
Machine Learning Performance Analysis for Bagging System Improvement: Key Factors, Model Optimization, and Loss Reduction in the Fertilizer Industry


Abstract
1. Introduction
1.1. Motivation
1.2. Literature Review and Gap
1.3. Hypotheses
1.4. Contributions
- A comparative evaluation of four ML algorithms (ANN, RFR, LR, SVR) using real-time sensor data from the Urea I Bagging Unit.
- A proposed design for an IoT-based Smart Bagging System for predictive control in fertilizer packaging.
- The identification of key variables affecting the fertilizer bagging process using machine learning technology.
- A demonstration of ML’s potential to automate setup, detect errors, and optimize process efficiency.
- An exploration of ML’s role in enabling auto-adjustment mechanisms in bagging systems for real-time operational optimization.
- The provision of novel insights and predictive approaches previously unaddressed in the domain of fertilizer packaging.
1.5. Previous Study and Research Positioning
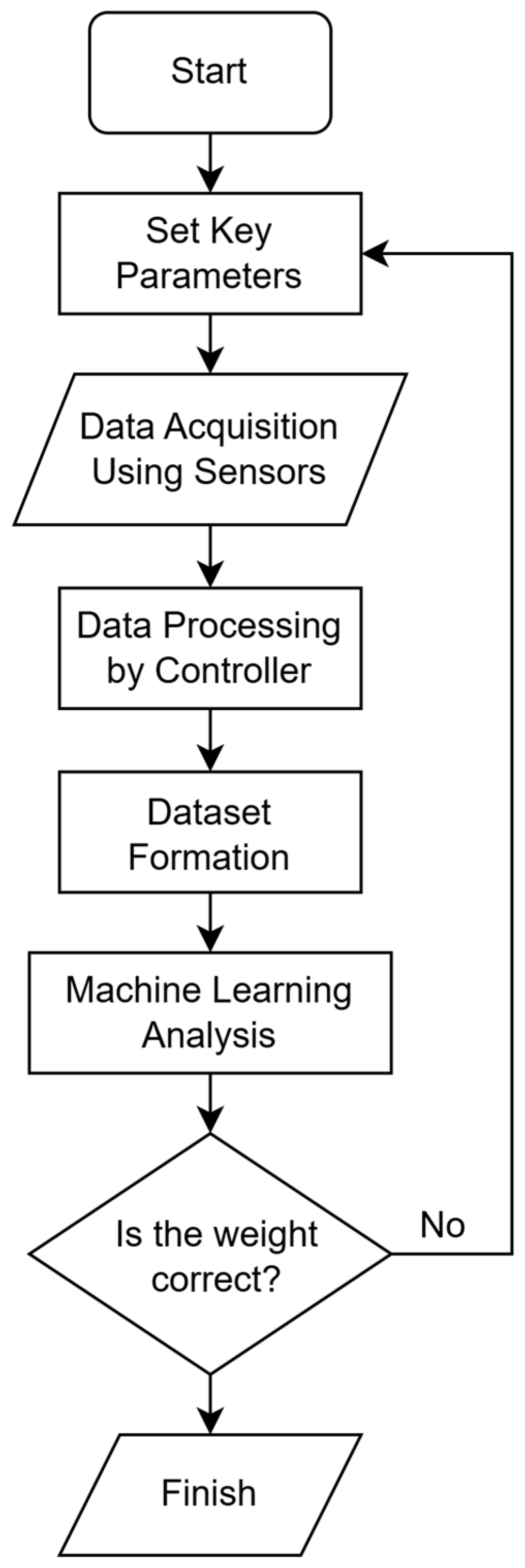
2. Methodology
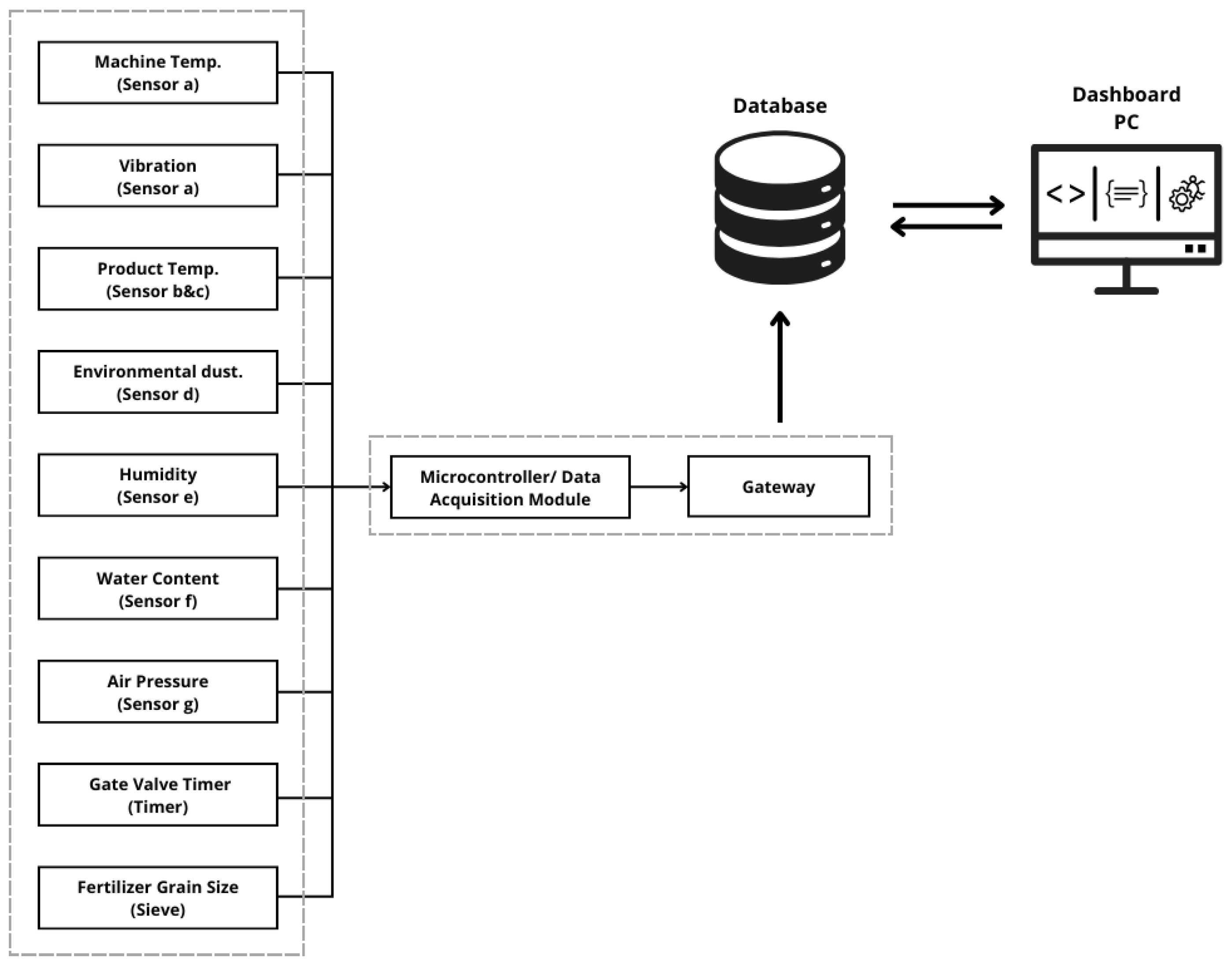
2.1. Data Acquisition Devices
- RS-485 Vibration and Temperature Sensor (Sensor A)—combines MEMS-based vibration and temperature sensing with high stability and anti-interference performance.
- RTD Controller (Sensor B)—regulates system temperature by interpreting resistance changes in the RTD input and adjusting thermal output accordingly.
- Thermocouple (Sensor C)—measures temperature based on thermoelectric voltage, allowing digital signal conversion.
- ZH03A Dust Sensor (Sensor D)—detects airborne dust particles using laser scattering with low power consumption and real-time response.
- THD Sensor (Sensor E)—monitors ambient temperature and humidity within operational limits of −19.9 °C to 60.0 °C and 0–99.9% RH.
- RS-485 Product Temp and Moisture Sensor (Sensor F)—captures product temperature and humidity with a wide input voltage range and RS-485 communication.
- WPT-70G Pressure Sensor (Sensor G)—measures pressure using piezoresistive technology, offering corrosion resistance and high accuracy.
- Granule Size Control—ensures urea fertilizer consistency using sieves that match standardized particle size for optimal flow and packing.
- Gate Valve Timing System—controls valve opening/closing via relay and timer to ensure precise bagging weight. Each sensor was selected for industrial-grade reliability, a fast response time, and integration capabilities for digital data collection.
2.2. Sensor Placement
2.3. Sampling Techniques
2.4. Particle Size Measurement
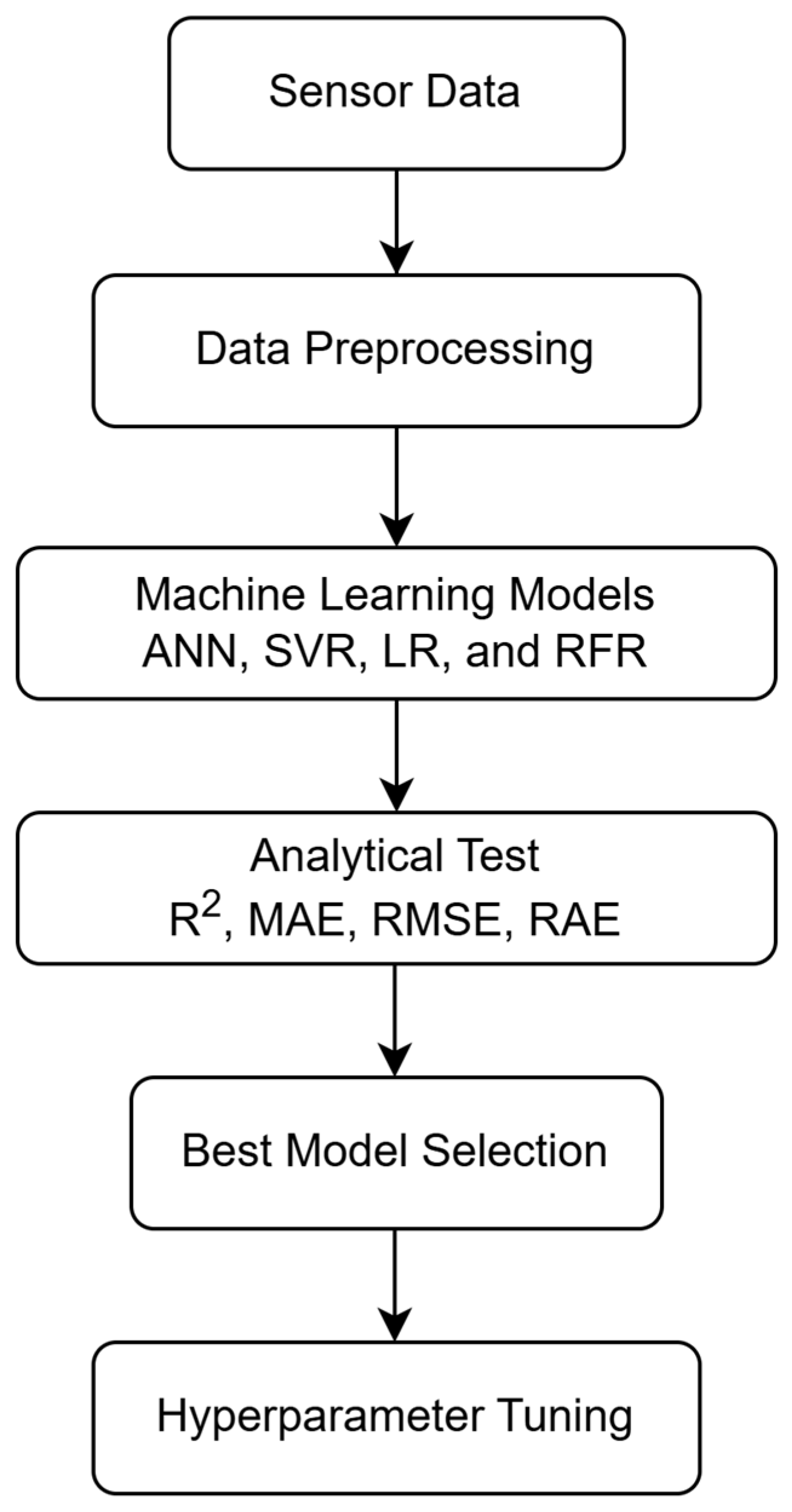
2.5. Data Processing Flow
2.6. Model Configuration for ML
3. Results and Discussion
3.1. Data Preparation and Sampling
3.2. Modeling Framework and Evaluation
3.3. Benchmark Comparison with Existing Manufacturing Models
3.4. Comparative Model Performance
3.4.1. Wilcoxon Test
3.4.2. Real-Time Feasibility
3.5. Attribute Importance and Interpretability
3.5.1. Ablation Analysis
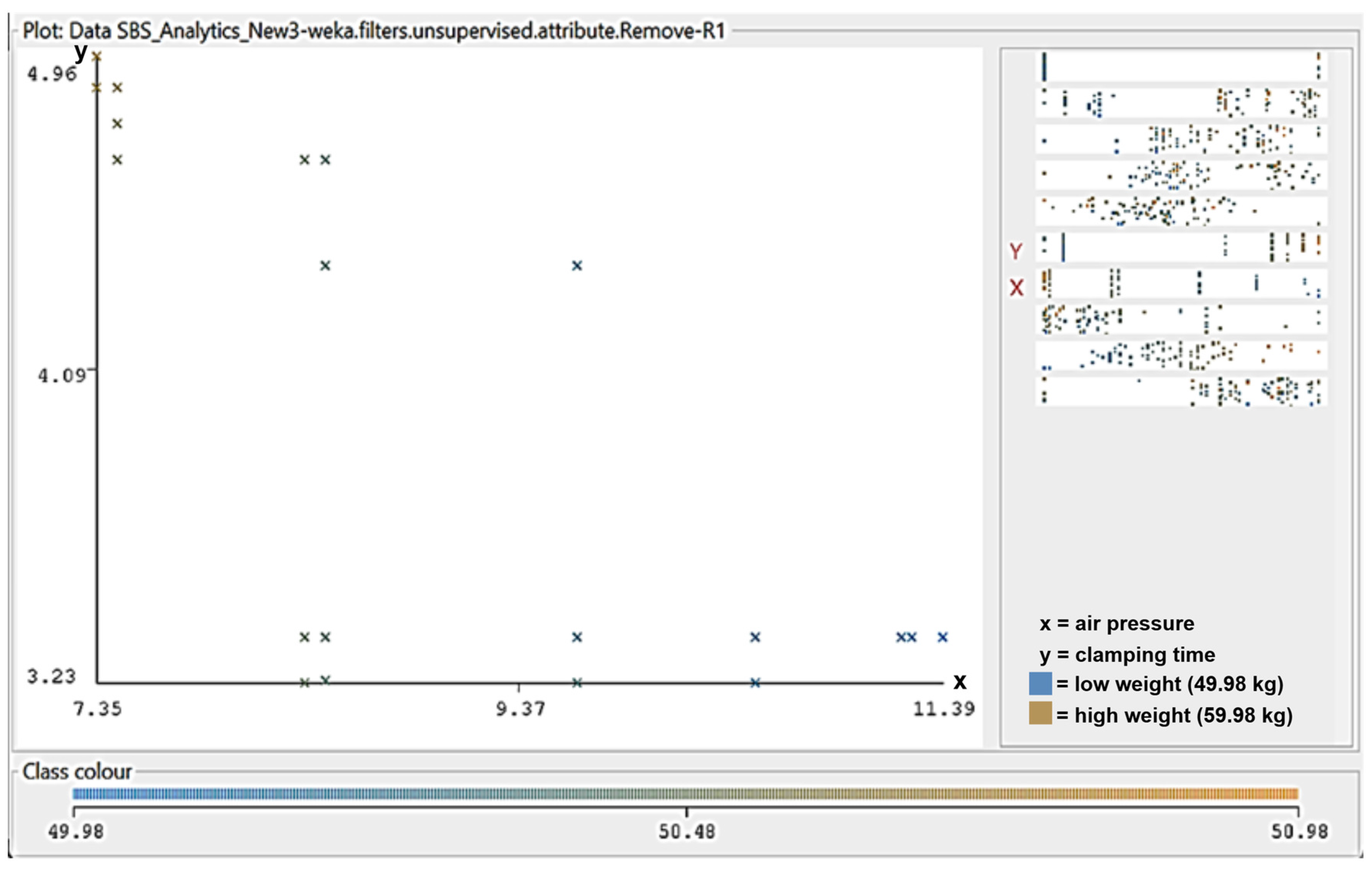
3.5.2. Clamping Time and Air Pressure
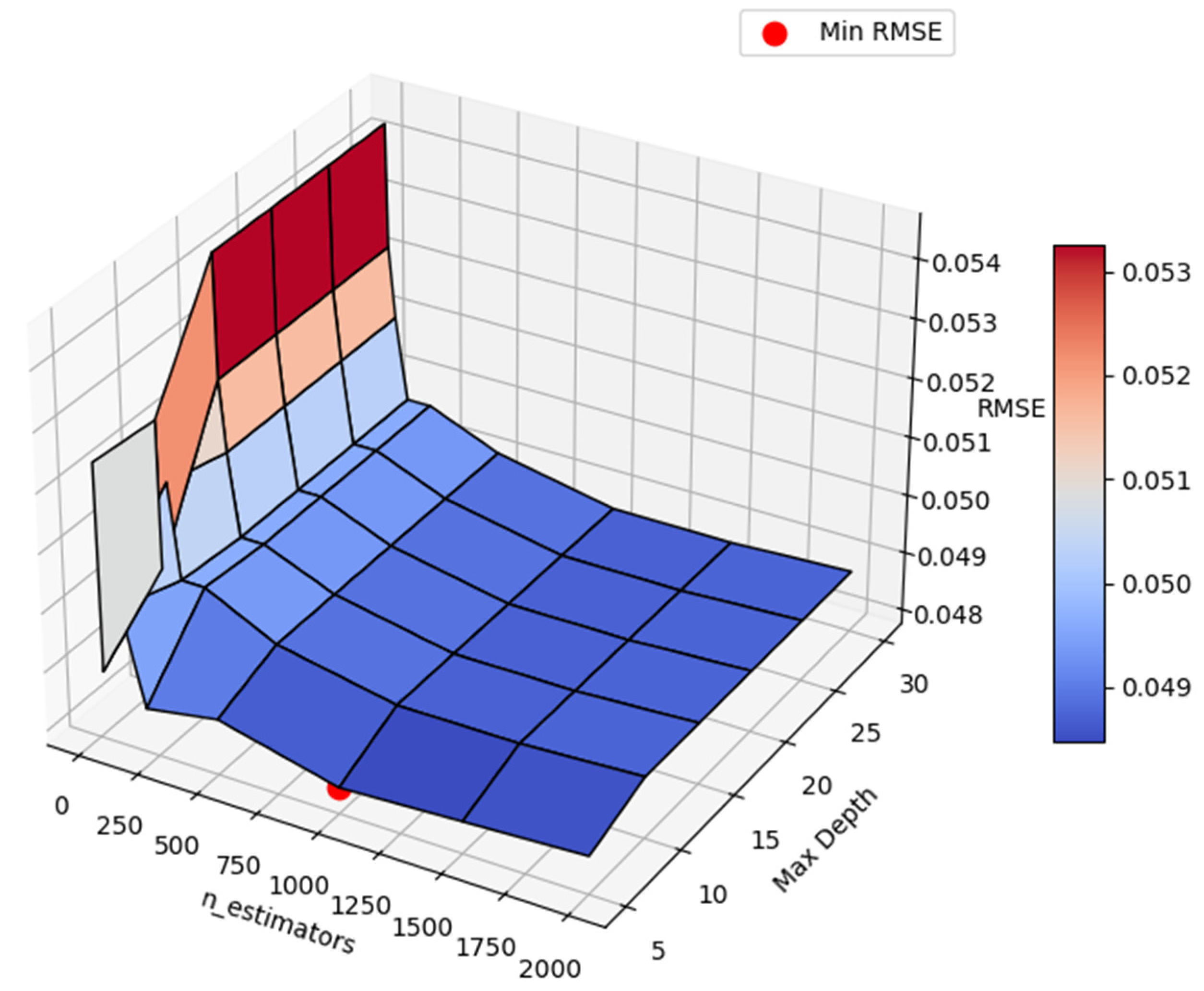
3.6. Hyperparameter Tuning and Optimization
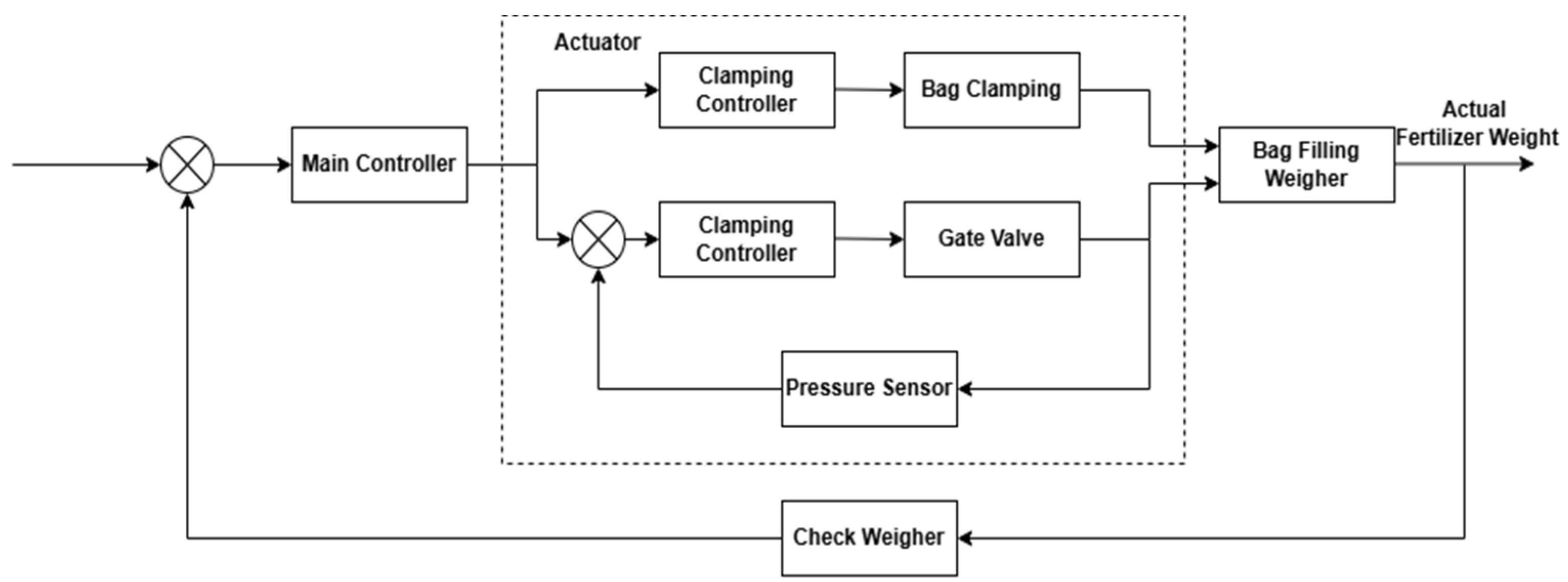
3.7. IoT and Real-Time Monitoring Implementation in Bagging System
3.8. Bagging System Improvement
3.9. Economic Impact Analysis
- Total losses per year:0.3 kg × 20,600,000 bags = 6,180,000 kg6180 tons × USD 330 = USD 2,039,400USD 2,039,400 × 15,000 = IDR 30,591,000,000
- The amount of savings from implementing ML assumes that the excess bag weight is reduced by up to 95%. This is based on the RMSE accuracy value of 4.83% (as the average prediction error per bag), then
- 3.
- Thus, the current losses are as follows:6180 tons × (1–0.95) = 309 tons309 tons × USD 330 = USD 101,970USD 101,970 × 15,000 = IDR 1,529,550,000
- 4.
- The estimated cost of implementing ML is around IDR 300,000,000–450,000,000 for cloud data storage, software development teams, sensors, and the IoT. Based on the straight-line depreciation method, the asset value will be divided evenly each year, assuming an economic life of three years.
3.10. Model Generalization and Transferability
4. Novelty and Research Contributions
- Integration of Attribute Importance and Predictive Modeling: This study represents one of the initial efforts to incorporate attribute importance analysis with ML regression techniques, specifically RFR, to identify the most significant parameters influencing bagging performance. Through data-driven feature selection, this research highlights the clamping time and air pressure as dominant control variables.
- Development of an Intelligent Auto-Readjusting System: The proposed Smart Bagging System uniquely combines open-loop and closed-loop control mechanisms to enable the automatic readjustment of real-time bagging parameters. This innovation addresses dynamic variations in production and ensures that product weights remain within the acceptable tolerance range (50.2–50.4 kg).
- IoT-Based Real-Time Monitoring Architecture: This work integrates IoT architecture with edge computing, enabling low-latency monitoring and predictive adjustment based on live sensor data. Combining the IoT and ML enhances operational agility, traceability, and predictive maintenance.
- Systematic Evaluation Using Five Performance Metrics: This research employs five different evaluation metrics, the R2, MAE, RMSE, RAE, and RRSE, to ensure a comprehensive assessment of model performance. This multidimensional evaluation enhances the accuracy and reliability of model selection.
- Substantial Economic Impact for Industrial Implementation: This system could reduce losses by up to 95%, saving around IDR 29 billion annually. This provides direct evidence of the system’s viability for large-scale implementation and highlights its contribution to achieving operational efficiency and sustainability in the fertilizer industry.
- Supporting SDG 9 and SDG 12: Besides its technical contribution, the Smart Bagging System also aligns with broader industrial development and sustainability goals. The integration of predictive analytics and IoT-based control mechanisms reflects the principle of industrial innovation (SDG 9) by applying intelligent digital solutions in conventional manufacturing environments. The significant loss reduction directly supports sustainable production and consumption (SDG 12) by increasing resource use efficiency in fertilizer packaging. Thus, this research offers technical advances and encourages greener and more responsible industrial practices.
5. Conclusions
6. Limitations
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| IDR | Indonesian Rupiah |
| IoT | Internet of Things |
| LR | Linear Regression |
| MAE | Mean Absolute Error |
| ML | Machine Learning |
| NPV | Net Present Value |
| PP | Payback Period |
| RAE | Relative Absolute Error |
| RFR | Random Forest Regression |
| RMSE | Root Mean Squared Error |
| RRSE | Root Relative Squared Error |
| SDGs | Sustainable Development Goals |
| SVR | Support Vector Regression |
| USD | United States Dollar |
References
- Kumar, I.; Rawat, J.; Mohd, N.; Husain, S. Opportunities of Artificial Intelligence and Machine Learning in the Food Industry. J. Food Qual. 2021, 2021, 4535567. [Google Scholar] [CrossRef]
- Expósito, A.; Velasco, F. Exploring environmental efficiency of the European agricultural sector in the use of mineral fertilizers. J. Clean Prod. 2020, 253, 119971. [Google Scholar] [CrossRef]
- Beach, N.; Reeve, G.; Marsh, C.; Kilby, P. Optimal Sorting of Product into Fixed Weight Packaging; Compac Sorting Equipment Ltd.: Auckland, New Zealand, 2004. [Google Scholar]
- Rahman, C.; Shamsuzzoha, A. Comparative Performance Analysis of Semi-automatic and Automatic cement packing process. In Proceedings of the International Conference on Mechanical Engineering, Orlando, FL, USA, 5–11 November 2005. [Google Scholar]
- Ilija, D.; Nada, S.; Nikola, T.; Andreja, R. Statistical process control in serbian food packaging. Int. J. Qual Res. 2014, 8, 323–334. [Google Scholar]
- Urea—Price—Chart—Historical Data—News. Available online: https://tradingeconomics.com/commodity/urea (accessed on 15 October 2024).
- Li, S.; Sarlioglu, B.; Jurkovic, S.; Patel, N.R.; Savagian, P. Analysis of Temperature Effects on Performance of Interior Permanent Magnet Machines for High Variable Temperature Applications. IEEE Trans. Ind. Appl. 2017, 53, 4923–4933. [Google Scholar] [CrossRef]
- Othman, M.H.; Sulaiman, H.; Main, N.M.; Li, L. Strength and Folding Performance of Polypropylene Packaging Samples in Hot Air and High Humidity Condition. Adv. Mater. Res. 2013, 748, 241–246. [Google Scholar] [CrossRef]
- Dmitriev, A.; Ziganshin, B.; Khaliullin, D.; Aleshkin, A. Study of Efficiency of Peeling Machine with Variable Deck. 2020. Available online: http://www.tf.llu.lv/conference/proceedings2020/Papers/TF249.pdf (accessed on 11 September 2024).
- Ammar, A.R. Effect of dust and sulfur content on the rate of wear of diesel engines working in the Jordanian desert. Alex. Eng. J. 2006, 45, 527–536. [Google Scholar]
- McElhaney, K.L. An analysis of check valve performance characteristics based on valve design. Nucl. Eng. Des. 2000, 197, 169–182. [Google Scholar] [CrossRef]
- Kelly, A.L.; Woodhead, M.; Coates, P.D. Comparison of Injection Moulding Machine Performance. 2005. Available online: https://bradscholars.brad.ac.uk/handle/10454/3414 (accessed on 10 November 2023).
- Llusa, M.; Faulhammer, E.; Biserni, S.; Calzolari, V.; Lawrence, S.; Bresciani, M.; Khinast, J. The effect of capsule-filling machine vibrations on average fill weight. Int. J. Pharm. 2013, 454, 381–387. [Google Scholar] [CrossRef]
- Primantara, A.; Ciptomulyono, U.; Al Kindhi, B. Bagging System Performance Analysis Using Artificial Neural Network, Random Forest Regression, Linear Regression, and Support Vector Regression. In Proceedings of the 2024 IEEE International Symposium on Consumer Technology (ISCT), Bali, Indonesia, 13–16 August 2024; pp. 618–622. Available online: https://ieeexplore.ieee.org/abstract/document/10791247 (accessed on 17 January 2025).
- Mahalik, N.P. Processing and packaging automation systems: A review. Sens. Instrum. Food Qual. Saf. 2009, 3, 12–25. [Google Scholar] [CrossRef]
- Qi, J.; Zhou, P.; Zheng, P.; Wu, H.; Yang, C.; Navarro-Alarcon, D.; Pan, J. Revolutionizing Packaging: A Robotic Bagging Pipeline with Constraint-aware Structure-of-Interest Planning. arXiv 2024, arXiv:2403.10309. [Google Scholar] [CrossRef]
- Tercan, H.; Meisen, T. Machine learning and deep learning based predictive quality in manufacturing: A systematic review. J. Intell. Manuf. 2022, 33, 1879–1905. [Google Scholar] [CrossRef]
- Kunwar, P.J. Analyzing Sorting and Packaging for Automation and Process Improvement. Available online: https://www.theseus.fi/handle/10024/267106 (accessed on 13 January 2025).
- Javaid, M.; Haleem, A.; Pratap Singh, R.; Khan, S.; Suman, R. Sustainability 4.0 and its applications in the field of manufacturing. Internet Things Cyber. Phys. Syst. 2022, 2, 82–90. [Google Scholar] [CrossRef]
- Fahle, S.; Prinz, C.; Kuhlenkötter, B. Systematic review on machine learning (ML) methods for manufacturing processes—Identifying artificial intelligence (AI) methods for field application. Procedia CIRP 2020, 93, 413–418. [Google Scholar] [CrossRef]
- Qian, P.; Pu, C.; Liu, L.; Luo, H.; Wu, J.; Jia, Y.; Liu, B.; Páez, L.M. Ultra-high-precision pneumatic force servo system based on a novel improved particle swarm optimization algorithm integrating Gaussian mutation and fuzzy theory. ISA Trans. 2024, 152, 453–466. [Google Scholar] [CrossRef]
- Zerehsaz, Y.; Sun, W.; Jin, J. Quality prediction using functional linear regression with in-situ image and functional sensor data. J. Qual. Technol. 2024, 56, 195–213. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe, G.J. Evaluating the Use of “Goodness-of-Fit” Measures in Hydrologic and Hydroclimatic Model Validation. Available online: https://agupubs.onlinelibrary.wiley.com/doi/10.1029/1998WR900018 (accessed on 9 April 2025).
- Sharma, S.; Shukla, R.; Chauhan, R.; Bhawsar, A. Experimental analysis of particle size distribution using electromagnetic sieves shaker. Int. J. Appl. Res. 2023, 9, 34–39. [Google Scholar] [CrossRef]
- Ali, H.I. A Review of Pneumatic Actuators (Modeling and Control). Aust. J. Basic Appl. Sci. 2009, 3, 440–454. [Google Scholar]
- Witten, Data Mining. 2016. Available online: https://shop.elsevier.com/books/data-mining/witten/978-0-12-804291-5 (accessed on 9 April 2025).
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 532–538. [Google Scholar] [CrossRef]
- Feng, H.; Chen, D.; Lv, H. Sensible and secure IoT communication for digital twins, cyber twins, web twins. Internet Things Cyber. Phys. Syst. 2021, 1, 34–44. [Google Scholar] [CrossRef]
- Kurnia, M.; Suprapto, S.; Ni’mah, Y.L. Adsorption of Remazol Blue And Indigosol Yellow Mixed Dyes Using Bidara Arab Leaves (Ziziphus spina-christi). Indones. J. Chem. Anal. IJCA 2024, 7, 23–33. [Google Scholar] [CrossRef]
- Zhong, Z.; Zhao, S.; Xia, J.; Luo, Q.; Zhou, Q.; Yang, S.; He, F.; Yao, Y. Regression prediction model for shear strength of cold joint in concrete. Structures 2024, 68, 107168. [Google Scholar] [CrossRef]
- Farahani, S.; Khade, V.; Basu, S.; Pilla, S. A data-driven predictive maintenance framework for injection molding process. J. Manuf. Process. 2022, 80, 887–897. [Google Scholar] [CrossRef]
- Louppe, G. Understanding Random Forests: From Theory to Practice. arXiv 2015, arXiv:1407.7502. [Google Scholar] [CrossRef]
- Chen, Q.; Qian, J.; Yang, H.; Li, J.; Lin, X.; Wang, B. Multiscale coupling analysis and modeling of airflow and heat transfer for warehouse-packaging-kiwifruit under forced-air cooling. Biosyst. Eng. 2024, 244, 166–176. [Google Scholar] [CrossRef]
- Takefuji, Y. Beyond XGBoost and SHAP: Unveiling true feature importance. J. Hazard. Mater. 2025, 488, 137382. [Google Scholar] [CrossRef]
- Deng, S.; Aldrich, C.; Liu, X.; Zhang, F. Explainability in Reservoir Well-logging Evaluation: Comparison of Variable Importance Analysis with Shapley Value Regression, SHAP and LIME. IFAC-Pap. 2024, 58, 66–71. [Google Scholar] [CrossRef]
- Mehdiyev, N.; Majlatow, M.; Fettke, P. Integrating permutation feature importance with conformal prediction for robust Explainable Artificial Intelligence in predictive process monitoring. Eng. Appl. Artif. Intell. 2025, 149, 110363. [Google Scholar] [CrossRef]
- Brown, M.G.L.; Peterson, M.G.; Tezaur, I.K.; Peterson, K.J.; Bull, D.L. Random forest regression feature importance for climate impact pathway detection. J. Comput. Appl. Math. 2025, 464, 116479. [Google Scholar] [CrossRef]
- Probst, P.; Wright, M.N.; Boulesteix, A.L. Hyperparameters and Tuning Strategies for Random Forest. 2019. Available online: https://wires.onlinelibrary.wiley.com/doi/10.1002/widm.1301 (accessed on 10 April 2025).
- Shen, Y.; Wang, Z.; Dong, H.; Liu, H. Multi-sensor multi-rate fusion estimation for networked systems: Advances and perspectives. Inf. Fusion 2022, 82, 19–27. [Google Scholar] [CrossRef]
- Kurs Transaksi BI. Available online: https://www.bi.go.id/id/statistik/informasi-kurs/transaksi-bi/default.aspx (accessed on 3 December 2024).
- Stenström, C.; Norrbin, P.; Parida, A.; Kumar, U. Preventive and corrective maintenance—Cost comparison and cost–benefit analysis. Struct. Infrastruct. Eng. 2016, 12, 603–617. [Google Scholar] [CrossRef]
- Kim, M.; Jeong, J.; Bae, S. Demand Forecasting Based on Machine Learning for Mass Customization in Smart Manufacturing. In Proceedings of the 2019 International Conference on Data Mining and Machine Learning, Hong Kong, China, 28–30 April 2019; (ICDMML 2019). Association for Computing Machinery: New York, NY, USA, 2019; pp. 6–11. [Google Scholar] [CrossRef]
- Curreri, F.; Patanè, L.; Xibilia, M.G. RNN- and LSTM-Based Soft Sensors Transferability for an Industrial Process. Sensors 2021, 21, 823. [Google Scholar] [CrossRef]
- Aliev, T.; Korolev, I.; Yasnov, M.; Nosonovsky, M.; Skorb, E.V. Rosé or white, glass or plastic: Computer vision and machine learning study of cavitation bubbles in sparkling wines. RSC Adv. 2025, 15, 5151–5158. [Google Scholar] [CrossRef]
- Arianti, N.D.; Muslih, M.; Sitorus, A.; Bulan, R. Oscillation effect dataset on the measurement accuracy of load-cell sensor applied to the weigh basket. Data Brief 2021, 38, 107453. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameter | Description | Value |
|---|---|---|---|
| SVR | C | Regularization parameter balancing error and model complexity | 1.0 (default WEKA) |
| ε (epsilon) | Defines error margin without penalty | 0.001 (default WEKA) | |
| ANN | Hidden layer | Number of neurons per hidden layer | Auto-computed (a in WEKA) |
| Architecture | One hidden layer with auto neuron calculation | Default WEKA | |
| LR | Intercept fitting | Enables bias term | True |
| Normalization | Whether input is normalized before training | False | |
| RFR | n_estimators | Number of decision trees in the ensemble | 100 (default WEKA) |
| max_depth | Maximum tree depth | 0 = unlimited (default WEKA) |
| Variable | Mean | StDev | Min | Max |
|---|---|---|---|---|
| Machine temperature (°C) | 45 | 1.46 | 41.19 | 50.25 |
| Humidity (%) | 59.4 | 3.86 | 52.4 | 63.7 |
| Product water content (%) | 64.36 | 8.03 | 38 | 79 |
| Air pressure (bar) | 8.75 | 1.25 | 7.35 | 11.39 |
| Percentage of on-spec fertilizer size (%) | 99.36 | 0.34 | 98.15 | 99.74 |
| Environmental dust (mg/m3) | 0.01 | 0 | 0.01 | 0.02 |
| Clamping time (s) | 4.09 | 0.72 | 3.23 | 4.97 |
| Product temperature (°C) | 36.14 | 4.21 | 24.75 | 44.25 |
| Machine vibration (mm/s) | 0.85 | 0.72 | 0.24 | 3.6 |
| Product weight (kg)—Y | 50.44 | 0.19 | 49.98 | 50.98 |
| ANN | RFR | LR | SVR | |
|---|---|---|---|---|
| R2 | 0.9360 | 0.9648 | 0.9077 | 0.9154 |
| Mean Absolute Error (MAE) | 0.0517 | 0.0328 | 0.0545 | 0.0468 |
| Root Mean Squared Error (RMSE) | 0.0680 | 0.0492 | 0.0775 | 0.0773 |
| Relative Absolute Error (RAE) (%) | 35.7247 | 22.6709 | 37.6533 | 32.3508 |
| Root Relative Squared Error (RRSE) (%) | 36.5109 | 26.4484 | 41.6324 | 41.5049 |
| Model 1 | Model 2 | Wilcoxon Statistic | p-Value | Significance (α < 0.05) |
|---|---|---|---|---|
| RFR | ANN | 0 | 0.001953 | Significant |
| RFR | SVR | 0 | 0.001953 | Significant |
| RFR | LR | 6 | 0.027344 | Significant |
| Model | Training Time (s) | Avg. Inference Time per Bag (ms) |
|---|---|---|
| RFR | 0.1461 | 12.0408 |
| ANN | 0.0295 | 1.3408 |
| SVR | 0.0022 | 1.5658 |
| LR | 0.0022 | 1.2288 |
| No. | Feature | Attribute Importance |
|---|---|---|
| 1 | Clamping time (s) | 0.37 |
| 2 | Air pressure (bar) | 0.34 |
| 3 | Humidity (%) | 0.10 |
| 4 | Machine vibration (mm/s) | 0.04 |
| 5 | Machine temperature (°C) | 0.04 |
| 6 | Percentage of on-spec fertilizer size (%) | 0.04 |
| 7 | Product water content (%) | 0.04 |
| 8 | Product temperature (°C) | 0.04 |
| 9 | Environmental dust (mg/m3) | 0.01 |
| Method | Advantages | Limitations | Ref. |
|---|---|---|---|
| Random Forest Importance |
|
| [6] |
| Permutation Importance |
|
| [40] |
| SHAP Values |
|
| [41] |
| Removed Feature | R2 | ΔR2 | Brief Interpretation |
|---|---|---|---|
| X1—Machine temperature (°C) | 0.9589 | −0.0106 | Minimal impact |
| X2—Humidity (%) | 0.9549 | −0.0067 | Very small effect |
| X3—Product water content (%) | 0.9601 | −0.0118 | Not significant |
| X4—Air pressure (bar) | 0.9513 | −0.003 | Very slight impact |
| X5—Percentage of on-spec fertilizer size (%) | 0.9498 | −0.0015 | Nearly neutral |
| X6—Environmental dust (mg/m3) | 0.9482 | 0 | No impact at all |
| X7—Clamping time (s) | 0.9721 | −0.0239 | Performance improved |
| X8—Product temperature (°C) | 0.9582 | −0.0009 | Almost no impact |
| X9—Machine vibration (mm/s) | 0.9395 | 0.0088 | Limited but relevant contribution |
| n_estimators | 10 | 20 | 50 | 100 | 200 | 500 | 1000 | 1500 | 2000 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Maxdepth | 5 | 0.0524 | 0.0489 | 0.0501 | 0.0501 | 0.0485 | 0.0487 | 0.0482 | 0.0483 | 0.0484 |
| 10 | 0.0523 | 0.0498 | 0.0513 | 0.0497 | 0.0497 | 0.0491 | 0.0487 | 0.0487 | 0.0488 | |
| 15 | 0.0543 | 0.0522 | 0.051 | 0.0496 | 0.0496 | 0.0491 | 0.0487 | 0.0487 | 0.0488 | |
| 20 | 0.0543 | 0.0522 | 0.051 | 0.0496 | 0.0496 | 0.0491 | 0.0487 | 0.0487 | 0.0488 | |
| 25 | 0.0543 | 0.0522 | 0.051 | 0.0496 | 0.0496 | 0.0491 | 0.0487 | 0.0487 | 0.0488 | |
| 30 | 0.0543 | 0.0522 | 0.051 | 0.0496 | 0.0496 | 0.0491 | 0.0487 | 0.0487 | 0.0488 | |
| No. | Details | Amount (IDR/year) |
|---|---|---|
| 1 | Losses before ML implementation | 30,591,000,000 |
| 2 | Estimated losses after ML implementation | 1,529,550,000 |
| 3 | ML implementation + maintenance costs | 250,000,000 |
| Total Savings | 28,811,450,000 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Primantara, A.; Ciptomulyono, U.; Kindhi, B.A. Machine Learning Performance Analysis for Bagging System Improvement: Key Factors, Model Optimization, and Loss Reduction in the Fertilizer Industry. AgriEngineering 2025, 7, 187. https://doi.org/10.3390/agriengineering7060187
Primantara A, Ciptomulyono U, Kindhi BA. Machine Learning Performance Analysis for Bagging System Improvement: Key Factors, Model Optimization, and Loss Reduction in the Fertilizer Industry. AgriEngineering. 2025; 7(6):187. https://doi.org/10.3390/agriengineering7060187
Chicago/Turabian StylePrimantara, Ari, Udisubakti Ciptomulyono, and Berlian Al Kindhi. 2025. "Machine Learning Performance Analysis for Bagging System Improvement: Key Factors, Model Optimization, and Loss Reduction in the Fertilizer Industry" AgriEngineering 7, no. 6: 187. https://doi.org/10.3390/agriengineering7060187
APA StylePrimantara, A., Ciptomulyono, U., & Kindhi, B. A. (2025). Machine Learning Performance Analysis for Bagging System Improvement: Key Factors, Model Optimization, and Loss Reduction in the Fertilizer Industry. AgriEngineering, 7(6), 187. https://doi.org/10.3390/agriengineering7060187