
Multi-Objective Optimization of Orchestra Scheduler for Traffic-Aware Networks


Abstract
Highlights
- OPTIMAOrchestra_ch4 achieves 0.72 mA current consumption with 100% reliability in static networks.
- The inmobile networks used in this study, i.e., both OPTIMAOrchestra variants, maintain 100% reliability with 6.36 mA current consumption.
- The proposed scheduler enhances network efficiency, balancing latency–energy trade-offs effectively.
- It supports large-scale, heterogeneous network deployments, crucial for the development of robust smart city infrastructures.
Abstract
1. Introduction
- Development of a custom script: This script generates diverse homogeneous and heterogeneous topologies within a simulated environment, utilizing a trusted third party to facilitate communication within the TSCH-Sim tool.
- Comparative analysis: A comprehensive analysis is conducted to identify the most suitable scheduler, ensuring efficient network operation.
- Optimized scheduling: We introduce an innovative autonomous scheduling function, OPTIMAOrchestra, incorporating an optimized slotframe and packet generation cycle.
- Enhanced cell-level optimization: A specific optimization strategy, OPTIMAOrchestra_ch4, is implemented to improve the transmission and reception of Enhanced Beacon (EB) packets within individual cells. This strategy includes attention shifts to prioritize unmatched broadcast and unicast traffic, followed by regular unicast data, while dynamically adjusting slotframe sizes for efficient resource utilization.
- Enhanced channel-level optimization: OPTIMAOrchestra_ch11 is implemented to enable a multi-channel hopping sequence in the networks to help in proactive cell collision avoidance.
2. Related Work
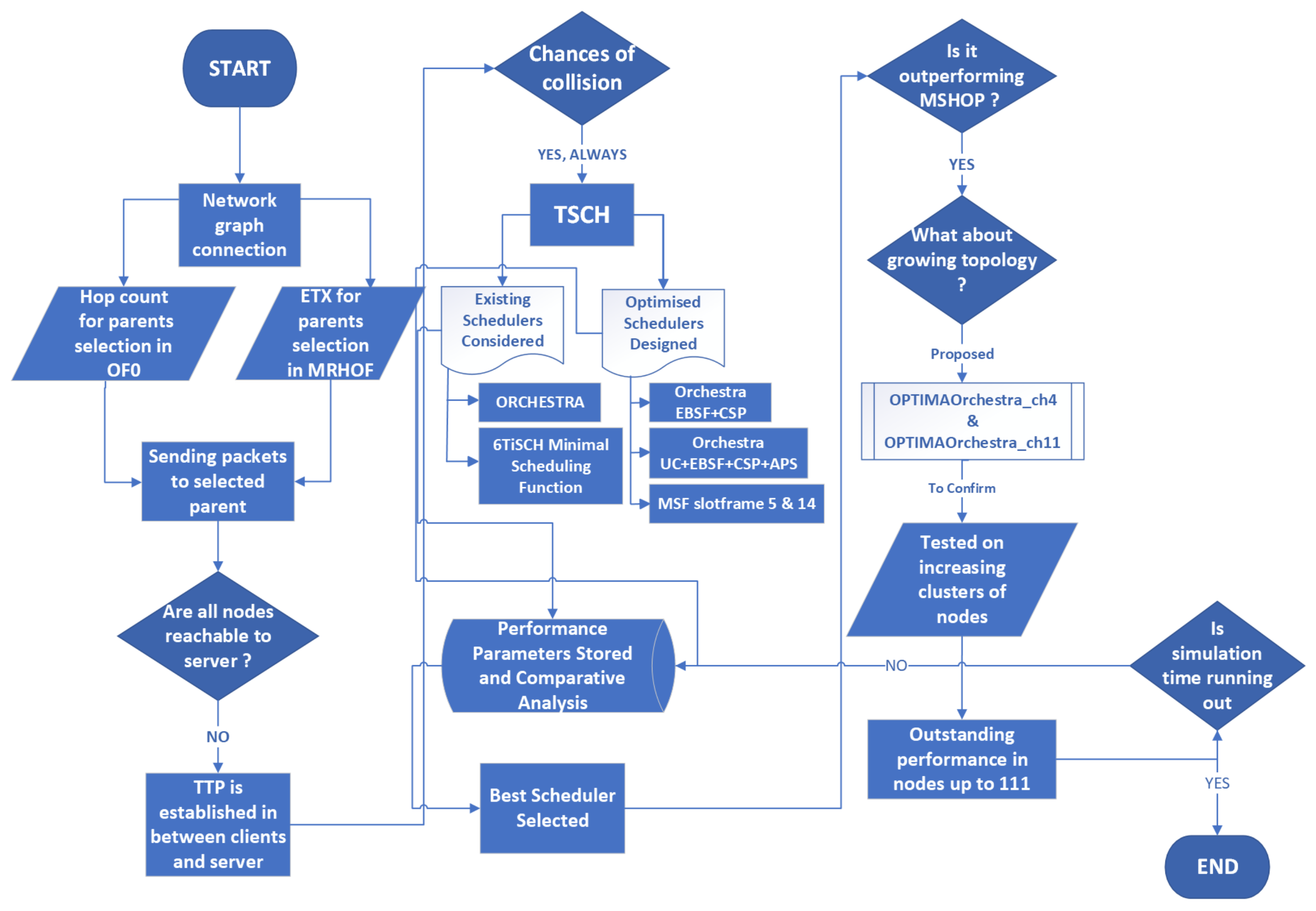
3. Methodology
3.1. Architecture Selection
3.2. Scheduling Approach
3.3. Scheduler Selection
- Orchestra
- 6TiSCH Minimal Scheduling Function
- OPTIMAOrchestra _ch4 and OPTIMAOrchestra _ch11 Design
- Slotframe Structure
- Beacon Frame Cycle: This is the slotframe size used for the time-synchronized EB communication. It is responsible for scheduling a single cell for Enhanced Beacon packet transmission and a single cell for EB packet reception from the time source node.
- Shared Frame Cycle: This rule is used for broadcast and unicast traffic. A slot is common for all nodes in the network for broadcast plus unicast for RPL signaling (DIO, DIS, DAO), repeating after certain slots.
- Unicast Frame Interval: This is the slotframe size used for the unicast slots for every node to its RPL preferred parent. This rule allocates slots for unicast packets, including a single cell for the node itself, a single cell to the parent, and a single cell for each neighbor with a direct route installed.
- Application Packet Transmission Interval: This refers to the time interval or duration between consecutive application (APP) packets sent by a node in a wireless network.
- Size Adoption
- Hopping Sequence
| Algorithm 1 Orchestra Operational Flow |
|
3.4. Scheduling, Slotting, and Hopping Utilized
3.5. Enabling the Mobility Parameter
| Algorithm 2 Mobility Model Algorithm |
|
4. Performance Evaluation
4.1. Simulation Setup
4.2. Metrics
- Reliability, in terms of packet delivery ratio, computed as:
- Latency, as the time between a packet being transmitted from the sender and being successfully received by the destination node:
- Current consumption, defined as the average current consumed by the average non-root node’s network stack, and computed as the time-weighted sum of current consumed by the CPU activity, radio receptions and transmissions, and low-power modes:
- Packet collision probability, computed as the probability that two or more packets will be transmitted in the same time slot and same channel in an overlapping radio range.
4.3. Scheduler Showdown: Performance in Smart Networks
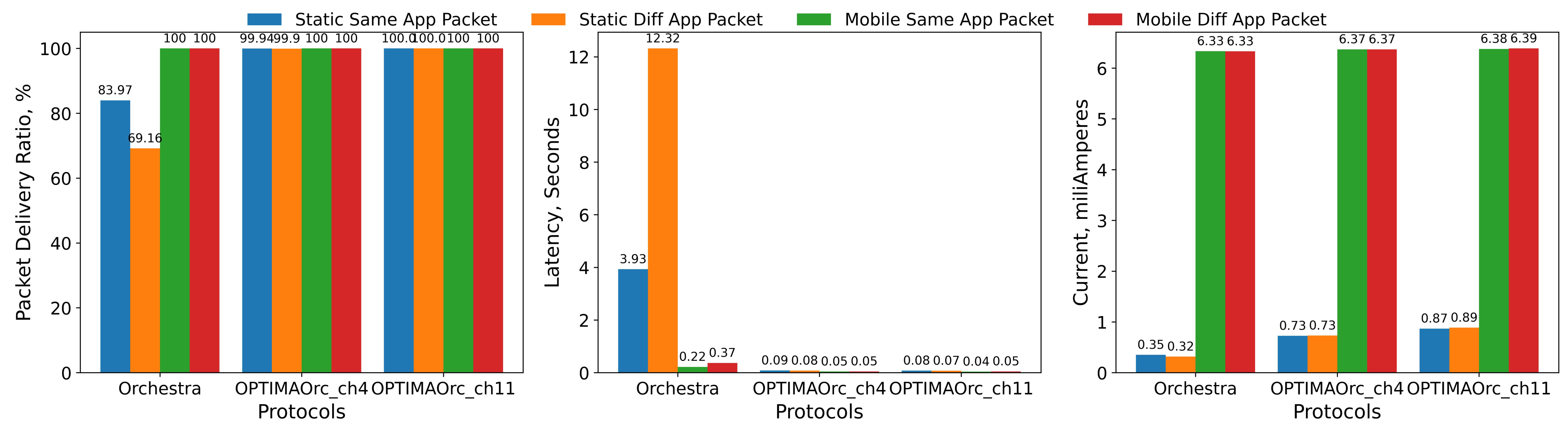
4.3.1. Reliability
- Static
- Mobile
4.3.2. Latency
- Static
- Mobile
4.3.3. Current Consumption
- Static
- Mobile
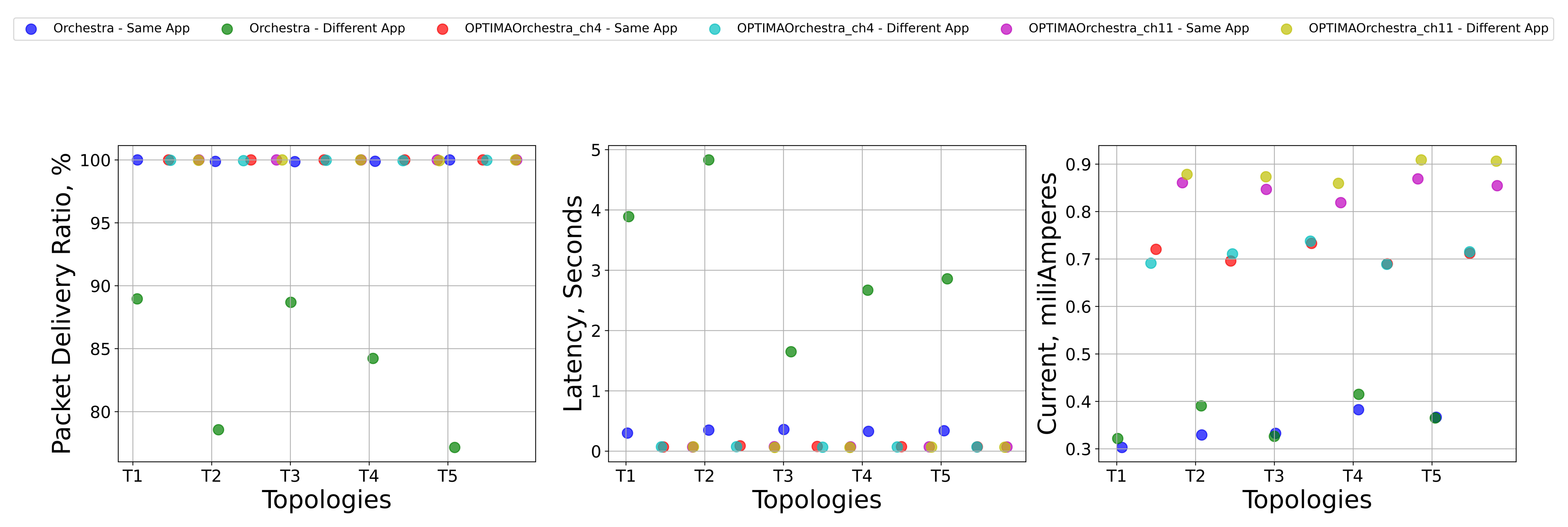
4.4. Tuning the Score in Homogeneous Topologies: Precision in Orchestra Scheduling
4.4.1. PDR, Latency, and Current Consumption
- Static
- Mobile
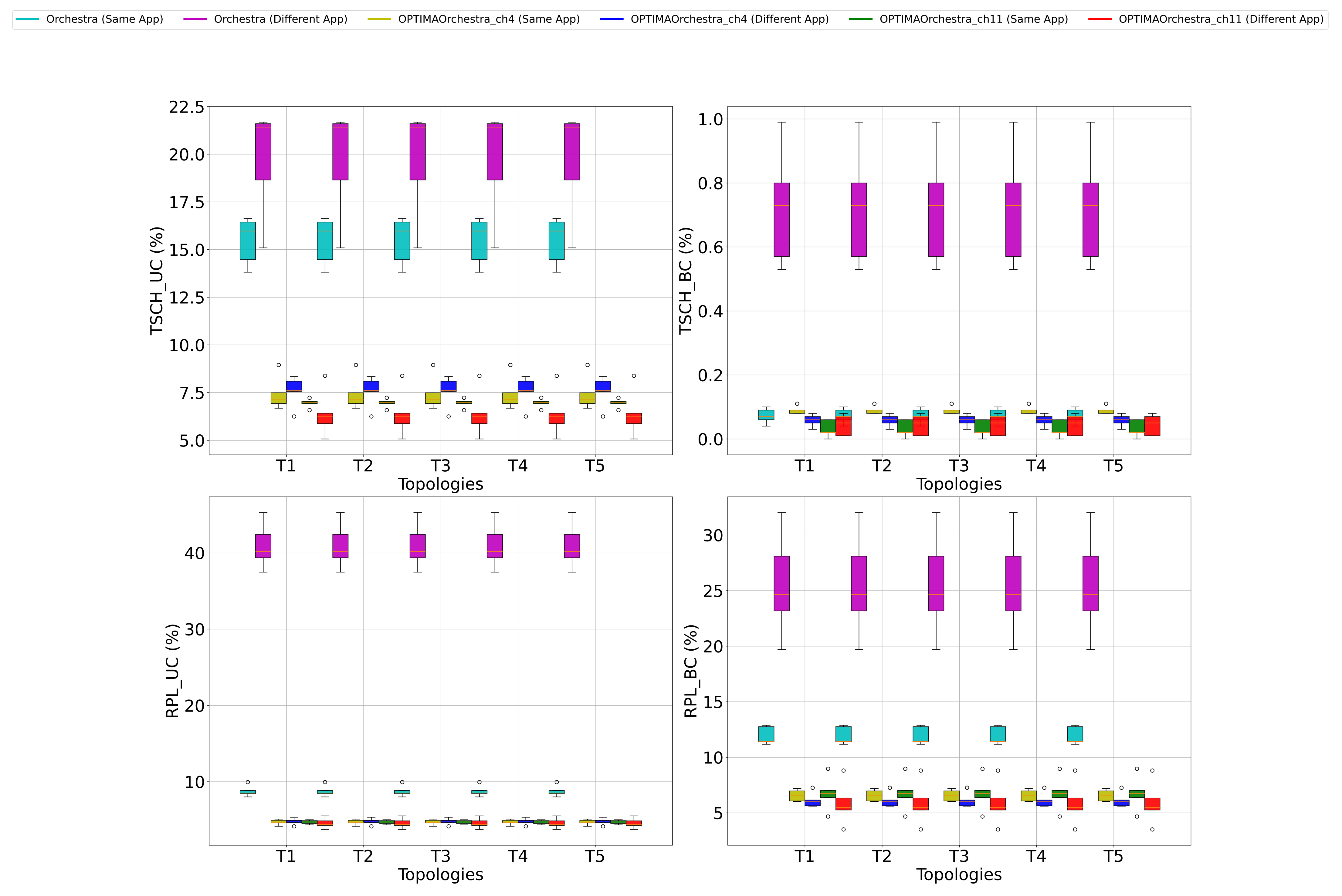
4.4.2. Collision
- Static
- Mobile
4.5. Effects of Different Application Packet Intervals
4.5.1. Homogeneous Topologies
4.5.2. Heterogeneous Topologies
- Static
- Mobile
4.6. Effect of OPTIMAOrchestra in Complex Environments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rajagopal, S.M.; Supriya, M.; Buyya, R. FedSDM: Federated learning based smart decision making module for ECG data in IoT integrated Edge-Fog-Cloud computing environments. Internet Things 2023, 22, 100784. [Google Scholar] [CrossRef]
- Panda, N.; Supriya, M. Blackhole Attack Prediction in Wireless Sensor Networks Using Support Vector Machine. In Advances in Signal Processing, Embedded Systems and IoT: Proceedings of Seventh ICMEET-2022, Andhra Pradesh, India, 22–23 July 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 321–331. [Google Scholar]
- Panda, N.; Supriya, M. Efficient data transmission using trusted third party in smart home environments. EURASIP J. Wirel. Commun. Netw. 2022, 2022, 118. [Google Scholar] [CrossRef]
- Scanzio, S.; Cena, G.; Valenzano, A. Enhanced Energy-Saving Mechanisms in TSCH Networks for the IIoT: The PRIL Approach. IEEE Trans. Ind. Inform. 2022, 19, 7445–7455. [Google Scholar] [CrossRef]
- Panda, N.; Supriya, M. Blackhole Attack Impact Analysis on Low Power Lossy Networks. In Proceedings of the 2022 IEEE 3rd Global Conference for Advancement in Technology (GCAT), Bangalore, India, 7–9 October 2022; pp. 1–5. [Google Scholar]
- Tabouche, A.; Djamaa, B.; Senouci, M.R. Traffic-aware reliable scheduling in TSCH networks for industry 4.0: A systematic mapping review. IEEE Commun. Surv. Tutorials 2023, 25, 2834–2861. [Google Scholar] [CrossRef]
- Ranjan, R.; Rana, O.; Nepal, S.; Yousif, M.; James, P.; Wen, Z.; Barr, S.; Watson, P.; Jayaraman, P.P.; Georgakopoulos, D.; et al. The next grand challenges: Integrating the Internet of Things and data science. IEEE Cloud Comput. 2018, 5, 12–26. [Google Scholar] [CrossRef]
- Watteyne, T.; Palattella, M.; Grieco, L. Using IEEE 802.15. 4e Time-Slotted Channel Hopping (TSCH) in the Internet of Things (IoT): Problem Statement. Technical Report. 2015. Available online: https://datatracker.ietf.org/doc/rfc7554/ (accessed on 1 January 2020).
- De Guglielmo, D.; Brienza, S.; Anastasi, G. IEEE 802.15. 4e: A survey. Comput. Commun. 2016, 88, 1–24. [Google Scholar] [CrossRef]
- Urke, A.R.; Kure, Ø.; Øvsthus, K. Experimental Evaluation of the Layered Flow-Based Autonomous TSCH Scheduler. IEEE Access 2023, 11, 3970–3982. [Google Scholar] [CrossRef]
- Deac, D.; Teshome, E.; Van Glabbeek, R.; Dobrota, V.; Braeken, A.; Steenhaut, K. Traffic Aware Scheduler for Time-Slotted Channel-Hopping-Based IPv6 Wireless Sensor Networks. Sensors 2022, 22, 6397. [Google Scholar] [CrossRef]
- Hauweele, D.; Koutsiamanis, R.A.; Quoitin, B.; Papadopoulos, G.Z. Thorough performance evaluation & analysis of the 6TiSCH minimal scheduling function (MSF). J. Signal Process. Syst. 2022, 94, 3–25. [Google Scholar]
- Thubert, P. RFC 9030: An Architecture for IPv6 over the Time-Slotted Channel Hopping Mode of IEEE 802.15. 4 (6TiSCH). 2021. Available online: https://datatracker.ietf.org/doc/rfc9030/ (accessed on 25 June 2022).
- Duquennoy, S.; Al Nahas, B.; Landsiedel, O.; Watteyne, T. Orchestra: Robust mesh networks through autonomously scheduled TSCH. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, Seoul, Republic of Korea, 1–5 November 2015; pp. 337–350. [Google Scholar]
- Lee, S.B.; Nguyen-Xuan, S.; Kwon, J.H.; Kim, E.J. Multiple Concurrent Slotframe Scheduling for Wireless Power Transfer-Enabled Wireless Sensor Networks. Sensors 2022, 22, 4520. [Google Scholar] [CrossRef]
- Hermeto, R.T.; Gallais, A.; Theoleyre, F. Scheduling for IEEE802. 15.4-TSCH and slow channel hopping MAC in low power industrial wireless networks: A survey. Comput. Commun. 2017, 114, 84–105. [Google Scholar] [CrossRef]
- Elsts, A.; Kim, S.; Kim, H.S.; Kim, C. An empirical survey of autonomous scheduling methods for TSCH. IEEE Access 2020, 8, 67147–67165. [Google Scholar] [CrossRef]
- Kim, S.; Kim, H.S.; Kim, C.k. A3: Adaptive autonomous allocation of TSCH slots. In Proceedings of the 20th International Conference on Information Processing in Sensor Networks (co-located with CPS-IoT Week 2021), Nashville, TN, USA, 18–21 May 2021; pp. 299–314. [Google Scholar]
- Kim, S.; Kim, H.S.; Kim, C. ALICE: Autonomous link-based cell scheduling for TSCH. In Proceedings of the 18th International Conference on Information Processing in Sensor Networks, Montreal, QC, Canada, 16–18 April 2019; pp. 121–132. [Google Scholar]
- Jeong, S.; Kim, H.S.; Paek, J.; Bahk, S. OST: On-demand TSCH scheduling with traffic-awareness. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Online, 6–9 July 2020; pp. 69–78. [Google Scholar]
- Jeong, S.; Paek, J.; Kim, H.S.; Bahk, S. TESLA: Traffic-aware elastic slotframe adjustment in TSCH networks. IEEE Access 2019, 7, 130468–130483. [Google Scholar] [CrossRef]
- Oh, S.; Hwang, D.; Kim, K.H.; Kim, K. Escalator: An autonomous scheduling scheme for convergecast in TSCH. Sensors 2018, 18, 1209. [Google Scholar] [CrossRef] [PubMed]
- Osman, M.; Nabki, F. OSCAR: An optimized scheduling cell allocation algorithm for convergecast in IEEE 802.15. 4e TSCH networks. Sensors 2021, 21, 2493. [Google Scholar] [CrossRef]
- Jung, J.; Kim, D.; Hong, J.; Kang, J.; Yi, Y. Parameterized slot scheduling for adaptive and autonomous TSCH networks. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Honolulu, HI, USA, 15–19 April 2018; pp. 76–81. [Google Scholar]
- Mohamadi, M.; Djamaa, B.; Senouci, M.R. Performance evaluation of TSCH-minimal and orchestra scheduling in IEEE 802.15. 4e networks. In Proceedings of the 2018 International Symposium on Programming and Systems (ISPS), Algiers, Algeria, 24–26 April 2018; pp. 1–6. [Google Scholar]
- Rekik, S.; Baccour, N.; Jmaiel, M.; Drira, K. A performance analysis of Orchestra scheduling for time-slotted channel hopping networks. Internet Technol. Lett. 2018, 1, e4. [Google Scholar] [CrossRef]
- Teshome, E.; Deac, D.; Thielemans, S.; Carlier, M.; Steenhaut, K.; Braeken, A.; Dobrota, V. Time slotted channel hopping and contikimac for ipv6 multicast-enabled wireless sensor networks. Sensors 2021, 21, 1771. [Google Scholar] [CrossRef]
- Hammoudi, S.; Ourzeddine, H.; Gueroui, M.; Harous, S.; Aliouat, Z. A Collision-Free Scheduling Algorithm with Minimum Data Redundancy Transmission for TSCH. Wirel. Pers. Commun. 2022, 124, 3159–3188. [Google Scholar] [CrossRef]
- Mohamadi, M.; Djamaa, B.; Senouci, M.R.; Grine, Y.; Laribi, R. An effective channel selection solution for reliable scheduling in industrial iot networks. J. Netw. Syst. Manag. 2022, 30, 59. [Google Scholar] [CrossRef]
- Kherbache, M.; Sobirov, O.; Maimour, M.; Rondeau, E.; Benyahia, A. Decentralized TSCH scheduling protocols and heterogeneous traffic: Overview and performance evaluation. Internet Things 2023, 22, 100696. [Google Scholar] [CrossRef]
- Nabi, M.; Habibollahi, M.; Saidi, H. Time Hopping: An Efficient Technique for Reliable Coexistence of TSCH-based IoT Networks. IEEE Internet Things J. 2023, 10, 13837–13848. [Google Scholar] [CrossRef]
- Cena, G.; Scanzio, S.; Valenzano, A. Ultra-Low Power Wireless Sensor Networks Based on Time Slotted Channel Hopping with Probabilistic Blacklisting. Electronics 2022, 11, 304. [Google Scholar] [CrossRef]
- Ha, Y.; Chung, S.H. Traffic-Aware 6TiSCH Routing Method for IIoT Wireless Networks. IEEE Internet Things J. 2022, 9, 22709–22722. [Google Scholar] [CrossRef]
- Kotsiou, V.; Papadopoulos, G.Z.; Chatzimisios, P.; Theoleyre, F. LDSF: Low-latency distributed scheduling function for industrial Internet of Things. IEEE Internet Things J. 2020, 7, 8688–8699. [Google Scholar] [CrossRef]
- Duquennoy, S.; Elsts, A.; Al Nahas, B.; Oikonomo, G. Tsch and 6tisch for contiki: Challenges, design and evaluation. In Proceedings of the 2017 13th International Conference on Distributed Computing in Sensor Systems (DCOSS), Ottawa, ON, Canada, 5–7 June 2017; pp. 11–18. [Google Scholar]
- Tapadar, K.N.; Khatua, M.; Tamarapalli, V. Traffic rate agnostic end-to-end delay optimization using receiver-based adaptive link scheduling in 6TiSCH networks. Ad Hoc Netw. 2024, 155, 103397. [Google Scholar] [CrossRef]
- Tanaka, Y.; Minet, P.; Vučinić, M.; Vilajosana, X.; Watteyne, T. YSF: A 6TiSCH scheduling function minimizing latency of data gathering in IIoT. IEEE Internet Things J. 2021, 9, 8607–8615. [Google Scholar] [CrossRef]
- Hammoudi, S.; Aliouat, Z.; Harous, S. Enhanced time-slotted channel hopping. Trans. Emerg. Telecommun. Technol. 2022, 33, e3638. [Google Scholar] [CrossRef]
- Zorbas, D.; Papadopoulos, G.Z.; Douligeris, C. Local or global radio channel blacklisting for ieee 802.15. 4-tsch networks? In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Municio, E.; Latré, S. Decentralized broadcast-based scheduling for dense multi-hop TSCH networks. In Proceedings of the Workshop on Mobility in the Evolving Internet Architecture, New York, NY, USA, 3–7 October 2016; pp. 19–24. [Google Scholar]
- Elsts, A. TSCH-Sim: Scaling up simulations of TSCH and 6TiSCH networks. Sensors 2020, 20, 5663. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Advancement | Result |
|---|---|---|
| TSCH [24] | Parameterized adaptive and autonomous scheduling | Minimizes latency and energy consumption |
| TSCH [25] | Comprehensive study on TSCH-minimal and Orchestra | Orchestra outperforms |
| TSCH [26] | Investigate the use of TSCH protocol with Orchestra scheduling | Orchestra is not convenient for several delay-sensitive IoT applications |
| TSCH [27] | Performance analysis of Bidirectional Multicast RPL Forwarding (BMRF) over TSCH | BMRF’s LL unicast was found to outperform the LL broadcast |
| TSCH [28] | Interference Collision-Free Scheduling (ICFS), and Interference Collision-Free Scheduling Without Redundant Data (ICFS-WRD) algorithms are proposed to reduce internal collisions | ICFS saves approximately 23% energy, and ICFS-WRD delivers packets twice as fast as ICFS |
| TSCH [29] | An effective local channel selection approach for reliable communication scheduling in TSCH networks is proposed | Results demonstrate the efficiency of the proposal in terms of performance parameters |
| TSCH [30] | An overview of the most relevant decentralized TSCH schedulers is shown | Orchestra outperforms all other schedulers |
| TSCH [10] | Comparison between layered schedulers, 6TiSCH, and Orchestra | Relationship between TSCH and RPL is governed by queue size and schedule capacity |
| TSCH [21] | TESLA, a traffic-aware elastic slotframe adjustment scheme for TSCH networks, is proposed | Large-scale 110-node and 79-node evaluation shows 70.2% energy savings |
| TSCH [4] | Strategy to cope up with idle listening | There is not a single winning strategy, as the behavior depends on specific operating conditions of WSN |
| TSCH [11] | An Orchestra-based scheduler for applications with unpredictable traffic bursts is proposed | Lower latency and higher packet delivery ratio |
| TSCH [31] | Time hopping to secure the reliability of coexisting TSCH | 50% improvement in collision ratio |
| TSCH [32] | Probabilistic blacklisting is proposed | Improved performance parameters |
| 6TiSCH [33] | A traffic-aware RPL method that utilizes the cell allocation information of TSCH MAC | Packet delivery ratio and bandwidth utilization are improved by up to 31% and 20% |
| 6TiSCH [34] | Low-latency Distributed Scheduling Function (LDSF) is proposed | Efficiency of the proposed LDSF algorithm is better than the Minimal Scheduling Function, Low-Latency Scheduling Function (LLSF), and Stratum |
| 6TiSCH [12] | Thorough description of the 6TiSCH architecture, the 6TiSCH Operation Sublayer (6top), and MSF is provided | Allocating multiple cells over MSF could exacerbate the problem of over-provisioning |
| 6TiSCH [35] | Outlines the challenges associated with implementing TSCH and 6TiSCH protocols in the Contiki operating system | Provides valuable insights into the design considerations and performance characteristics of TSCH and 6TiSCH protocols in Contiki |
| 6TiSCH [36] | Traffic rate-agnostic distributed link scheduling function (RTDS) for 6TiSCH networks is proposed | RTDS follows a receiver-based cell selection and allocation strategy to reduce a packet’s waiting time in the receiving nodes |
| 6TiSCH [37] | Optimized 6TiSCH scheduling function YSF is proposed | It produces a low end-to-end delay and high-end-to-end reliability |
| Symbols | Meaning |
|---|---|
| absolute time slot | |
| number of available radio channels | |
| F | lookup table function |
| N | total number of time slots |
| transmission time of the i-th time slot | |
| duration of each time slot | |
| average arrival rate of packets | |
| time slot of a node | |
| application packet transmission interval | |
| application packets generated per unit time | |
| Beacon Frame Cycle | |
| Shared Frame Cycle | |
| Unicast Frame Interval | |
| duration of a single time slot for BFC | |
| duration of a single time slot for SFC | |
| duration of a single time slot for UFI | |
| frequency of time slot in TSCH network | |
| packet transmission | |
| packet reception | |
| number of lost packets | |
| number of received packets | |
| total number of application packets sent | |
| reception time of the i-th packet | |
| transmission time of the i-th packet | |
| total current consumption | |
| total power consumption | |
| V | voltage level of the network |
| power consumption during transmission | |
| power consumption during reception | |
| power consumption of the CPU | |
| power consumption during low-power mode | |
| d | distance |
| R | data rate |
| F | channel condition |
| MAC layer packets acknowledged | |
| MAC layer packets sent | |
| probability of unicast collision | |
| C | number of available channels for communication |
| U | number of unicast transmissions attempted simultaneously |
| N | number of packet transmissions |
| probability of a broadcast collision | |
| p | probability of a node transmitting a broadcast message |
| Parameter | Value |
|---|---|
| Simulation tool | TSCH-Sim |
| Simulation runs | 10 |
| Simulation duration | 1 h |
| Scheduling algorithms | Orchestra, MSF |
| Number of channels | 4, 11 |
| Max packet retransmissions | 7 |
| Max queue size | 16 packets |
| TSCH slot duration | 10,000 s |
| MAC keep alive timeout | 60 s |
| MAC EB period | 16 s |
| Routing protocol | RPL |
| Application packet size | 100 |
| App. packet generation interval | 10, 40, 50, 60, 150, 200, 300 s |
| Warm-up period duration | 100 s |
| Number of nodes | 11, 21, 34, 45, 56, 64, 66, 67, 69, 75, 78, 80, 89, 100, 111, 551, 1111 |
| Number of mobile nodes | 6, 10 |
| Positioning layout | ellipse/star |
| Beacon frame size | 397, 200, 201 |
| Shared frame size | 31, 10, 11 |
| Unicast frame size | 17, 5 |
| Mobility model | static, RandomWaypoint |
| Mobility update period | 10 s |
| Mobility range x-axis | 300 m |
| Mobility range y-axis | 300 m |
| Mobility speed | 0.1 m/s |
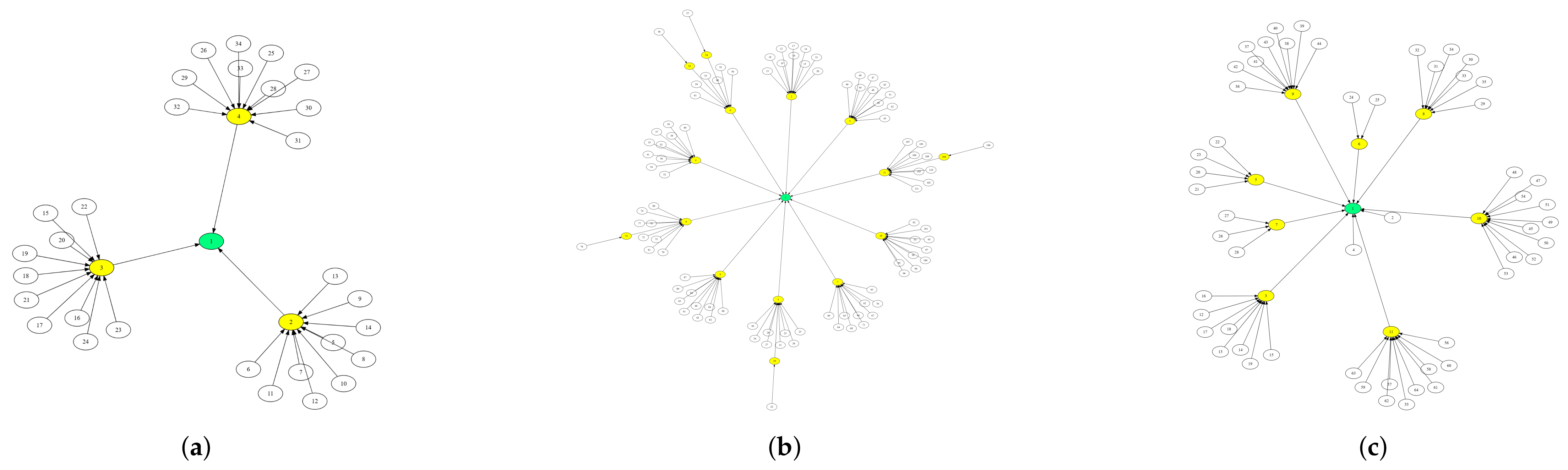
| No. of Clusters | Topology Name | Nodes per Cluster | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CL_1 | CL_2 | CL_3 | CL_4 | CL_5 | CL_6 | CL_7 | CL_8 | CL_9 | CL_10 | ||
| 10 | T1 | 0 | 0 | 0 | 6 | 8 | 8 | 7 | 9 | 10 | 10 |
| 10 | T2 | 0 | 2 | 4 | 6 | 8 | 8 | 7 | 9 | 10 | 10 |
| 10 | T3 | 0 | 8 | 0 | 4 | 2 | 3 | 7 | 9 | 10 | 10 |
| 10 | T4 | 10 | 10 | 5 | 5 | 5 | 5 | 5 | 8 | 8 | 8 |
| 10 | T5 | 10 | 8 | 9 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Topology | Scheduler | PDR (%) | Latency (s) | Current (mA) | TSCH_UC (%) | TSCH_BC (%) | RPL_UC (%) | RPL_BC (%) |
|---|---|---|---|---|---|---|---|---|
| 50_10 | Orchestra | 40.22 | 1.018 | 1876.7 | 31.10 | 1.98 | 46.58 | 34.57 |
| 50_10 | OPTIMAOrchestra_ch4 | 78.27 | 0.257 | 1839 | 31.01 | 1.70 | 37.82 | 18.00 |
| 50_10 | OPTIMAOrchestra_ch11 | 88.93 | 0.190 | 2398.2 | 22.75 | 0.49 | 27.68 | 13.10 |
| 100_10 | Orchestra | 21.48 | 2.568 | 4389.1 | 38.00 | 1.51 | 42.27 | 34.00 |
| 100_10 | OPTIMAOrchestra_ch4 | 23.08 | 0.607 | 3426.6 | 32.47 | 3.60 | 41.87 | 31.44 |
| 100_10 | OPTIMAOrchestra_ch11 | 42.15 | 0.194 | 5156.2 | 25.70 | 1.48 | 38.14 | 28.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panda, N.; Muthuraman, S.; Elsts, A. Multi-Objective Optimization of Orchestra Scheduler for Traffic-Aware Networks. Smart Cities 2024, 7, 2542-2571. https://doi.org/10.3390/smartcities7050099
Panda N, Muthuraman S, Elsts A. Multi-Objective Optimization of Orchestra Scheduler for Traffic-Aware Networks. Smart Cities. 2024; 7(5):2542-2571. https://doi.org/10.3390/smartcities7050099
Chicago/Turabian StylePanda, Niharika, Supriya Muthuraman, and Atis Elsts. 2024. "Multi-Objective Optimization of Orchestra Scheduler for Traffic-Aware Networks" Smart Cities 7, no. 5: 2542-2571. https://doi.org/10.3390/smartcities7050099
APA StylePanda, N., Muthuraman, S., & Elsts, A. (2024). Multi-Objective Optimization of Orchestra Scheduler for Traffic-Aware Networks. Smart Cities, 7(5), 2542-2571. https://doi.org/10.3390/smartcities7050099