Does Adoption of Ridehailing Result in More Frequent Sustainable Mobility Choices? An Investigation Based on the National Household Travel Survey (NHTS) 2017 Data

Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
3.1. National Household Travel Survey (NHTS) 2017 Data
3.2. Need for a Matched Sample
3.3. Getting Matched Samples using Propensity Score Matching
3.4. Summary Statistics
3.5. Multivariable Regression Models
3.6. Implementation of Regression Models
- Model NB-TRANSIT:
- Model NB-WALK:
- Model NB-BIKE:
- Model QP-VEHICLE:
3.7. Software and Packages Used for Analyses
4. Results
4.1. Interpretation of Regression Model Output
4.2. Multicollinearity and Goodness of Fit
4.3. Discussion on the Association between Ridehailing Adoption and Sustainable Mobility Choices after Controlling for the Confounders
5. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- The World Bank. Cities Around the World Want to Be Resilient and Sustainable. But What Does This Mean? Available online: https://www.worldbank.org/en/news/feature/2019/10/15/resilient-sustainable-cities-brazil-gpsc-conference. (accessed on 1 February 2020).
- Wang, S.; Ge, M. Everything You Need to Know About the Fastest-Growing Source of Global Emissions: Transport. Available online: https://www.wri.org/blog/2019/10/everything-you-need-know-about-fastest-growing-source-global-emissions-transport. (accessed on 1 February 2020).
- White, G.B. Stranded: How America’s Failing Public Transportation Increases Inequality. Available online: https://www.theatlantic.com/business/archive/2015/05/stranded-how-americas-failing-public-transportation-increases-inequality/393419/ (accessed on 1 February 2020).
- Sustainable Transportation and TDM. Available online: https://www.vtpi.org/tdm/tdm67.htm (accessed on 1 February 2020).
- Olafsson, A.S.; Nielsen, T.S.; Carstensen, T.A. Cycling in multimodal transport behaviours: Exploring modality styles in the Danish population. JTRG 2016, 52, 123–130. [Google Scholar] [CrossRef]
- Nobis, C. Facets and Causes of Sustainable Mobility Behavior. Transp. Res. Rec. J. Transp. Res. Board 2007, 1, 35–44. [Google Scholar] [CrossRef]
- Spickermann, A.; Grienitz, V.; von der Gracht, H.A. Heading towards a multimodal city of the future? Multi-stakeholder scenarios for urban mobility. Technol. Forecast. Soc. Chang. 2014, 89, 201–221. [Google Scholar] [CrossRef]
- Thematic Discussion 8: Multi-?-Modal Sustainable Transport and Transit Solutions: Connecting Rail, Maritime, Road and Air. Available online: https://sustainabledevelopment.un.org/content/documents/11694Thematicdiscussion8conceptnote.pdf (accessed on 1 February 2020).
- Bricka, S.; Carlson, T.; Geiselbrecht, T.; Miller, K.; Moran, M. Shared Mobility Programs: Guidebook for Agencies. Available online: https://groups.tti.tamu.edu/communications/files/2016/10/Shared-Mobility-Guidebook-0-6818-P1.pdf (accessed on 20 March 2020).
- Jiang, J. More Americans Are Using Ride-Hailing Apps. Available online: https://www.pewresearch.org/fact-tank/2019/01/04/more-americans-are-using-ride-hailing-apps/ (accessed on 11 March 2020).
- Rayle, L.; Dai, D.; Chan, N.; Cervero, R.; Shaheen, S. Just a better taxi? A survey-based comparison of taxis, transit, and ridesourcing services in San Francisco. Transp. Policy 2016, 45, 168–178. [Google Scholar] [CrossRef]
- Alemi, F. What Makes Travelers Use Ridehailing? Exploring the Latent Constructs behind the Adoption and Frequency of Use of Ridehailing Services, and Their Impacts on the Use of Other Travel Modes; University of California: Davis, CA, USA, 2018. [Google Scholar]
- Furuhata, M.; Dessouky, M.; Ordóñez, F.; Brunet, M.; Wang, X.; Koenig, S. Ridesharing: The state-of-the-art and future directions. Transp. Res. Part B 2013, 57, 28–46. [Google Scholar] [CrossRef]
- Chu, T. America’s Transportation History is Full of Mistakes. Let’s Not Make Another One. Available online: https://www.citylab.com/perspective/2019/09/transportation-future-mobility-technology-regulations-data/597748/ (accessed on 20 March 2020).
- Clewlow, R.R.; Mishra, G.S. Disruptive Transportation: The Adoption, Utilization, and Impacts of Ride-Hailing in the United States; UC Davis Institute of Transportation Studies: Davis, CA, USA, 2017. [Google Scholar]
- Rodier, C. The Effects of Ride Hailing Services on Travel and Associated Greenhouse Gas Emissions; UC Davis Institute of Transportation Studies: Davis, CA, USA, 2018. [Google Scholar]
- Henao, A.; Marshall, W.E. The impact of ride-hailing on vehicle miles traveled. Transportation 2019, 46, 2173–2194. [Google Scholar] [CrossRef]
- Feigon, S.; Murphy, C. Shared Mobility and the Transformation of Public Transit. Available online: http://www.trb.org/Publications/Blurbs/174653.aspx (accessed on 10 February 2020).
- Hampshire, R.C.; Simek, C.; Fabusuyi, T.; Di, X.; Chen, X. Measuring the Impact of an Unanticipated Disruption of Uber/Lyft in Austin, TX. Soc. Sci. Res. Netw. 2017. [Google Scholar] [CrossRef]
- Hall, J.D.; Palsson, C.; Price, J. Is Uber a substitute or complement for public transit? J. Urban. Econ. 2018, 108, 36–50. [Google Scholar] [CrossRef]
- Boisjoly, G.; Grisé, E.; Maguire, M.; Veillette, M.; Deboosere, R.; Berrebi, E.; El-Geneidy, A. Invest in the ride: A 14 year longitudinal analysis of the determinants of public transport ridership in 25 North American cities. Transp. Res. Part A 2018, 116, 434–445. [Google Scholar] [CrossRef]
- Graehler, M.J.; Mucci, R.A.; Erhardt, G.D. Understanding the recent transit ridership decline in major US cities: Service cuts or emerging modes? In Proceedings of the Transportation Research Board Annual Meeting, Washington, DC, USA, 13–17 January 2019. [Google Scholar]
- APA Dictionary of Psychology. Available online: http://dictionary.apa.org/self-selection-bias (accessed on 10 February 2020).
- Winship, C.; Morgan, S.L. The estimation of causal effects from observational data. Annu. Rev. Sociol. 1999, 25, 659–707. [Google Scholar] [CrossRef]
- 2017 National Household Travel Survey. Available online: https://nhts.ornl.gov (accessed on 10 February 2020).
- Anderson, M. Who Relies on Public Transit in the U.S. Available online: https://www.pewresearch.org/fact-tank/2016/04/07/who-relies-on-public-transit-in-the-u-s/ (accessed on 5 February 2020).
- Uber Help, Requests from Underage Riders. Available online: https://help.uber.com/driving-and-delivering/article/requests-from-underage-riders---?nodeId=43b84de6-758b-489e-b088-7ee69c749ccd (accessed on 24 January 2020).
- Lyft, Safety Policies. Available online: https://help.lyft.com/hc/en-us/articles/115012923127-Safety-policies (accessed on 10 February 2020).
- Gelman, A.; Hill, J. Data Analysis Using Regression and Multilevel/Hierarchical Models; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Piquero, A.R.; Weisburd, D. Handbook of Quantitative Criminology; Springer: New York, NY, USA, 2010. [Google Scholar]
- Mishra, G.S.; Clewlow, R.R.; Mokhtarian, P.L.; Widaman, K.F. Research in Transportation Economics the effect of carsharing on vehicle holdings and travel behavior: A propensity score and causal mediation analysis of the San Francisco Bay Area. Res. Transp. Econ. 2015, 52, 46–55. [Google Scholar] [CrossRef]
- Rosenbaum, P.R.; Rubin, D.B. The Central Role of the Propensity Score in Observational Studies for Causal Effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Ho, D.E.; Imai, K.; King, G.; Stuart, E.A. Matching as Nonparametric Preprocessing for Reducing Model Dependence in Parametric Causal Inference. Polit. Anal. 2007, 15, 199–236. [Google Scholar] [CrossRef]
- Claritas, Assessing the Role of Urbanicity. Available online: https://nhts.ornl.gov/assets/Assessing_the_Role_of_Urbanicity.pdf (accessed on 5 February 2020).
- Center, P.R. The Generations Defined. Available online: https://www.pewresearch.org/fact-tank/2018/04/11/millennials-largest-generation-us-labor-force/ft_18-04-02_generationsdefined2017_working-age/ (accessed on 2 February 2020).
- NHTS, Main Study Retrieval Questionnaire. Available online: https://nhts.ornl.gov/2016/pub/NHTS_Retrieval_Instrument_20161006.pdf (accessed on 10 February 2020).
- Coxe, S.; West, S.G.; Aiken, L.S. The Analysis of Count Data: A Gentle Introduction to Poisson Regression and Its Alternatives. J. Personal. Assess. 2009, 91, 121–136. [Google Scholar] [CrossRef] [PubMed]
- Long, J.S.; Freese, J. Regression Models for Categorical Dependent Variables using Stata; Stata Press: College Station, TX, USA, 2006. [Google Scholar]
- Marshall, W.E.; Ferenchak, N.N. Why cities with high bicycling rates are safer for all road users. J. Transp. Health 2018, 13, 285–301. [Google Scholar] [CrossRef]
- Zahran, S.; Brody, S.D.; Maghelal, P.; Prelog, A.; Lacy, M. Cycling and walking: Explaining the spatial distribution of healthy modes of transportation in the United States. Transp. Res. Part D 2008, 13, 461–469. [Google Scholar] [CrossRef]
- Wang, X.; Lindsey, G.; Hankey, S.; Hoff, K. Estimating Mixed-Mode Urban Trail Traffic Using Negative Binomial Regression Models. J. Urban Plan. Dev. 2014, 140, 1–9. [Google Scholar] [CrossRef]
- Hu, S.; Li, C.; Lee, C. Journal of the Chinese Institute of Engineers Model crash frequency at highway-railroad grade crossings using negative binomial regression. J. Chin. Inst. Eng. 2012, 35, 841–852. [Google Scholar] [CrossRef]
- Cao, X.; Handy, S.L.; Mokhtarian, P.L. The influences of the built environment and residential self-selection on pedestrian behavior: Evidence from Austin, TX. Transportation 2006, 33, 1–20. [Google Scholar] [CrossRef]
- Zhao, Y.; Kockelman, K.M. Household vehicle ownership by vehicle type: Application of a multivariate negative binomial model. In Proceedings of the Transportation Research Board’s 81st Annual Meeting, Washington, DC, USA, 13–17 January 2002. [Google Scholar]
- Young, M.; Lachapelle, U. Transportation behaviours of the growing Canadian single-person households. Transp. Policy 2016, 57, 41–50. [Google Scholar] [CrossRef]
- Harris, T.; Hardin, J.W.; Yang, Z. Modeling underdispersed count data with generalized Poisson regression. Stata J. 2012, 12, 736–747. [Google Scholar] [CrossRef]
- Giuffrè, O.; Granà, A.; Roberta, M.; Corriere, F. Handling Underdispersion in Calibrating Safety Performance Function at Urban, Four-Leg, Signalized Intersections. J. Transp. Saf. Secur. 2011, 3, 174–188. [Google Scholar] [CrossRef]
- Wilson, S.R.; Leonard, R.D.; Edwards, D.J.; Swieringa, K.A.; Underwood, M. Inference for Under-Dispersed Data: Assessing the Performance of an Airborne Spacing Algorithm. Available online: https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20190027465.pdf (accessed on 10 February 2020).
- Hoef, J.M.V.; Boveng, P.L. Quasi-poisson vs. negative binomial regression: How should we model overdispersed count data? Publ. Agencies Staff U.S. Dep. Commer. 2007, 142, 2766–2772. [Google Scholar]
- Lachapelle, U.; Noland, R.B. Does the commute mode affect the frequency of walking behavior? The public transit link. Transp. Policy 2012, 21, 26–36. [Google Scholar] [CrossRef]
- Lachapelle, U. Walk, Bicycle, and Transit Trips of Transit-Dependent and Choice Riders in the 2009 United States National Household Travel Survey. J. Phys. Act. Heal. 2015, 12, 1139–1147. [Google Scholar] [CrossRef] [PubMed]
- Bhat, C.R.; Pulugurta, V.A. Comparison of Two Alternative Behavioral Choice Mechanisms for Houshold Auto Ownership Decisions. Transp. Res. Part B Methodol. 1998, 32, 61–75. [Google Scholar] [CrossRef]
- Chen, N. How Do Socio-Demographics and The Built Environment Affect Individual Accessibility Based on Activity Space as A Transport Exclusion Indicator? Ohio State University: Columbus, OH, USA, 2016. [Google Scholar]
- Ho, D.E.; Imai, K.; King, G.; Stuart, E.A. MatchIt: Nonparametric Preprocessing for Parametric Causal Inference. J. Stat. Softw. 2011, 42, 1–28. [Google Scholar] [CrossRef]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing. In R Foundation for Statistical Computing; R Core Team: Vienna, Austria, 2013; ISBN 3-900051-07-0. [Google Scholar]
- Liu, L.; Jiang, C.; Zhou, S.; Liu, K.; Du, F. Impact of public bus system on spatial burglary patterns in a Chinese urban context. Appl. Geogr. 2017, 89, 142–149. [Google Scholar] [CrossRef]
- Highly Correlated Predictors. Available online: https://online.stat.psu.edu/stat462/node/179/ (accessed on 10 February 2020).
- Allison, P. When Can You Safely Ignore Multicolliniearity. Available online: https://statisticalhorizons.com/multicollinearity (accessed on 10 February 2020).
- Fox, J.; Weisberg, S. An R Companion to Applied Regression, 3th ed.; Sage: Thousand Oaks, CA, USA, 2019. [Google Scholar]
- Negative Binomial Regression|Stata Annotated Output. Available online: https://stats.idre.ucla.edu/stata/output/negative-binomial-regression/ (accessed on 10 February 2020).
- What Are the pseudo R-Squareds? Available online: https://stats.idre.ucla.edu/other/mult-pkg/faq/general/faq-what-are-pseudo-r-squareds/ (accessed on 10 February 2020).
- Pseudo R-Squared Measures. Available online: https://www.ibm.com/support/knowledgecenter/SSLVMB_24.0.0/spss/tutorials/plum_germcr_rsquare.html (accessed on 10 February 2020).
- Signorell, A. DescTools: Tools for Descriptive Statistics. Available online: https://cran.r-project.org/package=DescTools (accessed on 10 February 2020).
- McFadden, D. Quantitative Methods for Analyzing Travel Behavior of Individuals: Some Recent Developments; University of California: Berkeley, CA, USA, 1977. [Google Scholar]
- Jaffe, E. Uber and Public Transit are Trying to Get Along. Available online: https://www.citylab.com/solutions/2015/08/uber-and-public-transit-are-trying-to-get-along/400283/ (accessed on 2 February 2020).
- Building the Future of Public Transit Together. Available online: https://www.uber.com/us/en/transit/agency/ (accessed on 2 February 2020).
- Zhang, Y.; Zhang, Y. Exploring the Relationship between Ridesharing and Public Transit Use in the United States. Int. J. Environ. Res. Public Health 2018, 15, 1763. [Google Scholar] [CrossRef]
- Conway, M.W.; Salon, D.; King, D.A. Trends in Taxi Use and the Advent of Ridehailing, 1995–2017: Evidence from the US National Household Travel Survey. Urban Sci. 2018, 2, 79. [Google Scholar] [CrossRef]
- Sikder, S. Who Uses Ride-Hailing Services in the United States? Transp. Res. Rec. J. Transp. Res. Board 2019. [Google Scholar] [CrossRef]


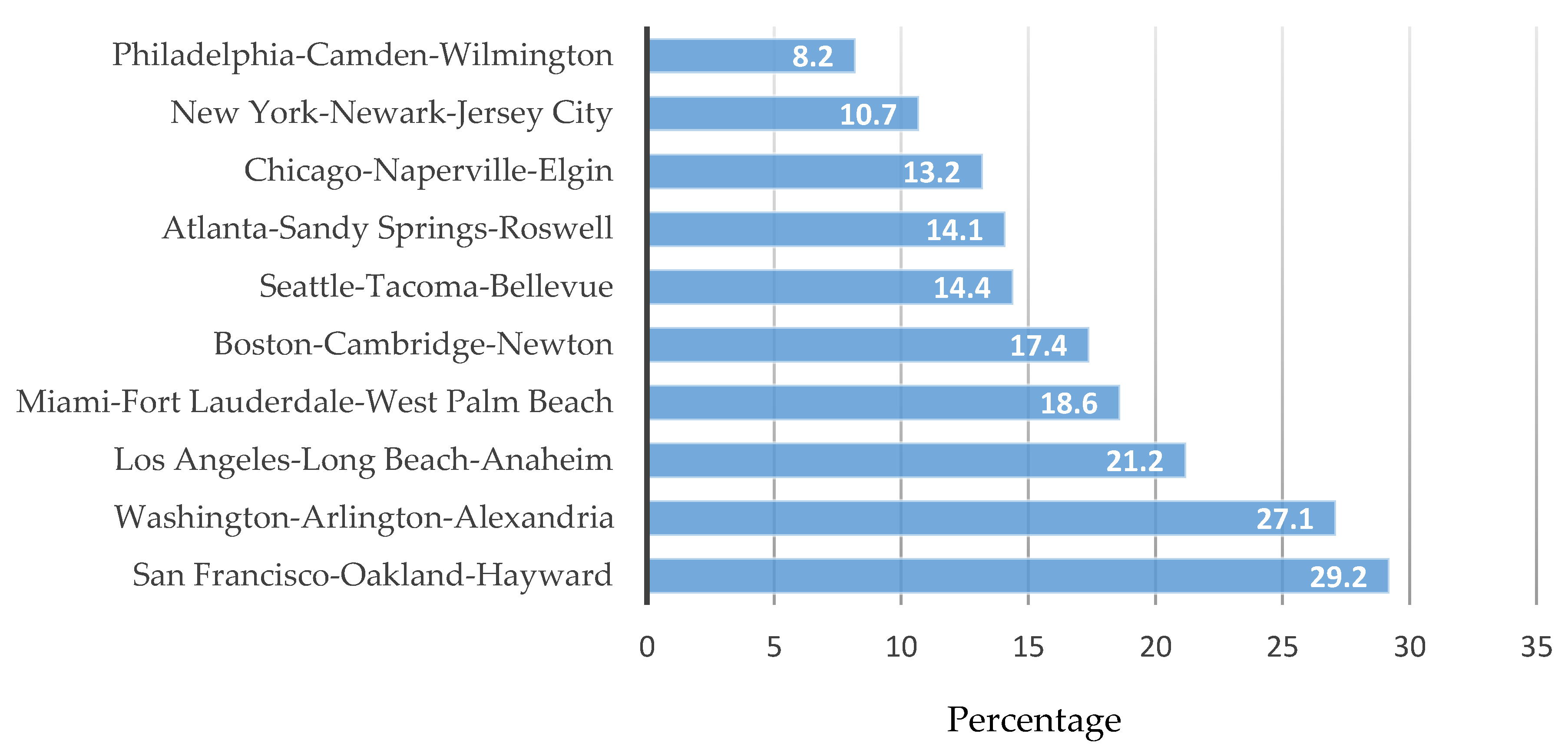{kind=link}
| Would Have Chosen If Ridehailing Services were Unavailable * | Article | |||||
|---|---|---|---|---|---|---|
| Rayle et al. [11] | Clewlow and Mishra [15] | Alemi [12] | Henao and Marshall [17] | Feigon and Murphy [18] | ||
| Generation X | Millennial | |||||
| Would not have made/Fewer Trips Transit Walk Bike Walk or Bike Drive private vehicle Other | -- 33% 8% 2% -- 6% 51% | 22% 15% 17% 7% -- 21% 19% | 7% 11.9% -- -- 11.9% 38.3% 30.9% | 9.2% 27.4% -- -- 24.6% 37.8% 1% | 12.22% 22.2% -- -- 11.9% 19% 34.7% | 0% 15% 6% 7% -- 20% 52% |
| Variable Name | Variable Description | Levels/Values |
|---|---|---|
| HBHUR | Urbanicity of Household Location (as defined by Claritas [34]) | Urban Suburban Second City Small Town Rural |
| INCOME * | Annual Household Income | Less than $50,000 $50,000 to $100,000 $100,000 or more |
| EDUCATION * | Educational Attainment | Below Bachelor’s Bachelor’s or above |
| RACE * | Race | White Black or African American Asian Others (American Indian or Alaska Native, Native Hawaiian or other Pacific Islander, Multiple responses selected, Some other race) |
| R_SEX | Sex | Male Female |
| HHSIZE | Count of Household Members | 1–13 |
| GENERATION * | Generation (as defined by the Pew Research Center [35]) | Post-Millennial (Aged between 18 and 20 )Millennial (Aged between 21 and 36) Generation X (Aged between 37 and 52) Baby Boomer (Aged between 53 and 71) Silent and Greatest (Aged 72 or above) |
| WRKCOUNT | Number of workers in household | 0–7 |
| LIF_CYC | Life Cycle classification for the household, derived by attributes pertaining to age, relationship, and work status | One adult, no children 2+ adults, no children One adult, youngest child 0–5 2+ adults, youngest child 0–5 One adult, youngest child 6–15 2+ adults, youngest child 6–15 One adult, youngest child 16–21 2+ adults, youngest child 16–21One adult, retired, no children 2+ adults, retired, no children |
| Variable Name | Question in the NHTS 2017 [36] | Values/Levels | Data Type |
|---|---|---|---|
| PTUSED | In the past 30 days, about how many days have you used public transportation such as buses, subways, streetcars, or commuter trains? | 0–240 | Count |
| NWALKTRIP | In the past 7 days, how many times did you take a walk outside including walks to exercise, go somewhere, or to walk the dog (e.g., walk to a friend’s house, walk around the neighborhood, walk to the store, etc.)? | 0–200 | Count |
| NBIKETRIP | In the past 7 days, how many times did you ride a bicycle outside including bicycling to exercise, or to go somewhere (e.g., bike to a friend’s house, bike around the neighborhood, bike to the store, etc.)? | 0–99 | Count |
| HHVEHCNT | How many vehicles are owned, leased, or available for regular use by the people who currently live in your household? Include motorcycles, mopeds, and RVs. | 0–12 | Count |
| CARSHARE | In the past 30 days, how many times did you use a car-sharing service where a car can be rented by the hour (e.g., Zipcar orCar2Go)? | 0 = Non-adopter 1 = Adopter | Binary |
| RIDEHAIL * | In the past 30 days, how many times have you purchased a ride with a smartphone rideshare app (e.g., Uber, Lyft, Sidecar)? | 0 = Non-adopter 1 = Adopter | Binary |
| Core-Based Statistical Area (CBSA) of the Respondent’s Home Address | Public Transit Trips | Walking Trips | Biking Trips | Household Vehicle | ||||
|---|---|---|---|---|---|---|---|---|
| Adopter | Non-Adopter | Adopter | Non-Adopter | Adopter | Non-Adopter | Adopter | Non-Adopter | |
|
New York–Newark–Jersey City, NY–NJ–PA ( ) | 12.57 * | 6.86 * | 12.25 * | 8.68 * | 0.80 * | 0.29 * | 1.48 * | 1.85 * |
|
Atlanta–Sandy Springs–Roswell, GA ( ) | 2.54 * | 0.72 * | 6.09 | 5.67 | 0.29 * | 0.17 * | 1.90 * | 2.14 * |
|
Boston–Cambridge–Newton, MA–NH ( ) | 9.19 * | 5.39 * | 11.60 | 9.50 | 0.62 | 0.68 | 1.26 * | 1.68 * |
|
Chicago–Naperville–Elgin, IL–IN–WI ( ) | 7.45 * | 4.19 * | 8.79 * | 6.71 * | 0.56 | 0.48 | 1.85 | 2.00 |
|
Los Angeles–Long Beach–Anaheim, CA ( ) | 2.14 * | 1.30 * | 7.11 * | 5.24 * | 0.51 * | 0.29 * | 2.02 * | 2.15 * |
| Miami–Fort Lauderdale–West Palm Beach, FL ( ) | 2.02 * | 0.49 * | 7.26 * | 4.57 * | 0.62 | 0.31 | 2.24 | 2.00 |
| Philadelphia–Camden–Wilmington, PA–NJ–DE–MD ( ) | 7.28 * | 2.13 * | 10.46 * | 7.31 * | 0.62 * | 0.13 * | 1.85 | 2.10 |
|
San Francisco–Oakland–Hayward, CA ( ) | 8.01 * | 3.91 * | 9.46 * | 6.16 * | 0.92 * | 0.45 * | 1.69 * | 2.16 * |
|
Seattle–Tacoma–Bellevue, WA ( ) | 6.52 * | 2.78 * | 7.93 | 6.66 | 0.93 * | 0.08 * | 1.71 * | 2.10 * |
| Washington–Arlington–Alexandria, DC–VA–MD–WV ( ) | 9.54 * | 4.70 * | 11.86 * | 7.41 * | 0.84 * | 0.35 * | 1.36 * | 1.70 * |
| Core-Based Statistical Area (CBSA) of the Respondent’s Home Address | Public Transit Trips | Walking Trips | Biking Trips | Household Vehicle | ||||
|---|---|---|---|---|---|---|---|---|
| Mean | Variance | Mean | Variance | Mean | Variance | Mean | Variance | |
|
New York–Newark–Jersey City, NY–NJ–PA | 9.72 | 157.56 | 10.47 | 154.75 | 0.54 | 10.34 | 1.66 | 1.58 |
| Atlanta–Sandy Springs–Roswell, GA | 1.63 | 26.66 | 5.88 | 65.12 | 0.23 | 1.28 | 2.02 | 0.98 |
| Boston–Cambridge–Newton, MA–NH | 7.29 | 103.83 | 10.55 | 112.84 | 0.65 | 6.34 | 1.47 | 1.28 |
| Chicago–Naperville–Elgin, IL–IN–WI | 5.82 | 110.44 | 7.75 | 80.93 | 0.52 | 3.56 | 1.93 | 1.42 |
| Los Angeles–Long Beach–Anaheim, CA | 1.72 | 32.86 | 6.17 | 64.48 | 0.40 | 3.00 | 2.09 | 1.32 |
| Miami–Fort Lauderdale–West Palm Beach, FL | 1.26 | 24.37 | 0.46 | 2.89 | 0.46 | 2.89 | 2.12 | 1.01 |
| Philadelphia–Camden–Wilmington, PA–NJ–DE–MD | 4.71 | 95.77 | 8.89 | 109.98 | 0.38 | 2.28 | 1.98 | 1.28 |
| San Francisco–Oakland–Hayward, CA | 5.96 | 91.43 | 7.81 | 73.32 | 0.69 | 5.06 | 1.92 | 1.39 |
| Seattle–Tacoma–Bellevue, WA | 4.65 | 63.91 | 7.30 | 49.17 | 0.51 | 3.37 | 1.90 | 1.21 |
| Washington=Arlington–Alexandria, DC–VA–MD–WV | 7.12 | 103.59 | 9.72 | 98.99 | 0.59 | 4.68 | 1.53 | 1.09 |
| Area Relevant to the Model | Model | |||
|---|---|---|---|---|
| NB-TRANSIT | NB-WALK | NB-BIKE | QP-VEHICLE | |
| New York–Newark–Jersey City, NY–NJ–PA | 1.570 * | 1.154 * | 1.872 * | 0.954 |
| Atlanta–Sandy Springs–Roswell, GA | 3.312 * | 0.952 | 1.096 | 0.930 * |
| Boston–Cambridge–Newton, MA–NH | 2.434 * | 1.120 | 0.765 | 0.935 |
| Chicago–Naperville–Elgin, IL–IN–WI | 1.651 * | 1.183 | 1.394 | 1.104 |
| Los Angeles–Long Beach–Anaheim, CA | 1.552 * | 1.274 * | 1.508 * | 0.976 |
| Miami–Fort Lauderdale–West Palm Beach, FL | 2.740 | 1.511 * | 1.260 | 1.153 * |
| Philadelphia–Camden–Wilmington, PA–NJ–DE–MD | 3.524 * | 1.099 | 6.101 * | 1.002 |
| San Francisco–Oakland–Hayward, CA | 1.528 * | 1.226 * | 1.063 | 0.911 * |
| Seattle–Tacoma–Bellevue, WA | 2.047 * | 0.942 | 7.975 * | 0.899 |
| Washington–-Arlington–Alexandria, DC–VA–MD–WV | 1.639 * | 1.221 * | 2.222 * | 1.007 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Das, V. Does Adoption of Ridehailing Result in More Frequent Sustainable Mobility Choices? An Investigation Based on the National Household Travel Survey (NHTS) 2017 Data. Smart Cities 2020, 3, 385-400. https://doi.org/10.3390/smartcities3020020
Das V. Does Adoption of Ridehailing Result in More Frequent Sustainable Mobility Choices? An Investigation Based on the National Household Travel Survey (NHTS) 2017 Data. Smart Cities. 2020; 3(2):385-400. https://doi.org/10.3390/smartcities3020020
Chicago/Turabian StyleDas, Vivekananda. 2020. "Does Adoption of Ridehailing Result in More Frequent Sustainable Mobility Choices? An Investigation Based on the National Household Travel Survey (NHTS) 2017 Data" Smart Cities 3, no. 2: 385-400. https://doi.org/10.3390/smartcities3020020
APA StyleDas, V. (2020). Does Adoption of Ridehailing Result in More Frequent Sustainable Mobility Choices? An Investigation Based on the National Household Travel Survey (NHTS) 2017 Data. Smart Cities, 3(2), 385-400. https://doi.org/10.3390/smartcities3020020