Abstract
Early Japanese books, classical humanities resources in Japan, have great historical and cultural value. However, Kuzushi-ji, the old character in early Japanese books, is scratched, faded ink, and lost due to weathering and deterioration over the years. The restoration of deteriorated early Japanese books has tremendous significance in cultural revitalization. In this paper, we introduce augmented identity loss and propose enhanced CycleGAN for deteriorated character restoration, which combines domain discriminators and augmented identity loss. This enhanced CycleGAN makes it possible to restore multiple levels of deterioration in the early Japanese books. It obtains the high readability of the actual deteriorated characters, which is proved by higher structural similarity(SSIM) and accuracy of deep learning models than standard CycleGAN and traditional image processing. In particular, SSIM increases by 8.72%, and the accuracy of ResNet50 for damaged characters improves by 1.1% compared with the competitive CycleGAN. Moreover, we realize the automatic restoration of pages of early Japanese books written about 300 years ago.
1. Introduction
Early Japanese books are a cultural heritage, have stored the wisdom of our ancestors, and contain much information about Japanese politics, economy, culture, etc. These early Japanese books are described by Kuzushi-ji, a kind of old Japanese character style, and are also one of the essential factors to symbolize early Japanese books. However, Kuzushi-ji is not used in the present day, causing only few experts of classical Japanese can read Kuzushi-ji and understand the contents of the books. To re-organize and preserve this cultural heritage, researchers have digitalized the early Japanese books and applied the combining Kuzushi-ji and Optical Character Recognition(OCR) to recognize the Kuzushi-ji [1,2,3]. Humanities research intuition such as the Center for Open Data(CODH) [4] and Art Research Center(ARC) of Ritsumeikan [5] digitize the early Japanese books and re-organize them for the database to prevent degradation and prompt combine computer science with humanities. Currently, lots of researchers apply deep learning and machine learning methods for cultural heritage protection, organization, etc. Literature organization is one of the hot topics in this area, such as the re-organization of OBI [6,7], Kuzushi-ji [1,2,8], and Rubbing [9]. In detail, Yue et al. aim to achieve a good accuracy recognition for Oracle Bone Inscription, which is ancient characters described on the tortoises’ shells and animals’ bones. Zhang et al. combine simple deep learning models and lexical analysis to recognize rubbing characters described on the bones from 3000 to 100 years ago. Lyu et al. use deep learning and image processing method for detecting and recognizing Kuzushi-ji. It is also the target literature of this paper.
However, the early Japanese books have been damaged, and some Kuzushi-ji is scratched and faded due to deterioration over the years. The damage increases the difficulty of Kuzushi-ji recognition and prevents early Japanese book re-organization accuracy. In the worst case, it causes the loss of some cultural heritage. Hence, the damaged Kuzushi-ji restoration becomes an emergency research topic for preserving cultural heritage.
Nowadays, we can realize high-quality and objective restoration thanks to developing generative models using deep learning. Generative Adversarial Nets(GANs) [10] are generative models that balance sampling speed and quality well. Image-to-Image translation based on GANs is thereby effective, and it has been studied in many different cases. GAN-based ancient characters restoration is focused on supervised image-to-image translation for inpainting damaged characters [11,12]. Su et al. inpainted masked characters in the book of Qing dynasty and Yi, handwritten ancient Chinese characters, with unmasked images and applied them to the practical ancient text. Wenjun et al. inpainted large-area damaged characters in the ancient Yongle Encyclopedia with ground truth and examples of them. To our knowledge, this is the first time the practical restoration of Kuzushi-ji and the early Japanese books using deep learning. When applying supervised image-to-image translation for Kuzushi-ji, the various types of damaged and distorted letter styles make it hard to prepare train data. Moreover, most damaged characters are weak damages, which makes GANs training difficult.
The problems are shown in Figure 1a, a piece of Early Japanese Books, which has several levels of deterioration such as faded ink, global, partial, and scratches, are expanded listed in Figure 1c.


Figure 1.
Restoration result of a page of the book by enhanced CycleGAN. The red square of (a) marks a part of deteriorated characters, and the red square of (b) marks restoration results.
To solve these problems, we propose an enhanced CycleGAN and aim to realize the restoration of deteriorated early Japanese books. An example of restoration through our proposal is shown in Figure 1b,d. In detail, we employ CycleGAN [13], unsupervised1 image-to-image translation based on GANs, for the training with only authentic damaged images and undamaged images. Then, we propose a robust CycleGAN for weak damages, which combines a domain discriminator [14] and augmented identity loss. The augmented identity loss improves the identity mapping loss for CycleGAN. The enhanced CycleGAN provides truth restoration and high readability for early Japanese books. The contribution detail of this paper is:
- We employ a domain discriminator for the restoration of deteriorated characters. It leads to improving the degree of restoration.
- We propose the augmented identity loss, which lets the generator learn the identity mapping by a large number of images and generalized images. The enhanced CycleGAN, combining the domain discriminator and augmented identity loss, realizes high-quality damage restoration. It is proved by the quantitative results using PSNR and SSIM.
- We indicate that image enhancement using image processing and CycleGAN increases the accuracy of Kuzushi-ji recognition. The proposed method is more effective than traditional image processing for the Kuzushi-ji expressed as RGB.
2. Related Works
2.1. Image Processing for Ancient Characters
The automatic analysis of ancient documents is dramatically improving due to deep learning development. Nevertheless, image pre-processing is vital because ancient documents suffered from deterioration. Binarization is the general and effective pre-processing method for denoising, sharpening, and background separating [8,15,16]. Simultaneously, it provides readable documents by thresholding faded ink, thin, weak text, ect. [17]. The Otsu method [6,18], an automatic threshold-determining algorithm, is frequently used because it handles efficiently for multiple ancient documents and characters. However, binarization causes the loss of character parts since it does thresholding. In this paper, we indicate that the enhanced CycleGAN has the advantage of more readable restoration and higher recognition accuracy for ancient characters than binarization.
2.2. Image-to-Image Translation Based on GANs
Generative Adversarial Nets(GANs) [10] consist of two networks, a generator, and a discriminator. The generator generates new images from random noise. The discriminator train to distinguish between real data and generated data. Conversely, the generator learns to have the discriminator in-distinguish between real data and generated images. As a result, the generator generates similar to real data. This development also contributes significantly to the evolution of image-to-image translation methods.
Isola et al. [19] propose the Pix2Pix, a supervised image-to-image translation based on conditional GAN, which enables high-quality image transformation. Pix2Pix uses paired images to train conditioning and its reconstruction. On the other hand, Zhu et al. [13] propose an unsupervised image-to-image translation with a cycle consistency loss, namely CycleGAN. The cycle consistency loss is a restriction that the original image via forward-backward translation returns to the original image. This is why CycleGAN allows capturing the input feature even though using unpaired images. CycleGAN is flexible and used in a variety of scenes such as super resolution [14], denoising [20], and repairing damaged images [21]. These CycleGAN-based applications for improving the quality of images contribute to accurate classification [22] or data augmentation [23].
2.3. Character Restoration Based on Image-to-Image Translation
Liu et al. [24] proposed characters inpainting using supervised image-to-image translation with feature extraction of a deep learning recognition model. Su et al. [11] restored the loss of ancient characters by two networks based on conditional GAN, the Shape restoration network and the Texture restoration network. Wenjun et al. [12] proposed GAN-based large damages inpainting for ancient characters by adding the attention module and the feature map of the example text to GANs. For early Japanese books, the actual deteriorated characters are faded ink and scratching, many are weak, global, or local as shown in Figure 1. To reproduce these paired images without omission is difficult and inefficient. Thus, we adopt CycleGAN to train with actual images, then propose a restoration model for the early Japanese books.
3. Approach
We propose CycleGAN with a domain discriminator and augmented identity loss for early Japanese book restoration. Our method is a practical approach for applying existent data from early Japanese books. However, there is partial and weak deterioration rather than a highly noticeable deterioration. The standard CycleGAN has a limitation for weak damage restoration. To solve it, we adopt the domain discriminator to increase the degrees of transformation by penalizing non-transform clearly in Figure 2. Then, the augmented identity loss improves the preservation of character shapes because it is equal to the identity mapping loss with enough and sufficient data. This proposed loss function combined with the domain discriminator is our proposed enhanced CycleGAN for character restoration and its structure shown in Figure 3. The two additional functions make higher quality restoration.
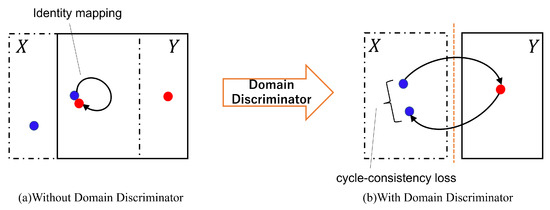
Figure 2.
An overview of Domain Discriminator’s work. When domain X is similar to domain Y, the discriminator cannot distinguish X and Y, so generators learn identity mapping (a). The domain discriminator clearly classifies X and Y to help domain transformation (b). The blue bullets show images in domain X, and the red bullets show images in domain Y.
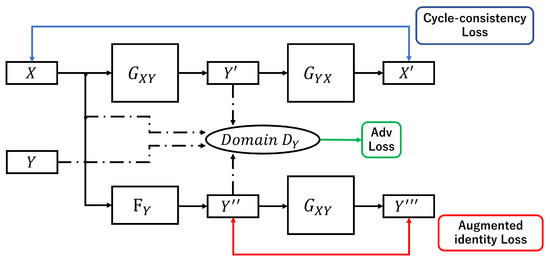
Figure 3.
The overviews of training of X→ Y by the proposed implementation. X is the inputs of in addition to the stadnadard inputs Y and because is the domain-D. Moreover, , the output of is also the input of to use aid loss. The output of is used for identity mapping loss of as the aid loss.
3.1. CycleGAN
We apply CycleGAN to restore damaged characters. CycleGAN is image transformation in two domains. In this paper, we describe domain X as the damaged domain and Y as the undamaged domain, and as the damage restoration. CycleGAN includes two discriminators and and two generators and . The adversarial loss with a least square error [13,25] between and is as follow:
denotes an expectation for data distribution . The object function of Equation (1) is:
Cycle-consistency loss enforce and to correlate inputs and outputs. The cycle-consistency loss is defined as:
In addition, the identity mapping loss is employed in CycleGAN as a help objective function. Identity loss helps to preserve features between the input and output, such as the color composition [13,26]. The identity loss is:
The full objective included the adversarial loss, the cycle-consistency loss, and the identity loss is:
3.2. Domain Discriminator
Kim et al. [14] introduce a domain discriminator (domain-d) to guide generated images following target domain distribution rather than the source domain. The domain-d learns the source domain as generated images. The reason why the standard CycleGAN occurs identity transformation is the images included with X and Y are satisfied with the loss functions of that CycleGAN as shown in the left of Figure 2. The high similarity between weak damaged and undamaged characters applies to them. The identity transformation of GXY and GYX is described as or mathematically. When , is not penalized by the adversarial loss, and does not transform x. Therefore, we employ domain discrimination which distinguishes for the penalty for .
The adversarial loss attached the domain-d with a least square error using and is:
In this study, we employ the domain-d for both and because this implementation improves the quality of generated images experimentally.
3.3. Augmented Identity Loss
In this section, we pay attention to the identity mapping loss(id loss) in CycleGAN. The id loss helps to keep the input’s color composition and shapes [13,26]. For this reason, it is suitable to preserve an author’s font styles and old book texture in the early Japanese books. According to Xu et al. [27], however, the id loss can constrain the degree of transformation. In addition, decreasing of id loss is less than other loss functions of CycleGAN, such as cycle-consistency loss and adversarial loss, when increasing the train data. We present the problem of id loss as follows:
- A larger amount of train data is necessary to decrease the id-loss sufficiently.
- When an image is appropriate, the identity mapping loss enforces the generator to learn incorrect identity transformation. In particular, the identity transformation learning of overlapping-domain images conflicts with image transformation to the other domain.
Therefore, We propose augmented identity loss(aid loss) as:
where . For the dynamic training of and , generated images for the first epochs are not high-quality. For this reason, we decide increases linearly with epoch following with [28]. and are new generators of GANs. close input to the distribution of domain-X, and close input to the distribution of domain-Y. The generated images are abundant and gradually change every epoch because and are trained simultaneously as the CycleGAN training.
Then, we use the two domain discriminators, domain- and domain-, to learn the adversarial loss of and . The domain discriminators guarantee that outputs of and are independent domain images.
Thereby, the object function of domain-d combined with aid loss is as below:
3.4. Full Objective
Based on our changes, the full objective of enhanced CycleGAN is:
The overall structure of enhanced CycleGAN is shown in Figure 3.
4. Experimentation
4.1. Datasets
In this paper, we use two Kuzushi-ji datasets to measure the performance of the proposal. One is KMNIST [29] which contains 28 × 28 image size and gray-scale character of 10 classes. KMNIST has 60,000 train data and 10,000 test data. The other is the “Nisemonogatari” dataset (NISE) [30] which is the Kuzushi-ji dataset cut from actual early Japanese books. The NISE contains 21,701 characters of images resized into RGB images with 468 classes. We divide them into damaged characters and undamaged characters for training. In the case of KMNIST, we visually choose 700 damaged characters from the 60,000 train data. We also choose 203 damaged characters from the 10,000 test data. Then, we define the remaining characters as undamaged train and test characters. In regard to NISE, we select 1518 damaged characters, then define 787 train characters (about 70%) and 381 test data(about 30%). The remaining data is undamaged train and test data. Table 1 reports the full number of damaged and undamaged characters. Considering the unbalance between damaged and undamaged train data, we pick constant 2000 characters from undamaged training data for the CycleGAN-based method.

Table 1.
Details the number of datasets. Only when CycleGAN-based methods training. The undamaged train data is fixed at 2000 while training CycleGAN.
Finally, we apply our proposal to the whole pages of “Nisemonogatari” [30] for observing the revival of an early Japanese book. This book is a parody book published about 300 years ago and written about Japanese society at that time. The acquisition conditions of the images are very important for this research. Since the conditions are changed depending on the literature’s size, shape, etc. Therefore, a digitization manual is made for literature and published in Japan, which is used for image acquisition [31]. The images of literature are taken based on this manual.
4.2. Training Condition
In this experiment, we train the CycleGAN-based methods according to the original implementation of [19]. The learning rate of G and D is 0.0002, but the learning rate of F is to avoid the mode collapse for aid loss. We describe that the aid loss is affected by the generated image quality of F in Section 4.5.1. These learning late of G and F decay linearly from 100 to 200 epoch. We employ two data augmentation methods: center cropping and horizontal flipping at 50%. The network architecture is similarly following [19] of the style transfer network from [32]. The network architecture of F is the same as G. We decide and
4.3. Comparing Conditions
To our knowledge, there is no experiential standard for deterioration restoration for faded ink and scratches. Hence, we measure Peak Signal-to-Noise Ratio(PSNR) [33] and Structure Similarity(SSIM) [34] between artificial damaged and restored images. We also compare the recognition accuracy of deep learning on restored images. Our proposed method is compared with the standard CycleGAN and binarization by the Otsu method. Regarding NISE, we preserve the 3-channels background by multiplying the binarized images and the original images.
4.3.1. PSNR/SSIM
To evaluate quantitatively, we reproduce the deteriorated images from undamaged images of the KMNIST and NISE in Figure 4. The deteriorated images are duplicated by adding to the pixel under a specific value . Here, is the damage level, and is the range of pixels value adding damage. R denotes the data range of the pixel value. We experiment with and for NISE, and and for KMNIST. Because a character part of KMNIST is a high pixel value, different from NISE, is added after inverting KMNIST pixels, the manually reproduced deteriorated image is inverted again. These artificially damaged images are made from undamaged test data.
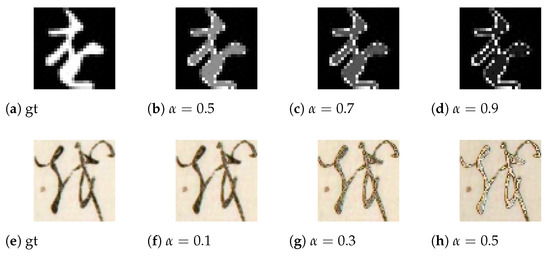
Figure 4.
Manual deteriorated images by image processing.
4.3.2. Accuracy Measurement of Deep Learning Model
Moreover, we metric the recognition accuracy of the restored images by pre-trained deep learning model for each dataset. We employ four models consisting of multiple layers such as LeNet [35], ResNet18, ResNet34, and ResNet50 [36]. We train these models using all of the damaged and undamaged train data and compare the accuracy.
Table 2 is the accuracy of damaged and undamaged test data. It proves accurate recognition is hard due to the damages, which is the direct cause of the decreasing accuracy of the early Japanese books.
Table 2.
Acc by the 4 types of classifiers on the test data of KMNIST and NISE.
4.4. Experimental Results
4.4.1. KMNIST
Figure 5 shows restoration results. The completely lost part is not restored by the binarization, but it succeeded in sharpening and clarification as shown in Figure 5b. Whereas, CycleGAN-based methods can connect the lost part (Figure 5c–e). Domain-d (Figure 5d) increases the degree of transformation more than the standard CycleGAN; however, it misses the characteristics. Our proposal, combining the domain-D and the augmented identity loss (Figure 5e), can restore satisfied both the degree of transformation and preserve the input’s features. Other restoration results of KMNIST are shown in Figure 6.

Figure 5.
Restoration result of the binarization and CycleGAN-based method for KMNIST. (a) The input data. (b) Binarization by Otsu method. (c) The standard CycleGAN. (d) The CycleGAN with domain discriminators. (e) The CycleGAN with combining domain discriminators and augmented identity loss.

Figure 6.
Restoration results of KMNIST.
Table 3 reports the experimental result by PSNR and SSIM. Our method is the best result for both PSNR and SSIM at . When it comes to the result of , SSIM increases by 10.93% compared with the results of inputs, and it is 3.13% higher than the standard CycleGAN. PSNR/SSIM of binarization is lower than CycleGAN-based methods with every . Table 4 reports the accuracy of restored characters. Binarization is the highest accuracy on all the classifiers even though the PSNR/SSIM is the lowest. On the other hand, the accuracy of binarized undamaged is lower than CycleGAN-based methods. Our proposed method is higher for damaged characters except for ResNet50 than the standard CycleGAN.
Table 3.
PSNR /SSIM of restored images on damage adding test data of KMNIST. The input is artificially processed damaged characters. The best results are shown in boldface.
Table 4.
The accuracy of restoration on damaged and undamaged KMNIST. The best results are shown in boldface.
4.4.2. Nisemonogatari
Figure 7 displays the restoration results for NISE. Binarization is hard to fix the lost part of the data as same as KMNIST(Figure 7b), and even CycleGAN cannot fix dilute and partially lost parts(Figure 7c). The domain discriminator(Figure 7d) obtains the same results as KMNIST which has huge changes and feature missing. ur proposal achieves superior restoration(Figure 7e). Other restoration results of NISE are shown in Figure 8.

Figure 7.
Restoration result of the binarization and CycleGAN-based method for NISE. (a) The input data. (b) Binarization by Otsu method. (c) The standard CycleGAN. (d) The CycleGAN with domain discriminators. (e) The CycleGAN with combining domain discriminators and augmented identity loss.

Figure 8.
Restoration results of NISE.
Table 5 reports the results of PSNR/SSIM on the NISE. Our method obtains the best results on . It is higher than the standard CycleGAN except for , moreover, the differences from the standard CycleGAN are just 0.55 for PSNR and 0.0019% for SSIM. In Table 6, the accuracy of binarization is lower than CycleGAN-based methods and inputs. Our method is higher accuracy for damaged characters than traditional methods and only one exceeds the inputs among the three classifiers.
Table 5.
PSNR/SSIM of restored images on damage adding test data of NISE. The input is artificially processed damaged characters. The best results are shown in boldface.
Table 6.
The accuracy of restoration on damaged and undamaged NISE. The best results are shown in boldface.
4.5. Full Page Restoration of the Early Japanese Book
Characters are extracted from the pages and divided into proper image sizes, then input to the Generator. Figure 9 shows the restoration results for the full pages (the Left is the damaged images, and the right is the restoration results). We observe a vivid ink color and the reconnection of scratched and lost parts. Through the restoration of the weak damages, whole characters are clarified on the page. Table 7 reports the processing times of full-page restoration by binarization and enhanced CycleGAN. For the CycleGAN-based method, we measure the times on the CPU and the GPU, which AMD Ryzen 9 3590X 16-Core Processor CPU and Nvidia GeForce GTX 1080ti GPU. Deep learning methods need longer processing time than traditional image processing. However, the restoration is automatic and far faster than human work. Furthermore, proposal achieves a better improvement than image processing method.

Figure 9.
Full pages restoration of Nisemonogatari by enhanced CycleGAN.
4.5.1. Effect of the Augmented Identity Loss
The aid loss is affected by generated image quality. Figure 10 shows output images by FY without domain-d and in different learning rates (lr). Without the domain-d, should generate undamaged characters, but we observe those characters contain faded ink and weak scratches. As shown in Table 8, the outputs of F without domain-d are not suitable for aid loss. Figure 10b shows that the generator at occurs the mode collapse, which outputs identical images. It decreases the accuracy of aid loss at compared with . These results indicate that aid loss works as data augmentation and data generalization for identity mapping loss.

Figure 10.
Outputs by in the cases of (a) Without domain-d (w/o d-d) and . (b) . (c) and with domain-d.
Table 8.
The detailed result by aid loss. The implementation Without domain-D (w/o dd) is not employed domain-D, but aid loss is used. W/o aid is only employed domain-d. The best results are shown in boldface.
5. Conclusions
We proposed deteriorated characters restoration using enhanced CycleGAN with the domain discriminator and the augmented identity loss. This enhanced CycleGAN enables high-quality restoration compared with the standard CycleGAN and binarization in the actual early Japanese book. Furthermore, it provides the revitalization of ancient documents and high readability. Our proposal encourages more accurate recognition of deep learning models in the actual book. In other words, high-quality restoration makes them readable for us as well as artificial intelligence. In this paper, we achieve slight-to-moderate damage restoration on a specific early Japanese book. However, our method has a limitation for complete damage because the damaged character is few, and it is based on CycleGAN. Furthermore, the early Japanese books have multiple types of deterioration and color configuration, and paper texture. In terms of future work, we aim to realize a high degree of freedom restoration for ancient documents.
Author Contributions
Methodology, H.K.; Software, R.I.; Project administration, L.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
For the dataset connection, please refer to Kuzushiji Dataset (Center for Open Data in the Humanities, National Institute of Japanese Literature). Available online: https://doi.org/10.20676/00000340.
Acknowledgments
Part of this research is supported by Ritsumeikan University, Art Research Center.
Conflicts of Interest
The authors declare no conflict of interest.
Note
| 1 | Unsupervised means paired teaching images is not necessarily. |
References
- Lyu, B.; Li, H.; Tanaka, A.T.; Meng, L. The Early Japanese Books Reorganization by Combining Image processing and Deep Learning. CAAI Trans. Intell. Technol. 2022, 7, 627–643. [Google Scholar] [CrossRef]
- Lamb, A.; Clanuwat, T.; Kitamoto, A. KuroNet: Regularized residual U-Nets for end-to-end Kuzushiji character recognition. SN Comput. Sci. 2020, 1, 1–15. [Google Scholar] [CrossRef]
- Chen, L.; Bing, L.; Hiroyuki, T.; Meng, L. A Method of Japanese Ancient Text Recognition by Deep Learning. Procedia Comput. Sci. 2020, 174, 276–279. [Google Scholar] [CrossRef]
- Available online: http://codh.rois.ac.jp/ (accessed on 10 May 2023).
- Available online: https://www.arc.ritsumei.ac.jp/ (accessed on 10 May 2023).
- Meng, L. Two-Stage Recognition for Oracle Bone Inscriptions. In Proceedings of the Image Analysis and Processing—ICIAP 2017; Battiato, S., Gallo, G., Schettini, R., Stanco, F., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 672–682. [Google Scholar]
- Yue, X.; Li, H.; Fujikawa, Y.; Meng, L. Dynamic Dataset Augmentation for Deep Learning-based Oracle Bone Inscriptions Recognition. J. Comput. Cult. Herit. 2022, 15, 1–20. [Google Scholar] [CrossRef]
- Lyu, B.; Tanaka, A.; Meng, L. Computer-assisted Ancient Documents Re-organization. Procedia Comput. Sci. 2022, 202, 295–300. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Z.; Tomiyama, H.; Meng, L. Deep Learning and Lexical Analysis Combined Rubbing Character Recognition. In Proceedings of the 2019 International Conference on Advanced Mechatronic Systems (ICAMechS), Kusatsu, Japan, 26–28 August 2019; pp. 57–62. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Su, B.; Liu, X.; Gao, W.; Yang, Y.; Chen, S. A restoration method using dual generate adversarial networks for Chinese ancient characters. Vis. Inform. 2022, 6, 26–34. [Google Scholar] [CrossRef]
- Wenjun, Z.; Benpeng, S.; Ruiqi, F.; Xihua, P.; Shanxiong, C. EA-GAN: Restoration of text in ancient Chinese books based on an example attention generative adversarial network. Herit. Sci. 2023, 11, 1–13. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Kim, G.; Park, J.; Lee, K.; Lee, J.; Min, J.; Lee, B.; Han, D.K.; Ko, H. Unsupervised real-world super resolution with cycle generative adversarial network and domain discriminator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, New Orleans, LA, USA, 19–20 June 2020; pp. 456–457. [Google Scholar]
- Chamchong, R.; Fung, C.C.; Wong, K.W. Comparing binarisation techniques for the processing of ancient manuscripts. In Proceedings of the Cultural Computing: Second IFIP TC 14 Entertainment Computing Symposium, ECS 2010, Held as Part of WCC 2010, Brisbane, Australia, 20–23 September 2010; pp. 55–64. [Google Scholar]
- Aravinda, C.; Lin, M.; Masahiko, A.; Amar, P.G. A complete methodology for kuzushiji historical character recognition using multiple features approach and deep learning Model. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 694–700. [Google Scholar]
- Sulaiman, A.; Omar, K.; Nasrudin, M.F. Degraded historical document binarization: A review on issues, challenges, techniques, and future directions. J. Imaging 2019, 5, 48. [Google Scholar] [CrossRef] [PubMed]
- Bangare, S.L.; Dubal, A.; Bangare, P.S.; Patil, S. Reviewing Otsu’s method for image thresholding. Int. J. Appl. Eng. Res. 2015, 10, 21777–21783. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 18–20 June 2017; pp. 1125–1134. [Google Scholar]
- Gu, J.; Yang, T.S.; Ye, J.C.; Yang, D.H. CycleGAN denoising of extreme low-dose cardiac CT using wavelet-assisted noise disentanglement. Med. Image Anal. 2021, 74, 102209. [Google Scholar] [CrossRef] [PubMed]
- Luleci, F.; Catbas, F.N.; Avci, O. CycleGAN for Undamaged-to-Damaged Domain Translation for Structural Health Monitoring and Damage Detection. arXiv 2022, arXiv:2202.07831. [Google Scholar] [CrossRef]
- Guo, X.; Liu, X.; Królczyk, G.; Sulowicz, M.; Glowacz, A.; Gardoni, P.; Li, Z. Damage detection for conveyor belt surface based on conditional cycle generative adversarial network. Sensors 2022, 22, 3485. [Google Scholar] [CrossRef]
- Sandfort, V.; Yan, K.; Pickhardt, P.J.; Summers, R.M. Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks. Sci. Rep. 2019, 9, 16884. [Google Scholar] [CrossRef]
- Liu, R.; Wang, X.; Lu, H.; Wu, Z.; Fan, Q.; Li, S.; Jin, X. SCCGAN: Style and characters inpainting based on CGAN. Mob. Netw. Appl. 2021, 26, 3–12. [Google Scholar] [CrossRef]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Taigman, Y.; Polyak, A.; Wolf, L. Unsupervised cross-domain image generation. arXiv 2016, arXiv:1611.02200. [Google Scholar]
- Xu, K.; Zhou, Z.; Wei, L. Effect analysis of image translation by controlling size of dataset and adjusting parameters for cyclegan. In Proceedings of the 2021 International Conference on Communications, Information System and Computer Engineering (CISCE), Beijing, China, 14–16 May 2021; pp. 458–461. [Google Scholar]
- Wang, T.; Lin, Y. CycleGAN with Better Cycles. 2019. Available online: https://ssnl.github.io/better_cycles/report.pdf (accessed on 10 May 2023).
- Clanuwat, T.; Bober-Irizar, M.; Kitamoto, A.; Lamb, A.; Yamamoto, K.; Ha, D. Deep learning for classical japanese literature. arXiv 2018, arXiv:1812.01718. [Google Scholar]
- Kuzushiji Dataset (Center for Open Data in the Humanities, National Institute of Japanese Literature). Available online: https://doi.org/10.20676/00000340 (accessed on 10 May 2023).
- National Institute of Japanese Literature. Manual for the Digitization of Japanese Historical Literature. 2022. Available online: https://www.nijl.ac.jp/pages/cijproject/images/digitization-manual/digitization-manual_NIJL-202205.pdf (accessed on 10 May 2023).
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Haffner, P.; Bottou, L.; Bengio, Y. Object recognition with gradient-based learning. In Shape, Contour and Grouping in Computer Vision; Springer: Berlin/Heidelberg, Germany, 1999; pp. 319–345. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).