

Developing Personalised Learning Support for the Business Forecasting Curriculum: The Forecasting Intelligent Tutoring System



Abstract
1. Introduction
- We develop a tutor to support learning of time series forecasting and classical time series decomposition, and name it FITS, for Forecasting Intelligent Tutoring System.
- Through a combination of forecasting literature review, analysis of think-aloud protocols, and expert opinion, we generate a set of best practices for designing such systems.
- We conduct a small sample pilot study to show that FITS can be used to develop a deeper understanding of learning effects and knowledge acquisition based on the analysis of student models, for example, using learning curves.
2. Task Analysis: Decomposed Time Series
3. Conceptual Design
3.1. Think Aloud Protocols Inform Pedagogy
3.1.1. From Procedure to Knowledge Acquisition
“So now I have- now we have, it’s meant to be divide by twelve but I put divide by two. Okay so now I have the moving average, twelve moving average er, what I do next is it is. So I think I’m going to try to take the actual data minus the moving average to, to see if there is any trend.”
“but I haven’t got the trend so I need to calculate the trend and get the error (how to calculate trend…)”
3.1.2. Review and Reflection
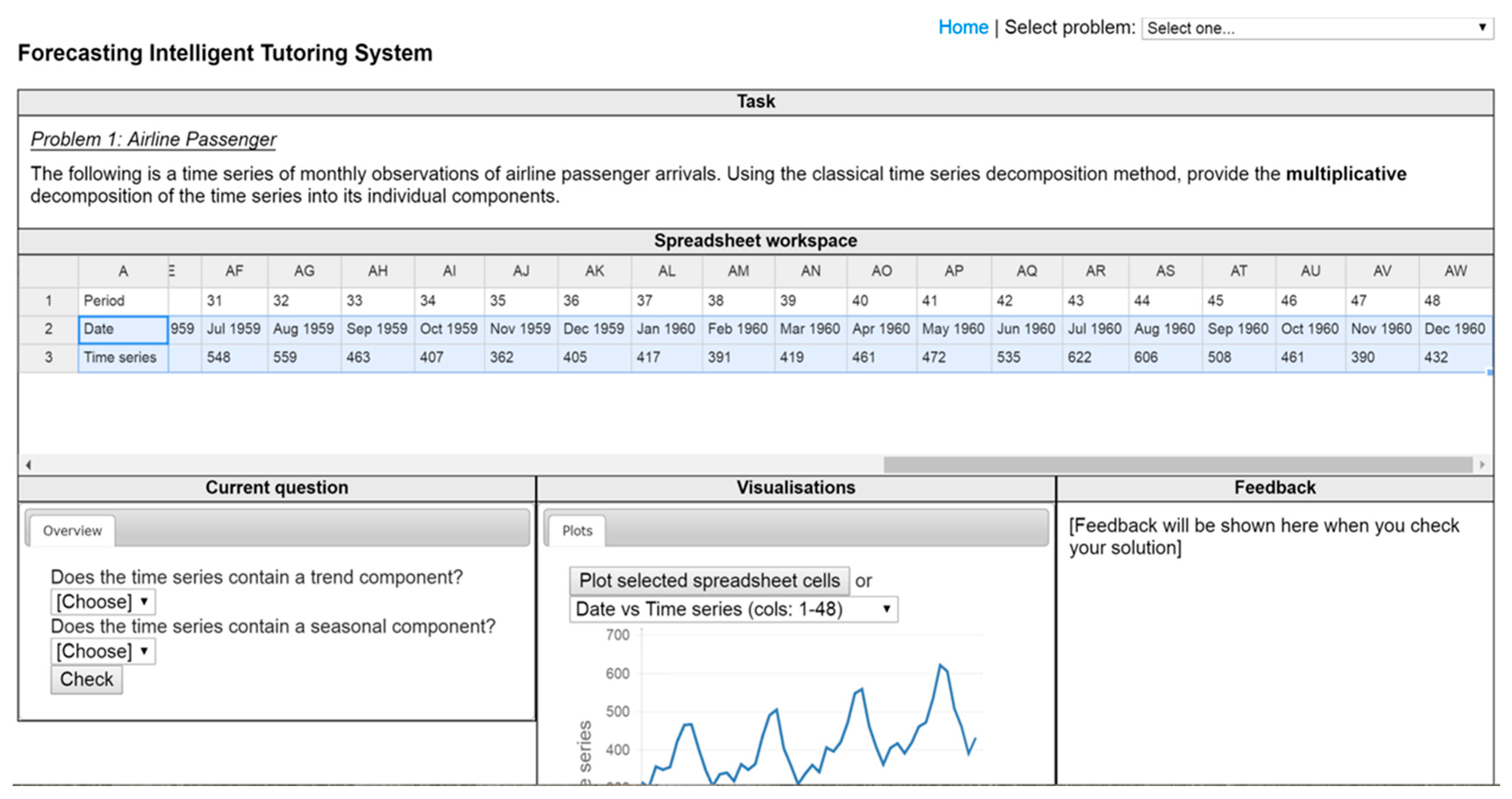
3.1.3. Data Visualisation
“So I have to decide the length of the centred moving average, I can try a couple- so it could be three for example so I just calculate the average values of three, of the past series and drag this down. Okay, I must round the values down to two decimal places so I’ll do that okay there it is so that’s the moving average and I can add it to the by three. Okay right so from this graph I can see that it is definitely not smooth enough”
3.2. Forecasting Literature Inform Design
3.2.1. Feedback
3.2.2. Data Availability
3.2.3. Data Visualisation
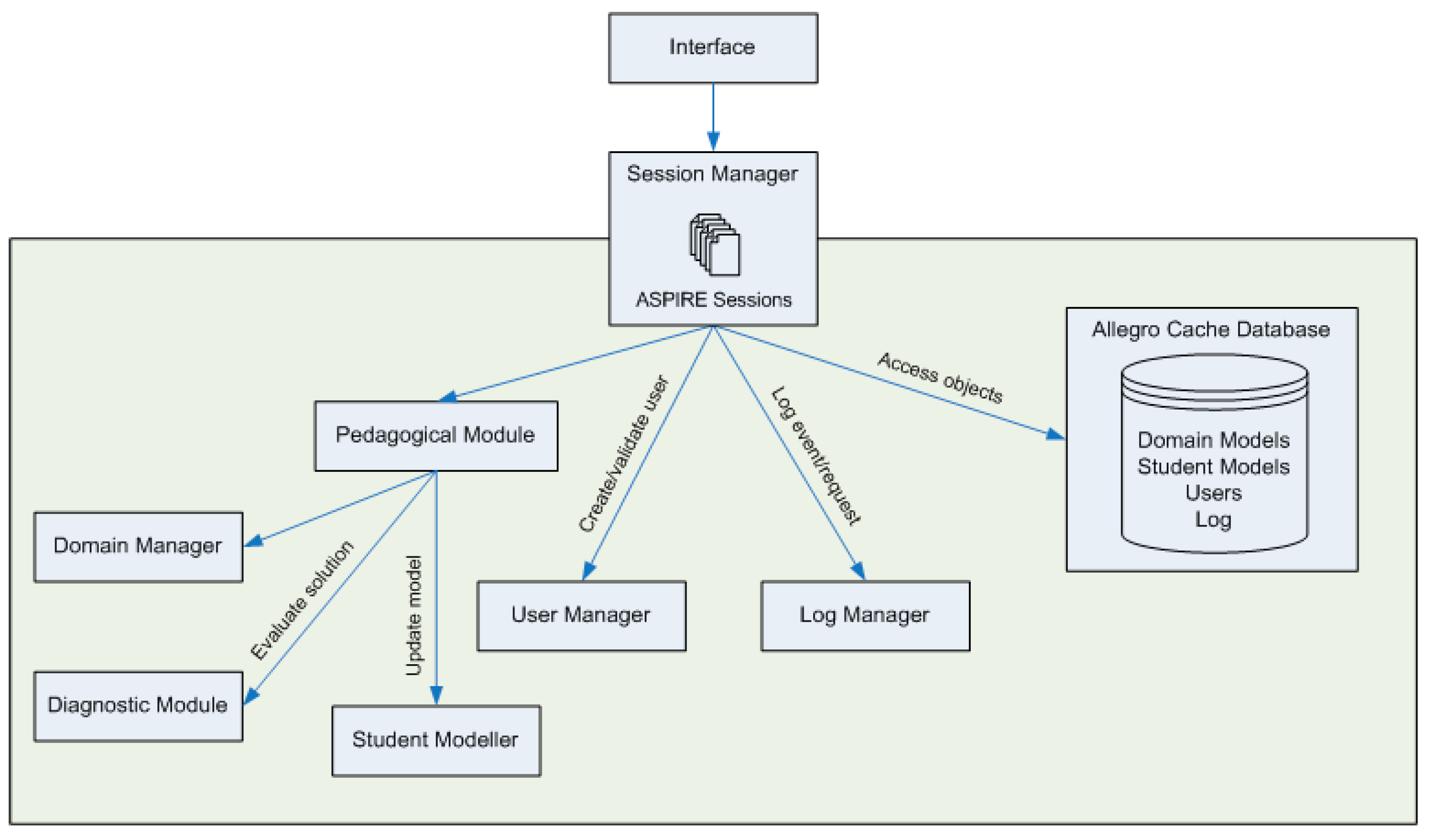
4. System Design and Architecture
4.1. Problem Design and Knowledge Representation
“it’s a bit unfortunate that you can’t skip a question you can’t answer. I was blocked twice and only got lucky to find the correct answer to the first block by chance.”
If <relevance condition> is true, then <satisfaction condition> had better also be true, otherwise something has gone wrong.
- (a)
- If the student was not working on the Noise Estimation step and the problem does not use additive decomposition, then the constraint would not be triggered (i.e., not relevant for this submission).
- (b)
- If the student was working on the Noise Estimation step, and the problem uses additive decomposition, then the constraint would be triggered (i.e., relevant for this submission). From here:
- If the student’s answer uses subtraction, then the constraint is recorded as being satisfied (i.e., the student has correctly carried out this concept).
- If the student’s answer does not use subtraction, then the constraint is recorded as being violated (i.e., the student has not carried out or incorrectly carried out this concept).
4.2. Student Interface
“So I have to decide the length of the centred moving average, I can try a couple- so it could be three for example … Okay right so from this graph I can see that it is definitely not smooth enough”
4.3. Feedback
- Quick Check, specifying whether the answer is correct or not;
- Error Flag, identifying only the part of the solution that is erroneous;
- Hint, identifying the first error and providing information about the domain principle that is violated by the student’s solution;
- Detailed Hint (a more detailed version of the hint);
- All Errors (hints about all errors);
- Show Solution.
5. Pilot Study
5.1. Experiment Design
5.2. Pre- and Post-Test
5.3. Sample Size
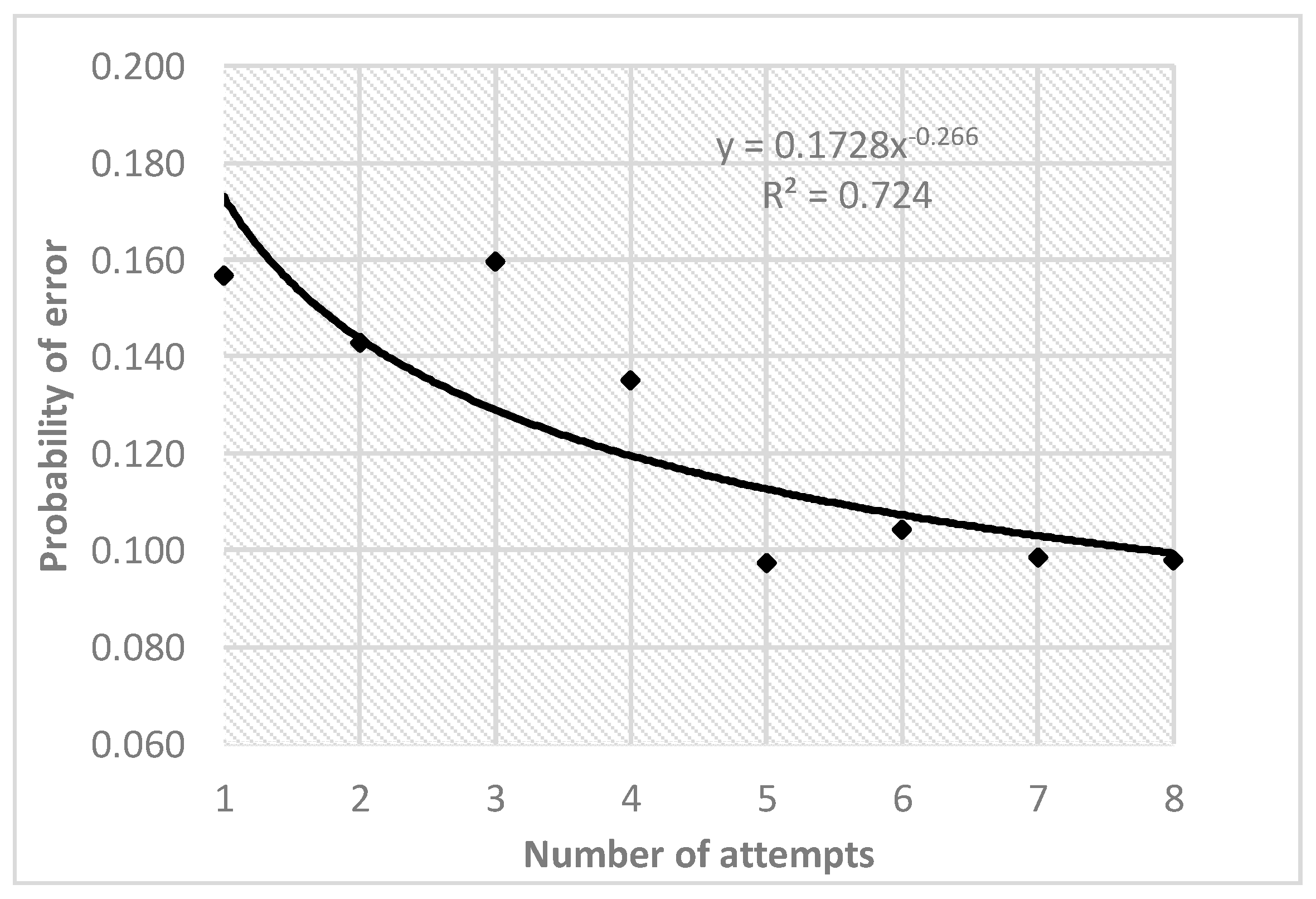
6. Data Analysis
6.1. Pre- and Post-Test
6.2. Student Models
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Problem Set
- 1.
- Passenger Airline
- 2.
- Boulder Temperatures
- 3.
- Crude Oil Price
- 4.
- S&P 500
- 5.
- US GDP
- 6.
- Google
- 7.
- Housing Starts
- 8.
- Netflix
- 9.
- Australian Beer Production
- 10.
- Unemployment Rate
Appendix B. Pre- and Post-Tests
Appended B.1. Pre-Test

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MSCI 523: Forecasting | |||||
| Pre-Test Classical Time Series Decomposition | |||||
| Student ID# ______________________ | |||||
| (Please note that the outcome of this test is used for research purposes only and is in no way linked to the grades within this course) | |||||
| Date | Value | Date | Value | Date | Value |
| January-56 | 1254 | January-58 | 1497 | January-60 | 1721 |
| February-56 | 1290 | February-58 | 1463 | February-60 | 1752 |
| March-56 | 1379 | March-58 | 1648 | March-60 | 1914 |
| April-56 | 1346 | April-58 | 1595 | April-60 | 1857 |
| May-56 | 1535 | May-58 | 1777 | May-60 | 2159 |
| June-56 | 1555 | June-58 | 1824 | June-60 | 2195 |
| July-56 | 1655 | July-58 | 1994 | July-60 | 2287 |
| August-56 | 1651 | August-58 | 1835 | August-60 | 2276 |
| September-56 | 1500 | September-58 | 1787 | September-60 | 2096 |
| October-56 | 1538 | October-58 | 1699 | October-60 | 2055 |
| November-56 | 1486 | November-58 | 1633 | November-60 | 2004 |
| December-56 | 1394 | December-58 | 1645 | December-60 | 1924 |
| January-57 | 1409 | January-59 | 1597 | ||
| February-57 | 1387 | February-59 | 1577 | ||
| March-57 | 1543 | March-59 | 1709 | ||
| April-57 | 1502 | April-59 | 1756 | ||
| May-57 | 1693 | May-59 | 1936 | ||
| June-57 | 1616 | June-59 | 2052 | ||
| July-57 | 1841 | July-59 | 2105 | ||
| August-57 | 1787 | August-59 | 2016 | ||
| September-57 | 1631 | September-59 | 1914 | ||
| October-57 | 1649 | October-59 | 1925 | ||
| November-57 | 1586 | November-59 | 1824 | ||
| December-57 | 1500 | December-59 | 1765 | ||
- Does the time series contain trend?
- Does the time series contain seasonality?
- What is the required length of the centred moving average?
- In which period are you first able to calculate the centred moving average (use the same date format given in the above e.g., December-89)?
- What is the value (to 2 decimal places) of the centred moving average for the period February-58?
- What is the value (to 2 decimal places) of the de-trended time series for the period August-58?
- What is the value of the seasonal index (to 2 decimal places) for the month of January?
- What is the value (to 2 decimal places) of the noise series for the period December-59?
Appended B.2. Post-Test
| MSCI 523: Forecasting | ||||||||
| Post-Test Classical Time Series Decomposition | ||||||||
| Student ID# ______________________ | ||||||||
| (Please note that the outcome of this test is used for research purposes only and is in no way linked to the grades within this course) | ||||||||
| Quarter | Date | Value | Quarter | Date | Value | Quarter | Date | Value |
| Q1 | March-71 | 6855 | Q1 | March-73 | 7539 | Q1 | March-75 | 7735 |
| Q2 | June-71 | 7335 | Q2 | June-73 | 7948 | Q2 | June-75 | 7984 |
| Q3 | September-71 | 7467 | Q3 | September-73 | 8157 | Q3 | September-75 | 8045 |
| Q4 | December-71 | 7952 | Q4 | December-73 | 8691 | Q4 | December-75 | 8646 |
| Q1 | March-72 | 7147 | Q1 | March-74 | 7601 | Q1 | ||
| Q2 | June-72 | 7636 | Q2 | June-74 | 7985 | Q2 | ||
| Q3 | September-72 | 7829 | Q3 | September-74 | 8186 | Q3 | ||
| Q4 | December-72 | 8332 | Q4 | December-74 | 8798 | Q4 | ||
- Does the time series contain trend?
- Does the time series contain seasonality?
- What is the required length of the centred moving average?
- In which period are you first able to calculate the centred moving average (use the same date format given in the above)?
- What is the value (to 2 decimal places) of the centred moving average for the period March-72?
- What is the value (to 2 decimal places) of the de-trended time series for this same period, that is, March-72?
- What is the value of the seasonal index (to 2 decimal places) for the Quarter ending March, that is, Q1?
- Based upon examination of the seasonal index numbers, are expenditures seasonal? Explain.
References
- Syntetos, A.A.; Babai, Z.; Boylan, J.E.; Kolassa, S.; Nikolopoulos, K. Supply chain forecasting: Theory, practice, their gap and the future. Eur. J. Oper. Res. 2016, 252, 1–26. [Google Scholar] [CrossRef]
- Ord, K.; Fildes, R. Principles of Business Forecasting; Cengage Learning: Boston, MA, USA, 2012. [Google Scholar]
- Fildes, R.; Goodwin, P.; Lawrence, M. The design features of forecasting support systems and their effectiveness. Decis. Support Syst. 2006, 42, 351–361. [Google Scholar] [CrossRef]
- Fildes, R.; Nikolopoulos, K.; Crone, S.F.; Syntetos, A.A. Forecasting and operational research: A review. J. Oper. Res. Soc. 2008, 59, 1150–1172. [Google Scholar] [CrossRef]
- Armstrong, J.S. Principles of Forecasting: A Handbook for Researchers and Practitioners; Springer Science & Business Media: Berlin, Germany, 2001; Volume 30. [Google Scholar]
- Aleven, V.; Rowe, J.; Huang, Y.; Mitrovic, A. Domain modeling for AIED systems with connections to modeling student knowledge: A review. In Handbook of Artificial Intelligence in Education; Edward Elgar Publishing: Northampton, MA, USA, 2023; pp. 127–169. [Google Scholar]
- Carbonell, J.R. AI in CAI: An artificial-intelligence approach to computer-assisted instruction. IEEE Trans. Man-Mach. Syst. 1970, 11, 190–202. [Google Scholar] [CrossRef]
- Elsom-Cook, M. Design Considerations of an Intelligent Tutoring System for Programming Languages; University of Warwick: Warwick, UK, 1984. [Google Scholar]
- McCalla, G. The history of artificial intelligence in education—The first quarter century. In Handbook of Artificial Intelligence in Education; Edward Elgar Publishing: Northampton, MA, USA, 2023; pp. 10–29. [Google Scholar]
- Koedinger, K.R.; Anderson, J.; Hadley, W.H.; Mark, M.A. Intelligent tutoring goes to school in the big city. Int. J. Artif. Intell. Educ. 1997, 8, 30–43. [Google Scholar]
- Conati, C.; Merten, C. Eye-tracking for user modeling in exploratory learning environments: An empirical evaluation. Knowl.-Based Syst. 2007, 20, 557–574. [Google Scholar] [CrossRef]
- VanLehn, K.; Lynch, C.; Schulze, K.; Shapiro, J.A.; Shelby, R.; Taylor, L.; Treacy, D.; Weinstein, A.; Wintersgill, M. The Andes physics tutoring system: Lessons learned. Int. J. Artif. Intell. Educ. 2005, 15, 147–204. [Google Scholar]
- Azevedo, R.; Taub, M.; Mudrick, N.V. Using multi-channel trace data to infer and foster self-regulated learning between humans and advanced learning technologies. In Handbook of Self-Regulation of Learning and Performance; Schunk, D., Greene, J.A., Eds.; Routledge: New York, NY, USA, 2018; pp. 254–270. [Google Scholar]
- Graesser, A.C.; Hu, X.; Nye, B.; VanLehn, K.; Kumar, R.; Heffernan, C.; Heffernan, N.; Woolf, B.; Olney, A.M.; Rus, V.; et al. ElectronixTutor: An intelligent tutoring system with multiple learning resources for electronics. Int. J. STEM Educ. 2018, 5, 15. [Google Scholar] [CrossRef]
- Mitrovic, A.; Ohlsson, S. Evaluation of a Constraint-Based Tutor for a Database Language. Int. J. Artif. Intell. Educ. 1999, 10, 238–256. [Google Scholar]
- Mitrovic, A.; Ohlsson, S.; Barrow, D.K. The effect of positive feedback in a constraint-based intelligent tutoring system. Comput. Educ. 2013, 60, 264–272. [Google Scholar] [CrossRef]
- Kern, T.; McGuigan, N.; Mitrovic, A.; Najar, A.S.; Sin, S. iCFS: Developing Intelligent Tutoring Capacity in the Accounting Curriculum. Int. J. Learn. High. Educ. 2014, 20, 91. [Google Scholar]
- Mitrovic, A.; McGuigan, N.; Martin, B.; Suraweera, P.; Milik, N.; Holland, J. Authoring Constraint-based Tutors in ASPIRE: A Case Study of a Capital Investment Tutor. In Proceedings of EdMedia: World Conference on Educational Media and Technology 2008; Luca, J., Weippl, E.R., Eds.; Association for the Advancement of Computing in Education (AACE): Vienna, Austria, 2008; pp. 4607–4616. [Google Scholar]
- Makridakis, S.; Wheelwright, S.C.; Hyndman, R.J. Forecasting: Methods and Applications, 3rd ed.; Wiley India Pvt. Limited: Hoboken, NJ, USA, 2008. [Google Scholar]
- Harvey, N. Improving judgment in forecasting. In Principles of Forecasting; Springer: Berlin/Heidelberg, Germany, 2001; pp. 59–80. [Google Scholar]
- Ericsson, K.A.; Simon, H.A. Protocol Analysis: Verbal Reports as Data, Revised ed.; MIT Press: Cambridge, MA, USA, 1993. [Google Scholar]
- Anderson, J.R. Problem solving and learning. Am. Psychol. 1993, 48, 35. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2014. [Google Scholar]
- Schmitt, N.; Coyle, B.W.; Saari, B.B. Types of task information feedback in multiple-cue probability learning. Organ. Behav. Hum. Perform. 1977, 18, 316–328. [Google Scholar] [CrossRef]
- Fischer, I.; Harvey, N. Combining forecasts: What information do judges need to outperform the simple average? Int. J. Forecast. 1999, 15, 227–246. [Google Scholar] [CrossRef]
- Harvey, N.; Fischer, I. Development of experience-based judgment and decision making: The role of outcome feedback. In The Routines of Decision Making; Psychology Press: London, UK, 2005; pp. 119–137. [Google Scholar]
- Tape, T.G.; Kripal, J.; Wigton, R.S. Comparing methods of learning clinical prediction from case simulations. Med. Decis. Mak. 1992, 12, 213–221. [Google Scholar] [CrossRef] [PubMed]
- Bolger, F.; Wright, G. Assessing the quality of expert judgment: Issues and analysis. Decis. Support Syst. 1994, 11, 1–24. [Google Scholar] [CrossRef]
- Anderson, J.R.; Corbett, A.T.; Koedinger, K.R.; Pelletier, R. Cognitive tutors: Lessons learned. J. Learn. Sci. 1995, 4, 167–207. [Google Scholar] [CrossRef]
- Mitrovic, A. Fifteen years of constraint-based tutors: What we have achieved and where we are going. User Model. User-Adapt. Interact. 2012, 22, 39–72. [Google Scholar] [CrossRef]
- Mitrovic, A.; Suraweera, P.; Martin, B.; Weerasinghe, A. DB-suite: Experiences with three intelligent, web-based database tutors. J. Interact. Learn. Res. 2004, 15, 409. [Google Scholar]
- Du Boulay, B. Recent meta-reviews and meta–analyses of AIED systems. Int. J. Artif. Intell. Educ. 2016, 26, 536–537. [Google Scholar] [CrossRef]
- Tversky, A.; Kahneman, D. Judgment under uncertainty: Heuristics and biases. In Utility, Probability, and Human Decision Making; Springer: Berlin/Heidelberg, Germany, 1975; pp. 141–162. [Google Scholar]
- Goldstein, D.G.; Gigerenzer, G. The recognition heuristic: How ignorance makes us smart. In Simple Heuristics That Make Us Smart; Oxford University Press: Oxford, UK, 1999; pp. 37–58. [Google Scholar]
- Angus-Leppan, P.; Fatseas, V. The forecasting accuracy of trainee accountants using judgemental and statistical techniques. Account. Bus. Res. 1986, 16, 179–188. [Google Scholar] [CrossRef]
- Dickson, G.W.; DeSanctis, G.; McBride, D.J. Understanding the effectiveness of computer graphics for decision support: A cumulative experimental approach. Commun. ACM 1986, 29, 40–47. [Google Scholar] [CrossRef]
- Lawrence, M.J.; Edmundson, R.H.; O’Connor, M.J. An examination of the accuracy of judgmental extrapolation of time series. Int. J. Forecast. 1985, 1, 25–35. [Google Scholar] [CrossRef]
- Lawrence, M.J. An exploration of some practical issues in the use of quantitative forecasting models. J. Forecast. 1983, 2, 169–179. [Google Scholar] [CrossRef]
- Harvey, N.; Bolger, F. Graphs versus tables: Effects of data presentation format on judgemental forecasting. Int. J. Forecast. 1996, 12, 119–137. [Google Scholar] [CrossRef]
- Mitrovic, A.; Martin, B.; Suraweera, P.; Zakharov, K.; Milik, N.; Holland, J.; McGuigan, N. ASPIRE: An authoring system and deployment environment for constraint-based tutors. Int. J. Artif. Intell. Educ. 2009, 19, 155–188. [Google Scholar]
- Ohlsson, S. Learning from performance errors. Psychol. Rev. 1996, 103, 241. [Google Scholar] [CrossRef]
- Ohlsson, S. Constraint-based student modeling. J. Artif. Intell. Educ. 1992, 3, 429–447. [Google Scholar]
- Conati, C.; Barral, O.; Putnam, V.; Rieger, L. Toward personalized XAI: A case study in intelligent tutoring systems. Artif. Intell. 2021, 298, 103503. [Google Scholar] [CrossRef]
- Khosravi, H.; Shum, S.B.; Chen, G.; Conati, C.; Tsai, Y.S.; Kay, J.; Knight, S.; Martinez-Maldonado, R.; Sadiq, S.; Gašević, D. Explainable Artificial Intelligence in education. Comput. Educ. Artif. Intell. 2022, 3, 100074. [Google Scholar] [CrossRef]
- Mullins, R.; Conati, C. Enabling understanding of AI-Enabled Intelligent Tutoring Systems. In Design Recommendations for Intelligent Tutoring Systems: Volume 8—Data Visualization; US Army Combat Capabilities Development Command–Soldier Center: Natick, MA, USA, 2020; pp. 141–148. [Google Scholar]



| Question | Length | Frequency | Noise | Trend | Seasonality | Decomposition |
|---|---|---|---|---|---|---|
| Airline passenger | 48 | Monthly | Low | Yes | Yes | Additive |
| Boulder | 48 | Monthly | Low | No | Yes | Additive |
| Crude Oil | 48 | Monthly | Structural Change | No | No | Multiplicative |
| S&P 500 | 48 | Monthly | Outlier | Yes | No | Multiplicative |
| US GDP | 16 | Quarterly | Outlier | Yes | No | Additive |
| 33 | Monthly | High | No | No | Multiplicative | |
| Housing Starts | 48 | Monthly | Medium | Yes | No | Additive |
| Netflix | 16 | Quarterly | Low | Yes | No | Additive |
| Australian Beer Production | 16 | Quarterly | Low | Yes | Yes | Additive |
| Unemployment Rate | 16 | Quarterly | Low | Yes | Yes | Multiplicative |
| Pre-Test | Post-Test | |
|---|---|---|
| Number of students | 4 | 4 |
| Minimum score | 3 | 4 |
| Maximum score | 9 | 15 |
| Mean | 5.75 | 7.11 |
| Median | 5.5 | 13.5 |
| Standard Deviation | 2.75 | 5.20 |
| Constraints Used | Solved Problems | Messages | Time (Mins) | Pre-Test | Post-Test | |
|---|---|---|---|---|---|---|
| Participant 1 | 43 | 10 | 140 | 87.23 | 9 | 15 |
| Participant 2 | 38 | 1 | 26 | 15.95 | 3 | 15 |
| Participant 3 | 43 | 10 | 144 | 110.38 | 7 | 12 |
| Participant 4 | 0 | 0 | 0 | 2.05 | 4 | 4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barrow, D.; Mitrovic, A.; Holland, J.; Ali, M.; Kourentzes, N. Developing Personalised Learning Support for the Business Forecasting Curriculum: The Forecasting Intelligent Tutoring System. Forecasting 2024, 6, 204-223. https://doi.org/10.3390/forecast6010012
Barrow D, Mitrovic A, Holland J, Ali M, Kourentzes N. Developing Personalised Learning Support for the Business Forecasting Curriculum: The Forecasting Intelligent Tutoring System. Forecasting. 2024; 6(1):204-223. https://doi.org/10.3390/forecast6010012
Chicago/Turabian StyleBarrow, Devon, Antonija Mitrovic, Jay Holland, Mohammad Ali, and Nikolaos Kourentzes. 2024. "Developing Personalised Learning Support for the Business Forecasting Curriculum: The Forecasting Intelligent Tutoring System" Forecasting 6, no. 1: 204-223. https://doi.org/10.3390/forecast6010012
APA StyleBarrow, D., Mitrovic, A., Holland, J., Ali, M., & Kourentzes, N. (2024). Developing Personalised Learning Support for the Business Forecasting Curriculum: The Forecasting Intelligent Tutoring System. Forecasting, 6(1), 204-223. https://doi.org/10.3390/forecast6010012