1. Introduction
Price forecasting has become a crucial tool to navigate the changes in market dynamics. It empowers stakeholders, including farmers, traders, and businesses, to make well-informed decisions in response to these price fluctuations [
1]. With accurate forecasting, one can anticipate future market trends and align production, procurement, and trading strategies accordingly. The evolution of statistical and machine learning techniques has significantly enhanced the precision of forecasting prices in various fields such as finance, agriculture, economics, and business [
2]. The learning process and the effectiveness of these techniques are compromised by redundant, noisy, or unreliable information. Assuming the data adhere to a systematic pattern with random noise, a successful denoising algorithm facilitates a profound grasp of the data generation process, resulting in more accurate forecasts [
3]. The wavelet transform method stands out as a prospective signal processing technique, offering simultaneous analysis in both the time domain and frequency domain [
4]. This transformation enhances the forecasting model’s capacity by capturing valuable information across multiple resolution levels.
In this paper, we explore the efficiency of wavelet-based denoising techniques on the time series data of price of important spices. Spices are natural plant substances that enhance the flavor, aroma, and color of food and drinks. They hold a rich history in culinary, medicinal, and cultural traditions. Common spices like cinnamon, cumin, paprika, turmeric, cloves, and black pepper offer unique tastes and health benefits, with anti-inflammatory, antioxidant, and antimicrobial properties [
5]. India has maintained a renowned status as the “land of species” for centuries, with the scents and tastes of a diverse array of spices profoundly influencing its culinary heritage. The spice market in India is of great importance for local consumption and serves as a significant contributor to the country’s export industry [
6]. According to data from the Indian Brand Equity Foundation (IBEF), India occupies the top position as the producer, consumer, and exporter of spices, with a remarkable production of 10.87 million tonnes in the 2021–2022 period. The surge in demand for spices from the food and beverages (F&B) sector, the widespread application of spices for medicinal uses, government-driven initiatives, and the promotion of sustainable sourcing are the leading catalysts behind the expansion of the India Spice Market [
7]. There has been a substantial increase of nearly 40 percent in the wholesale prices of spices at the Agricultural Produce Market Committee (APMC), Vashi. This rise in prices is indicative of significant changes in the market dynamics. So, this dataset holds significant potential for examining the impact of wavelet denoising techniques.
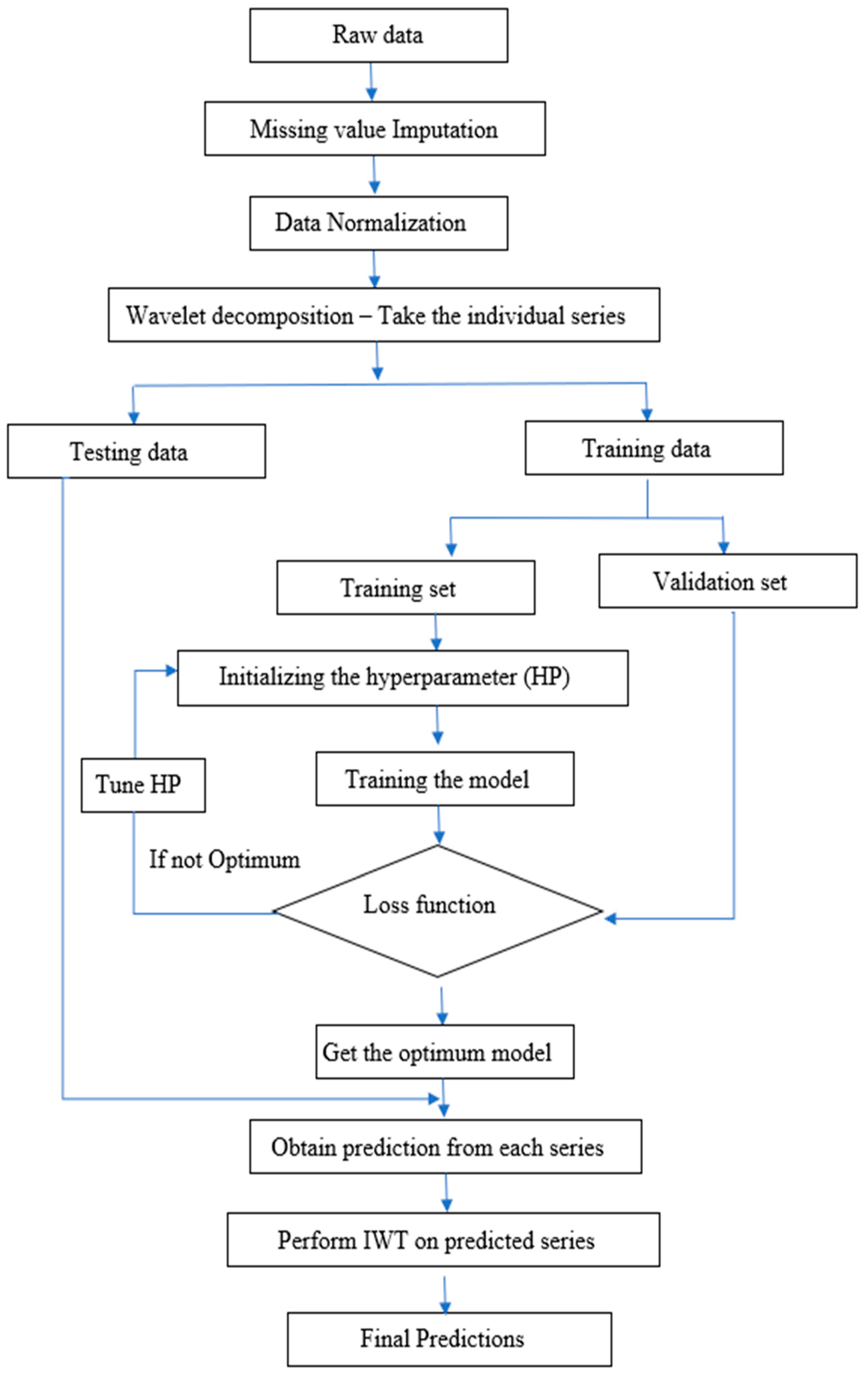
To assess the effectiveness of wavelet-based denoising, we employed predictive models, including autoregressive integrated moving average (ARIMA), artificial neural networks (ANN), support vector regression (SVR), and long short-term memory (LSTM). Each decomposed component, obtained through wavelet transforms, was subjected to these benchmark models, with hyperparameter optimization performed to fine-tune model performance. The level of decomposition in wavelet-based denoising acts as a critical parameter, influencing the trade-off between capturing intricate details and avoiding noise. The effectiveness of this technique hinges on finding the optimal level that enhances predictive accuracy by selectively filtering out noise while preserving the essential characteristics of the signal. This study not only explores the broader effectiveness of wavelet-based denoising but also accentuates the crucial role of identifying the optimal level of decomposition for this dataset.
The rest of this paper is arranged as follows.
Section 2 provides a comprehensive review of the existing literature, and the current research regarding wavelet-based hybrid models for price forecasting. The algorithms employed in the proposed forecasting model are explained in
Section 3. Subsequently,
Section 4 deals with the experimental analysis of proposed models and results. Finally,
Section 5 deals with the results of the real dataset and their conclusions along with references.
2. Background
In this section, we begin with a brief review on selected works that have proposed benchmark forecasting techniques and hybrid models integrating wavelet analysis for the purpose of price forecasting. Extensive research has been conducted in the realm of time series forecasting, leading to the proposal and evaluation of numerous modeling techniques [
8,
9]. The autoregressive integrated moving average (ARIMA) methodology has emerged as the most widely employed linear technique in time series analysis [
10]. Mao et al. [
11] assessed the price fluctuations of vegetables during COVID-19 in 2020. They employed a web-crawling technique to gather price data for three distinct categories of vegetables, i.e., leafy vegetables, root vegetables, and solanaceous fruits. Subsequently, an ARIMA model was applied for forecasting the prices in the short-term. However, due to its basic assumption of linearity, ARIMA fails to capture the volatility changes that signify the intricacies of time series data.
Machine learning has experienced groundbreaking developments in recent decades, particularly in the field of intelligent prediction technology. The capacity of machine learning algorithms to model the complex, non-linear associations between variables, provide a valuable tool for identifying patterns that conventional statistical methods may struggle to detect [
12]. The most widely used machine learning techniques are artificial neural networks (ANN), support vector regression (SVR), random forest (RF), decision trees, k-nearest neighbors (KNN), and gradient boosting methods (e.g., XGBoost), etc. Mahto et al. [
13] utilized ANN for predicting the seed prices of sunflower and soyabean from Akola market, Maharashtra and Kadari market, and Andhra Pradesh, respectively. Astudillo et al. [
14] investigated the potential of SVR with external recurrences to forecast copper closing prices at the London Metal Exchange for various future time horizons, including 5, 10, 15, 20, and 30 days. Jeong et al. [
15] applied an SVR model to predict the onion prices in South Korea. Zhang et al. [
16] forecasted corn, bean, and grain products using various intelligent models such as ANN, SVR, and extreme machine learning (ELM). Paul et al. [
17] attempted to examine the efficiency of different machine learning algorithms such as generalized neural network (GRNN), SVR, RF, and gradient boosting machine (GBM) for predicting the wholesale price of Brinjal across 17 primary markets in Odisha, India.
Deep learning, a subset of machine learning, showcases cutting-edge performance in forecasting intricate time series data [
18]. Enhanced understanding of the present often stems from past information, which lacks in conventional ANN. Recurrent neural networks (RNNs) utilize a feedback loop to retain and incorporate previous information, allowing for more precise predictions and decisions [
19,
20]. Different approaches relying on RNN have been implemented to forecast the prices of agricultural products. Then, long short-term memory (LSTM) [
21] was first introduced by Hochreiter and Schmidhuber in 1997, as an extension of RNN that solves the problem of exploding and vanishing gradients more effectively than the conventional RNN models. Chen et al. [
22] developed a web-based automated system for predicting agriculture commodity prices. Their study revealed that the LSTM model demonstrated lower error rates compared to other machine learning models, particularly when handling extensive historical data from Malaysia. Gu et al. [
23] proposed dual input attention long short-term memory (DIA-LSTM) for the efficient prediction of agricultural commodity prices like cabbage and radish in the South Korean market.
Cakici et al. [
24] found that equity anomalies can predict aggregate market returns, as their predictability, if any, is confined to specific anomalies and methodological choices. Dong et al. [
25] applied an array of shrinkage methods, incorporating machine learning, forecast combination, and dimension reduction, to effectively capture predictive signals in a high-dimensional environment. Incorporating wavelets as a preprocessing tool has provided a new perspective on the analysis of data characterized by noise [
26]. The denoising process, one of the earliest applications of the discrete wavelet transform (DWT), is designed to eliminate small segments of the signal identified as noise [
27]. Wavelet-based approaches are commonly used as versatile tools for both the analysis and synthesis of multicomponent signals, particularly for tasks such as noise removal. Removing noise from the signal not only expedites the processing of analysis but also enhances the efficiency of the model [
28]. Paul et al. [
29] conducted a comparative analysis of various wavelet functions, including Haar, Daubechies (D4), D6, and LA8, to assess their performance in forecasting the prices of tomatoes. Shabri et al. [
30] suggested that the augmentation of the wavelet technique in the SVM model results in improved forecasting performance compared to classical SVM and demonstrated its superiority over ANN. Garai et al. [
31] presented a methodology that combines stochastic and machine learning models, alongside the utilization of wavelet analysis, for the prediction of agricultural prices.
Chen et al. [
32] used the wavelet analysis as a denoising tool along with LSTM for the prediction the prices of Agricultural products in China. Liang et al. [
33] put forth a novel threshold-denoising function with the aim of decreasing the distortion levels in signal reconstruction. The outcomes unequivocally demonstrated that the proposed function, when combined with the LSTM model, surpassed the performance of other conventional models. Zhou et al. [
34] evaluated the deep neural network (DNN) models for equity-premium forecasting and compared them with ordinary least squares (OLS) and historical average (HA) models. They found that augmenting DNN models with 14 additional variables enhanced their forecasting performance, showcasing their adaptability and superiority in equity-premium prediction. Jaseena and Kovoor [
35] utilized wavelet transform to decompose wind speed data into high and low frequency subseries. Subsequently, they forecasted the low and high frequency subseries using LSTM and SVR, respectively. Peng et al. [
36] made an attempt to predict the stock movement for the next 11 days (medium-term) by using multiresolution wavelet reconstruction and RNN. Singla et al. [
37] proposed an ensemble model to forecast the 24-h ahead solar GHI for the location of Ahmadabad, Gujarat, India, by combining wavelet and BiLSTM networks (WT-BiLSTM (CF)). They also compared the forecasting performance of WT-BiLSTM (CF) with unidirectional LSTM, unidirectional GRU, BiLSTM, and wavelet-based BiLSTM models. Yeasin and Paul [
38] proposed an ensemble model consisting of 13 forecasting models including five deep learning, five machine learning, and three stochastic models for forecasting vegetable prices in India. Liang et al. [
39] constructed an Internet-based consumer price index (ICPI) from Baidu and Google searches using principal component analysis. Transfer entropy quantifies information flow between online behavior and future markets. The GWO-CNN-LSTM model, incorporating ICPI and transfer entropy, forecasts daily prices of corn, soybean, PVC, egg, and rebar futures. Cai et al. [
40] had proposed a variational mode decomposition method along with deep learning model to forecast the hourly PM2.5 concentration. Deng et al. [
41] used multivariate empirical mode decomposition along with LSTM while dealing with forecasting of multi-step-ahead stock prices. Lin et al. [
42] decomposed the crude oil price data using wavelet transform and fed into a BiLSTM-Attention-CNN model for predicting the future price.
However, there exists a very low number of studies related to the gain in prediction accuracy of the models based on wavelet decomposed series compared to usual benchmark models. The present study illustrates this in detail, with application of machine learning, deep learning, and stochastic models in conjunction with wavelet denoising.
4. Result and Discussion
4.1. Data Description
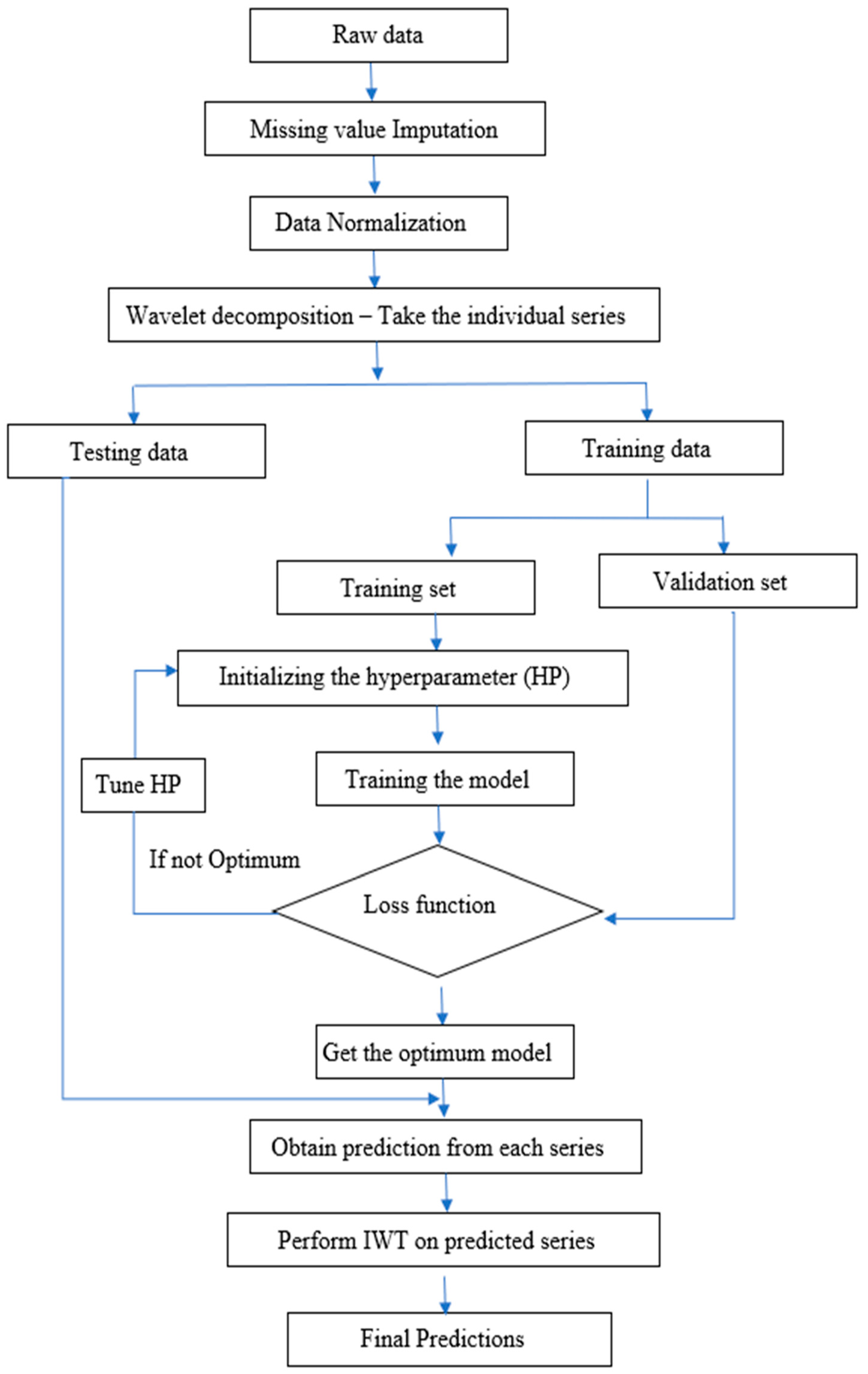
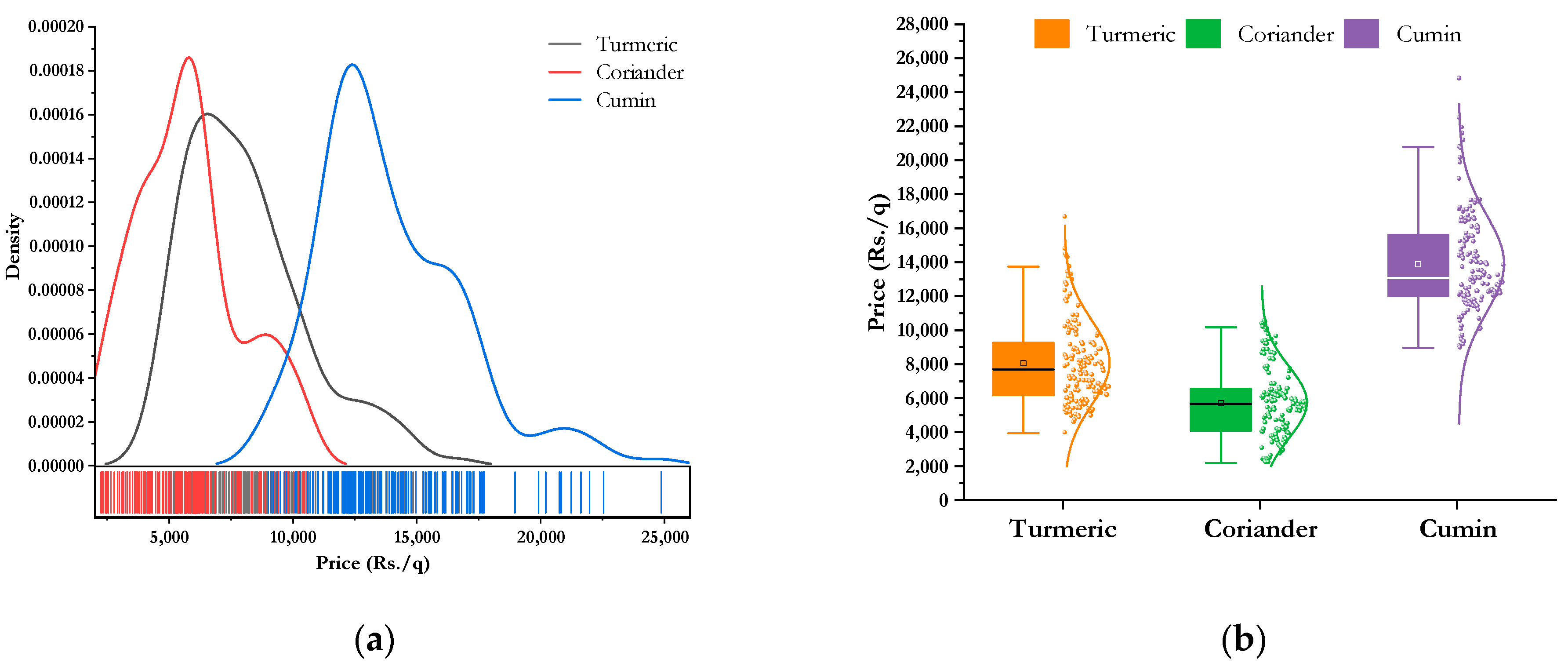
The current study focused on the monthly wholesale price data of three important spices (i.e., turmeric, coriander, and cumin) from different markets of India, where data series were collected from the AGMARKNET Portal
http://agmarknet.gov.in/ (accessed on 3 July 2023) for the period of January 2010 to December 2022. Turmeric data were gathered from 18 distinct markets, while coriander and cumin data were obtained from 27 markets each. The choice of markets and commodities was determined by their significant market share and their representative characteristics within their respective categories. The overall price for each commodity was calculated as the weighted average price across all markets for that specific commodity. The weight assigned to each market was determined by the inverse of the arrival quantity:
where
N is the number of markets in that commodity and
t is time period. The price patterns of three spices are illustrated in
Figure 4. The dataset consists of a total of 156 observations across all commodities. The final 29 observations were set aside for testing and post-sample prediction, leaving 127 observations for model development in each case.
Table 1 represents the descriptive statistics of different commodities.
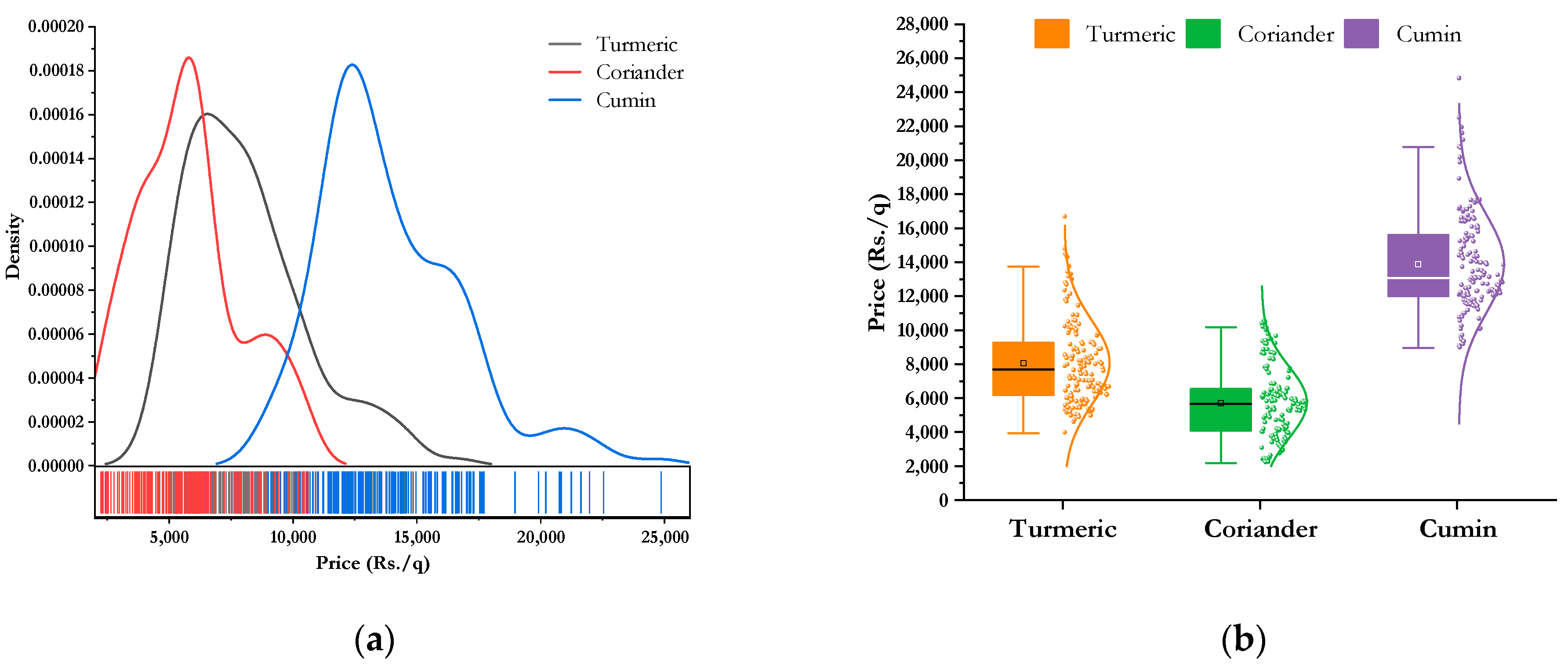
Table 1 indicates that all the prices series were non-normal and have high kurtosis. The Jarque–Bera test and Shapiro–Wilk’s test are statistical methods employed to evaluate whether a dataset follows normal distribution. The null hypothesis of both the tests are that data follow a normal distribution. It is inferred from the table that all the three commodities are non-normal. The variability in price is less for cumin as compared to other two spices. The kernel density and the box-plot of different price series are plotted in
Figure 5.
Figure 5 also demonstrates high kurtosis and positive skew.
4.2. Application of Benchmark Models
The primary contenders in the field of predictive modelling start with ARIMA. The process initiates with checking the stationarity of the underlying data through an augmented Dickey–Fuller (ADF) test and the results are outlined in
Table 2. All the three series exhibited non-stationarity which is converted into stationarity by differencing. The order of the model was tentatively identified using the autocorrelation function (ACF) and partial autocorrelation function (PACF). Ultimately, the selection of the best model for individual commodity prices was performed based on the minimum values of Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC).
Before proceeding for the application of machine learning and deep learning techniques, the presence of volatility clustering was tested by means of the autoregressive conditional heteroscedastic-Lagrange multiplier (ARCH-LM) test. It is found that for all three series, the test is not significant indicating absence of any volatility clustering.
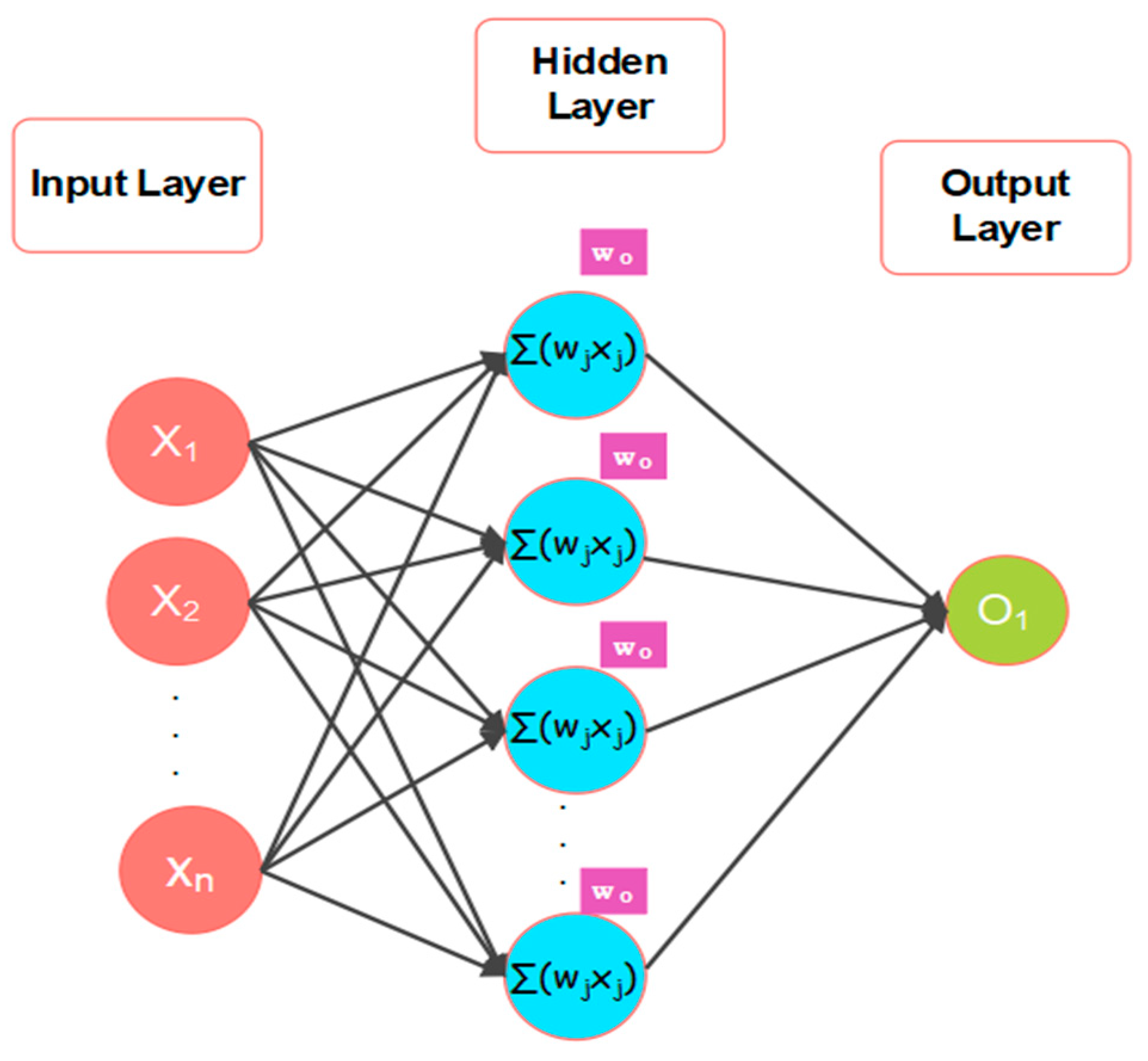
The individual price series was subjected to ANN, SVR and LSTM model. In the process of developing an ANN, selection of input lag value is a crucial step. Here, the input lag value was selected as 12 with the help of ACF. The ANN model used in this study is the standard two-layer feed forward network. The efficiency of the model can be improved by finding the best set of hyperparameter values for the training dataset. The hyperparametric search space for ANN were the number of nodes per layer = {6, 7, 8, 9,10, 11, 12}, number of epochs = {10 to 100 with step 10}, and batch size = {16, 32, 64, 128}. The hyperparameters were optimized by using grid search method.
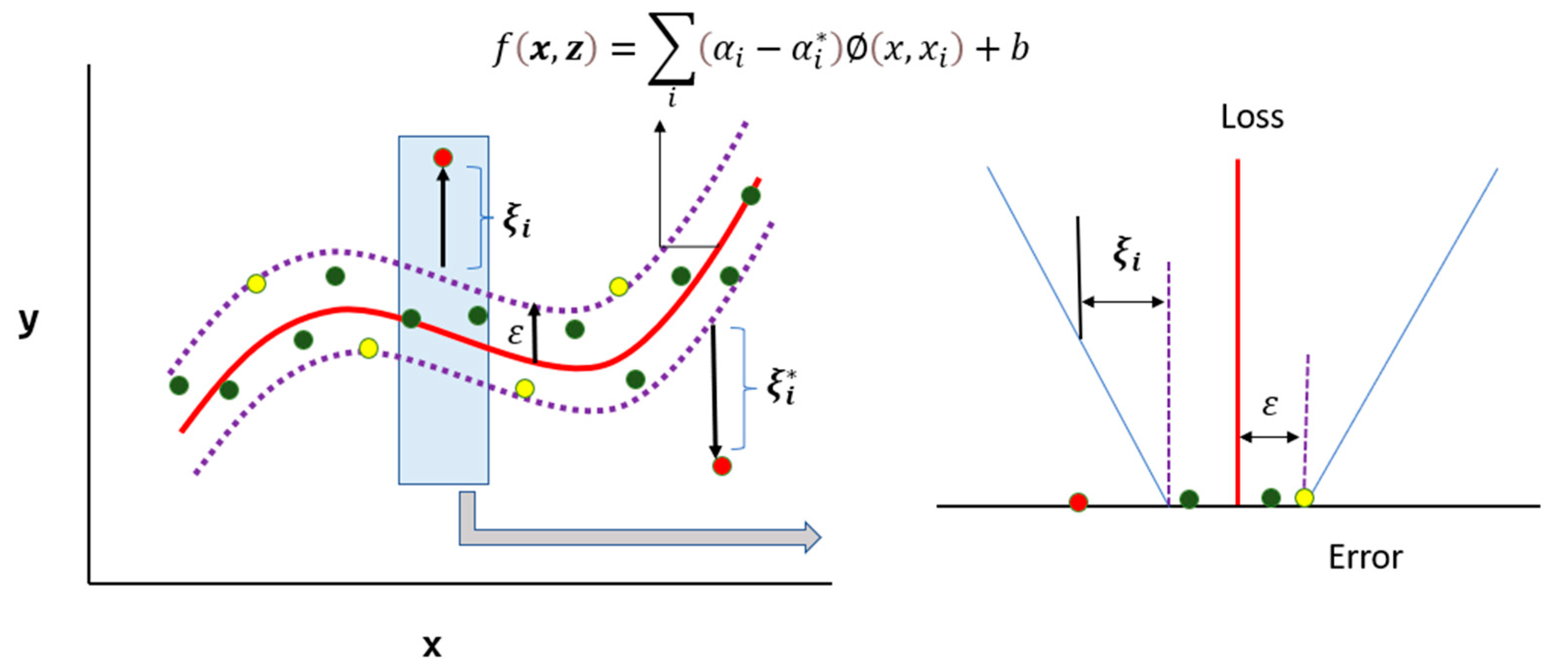
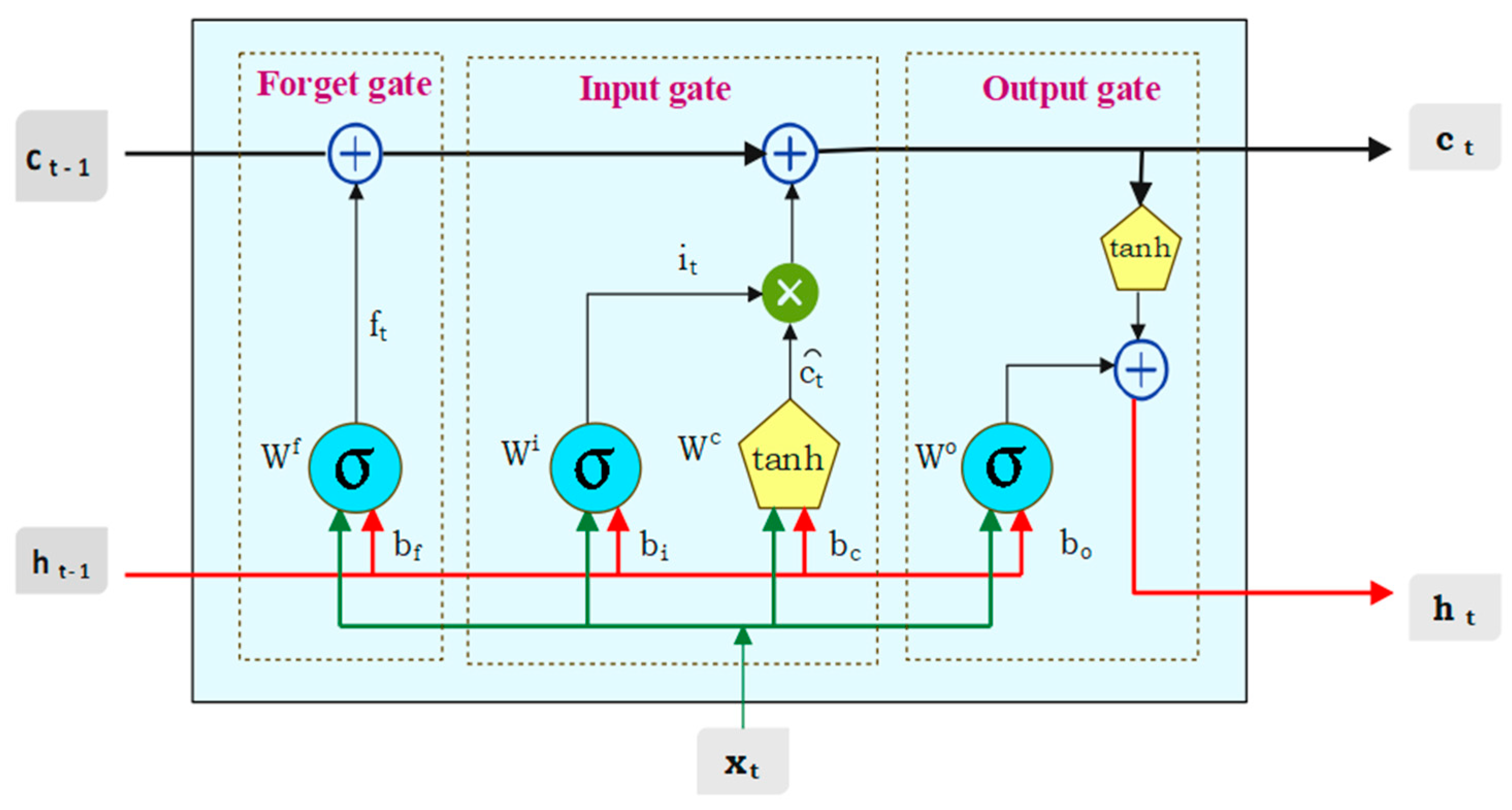
For building the SVR model, the actual value yt was assumed to be a function of its previous lag values. The model uses an RBF kernel, and the hyperparameters C (Regularization parameter), ε (epsilon), and γ (kernel width) were optimized using grid search over the following ranges: C = {1, 10,…, 1000 with step 10.}, ε = { 0.01, 0.02,…, 0.30}, γ = {3, 4,…, 15}. In order to build LSTM model, lag values were established at 12. The Hyperparameter search space for LSTM were the number of LSTM units = {32, 64, 128}, number of epochs = {50, 100, 200}, and batch size = {16, 32, 64, 128}.
The best hyperparameters are selected based on the performance of the model on a hold-out validation set. Once the hyperparameters have been tuned, the model is evaluated on a test set to assess its performance on unseen data. The model’s performance on the test data can be evaluated using a variety of metrics, such as the mean absolute error (MAE), root mean square error (RMSE), and mean absolute percentage error (MAPE).
Table 3 provides a clear overview of various accuracy measures of different models, including LSTM, SVR, ANN, and ARIMA, across the crops turmeric, coriander, and cumin. For turmeric, LSTM demonstrated a substantial 21.4% reduction in RMSE compared to SVR. In the case of coriander, LSTM achieved an impressive 40.7% reduction in RMSE relative to SVR. For cumin, LSTM showcased a significant 37.3% decrease in RMSE compared to SVR. For all the three crops (turmeric, coriander, cumin), the LSTM model consistently outperformed other models in terms of RMSE, MAPE, and MAE, suggesting they are generally better at capturing the underlying patterns in the data.
4.3. Denoising Using Wavelet
While there are numerous methods available for predicting prices series, they do not consistently meet expected performance levels, as each method comes with its own set of advantages and disadvantages. Denoising helps us to filter out this extraneous noise, enabling the model to focus on the relevant patterns and relationships in the data. So, the original series were denoised using wavelet transform before applying the model. The Haar wavelet filter was used for wavelet transformation. The maximum (
and minimum (
levels of decomposition for price series were 7 and 5, respectively. So, each series was decomposed at all three levels and fed as input to ARIMA, ANN, SVR, and LSTM models. The hyperparameters of the models were tuned using a grid search over a range of possible values as mentioned before.
Table 4,
Table 5 and
Table 6 represent the accuracy measure of various models on the test data with different levels of decomposition (bold denotes the lowest of each accuracy metrics). Here, H5, H6, and H7 represent the wavelet decomposition with the Haar filter and level of decomposition as 5, 6, and 7, respectively.
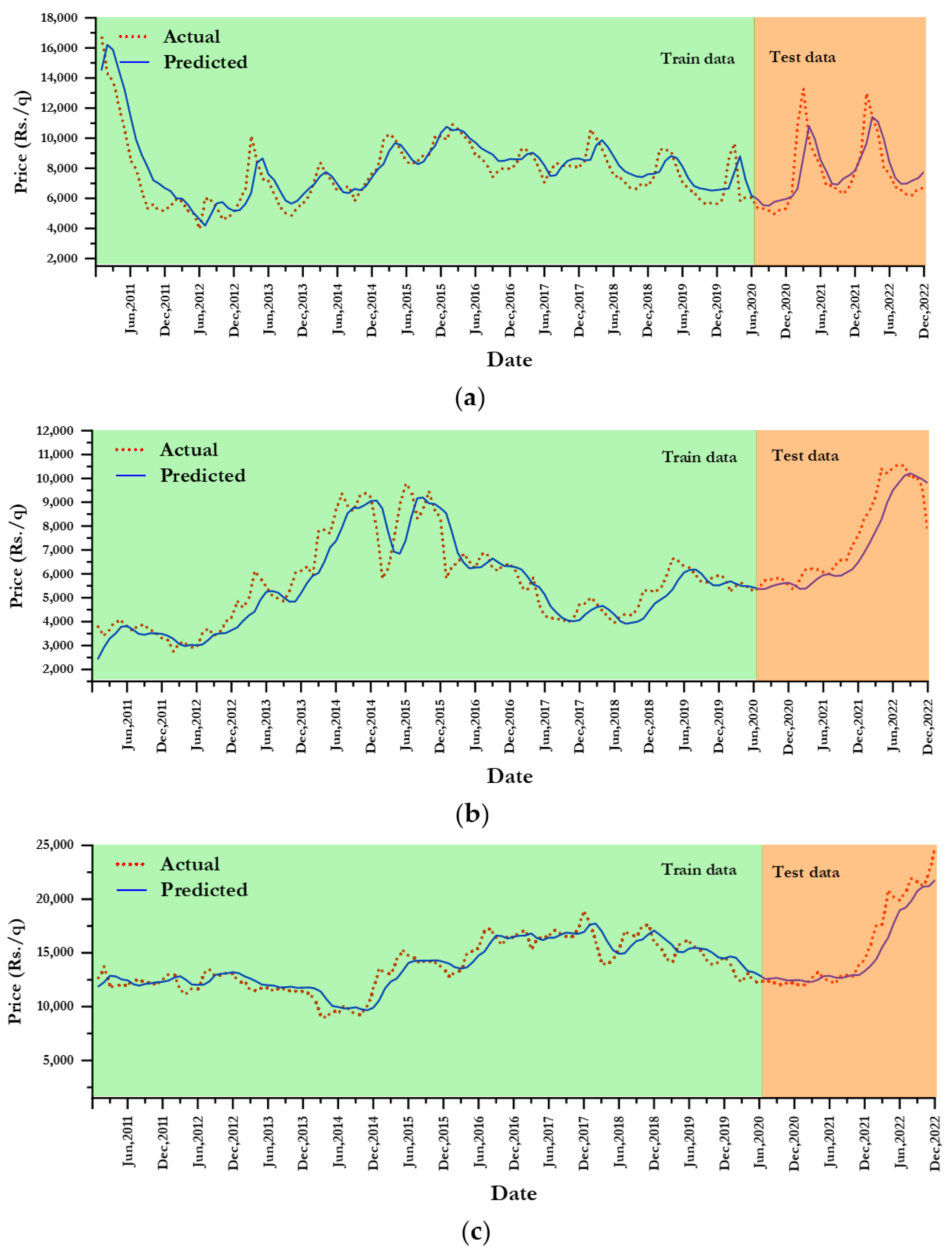
For turmeric, decomposition level H6 was optimal for WLSTM, offering the highest accuracy across all metrics, whereas WSVR and WARIMA performed best at H7 and H5 decomposition levels, respectively. For coriander, decomposition level H6 exhibited the lowest RMSE, MAPE, and MAE, indicating better predictive accuracy compared to other levels across all models (WLSTM, WSVR, and WANN), except WARIMA. For cumin prices, the most effective decomposition level was H7 and H5 for WLSTM and WARIMA, respectively, presenting the lowest RMSE, MAPE, and MAE. Across all models in cumin, decomposition level H6 tended to consistently offer the best predictive accuracy, as it frequently displayed the lowest values for RMSE, MAPE, and MAE. The WLSTM model outperformed the other models (WSVR, WANN, and WARIMA) on all three datasets (turmeric, coriander, and cumin). The performance of the best fitted model, i.e., WLSTM, for both training and testing sets is presented in
Figure 6.
4.4. Impact of Denoising
Table 7 explains the influence of denoising in the current dataset. Among the different levels of decomposition, the optimum level of decomposition was selected based on the minimum values of accuracy measures and subsequently compared with a benchmark model. The percentage decrease (%↓) in error was calculated for finding the improvement achieved by the wavelet-based denoising model (WLSTM, WSVR, WANN, WARIMA) over their respective baseline models. In all three commodities, percentage of error reduction due to denoising was greater than 30% when compared to traditional LSTM. For turmeric, WLSTM achieved a significant 35.22% reduction in RMSE compared to LSTM. Coriander showed an even more substantial reduction of 42.38% in RMSE with WLSTM. Cumin also exhibited 34.75% reduction in RMSE when using WLSTM. WSVR demonstrated superior performance compared to SVR, achieving substantial reductions in RMSE of 30.46%, 21.67%, and 28.68% for turmeric, coriander, and cumin, respectively. Similarly, wavelet-based ANN and ARIMA also had a significant reduction in error when compared to benchmark models.
The technique for order preference by similarity to ideal solution (TOPSIS) has been applied for finding the best model with respect to each of the series under consideration. Equal weightage has been given to each of the performance measures, i.e., RMSE, MAPE, and MAE. The TOPSIS scores and ranks were computed for wavelet-based denoising models and the same is presented in
Table 8.
Table 8 indicates that the WLSTM occupied the top three ranks in all the price series. Moreover, the Diebold–Mariano (DM) test was applied to see the significant differences in predictive accuracy between the two models. The result of the DM test is reported in
Table 9, which indicates the significant differences between the wavelet-based denoising model and the individual benchmark model. Overall, the results clearly demonstrated the effectiveness of wavelet-based denoising in reducing errors across the different spice crops and forecasting techniques.
5. Conclusions
In the current study, the effect of wavelet-based denoising was illustrated on the monthly wholesale prices of three pivotal spices—turmeric, coriander, and cumin, collected from the diverse markets across India. Wavelet denoising involves the application of methods or algorithms to filter out the extraneous noise, enabling the model to focus on the relevant patterns and relationships in the data. The various levels of decomposition were taken into account for studying the effectiveness of denoising. The benchmark modeling phase commenced with the deployment of the ARIMA model, a widely recognized time series forecasting method. The modeling spectrum expanded to include artificial neural networks (ANN), support vector regression (SVR), and long short-term memory (LSTM) models. These models were subjected to hyperparameter optimization through a grid search method, aiming to fine-tune the parameters for optimal performance. Also, the efficacy of wavelet-based denoising was assessed by comparing it with a benchmark model using three accuracy metrics, namely, RMSE, MAPE, and MAE. The results on the test set unequivocally indicated the consistent superiority of LSTM across all three spices, showcasing its adeptness in capturing the intricate patterns inherent in the data. The performance of each model may vary with different decomposition levels, emphasizing the importance of carefully selecting the appropriate level based on specific modeling objectives and metric priorities. The comparative analysis between the wavelet-based denoising models (WLSTM, WSVR, WANN, WARIMA) and their traditional counterparts provided resounding affirmation regarding the substantial enhancement in predictive accuracy introduced by wavelet transforms. Across all three spices, denoising consistently led to significant reductions in error metrics, with percentage decreases ranging from 30% to over 40%.
In general, Wavelet LSTM at H6 appears to be a robust choice for accurate price predictions across all spices. The order of preference for model performance, based on the provided metrics, could be WLSTM > WARIMA > WSVR > WANN for turmeric, WLSTM > WANN > WSVR > WARIMA for coriander, and WLSTM > WSVR > WANN> WARIMA for cumin. The final step in the comparative analysis involved the application of the TOPSIS method. This method offered a comprehensive evaluation, considering all three performance metrics with equal weightage. The TOPSIS scores and ranks reaffirmed WLSTM’s superiority, consistently placing it at the forefront across all decomposition levels and spices. The DM test also resulted in significant differences in prediction accuracy between wavelet-based models with that of the usual model. Indeed, the computational intensity of wavelet-based denoising, particularly with sophisticated algorithms, is a notable limitation. Processing large datasets or implementing real-time denoising may pose challenges in terms of computational resources. The effectiveness of wavelet-based denoising is highly dependent on the choice of the wavelet function. The other wavelet filters may be explored in future research to gain a clear idea about the selection of suitable filter and level for a specific pattern existed in the time series.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}