


PC-ILP: A Fast and Intuitive Method to Place Electric Vehicle Charging Stations in Smart Cities

Abstract
:1. Introduction
1.1. Salient Features of PC-ILP
1.2. List of Contributions
2. Background
2.1. Mathematical Techniques
2.1.1. Clustering
2.1.2. Medial Axis Transform (MAT)
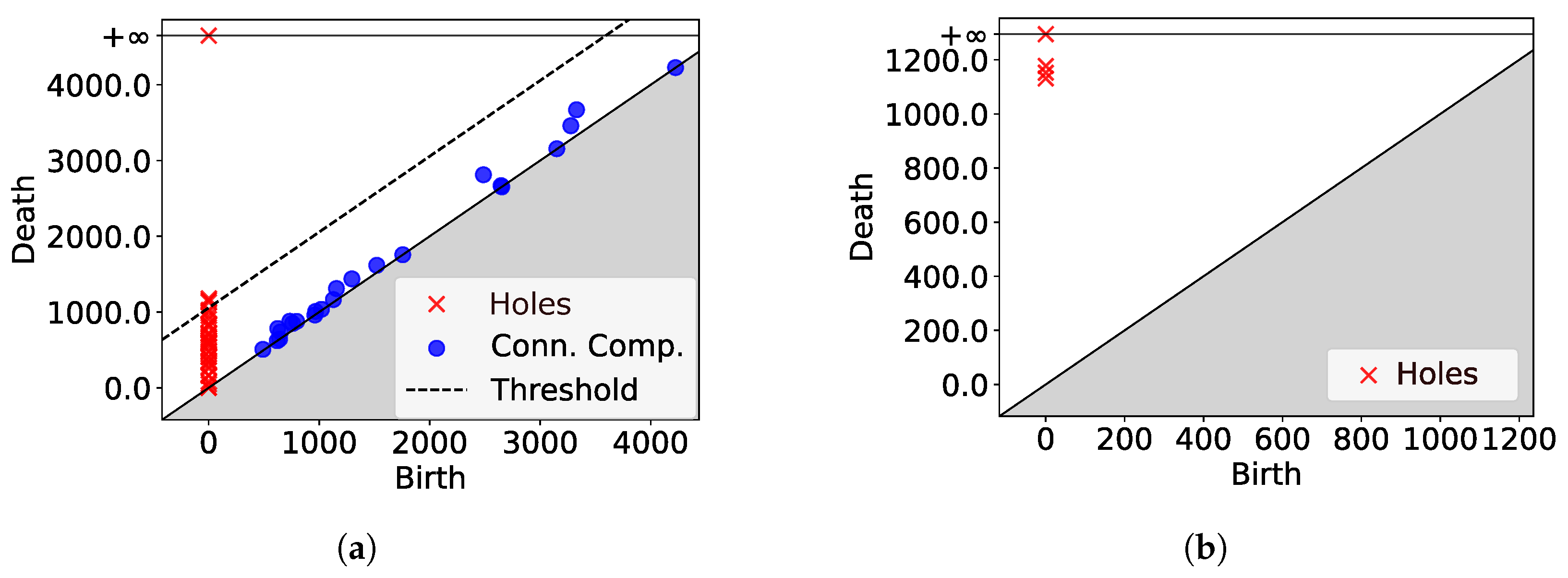
2.1.3. Topological Data Analysis (TDA) and Persistence Homology
2.2. Simulation of Urban Mobility (SUMO): Traffic Simulator
2.3. JAYA Algorithm
3. Problem Formulation
3.1. Additional Constraints
4. Characterization
Clustering Algorithm—Identification of the Clusters in a City
5. Material and Methods
5.1. Overview of the Scheme
5.2. Placement of Charging Stations (Primary Objective)
| Algorithm 1: PC-ILP (online stage) |
 |
5.2.1. Create Database of Precomputed Solutions (Offline)
- ▸ Normalization of the latitude and longitude: Each of the CCS nodes in a shape is denoted by a pair of latitude and longitude coordinates. Now, across cities, the constituent topological shapes may remain the same, but their sizes may vary significantly. Since it is not possible to store the results for all potential basic shape sizes in a database, we normalize the values of the longitudes and latitudes for different shapes. Normalizing the geographical coordinates in a large urban city to store a scaled version of the geographical information is a well-known concept that is used in urban city planning [58,59,60,61,62]. It helps to simplify and generalize the geographic data (nodes), making them more manageable.
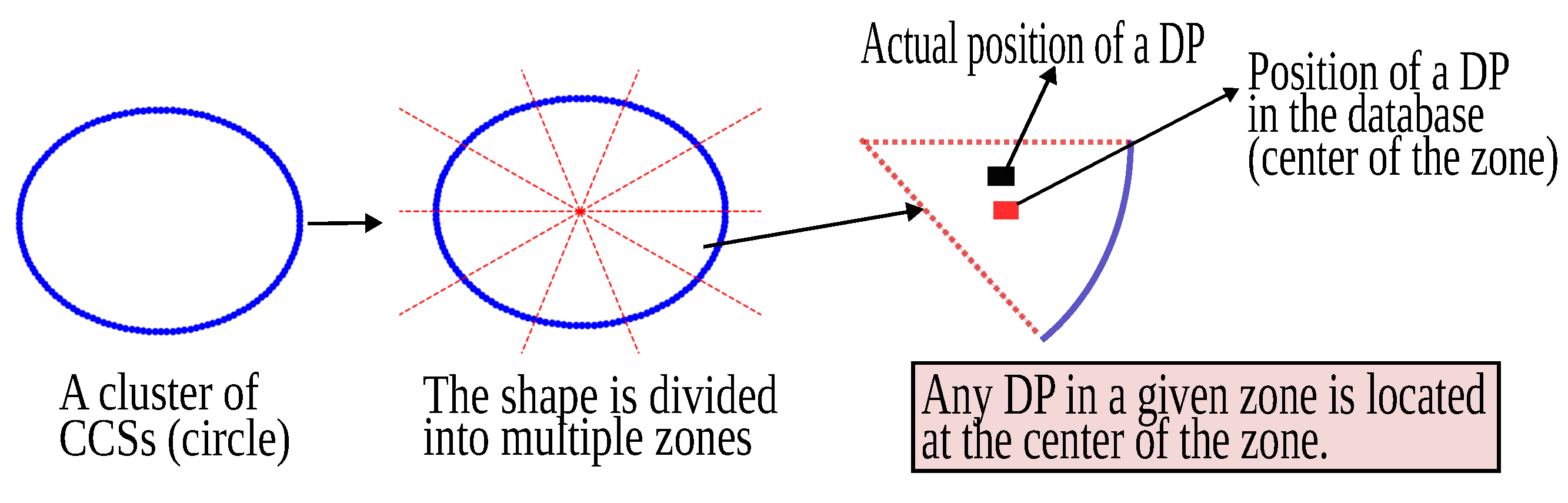
- ▸ Patterns of DP distribution in a shape: DPs denote the points at which a demand for charging exists. We place DPs manually based on the density of CCSs, the presence of public amenities like malls and hospitals, and downtown areas. To characterize the location of DPs, we subdivide all the normalized shapes into zones. If a DP falls in a zone, we assume that it is in the centroid of the zone (refer to Figure 8). This means that there is some feature of interest in the city and all the roads in the vicinity lead to it.
5.2.2. Locating Potential Charging Stations in the Input Map
5.2.3. Clustering Algorithm
- ▸ Mapping DPs to clusters: In the next step, we map each DP (represented as ) to its nearest cluster . A single cluster can be mapped to many DPs, creating a many-to-one mapping. To map DPs to a cluster, we first compute the convex hull for each cluster using the QuickHull algorithm [63]. We categorize the DPs into two categories based on their position relative to the convex hull. ➀ The DPs that are contained within the convex hull of a cluster are automatically mapped to . ➁ The DPs that fall outside the convex hull of all clusters are mapped to the closest cluster using the Assign function as described in Algorithm 2. Basically, the clusters are characterized by their centroids. We find the cluster closest to a DP by estimating the distance between the centroid of the cluster and the DP. We map the DP to its nearest cluster based on the minimum distance to each centroid [64].
| Algorithm 2: Function |
 |
5.2.4. Shape Identification Using a Convolutional Neural Network (CNN)
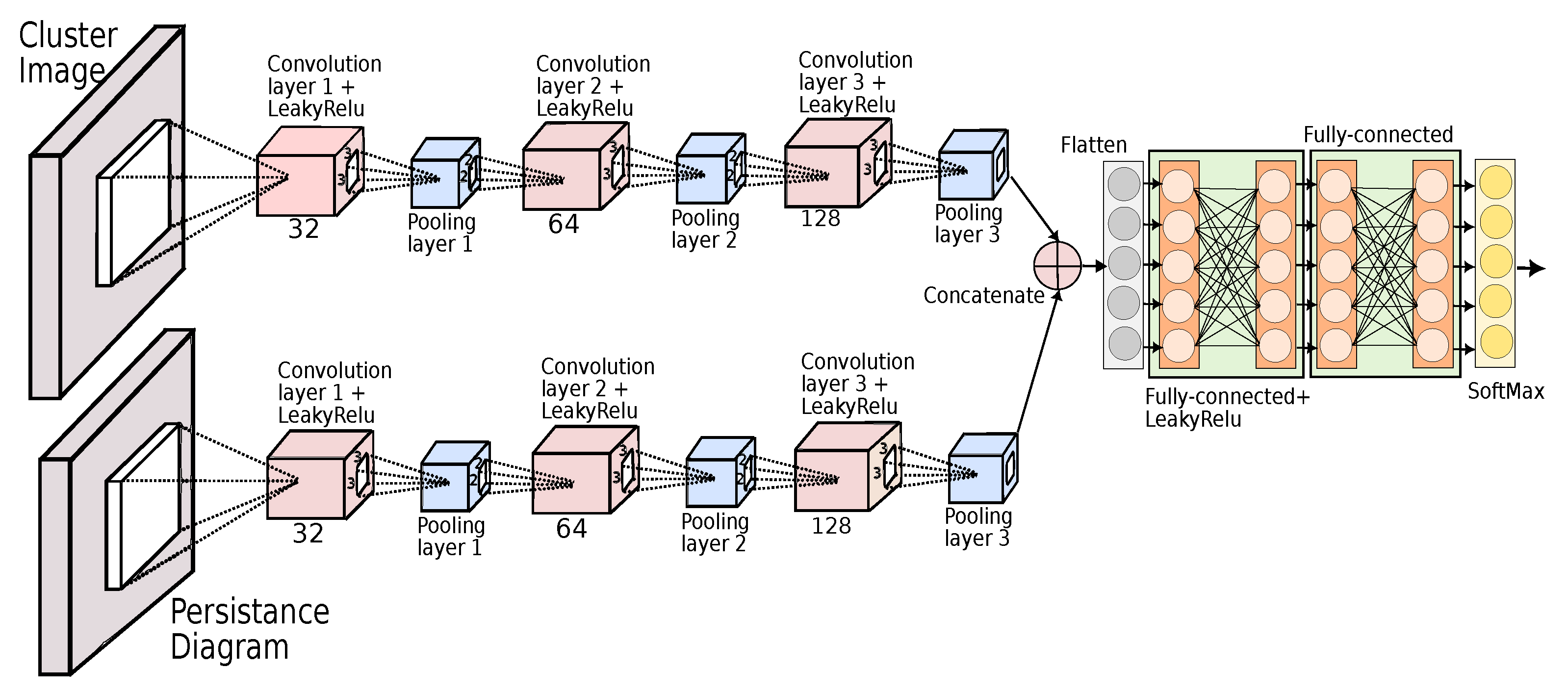
- ▸ Model architecture: The proposed model architecture comprises two parallel CNN layers, as depicted in Figure 9. Both layers consist of an identical three-layer CNN architecture. In the three sequential convolutional layers, the number of filters increases in the sequence (32, 64, 128). Each convolutional layer is followed by a Leaky ReLU activation function and a maxpooling layer with a pool factor of . Finally, we employ a regularization technique called dropout, which involves randomly deactivating the neurons within a layer. The respective dropout percentages for the three convolutional layers are , , and .
5.2.5. Retrieval of the Precomputed Solution from the Database
| Algorithm 3: Function |
 |
5.2.6. Mapping the Precomputed Solution
| Algorithm 4: Function |
 |
5.3. Repairing an Infeasible Solution
| Algorithm 5: Function |
 |
5.4. Chargers at Each Charging Station (Additional Objective)
6. Results and Discussion
6.1. Setup
- ▸ Benchmarks: We consider the top 50 cities by population (source: [66]). We focus on the areas that have a high population density in the cities (35–387 km). The details are shown in Table 4. We can make some broad observations based on the maps of the cities (also visualized using our MapperCS tool). We observe that American cities have historically been laid out as grids (meshes), whereas European towns have predominantly adopted a radial organization (all the arterial roads are oriented towards the center of the city). We show two examples in Figure 13 for sections of downtown Paris and New York.
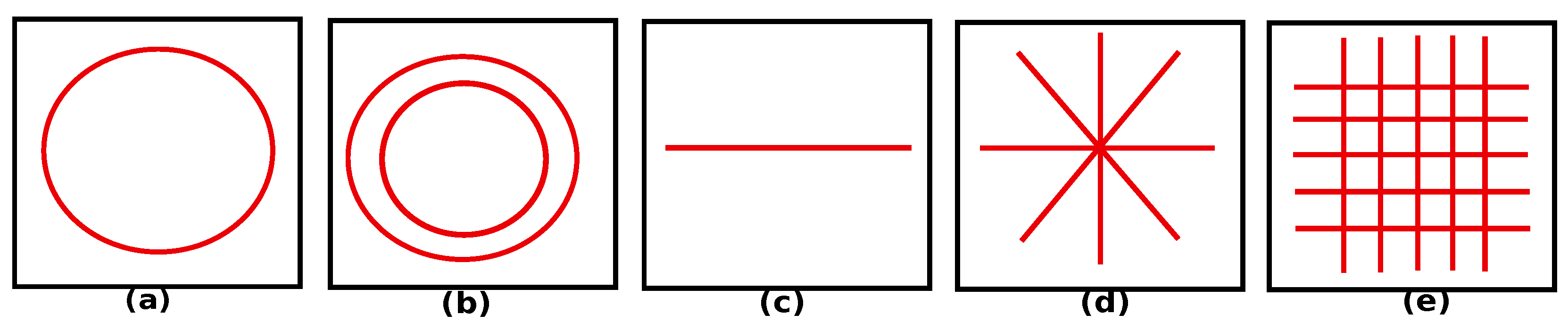
- ▸ Dataset for the CNN-based algorithm: The shapes of the clusters of CCSs are identified using a CNN model (see Section 5.2.4). The training dataset contains clusters that can be classified into five basic shapes, namely, circle, mesh, star, line, and concentric circle. Each cluster is defined by its point cloud representation and the PD of its MAT. We trained our model using synthetic data, because in this case we can generate as much as synthetic data as we want (we are not limited by the training set size or real-world constraints regarding the availability of data). For instance, if we want to generate synthetic data for a star, then we lay a random number of points out as a star, and then perturb them randomly. In this way, we can generate a lot of training examples for a given topology. The same approach can be repeated for other topologies and we can continue training our model. Note that there is no need for manual annotation here because we already know which basic shape a given point cloud corresponds to. We used the point clouds (CCS locations) in the 50 cities as test cases. Table 5 shows the number of shapes found across our dataset of 50 cities.
6.2. Parameters for the Creation of the Precomputed Database
6.2.1. Number of Zones in Each Shape
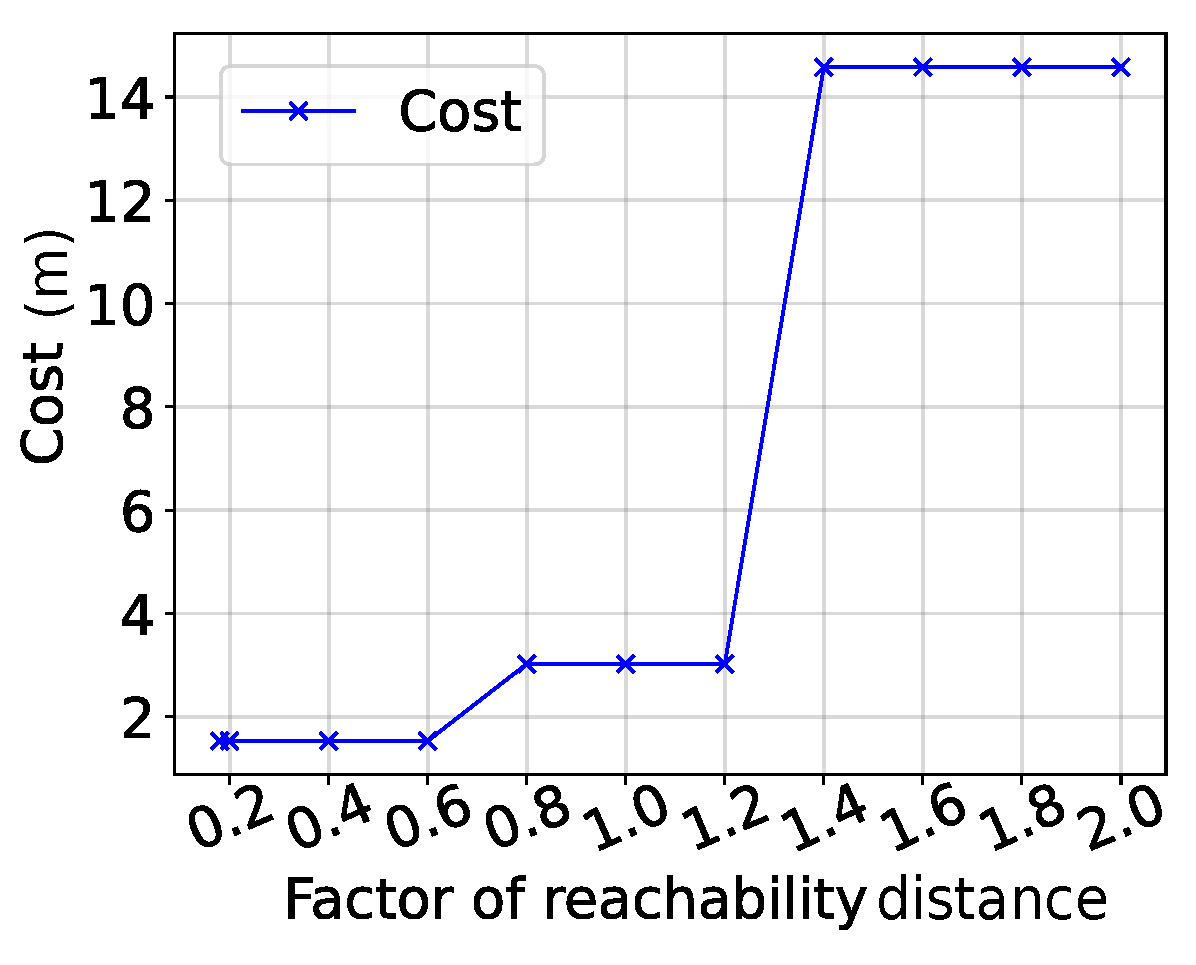
6.2.2. Reachability Distance ()
6.2.3. Budget ()
6.3. Performance Analysis
6.3.1. Microbenchmarks
- ▸ Cost vs. budget: We evaluate the performance of the algorithms by gradually increasing the allocated budget while keeping the CCSs and DPs fixed.
- ▸ Cost vs. DPs: Next, we study the impact of gradually increasing the number of DPs while keeping the CCSs and the budget constant. We evaluate the algorithms on the same metrics as before. Figure 17 compares the three algorithms plotted against increasing DPs. Figure 17a shows that PC-ILP performs better than the standard ILP, LGEG, and JAYA over the entire range of DPs with respect to cost. We also observe that all costs rise with an increase in the number of DPs. This is due to the budget being constant.
- Summary: We have thus established that PC-ILP performs far better than LGEG, JAYA, and standard ILP while providing marginally better solutions at the same time. Subsequently, we focus on estimating the performance of all the algorithms on a set of macrobenchmarks.
6.3.2. Macrobenchmarks: 50 Cities
6.4. Scalability Analysis
6.5. Overheads of Fixing Violated Constraints
6.6. Overheads of Adding Additional Constraints
7. Related Work
7.1. Mathematical-Programming-Based Approaches
7.2. Heuristic-Based Approaches
7.3. Hybrid Approaches
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| EV | Electric vehicle |
| CCSs | Candidate charging stations |
| CS | Charging station |
| DP | Demand point |
| ILP | Integer linear programming |
| PC-ILP | Persistence-based clustering-assisted integer linear programming |
| MAT | Medial axis transform |
| DBSCAN | Density-based spatial clustering of applications with noise |
| SUMO | Simulation of Urban Mobility |
| PD | Persistence diagram |
| ToMATo | Topological mode analysis tool |
| LGEG | Lazy greedy with effective gain |
| LGDG | Lazy greedy with direct gain |
| MINLP | Mixed-integer nonlinear programming |
References
- Kapustin, N.O.; Grushevenko, D.A. Long-term electric vehicles outlook and their potential impact on electric grid. Energy Policy 2020, 137, 111103. [Google Scholar] [CrossRef]
- Ullah, I.; Liu, K.; Layeb, S.B.; Severino, A.; Jamal, A. Optimal Deployment of Electric Vehicles’ Fast-Charging Stations. J. Adv. Transp. 2023, 2023, 6103796. [Google Scholar] [CrossRef]
- Zhong, P.; Xu, A.; Kang, Y.; Zhang, S.; Zhang, Y. An optimal deployment scheme for extremely fast charging stations. Peer-to-Peer Netw. Appl. 2022, 15, 1486–1504. [Google Scholar] [CrossRef]
- Shafiei, M.; Ghasemi-Marzbali, A. Fast-charging station for electric vehicles, challenges and issues: A comprehensive review. J. Energy Storage 2022, 49, 104136. [Google Scholar] [CrossRef]
- Mohanty, A.K.; Babu, P.S. Optimal Placement of Electric Vehicle Charging Stations Using JAYA Algorithm. In Proceedings of the Recent Advances in Power Systems; Gupta, O.H., Sood, V.K., Eds.; Springer: Singapore, 2021; pp. 259–266. [Google Scholar]
- Zafar, U.; Bayram, I.S.; Bayhan, S. A GIS-based Optimal Facility Location Framework for Fast Electric Vehicle Charging Stations. In Proceedings of the 2021 IEEE 30th International Symposium on Industrial Electronics (ISIE), Kyoto, Japan, 20–23 June 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Wu, X.; Feng, Q.; Bai, C.; Lai, C.S.; Jia, Y.; Lai, L.L. A novel fast-charging stations locational planning model for electric bus transit system. Energy 2021, 224, 120106. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Li, F.; Wu, B.; Chiang, Y.Y.; Zhang, X. Efficient Deployment of Electric Vehicle Charging Infrastructure: Simultaneous Optimization of Charging Station Placement and Charging Pile Assignment. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6654–6659. [Google Scholar] [CrossRef]
- Fang, C.; Lu, H.; Hong, Y.; Liu, S.; Chang, J. Dynamic Pricing for Electric Vehicle Extreme Fast Charging. Trans. Intell. Transport. Syst. 2020, 22, 531–541. [Google Scholar] [CrossRef]
- Bilal, M.; Rizwan, M.M. Electric vehicles in a smart grid: A comprehensive survey on optimal location of charging station. IET Smart Grid 2020, 3, 267–279. [Google Scholar] [CrossRef]
- Vazifeh, M.M.; Zhang, H.; Santi, P.; Ratti, C. Optimizing the deployment of electric vehicle charging stations using pervasive mobility data. Transp. Res. Part A Policy Pract. 2019, 121, 75–91. [Google Scholar] [CrossRef]
- Khan, W.; Ahmad, F.; Alam, M.S. Fast EV charging station integration with grid ensuring optimal and quality power exchange. Eng. Sci. Technol. Int. J. 2019, 22, 143–152. [Google Scholar] [CrossRef]
- Kavianipour, M.; Fakhrmoosavi, F.; Singh, H.; Ghamami, M.; Zockaie, A.; Ouyang, Y.; Jackson, R. Electric vehicle fast charging infrastructure planning in urban networks considering daily travel and charging behavior. Transp. Res. Part D Transp. Environ. 2021, 93, 102769. [Google Scholar] [CrossRef]
- Sachan, S.; Deb, S.; Singh, S.N.; Singh, P.P.; Sharma, D.D. Planning and operation of EV charging stations by chicken swarm optimization driven heuristics. Energy Convers. Econ. 2021, 2, 91–99. [Google Scholar] [CrossRef]
- Wang, J. Optimization of Ev Charging Pile Layout on Account of Ant Colony Algorithm. In Proceedings of the Cyber Security Intelligence and Analytics; Xu, Z., Alrabaee, S., Loyola-González, O., Cahyani, N.D.W., Ab Rahman, N.H., Eds.; Springer Nature: Cham, Switzerland, 2023; pp. 450–458. [Google Scholar]
- Garcia Alvarez, J.; González, M.Á.; Rodriguez Vela, C.; Varela, R. Electric vehicle charging scheduling by an enhanced artificial bee colony algorithm. Energies 2018, 11, 2752. [Google Scholar] [CrossRef]
- Yang, H.; Gao, Y.; Farley, K.B.; Jerue, M.; Perry, J.; Tse, Z. EV usage and city planning of charging station installations. In Proceedings of the 2015 IEEE Wireless Power Transfer Conference (WPTC), Boulder, CO, USA, 13–15 May 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Mahadeva Iyer, V.; Gulur, S.; Gohil, G.; Bhattacharya, S. Extreme fast charging station architecture for electric vehicles with partial power processing. In Proceedings of the 2018 IEEE Applied Power Electronics Conference and Exposition (APEC), San Antonio, TX, USA, 4–8 March 2018; pp. 659–665. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, Y.; Cui, Y. Challenges and opportunities towards fast-charging battery materials. Nat. Energy 2019, 4, 540–550. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Dong, H.; Hu, Z.; Mi, C. Enabling Extreme Fast Charging Technology for Electric Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 466–470. [Google Scholar] [CrossRef]
- Ge, S.; Feng, L.; Liu, H. The planning of electric vehicle charging station based on Grid partition method. In Proceedings of the 2011 International Conference on Electrical and Control Engineering, Yichang, China, 16–18 September 2011; pp. 2726–2730. [Google Scholar] [CrossRef]
- Du, B.; Tong, Y.; Zhou, Z.; Tao, Q.; Zhou, W. Demand-aware charger planning for electric vehicle sharing. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1330–1338. [Google Scholar] [CrossRef]
- Emelichev, V.; Girlich, E.; Nikulin, Y.; Podkopaev, D. Stability and Regularization of Vector Problems of Integer Linear Programming. Optimization 2002, 51, 645–676. [Google Scholar] [CrossRef]
- Sriabisha, R.; Yuvaraj, T. Optimum placement of Electric Vehicle Charging Station using Particle Swarm Optimization Algorithm. In Proceedings of the 2023 9th International Conference on Electrical Energy Systems (ICEES), Tokyo, Japan, 13–14 November 2023; pp. 283–288. [Google Scholar]
- Zhang, L.; Gao, T.; Cai, G.; Hai, K.L. Research on electric vehicle charging safety warning model based on back propagation neural network optimized by improved gray wolf algorithm. J. Energy Storage 2022, 49, 104092. [Google Scholar] [CrossRef]
- Jordanov, I.; Jain, R. Knowledge-Based and Intelligent Information and Engineering Systems; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Fredriksson, H.; Dahl, M.; Holmgren, J. Optimal placement of charging stations for electric vehicles in large-scale transportation networks. Procedia Comput. Sci. 2019, 160, 77–84. [Google Scholar] [CrossRef]
- Chaieb, M.; Jemai, J.; Mellouli, K. A hierarchical decomposition framework for modeling combinatorial optimization problems. Procedia Comput. Sci. 2015, 60, 478–487. [Google Scholar] [CrossRef]
- Koch, P.; Bagheri, S.; Konen, W.; Foussette, C.; Krause, P.; Bäck, T. A new repair method for constrained optimization. In Proceedings of the 2015 Annual Conference on Genetic and Evolutionary Computation, Madrid, Spain, 11–15 July 2015; pp. 273–280. [Google Scholar]
- Bagheri, S.; Konen, W.; Emmerich, M.; Bäck, T. Self-adjusting parameter control for surrogate-assisted constrained optimization under limited budgets. Appl. Soft Comput. 2017, 61, 377–393. [Google Scholar] [CrossRef]
- Batty, M.; Longley, P.A. Fractal Cities: A Geometry of Form and Function; Academic Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Amenta, N.; Choi, S.; Kolluri, R.K. The power crust, unions of balls, and the medial axis transform. Comput. Geom. 2001, 19, 127–153. [Google Scholar] [CrossRef]
- Patel, A. Generalized persistence diagrams. J. Appl. Comput. Topol. 2018, 1, 397–419. [Google Scholar] [CrossRef]
- OpenStreetMap Contributors. 2017. Available online: https://planet.osm.org (accessed on 16 June 2023).
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 1 January 1967; pp. 281–297. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.P.; Sander, J. OPTICS: Ordering Points to Identify the Clustering Structure. SIGMOD Rec. 1999, 28, 49–60. [Google Scholar] [CrossRef]
- Chazal, F.; Guibas, L.J.; Oudot, S.Y.; Skraba, P. Persistence-Based Clustering in Riemannian Manifolds. J. ACM 2013, 60, 1–38. [Google Scholar] [CrossRef]
- Lee, D.T. Medial Axis Transformation of a Planar Shape. IEEE Trans. Pattern Anal. Mach. Intell. 1982, PAMI-4, 363–369. [Google Scholar] [CrossRef]
- Chazal, F.; Michel, B. An Introduction to Topological Data Analysis: Fundamental and Practical Aspects for Data Scientists. Front. Artif. Intell. 2021, 4, 108. [Google Scholar] [CrossRef]
- Maria, C.; Dlotko, P.; Rouvreau, V.; Glisse, M. Rips complex. In GUDHI User and Reference Manual, 3.8.0 ed.; GUDHI Editorial Board, 2023; Available online: https://gudhi.inria.fr/python/latest/rips_complex_user.html (accessed on 16 August 2023).
- Rouvreau, V.; Montassif, H. Čech complex. In GUDHI User and Reference Manual, 3.8.0 ed.; GUDHI Editorial Board, 2023; Available online: https://gudhi.inria.fr/doc/latest/group__cech__complex.html (accessed on 16 August 2023).
- Goričan, P.; Virk, Ž. Critical Edges in Rips Complexes and Persistence. 2023. Available online: http://xxx.lanl.gov/abs/2304.05185 (accessed on 16 August 2023).
- Krajzewicz, D. Traffic Simulation with SUMO—Simulation of Urban Mobility. In Fundamentals of Traffic Simulation; Springer: New York, NY, USA, 2010; pp. 269–293. [Google Scholar] [CrossRef]
- Rao, R. Jaya: A Simple and New Optimization Algorithm for Solving Constrained and Unconstrained Optimization Problems. Int. J. Ind. Eng. Comput. 2016, 7, 19–34. [Google Scholar]
- Dilip, K.N. Optimal Placement of Electric Vehicle Charging Stations with Electricity Theft Control; Indian Institute of Technology Delhi: New Delhi, India, 2020. [Google Scholar]
- Chen, H.; Hu, Z.; Luo, H.; Qin, J.; Rajagopal, R.; Zhang, H. Design and Planning of a Multiple-Charger Multiple-Port Charging System for PEV Charging Station. IEEE Trans. Smart Grid 2019, 10, 173–183. [Google Scholar] [CrossRef]
- Zhang, H.; Hu, Z.; Xu, Z.; Song, Y. Optimal Planning of PEV Charging Station with Single Output Multiple Cables Charging Spots. IEEE Trans. Smart Grid 2017, 8, 2119–2128. [Google Scholar] [CrossRef]
- Garwa, N.; Niazi, K.R. Impact of EV on integration with grid system—A review. In Proceedings of the 2019 8th International Conference on Power Systems (ICPS), Rajasthan, India, 20–22 December 2019; pp. 1–6. [Google Scholar]
- Zhu, J.; Li, Y.; Yang, J.; Li, X.; Zeng, S.; Chen, Y. Planning of electric vehicle charging station based on queuing theory. J. Eng. 2017, 2017, 1867–1871. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, X.; Zhou, X. Distribution route optimization for electric vehicles in urban cold chain logistics for fresh products under time-varying traffic conditions. Math. Probl. Eng. 2020, 2020, 9864935. [Google Scholar] [CrossRef]
- Sester, M. Optimization approaches for generalization and data abstraction. Int. J. Geogr. Inf. Sci. 2005, 19, 871–897. [Google Scholar] [CrossRef]
- Sakai, T.; Imiya, A. Fast spectral clustering with random projection and sampling. In Proceedings of the International Workshop on Machine Learning and Data Mining in Pattern Recognition, Leipzig, Germany, 23–25 July 2009; pp. 372–384. [Google Scholar]
- Yuan, F.; Sawaya, K.E.; Loeffelholz, B.C.; Bauer, M.E. Land cover classification and change analysis of the Twin Cities (Minnesota) Metropolitan Area by multitemporal Landsat remote sensing. Remote Sens. Environ. 2005, 98, 317–328. [Google Scholar] [CrossRef]
- Yang, Q.; Sun, S.; Deng, S.; Zhao, Q.; Zhou, M. Optimal sizing of PEV fast charging stations with Markovian demand characterization. IEEE Trans. Smart Grid 2018, 10, 4457–4466. [Google Scholar] [CrossRef]
- Sklansky, J.; Gonzalez, V. Fast polygonal approximation of digitized curves. Pattern Recognit. 1980, 12, 327–331. [Google Scholar] [CrossRef]
- Ma, Q.; Wu, J.; He, C.; Hu, G. Spatial scaling of urban impervious surfaces across evolving landscapes: From cities to urban regions. Landsc. Urban Plan. 2018, 175, 50–61. [Google Scholar] [CrossRef]
- Sözen, A.; Arcaklıoğlu, E.; Özalp, M.; Çağlar, N. Forecasting based on neural network approach of solar potential in Turkey. Renew. Energy 2005, 30, 1075–1090. [Google Scholar] [CrossRef]
- Jiang, B.; Liu, X. Scaling of geographic space from the perspective of city and field blocks and using volunteered geographic information. Int. J. Geogr. Inf. Sci. 2012, 26, 215–229. [Google Scholar] [CrossRef]
- Panakkat, A.; Adeli, H. Recurrent neural network for approximate earthquake time and location prediction using multiple seismicity indicators. Comput.-Aided Civ. Infrastruct. Eng. 2009, 24, 280–292. [Google Scholar] [CrossRef]
- Ouammi, A.; Zejli, D.; Dagdougui, H.; Benchrifa, R. Artificial neural network analysis of Moroccan solar potential. Renew. Sustain. Energy Rev. 2012, 16, 4876–4889. [Google Scholar] [CrossRef]
- Barber, C.B.; Dobkin, D.P.; Huhdanpaa, H. The Quickhull Algorithm for Convex Hulls. ACM Trans. Math. Softw. 1996, 22, 469–483. [Google Scholar] [CrossRef]
- Rezaei, M. Improving a Centroid-Based Clustering by Using Suitable Centroids from Another Clustering. J. Classif. 2020, 37, 352–365. [Google Scholar] [CrossRef]
- OpenStreetMap Wiki Contributors. Overpass API/Overpass QL. OpenStreetMap Wiki, 2023. Page Name: Overpass API/Overpass QL, Date Retrieved: 4 July 2023 12:04 UTC, Page Version ID: 2550700. Available online: https://wiki.openstreetmap.org/w/index.php?title=Overpass_API/Overpass_QL&oldid=2550700 (accessed on 15 October 2023).
- UN. World Urbanization Prospects. 2018. Available online: https://population.un.org/wup/ (accessed on 15 October 2023).
- Gopalakrishnan, R.; Biswas, A.; Lightwala, A.; Vasudevan, S.; Dutta, P.; Tripathi, A. Demand prediction and placement optimization for electric vehicle charging stations. arXiv 2016, arXiv:1604.05472. [Google Scholar]
- Lam, A.Y.; Leung, Y.W.; Chu, X. Electric vehicle charging station placement. In Proceedings of the 2013 IEEE International Conference on Smart Grid Communications (SmartGridComm), Vancouver, BC, Canada, 21–24 October 2013; pp. 510–515. [Google Scholar] [CrossRef]
- Veneri, O.; Ferraro, L.; Capasso, C.; Iannuzzi, D. Charging infrastructures for EV: Overview of technologies and issues. In Proceedings of the 2012 Electrical Systems for Aircraft, Railway and Ship Propulsion, Bologna, Italy, 16–18 October 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Brandstätter, G.; Leitner, M.; Ljubić, I. Location of charging stations in electric car sharing systems. Transp. Sci. 2020, 54, 1408–1438. [Google Scholar] [CrossRef]
- Chen, T.D.; Kockelman, K.M.; Khan, M. The electric vehicle charging station location problem: A parking-based assignment method for Seattle. In Proceedings of the Transportation Research Board 92nd Annual Meeting, Washington, DC, USA, 13–17 January 2013; Volume 340, pp. 13–1254. [Google Scholar]
- Lam, A.Y.S.; Leung, Y.W.; Chu, X. Electric Vehicle Charging Station Placement: Formulation, Complexity, and Solutions. IEEE Trans. Smart Grid 2014, 5, 2846–2856. [Google Scholar] [CrossRef]
- Awasthi, A.; Venkitusamy, K.; Padmanaban, S.; Selvamuthukumaran, R.; Blaabjerg, F.; Singh, A.K. Optimal planning of electric vehicle charging station at the distribution system using hybrid optimization algorithm. Energy 2017, 133, 70–78. [Google Scholar] [CrossRef]
- Battapothula, G.; Yammani, C.; Maheswarapu, S. Multi-objective simultaneous optimal planning of electrical vehicle fast charging stations and DGs in distribution system. J. Mod. Power Syst. Clean Energy 2019, 7, 923–934. [Google Scholar] [CrossRef]
- Sadeghi-Barzani, P.; Rajabi-Ghahnavieh, A.; Kazemi-Karegar, H. Optimal fast charging station placing and sizing. Appl. Energy 2014, 125, 289–299. [Google Scholar] [CrossRef]
- Rajabi-Ghahnavieh, A.; Sadeghi-Barzani, P. Optimal Zonal Fast-Charging Station Placement Considering Urban Traffic Circulation. IEEE Trans. Veh. Technol. 2017, 66, 45–56. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware Settings | |
| Chip: Apple M1 | CPU cores: 8 |
| GPU: Apple M1 8-core GPU | DRAM: 8 GB |
| Software Settings | |
| Operating System: MacOS Monterrey 12.6 | Python Version: 3.7 |
| TensorFlow Version: 2.11.0 | Tkinter Version: 8.6.12 |
| Gudhi Version: 3.8.0 | CVXPY Version: 1.3.1 |
| Parameter | Description |
|---|---|
| The CCSs depict the potential charging stations across the city. | |
| The reachability distance is the maximum distance an EV user needs to travel from a DP. | |
| The budget represents the maximum possible number of CSs in a city. | |
| The demand points correspond to the points in the city that demand EV charging. |
| Symbol | Definition | Symbol | Definition |
|---|---|---|---|
| Number of CCSs | The distance matrix between DPs and CCSs | ||
| Number of DPs | Mapping between cluster and DPs | ||
| Reachability distance | Budget (max allowed CSs) | ||
| Total number of CSs | The supply matrix (DP-CS allocation) | ||
| Boolean array that indicates whether a CCS is a CS | A set of basic shapes and DP distribution | ||
| A set of clusters | Precomputed database | ||
| S | The shape of a cluster | A similar shape retrieved from the database | |
| Size of the set X | Concatenate x and y |
| City, Country | Area (km) | City, Country | Area (km) | City, Country | Area (km) |
|---|---|---|---|---|---|
| New York, USA | 386.79 | Lima, Peru | 241.31 | Lahore, Pakistan | 160.17 |
| Paris, France | 102.34 | Xian, China | 220.28 | Mumbai, India | 291.42 |
| Karachi, Pakistan | 153.01 | Beijing, China | 207.69 | Moscow, Russia | 128.10 |
| Rio de Janeiro, Brazil | 171.39 | Shanghai, China | 157.75 | Bangalore, India | 125.20 |
| Lagos, Nigeria | 165.09 | Seoul, South Korea | 166.19 | Ahmedabad, India | 147.39 |
| Hyderabad, India | 276.80 | Manila, Philippines | 151.15 | Chicago, USA | 139.47 |
| Bogota, Colombia | 205.81 | Chennai, India | 127.07 | Delhi, India | 257.32 |
| Tokyo, Japan | 169.75 | Sao Paulo, Brazil | 240.79 | Hangzhou, China | 162.14 |
| Tianjin, China | 114.95 | Istanbul, Turkey | 270.62 | Nanjing, China | 300.42 |
| Ho Chi Minh, Vietnam | 179.39 | Kinshasa, Congo | 153.25 | Cairo, Egypt | 170.04 |
| Madrid, Spain | 173.26 | Chongqing, China | 352.70 | Osaka, Japan | 111.54 |
| Jakarta, Indonesia | 183.40 | Kolkata, India | 150.39 | Chengdu, China | 170.70 |
| Buenos Aires, Argentina | 158.54 | Los Angeles, USA | 177.53 | Dhaka, Bangladesh | 185.52 |
| Luanda, Angola | 216.53 | Kuala Lumpur, Malaysia | 287.39 | Tehran, Iran | 128.08 |
| London, UK | 106.80 | Nagoya, Japan | 103.43 | Hong Kong, China | 316.96 |
| Shenzhen, China | 140.79 | Guangzhou, China | 132.14 | Mexico city, Mexico | 192.33 |
| Wuhan, China | 198.08 | Bangkok, Thailand | 183.51 | Berlin, Germany | 35.80 |
| Shape | Data Points |
|---|---|
| Circle | 3600 |
| Line | 2889 |
| Star | 2189 |
| Concentric circle | 1248 |
| Mesh | 203 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bose, M.; Dutta, B.R.; Shrivastava, N.; Sarangi, S.R. PC-ILP: A Fast and Intuitive Method to Place Electric Vehicle Charging Stations in Smart Cities. Smart Cities 2023, 6, 3060-3092. https://doi.org/10.3390/smartcities6060137
Bose M, Dutta BR, Shrivastava N, Sarangi SR. PC-ILP: A Fast and Intuitive Method to Place Electric Vehicle Charging Stations in Smart Cities. Smart Cities. 2023; 6(6):3060-3092. https://doi.org/10.3390/smartcities6060137
Chicago/Turabian StyleBose, Mehul, Bivas Ranjan Dutta, Nivedita Shrivastava, and Smruti R. Sarangi. 2023. "PC-ILP: A Fast and Intuitive Method to Place Electric Vehicle Charging Stations in Smart Cities" Smart Cities 6, no. 6: 3060-3092. https://doi.org/10.3390/smartcities6060137
APA StyleBose, M., Dutta, B. R., Shrivastava, N., & Sarangi, S. R. (2023). PC-ILP: A Fast and Intuitive Method to Place Electric Vehicle Charging Stations in Smart Cities. Smart Cities, 6(6), 3060-3092. https://doi.org/10.3390/smartcities6060137