

Assessing Spurious Correlations in Big Search Data


Abstract
1. Introduction
2. Materials and Methods
3. Results
4. Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Doornik, J.A.; Hendry, D.F. Statistical model selection with “Big Data”. Cogent Econ. Financ. 2015, 3, 1. [Google Scholar] [CrossRef]
- Bento, A.I.; Nguyen, T.; Wing, C.; Simon, K. Evidence from internet search data shows information-seeking responses to news of local COVID-19 cases. Proc. Natl. Acad. Sci. USA 2020, 117, 11220–11222. [Google Scholar] [CrossRef] [PubMed]
- Bentzen, J.S. In crisis, we pray: Religiosity and the COVID-19 pandemic. J. Econ. Behav. Organ. 2021, 192, 541–583. [Google Scholar] [CrossRef] [PubMed]
- Choi, H.; Varian, H. Predicting the Present with Google Trends. Economic Record. 2012, 88, 2–9. [Google Scholar] [CrossRef]
- Carneiro, H.A.; Mylonakis, E. Google Trends: A Web-Based Tool for Real-Time Surveillance of Disease Outbreaks. Clin. Infect. Dis. 2009, 49, 1557–1564. [Google Scholar] [CrossRef]
- Cooper, C.P.; Mallon, K.P.; Leadbetter, S.; A Pollack, L.; A Peipins, L.; Jansen, J. Cancer Internet Search Activity on a Major Search Engine, United States 2001-2003. J. Med. Internet Res. 2005, 7, e36. [Google Scholar] [CrossRef]
- Chi, T.-L.; Liu, H.-T.; Chang, C.-C. Hedging performance using google Trends–Evidence from the indian forex options market. Int. Rev. Econ. Financ. 2023, 85, 107–123. [Google Scholar] [CrossRef]
- Wang, D.; Guerra, A.; Wittke, F.; Lang, J.C.; Bakker, K.; Lee, A.W.; Finelli, L.; Chen, Y.-H. Real-Time Monitoring of Infectious Disease Outbreaks with a Combination of Google Trends Search Results and the Moving Epidemic Method: A Respiratory Syncytial Virus Case Study. Trop. Med. Infect. Dis. 2023, 8, 75. [Google Scholar] [CrossRef]
- Khosrowjerdi, M.; Fylking, C.B.; Zeraatkar, N. Online information seeking during the COVID-19 pandemic: A cross-country analysis. IFLA J. 2023. [Google Scholar] [CrossRef]
- Johnson, A.; Mikati, T.; Mehta, S.D. Examining the themes of STD-related Internet searches to increase specificity of disease forecasting using Internet search terms. Nat. Sci. Rep. 2016, 6, 36503. [Google Scholar] [CrossRef]
- Letchford, A.; Preis, T.; Moat, H. Quantifying the Search Behaviour of Different Demographics Using Google Correlate. PLoS ONE 2016, 11, e0149025. [Google Scholar] [CrossRef] [PubMed]
- Markey, P.M.; Markey, C.N. Changes in pornography-seeking behaviors following political elections: An examination of the challenge hypothesis. Evol. Hum. Behav. 2010, 31, 442–446. [Google Scholar] [CrossRef]
- Mavragani, A.; Ochoa, G.; Tsagarakis, K.P. Assessing the Methods, Tools, and Statistical Approaches in Google Trends Research: Systematic Review. J. Med. Internet Res. 2018, 20, e270. [Google Scholar] [CrossRef] [PubMed]
- Rashad, A.S. The Power of Travel Search Data in Forecasting the Tourism Demand in Dubai. Forecasting 2022, 4, 674–684. [Google Scholar] [CrossRef]
- Ginsberg, J.; Mohebbi, M.H.; Patel, R.S.; Brammer, L.; Smolinski, M.S.; Brilliant, L. Detecting influenza epidemics using search engine query data. Nature 2009, 457, 1012–1014. [Google Scholar] [CrossRef]
- Franzén, A. Big data, big problems: Why scientists should refrain from using Google Trends. Acta Sociol. 2023. [Google Scholar] [CrossRef]
- Stroubakis, G. Learning More and Knowing Less: Big Data, Spurious Correlations, and the Problem of Ignorance. UWSpace. 2022. Available online: http://hdl.handle.net/10012/18826 (accessed on 27 February 2023).
- Calude, C.S.; Longo, G. The Deluge of Spurious Correlations in Big Data. Found. Sci. 2017, 22, 595–612. [Google Scholar] [CrossRef]
- Lazer, D.; Kennedy, R.; King, G.; Vespignani, A. The parable of Google Flu: Traps in Big Data Analysis. Science 2014, 343, 1203–1205. [Google Scholar] [CrossRef]
- Smith, G. Step away from stepwise. J. Big Data 2018, 5, 32. [Google Scholar] [CrossRef]
- Vigen, T. Spurious Correlations: Correlation does not Equal Causation; Hachette Books: New York, NY, USA, 2015. [Google Scholar]
- Meng, X.-L. Statistical Paradises and Paradoxes in Big Data (I): Law of Large Populations, Big Data Paradox, and the 2016 US Presidential Election. Ann. Appl. Stat. 2018, 12, 685–726. [Google Scholar] [CrossRef]
- L’Heureux, A.; Grolinger, K.; Captretz, M.A. Machine Learning with Big Data: Challenges and Approaches. IEEE Access 2017, 5, 7776–7797. [Google Scholar] [CrossRef]
- Bonferroni, C.E. Il Calcolo Delle Assicurazioni su Gruppi di Teste; Tipografia del Senato: Rome, Italy, 1935; pp. 13–60. [Google Scholar]
- Bonferroni, C.E. Teoria statistica delle classi e calcolo delle probabilità. Pubbl. R Ist. Super. Sci. Econ. E Commer. Firenze 1936, 8, 3–62. [Google Scholar]
- Haig, B.D. What Is a Spurious Correlation. Underst. Stat. 2003, 2, 125–132. [Google Scholar] [CrossRef]
- Mohebbi, M.; Vanderkam, D.; Kodysh, K.; Schonberger, R.; Choi, H.; Kumar, S. Google Correlate Whitepaper. Google. 2011. Available online: http://corista.com/wp-content/uploads/2014/11/www.google.com_trends_correlate_whitepaper.pdf (accessed on 19 October 2022).
- Castle, J.L.; Doornik, J.A.; Hendry, D.F. Modelling non-stationary ‘Big Data’. Int. J. Forecast. 2021, 37, 1556–1575. [Google Scholar] [CrossRef]
- Hosni, H.; Volpiani, A. Forecasting in Light of Big Data. Philos. Technol. 2018, 31, 557–569. [Google Scholar] [CrossRef]
- Fan, J.; Shao, Q.-M.; Zhou, W.-X. Are discoveries spurious? Distributions of maximum spurious correlations and their applications. Ann. Stat. 2018, 46, 989–1017. [Google Scholar] [CrossRef]
- Payne, N. No One Cares That ‘Google Correlate’ the SEO Keyword Research Tool Is to Be Discontinued. 2019. Available online: https://www.linkedin.com/pulse/one-cares-google-correlate-seo-keyword-research-tool-nina-payne (accessed on 24 February 2023).
- Lee, N.; Greenley, G. The primacy of data? Eur. J. Mark. 2008, 42, 1141–1144. [Google Scholar] [CrossRef]
- Dennis, W.; Mendenhall, W., III; Scheaffer, R.L. Mathematical Statistics with Applications, 5th ed.; Wadsworth Publishing Company: Belmont, CA, USA, 1996. [Google Scholar]
- NORM.INV Function. Available online: https://support.microsoft.com/en-us/topic/54b30935-fee7-493c-bedb-2278a9db7e13 (accessed on 26 January 2023).
- MacDougall, J. How to Create a Normally Distributed Set of Random Numbers in Excel. Available online: https://www.howtoexcel.org/normal-distribution/ (accessed on 26 January 2023).
- GAMMA.INV Function. Available online: https://support.microsoft.com/en-us/office/gamma-inv-function-74991443-c2b0-1654be5-aaab-1aa4d71fbb18 (accessed on 26 January 2023).
- Random Walk. Available online: https://en.wikipedia.org/wiki/Random_walk (accessed on 2 February 2023).





{kind=link}
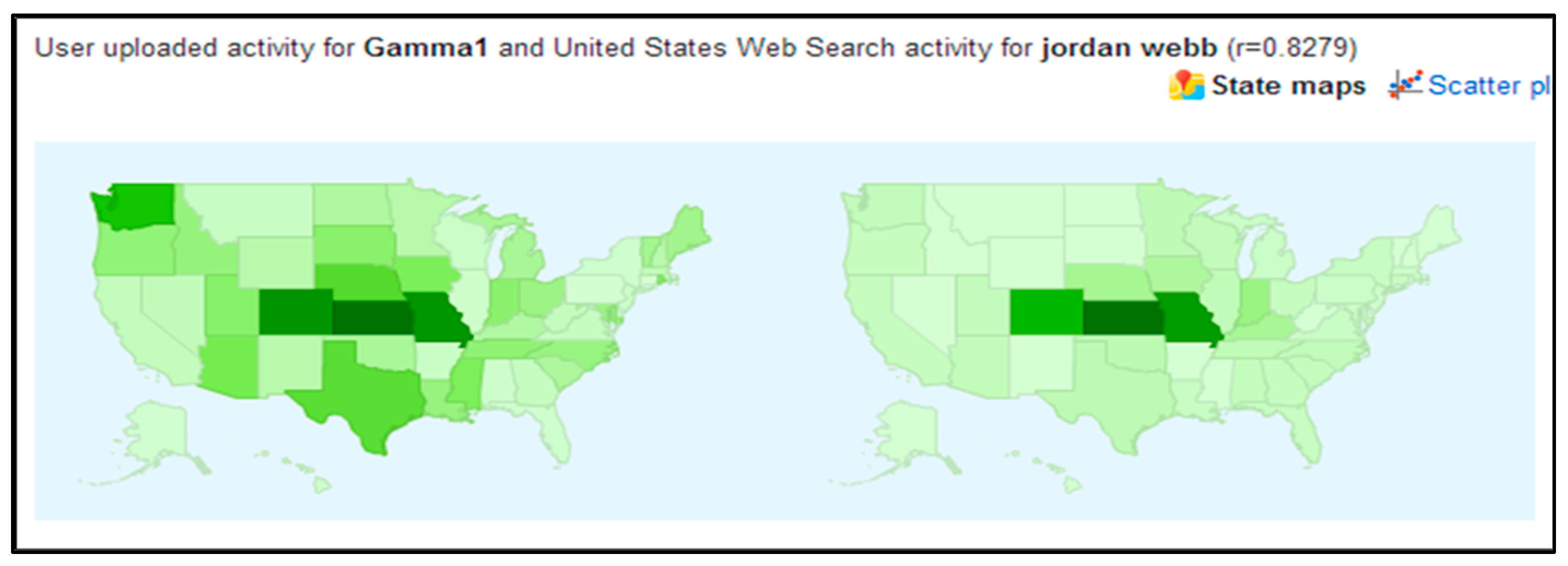{kind=link}
{kind=link}
{kind=link}
| Gamma Run (top 90 results with maximum correlation 0.72 to minimum correlation 0.65): whistling, ron jones, red ticking, purdy, james alan, auburn golf, city of mount vernon, maximilien, weather mount vernon, eastgate park, tucker park, pine box, richard pope, nancy stewart, auburn theater, liquid lime, rock orchestra, state abortion laws, hunter tree, elma,, amazon grocery, burger master, state adoption, foley library, diagnoser, stanley and, lynnwood apartments, state congress, college running, baker lab, motor trucks, state polls, mount vernon zip, the rainier, scan tv, callison, hope place, ivan the gorilla, hooverville, auburn medical center, weight loss for life, pignataro, funtasia, ballard, gates hall, days inn auburn, elma, pi, weather in mount vernon, ken hutcherson, 5 tv, genealogy search engine, state congressional districts, state rivers, 1077, ups university, capital mall, mill creek, phinney, idiot pilot, lakewood cinema, center laser, narrows bridge, white center, the airlock, emerald ridge, bainbridge high, bainbridge high school, avacyn restored spoilers, healthfinder, small works, the mural, state pta, the other coast, the patriarchs, mount vernon police department, row to hoe, home lodge, bonney, evergreen medical center, treehouse for kids, bellevue high school, three dollar bill, james g, reid realty, the family pet, figgy, bellevue high, teneriffe, egg nest. |
| Random Walk Run (top 90 results with maximum correlation 0.9532 to minimum correlation 0.9353): inmate locator, chase, period calculator, best wordpress, 26 weeks pregnant, 14 weeks pregnant, 29 weeks pregnant, view text messages, jail inmates, 15 weeks pregnant, nyc midtown, 18 weeks pregnant, wordpress page, landers mclarty, chances of getting pregnant, 33 weeks pregnant, pain during pregnancy, hard to get, on a mac, wordpress admin, mucus in stool, weeks pregnant, miami dade inmate, franklin tn, 32 weeks pregnant, clip in hair, how to text, madison heights mi, email to text, 25 weeks pregnant, do girls like, skype history, 33165, clip in hair extensions, find my cell, songs like, what song goes, could i be pregnant, what is a good, like a guy, lansing mi, macbook pro screen, 33186, m and t, find my cell phone, best pdf, 23 weeks pregnant, clip in, plugin for wordpress, dade inmate search, your high, canton mi, fg, 19 weeks pregnant, allen tx, girl you like, miami dade inmate search, okemos mi, gluten free?, uitableview, what does te, acoustic chords, county jail inmates, chase bank in, birds barbershop, in charlotte nc, chico ca, what is the easiest, pregnant symptoms, xps to pdf, altamonte springs fl, dream mean, during pregnancy, good name, how far along am i, 31 weeks pregnant, how far along am, lls, livonia mi, chase on, restore to factory, a pregnancy test, move wordpress, in memphis tn, artists like, how do you tell, grand rapids mi, jquery scroll, kp.org, frederick md. |
| Uniform | Normal | Gamma (1, 1) | Spatial | Random Walk | Mean Reverting | |
|---|---|---|---|---|---|---|
| Uniform | 0.66 | |||||
| Normal | 0.62 | 0.63 | ||||
| Gamma (1, 1) | 0.59 | 0.61 | 0.80 | |||
| Spatial | 0.68 | 0.62 | 0.62 | 0.73 | ||
| Random Walk | 0.59 | 0.64 | 0.62 | 0.59 | 0.98 | |
| Mean Reverting | 0.61 | 0.63 | 0.66 | 0.61 | 0.88 | 0.82 |
| Max Overall | 0.68 | 0.64 | 0.80 | 0.73 | 0.98 | 0.88 |
| Probability Distribution from Which Random Variables Were Drawn | N of RVs | Portion of Random Variables with Spurious Correlation > 0.6 | Mean Largest Correlation per Variable (Standard Deviation) | 95th Percentile of Largest Spurious Correlation across Variables | Largest Correlation Found across Variables |
|---|---|---|---|---|---|
| Spatial | 500 | 68% | 0.66 (0.04) | 0.72 | 0.78 |
| Gamma (1, 1) | 600 | 97% | 0.71 (0.06) | 0.82 | 0.91 |
| Std. Normal | 499 | 33% | 0.63 (0.02) | 0.66 | 0.71 |
| Uniform | 500 | 22% | 0.63 (0.02) | 0.64 | 0.7 |
| Mean-Reverting | 500 | 76% | 0.69 (0.06) | 0.78 | 0.85 |
| Random Walk | 500 | 99% | 0.87 (0.08) | 0.97 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Richman, J.T.; Roberts, R.J. Assessing Spurious Correlations in Big Search Data. Forecasting 2023, 5, 285-296. https://doi.org/10.3390/forecast5010015
Richman JT, Roberts RJ. Assessing Spurious Correlations in Big Search Data. Forecasting. 2023; 5(1):285-296. https://doi.org/10.3390/forecast5010015
Chicago/Turabian StyleRichman, Jesse T., and Ryan J. Roberts. 2023. "Assessing Spurious Correlations in Big Search Data" Forecasting 5, no. 1: 285-296. https://doi.org/10.3390/forecast5010015
APA StyleRichman, J. T., & Roberts, R. J. (2023). Assessing Spurious Correlations in Big Search Data. Forecasting, 5(1), 285-296. https://doi.org/10.3390/forecast5010015