Improving Speech Quality for Hearing Aid Applications Based on Wiener Filter and Composite of Deep Denoising Autoencoders


Abstract
1. Introduction
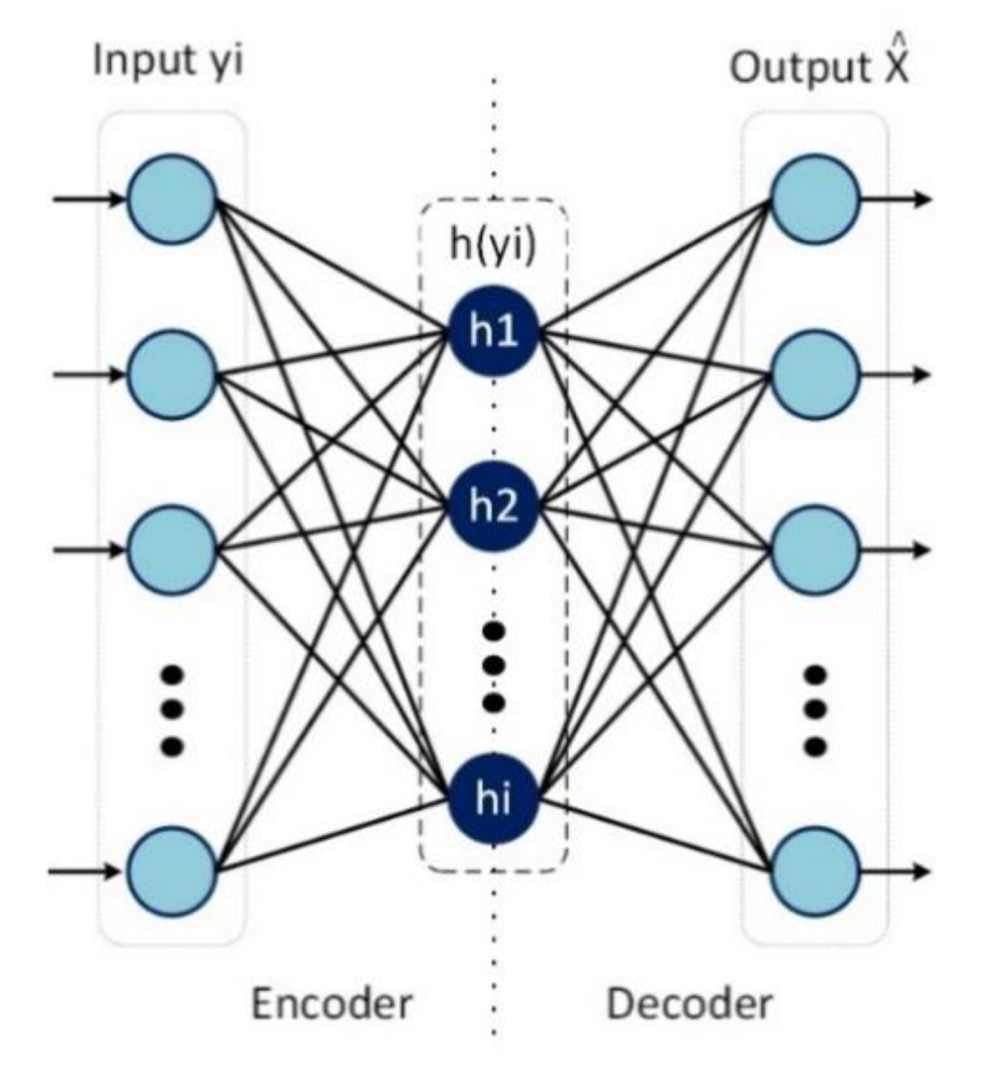
2. Denoising Autoencoder Based Noise Reduction
2.1. Denoising Autoencoder
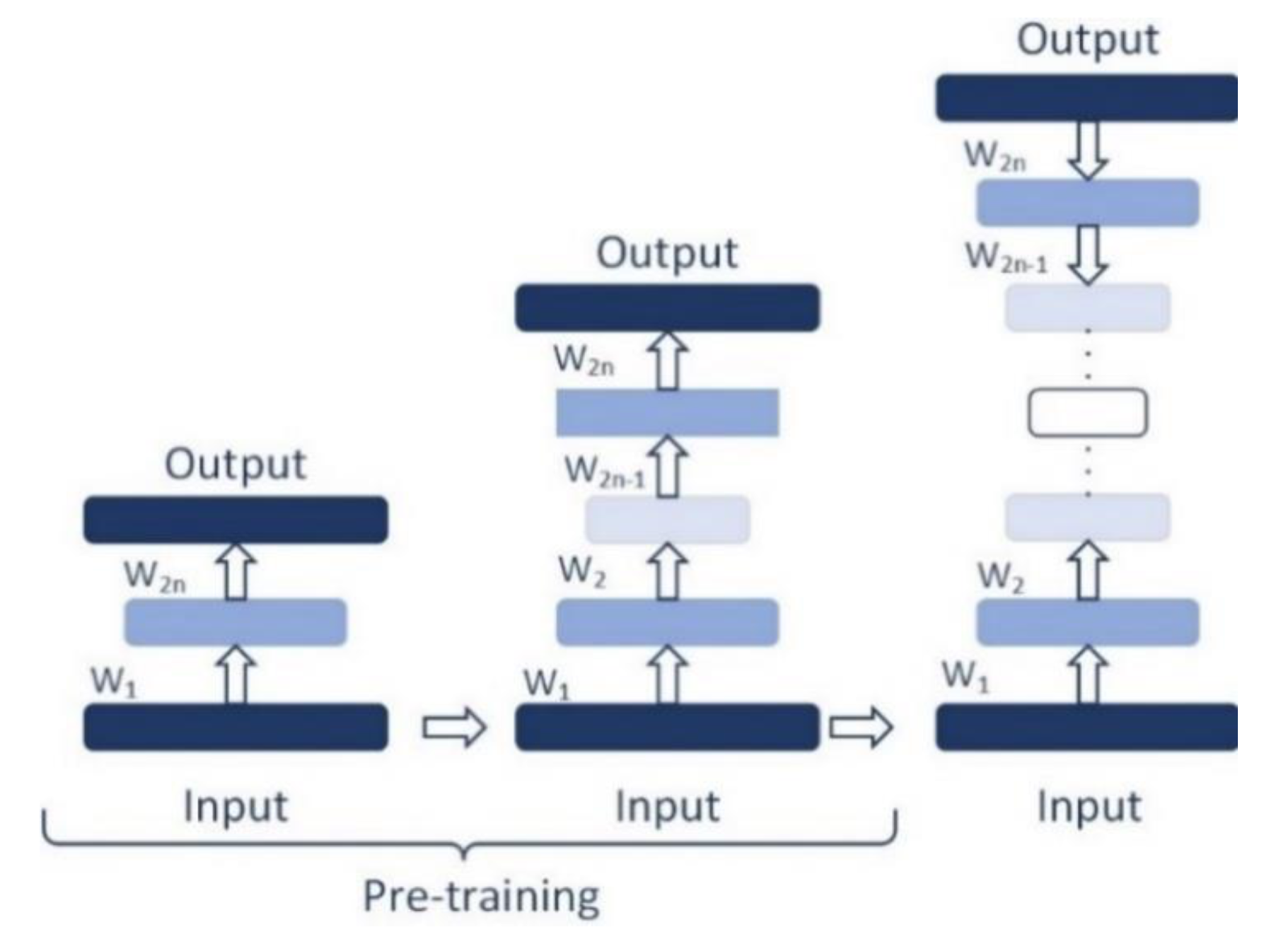
2.2. Effect of Depth (Layer by Layer Pre-Training)
3. Speech Perception and Hearing Aids
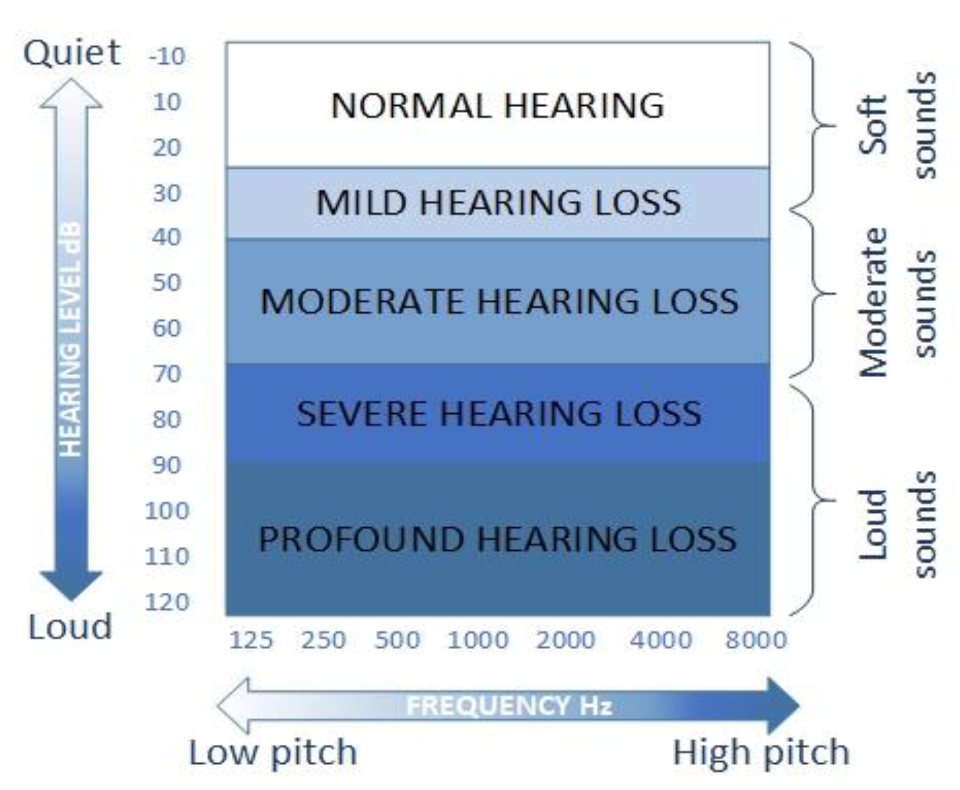
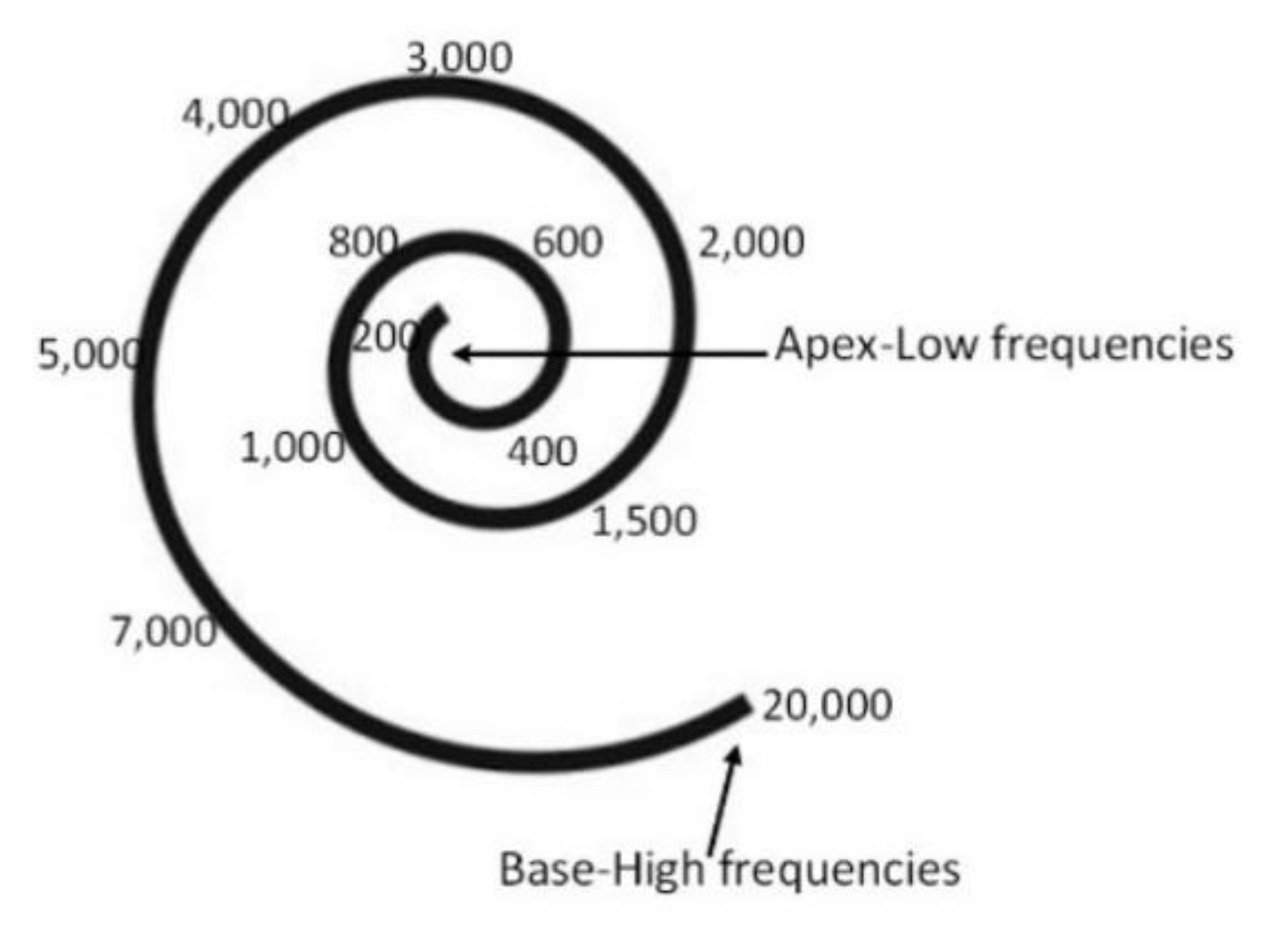
3.1. Hearing and Perception
3.2. Audiogram of Sensorineural Hearing Loss
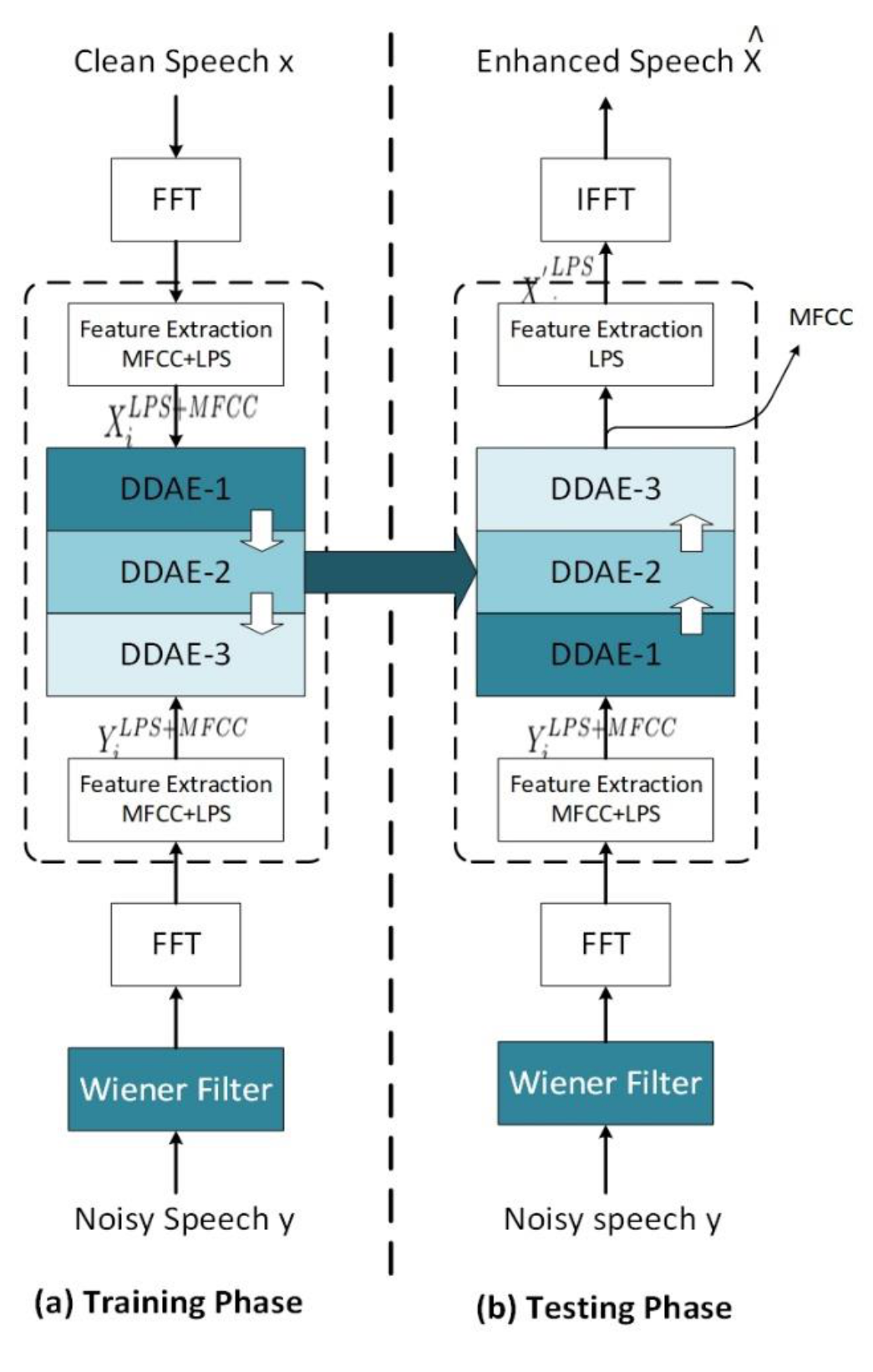
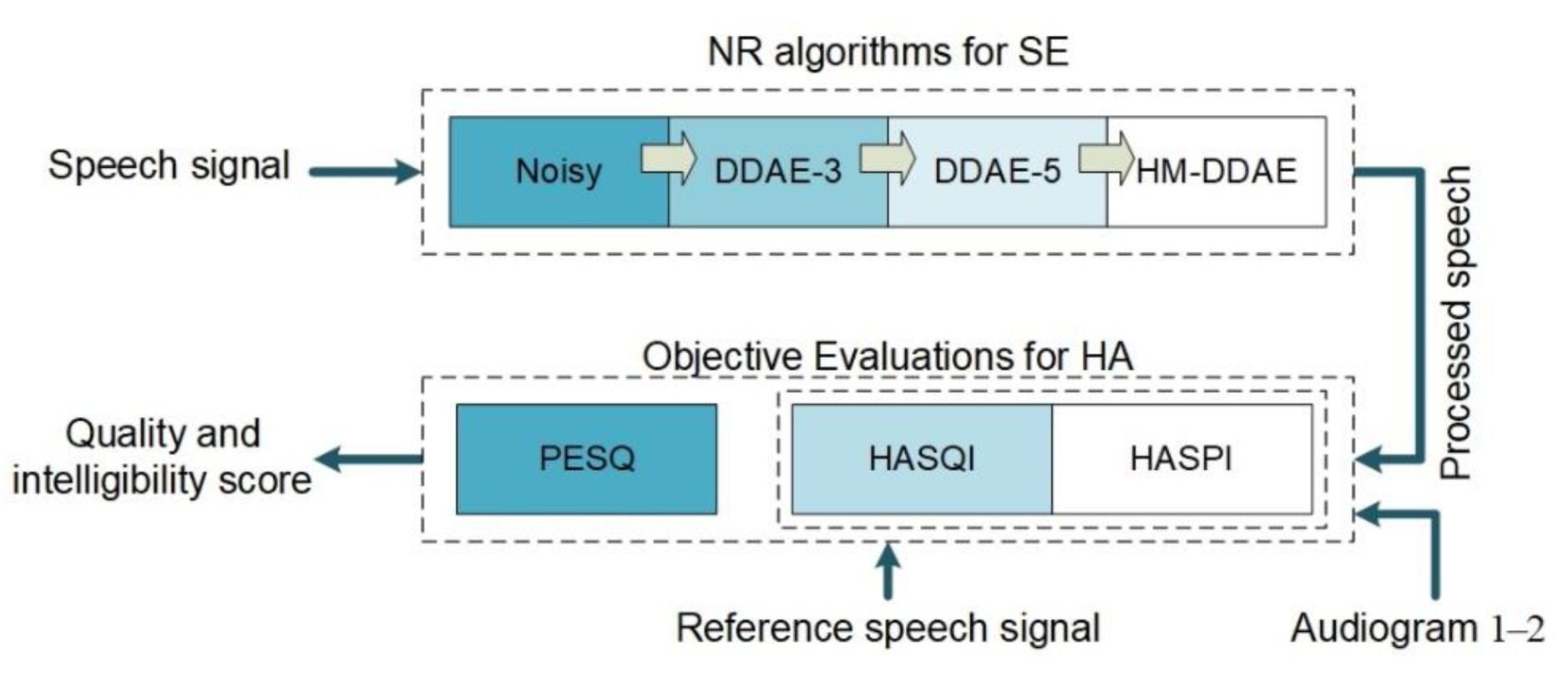
4. Proposed Hearing Aid System
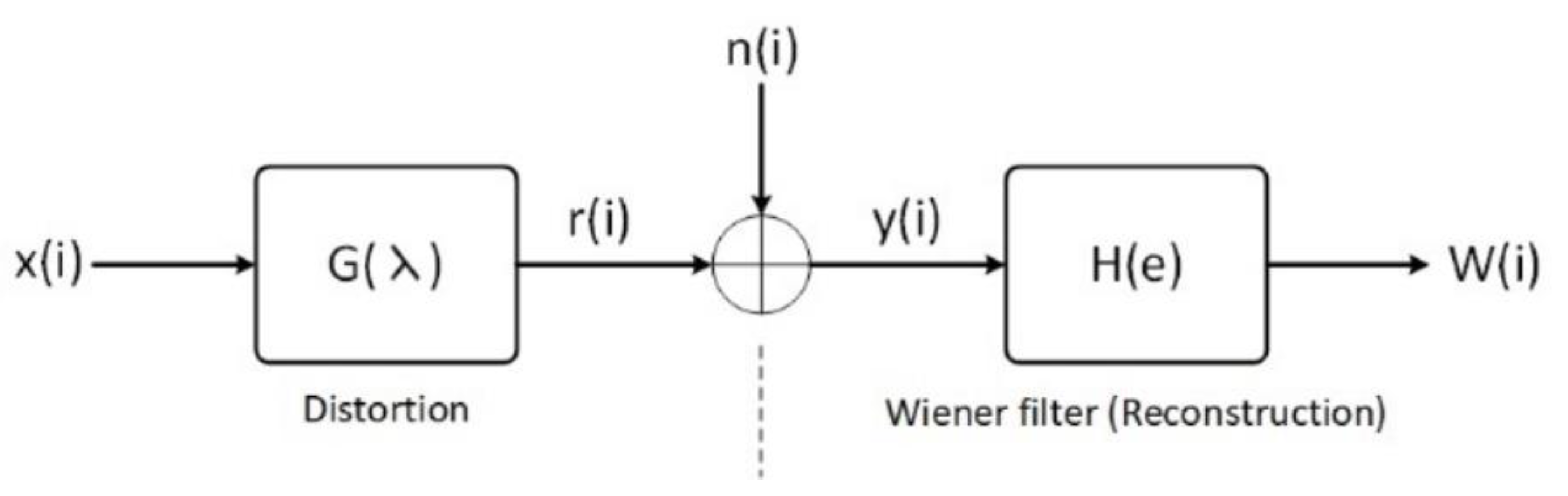
4.1. Wiener Filter (WF)
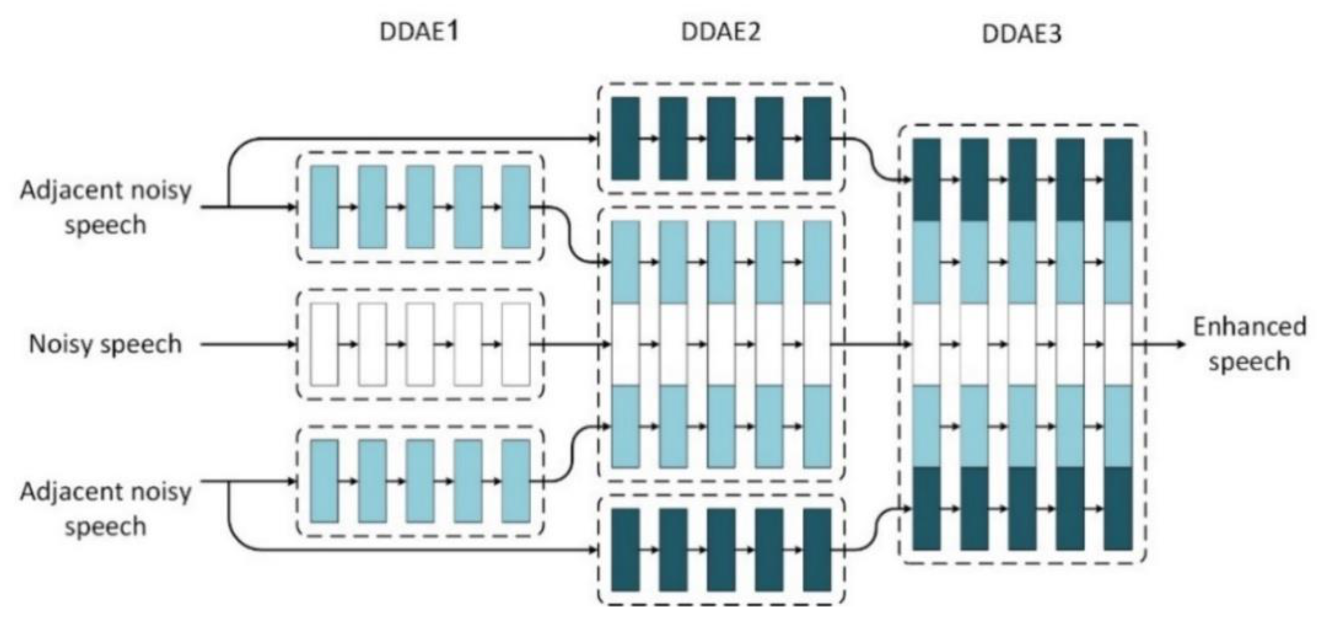
4.2. Composite of Deep Denoising Autoencoder (C-DDAEs)
4.2.1. Training Phase (Offline)
- has three hidden layers and 128 units for each layer. One magnitude spectrum with 513-dimensionalis used as the input in the t- time frame.
- is with three hidden layers and 512 units for each layer. The three frames spectra used .
- has three hidden layers and 1024 units for each layer. The three frames used .
4.2.2. Testing Phase (Online)
- The mean and variance de-normalizations applied to process the output of the DDAE model;
- The exponential transform applied to the de-normalized features;
- The Mel-to-spectrum transform used to obtain the amplitude features;
- The inverse fast Fourier transform (IFFT) applied to convert spectral LPS speech features to time-domain waveforms.
5. Experiments
5.1. Experimental Setup and Process
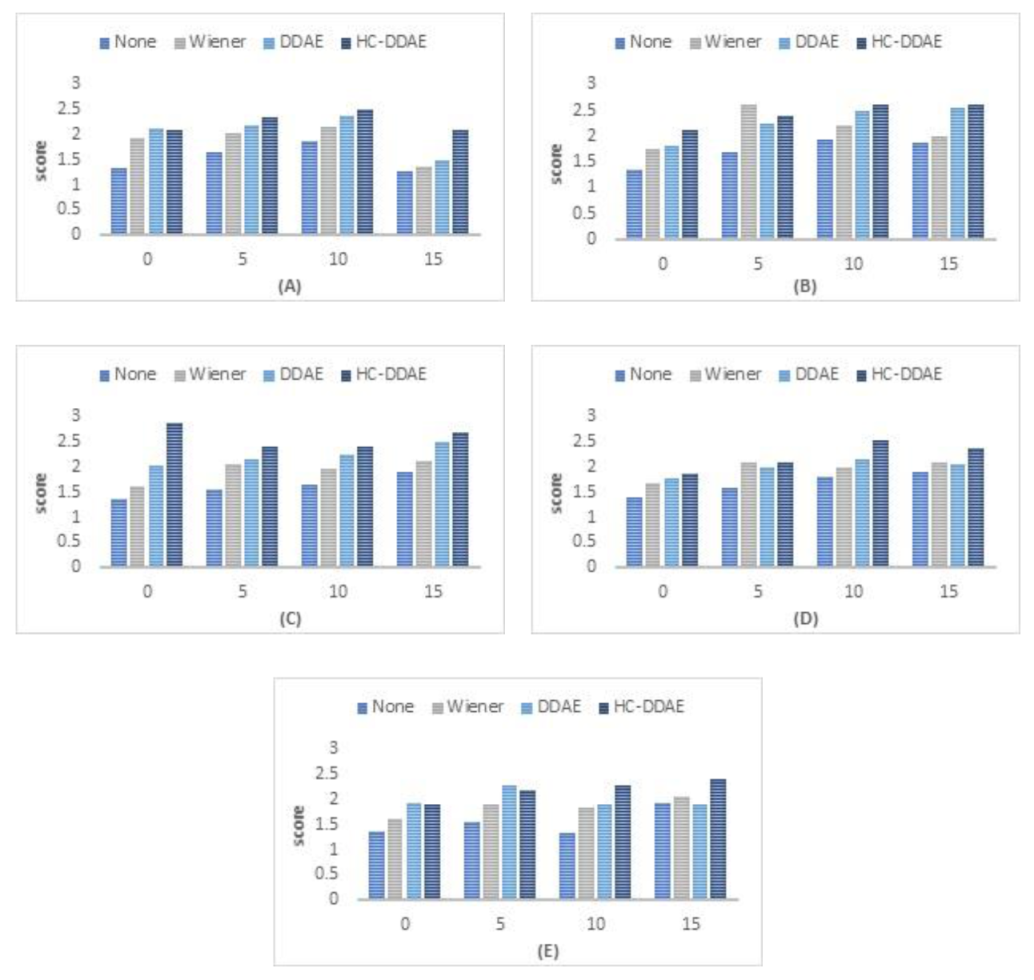
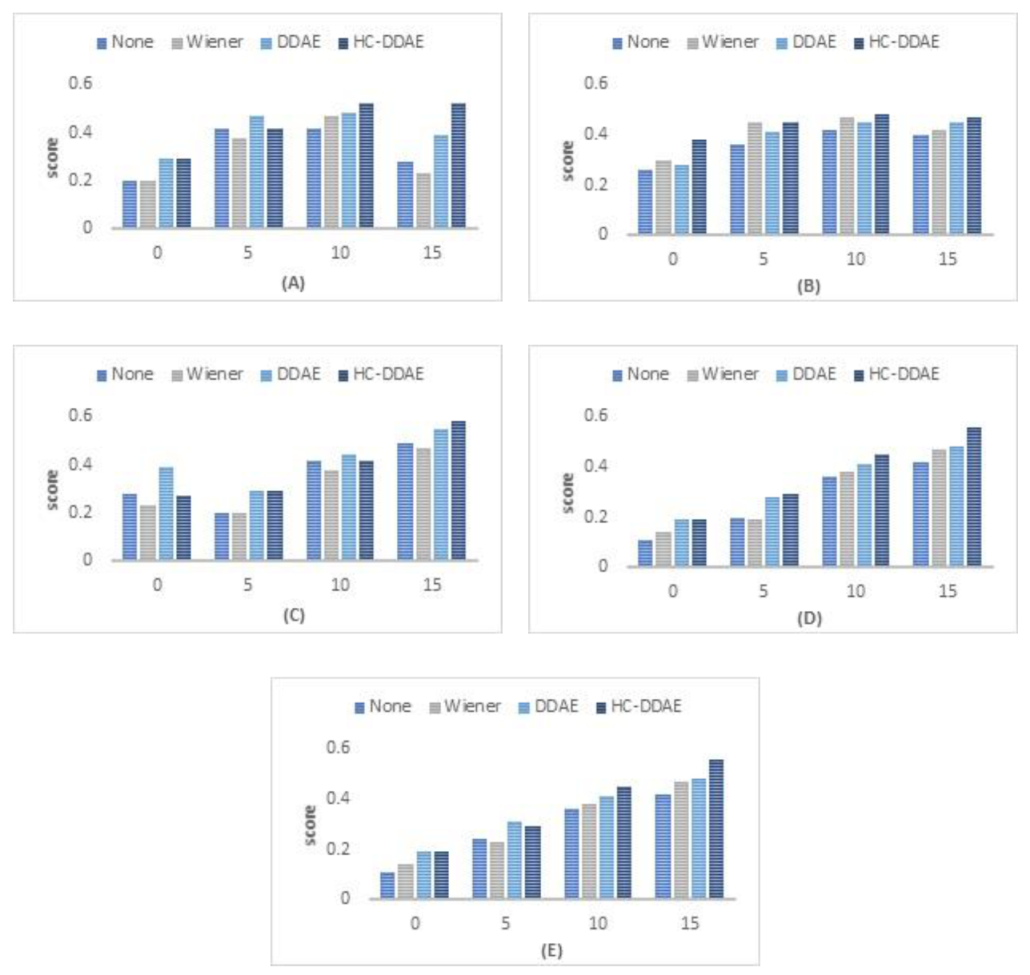
5.1.1. Experiment 1: Variations in the Types of Noise
5.1.2. Experiment 2: Variations in Gender
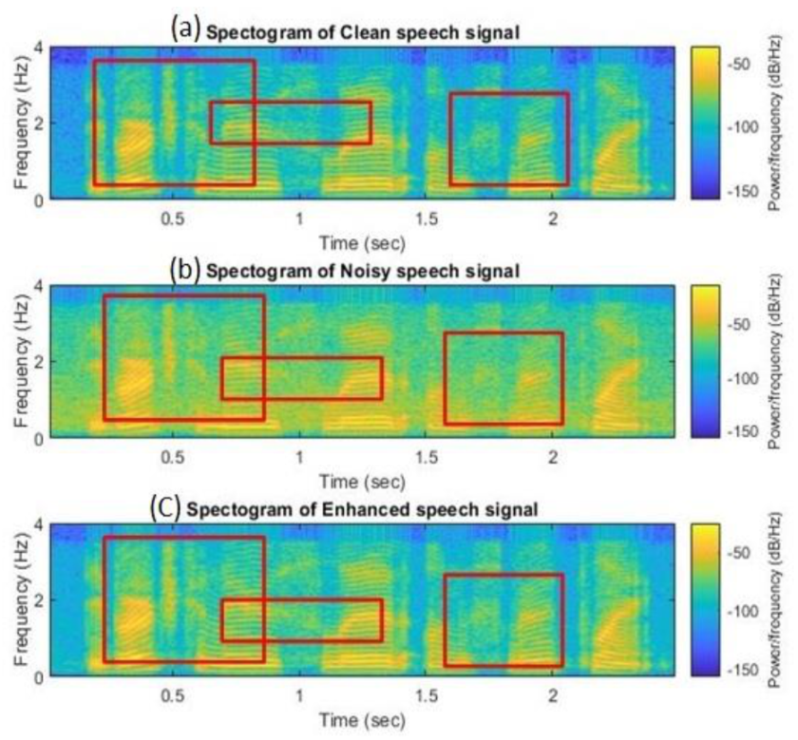
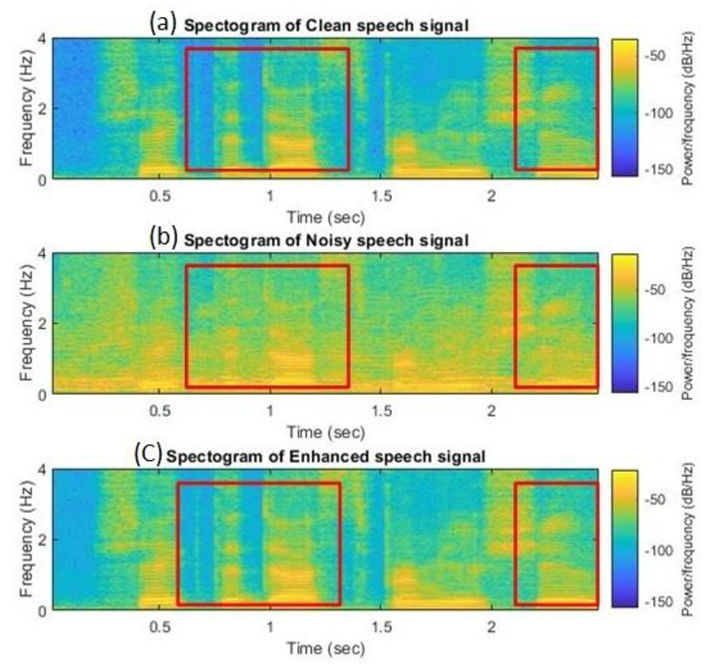
5.2. Comparison of Spectrograms
6. Speech Quality and Intelligibility Evaluation
6.1. Objective Evaluation
6.1.1. Speech Quality Perception Evaluation (PESQ)
6.1.2. Hearing Aid Speech Quality Index (HASQI)
6.1.3. Hearing Aid Speech Perception Index (HASPI)
6.2. Evaluation Procedure
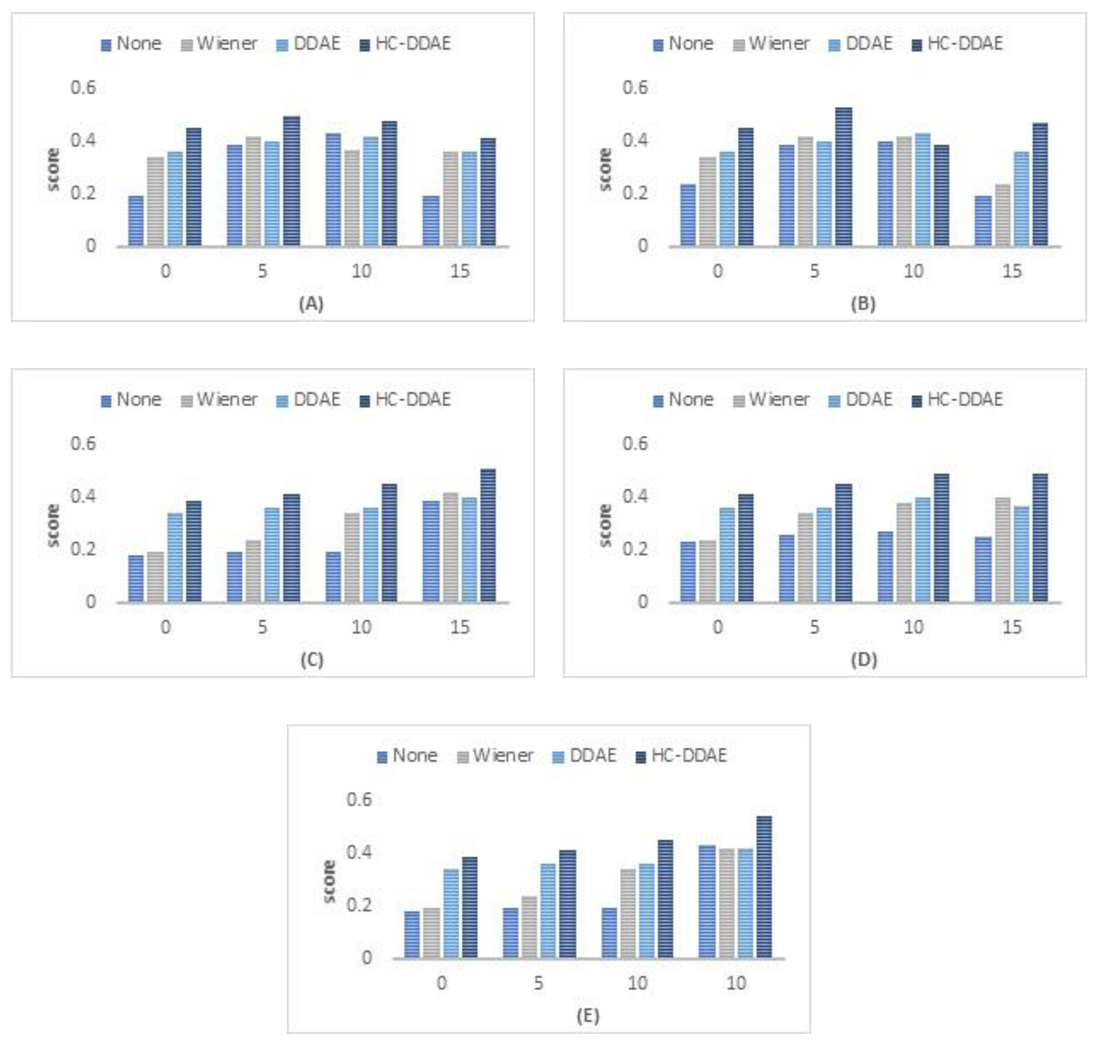
6.3. Results and Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lin, B.M.; Curhan, S.G.; Wang, M.; Eavey, R.; Stankovic, K.M.; Curhan, G.C. Hypertension, Diuretic Use, and Risk of Hearing Loss. Am. J. Med. 2016, 129, 416–422. [Google Scholar] [CrossRef]
- World Health Organization (2018 March). 10 Facts about Deafness. Available online: http://origin.who.int/features/factfiles/deafness/en/ (accessed on 13 August 2020).
- Jiang, W.; Zhao, F.; Guderley, N.; Manchaiah, V. Daily music exposure dose and hearing problems using personal listening devices in adolescents and young adults: A systematic review. Int. J. Audiol. 2016, 55, 197–205. [Google Scholar] [CrossRef] [PubMed]
- Scollie, S.; Glista, D.; Scollie, S. Diagnosis and Treatment of Severe High Frequency Hearing Loss. In Proceedings of the Phonak Adult Care Conference, Chicago, IL, USA, 2006, 13–15 November 2006; pp. 169–179. [Google Scholar]
- Preminger, J.E.; Carpenter, R.; Ziegler, C.H. A Clinical Perspective on Cochlear Dead Regions: Intelligibility of Speech and Subjective Hearing Aid Benefit. J. Am. Acad. Audiol. 2005, 16, 600–613. [Google Scholar] [CrossRef]
- Chen, F.; Loizou, P.C. Impact of SNR and gain-function over- and under-estimation on speech intelligibility. Speech Commun. 2012, 54, 272–281. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Levitt, H. Noise reduction in hearing aids: A review. J. Rehabil. Res. Dev. 2001, 38, 111–121. [Google Scholar] [PubMed]
- Chung, K. Challenges and Recent Developments in Hearing Aids: Part I. Speech Understanding in Noise, Microphone Technologies and Noise Reduction Algorithms. Trends Amplif. 2004, 8, 83–124. [Google Scholar] [CrossRef]
- Harbach, A.A.; Arora, K.; Mauger, S.J.; Dawson, P.W. Combining directional microphone and single-channel noise reduction algorithms: A clinical evaluation in difficult listening conditions with cochlear implant users. Ear Hear. J. 2012, 33, 13–23. [Google Scholar]
- Buechner, A.; Brendel, M.; Saalfeld, H.; Litvak, L.; Frohne-Buechner, C.; Lenarz, T. Results of a Pilot Study With a Signal Enhancement Algorithm for HiRes 120 Cochlear Implant Users. Otol. Neurotol. 2010, 31, 1386–1390. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Y.; Yoho, S.E.; Wang, D.; Healy, E.W. Large-scale training to increase speech intelligibility for hearing-impaired listeners in novel noises. J. Acoust. Soc. Am. 2016, 139, 2604–2612. [Google Scholar] [CrossRef]
- Sun, M.; Zhang, X.; Zheng, T.F. Unseen noise estimation using a separable deep autoencoder for speech enhancement. IEEE/Acm Trans. Audio Speech Lang. Process. 2016, 24, 93–104. [Google Scholar] [CrossRef]
- Lai, Y.H.; Zheng, W.Z.; Tang, S.T.; Fang, S.H.; Liao, W.H.; Tsao, Y. Improving the performance of hearing aids in noisy environments based on deep learning technology. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; Volume 20, pp. 404–408. [Google Scholar]
- Xu, Y.; Du, J.; Dai, L.-R.; Lee, C.-H. A Regression Approach to Speech Enhancement Based on Deep Neural Networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 23, 7–19. [Google Scholar] [CrossRef]
- Lai, Y.-H.; Chen, F.; Wang, S.-S.; Lu, X.; Tsao, Y.; Lee, C.-H. A Deep Denoising Autoencoder Approach to Improving the Intelligibility of Vocoded Speech in Cochlear Implant Simulation. IEEE Trans. Biomed. Eng. 2016, 64, 1568–1578. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Tsao, Y.; Matsuda, S.; Hori, C. Ensemble modelling of denoising autoencoder for speech spectrum restoration. In Proceedings of the 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 885–889. [Google Scholar]
- Lu, X.; Tsao, Y.; Matsuda, S.; Hori, C. Speech enhancement based on deep denoising autoencoder. Interspeech 2013, 2013, 436–440. [Google Scholar]
- Lai, Y.-H.; Tsao, Y.; Lu, X.; Chen, F.; Su, Y.-T.; Chen, K.-C.; Chen, Y.-H.; Chen, L.-C.; Li, L.P.-H.; Lee, C.-H. Deep Learning–Based Noise Reduction Approach to Improve Speech Intelligibility for Cochlear Implant Recipients. Ear Hear. 2018, 39, 795–809. [Google Scholar] [CrossRef]
- Huang, P.; Kim, M.; Hasegawa-Johnson, M.; Smaragdis, P. Joint optimization of masks and deep recurrent neural networks for monaural source separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 2136–2147. [Google Scholar] [CrossRef]
- Xu, Y.; Du, J.; Dai, L.-R.; Lee, C.-H. An experimental study on speech enhancement based on deep neural networks. IEEE Signal. Process. Lett. 2014, 21, 65–68. [Google Scholar] [CrossRef]
- Kim, M. Collaborative Deep learning for Speech Enhancement: A Run time- Model Selection Method Using Autoencoders. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Ororbia, A.; Giles, C.; Reitter, D. Online Semi-Supervised Learning with Deep Hybrid Boltzmann Machines and Denoising Autoencoders. arXiv 2016, arXiv:1511.06964. [Google Scholar]
- Xu, Y.; Du, J.; Huang, Z.; Dai, L.R.; Lee, C.H. Multi-Objective Learning and Mask-Based Post-Processing for Deep Neural Network Based Speech Enhancement. arXiv 2017, arXiv:1703.07172v1. [Google Scholar]
- Seyyed sallehi, S.Z.; Seyyed sallehi, S.A. A fast and efficient pre-training method based on layer-by layer maximum discrimination for deep neural networks. Neurocomputing 2015, 168, 669–680. [Google Scholar] [CrossRef]
- Souza, P. Speech Perception and Hearing Aids; Springer Handbook of Auditory research: Berlin, Germany, 2016; Volume 56, pp. 151–180. [Google Scholar]
- Healy, E.W.; Yoho, S.E.; Wang, Y.; Wang, D. An algorithm to improve speech recognition in noise for hearing-impaired listeners. J. Acoust. Soc. Am. 2013, 134, 3029–3038. [Google Scholar] [CrossRef]
- Healy, E.W.; Yoho, S.E.; Wang, Y.; Apoux, F.; Wang, D. Speech-cue transmission by an algorithm to increase consonant recognition in noise for hearing-impaired listeners. J. Acoust. Soc. Am. 2014, 136, 3325–3336. [Google Scholar] [CrossRef]
- Lai, Y.; Zheng, W. Multi-objective learning based speech enhancement method to increase speech quality and intelligibility for hearing aid device users. Biomed. Signal. Process. Control. 2019, 48, 35–45. [Google Scholar] [CrossRef]
- WHO. Deafness and Hearing Loss. Available online: http://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss (accessed on 13 August 2020).
- Vergin, R.; O’Shaughnessy, D.; Farnat, A. Generalized Mel frequency cepstral coefficients for large vocabulary speaker-independent continuous speech recognition. IEEE Trans. 1999, 7, 525–532. [Google Scholar] [CrossRef][Green Version]
- Yin, X.; Ling, Z.; Lei, M.; Dai, L. Considering Global Variance of the Log Power Spectrum Derived from Mel-Cepstrum in HMM-based Parametric Speech Synthesis. In Proceedings of the 13th Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- NOIZEUS: A Noisy Speech Corpus for Evaluation of Speech Enhancement Algorithms. Available online: https://ecs.utdallas.edu/loizou/speech/noizeus/ (accessed on 13 August 2020).
- Duan, Z.; Mysore, G.J.; Smaragdis, P. Online PLCA for real-time semi-supervised source separation, International Conference on Latent Variable Analysis and Signal Separation (LVA/ICA). In International Conference on Latent Variable Analysis and Signal Separation; Springer: Berlin/Heidelberg, Germany, 2012; pp. 34–41. [Google Scholar]
- Tsao, Y.; Lai, Y.H. Generalized maximum a posteriori spectral amplitude estimation for speech enhancement. Speech Commun. 2016, 76, 112–126. [Google Scholar] [CrossRef]
- Deng, L.; Seltzer, M.; Yu, D.; Acero, A.; Mohamed, A.R.; Hinton, G. Binary Coding of Speech Spectrograms Using a Deep Auto-encoder. In Proceedings of the 11th Annual Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Beerends, J.; Hekstra, A.; Rix, A.W.; Hollier, M.P. Perceptual evaluation of speech quality (PESQ) the new ITU standard for end-to-end speech quality assessment part 2: Psychoacoustic model. J. Audio Eng. Soc. 2002, 50, 765–778. [Google Scholar]
- Kates, S.J.; Arehart, K. The hearing-aid speech quality index (HASQI). J. Audio Eng. Soc. 2010, 58, 363–381. [Google Scholar]
- Kates, J.M.; Arehart, K.H. The hearing-aid speech perception index (HASPI). Speech Commun. 2014, 65, 75–93. [Google Scholar] [CrossRef]
- Gupta, S.; Jaafar, J.; Ahmad, W.F.W.; Bansal, A. Feature Extraction Using Mfcc. Signal. Image Process. Int. J. 2013, 4, 101–108. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frequency (kHz) in dB HL | |||||||
|---|---|---|---|---|---|---|---|
| Audiogram | 0.25 | 0.5 | 1 | 2 | 4 | 8 | |
| 1 | Plane loss | 60 | 60 | 60 | 60 | 60 | 60 |
| 2 | Reverse tilt loss | 70 | 70 | 70 | 50 | 10 | 10 |
| 3 | Moderate tilt high-frequency loss | 40 | 40 | 50 | 60 | 65 | 65 |
| 4 | Steep slope high-frequency loss with standard low-frequency threshold | 0 | 0 | 0 | 60 | 80 | 90 |
| 5 | Steep slope high-frequency loss with mild low-frequency hearing loss | 0 | 15 | 30 | 60 | 80 | 85 |
| 6 | Mild to moderate tilt high-frequency hearing loss. In this study | 14 | 14 | 11 | 14 | 24 | 39 |
| 7 | 24 | 24 | 25 | 31 | 46 | 60 | |
| (1) White Noise | 0 | 5 | 10 | 15 |
| None | 1.34 | 1.54 | 1.73 | 2.12 |
| Wiener Filter | 1.64 | 2.02 | 2.2 | 2.34 |
| DDAE | 1.86 | 2.16 | 2.38 | 2.5 |
| HC-DDAEs | 1.28 | 1.38 | 1.49 | 2.09 |
| (2) Pink Noise | 0 | 5 | 10 | 15 |
| None | 1.34 | 1.61 | 1.8 | 2.12 |
| Wiener Filter | 1.69 | 1.9 | 2.25 | 2.4 |
| DDAE | 1.92 | 2.2 | 2.49 | 2.6 |
| HC-DDAEs | 1.87 | 1.98 | 2.53 | 2.62 |
| (3) Train Noise | 0 | 5 | 10 | 15 |
| None | 1.38 | 1.54 | 1.66 | 1.91 |
| Wiener Filter | 1.62 | 2.07 | 1.97 | 2.11 |
| DDAE | 2.02 | 2.16 | 2.26 | 2.5 |
| HC_DDAEs | 2.87 | 2.41 | 2.41 | 2.69 |
| (4) Babble Noise | 0 | 5 | 10 | 15 |
| None | 1.4 | 1.59 | 1.8 | 1.91 |
| Wiener Filter | 1.67 | 2.09 | 1.99 | 2.09 |
| DDAE | 1.78 | 1.99 | 2.16 | 2.06 |
| HC_DDAEs | 1.87 | 2.09 | 2.53 | 2.36 |
| (5) Restaurant Noise | 0 | 5 | 10 | 15 |
| None | 1.36 | 1.57 | 1.34 | 1.94 |
| Wiener Filter | 1.63 | 1.91 | 1.84 | 2.07 |
| DDAE | 1.92 | 2.28 | 1.89 | 1.89 |
| HC_DDAEs | 1.91 | 2.19 | 2.29 | 2.42 |
| Noise | Gender | None | Wiener | DDAE | HC-DDAEs |
|---|---|---|---|---|---|
| Train | Male | 1.38 | 1.7 | 2.32 | 2.46 |
| Female | 1.34 | 1.78 | 2.1 | 2.51 | |
| Babble | Male | 1.87 | 2.02 | 2.08 | 2.12 |
| Female | 1.92 | 1.96 | 2.16 | 2.57 | |
| Car | Male | 1.51 | 2.21 | 2.61 | 2.73 |
| Female | 1.82 | 2.1 | 2.12 | 2.54 | |
| Exhibition hall | Male | 1.53 | 1.99 | 1.78 | 2.13 |
| Female | 1.57 | 1.68 | 2.01 | 2.36 | |
| Restaurant | Male | 1.38 | 1.79 | 2.34 | 2.47 |
| Female | 1.62 | 1.79 | 2.39 | 2.41 | |
| Street | Male | 1.29 | 2 | 2.01 | 2.27 |
| Female | 1.31 | 1.88 | 2.1 | 2.34 | |
| Airport | Male | 1.38 | 1.79 | 2.02 | 2.48 |
| Female | 1.42 | 1.99 | 2.1 | 2.17 | |
| Railway station | Male | 1.76 | 1.78 | 2.13 | 2.09 |
| Female | 1.71 | 1.95 | 2.4 | 2.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lazim, R.Y.; Yun, Z.; Wu, X. Improving Speech Quality for Hearing Aid Applications Based on Wiener Filter and Composite of Deep Denoising Autoencoders. Signals 2020, 1, 138-156. https://doi.org/10.3390/signals1020008
Lazim RY, Yun Z, Wu X. Improving Speech Quality for Hearing Aid Applications Based on Wiener Filter and Composite of Deep Denoising Autoencoders. Signals. 2020; 1(2):138-156. https://doi.org/10.3390/signals1020008
Chicago/Turabian StyleLazim, Raghad Yaseen, Zhu Yun, and Xiaojun Wu. 2020. "Improving Speech Quality for Hearing Aid Applications Based on Wiener Filter and Composite of Deep Denoising Autoencoders" Signals 1, no. 2: 138-156. https://doi.org/10.3390/signals1020008
APA StyleLazim, R. Y., Yun, Z., & Wu, X. (2020). Improving Speech Quality for Hearing Aid Applications Based on Wiener Filter and Composite of Deep Denoising Autoencoders. Signals, 1(2), 138-156. https://doi.org/10.3390/signals1020008