


Characterization of Irrigated Rice Cultivation Cycles and Classification in Brazil Using Time Series Similarity and Machine Learning Models with Sentinel Imagery

 , , and
, , and 
Abstract
1. Introduction
2. Material and Methods
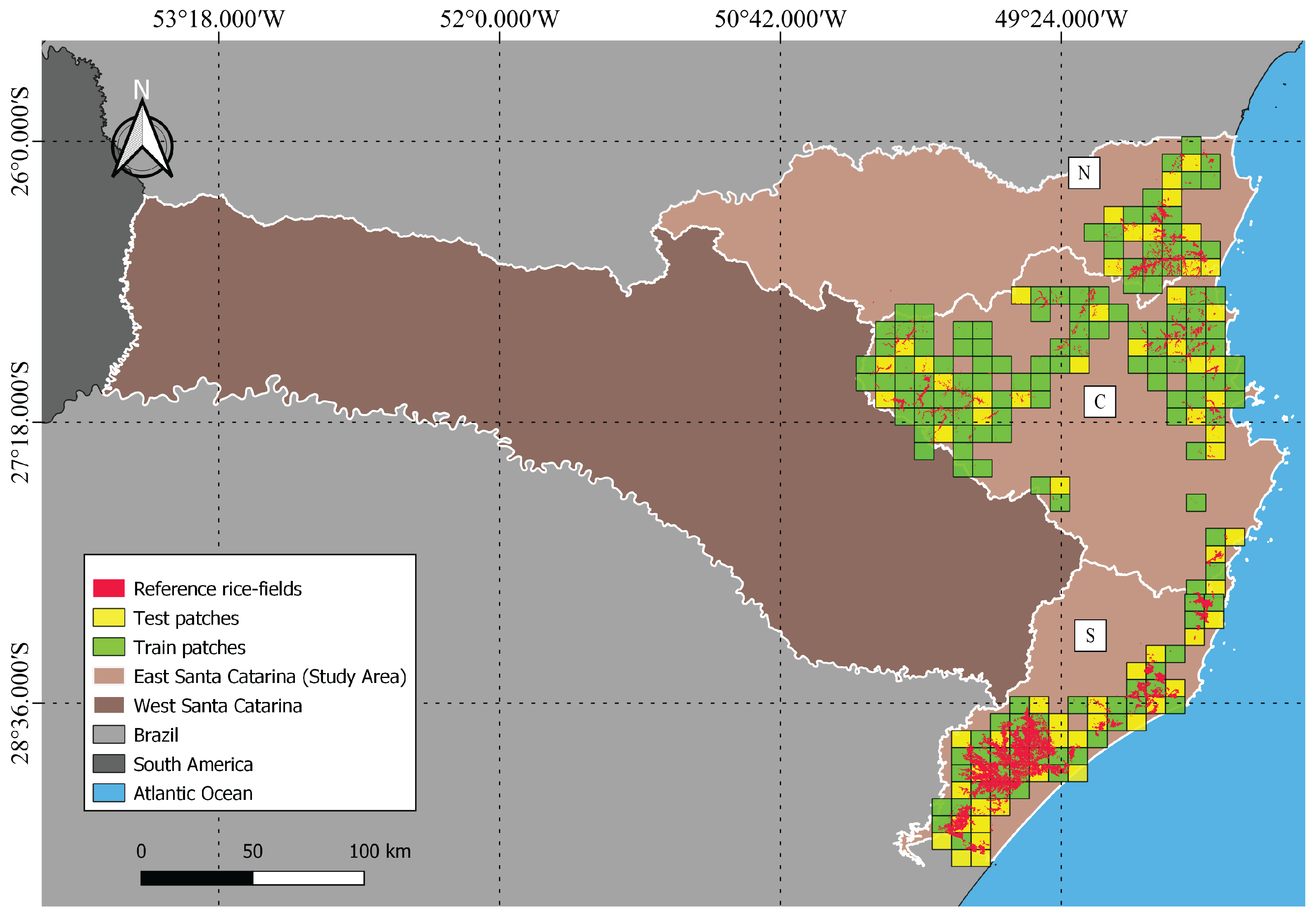
2.1. Study Areas
2.2. Satellite Data Description and Pre-Processing
2.2.1. Sentinel-1 GRD
2.2.2. Sentinel-2
2.3. Irrigated Rice Fields Reference Data
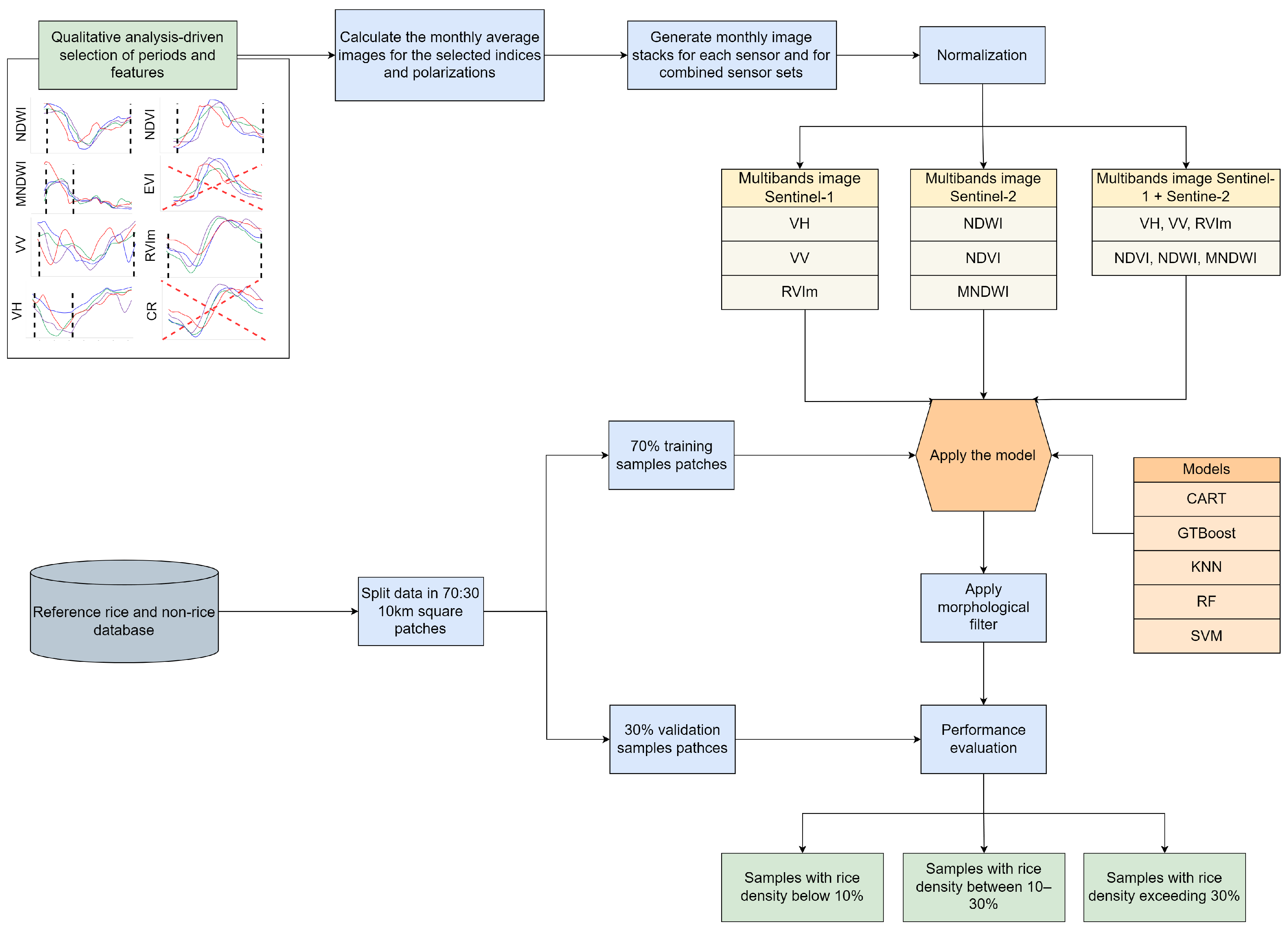
2.4. Data Preparation and Experimental Design
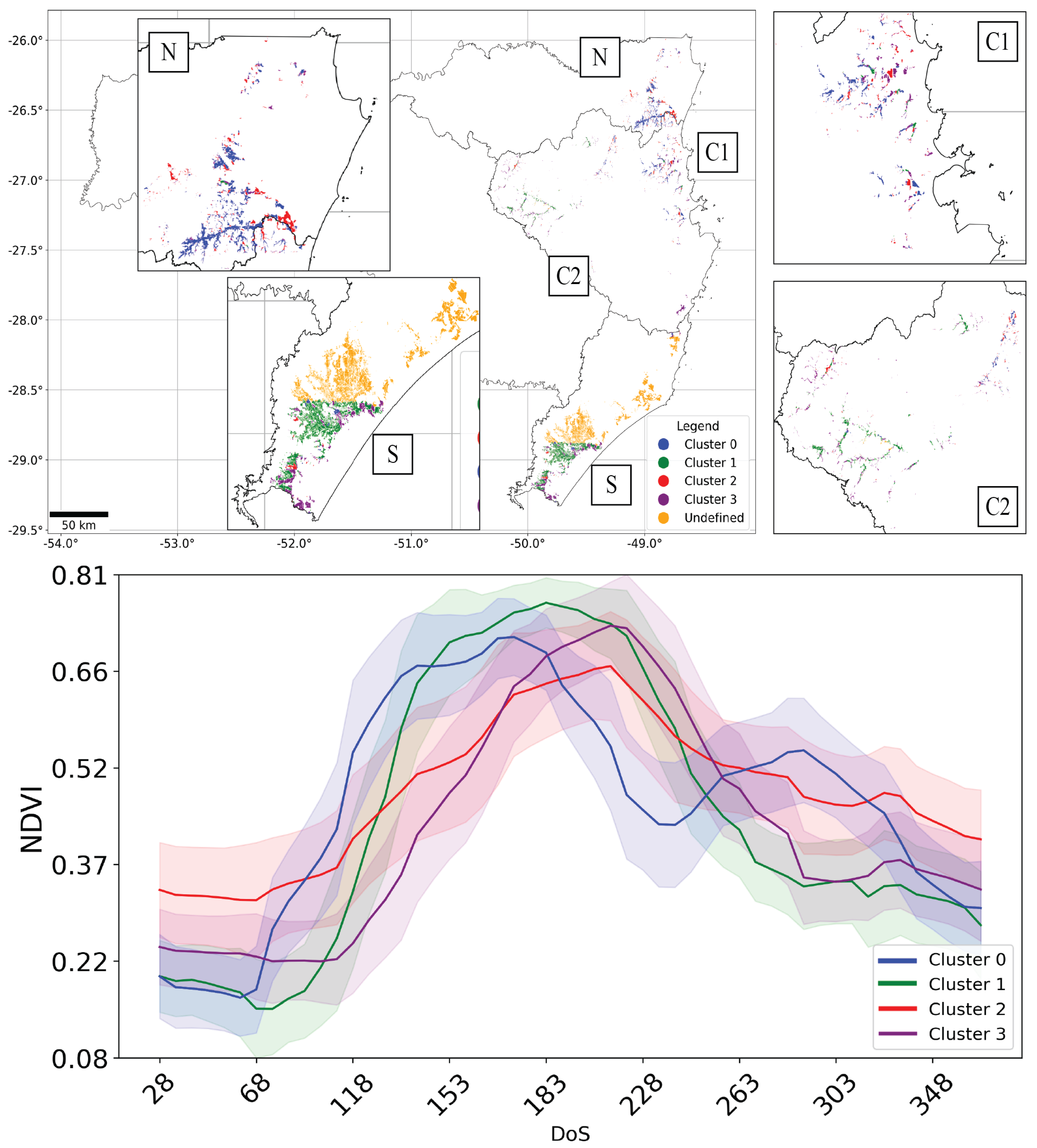
2.5. Time Series Clusterization
Transformation and Extraction of Satellite Features
2.6. Rice Classification
2.6.1. Satellite Data Preparation
2.6.2. Irrigated Rice Samples
2.6.3. Classification Models Training
2.6.4. Classification Evaluation Metrics
3. Results
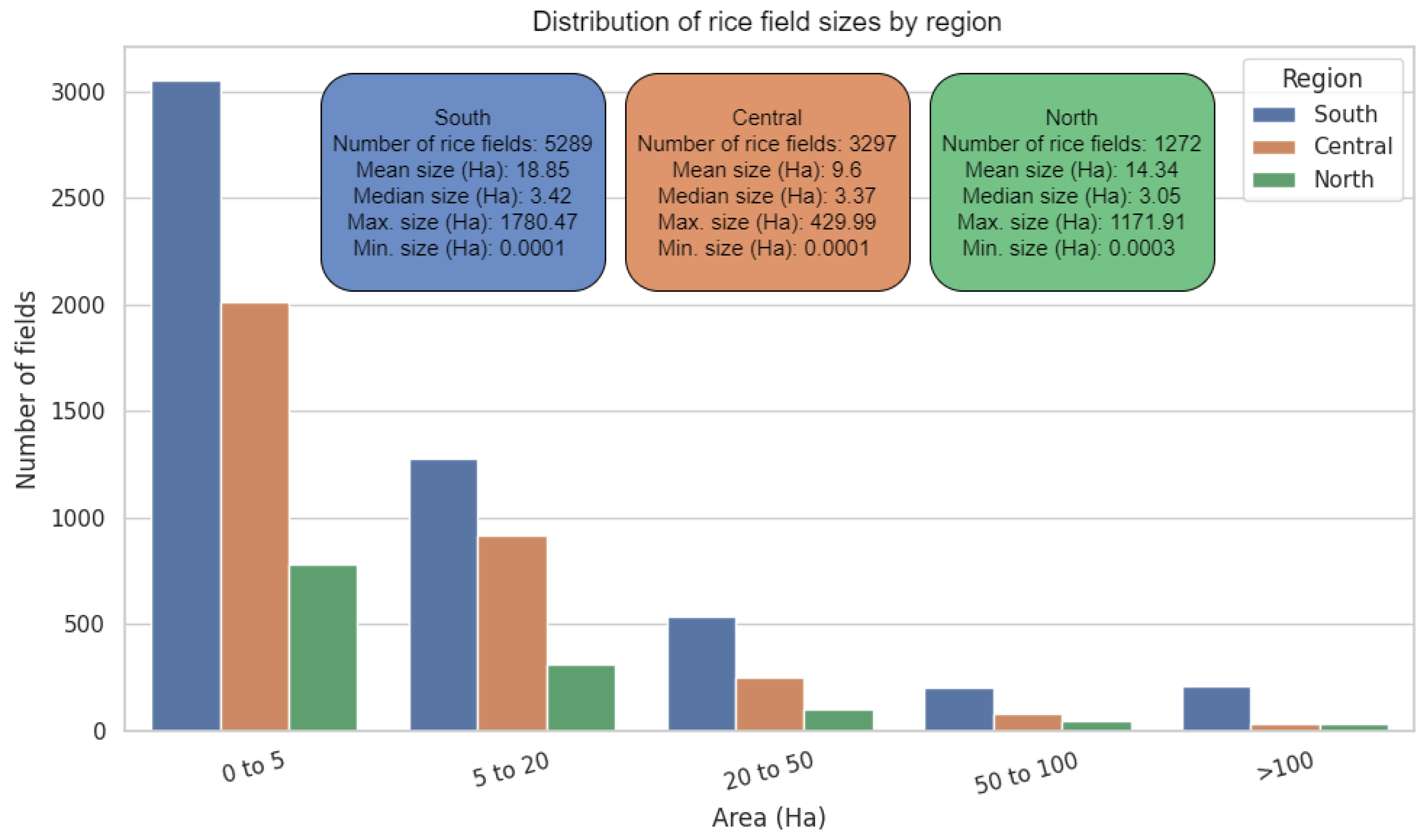
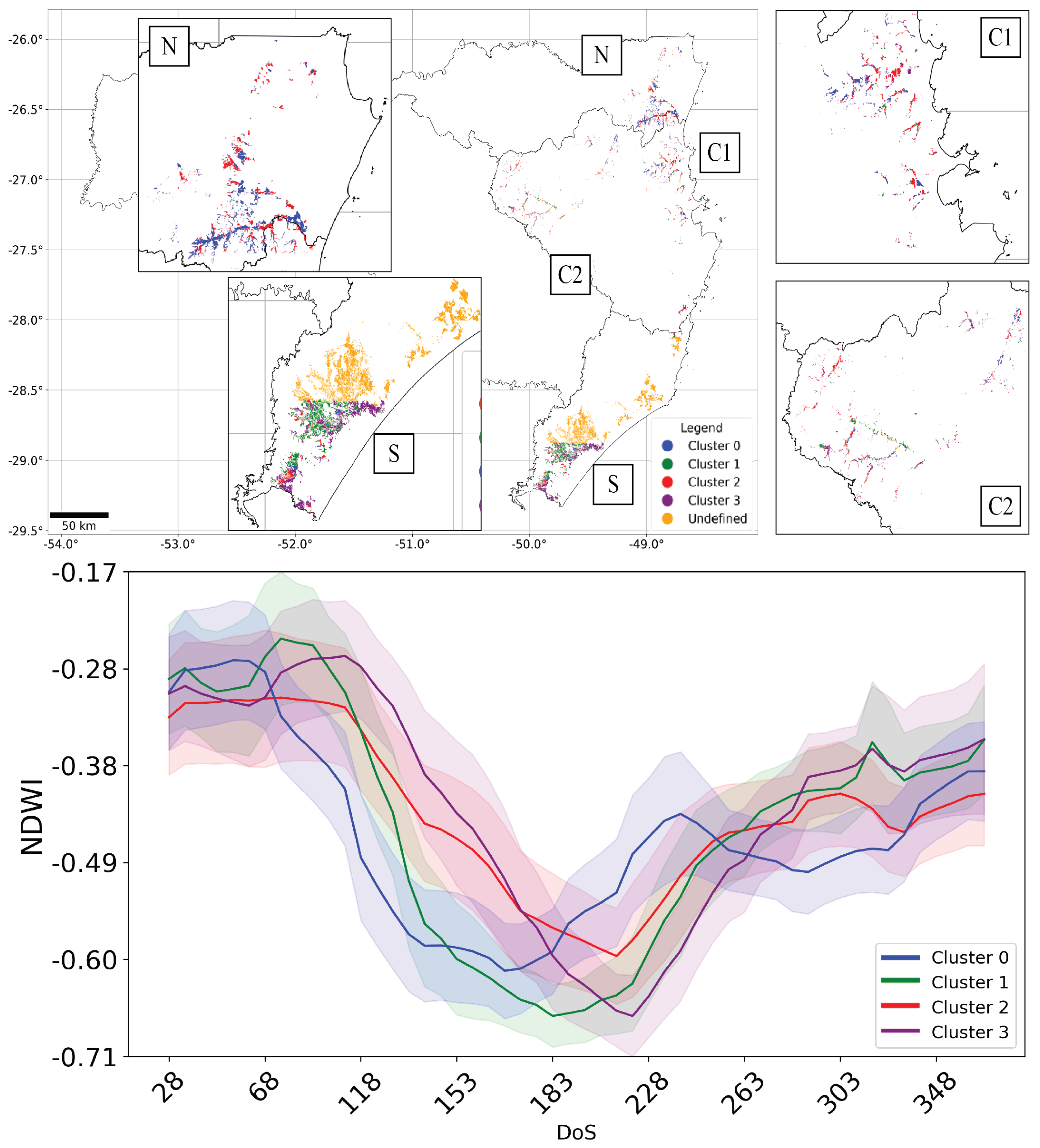
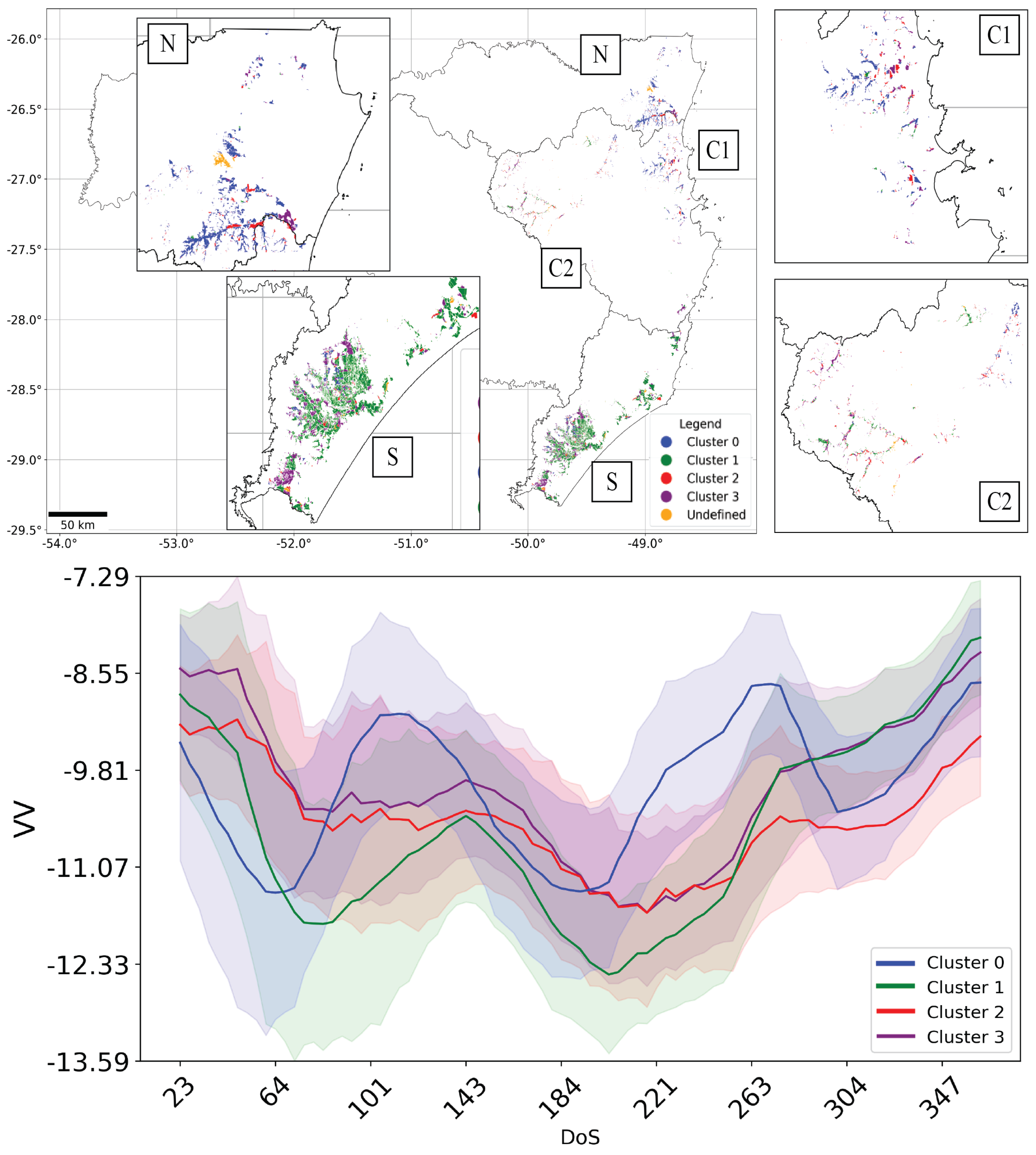
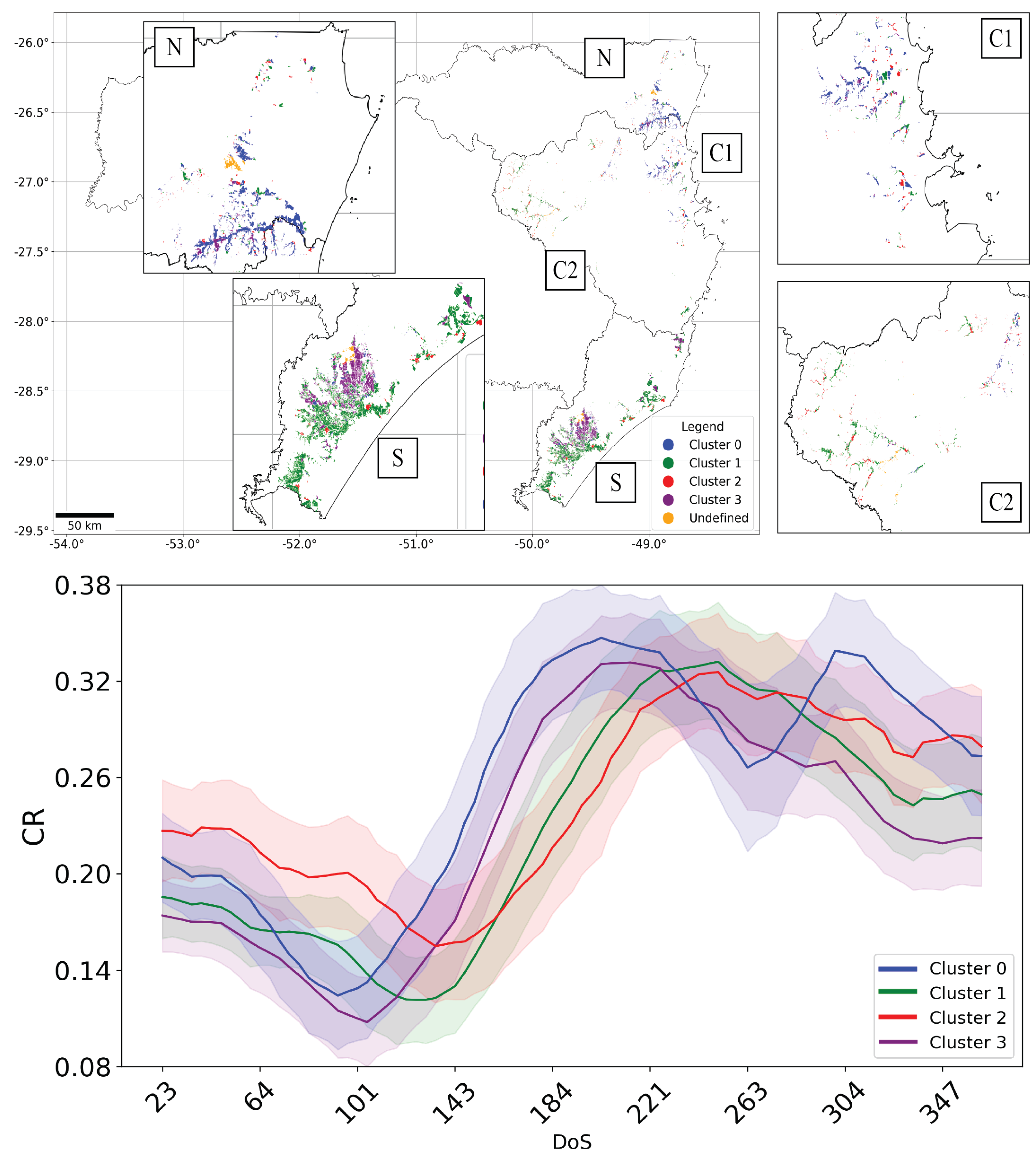
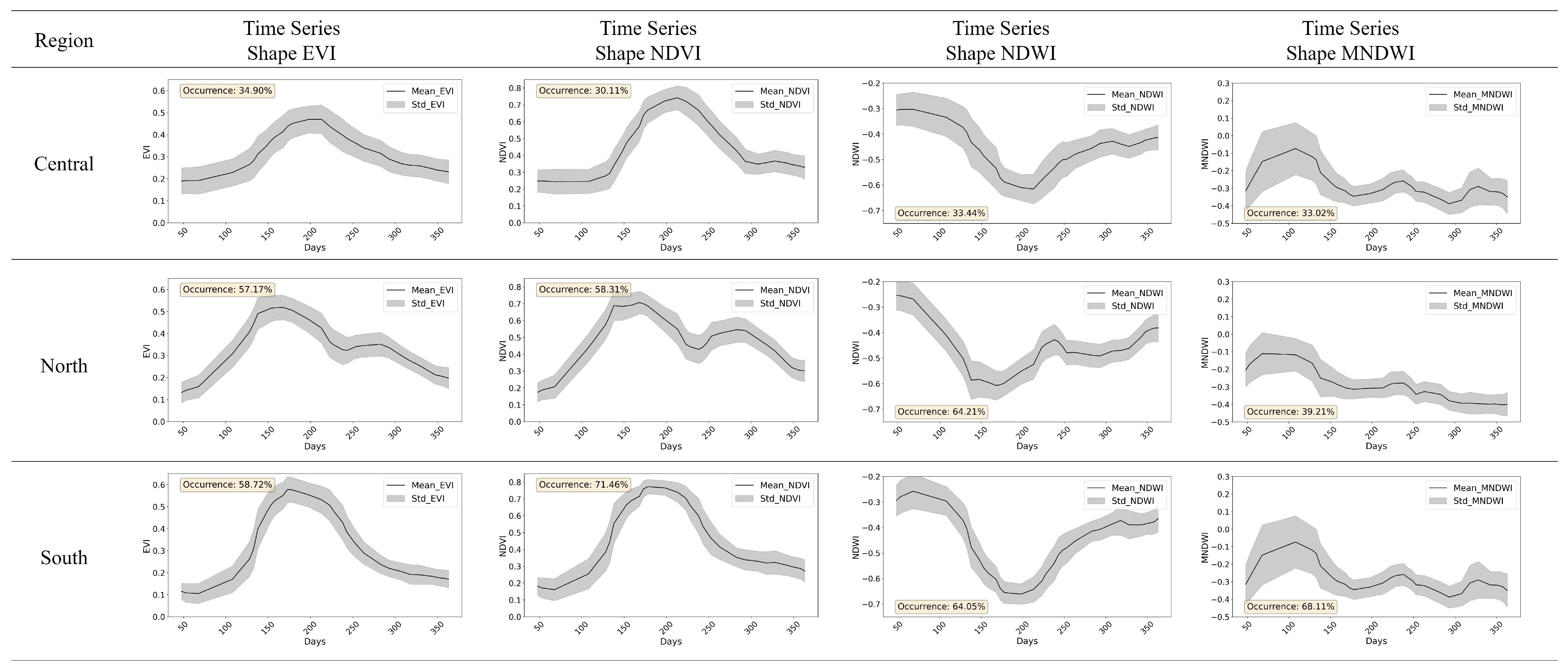
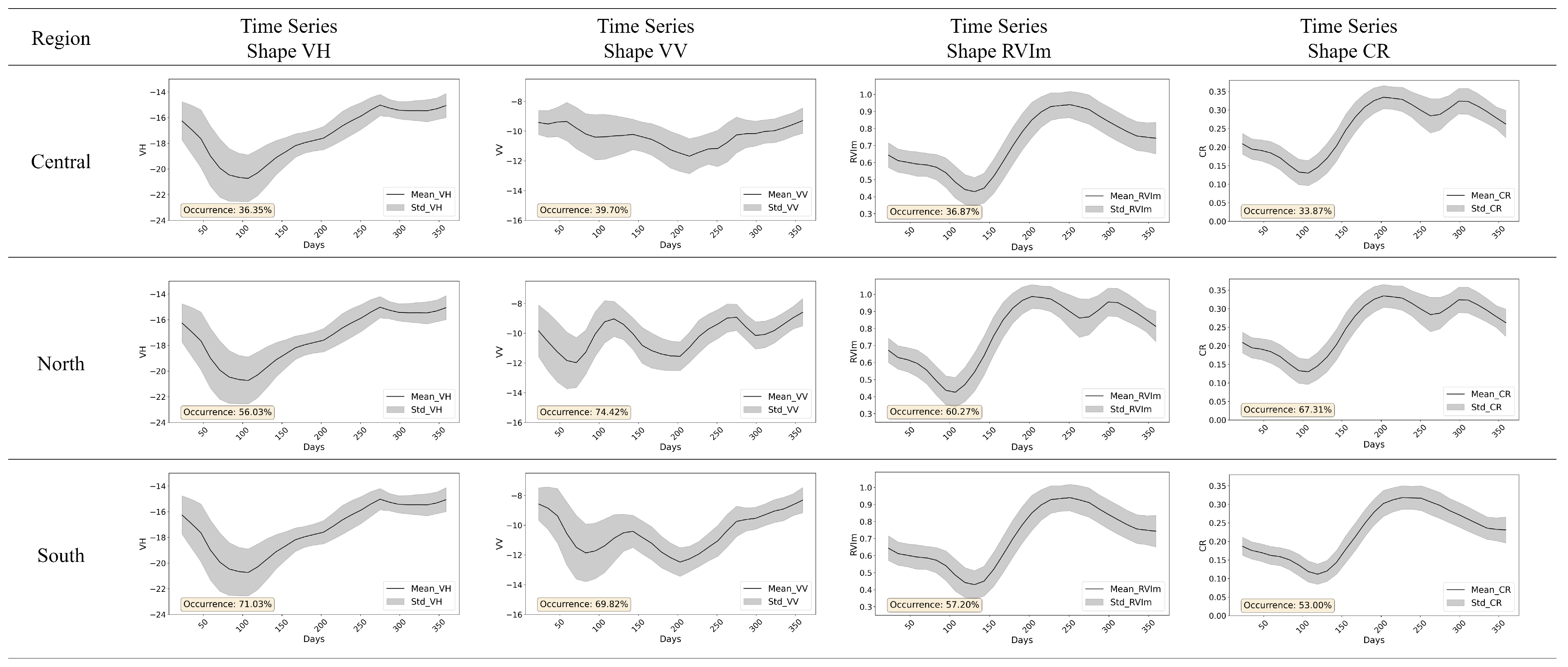
3.1. Exploratory Analysis and Spatial Distribution of Different Irrigated Rice Fields Time Series
Most Representative Time Series Characterization Results
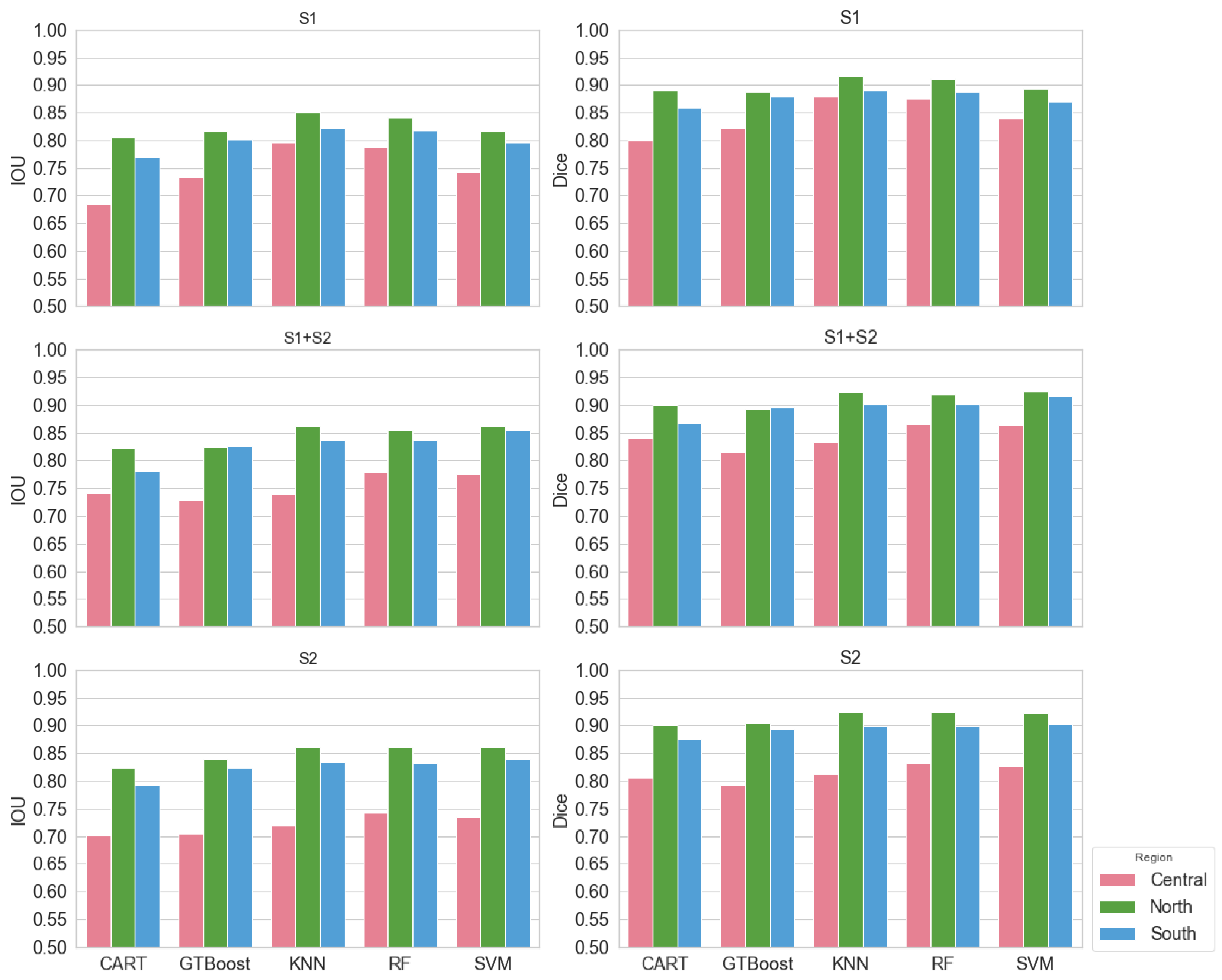
3.2. Classification Results
3.2.1. Overall Performance of the Models
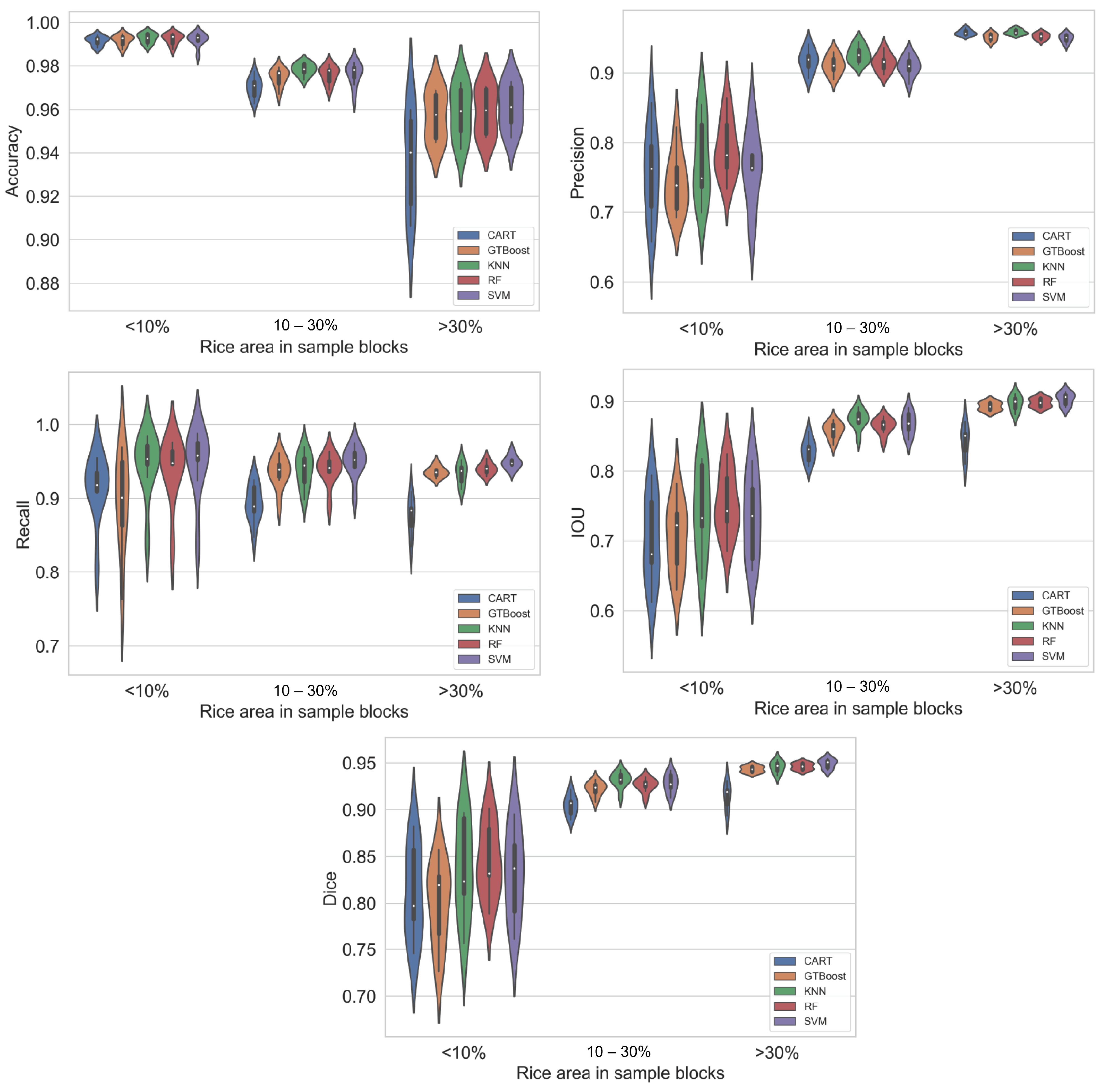
3.2.2. Performance of the Models Based on Rice Fileds Density
4. Discussion
4.1. Irrigated Rice Time Series Clustering
4.2. Irrigated Rice Classification
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- FAO-Food and Agriculture Organization of the United Nations. FAOSTAT: FAO Statistical Databases. 2022. Available online: https://www.fao.org/faostat/en/#data/QCL/visualize (accessed on 20 June 2023).
- CONAB-Companhia Nacional de Abastecimento. Acompanhamento da Safra Brasileira de Grãos-Safra 2023/24-6° Levantamento. 2024. Available online: https://www.conab.gov.br/info-agro/safras/graos/boletim-da-safra-de-graos/item/download/52225_79be7813e39c3746ab9121250bbfb5c5 (accessed on 15 August 2024).
- Chen, N.; Yu, L.; Zhang, X.; Shen, Y.; Zeng, L.; Hu, Q.; Niyogi, D. Mapping paddy rice fields by combining multi-temporal vegetation index and synthetic aperture radar remote sensing data using google earth engine machine learning platform. Remote Sens. 2020, 12, 2992. [Google Scholar] [CrossRef]
- Oad, V.K.; Dong, X.; Arfan, M.; Kumar, V.; Mohsin, M.S.; Saad, S.; Lü, H.; Azam, M.I.; Tayyab, M. Identification of shift in sowing and harvesting dates of rice crop (L. Oryza sativa) through remote sensing techniques: A case study of larkana district. Sustainability 2020, 12, 3586. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, H.; Zhang, Z.; Zhang, L.; Luo, Y.; Han, J.; Tao, F. Asian Rice Calendar Dynamics Detected by Remote Sensing and Their Climate Drivers. Remote Sens. 2022, 14, 4189. [Google Scholar] [CrossRef]
- do Vale, M.L.C.; Hickel, E.R.; de Andrade, A.; Back, A.J.; Pandolfo, C.; de Oliveira, D.G.; Wickert, E.; Masiero, F.C.; Martins, G.N.; Guimarães, G.G.F.; et al. Recomendações para a produção de arroz irrigado em Santa Catarina: 4a. ed. Sist. Produção 2022, 4, 1587. [Google Scholar]
- Ramadhani, F.; Pullanagari, R.; Kereszturi, G.; Procter, J. Automatic mapping of rice growth stages using the integration of sentinel-2, mod13q1, and sentinel-1. Remote Sens. 2020, 12, 3613. [Google Scholar] [CrossRef]
- Stroppiana, D.; Boschetti, M.; Azar, R.; Barbieri, M.; Collivignarelli, F.; Gatti, L.; Fontanelli, G.; Busetto, L.; Holecz, F. In-season early mapping of rice area and flooding dynamics from optical and SAR satellite data. Eur. J. Remote Sens. 2019, 52, 206–220. [Google Scholar] [CrossRef]
- Prudente, V.H.R.; Martins, V.S.; Vieira, D.C.; e Silva, N.R.d.F.; Adami, M.; Sanches, I.D. Limitations of cloud cover for optical remote sensing of agricultural areas across South America. Remote Sens. Appl. Soc. Environ. 2020, 20, 100414. [Google Scholar] [CrossRef]
- Whitcraft, A.K.; Vermote, E.F.; Becker-Reshef, I.; Justice, C.O. Cloud Cover throughout the Agricultural Growing Season: Impacts on Passive Optical Earth Observations. Remote Sens. Environ. 2015, 156, 438–447. [Google Scholar] [CrossRef]
- Veloso, A.; Mermoz, S.; Bouvet, A.; Le Toan, T.; Planells, M.; Dejoux, J.F.; Ceschia, E. Understanding the temporal behavior of crops using Sentinel-1 and Sentinel-2-like data for agricultural applications. Remote Sens. Environ. 2017, 199, 415–426. [Google Scholar] [CrossRef]
- Dingle Robertson, L.; Davidson, A.; McNairn, H.; Hosseini, M.; Mitchell, S.; De Abelleyra, D.; Verón, S.; Cosh, M.H. Synthetic Aperture Radar (SAR) image processing for operational space-based agriculture mapping. Int. J. Remote Sens. 2020, 41, 7112–7144. [Google Scholar] [CrossRef]
- Bazzi, H.; Baghdadi, N.; El Hajj, M.; Zribi, M.; Minh, D.H.T.; Ndikumana, E.; Courault, D.; Belhouchette, H. Mapping paddy rice using Sentinel-1 SAR time series in Camargue, France. Remote Sens. 2019, 11, 887. [Google Scholar] [CrossRef]
- Phan, H.; Le Toan, T.; Bouvet, A.; Nguyen, L.D.; Pham Duy, T.; Zribi, M. Mapping of rice varieties and sowing date using X-band SAR data. Sensors 2018, 18, 316. [Google Scholar] [CrossRef] [PubMed]
- Yonezawa, C.; Watanabe, M. Airborne L-band SAR observation for paddy rice fields in semi-mountainous region. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5073–5076. [Google Scholar] [CrossRef]
- Crisóstomo de Castro Filho, H.; Abílio de Carvalho Júnior, O.; Ferreira de Carvalho, O.L.; Pozzobon de Bem, P.; dos Santos de Moura, R.; Olino de Albuquerque, A.; Rosa Silva, C.; Guimaraes Ferreira, P.H.; Fontes Guimarães, R.; Trancoso Gomes, R.A. Rice crop detection using LSTM, Bi-LSTM, and machine learning models from Sentinel-1 time series. Remote Sens. 2020, 12, 2655. [Google Scholar] [CrossRef]
- de Bem, P.P.; de Carvalho Júnior, O.A.; de Carvalho, O.L.F.; Gomes, R.A.T.; Guimarães, R.F.; Pimentel, C.M.M. Irrigated rice crop identification in Southern Brazil using convolutional neural networks and Sentinel-1 time series. Remote Sens. Appl. Soc. Environ. 2021, 24, 100627. [Google Scholar] [CrossRef]
- Fernandes Filho, A.S.; Fonseca, L.M.G.; Bendini, H.d.N. Mapping Irrigated Rice in Brazil Using Sentinel-2 Spectral–Temporal Metrics and Random Forest Algorithm. Remote Sens. 2024, 16, 2900. [Google Scholar] [CrossRef]
- Zhao, R.; Li, Y.; Ma, M. Mapping paddy rice with satellite remote sensing: A review. Sustainability 2021, 13, 503. [Google Scholar] [CrossRef]
- Sujud, L.; Jaafar, H.; Hassan, M.A.H.; Zurayk, R. Cannabis detection from optical and RADAR data fusion: A comparative analysis of the SMILE machine learning algorithms in Google Earth Engine. Remote Sens. Appl. Soc. Environ. 2021, 24, 100639. [Google Scholar] [CrossRef]
- Onojeghuo, A.O.; Blackburn, G.A.; Wang, Q.; Atkinson, P.M.; Kindred, D.; Miao, Y. Mapping paddy rice fields by applying machine learning algorithms to multi-temporal Sentinel-1A and Landsat data. Int. J. Remote Sens. 2018, 39, 1042–1067. [Google Scholar] [CrossRef]
- Guan, X.; Huang, C.; Liu, G.; Meng, X.; Liu, Q. Mapping rice cropping systems in Vietnam using an NDVI-based time-series similarity measurement based on DTW distance. Remote Sens. 2016, 8, 19. [Google Scholar] [CrossRef]
- Kontgis, C.; Schneider, A.; Ozdogan, M. Mapping rice paddy extent and intensification in the Vietnamese Mekong River Delta with dense time stacks of Landsat data. Remote Sens. Environ. 2015, 169, 255–269. [Google Scholar] [CrossRef]
- Lei, T.C.; Wan, S.; Wu, Y.C.; Wang, H.P.; Hsieh, C.W. Multi-temporal data fusion in MS and SAR images using the dynamic time warping method for paddy Rice classification. Agriculture 2022, 12, 77. [Google Scholar] [CrossRef]
- IBGE-Brazilian Institute of Geography and Statistics. Panorama-Santa Catarina. 2021. Available online: https://cidades.ibge.gov.br/brasil/sc/panorama (accessed on 8 July 2024).
- Monteiro, M.A. Caracterização climática do estado de Santa Catarina: Uma abordagem dos principais sistemas atmosféricos que atuam durante o ano. Geosul 2001, 16, 69–78. Available online: https://periodicos.ufsc.br/index.php/geosul/article/view/14052 (accessed on 10 July 2024).
- CONAB-Companhia Nacional de Abastecimento. Acompanhamento da Safra Brasileira de Grãos-Safra 2022/23. 2023. Available online: https://www.conab.gov.br/info-agro/safras/graos/boletim-da-safra-de-graos/item/download/47720_642c6cc3d60e063c21c87a3094e7f5f7 (accessed on 26 May 2024).
- EPAGRI-Empresa de Pesquisa Agropecuária e Extensão Rural de Santa Catarina. Zoneamento Agroecológico e Socioeconômico. 2022. Available online: https://ciram.epagri.sc.gov.br/index.php/solucoes/zoneamento/ (accessed on 30 March 2024).
- Fritzsons, E.; Mantovani, L.E.; Wrege, M.S. Relaçãoo entre altitude e temperatura: Uma contribuição ao zoneamento climático no estado de Santa Catarina, Brasil. Rev. Bras. De Climatol. 2016, 18. [Google Scholar] [CrossRef]
- Wrege, M.S.; Steinmetz, S.; Reisser Junior, C.; de Almeida, I.R. Atlas climático da Região Sul do Brasil: Estados do Paraná, Santa Catarina e Rio Grande do Sul; Embrapa Clima Temperado: Pelotas, Brazil; Embrapa Florestas: Colombo, Sri Lanka, 2012; Available online: http://www.infoteca.cnptia.embrapa.br/infoteca/handle/doc/1045852 (accessed on 28 March 2024).
- Vibrans, A.C.; Nicoletti, A.L.; Liesenberg, V.; Refosco, J.C.; de Araújo Kohler, L.P.; Bizon, A.R.; Lingner, D.V.; Dal Bosco, F.; Bueno, M.M.; da Silva, M.S.; et al. MonitoraSC: Um novo mapa de cobertura florestal e uso da terra de Santa Catarina. Agropecuária Catarin. 2021, 34, 42–48. [Google Scholar] [CrossRef]
- Garcia, A.D.B.; Islam, M.S.; Prudente, V.H.R.; Sanches, I.D.; Cheng, I. Irrigated rice-field mapping in Brazil using phenological stage information and optical and microwave remote sensing. Appl. Comput. Geosci. 2025, 25, 100223. [Google Scholar] [CrossRef]
- Garcia, A.D.B.; Prudente, V.H.R.; da Silva, D.T.; Chaves, M.E.D.; Trabaquini, K.; Sanches, I.D. Detailed Mapping of Irrigated Rice Fields Using Remote Sensing data and Segmentation Techniques: A case of study in Turvo, Santa Catarina, Brazil. J. Inf. Data Manag. 2025, 16, 92–109. [Google Scholar] [CrossRef]
- Torres, R.; Snoeij, P.; Geudtner, D.; Bibby, D.; Davidson, M.; Attema, E.; Potin, P.; Rommen, B.; Floury, N.; Brown, M.; et al. GMES Sentinel-1 mission. Remote Sens. Environ. 2012, 120, 9–24. [Google Scholar] [CrossRef]
- Dasari, K.; Anjaneyulu, L. Importance of Speckle filter window Size and its impact on Speckle reduction in SAR images. Int. J. Adv. Microw. Technol. (IJAMT) 2017, 2, 98–102. [Google Scholar]
- Garcia, A.D.B.; Sanches, I.D.; Adami, M.; Gama, F.F. Performance evaluation of speckle filters for paddy rice areas based on Sentinel-1 satellite images. In Proceedings of the Anais do XX Simpósio Brasileiro de Sensoriamento Remoto, Florianópolis, Brazil, 2–5 April 2023; Volume 20, pp. 644–647. Available online: https://proceedings.science/sbsr-2023/trabalhos/perfomance-evaluation-of-speckle-filters-for-paddy-rice-areas-based-on-sentinel?lang=en (accessed on 10 October 2024).
- Quegan, S.; Yu, J.J. Filtering of multichannel SAR images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2373–2379. [Google Scholar] [CrossRef]
- Mullissa, A.; Vollrath, A.; Odongo-Braun, C.; Slagter, B.; Balling, J.; Gou, Y.; Gorelick, N.; Reiche, J. Sentinel-1 sar backscatter analysis ready data preparation in Google Earth Engine. Remote Sens. 2021, 13, 1954. [Google Scholar] [CrossRef]
- Doblas, J.; Frery, A.C.; Sant’Anna, S.J.S.; Carneiro, A.; Shimabukuro, Y.E. Assessment of nonlocal means stochastic distances speckle reduction for SAR time series. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 3265–3268. [Google Scholar] [CrossRef]
- Santos, E.P.d.; Moreira, M.C.; Fernandes-Filho, E.I.; Demattê, J.A.M.; Dionizio, E.A.; Silva, D.D.d.; Cruz, R.R.P.; Moura-Bueno, J.M.; Santos, U.J.d.; Costa, M.H. Sentinel-1 imagery used for estimation of soil organic carbon by dual-polarization SAR vegetation indices. Remote Sens. 2023, 15, 5464. [Google Scholar] [CrossRef]
- Mandal, D.; Kumar, V.; Ratha, D.; Dey, S.; Bhattacharya, A.; Lopez-Sanchez, J.M.; McNairn, H.; Rao, Y.S. Dual polarimetric radar vegetation index for crop growth monitoring using sentinel-1 SAR data. Remote Sens. Environ. 2020, 247, 111954. [Google Scholar] [CrossRef]
- Copernicus. New Products Available: The Sensor Invariant Atmospheric Correction (SIAC) Based Mosaics Albedo. 2023. Available online: https://land.copernicus.eu/en/news/new-products-available-the-sensor-invariant-atmospheric-correction-siac-based-mosaics-albedo (accessed on 23 July 2024).
- Yin, F.; Lewis, P.E.; Gómez-Dans, J.L. Bayesian atmospheric correction over land: Sentinel-2/MSI and Landsat 8/OLI. Geosci. Model Dev. 2022, 15, 7933–7976. [Google Scholar] [CrossRef]
- Google. Google Earth Engine Developers: Resampling and Reducing Resolution. 2024. Available online: https://developers.google.com/earth-engine/guides/resample (accessed on 1 May 2024).
- Jiang, Z.; Huete, A.R.; Didan, K.; Miura, T. Development of a two-band enhanced vegetation index without a blue band. Remote Sens. Environ. 2008, 112, 3833–3845. [Google Scholar] [CrossRef]
- Fraga, H.; Amraoui, M.; Malheiro, A.C.; Moutinho-Pereira, J.; Eiras-Dias, J.; Silvestre, J.; Santos, J.A. Examining the relationship between the Enhanced Vegetation Index and grapevine phenology. Eur. J. Remote Sens. 2014, 47, 753–771. [Google Scholar] [CrossRef]
- Halos, S.H.; Abed, F.G. Effect of spring vegetation indices NDVI & EVI on dust storms occurrence in Iraq. In AIP Conference Proceedings; AIP Publishing: Karbala City, Iraq, 2019; Volume 2144, p. 040015. [Google Scholar] [CrossRef]
- Sanches, I.D.; Feitosa, R.Q.; Diaz, P.M.A.; Soares, M.S.; Luiz, A.J.L.; Schultz, B.; Maurano, L.E.P. Campo Verde Database: Seeking to Improve Agricultural Remote Sensing of Tropical Areas. IEEE Geosci. Remote Sens. Lett. 2018, 15, 369–373. [Google Scholar] [CrossRef]
- Sanches, I.D.; Feitosa, R.Q.; Montibeller, B.; Achanccaray Diaz, P.M.; Luiz, A.J.B.; Soares, M.D.; Prudente, V.H.R.; Vieira, D.C.; Maurano, L.E.P.; Happ, P.N.; et al. First Results of the Lem Benchmark Database for Agricultural Applications. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2020, XLIII-B5-2020, 251–256. [Google Scholar] [CrossRef]
- Oldoni, L.V.; Sanches, I.D.; Picoli, M.C.A.; Covre, R.M.; Fronza, J.G. LEM+ dataset: For agricultural remote sensing applications. Data Brief 2020, 33, 106553. [Google Scholar] [CrossRef]
- ANA-Agência Nacional de Águas e Saneamento. Mapeamento do Arroz Irrigado no Brasil. 2020. Available online: https://metadados.snirh.gov.br/geonetwork/srv/api/records/1ac9b37f-0745-44f9-a60b-6a2bd366bbe1 (accessed on 7 August 2023).
- Reyes, F.; Casa, R.; Tolomio, M.; Dalponte, M.; Mzid, N. Soil properties zoning of agricultural fields based on a climate-driven spatial clustering of remote sensing time series data. Eur. J. Agron. 2023, 150, 126930. [Google Scholar] [CrossRef]
- Beuchle, R.; Grecchi, R.C.; Shimabukuro, Y.E.; Seliger, R.; Eva, H.D.; Sano, E.; Achard, F. Land cover changes in the Brazilian Cerrado and Caatinga biomes from 1990 to 2010 based on a systematic remote sensing sampling approach. Appl. Geogr. 2015, 58, 116–127. [Google Scholar] [CrossRef]
- Li, H.; Song, X.P.; Hansen, M.C.; Becker-Reshef, I.; Adusei, B.; Pickering, J.; Wang, L.; Wang, L.; Lin, Z.; Zalles, V.; et al. Development of a 10-m resolution maize and soybean map over China: Matching satellite-based crop classification with sample-based area estimation. Remote Sens. Environ. 2023, 294, 113623. [Google Scholar] [CrossRef]
- McNairn, H.; Champagne, C.; Shang, J.; Holmstrom, D.; Reichert, G. Integration of optical and Synthetic Aperture Radar (SAR) imagery for delivering operational annual crop inventories. ISPRS J. Photogramm. Remote Sens. 2009, 64, 434–449. [Google Scholar] [CrossRef]
- Tavenard, R.; Faouzi, J.; Vandewiele, G.; Divo, F.; Androz, G.; Holtz, C.; Payne, M.; Yurchak, R.; RuBwurm, M.; Kolar, K.; et al. Tslearn, a machine learning toolkit for time series data. J. Mach. Learn. Res. 2020, 21, 1–6. [Google Scholar]
- Cuturi, M. Fast global alignment kernels. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 929–936. Available online: http://www.icml-2011.org/papers/489_icmlpaper.pdf (accessed on 11 July 2024).
- Cuturi, M.; Blondel, M. Soft-dtw: A differentiable loss function for time-series. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 894–903. Available online: http://proceedings.mlr.press/v70/cuturi17a/cuturi17a.pdf (accessed on 5 July 2024).
- Jiang, J.; Lai, S.; Jin, L.; Zhu, Y. Dsdtw: Local representation learning with deep soft-dtw for dynamic signature verification. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2198–2212. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Talukdar, S.; Singha, P.; Mahato, S.; Pal, S.; Liou, Y.A.; Rahman, A. Land-use land-cover classification by machine learning classifiers for satellite observations—A review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef]
- Pech-May, F.; Aquino-Santos, R.; Rios-Toledo, G.; Posadas-Durán, J.P.F. Mapping of land cover with optical images, supervised algorithms, and google earth engine. Sensors 2022, 22, 4729. [Google Scholar] [CrossRef]
- Salas, E.A.L.; Kumaran, S.S.; Bennett, R.; Willis, L.P.; Mitchell, K. Machine Learning-Based Classification of Small-Sized Wetlands Using Sentinel-2 Images. AIMS Geosci. 2024, 10, 62–79. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Liu, L.; Guo, Y.; Li, Y.; Zhang, Q.; Li, Z.; Chen, E.; Yang, L.; Mu, X. Comparison of machine learning methods applied on multi-source medium-resolution satellite images for Chinese pine (Pinus tabulaeformis) extraction on Google Earth Engine. Forests 2022, 13, 677. [Google Scholar] [CrossRef]
- Liu, Z.; Li, N.; Wang, L.; Zhu, J.; Qin, F. A multi-angle comprehensive solution based on deep learning to extract cultivated land information from high-resolution remote sensing images. Ecol. Indic. 2022, 141, 108961. [Google Scholar] [CrossRef]
- Yuan, K.; Zhuang, X.; Schaefer, G.; Feng, J.; Guan, L.; Fang, H. Deep-learning-based multispectral satellite image segmentation for water body detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7422–7434. [Google Scholar] [CrossRef]
- Sakamoto, T.; Sprague, D.S.; Okamoto, K.; Ishitsuka, N. Semi-automatic classification method for mapping the rice-planted areas of Japan using multi-temporal Landsat images. Remote Sens. Appl. Soc. Environ. 2018, 10, 7–17. [Google Scholar] [CrossRef]
- Rehman, T.H.; Borja Reis, A.F.; Akbar, N.; Linquist, B.A. Use of normalized difference vegetation index to assess N status and predict grain yield in rice. Agron. J. 2019, 111, 2889–2898. [Google Scholar] [CrossRef]
- Gu, Y.; Wylie, B.K.; Howard, D.M.; Phuyal, K.P.; Ji, L. NDVI saturation adjustment: A new approach for improving cropland performance estimates in the Greater Platte River Basin, USA. Ecol. Indic. 2013, 30, 1–6. [Google Scholar] [CrossRef]
- Chang, L.; Chen, Y.T.; Wang, J.H.; Chang, Y.L. Rice-field mapping with Sentinel-1A SAR time-series data. Remote Sens. 2020, 13, 103. [Google Scholar] [CrossRef]
- Fatchurrachman; Rudiyanto; Soh, N.C.; Shah, R.M.; Giap, S.G.E.; Setiawan, B.I.; Minasny, B. Automated near-real-time mapping and monitoring of rice growth extent and stages in Selangor Malaysia. Remote Sens. Appl. Soc. Environ. 2023, 31, 100993. [Google Scholar] [CrossRef]
- Phan, H.; Le Toan, T.; Bouvet, A. Understanding dense time series of Sentinel-1 backscatter from rice fields: Case study in a province of the Mekong Delta, Vietnam. Remote Sens. 2021, 13, 921. [Google Scholar] [CrossRef]
- McNairn, H.; Brisco, B. The application of C-band polarimetric SAR for agriculture: A review. Can. J. Remote Sens. 2004, 30, 525–542. [Google Scholar] [CrossRef]
- Nasirzadehdizaji, R.; Balik Sanli, F.; Abdikan, S.; Cakir, Z.; Sekertekin, A.; Ustuner, M. Sensitivity analysis of multi-temporal Sentinel-1 SAR parameters to crop height and canopy coverage. Appl. Sci. 2019, 9, 655. [Google Scholar] [CrossRef]
- Xu, S.; Qi, Z.; Li, X.; Yeh, A.G.O. Investigation of the effect of the incidence angle on land cover classification using fully polarimetric SAR images. Int. J. Remote Sens. 2019, 40, 1576–1593. [Google Scholar] [CrossRef]
- Barsi, A.; Kugler, Z.; László, I.; Szabó, G.; Abdulmutalib, H.M. Accuracy dimensions in remote sensing. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 61–67. [Google Scholar] [CrossRef]
- Ahmed, S.; Mahmoud, A.S.; Farg, E.; Mohamed, A.M.; Moustafa, M.S.; Abutaleb, K.; Saleh, A.M.; AbdelRahman, M.A.; AbdelSalam, H.M.; Arafat, S.M. Investigation on the use of ensemble learning and big data in crop identification. Heliyon 2023, 9, e13339. [Google Scholar] [CrossRef]
- Gupta, P.; Kanga, S.; Mishra, V.N.; Kumar, S.; Singh, T.S. A Comparative Study and Machine Learning Enabled Efficient Classification for Multispectral Data in Agriculture. Baghdad Sci. J. 2024, 21, 2462. [Google Scholar] [CrossRef]
- Nitze, I.; Schulthess, U.; Asche, H. Comparison of machine learning algorithms random forest, artificial neural network and support vector machine to maximum likelihood for supervised crop type classification. In Proceedings of the 4th International Conference on Geographic Object-Based Image Analysis—GEOBIA, Rio de Janeiro, Brazil, 7–9 May 2012; Volume 79, p. 3540. Available online: http://mtc-m16c.sid.inpe.br/col/sid.inpe.br/mtc-m18/2012/05.30.22.11/doc/index.html (accessed on 1 August 2024).
- Qian, Y.; Zhou, W.; Yan, J.; Li, W.; Han, L. Comparing machine learning classifiers for object-based land cover classification using very high resolution imagery. Remote Sens. 2014, 7, 153–168. [Google Scholar] [CrossRef]
- Fang, P.; Zhang, X.; Wei, P.; Wang, Y.; Zhang, H.; Liu, F.; Zhao, J. The classification performance and mechanism of machine learning algorithms in winter wheat mapping using Sentinel-2 10 m resolution imagery. Appl. Sci. 2020, 10, 5075. [Google Scholar] [CrossRef]
- Denize, J.; Hubert-Moy, L.; Betbeder, J.; Corgne, S.; Baudry, J.; Pottier, E. Evaluation of using sentinel-1 and-2 time-series to identify winter land use in agricultural landscapes. Remote Sens. 2018, 11, 37. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Mack, B.; Conrad, C. Crop type classification using fusion of sentinel-1 and sentinel-2 data: Assessing the impact of feature selection, optical data availability, and parcel sizes on the accuracies. Remote Sens. 2020, 12, 2779. [Google Scholar] [CrossRef]
- Dimov, D.; Löw, F.; Ibrakhimov, M.; Stulina, G.; Conrad, C. SAR and optical time series for crop classification. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 811–814. [Google Scholar] [CrossRef]
- Trisasongko, B.H.; Panuju, D.R.; Paull, D.J.; Jia, X.; Griffin, A.L. Comparing six pixel-wise classifiers for tropical rural land cover mapping using four forms of fully polarimetric SAR data. Int. J. Remote Sens. 2017, 38, 3274–3293. [Google Scholar] [CrossRef]
- Freeman, E.A.; Moisen, G.G.; Coulston, J.W.; Wilson, B.T. Random forests and stochastic gradient boosting for predicting tree canopy cover: Comparing tuning processes and model performance. Can. J. For. Res. 2016, 46, 323–339. [Google Scholar] [CrossRef]
- Jin, Z.; Azzari, G.; You, C.; Di Tommaso, S.; Aston, S.; Burke, M.; Lobell, D.B. Smallholder maize area and yield mapping at national scales with Google Earth Engine. Remote Sens. Environ. 2019, 228, 115–128. [Google Scholar] [CrossRef]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Toscano, P.; Cheng, Y.S.; Guo, H.Y.; Syu, C.H. A phenological object-based approach for rice crop classification using time-series Sentinel-1 Synthetic Aperture Radar (SAR) data in Taiwan. Int. J. Remote Sens. 2021, 42, 2722–2739. [Google Scholar] [CrossRef]
- Wang, L.; Ma, H.; Li, J.; Gao, Y.; Fan, L.; Yang, Z.; Yang, Y.; Wang, C. An automated extraction of small-and middle-sized rice fields under complex terrain based on SAR time series: A case study of Chongqing. Comput. Electron. Agric. 2022, 200, 107232. [Google Scholar] [CrossRef]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Minh, V.Q. Assessment of Sentinel-1A data for rice crop classification using random forests and support vector machines. Geocarto Int. 2018, 33, 587–601. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | Aug | Sep | Oct | Nov | Dec | Jan | Feb | Mar | Apr |
|---|---|---|---|---|---|---|---|---|---|
| North | S/E | S/E/VD | S/E/VD | S/E/VD | VD/F | GF/M | M/H | H | |
| Central | S/E | S/E/VD | S/E/VD | S/E/VD | VD/F | F/GF | GF/M/H | M/H | H |
| South | S/E | S/E/VD | S/E/VD | S/E/VD | VD/F | F/GF | GF/M/H | M/H | H |
| Characteristic | Value |
|---|---|
| Platform | B |
| Image format | GRD (Ground Range Detected) |
| Acquisition mode | IW (Interferometric Wide Swath) |
| Acquisition orbit | Descending |
| Incidence angle | 29° to 46° |
| Resolution | 10 m |
| Swath width | 250 Km |
| Polarization | VV and VH |
| Frequency | 5.4 (GHz) |
| Revisit time | 12 days |
| Dataset availability | Apr/2016 to Dec/2021 |
| Spectral Bands (µm) | Resolution (m) | Band ID |
|---|---|---|
| Blue (0.45–0.52) | 10 | B2 |
| Green (0.54–0.57) | 10 | B3 |
| Red (0.65–0.68) | 10 | B4 |
| NIR (0.78–0.89) | 10 | B8 |
| SWIR 1 (1.56–1.65) | 20 | B11 |
| Region | Train | Test | Total | Mean | Median | Max. | Min. |
|---|---|---|---|---|---|---|---|
| North | 22 | 10 | 32 | 46 | 30 | 172 | 3 |
| Central | 88 | 26 | 114 | 29 | 18 | 170 | 1 |
| South | 38 | 27 | 65 | 89 | 41 | 520 | 2 |
| Total | 148 | 63 | 211 |
| Model | Parameters |
|---|---|
| CART | maxNodes: default (null) |
| minLeafPopulation: default (1) | |
| GTBoost | numberOfTrees: 50 |
| shrinkage: default (0.005) | |
| samplingRate: default (0.7) | |
| maxNodes: default (null) | |
| loss: default (LeastAbsoluteDeviation) | |
| seed: 1 | |
| KNN | k: 5 |
| searchMethod: AUTO | |
| metric: default (EUCLIDEAN) | |
| RF | numberOfTrees: 50 |
| variablesPerSplit: default (sqrt of number of variables) | |
| minLeafPopulation: default (1) | |
| bagFraction: default (0.5) | |
| maxNodes: default (null) | |
| seed: 1 | |
| SVM | decisionProcedure: default (Voting) |
| svmType: C_SVC | |
| kernelType: RBF | |
| shrinking: default (true) | |
| gamma: 0.30 | |
| cost: 50 | |
| seed: 1 |
| Model | Accuracy | Precision | Recall | IOU | Dice | OE | CE |
|---|---|---|---|---|---|---|---|
| 0.977 | 0.789 | 0.904 | 0.724 | 0.829 | 9.60% | 21.07% | |
| 0.979 | 0.847 | 0.868 | 0.751 | 0.844 | 13.19% | 15.28% | |
| 0.980 | 0.806 | 0.926 | 0.755 | 0.851 | 7.37% | 19.41% | |
| 0.982 | 0.794 | 0.907 | 0.752 | 0.838 | 9.32% | 20.64% | |
| 0.984 | 0.818 | 0.877 | 0.758 | 0.837 | 12.33% | 18.17% | |
| 0.984 | 0.792 | 0.915 | 0.759 | 0.841 | 8.45% | 20.81% | |
| 0.984 | 0.849 | 0.942 | 0.803 | 0.882 | 5.78% | 15.05% | |
| 0.985 | 0.827 | 0.918 | 0.776 | 0.858 | 8.23% | 17.26% | |
| 0.986 | 0.811 | 0.956 | 0.783 | 0.865 | 4.39% | 18.86% | |
| 0.983 | 0.833 | 0.946 | 0.794 | 0.877 | 5.39% | 16.73% | |
| 0.985 | 0.850 | 0.911 | 0.789 | 0.868 | 8.93% | 15.03% | |
| 0.985 | 0.837 | 0.949 | 0.801 | 0.881 | 5.14% | 16.26% | |
| 0.981 | 0.781 | 0.953 | 0.751 | 0.844 | 4.71% | 21.89% | |
| 0.985 | 0.839 | 0.920 | 0.786 | 0.866 | 7.97% | 16.13% | |
| 0.987 | 0.833 | 0.959 | 0.807 | 0.885 | 4.05% | 16.68% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garcia, A.D.B.; Sanches, I.D.; Prudente, V.H.R.; Trabaquini, K. Characterization of Irrigated Rice Cultivation Cycles and Classification in Brazil Using Time Series Similarity and Machine Learning Models with Sentinel Imagery. AgriEngineering 2025, 7, 65. https://doi.org/10.3390/agriengineering7030065
Garcia ADB, Sanches ID, Prudente VHR, Trabaquini K. Characterization of Irrigated Rice Cultivation Cycles and Classification in Brazil Using Time Series Similarity and Machine Learning Models with Sentinel Imagery. AgriEngineering. 2025; 7(3):65. https://doi.org/10.3390/agriengineering7030065
Chicago/Turabian StyleGarcia, Andre Dalla Bernardina, Ieda Del’Arco Sanches, Victor Hugo Rohden Prudente, and Kleber Trabaquini. 2025. "Characterization of Irrigated Rice Cultivation Cycles and Classification in Brazil Using Time Series Similarity and Machine Learning Models with Sentinel Imagery" AgriEngineering 7, no. 3: 65. https://doi.org/10.3390/agriengineering7030065
APA StyleGarcia, A. D. B., Sanches, I. D., Prudente, V. H. R., & Trabaquini, K. (2025). Characterization of Irrigated Rice Cultivation Cycles and Classification in Brazil Using Time Series Similarity and Machine Learning Models with Sentinel Imagery. AgriEngineering, 7(3), 65. https://doi.org/10.3390/agriengineering7030065