
Lightweight Pepper Disease Detection Based on Improved YOLOv8n

 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
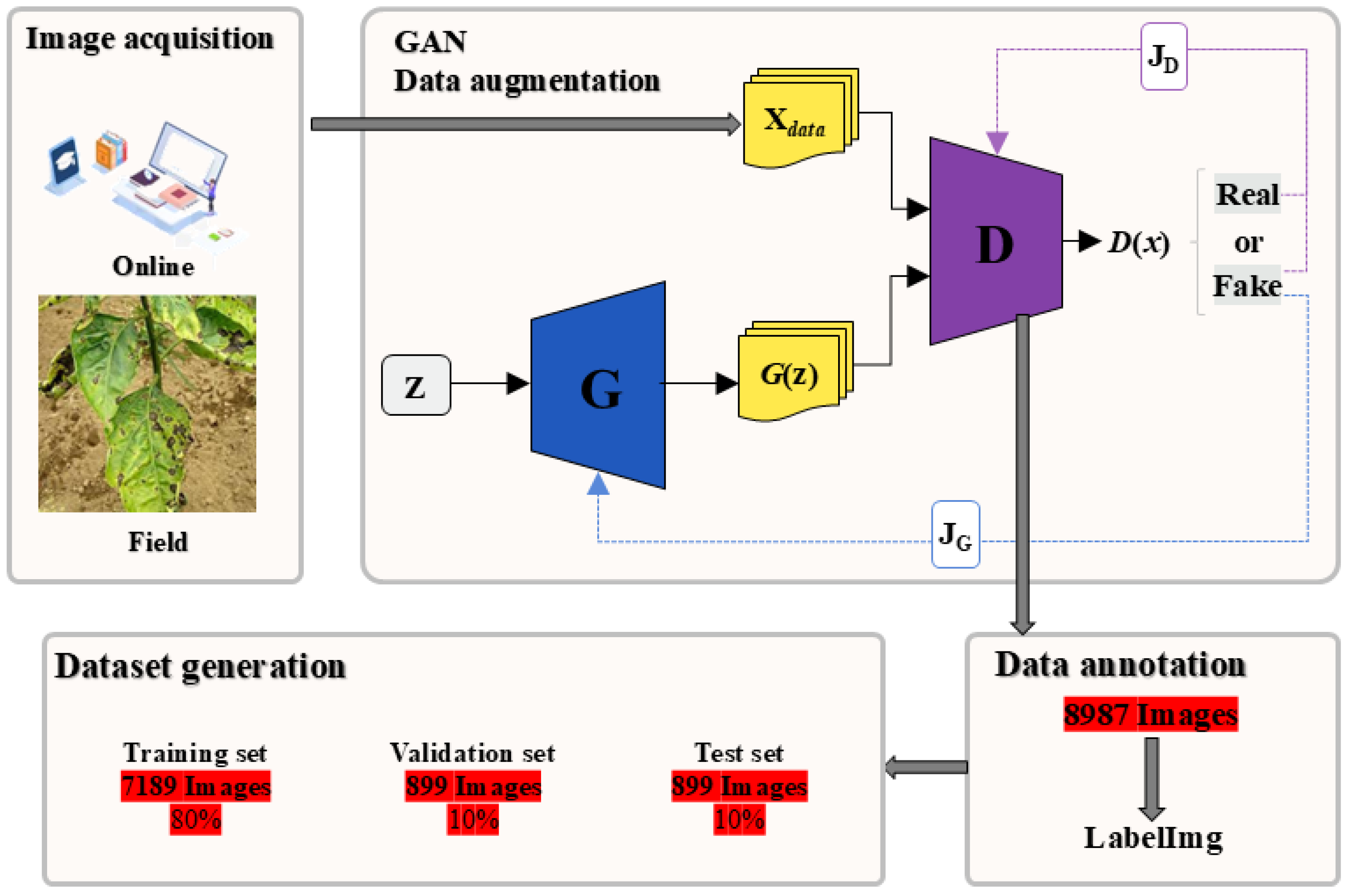
2.1. Establishment of the Dataset
2.2. Pepper Target Detection Methods
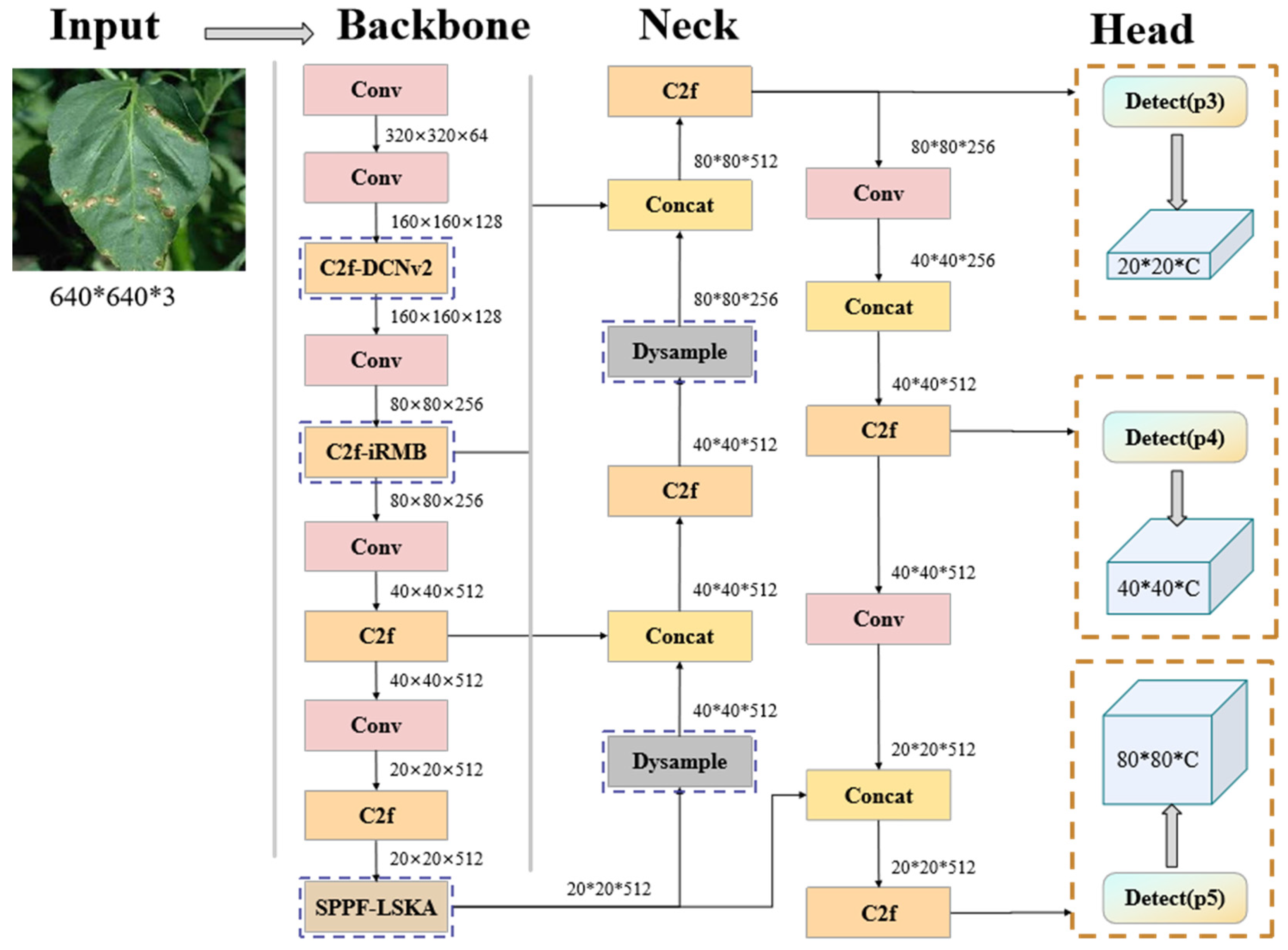
2.2.1. YOLOv8 Convolutional Network Modeling
2.2.2. Proved DD-YOLO Algorithm
- (1)
- C2f-iRBM module
- (2)
- C2f-DCNv2 module
- (3)
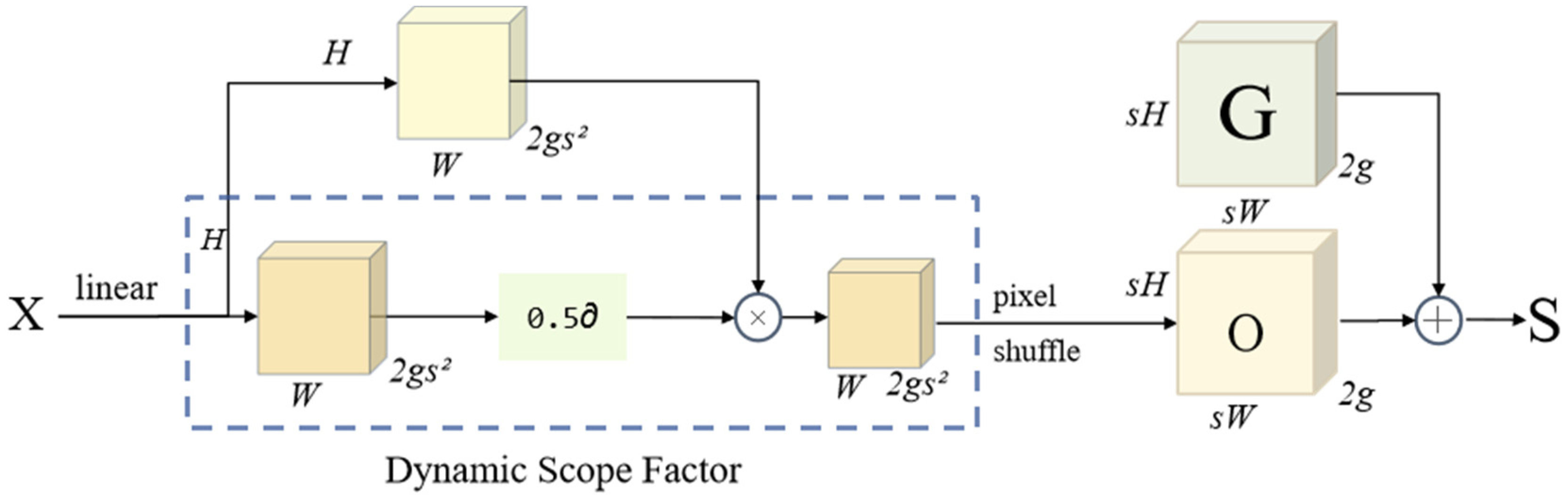
- Fusion of DySample sampling operators
- (4)
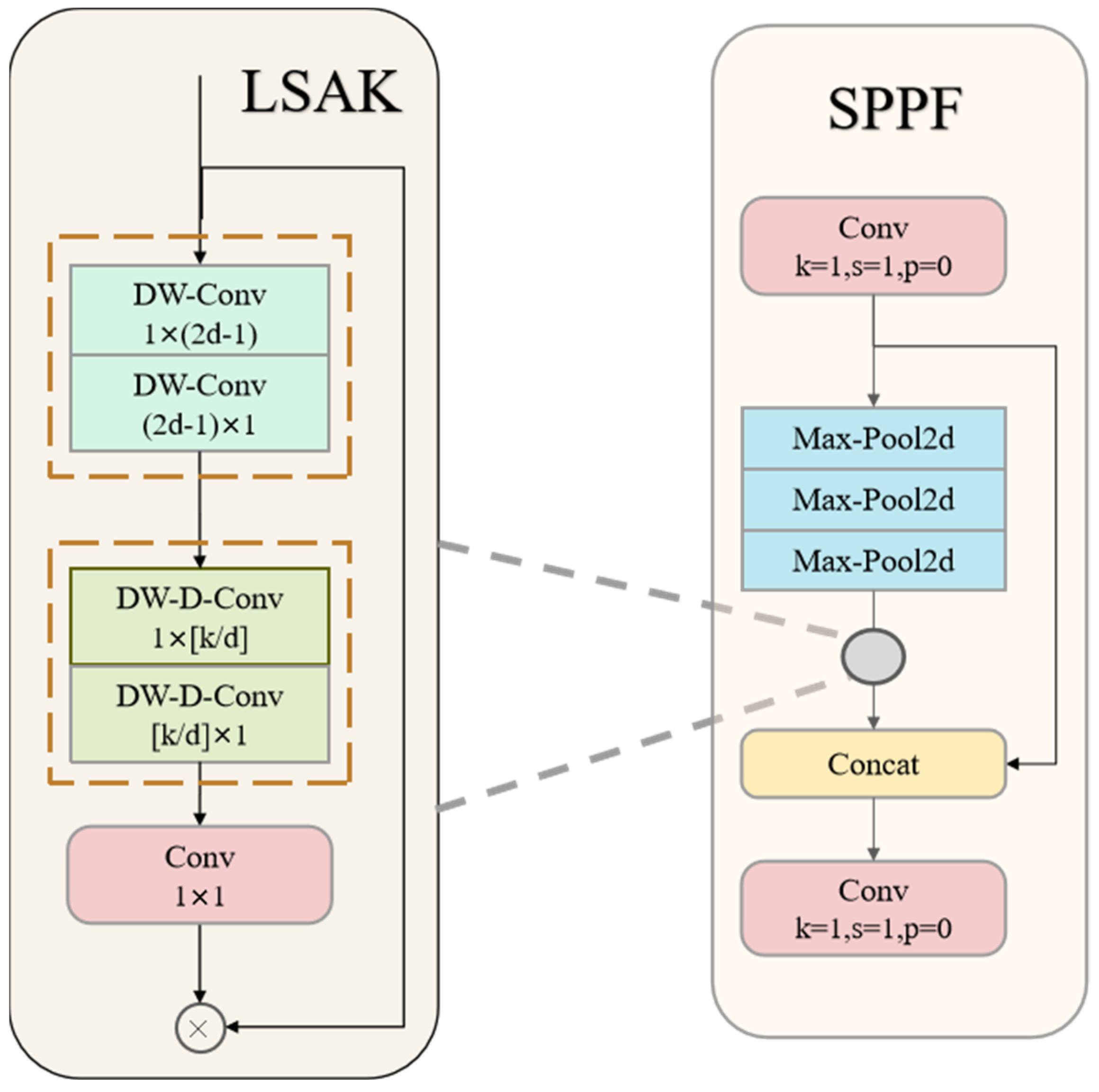
- Add the Attention Mechanism LSKA
2.3. Perimental Platform and Parameter Settings
3. Results
3.1. Analysis of the Rationality of the Model Improvement Method
3.1.1. Generalization Validation Experiment of GAN
3.1.2. Comparison of Other Lightweight Model Backbone Networks
3.1.3. Visualization of C2f-DCNv2 Model Features
3.1.4. Dysample Heat Map
3.2. Ablation Experiments
3.3. Detection Model Comparison Experiment
3.4. Detection Comparison
3.5. Lightweight Deployment
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, S.; Xiu, Y.; Kong, J.; Yang, C.; Zhao, C. An effective pyramid neural network based on graph-related attentions structure for fine-grained disease and pest identification in intelligent agriculture. Agriculture 2023, 13, 567. [Google Scholar] [CrossRef]
- Franczuk, J.; Tartanus, M.; Rosa, R.; Zaniewicz-Bajkowska, A.; Dębski, H.; Andrejiová, A.; Dydiv, A. The effect of mycorrhiza fungi and various mineral fertilizer levels on the growth, yield, and nutritional 450 value of sweet pepper (Capsicum annuum L.). Agriculture 2023, 13, 857. [Google Scholar] [CrossRef]
- Yang, Z.; Feng, H.; Ruan, Y.; Weng, X. Tea tree pest detection algorithm based on improved YOLOv7-Tiny. Agriculture 2023, 13, 1031. [Google Scholar] [CrossRef]
- Su, T.; Mu, S.; Shi, A.; Cao, Z.; Dong, M. A CNN-LSVM model for imbalanced images identification of wheat leaf. Neural Netw. World 2019, 29, 345–361. [Google Scholar] [CrossRef]
- Xi, R.; Hou, J.; Lou, W. Potato bud detection with improved faster R-CNN. Trans. ASABE 2020, 63, 557–569. [Google Scholar] [CrossRef]
- Li, Y.; Nie, J.; Chao, X. Do we really need deep CNN for plant diseases identification? Comput. Electron. Agric. 2020, 178, 105803. [Google Scholar] [CrossRef]
- Pattnaik, G.; Shrivastava, V.K.; Parvathi, K. Transfer learning-based framework for classification of pest in tomato plants. Appl. Artif. Intell. 2020, 34, 981–993. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X. Tomato diseases and pests detection based on improved YOLO V3 convolutional neural network. Front. Plant science 2020, 11, 898. [Google Scholar] [CrossRef]
- Zheng, J.; Wang, X.; Shi, Y.; Zhang, X.; Wu, Y.; Wang, D.; Huang, X.; Wang, Y.; Wang, J.; Zhang, J. Keypoint detection and diameter estimation of cabbage (Brassica oleracea L.) heads under varying occlusion degrees via YOLOv8n-CK network. Comput. Electron. Agric. 2024, 226, 109428. [Google Scholar] [CrossRef]
- Gai, R.; Chen, N.; Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Comput. Appl. 2023, 35, 13895–13906. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Kini, A.S.; Prema, K.V.; Pai, S.N. Early stage black pepper leaf disease prediction based on transfer learning using ConvNets. Sci. Rep. 2024, 14, 1404. [Google Scholar]
- Yue, X.; Li, H.; Song, Q.; Zeng, F.; Zheng, J.; Ding, Z.; Kang, G.; Cai, Y.; Lin, Y.; Xu, X.; et al. YOLOv7-GCA: A Lightweight and High-Performance Model for Pepper Disease Detection. Agronomy 2024, 14, 618. [Google Scholar] [CrossRef]
- Ma, N.; Wu, Y.; Bo, Y.; Yan, H. Chili pepper object detection method based on improved YOLOv8n. Plants 2024, 13, 2402. [Google Scholar] [CrossRef] [PubMed]
- Teixeira, A.C.; Ribeiro, J.; Morais, R.; Sousa, J.J.; Cunha, A. A systematic review on automatic insect detection using deep learning. Agriculture 2023, 13, 713. [Google Scholar] [CrossRef]
- Liu, Z.; Abeyrathna, R.R.D.; Sampurno, R.M.; Nakaguchi, V.M.; Ahamed, T. Faster-YOLO-AP: A lightweight apple detection algorithm based on improved YOLOv8 with a new efficient PDWConv in orchard. Comput. Electron. Agric. 2024, 223, 109118. [Google Scholar] [CrossRef]
- Ma, Z.; Wang, Y.; Zhang, T.; Wang, H.; Jia, Y.; Gao, R.; Su, Z. Maize leaf disease identification using deep transfer convolutional neural networks. Int. J. Agric. Biol. Eng. 2022, 15, 187–195. [Google Scholar] [CrossRef]
- Vijayakumar, A.; Vairavasundaram, S. YOLO-based object detection models: A review and its applications. Multimedia. Tools Appl. 2024, 83, 83535–83574. [Google Scholar] [CrossRef]
- Wang, Q.; Cheng, M.; Huang, S.; Cai, Z.; Zhang, J.; Yuan, H. A deep learning approach incorporating YOLO v5 and attention mechanisms for field real-time detection of the invasive weed Solanum rostratum Dunal seedlings. Comput. Electron. Agric. 2022, 199, 107194. [Google Scholar] [CrossRef]
- Zhang, J.; Li, X.; Li, J.; Liu, L.; Xue, Z.; Zhang, B.; Jiang, Z.; Huang, T.; Wang, Y.; Wang, C. Rethinking Mobile Block for Efficient Attention-based Models. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 1389–1400. [Google Scholar]
- Lu, J.; Tan, L.; Jiang, H. Review on convolutional neural network (CNN) applied to plant leaf disease classification. Agriculture 2021, 11, 707. [Google Scholar] [CrossRef]
- Li, B.; Huang, S.; Zhong, G. LTEA-YOLO: An Improved YOLOv5s Model for Small Object Detection. IEEE Access 2024, 12, 99768–99778. [Google Scholar] [CrossRef]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lau, K.W.; Po, L.-M.; Rehman, Y.A.U. Large separable kernel attention: Rethinking the large kernel attention design in cnn. Expert Syst. Appl. 2024, 236, 121352. [Google Scholar] [CrossRef]
- Jin, X.; Sun, Y.; Che, J.; Bagavathiannan, M.; Yu, J.; Chen, Y. A novel deep learning-based method for detection of weeds in vegetables. Pest Manag. Sci. 2022, 78, 1861–1869. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Yang, S.; Xing, Z.; Wang, H.; Dong, X.; Gao, X.; Liu, Z.; Zhang, X.; Li, S.; Zhao, Y. Maize-YOLO: A new high-precision and real-time method for maize pest detection. Insects 2023, 14, 278. [Google Scholar] [CrossRef]
- Gao, J.; French, A.P.; Pound, M.P.; He, Y.; Pridmore, T.P.; Pieters, J.G. Deep convolutional neural networks for image-based Convolvulus sepium detection in sugar beet fields. Plant Methods 2020, 16, 1–12. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.C.; Mbouembe, P.L.T.; Kim, J.H. YOLO-tomato: A robust algorithm for tomato detection based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Zhou, X.; Yi, J.; Xie, G.; Jia, Y.; Xu, G.; Sun, M. Human detection algorithm based on improved YOLO v4. Inf. Technol. Control. 2022, 51, 485–498. [Google Scholar] [CrossRef]
- Zhang, W.; Gao, X.-Z.; Yang, C.-F.; Jiang, F.; Chen, Z.-Y. A object detection and tracking method for security in intelligence of unmanned surface vehicles. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 1279–1291. [Google Scholar] [CrossRef]
- Creswell, A.; Bharath, A.A. Inverting The Generator Of A Generative Adversarial Network. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1967–1974. [Google Scholar] [CrossRef] [PubMed]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef]
- Motamed, S.; Rogalla, P.; Khalvati, F. Data augmentation using Generative Adversarial Networks (GANs) for GAN-based detection of Pneumonia and COVID-19 in chest X-ray images. Inform. Med. Unlocked 2021, 27, 100779. [Google Scholar] [CrossRef] [PubMed]
- Kaur, P.; Khehra, B.S.; Mavi, E.B.S. Data augmentation for object detection: A review. In Proceedings of the 2021 IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Lansing, MI, USA, 9–11 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 537–543. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Shen, L.; Su, J.; He, R.; Song, L.; Huang, R.; Fang, Y.; Song, Y.; Su, B. Real-time tracking and counting of grape clusters in the field based on channel pruning with YOLOv5s. Comput. Electron. Agric. 2023, 206, 107662. [Google Scholar] [CrossRef]
- Fan, S.; Liang, X.; Huang, W.; Zhang, V.J.; Pang, Q.; He, X.; Li, L.; Zhang, C. Real-time defects detection for apple sorting using NIR cameras with pruning-based YOLOV4 network. Comput. Electron. Agric. 2022, 193, 106715. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Train | Val | Test | All | Labels |
|---|---|---|---|---|---|
| leaf curl of pepper | 1185 | 148 | 148 | 1481 | 10,494 |
| pepper whitefly | 1119 | 140 | 141 | 1400 | 11,568 |
| pepper yellowish | 1314 | 164 | 165 | 1643 | 13,608 |
| leaf spot of pepper | 1199 | 151 | 150 | 1500 | 13,860 |
| powdery mildew of pepper | 1156 | 145 | 144 | 1445 | 14,010 |
| pepper scab | 1216 | 151 | 151 | 1518 | 13,536 |
| All | 7189 | 899 | 899 | 8987 | 77,076 |
| Configuration | Specific model |
| mirroring | PyTorch 1.11.0 Python 3.8 (ubuntu20.04) Cuda 11.3 |
| GPU | RTX 2080 Ti (11 GB) × 1 |
| CPU | 12 vCPU Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz |
| GAN | Precision P/% | Recall R/% | mAP50/% | Weights/MB | Parameters | GFLOPs |
|---|---|---|---|---|---|---|
| × | 91.6 | 88.9 | 94.4 | 4.8 | 2,296,804 | 7.2 |
| √ | 92.9 | 92.3 | 96.3 | 4.8 | 2,296,804 | 7.2 |
| Backbone Network | P/% | R/% | mAP/% | GFLOPs |
|---|---|---|---|---|
| C2f-iRMB | 88.7 | 86.3 | 91.7 | 7.0 |
| HGNetV2 | 82.1 | 78.5 | 84.6 | 6.9 |
| chostHGNetV2 | 80.7 | 77.3 | 83.2 | 6.8 |
| RepHGNetV2 | 81.5 | 77.9 | 84.8 | 6.9 |
| C2f-AKConv | 85.8 | 82.1 | 88.2 | 7.2 |
| C2f-MSBlock | 83.4 | 79.7 | 86.3 | 7.7 |
| Test No. | DCNV2 | iRMB | DySample | LSKA | Precision P/% | Recall R/% | mAP50/% | Weights/MB | Parameters | GFLOPs |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | 86.1 | 87.9 | 92.9 | 6.2 | 3,006,818 | 8.1 |
| 2 | √ | × | × | × | 91.2 | 90.5 | 95.8 | 6.3 | 3,038,205 | 8.0 |
| 3 | × | √ | × | × | 88.7 | 86.3 | 91.7 | 5.5 | 2,634,194 | 7.0 |
| 4 | × | × | √ | × | 91.8 | 91.2 | 95.6 | 6.3 | 3,019,170 | 8.1 |
| 5 | × | × | × | √ | 91.3 | 90.9 | 95.1 | 6.8 | 3,279,714 | 8.3 |
| 6 | √ | √ | × | × | 89.7 | 88.1 | 93.9 | 6.0 | 2,893,549 | 7.1 |
| 7 | × | √ | √ | × | 89.6 | 86.2 | 92.3 | 5.5 | 2,646,546 | 7.1 |
| 8 | × | × | √ | √ | 91.5 | 90.3 | 95.0 | 6.8 | 3,292,066 | 8.3 |
| 9 | √ | × | √ | × | 91.4 | 90.4 | 95.2 | 6.3 | 3,050,557 | 8.0 |
| 10 | √ | × | × | √ | 92.7 | 90.6 | 95.7 | 6.8 | 3,311,101 | 8.2 |
| 11 | × | √ | × | √ | 88.2 | 85.9 | 91.5 | 6.1 | 2,907,090 | 7.3 |
| 12 | √ | √ | √ | × | 89.3 | 88.5 | 93.1 | 6.0 | 2,905,901 | 7.1 |
| 13 | × | √ | √ | √ | 89.4 | 85.2 | 91.9 | 6.1 | 2,919,442 | 7.3 |
| 14 | √ | × | √ | √ | 91.9 | 90.1 | 95.3 | 6.9 | 3,323,453 | 8.2 |
| 15 | √ | √ | × | √ | 89.1 | 87.1 | 92.7 | 6.6 | 3,166,445 | 7.3 |
| 16 | √ | √ | √ | √ | 92.9 | 92.3 | 96.3 | 4.8 | 2,296,804 | 7.2 |
| Class | Precision/% | Recall/% | mAP50/% | mAP50-95/% |
|---|---|---|---|---|
| all | 92.9 | 92.3 | 96.3 | 76.5 |
| leaf curl of pepper | 87.2 | 81.5 | 90.8 | 56.1 |
| pepper whitefly | 93.7 | 92.9 | 97.5 | 71.6 |
| pepper yellowish | 86.2 | 82.7 | 91.8 | 55.2 |
| leaf spot of pepper | 93.1 | 97.2 | 99.0 | 88.0 |
| powdery milder of pepper | 97.9 | 99.6 | 99.4 | 91.0 |
| pepper scab | 99.4 | 100.0 | 99.5 | 97.2 |
| Models | Precision % | Recall % | mAP@0.5 % | mAP@0.5~0.95 % |
|---|---|---|---|---|
| SSD | 86.0 | 80.6 | 86.2 | 82.8 |
| Faster-RCNN | 62.3 | 93.8 | 88.5 | 73.6 |
| MobileNet-SSD | 71.8 | 66.3 | 77.7 | 50.2 |
| YOLOv5n | 64.9 | 70.2 | 72.1 | 41.8 |
| YOLOv7-tiny | 82.4 | 79.3 | 85.7 | 58.5 |
| YOLOv10n | 88.2 | 85.0 | 91.9 | 71.2 |
| YOLOv8n | 86.1 | 87.9 | 92.9 | 72.7 |
| DD-YOLO | 92.9 | 92.3 | 96.3 | 76.5 |
| Models | Weights/MB | Precision/% | Recall/% | mAP50/% | Detection Latency/ms | TensorRT Acceleration |
|---|---|---|---|---|---|---|
| YOLOv8n | 6.2 | 86.1 | 87.9 | 92.9 | 150.7 | × |
| 27.5 | 85.7 | 87.5 | 92.9 | 77.2 | √ | |
| DD-YOLO | 4.8 | 92.9 | 92.3 | 96.3 | 126.4 | × |
| 18.1 | 92.6 | 92.3 | 96.3 | 67.6 | √ |
| Model | Loss_D | Loss_G | D (x) | D (G(z)) |
|---|---|---|---|---|
| GAN | 0.0004~4.6782 | 2.74~28.27 | 0.78~1.00 | 0.0000~0.0948 |
| Disease Class | FPR (Before GAN)/% | FPR (After GAN)/% |
|---|---|---|
| Leaf curl of pepper | 8.38 | 3.29 |
| Pepper whitefly | 10.37 | 5.39 |
| Pepper yellowish | 12.93 | 1.26 |
| Leaf spot of pepper | 11.25 | 3.11 |
| Powdery mildew of pepper | 11.78 | 3.83 |
| Pepper scab | 0 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Huang, J.; Wang, S.; Bao, Y.; Wang, Y.; Song, J.; Liu, W. Lightweight Pepper Disease Detection Based on Improved YOLOv8n. AgriEngineering 2025, 7, 153. https://doi.org/10.3390/agriengineering7050153
Wu Y, Huang J, Wang S, Bao Y, Wang Y, Song J, Liu W. Lightweight Pepper Disease Detection Based on Improved YOLOv8n. AgriEngineering. 2025; 7(5):153. https://doi.org/10.3390/agriengineering7050153
Chicago/Turabian StyleWu, Yuzhu, Junjie Huang, Siji Wang, Yujian Bao, Yizhe Wang, Jia Song, and Wenwu Liu. 2025. "Lightweight Pepper Disease Detection Based on Improved YOLOv8n" AgriEngineering 7, no. 5: 153. https://doi.org/10.3390/agriengineering7050153
APA StyleWu, Y., Huang, J., Wang, S., Bao, Y., Wang, Y., Song, J., & Liu, W. (2025). Lightweight Pepper Disease Detection Based on Improved YOLOv8n. AgriEngineering, 7(5), 153. https://doi.org/10.3390/agriengineering7050153