1. Introduction
Climate change is certainly one of the most urgent challenges of the 21st century, presenting significant threats to ecosystems, economies, and societies globally [
1]. Its effects, while felt worldwide, vary greatly across different geographic regions. For example, rising sea levels, increased coastal erosion, and more frequent extreme weather events impact various areas in distinct ways. Understanding these regional differences is essential for developing localized, tailored interventions [
2]. The scientific community has produced a substantial body of research trying to comprehend these diverse effects, leading to a wealth of peer-reviewed articles and reports. However, the total volume and complexity of this literature make it nearly impossible for decision-makers, policymakers, and stakeholders to stay up to date with the latest findings and apply them effectively [
3]. These challenges are further worsened by the increasing vulnerability of critical infrastructure systems to natural risks driven by anthropogenic climate change. Essential infrastructure, including roads, bridges, airports, and power plants, faces significant disruptions due to climate impacts such as extreme weather events and temperature fluctuations [
4]. These disruptions can threaten community safety, cause financial losses, and lead to long-term socioeconomic damage. As the field of climate change research grows rapidly, decision-makers struggle to synthesize the vast amount of information available, underscoring the need for actionable and understandable insights that can guide the development of climate adaptation strategies [
5]. Enhancing the resilience of critical infrastructure systems is vital for reducing future disruptions and safeguarding communities [
6]. This paper advances the state of climate research by introducing an efficient framework for analyzing regional impacts using NLP. By implementing Named Entity Recognition (NER) on a vast collection of climate literature, we identify specific geographic regions and examine the dominant climate-related themes in these areas. Our analysis provides a comprehensive understanding of the frequency and severity of regional climate impacts, offering critical information for policymakers and planners. By equipping stakeholders with these geo-specific insights, we aim to support the development of evidence-based mitigation strategies and adaptive planning, ultimately contributing to a more resilient and adaptive global future.
Unlike prior studies that treated climate information at a global or national level, the presented innovation lies in the multi-layered fusion of advanced NLP techniques, spanning supervised and weak learning with social media discourse and scientific corpora, to enable both location-specific extraction and infrastructure-relevant interpretation. Furthermore, this research integrates both qualitative and quantitative evidence streams using BERT-based sentiment analysis and topic modeling to create a hybrid, explainable pipeline that not only identifies climate threats but also interprets public concern about urban infrastructure vulnerabilities. The presented framework is novel in its ability to bridge AI-driven climate analysis with practical resilience planning through the comprehensive lens of linguistic, spatial, and infrastructural dimensions.
The main contributions of this paper are summarized below:
Development of a Location-Aware NLP Framework: This research introduces a custom Named Entity Recognition (NER) system to extract and analyze geographic references from large-scale climate literature, enabling fine-grained, region-specific climate risk assessments.
Construction of Domain-Specific Corpora via Weak and Supervised Learning: Two tailored corpora—focused on climate hazards and critical infrastructure—were created to support more precise language modeling and contextual understanding in climate discourse.
Integration of Social Media Sentiment with Scientific Discourse: By analyzing over 30,000 climate-related tweets using BERT-based sentiment models and topic modeling, public perceptions and discourse patterns related to infrastructure vulnerabilities and climate activism were captured.
Cross-Modal Analysis Linking Climate Hazards and Infrastructure Resilience: The presented method investigates the intersection of specific climate hazards with infrastructure sectors (e.g., transportation, energy), offering actionable insights for policy and planning.
Explainable AI for Policy-Relevant Interpretation: Through SHAP-based interpretation of model outputs, the most influential features in regional climate narratives were identified, bridging the gap between AI predictions and transparent, policy-oriented insights.
2. Literature Review
This section provides a brief review of research related to the presented topic.
2.1. Global Climate Discourse and Activism
The global significance of climate change has gained the attention of public leaders and activists alike, particularly following the 2015 Paris Agreement, which marked an important moment in the international effort to combat climate change [
7]. With the 196 participating states legally bound to limit the global temperature rise to 1.5 °C above pre-industrial levels, this threshold has become a central point for scientists, policymakers, and climate activists, including movements like Fridays for Future (FFF), initiated by Greta Thunberg [
8,
9]. These movements, alongside the rise of social media platforms like Twitter, have increased the global discourse on climate change, enabling individuals to express a wide range of opinions, from supporting mitigation strategies to denying climate change itself [
10]. This complex socio-linguistic landscape requires closer examination, as understanding public sentiment and discourse can inform more effective climate action and policy-making [
11].
2.2. AI and NLP in Climate Literature Analysis
Artificial intelligence (AI) techniques, particularly natural language processing (NLP) and machine learning, offer a promising solution to efficiently analyze large volumes of climate-related literature [
12]. Traditional unsupervised learning techniques face challenges when dealing with unstructured data, making it difficult to categorize documents based on user-defined topics of interest [
13]. To address this limitation, weak supervision was introduced to programmatically label documents with minimal human input [
14]. This approach uses semantic embedding techniques to define labeling functions, generating probabilistic labels for documents related to climate risks and critical infrastructure. Once labeled, the corpus can be analyzed using supervised learning models, allowing decision-makers to identify relevant information and make informed, data-driven decisions on climate adaptation [
15].
2.3. NLP Applications in Climate Impact Studies
Advanced NLP methods have further expanded the capability of automated textual analysis in the climate domain. These techniques can autonomously extract and interpret information from the scientific climate literature, offering region-specific insights [
16,
17]. Studies have shown a wide range of NLP applications in climate change, including policy analysis, tracking adaptation efforts, weather prediction, and public sentiment assessment [
18,
19]. Additionally, models such as BERT have been used to identify geographic locations and their associated climate impacts, enabling more targeted and actionable insights.
2.4. Social Media Discourse on Climate Change
Climate discourse on social media platforms such as Twitter involves a broad range of expressions, including different stances, hate speech, and humor. Analyzing these stances—supportive, skeptical, or denying—can offer insights into public sentiment and help identify shifting trends that may influence policy directions [
20]. Examining hate speech reveals how divisive rhetoric can hinder consensus-building, while understanding the use of humor uncovers how users process complex climate issues [
21,
22]. These elements of communication play crucial roles in shaping the overall narrative and effectiveness of climate advocacy online.
2.5. Language Models for Climate Sentiment Analysis
To thoroughly explore these nuanced components—stance, hate speech, and humor—advanced language models (LMs) offer powerful analytical tools. However, their effective use depends on well-annotated datasets, which are currently limited. Applying these models to social media conversations can reveal deeper patterns of emotion, perception, and interaction, informing strategies for encouraging evidence-based, inclusive, and respectful engagement in climate discourse [
23].
2.6. Social Media as a Tool for Climate Insight
Social media has emerged as a transformative force over the past two decades, enabling widespread exchange of ideas and community mobilization [
24]. It has become a valuable platform for awareness-building and rapid opinion shifts. Both academia and industry have increasingly used social media data to study group behaviors and public opinion [
25]. With platforms like Twitter producing massive volumes of user-generated content, natural language processing has become an essential tool for analyzing sentiment and capturing collective viewpoints.
2.7. Evolution of NLP for Sentiment Analysis
NLP techniques have evolved considerably to meet the demands of analyzing digital text, particularly in the dynamic context of social media [
26]. Techniques range from statistical models like SVM to rule-based approaches such as VADER and TextBlob, and more recently, deep learning models like BERT have become the state of the art. Despite these advancements, the intersection of NLP and climate-related public opinion, particularly regarding the United Nations’ Sustainable Development Goals (SDGs), remains underexplored [
27]. Leveraging Twitter data through NLP can uncover sentiment on critical goals like clean energy and sustainable cities, thereby guiding climate policy.
2.8. Sentiment Analysis for Sustainable Development
Sentiment analysis in climate-related Twitter discourse has gained traction but remains in the early stages [
28]. Previous studies have primarily used lexicon-based or traditional methods to assess sentiment, often comparing geographic differences in public opinion. However, research explicitly linking sentiment to SDGs is limited. There is growing recognition of AI’s potential in contributing to sustainability, and the use of NLP in monitoring public sentiment provides a promising avenue for enhancing climate change mitigation and adaptation strategies.
3. Dataset
The data were collected in real time using the Twitter API, which gathers information from Twitter’s public timeline. This API offers free and a research versions, allowing users to download tweets, location data, and other features. Access to the Twitter API was facilitated by the open-source package Tweepy, which simplifies the process of automating interactions with the API. Using Tweepy, specific keywords were defined to retrieve relevant tweets. The data collection process focused on tweets posted between 1 January 2023 and 30 March 2024. Tweets were selected based on hashtags such as #climatecrisis, #climatechange, #ClimateEmergency, #ClimateTalk, #globalwarming, and activism-related tags like #fridaysforfuture, #actonclimate, #climatestrike, #extinctionrebellion, #ClimateAlliance, #climatejustice, and #climateaction. The dataset was compiled using the Twitter API, facilitating the extraction of tweets meeting the specified criteria within the chosen time frame. Before applying the different models, the data required pre-processing to ensure they were easily readable by the models. The extent of pre-processing varies; general transfer learning models typically require less pre-processing than lexicon-based models, as more information may be relevant to the learning process. Many Python version 3.8 packages offer models with built-in pre-processing functions. Regardless of the model used, the following pre-processing steps were applied to all data: (1) removal of links, HTML, and HTTP URLs; (2) exclusion of videos; (3) elimination of @usernames; and (4) removal of trailing white space. Since the API collects tweets with keywords in links, some tweets lost the keywords during pre-processing. These were excluded, as they no longer provided sentiment-related information. Duplicates and retweets were also filtered out. Only tweets in English were included, and 30,000 tweets were extracted. To increase the dataset’s diversity and enhance its geographical significance, efforts were made to ensure that the collected tweets spanned a wide range of regions. This included expanding keyword searches to include geo-tagged tweets and integrating Named Entity Recognition (NER) tools to identify and categorize geographic references such as countries, cities, and landmarks. Furthermore, although the current dataset covers tweets from January 2023 to March 2024, additional data collection phases are planned to incorporate tweets from earlier and later time periods. This temporal expansion will support longitudinal analyses and contribute to a more comprehensive understanding of evolving public sentiment on climate change. To enhance the robustness of data collection, the keyword-based filtering approach was compared with other methods, such as random sampling and topic modeling-based selection. Latent Dirichlet Allocation (LDA) was applied to an initial dataset to identify climate-related topics beyond the predefined keywords, ensuring a broader coverage. Additionally, Named Entity Recognition (NER) models were tested to extract relevant climate-related entities from tweets. The performance of these approaches was evaluated based on relevance scores and data diversity. Furthermore, to address challenges in sentiment analysis caused by sarcasm, humor, and nuanced expressions, pre-trained models like RoBERTa and ALBERT designed to handle complex linguistic features were integrated. Sentiment labels were refined using contextual embedding techniques, and a human-annotated subset was used to fine-tune the model. A hybrid approach combining rule-based sentiment detection with deep learning helped improve the classification accuracy, particularly for sarcastic or ambiguous tweets.
4. Materials and Methods
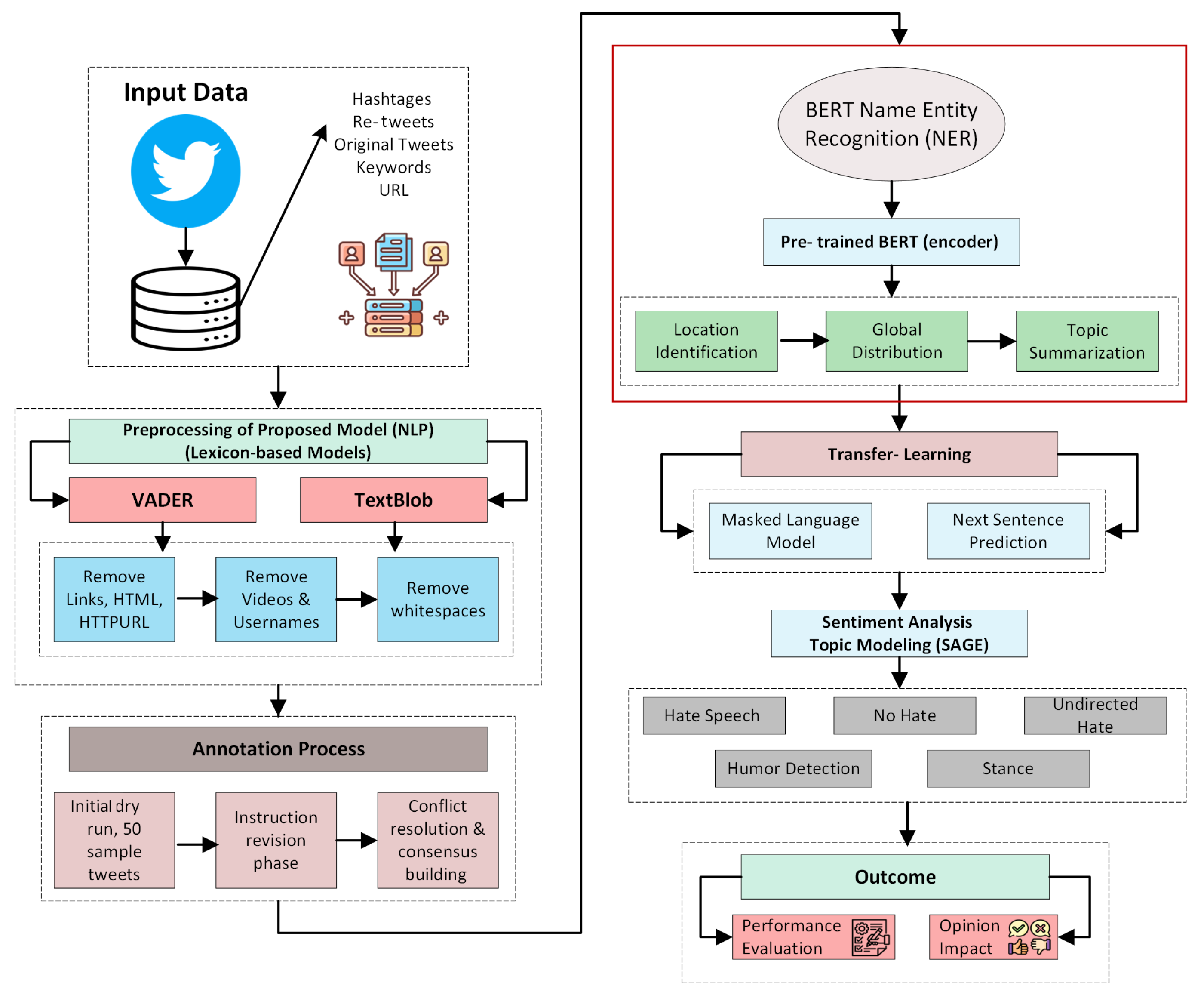
This section comprehensively explains the proposed sentiment analysis of climate change impacts. First, the data collection and pre-processing phases are discussed. Next, the annotation process is presented in detail. Afterward, the transfer learning approach and topic modeling process are given for further information.
Figure 1 shows the step-by-step architecture of the proposed system.
While the proposed method leverages several established techniques such as BERT-based sentiment classification, SAGE for keyword extraction, and topic labeling, it is not merely a straightforward combination. The innovation lies in the integrated framework that connects sentiment analysis with stance and hate speech detection, using a multi-label classification pipeline tailored to climate discourse. Additionally, keyword salience is used not only for interpretation but also to explore inter-class semantic overlaps, which enhances explainability. The pipeline has been specifically adapted to climate-related social media discourse by refining label definitions, tuning model thresholds, and applying class-specific pre-processing to improve performance and interpretability.
4.1. Valence-Aware Dictionary and Sentiment Reasoner
VADER (valence-aware dictionary and sentiment reasoner) is a lexicon-based model developed in 2004 by Hutto and Gilbert for sentiment analysis, particularly in micro-blogging environments like Twitter. It is considered a gold standard because its lexicon classification is entirely human-generated. According to Hutto and Gilbert’s research, VADER surpasses individual human raters in performance and generalizes more effectively across different contexts compared to other sentiment analysis tools. For more details on its development process, refer to Hutto and Gilbert’s paper,
Vader: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. VADER is available as a Python version 3.8 package called ‘vaderSentiment’ and is widely used for its simplicity and effectiveness in sentiment analysis. It accounts for various textual features like capitalization, punctuation, emojis, smileys, and slang. VADER provides a sentiment score in four categories: compound, positive (pos), negative (neg), and neutral (neu). The compound score is the aggregate of valence scores for each word, adjusted using rules and normalized to a scale between −1 (extreme negative) and +1 (extreme positive). The other three categories (pos, neg, neu) represent the proportion of the text that falls into positive, negative, and neutral sentiment, respectively.
Table 1 below shows examples of how VADER can be applied to different sentences drawn from various sources. In the first two examples in
Table 2, VADER shows its ability to recognize booster words like ‘extremely’, leading to a higher positive sentiment score in the second sentence. Example three demonstrates how VADER can interpret mildly positive statements, while examples four and five showcase its capacity to process slang and emoticons.
4.2. TextBlob for Sentiment Analysis
In addition to the annotation process, sentiment analysis was conducted using TextBlob, an open-source Python version 3.8 package for NLP tasks. TextBlob provides various NLP functionalities, such as part-of-speech tagging, noun phrase extraction, and sentiment analysis. The sentiment analysis in TextBlob is measured through two primary scores:
Polarity: Polarity measures the sentiment of a sentence on a scale ranging from −1 (very negative) to 1 (very positive), indicating the emotional tone conveyed in the text.
Subjectivity: Subjectivity measures how much the writer of a sentence is influenced by personal feelings, opinions, or biases, with a scale from 0 (very objective) to 1 (very subjective).
Each word in the TextBlob lexicon is assigned scores for polarity, subjectivity, and intensity, which are aggregated to determine the sentiment of the overall text, as presented in
Table 2. The sentiment analysis scores for each category provide a quantitative assessment of the emotional and subjective content within the dataset. By employing rigorous annotation processes and sentiment analysis tools like TextBlob, this study ensured that the dataset not only captured nuanced climate-related discourse but also provided valuable insights into the emotional and subjective aspects of the text.
Although lexicon-based models like VADER and TextBlob have been historically foundational in sentiment analysis, their role in this study was deliberately restricted to the annotation and weak labeling phase. These tools were employed to generate initial sentiment labels due to their efficiency, transparency, and suitability for large-scale unsupervised data labeling. Their complementary scoring mechanisms—VADER’s focus on valence and social media slang, and TextBlob’s emphasis on polarity and subjectivity—allowed the combination to capture nuanced emotional tones across climate-related tweets. However, these lexicon-based outputs were not used for the final sentiment classification tasks. Instead, transformer-based models such as RoBERTa and ALBERT were later integrated into the system to refine the sentiment predictions and handle complex linguistic features like sarcasm and ambiguity. This hybrid strategy—using VADER/TextBlob for the initial annotation and transformer models for the final prediction—leverages the strengths of both traditional and modern NLP methods, balancing interpretability with state-of-the-art performance.
4.3. Combining VADER and TextBlob for Sentiment Annotation
To enhance the reliability and depth of sentiment annotation, both VADER and TextBlob were utilized due to their complementary strengths. VADER is effective at capturing informal language features like slang and emojis, while TextBlob provides additional insight through polarity and subjectivity scores. The sentiment label for each tweet was determined based on the agreement between both tools. Specifically, if both VADER and TextBlob assigned the same sentiment polarity (positive, negative, or neutral), that label was directly assigned to the tweet. In cases of disagreement where the tools produced conflicting sentiment categories, a rule-based reconciliation strategy was employed. First, VADER’s compound score was given priority when emojis, slang, or informal punctuation were detected in the tweet, as these are areas where VADER excels. Conversely, if the tweet was more formal or lexically rich, TextBlob’s polarity score was preferred. For tweets with marginal or ambiguous scores from both tools (i.e., compound values near 0 in VADER and polarity values near 0 in TextBlob), the sentiment was labeled as ’neutral’ to reduce misclassification risk. This combined lexicon-based approach aimed to improve the annotation quality by leveraging the distinct capabilities of both models, thereby capturing a wider spectrum of sentiment expressions within climate-related discourse.
4.4. Normalization of Sentiment Scores
To ensure consistency and comparability between the sentiment scores generated by VADER and TextBlob, a min-max normalization technique was applied. This method transforms the sentiment scores into a common scale of [0, 1], allowing for a unified interpretation of polarity values across both models. For VADER, the compound score, which originally ranges from −1 to +1, was normalized using the following equation:
This mapped the score to the interval [0, 1], where 0 corresponds to −1 (extremely negative) and 1 corresponds to +1 (extremely positive). Similarly, for TextBlob, the polarity score (also ranging from −1 to +1) was normalized using the same equation:
These normalized scores were then used for further analysis, including threshold-based labeling of sentiment classes. Tweets with normalized scores above 0.6 were labeled as positive, below 0.4 as negative, and those in between as neutral. This normalization procedure facilitated a more accurate and fair integration of the two models’ outputs during the annotation process.
4.5. Annotation Process and Methodology for Dataset Reliability
The effectiveness of datasets in natural language processing (NLP) tasks heavily depends on the accuracy of annotations. Without meticulous annotations, the performance of models in downstream tasks can be severely compromised, resulting in skewed or misleading outcomes [
29,
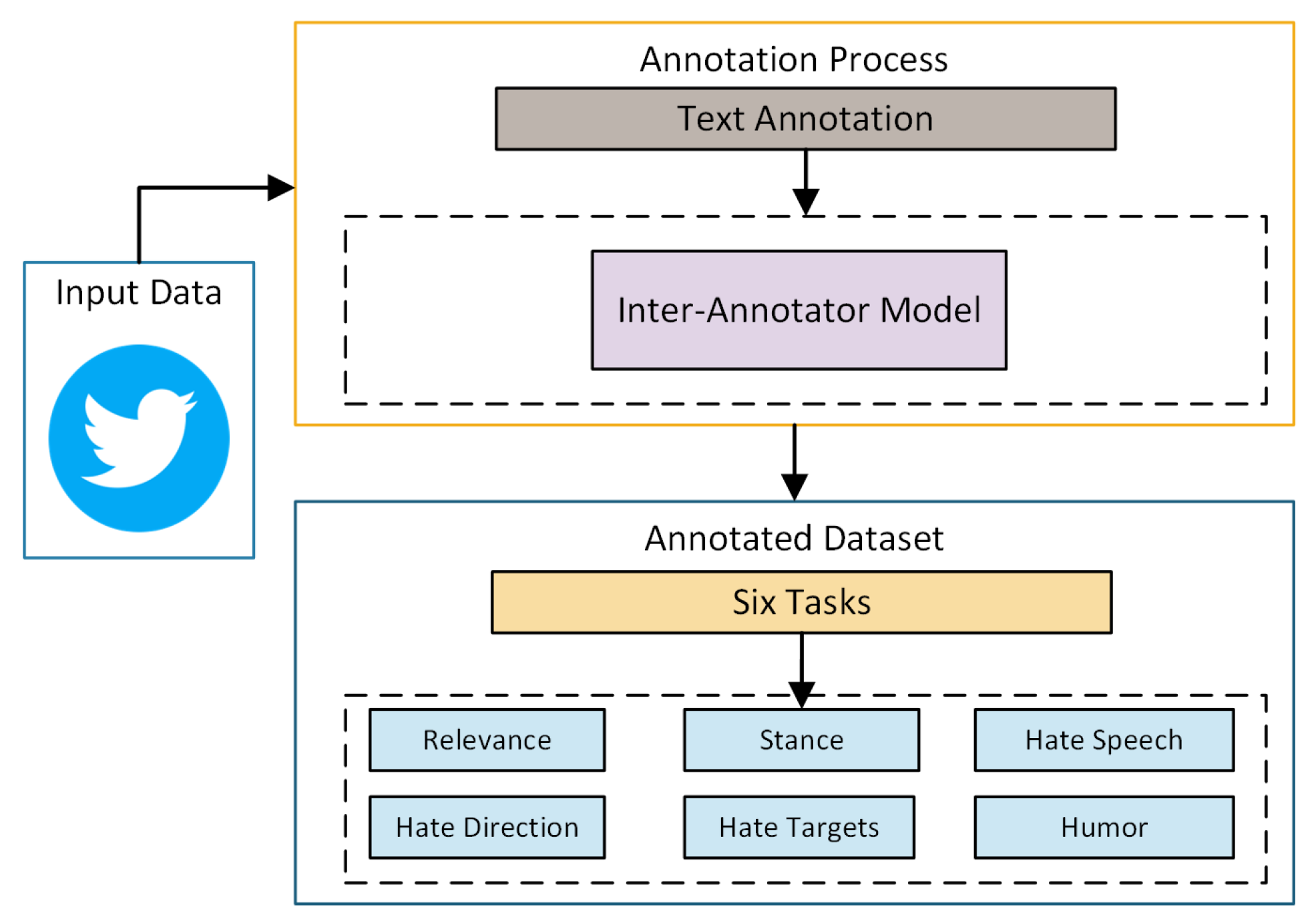
30]. To mitigate this, an experienced team of four annotators were engaged to ensure high-quality annotations. These annotators were provided with comprehensive guidelines that outlined specific tasks, associated labels, and relevant examples. Given their extensive understanding of climate-related discourse, they were well-equipped to interpret the guidelines and maintain objectivity throughout the annotation process. To enhance the accuracy and consistency of the annotations, an iterative process was employed, which integrated feedback from the annotators. This approach ensured continuous improvement in both the instructions and the resulting annotations. The dataset was annotated for six distinct tasks, including relevance, stance, hate speech, the direction of hate speech, targets of hate speech, and humor. A structured three-phase annotation schema was implemented to address any inconsistencies or inaccuracies, ensuring a reliable and comprehensive dataset.
Initial Dry Run: The annotation process began with a dry run involving 50 sample tweets. This phase aimed to assess the clarity and effectiveness of the annotation instructions. Given the complexity of climate change discourse, the annotators were introduced to contextual nuances to help them navigate potential challenges. During this phase, difficulties arose, particularly in identifying humor and hate speech, which informed the refinement of the guidelines.
Instruction Revision Phase: Following the dry run, 200 additional tweets were annotated with revised instructions. The feedback from the initial phase was incorporated into the guidelines, improving clarity and precision. The refinements particularly helped in accurately identifying hate speech and its intended targets.
Conflict Resolution and Consensus Building: In the final stage, the annotators collaboratively discussed discrepancies that emerged during the annotation of 200 more tweets. This phase emphasized consensus-building and resolving ambiguities. Regular meetings were held with experts, including professors specializing in annotation, to ensure the accuracy of the annotations. The collaborative discussions not only resolved ambiguities but also reinforced the consistency and reliability of the dataset.
This methodical approach, which involved thorough cross-checking and ongoing revisions, ensured that the dataset was both reliable and comprehensive, with annotations that accurately reflected the nuances of the underlying climate-related discourse.
Figure 2 shows the annotation process structure as described above.
4.6. Geographic Entities Identification
This section outlines the process of extracting geographic insights from a corpus of climate change articles, focusing on identifying and categorizing mentions of cities, countries, and other significant geographical entities. By employing advanced text analysis techniques, the aim was to create a spatial understanding of the content and better contextualize the events and trends discussed in the articles. This approach allows us to visualize the regional focus of the material and understand how different geographic locations are integrated into the broader climate change narrative. To achieve this, the BERT Named Entity Recognition (NER) system was leveraged, which uses a deeply bidirectional transformer architecture to analyze text. BERT’s ability to process context from both directions enables it to identify and categorize named entities, such as locations, within the text. When fine-tuned for NER tasks, BERT effectively extracts geographic data by recognizing and classifying entities like names, dates, and organizations, specifically focusing on identifying location information in our climate-related corpus. BERT NER is particularly adept at distinguishing locations (LOC), organizations (ORG), persons (PER), and miscellaneous entities (MISC), by isolating the location-based entities, a detailed geographic map of climate change discourse was generated, highlighting regions of interest, concern, and discussion across the literature. To further refine this process, LocationTagger integrated a tool to distinguish between countries, states, and cities. While BERT NER provides a broad range of location data, LocationTagger enhanced this by categorizing each geographic mention into specific categories, reducing the ambiguity and noise in the final dataset. This two-step process, extracting locations with BERT NER and then classifying them with LocationTagger, allowed for a more granular and comprehensive geographic representation of the climate change corpus, offering valuable insights into the spatial dimensions of climate-related discussions.
4.7. Topic Modeling of Climate Hazards and Critical Infrastructure
Tagging documents with specific countries, states, and cities can tailor topic modeling to individual geographic regions. Topic modeling is a powerful unsupervised technique to identify key topics within documents. When applied to specific locations, it helps extract insights that are region-specific and relevant. This allows us to better understand and address each geographic area’s unique needs and characteristics. A commonly used topic modeling approach is Latent Dirichlet Allocation (LDA), which views a document as a mixture of topics, each containing a word distribution. However, LDA has limitations, such as its inability to account for the semantic relationships between words. To overcome this, BERTopic utilized a more advanced model that leverages BERT embeddings to capture the semantic nuances within the text.
BERTopic works by first generating document embeddings using pre-trained BERT models. These embeddings are then reduced in dimensionality using the Uniform Manifold Approximation and Projection (UMAP) method, simplifying the data without losing the essential structure. The reduced embeddings are then clustered using hierarchical density-based spatial clustering (HDBSCAN), resulting in groups of semantically related documents, each representing a distinct topic. Cluster-based term frequency–inverse document frequency (c-TF-IDF) was used to determine the importance of words within these clusters. Unlike traditional TF-IDF, which measures word importance at the document level, c-TF-IDF evaluates the significance of words within the entire cluster, offering a more focused analysis of each topic.
Once topics are identified, the next step is to summarize the documents associated with each topic. BERTopic provides a list of representative documents based on their centrality within each cluster, ensuring the selection of the most relevant content. This process is further refined using the c-TF-IDF method to highlight the documents that best represent the core themes of each topic. To make these insights more accessible, Large Language Models (LLMs) are applied for text summarization. With their advanced natural language processing capabilities, LLMs generate concise and coherent summaries that capture the essence of the original documents. This approach allows readers to quickly grasp each topic’s main ideas and insights, without needing to read through the entire document. Combining topic modeling with LLM-driven summarization was an efficient way to interpret and disseminate the rich information contained within the dataset.
5. Results
The sentiment analysis of climate-related discourse revealed an overall positive sentiment toward climate action, with a high frequency of supportive terms related to sustainability, renewable energy, and environmental responsibility. The BERT-based model demonstrated superior accuracy in detecting sentiment compared to traditional lexicon-based methods, highlighting its effectiveness in handling the complexities of social media language. However, sentiment varied across different topics, with climate activism and renewable energy discussions generating significantly more positive responses, while discussions on climate policy and infrastructure vulnerability exhibited more mixed reactions. This divergence suggests that while public sentiment generally supports climate-related initiatives, there remains skepticism or concern regarding the feasibility and implementation of policies addressing urban infrastructure challenges.
The results are presented in two sections: the first focuses on sentiment analysis using various methods, followed by an evaluation of model accuracy.
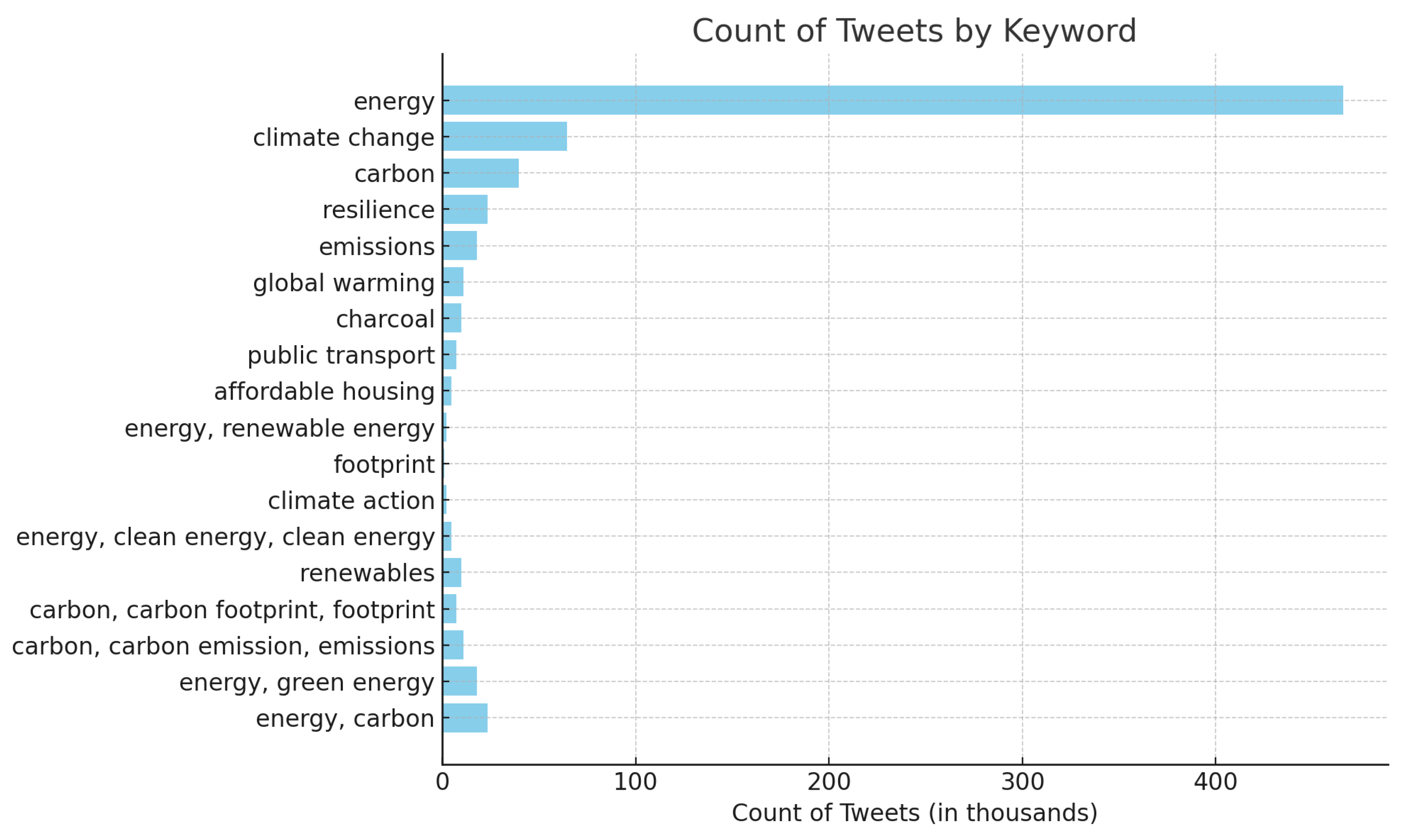
Figure 3 provides a bar plot illustrating the distribution of keyword frequencies, with the most frequently occurring terms listed on the right side. Throughout this section, the transfer learning model utilizing BERT and regression techniques will be referred to as the BERT model or simply BERT.
Furthermore, aligning the sentiment analysis results with real-world trends reveals an interesting correlation: regions with a high frequency of positive climate sentiment also showed increased engagement with sustainability policies, such as green infrastructure projects and local climate initiatives. This suggests that public discourse, as reflected in sentiment trends, may serve as a valuable indicator of policy acceptance and behavioral shifts. However, further research is needed to establish direct causal links between sentiment trends and policy outcomes. These findings emphasize the role of social media in shaping public opinion on climate action. Policymakers and urban planners can leverage sentiment insights to gauge public support, identify areas of concern, and design more effective climate adaptation strategies that align with community priorities.
5.1. Annotator Consistency Evaluation
Ensuring annotation consistency is essential for the reliability of analysis outcomes. Fleiss Kappa was applied as a statistical measure to evaluate the inter-annotator agreement across all six tasks.
Table 3 presents the results, indicating the following k-values: Task A (2-class: Relevant vs. Non-Relevant) = 0.93, Task B (3-class: Support, Denial, or Neutral) = 0.81, Task C (2-class: Hate vs. Non-Hate) = 0.73, Task D (2-class: Directed vs. Undirected) = 0.77, Task E (3-class: Individual, Organization, or Community) = 0.70, and and Task F (2-class: Humor vs. Non-Humor) = 0.79. Additionally, phase-wise, Cohen’s Kappa analysis highlighted that our 3-step annotation process improved the annotation accuracy and minimized conflicts.
5.2. Sentiment Analysis Performance and Evaluation
For the output from BERT, the optimal regression model was determined using a grid search, selecting the ‘liblinear’ solver with an l1 penalty. This model achieved an accuracy of 0.83%. To evaluate the models, 350 tweets were annotated with either two (positive and negative) or three (positive, neutral, and negative) labels. The dataset with three labels assessed VADER and TextBlob, while the binary dataset was utilized for BERT. Definitions of performance metrics:
Support: Number of actual samples for each class in the test dataset.
Weighted Average:
where TP is true positive, FP is false positive, TN is true negative, and FN is false negative. For the weighted average,
y represents the set of true label pairs,
the predicted label pairs,
L the set of labels,
the subset of label
ℓ (similarly for
), and
The performance results for each model, calculated using the equations above, are provided in
Table 4.
Among the five tested models, VADER, TextBlob, BERT, RoBERTa, and ALBERT, the final sentiment classification system was based solely on the BERT model, which was fine-tuned on the climate-related Twitter dataset used in this study. This decision was made after a comprehensive evaluation demonstrated that BERT achieved the highest accuracy, F1-score, and overall performance, as shown in
Table 4. While VADER and TextBlob served as lexicon-based baselines, and RoBERTa and ALBERT provided comparative deep learning benchmarks, the outputs were not aggregated. Instead, the superior-performing model, BERT, was selected as the final system for the downstream sentiment analysis tasks. This approach ensured consistency, performance, and scalability in sentiment evaluation across climate-related tweets.
To enable a direct comparison among the sentiment analysis models, the sentiment scores produced by VADER and TextBlob were rescaled to match the BERT output range of 0 to 1. This normalization was performed using min-max scaling, as shown in the Equation below. After scaling, the normalized scores allowed for a consistent evaluation across the different models, where X represents the value being rescaled:
The analysis of Valence (V), Arousal (A), and Dominance (D) across all categories was conducted using the NRC VAD lexicon. For each class, V, A, and D scores were evaluated for individual tweets by averaging the corresponding scores of words within the tweet. Box plots were then created for each class to represent these scores. Individual Hate, Community Hate, and Oppose categories displayed the broadest range of valence scores, likely due to the strong polarizations expressed within these tweets. The lower levels of Arousal and higher levels of Dominance observed across all classes suggest that climate change discussions on Twitter are generally calm yet assertive in tone.
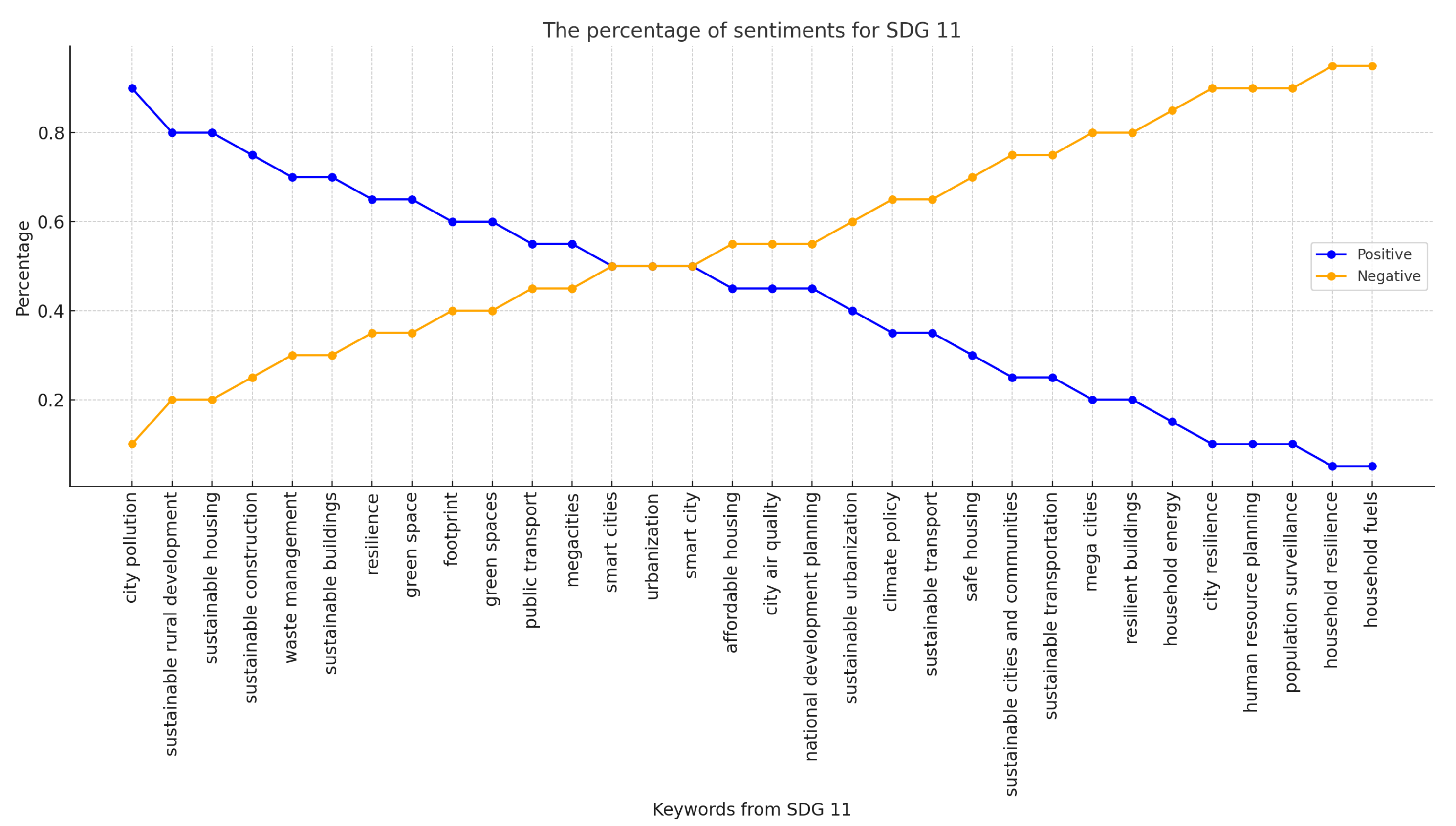
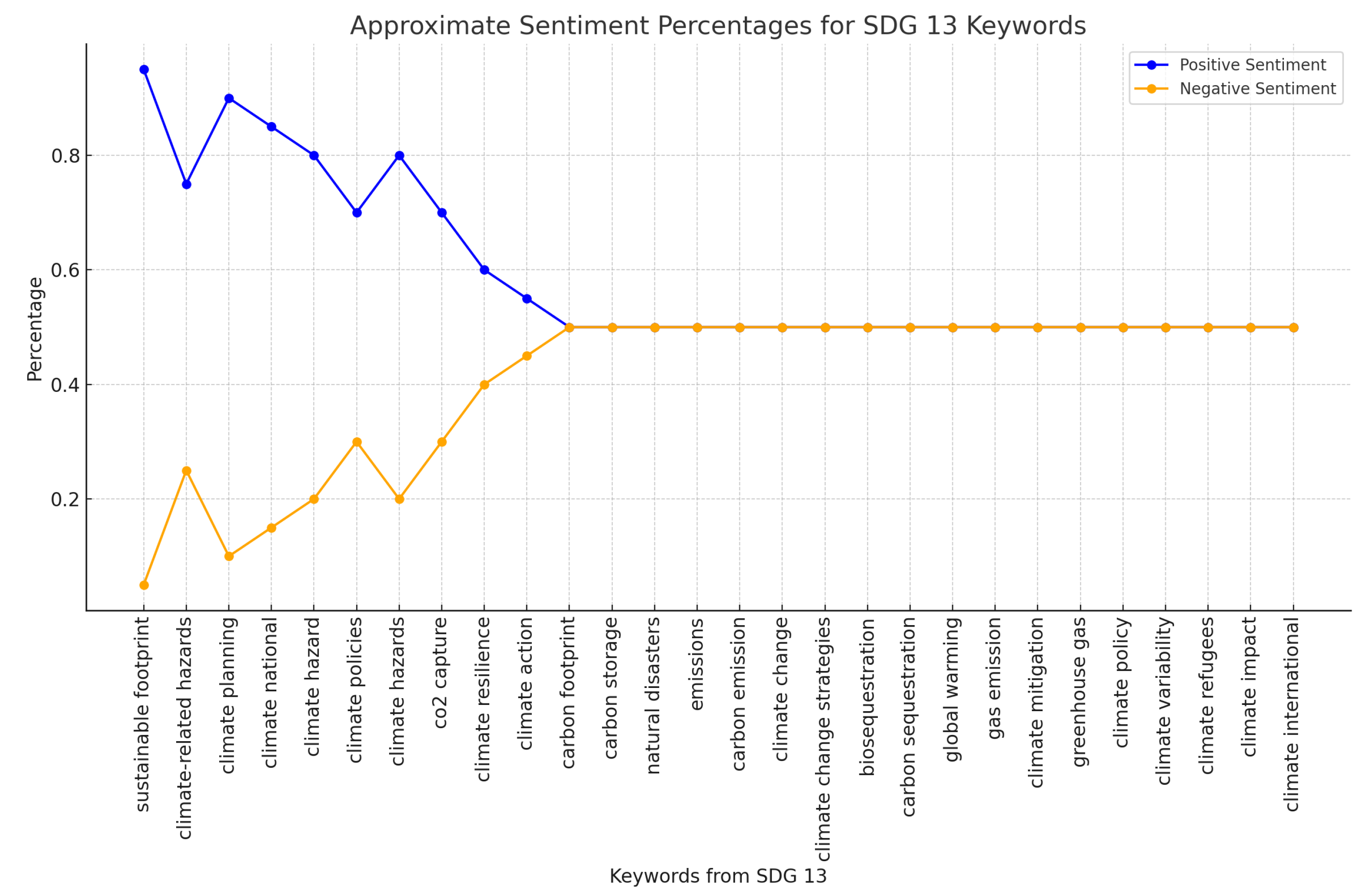
Figure 4 and
Figure 5 show the results of the SDG 11 and SDG 13 word groups.
The topic modeling technique SAGE (Sparse Additive Generative Models of Text) was employed to identify key terms across different class labels in the dataset. SAGE is effective in distinguishing words that differentiate specific segments of a corpus. SAGE was chosen over traditional models such as LDA due to its ability to model deviations from a background word distribution using a log-linear generative approach, which is particularly well suited for classification tasks requiring contrastive keyword analysis across labeled categories. Unlike LDA, which uncovers latent topics based on word co-occurrences, SAGE emphasizes words that are statistically significant in distinguishing between predefined classes, making it more appropriate for analyzing stance- and hate-based labels. The implementation of SAGE involved setting the regularization strength () to control sparsity in word weights, using a filtered vocabulary of tokens appearing in at least 10 documents, and applying standard text preprocessing such as lowercasing, lemmatization, and removal of hashtags and stopwords. The top most salient keywords for each label were then extracted based on the absolute values of the model’s learned coefficients.
The dataset was refined for keyword analysis by removing hashtags and stopwords and focusing only on relevant and meaningful words.
Table 5 presents the most prominent keywords identified by SAGE for each class and their salience scores. For instance, the Support label included words like join and prioritize, encouraging people to engage with the FFF movement. Additionally, there were shared terms between the denial label and specific hate labels, as denial tweets sometimes suggest underlying hate sentiments. Terms like corporation and company names such as
Sumitom and
JICA were pertinent to the organization hate label, while terms addressing communities, such as white and German, were notable in the community hate label.
6. Theoretical Contributions and Practical Implications
This research makes several theoretical contributions by advancing the application of Natural Language Processing (NLP) in climate-related sentiment analysis. Existing studies on sentiment analysis often focus on general domains, without considering the complexities of climate discourse, which includes diverse linguistic patterns, slang, and regional variations. By leveraging a BERT-based model with transfer learning, this study enhances sentiment classification accuracy in climate-related social media discussions, addressing limitations in dictionary-based sentiment models that struggle with contextual nuances. Additionally, this study introduces a domain-specific corpus tailored for climate hazards and critical infrastructure, filling a gap in NLP applications for climate risk assessment.
From a practical perspective, this research provides valuable insights for policymakers, urban planners, and sustainability practitioners. By identifying public sentiment trends related to climate change and infrastructure vulnerabilities, this study enables decision-makers to understand public concerns better and prioritize adaptive strategies. Sentiment shifts can signal areas where misinformation, skepticism, or strong support for climate policies exist, allowing for targeted public engagement and policy refinement. Moreover, the study’s focus on urban infrastructure sustainability highlights the need for data-driven approaches in resilience planning. The sentiment analysis results reveal concerns related to transportation, energy, and water systems, helping governments and organizations tailor mitigation strategies to address public anxieties and real-world infrastructure risks. By integrating sentiment analysis into climate action planning, policymakers can design more responsive and publicly supported interventions. This research bridges the gap between computational social science and climate adaptation strategies, demonstrating how AI-driven sentiment analysis can serve as a tool for research and policy-making. Future studies could expand on these findings by integrating multi-platform data sources and real-time monitoring of climate-related discussions to enhance decision-making frameworks further.
Baseline Method for Comparison
To evaluate the effectiveness of the proposed framework, its performance was compared against a baseline method. As a baseline, a traditional machine learning pipeline was implemented, which combined Term Frequency-Inverse Document Frequency (TF-IDF) feature extraction with a Support Vector Machine (SVM) classifier. This method has been widely adopted in sentiment analysis and text classification tasks due to its simplicity and interpretability [
31]. In the baseline setup, climate-related tweets underwent preprocessing steps including tokenization, stopword removal, and stemming. The processed tokens were transformed into numerical feature vectors using TF-IDF. These vectors were subsequently used to train an SVM classifier with a linear kernel to predict sentiment polarity (positive, neutral, or negative). Although the baseline model lacked deep contextual understanding and explainability, it served as a practical benchmark for assessing the enhancements introduced by the proposed deep-learning-based and explainable AI (XAI)-augmented framework. Performance comparisons between the baseline and the proposed method are reported using metrics such as accuracy, F1-score, and Root Mean Squared Error (RMSE) for regression-based sentiment strength prediction, highlighting the added value of advanced natural language processing techniques.
Table 6 shows the proposed BERT + SHAP approach results with the baseline in term of accuracy, F1-score and RMSE.
7. Discussion
Working with social media text data presents significant challenges due to variations in slang, dialects, and informal expressions. This study’s BERT-based model using transfer learning with logistic regression outperformed dictionary-based models like VADER and TextBlob. The BERT model’s advantage lies in its ability to recognize complex linguistic structures due to its training on large corpora. The dictionary-based models struggled, especially with keywords with inherent sentiment scores, introducing biases. The dataset used in this study was limited in scope and representativeness, with a large portion of the initial data removed to ensure relevance. Certain keywords proved uncommon in social media language, while broader terms presented challenges due to their multiple meanings. More targeted keyword selection and advanced data preprocessing techniques, such as semantic filtering, could improve the data quality. Furthermore, there were limitations from the Twitter API, such as restricted keyword linkage and reduced precision. Including data from other social media platforms and using a climate-specific dataset could enhance understanding of public sentiment toward the SDGs.
Despite these challenges, an overall positive sentiment was associated with climate-related keywords, even for terms typically perceived negatively. This suggests a general support for climate action, although context, such as sarcasm or opposing sentiments, can complicate interpretations. Comparing sentiment trends over time and across different SDGs may reveal patterns in public discourse and reactions to policy initiatives. Expanding the research to include SDGs beyond climate would provide a fuller picture of how sentiment reflects progress toward global goals.
Furthermore, the sentiment analysis results offer key insights into the impact of climate change on urban infrastructure and sustainability. Negative sentiments frequently aligned with concerns about infrastructure resilience, extreme weather disruptions, and urban planning challenges. The findings highlight public anxieties about transportation networks, energy systems, and water infrastructure vulnerabilities due to climate-related events. By analyzing sentiment shifts, this study reveals how communities perceive infrastructure risks, which can inform policymakers in developing adaptive and sustainable urban solutions. This research bridges the gap between AI-driven sentiment analysis and real-world urban sustainability challenges, emphasizing the role of public discourse in shaping climate adaptation strategies.
However, several limitations must be acknowledged to contextualize the reliability and applicability of the findings. First, the reliance on Twitter data constrains the generalization of results, as Twitter users do not represent the broader population, potentially introducing demographic and ideological biases. Additionally, even with advanced models like BERT, sentiment analysis may misinterpret nuances such as sarcasm, humor, or implicit sentiments, leading to classification errors. The study also did not account for temporal variations in sentiment, which could provide deeper insights into public attitudes evolving over time. Future work should incorporate multi-platform analysis, real-time monitoring, and improved sentiment calibration techniques to enhance the robustness of the findings and ensure a more comprehensive understanding of climate-related discourse. From a theoretical perspective, this study contributes to computational social science by demonstrating how NLP-driven sentiment analysis can extend beyond general opinion mining to reveal structured insights about public concerns in the context of climate resilience. This research underscores the intersection between public discourse and infrastructure adaptation by integrating climate-focused sentiment analysis with urban sustainability frameworks.
In terms of practical implications, these findings offer actionable insights for urban planners, policymakers, and climate strategists. Governments and municipalities can leverage sentiment trends to identify regions where public concern about climate impacts is high and prioritize investments in resilient infrastructure accordingly. Additionally, policymakers can implement climate communication strategies based on sentiment trends to enhance public engagement and support for sustainability initiatives. This approach aligns with participatory governance models, where citizen sentiment is the input for policy formulation. Moreover, real-time sentiment tracking could help authorities detect emerging climate-related concerns, allowing for proactive interventions before infrastructure vulnerabilities escalate into crises.
However, several limitations must be acknowledged to contextualize the reliability and applicability of the findings. First, the reliance on Twitter data constrains the generalization of results, as Twitter users do not represent the broader population, potentially introducing demographic and ideological biases. Additionally, even with advanced models like BERT, sentiment analysis may misinterpret nuances such as sarcasm, humor, or implicit sentiments, leading to classification errors. The study also did not account for temporal variations in sentiment, which could provide deeper insights into evolving public attitudes over time. Future work should incorporate multi-platform analysis, real-time monitoring, and improved sentiment calibration techniques to enhance the robustness of the findings and ensure a more comprehensive understanding of climate-related discourse.
8. Conclusions
In this study, the BERT-based models demonstrated a clear advantage over rule-based models like VADER and TextBlob regarding precision, recall, and F1-score for climate-related sentiment analysis. Rule-based models tended to introduce biases due to their reliance on keyword sentiment scores, whereas the BERT contextual approach allowed for more nuanced analysis without this limitation. Enhancing data filtering capabilities on platforms like Twitter could reduce noise and improve the data relevance for similar analyses. Our findings revealed a generally positive sentiment across tweets related to different SDGs, suggesting that sentiment analysis may serve as a useful indicator of public support for SDG themes. This research represents an important step in understanding public sentiment surrounding climate change and SDG topics on social media. However, several limitations should be acknowledged. First, the reliance on English-language tweets may overlook sentiment expressed in other languages, potentially introducing cultural and linguistic biases. Second, the presence of sarcasm, irony, or implicit sentiment may still pose challenges for even the most advanced contextual models. Third, while the study focused on Twitter data, the results may not generalize to other platforms or offline discourse. Addressing these limitations in future work by incorporating multilingual models, advanced sarcasm detection, and cross-platform analysis could enhance the comprehensiveness and validity of the findings.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}