
Perceptual Evaluation of Speech Quality for Inexpensive Recording Equipment


Abstract
1. Introduction
2. Audio Quality Assessment Techniques
2.1. Subjective Speech Testing
2.2. Objective Speech Testing
3. Practical Experiment
3.1. Introduction
3.2. Procedure
4. Signal Processing
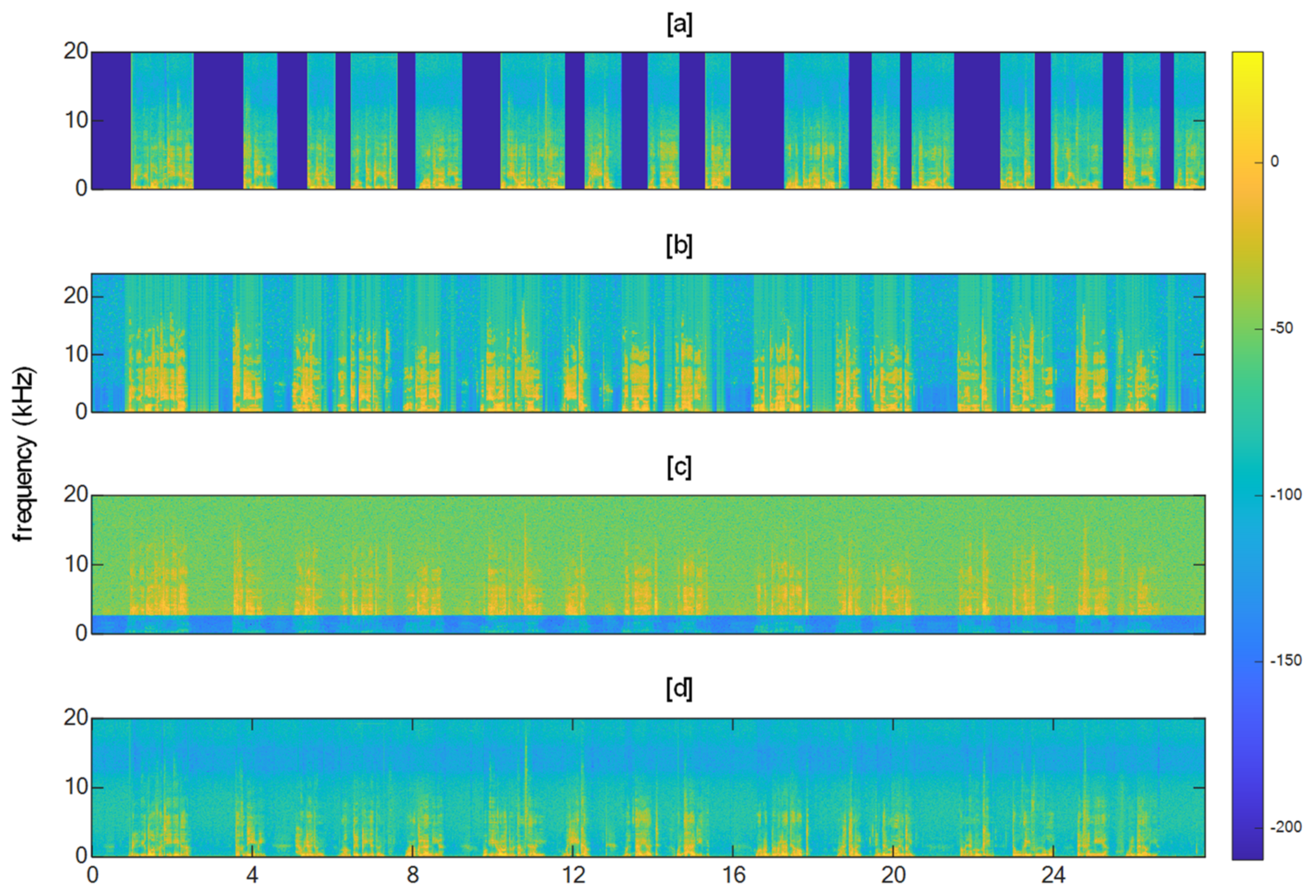
4.1. Test Samples
4.2. Speech Activity Detection (SAD)
4.3. High-Pass Filtering
4.4. Wiener Filtering
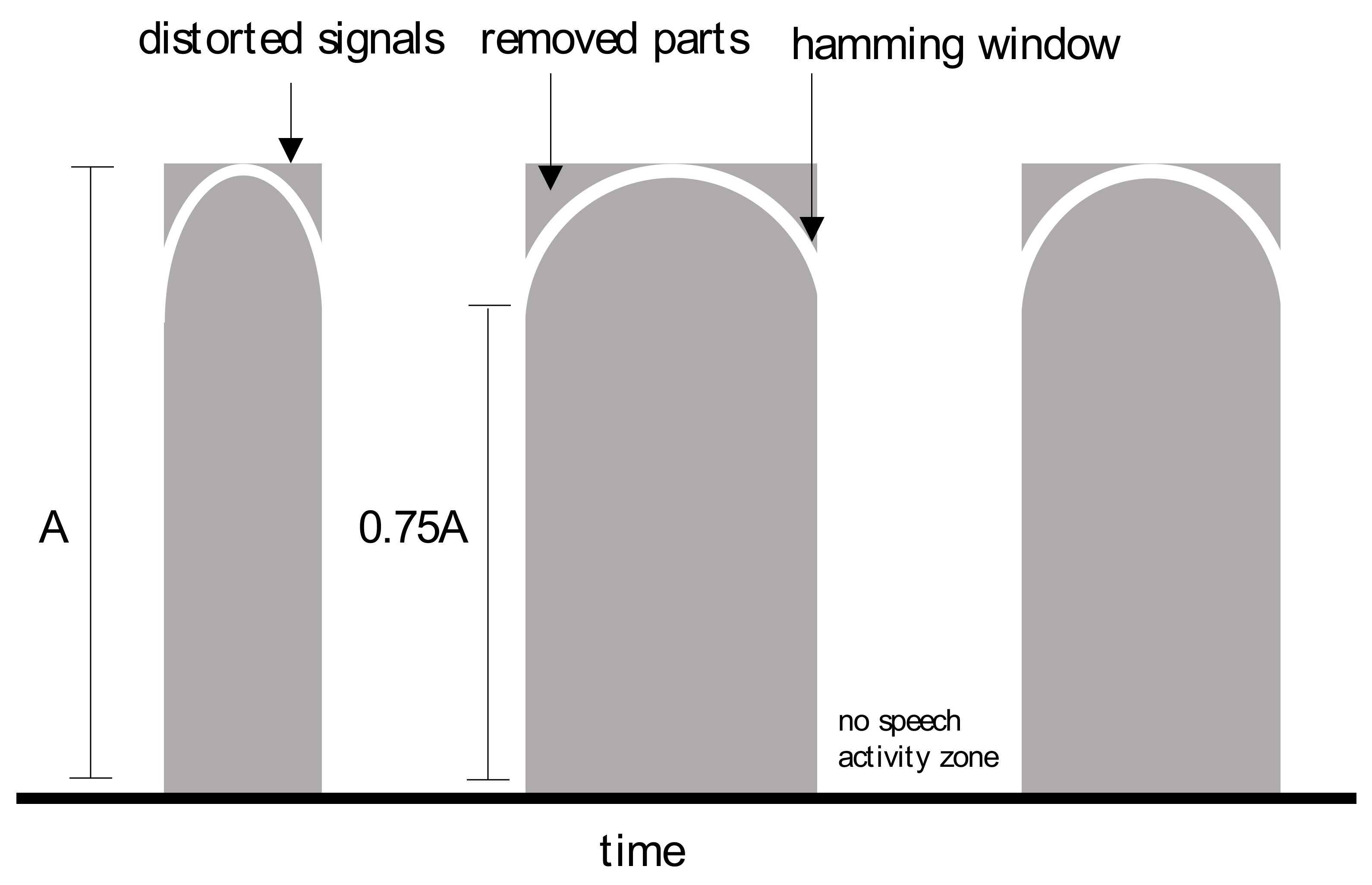
4.5. Windowing
5. Results
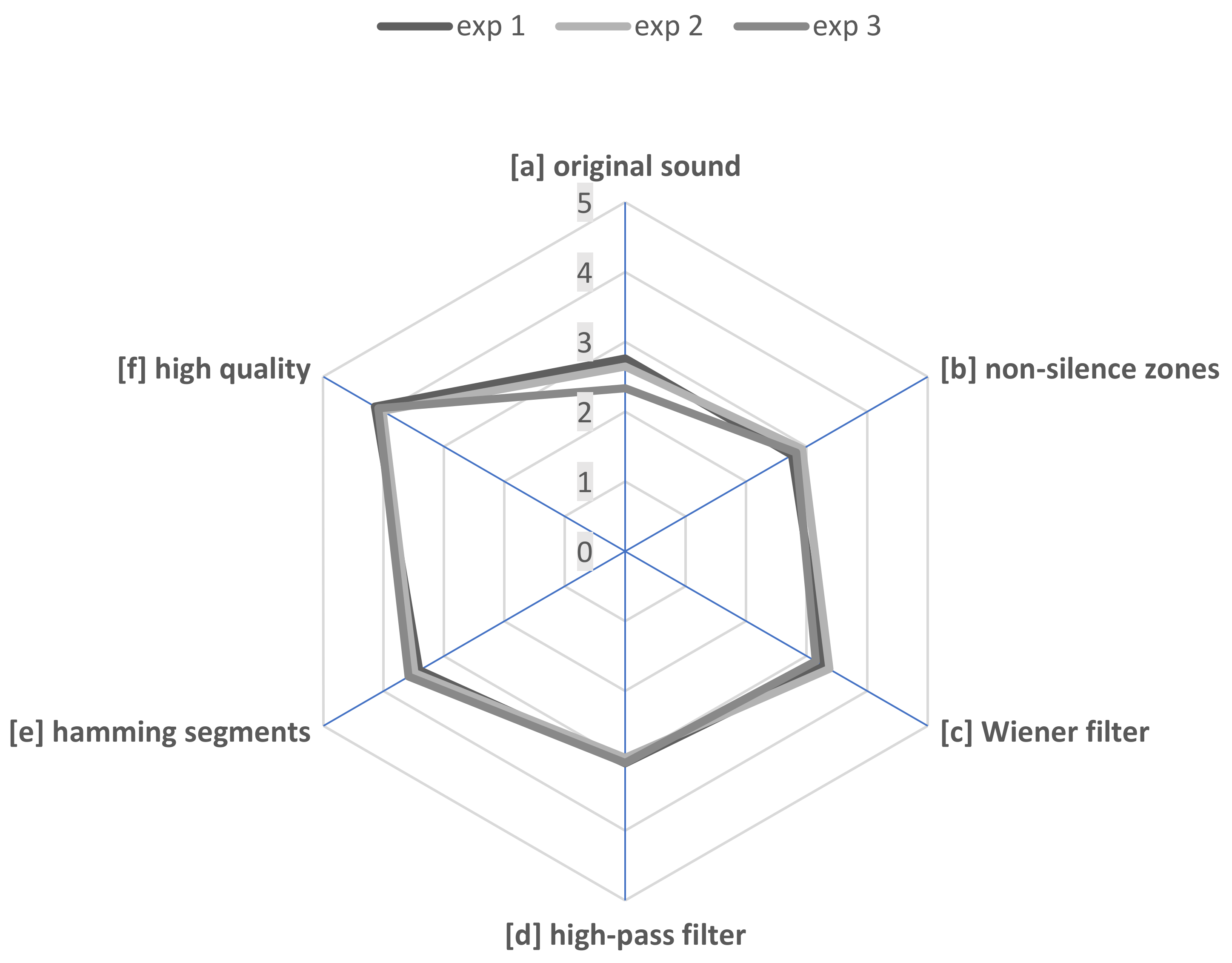
5.1. Experimental Results
5.2. Results of the Speech Quality Test
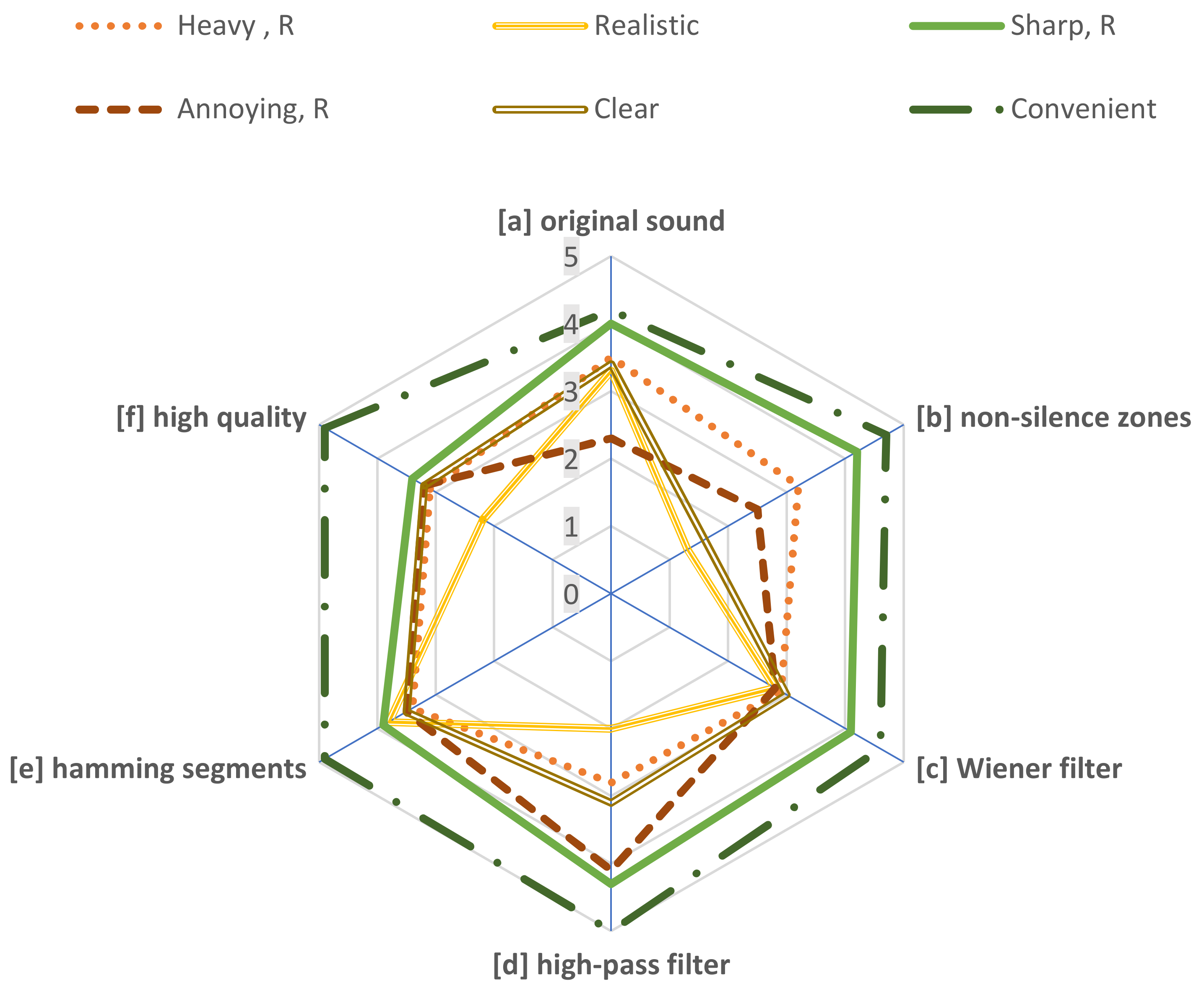
5.3. Results of the Modified Assessment
- Heavy, reversed: the pitch was higher than expected, or the voice turned into a ‘robotic’ sounding tone.
- Realistic: closer to the real (reference) voice of the reader.
- Sharp, reversed: the speech was at a sharper pitch where the frequency was lowered.
- Annoying, reversed: a measure of how annoyed the listener became with the voice, and it included the presence of unwanted noise.
- Clear: the words and sentences were clear and heard in an understandable manner.
- Convenient: the user could listen to the clip for longer durations without getting annoyed.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Heavy, R | Realistic | Sharp, R | Annoying, R | Clear | Convenient |
|---|---|---|---|---|---|---|
| [a] | 3.5 | 3.2 | 2.9 | 2.8 | 3.4 | 3.1 |
| [b] | 3.3 | 2.3 | 2.8 | 2.0 | 3.8 | 2.2 |
| [c] | 4.0 | 4.2 | 4.1 | 4.3 | 3.9 | 3.4 |
| [d] | 2.3 | 1.5 | 2.8 | 4.1 | 3.5 | 3.2 |
| [e] | 3.4 | 1.6 | 3.0 | 3.1 | 3.5 | 3.2 |
| [f] | 4.2 | 4.7 | 4.6 | 5.0 | 4.9 | 4.9 |
| R: reversed | ||||||

6. Discussion
7. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Net-Informations, “1G Vs. 2G Vs. 3G Vs. 4G Vs. 5G”. Available online: http://net-informations.com/q/diff/generations (accessed on 4 June 2020).
- Staderini, E.M. Inexpensive Microphone Enables Everyday Digital Recording of Deglutition Murmurs. In Proceedings of the 2014 8th International Symposium on Medical Information and Communication Technology (ISMICT), Florence, Italy, 2–4 April 2014; IEEE: Piscataway Township, NJ, USA, 2014; pp. 1–5. [Google Scholar]
- Rempel, R.S.; Francis, C.M.; Robinson, J.N.; Campbell, M. Comparison of audio recording system performance for detecting and monitoring songbirds. J. Field Ornithol. 2013, 84, 86–97. [Google Scholar] [CrossRef]
- International Telecommunication Union. Rec. P.861, Objective Quality Measurement of Telephone-Band (300-3400 Hz) Speech Codecs; International Telecommunication Union: Geneva, Switzerland, 1996. [Google Scholar]
- Smith, S.W. Audio Processing. In Digital Signal Processing; California Technical Publishing: San Diego, CA, USA, 2003; pp. 351–372. [Google Scholar]
- International Telecommunication Union. P.800: Methods for Subjective Determination of Transmission Quality; International Telecommunication Union: Geneva, Switzerland, 1996. [Google Scholar]
- Avetisyan, H.; Holub, J. Subjective speech quality measurement with and without parallel task: Laboratory test results comparison. PLoS ONE 2018, 13, e0199787. [Google Scholar] [CrossRef] [PubMed]
- Pomy, J. POLQA The Next Generation Mobile Voice Quality Testing Standard. 2011. Available online: https://www.itu.int/ITU-D/tech/events/2011/Moscow_ZNIIS_April11/Presentations/09-Pomy-POLQA.pdf (accessed on 1 June 2020).
- Arifianto, D.; Sulistomo, T.R. Subjective evaluation of voice quality over GSM network for quality of experience (QoE) measurement. In Proceedings of the 2015 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Nusa Dua Bali, Indonesia, 9–12 November 2015; pp. 148–152. [Google Scholar] [CrossRef]
- Goodman, D.; Nash, R. Subjective quality of the same speech transmission conditions in seven different countries. In Proceedings of the ICASSP 1982 IEEE International Conference on Acoustics, Speech, and Signal Processing, Paris, France, 3–5 May 1982; Volume 7, pp. 984–987. [Google Scholar] [CrossRef]
- Damiani, E.; Howlett, R.J.; Jain, L.C.; Gallo, L.; de Pietro, G. Intelligent Interactive Multimedia Systems and Services. In Smart Innovation, Systems and Technologies; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Ipsic, I. (Ed.) Speech and Language Technologie; InTech: London, UK, 2011. [Google Scholar]
- Benesty, J.; Sondhi, M.M.; Huang, J. Springer Handbook of Speech Processing; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Stupakov, A.; Hanusa, E.; Bilmes, J.; Fox, D. Cosine-a Corpus of Multi-Party Conversational Speech in Noisy Environments. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; IEEE: Piscataway Township, NJ, USA, 2009; pp. 4153–4156. [Google Scholar]
- Richey, C.; Barrios, M.A.; Armstrong, Z.; Bartels, C.; Franco, H.; Graciarena, M.; Lawson, A.; Nandwana, M.K.; Stauffer, A.; van Hout, J.; et al. Voices obscured in complex environmental settings (voices) corpus. arXiv 2018, arXiv:1804.05053. [Google Scholar]
- Cooke, M.; Barker, J.; Cunningham, S.; Shao, X. An audiovisual corpus for speech perception and automatic speech recognition. J. Acoust. Soc. Am. 2006, 120, 2421–2424. [Google Scholar] [CrossRef] [PubMed]
- Hou, J.-C.; Wang, S.-S.; Lai, Y.-H.; Tsao, Y.; Chang, H.-W.; Wang, H.-M. Audio-visual speech enhancement using multimodal deep convolutional neural networks. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 117–128. [Google Scholar] [CrossRef]
- Ephrat, A.; Mosseri, I.; Lang, O.; Dekel, T.; Wilson, K.; Hassidim, A.; Freeman, W.T.; Rubinstein, M. Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. ACM Trans. Graph. 2018, 37, 112. [Google Scholar] [CrossRef]
- Bailly-Bailli´ere, E.; Bengio, S.; Bimbot, F.; Hamouz, M.; Kittler, J.; Mari´ethoz, J.; Matas, J.; Messer, K.; Popovici, V.; Por´ee, F.; et al. The banca database and evaluation protocol. In Proceedings of the International Conference on Audio- and Video-Based Biometric Person Authentication, Guildford, UK, 9–11 June 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 625–638. [Google Scholar]
- Lee, B.; Hasegawa-Johnson, M.; Goudeseune, C.; Kamdar, S.; Borys, S.; Liu, M.; Huang, T. Avicar: Audio-visual speech corpus in a car environment. In Proceedings of the Eighth International Conference on Spoken Language Processing, Jeju Island, Korea, 4–8 October 2004. [Google Scholar]
- Gogate, M.; Dashtipour, K.; Adeel, A.; Hussain, A. CochleaNet: A robust language-independent audio-visual model for real-time speech enhancement. Inf. Fusion 2020, 63, 273–285. [Google Scholar] [CrossRef]
- Gogate, M.; Dashtipour, K.; Hussain, A. Visual Speech in Real Noisy Environments (VISION): A Novel Benchmark Dataset and Deep Learning-based Baseline System. Proc. Interspeech 2020, 2020, 4521–4525. [Google Scholar]
- Schinkel-Bielefeld, N.; Zhang, J.; Qin, Y.; Leschanowsky, A.K.; Fu, S. Perception of coding artifacts by nonnative speakers—A study with Mandarin Chinese and German speaking listeners. AES J. Audio Eng. Soc. 2018, 66, 60–70. [Google Scholar] [CrossRef]
- Milner, B.; Almajai, I. Noisy audio speech enhancement using Wiener filters derived from visual speech. In Proceedings of the International Workshop on Auditory-Visual Speech Processing (AVSP), Hilvarenbeek, The Netherlands, 1–3 September 2007. ISCA, Archive. [Google Scholar]
- Stiefelhagen, R.; Garofolo, J. Multimodal Technologies for Perception of Humans; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4122. [Google Scholar]
- Hashmi, A.; Kalashnikov, A.N. Sensor data fusion for responsive high resolution ultrasonic temperature measurement using piezoelectric transducers. Ultrasonics 2019, 99. [Google Scholar] [CrossRef] [PubMed]
- Zandan, N. The Power of Pause. Available online: https://www.quantifiedcommunications.com/blog/the-power-of-pause (accessed on 6 June 2020).
- Fosler-Lussier, E.; Morgan, N. Effects of speaking rate and word frequency on pronunciations in conversational speech. Speech Commun. 1999, 29, 137–158. [Google Scholar] [CrossRef]
- Facts about Speech intelligibility: Human Voice Frequency Range. Available online: https://www.dpamicrophones.com/mic-university/facts-about-speech-intelligibility (accessed on 1 June 2020).
- Bhagat, R.; Kaur, R. Improved Audio Filtering Using Extended High Pass Filters. Int. J. Eng. Res. Technol. 2013, 2, 81–84. [Google Scholar]
- Kirubagari, B.; Selvaganesh, R. A Noval Approach in Speech Enhancement for Reducing Noise Using Bandpass Filter and Spectral Subtraction. Bonfring Int. J. Res. Commun. Eng. 2012, 2, 5–8. [Google Scholar]
- Hansen, M. Assessment and Prediction of Speech Transmission Quality with an Auditory Processing Model. Ph.D. Thesis, University of Oldenburg, Oldenburg, Germany, 1998. [Google Scholar]
- Lawrie, J.B.; Abrahams, I.D. A brief historical perspective of the Wiener-Hopf technique. J. Eng. Math. 2007. [Google Scholar] [CrossRef]
- Upadhyay, N.; Jaiswal, R.K. Single Channel Speech Enhancement: Using Wiener Filtering with Recursive Noise Estimation. Procedia Comput. Sci. 2016. [Google Scholar] [CrossRef]
- Plapous, C.; Marro, C.; Scalart, P. Improved Signal-to-Noise Ratio Estimation for Speech Enhancement. IEEE Trans. Audio Speech, Lang. Process. 2006, 14, 2098–2108. [Google Scholar] [CrossRef]
- Scalart, P. Wiener Filter for Noise Reduction and Speech Enhancement. MATLAB Central File Exchange. 2020. Available online: https://www.mathworks.com/matlabcentral/fileexchange/24462-wiener-filter-for-noise-reduction-and-speech-enhancement (accessed on 10 June 2020).
- Mic University. The Basic about Distortion in Mics. DPA Microphones. 2018. Available online: https://www.dpamicrophones.com/mic-university/the-basics-about-distortion-in-mics (accessed on 2 June 2020).
- International Electrotechnical Commission. IEC 60.268 Sound System Equipment, Part 2: Explanation of General Terms and Calculation Methods; IEC: Geneva, Switzerland, 1987. [Google Scholar]
- Blagouchine, I.V.; Moreau, E. Analytic method for the computation of the total harmonic distortion by the cauchy method of residues. IEEE Trans. Commun. 2011. [Google Scholar] [CrossRef]






| Inexpensive Microphone | Rode NT1-Kit | |
|---|---|---|
| Max value | 1.049 | 0.8594 |
| Min value | −1.0003 | −0.24954 |
| Mean value | −3.7901 × 10−5 | −2.3820 × 10−5 |
| RMS value | 0.22281 | 0.123398 |
| Dynamic range D (dB) | 164.8592 | 158.0119 |
| Crest factor Q | 13.4568 | 22.3666 |
| Autocorrelation time (s) | 1.4091 | 0.0092063 |
| Mean noise | 0.25 | 0.15 |
| Dataset | Modality | Speakers | Environment |
|---|---|---|---|
| COSINE [14] | Audio-only | 133 | Noisy |
| VOICES [15] | Audio-only | 300 | Not Noisy |
| GRID [16] | Audio—Visual | 34 | - |
| Mandarin Sentences [17] | Audio—Visual | 1 | - |
| AVSPEECH [18] | Audio—Visual | - | - |
| BANCA [19] | Audio—Visual | 208 | Noisy |
| AVICAR [20] | Audio—Visual | 100 | Noisy |
| ASPIRE [21] | Audio—Visual | 3 | Noisy |
| VISION [22] | Audio—Visual | 209 | Noisy |
| Proposed | Audio-only | 1 | Not Noisy |
| Method | Run 1 | Run 2 | Run 3 | AVG | STD | Δ from Ref. [a] |
|---|---|---|---|---|---|---|
| [a] | 2.76 | 2.65 | 2.34 | 2.58 | 0.35 | 0 |
| [b] | 2.76 | 2.93 | 2.83 | 2.84 | 0.16 | 0.26 |
| [c] | 3.29 | 3.37 | 3.15 | 3.27 | 0.22 | 0.92 |
| [d] | 3.03 | 2.96 | 3.03 | 3.01 | 0.24 | 0.43 |
| [e] | 3.41 | 3.49 | 3.59 | 3.50 | 0.30 | 0.69 |
| [f] | 4.14 | 4.02 | 4.09 | 4.08 | 0.59 | 1.50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hashmi, A. Perceptual Evaluation of Speech Quality for Inexpensive Recording Equipment. Acoustics 2021, 3, 200-211. https://doi.org/10.3390/acoustics3010014
Hashmi A. Perceptual Evaluation of Speech Quality for Inexpensive Recording Equipment. Acoustics. 2021; 3(1):200-211. https://doi.org/10.3390/acoustics3010014
Chicago/Turabian StyleHashmi, Anas. 2021. "Perceptual Evaluation of Speech Quality for Inexpensive Recording Equipment" Acoustics 3, no. 1: 200-211. https://doi.org/10.3390/acoustics3010014
APA StyleHashmi, A. (2021). Perceptual Evaluation of Speech Quality for Inexpensive Recording Equipment. Acoustics, 3(1), 200-211. https://doi.org/10.3390/acoustics3010014