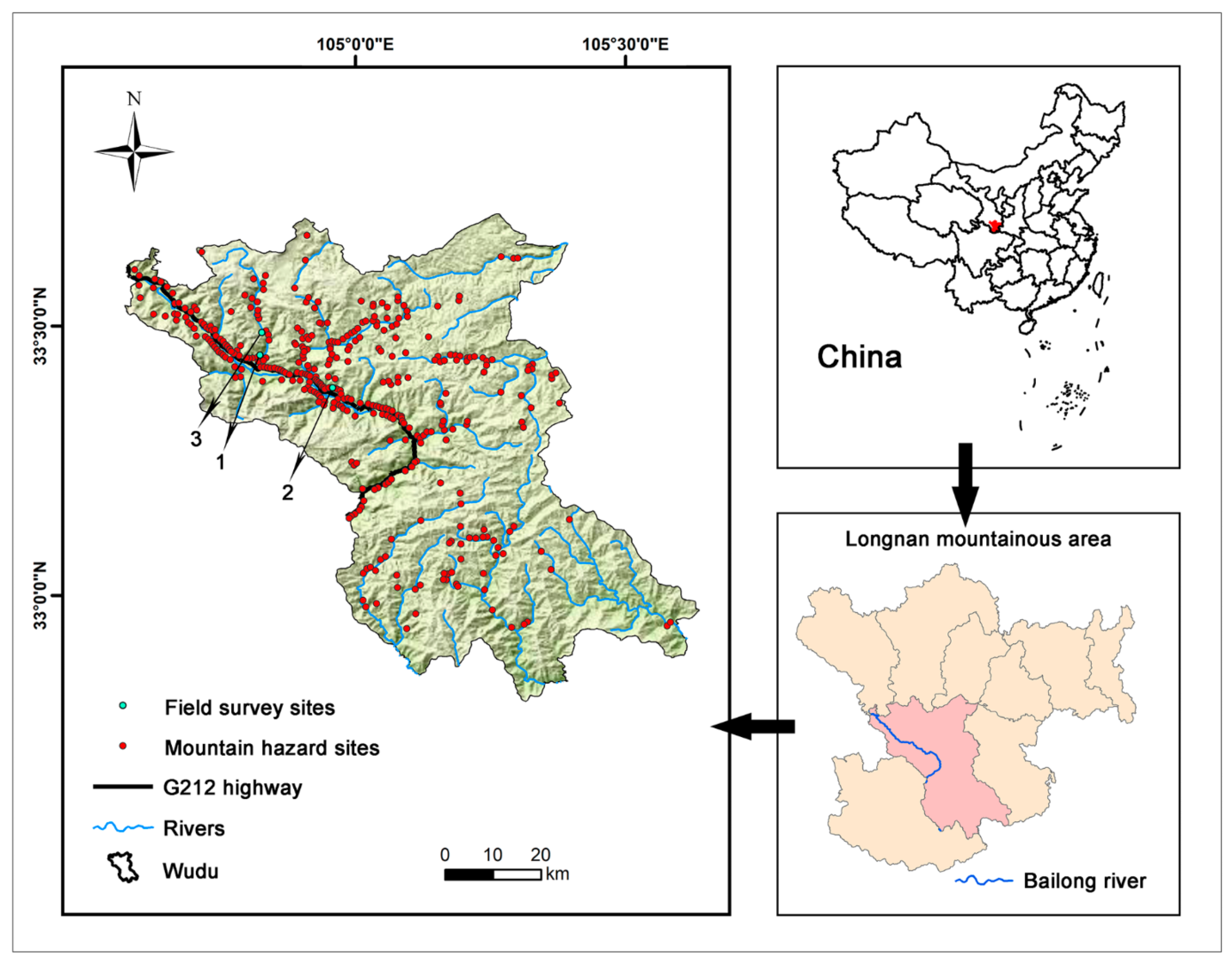
2.1. Study Area
2.2. Data Preparation
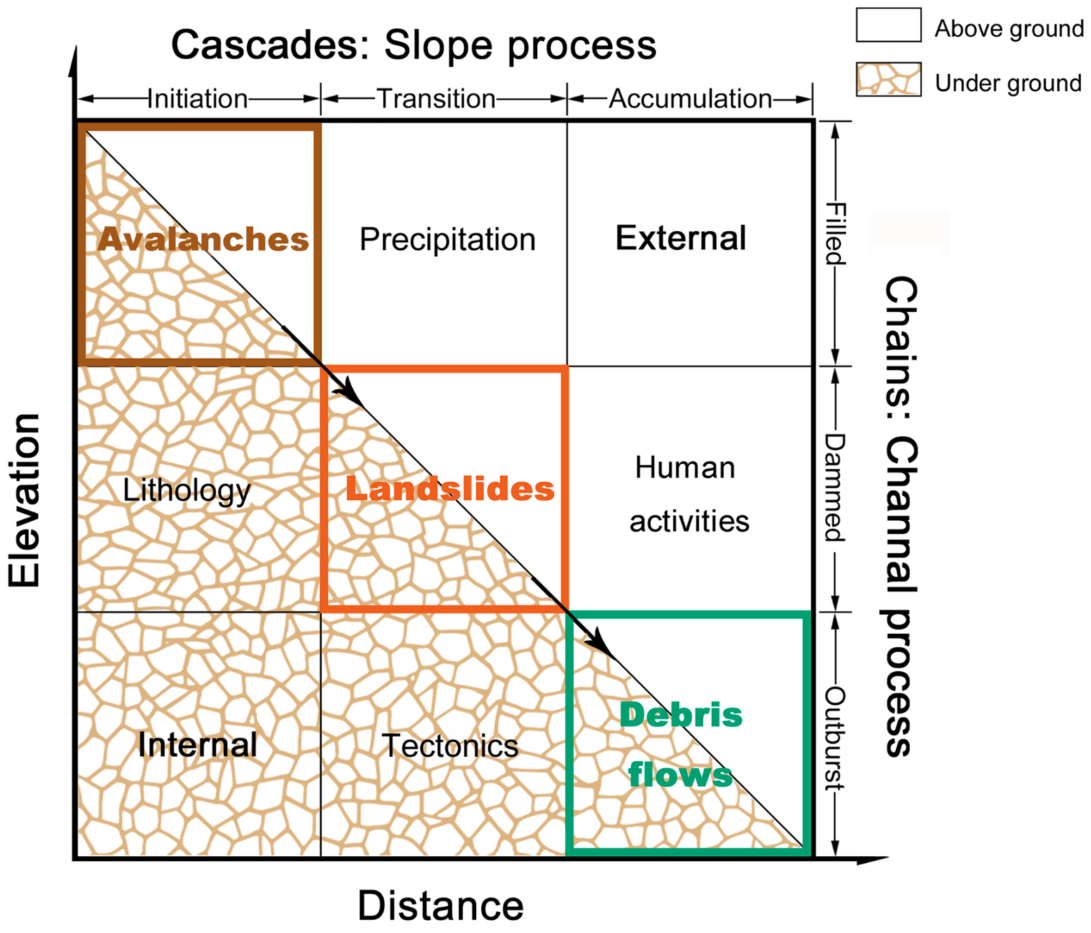
2.2.1. Mountain Hazard Inventory
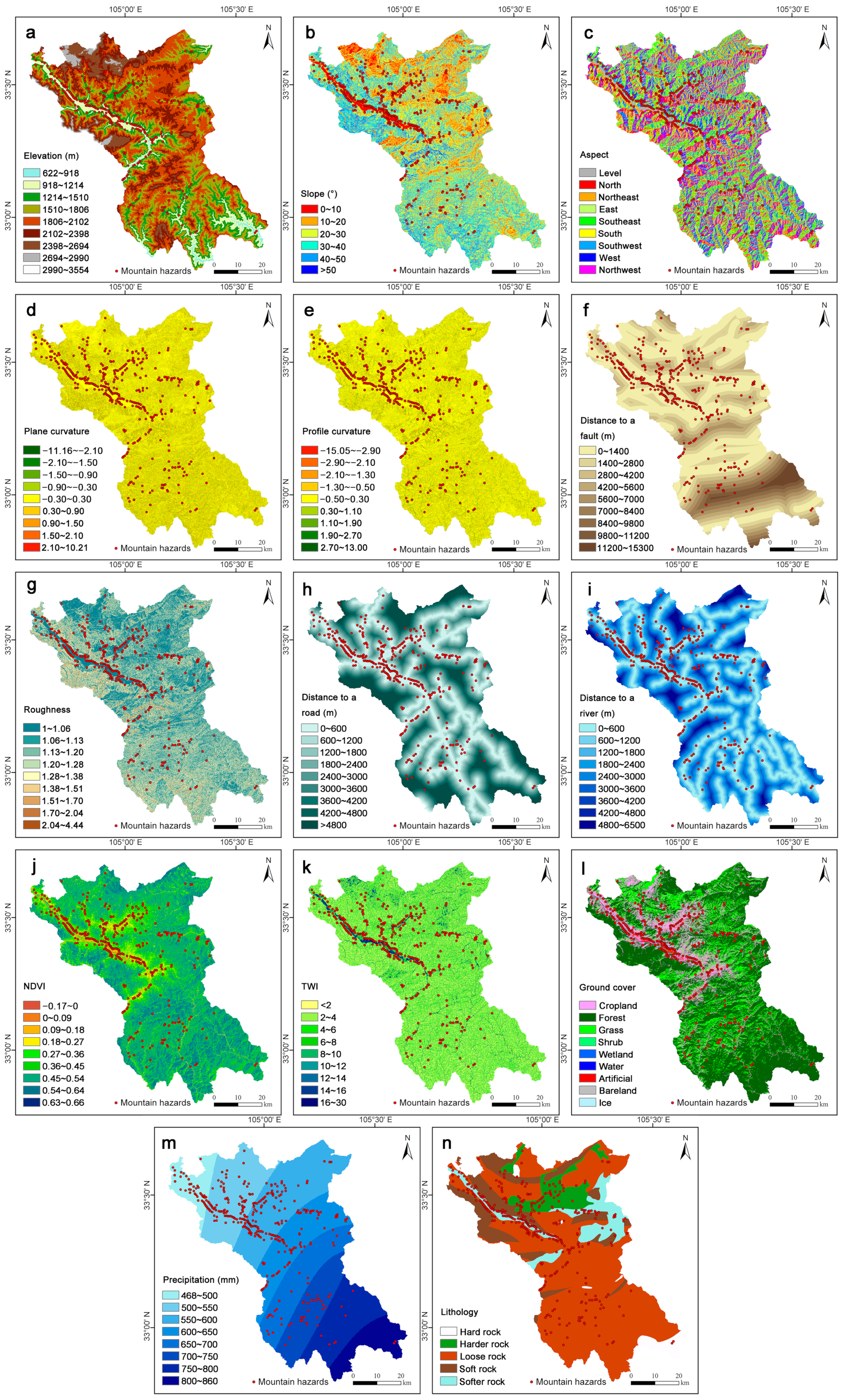
2.2.2. Mountain Hazard Influencing Factors
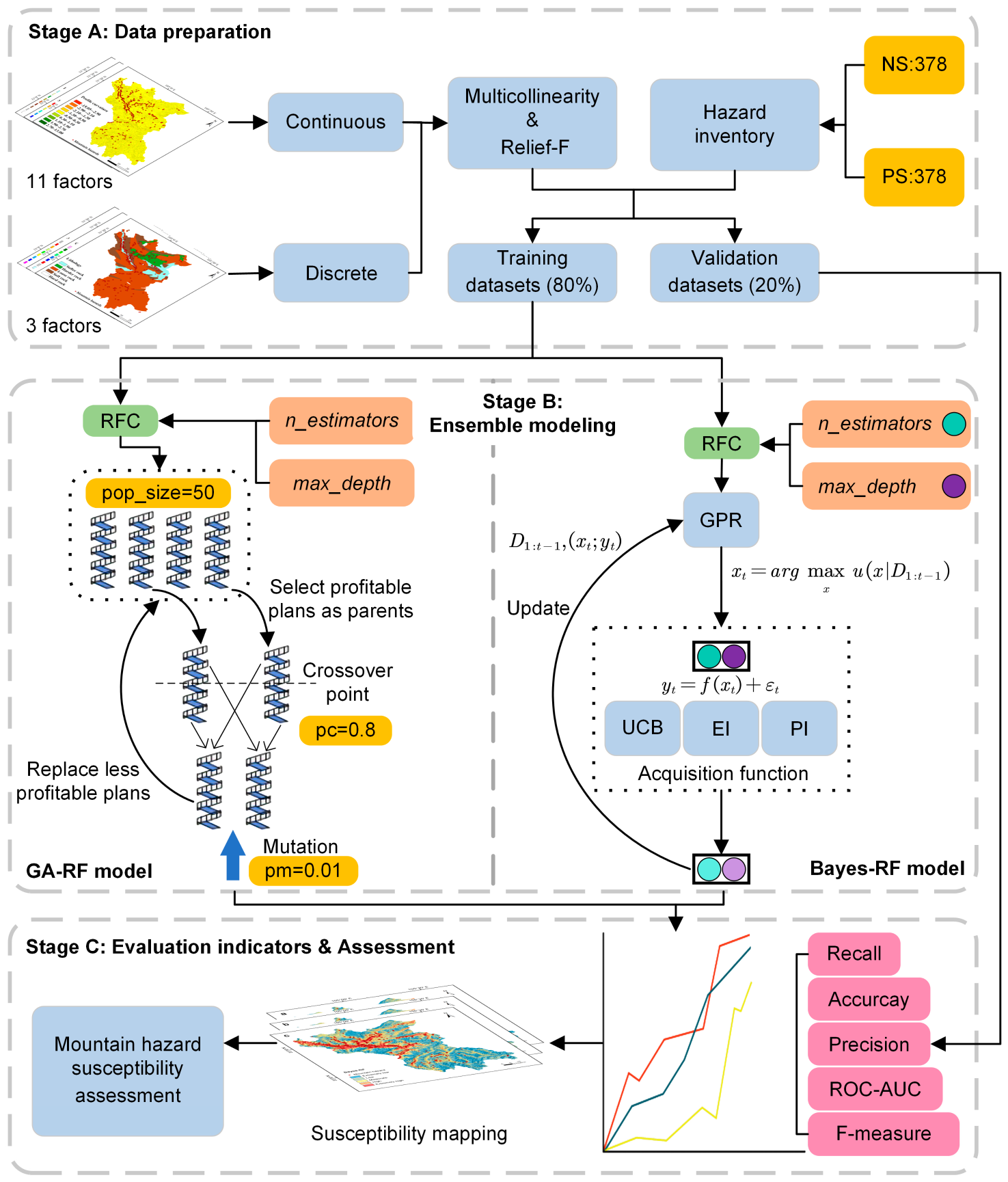
3. Methodology
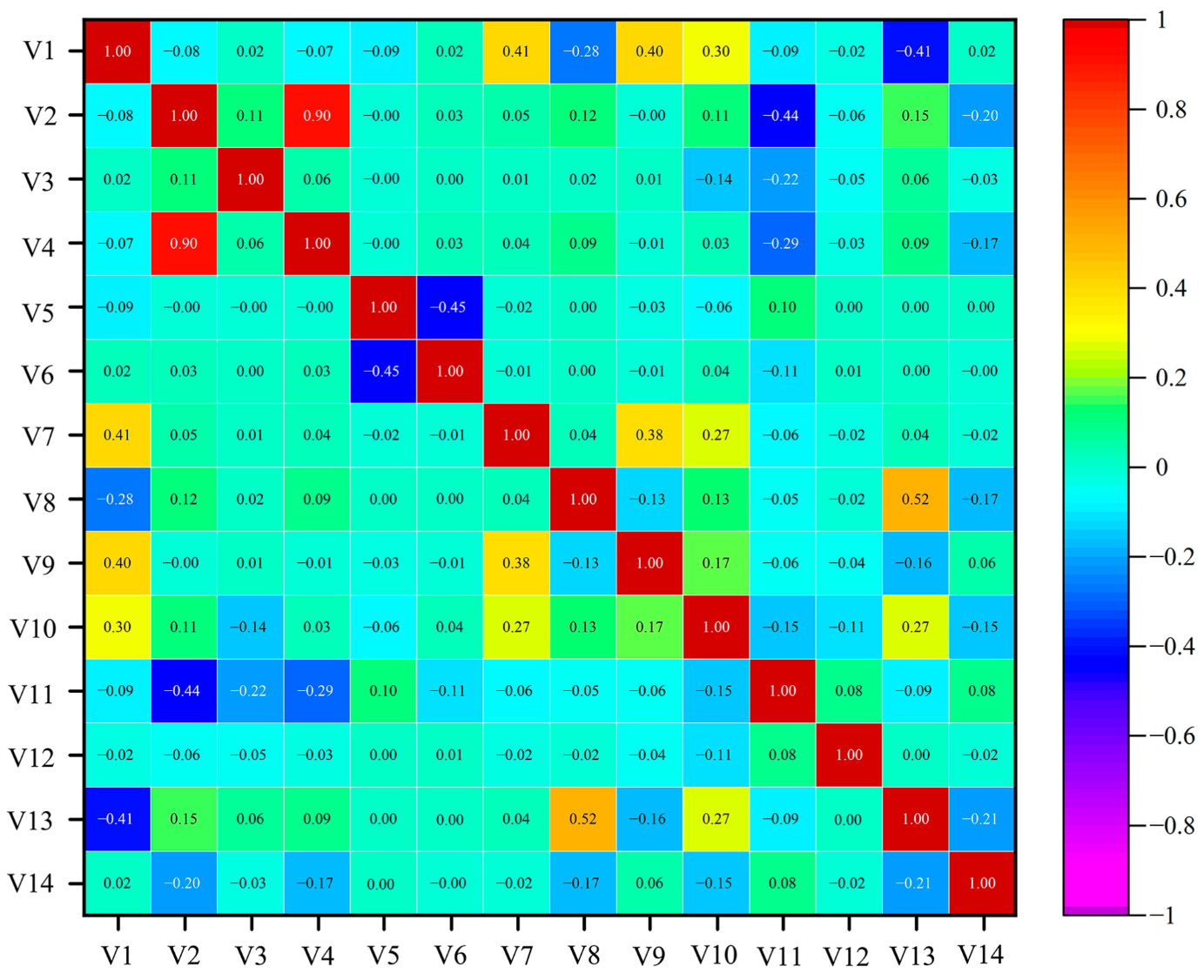
3.1. Evaluation of Influencing Factors
3.1.1. Multicollinearity Analysis
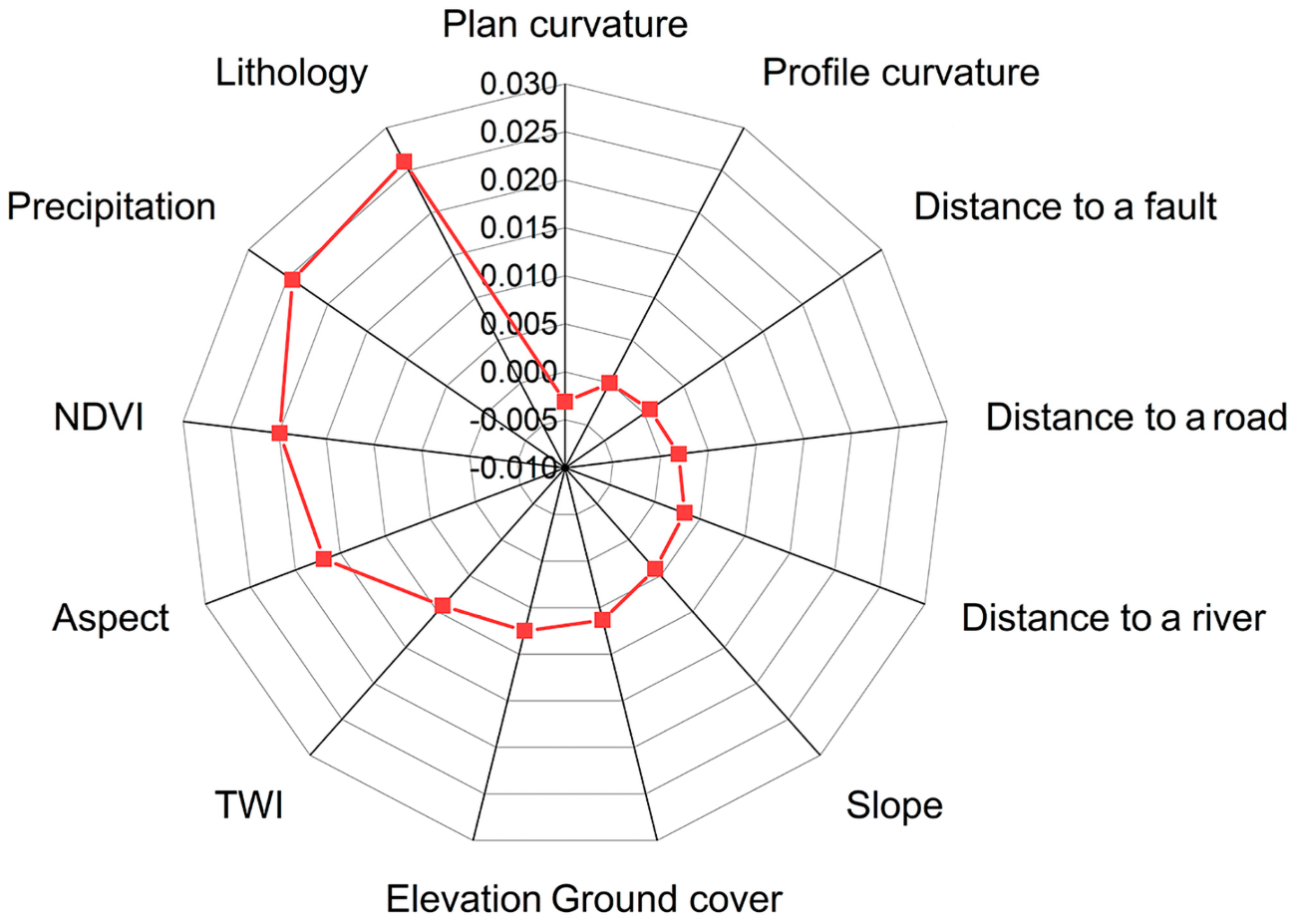
3.1.2. Relief-F
3.2. Random Forest (RF)
- A training set is formed by sampling N times from N original samples in the form of sample bagging. The unsampled samples are called Out-Of-Bag (OOB) data and can be used to evaluate the model’s performance; this is known as OOB estimation.
- For each training set, a decision tree is generated. Assuming that the sample has M features and the number of features F ≤ M is specified, F features are randomly selected from the M features as the split feature set at each internal node of the decision tree, and the node is split by the best split in the split feature set. The value of F is generally kept constant and is usually taken as F = M/3 for the regression and as shown in (6) for the classification.
- 3.
- Decision trees are generated using classification and regression tree algorithms with each tree growing freely without pruning.
- 4.
- The above steps are repeated k times to obtain a total of k training sets, forming k decision trees, where each tree corresponding to the unselected sample set forms a total of k out-of-bag data points.
- 5.
- The generated k decision trees form an RF, and a regression analysis or classification prediction is performed on the new data. When used for regression, the final result is the mean of the computed results of each tree. When used for classification, the final result is generated by voting on the results of each tree.
3.3. Optimization Algorithm
3.3.1. Bayesian Hyperparameter Optimization
3.3.2. Genetic Algorithm (GA) Hyperparameter Optimization
3.4. Model Validation and Comparison
3.4.1. Model Performance Evaluation Metrics
3.4.2. Mountain Hazard Susceptibility Mapping
4. Results
4.1. Importance of Influencing Factors
4.2. Hyperparametric Optimized RF Model
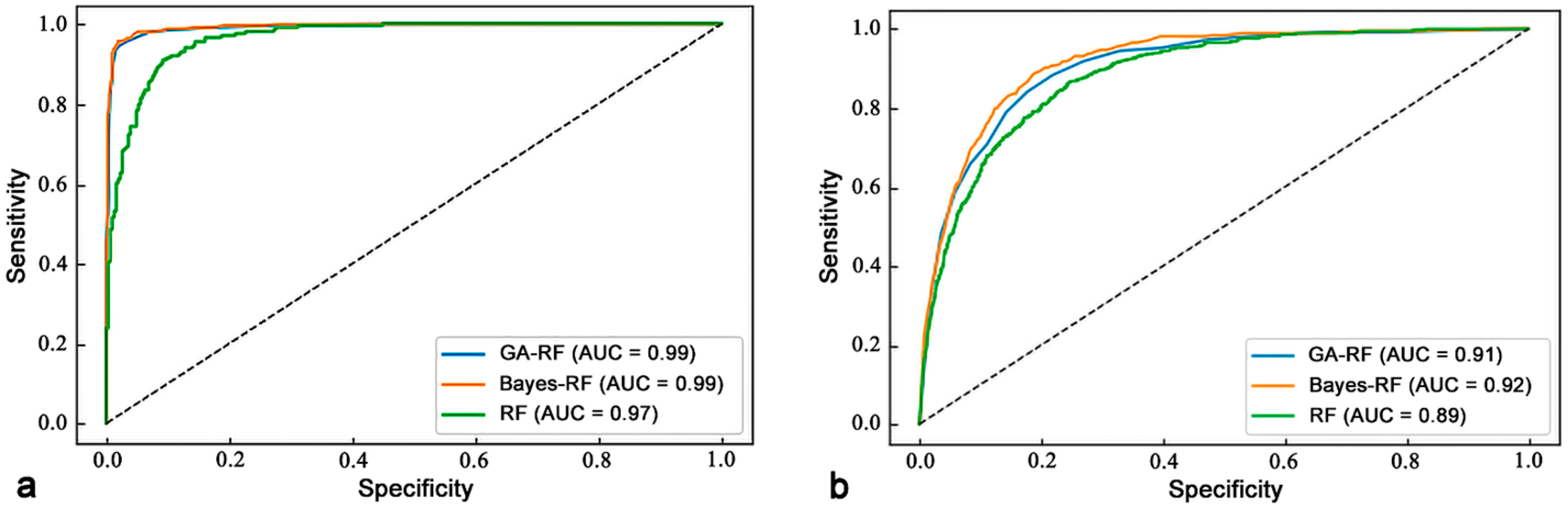
4.3. Model Validation and Comparison
5. Discussion
5.1. Susceptibility Responses to Human Activities
5.2. Model Optimization and Performance Improvement
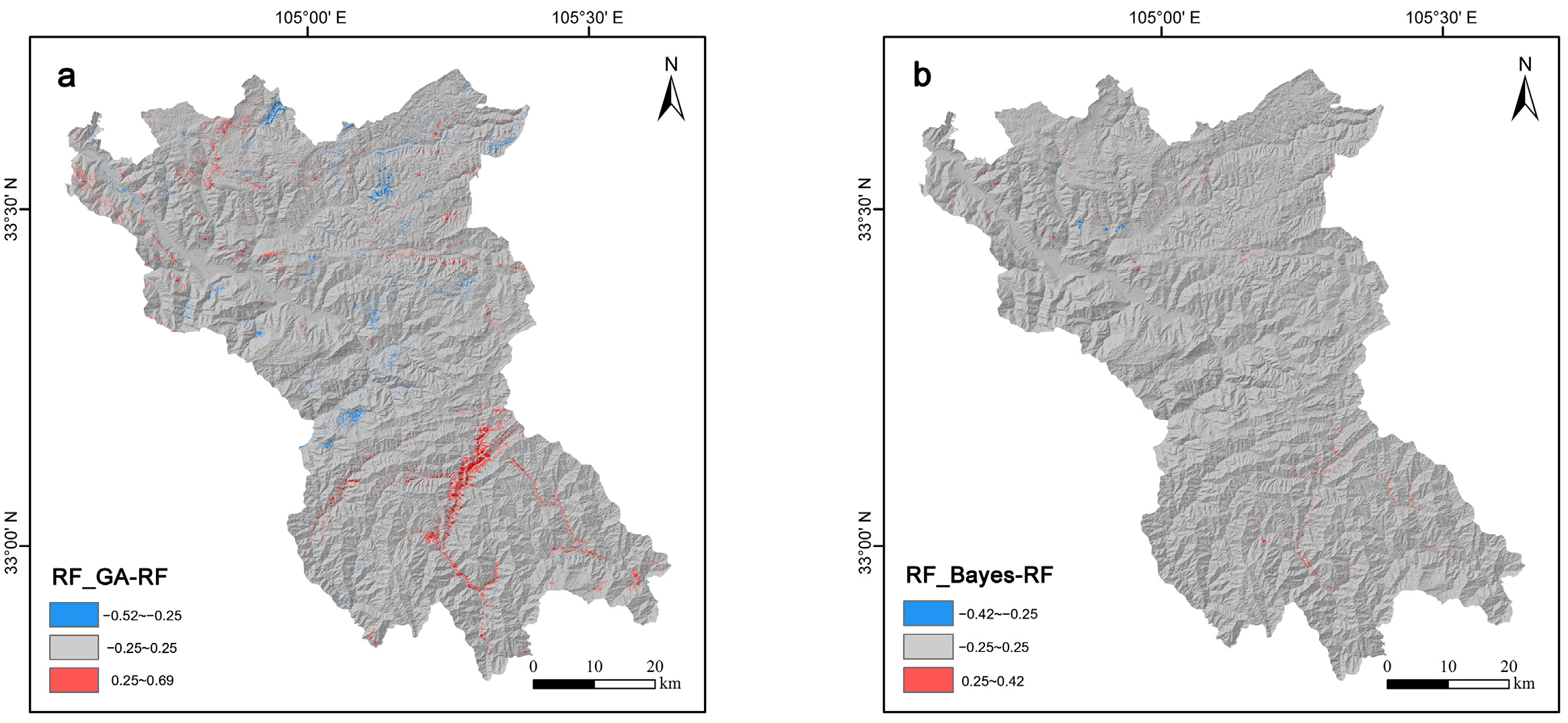
5.3. Assessment of Susceptibility Mapping Accuracy
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Value | Type | Pixels in Domain | Pixel (%) | Hazard Points | Hazard (%) | FR |
|---|---|---|---|---|---|---|---|
| Geomorphology and structure | |||||||
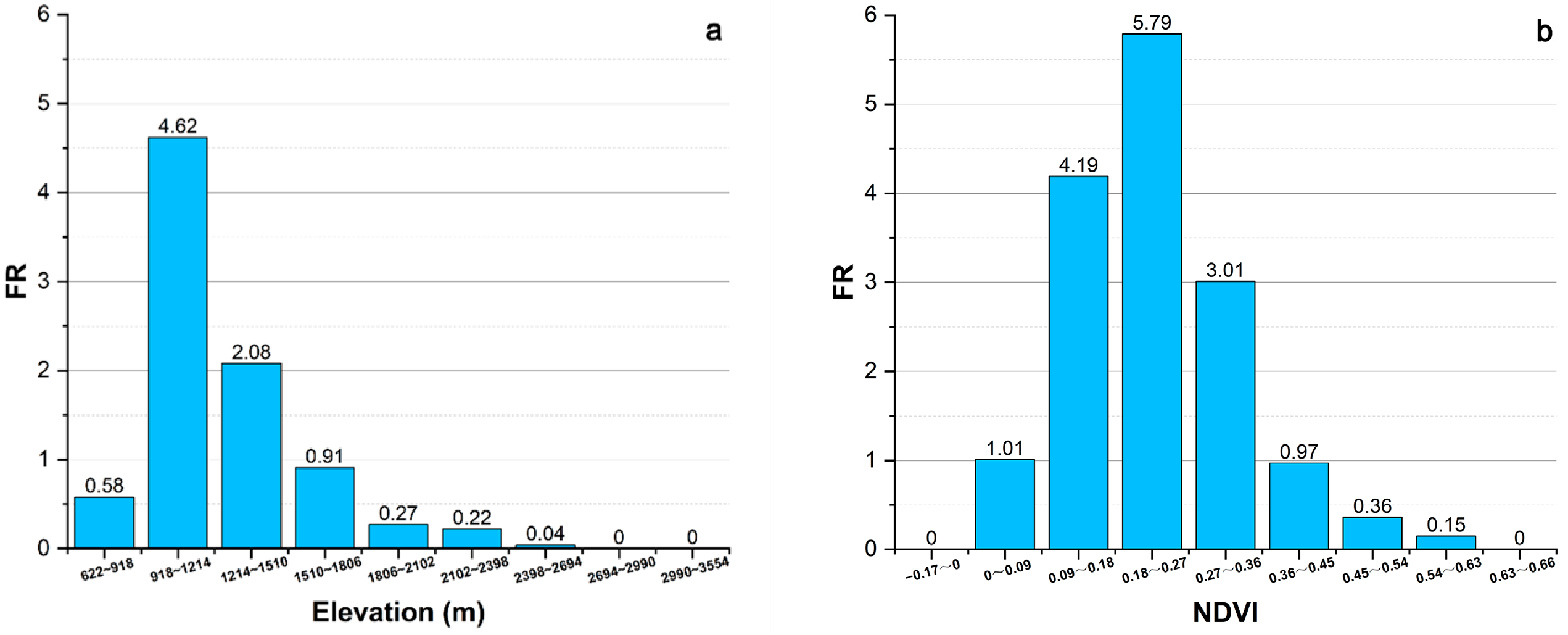
| Elevation (m) | 622–918 | Continuous | 46,842 | 0.91 | 2 | 0.53 | 0.58 |
| 918–1214 | 381,802 | 7.39 | 129 | 34.13 | 4.62 | ||
| 1214–1510 | 773,992 | 14.99 | 118 | 31.22 | 2.08 | ||
| 1510–1806 | 1,292,308 | 25.02 | 86 | 22.75 | 0.91 | ||
| 1806–2102 | 1,548,613 | 29.99 | 31 | 8.20 | 0.27 | ||
| 2102–2398 | 671,677 | 13.01 | 11 | 2.91 | 0.22 | ||
| 2398–2694 | 349,662 | 6.77 | 1 | 0.26 | 0.04 | ||
| 2694–2990 | 90,410 | 1.75 | 0 | 0.00 | 0.00 | ||
| 2990–3554 | 9129 | 0.18 | 0 | 0.00 | 0.00 | ||
| Slope (°) | 0°–10° | Continuous | 510,164 | 9.91 | 39 | 10.32 | 1.04 |
| 10°–20° | 897,118 | 17.42 | 77 | 20.37 | 1.17 | ||
| 20°–30° | 1,664,789 | 32.33 | 135 | 35.71 | 1.10 | ||
| 30°–40° | 1,494,180 | 29.02 | 103 | 27.25 | 0.94 | ||
| 40°–50° | 509,507 | 9.89 | 22 | 5.82 | 0.59 | ||
| >50° | 73,906 | 1.44 | 2 | 0.53 | 0.37 | ||
| Aspect | Level | Discrete | 144,270 | 2.80 | 10 | 2.65 | 0.94 |
| North | 613,964 | 11.92 | 32 | 8.47 | 0.71 | ||
| Northeast | 648,775 | 12.60 | 56 | 14.81 | 1.18 | ||
| East | 621,581 | 12.07 | 55 | 14.55 | 1.21 | ||
| Southeast | 683,261 | 13.27 | 56 | 14.81 | 1.12 | ||
| South | 603,608 | 11.72 | 63 | 16.67 | 1.42 | ||
| Southwest | 666,433 | 12.94 | 41 | 10.85 | 0.84 | ||
| West | 570,245 | 11.07 | 27 | 7.14 | 0.65 | ||
| Northwest | 597,527 | 11.60 | 38 | 10.05 | 0.87 | ||
| Plan curvature | −11.16 to −2.10 | Continuous | 15,881 | 0.31 | 0 | 0.00 | 0.00 |
| −2.10 to −1.50 | 53,862 | 1.04 | 1 | 0.26 | 0.25 | ||
| −1.50 to −0.90 | 251,392 | 4.87 | 13 | 3.44 | 0.71 | ||
| −0.90 to −0.30 | 997,039 | 19.31 | 63 | 16.67 | 0.86 | ||
| −0.30 to 0.30 | 2,463,614 | 47.71 | 206 | 54.50 | 1.14 | ||
| 0.30–0.90 | 1,028,772 | 19.92 | 73 | 19.31 | 0.97 | ||
| 0.90–1.50 | 275,196 | 5.33 | 16 | 4.23 | 0.79 | ||
| 1.50–2.10 | 60,030 | 1.16 | 5 | 1.32 | 1.14 | ||
| 2.10–10.21 | 18,475 | 0.36 | 1 | 0.26 | 0.74 | ||
| Profile curvature | −15.05 to −2.90 | Continuous | 12,555 | 0.24 | 0 | 0.00 | 0.00 |
| −2.90 to −2.10 | 33,546 | 0.65 | 0 | 0.00 | 0.00 | ||
| −2.10 to −1.30 | 142,997 | 2.77 | 13,500 | 3.97 | 1.43 | ||
| −1.30 to −0.50 | 612,532 | 11.86 | 27,900 | 8.20 | 0.69 | ||
| −0.50 to 0.30 | 3,107,184 | 60.17 | 206,100 | 60.58 | 1.01 | ||
| 0.30–1.10 | 971,309 | 18.81 | 71,100 | 20.90 | 1.11 | ||
| 1.10–1.90 | 212,169 | 4.11 | 19,800 | 5.82 | 1.42 | ||
| 1.90–2.70 | 52,221 | 1.01 | 1800 | 0.53 | 0.52 | ||
| 2.70–13.00 | 19,748 | 0.38 | 0 | 0.00 | 0.00 | ||
| Distance to a fault (m) | 0–1400 | Continuous | 2,061,661 | 39.92 | 167 | 44.18 | 1.11 |
| 1400–2800 | 1,206,521 | 23.36 | 103 | 27.25 | 1.17 | ||
| 2800–4200 | 713,656 | 13.82 | 67 | 17.72 | 1.28 | ||
| 4200–5600 | 389,221 | 7.54 | 18 | 4.76 | 0.63 | ||
| 5600–7000 | 247,265 | 4.79 | 12 | 3.17 | 0.66 | ||
| 7000–8400 | 174,649 | 3.38 | 6 | 1.59 | 0.47 | ||
| 8400–9800 | 152,306 | 2.95 | 3 | 0.79 | 0.27 | ||
| 9800–11,200 | 133,363 | 2.58 | 2 | 0.53 | 0.20 | ||
| 11,200–15,300 | 85,687 | 1.66 | 0 | 0.00 | 0.00 | ||
| Roughness | 1–1.06 | Continuous | 1,206,403 | 23.42 | 108 | 28.57 | 1.22 |
| 1.06–1.13 | 1,227,880 | 23.84 | 103 | 27.25 | 1.14 | ||
| 1.13–1.20 | 956,001 | 18.56 | 79 | 20.90 | 1.13 | ||
| 1.20–1.28 | 731,988 | 14.21 | 43 | 11.38 | 0.80 | ||
| 1.28–1.38 | 516,868 | 10.04 | 23 | 6.08 | 0.61 | ||
| 1.38–1.51 | 301,528 | 5.85 | 11 | 2.91 | 0.50 | ||
| 1.51–1.70 | 146,928 | 2.85 | 10 | 2.65 | 0.93 | ||
| 1.70–2.04 | 52,998 | 1.03 | 1 | 0.26 | 0.26 | ||
| 2.04–4.44 | 10,056 | 0.20 | 0 | 0.00 | 0.00 | ||
| External dynamic geological environment | |||||||
| Distance to a road (m) | 0–600 | Continuous | 1,063,274 | 20.59 | 236 | 62.43 | 3.03 |
| 600–1200 | 764,896 | 14.81 | 75 | 19.84 | 1.34 | ||
| 1200–1800 | 665,424 | 12.88 | 23 | 6.08 | 0.47 | ||
| 1800–2400 | 576,527 | 11.16 | 14 | 3.70 | 0.33 | ||
| 2400–3000 | 491,529 | 9.52 | 12 | 3.17 | 0.33 | ||
| 3000–3600 | 418,827 | 8.11 | 7 | 1.85 | 0.23 | ||
| 3600–4200 | 329,689 | 6.38 | 3 | 0.79 | 0.12 | ||
| 4800–5400 | 254,513 | 4.93 | 5 | 1.32 | 0.27 | ||
| >5400 | 599,710 | 11.61 | 3 | 0.79 | 0.07 | ||
| Distance to river (m) | 0–600 | Continuous | 1,044,339 | 20.22 | 175 | 46.30 | 2.29 |
| 600–1200 | 974,622 | 18.87 | 112 | 29.63 | 1.57 | ||
| 1200–1800 | 887,629 | 17.19 | 33 | 8.73 | 0.51 | ||
| 1800–2400 | 755,208 | 14.62 | 15 | 3.97 | 0.27 | ||
| 2400–3000 | 588,124 | 11.39 | 19 | 5.03 | 0.44 | ||
| 3000–3600 | 411,297 | 7.96 | 15 | 3.97 | 0.50 | ||
| 3600–4200 | 254,621 | 4.93 | 6 | 1.59 | 0.32 | ||
| 4200–4800 | 140,460 | 2.72 | 2 | 0.53 | 0.19 | ||
| 4800–6500 | 108,065 | 2.09 | 1 | 0.26 | 0.13 | ||
| NDVI | −0.17 to 0 | Continuous | 5922 | 0.11 | 0 | 0.00 | 0.00 |
| 0–0.09 | 13,499 | 0.26 | 1 | 0.26 | 1.01 | ||
| 0.09–0.18 | 52,154 | 1.01 | 16 | 4.23 | 4.19 | ||
| 0.18–0.27 | 198,057 | 3.84 | 84 | 22.22 | 5.79 | ||
| 0.27–0.36 | 522,153 | 10.11 | 115 | 30.42 | 3.01 | ||
| 0.36–0.45 | 1,280,418 | 24.79 | 91 | 24.07 | 0.97 | ||
| 0.45–0.54 | 2,374,744 | 45.98 | 63 | 16.67 | 0.36 | ||
| 0.54–0.63 | 716,918 | 13.88 | 8 | 2.12 | 0.15 | ||
| 0.63–0.66 | 345 | 0.01 | 0 | 0.00 | 0.00 | ||
| TWI | <2 | Continuous | 1,407,116 | 27.32 | 86 | 22.75 | 0.83 |
| 2–4 | 1,029,832 | 20.00 | 95 | 25.13 | 1.26 | ||
| 4–6 | 1,566,516 | 30.42 | 94 | 24.87 | 0.82 | ||
| 6–8 | 649,138 | 12.61 | 52 | 13.76 | 1.09 | ||
| 8–10 | 225,259 | 4.37 | 24 | 6.35 | 1.45 | ||
| 10–12 | 100,898 | 1.96 | 12 | 3.17 | 1.62 | ||
| 12–14 | 36,637 | 0.71 | 4 | 1.06 | 1.49 | ||
| 14–16 | 64,978 | 1.26 | 5 | 1.32 | 1.05 | ||
| 16–30 | 69,240 | 1.34 | 6 | 1.59 | 1.18 | ||
| Ground cover | Cropland | Discrete | 727,981 | 14.10 | 158 | 41.80 | 2.97 |
| Forest | 3,133,568 | 60.68 | 118 | 31.22 | 0.51 | ||
| Grass | 1,197,002 | 23.18 | 70 | 18.52 | 0.80 | ||
| Shrub | 10,382 | 0.20 | 0 | 0.00 | 0.00 | ||
| Wetland | 800 | 0.02 | 0 | 0.00 | 0.00 | ||
| Water | 6002 | 0.12 | 0 | 0.00 | 0.00 | ||
| Artificial | 58,798 | 1.14 | 19 | 5.03 | 4.41 | ||
| Bareland | 29,843 | 0.58 | 13 | 3.44 | 5.95 | ||
| Ice | 27 | 0.00 | 0 | 0.00 | 0.00 | ||
| Precipitation (mm) | 468–500 | Continuous | 301,757 | 5.84 | 39 | 10.32 | 1.77 |
| 500–550 | 815,298 | 15.79 | 97 | 25.66 | 1.63 | ||
| 550–600 | 1,084,602 | 21.01 | 107 | 28.31 | 1.35 | ||
| 600–650 | 701,797 | 13.59 | 73 | 19.31 | 1.42 | ||
| 650–700 | 678,150 | 13.13 | 24 | 6.35 | 0.48 | ||
| 700–750 | 573,149 | 11.10 | 28 | 7.41 | 0.67 | ||
| 750–800 | 644,650 | 12.48 | 8 | 2.12 | 0.17 | ||
| 800–860 | 364,114 | 7.05 | 2 | 0.53 | 0.08 | ||
| Engineering geological petrofabric | |||||||
| Lithology | Loose rock | Discrete | 3,419,409 | 66.21 | 172 | 45.50 | 0.69 |
| Softer rock | 745,401 | 14.43 | 45 | 11.90 | 0.82 | ||
| Soft rock | 460,951 | 8.93 | 102 | 26.98 | 3.02 | ||
| Harder rock | 399,788 | 7.74 | 55 | 14.55 | 1.88 | ||
| Hard rock | 138,832 | 2.69 | 4 | 1.06 | 0.39 | ||
References
- Aksha, S.K.; Resler, L.M.; Juran, L.; Carstensen, L.W., Jr. A geospatial analysis of multi-hazard risk in Dharan, Nepal. Geomat. Nat. Hazards Risk 2020, 11, 88–111. [Google Scholar] [CrossRef]
- Shi, P.; Ye, T.; Wang, Y.; Zhou, T.; Xu, W.; Du, J.; Wang, J.; Li, N.; Huang, C.; Liu, L.; et al. Disaster Risk Science: A Geographical Perspective and a Research Framework. Int. J. Disaster Risk Sci. 2020, 11, 426–440. [Google Scholar] [CrossRef]
- Du, W.; Sheng, Q.; Fu, X.; Chen, J.; Zhou, Y. A TPDP-MPM-based approach to understanding the evolution mechanism of landslide-induced disaster chain. J. Rock Mech. Geotech. Eng. 2022, 14, 1200–1209. [Google Scholar] [CrossRef]
- Yong, C.; Jinlong, D.; Fei, G.; Bin, T.; Tao, Z.; Hao, F.; Li, W.; Qinghua, Z. Review of landslide susceptibility assessment based on knowledge mapping. Stoch. Environ. Res. Risk Assess. 2022, 36, 2399–2417. [Google Scholar] [CrossRef]
- Shao, X.; Xu, C. Earthquake-induced landslides susceptibility assessment: A review of the state-of-the-art. Nat. Hazards Res. 2022, 2, 172–182. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Rahmati, O. Prediction of the landslide susceptibility: Which algorithm, which precision? Catena 2018, 162, 177–192. [Google Scholar] [CrossRef]
- Trigila, A.; Iadanza, C.; Esposito, C.; Scarascia-Mugnozza, G. Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 2015, 249, 119–136. [Google Scholar] [CrossRef]
- Karaman, M.O.; Çabuk, S.N.; Pekkan, E. Utilization of frequency ratio method for the production of landslide susceptibility maps: Karaburun Peninsula case, Turkey. Environ. Sci. Pollut. Res. 2022, 29, 91285–91305. [Google Scholar] [CrossRef]
- Zare, N.; Hosseini, S.A.O.; Hafizi, M.K.; Najafi, A.; Majnounian, B.; Geertsema, M. A Comparison of an adaptive neuro-fuzzy and frequency ratio model to landslide-susceptibility mapping along forest road networks. Forests 2021, 12, 1087. [Google Scholar] [CrossRef]
- Zuo, X.Z.; Zhang, Z.; Su, Y.-H.; Liu, Y.; Ge, Q.; Tian, J.-F. Extraction Algorithm of NDVI Based on GPU Multi-stream Parallel Model. Comput. Sci. 2020, 47, 25–29. [Google Scholar]
- Liu, J.; Xu, Z.; Chen, F.; Chen, F.; Zhang, L. Flood hazard mapping and assessment on the Angkor world heritage site, Cambodia. Remote Sens. 2019, 11, 98. [Google Scholar] [CrossRef]
- Aditian, A.; Kubota, T.; Shinohara, Y. Comparison of GIS-based landslide susceptibility models using frequency ratio, logistic regression, and artificial neural network in a tertiary region of Ambon, Indonesia. Geomorphology 2018, 318, 101–111. [Google Scholar] [CrossRef]
- Kalantar, B.; Pradhan, B.; Naghibi, S.A.; Motevalli, A.; Mansor, S. Assessment of the effects of training data selection on the landslide susceptibility mapping: A comparison between support vector machine (SVM), logistic regression (LR) and artificial neural networks (ANN). Geomat. Nat. Hazards Risk 2018, 9, 49–69. [Google Scholar] [CrossRef]
- Arabameri, A.; Pal, S.C.; Rezaie, F.; Chakrabortty, R.; Saha, A.; Blaschke, T.; Di Napoli, M.; Ghorbanzadeh, O.; Ngo, P.T.T. Decision tree based ensemble machine learning approaches for landslide susceptibility mapping. Geocarto Int. 2021, 37, 4594–4627. [Google Scholar] [CrossRef]
- Pham, B.T.; Phong, T.V.; Nguyen-Thoi, T.; Parial, K.; Singh, S.K.; Ly, H.B.; Prakash, I. Ensemble modeling of landslide susceptibility using random subspace learner and different decision tree classifiers. Geocarto Int. 2020, 37, 735–757. [Google Scholar] [CrossRef]
- Yu, C.; Chen, J. Application of a GIS-based slope unit method for landslide susceptibility mapping in Helong City: Comparative assessment of ICM, AHP, and RF model. Symmetry 2020, 12, 1848. [Google Scholar] [CrossRef]
- Park, S.; Kim, J. Landslide susceptibility mapping based on random forest and boosted regression tree models, and a comparison of their performance. Appl. Sci. 2019, 9, 942. [Google Scholar] [CrossRef]
- Kamran, K.V.; Feizizadeh, B.; Khorrami, B.; Ebadi, Y. A comparative approach of support vector machine kernel functions for GIS-based landslide susceptibility mapping. Appl. Geomat. 2021, 13, 837–851. [Google Scholar] [CrossRef]
- Sheng, M.; Liu, Z.; Zhang, X.; Hu, S.; Guo, Z.; Huang, F. Landslide susceptibility prediction based on frequency ratio analysis and support vector machine. Sci. Technol. Eng. 2021, 21, 10620–10628. [Google Scholar]
- Wang, Z.; Brenning, A. Active-learning approaches for landslide mapping using support vector machines. Remote Sens. 2021, 13, 2588. [Google Scholar] [CrossRef]
- Sun, D.; Xu, J.; Wen, H.; Wang, D. Assessment of landslide susceptibility mapping based on Bayesian hyperparameter optimization: A comparison between logistic regression and random forest. Eng. Geol. 2021, 281, 105972. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, S. GIS-based comparative study of Bayes network, Hoeffding tree and logistic model tree for landslide susceptibility modeling. Catena 2021, 203, 105344. [Google Scholar] [CrossRef]
- Mabdeh, A.N.; Al-Fugara, A.; Ahmadlou, M.; Al-Adamat, R.; Al-Shabeeb, A.R. GIS-based landslide susceptibility assessment and mapping in Ajloun and Jerash governorates in Jordan using genetic algorithm-based ensemble models. Acta Geophys. 2022, 70, 1253–1267. [Google Scholar] [CrossRef]
- Conforti, M.; Pascale, S.; Robustelli, G.; Sdao, F. Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo River catchment (northern Calabria, Italy). Catena 2014, 113, 236–250. [Google Scholar] [CrossRef]
- Polykretis, C.; Chalkias, C. Comparison and evaluation of landslide susceptibility maps obtained from weight of evidence, logistic regression, and artificial neural network models. Nat. Hazards 2018, 93, 249–274. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B.; Lee, S. Application of convolutional neural networks featuring Bayesian optimization for landslide susceptibility assessment. Catena 2020, 186, 104249. [Google Scholar] [CrossRef]
- Sun, D.; Wen, H.; Wang, D.; Xu, J. A random forest model of landslide susceptibility mapping based on hyperparameter optimization using Bayes algorithm. Geomorphology 2020, 362, 107201. [Google Scholar] [CrossRef]
- Pašek, J. Inventaire Des Glissements de Terrain. Bull. Int. Assoc. Eng. Geol. Bull. Lassociation Int. Géologie Lingénieur 1975, 12, 73–74. [Google Scholar] [CrossRef]
- Chen, W.; Zhao, Z.; Liu, G. Rsearch on Engineering Geology of Gansu Section of Lanzhou-Haikou Expressway; Lanzhou Univ. Press: Lanzhou, China, 2006. [Google Scholar]
- Qi, S.; Liu, D.; Ma, J.; Tian, L. An assessment index system for landslide risk in Bailong river basin. J. Lanzhou Univ. Nat. Sci. 2014, 50, 356–362. [Google Scholar]
- Li, S. Discussion on landslide activities in Bailong River Basin of Wudu. Bull. Soil Water Conserv. 1997, 17, 28–32. [Google Scholar]
- Li, S. Preliminary study of the landslides in middle reaches of Bailong River. Hydrogeol. Eng. Geol. 1995, 22, 13–15. [Google Scholar]
- Ma, Z.; Mei, G. Deep learning for geological hazards analysis: Data, models, applications, and opportunities. Earth-Sci. Rev. 2022, 223, 103858. [Google Scholar] [CrossRef]
- Liu, Y. Risk analysis and zoning of geological hazards (chiefly landslide, rock fall and debris flow) in China. Chin. J. Geol. Hazard Control 2003, 14, 95–99. [Google Scholar]
- Ning, N.; Tian, L.; Zhang, P.; Qi, S.; Ma, J. The hazards assessment of debris flow in wudu of southern Gansu, China. Mt. Res. 2013, 31, 601–609. [Google Scholar]
- Santacana, N.; Baeza, B.; Corominas, J.; De Paz, A.; Marturiá, J. A GIS-based multivariate statistical analysis for shallow landslide susceptibility mapping in La Pobla de Lillet area (Eastern Pyrenees, Spain). Nat. Hazards 2003, 30, 281. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, Y.; Chen, X.; Liu, Y. Bibliometric Analysis of Global NDVI Research Trends from 1985 to 2021. Remote Sens. 2022, 14, 3967. [Google Scholar] [CrossRef]
- Beven, K.J.; Kirkby, M.J. A physically based, variable contributing area model of basin hydrology/Un modèle à base physique de zone d’appel variable de l’hydrologie du bassin versant. Hydrol. Sci. J. 1979, 24, 43–69. [Google Scholar] [CrossRef]
- Obled, C.; Wendling, J.; Beven, K. The sensitivity of hydrological models to spatial rainfall patterns: An evaluation using observed data. J. Hydrol. 1994, 159, 305–333. [Google Scholar] [CrossRef]
- Tarboton, D.G. A new method for the determination of flow directions and upslope areas in grid digital elevation models. Water Resour. Res. 1997, 33, 309–319. [Google Scholar] [CrossRef]
- Ning, N.M.; Ma, J.; Zhang, P.; Qi, S.; Tian, L. Debris Flow Hazard Assessment for the Bailongjiang River, Southern Gansu. Resour. Sci. 2013, 35, 892–899. [Google Scholar]
- Liao, M.; Wen, H.; Yang, L. Identifying the essential conditioning factors of landslide susceptibility models under different grid resolutions using hybrid machine learning: A case of Wushan and Wuxi counties, China. Catena 2022, 217, 106428. [Google Scholar] [CrossRef]
- Wu, Y.; Ke, Y.; Chen, Z.; Liang, S.; Zhao, H.; Hong, H. Application of alternating decision tree with AdaBoost and bagging ensembles for landslide susceptibility mapping. Catena 2020, 187, 104396. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar]
- Alimohammadlou, Y.; Najafi, A.; Gokceoglu, C. Estimation of rainfall-induced landslides using ANN and fuzzy clustering methods: A case study in Saeen Slope, Azerbaijan province, Iran. Catena 2014, 120, 149–162. [Google Scholar] [CrossRef]
- Nhu, V.-H.; Shirzadi, A.; Shahabi, H.; Chen, W.; Clague, J.J.; Geertsema, M.; Jaafari, A.; Avand, M.; Miraki, S.; Asl, D.T.; et al. Shallow landslide susceptibility mapping by random forest base classifier and its ensembles in a semi-arid region of Iran. Forests 2020, 11, 421. [Google Scholar] [CrossRef]
- Chuanhua, Z.; Shouwen, Z. GIS Based Analysis of Accessibility Impact of BRT and Metro Line in Hefei China. Geogr. Geo Inf. Sci. 2014, 30, 21–24. [Google Scholar]
- Schonlau, M.; Zou, R.Y. The random forest algorithm for statistical learning. Stata J. 2020, 20, 3–29. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Phan, T.N.; Kuch, V.; Lehnert, L.W. Land cover classification using Google Earth Engine and random forest classifier—The role of image composition. Remote Sens. 2020, 12, 2411. [Google Scholar] [CrossRef]
- Zhang, C.-c.; Cui, L.; Yang, G. Comparative Study for Ensemble Learning Algorithms. J. Hebei Univ. Nat. Sci. Ed. 2007, 27, 551. [Google Scholar]
- Xiao, C.; Tian, Y.; Shi, W.; Guo, Q.; Wu, L. A new method of pseudo absence data generation in landslide susceptibility mapping with a case study of Shenzhen. Sci. China Technol. Sci. 2010, 53, 75–84. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R. Landslide susceptibility mapping using machine learning algorithms and comparison of their performance at Abha Basin, Asir Region, Saudi Arabia. Geosci. Front. 2021, 12, 639–655. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. Adv. Neural. Inf. Process. Syst 2012, 25, 2951–2959. [Google Scholar]
- Ghahramani, Z. Probabilistic machine learning and artificial intelligence. Nature 2015, 521, 452–459. [Google Scholar] [CrossRef]
- Shano, L.; Raghuvanshi, T.K.; Meten, M. Landslide susceptibility evaluation and hazard zonation techniques–A review. Geoenvironmental Disasters 2020, 7, 18. [Google Scholar] [CrossRef]
- Bennett, G.L.; Miller, S.R.; Roering, J.J.; Schmidt, D.A. Landslides, threshold slopes, and the survival of relict terrain in the wake of the Mendocino Triple Junction. Geology 2016, 44, 363–366. [Google Scholar] [CrossRef]
- Kornejady, A.; Ownegh, M.; Bahremand, A. Landslide susceptibility assessment using maximum entropy model with two different data sampling methods. Catena 2017, 152, 144–162. [Google Scholar] [CrossRef]
- Hong, H.; Jaafari, A.; Zenner, E.K. Predicting spatial patterns of wildfire susceptibility in the Huichang County, China: An integrated model to analysis of landscape indicators. Ecol. Indic. 2019, 101, 878–891. [Google Scholar] [CrossRef]
- Pham, B.T.; Jaafari, A.; Prakash, I.; Bui, D.T. A novel hybrid intelligent model of support vector machines and the MultiBoost ensemble for landslide susceptibility modeling. Bull. Eng. Geol. Environ. 2019, 78, 2865–2886. [Google Scholar] [CrossRef]
- Lin, J.; Chen, W.; Qi, X.; Hou, H. Risk assessment and its influencing factors analysis of geological hazards in typical mountain environment. J. Clean. Prod. 2021, 309, 127077. [Google Scholar] [CrossRef]
- Feifan, R.; Wenwu, C.; Wenfeng, H. Study on reason and spatial-temporal distribution characteristics of debris flow in Longnan area along G212. Chin. J. Rock Mech. Eng. 2008, 27, 3237–3243. [Google Scholar]
- Namous, M.; Hssaisoune, M.; Pradhan, B.; Lee, C.-W.; Alamri, A.; Elaloui, A.; Edahbi, M.; Krimissa, S.; Eloudi, H.; Ouayah, M.; et al. Spatial Prediction of Groundwater Potentiality in Large Semi-Arid and Karstic Mountainous Region Using Machine Learning Models. Water 2021, 13, 2273. [Google Scholar] [CrossRef]
- Rong, G.; Alu, S.; Li, K.; Su, Y.; Zhang, J.; Zhang, Y.; Li, T. Rainfall induced landslide susceptibility mapping based on Bayesian optimized random forest and gradient boosting decision tree models—A case study of Shuicheng County, China. Water 2020, 12, 3066. [Google Scholar] [CrossRef]
- Wu, J.; Chen, X.Y.; Zhang, H.; Xiong, L.D.; Lei, H.; Deng, S.H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol 2019, 17, 26–40. [Google Scholar]
- Meena, S.R.; Puliero, S.; Bhuyan, K.; Floris, M.; Catani, F. Assessing the importance of conditioning factor selection in landslide susceptibility for the province of Belluno (region of Veneto, northeastern Italy). Nat. Hazards Earth Syst. Sci. 2022, 22, 1395–1417. [Google Scholar] [CrossRef]
- Yilmaz, I. The effect of the sampling strategies on the landslide susceptibility mapping by conditional probability and artificial neural networks. Environ. Earth Sci. 2010, 60, 505–519. [Google Scholar] [CrossRef]
- Mersha, T.; Meten, M. GIS-based landslide susceptibility mapping and assessment using bivariate statistical methods in Simada area, northwestern Ethiopia. Catena 2020, 7, 20. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Merghadi, A.; Shirzadi, A.; Nguyen, H.; Hussain, Y.; Avtar, R.; Chen, Y.; Pham, B.T.; Yamagishi, H. Different sampling strategies for predicting landslide susceptibilities are deemed less consequential with deep learning. Sci. Total Environ. 2020, 720, 137320. [Google Scholar] [CrossRef]
- Zhao, F.; Meng, X.; Zhang, Y.; Chen, G.; Su, X.; Yue, D. Landslide susceptibility mapping of karakorum highway combined with the application of SBAS-InSAR technology. Sensors 2019, 19, 2685. [Google Scholar] [CrossRef]
- Xiao, T.; Segoni, S.; Chen, L.; Yin, K.; Casagli, N. A step beyond landslide susceptibility maps: A simple method to investigate and explain the different outcomes obtained by different approaches. Landslides 2020, 17, 627–640. [Google Scholar] [CrossRef]










| No. | Name | Type | Time | Size (104 m2) | Economic Loss (USD) | Main Conditioning Factors |
|---|---|---|---|---|---|---|
| 1 | Dujia gully | Landslide | August 2015 | 590 | 29,000 | Lithology, Fluvial erosion |
| 2 | Taoshu gully | Debris flow | August 2020 | 85 | 36,369 | Topography, Rainfall |
| 3 | Xiaoshui gully | Avalanche | March 2008 | 68 | 29,095 | Lithology, Human activity |
| Variables | TOL | VIF |
|---|---|---|
| Elevation | 0.423 | 2.363 |
| Slope | 0.169 | 5.914 |
| Aspect | 0.912 | 1.097 |
| Plan curvature | 0.768 | 1.302 |
| Profile curvature | 0.744 | 1.345 |
| Distance to a road | 0.574 | 1.741 |
| Distance to a river | 0.655 | 1.528 |
| Distance to a fault | 0.792 | 1.263 |
| Roughness | 0.191 | 5.229 |
| Lithology | 0.870 | 1.150 |
| NDVI | 0.441 | 2.266 |
| TWI | 0.732 | 1.367 |
| Ground cover | 0.947 | 1.056 |
| Precipitation | 0.540 | 1.851 |
| Model | TP | TN | FP | FN | ACC | Recall | Precision | F1 |
|---|---|---|---|---|---|---|---|---|
| RF | 302 | 721 | 76 | 41 | 89.74 | 88.05 | 79.89 | 83.78 |
| GA-RF | 354 | 751 | 24 | 11 | 96.93 | 96.99 | 93.65 | 95.29 |
| Bayes-RF | 355 | 752 | 23 | 10 | 97.11 | 97.26 | 93.92 | 95.56 |
| Model | Class | Area of Zones (%) | Number of Hazards | Hazard Percentage (%) | FR |
|---|---|---|---|---|---|
| RF | Extremely high | 9.36 | 227 | 60.05 | 6.415 |
| High | 10.57 | 73 | 19.31 | 1.827 | |
| Moderate | 16.38 | 45 | 11.90 | 0.727 | |
| Low | 29.30 | 23 | 6.08 | 0.208 | |
| Extremely low | 34.39 | 10 | 2.65 | 0.077 | |
| GA-RF | Extremely high | 8.12 | 254 | 67.20 | 8.273 |
| High | 12.54 | 72 | 19.05 | 1.519 | |
| Moderate | 17.35 | 36 | 9.52 | 0.549 | |
| Low | 31.64 | 14 | 3.70 | 0.117 | |
| Extremely low | 30.35 | 2 | 0.53 | 0.017 | |
| Bayes-RF | Extremely high | 8.03 | 251 | 66.40 | 8.266 |
| High | 11.37 | 85 | 22.49 | 1.977 | |
| Moderate | 17.19 | 26 | 6.88 | 0.400 | |
| Low | 29.13 | 15 | 3.97 | 0.136 | |
| Extremely low | 34.27 | 1 | 0.26 | 0.008 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Chen, Z.; Ma, K.; Zhang, Z. Machine-Learning-Based Hybrid Modeling for Geological Hazard Susceptibility Assessment in Wudou District, Bailong River Basin, China. GeoHazards 2023, 4, 157-182. https://doi.org/10.3390/geohazards4020010
Wang Z, Chen Z, Ma K, Zhang Z. Machine-Learning-Based Hybrid Modeling for Geological Hazard Susceptibility Assessment in Wudou District, Bailong River Basin, China. GeoHazards. 2023; 4(2):157-182. https://doi.org/10.3390/geohazards4020010
Chicago/Turabian StyleWang, Zhijun, Zhuofan Chen, Ke Ma, and Zuoxiong Zhang. 2023. "Machine-Learning-Based Hybrid Modeling for Geological Hazard Susceptibility Assessment in Wudou District, Bailong River Basin, China" GeoHazards 4, no. 2: 157-182. https://doi.org/10.3390/geohazards4020010
APA StyleWang, Z., Chen, Z., Ma, K., & Zhang, Z. (2023). Machine-Learning-Based Hybrid Modeling for Geological Hazard Susceptibility Assessment in Wudou District, Bailong River Basin, China. GeoHazards, 4(2), 157-182. https://doi.org/10.3390/geohazards4020010