2. Data
To address the research objective, to conduct various experiments, to evaluate results and lastly to discuss them (
Section 1.4), a huge amount of REC time series is essential, ones that encompass necessary attributes such as non-stationarity (Definition 2), discontinuity (Definition 3), stochasticity (Definition 5), autoregression (Definition 6), seasonality (Definition 7), trend (Definition 8), periodicity (Definition 9) and NON-IID on various clients. In
Appendix B,
Figure A2 illustrates differences between these terms, where (a), (b), (c), (d), (f) and (g) are showing non-stationary characteristics (Definition 2). For simplicity, we assume that RECs are composed of various districts (
Section 1.2). Since no real dataset fulfills these requirements, we firstly generate stationary as well as distinctive district electricity consumption time series (DECTS) based on different socio-economic factors (
Section 2.1). Subsequently, we use these to construct RECs with dynamic portfolios, resulting in non-stationary and discontinous time series (
Section 2.2).
Definition 5 (Stochasticity)
. The stochasticity of a time series refers to the inherent randomness or unpredictability in the data.
Definition 6 (Autoregression)
. Autoregression is a time series modeling technique where future values are predicted based on past values of the same series.
Definition 7 (Seasonality)
. Seasonality in time series is a long-term characteristic pattern that repeats at regular intervals (years).
Definition 8 (Trend)
. The trend of a time series represents a long-term linear or even non-linear time-dependency in the data, typically showing sustained increase or decrease over time.
Definition 9 (Periodicity)
. The periodicity of a time series refers to short-term, repetitive occurrences of specific patterns such as day of week or hour of day.
2.1. Synthesis and Analysis of Synthetic Electrical Load Time Series at District Scale
We utilize a public dataset that provides more than 5500 household electricity consumption time series with a 30-min temporal resolution, classified into 18 different ACORN groups (Definition 10), to handle the huge amount of DECTS with diverse characteristics. Since these time series are highly stochastic, we proceed as introduced in [
15]: (i) Clustering ACORN household electricity consumption time series, and transforming and scaling non-Gaussian distributed data, (ii) aggregating household data to the level of districts and extracting the time series process to ensure adequate sampling of training data, (iii) training a two-step probabilistic forecasting model to ensure both seasonal and short-term variations, and (iv) iterativly generate synthetic time series. This approach is applied in conjunction with weather data (temperature, relative humidity) of central Germany for the years 2018 and 2019. It results in a total of 55 distinct ACORN subgroups, each with specific time series characteristics influenced by socio-economic factors and household size. To gain a clearer understanding of the diversity of their characteristics, we firstly calculate a correlation matrix
to obtain correlations between all ACORN subgroups. We then perform principal component analysis to reduce the dimensions to two and to illustrate it with a scatter plot (
Figure 2). Since many ACORN subgroups possess similar electricity consumption characteristics, aggregating them to the level of a REC will not generate diverse time series. Therefore, we additionally apply K-means clustering with the number of clusters set to
, extracting the ten most distinctive subgroups. The effect of this filtering method is demonstrated in
Table 1, showing lower mean values and higher standard deviations of
for the ten most distinctive subgroups, resulting in a higher diversity.
Definition 10 (ACORN, taken from [
26])
. ACORN is a segmentation tool which categorizes UK’s population into demographic types. 2.2. Generate Dynamic Portfolios of Renewable Energy Communities
Besides the general definition of non-stationarity (Definition 2), there even exist more refined ones named cyclostationarity (Definition 11) [
27]. Since synthetic REC time series (RECTS) should be constructed to satisfy a dynamic portfolio, they must not exhibit this characteristic. Keeping this in mind and given a set of 300 DECTS for each ACORN subgroup, we generate diverse RECTS from the ten most distintive ones (
Section 2.1) in respect of certain constraints (Algorithm 1):
No unique DECTS have to be used twice.
Each RECTS is composed of different DECTS in varying quantities
, depicting a time dependent residents composition vector
(Equation (
1)) for each REC.
Since and only 300 DECTS exist for each ACORN subgroup, the quantity of RECTS is confined to 70.
Each REC is assigned both a random start and a random end with random various probabilities that is set to zero.
The residents composition of REC is linearly developed using start and end .
Every new day, one of ten ACORN subgroups is randomly chosen and either a new DECTS is added or an existing one is excluded, unless the linear development curve from start to end is undershot or exceeded by more than 1.
Quantity of specific ACORN subgroup at time t
Index of specific ACORN subgroup,
Index of time with a daily temporal resolution
Definition 11 (Cyclostationarity, taken from [
27])
. A time series may exhibit both seasonality as well as periodicity and can still remain predictable, as these cyclical patterns repeat at regular intervals. Removing these two components will strongly lead to a stationary time series. 2.3. Analyze Time Series of Renewable Energy Communities
While
Section 2.2 generates RECTS (examples of those can be found in
Appendix A and
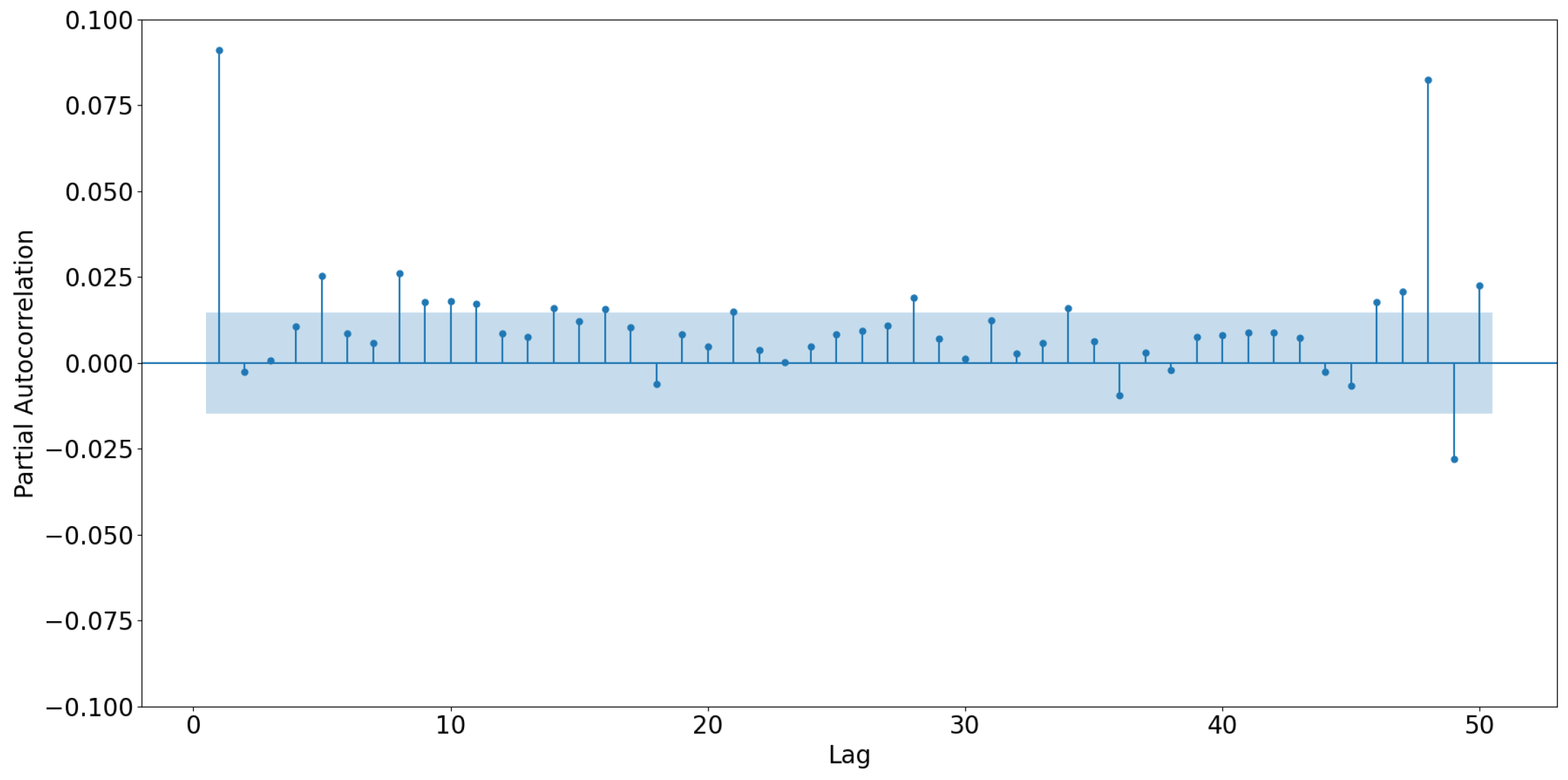
Figure A1), we still have to test for required time series attributes. To address non-stationarity, we remove seasonality (week of the year), periodicity (day of the week, hour, minute), and even the long-term trend from the original time series by applying a Seasonal-Trend decomposition using LOESS of the Python statsmodels package. Subsequently, we apply the Augmented Dickey-Fuller (ADF) test on a representative RECTS, considering only timestamps at 12:00 (
Figure 3). The Dickey-Fuller test is a statistical method for testing whether a time series is non-stationary and contains a unit root. The null hypothesis is that there is a unit root, suggesting that the time series has a stochastic trend. The ADF test considers extra lagged terms (we use
to account for an entire week) of the time series’ first difference in the test regression to account for serial correlation. Since
, the null hypothesis can not be rejected, demonstrating non-stationarity of RECTS (
Table 2, for all RECTS see
Appendix D and
Table A1).
| Algorithm 1: Generation of non-stationary and discontinous RECTS |
![Smartcities 07 00082 i001]() |
Discontinuity is often attributed to a change point, which indicates a transition from one state to another in the process generating the time series data. Various algorithms have been utilized to detect change points in data, including likelihood ratio, subspace model, probabilistic, kernal-based, graph-based and clustering methods [
28]. In contrary, a boxplot is easy to use and give overview about data distribution, skewness and outliers [
29]. In this, the box shows the interqurtile range (IQR) which is the distance between the first (Q1) and third (Q3) quartiles. The whiskers extend from the box to the highest and lowest values within
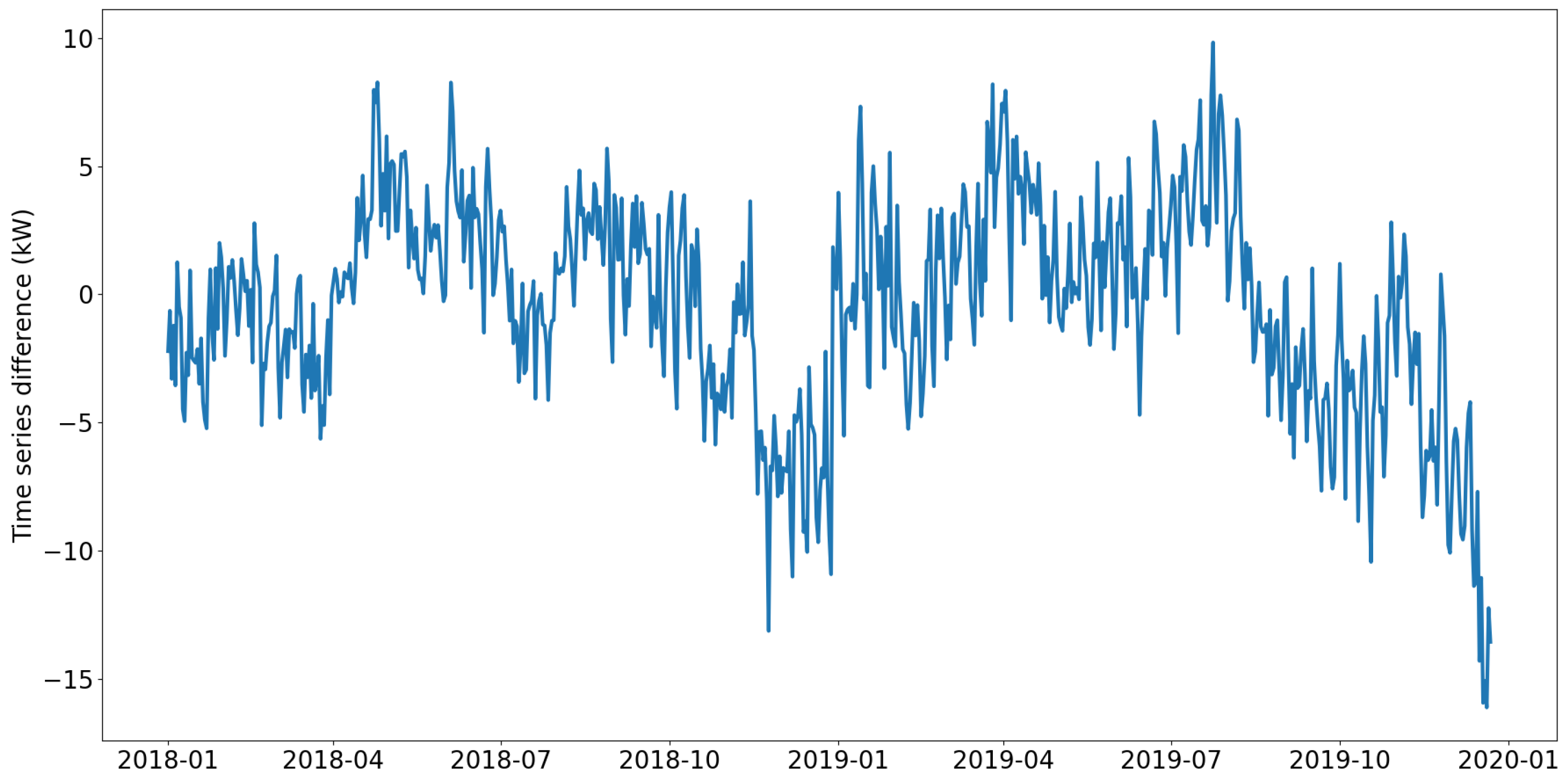
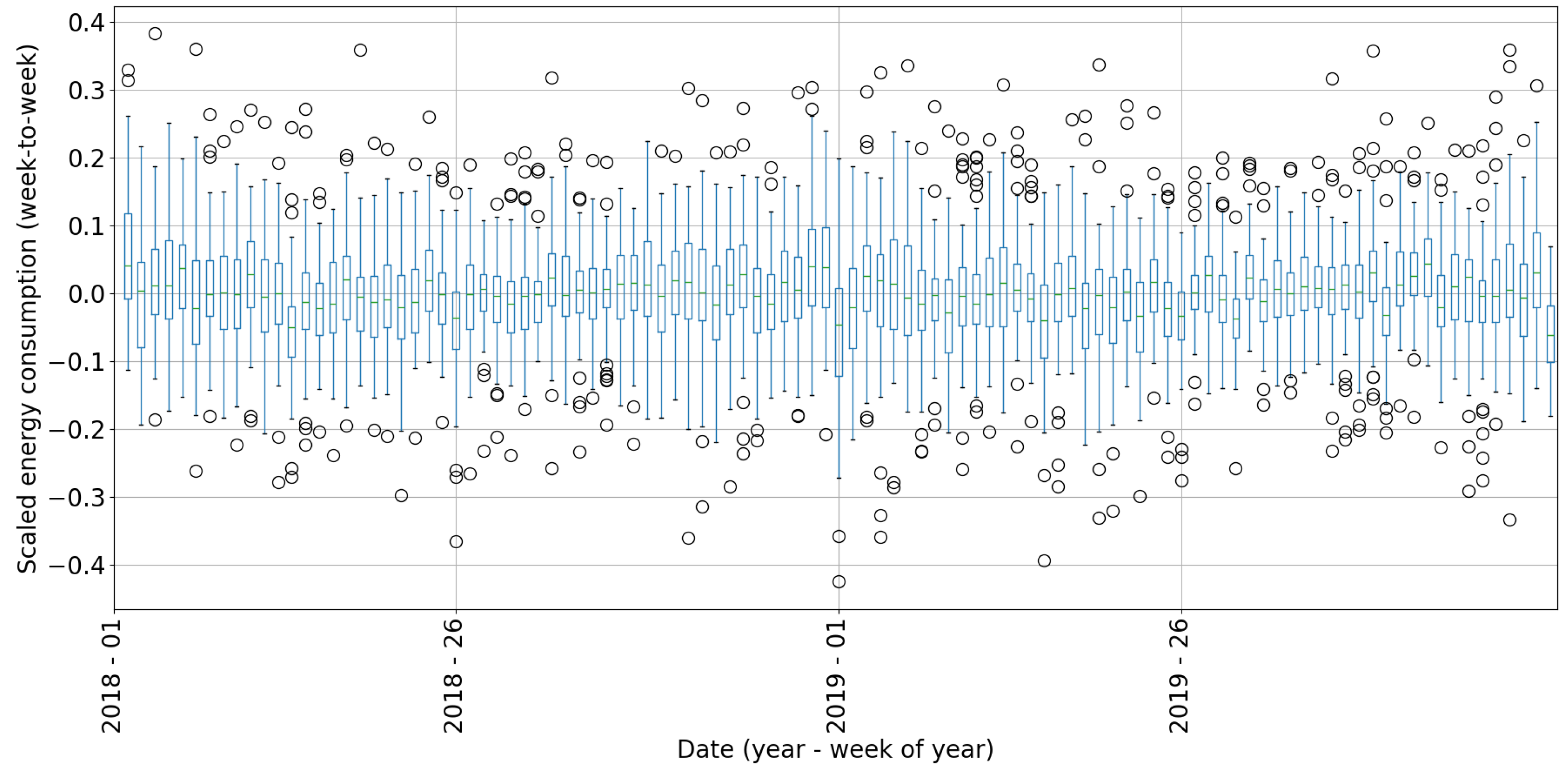
. The line in the middle of the box represents the median or the second quartile (Q2) of the data. Points outside the whiskers represent outliers. To analyze discontinuity in RECTS, we firstly calculate mean daily sequences for each week of the year. Subsequently, we compute differential time series (time series minus its lagged version with shift of 1). Considering that all 70 RECTS have varying magnitudes, we normalize them by utilizing Equation (
2). Then, we use a boxplot to illustrate the distribution of all generated RECTS for each week of the year (
Figure 4), showing a huge number of outliers and proving discontinuity in data.
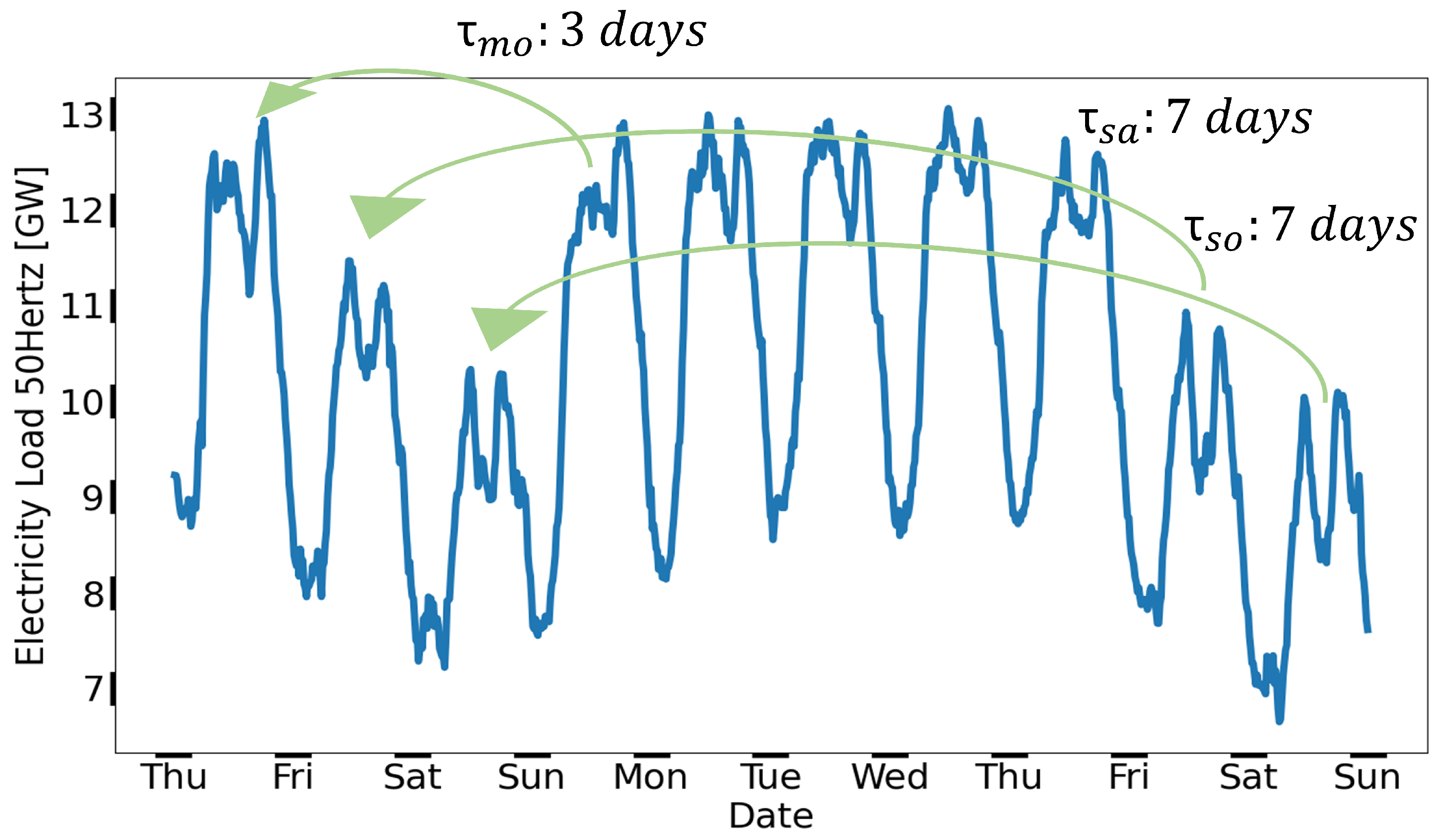
Another requirement involves handling NON-IID data across multiple clients, which can be simply demonstrated by illustrating correlations among all generated RECTS.
Figure 5 shows their correlation matrix
, with highest correlations on the diagonal—representing correlations of each RECTS to itself. Since each REC is individually developed using diverse
at start and end point, correlations are much lower than the ones of DECTS (compare
Table 1 with
Table 3). This strongly indicates, that RECTS possess a high degree of NON-IID data, which must be adequatly considered within a time series forecasting model and FL.
2.4. Transformation
Time series data should be scaled before being used in machine learning, particularly because of algorithm performance and gradient descent optimization. In our work, we utilize Equation (
3) to scale data within the range
by setting
and
. To rescale transformed data to its original magnitude, we use Equation (
4)
5. Discussion
This work introduces the European energy market, with a particular emphasis on dynamic portfolios of RECs, which have the potential to introduce new business models, enhance energy efficiency, and reduce electricity costs for their members. Besides fostering energy sharing (tenant electricity, electric vehicle charging, etc.), dynamic portfolios also contain risks concerning energy management tasks, e.g., forecasting energy demand or optimizing the energy system including demand side management, which could lead to financial losses, stress on the grid, operational inefficiencies, and member dissatisfaction. The goal of this work is to develop a forecast framework that overcomes non-stationary, discontinuous, and NON-IID time series.
Since no real data is available, we synthesize RECTS by initially creating numerous district time series with diverse characteristics and subsequently aggregating them time-dependently. Given only this type of data, we can only simulate the forecasting of RECTS approximately. Various analyses confirm that the generated time series are non-stationary, discontinuous, and NON-IID, as these attributes are prerequisites of the research question. Daily portfolio changes may appear extreme, but they can occur if there is a company whose business model involves automatically optimizing portfolios based on the day of the week, accounting for varying patterns of electricity consumption and generation.
To create model input arrays, we refer closely to ARIX time series processing equations, omitting the differencing filter, as neural networks are capable of automatically extracting this feature. Since the composition of residents in RECs might change daily, we divide these arrays into past, present, and future ones. Thereby, we clearly describe the engineering of calendar data to include temporal dependencies of RECTS. To determine the effect of residents composition on RECTS characteristics, we assume that we possess this information for all RECs and days. While such information does not actually exist, we must first label each member time series within a REC by using a sophisticated classification algorithm.
We then develop a forecasting model based on a FNN architecture with three input layers, each taking into account a separate input array representing a specific time interval within the time series process. As each layer extracts latent features across various time horizons, the forecasting model is capable of handling dynamic portfolios. As our primary objective is to analyze the feasibility of a forecasting model trained using FL, we omit considerations of other neural network architectures, such as sequence-to-sequence networks or temporal convolutional networks which might result in better forecast accuracies. Furthermore, we omit hyperparameter optimization regarding the activation function, the number of neurons, and the number of hidden layers to identify optimal settings.
To train a forecasting model across multiple clients with FL, we employ Federated Averaging exclusively for updating model weights, and use stochastic gradient descent for local model training. Additionally, we apply only one training epoch on each client and experiment with various configurations regarding data sharing, batch size, and learning rate to mitigate weight divergence issues. In contrast, we did not consider techniques such as FedProx [
48] and FedDyn [
49] that involve the regularization of model weight updates, learning rate degradation [
49,
50], layer-wise training [
51], and a varying quantity of training data samples [
50]. Since model convergence strongly depends on the interaction between sample size, batch size, and learning rate, this issue was be analyzed and by a more in-depth optimization, there could be significant potential for improvement in model convergence and performance.
Additionally, we perform multiple training sessions of the forecasting model using FL, taking into account various configurations related to the number of shared time series, the learning rate, and the batch size in order to determine the best setting. This one is subsequently applied in similar experiments to demonstrate the effectiveness of our framework, showing that the FL Model and the CL Model have nearly identical performance. Hence, our framework is capable of aggregating knowledge from multiple clients, learning domain-invariant features, and extracting cross-domain behaviors through the application of FL. Moreover, it is transferable to new unseen data. Nevertheless, more sensitivity studies on hyperparameter tuning must be conducted, e.g., testing the required quantity of RECTS to extract the relational knowledge necessary to cause failure, and the application in a real-world scenario should be analyzed. Since the number of RECs could potentially increase significantly, there could be advantages in using FL regarding training time.
In comparison to similar studies, we not only evaluate our framework using generic error metrics like MAE or RMSE, but also focus intensively on remaining frequencies in the residuals (compare with [
38,
39,
41,
42]). Since many different RECs could potentially participate in such a forecasting community, some might suffer from data poisoning attacks. In this case, the FL framework should detect and correct anomalies in each time series to ensure robust forecast model training [
52,
53].
While this research proposes a method to train a forecast model for non-stationary, discontinuous, and NON-IID time series across multiple clients, several challenges remain for deploying FL in large-scale systems. Each client may possess different hardware configurations regarding smart meters, data management systems, CPUs, and GPUs, potentially leading to communication issues. To address these issues and ensure interoperability, it is recommended to aggregate model weights asynchronously. Furthermore, there is a need for standardized protocols and APIs that enable seamless participation of various data management systems in FL. This includes standardizing data access, processing, and updating methods within the FL context, using techniques such as homomorphic encryption or differential privacy [
54]. As participating clients may have time series data with varying temporal resolutions, quality, and quantities, data pre-processing steps such as missing value substitution or anomaly detection must be adapted accordingly. Intelligent weight averaging algorithms like FedProx [
48] and FedDyn [
49] can help to reduce communication overhead, improving the overall efficiency and robustness of the FL system.
Since our approach can extract domain-invariant features and identify correlations between domains based on temporal and exogenous variables, it can also be applied to time series data from other sectors such as retail, e-commerce, and financial markets. Economic data generally exhibit cycles and trends due to factors like financial crises, policy changes, and technological innovations. Utilizing extensive labeled or structural data that approximately describes the entire ecosystem could enable more accurate predictions of future changes, thereby minimizing financial risks.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}