Forecasting the Preparatory Phase of Induced Earthquakes by Recurrent Neural Network



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
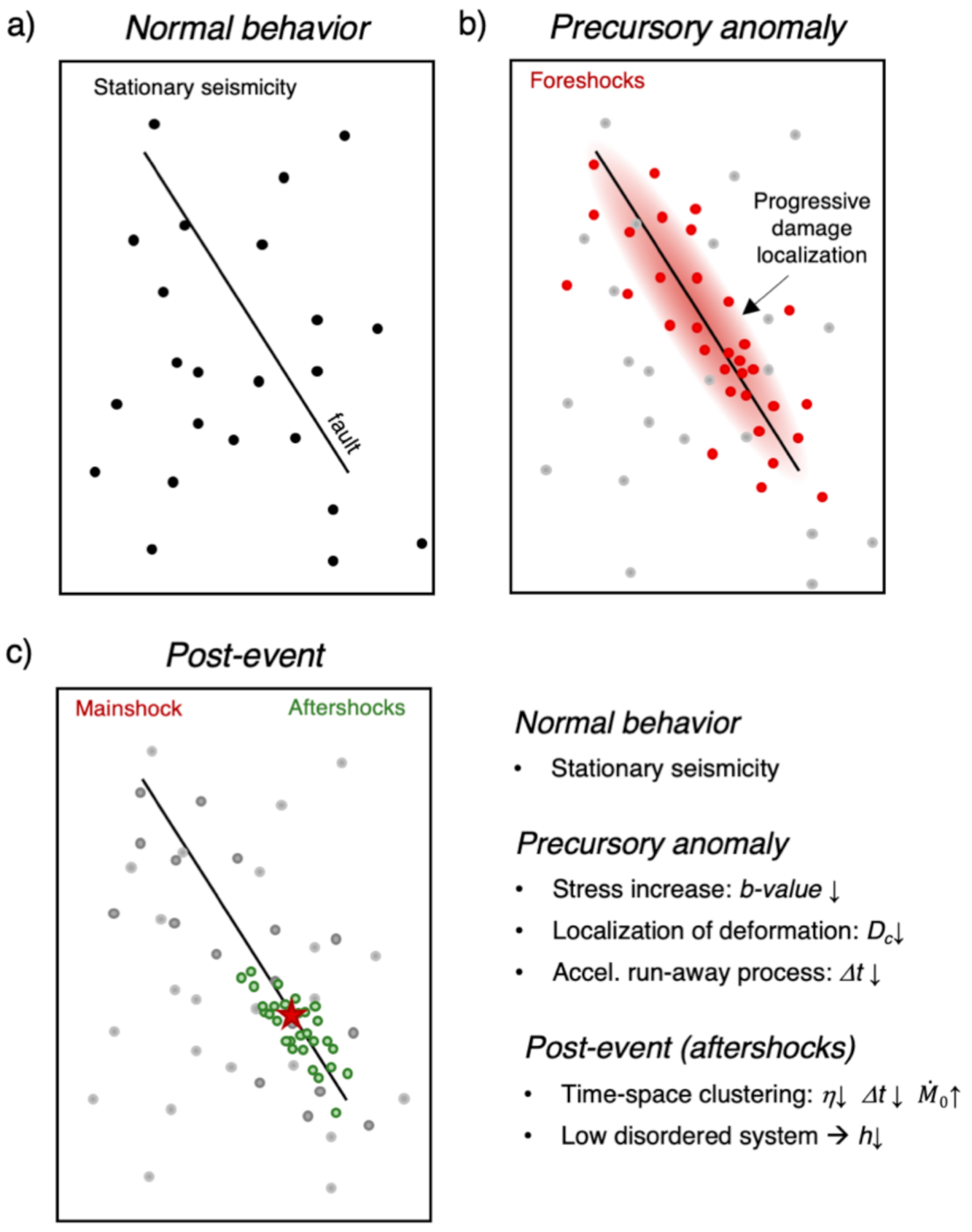
:1. Introduction
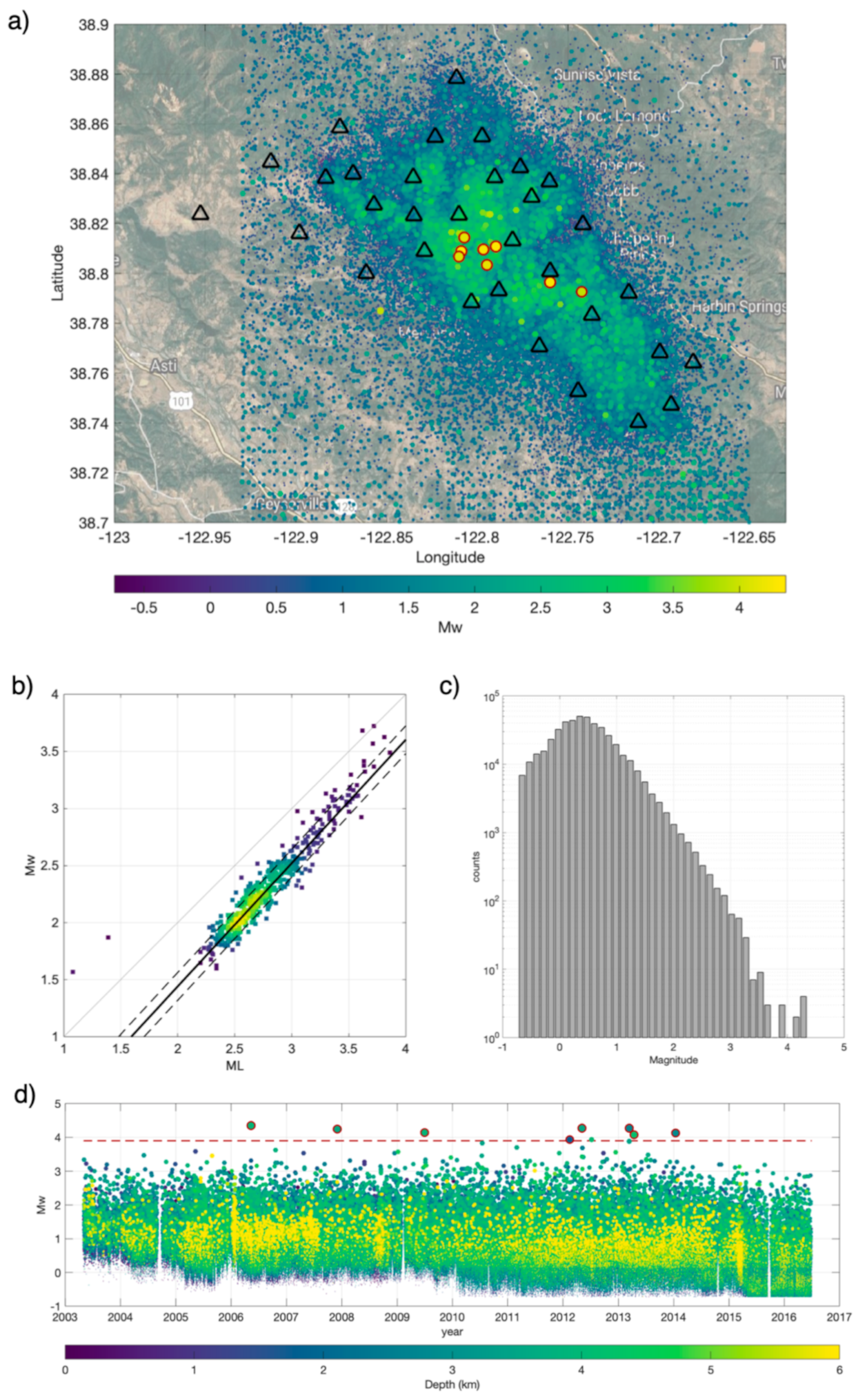
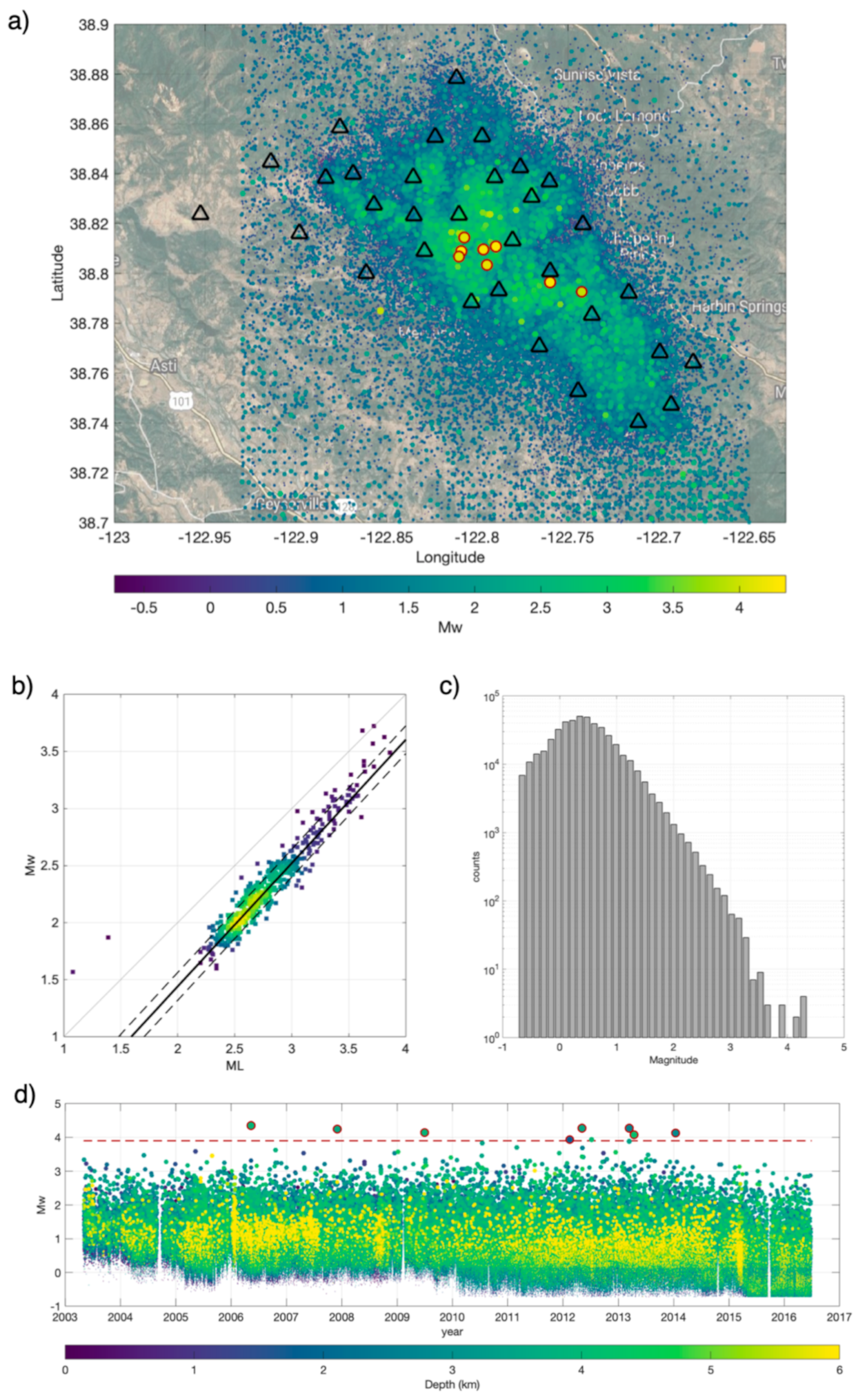
2. Features
2.1. Features Computation and General Working Outline
2.2. Duration of Event Groups and Inter-Event Time
2.3. Moment Magnitude and Moment Rate
2.4. b-Value and Completeness Magnitude Mc
2.5. Fractal Dimension
2.6. Nearest-Neighbor Distance, η, Analysis
2.7. Shannon’s Information Entropy
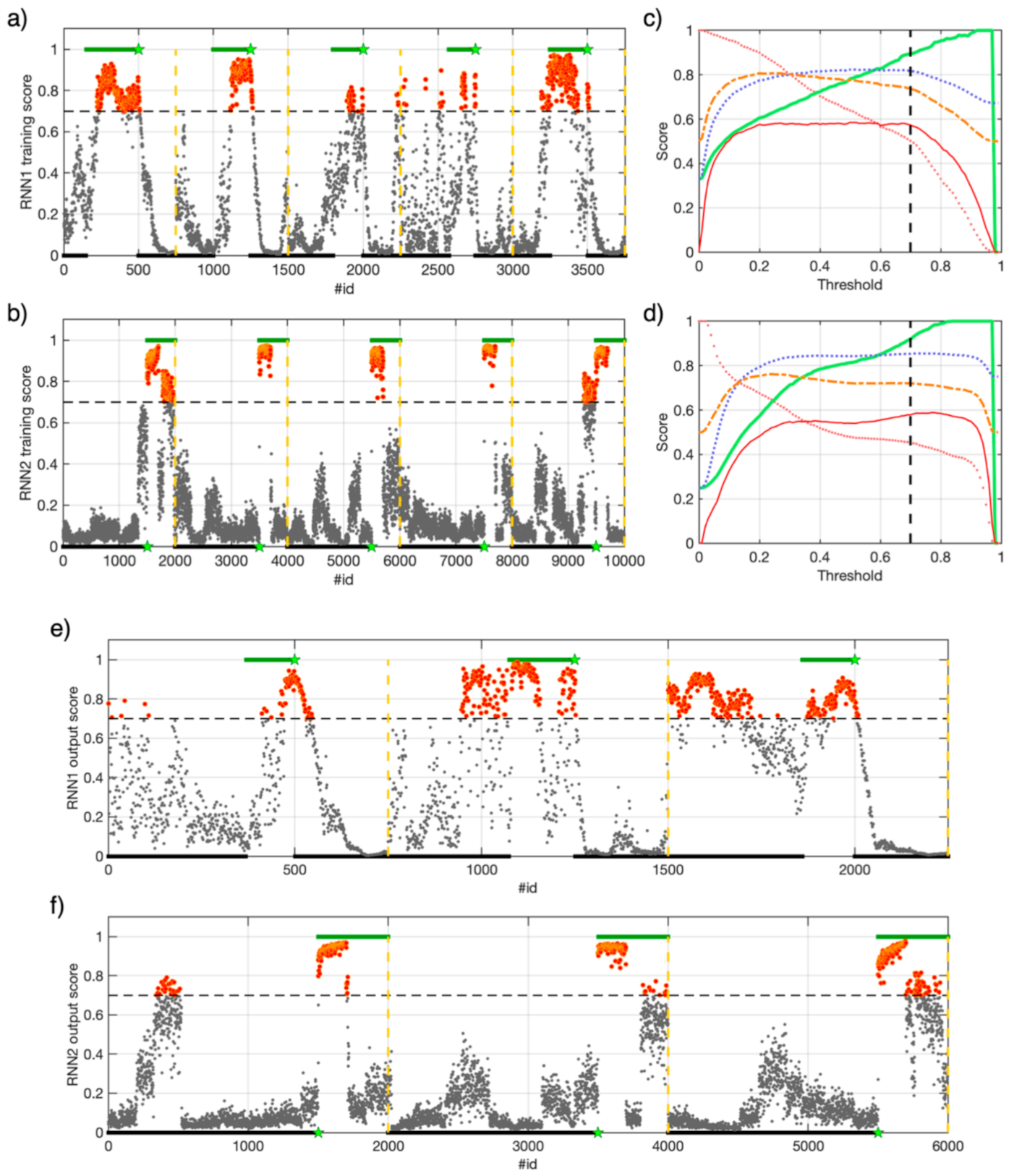
3. Methods
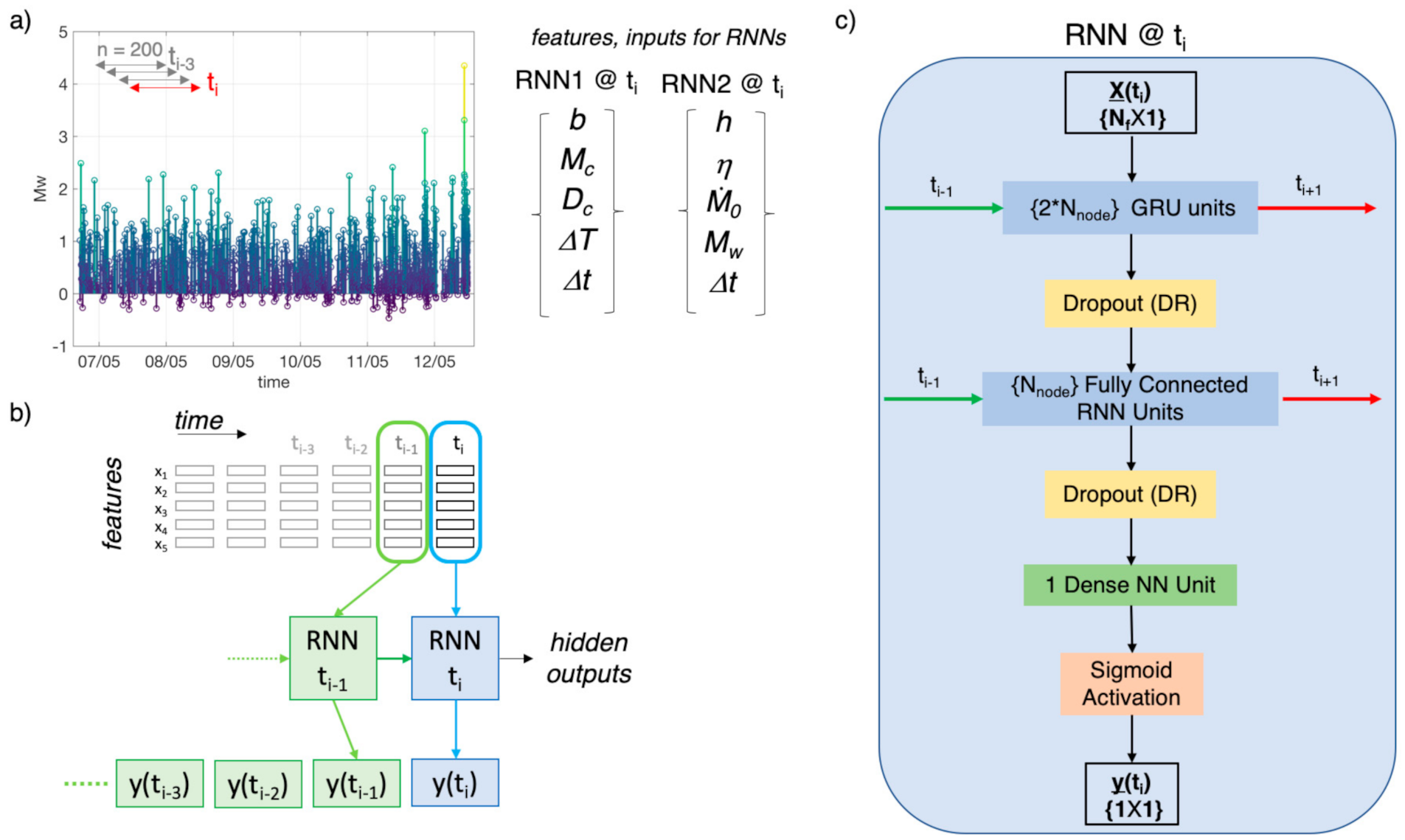
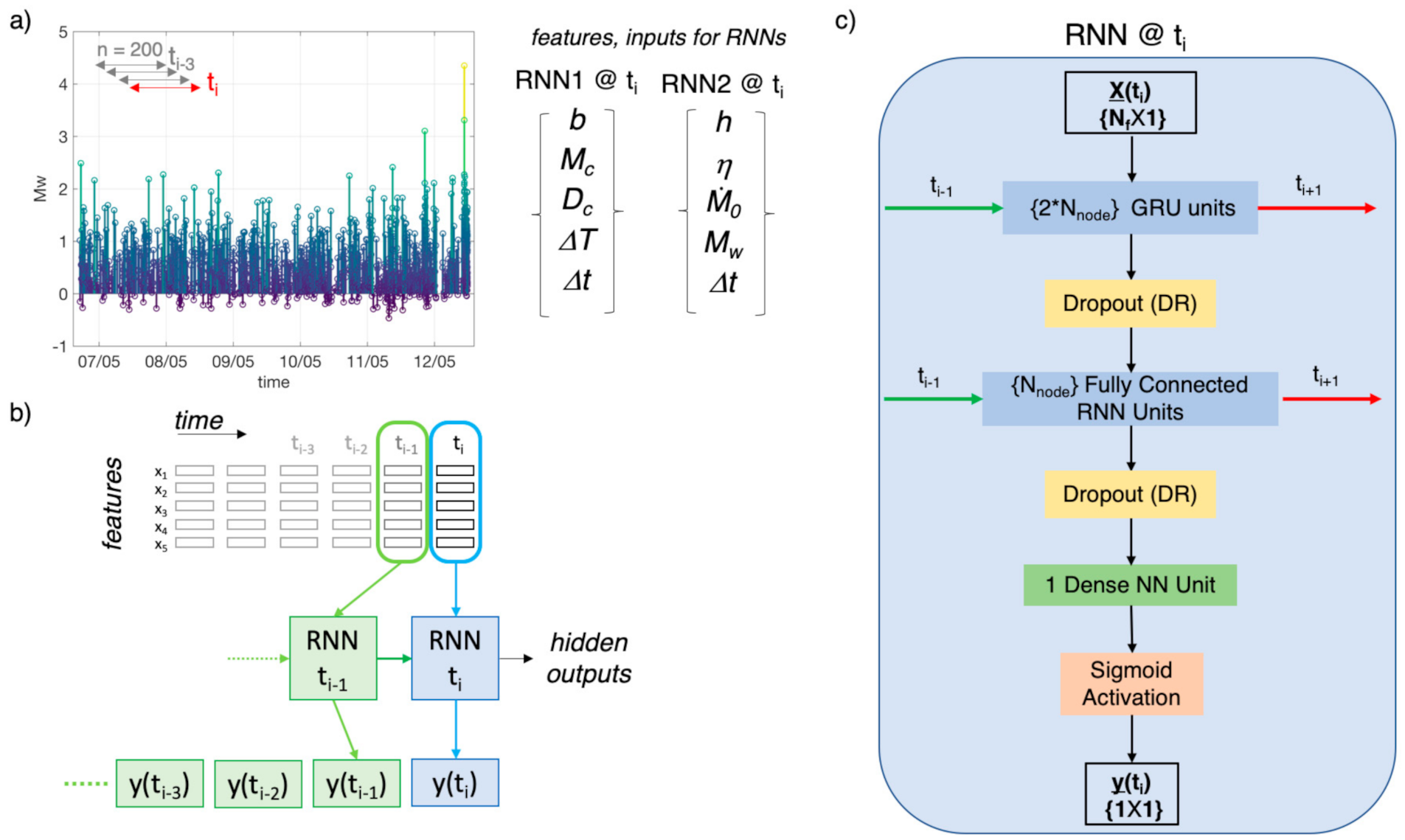
3.1. Recurrent Neural Networks and ML Layers
3.2. Step-By-Step Description of Data-Analysis by RNN
- (1)
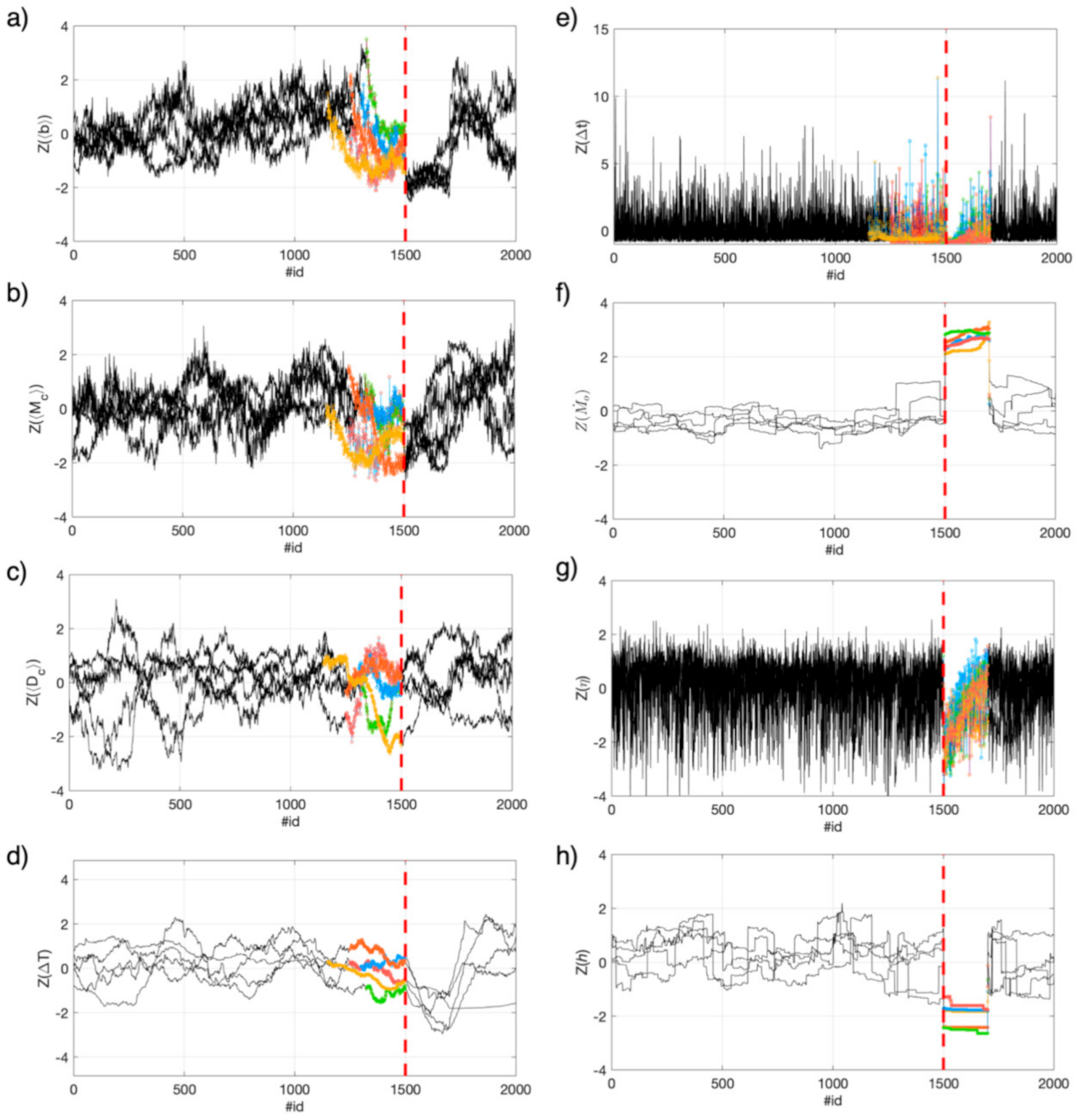
- Once the spatial-temporal characteristics (features) of seismicity have been extracted, we selected windows of data for the RNN analyses (i.e., 750 and 2000 earthquakes around the five M4 events for RNN1 and RNN2, respectively). In particular, for each M4 series in RNN1, we consider 499 events before the M4 event, the M4 itself, and 250 events after it. For RNN2, instead, we consider 1500 events before the M4, the M4 itself, and 499 after it. The different amount of data in the M4 series for RNN1 and RNN2 has been tuned for optimizing the training performance.
- (2)
- Each M4 series has been standardized, which consist of, for each selected window, removing the mean and dividing for the standard deviation. This procedure is necessary since features span varying degrees of magnitude and units and these aspects can degrade the RNN performance [72] After the standardization, each feature is distributed as a standard normal distribution, N(0,1).
- (3)
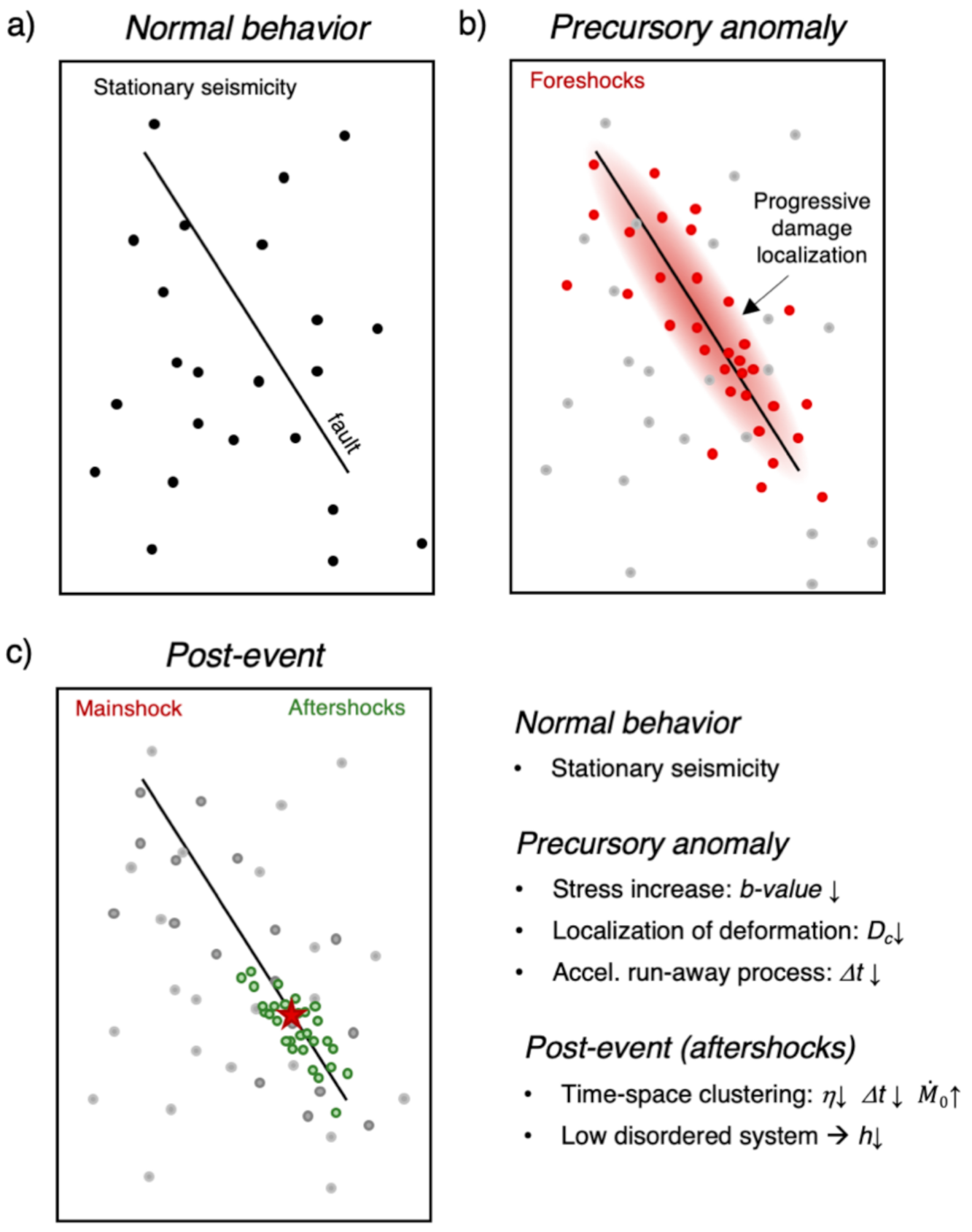
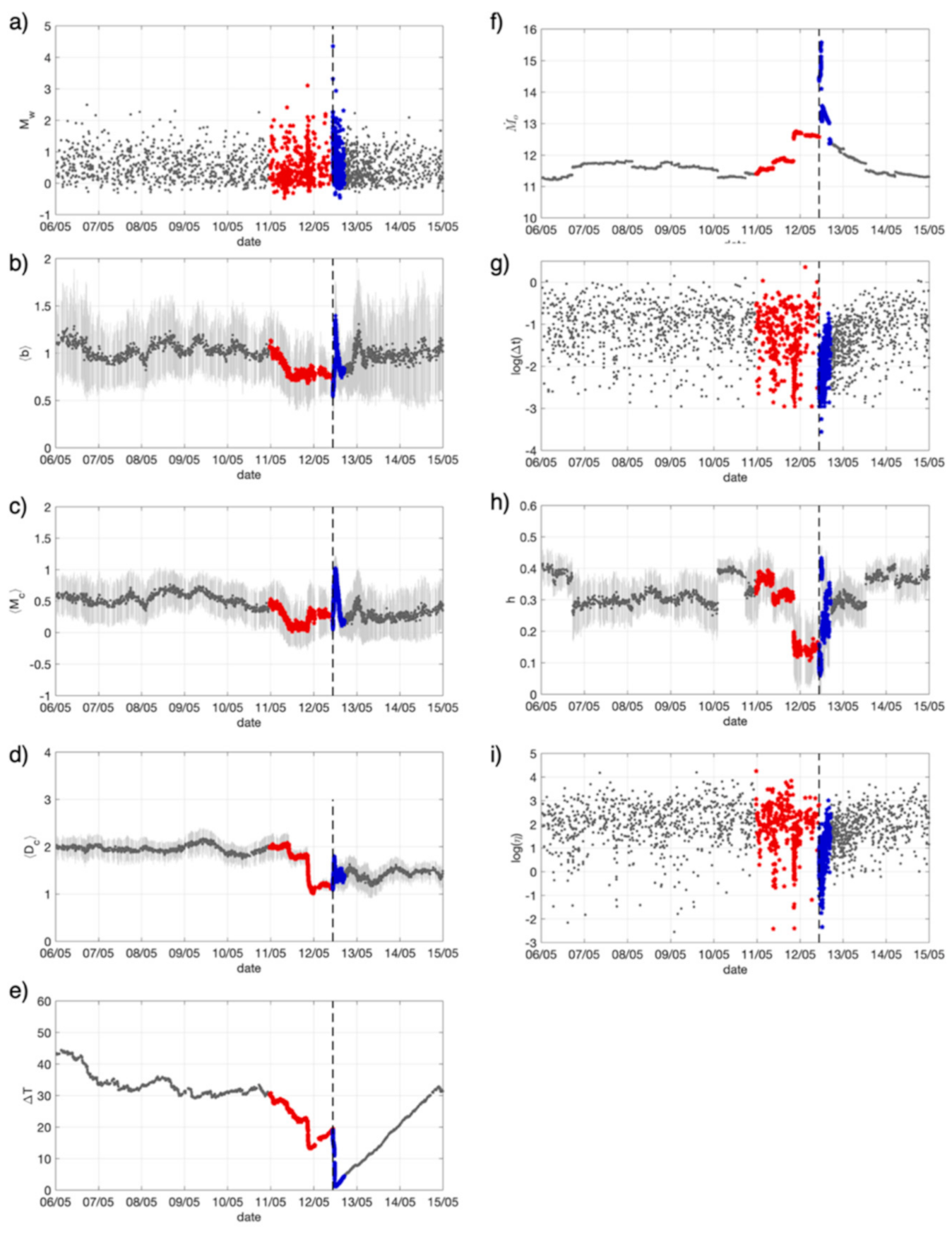
- In order to train the models, we assigned a label to each earthquake. Indeed, being RNN used here for sequential data classification, it is necessary train it with a simple binary (0/1) classification scheme. Therefore, in RNN1, the one aiming to identify the preparatory phase, we assigned value 1 to those events preceding the M4s that have been interpreted based on expert opinion as belonging to the preparatory phase and label 0 to all the others (background and aftershocks). In RNN2, aiming to identify aftershocks, we assigned label 1 to aftershocks and label 0 to the others (background and foreshocks). In particular, in RNN1, for each M4 series, we selected a different number of events as belonging to the preparatory phase (i.e., ranging from 175 to 350 events) looking at the trend of parameters like b-value, Mc and Dc that we know likely related to the preparatory phase [27]. In RNN2, we decided to label all the 499 events following a M4 as aftershocks.
- (4)
- The event catalogue is therefore transformed into two datasets (train and test) for RNN, in which lines contain the features and the labels (i.e., for line i, corresponding the at origin time of ith event, we have {b-valuei, Mci, Dci, ∆Ti, 0i, ∆ti, ηi, hi, Mwi, label1i, label2i}).
- (5)
- We split the dataset in training and testing sets. The train set consists of the first five M4 series, while the testing one consists of the last three M4 series.
- (6)
- We trained the model to find the best hyperparameters, which of course, could change between RNN1 and RNN2.
- (7)
- The model has been validated on the train set separately (with the proper label) for RNN1 and RNN2 using a trial-and-error procedure to select the best features for the two models, and a leave-one-out (LOO) cross-validation to tune the hyperparameters. The LOO is performed leaving one M4 series per time and training the model on the other four. Hence, each model resulting from four M4 series is used to predict the target on the excluded M4 series. We decided to use AUC (area under the curve) as validation score because it is independent from the threshold selection. The mean of the five AUC values from the LOO validation is used to evaluate the hyperparameters configuration. We chose to explore three hyperparameters, which are Nnode (in the range 3–20), DR (between 0 and 0.5), and the learning rate LR (between 1 × 10−5 and 1 × 10−3) with which the model is fitted.
- (8)
- A similar leave-one-out (LOO) approach has been carried out also to perform a feature importance analysis. In this case, considering the five M4 series, we proceeded at removing one by one features and checking the performance with respect to the case with all features. On one hand, our tuning led to select for RNN1 the features b-value, Mc, Dc, ∆T and ∆t. On the other hand, we selected for RNN2 to features 0, ∆t, η, h and Mw.
- (9)
- The performance of the RNN1 and RNN2 models has been assessed using the testing dataset of three M4 series.
4. Results
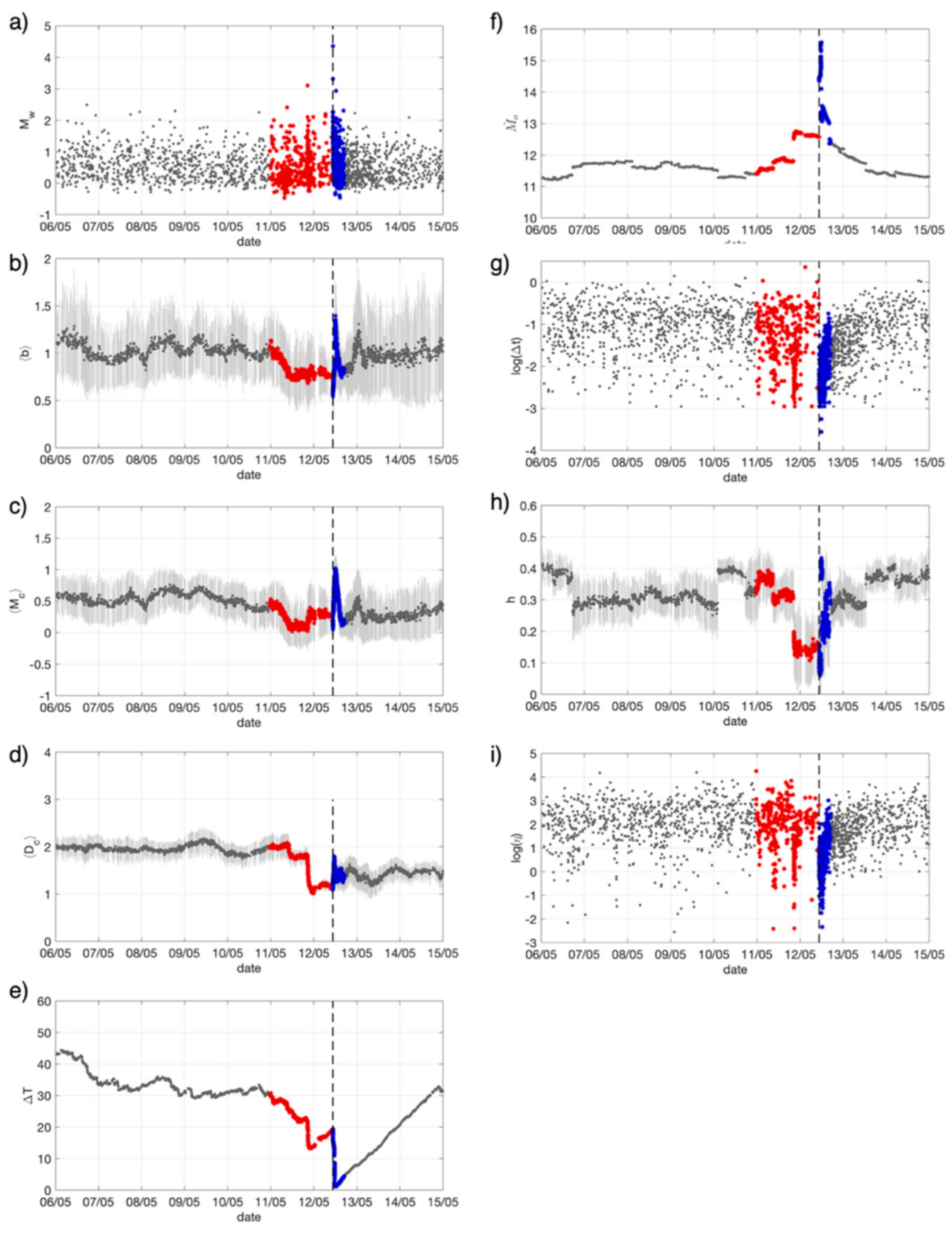
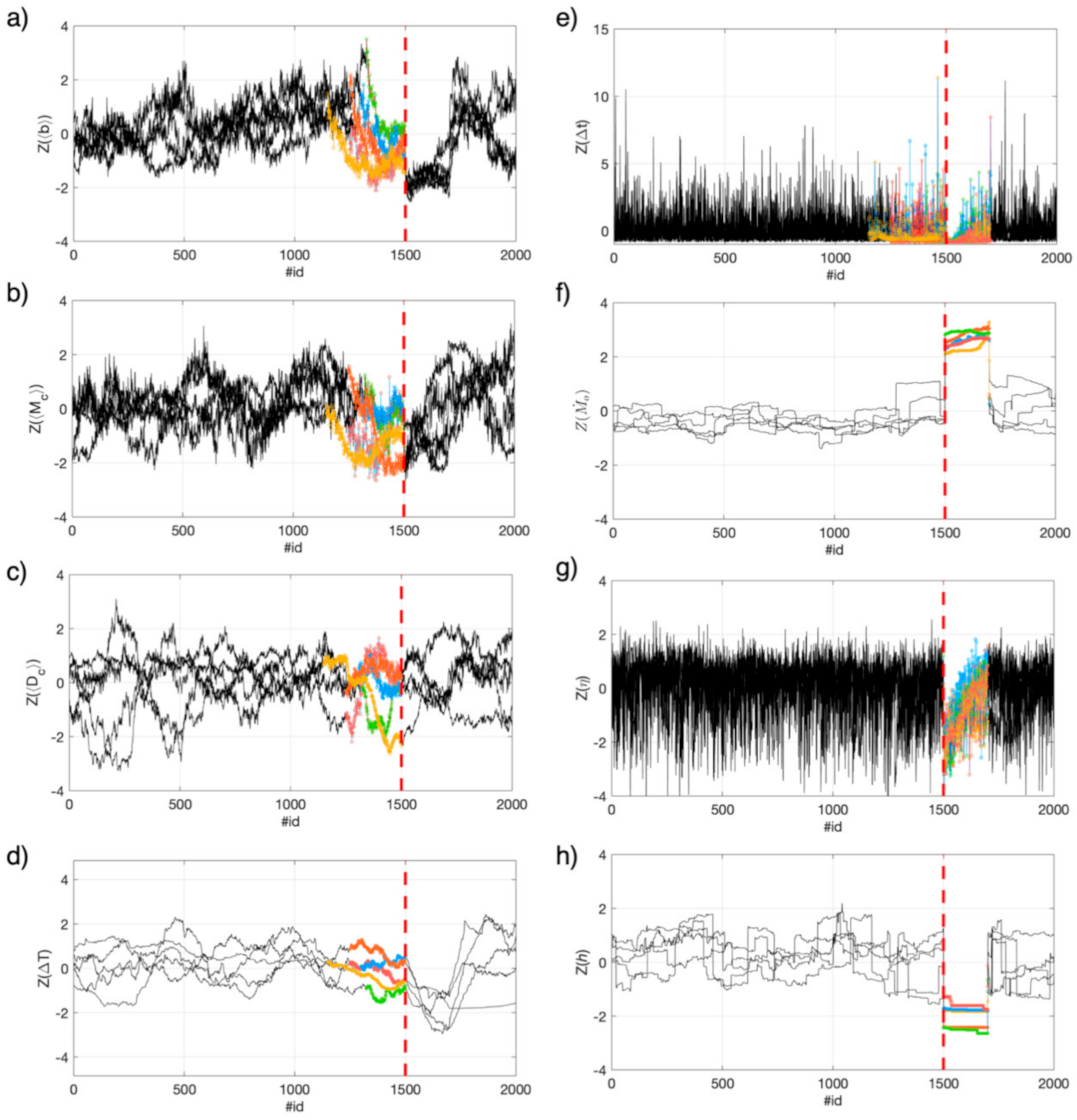
4.1. Observing Seismicity Occurrence from Features Perspective
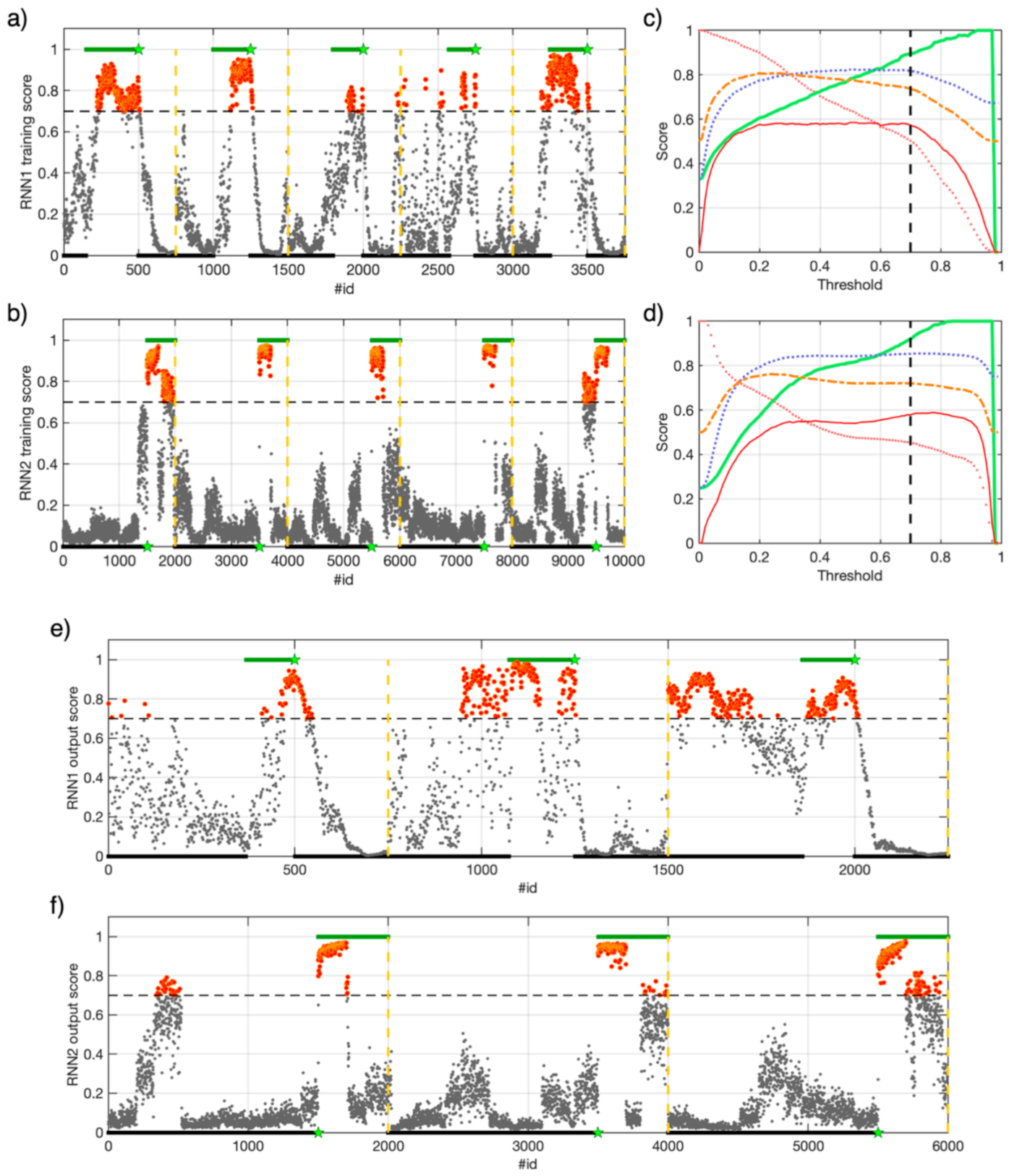
4.2. RNNs Tuning Trough Cross-Validation on a Training Dataset
4.3. Training RNN1 and RNN2
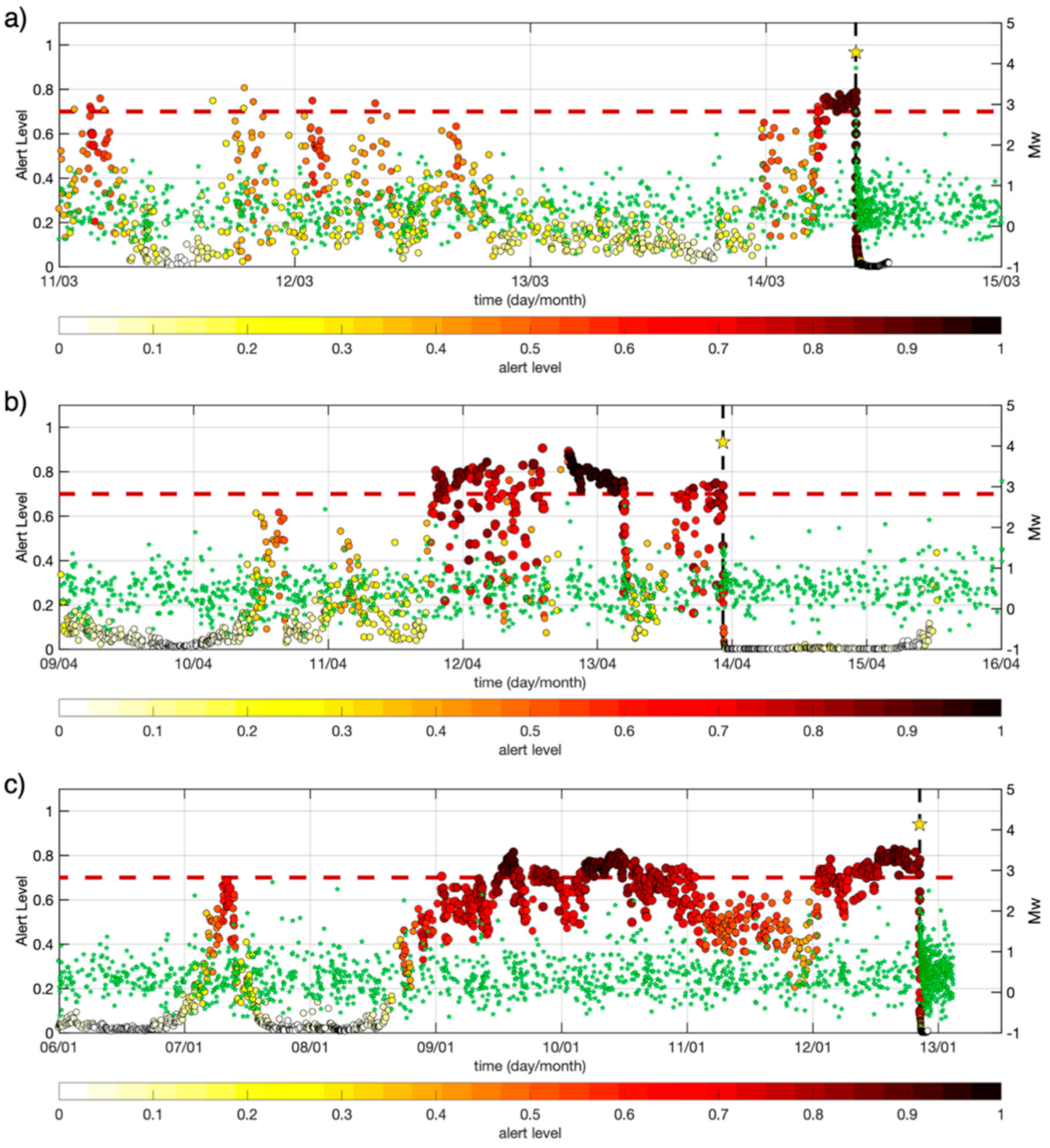
4.4. Testing RNN1 and RNN2
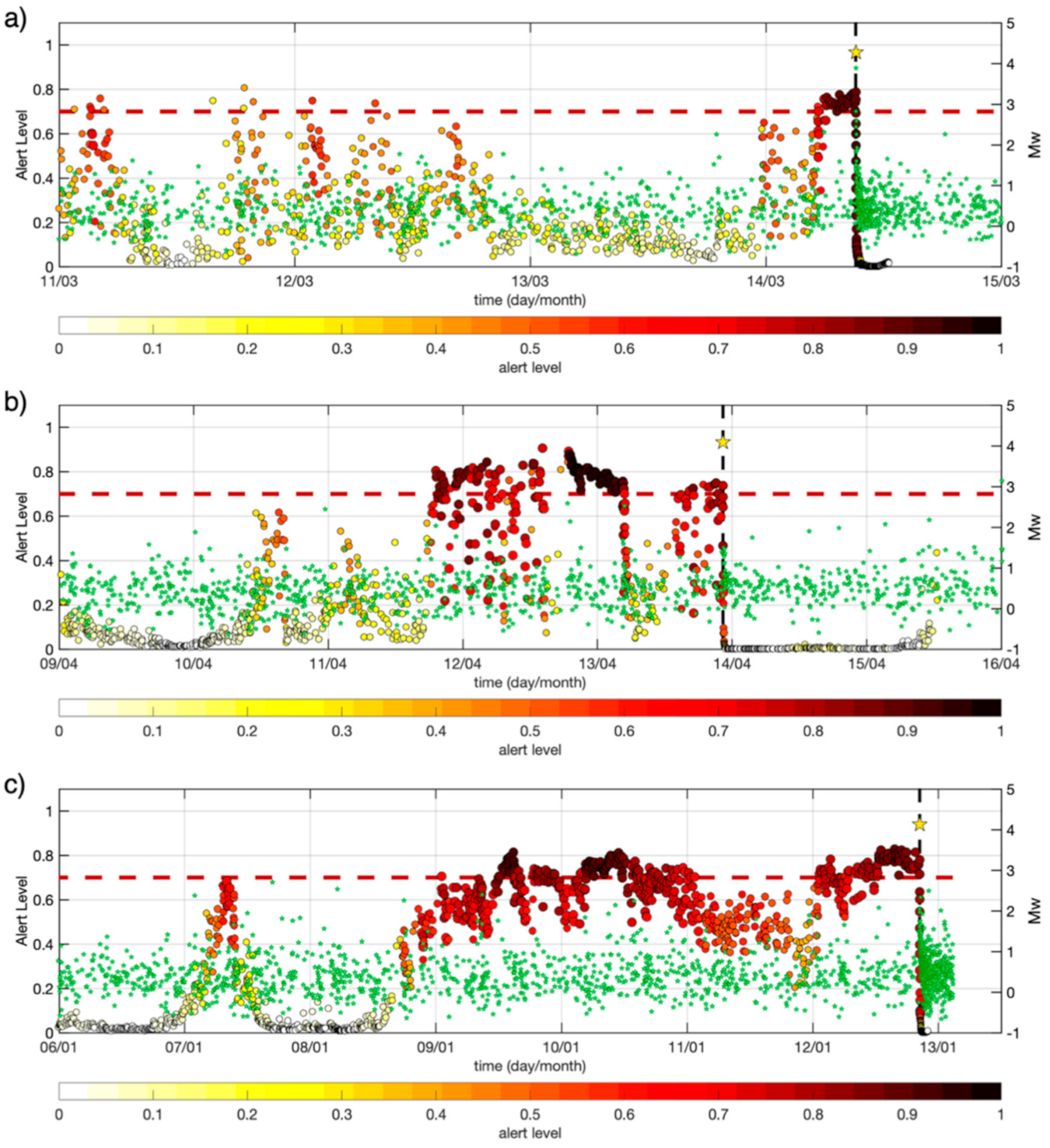
4.5. Conceptualization of an Alert Algorithm
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Resources
References
- Rikitake, T. Earthquake precursors. Bull. Seismol. Soc. Am. 1975, 65, 1133–1162. [Google Scholar]
- Dieterich, J.H. Preseismic fault slip and earthquake prediction. J. Geophys. Res. Space Phys. 1978, 83, 3940–3948. [Google Scholar] [CrossRef]
- Jones, L.M.; Molnar, P. Some characteristics of foreshocks and their possible relationship to earthquake prediction and premonitory slip on faults. J. Geophys. Res. Space Phys. 1979, 84, 3596–3608. [Google Scholar] [CrossRef]
- Jones, L.M. Foreshocks and time-dependent earthquake hazard assessment in southern california. Bull. Seismol. Soc. Am. 1985, 75, 1669–1679. [Google Scholar]
- Abercrombie, R.E.; Mori, J. Occurrence patterns of foreshocks to large earthquakes in the western United States. Nat. Cell Biol. 1996, 381, 303–307. [Google Scholar] [CrossRef]
- Dodge, D.A.; Beroza, G.C.; Ellsworth, W.L. Detailed observations of California foreshock sequences: Implications for the earthquake initiation process. J. Geophys. Res. Space Phys. 1996, 101, 22371–22392. [Google Scholar] [CrossRef] [Green Version]
- Lapusta, N.; Rice, J.R. Nucleation and early seismic propagation of small and large events in a crustal earthquake model. J. Geophys. Res. Space Phys. 2003, 108, 2205. [Google Scholar] [CrossRef] [Green Version]
- Kanamori, H. The Nature of Seismicity Patterns before Large Earthquakes. In Earthquake Prediction: An International Review; Simpson, W., Richards, G., Eds.; Wiley: Hoboken, NJ, USA, 1981; pp. 1–19. [Google Scholar]
- Mignan, A. Functional shape of the earthquake frequency-magnitude distribution and completeness magnitude. J. Geophys. Res. Space Phys. 2012, 117. [Google Scholar] [CrossRef]
- Ohnaka, M. Earthquake source nucleation: A physical model for short-term precursors. Tectonophysics 1992, 211, 149–178. [Google Scholar] [CrossRef]
- Das, S.; Scholz, C.H. Theory of time-dependent rupture in the Earth. J. Geophys. Res. Space Phys. 1981, 86, 6039–6051. [Google Scholar] [CrossRef] [Green Version]
- Mignan, A. The debate on the prognostic value of earthquake foreshocks: A meta-analysis. Sci. Rep. 2015, 4, 4099. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Helmstetter, A.; Sornette, D. Foreshocks explained by cascades of triggered seismicity. J. Geophys. Res. Space Phys. 2003, 108, 2457. [Google Scholar] [CrossRef] [Green Version]
- Felzer, K.R.; Abercrombie, R.E.; Ekström, G. A Common Origin for Aftershocks, Foreshocks, and Multiplets. Bull. Seismol. Soc. Am. 2004, 94, 88–98. [Google Scholar] [CrossRef]
- Trugman, D.T.; Ross, Z.E. Pervasive Foreshock Activity Across Southern California. Geophys. Res. Lett. 2019, 46, 8772–8781. [Google Scholar] [CrossRef] [Green Version]
- Bouchon, M.; Durand, V.; Marsan, D.; Karabulut, H.; Schmittbuhl, J. The long precursory phase of most large interplate earthquakes. Nat. Geosci. 2013, 6, 299–302. [Google Scholar] [CrossRef]
- Hauksson, E.; Stock, J.M.; Hutton, K.; Yang, W.; Vidal-Villegas, J.A.; Kanamori, H. The 2010 M w 7.2 El Mayor-Cucapah Earthquake Sequence, Baja California, Mexico and Southernmost California, USA: Active Seismotectonics along the Mexican Pacific Margin. Pure Appl. Geophys. 2011, 168, 1255–1277. [Google Scholar] [CrossRef]
- Kato, A.; Obara, K.; Igarashi, T.; Tsuruoka, H.; Nakagawa, S.; Hirata, N. Propagation of Slow Slip Leading Up to the 2011 Mw 9.0 Tohoku-Oki Earthquake. Science 2012, 335, 705–708. [Google Scholar] [CrossRef] [Green Version]
- Socquet, A.; Valdes, J.P.; Jara, J.; Cotton, F.; Walpersdorf, A.; Cotte, N.; Specht, S.; Ortega-Culaciati, F.; Carrizo, D.; Norabuena, E. An 8 month slow slip event triggers progressive nucleation of the 2014 Chile megathrust. Geophys. Res. Lett. 2017, 44, 4046–4053. [Google Scholar] [CrossRef] [Green Version]
- Ellsworth, W.; Bulut, F. Nucleation of the 1999 Izmit earthquake by a triggered cascade of foreshocks. Nat. Geosci. 2018, 11, 531–535. [Google Scholar] [CrossRef]
- Piña-Valdés, J.; Socquet, A.; Cotton, F.; Specht, S. Spatiotemporal Variations of Ground Motion in Northern Chile before and after the 2014 Mw 8.1 Iquique Megathrust Event. Bull. Seism. Soc. Am. 2018, 108, 801–814. [Google Scholar] [CrossRef]
- Yoon, C.E.; Yoshimitsu, N.; Ellsworth, W.; Beroza, G.C. Foreshocks and Mainshock Nucleation of the 1999 M w 7.1 Hector Mine, California, Earthquake. J. Geophys. Res. Solid Earth 2019, 124, 1569–1582. [Google Scholar] [CrossRef]
- Ruiz, S.; Aden-Antoniow, F.; Báez, J.C.; Otarola, C.; Potin, B.; Del Campo, F.; Poli, P.; Flores, C.; Satriano, C.; Leyton, F.; et al. Nucleation Phase and Dynamic Inversion of the Mw 6.9 Valparaíso 2017 Earthquake in Central Chile. Geophys. Res. Lett. 2017, 44, 10290–10297. [Google Scholar] [CrossRef]
- Malin, P.E.; Bohnhoff, M.; Blümle, F.; Dresen, G.; Martínez-Garzón, P.; Nurlu, M.; Ceken, U.; Kadirioglu, F.T.; Kartal, R.F.; Kilic, T.; et al. Microearthquakes preceding a M4.2 Earthquake Offshore Istanbul. Sci. Rep. 2018, 8, 16176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ross, Z.E.; Trugman, D.T.; Hauksson, E.; Shearer, P.M. Searching for hidden earthquakes in Southern California. Science 2019, 364, 767–771. [Google Scholar] [CrossRef] [Green Version]
- Kato, A.; Ben-Zion, Y. The generation of large earthquakes. Nat. Rev. Earth Environ. 2020. [Google Scholar] [CrossRef]
- Dresen, G.; Kwiatek, G.; Goebel, T.; Ben-Zion, Y. Seismic and Aseismic Preparatory Processes Before Large Stick–Slip Failure. Pure Appl. Geophys. 2020, 177, 5741–5760. [Google Scholar] [CrossRef]
- Durand, V.; Bentz, S.; Kwiatek, G.; Dresen, G.; Wollin, C.; Heidbach, O.; Martínez-Garzòn, P.; Cotton, F.; Nurlu, M.; Bohnhoff, M. A Two-Scale Preparation Phase Preceded an Mw 5.8 Earthquake in the Sea of Marmara Offshore Istanbul, Turkey, Seismol. Res. Lett. 2020. [Google Scholar] [CrossRef]
- Sánchez-Reyes, H.S.; Essing, D.; Beaucé, E.; Poli, P. The imbricated foreshock and aftershock activities of the Balsorano (Italy) Mw 4.4 normal fault earthquake and implications for earthquake initiation. ESSOAr 2020. [Google Scholar] [CrossRef]
- Rouet-Leduc, B.; Hulbert, C.; Lubbers, N.; Barros, K.; Humphreys, C.J.; Johnson, P.A. Machine Learning Predicts Laboratory Earthquakes. Geophys. Res. Lett. 2017, 44, 9276–9282. [Google Scholar] [CrossRef]
- DeVries, P.M.R.; Viégas, F.; Wattenberg, M.; Meade, B.J. Deep learning of aftershock patterns following large earthquakes. Nature 2018, 560, 632–634. [Google Scholar] [CrossRef]
- Gonzalez, J.; Yu, W.; Telesca, L. Earthquake Magnitude Prediction Using Recurrent Neural Networks. Proceedings 2019, 24, 22. [Google Scholar] [CrossRef]
- Viegas, G.; Hutchings, L. Characterization of induced seismicity near an injection well at the northwest Geysers geothermal field, California, Geotherm. Resour. Counc. Trans. 2011, 35, 1773–1780. [Google Scholar]
- Hanks, T.C.; Kanamori, H. A moment magnitude scale. J. Geophys. Res. Space Phys. 1979, 84, 2348–2350. [Google Scholar] [CrossRef]
- Gutenberg, B.; Richter, C.F. Earthquake magnitude, intensity, energy, and acceleration. Bull. Seismol. Soc. Am. 1942, 32, 163–191. [Google Scholar]
- Grassberger, P.; Procaccia, I. Measuring the strangeness of strange attractors. Physica 1983, 9, 189–208. [Google Scholar]
- Zaliapin, I.; Ben-Zion, Y. Earthquake clusters in southern California I: Identification and stability. J. Geophys. Res. Solid Earth 2013, 118, 2847–2864. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 623–656. [Google Scholar] [CrossRef]
- Telesca, L.; Lapenna, V.; Lovallo, M. Information entropy analysis of seismicity of Umbria-Marche region (Central Italy). Nat. Haz. Earth Syst. Sci. 2004, 4, 691–695. [Google Scholar] [CrossRef] [Green Version]
- Bressan, G.; Barnaba, C.; Gentili, S.; Rossi, G. Information entropy of earthquake populations in northeastern Italy and western Slovenia. Phys. Earth Planet. Inter. 2017, 271, 29–46. [Google Scholar] [CrossRef]
- Goebel, T.; Becker, T.W.; Schorlemmer, D.; Stanchits, S.; Sammis, C.G.; Rybacki, E.; Dresen, G. Identifying fault heterogeneity through mapping spatial anomalies in acoustic emission statistics. J. Geophys. Res. Space Phys. 2012, 117. [Google Scholar] [CrossRef] [Green Version]
- Kwiatek, G.; Goebel, T.H.W.; Dresen, G. Seismic moment tensor andbvalue variations over successive seismic cycles in laboratory stick-slip experiments. Geophys. Res. Lett. 2014, 41, 5838–5846. [Google Scholar] [CrossRef] [Green Version]
- Gulia, L.; Wiemer, S. Real-time discrimination of earthquake foreshocks and aftershocks. Nat. Cell Biol. 2019, 574, 193–199. [Google Scholar] [CrossRef] [PubMed]
- Amitrano, D. Brittle-ductile transition and associated seismicity: Experimental and numerical studies and relationship with thebvalue. J. Geophys. Res. Space Phys. 2003, 108. [Google Scholar] [CrossRef] [Green Version]
- Scholz, C.H. On the stress dependence of the earthquake b value. Geophys. Res. Lett. 2015, 42, 1399–1402. [Google Scholar] [CrossRef] [Green Version]
- De Rubeis, V.; Dimitriu, P.; Papadimitriou, E.; Tosi, P. Recurrent patterns in the spatial behaviour of Italian seismicity revealed by the fractal approach. Geophys. Res. Lett. 1993, 20, 1911–1914. [Google Scholar] [CrossRef]
- Legrand, D.; Cistemas, A.; Dorbath, L. Mulifractal analysis of the 1992 Erzincan aftershock sequence. Geophys. Res. Lett. 1996, 23, 933–936. [Google Scholar] [CrossRef]
- Murase, K. A Characteristic Change in Fractal Dimension Prior to the 2003 Tokachi-oki Earthquake (M J = 8.0), Hokkaido, Northern Japan. Earth Planets Space 2004, 56, 401–405. [Google Scholar] [CrossRef] [Green Version]
- Aki, K. A probabilistic synthesis of precursory phenomena. In Earthquake Prediction, American Geophysical Union; Maurice Ewing Series 4; Simpson, D.W., Richards, P.G., Eds.; Wiley: Hoboken, NJ, USA, 1981; pp. 566–574. [Google Scholar]
- King, C.-Y. Earthquake prediction: Electromagnetic emissions before earthquakes. Nat. Cell Biol. 1983, 301, 377. [Google Scholar] [CrossRef]
- Main, I.G. Damage mechanics with long-range interactions: Correlation between the seismic b-value and the two point correlation dimension. Geophys. J. Int. 1992, 111, 531–541. [Google Scholar] [CrossRef] [Green Version]
- Henderson, J.; Main, I. A simple fracture-mechanical model for the evolution of seismicity. Geophys. Res. Lett. 1992, 19, 365–368. [Google Scholar] [CrossRef]
- Wyss, M. Fractal Dimension and b-Value on Creeping and Locked Patches of the San Andreas Fault near Parkfield, California. Bull. Seism. Soc. Am. 2004, 94, 410–421. [Google Scholar] [CrossRef]
- Goebel, T.H.; Kwiatek, G.; Becker, T.W.; Brodsky, E.E.; Dresen, G. What allows seismic events to grow big? Insights from b-value and fault roughness analysis in laboratory stick-slip experiments. Geology 2017, 45, 815–818. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Panakkat, A.; Adeli, H. Neural network models for earthquake magnitude prediction using multiple seismicity indicators. Int. J. Neural Syst. 2007, 17, 13–33. [Google Scholar] [CrossRef] [PubMed]
- Reyes, J.; Morales-Esteban, A.; Martínez-Álavarez, F. Neural networks to predict earthquakes in Chile. Appl. Soft Comput. 2013, 13, 1314–1328. [Google Scholar] [CrossRef]
- Mignan, A.; Broccardo, M. Neural Network Applications in Earthquake Prediction (1994–2019): Meta-Analytic and Statistical Insights on Their Limitations. Seism. Res. Lett. 2020, 91, 2330–2342. [Google Scholar] [CrossRef]
- Marzocchi, W.; Spassiani, I.; StalloneiD, A.; Taroni, M. How to be fooled searching for significant variations of the b-value. Geophys. J. Int. 2019, 220, 1845–1856. [Google Scholar] [CrossRef]
- Picozzi, M.; Oth, A.; Parolai, S.; Bindi, D.; De Landro, G.; Amoroso, O. Accurate estimation of seismic source parameters of induced seismicity by a combined approach of generalized inversion and genetic algorithm: Application to The Geysers geothermal area, California. J. Geophys. Res. Solid Earth 2017, 122, 3916–3933. [Google Scholar] [CrossRef]
- Woessner, J. Assessing the Quality of Earthquake Catalogues: Estimating the Magnitude of Completeness and Its Uncertainty. Bull. Seism. Soc. Am. 2005, 95, 684–698. [Google Scholar] [CrossRef]
- Wiemer, S. A Software Package to Analyze Seismicity: ZMAP. Seism. Res. Lett. 2001, 72, 373–382. [Google Scholar] [CrossRef]
- Aki, K. Maximum likelihood estimation of b in the formula log N = a-bM and its confidence limits. Bull. Seism. Soc. Am. 1965, 43, 237–239. [Google Scholar]
- Henderson, J.R.; Barton, D.J.; Foulger, G.R. Fractal clustering of induced seismicity in The Geysers geothermal area, California. Geophys. J. Int. 1999, 139, 317–324. [Google Scholar] [CrossRef] [Green Version]
- Zaliapin, I.; Gabrielov, A.; Keilis-Borok, V.; Wong, H. Clustering Analysis of Seismicity and Aftershock Identification. Phys. Rev. Lett. 2008, 101, 018501. [Google Scholar] [CrossRef] [Green Version]
- Zaliapin, I.; Ben-Zion, Y. Discriminating Characteristics of Tectonic and Human-Induced Seismicity. Bull. Seism. Soc. Am. 2016, 106, 846–859. [Google Scholar] [CrossRef]
- Kanamori, H.; Hauksson, E.; Hutton, L.K.; Jones, L.M. Determination of earthquake energy release and ML using TER-RAscope. Bull. Seismol. Soc. Am. 1993, 83, 330–346. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nat. Cell Biol. 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hochreiter, S. The Vanishing Gradient Problem DURING Learning Recurrent Neural Nets and Problem Solutions. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learning Res. 2014, 15, 1929–1958. [Google Scholar]
- Shanker, M.; Hu, M.; Hung, M. Effect of data standardization on neural network training. Omega 1996, 24, 385–397. [Google Scholar] [CrossRef]
- Efron, B. Bootstrap methods: Another look at the jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Matthews, B.W. Comparison of the predicted andobserved secondary structure of T4 phage lysozyme. Biochim. Biophys. Acta BBA Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martínez-Garzón, P.; Kwiatek, G.; Sone, H.; Bohnhoff, M.; Dresen, G.; Hartline, C. Spatiotemporal changes, faulting regimes, and source parameters of induced seismicity: A case study from The Geysers geothermal field. J. Geophys. Res. Solid Earth 2014, 119, 8378–8396. [Google Scholar] [CrossRef] [Green Version]
- Kwiatek, G.; Martínez-Garzón, P.; Dresen, G.; Bohnhoff, M.; Sone, H.; Hartline, C. Effects of long-term fluid injection on induced seismicity parameters and maximum magnitude in northwestern part of The Geysers geothermal field. J. Geophys. Res. Solid Earth 2015, 120, 7085–7101. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Picozzi, M.; Iaccarino, A.G. Forecasting the Preparatory Phase of Induced Earthquakes by Recurrent Neural Network. Forecasting 2021, 3, 17-36. https://doi.org/10.3390/forecast3010002
Picozzi M, Iaccarino AG. Forecasting the Preparatory Phase of Induced Earthquakes by Recurrent Neural Network. Forecasting. 2021; 3(1):17-36. https://doi.org/10.3390/forecast3010002
Chicago/Turabian StylePicozzi, Matteo, and Antonio Giovanni Iaccarino. 2021. "Forecasting the Preparatory Phase of Induced Earthquakes by Recurrent Neural Network" Forecasting 3, no. 1: 17-36. https://doi.org/10.3390/forecast3010002
APA StylePicozzi, M., & Iaccarino, A. G. (2021). Forecasting the Preparatory Phase of Induced Earthquakes by Recurrent Neural Network. Forecasting, 3(1), 17-36. https://doi.org/10.3390/forecast3010002