

Generative Adversarial Framework with Composite Discriminator for Organization and Process Modelling—Smart City Cases




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
Highlights
- What are the main findings?
- We successfully apply generative AI techniques (in particular, generative adversarial modeling) to speed up and streamline the development of organizational structures and processes, which is demanded in volatile smart city environments.
- We demonstrate the developed idea of the original composite discriminator, taking advantage of separate evaluation of tacit and explicit domain knowledge on smart city related scenarios, namely logistics system model generation and smart tourist trip booking process model generation
- We show that the developed mechanism of generating and using meaningful augmentations enables learning on limited datasets.
- What is the implication of the main finding?
- The developed approach offers an effective solution for the fast generation of organizational structures and process models, accounting for both tacit and explicit requirements and constraints.
- By automating the creation of organization structures and processes, the approach can contribute to the adaptability of smart city structures and processes and their fast adaptation to changing requirements.
- The approach can be applied to other domains and could be a starting point for research efforts in related scientific fields.
Abstract
1. Introduction
2. Related Works
2.1. Decision Support in Organization and Process Modelling
2.2. Application of Neural Networks to Organization and Process Modelling
3. Proposed Approach
- functional constraint on the number of vehicles for a given volume of deliveries (): ;
- functional fuzzy constraint on the number of employees for a given supply volume (): ;
- functional fuzzy constraint of the influence of the leader’s leadership qualities () on the employee productivity: .
- if there is a possibility of a stable social connection, it is reasonable to provide additional control;
- the logistics department usually includes roles of the head of logistics department and driver, as well as the resource vehicle;
- products as a rule require assembly.
- possible product configurations;
- the volume of product deliveries per month (;
- functional dependencies for calculating the number of vehicles () and drivers ();
- matrices of candidates’ characteristics.
4. Algorithms Used
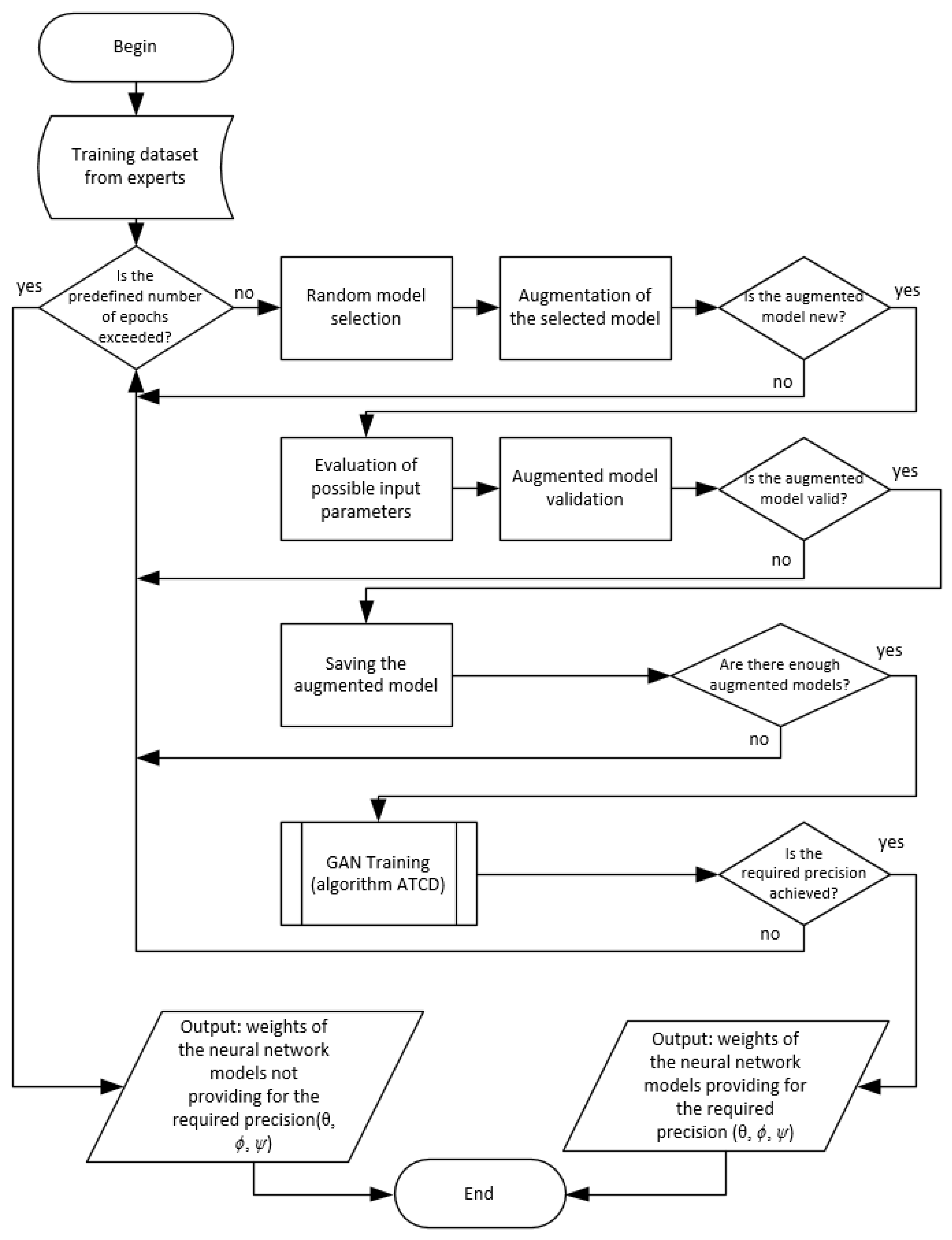
- An algorithm of training a generative neural network model with elements of autonomous self-learning through the formation of augmented training data that considers both the experience of experts and parametric patterns (ATGM);
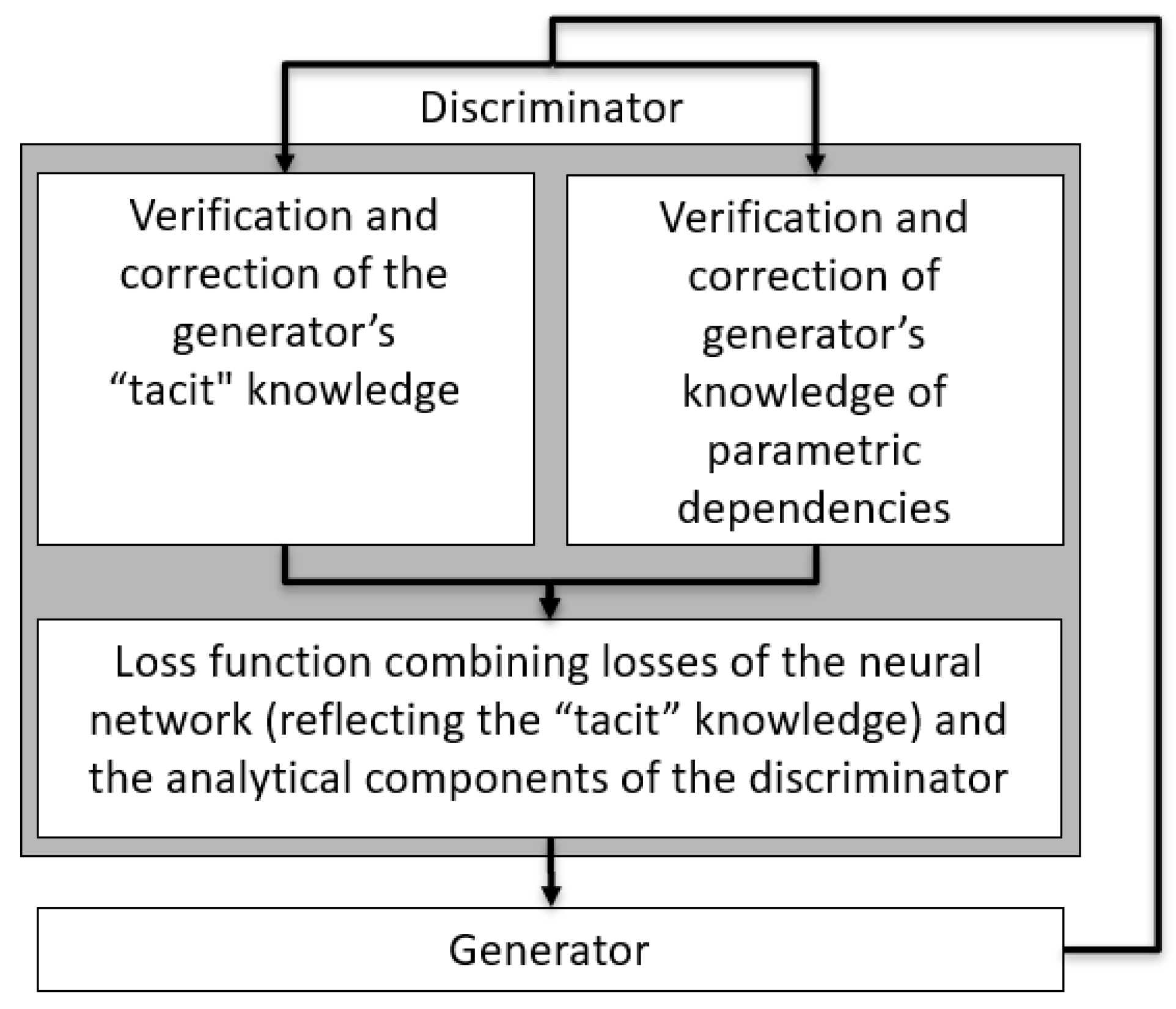
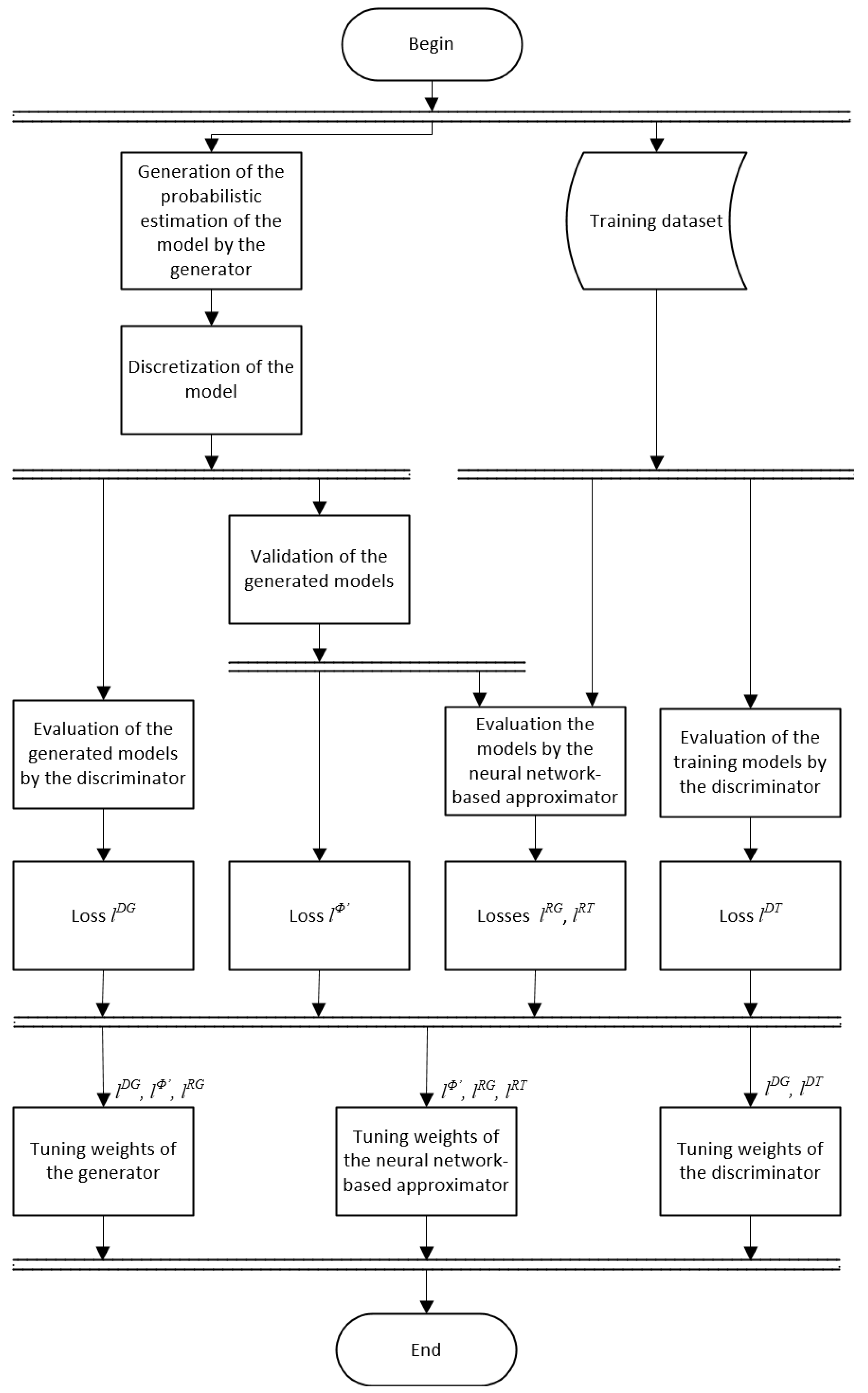
- An algorithm or creation and training a composite discriminator that combines the properties of neural and analytical approaches (ATCD);
- An algorithm of multi-level model generation with a complex topology of connections at the level of the system as a whole and at the level of its components (AMGS).
4.1. The ATGM Algorithm
4.2. The ATCD Algorithm
4.3. The ATGM Algorithm for Complementing Existing Models
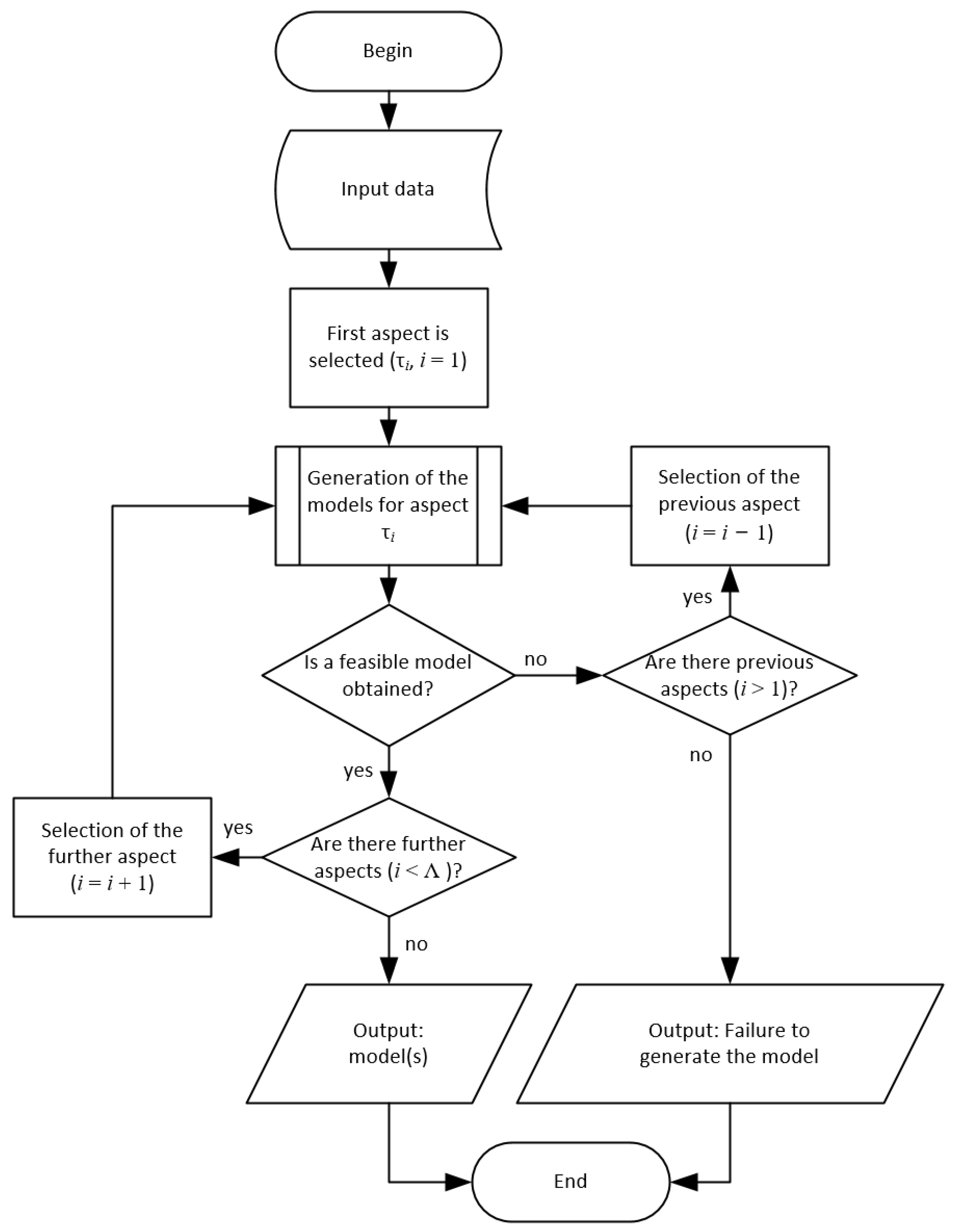
4.4. The AMGS Algorithm
5. Experiments
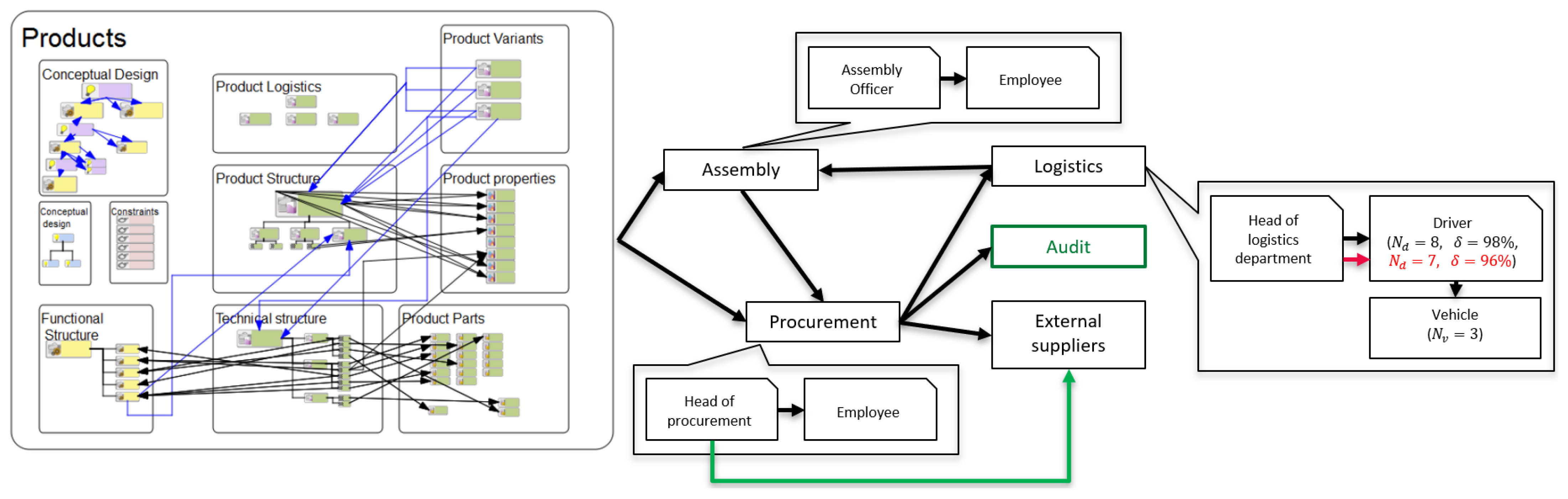
5.1. Smart Logistics System Modelling Use Case
5.1.1. Smart Logistics System Modelling Dataset
- 20 logistics system models (note the small number of these models: the size of the datasets models the typical situation when there are only a few samples available for training a generative model);
- a set of business rules and constraints, reflecting the relationships between parameters of units (e.g., possible relationship between a unit’s workload and its personnel).
5.1.2. Quality Metrics
5.1.3. Model Parameters
5.2. Smart Tourist Trip Booking Process Use Case
5.2.1. Smart Tourist Trip Booking Process Dataset
- An analysis of model types within the dataset was conducted.
- From the entire dataset, only BPMN models were selected. However, since the type is not defined for most models and models described in BPMN 2.0 notation have different types (e.g., “BPMN 2.0”, “Business Process Diagram (BPMN 2.0)”), the presence of the keyword “bpmn2.0#” in the model text was chosen as the selection criterion. This resulted in the selection of 618,861 models.
- In the final step, models written in English containing the phrase “Travel Booking” were filtered. The resulting set of 29 models was used as the training dataset.
5.2.2. Definition of Explicit Constraints on Process Models
- Each model must have start and end nodes.
- Any node, except the start node, must have an incoming edge.
- Any node, except the end node, must have an outgoing edge.
- The start node must not have incoming edges.
- The end node must not have outgoing edges.
- If a “Transaction Start” node is present, the model must include both “Transaction Success” and “Transaction Failure” nodes.
- If a “Transaction Start” node is absent, the model should not include “Transaction Success” or “Transaction Failure” nodes.
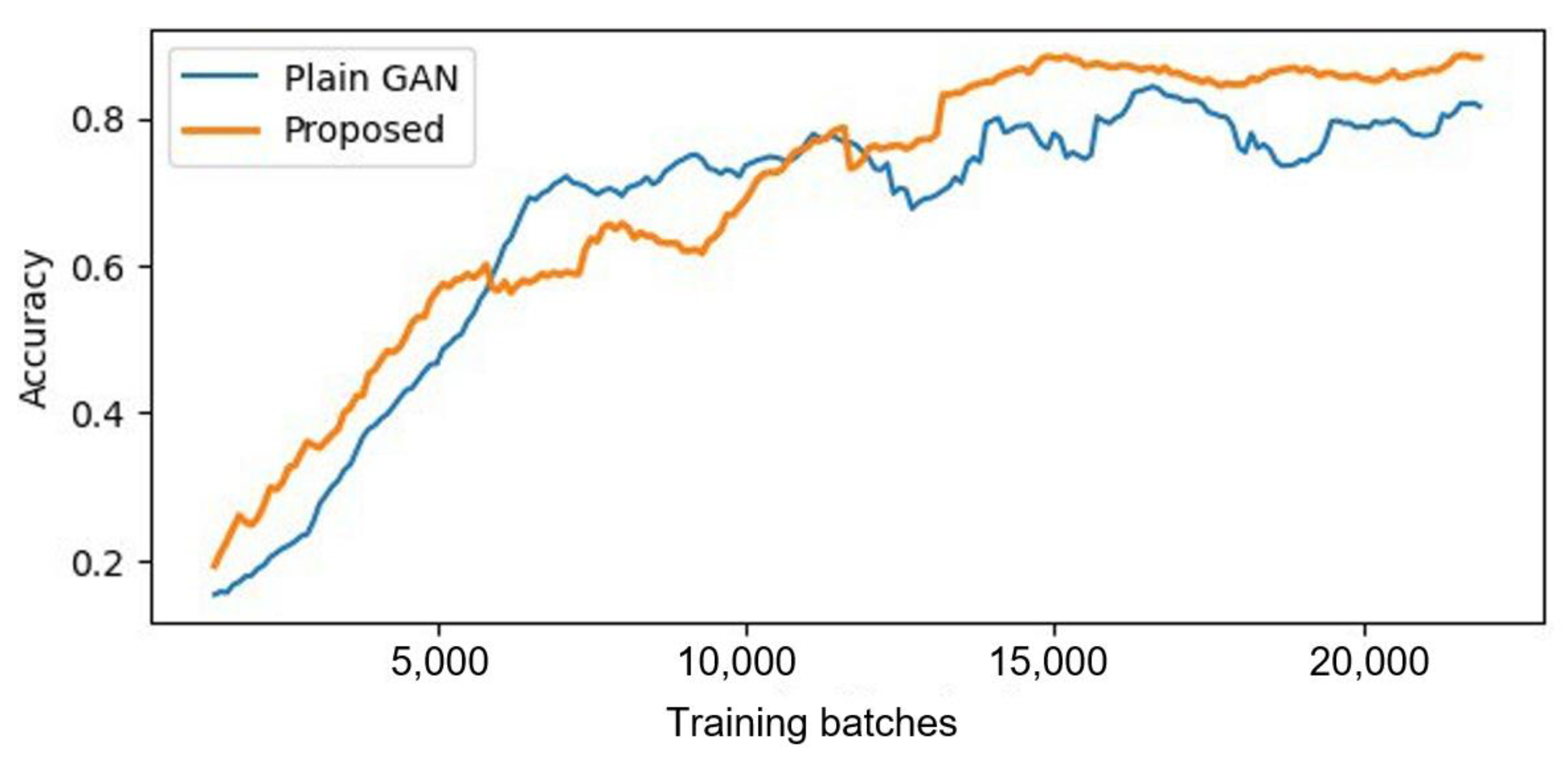
5.2.3. Training Process
| Listing 1. The listing of intermediate training results of the generative adversarial model. |
| The number of model parameters: 57,329 Start training... Elapsed [0:00:02], Iteration [100/5000], D/loss_real: 0.0198, D/loss_fake: 0.0145, V/loss: 0.1778, G/loss_fake: 4.2388, G/loss_value: 0.2441, G/loss_compliance: 0.1807, Accuracy: 1.0000 Elapsed [0:00:05], Iteration [200/5000], D/loss_real: 0.0063, D/loss_fake: 0.0075, V/loss: 0.0549, G/loss_fake: 5.0640, G/loss_value: 0.1221, G/loss_compliance: 0.2261, Accuracy: 1.0000 Elapsed [0:00:07], Iteration [300/5000], D/loss_real: 0.0019, D/loss_fake: 0.0033, V/loss: 0.0211, G/loss_fake: 5.7244, G/loss_value: 0.0946, G/loss_compliance: 0.1965, Accuracy: 1.0000 Elapsed [0:00:10], Iteration [400/5000], D/loss_real: 0.0007, D/loss_fake: 0.0014, V/loss: 0.0096, G/loss_fake: 6.6027, G/loss_value: 0.0664, G/loss_compliance: 0.2728, Accuracy: 1.0000 Elapsed [0:00:12], Iteration [500/5000], D/loss_real: 0.0003, D/loss_fake: 0.0007, V/loss: 0.7485, G/loss_fake: 7.2087, G/loss_value: 0.0911, G/loss_compliance: 0.2408, Accuracy: 0.1111 Saved model checkpoints into output/data_sap_process_models... |
- Iteration: The iteration number and the total number of specified training iterations.
- D/loss_real: The value of the discriminator’s loss function when evaluating “real” samples (samples from the training set).
- D/loss_fake: The value of the discriminator’s loss function when evaluating “fake” samples (samples generated by the generator).
- V/loss: The value of the loss function of the constraint approximator.
- G/loss_fake: The value of the generator’s loss function as determined by the discriminator (indicating how much the generated samples differ from the real ones).
- G/loss_value: The value of the generator’s loss function as determined by the constraint approximator (indicating how well the generated samples conform to the specified constraints).
- G/loss_compliance: The value of the generator’s loss function obtained by comparing how well the generated samples adhere to the specified initial parameters.
- Accuracy: The “accuracy” of the generated samples in terms of structural constraints (the admissibility of combinations of nodes and edges within the model).
5.2.4. Process Model Generation Procedure
- Specification of input parameters. At this step, the input data vector for the process model generator is formed. For example, one might specify the generation of booking process to include the task “Book flight” and not include the task “Book attraction”.
- Generation of a set of process models. At this step, the trained generator generates a set of process models according to the input parameters.
- Evaluation of generated process models. Since neural networks cannot guarantee precise results, after generating a certain number of models, the sampling procedure is applied: only those models that meet the specified parameters and input criteria are selected. If after the sampling procedure the number of generated process models is not sufficient, the generation process (Step 2) may be repeated.
- Selection of the most appropriate process model. From the obtained set of models, the user selects the most suitable ones. For example, based on the initial condition specified in Step 1, the following model variants were generated (Listings 2–6).
| Listing 2. Generated process model for smart tourist trip booking (variant 1). |
| Task 1: Check request Task 6: Notify customer Task 7: Success Task 8: Booking error Task 9: Book flight Task 11: Book bus Connection (1, 9) from Check request to Book flight Connection (1, 11) from Check request to Book bus Connection (7, 6) from Success to Notify customer Connection (8, 6) from Booking error to Notify customer Connection (9, 7) from Book flight to Success Connection (9, 8) from Book flight to Booking error Connection (11, 7) from Book bus to Success Connection (11, 8) from Book bus to Booking error |
| Listing 3. Generated process model for smart tourist trip booking (variant 2). |
| Task 1: Check request Task 2: Manual handling Task 6: Notify customer Task 8: Booking error Task 9: Book flight Task 11: Book bus Connection (1, 2) from Check request to Manual handling Connection (1, 9) from Check request to Book flight Connection (1, 11) from Check request to Book bus Connection (2, 6) from Manual handling to Notify customer Connection (8, 6) from Booking error to Notify customer Connection (9, 8) from Book flight to Booking error Connection (11, 8) from Book bus to Booking error |
| Listing 4. Generated process model for smart tourist trip booking (variant 3). |
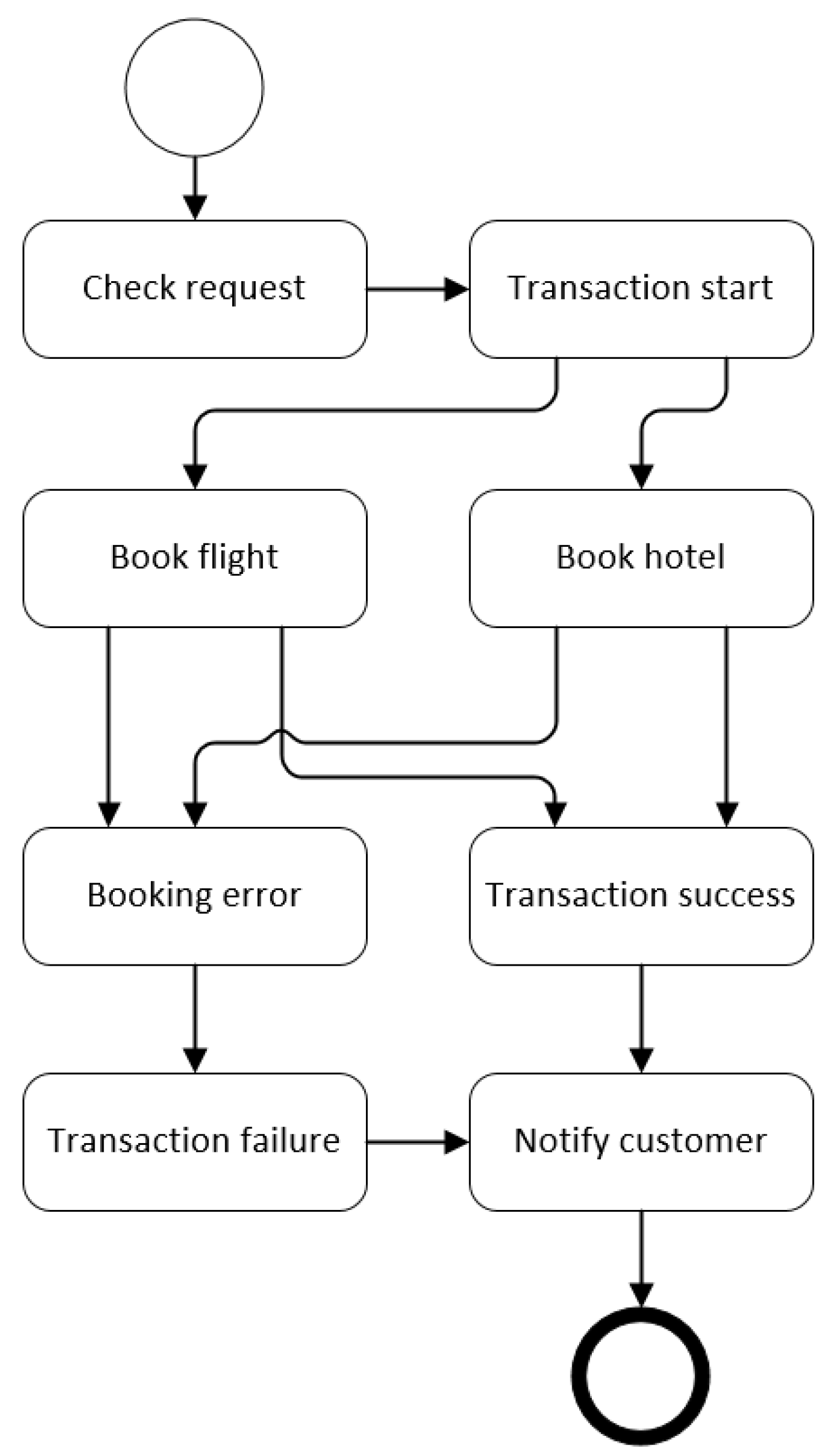
| Task 1: Check request Task 3: Transaction start Task 4: Transaction success Task 5: Transaction failure Task 6: Notify customer Task 7: Success Task 8: Booking error Task 9: Book flight Task 11: Book bus Connection (1, 3) from Check request to Transaction start Connection (1, 9) from Check request to Book flight Connection (1, 11) from Check request to Book bus Connection (3, 9) from Transaction start to Book flight Connection (3, 11) from Transaction start to Book bus Connection (4, 6) from Transaction success to Notify customer Connection (5, 6) from Transaction failure to Notify customer Connection (7, 4) from Success to Transaction success Connection (7, 6) from Success to Notify customer Connection (8, 5) from Booking error to Transaction failure Connection (8, 6) from Booking error to Notify customer Connection (9, 7) from Book flight to Success Connection (9, 8) from Book flight to Booking error Connection (11, 7) from Book bus to Success Connection (11, 8) from Book bus to Booking error |
| Listing 5. Generated process model for smart tourist trip booking (variant 4). |
| Task 1: Check request Task 3: Transaction start Task 4: Transaction success Task 5: Transaction failure Task 6: Notify customer Task 8: Booking error Task 9: Book flight Task 10: Book hotel Connection (1, 3) from Check request to Transaction start Connection (3, 9) from Transaction start to Book flight Connection (3, 10) from Transaction start to Book hotel Connection (4, 6) from Transaction success to Notify customer Connection (5, 6) from Transaction failure to Notify customer Connection (8, 5) from Booking error to Transaction failure Connection (9, 6) from Book flight to Transaction success Connection (10, 6) from Book flight to Transaction success Connection (9, 8) from Book flight to Booking error Connection (10, 8) from Book hotel to Booking error |
| Listing 6. Generated process model for smart tourist trip booking (variant 5). |
| Task 1: Check request Task 2: Manual handling Task 3: Transaction start Task 4: Transaction success Task 5: Transaction failure Task 6: Notify customer Task 8: Booking error Task 9: Book flight Task 10: Book hotel Connection (1, 2) from Check request to Manual handling Connection (1, 3) from Check request to Transaction start Connection (2, 6) from Manual handling to Notify customer Connection (3, 9) from Transaction start to Book flight Connection (3, 10) from Transaction start to Book hotel Connection (4, 6) from Transaction success to Notify customer Connection (5, 6) from Transaction failure to Notify customer Connection (8, 5) from Booking error to Transaction failure Connection (8, 6) from Booking error to Notify customer Connection (9, 8) from Book flight to Booking error Connection (10, 8) from Book hotel to Booking error |
6. Programming Library
7. Discussion
- Generating large-scale complex organizational systems can be a challenging task for GANs. The proposed approach mitigates this limitation in the following ways. First, the usage of the composite discriminator enables reducing the complexity of GAN training due to separate handling of explicit constraints and, especially, differentiable constraints, which makes it possible to simplify and speed up the training of GANs for such models. Second, the introduced the AMGS algorithm for the step-by-step detailing of the generated model makes it possible to generate several simpler models instead of one complex model. These means do not remove the limitation completely, but in many cases they do.
- The definition of constraints for a particular model, as well as the augmentation generation procedure, is a complex and often iterative process. It might require numerous tests to achieve convergence of the GAN training. Further, depending on the model complexity, the structures and sizes of the neural networks used can require adjustment. We have not studied the dependency of the sizes of the GAN models on the complexity of the dataset models. In fact, the selection of the GAN models’ sizes can be challenging due to the necessity to find the balance between the modelling graph complexity and the training set available. This issue is currently considered as one of the topics of future research.
- One more limitation is related to the absence of a standard for describing datasets in the developed library. However, the library is still under development and since it is open-source we invite other developers to contribute.
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yaqoob, I.; Salah, K.; Jayaraman, R.; Omar, M. Metaverse Applications in Smart Cities: Enabling Technologies, Opportunities, Challenges, and Future Directions. Internet Things 2023, 23, 100884. [Google Scholar] [CrossRef]
- Pandya, S.; Srivastava, G.; Jhaveri, R.; Babu, M.R.; Bhattacharya, S.; Maddikunta, P.K.R.; Mastorakis, S.; Piran, M.J.; Gadekallu, T.R. Federated Learning for Smart Cities: A Comprehensive Survey. Sustain. Energy Technol. Assess. 2023, 55, 102987. [Google Scholar] [CrossRef]
- Huda, N.U.; Ahmed, I.; Adnan, M.; Ali, M.; Naeem, F. Experts and Intelligent Systems for Smart Homes’ Transformation to Sustainable Smart Cities: A Comprehensive Review. Expert Syst. Appl. 2024, 238, 122380. [Google Scholar] [CrossRef]
- Tupayachi, J.; Xu, H.; Omitaomu, O.A.; Camur, M.C.; Sharmin, A.; Li, X. Towards Next-Generation Urban Decision Support Systems through AI-Powered Construction of Scientific Ontology Using Large Language Models—A Case in Optimizing Intermodal Freight Transportation. Smart Cities 2024, 7, 2392–2421. [Google Scholar] [CrossRef]
- Kolhe, R.V.; William, P.; Yawalkar, P.M.; Paithankar, D.N.; Pabale, A.R. Smart City Implementation Based on Internet of Things Integrated with Optimization Technology. Meas. Sens. 2023, 27, 100789. [Google Scholar] [CrossRef]
- Müller-Eie, D.; Kosmidis, I. Sustainable Mobility in Smart Cities: A Document Study of Mobility Initiatives of Mid-Sized Nordic Smart Cities. Eur. Transp. Res. Rev. 2023, 15, 36. [Google Scholar] [CrossRef]
- Kutty, A.A.; Kucukvar, M.; Onat, N.C.; Ayvaz, B.; Abdella, G.M. Measuring Sustainability, Resilience and Livability Performance of European Smart Cities: A Novel Fuzzy Expert-Based Multi-Criteria Decision Support Model. Cities 2023, 137, 104293. [Google Scholar] [CrossRef]
- Olaniyi, O.O.; Okunleye, O.J.; Olabanji, S.O. Advancing Data-Driven Decision-Making in Smart Cities through Big Data Analytics: A Comprehensive Review of Existing Literature. Curr. J. Appl. Sci. Technol. 2023, 42, 10–18. [Google Scholar] [CrossRef]
- Doctorarastoo, M.; Flanigan, K.; Bergés, M.; Mccomb, C. Exploring the Potentials and Challenges of Cyber-Physical-Social Infrastructure Systems for Achieving Human-Centered Objectives. In Proceedings of the 10th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, Istanbul, Turkey, 15–16 November 2023; ACM: New York, NY, USA, 2023; pp. 385–389. [Google Scholar]
- Zang, T.; Wang, S.; Wang, Z.; Li, C.; Liu, Y.; Xiao, Y.; Zhou, B. Integrated Planning and Operation Dispatching of Source–Grid–Load–Storage in a New Power System: A Coupled Socio–Cyber–Physical Perspective. Energies 2024, 17, 3013. [Google Scholar] [CrossRef]
- Metta, M.; Dessein, J.; Brunori, G. Between On-Site and the Clouds: Socio-Cyber-Physical Assemblages in on-Farm Diversification. J. Rural Stud. 2024, 105, 103193. [Google Scholar] [CrossRef]
- Kusiak, A. Generative Artificial Intelligence in Smart Manufacturing. J. Intell. Manuf. 2024, 36, 1–3. [Google Scholar] [CrossRef]
- Krichen, M. Generative Adversarial Networks. In Proceedings of the 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Delhi, India, 6–8 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–7. [Google Scholar]
- Chakraborty, T.; Reddy, K.S.U.; Naik, S.M.; Panja, M.; Manvitha, B. Ten Years of Generative Adversarial Nets (GANs): A Survey of the State-of-the-Art. Mach. Learn. Sci. Technol. 2024, 5, 011001. [Google Scholar] [CrossRef]
- Lin, H.; Liu, Y.; Li, S.; Qu, X. How Generative Adversarial Networks Promote the Development of Intelligent Transportation Systems: A Survey. IEEE/CAA J. Autom. Sin. 2023, 10, 1781–1796. [Google Scholar] [CrossRef]
- Liu, M.; Wei, Y.; Wu, X.; Zuo, W.; Zhang, L. Survey on Leveraging Pre-Trained Generative Adversarial Networks for Image Editing and Restoration. Sci. China Inf. Sci. 2023, 66, 151101. [Google Scholar] [CrossRef]
- Kao, P.-Y.; Yang, Y.-C.; Chiang, W.-Y.; Hsiao, J.-Y.; Cao, Y.; Aliper, A.; Ren, F.; Aspuru-Guzik, A.; Zhavoronkov, A.; Hsieh, M.-H.; et al. Exploring the Advantages of Quantum Generative Adversarial Networks in Generative Chemistry. J. Chem. Inf. Model. 2023, 63, 3307–3318. [Google Scholar] [CrossRef]
- Koschmider, A.; Hornung, T.; Oberweis, A. Recommendation-Based Editor for Business Process Modeling. Data Knowl. Eng. 2011, 70, 483–503. [Google Scholar] [CrossRef]
- Kuschke, T.; Mäder, P. Pattern-Based Auto-Completion of UML Modeling Activities. In Proceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering, Vasteras, Sweden, 15–19 September 2014; ACM: New York, NY, USA, 2014; pp. 551–556. [Google Scholar]
- Wieloch, K.; Filipowska, A.; Kaczmarek, M. Autocompletion for Business Process Modelling. In Business Information Systems Workshops, Proceedings of the BIS 2011 International Workshops and BPSC International Conference, Poznań, Poland, 15–17 June 2011; Lecture Notes in Business Information Processing; Springer: Berlin/Heidelberg, Germany, 2011; Volume 97, pp. 30–40. [Google Scholar] [CrossRef]
- Born, M.; Brelage, C.; Markovic, I.; Pfeiffer, D.; Weber, I. Auto-Completion for Executable Business Process Models. In Business Process Management Workshops, Proceedings of the BPM 2008 International Workshops, Milano, Italy, 1–4 September 2008; Lecture Notes in Business Information Processing; Springer: Berlin/Heidelberg, Germany, 2009; Volume 17, pp. 510–515. [Google Scholar] [CrossRef]
- Mazanek, S.; Minas, M. Business Process Models as a Showcase for Syntax-Based Assistance in Diagram Editors. In Model Driven Engineering Languages and Systems, Proceedings of the 12th International Conference, MODELS 2009, Denver, CO, USA, 4–9 October 2009; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5795, pp. 322–336. [Google Scholar] [CrossRef]
- Clever, N.; Holler, J.; Shitkova, M.; Becker, J. Towards Auto-Suggested Process Modeling—Prototypical Development of an Auto-Suggest Component for Process Modeling Tools. In Proceedings of the Enterprise Modelling and Information Systems Architectures (EMISA 2013), St. Gallen, Switzerland, 5–6 September 2013; Gesellschaft für Informatik e.V.: Bonn, Germany, 2013; pp. 133–145. [Google Scholar]
- Fellmann, M.; Zarvić, N.; Thomas, O. Business Processes Modelling Assistance by Recommender Functionalities: A First Evaluation from Potential Users. In Perspectives in Business Informatics Research, Proceedings of the 16th International Conference, BIR 2017, Copenhagen, Denmark, 28–30 August 2017; Lecture Notes in Business Information Processing; Springer: Cham, Switzerland, 2017; Volume 295, pp. 79–92. [Google Scholar] [CrossRef]
- Li, Y.; Cao, B.; Xu, L.; Yin, J.; Deng, S.; Yin, Y.; Wu, Z. An Efficient Recommendation Method for Improving Business Process Modeling. IEEE Trans. Ind. Inform. 2014, 10, 502–513. [Google Scholar] [CrossRef]
- Nair, A.; Ning, X.; Hill, J.H. Using Recommender Systems to Improve Proactive Modeling. Softw. Syst. Model. 2021. [Google Scholar] [CrossRef]
- van Gils, B.; Proper, H.A. Enterprise Modelling in the Age of Digital Transformation. In The Practice of Enterprise Modeling, Proceedings of the 11th IFIP WG 8.1. Working Conference, PoEM 2018, Vienna, Austria, 31 October–2 November 2018; Lecture Notes in Business Information Processing; Springer: Cham, Switzerland, 2018; Volume 335, pp. 257–273. [Google Scholar] [CrossRef]
- Awadid, A.; Bork, D.; Karagiannis, D.; Nurcan, S. Toward Generic Consistency Patterns in Multi-View Enterprise Modelling. In Proceedings of the ECIS 2018 Proceedings; Association for Information Systems (AIS), Portsmouth, UK, 23–28 June 2018; p. 146. [Google Scholar]
- Khider, H.; Hammoudi, S.; Meziane, A. Business Process Model Recommendation as a Transformation Process in MDE: Conceptualization and First Experiments. In Proceedings of the 8th International Conference on Model-Driven Engineering and Software Development, Valletta, Malta, 25–27 February 2020; SciTePress: Setúbal, Portugal, 2020; pp. 65–75. [Google Scholar]
- Fayoumi, A. Toward an Adaptive Enterprise Modelling Platform. In The Practice of Enterprise Modeling, Proceedings of the 11th IFIP WG 8.1. Working Conference, PoEM 2018, Vienna, Austria, 31 October–2 November 2018; Lecture Notes in Business Information Processing; Springer: Cham, Switzerland, 2018; Volume 335, pp. 362–371. [Google Scholar] [CrossRef]
- Wang, J.; Gui, S.; Cao, B. A Process Recommendation Method Using Bag-of-Fragments. Int. J. Intell. Internet Things Comput. 2019, 1, 32. [Google Scholar] [CrossRef]
- Jangda, A.; Polisetty, S.; Guha, A.; Serafini, M. Accelerating Graph Sampling for Graph Machine Learning Using GPUs. In Proceedings of the Sixteenth European Conference on Computer Systems, Edinburgh, UK, 26–28 April 2021; ACM: New York, NY, USA, 2021; pp. 311–326. [Google Scholar]
- Valera, M.; Guo, Z.; Kelly, P.; Matz, S.; Cantu, V.A.; Percus, A.G.; Hyman, J.D.; Srinivasan, G.; Viswanathan, H.S. Machine Learning for Graph-Based Representations of Three-Dimensional Discrete Fracture Networks. Comput. Geosci. 2018, 22, 695–710. [Google Scholar] [CrossRef]
- Chen, C.; Ye, W.; Zuo, Y.; Zheng, C.; Ong, S.P. Graph Networks as a Universal Machine Learning Framework for Molecules and Crystals. Chem. Mater. 2019, 31, 3564–3572. [Google Scholar] [CrossRef]
- Na, G.S.; Chang, H.; Kim, H.W. Machine-Guided Representation for Accurate Graph-Based Molecular Machine Learning. Phys. Chem. Chem. Phys. 2020, 22, 18526–18535. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, R.F.; Nazemzadeh, N.; Sillesen, L.W.; Andersson, M.P.; Gernaey, K.V.; Mansouri, S.S. Hybrid Machine Learning Assisted Modelling Framework for Particle Processes. Comput. Chem. Eng. 2020, 140, 106916. [Google Scholar] [CrossRef]
- Wang, H.; Wang, J.; Wang, J.; Zhao, M.; Zhang, W.; Zhang, F.; Xie, X.; Guo, M. GraphGAN: Graph Representation Learning With Generative Adversarial Nets. Proc. AAAI Conf. Artif. Intell. 2018, 32, 2508–2515. [Google Scholar] [CrossRef]
- Wang, H.; Wang, J.; Wang, J.; Zhao, M.; Zhang, W.; Zhang, F.; Li, W.; Xie, X.; Guo, M. Learning Graph Representation with Generative Adversarial Nets. IEEE Trans. Knowl. Data Eng. 2021, 33, 3090–3103. [Google Scholar] [CrossRef]
- Zhao, M.; Zhang, Y. GAN-based Deep Neural Networks for Graph Representation Learning. Eng. Rep. 2022, 4, e12517. [Google Scholar] [CrossRef]
- Fan, S.; Huang, B. Labeled Graph Generative Adversarial Networks. arXiv 2019, arXiv:1906.03220. [Google Scholar]
- Fan, S.; Tech, V.; Huang, B. Deep Generative Models for Labelled Graphs. In Proceedings of the Deep Generative Models for Highly Structured Data (ICLR 2019 Workshop), New Orleans, LA, USA, 6–9 May 2019; pp. 1–10. [Google Scholar]
- Zhou, D.; Zheng, L.; Xu, J.; He, J. Misc-GAN: A Multi-Scale Generative Model for Graphs. Front. Big Data 2019, 2, 3. [Google Scholar] [CrossRef]
- Jia, N.; Tian, X.; Gao, W.; Jiao, L. Deep Graph-Convolutional Generative Adversarial Network for Semi-Supervised Learning on Graphs. Remote Sens. 2023, 15, 3172. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- De Cao, N.; Kipf, T. MolGAN: An Implicit Generative Model for Small Molecular Graphs. arXiv 2018, arXiv:1805.11973. [Google Scholar] [CrossRef]
- Macedo, B.; Ribeiro Vaz, I.; Taveira Gomes, T. MedGAN: Optimized Generative Adversarial Network with Graph Convolutional Networks for Novel Molecule Design. Sci. Rep. 2024, 14, 1212. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Liello, L.D.; Ardino, P.; Gobbi, J.; Morettin, P.; Teso, S.; Passerini, A.; Di Liello, L.; Ardino, P.; Gobbi, J.; Morettin, P.; et al. Efficient Generation of Structured Objects with Constrained Adversarial Networks. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual, 6–12 December 2020; Volume 2020-Decem, p. 12. [Google Scholar]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications. IEEE Trans. Knowl. Data Eng. 2021, 35, 3313–3332. [Google Scholar] [CrossRef]
- Jabbar, A.; Li, X.; Omar, B. A Survey on Generative Adversarial Networks: Variants, Applications, and Training. ACM Comput. Surv. 2022, 54, 157. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shilov, N.; Ponomarev, A.; Ryumin, D.; Karpov, A. Generative Adversarial Framework with Composite Discriminator for Organization and Process Modelling—Smart City Cases. Smart Cities 2025, 8, 38. https://doi.org/10.3390/smartcities8020038
Shilov N, Ponomarev A, Ryumin D, Karpov A. Generative Adversarial Framework with Composite Discriminator for Organization and Process Modelling—Smart City Cases. Smart Cities. 2025; 8(2):38. https://doi.org/10.3390/smartcities8020038
Chicago/Turabian StyleShilov, Nikolay, Andrew Ponomarev, Dmitry Ryumin, and Alexey Karpov. 2025. "Generative Adversarial Framework with Composite Discriminator for Organization and Process Modelling—Smart City Cases" Smart Cities 8, no. 2: 38. https://doi.org/10.3390/smartcities8020038
APA StyleShilov, N., Ponomarev, A., Ryumin, D., & Karpov, A. (2025). Generative Adversarial Framework with Composite Discriminator for Organization and Process Modelling—Smart City Cases. Smart Cities, 8(2), 38. https://doi.org/10.3390/smartcities8020038