1. Introduction
In recent years, discrete Tchebichef transform (DTT) became widely applied in image compression [
1,
2,
3,
4,
5,
6,
7,
8], video coding [
8,
9,
10], signal processing [
11], image segmentation [
12], image denoising [
13], speech recognition [
14,
15], etc. DTT is a linear orthonormal transform obtained from orthogonal Tchebichef polynomials. Compared with discrete cosine transform (DCT), DTT demonstrates similar energy compactness and decorrelation for images of nature scenes. Furthermore, DTT outperforms DCT in images with significant illumination variations. Owing to its energy compactness and decorrelation, DTT is extensively used and highly effective in image compression [
1,
2,
3,
4,
5,
6,
7,
8,
16,
17]. For example, in [
10], the proposed DTT approximation was embedded in the software library x264 [
18] for encoding video streams into the H.264/AVC standard [
19]. It requires 38% fewer additions and eliminates bit-shifting operations compared to the 8-point integer approximation of the DCT currently used in H.264/AVC [
20,
21]. The latter requires 32 additions and 14 bit-shifting operations.
The signal processing in the DTT domain is applied in neural signal compression when the neural recording microsystems are designed with specific requirements for the power consumption, chip area, and the wireless interfacing data rate [
22].
In [
23], DTT was embedded in the wavelet-based still image coder SPECK. The resulting coder HLDTT has shown a significant improvement in peak signal-to-noise ratio at lower bit rates. Also, a reduction in encoding and decoding time over DCT-based embedded coders was achieved to realize a low-power image compression system for hand-held portable devices [
7].
Other areas of DTT application are also of interest. In [
24], a digital watermarking algorithm using DTT was proposed as more robust to Gaussian noise attacks. To add a watermark, the initial image is split into nonoverlapped blocks, and DTT is performed for each of them. A watermark image was embedded into the largest DTT coefficients of each block, resulting in time savings compared to DCT [
24].
In various applications, reducing the computational time for DTT is essential for achieving real-time or high-performance implementations. The literature describes two primary types of DTT based on their applications: real DTT and integer DTT. The original real DTT matrix can be derived by multiplying each row of the integer DTT matrix by a specific coefficient. Consequently, fast algorithms for real DTT can be efficiently developed based on the fast algorithms designed for integer DTT [
17].
Because the main application of DTT is image compression and video coding, the developing of fast DTT algorithms is oriented towards the standards of these applications. As a consequence, fast algorithms were constructed for the 4 × 4 and 8 × 8 two-dimensional (2D) integer DTT and its approximations [
1,
8,
10,
25,
26,
27,
28,
29,
30,
31,
32,
33]. The authors are not aware of any articles devoted to designing fast DTT algorithms for input sequences of lengths different from 4 and 8. However, along with image compression, DTT is utilized for various tasks such as signal and image denoising, segmentation, and classification, where the result is often affected by the size of the processing window. In these situations, restricting the window size to values of 4 and 8 is not relevant. Moreover, short-length DTT algorithms can be included as typical modules to develop long-length algorithms [
34,
35].
Therefore, an urgent problem is constructing fast DTT algorithms for short-length input sequences. Next, to determine the appropriate strategy for developing such fast DTT algorithms, the articles related to this problem are considered.
1.1. State of the Art of the Problem
To design fast DTT algorithms, the polynomial algebraic approach, sparse matrix factorization, and different heuristics are applied [
22,
25,
26,
27,
28,
29,
30,
31,
32,
33]. Recursive expressions for obtaining the entries for DTT matrices do not facilitate the development of fast radix-type algorithms, although such algorithms are efficiently and widely employed for orthogonal trigonometric transforms [
36]. Thus, in [
30], the polynomial algebraic approach is used to construct the fast algorithm for the 2D 4 × 4 real DTT. The expressions for transform matrix entries were regrouped to determine the products of Tchebichef polynomials via the linear combinations of new basis functions. These results reduce multiplications by 50% and additions by 31% compared to the naive product bearing in mind the separability and symmetry of the DTT matrix. However, very cumbersome mathematical calculations of the algebraic approach are an obstacle to obtaining fast algorithms for DTTs with other input sequence lengths.
In [
1], multiplier-less algorithms were proposed for one-dimensional (1D) and 2D integer 8 × 8 DTTs. These algorithms were obtained heuristically, although they used butterfly architecture. The sparse matrix factorization or data flow graphs are not presented for them. Despite this, these algorithms are considered to be among the most effective. In the 1D case, the number of additions was reduced by 50% compared to a naive method when considering the separability and symmetry properties of the DTT. In addition, 29 shifts were required in the 1D case. However, the above heuristics were proposed to construct an algorithm specifically for the case of an 8 × 8 integer DTT. Generalization of it to cases of other lengths of data sequence was not considered.
The primary way to obtain fast DTT algorithms is sparse matrix factorization and/or construction of data flow graphs with butterfly architecture [
28,
29,
30,
31,
32,
33]. For example, in [
28,
29], sparse matrix factorization was proposed for a 4 × 4 real 2D DTT. Although an additional 20 shifts were required, it reduced multiplications by 81% and additions by 17% compared with the naive product bearing in mind the separability and symmetry of the DTT matrix. Proposed in [
10], a fast algorithm with butterfly architecture for a 1D DTT approximation required only 20 additions, reducing operations by 55% compared to [
1]. In [
8], fast algorithms for 4 × 4 and 8 × 8 integer 1D DTTs were presented for data flow graphs based on butterfly architecture. The algorithms for 4 × 4/8 × 8 2D DTTs were also implemented using Verilog HDL [
8].
Hence, efficient fast DTT algorithms are developed via sparse matrix factorization or data flow graphs with butterfly architecture. In general, such an approach is appropriate for designing fast DTT algorithms for even lengths of input sequences, including lengths different from 4 and 8. However, when dealing with odd lengths, problems arise in constructing butterflies, and thus the choice of an approach for constructing fast DTT algorithms for odd lengths remains open. Thus, the above short review of existing fast DTT algorithms allowed us to determine unsolved parts of the general problem of developing fast DTT algorithms for short-length input sequences.
1.2. The Main Contributions of This Paper
As previously mentioned, fast
N-point DTT algorithms for short-length signals can be developed via data flow graphs with a butterfly architecture and sparse matrix factorization. However, for some values of
N, constructing such architecture can be challenging. To address this shortcoming, we propose using the structural approach in addition to sparse matrix factorization to develop fast real DTT algorithms for short-length input signals. This approach was successfully applied to factorize the matrices of trigonometric transforms in [
37,
38,
39,
40]. As a result, the number of arithmetic operations for these transforms was significantly reduced. According to the structural approach, the rows and columns of the transform matrix are rearranged, possibly changing the sign of some rows or columns. Then, the predefined templates are searched and extracted from the transform matrix. Based on the predetermined factorization of templates, the factorization of the entire transform matrix is obtained.
The structural approach to DTT matrix decomposition is due to the symmetrical structure of the DTT coefficients matrix. However, as N increases, template extraction becomes a cumbersome process. That is why it is relevant to integrate the structural approach into the construction of data flow graphs with butterfly architecture. The efficiency of this trick owes to the symmetry of DTT coefficients, which can be paired for constructing butterfly modules. Thus, this research aims to reduce the computational complexity of a 1D real DTT by developing fast algorithms. These algorithms combine sparse matrix factorization with the structural approach for input sequences of length N= 3, 4, 5, 6, 7, 8.
The paper is organized as follows. The problem of reducing the computational complexity of DTT and the aim of the research are introduced in
Section 1. Notations and a mathematical background are presented in
Section 2. Next, in
Section 3, fast algorithms for a real DTT are designed for
N in the range from 3 to 8. A discussion of the research results is presented in
Section 4 and
Section 5. Also, the computational costs required to implement the developed and existing algorithms are compared. In
Section 6 the conclusions are provided.
2. Short Background
Real 1D DTT can be expressed as follows [
1,
17,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33]:
where
is the output sequence after direct DTT;
is a kernel of DTT;
is the input data sequence; and
N is the number of signal samples. The kernel of DTT can be obtained as
DTT satisfies the separability and even symmetry properties. Specifically,
, and 2D DTT can be computed via 1D DTT by applying a row-column decomposition. In matrix notation, real 1D DTT is defined as follows [
1,
17,
23,
24,
32]:
where
,
,
.
The factorization of the matrix
on integer and float numbers can be obtained as:
where
is the integer 1D DTT matrix,
,
The numbers
and
are defined as [
17]:
In this paper, we use the following notations: is an order N identity matrix; is a 2 × 2 Hadamard matrix; is an N×M matrix of ones (a matrix where every element is equal to one); ⊗ is the Kronecker product of two matrices; ⊕ is the direct sum of two matrices. An empty cell in a matrix means it contains zero. The multipliers were marked as .
3. Reduced Complexity DTT Algorithms for Short-Length Input Sequences
3.1. Algorithm for 3-Point DTT
To design the algorithm for three-point real DTT, we express the latter as a matrix-vector product:
where
,
,
with
. The vector
is computed by expression (5), where
,
. As a result, we yield
=
or
≈
.
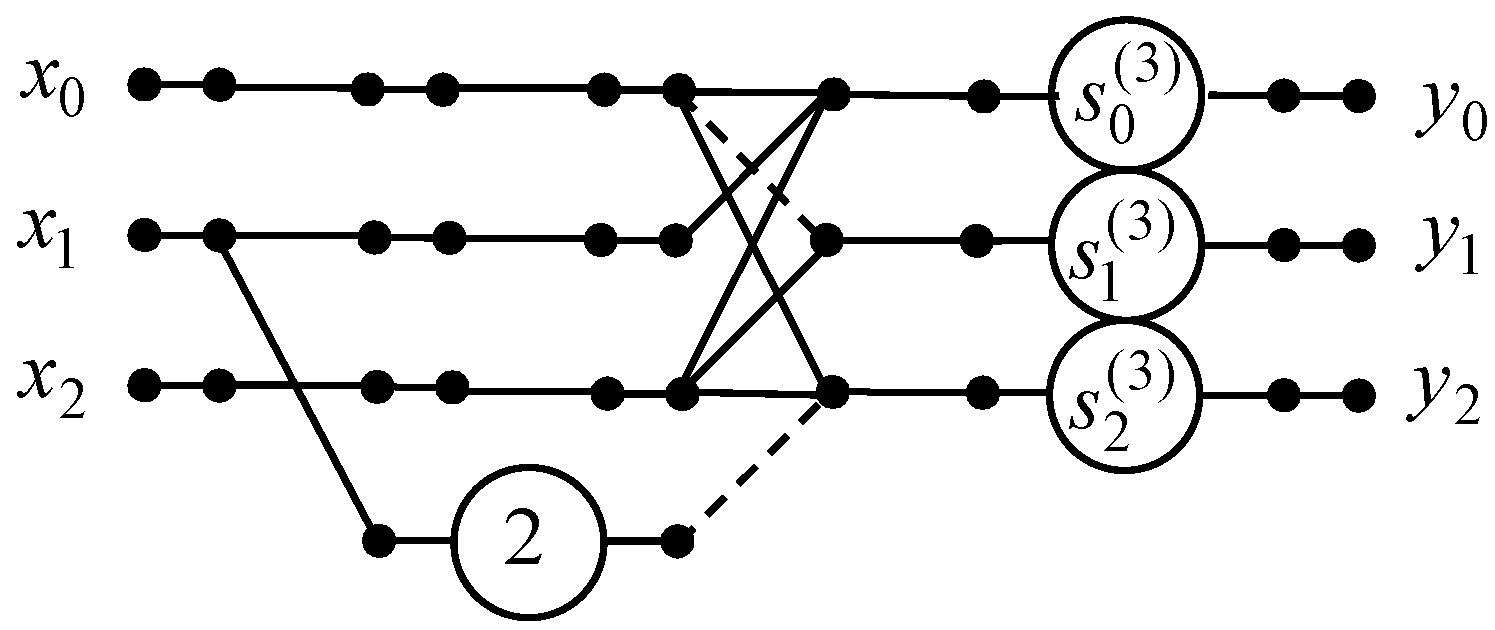
We developed the 3-point real DTT algorithm via construction of the data flow graph that is shown in
Figure 1. If we apply the three-point DTT algorithm, we can reduce the number of multiplications from 8 to 3, while the number of additions remains unchanged.
3.2. Algorithm for 4-Point DTT
Let us construct the algorithm for 4-point real-valued DTT, which is expressed as
where
,
,
. Vector
was computed using expression (5) as
=
or
≈
.
We use the structural approach [
37,
38,
39,
40] to design the algorithm for 4-point real DTT. Let us define the permutations
and
for altering the order of the rows and columns of matrix
, respectively. The obtained matrix
matches the matrix pattern
where
,
. Therefore,
. The matrix
can be decomposed as [
37,
38]:
where
.
We give the matrix factorization for the algorithm of 4-point DTT as follows:
where
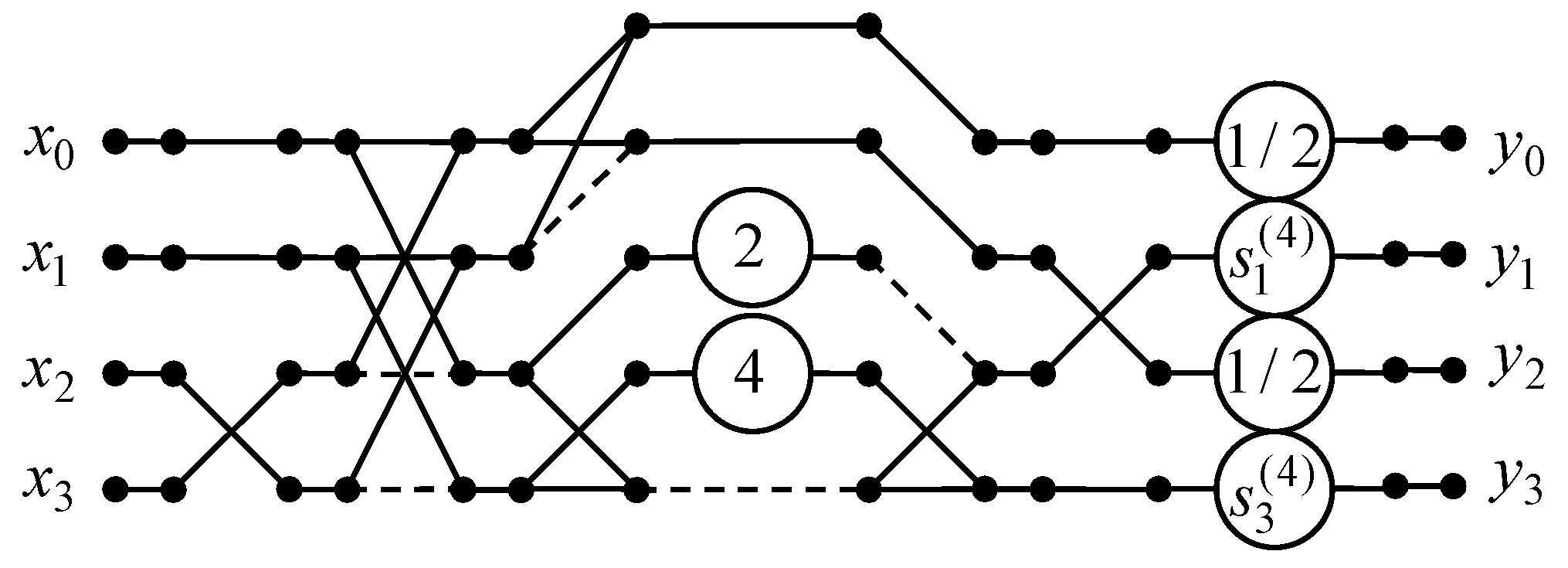
Figure 2 shows a data flow graph of the proposed four-point DTT algorithm. Note that for
N = 4, the initial 4-point real DTT requires 8 real-valued multiplications, 8 shifts, and 12 additions. If we use the proposed four-point DTT algorithm, then the number of multiplications, additions, and shifts may be reduced from 8 to 2, from 12 to 9, and from 8 to 5, respectively.
3.3. Algorithm for 5-Point DTT
To develop the algorithm for 5-point 1D DTT, we express this transform as follows:
where
,
,
.
The vector is computed by expression (5) where , , . As a result, we yield = or = .
Denoting
=
=
=
we obtain the matrix
We again apply the structural approach [
37,
38,
39,
40] to develop the algorithm for 5-point 1D real DTT. The permutations
and
are defined to alter the order of columns and rows of matrix
, respectively, as
After permutation, the obtained matrix
is decomposed into two components [
37,
39]:
where
and
.
The structure of matrix
allows for reducing the number of operations without further transforms because the elements in the third row are identical except for the sign. After eliminating the rows and columns having only zero elements in matrix
, we yield matrix
:
Matrix
matches the template
, where
and
. Hence, matrix
can be factorized as [
37,
38]:
Let us swap the rows of matrix
and alter the sign of the second row of matrix
. Then, the obtained matrices
and
match the templates
and
, where
. Then [
37,
40],
where
,
,
. Matrices
and
are defined as in expression (9).
Based on Equations (16) and (19), we derive the factorization of the 5-point DTT matrix:
where
As was mentioned in
Section 2, an empty cell in matrices means it contains zero.
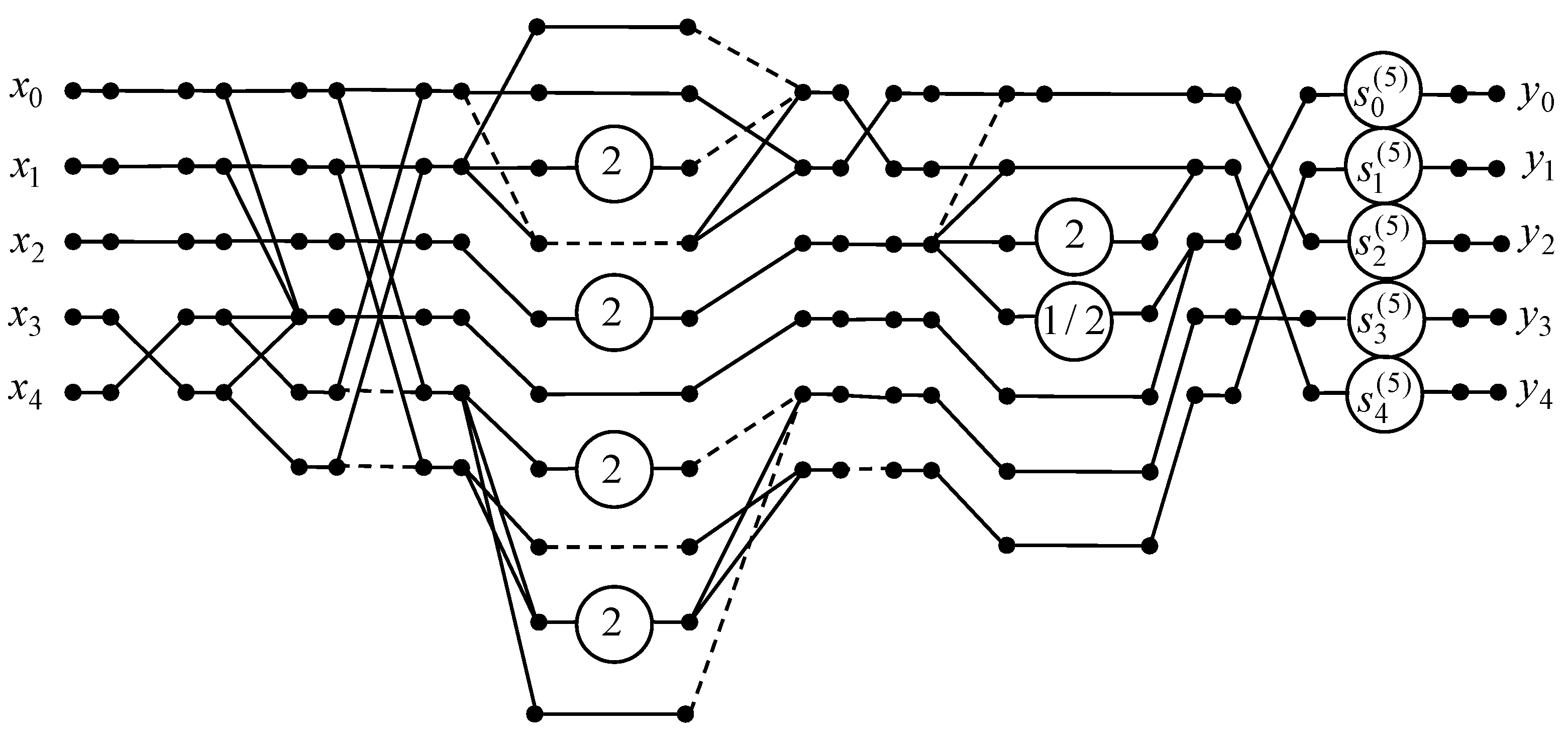
A data flow graph of the developed 5-point DTT algorithm is presented in
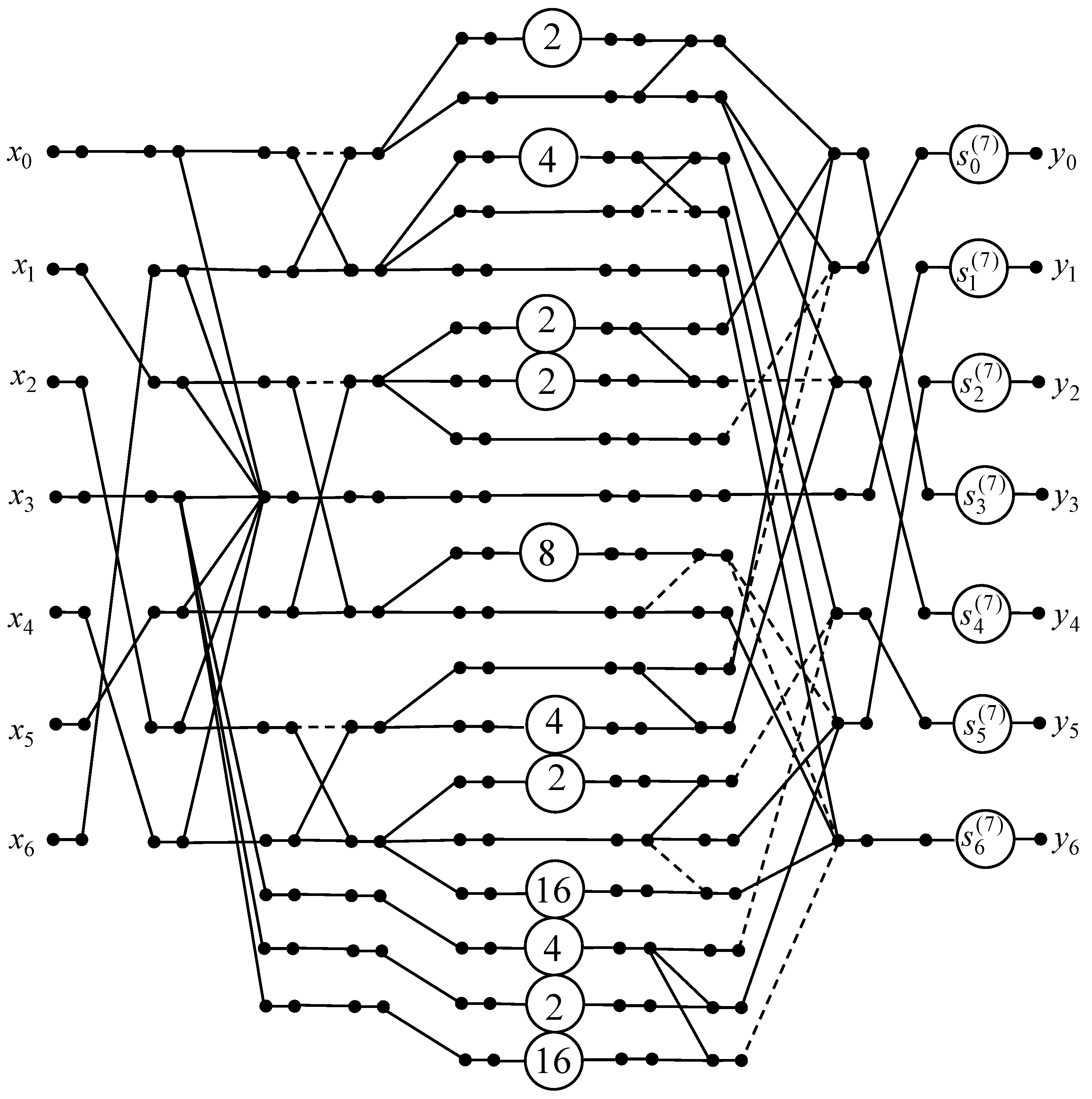
Figure 3. Note that the original 5-point real DTT requires 23 real-valued multiplications and 18 additions, as two entries in the transform matrix are equal to zero. Using the proposed 5-point DTT algorithm, the required number of multiplications can be reduced from 23 to 5. The number of additions is increased from 18 to 19, and 6 shifts are required.
3.4. Algorithm for 6-Point DTT
Let us obtain the algorithm for 6-point 1D DTT, which is expressed as follows:
where
,
,
.
The vector is computed by expression (5), where , . As a result, we yield = or ≈.
Let us denote
=
=
;
then, matrix
is represented as
The columns and rows of
are permutated according to
and
, which are defined in the following form:
and
. The permutation matrices are as follows:
The resulting matrix
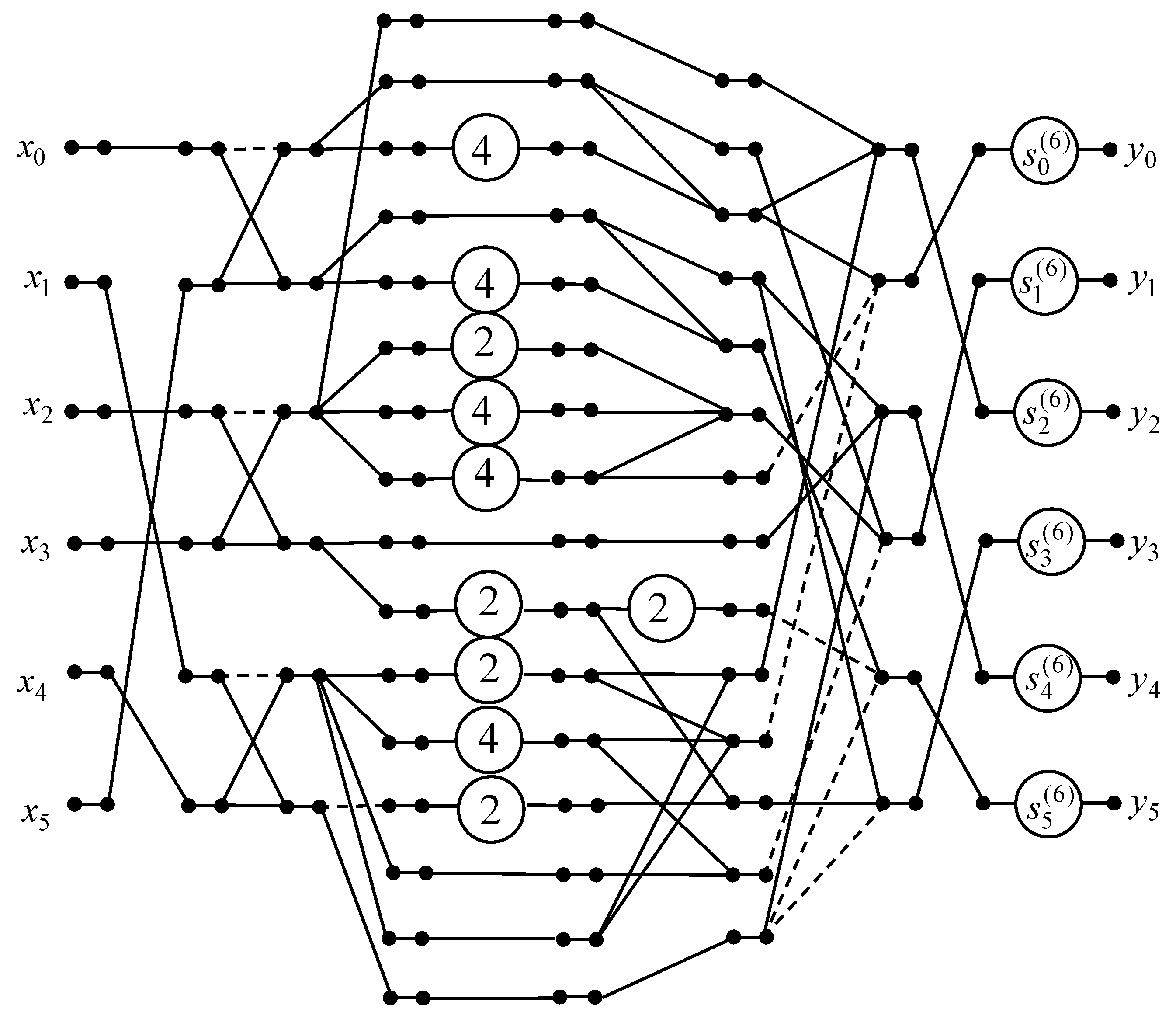
contains repeated elements that enable butterfly module extraction and construction of the data flow graph for 6-point 1D DTT calculation. A derived data flow graph of the proposed 6-point 1D DTT algorithm is shown in
Figure 4.
Further, we compose the factorization of the matrix of 6-point 1D DTT from the matrices for calculations at each layer of the graph. Thus, at the first layer, we obtain the matrix where .
The second layer of calculations is described by matrix
which can be expressed via matrix
as follows:
In this matrix and the matrices below, an empty cell indicates that it contains zero. We have diagonal matrix
at the third layer of calculation and matrices
and
at the fourth and fifth layers of calculation:
Next, we take into consideration the permutation matrices
and
and matrices
,
,
,
at different computing layers of the data flow graph from
Figure 4 to obtain factorization of the 6-point 1D DTT matrix:
Let us consider the data flow graph of the developed 6-point 1D DTT algorithm (
Figure 4). It should be noted that the initial 6-point real DTT requires 36 real-valued multiplications and 30 additions. If we apply the developed 6-point 1D DTT algorithm, the number of real-valued multiplications is reduced to 6. The number of additions is decreased from 30 to 27, and 15 shifts are required.
3.5. Algorithm for 7-Point DTT
To design the algorithm for the 7-point 1D DTT we represent this transform as follows:
where
,
,
.
Vector is computed by expression (5), where , , , . As a result, we yield = [, , , , , , or ≈ [0.3780, 0.1890, 0.1091, 0.4082, 0.0806, 0.1091, 0.0329.
If we denote
matrix
can be represented as
We developed the 7-point real DTT algorithm using a sparse matrix factorization [
8,
28,
29,
41] and the structural approach [
37,
40]. The structural approach was used to decompose the initial DTT matrix into submatrices. Sparse matrix factorization allows for the design of the data flow graph of the algorithm. To change the order of columns and rows, we define permutations
and
as follows:
The permutation matrices are expressed as:
After permutation, matrix
acquires the following structure:
Next, matrix
is decomposed into two components:
where
Matrix
has identical entries in its fourth row. This allows us to reduce the number of operations without further transformations. Next, we eliminate the row and column containing only zero entries in matrix
and obtain matrix
:
Matrix
contains repeated elements, enabling the design of the data flow graph for the 7-point 1D DTT calculation.
Figure 5 shows the obtained data flow graph of the developed 7-point 1D DTT algorithm.
Further, we create the factorization of the matrix of 7-point 1D DTT using the matrices for calculations at each layer of the graph. As a result, we obtain matrix
at the first layer of calculations:
The second layer of calculations is described by matrix
which can be expressed as follows:
where
. Matrices
and
provide calculations at the third and fifth layers of the data flow graph in
Figure 5:
We have diagonal matrix
at the fourth layer of calculation, and matrix
at the sixth layer of calculation as follows:
Combining the permutation matrices
and
and matrices
,
,
,
, and
at different computing layers of the data flow graph from
Figure 5, we derive the factorization of the 7-point 1D DTT matrix:
Let us consider the data flow graph of the designed 7-point 1D DTT algorithm from
Figure 5. We notice that the initial 7-point real DTT requires 44 real-valued multiplications and 37 additions because five elements of the matrix
are zeros. If the data are transformed by the proposed 7-point 1D DTT algorithm, then the number of real-valued multiplications is reduced to 7. The number of additions remains the same, and 22 shifts are required.
3.6. Algorithm for 8-Point DTT
Let us design the algorithm for 8-point DTT. Eight-point DTT is expressed as follows:
where
,
,
.
The vector
is computed by expression (5). As a result, we obtain
= [
,
,
,
,
,
,
,
or
≈ [0.3536, 0.0772, 0.0772, 0.0615, 0.0403, 0.0214, 0.0615, 0.0171
. If we denote
then matrix
can be represented as
The order of columns and rows is altered with the permutations of matrix
and
, respectively. The permutation matrices are as follows:
Matrix
acquires the following structure:
The repeated elements are contained in matrix
. They facilitate the design of butterfly modules in the data flow graph for the 8-point 1D DTT calculation. An obtained data flow graph of the developed 8-point 1D DTT algorithm is presented in
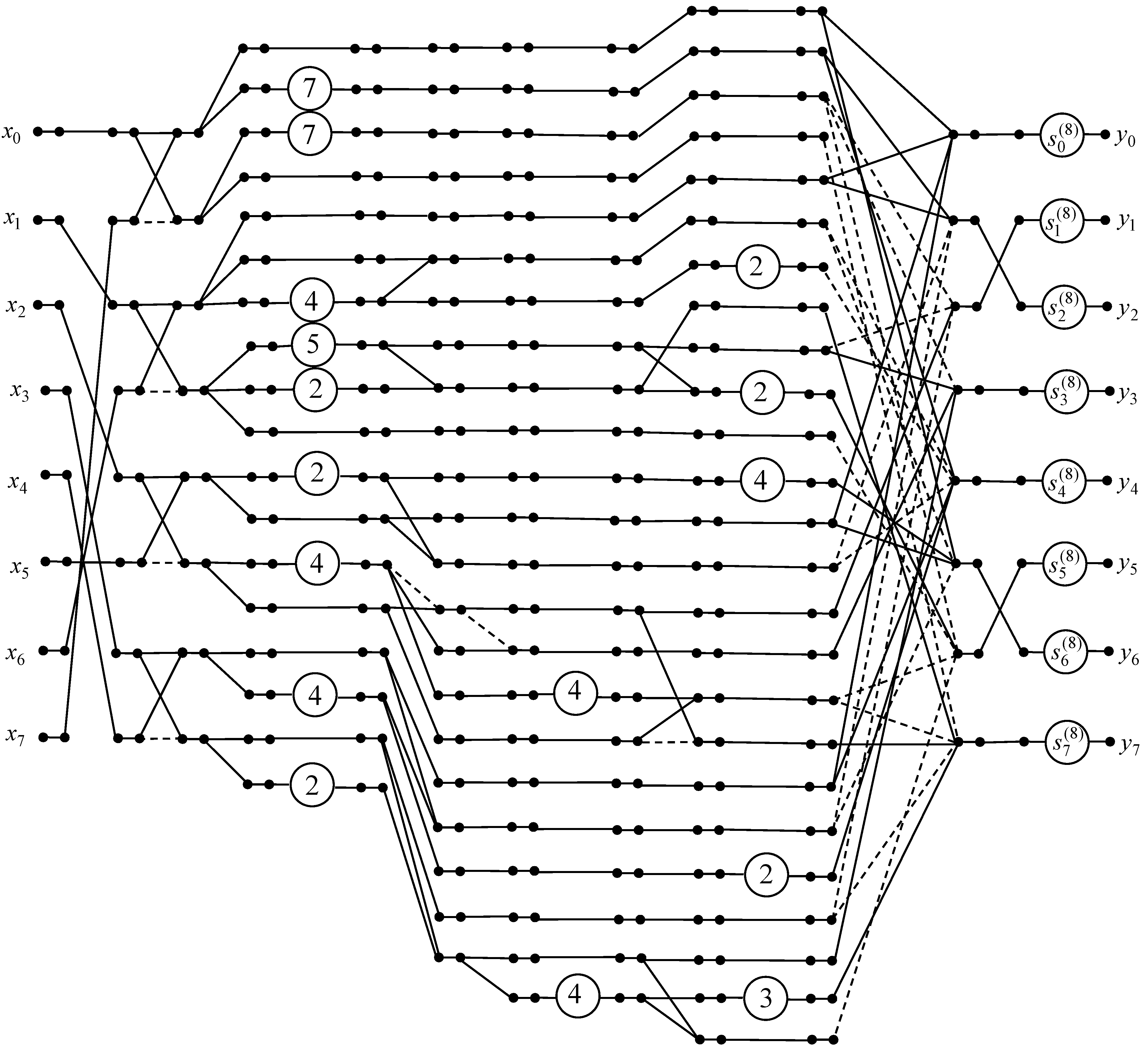
Figure 6.
Let us derive the factorization of the matrix of 8-point 1D DTT. We consider the matrices for computations on each layer of the graph. The matrices
are obtained at the first and second layers of the graph, respectively.
We have the diagonal matrix
at the third layer of calculation. The fourth, fifth and sixth layers of computations of the data flow graph in
Figure 6 are implemented with the matrices
,
, and
:
Let us define matrices and .
Then, we obtain matrix
, which provides calculations at the seventh layer of the data flow graph in
Figure 6. Matrix
is defined by Equation (9). The computations at the eighth and ninth layers of the data flow graph in
Figure 6 are provided with diagonal matrix
and matrix
:
We multiply matrices
,
,
,
,
,
,
,
,
,
, and
with each other. As a result, the factorization of the 8-point 1D DTT matrix is obtained:
We have presented some elements of diagonal matrices and as 7 = 8 − 1, 5 = 4 + 1, 3 = 2 + 1. It should be noted that initial 8-point real DTT requires 64 real-valued multiplications and 56 additions. Applying the proposed 8-point 1D DTT algorithm, we can reduce the number of real-valued multiplications to 8. Therefore, the total number of operations for the proposed 8-point 1D DTT algorithm is 53 additions, 8 real-valued multiplications, and 27 shifts.
3.7. Generalization of the Proposed Algorithms
Let us describe a generalization for N > 8 regarding the proposed N-point DTT algorithms, where N ranges from 3 to 8. The N-point DTT with N > 8 is also expressed by Equation (4). Further, we consider the even and odd lengths of input sequences separately.
At first, we suppose that
N is even. Based on the symmetry of integer DTT, the following permutation of columns of the integer 1D DTT matrix
can be used:
Rearranging the rows is not necessary at all; however, if it is feasible to organize the rows such that pairs of equal-signed elements create 2 × 2 blocks, which can help minimize the number of additions and shifts required. This trick offers a reducing the number of integer multiplications.
Next, we start designing the data flow graph from inputs to outputs by adding the permutation of inputs at the first computational level. Then, we pairwise combine the outputs from the first computational level into butterfly modules and the outputs of each such module are transmitted to a line of integer multipliers. Every multiplication by an integer can be implemented by additions and shifts. The results of the multiplications are added together to obtain the outputs of integer DTT, and permutation of outputs is performed. The outputs of real DTT are calculated using the outputs of integer DTT multiplied by the specific coefficients as described in Equation (4).
Let us consider an odd
N. The order of the columns of the integer DTT matrix
is changed using the permutation
where
denotes the whole part of
. Columns
,
, and
remain in their places, and the remaining columns are grouped in pairs as in Equation (60). The symmetry of DTT is taken into account again.
The first and [N/2] + 1 rows are swapped. The order of the remaining rows can be left unchanged, or they can be swapped to reduce the number of multiplications and shifts as in the case of even N.
Next, we represent the transform matrix
after permutations as the sum of two matrices
and
of the same size as matrix
:
.
Matrix includes the [N/2] + 1 row and the [N/2] + 1 column of matrix , and the rest of its elements are zero. In matrix , the [N/2] + 1 row and the [N/2] + 1 column are filled with zeros, and the rest of the elements are the same as in matrix . Then, matrix has identical entries in its [N/2] + 1 row. This allows us to reduce the number of operations without further transformations. Next, we eliminate the row and column containing only zero entries in matrix and obtain matrix . Matrix has an even size. Therefore, a data flow graph of the fast algorithm for the transform with matrix can be constructed similarly to the previous case.
To obtain the data flow graph for the transform with matrix , we add the path, corresponding to the [N/2] + 1 output after the column permutation, to the data flow graph for the transform with matrix . The edges of the resulting graph that enter the node at this path immediately after column permutation are constructed using a structural approach similar to the case of N = 7. Again, for odd N, the outputs of integer DTT after row permutation are multiplied by the specific coefficients to obtain the outputs of real DTT.
4. Results
We used the MATLAB R2023b software for the experimental research of the proposed algorithms. The correctness of the designed algorithms was tested. For this, the DTT matrices were obtained using Equations (4)–(6) for N = 3, 4, 5, 6, 7, 8 at first. Next, the factorizations of 1D DTT matrices were calculated with the expressions (7), (10), (20), (32), (46), and (58). The correctness of the proposed algorithms was indicated via the coincidence of the elements of 1D DTT matrices and the elements of the products of the matrices included in the factorizations of the DTT matrices for the same N.
Further, the computational complexity of the developed algorithms was evaluated, and the results are illustrated in
Table 1. In parentheses, we show the difference in the number of operations as a percentage. The minus sign indicates a reduction in the number of operations compared to the direct method, while the plus sign indicates an increase. As can be seen from
Table 1, the number of multiplications decreased by an average of 78% for
N = 3, 4, 5, 6, 7, 8. At the same time, the number of additions decreased by an average of 5% for the same
N. The calculation of the direct matrix-vector product for
N = 4 additionally requires 8 shifts.
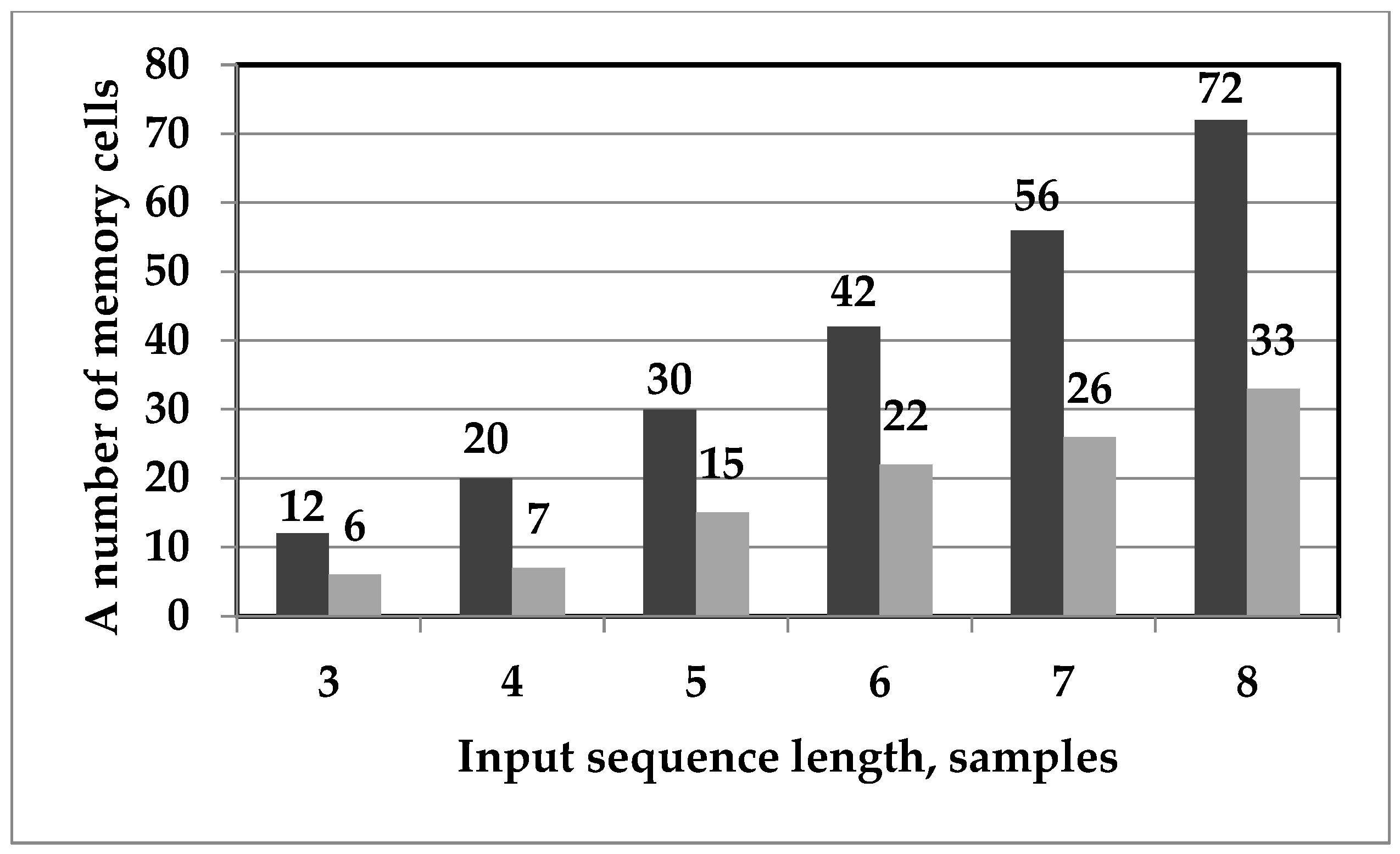
After evaluating the effectiveness of the solutions by calculating the number of arithmetic operations required to implement the obtained algorithms, the additional evaluations’ memory consumption is provided in
Figure 7. The proposed real DTT algorithms required 54% less memory than the direct matrix-vector product.
The evaluation of memory costs for the proposed algorithms demonstrates their limitations. However, unlike the evaluation of arithmetic complexity, the memory costs depend on the method of implementing the algorithm and the platform on which the algorithm is implemented. In addition, memory consumption is also affected by the skill and experience of the designer. In general, the proposed algorithms allow both software and hardware implementation. Moreover, both software and hardware implementation can use various approaches and tricks, that lead to certain memory costs, time delays, and hardware resource usage. As for memory, the calculations can be implemented so that the same memory cells are used at each subsequent stage of algorithm implementation if such a possibility exists. The proposed algorithms can be implemented sequentially, in parallel, or in parallel sequentially, depending on the structure and capabilities of the implementation platform. This implementation affects the time delay in obtaining results.
A deeper analysis shows that when implementing the proposed algorithms at the hardware level using maximum parallelization of calculations, intermediate memory in asynchronous mode may not be needed. If we organize pipeline processing, then we have to insert time delays that align the data flow. In this case, additional buffer memory will be needed. Thus, the evaluation of the efficiency of algorithmic solutions in terms of memory requirements, although it somehow characterizes these solutions, is very subjective. Therefore, since we do not consider implementation issues, it is the evaluation of arithmetic complexity that is, although not exhaustive, the most reliable and accurate characteristic of the efficiency of the proposed solutions.
5. Discussion of Computational Complexity
In
Table 2, we present the number of additions, shifts, and multiplications for the 1D DTT algorithms known from the literature. It is important to note that in references [
1,
41], the number of additions and shifts for integer DTT was evaluated. Therefore, we added to the corresponding rows of
Table 2 the minimal number of multiplications needed to implement real DTT. As a consequence, the results in
Table 2 show that the number of multiplications for the proposed algorithm is the same for
N = 4 and
N = 8 as compared with [
1,
41]. At the same time, we reduced the multiplication by 67–72% compared with [
8]. However, the number of additions increased by 12–66%, and additional shifts are required.
The advantage of the proposed solutions is that the length of the input data sequence for the proposed DTT fast algorithms is not limited by 4 and 8. The obtained algorithms are multiplier-free for integer DTT. They can calculate integer DTT and real DTT. The data flow graphs constructed for the proposed algorithms have a modular structure that is well-suited for hardware implementation. A carefully selected heuristic for certain values of
N can greatly decrease the computational complexity of the DTT algorithm, as in [
1]. However, extending the proposed algorithms to cases where
N is greater than 8 enables the design of a fast DTT algorithm for input sequences of any length.
6. Conclusions
In this paper, the algorithms for real DTT with reduced multiplicative complexity are developed by combining sparse matrix factorization with the structural approach. The obtained algorithms have butterfly architecture and are multiplication-free for the integer DTT. The combination of the structural approach with sparse matrix factorization enables the design of fast algorithms without restricting input sequence length to 4 or 8. A matrix factorization of each proposed solution was constructed with sparse diagonal and quasi-diagonal matrices. Another advantage of the obtained algorithms is that their representation via the data flow graphs provides a layout for the VLSI implementation of the proposed solutions.
The computational complexity of the proposed algorithms was compared with the computational complexity of direct matrix-vector products. As a result, it was found that the obtained factorizations of real DTT matrices reduce the number of multiplications by an average of 78% in the range of signal lengths from 3 to 8. Meanwhile, the average number of additions in the same range of signal lengths decreased by nearly 5%. Although additional shifts are required instead of multiplications, they are less time- and resource-consuming.
Comparison with fast DTT algorithms known from the literature was provided for input signal lengths 4 and 8. It was shown that the proposed algorithms have the same or slightly worse computational complexity. The latter is caused by the versatility of combining the structural approach with a sparse matrix factorization compared to the specificity of existing solutions.
Future research development may involve constructing a fast orthogonal projection of DTT using the Kronecker product. Reducing the computational complexity of this form of DTT may be used in applications such as speech enhancement [
42] and filter design [
43].





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}