
Optimizing Dynamic Mode Decomposition for Video Denoising via Plug-and-Play Alternating Direction Method of Multipliers †


Abstract
1. Introduction
1.1. Background
1.2. Related Work
1.3. Contribution
- Introducing a novel minimization problem that simultaneously removes noise from DMD modes and improves their reconstructed video quality. This problem includes two implicit regularization terms for the DMD modes and their reconstructed video, along with two constraints on the reconstructed video: one for reconstruction error and the other to ensure real numbers.
- The development of the PnP-ADMM algorithm is based on the plug-and-play framework and Gaussian denoisers. This algorithm solves the proposed minimization problem and aims to obtain optimal DMD modes capable of reconstructing a smooth and noiseless video.
- Two advanced noise removal methods, the total variation (TV) algorithm and BM3D, are employed as Gaussian denoisers to implicitly regularize the DMD modes and their reconstructed video within the optimization algorithm.
2. Preliminaries
2.1. Dynamic Mode Decomposition
- (i)
- Calculate the (reduced) singular value decomposition (SVD) of the matrix as , where , , and , with the rank r.
- (ii)
- Let be defined by .
- (iii)
- Compute the eigenvalue decomposition of as , where is a matrix configured by arranging the eigenvectors and is a diagonal matrix having eigenvalues as the diagonal elements.
- (iv)
- The DMD mode is obtained by .
- (v)
- Then, we define as
- (vi)
- Estimate the diagonal matrix by minimizing the cost function
- (vii)
- Finally, is represented by as
2.2. Plug-and-Play Alternating Direction Method of Multipliers
2.3. Proximal Tools
2.4. Total Variation
| Algorithm 1 Solved algorithm for Equation (16) |
|
3. Proposed Methods
3.1. Data Model
3.2. Minimization Problem
3.3. Optimization
| Algorithm 2 Proposed algorithm for Equation (23) |
|
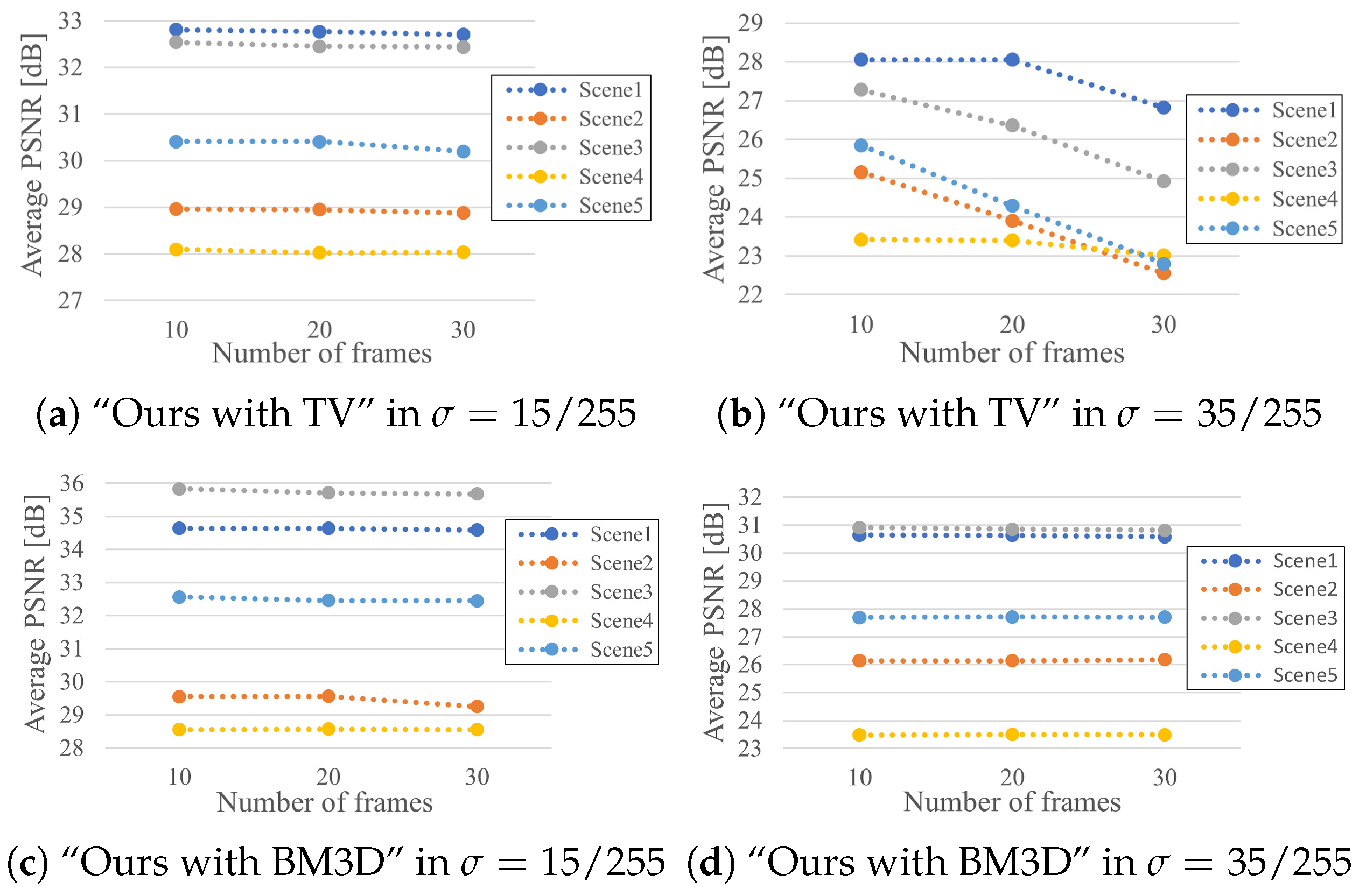
4. Experiments
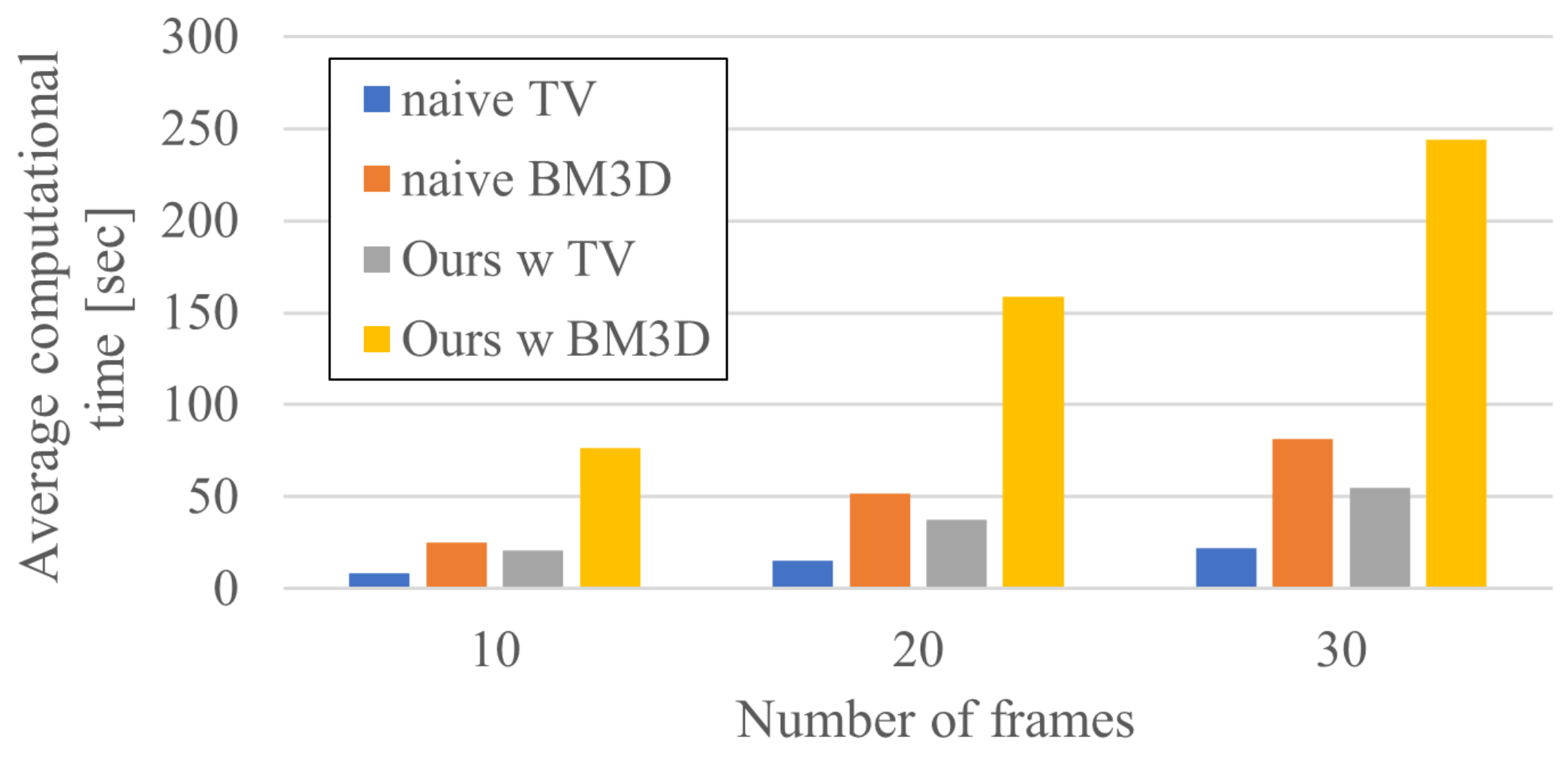
- Naive TV was performed in less than 10 s.
- Naive BM3D was performed in about 25 s.
- “Ours with TV” was performed in about 20 s and shorter execution time than naive BM3D.
- “Ours with BM3D” was performed in about 75 s and about three times slower than naive BM3D.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Grosek, J.; Kutz, J.N. Dynamic mode decomposition for real-time background/foreground separation in video. arXiv 2014, arXiv:1404.7592. [Google Scholar]
- Kutz, J.N.; Fu, X.; Brunton, S.L.; Erichson, N.B. Multi-resolution Dynamic Mode Decomposition for Foreground/Background Separation and Object Tracking. In Proceedings of the IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 921–929. [Google Scholar] [CrossRef]
- Kutz, J.N.; Grosek, J.; Brunton, S.L. Dynamic mode decomposition for robust pca with applications to foreground/background subtraction in video streams and multi-resolution analysis. In CRC Handbook on Robust Low-Rank and Sparse Matrix Decomposition: Applications in Image and Video Processing; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Erichson, N.B.; Donovan, C. Randomized low-rank dynamic mode decomposition for motion detection. Comput. Vis. Image Underst. 2016, 146, 40–50. [Google Scholar] [CrossRef]
- Dicle, C.; Mansour, H.; Tian, D.; Benosman, M.; Vetro, A. Robust low-rank dynamic mode decomposition for compressed domain crowd and traffic flow analysis. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Pendergrass, S.; Brunton, S.L.; Kutz, J.N.; Erichson, N.B.; Askham, T. Dynamic Mode Decomposition for Background Modeling. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 1862–1870. [Google Scholar] [CrossRef]
- Takeishi, N.; Kawahara, Y.; Yairi, T. Sparse nonnegative dynamic mode decomposition. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2682–2686. [Google Scholar] [CrossRef]
- Bi, C.; Yuan, Y.; Zhang, J.; Shi, Y.; Xiang, Y.; Wang, Y.; Zhang, R. Dynamic Mode Decomposition Based Video Shot Detection. IEEE Access 2018, 6, 21397–21407. [Google Scholar] [CrossRef]
- Erichson, N.B.; Brunton, S.L.; Kutz, J.N. Compressed dynamic mode decomposition for background modeling. J. Real-Time Image Process. 2019, 16, 1479–1492. [Google Scholar] [CrossRef]
- Schmid, P.J. Dynamic mode decomposition of numerical and experimental data. J. Fluid Mech. 2010, 656, 5–28. [Google Scholar] [CrossRef]
- Mezić, I. Analysis of Fluid Flows via Spectral Properties of the Koopman Operator. Annu. Rev. Fluid Mech. 2013, 45, 357–378. [Google Scholar] [CrossRef]
- Kutz, J.N.; Brunton, S.L.; Brunton, B.W.; Proctor, J.L. Dynamic Mode Decomposition; Socoety for Industiral and Applied Mathemathics: Philadelphia, PA, USA, 2016. [Google Scholar] [CrossRef]
- Dawson, S.T.; Hemati, M.S.; Williams, M.O.; Rowley, C.W. Characterizing and correcting for the effect of sensor noise in the dynamic mode decomposition. Exp. Fluids 2016, 57, 42. [Google Scholar] [CrossRef]
- Hemati, M.S.; Rowley, C.W.; Deem, E.A.; Cattafesta, L.N. De-biasing the dynamic mode decomposition for applied Koopman spectral analysis of noisy datasets. Theor. Comput. Fluid Dyn. 2017, 31, 349–368. [Google Scholar] [CrossRef]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear Total Variation Based Noise Removal Algorithms. Phys. D 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Bresson, X.; Chan, T.F. Fast Dual Minimization of the Vectorial Total Variation Norm and Applications to Color Image Processing. Inverse Probl. Imag. 2008, 2, 455–484. [Google Scholar] [CrossRef]
- Chambolle, A. An Algorithm for Total Variation Minimization and Applications. J. Math. Imag. Vis. 2004, 20, 89–97. [Google Scholar] [CrossRef]
- Blomgren, P.; Chan, T.F. Color TV: Total variation methods for restoration of vector-valued images. IEEE Trans. Image Process. 1998, 7, 304–309. [Google Scholar] [CrossRef] [PubMed]
- Chan, S.H.; Khoshabeh, R.; Gibson, K.B.; Gill, P.E.; Nguyen, T.Q. An augmented Lagrangian method for total variation video restoration. IEEE Trans. Image Process. 2011, 20, 3097–3111. [Google Scholar] [CrossRef] [PubMed]
- Matsuoka, R.; Ono, S.; Okuda, M. Transformed-Domain Robust Multiple-Exposure Blending With Huber Loss. IEEE Access 2019, 7, 162282–162296. [Google Scholar] [CrossRef]
- Matsuoka, R.; Okuda, M. Beyond Staircasing Effect: Robust Image Smoothing via ℓ0 Gradient Minimization and Novel Gradient Constraints. Signals 2023, 4, 669–686. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Egiazarian, K. Video denoising by sparse 3D transform-domain collaborative filtering. In Proceedings of the 2007 15th European Signal Processing Conference, Poznan, Poland, 3–7 September 2007; pp. 145–149. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Color image denoising via sparse 3D collaborative filtering with grouping constraint in luminance-chrominance space. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16 September–19 October 2007; Volume 1, pp. 1–313. [Google Scholar]
- Maggioni, M.; Boracchi, G.; Foi, A.; Egiazarian, K. Video denoising, deblocking, and enhancement through separable 4-D nonlocal spatiotemporal transforms. IEEE Trans. Image Process. 2012, 21, 3952–3966. [Google Scholar] [CrossRef] [PubMed]
- Mäkinen, Y.; Azzari, L.; Foi, A. Collaborative filtering of correlated noise: Exact transform-domain variance for improved shrinkage and patch matching. IEEE Trans. Image Process. 2020, 29, 8339–8354. [Google Scholar] [CrossRef] [PubMed]
- Anami, S.; Matsuoka, R. Noise Removal for Dynamic Mode Decomposition Based on Plug-and-Play ADMM. In Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; pp. 1405–1409. [Google Scholar]
- Tu, J.H. Dynamic Mode Decomposition: Theory and Applications. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 2013. [Google Scholar]
- Brunton, S.L.; Proctor, J.L.; Tu, J.H.; Kutz, J.N. Compressed sensing and dynamic mode decomposition. J. Comput. Dyn. 2015, 2, 165. [Google Scholar] [CrossRef]
- Gabay, D.; Mercier, B. A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput. Math. Appl. 1976, 2, 17–40. [Google Scholar] [CrossRef]
- Venkatakrishnan, S.V.; Bouman, C.A.; Wohlberg, B. Plug-and-play priors for model-based reconstruction. In Proceedings of the IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 945–948. [Google Scholar]
- Chan, S.H.; Wang, X.; Elgendy, O.A. Plug-and-play ADMM for image restoration: Fixed-point convergence and applications. IEEE Trans. Comput. Imag. 2016, 3, 84–98. [Google Scholar] [CrossRef]
- Moreau, J.J. Fonctions convexes duales et points proximaux dans un espace hilbertien. C. R. Acad. Sci. 1962, 255, 2897–2899. [Google Scholar]
- Combettes, P.L.; Pesquet, J.C. A proximal decomposition method for solving convex variational inverse problems. Inverse Probl. 2008, 24, 065014. [Google Scholar] [CrossRef]
- Duval, V.; Aujol, J.F.; Vese, L.A. Mathematical Modeling of Textures: Application to Color Image Decomposition with a Projected Gradient Algorithm. J. Math. Imag. Vis. 2010, 37, 232–248. [Google Scholar] [CrossRef]
- Jodoin, P.M.; Maddalena, L.; Petrosino, A.; Wang, Y. Extensive Benchmark and Survey of Modeling Methods for Scene Background Initialization. IEEE Trans. Image Process. 2017, 26, 5244–5256. [Google Scholar] [CrossRef] [PubMed]
- Pont-Tuset, J.; Perazzi, F.; Caelles, S.; Arbelaez, P.; Sorkine-Hornung, A.; Gool, L.V. The 2017 DAVIS Challenge on Video Object Segmentation. arXiv 2017, arXiv:1704.00675. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene | [Frame] | [Frame] | [Frame] | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noisy |
Naive
TV |
Naive
BM3D |
Ours with
TV |
Ours with
BM3D | Noisy |
Naive
TV |
Naive
BM3D |
Ours with
TV |
Ours with
BM3D | Noisy |
Naive
TV |
Naive
BM3D |
Ours with
TV |
Ours with
BM3D | ||
| 1 | 15/255 | 24.62 | 32.29 | 34.14 | 32.81 (0.4) | 34.64 (0.1) | 24.62 | 32.27 | 33.06 | 32.77 (0.5) | 34.64 (0.1) | 24.62 | 32.27 | 33.05 | 32.70 (0.6) | 34.59 (0.1) |
| 25/255 | 20.23 | 30.21 | 31.81 | 30.31 (0.8) | 32.24 (0.3) | 20.23 | 30.28 | 31.65 | 30.25 (0.9) | 32.19 (0.3) | 20.23 | 29.95 | 31.65 | 30.25 (0.9) | 32.18 (0.3) | |
| 35/255 | 17.45 | 28.53 | 30.50 | 28.06 (0.9) | 30.64 (0.5) | 17.45 | 28.53 | 30.49 | 28.06 (0.9) | 30.63 (0.5) | 17.45 | 27.56 | 30.36 | 26.82 (0.9) | 30.59 (0.6) | |
| 2 | 15/255 | 24.66 | 28.37 | 29.46 | 28.96 (0.5) | 29.55 (0.4) | 24.66 | 28.36 | 29.50 | 28.95 (0.6) | 29.56 (0.6) | 24.66 | 28.37 | 28.78 | 28.88 (0.8) | 29.25 (0.1) |
| 25/255 | 20.32 | 26.34 | 27.47 | 26.55 (0.7) | 27.48 (0.8) | 20.32 | 26.52 | 27.00 | 26.54 (0.9) | 27.28 (0.4) | 20.32 | 26.29 | 27.04 | 26.02 (0.9) | 27.32 (0.4) | |
| 35/255 | 17.55 | 25.18 | 26.09 | 25.16 (0.9) | 26.14 (0.5) | 17.55 | 25.02 | 26.00 | 23.91 (0.9) | 26.14 (0.5) | 17.54 | 24.34 | 26.03 | 22.55 (0.9) | 26.18 (0.5) | |
| 3 | 15/255 | 24.76 | 31.85 | 34.80 | 32.54 (0.4) | 35.83 (0.1) | 24.76 | 31.85 | 34.77 | 32.45 (0.6) | 35.71 (0.2) | 24.76 | 32.23 | 34.73 | 32.44 (0.6) | 35.68 (0.1) |
| 25/255 | 20.44 | 29.25 | 32.74 | 29.63 (0.8) | 33.08 (0.3) | 20.44 | 29.57 | 32.74 | 29.61 (0.9) | 33.07 (0.3) | 20.45 | 29.41 | 32.70 | 29.09 (0.9) | 33.03 (0.3) | |
| 35/255 | 17.64 | 27.57 | 30.80 | 27.28 (0.9) | 30.91 (0.7) | 17.65 | 26.92 | 30.73 | 26.36 (0.9) | 30.86 (0.6) | 17.65 | 25.60 | 30.72 | 24.92 (0.9) | 30.82 (0.6) | |
| 4 | 15/255 | 24.75 | 26.84 | 28.49 | 28.10 (0.3) | 28.55 (0.4) | 24.74 | 26.90 | 28.51 | 28.02 (0.5) | 28.57 (0.6) | 24.74 | 26.91 | 28.51 | 28.03 (0.6) | 28.55 (0.7) |
| 25/255 | 20.43 | 24.31 | 25.66 | 25.17 (0.5) | 25.67 (0.7) | 20.43 | 24.93 | 25.27 | 25.16 (0.8) | 25.27 (0.2) | 20.43 | 24.93 | 25.28 | 25.16 (0.8) | 25.40 (0.2) | |
| 35/255 | 17.66 | 23.16 | 23.30 | 23.42 (0.8) | 23.49 (0.3) | 17.66 | 23.42 | 23.25 | 23.40 (0.9) | 23.51 (0.3) | 17.66 | 23.24 | 23.25 | 23.01 (0.9) | 23.50 (0.3) | |
| 5 | 15/255 | 24.71 | 30.00 | 31.22 | 30.41 (0.6) | 32.56 (0.2) | 24.70 | 29.99 | 31.12 | 30.41 (0.7) | 32.46 (0.2) | 24.70 | 30.34 | 31.12 | 30.20 (0.9) | 32.45 (0.2) |
| 25/255 | 20.41 | 27.43 | 29.26 | 27.68 (0.8) | 29.67 (0.4) | 20.39 | 27.67 | 29.18 | 27.57 (0.9) | 29.66 (0.3) | 20.38 | 27.09 | 29.17 | 26.70 (0.9) | 29.65 (0.4) | |
| 35/255 | 17.64 | 25.92 | 27.55 | 25.85 (0.9) | 27.70 (0.7) | 17.61 | 24.81 | 27.67 | 24.29 (0.9) | 27.72 (0.9) | 17.61 | 23.33 | 27.66 | 22.80 (0.9) | 27.71 (0.6) | |
| Scene | [Frame] | [Frame] | [Frame] | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noisy |
Naive
TV |
Naive
BM3D |
Ours with
TV |
Ours with
BM3D | Noisy |
Naive
TV |
Naive
BM3D |
Ours with
TV |
Ours with
BM3D | Noisy |
Naive
TV |
Naive
BM3D |
Ours with
TV |
Ours with
BM3D | ||
| 1 | 15/255 | 0.4092 | 0.8536 | 0.8857 | 0.8618 (0.5) | 0.8953 (0.1) | 0.4094 | 0.8536 | 0.8620 | 0.8609 (0.6) | 0.8955 (0.1) | 0.4095 | 0.8534 | 0.8617 | 0.8590 (0.7) | 0.8933 (0.1) |
| 25/255 | 0.2383 | 0.8042 | 0.8374 | 0.8044 (0.9) | 0.8502 (0.3) | 0.2381 | 0.8017 | 0.8323 | 0.7909 (0.9) | 0.8484 (0.2) | 0.2381 | 0.7613 | 0.8324 | 0.7904 (0.9) | 0.8480 (0.2) | |
| 35/255 | 0.1591 | 0.7215 | 0.8077 | 0.6779 (0.9) | 0.8135 (0.5) | 0.1591 | 0.7222 | 0.8075 | 0.6783 (0.9) | 0.8133 (0.5) | 0.1592 | 0.6367 | 0.7929 | 0.5783 (0.9) | 0.8107 (0.7) | |
| 2 | 15/255 | 0.6173 | 0.7465 | 0.7792 | 0.7865 (0.5) | 0.7822 (0.4) | 0.6197 | 0.7501 | 0.7833 | 0.7912 (0.6) | 0.7854 (0.6) | 0.6202 | 0.7514 | 0.7370 | 0.7887 (0.8) | 0.7659 (0.1) |
| 25/255 | 0.4191 | 0.6513 | 0.6842 | 0.6800 (0.7) | 0.6852 (0.8) | 0.4226 | 0.6760 | 0.6446 | 0.6824 (0.9) | 0.6687 (0.2) | 0.4233 | 0.6757 | 0.6487 | 0.6641 (0.9) | 0.6725 (0.2) | |
| 35/255 | 0.3022 | 0.6031 | 0.5991 | 0.6084 (0.9) | 0.6045 (0.5) | 0.3062 | 0.6097 | 0.5939 | 0.5577 (0.9) | 0.6114 (0.5) | 0.3066 | 0.5795 | 0.5982 | 0.4961 (0.9) | 0.6159 (0.5) | |
| 3 | 15/255 | 0.4541 | 0.8882 | 0.9123 | 0.8918 (0.6) | 0.9241 (0.1) | 0.4541 | 0.8879 | 0.9118 | 0.8903 (0.8) | 0.9216 (0.1) | 0.4556 | 0.8868 | 0.9115 | 0.8900 (0.8) | 0.9218 (0.1) |
| 25/255 | 0.2913 | 0.8449 | 0.8907 | 0.8445 (0.9) | 0.8966 (0.3) | 0.2913 | 0.8394 | 0.8897 | 0.8263 (0.9) | 0.8950 (0.5) | 0.2925 | 0.7969 | 0.8891 | 0.7633 (0.9) | 0.8940 (0.3) | |
| 35/255 | 0.2082 | 0.7530 | 0.8658 | 0.7108 (0.9) | 0.8679 (0.5) | 0.2081 | 0.6728 | 0.8639 | 0.6200 (0.9) | 0.8661 (0.5) | 0.2088 | 0.5611 | 0.8554 | 0.5139 (0.9) | 0.8651 (0.5) | |
| 4 | 15/255 | 0.7696 | 0.8540 | 0.8963 | 0.8876 (0.4) | 0.8965 (0.8) | 0.7676 | 0.8545 | 0.8966 | 0.8821 (0.5) | 0.8969 (0.6) | 0.7678 | 0.8545 | 0.8966 | 0.8863 (0.6) | 0.8972 (0.1) |
| 25/255 | 0.6069 | 0.7631 | 0.8174 | 0.8062 (0.5) | 0.8178 (0.1) | 0.6045 | 0.7955 | 0.7971 | 0.8050 (0.8) | 0.8175 (0.1) | 0.6043 | 0.7952 | 0.7971 | 0.8047 (0.8) | 0.8076 (0.2) | |
| 35/255 | 0.4835 | 0.7177 | 0.7058 | 0.7365 (0.8) | 0.7530 (0.2) | 0.4813 | 0.7350 | 0.7032 | 0.7347 (0.9) | 0.7526 (0.2) | 0.4810 | 0.7255 | 0.7031 | 0.7138 (0.9) | 0.7523 (0.2) | |
| 5 | 15/255 | 0.5465 | 0.8786 | 0.8990 | 0.8810 (0.7) | 0.9167 (0.1) | 0.5442 | 0.8766 | 0.8962 | 0.8774 (0.9) | 0.9141 (0.1) | 0.5457 | 0.8511 | 0.8956 | 0.8350 (0.9) | 0.9140 (0.1) |
| 25/255 | 0.3851 | 0.8186 | 0.8663 | 0.8142 (0.9) | 0.8761 (0.4) | 0.3821 | 0.7947 | 0.8628 | 0.7719 (0.9) | 0.8734 (0.3) | 0.3819 | 0.7175 | 0.8612 | 0.6849 (0.9) | 0.8725 (0.3) | |
| 35/255 | 0.2914 | 0.7450 | 0.8319 | 0.7178 (0.9) | 0.8341 (0.7) | 0.2883 | 0.6049 | 0.8228 | 0.5676 (0.9) | 0.8310 (0.6) | 0.2874 | 0.5102 | 0.8205 | 0.4828 (0.9) | 0.8292 (0.5) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yamamoto, H.; Anami, S.; Matsuoka, R. Optimizing Dynamic Mode Decomposition for Video Denoising via Plug-and-Play Alternating Direction Method of Multipliers. Signals 2024, 5, 202-215. https://doi.org/10.3390/signals5020011
Yamamoto H, Anami S, Matsuoka R. Optimizing Dynamic Mode Decomposition for Video Denoising via Plug-and-Play Alternating Direction Method of Multipliers. Signals. 2024; 5(2):202-215. https://doi.org/10.3390/signals5020011
Chicago/Turabian StyleYamamoto, Hyoga, Shunki Anami, and Ryo Matsuoka. 2024. "Optimizing Dynamic Mode Decomposition for Video Denoising via Plug-and-Play Alternating Direction Method of Multipliers" Signals 5, no. 2: 202-215. https://doi.org/10.3390/signals5020011
APA StyleYamamoto, H., Anami, S., & Matsuoka, R. (2024). Optimizing Dynamic Mode Decomposition for Video Denoising via Plug-and-Play Alternating Direction Method of Multipliers. Signals, 5(2), 202-215. https://doi.org/10.3390/signals5020011