1. Introduction
Strawberry (
Fragaria ×
ananassa Duch.) is a globally significant economic crop. Its yield and quality are markedly influenced by the dynamic relationship between the source (photosynthetic leaves) and the sink (developing fruits) [
1]. In plant physiology, the terms ‘source’ and ‘sink’ are used to describe organs that produce and store assimilates, respectively. Leaves predominantly act as a source due to photosynthesis, producing carbohydrates that are translocated to developing fruits, the primary sink organs [
2,
3,
4]. However, it is acknowledged that leaves themselves can temporarily act as sinks, especially during early development or under stress conditions [
5]. In our study, leaves are specifically considered as sources in the context of mature strawberry plants actively transferring assimilates to developing fruits. The strength of the sink–source relationship determines the fruit’s ability to compete for carbon, a critical factor affecting fruit growth and quality. Studies have demonstrated that sink–source strength is determined by both the size of the sink–source (e.g., fruit weight and volume) and the activity of the sink–source (e.g., metabolic efficiency) [
6]. During the early growth stages of strawberries, organ size is the primary factor influencing sink–source strength [
7]. To measure the size of each organ during these growth stages, strawberry point cloud data must first be acquired and then segmented into individual organ point clouds.
By segmenting the three-dimensional structure of strawberry organs from their point cloud representations, we can precisely quantify key morphological traits—volume, surface area, angles, and counts—for each organ. If we can accurately quantify these morphological traits of each organ, it will be possible to acquire and analyze a time-series of whole-plant point cloud models from the seedling to maturity. This will enable detailed analysis of source–sink dynamics during strawberry development in future works. Moreover, comparative analyses across different cultivars afford critical insights into varietal differences in both morphology and assimilate partitioning, thereby informing breeding programs. Analogous approaches have been demonstrated in other crops: Daviet et al. reconstructed maize plants at multiple growth stages to track organ-level volumetric changes and quantify source–sink fluxes (e.g., leaf photosynthate allocation versus ear storage) [
8]. Liu et al. developed an automated point cloud segmentation pipeline for cotton that isolates stems, leaves, and bolls and computes their volume, surface area, and count for high-throughput phenotyping [
9].
In recent years, with the advancement of DL technology, numerous models have achieved excellent results in semantic segmentation tasks on public datasets such as S3DIS and ScanNet [
10,
11]. In the context of strawberry organ segmentation, many researchers have utilized 2D DL models with RGB images to achieve outstanding performance. For example, Fujinaga employed the DeepLabV3+ model for semantic segmentation of strawberries via RGB images in the development of a strawberry-picking robot [
12]. However, RGB-based semantic segmentation faces challenges such as data loss owing to leaf occlusion. Other researchers have adopted 3D point clouds for strawberry semantic segmentation. For example, Le Louëdec and Cielniak [
13] evaluated the performance of stereo and time-of-flight cameras in perceiving and segmenting strawberry shapes and proposed a convolutional network that integrates point clouds and normal information. They revealed the potential and limitations of 3D perception technology in such scenarios. Although satisfactory segmentation results can be achieved, there remains room for improvement in segmenting strawberry organs.
In addition to strawberry segmentation, other studies have applied point cloud semantic segmentation to different plants. Patel et al. [
14] used LiDAR point clouds and DL models (e.g., PointNet++) to achieve high-precision segmentation (91.5%) of sorghum plant organs (stems, leaves, and panicles) and extract phenotypic features, with results highly correlated with manual measurements (R
2 up to 0.97). This provided an efficient automated solution for high-throughput plant phenotyping. Yang et al. [
15] addressed the issue of insufficient training data for semantic segmentation of corn organs by developing an automatic labeling tool, employing PointNet++ for semantic segmentation and HAIS. Moreover, when DL models are selected for semantic segmentation, there is no systematic investigation into whether the neural network structure is suitable for plant organ segmentation. When faced with numerous state-of-the-art (SOTA) models, determining the neural network structure most beneficial for strawberry organ segmentation is challenging.
To address these challenges, this study selected eight DL models—PointNet++ [
16], Point-MetaBase [
17], Point Transformer V2 [
18], Swin3D [
19], KPConv [
20], Rand-LA-Net [
21], PointCNN [
22], and Sparse Unet [
23]—to systematically evaluate and compare the performance of existing DL models for strawberry organ semantic segmentation tasks, aiming to identify architectures suitable for precision farming applications. For the dataset, we utilized the open-source LAST-Straw strawberry dataset, which was captured via a high-precision handheld scanner that accurately reproduced the true colors and structures of strawberries, laying the groundwork for correctly learning structural features for organ segmentation [
24]. Additionally, another portion of the dataset, consisting of an in-house Japanese strawberry point cloud collection, was collected by the authors to enhance model robustness. This part of the dataset was acquired using a 3D Gaussian splatting method, which generates high-precision point cloud models by capturing a series of images or videos and employing DL neural networks. This method faithfully reproduces the true structure and color of strawberries [
25]. Our research contributions can be summarized as follows:
Given the limited existing studies on this topic, this work evaluates the performance of eight neural network models for strawberry organ semantic segmentation.
Considering the complexity of the scenes and the characteristics of each point, we provide specific recommendations for selecting DL architectures for plant organ segmentation. Furthermore, we reveal the specific limitations of existing DL architectures when segmenting rare classes in strawberry organs. These findings could inform future selection or adaptation of existing architectures for improved performance in similar tasks.
2. Materials and Methods
2.1. Dataset Composition and Acquisition
To demonstrate the effectiveness and robustness of DL semantic segmentation for strawberry organ segmentation, we utilized the annotated LAST-Straw dataset and captured a portion of the strawberry dataset from Japanese strawberries. This dataset consists of 13 annotated LAST-Straw strawberry point cloud files and 11 strawberry point cloud files from the Japanese cultivar dataset captured by the authors. Out of the 24 pots of strawberries in the overall dataset, 15 pots were used as the training set, 6 pots were used as the validation set, and 3 pots were used as the test set. The number of point clouds for each category in the dataset, along with the division into training, validation, and test sets, is shown in
Table 1. The overall proportions of the training, validation, and test sets are 53%, 27%, and 20%, respectively. According to the data in
Table 2, the leaf category has the highest overall proportion, reaching about 85%, followed by the stem category with approximately 9%. The berry and flower categories account for only about 3% and 4%, respectively. This data reflects the extreme imbalance of point clouds across categories, posing a challenge for neural network models to perform effective semantic segmentation tasks.
2.1.1. LAST-Straw Dataset
The dataset includes Driscoll’s Katrina (variety A) and Driscoll’s Zara (variety B) strawberry varieties. The Last-Straw dataset was captured by the University of Lincoln, UK, using the EinScan Pro 2X Plus handheld 3D scanner (Hangzhou, China). The scanner is equipped with an LED light source that projects specific structured light patterns (typically a series of stripes or grids) onto the surface of the object being scanned. When the structured light is projected onto the object’s surface, the light patterns deform because of the varying shapes of the object. Using the principle of triangulation, the scanner calculates the three-dimensional coordinates (X, Y, Z) of each point on the object’s surface on the basis of the known angle between the light source and the camera, as well as the degree of pattern deformation. The dataset provides high-precision, high-quality strawberry point cloud data with color information. Using EXScanPro (version 3.7.4) provided by Shining 3D, the data can be directly exported as OBJ models and then converted to XYZ-format point cloud files in CloudCompare (version 2.11.alpha).
2.1.2. Japanese Cultivar Dataset
The dataset captured in this study consists of eleven plants from three Japanese strawberry varieties: Sachinoka, Toyonoka, and Fukuba. The three types of strawberry plants were cultivated in an artificial climate chamber at the Faculty of Agriculture and Life Sciences, University of Tokyo, as shown in
Figure 1, with strawberry point cloud data captured at regular intervals of nine days. The Japanese cultivar dataset was captured using the Scaniverse (version 4.0.7) software installed on an iPhone 15 with iOS 18.3.2, and the 3DGS (3D Gaussian Splatting) mode of the software was employed to generate the point cloud models of the scanned objects. The working principle of 3DGS is based on extracting spatial data points from video or image inputs and initializing these points as a splat cloud defined by Gaussian functions. Each Gaussian splat has a position (X, Y, Z), color, and a covariance matrix, which describes its shape and orientation. The scanning process generates a three-dimensional radiance field representation by analyzing the perspective changes of the object in the video frames, combined with light field information. The files output by Scaniverse undergo various preprocessing steps in CloudCompare.
2.2. Data Preprocessing
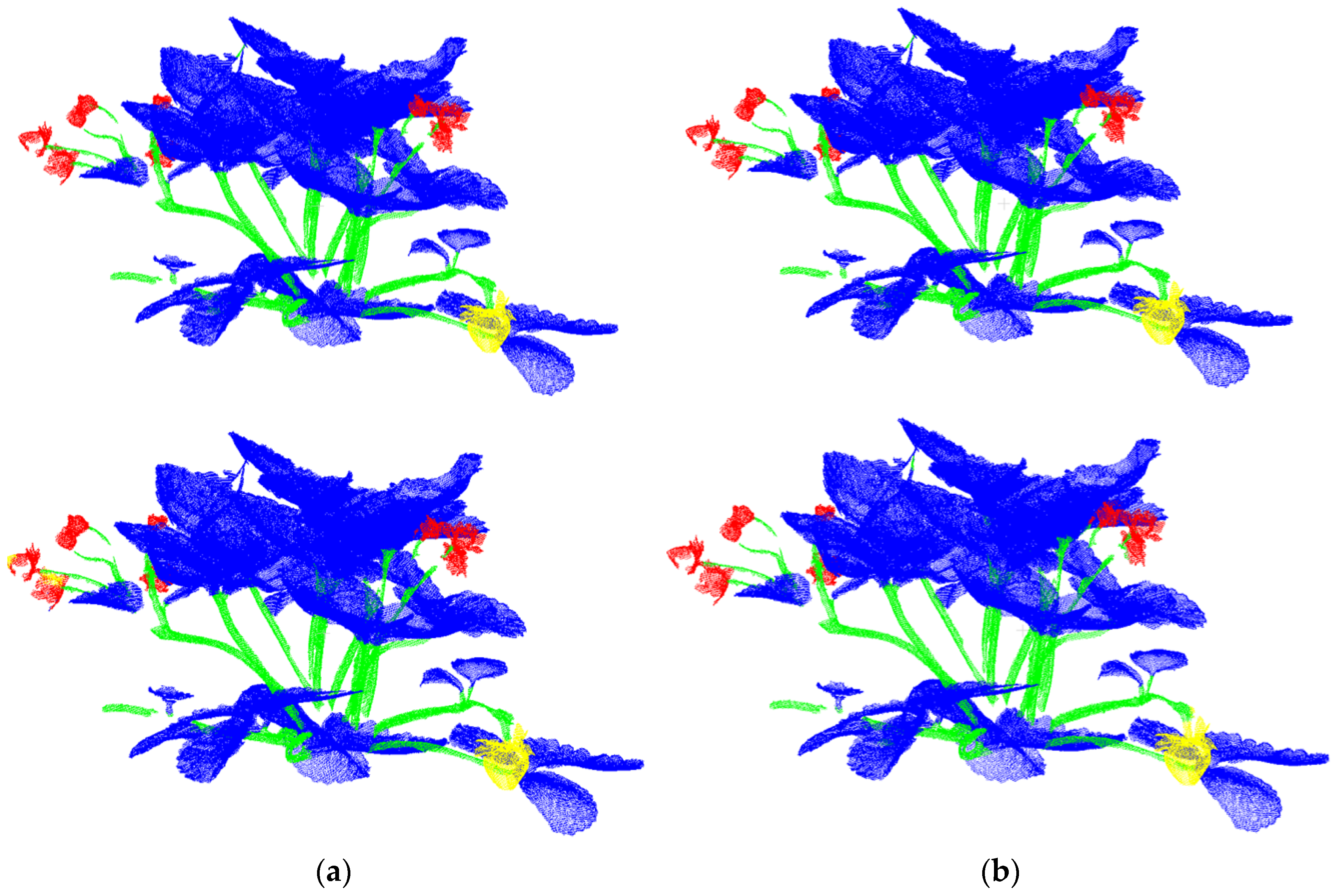
Owing to the complex nature of point cloud data, such as the raw point cloud shown in
Figure 2, which inherently contains a significant amount of noise, data preprocessing is essential before training commences. We applied different preprocessing techniques to the two distinct datasets. For the LAST-Straw dataset preprocessing, the original labels included eleven categories—such as soil, buds, and point clouds of neighboring strawberry plants—not belonging to the target plant. To align label categories with our in-house dataset and minimize ambiguity, we removed all of these extra labels, retaining only four classes: leaf, stem, berry, and flower. We also uniformly scaled the point clouds to ensure smooth data ingestion by the models. Since the Shining 3D software applies point cloud denoising during export, no further filtering was performed on the LAST-Straw data.
For the Japanese cultivar dataset preprocessing, we carried out the following preprocessing steps. First, for label annotation, we manually segmented the strawberry point clouds in CloudCompare and assigned the corresponding labels, ensuring that the point cloud file formats and label categories matched those of the LAST-Straw dataset. Next, for point cloud data processing, to remove noise generated by 3DGS, we applied radius filtering to select and eliminate outliers. Radius filtering removes isolated points with insufficient neighboring points by setting a radius threshold, thereby reducing noise while preserving the main structure. Finally, we performed coordinate transformations and scale adjustments on this dataset’s point clouds to ensure their scale was consistent with that of the LAST-Straw dataset.
2.3. Model Selection
With the advent of DL, numerous point cloud semantic segmentation models have emerged. Early voxelization methods discretize point clouds into regular or adaptive 3D grids and apply 3D convolutional neural networks for classification and segmentation. However, these approaches suffer from high memory demands and loss of geometric information. Subsequently, projection methods project point clouds into 2D representations (such as multiview images or depth maps) and leverage mature 2D convolutional networks for processing. Although these methods offer strong real-time performance, they sacrifice 3D spatial relationships. It was not until the introduction of PointNet, which directly operates on sparse raw point clouds, that the limitations of voxelization and projection were fully overcome. Although PointNet addresses the issue of local feature extraction, it overlooks global features, leading to the development of PointNet++, which introduced hierarchical multiscale feature extraction. This was followed by RandLA-Net, which improved efficiency and local geometric modeling through random sampling and adaptive feature aggregation. Convolution-based methods, such as PointCNN, adapt standard convolution with X-Conv, whereas KPConv uses kernel point convolution to handle complex geometries. Sparse UNet will first voxelize the point cloud and then perform convolution operations on the voxels containing only the point cloud. Transformer-based methods, such as Point Transformer, employ local self-attention mechanisms, with PTv2 and PTv3 enhancing robustness through grouping and patch attention and Swin3D using sliding window attention for multiscale feature extraction to model local and global contexts in complex scenes.
Table 3 shows the basic principles, publication dates, and mIoU performance on the public ScanNet dataset for eight DL models. ScanNet is an open-source point cloud dataset focused primarily on indoor furniture and objects, where the data consists mainly of a room containing various furniture and items, each with corresponding labels. The point cloud distribution in the ScanNet dataset differs significantly from that in the strawberry dataset. Therefore, some models that perform well on ScanNet may not necessarily excel at the task of strawberry organ segmentation. On the basis of these principles, we selected eight representative models: PointNet++, PointMetaBase, Point Transformer V2, Swin3D, KPConv, RandLA-Net, PointCNN, and Sparse UNet.
2.3.1. PointNet++
PointNet++ [
16] is a point-based point cloud semantic segmentation model that inherits the advantages of PointNet [
26] in handling unordered point cloud data while enhancing the capture of local geometric features through hierarchical feature extraction. It employs set abstraction modules utilizing K-nearest neighbors (KNNs) to progressively extract point cloud features from local to global scales and uses the farthest point sampling and grouping mechanisms to improve the coverage and accuracy of feature extraction.
2.3.2. PointMetaBase
PointMetaBase [
17] provides a detailed analysis of mainstream architectures in terms of neighbor update, neighbor aggregation, point update, and positional embedding. It adjusts the order of neighbor aggregation and MLP linear transformations to save computation time and improve performance. Before the neighbor aggregation stage, the model integrates explicit position embedding to directly embed geometric positional information into features, enhancing the perception of spatial information [
18]. The entire structure adopts hierarchical abstraction modules (PointMetaSA) and uses max pooling to progressively extract local and global features. Each stage achieves efficient feature extraction through the interaction of these core components and has low computational complexity.
2.3.3. Point Transformer V2
The workflow of this model includes grouped vector attention (GVA) [
18], improved positional encoding, and a partition-based pooling method. The GVA groups vector attention and shares weights, reducing the number of parameters while preserving the advantages of multihead attention [
27]. By integrating multiplicative and additive positional encoding mechanisms, geometric positional information is embedded into the features, enhancing spatial relationship modeling capabilities. In the pooling stage, a partition-based pooling approach is adopted, improving spatial alignment and efficiency through local aggregation via grid partitioning. Ultimately, a U-Net-style encoder–decoder structure is utilized to progressively extract and fuse multiscale features, achieving efficient point cloud understanding.
2.3.4. Swin3D
Swin3D [
19] is based on multilevel sparse voxel grids, employs sparse convolution to perform initial feature embedding, and leverages multistage Swin3D blocks to achieve multiscale feature extraction [
23]. Each block uses self-attention mechanisms [
27] with regular and shifted windows (W-MSA3D and SW-MSA3D) combined with context-relative signal embedding (cRSE) to capture the geometric and attribute information of the point cloud. Downsampling is performed via KNN and pooling, progressively extracting local and global features and supporting flexible integration with task-specific decoders.
2.3.5. KPConv
KPConv [
20] is a DL model designed specifically for point cloud analysis, with its architecture centered around the concept of kernel points. Kernel points are a set of predefined points in 3D space that specify positions relative to each point in the point cloud, allowing the convolution operation to collect feature contributions. During the convolution process, the model examines the local neighborhood of each point in the point cloud and computes a weighted sum of the features of neighboring points on the basis of the positions of the kernel points and a correlation function (such as Gaussian or distance-based linear decay). The positions of these kernel points are learned and continuously adjusted during training, enabling the model to adapt to the specific geometric structure of the point cloud data.
2.3.6. RandLA-Net
The network structure of RandLA-Net [
21] is based on efficient random sampling and local feature aggregation (LFA), designed as an encoder–decoder architecture. The encoder progressively reduces the scale of the point cloud through random sampling while employing LFA modules to extract local geometric and feature relationships. The LFA module comprises local spatial encoding and attentive pooling, which expand the receptive field to preserve complex geometric details [
28]. The decoder performs upsampling via nearest-neighbor interpolation and fuses intermediate features from the encoder via skip connections, ultimately predicting the semantic label for each point through fully connected layers.
2.3.7. PointCNN
PointCNN [
22] is a convolution-based neural network whose architecture is centered on an innovative X-transformation mechanism. X-transformation is a learnable function that maps the unordered points of a point cloud into a latent space, where they can be organized in a canonical order suitable for convolution. During the convolution process, for each point in the point cloud, the model leverages this transformation to align the local features, enabling standard convolution operations—originally designed for grid-structured data—to be applied effectively on irregular point clouds. The X-transformation is optimized during training, allowing the model to adapt to the unique geometric properties of the input point cloud data. The PointCNN architecture typically comprises multiple layers that progressively extract and refine features through these transformed convolutions, making it a robust solution for tasks such as point cloud classification and segmentation by directly processing raw, unstructured data with convolutional feature extraction.
2.3.8. Sparse UNet
Sparse Unet [
23,
29], a convolution-based neural network model, effectively mitigates the inherent limitations of traditional convolution—specifically, sparsity loss and expansion inefficiencies—by restricting convolutional operations to occupied regions within a point cloud. The methodology commences with the voxelization of the point cloud into a discrete grid, wherein only voxels containing points are preserved as input. Sparse UNet subsequently adopts an architecture analogous to conventional convolutional neural networks, integrating downsampling, upsampling, and residual modules to facilitate robust feature extraction. By judiciously selecting an appropriate voxel size, the model ensures that its receptive field adequately encompasses local regions, thereby enabling effective feature capture even for sparse point clouds and underrepresented classes. Crucially, the sparse convolution mechanism substantially reduces computational complexity, rendering Sparse UNet highly efficient for processing large-scale point clouds.
2.4. Implementation Details
For the selection of code to reproduce the eight open-source models, most of the chosen implementations were compiled using PyTorch (version 1.12.1). For PointNet++, we selected the version compiled by Xu via PyTorch, which has undergone extensive testing and demonstrated performance equivalent to that of the original TensorFlow version [
30]. Point Transformer V2 and PointMetaBase utilized the open-source code provided by the paper authors. KPConv was originally compiled in TensorFlow, so we opted for the PyTorch-compiled version by Hugues in this study [
31]. Notably, for the reproduction of Swin3D and Sparse UNet, we chose the compiled versions from the Pointcept project [
32]. The Pointcept is an open-source point cloud DL framework that includes numerous models. Although the PyTorch-compiled versions of PointCNN and RandLA-Net are available, because of insufficient project maintenance, the PyTorch versions exhibit inconsistent performance compared with the original code in certain task scenarios. Therefore, we chose to reproduce these two models via their original TensorFlow-based code.
4. Discussion
4.1. Semantic Segmentation Results of the Models
4.1.1. PointNet++
As pioneering work among point-based methods, the PointNet++ [
16] approach of directly extracting features from points has influenced numerous DL methods. However, in the current task, its farthest point sampling (FPS) combined with the KNN feature aggregation method performs poorly in extracting features from rare classes. Owing to the KNN computation, features of points in rare classes may be overwhelmed by features of points in more dominant classes. FPS (and its uniform sampling variants) ignores semantic distribution, leading to insufficient sampling in boundary or rare-class regions—a behavior also confirmed by other studies [
35]. Moreover, PointNet++ does not incorporate an additional positional encoding embedding module for the point cloud, causing the XYZ coordinates of the point cloud to be aggregated together with the point cloud features. This results in the positional information of rare classes being difficult to preserve during the feature aggregation process.
4.1.2. PointMetaBase
PointMetaBase [
17] achieved the second-best performance in this experiment, with IoU results of 65 and 68 for the “flower” and “berry” classes in validation dataset, respectively. As a point-based method, the most significant distinction between PointMetaBase and PointNet++ lies in its incorporation of an explicit positional embedding module. Through a trainable MLP network, positional information is more effectively embedded into the aggregated features, which are subsequently fed into a max pooling module. Additionally, PointMetaBase employs an “MLP-before-Group” strategy, which reduces computational complexity and accelerates training speed. Moreover, PointMetaBase replaces the vector attention mechanism with max pooling, significantly reducing the number of parameters without compromising training effectiveness. This mechanism collaborates with the neighbor update function, providing efficient aggregation capabilities. The selection and application of PointMetaBase’s structural modules represent the optimal combination determined by the original authors after multiple ablation experiments, and its performance convincingly demonstrates the effectiveness of its modular design [
17].
4.1.3. Point Transformer V2
Point Transformer V2 (PTV2) [
18], as a transformer-based model, employs a vector attention mechanism to extract point cloud features. Building on PTV1, PTV2 enhances the standard global vector attention mechanism with a GVA approach and incorporates explicit positional encoding to strengthen the perception of local structures. However, despite the strength of attention mechanisms in capturing long-range dependencies within point clouds, they exhibit significant limitations in extracting features from rare classes [
36,
37,
38]. This limitation stems from PTV2’s lack of mechanisms to prioritize or amplify the fine-grained patterns of rare classes. Without such localized feature extraction capabilities, the self-attention mechanism tends to homogenize feature representations, favoring the dominant patterns of majority classes while overlooking the sparse local structures of rare classes.
4.1.4. Swin3D
The Swin3D model [
19], currently a SOTA performer on certain public datasets, did not achieve outstanding results in this task. It combines sparse convolutional networks with self-attention, first voxelizing the point cloud and then performing attention operations on the sparse voxel features. Although this hybrid design partially mitigates sparsity issues by operating on voxelized regions, its self-attention component struggles to adequately emphasize the local geometric characteristics of rare classes [
36,
37,
38]. Even when constrained within sparse voxels, the attention mechanism distributes focus across the entire voxelized space, failing to sufficiently highlight the subtle features of rare classes overshadowed by the dominant majority class points.
4.1.5. KPConv
KPConv [
20] operates directly on raw point clouds, relying on kernel points and local neighborhoods. Although this method excels at capturing complex local geometric structures, its performance is challenged when the number of points in rare classes is extremely low. Additionally, the number and selection of kernel points influence the feature extraction performance for rare classes. In such cases, local neighborhoods may be dominated by points from more common classes, thereby compromising the accuracy of rare class feature extraction [
39,
40].
4.1.6. RandLA-Net
The RandLA-Net [
21] method performed poorly in this experiment. Originally designed for rapid semantic segmentation tasks without sacrificing accuracy, its random sampling approach clearly fails to meet the requirements for extracting features from rare classes. Although it incorporates explicit positional encoding to enhance contextual relationships in point clouds, the random sampling strategy significantly reduces the likelihood of rare class points being selected, resulting in their features being underrepresented in subsequent feature extraction modules. The original RandLA-Net paper likewise notes that its random downsampling strategy may directly discard sparse or minority-class points during processing, thereby preventing those rare class features from being fully utilized by the subsequent network [
21].
4.1.7. PointCNN
The X-Conv operation in PointCNN [
22] transforms unordered point clouds into a convolution-friendly structure via FPS and X-transformation. However, when processing data with sparse and unevenly distributed rare classes, such as strawberry point clouds, it may fail because of FPS’s tendency to select uniformly distributed points, potentially overlooking rare class points, or because of X-transformation’s weighting and reordering process (which generates a transformation matrix via MLP from local coordinates), assigning lower weights to rare class features and possibly suppressing them, causing these features to be “overwhelmed” or blurred by more common classes [
35]. Although PointCNN employs an encoder–decoder structure to integrate global information, if rare class features are weakened in early layers, subsequent layers may struggle to recover them, thus diminishing the model’s ability to extract features from rare classes [
41]. This issue may be exacerbated when the geometric characteristics of the dataset deviate from the model’s assumption, highlighting a lack of sufficient robustness.
4.1.8. Sparse UNet
Sparse UNet [
23] achieved the best results in this experiment, with IoU scores for the “flower” and “berry” classes exceeding 78 and 61. Despite its simple structure, Sparse UNet effectively retains all possible features by performing robust convolutional feature extraction on voxel blocks containing existing point clouds. Combined with downsampling, upsampling, and residual modules and aided by appropriately sized voxels, Sparse UNet ensures that its receptive field covers sufficient local regions, thereby effectively capturing features from sparse point clouds and rare classes [
42].
4.2. Recommendations on Suitable Architectures and Future Research Directions
Based on the benchmarking results presented in this study, we identified certain characteristics of neural network architectures that are particularly beneficial for semantic segmentation tasks involving strawberry organs, especially considering the extreme imbalance of classes such as flowers (4%) and berries (3%). Among the evaluated models, Sparse UNet and PointMetaBase demonstrated superior capabilities in capturing fine-grained features from rare classes, owing to their efficient convolutional operations, explicit positional encoding modules, and robust feature aggregation strategies. In contrast, models utilizing traditional uniform sampling methods, such as PointCNN and RandLA-Net, exhibited limitations in effectively addressing class imbalance, leading to suboptimal segmentation performance for minority classes.
Our experimental findings suggest that architectures incorporating the following components tend to perform better in scenarios with imbalanced point cloud data such as the strawberry organ semantic segmentation task:
Adaptive sampling methods, which ensure adequate representation of minority classes during feature extraction.
Explicit positional encoding, as demonstrated in PointMetaBase, enhancing the model’s sensitivity to subtle spatial structures.
Sparse convolutional operations, as shown in Sparse UNet, which effectively handle sparse data distributions by preserving critical local geometric information.
It is important to note, however, that these recommendations arise strictly from comparative experimental observations rather than from direct structural modifications or ablation tests within this study.
In our future research, we intend to explicitly address the challenges identified here by developing novel architectures specifically optimized for class-imbalanced scenarios commonly encountered in plant organ segmentation tasks. These future developments will incorporate comprehensive ablation studies to rigorously validate the contribution of each proposed module or strategy. The insights and comparative baseline results provided by the current benchmark study will serve as a solid foundation for these subsequent explorations, guiding systematic architectural improvements and methodological innovations.







{kind=link}
{kind=link}
{kind=link}