
Benchmarking Large Language Models in Evaluating Workforce Risk of Robotization: Insights from Agriculture

 ,
, 
 ,
,  and
and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Agricultural Occupations Included in the Assessment Framework
2.2. Large Language Models Used as Assessors
- ChatGPT, powered by OpenAI’s GPT series [37], is renowned for its ability to generate coherent and contextually relevant responses across various topics. For this study, the latest freely available “ChatGPT-3.5” model was specifically utilized, given its enhanced capability to handle complex tasks, produce detailed outputs, and maintain extended dialogues.
- Copilot is an AI-powered assistant integrated into Microsoft applications [43]. In particular, the “Microsoft 365 Copilot” version, currently available for free use, exploits advanced natural language processing to provide contextually relevant and coherent responses, primarily assisting with tasks such as automating repetitive cognitive processes, making it a valuable tool for the present study.
- “Gemini 2.0 Flash”, the recent version of the Gemini series developed by Google AI [44], is especially notable for its integration into Google’s vast array of services and its deep learning capabilities. Its ability to handle complex reasoning tasks and provide accurate information makes it an essential resource for the current analysis.
2.3. Methodology Steps for Assessing the Susceptibility of Agricultural Occupations to Robotization and Their Cognitive/Manual Versus Routine/Non-Routine Levels
2.3.1. Data Preparation
2.3.2. Sequence of Customized Prompts
Preliminary Setup and Contextualization
- LLM identification
- Occupation context
- Framework initialization
Three-Step Assessment Methodology
- Step 1: Task importance assessment
- Step 2: Potential to robotization of each task assessment
- Step 3: Task attribute indexing
- Occupations with correspond to a low susceptibility rate to robotization (green zone);
- Occupations with correspond to a moderate susceptibility rate to robotization (yellow zone);
- Occupations with correspond to a high susceptibility rate to robotization (red zone).
2.3.3. Evaluation of LLM Assessments
2.3.4. Indicative Example Illustrating the Methodology Assessment
3. Results
3.1. Task Importance Assessment
3.2. Potential to Robotization of Each Occupation Assessment
3.2.1. Summary of the Calculated Susceptibility Rates to Robotization
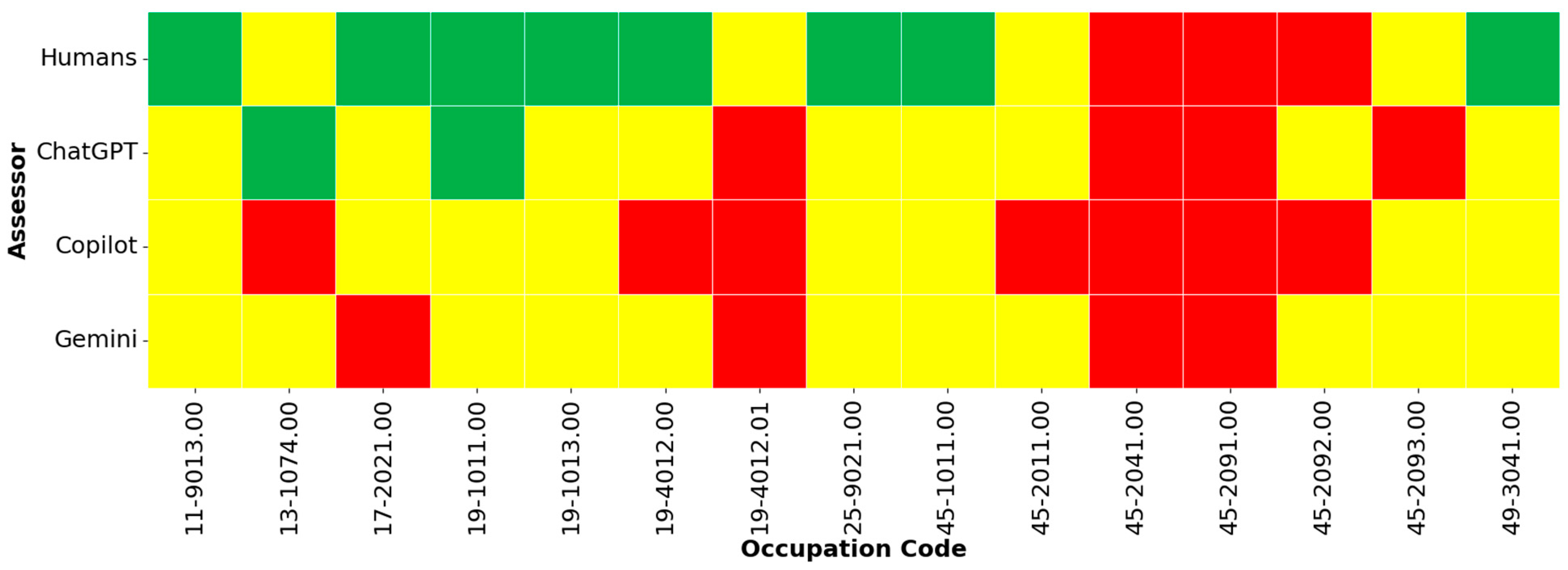
3.2.2. Classification of Occupations into Three Susceptibility to Robotization Zones
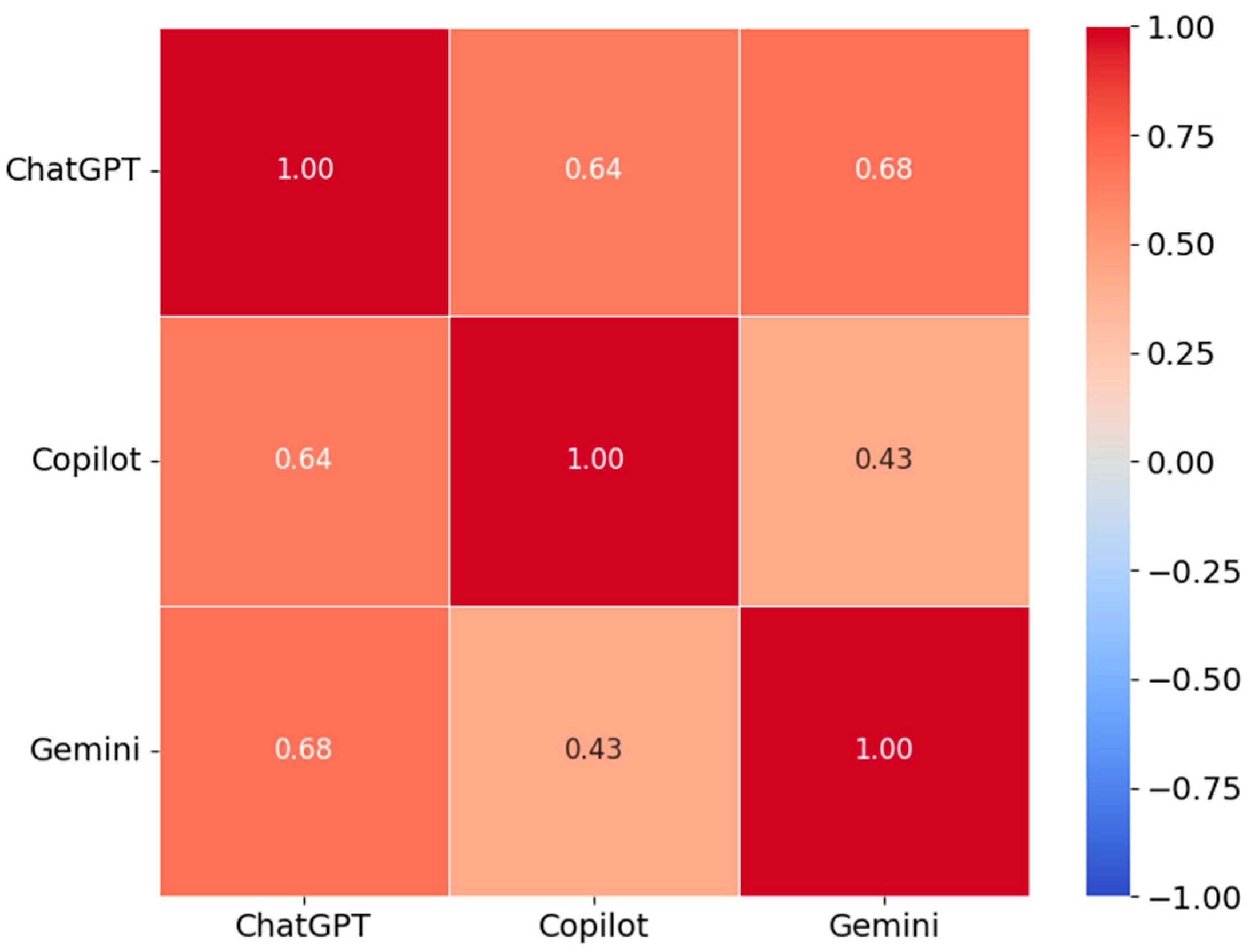
3.2.3. Error Analysis: LLM Versus Human Robotization Susceptibility Assessments
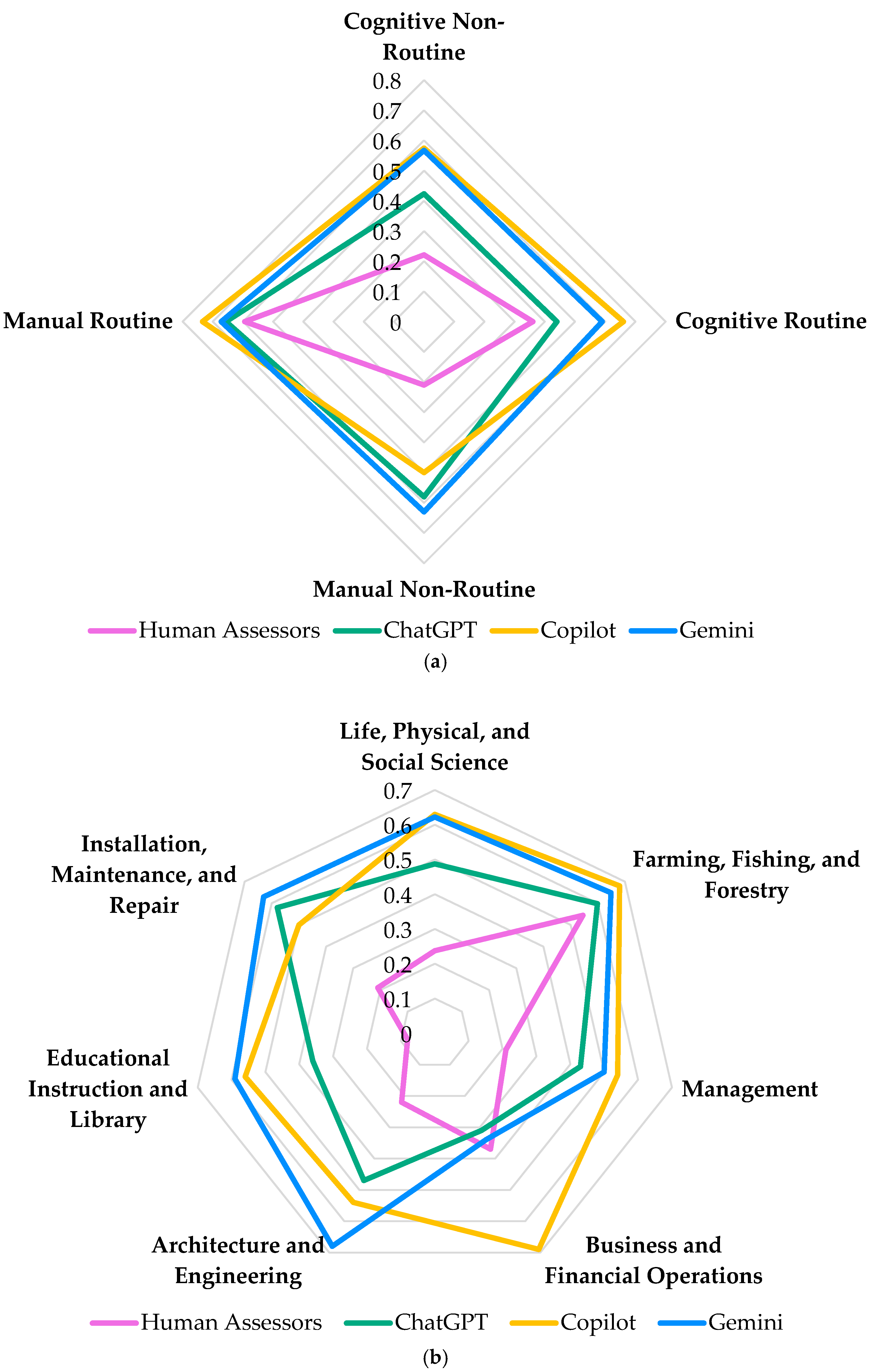
3.2.4. Task Characteristics and Occupational Group Analysis
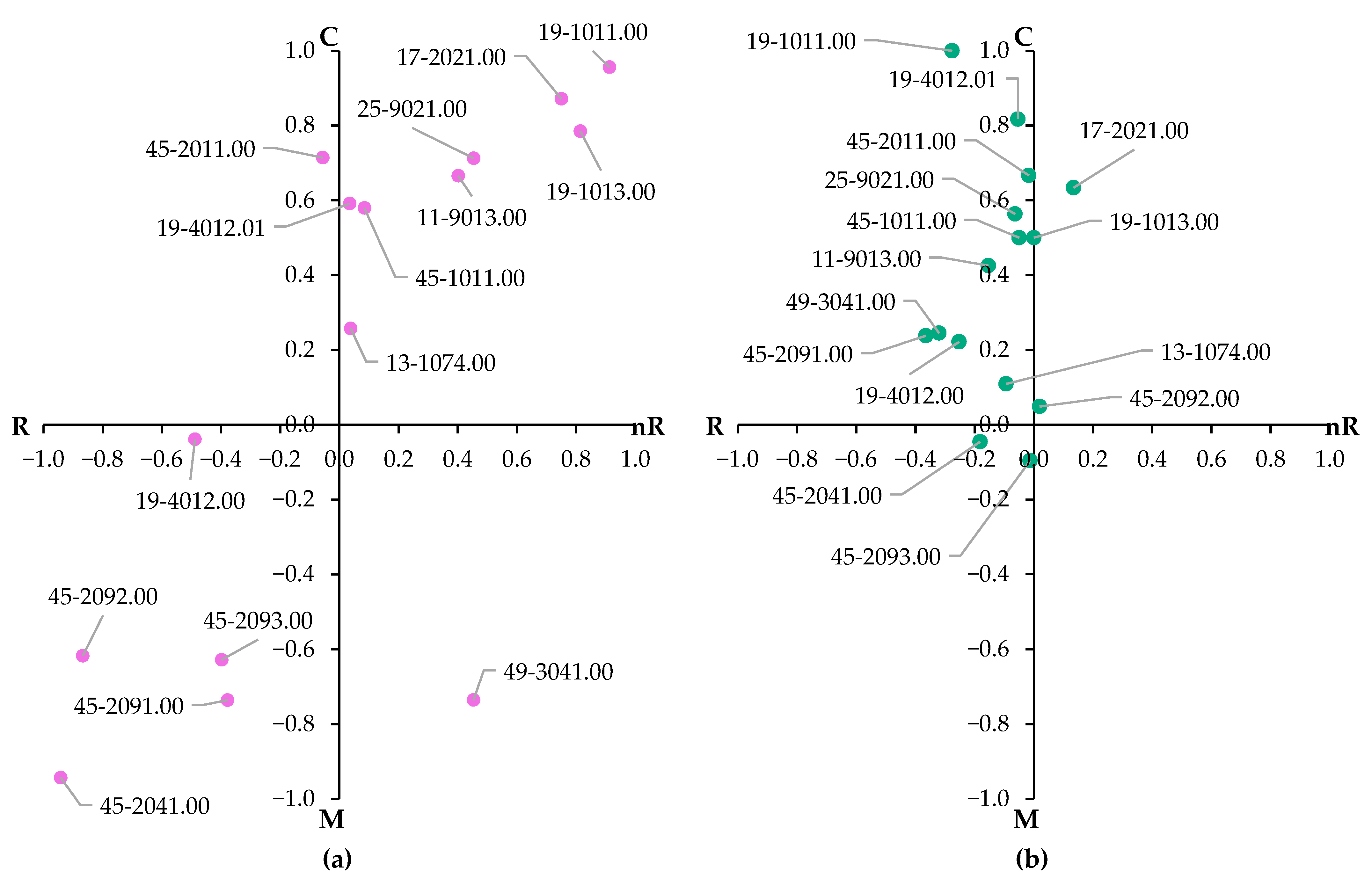
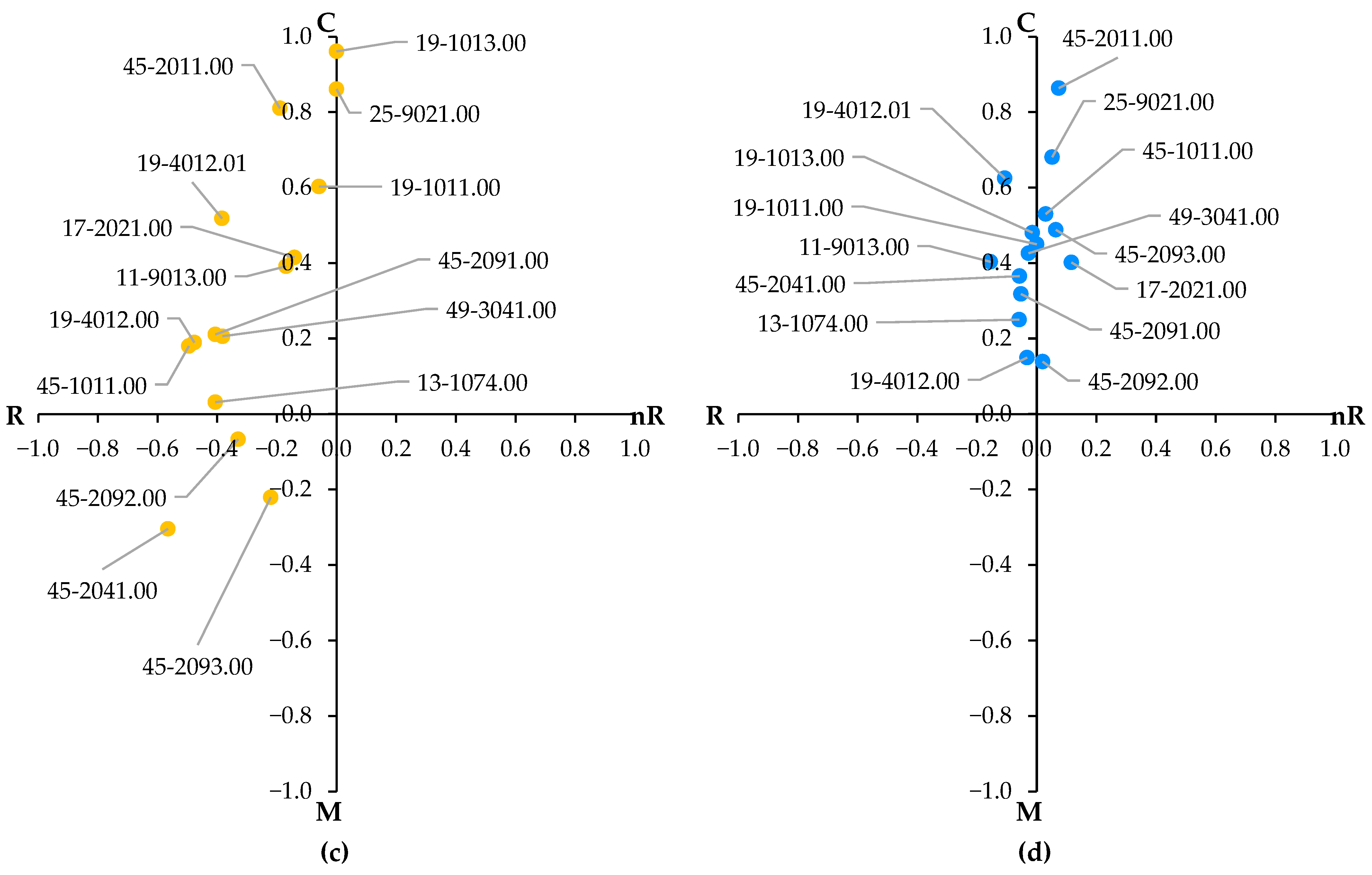
3.3. Mapping of Occupations Based on Their Cognitive/Manual and Routine/Non-Routine Characteristics
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- “What specific LLM version I am using now?”;
- “I will provide information about an agriculture-related occupation along with a list of its tasks…”. The information is sourced from the open-source online tool O*NET [22];
- “Based on this information, I am going to ask you to assign specific scores for several aspects of these tasks.”;
- “1st step: I want you to rate the importance weight of each individual task for this occupation using the following scale: (a) Not important: Score 1; (b) Slightly important: Score 2; (c) Important: Score 3; (d) Very important: Score 4; (e) Strongly important: Score 5.”;
- “2nd step: For each task assign an index for the potential to robotization. The rating refers to three scores, namely: (a) Score 0: there is no technology at technology readiness level (TRL) 3 or higher demonstrated, or there is no reasonable indication that the task can be computerized or robotized in the short- or mid-term future; (b) Score 0.5: a significant part (or parts) of the task can be computerized or robotized; and (c) Score 1: there is an existing technology or a technology under development at least at TRL 3 that can be implemented for the execution of the task.”;
- “3rd step: Assign an index for the nature of each task from the set [0, 0.25, 0.5, 0.75, 1] to each task to quantify the contribution of (a) Cognitive routine; (b) Cognitive non-routine; (c) Manual routine; and (d) Manual non-routine attributes to the execution of the task. These values must sum to 1 for each task.”
References
- Didier, N. Turning fragments into a lens: Technological change, industrial revolutions, and labor. Technol. Soc. 2024, 77, 102497. [Google Scholar] [CrossRef]
- Qu, Y.; Fan, S. Is there a “Machine Substitution”? How does the digital economy reshape the employment structure in emerging market countries. Econ. Syst. 2024, 48, 101237. [Google Scholar] [CrossRef]
- Marinoudi, V.; Sørensen, C.G.; Pearson, S.; Bochtis, D. Robotics and labour in agriculture. A context consideration. Biosyst. Eng. 2019, 184, 111–121. [Google Scholar] [CrossRef]
- Upreti, A.; Sridhar, V. Effect of automation of routine and non-routine tasks on labour demand and wages. IIMB Manag. Rev. 2024, 36, 289–308. [Google Scholar] [CrossRef]
- Zeyer-Gliozzo, B. Returns to formal, non-formal, and informal further training for workers at risk of automation. J. Educ. Work 2024, 37, 382–402. [Google Scholar] [CrossRef]
- Leng, J.; Zhu, X.; Huang, Z.; Li, X.; Zheng, P.; Zhou, X.; Mourtzis, D.; Wang, B.; Qi, Q.; Shao, H.; et al. Unlocking the power of industrial artificial intelligence towards Industry 5.0: Insights, pathways, and challenges. J. Manuf. Syst. 2024, 73, 349–363. [Google Scholar] [CrossRef]
- Gardezi, M.; Joshi, B.; Rizzo, D.M.; Ryan, M.; Prutzer, E.; Brugler, S.; Dadkhah, A. Artificial intelligence in farming: Challenges and opportunities for building trust. Agron. J. 2024, 116, 1217–1228. [Google Scholar] [CrossRef]
- Bayly-Castaneda, K.; Ramirez-Montoya, M.-S.; Morita-Alexander, A. Crafting personalized learning paths with AI for lifelong learning: A systematic literature review. Front. Educ. 2024, 9, 1424386. [Google Scholar] [CrossRef]
- Patino, A.; Naffi, N. Lifelong training approaches for the post-pandemic workforces: A systematic review. Int. J. Lifelong Educ. 2023, 42, 249–269. [Google Scholar] [CrossRef]
- Arntz, M. The risk of automation for jobs in OECD countries: A comparative analysis. In OECD Social, Employment and Migration Working Papers, No. 189; OECD Publishing: Paris, France, 2016. [Google Scholar]
- Nedelkoska, L.; Quintini, G. Automation, skills use and training. In OECD Social, Employment and Migration Working Papers, No. 202; OECD Publishing: Paris, France, 2018. [Google Scholar]
- Foster-McGregor, N.; Nomaler, Ö.; Verspagen, B. Job Automation Risk, Economic Structure and Trade: A European Perspective. Res. Policy 2021, 50, 104269. [Google Scholar] [CrossRef]
- Pouliakas, K. Determinants of automation risk in the EU labour market: A skills-needs approach. In IZA Discussion Papers No. 11829; Institute of Labor Economics (IZA): Bonn, Germany, 2018. [Google Scholar]
- Albuquerque, P.H.M.; Saavedra, C.A.P.B.; de Morais, R.L.; Peng, Y. The Robot from Ipanema goes Working: Estimating the Probability of Jobs Automation in Brazil. Lat. Am. Bus. Rev. 2019, 20, 227–248. [Google Scholar] [CrossRef]
- Zhou, G.; Chu, G.; Li, L.; Meng, L. The effect of artificial intelligence on China’s labor market. China Econ. J. 2020, 13, 24–41. [Google Scholar] [CrossRef]
- Le Roux, D.B. Automation and employment: The case of South Africa. Afr. J. Sci. Technol. Innov. Dev. 2018, 10, 507–517. [Google Scholar]
- Parschau, C.; Hauge, J. Is automation stealing manufacturing jobs? Evidence from South Africa’s apparel industry. Geoforum 2020, 115, 120–131. [Google Scholar] [CrossRef]
- Marinoudi, V.; Lampridi, M.; Kateris, D.; Pearson, S.; Sørensen, C.G.; Bochtis, D. The future of agricultural jobs in view of robotization. Sustainability 2021, 13, 12109. [Google Scholar] [CrossRef]
- Filippi, E.; Bannò, M.; Trento, S. Automation technologies and their impact on employment: A review, synthesis and future research agenda. Technol. Forecast. Soc. Change 2023, 191, 122448. [Google Scholar] [CrossRef]
- Petrich, L.; Lohrmann, G.; Neumann, M.; Martin, F.; Frey, A.; Stoll, A.; Schmidt, V. Detection of Colchicum autumnale in drone images, using a machine-learning approach. Precis. Agric. 2020, 21, 1291–1303. [Google Scholar] [CrossRef]
- Frey, C.B.; Osborne, M.A. The future of employment: How susceptible are jobs to computerisation? Technol. Forecast. Soc. Change 2017, 114, 254–280. [Google Scholar] [CrossRef]
- O*NET OnLine. Available online: https://www.onetonline.org/ (accessed on 6 February 2024).
- Crowley, F.; Doran, J.; McCann, P. The vulnerability of European regional labour markets to job automation: The role of agglomeration externalities. Reg. Stud. 2021, 55, 1711–1723. [Google Scholar] [CrossRef]
- David, B. Computer technology and probable job destructions in Japan: An evaluation. J. Jpn. Int. Econ. 2017, 43, 77–87. [Google Scholar] [CrossRef]
- Haiss, P.; Mahlberg, B.; Michlits, D. Industry 4.0—The future of Austrian jobs. Empirica 2021, 48, 5–36. [Google Scholar] [CrossRef]
- Zemtsov, S. Robots and potential technological unemployment in the Russian regions: Review and preliminary results. Vopr. Ekon. 2017, 7, 1–16. [Google Scholar] [CrossRef]
- Blanas, S.; Gancia, G.; Lee, S.Y. Who is afraid of machines? Econ. Policy 2019, 34, 627–690. [Google Scholar] [CrossRef]
- Borjas, G.J.; Freeman, R.B. From Immigrants to Robots: The Changing Locus of Substitutes for Workers. RSF Russell Sage Found. J. Soc. Sci. 2019, 5, 22–42. [Google Scholar] [CrossRef]
- Jung, J.H.; Lim, D.-G. Industrial robots, employment growth, and labor cost: A simultaneous equation analysis. Technol. Forecast. Soc. Change 2020, 159, 120202. [Google Scholar] [CrossRef]
- Marinoudi, V.; Benos, L.; Villa, C.C.; Lampridi, M.; Kateris, D.; Berruto, R.; Pearson, S.; Sørensen, C.G.; Bochtis, D. Adapting to the Agricultural Labor Market Shaped by Robotization. Sustainability 2024, 16, 7061. [Google Scholar] [CrossRef]
- Marinoudi, V.; Benos, L.; Villa, C.C.; Kateris, D.; Berruto, R.; Pearson, S.; Sørensen, C.G.; Bochtis, D. Large language models impact on agricultural workforce dynamics: Opportunity or risk? Smart Agric. Technol. 2024, 9, 100677. [Google Scholar] [CrossRef]
- Sufi, F. Generative Pre-Trained Transformer (GPT) in Research: A Systematic Review on Data Augmentation. Information 2024, 15, 99. [Google Scholar] [CrossRef]
- Patil, R.; Gudivada, V. A Review of Current Trends, Techniques, and Challenges in Large Language Models (LLMs). Appl. Sci. 2024, 14, 2074. [Google Scholar] [CrossRef]
- Gmyrek, P.; Berg, J.; Bescond, D. Generative AI and Jobs: A Global Analysis of Potential Effects on Job Quantity and Quality; ILO Working paper 96; International Labour Office: Geneva, Switzerland, 2023. [Google Scholar]
- Eloundou, T.; Manning, S.; Mishkin, P.; Rock, D. GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models; University of Pennsylvania: Philadelphia, PA, USA, 2023. [Google Scholar]
- Eisfeldt, A.L.; Schubert, G.; Zhang, M.B.; Taska, B. Generative AI and Firm Values; National Bureau of Economic Research: Cambridge, MA, USA, 2023. [Google Scholar] [CrossRef]
- OpenAI Platform. Models Overview. Available online: https://platform.openai.com/docs/models (accessed on 6 February 2025).
- Bechar, A. Agricultural Robotics for Precision Agriculture Tasks: Concepts and Principles. In Innovation in Agricultural Robotics for Precision Agriculture: A Roadmap for Integrating Robots in Precision Agriculture; Bechar, A., Ed.; Springer International Publishing: Cham, Switzerland, 2021; pp. 17–30. ISBN 978-3-030-77036-5. [Google Scholar]
- Bazargani, K.; Deemyad, T. Automation’s Impact on Agriculture: Opportunities, Challenges, and Economic Effects. Robotics 2024, 13, 33. [Google Scholar] [CrossRef]
- Vasconez, J.P.; Kantor, G.A.; Cheein, F.A.A. Human–robot interaction in agriculture: A survey and current challenges. Biosyst. Eng. 2019, 179, 35–48. [Google Scholar]
- Oliveira, L.F.P.; Moreira, A.P.; Silva, M.F. Advances in Agriculture Robotics: A State-of-the-Art Review and Challenges Ahead. Robotics 2021, 10, 52. [Google Scholar] [CrossRef]
- Navas, E.; Fernández, R.; Sepúlveda, D.; Armada, M.; Gonzalez-de-Santos, P. Soft Grippers for Automatic Crop Harvesting: A Review. Sensors 2021, 21, 2689. [Google Scholar] [CrossRef]
- Microsoft Microsoft 365. Copilot. Available online: https://www.microsoft.com/en-us/microsoft-365/copilot (accessed on 6 February 2025).
- Google DeepMind. Gemini 2.0. Available online: https://deepmind.google/technologies/gemini/ (accessed on 6 February 2025).
- Yogarajan, V.; Dobbie, G.; Keegan, T.T. Debiasing large language models: Research opportunities. J. R. Soc. New Zeal. 2025, 55, 372–395. [Google Scholar] [CrossRef]
- Zhang, R.; Li, H.-W.; Qian, X.-Y.; Jiang, W.-B.; Chen, H.-X. On large language models safety, security, and privacy: A survey. J. Electron. Sci. Technol. 2025, 23, 100301. [Google Scholar] [CrossRef]
- Grieve, B.D.; Duckett, T.; Collison, M.; Boyd, L.; West, J.; Yin, H.; Arvin, F.; Pearson, S. The challenges posed by global broadacre crops in delivering smart agri-robotic solutions: A fundamental rethink is required. Glob. Food Secur. 2019, 23, 116–124. [Google Scholar] [CrossRef]
- Ukhurebor, K.E.; Adetunji, C.O.; Olugbemi, O.T.; Nwankwo, W.; Olayinka, A.S.; Umezuruike, C.; Hefft, D.I. Chapter 6—Precision agriculture: Weather forecasting for future farming. In AI, Edge and IoT-Based Smart Agriculture; Abraham, A., Dash, S., Rodrigues, J.J.P.C., Acharya, B., Pani, S.K., Eds.; Intelligent Data-Centric Systems; Academic Press: Cambridge, MA, USA, 2022; pp. 101–121. ISBN 978-0-12-823694-9. [Google Scholar]
- Benos, L.; Sørensen, C.G.; Bochtis, D. Field Deployment of Robotic Systems for Agriculture in Light of Key Safety, Labor, Ethics and Legislation Issues. Curr. Robot. Rep. 2022, 3, 49–56. [Google Scholar] [CrossRef]
- Benos, L.; Bechar, A.; Bochtis, D. Safety and ergonomics in human-robot interactive agricultural operations. Biosyst. Eng. 2020, 200, 55–72. [Google Scholar] [CrossRef]
- Ashqar, H.I. Benchmarking LLMs for Real-World Applications: From Numerical Metrics to Contextual and Qualitative Evaluation. TechRxiv. 2025. [Google Scholar] [CrossRef]
- da Silveira, F.; da Silva, S.L.C.; Machado, F.M.; Barbedo, J.G.A.; Amaral, F.G. Farmers’ perception of the barriers that hinder the implementation of agriculture 4.0. Agric. Syst. 2023, 208, 103656. [Google Scholar] [CrossRef]
- Khanna, M.; Atallah, S.S.; Kar, S.; Sharma, B.; Wu, L.; Yu, C.; Chowdhary, G.; Soman, C.; Guan, K. Digital transformation for a sustainable agriculture in the United States: Opportunities and challenges. Agric. Econ. 2022, 53, 924–937. [Google Scholar] [CrossRef]
- Singh, A.K.; Lamichhane, B.; Devkota, S.; Dhakal, U.; Dhakal, C. Do Large Language Models Show Human-like Biases? Exploring Confidence—Competence Gap in AI. Information 2024, 15, 92. [Google Scholar] [CrossRef]
- Dorner, F.E.; Nastl, V.Y.; Hardt, M. Limits to scalable evaluation at the frontier: LLM as Judge won’t beat twice the data. arXiv 2024, arXiv:2410.13341. [Google Scholar]
- Malberg, S.; Poletukhin, R.; Schuster, C.M.; Groh, G. A Comprehensive Evaluation of Cognitive Biases in LLMs. arXiv 2024, arXiv:2410.15413. [Google Scholar]
- Kruger, J.; Dunning, D. Unskilled and Unaware of It: How Difficulties in Recognizing One’s Own Incompetence Lead to Inflated Self-Assessments. Pers. Soc. Psychol. 1999, 77, 1121. [Google Scholar]
- Dunning, D. Chapter five—The Dunning–Kruger Effect: On Being Ignorant of One’s Own Ignorance. In Advances in Experimental Social Psychology; Olson, J.M., Zanna, M.P., Eds.; Academic Press: Cambridge, MA, USA, 2011; Volume 44, pp. 247–296. [Google Scholar]
- Wei, X.; Kumar, N.; Zhang, H. Addressing bias in generative AI: Challenges and research opportunities in information management. Inf. Manag. 2025, 62, 104103. [Google Scholar] [CrossRef]
- Hassija, V.; Chamola, V.; Mahapatra, A.; Singal, A.; Goel, D.; Huang, K.; Scardapane, S.; Spinelli, I.; Mahmud, M.; Hussain, A. Interpreting Black-Box Models: A Review on Explainable Artificial Intelligence. Cogn. Comput. 2024, 16, 45–74. [Google Scholar] [CrossRef]
- Benos, L.; Tsaopoulos, D.; Tagarakis, A.C.; Kateris, D.; Busato, P.; Bochtis, D. Explainable AI-Enhanced Human Activity Recognition for Human–Robot Collaboration in Agriculture. Appl. Sci. 2025, 15, 650. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Occupation | O*NET Code | Tasks |
|---|---|---|
| Farmers, Ranchers, and Other Agricultural Managers | 11-9013.00 | 30 |
| Farm Labor Contractors | 13-1074.00 | 8 |
| Agricultural Engineers | 17-2021.00 | 14 |
| Animal Scientists | 19-1011.00 | 9 |
| Soil and Plant Scientists | 19-1013.00 | 27 |
| Agricultural Technicians | 19-4012.00 | 26 |
| Precision Agriculture Technicians | 19-4012.01 | 22 |
| Farm and Home Management Educators | 25-9021.00 | 15 |
| First-Line Supervisors of Farming, Fishing, and Forestry Workers | 45-1011.00 | 30 |
| Agricultural Inspectors | 45-2011.00 | 22 |
| Graders and Sorters, Agricultural Products | 45-2041.00 | 6 |
| Agricultural Equipment Operators | 45-2091.00 | 17 |
| Farmworkers and Laborers, Crop, Nursery, and Greenhouse | 45-2092.00 | 30 |
| Farmworkers, Farm, Ranch, and Aquacultural Animals | 45-2093.00 | 22 |
| Farm Equipment Mechanics and Service Technicians | 49-3041.00 | 14 |
| Occupation | O*NET Code | Humans | ChatGPT | Copilot | Gemini | Mean LLM Rating |
|---|---|---|---|---|---|---|
| Farmers, Ranchers, and Other Agricultural Managers | 11-9013.00 | 0.21 | 0.43 | 0.54 | 0.50 | 0.49 |
| Farm Labor Contractors | 13-1074.00 | 0.37 | 0.31 | 0.69 | 0.34 | 0.45 |
| Agricultural Engineers | 17-2021.00 | 0.22 | 0.47 | 0.54 | 0.68 | 0.56 |
| Animal Scientists | 19-1011.00 | 0.17 | 0.28 | 0.40 | 0.60 | 0.43 |
| Soil and Plant Scientists | 19-1013.00 | 0.06 | 0.43 | 0.43 | 0.57 | 0.48 |
| Agricultural Technicians | 19-4012.00 | 0.21 | 0.52 | 0.81 | 0.62 | 0.65 |
| Precision Agriculture Technicians | 19-4012.01 | 0.51 | 0.72 | 0.88 | 0.70 | 0.77 |
| Farm and Home Management Educators | 25-9021.00 | 0.08 | 0.36 | 0.56 | 0.59 | 0.50 |
| First-Line Supervisors of Farming, Fishing, and Forestry Workers | 45-1011.00 | 0.15 | 0.39 | 0.56 | 0.56 | 0.50 |
| Agricultural Inspectors | 45-2011.00 | 0.36 | 0.44 | 0.66 | 0.59 | 0.56 |
| Graders and Sorters, Agricultural Products | 45-2041.00 | 0.92 | 0.84 | 0.87 | 0.94 | 0.88 |
| Agricultural Equipment Operators | 45-2091.00 | 0.71 | 0.67 | 0.73 | 0.70 | 0.70 |
| Farmworkers and Laborers, Crop, Nursery, and Greenhouse | 45-2092.00 | 0.67 | 0.52 | 0.66 | 0.57 | 0.58 |
| Farmworkers, Farm, Ranch, and Aquacultural Animals | 45-2093.00 | 0.46 | 0.73 | 0.60 | 0.53 | 0.62 |
| Farm Equipment Mechanics and Service Technicians | 49-3041.00 | 0.21 | 0.58 | 0.50 | 0.63 | 0.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benos, L.; Marinoudi, V.; Busato, P.; Kateris, D.; Pearson, S.; Bochtis, D. Benchmarking Large Language Models in Evaluating Workforce Risk of Robotization: Insights from Agriculture. AgriEngineering 2025, 7, 102. https://doi.org/10.3390/agriengineering7040102
Benos L, Marinoudi V, Busato P, Kateris D, Pearson S, Bochtis D. Benchmarking Large Language Models in Evaluating Workforce Risk of Robotization: Insights from Agriculture. AgriEngineering. 2025; 7(4):102. https://doi.org/10.3390/agriengineering7040102
Chicago/Turabian StyleBenos, Lefteris, Vasso Marinoudi, Patrizia Busato, Dimitrios Kateris, Simon Pearson, and Dionysis Bochtis. 2025. "Benchmarking Large Language Models in Evaluating Workforce Risk of Robotization: Insights from Agriculture" AgriEngineering 7, no. 4: 102. https://doi.org/10.3390/agriengineering7040102
APA StyleBenos, L., Marinoudi, V., Busato, P., Kateris, D., Pearson, S., & Bochtis, D. (2025). Benchmarking Large Language Models in Evaluating Workforce Risk of Robotization: Insights from Agriculture. AgriEngineering, 7(4), 102. https://doi.org/10.3390/agriengineering7040102