1. Introduction
Fluvial floods occur when the water level in a river, lake, or stream rises due to excessive rain or snowmelt, submerging neighboring land in a mostly dry state. Since 2000, floods have been accountable for 39% of the natural disasters that have happened worldwide [
1]. By 2022, the global impact of flooding accounted for more than 54 million victims, causing the deaths of approximately 7400 people [
2]. Being a hazardous natural disaster, flooding has resulted in the highest number of fatalities compared to any other disaster type [
3]. The impacts of climate change, rapid population growth, rising sea levels, the poor maintenance of drainage systems, and development activities such as urbanization, land use changes, deforestation, and infrastructure development in river basins are the most common reasons for the severe increase in flooding [
4,
5,
6,
7,
8].
The complete control of flooding is unachievable due to its chaotic nature. Therefore, flood preparedness is the most effective approach to mitigating damage due to floods. Better flood preparedness can be achieved through forecasting flood occurrences with a considerable time gap [
3,
9,
10,
11]. When conducting flood forecasting, obtaining accurate forecasts, especially for flash flood events and major floods, is considered a crucial aspect of both hydrology and disaster management [
12].
Flood forecasting is conducted using several methods that come under hydraulic, hydrologic, traditional statistical, machine learning, or deep learning modeling categories (e.g., [
3,
9,
10,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35]). Some studies have experimented with ensemble modeling and gained better performance levels (e.g., [
16,
17,
19,
36]). This is because obtaining accurate forecasts for weather-related phenomena, especially capturing extreme events (e.g., extreme rainfall, flash floods), may not be achievable with a single (or pure) modeling technique [
37].
Research studies that model flood occurrence using classification methods are very rare (e.g., [
14,
15,
19]). This is due to the substantial class imbalance resulting from the varying intensities of flood levels. Therefore, most flood-related studies have been conducted to forecast water levels or the discharge/streamflow of rivers that are vulnerable to floods (e.g., [
3,
18,
21,
22,
24,
35]). However, discharge- or streamflow-based forecasting may lead to erroneous flood warnings because of the conversion of data [
24]. Therefore, to obtain trustworthy flood forecasts, first the water level of a particular river basin should be modeled, and then the risk levels must be identified based on pre-defined cut-off values for flood risk levels.
Flood forecasting models consist of a vast set of spatiotemporal weather–meteorological predictor variables. The water levels or discharge of neighboring stations, their topographical information, rainfall intensity, soil moisture, and river elevation are the most prominent among them [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24]. In order to reduce model complexity, the selection of the best set of predictor variables and their significant past lags (i.e., historical window size) is also imperative [
38]. Moreover, many studies underscore the fact that adequate flood preparedness requires forecasts of such events at least 3 to 15 (extremely satisfactory) days in advance. [
1,
11,
14].
Heavy or extreme rainfall on a particular day triggers a sudden rise in water levels [
38]. Therefore, flood forecasts generated several days in advance must be subsequently updated using rainfall forecasts corresponding to these future days. However, the cruciality of an accurate rainfall forecast before forecasting a flood has been identified by a limited number of hydrological studies (e.g., [
19,
23,
34,
39]).
Conventional studies have used the Time Series Data Mining approach (TSDM), which involves statistical tools such as the Autoregressive (AR) model, K-Nearest Neighbor (KNN), and K-means clustering (e.g., [
13,
14,
15]). Study [
13] did not report the accuracy of its flood model. In study [
14], flood warnings were issued more than five days in advance based on precipitation classification. Although it captures over 90% of extreme precipitation events, not all such events necessarily lead to severe flooding. The TSDM classification model introduced in [
15] includes a station-specific parameter selection step before forecasting flood events. Study [
19] issued flood warnings based on rainfall event (class) forecasts. However, an accurate flood warning system often depends on a water level forecasting model.
Studies using hydraulic or hydrologic models mainly focus on inundation mapping and satellite image analysis (e.g., [
16,
17]), along with several topographical characteristics of the river basin (e.g., river-cross section, land cover, and elevation data). These models, which give longer lead times and lower error rates (e.g., [
17]), should be tested for generalizability over extended periods.
Traditional methods like TSDM cannot capture the complex relationships between geophysical variables. They are also more prone to producing highly inaccurate predictions when dealing with nonstationary data, missing values, and the unavailability of important weather-related variables. In such cases, machine learning and deep learning (ML and DL) methods have shown to be promising and efficient tools [
19,
20,
23].
Among the studies that use ML, many applied Artificial Neural Network (ANN), Support Vector Machine (SVM), or Support Vector Regression (SVR) (e.g., [
3,
18,
21,
24]) approaches. Study [
18] compared a SVM and ANN for modeling daily water levels. Studies [
3,
21,
24], which used ANN, SVR, and Neurofuzzy methods, respectively, modeled the hourly river stage (i.e., water level) or river flow and produced short-term flood forecasts, usually a few hours ahead (<7 h). However, this short lead time is usually insufficient for efficient flood preparedness. These studies mainly utilized rainfall and water level/discharge data for flood modeling. Study [
3] emphasized that a hybrid approach combining ANN with Fuzzy computing produced better forecasts with longer lead times compared to using a single model alone. The effectiveness of hybrid flood models in improving forecasting accuracy was further highlighted in [
20,
23].
Compared to ML methods, DL allows the use of long-time lags (i.e., sequential inputs of past lags) when making multi-step-ahead forecasts. Moreover, these methods are well-suited to handling the chaotic and dynamic nature of time series data [
19]. The flood modeling in studies [
19,
20,
22,
29,
30,
35] used numerous variants of LSTM such as Smoothing-LSTM (ES-LSTM), Bidirectional LSTM (Bi-LSTM), Conv-LSTM, Stacked LSTM, Vanilla LSTM, and Encoder–Decoder Double-Layer LSTM (ED-DLSTM) for modeling flood occurrence or river discharge. Although these studies demonstrated the strong performance of their LSTM models (e.g., [
20]) in both long and short-term flood forecasting, they pay limited attention to explaining forecasting accuracy across different forecasting horizons and to the generalizability of results. Notably, the urban flood forecasting and alerting model in study [
33] showed that Bi-LSTM outperformed the other models used in the study, including an ANN and Stacked LSTM.
In general, the existing studies on flood forecasting have several common limitations. These limitations include difficulty in capturing rapid rises in water level (e.g., [
39,
40]), reliance on a limited set of predictors, a narrow focus on rainfall forecasting, shorter forecasting horizons or lead times (e.g., [
41]), performance evaluation using a single metric, difficulty in generalizing their results, a lack of details on deployment strategies, and dependence on a single model which may lead to false predictions [
19]. Therefore, our study aimed to address these existing research gaps by
- (i)
Employing variants of the LSTM model (i.e., Vanilla and Stacked Bi-LSTM) to forecast future water levels (the basis for this selection was set by studies [
33,
38] evidencing accurate flood forecasting and the capture of extreme events, respectively);
- (ii)
Incorporating rainfall and water level data as predictors after applying better filtering methods (e.g., Granger Causality and cross-correlation tests [
38,
42]);
- (iii)
Generating multiple-days-ahead forecasts for reliable flood preparedness;
- (iv)
Introducing a novel hybrid model which further enhances the water level forecasts obtained from LSTM models by incorporating three-days-ahead rainfall forecasts obtained from our previous study [
38];
- (v)
Conducting residual analysis and modeling to further improve the water level forecasts;
- (vi)
Applying the proposed hybrid methodology to a flood-prone river basin located in Sri Lanka.
Floods are recognized as a major destructive natural disaster in Sri Lanka due to the country’s unique climatological and geographical conditions [
32]. Every 2 to 3 years, the country experiences a flash flood event, affecting around 200,000 civilians [
33]. Sri Lanka has 103 major river basins, of which 17 (such as Kalu, Kelani, and Nilwala) rivers are particularly vulnerable to flooding. Some existing flood warning systems do not function properly. Furthermore, the recently introduced Real-Time Water Level Monitoring Application measures the current water levels of vulnerable rivers and can only issue flood warnings a few hours before an event [
9,
33,
43]. Therefore, there is a clear need for the development of an effective flood forecasting and warning system in Sri Lanka. This study focuses on the Kalu River Basin due to its specific characteristics. The Kalu River is the third longest river in the country and discharges the highest volume of water (approximately 4032 × 106 m
3) into the sea. The basin receives an average annual rainfall of about 4000 mm and spans a total catchment area of around 2719 km
2. Its upper catchment area is mountainous. The river flows through Ratnapura, which is more susceptible to frequent flooding, and finally reaches the sea at Kalutara, located in the down-stream area of the basin. The river travels about 36 km before reaching Ratnapura town, where it joins the Wey River, and flows another 76.5 km to the sea at Kalutara. Along this path the basin shows steep gradients in the upper-stream area and mild gradients in the down-stream area [
9,
33,
34]. There is an urgent need for an accurate flood forecasting system that can issue early flood warnings to the vulnerable civilians and authorities in Ratnapura, enabling better flood preparedness.
However, only a limited amount of research has been conducted on Sri Lankan River basins [
9,
32,
33,
34,
39], and only a few studies [
9,
32,
33,
39] have specifically focused on flood events occurring in the Kalu River Basin. Among them, studies [
9,
32,
39] focused on Rathnapura, the most flood-prone area. Studies [
32,
34,
39] carried out rainfall forecasting as a prior step to assessing flood susceptibility.
Study [
33] gives flood forecasts with only a 4-hours lead time, while [
34] achieves a 24-hours lead time. Both are still insufficient for effective flood readiness. Inundation area, flood risk levels, and inundation depth were major concerns in studies [
9,
32,
34]. Only study [
32] produced flood forecasts for a 100-year return period, but it did not validate its model with the actual data. Study [
39] could predict peak flows, but with some uncertainties. Identifying this existing gap in flood-related research in Sri Lanka, our study proposes a novel hybrid model aimed at delivering reliable flood warnings.
The next section of the paper describes the methodology used. The
Section 3 highlights the key findings and limitations. Finally, the
Section 4 summarizes the study and proposes directions for future research.
3. Results and Discussion
3.1. Feature Selection for WL Modeling
Before modeling WLs at Ratnapura with predictors (daily WLs of Ratnapura gauging station and its neighboring stations Dela, Ellagawa, Putupaula, and Millakanda, and the daily rainfall at Ratnapura), the Granger Causality Test and cross-correlation analysis were conducted to identify the most important feature set to model. This was performed, maintaining the balance between information loss and the curse of dimensionality. However, before applying the aforementioned tests, the joint covariance stationarity was examined between the response variable and each of predictor variables. The results confirmed the presence of joint covariance stationarity among the variables. Consequently, the Granger Causality Test and cross-correlation analysis were conducted.
3.1.1. Granger Causality Test Results
First, bivariate causality was analyzed between the WLs at Ratnapura and the time series of each of the potential predictor variables, testing up to their past 14 (2 weeks) lags. This is because two weeks into the past is sufficient enough to capture a long-term relationship in terms of daily water levels. The results are summarized in
Table 2 below.
The above table indicates the significance of all of the 14 past lags of each predictor variable considered. However, adding all these lags to the model will increase the complexity of the model and computational cost [
38]. Therefore, as a second verification the study calculated the cross-correlation between the WLs at Ratnapura and each of the predictor variables.
3.1.2. Cross-Correlation Analysis Results
The cross-correlation between the WLs at Ratnapura and the time series of each of the potential predictor variable was computed up to 14 delay points. The significant past lag sizes are depicted in
Spreadsheets S1 for more details.
Table 3 shows that different past lag sizes for the predictor variables are significant. However, both the Ganger Causality test and the above outcomes confirmed the importance of all the considered predictor variables in modeling the WL at the target station.
When choosing the past lags of these important predictor variables, the maximum past lag size was set to 10 as the maximum significant lag size depicted in cross-correlation analysis was 10. In fact, the focus of our study was to conduct short-term flood forecasting. Thus, looking for variations over a very long time period will not result in the significant accuracy of the models. At the same time, taking the minimum lag size (i.e., 4) will create information loss. Therefore, the past 10 days of values for all the predictors (since all of them became significant) were used to train the Vanilla Bi-LSTM and Stacked Bi-LSTM models.
In addition to the aforementioned methods used in identifying the importance features, a graphical summary of time series variables, including the daily WLs at Ratnapura, was obtained to achieve a preliminary understanding of how these variables were correlated. The results are depicted in
Spreadsheets S2. According to the illustration, the positive correlation between the features and the target could be underscored with a sightly varying degree of association.
3.2. Outcome of Water Level Modeling
Results from Long Short-Term Memory (LSTM) Models
Accurate forecasting of fluvial flood risk for longer periods is usually beyond the scope of possibility due to dynamic weather patterns. Furthermore, alerting residents to flood risk a maximum of 3 days ahead would be sufficient for the vulnerable parties to take necessary actions. Therefore, the forecasting horizons (or n_outputs) of the LSTM models were set to 1 to 3 days ahead. The number of inputs from the six predictor variables to each training iteration (i.e., n_inputs) was 10, as mentioned in
Section 3.1. Initially, both Vanilla Bi-LSTM and Stacked Bi-LSTM were employed to forecast WLs at the target station for the years 2016–2019.
Table 4 provides the common parameter settings of the Bi-LSTM models, achieved through random search.
To generalize the results of the initial Bi-LSTM model (which is denoted as Model A), this study chose the moving windows training and testing mechanism illustrated in
Figure 4.
Even though both models could produce WL forecasts with low error rates, these might not have indicated whether high water level rises (i.e., a major interest of this study) were captured accurately. The lower RMSEs or MAEs could be generated through a high proportion of accurate forecasts for the low/moderate water levels existing in the data. Therefore, to verify the model performance in forecasting high water levels, the following step was carried out.
The WL forecasts produced for the years 2016, 2017, 2018, and 2019 were categorized according to the criteria of flood risk levels (WL < 16.5 m MSL, ‘No Flood’; WL < 19.5 m MSL, ‘Alert Level’; WL < 21 m MSL, ‘Minor Level’; WL < 21.75 m MSL, ‘Major Level’; and WL ≥ 21.75 m MSL, ‘Critical Level’). These flood risk levels were defined by the Department of Irrigation, Sri Lanka, in the study mentioned in [
44]. This was carried out to identify whether the fitted models could accurately capture the high water levels that result in harmful consequences. The results are summarized in
Table 5a,b.
The said period (2016–2018) includes a few critical water level increases (i.e., two events in 2017). Even though in the Vanilla Bi-LSTM model, the 1-day-ahead (p1) and 3-days-ahead (p3) forecasts could correctly predict these events, the 2-days-ahead (p2) forecasts captured only one event. However, that event was misclassified as a ‘Major’ flood event, which also warned about the approximately similar severity of upcoming harmful consequences. On the other hand, the Stacked LSTM model produced accurate forecasts for these ‘Critical’ events in the first two-days-ahead forecasts. Unfortunately, it forecasted one ‘Critical’ event that happened in 2017 as a ‘Minor’ flood event in its three-days-ahead forecast, producing unsatisfactory results in flood warning. The forecasting of ‘Alert Level’ events by both methods was satisfactory (accuracy rates were more than 70% in all years). Only one ‘Minor’ event showed up in 2017, and it was correctly detected by forecasts of all three forecasting time horizons by both the Vanilla and Stacked Bi-LSTM models. However, out of the two ‘Minor’ flood events that occurred in 2018, only one event was identified by the 2-days-ahead forecast, and no events were detected by the 3-days-ahead forecast of the Vanilla Bi-LSTM model, while the Stacked Bi-LSTM model could accurately capture these events in all three step-ahead forecasts.
Due to the better performance of Vanilla Bi-LSTM in capturing ‘Critical’ flood events at the farthest forecasting step (i.e., 3-days-ahead forecast), that model was chosen to have further improvements made to it. Another reason for this selection was the time efficiency and lower computational cost created by the simplicity of the Vanilla Bi-LSTM model when training the model (i.e., the minimum time taken to model WLs when compared with Stacked Bi-LSTM).
To verify the performance depicted by the Vanilla Bi-LSTM model, forecasting errors of these three step-ahead WL forecasts were examined using several months of data (January, April–June, November) from 2016 in which low, moderate, and extreme flood incidents had occurred. Additionally, the consistency of the forecasts was tested by training the same model 10 times (i.e., the WLs of the same month were modeled 10 times using the same model). Therefore, the run size was 10. The training period was two years, from 2014 to 2015. The description of the model is further illustrated in
Figure 5.
The averages of the WL forecasts across the 10 runs were plotted along with the actual WLs separately for the 1-day-ahead (p1) and 3-days-ahead (p3) forecasting horizons in order to check whether the forecasts significantly differed in each run. The results are depicted in
Spreadsheets S3.
According to
Spreadsheets S3, it can be identified that the Vanilla Bi-LSTM model can forecast the higher WLs with high accuracy, while the forecasts for the lower WLs are satisfactory. The short-term forecast (i.e., 1-day-ahead forecast) was captured by the fitted model with higher accuracy, but the forecasting accuracy decreased as the forecasting horizon increased. Whichever model was used to model the same set of data, it resulted in approximately the same output, evidencing the suitability of the Bi-LSTM model in modeling WLs at Ratnapura using six predictor variables.
Table 6 further confirms the suitability of the Vanilla Bi-LSTM model, illustrating the lower error rates in both RMSE and MAE (<0.4 m MSL) produced for 1- to 3-days-ahead WL forecasts for the selected months.
Even though Vanilla Bi-LSTM was capable of producing satisfactory flood level forecasts for three days in future, we experimented with the forecasting accuracy of this model up to 7-days-ahead forecasts.
Spreadsheets S4 summarizes the 7-days-ahead forecasts made by the Vanilla Bi-LSTM model for a selected testing period that depicted considerably high WLs rises.
Predicting a non-flood event as an ‘Alert’ level or vice versa will not cause a significant negative impact in flood warning. Even the misprediction of an ‘Alert level’ even as a ‘Minor’ flood level event or vice versa, will not create a major impact. Forecasting a ‘Major’ event as a ‘Critical level’ event or vice versa will add more or less effort in following safety measures. Nevertheless, forecasting a ‘Critical level’ or ‘Major level’ event as an ‘Alert level’, ‘Minor level’, or ‘No flood’ event will result in the devastation of life and property. On the other hand, identifying a ‘No flood’ event or an ‘Alert Level’ event as an actionable event will result in an unnecessary burden for the victims and relevant authorities who take immediate disaster management actions. Therefore, this study was highly concerned about these matters when developing the model; hence, we attempted to make improvements to the final forecasts, as described in the following section.
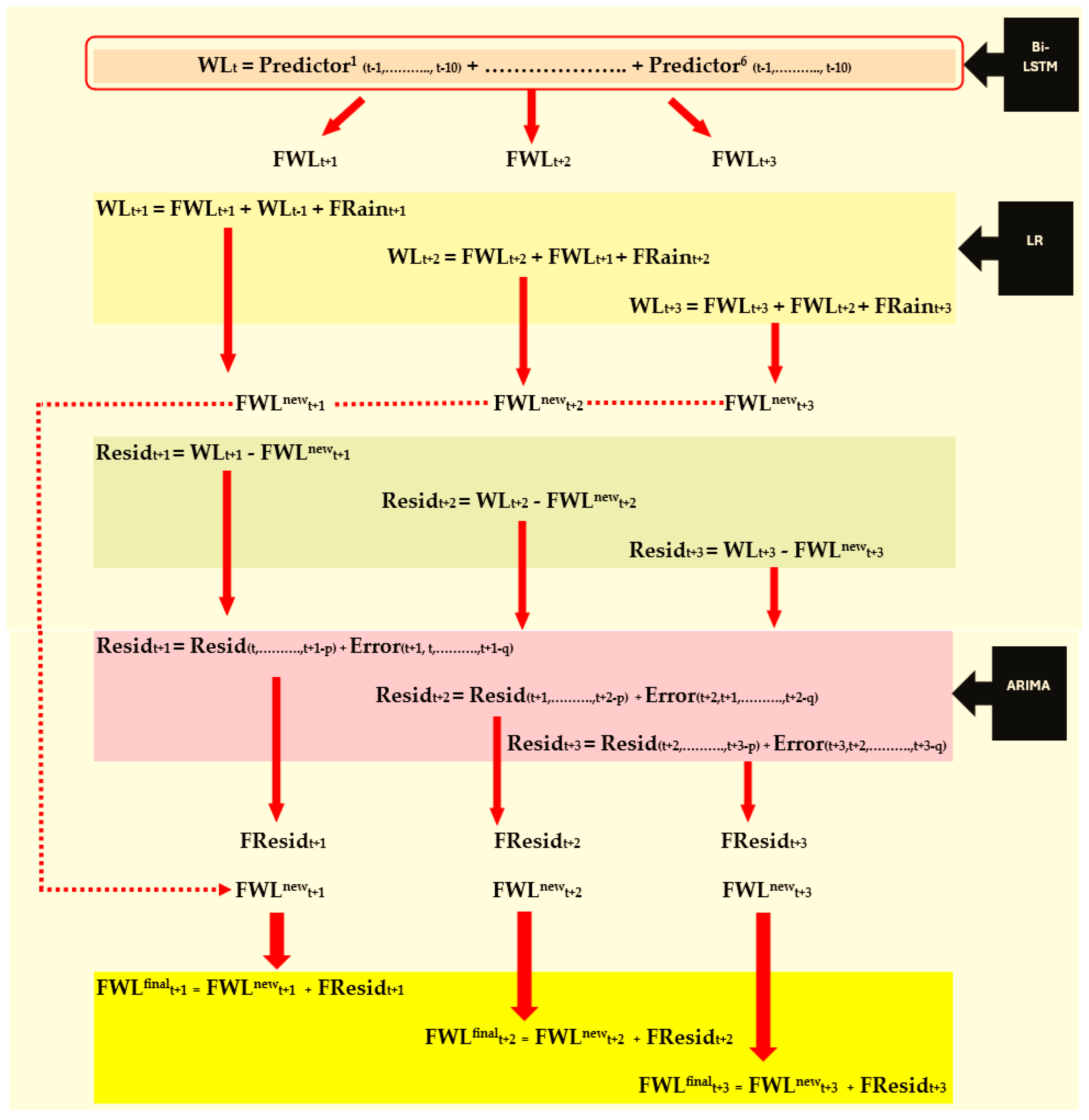
3.3. Improving the Accuracy of Forecasts Obtained by the Bi-LSTM Model
To further improve the forecasts obtained by the Vanilla Bi-LSTM model (i.e., Model A), these forecasts, together with the rainfall forecasts produced by our previous work [
38], were incorporated into a base model to predict the actual WL. As mentioned in
Section 1, this was because the water level of a river on a given day is expected to rise as a result of a considerable amount of rainfall on that same day.
Improvements were made to the forecasts obtained for the years 2017, 2018, and 2019, with the accumulating training periods starting from 2016. To integrate the actual WLs with both forecasted WLs and forecasted rainfall using a simple statistical model, a separate model using the Linear Regression approach (Model B) was introduced.
However certain assumptions needed be given thorough attention before applying the Regression modeling technique to the time series variables considered. One important aspect is the dependency between the time series observations. This was addressed by estimating regression parameters with the GLS estimation method.
When improving 1-day-ahead WL forecasts, the actual WL was modeled on the 1-day-ahead WL forecast, the actual water level at the previous day, and the 1-day-ahead rainfall forecast. The 2-day-ahead forecast was improved in the same way, but the actual water level on the previous day was replaced with the 1-day-ahead WL forecast since the actual WL for the second day would not be available at the time of forecasting. Likewise, the 3-day-ahead WL forecast was improved by modeling the 3-day-ahead actual WL on 3-day-ahead WL forecast, the 2-day-ahead WL forecast, and 3-day-ahead rainfall forecast.
This model was initially tested on the data for the year 2017. Since this integrated approach produced improved forecasts, we proceeded with Model B to generate improved forecasts for the rest of the years, 2018 and 2019.
Table 7 compares the performances of the fitted models by separating the WLs into the flood risk levels as set out in
Section 3.2. Overall, Model B shows an improved performance in terms of the forecasting accuracy for the longest forecasting period considered (i.e., 3 days ahead) and also the severity of the flood level.
In 2018, only ‘Alert’ and ‘Minor’ level flood events occurred. It is remarkable that all the ‘Minor’ flood events were forecasted accurately by Model B, a result which could not be attained by Model A (Vanilla Bi-LSTM), as shown in
Table 5a. Similarly, the high forecasting ability of Model B can be noticed in 2017. It forecasts ‘Critical’ events accurately in each time-step. Furthermore, the capability of the improved model (Model B) in forecasting ‘Alert Levels’ of floods is satisfactory. An accurate forecasting of the only ‘Minor’ flood event happened in 2017 was misidentified by the improved model in its 1st two days ahead forecasts. However, those events were identified as risk levels even though mis-classified as high-risk flood events (i.e., ‘Critical’ or ‘Major’).
Table 8 summarizes the forecasting accuracy of Model B for test periods from 2017 to 2019. A summary of the results obtained by Model B for this entire period is depicted in
Spreadsheets S5.
According to the table, it can be noticed that the fitted model (i.e., Model B) could produce improved forecasts for WLs, with more than 65% accuracy, though the accuracy decreases as the forecasting horizon increases.
3.4. Further Investigating the Validity of the Models: Model Performance with Recent Data
The validity of the aforementioned hybrid approach (Model B) was further tested using recently available data (i.e., from 2020) with the same set of predictor variables. The previously trained Vanilla Bi-LSTM model for 2014–2018 was used to forecast the WLs in 2020. Then, the fitted Regression model for the period 2016–2018 was used to improve WL forecasts for 2020. Another reason for continuing the validation process was to assess the adequacy of the finally fitted model in generating better forecasts for the extended period without re-training.
Within the period considered, only four events with an ‘Alert Level’ of flood risk appeared.
Table 9 and
Table 10 demonstrate the performance of the Vanilla Bi-LSTM model (Model A) and the improved model (Model B). The models’ summaries can be found in
Spreadsheets S5.
The comparison of these model performances implies that the hybrid model that uses both Bi-LSTM and Multiple Linear Regression did not forecast the ‘Alert Level’ flood events as ‘No Flood’ events for any forecasting horizon, even though it recognized some of those events as ‘Minor’ flood events. However,
Table 9 evidences the weak performance of Model B. The comparison of these model performances implies that the Vanilla Bi-LSTM model (Model A) is more suitable for forecasting lower flood levels, whereas when the focus is to forecast critical flood levels with a longer forecasting horizon, the hybrid model that uses both Bi-LSTM and Linear Regression (i.e., Model B) is more appropriate.
The forecasting accuracy for each time-step depicts the same performance pattern shown in the previous section. Even though it decreases slightly when the forecast horizon increases, the percentage is always above 70%.
3.5. Residual Analysis of Model B and Modeling to Reduce Forecasting Error
As Model B produced three Time Series Regression models (corresponding to the three forecasting horizons considered), the residuals of these models were thoroughly examined. First, the stationarity of the three residual series were tested using the ADF test. Then, ACF and PACF plots were obtained to check for significant autocorrelation and partial autocorrelations. If the plots showed significant spikes at initial lags, a suitable ARIMA model was built for the residual series. Again, the residuals of the ARIMA models were examined to confirm if they followed the White Noise series using the Ljung–Box test. The summary of the fitted models is depicted in
Table 11. A complete illustration of the residual analysis including ACF and PACF plots for the entire study period is shown in
Spreadsheets S5.
Forecasts for the months that showed high WL rises (these events mostly appeared in the month of May) were obtained using the fitted ARIMA models. The final WL forecasts were obtained by adding those forecasted values obtained from the ARIMA models to the WL forecasts obtained from the improved Model B. The results are illustrated in
Spreadsheets S5. Even though the final WL forecasts slightly improved upon the forecasts obtained from the hybrid model, there was not much of an effect on flood risk categorization, especially on the high flood risk levels. However, the misclassification of the two ‘Alert Level’ events in the 3-day-ahead forecast mentioned in
Section 3.4 was slightly improved after adjustments to the residual series. One ‘Alert Level’ event was forecasted with a value of 19.51 m MSL (very close to the upper bound of ‘Alert Level’, 19.5 m MSL) by the final model and was forecasted as 19.77 m MSL by Model B. Overall, this implies that the results generated by the hybrid model are good enough for issuing accurate flood warnings.
Moreover, the results indicate the superiority of the hybrid model which combines Vanilla Bi-LSTM and a Time Series Regression model with the GLS estimation method. This model is capable of producing accurate forecasts of WLs, thereby predicting the flood risk level at the target station. This was an unachievable target for many past studies. Obtaining flood risk levels based on WL forecasts produces more precise warnings since direct flood risk forecasting leads to an imbalance classification problem. The severe imbalance in flood levels imposes an additional challenge for researchers, who must select effective resampling methods to achieve data balance. By overcoming these aforementioned challenges, the hybrid model proposed in this study is capable of forecasting even severe flood events 3 days in advance. Moreover, this augmented flood forecasting approach enables a significant lead time for better flood preparedness. Therefore, the proposed methodology suits the forecasting of flood events for the highly vulnerable Ratnapura area.
4. Conclusions
This study proposes a novel hybrid forecasting approach which combines deep learning with a traditional statistical method, Time Series Regression. The study also applies two statistical techniques (the Granger Causality test and cross-correlation analysis) for feature selection to model WLs at Ratnapura. The novelty of the study lies in its sequential modeling of WLs at the target station with Bi-LSTM and its improving of forecasting accuracy, especially of the actionable levels of floods (Minor to Critical) by incorporating the Time Series Regression model. Further, this model is capable of capturing the real-time weather dynamics created by the unexpected occurrence of a rainfall event. Therefore, this dynamic hybrid model shows better performance than that of the Vanilla Bi-LSTM model in terms of forecasting accuracy.
The current study enables a significant forecasting horizon of 3 days, providing a considerable time gap for taking flood mitigatory measures that could not be attained by past studies [
9,
33,
34] performed based on different river basins in Sri Lanka. Moreover, our study has carried out several trials of validation to verify the applicability and accuracy of the hybrid model, which was given meager concern by previous work (e.g., [
32]). The study [
24] that used a Neurofuzzy model for short-term flood forecasting in the Kolar Basin in India could only capture 47.95% of the peak flow values that caused flood events. This rate of accuracy was enabled only in its one-hour-ahead forecast. The hybrid model introduced in our study is capable of forecasting flood events with more than 80% accuracy in its one- and two-days-ahead forecasts, while producing accuracy of 65% in its three-days-ahead forecast. Moreover, the proposed model performs well in forecasting actionable flood events, with an accuracy of 80% or more across all forecasting horizons.
The unavailability of some important predictors such as soil moisture and river velocity, the significant percentage of missingness among WL data, and the lack of superior computer power in training the models are identified as major limitations of this study. The fitted model in this study uses data from only a few nearby WL gauging stations that are currently in function. A better performance could have been achieved if data from a higher number of nearby WL gauging stations were available.
Going further ahead, our future work aims to obtain the spreads of inundation (as maps) based on river discharge data and forecasted WLs. This will facilitate the clear presentation of flood risk assessments and the issuance of warnings to civilians settled down in the down-stream area of the river basin in advance of a devastating outcome. The overall methodology has potential to be developed as an accurate flood forecasting and warning system, for which there is still a high demand in Sri Lanka and also at the global level. Furthermore, the proposed hybrid model can be tested on WL data of other flood-susceptible river basins in Sri Lanka. Additionally, the modeling approach proposed in this study could be applied, with suitable adjustments, to generate flood warning systems around the globe.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}