1. Introduction
Forecasting electricity prices is a topic that has been largely explored in the last two decades, following the process of energy markets deregulation started at the end of the last century [
1,
2]. Decisions made by actors operating in the electricity market, such as regulators, generators, traders, and final users, are conditioned by future prices. There is a plethora of articles dealing with the estimation of models for the interpretation of the time dynamics and prediction of electricity prices [
3,
4,
5]. The set of regressors used in these models is extremely heterogeneous, thus criteria for the selection and ranking of the most predictive variables are necessary.
Machine learning models have recently attracted great attention in the literature [
6,
7,
8,
9]. There are many reasons behind this choice, on top of that high flexibility and possibility to include a big number of regressors [
10]. Proper modifications of algorithms based on neural-like structures can help to adapt flexible linear polynomial structures [
11].
Although some papers claim the superiority of machine learning methods to simpler linear models in predicting electricity prices, it is not clear whether the application of very sophisticated black-box models is really motivated by non-linearity tests and their forecasting performances are really better than those of simpler and easier to interpret linear models ([
12], Sectons 3.4.5). The present paper tries to give a contribution to this stream of literature by comparing the performance of two machine learning models, Random Forests (RF) and support vector machines (SVM), with that of linear autoregressive (AR) models with and without LASSO penalization [
13] using data observed on the Italian electricity market (IPEX).
The results, showing that simple linear models do not perform worse (sometimes, even better) than machine learning models, are not totally expected, but are in line with those found by Fezzi and Mosetti [
14]. The deregulated wholesale Italian electricity market is one of the most widely studied market in the world [
5,
15] for several reasons. First, IPEX is one of the most transparent electricity market in the world [
16]. Micro-data on bid-offer quantity and price are made available with a two-week delay containing detailed information related to operator and plant name. Multivariate relations between several variables could be explored on the Italian market, using high-frequency data and results could be easily reproduced by any interested researchers. Second, IPEX is a typical zonal market where a unique national market price (PUN) is observed just when market splitting does not occur. In all the remaining settlement periods, PUN is obtained as a quantity-weighted average of the zonal prices observed in real and virtual zones in which the country is split. The equilibrium price is settled comparing the aggregated demand and supply curves. The algorithm used in the auctions should take into account physical constrains due to the limits in the transmission of power among geographical zones. When the quantities demanded in one or more zones are higher than the limits, a congestion event occurs and the market is split into different market zones with different equilibrium prices. For further details, see [
16]. The zonal structure of the IPEX allows researchers and practitioners to explore the main pros and cons of markets integration, which is a hot topic in view of the European energy markets integration pursued by the European Union [
17]. The impact of possible grid congestion events on prices and volatility observed on the Italian zonal market [
4] could be considered as a small-scale experiment of the expected effects on the integrated European market. Finally, the high penetration of renewable sources in the generation mix of the IPEX enables the analysis of the influence of the so-called merit order effect [
18] on equilibrium prices and quantities.
In addition to the evaluation of the forecasting performance of models, the present paper aims at contributing to the literature in two directions. First, we include, among the regressors, intra-day prices. There is an increasing interest in modelling intra-day electricity markets [
19,
20,
21], but their impact on the forecasting of spot prices, to the best of our knowledge, has not been studied yet. Second, we explore the possibility to select the best predictors extending the variable importance index, originally proposed in the framework of RF, to SVM and linear models.
The paper is organized as follows.
Section 2 introduces the main notation and mathematics behind the non-linear and linear models taken into account in the present study. Moreover, it contains theory regarding the variable importance measurements.
Section 3 reports the results of the analysis whereas conclusions follow in
Section 4.
2. Material and Methods
Let
be the Data Generating Process (DGP) which has produced the observed univariate time series
, and suppose we are interested in predicting its future. Let us assume that the unknown DGP is a possibly non-linear function
of
p past states of
and
m exogenous variables plus a random noise; the DGP can be formalized as:
where
is a random shock (or disturbance term),
and
is the vector of exogenous variables available at time
t.
The observed time series of length
T,
, can be rearranged in a set of
pairs of type
, producing the following matrix
which forms the first
columns of the
data matrix
, where
is the
matrix of the exogenous variables.
Starting from this general setting, in the following paragraphs we will briefly introduce the methods that will be used to forecast electricity spot prices: linear autoregressive models, LASSO-regularized autoregressive models, SVM, and RF.
The first specification of the function
in (
1) determines the well-known autoregressive model with exogenous variables (ARX), which will be considered as the benchmark model. There are many reasons underlying the choice of the benchmark. First, AR linear models are the simplest and easiest way to approximate the DGP of time series. Moreover, parameters can be very conveniently interpreted because they measure partial correlation of each regressor with the dependent variable. Finally, linear models are not computationally intensive and are implemented in any statistical software. For these reasons, most of the papers dealing with energy forecasting relies on the estimation of linear AR models.
The general formulation of an ARX (
p,
) with
m exogenous variables is the following:
where
is a white noise with zero mean and
,
B is the backshift operator. This is a general formulation which allows the exogenous variables to be delayed. Although a general formulation has been introduced, in the present work we will use only one time span for each exogenous variable. Equation (
2) implies a linear model in which the regressors are the set of delayed
,
, and the
m exogenous variables
. So, for the generic time span
t, with
, the record of regressors is
x =
.
Since model (
2) contains a large number of covariates, in order to reduce the variance of the parameter estimates and control for overfitting, a regularised version of the same model is fit, as well. Thus, a first modification of the ARX model is denoted as ARX-L model and implements a selection of explanatory variables and the shrinkage of their coefficients towards zero through the LASSO-regularized linear least-squares regression [
22,
23]. The coefficient estimates are obtained by minimizing:
The second modification of the ARX model is called ARX-L Int. and it takes into account not only the regressors but also the interactions between each pair of them and then it performs a selection of explanatory variables through the LASSO-regularized linear least-squares regression.
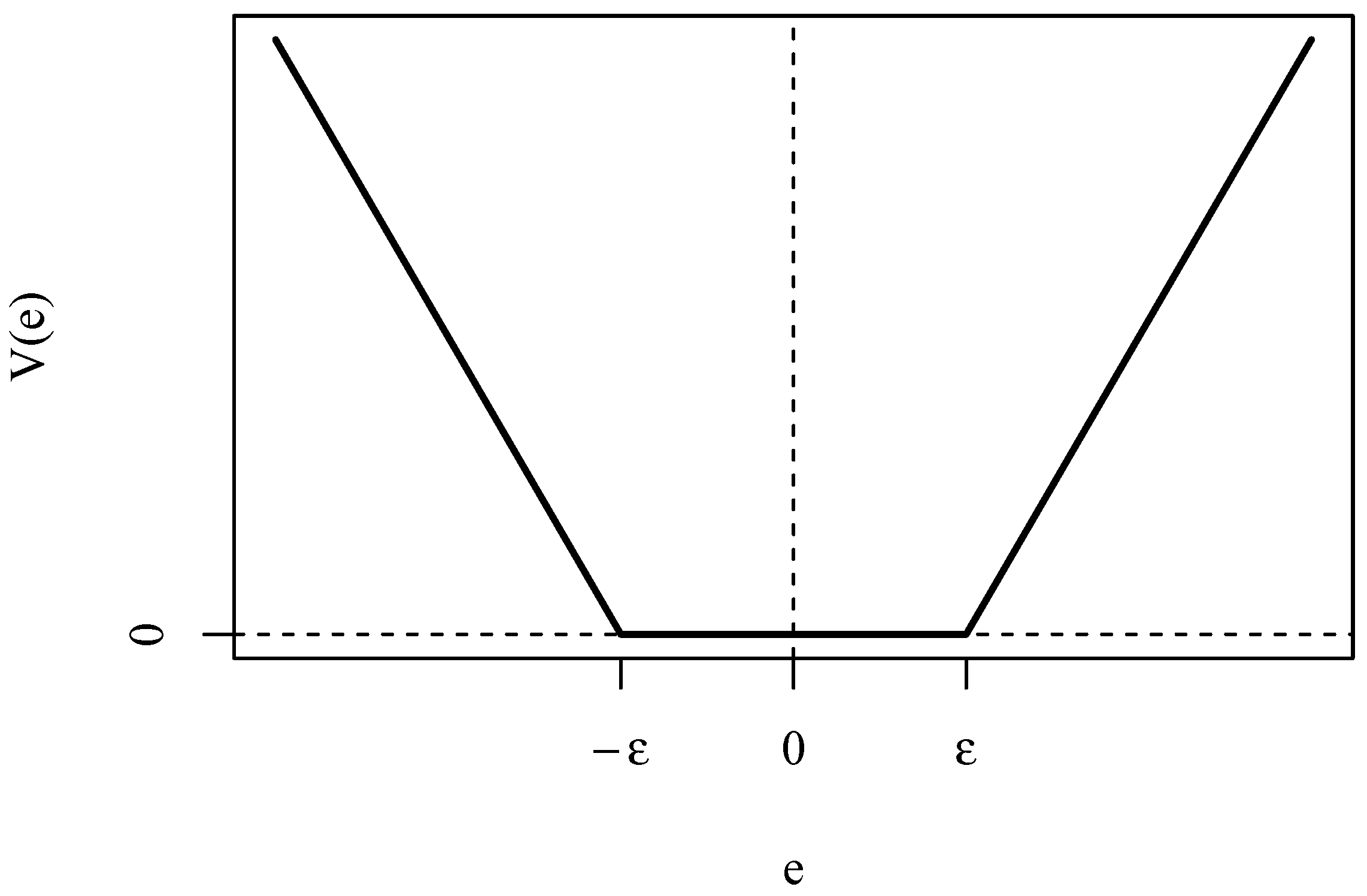
Support vector machines (SVM) are machine learning models born for classification [
24] and then adapted to regression [
25,
26,
27]. The regularized loss function for SVM is
with loss
shown in
Figure 1.
When
is linear, it can be shown that the regressors
enter the solution of the minimization only through the inner products
and this allows the use of the so-called
kernel trick for expanding the class of functions that approximate
. Indeed, we can approximate the unknown expectation function using a basis expansion:
where
are basis functions and
S is the number of basis functions used to approximate
. Since only inner products are relevant for the solution, one does not need to explicitly compute this expansion, but one can simply substitute the inner products with the kernel function
In our application we used the radial-basis function:
Since this expansion through basis functions introduces interactions among the regressors, we expect SVM to be able to capture the mutual dependence of the within-week and within-year seasonal patterns.
The last model considered is the Random Forests (RF; Breiman, 2001). It follows a non-linear approach to the forecasting problem and it originated outside the time series ambit, so it is necessary to motivate its application in this context. RF is a modification of the bootstrap aggregation procedure called bagging introduced by [
28]. Bagging belongs to the family of ensemble learning models and consists in producing a number
B of bootstrap samples from the available observed sample, estimating a model, called base learner, on each bootstrap sample and then aggregating their predictions. Ordinary bootstrap is suitable for independent and equally distributed observations, so not for time series. Nevertheless, in the case of time series, one assumes that all of the memory of the past regarding
, required for a one-step-ahead prediction, is preserved in the lagged vectors
, so under this assumption the units to be sampled are not the single
(with the related exogenous), but the rows of the matrix
. Alternatively, limited to the submatrix
of
, resampling the rows of
can be viewed as applying the moving block bootstrap [
29], where the block length is equal to
and the overlapping blocks are the vectors
. Ref. [
30] have explored the applicability of bagging for time series forecasting. The base learner used in RF is the regression tree, which is the specification of a decision tree when the target variable is continuous. A decision tree [
31] is a machine learning model that recursively partitions the data space generated by
k explanatory variables into regions, identified by the leaf nodes of the tree, that are homogeneous with respect to a target variable, and fits a simple model in each region. To identify these regions, the splitting and pruning activity is evaluated using a measure of node impurity. The application of this kind of model for time series forecasting is not new in literature; for example, Ref. [
32] compared the predictive power of eight machine learning models, including the regression tree, whereas [
33] studied the empirical forecast performances of boosting algorithms for predicting real world time series considering as base models the regression tree and the multilayer perceptron. As said before, RF is a modification of the bagging algorithm with a decision tree as base learner, introducing a random selection of input features which causes a collection of de-correlated trees. In fact, if in bagging method the sampling is completed considering instances from only the training set, with random forest the tree-growing process is performed also through random selection of input variables. The parameters involved in a RF specification are the number of trees forming the forest (
), the number of covariates that are randomly selected at each split step (
) and the minimum number of observations presented into a leaf node (
). When the target variable is continuous, a typical choice for
is
, where
k is the number of the considered explanatory variables, whereas 5 is the choice for
.
Variable Importance Measures
When using RF, the well interpretable structure of the tree is lost, but it is possible to retrieve some information regarding the explicative role played by the regressors via variable importance measure (VIM). A VIM is a tool that can be computed not only in the context of the RF. In fact, we can distinguish between two types of methods, when dealing with VIM, that is model-specific and model-agnostic methods [
34]. The model-specific methods use specific elements of the structure of the considered model whereas the model-agnostic methods do not assume anything about the structure of the considered model.
The method described below, applied in the RF context, belongs to the first type of methods. Following [
31], let
be the set of predictor variables for the target variable
Y, the importance of a variable
in explaining
Y is defined as the total decrease in heterogeneity of
Y given the by the knowledge of
when the regressors’ space is partitioned recursively. A VIM, called Total Decrease in Node Impurity (TDNI), derived by this approach is obtained by the sum of all the decreases in the heterogeneity index in the nodes of the tree. Given the different nature of the variables forming
in many contexts of application, we need to ask if the nature of a regressor plays a role in the evaluation of its importance. Ref. [
31] noted that the TDNI measures tend to favor covariates with more values (for example continuous variables are favored over categorical variables), so a correction that overcome this limit must be applied. In this study, the heuristic correction proposed by [
35,
36] was implemented, given that the set of covariates was composed by continuous, dichotomous and polytomous category variables. Ref. [
36] have shown that this method can effectively reduce the bias due to different measurement levels of the covariates, producing a correct ranking of them according to their importance.
In order to investigate the influence of the predictor variables on the electricity price predicted by the other methods implemented in the paper, we use a model-agnostic method based on permutations [
34]. It is based on the loss function
which quantifies the goodness of fit of the model in use, where
denotes the matrix containing the observed values of the covariates,
denotes the observed values of
Y and
denotes the corresponding predictions.
This loss function can be the value of log-likelihood or any other model performance measure, such as, for example, the root mean squared error. The method can summarized in the following steps: compute the loss function for the original data and then, for each regressor , (1) modify the matrix by permuting its j-th column, obtaining ; (2) compute the predictions based on ; (3) calculate the loss function ; and (4) quantify the importance of using directly or calculating or . In general, this procedure is performed several times, in order to lose the dependency of the result to the particular permutations observed, and so the final VIM is an average VIM.
As it is well known, decision and regression trees model interactions through different paths of partitions of the feature space: the variables and values selected at lower layers of the trees depend on the variables and values selected in upper layers. Of course, RF is an ensemble of decision trees. Support vector machines/regressions produce interactions among variables by using bivariate kernels, that is, by building a new feature space that includes these non-linear functions of every variable pair. Thus, both methods automatically include interactions among variables. However, being black-box models, it is not straightforward to disentangle the direct effect of one variable from its effect through interactions with other variables. It is important to stress that the variable importance method used in this paper to assess the predictive power of each regressor, measures the effect produced by excluding one variable from the model. In principle, it is possible to think of methods to evaluate the importance of the interactions, even though, to the best of our knowledge nobody did it. For example, to measure the interactions among the variables we could use the difference between the loss in RMSE when randomly permuting all of them and the sum of the RMSE losses due to the permutation of each of three variables taken one at a time. However, the number of measures to consider would be extremely large because all variables potentially interact. Consider the extremely simple case of four regressors: and . We would have to measure the interactions among:
Every unique pair ,
Every unique triplet ,
All variables .
This amounts to 11 measures of interaction. For m variables, the number of interactions to consider is . In our model, we consider tens of variables and the number of interaction measures to consider are in the order of millions.
3. Empirical Analysis
The time series used in the present work concern the electricity prices from the Italian Power Exchange (IPEX) market. They cover the period from 1 January 2015 to 31 August 2019; the eight months of 2019 were left out for out-of-sample forecasting. The data have an hourly frequency; therefore, each day consists of 24 load periods, with 00:00–01:00 a.m. defined as period 1. Spot price is denoted as , where t specifies the day and j the load period, .
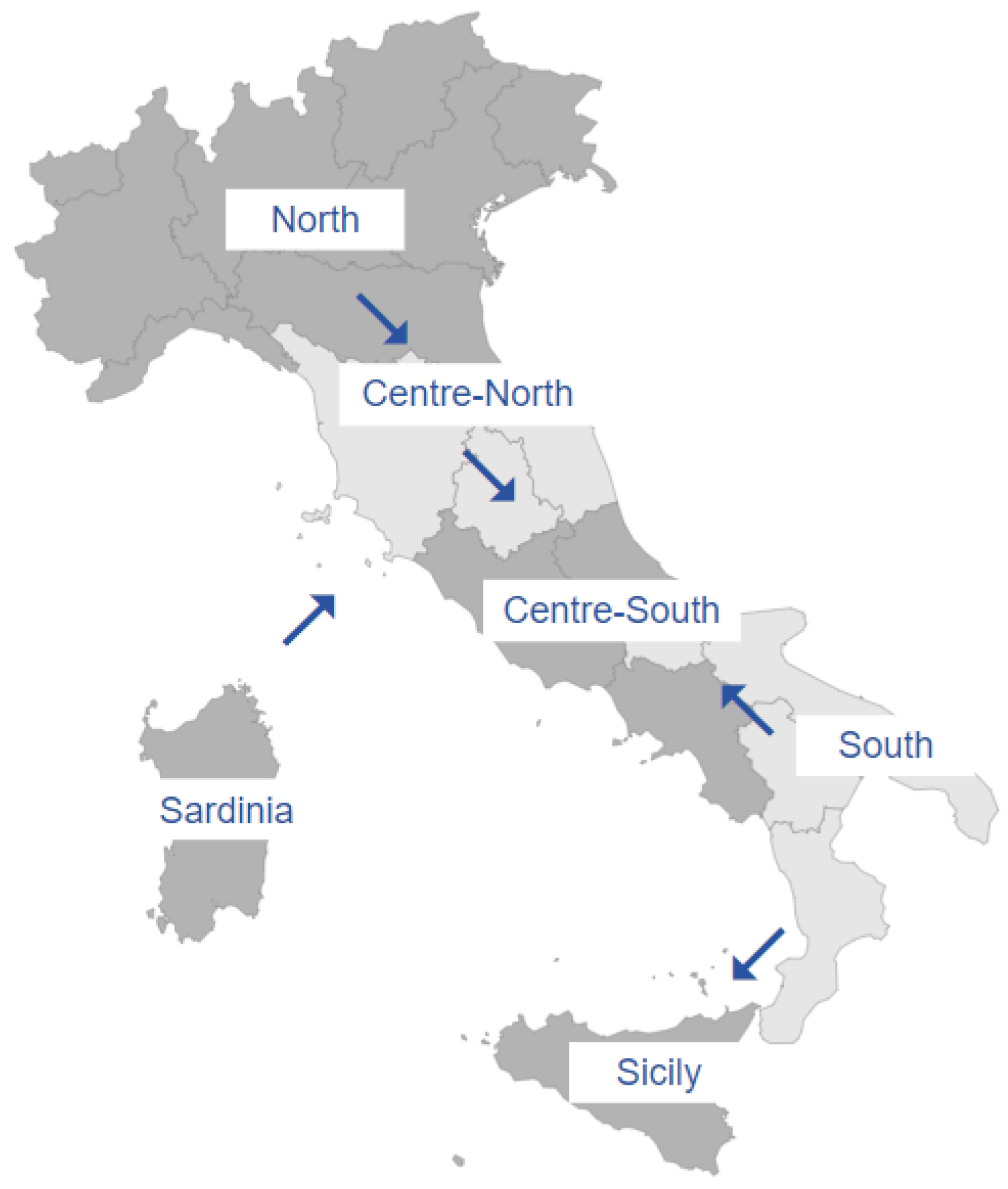
The Italian electricity market is divided into different zones, which were the following six until 31 December 2020: North (NOR), Centre-North (CNOR), Centre-South (CSOU), South (SOU), Sicily (SIC), and Sardinia (SAR). In the map displayed in
Figure 2, the six physical zones of the Italian market are shown. The map holds just until the end of 2020, while from January 2021 the geographical structure of the market has been modified: one region of the Centre-North zone has been moved to the Centre-South macro-region and a new macro-zone has been introduced, formed by just one region, Calabria, which has been separated from the South macro-zone. Considering that electricity prices and demand have been strongly affected by the COVID-19 outbreak and the structural change of the zonal market in 2021, the choice to stop the data collection in 2019 is highly motivated. It is important to bear in mind that, usually, auctions are made by considering all bids and offers made by market operators at national level. The final unique national price is set by the intersection of the aggregated national supply and demand curves. Inefficiency of the interconnections among zones, which can be observed on the map, implies however a market splitting in two or more macro-zones with different equilibrium prices fixed by the intersections between aggregated partial demand and supply curves. For this reason, time series of zonal prices are often studied and modeled separately. Different probabilities of congestion events between macro-zones and different generation mix can be observed in the Italian macro-zones: this motivates separate estimated models for each zone.
In this study, following a widespread practice in literature, each hourly time series was modeled separately, thereby eliminating the problem of modeling intra-daily periodicity. Moreover, each zone was considered separately.
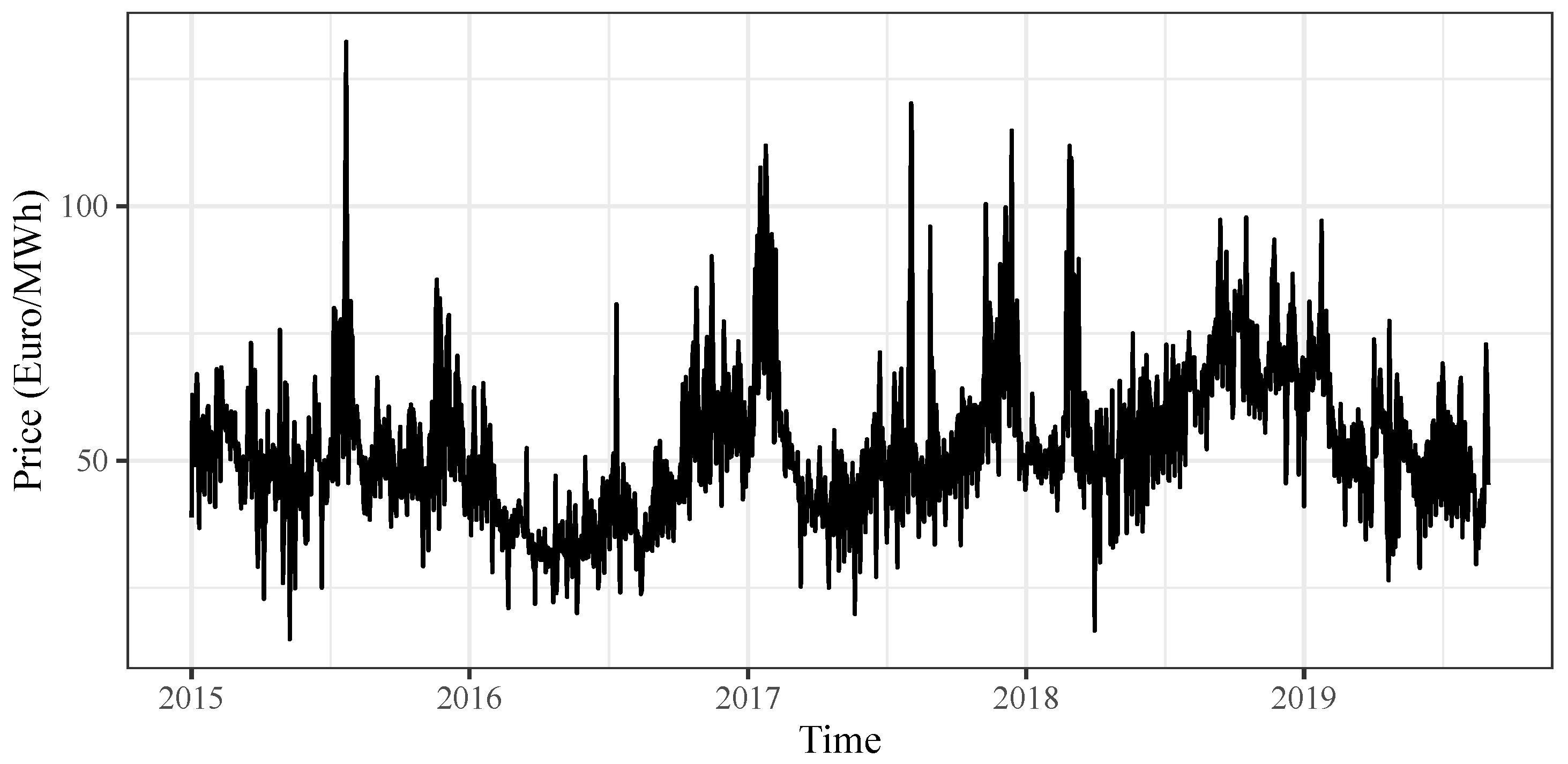
Figure 3 shows the time series of prices in a typical peak hour (12 a.m.) observed in the North zone.
Some stylized facts of electricity prices can be observed, such as the seasonal pattern related to astronomical seasons and the presence of a few spikes. It is worth stressing that multi-scale seasonality is observed on electricity prices: besides yearly fluctuations, weekly, and daily cycles are observed strictly related to the cycles of demand. Several sources of price spikes can be mentioned. They are always related to a sudden increase or decrease in demand and supply of electricity which can be caused by extreme weather events (very hot or cold days) or by plant failures. Of course, parameter estimates can be strongly influenced by the presence of spikes and robust methods should be applied [
5].
Table 1 shows the unit root test (Phillips–Perron), for each zone of the market and for all settlement periods of the day.
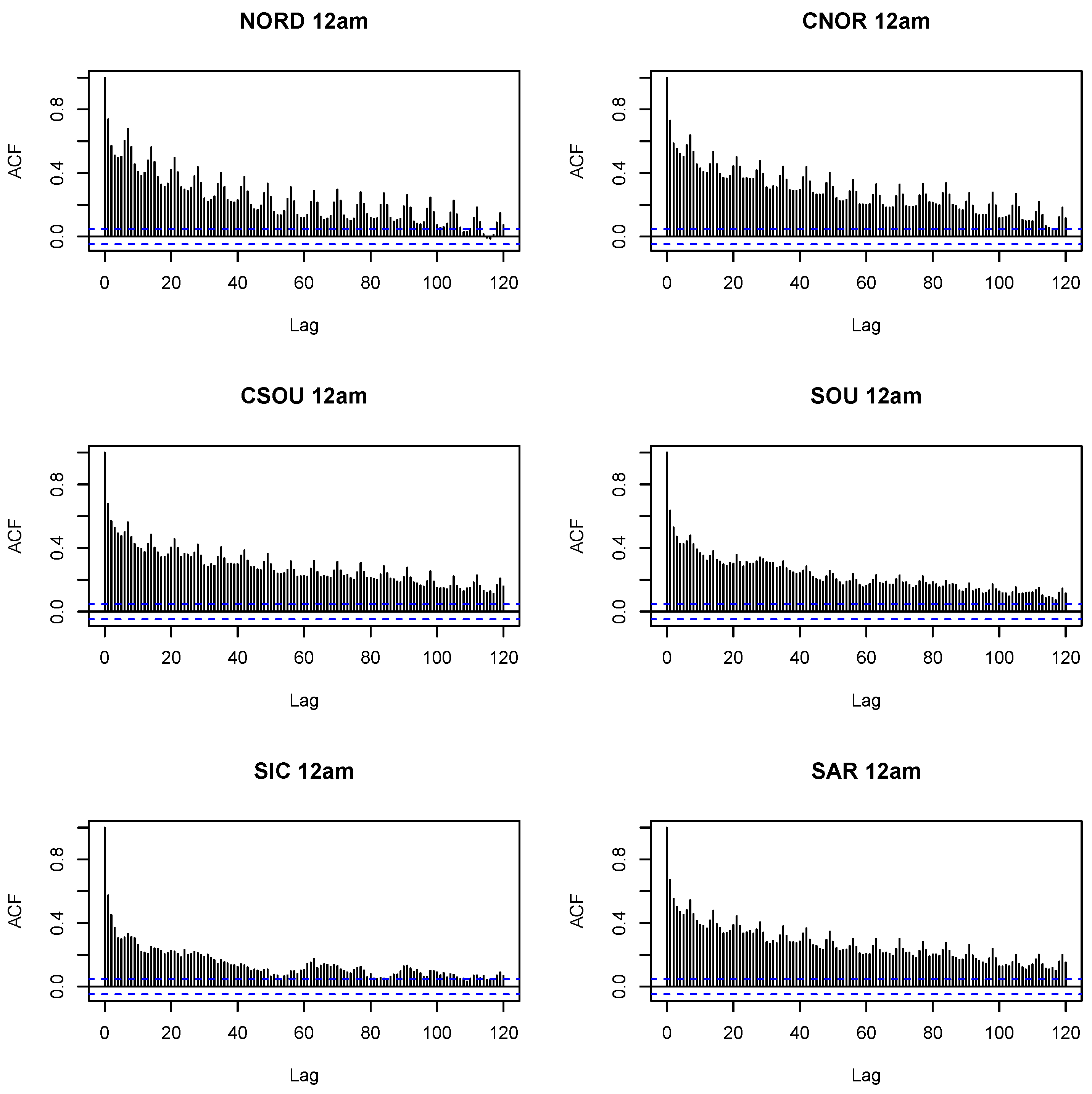
Figure 4 displays the autocorrelation function until lag 120 of the level of prices observed in each zone in the middle of the day. Plots in each hour of the day are very similar and are not shown for lack of space. The test always rejects the presence of a unit root, while from the ACF plots weekly seasonality is evident. This seasonality is captured in the RF specification by the number-of-day variable, and by harmonics in the other models. Models could be estimated on first differences to check for robustness. However, as the results on unit root are very clear, we decided to avoid this analysis, to stay focused on the main goal of the paper.
Many authors indicate mean reversion (see, for instance, [
10,
12]) as a typical feature of electricity price time series because unit root test tend to reject the null of integration. This is hard to believe because gas prices are well described by integrated processes and electricity prices depend also on gas prices (at the time of writing, the relation between gas and electricity prices is extremely evident!). The reason for the rejection of unit root tests is that the signal (with unit root) is generally buried in a high-variance noise (multi-scale seasonality, relation to weather conditions, strategies of the companies playing in the market, plant outages, lines congestions, etc.). So why are we modelling levels and not increments?
We provide regressors that, in case of unit roots, are certainly cointegrated with the outcome variable, namely the intermediate markets. Regressions with cointegrated variables are valid.
We are interested in short-term forecasts and for this case even the eventual attraction of a stationary model prediction towards the marginal mean of the time series is generally negligible.
The range of the time series tends to be constant throughout the time and this enables the use of tree-based models (such as RF), which produce predictions only in the range observed in the training set.
In this study, we integrate the information given by the price at time
, labelled as
y1,
y2, …,
y7, with a set of deterministic and exogenous regressors (see [
1,
37]) listed below, in order to improve the capability of the models in hand to predict the future: Data can be downloaded, upon request (
luigi.grossi@unipd.it), at the following link:
https://drive.google.com/drive/folders/1N-seSvGxQ7hzhocO4hm4WJpxzai1BVqV?usp=share_link (Last update: 30 November 2022).
The day of the year (day),
The day of the week (dayweek), a categorical variable with seven classes,
A calendar dummy for holidays (calendar),
The one-day-ahead predicted demand of electricity (demand, source: Italian Electricity Market Manager, GME),
The one-day-ahead predicted wind generation (wind, source: TERNA SpA),
Four Intra-Day Market (IDM) prices at time .
The day of the year is a discrete variable with values from 1 to 366 counting the day number since 1st January of every year. It is used only for the RF, whereas it is replaced by sinusoids at the first 16 harmonics with base period 365 for all the other models. In other words, the following 32 regressors are added to the models: , with and .
The reason for this choice relies on the following motivation. Since RF are based on trees, which approximate smooth functions with steps, we provide the RF regression with information on the within-year seasonal periodicity through a variable counting the number of days since the beginning of each year letting the trees find the differences in the sub-periods. Instead, for linear models, such as ARX and ARX-L, or models, such as SVM, that take smooth transforms of the regressors, we provide information on the within-year seasonal periodicity through low-frequency sinusoids. The choice of the number of harmonics (16) is based on the authors’ experience working with Italian price data: the number of harmonics used for other countries is generally much smaller, but the typical drop in electricity consumption (and, thus, prices) on Winter and Summer holidays in Italy requires more sinusoids to be well captured.
Differently from what has been completed so far in the literature, we explore the role played by prices observed on Intra-Day Market (IDM). The IDM allows market participants to modify the schedules defined in the Day-Ahead Market by submitting additional supply offer or demand bids and is organized in seven sessions. Nevertheless, in this study we consider only the first four (IDM1, IDM2, IDM3, and IDM4) with the following timing: IDM1 opens at 12.55 p.m. of the day before the day of delivery and closes at 3 p.m. of the same day (its results are made known within 3.30 p.m. of the day before the day of delivery); IDM2 opens at 12.55 p.m. of the day before the day of delivery and closes at 4.30 p.m. of the same day (its results are made known within 5 p.m. of the day before the day of delivery); IDM3 opens at 5.30 p.m. of the day before the day of delivery and closes at 11.45 p.m. of the same day (its results are made known within 00.15 p.m. of the day of delivery); and IDM4 opens at 5.30 p.m. of the day before the day of delivery and closes at 3.45 a.m. of the day of delivery (its results are made known within 4.15 a.m. of the day of closing of the sitting). Given the different schedule of the sessions, the four regressors related to the IDM market are not all available for all the 24 h.
As seen in
Section 2, the methods under study depend on some hyper-parameters and their tuning is performed as follows. For the ARX-L and ARX-L Int. the hyper-parameter for
penalization,
, is fixed zone by zone and hour by hour by 10-fold cross-validation. For SVM, we use a radial kernel function with
and
determined by 10-fold cross-validation on a grid of
predetermined values, whereas for RF,
and
are set equal to the typical choices, and
10,000.
We calculate the one-day ahead prediction using a rolling window procedure for the eight months of 2019 and the forecasting performance is evaluated by means of a modified version of the Root Mean Squared Percentage Error (RMSPE) and the Mean Absolute Percentage Error (MAPE).
Two simple benchmarks have been introduced. The first is the Random Walk (RW), under the trivial hypothesis that the price observed in
t could be predicted by the price observed in
(naive model). Comparisons of the estimated models to the RW are shown in
Table 2. The second benchmark is the “naive week” RW, under the hypothesis that the daily price in
t could be predicted by the price in
(same day of the previous week). Results are displayed in
Table A1. Adjustment for holidays has been considered. As can be noted, all values are less than 1, proving that all models perform better than the corresponding naive model.
Moreover, the significance of prediction differences between models is evaluated with the one-tailed Diebold–Mariano test [
38], with the null hypothesis declared as “prediction performance of model A is equal or worse than model B”. Nevertheless, in what follows, we show and discuss only the results obtained applying RMSPE, given that the same conclusions arise from the MAPE analysis. MAPE values are shown in
Table A2.
Table 3 contains the ratio of the mean value of RMSE over peak (14 h) and off-peak (10 h) hours over the corresponding average price. For instance in
Table 3, the value in the first line, first column, is obtained as the ratio of the RMSEs generated by ARX model in each of the 14 peak hours in the NOR zone, over the average price observed on the forecasting horizon in the NOR zone. This generalized version of the RMSPE is better than the proper RMSPE because it avoids the bias related to cases in which prices close to zero generate very large ratios. It is of interest to distinguish between these two types of hours because companies adopt different strategies when demand is high or low. All the models perform better during the off-peak hours, since when demand is low the supply curve is rather flat and the elasticity of the price rather low (i.e., unexpected changes in demand have a small effect on the equilibrium price). Moreover, the predictive performances seems equivalent for the North and the Center-North of Italy, whereas they become worse moving from the North to the South and islands. Electricity prices for Sicily appear quite difficult to accurately predict due to the frequent and scarcely predictable switch between two regimes: as a separate market with a higher price and as part of the Italian market with a common (lower) price. Looking at the values of the RMSPE, in the peak hours SVM seems to outperform the other models in the North whereas the ARX seems to show better predictive capacities in the remaining areas. In the off-peak hours ARX seems to outperform the other models in all the areas except for Sicily and Sardinia where RF seems to predict slightly better the spot prices.
In order to inspect more deeply the predictive performances of the models, the performances on the single hours were considered.
Table 4 displays, for each hour, the model with the lowest RMSE and in brackets the number of significant Diebold and Mariano tests. This number ranges between 0 and 4, with 0 meaning that the RMSE of the best model is not significantly lower than the RMSE of the other 4 competitors, and 4 meaning that the RMSE of the best model is always significantly lower. For most of the hours the ARX has the lowest RMSE in all the areas, with the exception of North and peak hours, where the SVM outperforms for most of the hours, and Sicily, Sardinia, and off-peak hours, where RF outperforms for most of the hours. Nevertheless, in very few cases the number of significant Diebold and Mariano tests reaches 4.
In order to investigate more deeply the observed results, we analyze the role of the used explanatory variables in the models’ performance calculating the VIM for RF, ARX-L, and SVM. The implemented methods are described in
Section 2. To summarize the results, we took into account only the covariates that occupy one of the first five positions in the ranking produced by the VIMs. Moreover, with the aim to discriminate the relevance of the ranking, we assign the values reported in
Table 5 to the five positions.
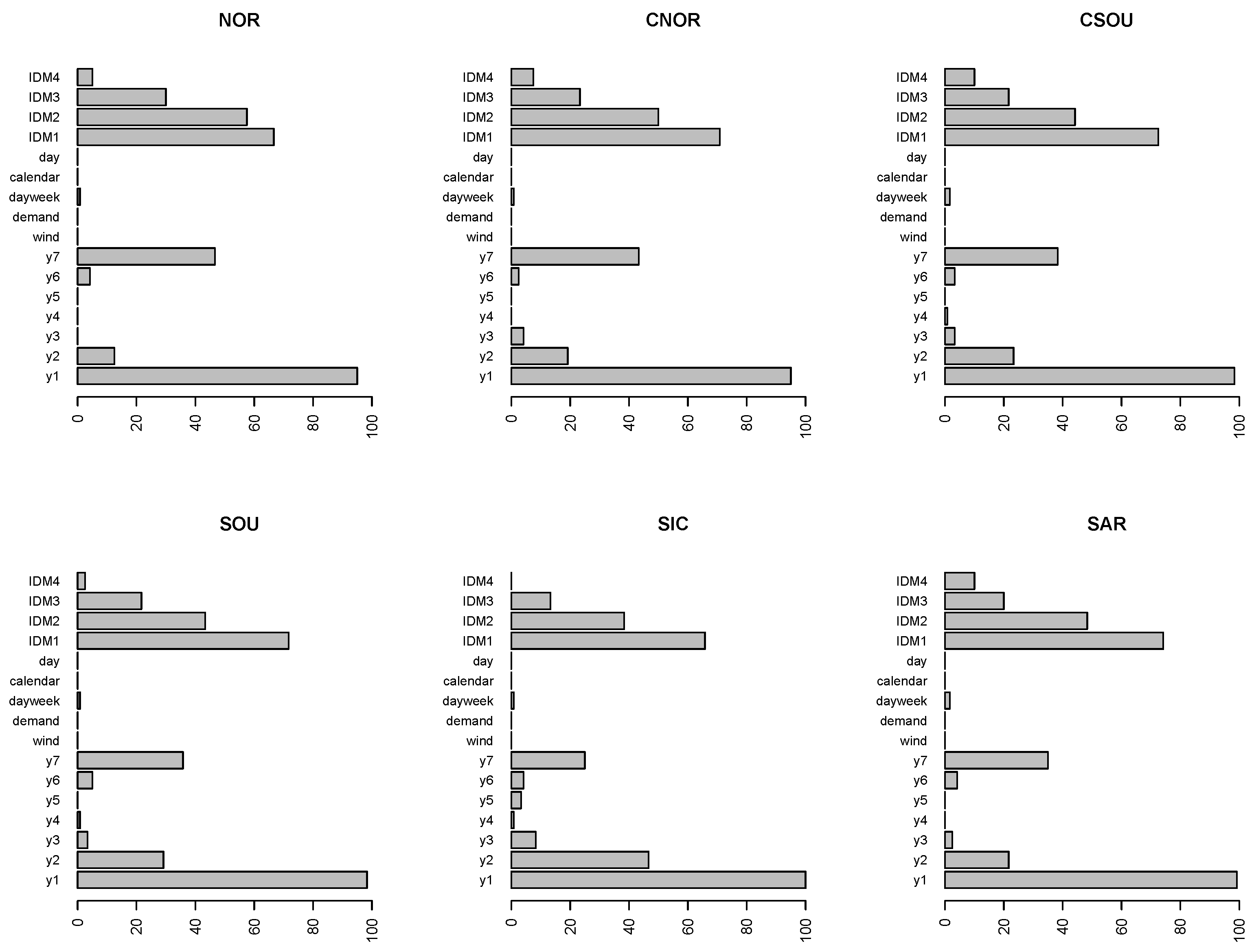
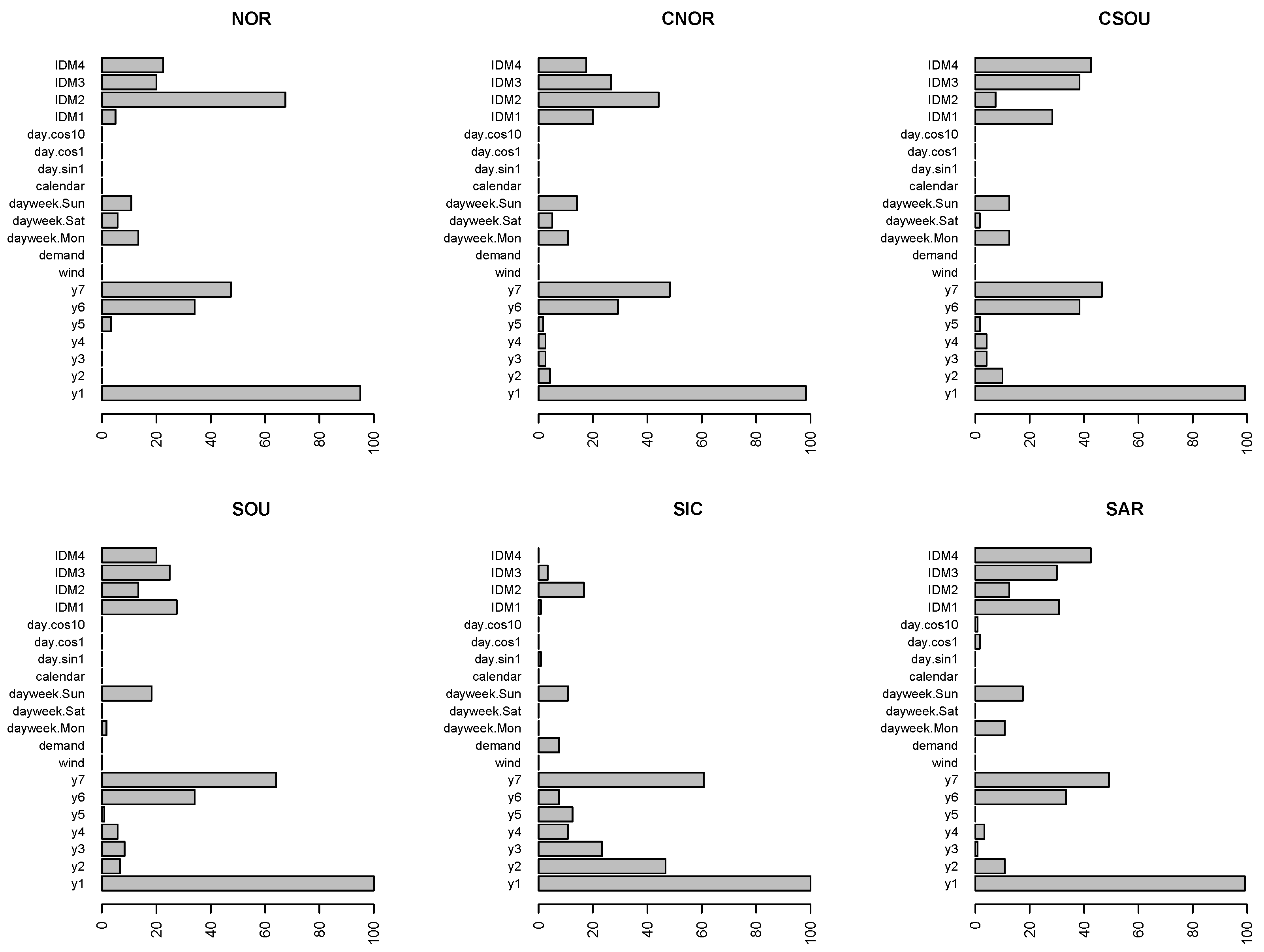
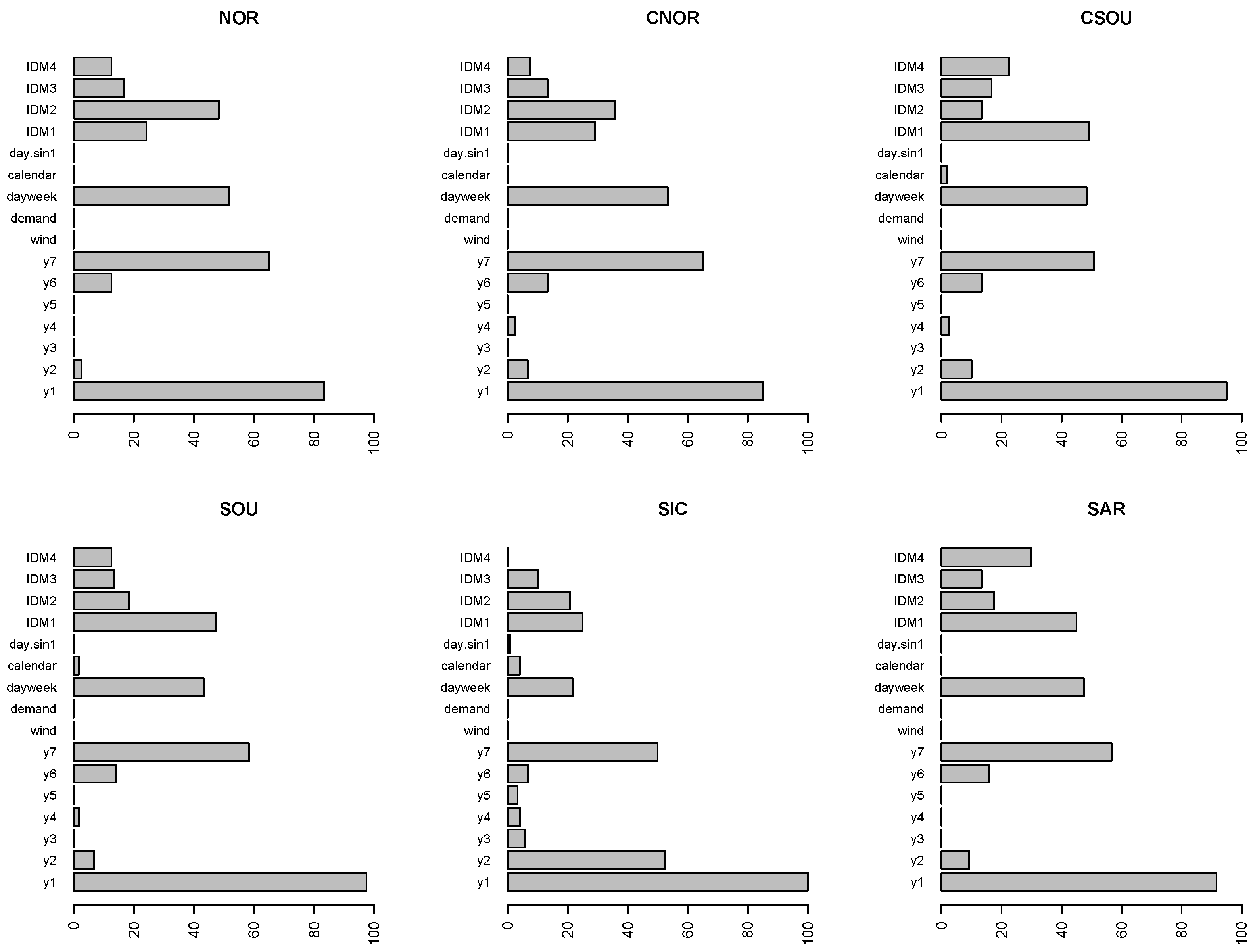
Figure 5,
Figure 6 and
Figure 7 compare the relevance of regressors obtained in the different zones using the modified version of the variable importance index when RF predictions are evaluated, and using the model-agnostic method based on permutations for the evaluation of forecasts from SVM and ARX-L.
The bars represent the weighted percentage of times the variables are within the fifth position out of the 24 h. To evaluate correctly the results, we have to consider that prices for the last two sessions of the IDM are not available for all the 24 h, so for IDM3 and IDM4 the bars refer to the weighted percentage out the 12 and 8 h, respectively.
For all three models, the lagged spot prices until the seventh lag, and, in particular, the first and the seventh delay, are among the most important variables.
Intraday prices generated across all IDMs are at the top in the VIM rankings, as well. Nevertheless, differences can be spotted comparing the three models. In general, all the IDMs seem less important for both SVM and ARX-L, than for RF.
In the case of RF, the IDM1 and IDM2 are the most important in all the six zones, and the importance of IDM1 is comparable with the first lagged spot price.
When ARX-L is used (
Figure 6), the IDM4 plays a predominant role within the IDMs in the Center-South and Sardinia, whereas in North and Centre-North IDM2 is the most important. Differently from the other zones, in Sicily intra-day markets are almost negligible, while the autoregressive structure looks very strong.
Looking at
Figure 7 concerning SVM, IDM1 is the most important of the four IDMs in all the zones moving from Centre-South to the islands, whereas in North and Centre-North IDM2 is the most important. Moreover, the day of the week variable plays a relevant role in all zones.
The high relevance of the autoregressive structure of spot prices until the seventh lag is a common feature of all models in all zones. It is sensible to assume that this common feature could be the main explanation of the excellent forecasting performance of linear AR models. To test this assumption, the forecasting exercise has been repeated removing the lagged spot prices from the set of regressors. As pointed out by one of the reviewers, the model obtained by stripping the model from lagged prices is improperly called AR model because a simple regression model on exogenous variables is estimated. However, we prefer to maintain the same label to stress the link with the previous tables. The fitting of the all models without lagged prices is obviously worse. The exercise has been carried out just to measure the different contribution of past information on the prediction using different models. The decrease in the forecasting performance is expected, but the extent of the deterioration is different and gives an idea of the relevance of exogenous variable in various models. We are aware that the exercise has no practical implications. For this reason we do not perform any out-of-sample forecasting test. The comparison between the models with and without the lagged prices is displayed in
Table 6, which contains the percentage variation of the average RMSE computed on the two versions of the models for each zone, that is:
All figures in
Table 6 are negative, as expected. Similar results have been found for MAE.
Looking at the peak hours, the biggest reduction in predictive capability in all zones except Sicily, occurs for SVM; nevertheless, this reduction is similar to that of ARX models. Therefore, the impact of past prices on the predictions of ARX and SVM models is bigger than in all the other cases.
During the off-peak hours, the ARX models show the highest reduction of predictive capability in all zones, but the North. The case of RF is quite interesting. For this model, the reduction of forecasting ability due to the exclusion of lagged spot prices is lower than for SVM and ARX models in almost all 24 h. The relevant role played by IDMs in RF models seems to replace the contribution of lagged spot prices.
The effect of exogenous covariates on the forecasting performance has been explored as well. In this case, the percentage variation of the average RMSE (MAE) over each zone is computed as follows:
As expected, the sign of these variations for RMSE (
Table 7) is always negative. Similar results have been found for MAE.
During peak hours, RF models show the lowest reduction in predictive power in all zones except Sicily, whereas during off-peak hours and in all zones except Sicily, ARX and SVM models lose more predictive power than other models.
Comparing the last two analyses reported in
Table 6 and
Table 7, the highest reduction in the predictive power occurs when the exogenous variables are removed, during the peak hours in Northern Italy (NOR+CNOR), for all models but RF. This result stresses the crucial role played by IDMs in forecasting spot prices in an area which covers more than 50% of the total national power generation.
On the contrary, during off-peak hours, for all models and hours, the highest reduction in the predictive power occurs when the lagged spot prices are removed, showing a lower contribution to the predictive accuracy of the exogenous variables with respect to lagged prices. To have an idea about the impact of intra-day prices, the same exercise could have been performed by simply removing the IDM variables. However, as can be seen from the variable importance plots (
Figure 5,
Figure 6 and
Figure 7), the most important variables are always
and
lags on the day ahead price and the IDM variables. Wind and Demand are never crucial. For this reason, we expect that the exercise will lead to the same results obtained when all exogenous regressors are included.
4. Conclusions
The initial research question motivating this study concerns the potential prevalence of sophisticated non-linear methods, such as SVM and RF models, on the simple linear AR model, taken as the benchmark, in predicting one-day ahead spot price. We found that, when estimated in the macro-zones of the Italian electricity market, there is not a clear dominance of one model and in all hours of the day. SVM regressions seem to outperform the other models in the North zone in peak hours (10 h out of 14). It is worth stressing that North is the most important area of the Italian market as it covers about 50% of the national generation. AR models perform better in the other zones. However, statistical prevalence is hard to be found, suggesting that the simplest model (ARX, that is AR with exogenous variables) in general makes a good job in predicting spot prices. Summarizing the results shown in
Table 4, the simple ARX model gives the best prediction in 79% of cases considering peak hours in CNOR and CSOU.
Connected with the initial research question, we have studied the issue of variable selection connected to the forecasting performance of models. In addition to the autoregressive structure of the generating process, we considered some exogenous variables commonly used in the literature and available on the Italian market, that is, predicted demand and wind generation, and intra-daily market prices. To the best of our knowledge, the impact of intra-daily market information on the prediction of spot prices is a new research question, never explored before. The influence of regressors on the forecasting ability of different models has been measured using variable importance measures (VIM), which give a clear idea about the most relevant set of regressors. VIM have been originally developed in the framework of RF, given that the structure of the trees involved in the forest and, consequently, the role of the variables are lost. In this paper, we have extended the VIM analysis to ARX and SVM models by applying a model-agnostic method based on permutations. We have found that, for all models, lagged spot prices up to seven days, and IDMs play a crucial role in the prediction step.
For RF, IDM1 and IDM2 are the most important regressors in all six zones, and the importance of IDM1 is comparable to that of the spot price of the same hour on the previous day. For SVM and ARX models, the importance of IDMs is less evident than for RF, although their role is not negligible. The analysis of the impact of the autoregressive structure of the spot prices on the forecasting ability has revealed that, in Northern Italy and in peak hours, IDMs are a crucial set of information to predict spot prices.
The final message is that, for forecasting electricity prices, variables’ construction and selection (or feature engineering, using machine learning jargon), both in the step of dataset preparation and during model estimation is more important than the use of complex non-linear models. Linear models, combined with penalization criteria, provide good forecasting performances, and have great computational and interpretation advantages.
Further research will be devoted to the study of some theoretical properties of RF for dependent data and to the introduction of additional exogenous variables, such as marginal technologies, weather variables, and fuel prices. The main limit of the paper is that just two machine learning models among the large range of machine learning models proposed in the literature have been considered. Although RF and SVM are massively used in the prediction of time series there are other emerging techniques that would be worth to explore. Among these, we just mention the Gradient Boosting and the Dynamic Trees [
39] for online forecasting, which have proven to be very effective in the prediction of electricity prices [
40,
41]. The comparison with other promising machine learning models will be explored in future papers. A possible integration with robust interval prediction will be also studied.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






