1. Introduction
Economic forecasting is challenging—and always has been. No clear consensus as to the ‘best’ or even ‘good’ approaches has arisen in the literature. Sophisticated methods often fail to beat a simple autoregressive model. Even when a small advantage is shown, this may fail to survive in slightly different settings or time periods. What does hold is that all theoretical results that assume stationarity are irrelevant. Instead, small shocks occur regularly and their effects can cumulate, and large shocks and structural breaks happen intermittently. Causes of such breaks can be financial crises, trade wars, conflicts, policy changes, and pandemics etc. Consequently, nonstationarities can arise from both unit roots and structural breaks in mean or variance.
The sequence of forecasting ‘competitions’ commencing with [
1] analysing 111 time series, through [
2,
3,
4] with M3, then M4 (see [
5], held by the M Open Forecasting Center at the University of Nicosia in Cyprus) created realistic, immutable, and shared data sets that could be used as testbeds for forecasting methods. Ref. [
6] provides a more general history and [
7] consider their role in improving forecasting practice and research. However, interpretations of the findings from the competitions have been ambiguous as exemplified by the different conclusions drawn by [
4,
8,
9]. There are also limitations to the data: variables are anonymized, and have unknown and differing sample periods. This prevents the use of subject matter expertise or any judgemental adjustment irrespective of skill or knowledge (as analyzed by e.g., [
10]). It also creates problems for methods that try to link variables for forecasting: the misaligned sample periods may cause some variables to be ahead in time of others. Unfortunately, this also rules out any multiple variable or factor approaches. Nevertheless, such forecasting competitions have made valuable contributions to improving the quality of economic forecasting methods, as well as increasing our understanding of methods and techniques. A useful addition to M4 was the request for interval forecasts: good expressions of the uncertainty of a forecast are just as important as the forecasts themselves, a feature emphasized by the ‘fan charts’ used by the Bank of England in their
Inflation Reports: see [
11]. Probabilities of rain are now a routine aspect of weather forecasts, and forecast uncertainty should be quantified in other settings as well.
By combining the insights from our research, the literature, M4 results, and forecasting the COVID-19 pandemic, there seem to emerge a few relatively general ’principles’ for economic forecasting:
- (I)
dampen trends/growth rates;
- (II)
average across forecasts from ‘non-poisonous’ methods;
- (III)
include forecasts from robust devices in that average;
- (IV)
select variables in forecasting models at a loose significance;
- (V)
update estimates as data arrive, especially after forecast failure;
- (VI)
‘shrink’ estimates of autoregressive parameters in small samples;
- (VII)
adapt choice of predictors to data frequency;
- (VIII)
address ‘special features’ like seasonality.
The authors made a submission to the M4 competition that did well in many aspects. Here we aim to interpret such results, and those of some methods that did well in M3 and M4, in light of these principles. As part of this, we first summarize the properties of the M4 data set, which leads to improved benchmark forecast methods.
Our forecast method,
Card, is formally described in [
12]. The procedure is based on simple autoregressive models, augmented with a damped trend (I) (see e.g., [
13], followed by many applications) and some robustification through differencing (III), as our earlier research has emphasised the key role of location shifts in forecast failure (see [
14,
15]). Forecast combination (II) is also used as it is found to be risk reducing and can even outperform the best of the methods averaged over (dating from [
16], and widely used). ‘Wild’ forecasts from small data samples are monitored (VI), and seasonality is handled (VIII). As only univariate methods seemed feasible, (IV) was not relevant (see [
17], for an analysis), although some entrants used the data in other series which may lead to infeasible methods. Also note that [
18] show that additional explanatory variables in models need not improve forecasts even when their future values are known. (V) could not be implemented given the structure of the competitions (see e.g., [
19], for its advantages following a break in the included variables), although we did graph recursive forecasts. Finally, we know (VII) matters, as different entries performed best at different data frequencies. Below we show that some further improvement can be made by paying more attention to our principles. Furthermore, an improved formulation of the forecast standard errors is provided for our method.
M4 is the fourth generation of M forecast competitions, created by Spyros Makridakis and the M4 team. M4 provides a database of 100,000 series requiring out-of-sample forecasts. This large size makes it a computational challenge too. Efficient production of forecasts is useful, even more so when studying subsample properties. The previous competition, M3, consisted of “only” 3003 variables. The best performing method in the M3 competition is the so-called
Theta method, see [
4] and
Section 2.2 below, so many papers take that as the benchmark to beat. Ref. [
20] demonstrated the non-invariance of evaluation metrics to linear transformations that leave forecasting models invariant, but the choice was set by the organisers and is discussed in
Section 2.4.
Proper handling of seasonality is expected to be an important aspect of forecasting. This implies that the exercise has some similarities to the X12-ARIMA (autoregressive-integrated moving average) programme of the US Census Bureau, see [
21]. The X12 approach involves estimating a seasonal ARIMA model to extend the series with forecasts, followed by smoothing using a sequence of moving averages in the seasonal and deseasonalized directions. Estimated moving averages are sensitive to outliers and structural breaks, and procedures need to make allowance for this.
The remainder of this paper is as follows. We discuss the structure of M4 and its benchmark methods in
Section 2, and we describe M4 data properties in
Section 3. Next, we adapt the
Theta method, and introduce a simple but effective variant in
Section 4. We also consider the expected outcomes of the accuracy measures and study the performance of the new benchmark methods. In
Section 5 we discuss how the heterogeneity and independence of time-series samples affects outcomes and propose a simulation experiment that captures the salient features of yearly M4. In
Section 6 we consider improvements to the
Card method, leading to
Cardt. This plays a prominent role in our COVID-19 forecasts, see
Section 8.
Section 7 evaluates
Cardt with the M3 and M4 data. Finally,
Section 9 concludes. Derivations and supplementary results are presented in appendices.
2. M4 Competition
We compare the design of the M4 competition to that of M3 in
Section 2.1. The objective of M4 is to mimimize two error measures, one for the point forecasts, and another for the interval forecasts,
Section 2.4. The former, denoted overall weighted average (OWA), standardizes using one of the benchmark methods. Hence, these are described in
Section 2.2 for annual data, with adjustments for seasonality in
Section 2.3.
2.1. Overview
In many respects, M4 is a direct successor to the M3 competition. A range of annual, quarterly, and monthly time series is provided with the aim to make out-of-sample forecasts for each of these series up to a specified horizon. These forecasts are evaluated against a sample that has been held back by the organizers. The time series are anonymized: name and sample dates are unknown, and the series are rescaled. The variables are categorized as demographic, finance, industry, macro, micro, and other. Most forecast applications ignore these categories. Evaluation is on a selection of performance metrics, such as variants of the mean absolute percentage error (MAPE). The M3 data set has become widely used as a benchmark for new forecast methods.
There are some differences between M3 and M4 as well. M4 is much larger at 100,000 time series, whereas M3 has 3003. M4 introduces weekly, daily, and hourly data; M3 has a small set with "other" frequency. M4 includes a possibility to report interval forecasts. By encouraging participants to publish their methods on Github, M4 achieves a greater level of replicability.
M4 was run as a proper competition, with monetary prizes for those methods scoring best on a single criterion, separately for the point forecasts and intervals. M3, on the other hand, evaluated the forecasts on five criteria, but did not produce an overall ranking. M3 also included an opportunity to receive interim feedback on the forecast performance, as reported by [
22].
M4 addresses several of the shortcomings that were raised in the special issue on M3 of the
International Journal of Forecasting (2001, 17): addition of weekly data and interval forecasts, more seasonal data, and potentially a more representative data set through the vast number of series. The M3 report did not include a statistical test to see whether forecasts are significantly different. This was added later by [
23], and included in the M4 report, although not split by frequency.
Other shortcomings remain. Different performance metrics will result in different rankings. The series are all positive, and forecasting growth rates may also completely change the ranking of forecasting procedures. Finally, the design is inherently univariate. No sample information is available, so some series may contain future information on other series. As a consequence, methods that use other series may inadvertently be infeasible: in practice we never know future outcomes, except for deterministic or predetermined variables.
Some basic aspects of the M4 data are given in
Table 1, including values of the forecast horizon
H that are specific to each frequency. The yearly, monthly, and quarterly series together constitute
of the sample, so will dominate the overall results. The frequency is given through the labels “hourly”, “weekly” etc. but not otherwise provided. Hence, daily data could be for five weekdays or a full seven day week. The evaluation frequency
m is used in the performance measures (
Section 2.4). It is left to the participants to choose the frequency
S (or dual frequencies
S and
) for their methods.
Table 1 records the lengths of shortest and longest series under
and
. This is for the competition (or training) version of the data, so excluding the
H observations that were held back until after the competition. The sample sizes of annual data range from 13 to 835, but it is unlikely that there is a benefit from using information of more than 800 ‘years’ ago.
2.2. M4 Benchmark Forecasting Methods
The organizers of M4 used ten forecast methods as benchmark methods: these would be evaluated and included in the final results by the organizers. These benchmark methods comprised three random-walk type extrapolation methods, five based on exponential smoothing, and two machine learning methods. We review random walk, exponential smoothing, and
Theta forecasts, but ignore the basic machine learning and neural network approaches. Ref. [
24] show the inferior forecasting performance of some machine learning and artificial intelligence methods on monthly M3 data.
The random walk forecasts of annual and nonseasonal data are a simple extrapolation of the last observation. This is called
Naive2 forecasts in M4 (and the same as
Naive1 in the absence of seasonality). Denoting the target series as
, the objective is to forecast
, in this case:
Exponential smoothing (ES) methods are implemented as single source of innovation models, see [
25,
26]. They can be formulated using an additive or multiplicative (or mixed) representation. The additive exponential smoothing (AES) model has the following recursive structure:
where
is the observed time series,
the one-step prediction error,
the level, and
the slope. Given initial conditions
and
, the coefficients
and
can be estimated by maximum likelihood. An alternative approach is to add the initial conditions as additional parameters for estimation. Forecasting simply continues the recursion with
, keeping the parameters fixed.
AES includes the following forecasting methods, among others:
| SES | Simple exponential smoothing | , |
| HES | Holt’s exponential smoothing, | |
| Theta2 | Theta(2) method | defined in (1).
|
The
SES and
HES models with infinite startup are ARIMA
and ARIMA
models respectively, see [
25] (Ch.11). A dampened trend model adjusts the slope equation to
where
. Holt–Winters exponential smoothing adds a seasonal equation to the system (see [
27,
28]).
The
Theta method of [
29] first estimates a linear trend model
by OLS. The
Theta forecasts are then the sum of the extrapolated trend and forecasts from the model for
, with weights
and one respectively. The suggested model for
is SES, in which case this method can be implemented within the AES framework, as shown by [
30].
Theta2, i.e., using
, had the best sMAPE (see
Section 2.4 below) in the M3 competition, see [
4]. It is also the best benchmark method by the overall criterion (
5), so we ignore the others.
The AES estimates depend on several factors: initial conditions of the recursion, imposition of parameter constraints, and objective function. We have adopted different conventions for the initial conditions, so, in general, will get different results from the R forecast package ([
31]). The exception to this is
SES with
and
as an estimated parameter. We also get almost identical results for
Theta2. We impose
, and set
, which conditions on the first observation to force
. For the yearly M3 data with
we obtain an sMAPE of 16.72, where [
30] (Table 1) report 16.62 (the submission to M3 has sMAPE of 16.97).
2.3. Seasonality in the M4 Benchmark Methods
Let
denote the terms of the autocorrelation function (ACF) of a time series with
T observations. The seasonality decision in the M4 benchmarks for frequency
is based on the squared
Sth autocorrelation of the series
:
If this test of nonseasonality rejects with a p-value of or less, the series is seasonally adjusted with an filter (or just if S is odd). The benchmark is applied to the seasonally adjusted series, and the forecasts are then recolored with the seasonality. The seasonal adjustments use multiplicative adjustment throughout.
Assuming the frequency
S is even, the seasonal component is the deviation from a smooth ‘trend’:
Now let
denote the average for each season
from the
observations
(so not all seasons need to have the same number of observations). These seasonal estimates are normalized to the frequency:
The seasonally adjusted series is
Finally, the forecasts from the seasonally adjusted series are multiplied by the appropriate seasonal factors. For the
Naive2 method, assuming observation
is for period
S, the forecasts are:
2.4. M4 Forecast Evaluation
M4 uses two scoring measures, called MASE ([
32]) and sMAPE ([
33]). For time-series
with forecasts
produced over
and seasonal frequency
m (which is allowed to differ from the frequency
S for seasonal adjustment):
The denominator of MASE is the average of the seasonal difference over the ‘estimation period’:
MASE is infinite if the series is constant within each season: in that case we set it to zero.
Next, the sMAPE and MASE are each averaged over all forecasts in the evaluation set. To facilitate comparison, these averages can be scaled by the average accuracy of the benchmark
Naive2 forecasts. This leads to the final objective criterion of M4 for method
X:
A
forecast interval is expressed as
. Accuracy of each forecast interval for all series and horizons
h is assessed on the basis of mean scaled interval score (MSIS):
M4 uses
, so that any amount outside the bands is penalized by forty times that amount. Ref. [
34] (p. 370) show that the interval score is ‘proper,’ meaning that it is optimized at the true quantiles.
We can also count the number of outcomes that are outside the given forecast interval. For a pointwise interval, we aim to be outside in about of cases, corresponding to a coverage difference of close to zero.
3. M4 Data
The large dimension of the M4 data set makes it impossible to look at all series in detail. But a limited exploration makes it clear that most variables appear to be in levels, and many have strong signs of seasonality. This section focuses on time-series properties that may affect the implementation of forecast procedures: sample size (
Section 3.2), using logarithms (
Section 3.3), persistence (
Section 3.4), and testing seasonality (
Section 3.5).
All results in this section are based on the training data, so exclude the sample that was held back to evaluate the submitted forecasts.
3.1. Properties of Interest
Understanding the properties of large datasets is a challenge. Ref. [
35] propose a solution for M3, which is applied to M4 in [
36]. They characterize each series on six aspects, each on a scale of zero to one. This is then summarized by the first two principal components. If we ignore the estimate of the seasonal periodicity, then three aspects are based on an additive decomposition in trend, seasonal, and residual: relative variance of the trend, relative variance of the seasonal, and first order autocorrelation coefficient of the residual. The remaining two aspects are an estimate of the spectral entropy, and the estimated Box-Cox parameter. Ref. [
36] refer to the entropy measure as “forecastability”, and, rather unusually, autocorrelation in the residuals as “linearity” and Box-Cox as “stability”.
These aspects are not so helpful to us as a forecaster: we wish to decide whether to use logarithms or not (i.e. an additive versus multiplicative model), whether there is seasonality or not, and if first differences are a transformation that helps with forecasting. Ideally we would also like to know if the series has been subject to large breaks, and perhaps the presence of nonlinearity.
3.2. Sample Size
Yearly, quarterly, and monthly data have a small number of series with a very large sample size, which is unlikely to benefit forecasting.
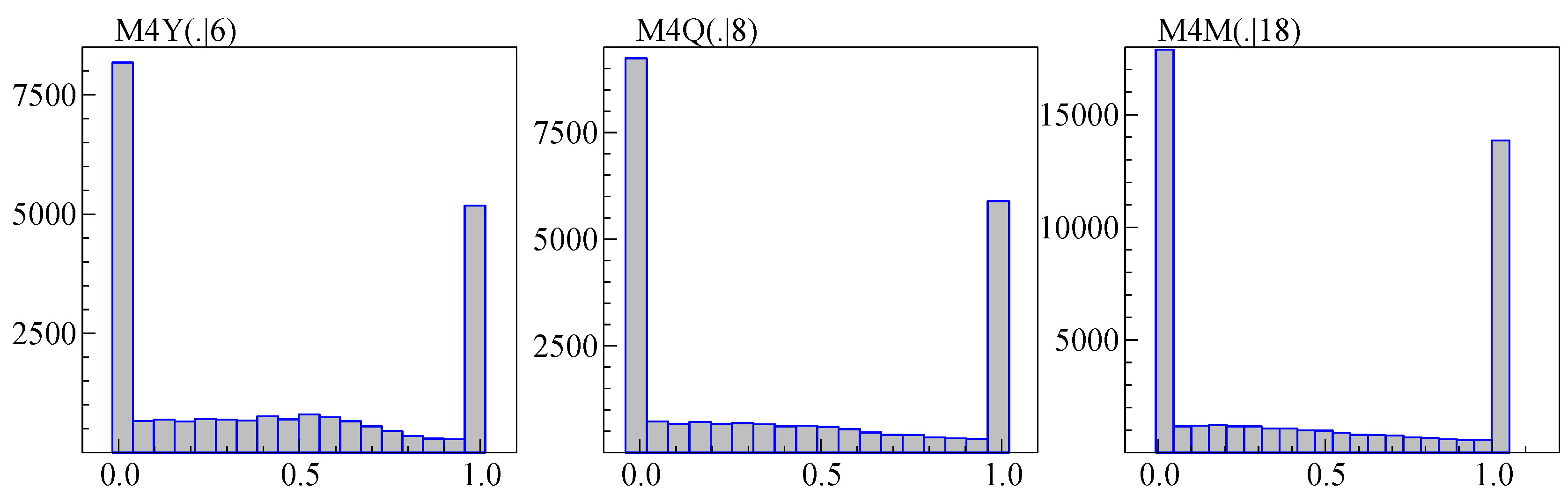
Figure 1 shows the distribution of sample size at each frequency. Yearly, quarterly, monthly, and weekly data have been truncated to 40 years of data, and daily data to 1500 observations.
Along the vertical axis is the bar chart of the frequencies of the different sample sizes. So for annual data about a third has sample size 40 after truncation, and the next biggest group has 29 observations. The same information is shown cumulatively as well in the line that runs from zero at the bottom left, to unity in the top right. This dual perspective reveals the central tendency without hiding the tails.
The truncation has a relatively large impact on daily data. Hourly data only comes in two sample sizes.
3.3. Logarithms
The benchmark methods do not take any transformations of the variables. In contrast, ref. [
37] use a Box–Cox transformation (see [
38]) in their bagging method. Ref. [
39] improve on the
Theta method in the M4 competition by using a Box–Cox transformation. In both cases the transformation is restricted to
, where
corresponds to the logarithmic transformation and otherwise:
So indicates the absence of any transformation. The difference between their two approaches is that the former does the Box–Cox transformation before deseasonalization, and the latter afterwards. We found that this distinction matters little: the values of estimated before or after multiplicative seasonal adjustments are similar: in quarterly M4 and monthly M3 the correlation between the estimates exceeds .
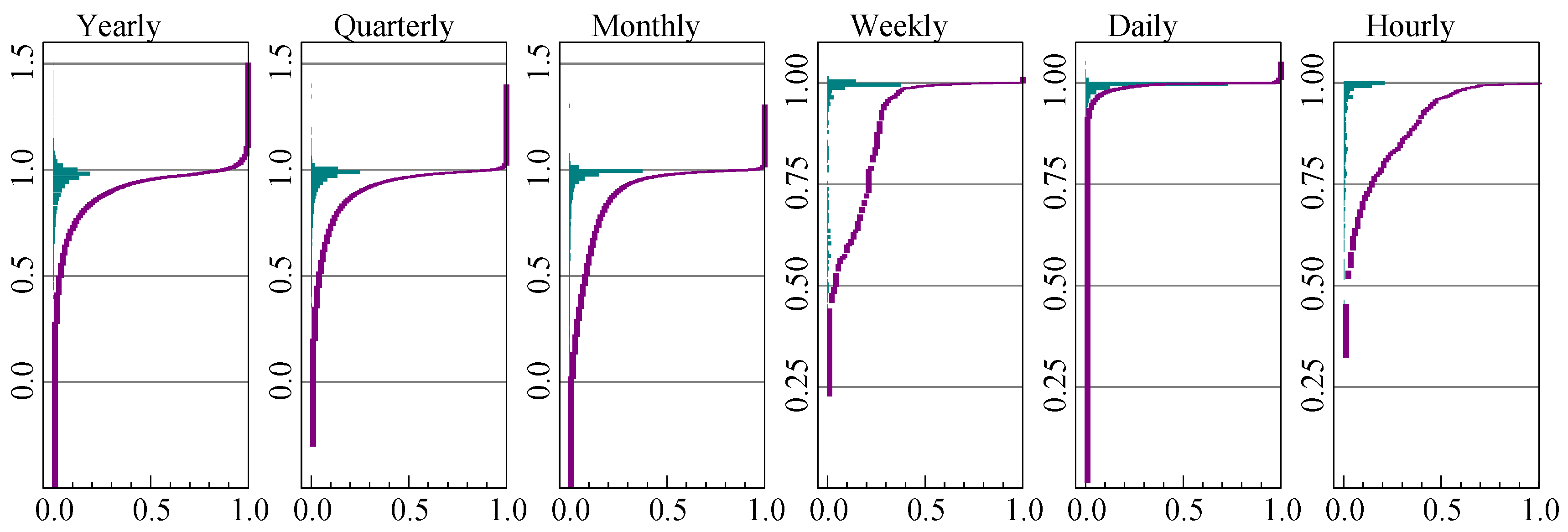
Figure 2 shows the histogram of
estimated by maximum likelihood in a model on a constant and trend (and restricted to be between zero and one), using samples truncated as described in the previous section. This amounts to minimizing the adjusted variance as a function of
. The U shapes in
Figure 2 indicate that the choice is mainly between logarithms and levels (Ref. [
35] find a similar U shape for M3). This suggests a simpler approach, such as comparing the variance when using levels to that using logs. Removing the trend by differencing leads to an approach as in [
40], i.e., using logs when
in combination with:
where
is the sample variance of
and
is the sample mean of
. Using (
7) means that the iterative estimation of
can be avoided.
All observations in M3 and M4 are positive, and experimentation suggests a benefit from preferring logs when
. The
term in (
7) is introduced to allow a bias towards using logarithms.
3.4. Persistence
To assess persistence, we estimate
by OLS from
The seasonal dummies are excluded if the sample size is small () and for daily data.
The distribution of the autoregressive coefficient is plotted in
Figure 3 for each frequency. The labels along each vertical axis correspond to the value of
, while the frequencies and proportions are on the horizontal axes.
The estimates of cluster near unity at all frequencies, corresponding to very high persistence in the data. However, more than is above unity for annual data, which is likely caused by small samples. To a lesser extent this is found at the higher frequencies as well. Almost all daily series have a unit root.
Except for hourly data, the seasonal adjustment does not have much visual impact on the graphs.
3.5. Seasonality
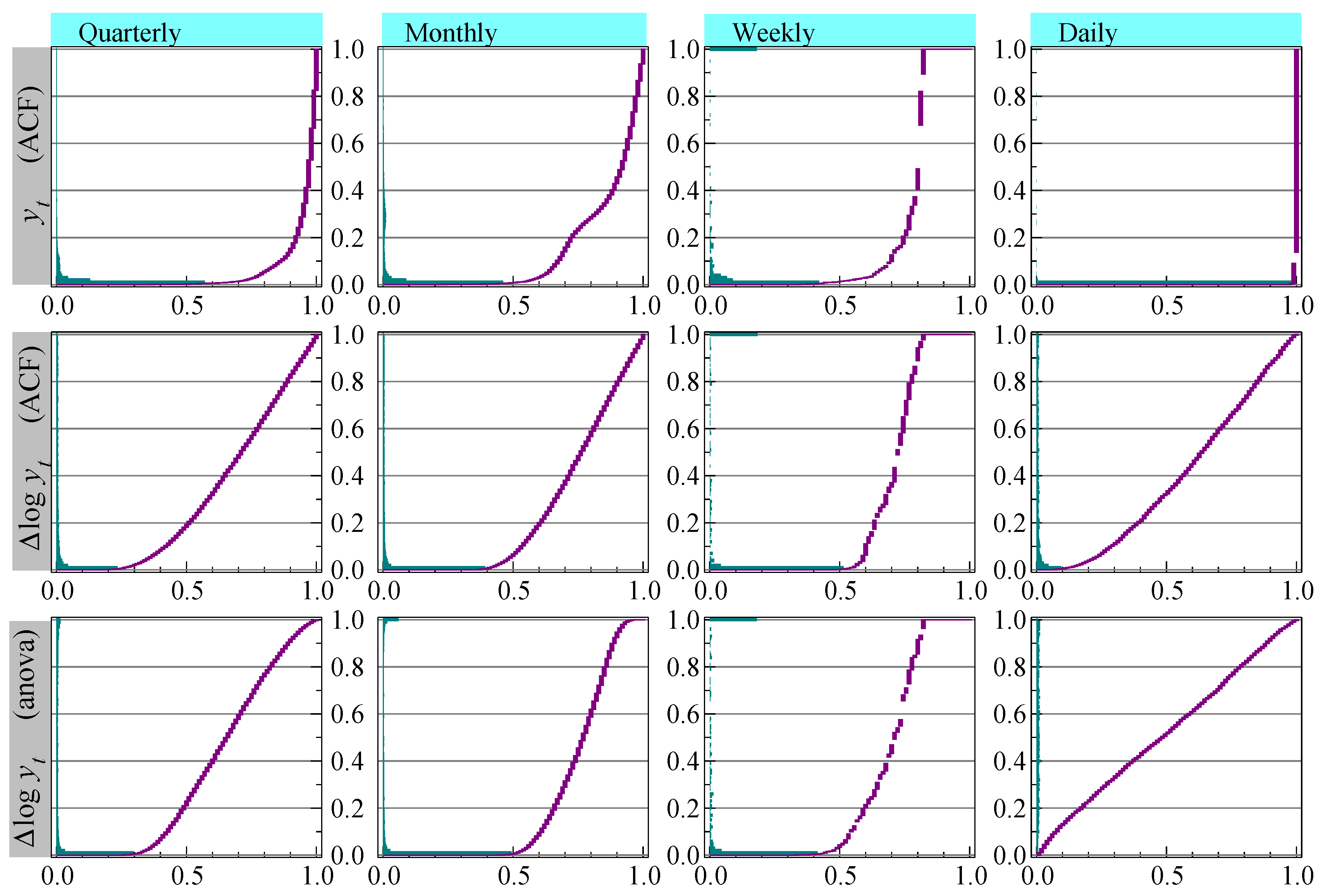
The top row of
Figure 4 shows the distribution of the
p-values of the test for a seasonal root (
2), applied to the original
(without sample truncation). This is the method used in the benchmarks, with the exception of daily data that we gave
to highlight the impact on inference. The vertical axis has the
p-values, and testing quarterly data at
would say that almost
is seasonal. For monthly data it is close to
and for daily data almost all is classified as seasonal at a frequency of five.
The null hypothesis for test (
2) assumes that there is no significant lower order serial correlation, which is mostly proven wrong by
Figure 3. As a consequence, the incidence of seasonality is over-estimated, most strongly for daily data. A more accurate representation is to apply the test to
. This is shown in the middle row of graphs, now with a lower incidence of seasonality where almost none of the daily data, again tested with
, appear to have seasonality.
X-11, see [
41], incorporates an
analysis of variance-based (ANOVA) test for stable seasonality, which has as the null hypothesis that the
S seasonal means are equal:
The sample size is adjusted to have
Y years with
S periods, and
denotes the mean of the observations pertaining to season
j. The bottom row of graphs shows the
p-values of the ANOVA test for stable seasonality, applied to
and as used in [
12].
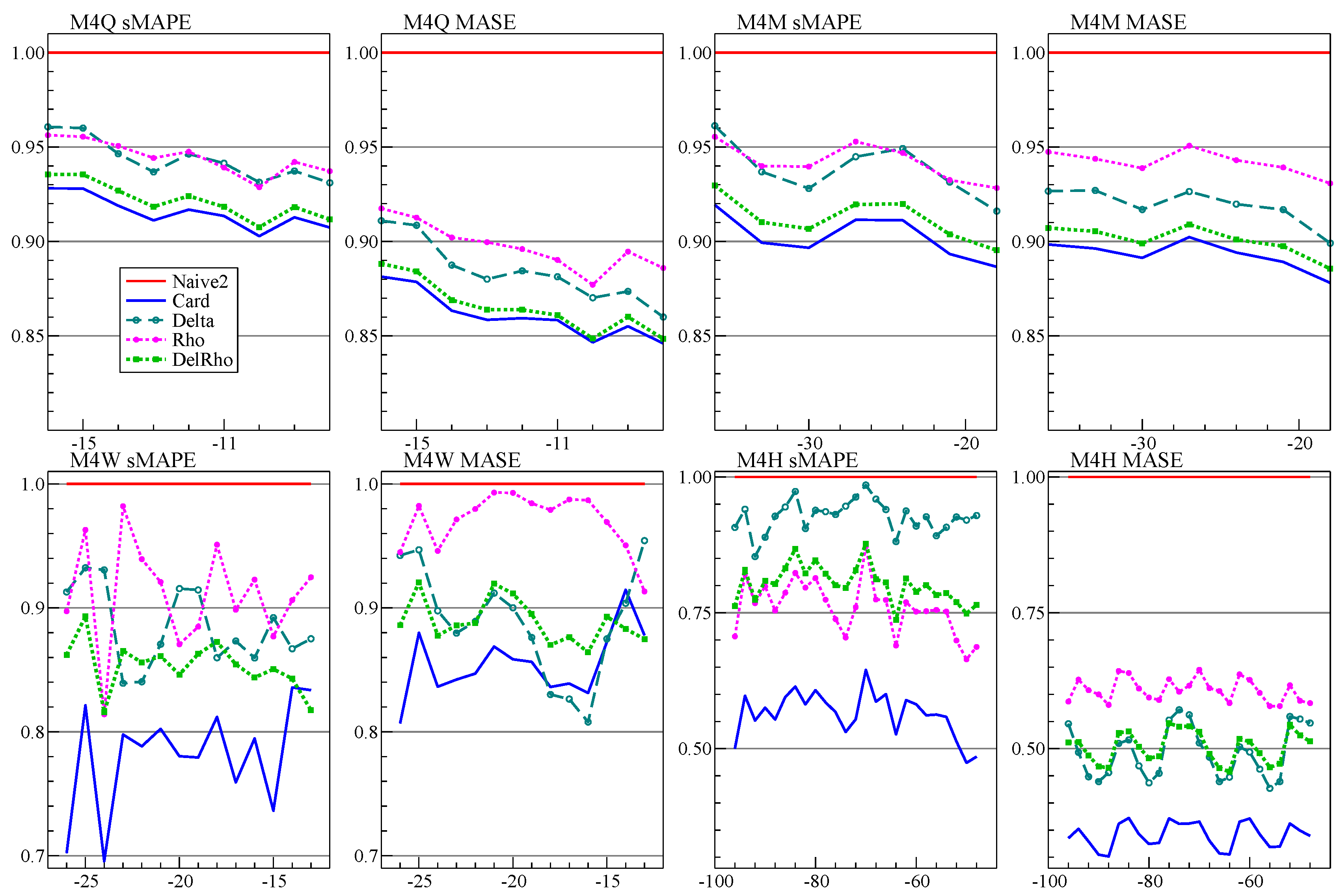
6. The Cardt Method
Our submission to the M4 competition was labeled
Card, summarized in
Section 6.1. We introduce some small adjustments to that method, first a robust adjustment in
Section 6.2, then adding
THIMA to create
Cardt in
Section 6.3. We also derive interval forecasts that can be used at different significance levels and sample sizes in
Section 6.4.
6.1. The Original Card Method
Card combined two autoregressive methods, incorporating trend dampening, some robustness against structural breaks, and limiting the autoregressive coefficient to prevent wild forecasts. The forecasts were obtained from a final ‘calibration’ step. [
12] provide a technical description.
The first forecast method in Card is based on estimating the growth rates from first differences—hence labeled Delta method—but with removal of the largest values and additional dampening. The second method, called Rho, estimates a simple autoregressive model, possibly switching to a model in first differences with dampened mean.
Next, the forecasts of
Rho and
Delta are averaged with equal weights. Calibration treats the hold-back forecasts as if they were observed, and re-estimates a model that is a richer version of the first-stage autoregressive model (see (
A5) in
Appendix B). The fitted values over the forecast period (now pseudo in-sample) are the new forecasts. At this stage there is no issue with overfitting or explosive roots, because no further extrapolation is made.
Calibration makes little difference for annual or daily data, which have no seasonality. It does, however, provide almost uniform improvements in all other cases, in some cases substantially so. This experience is also reported for the X12-ARIMA procedure ([
21]), although there the ARIMA model comes first, providing a forecast extension that is used in the X11 procedure. Our procedure could be a flexible alternative.
Card made initial decisions about the use of logarithms, differences versus levels, and the presence of seasonality:
Let denote the initial series. If : , else .
This entails that logs were always used in both the M3 and M4 data.
If then forecast from a dynamic model, else directly forecast the levels using a static model.
The static model only occurs in M4 at a rate of (yearly), (quarterly), (monthly), and almost never at the other data frequencies.
The presence of seasonality is tested at
based on the ANOVA test (
8) using
or
(depending on the previous step).
In our application to M4, we limited the number of observations of annual, quarterly, and monthly data to 40 years, and daily data to 4 years. The choice of 40 was a compromise between recency to avoid distortion from distant shifts yet sufficient data for parameter estimation. The longer the estimation sample, the greater the possibility of distributional shifts in the earlier data that would be inimical to forecasting. For hourly data, the Rho and Delta are calibrated, then averaged, then calibrated again; calibration is done with autoregressive lag six instead of one. For weekly data, Rho is applied to the four-weekly averages (giving frequency 13), and calibrated before averaging with Delta.
For hourly data,
, we add a second frequency
to reflect the diurnal rhythm:
creates an additional frequency of
for the weekly pattern. In [
12] we specified the daily frequency as
, but this was not beneficial, and we change it here to
. So no distinction is made anymore between yearly and daily data.
The Ox ([
46]) code to replicate our Card submission was uploaded to Github shortly after the M4 competition deadline.
6.2. Robust Adjustments to Card
6.2.1. Robust 1-Step Forecasts of AR(1) Model
A correction can make the forecast more robust when there is an unmodeled break at the forecast origin. To illustrate, consider a stationary autoregressive model of order one, AR(1):
In the current setting, all components in
are deterministic, so known for the forecast period (see [
17] for an analysis where the future
’s are not known). The one-step forecast is
The robust forecast is taken from the differenced model:
The robust forecast is an intercept correction based on the last residual. When nothing changes,
, but the variance is increased by
. However, if there is a location shift in
at
T, this is captured in the residual, so there is a trade-off between the increased variance and the reduction in bias. A seasonal equivalent can be based on the seasonally differenced model:
6.2.2. One-Step Ahead Robust Adjustment for Rho
Let
denote the value of
x truncated to be between
a and
b. The following adjustment is to the 1-step forecasts, but only if
Rho is not already using first differences:
R is the averaged residual following (
11), which is limited to two residual standard errors. Half of that is added to the one-step forecast.
Experimentation with M4 shows that the robust version of
Rho using (
12) shows no benefit for monthly and weekly data: here the gains and losses are similar. The benefit is substantial for quarterly, daily, and hourly data. It is small but consistent for annual data. The results for M3 are similar: no improvement for monthly data, although the annual improvement is more pronounced.
6.2.3. One and Two-Step Robust Adjustment after Calibration
At very short horizons, calibration performs worse than the inputs to calibration. We therefore made a small change for the first two forecasts, taking the average of the original and calibrated forecasts. Beyond , the forecasts are unchanged at the fitted values from calibration.
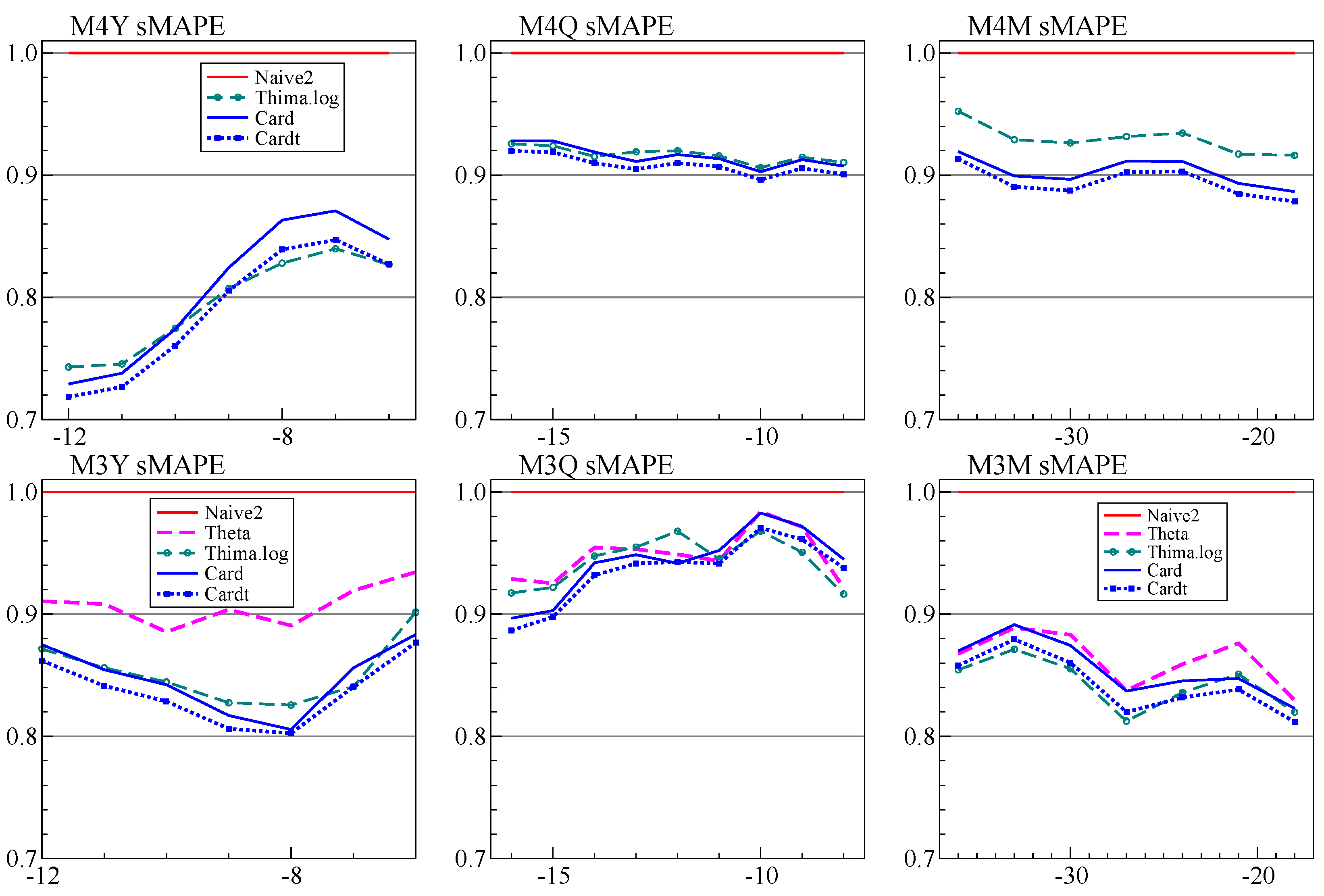
6.3. Cardt: More Averaging by Adding THIMA
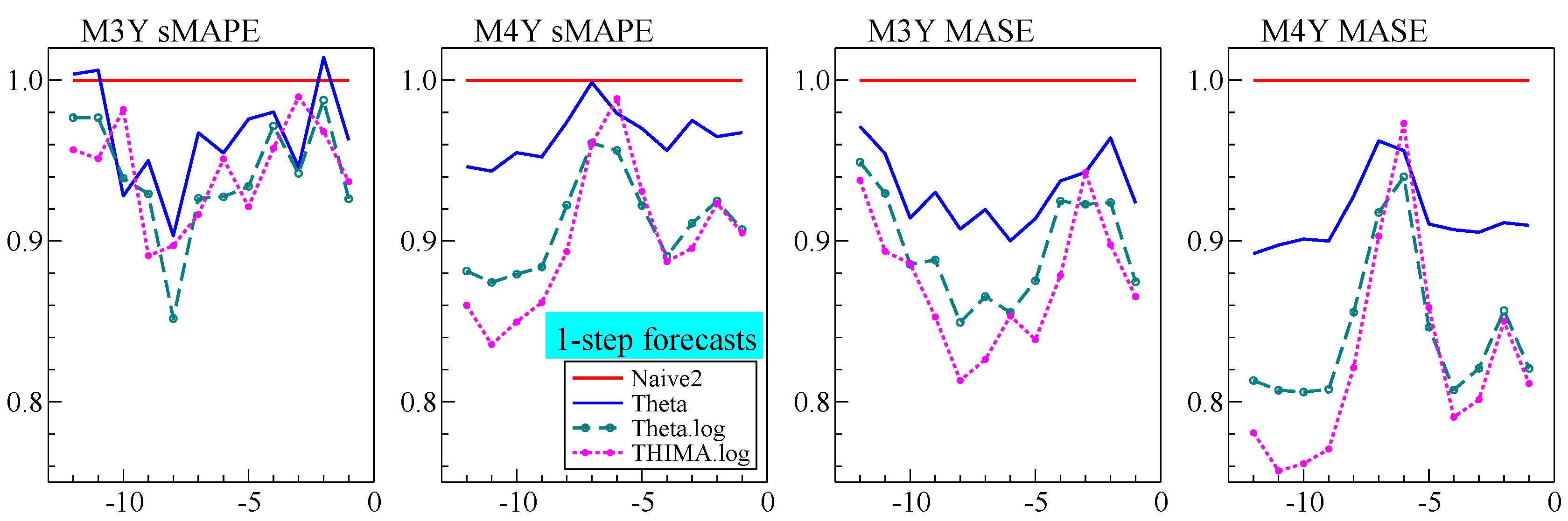
Our annual forecasts using
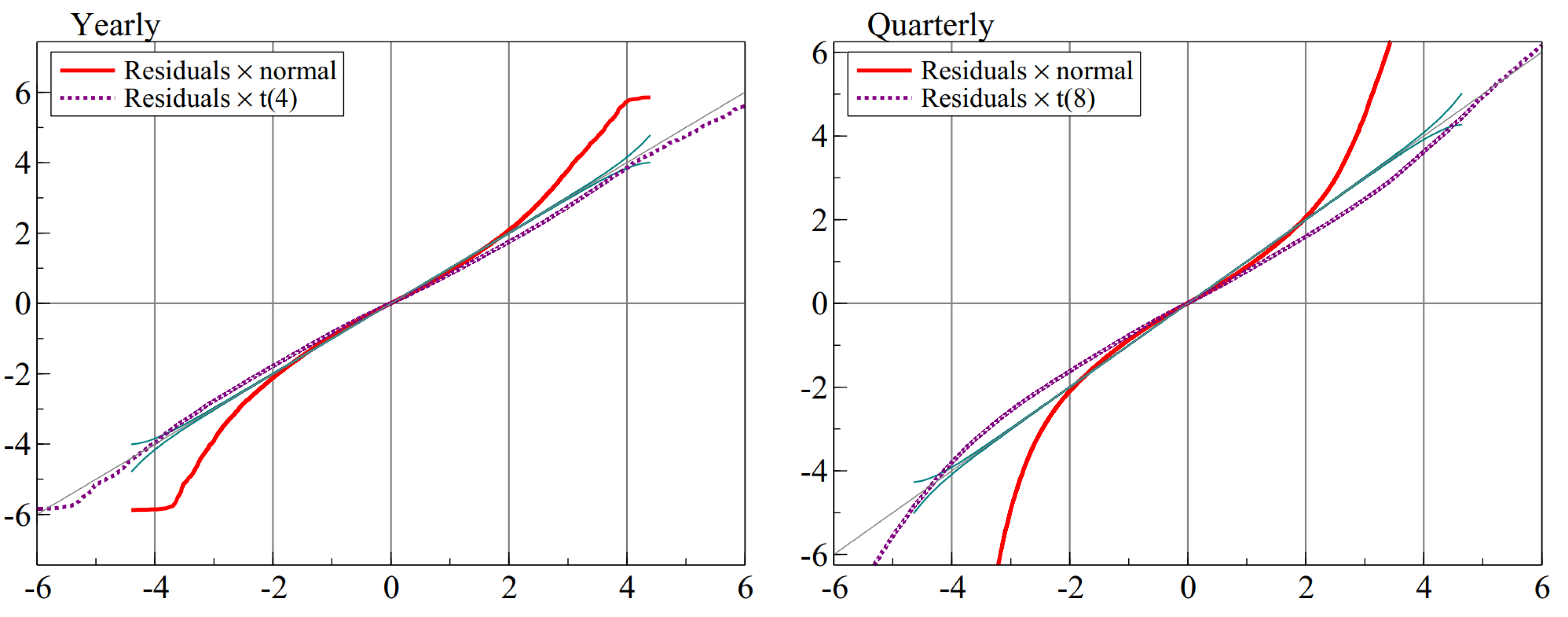
Card did not do as well as expected. Part of the explanation is that holding back twelve observations from the full M4 data set is quite different from withholding six, as was illustrated in
Figure 5. At the time we considered adding a Theta-like forecast to the average prior to calibration, but decided against this. That was a mistake, and
Cardt for frequencies up to twelve now uses the calibrated average of
Rho,
Delta, and
THIMA.log.
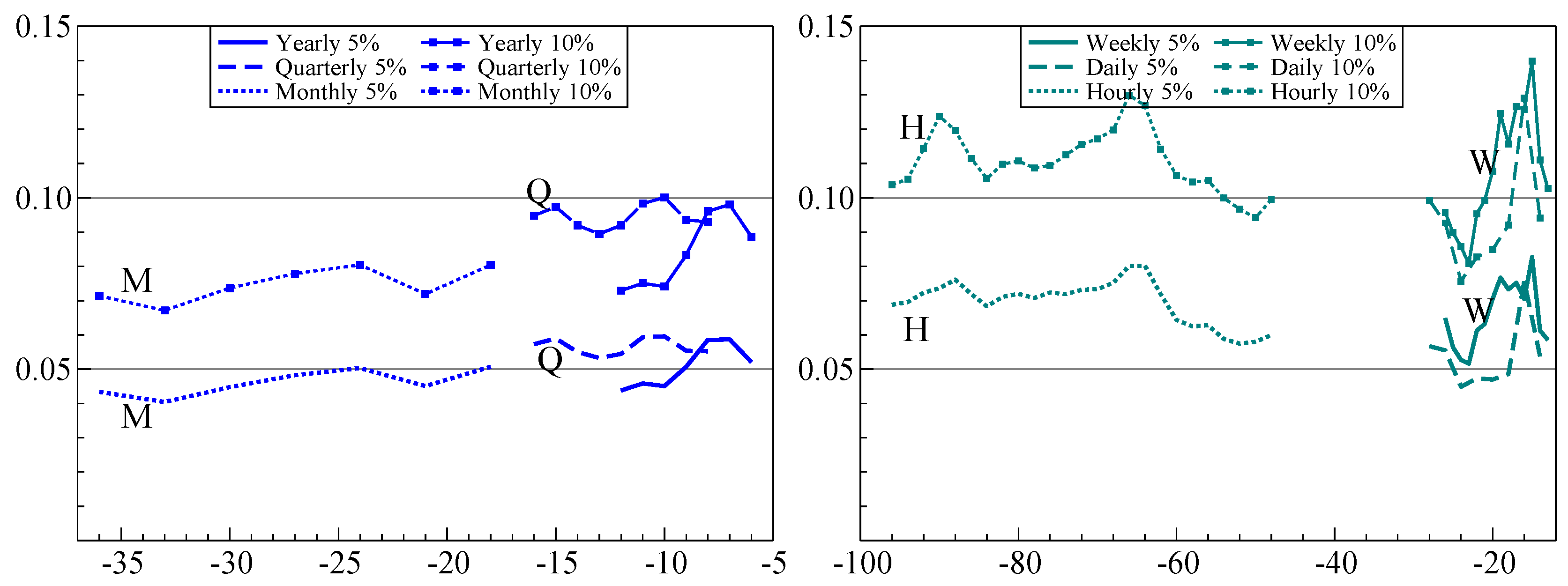
6.4. Forecast Intervals
The forecast intervals of an AR(1) model with drift,
, grow with the horizon
h when the errors are IID:
This is slower than the mean effect:
Our submitted approach was based on
with
forecast interval:
where
is an adjusted estimate of the autoregressive parameter and
is determined by withholding data from the competition data set, aiming for a
interval. Even though this approach did well, it suffers from being asymptotically invalid, as well as being fixed at the
interval.
Our new approach makes a small-sample adjustment to the standard formula for the forecast interval. The basis for this is the calibration formula (see (
A5) in
Appendix B), which, however, is somewhat simplified and restrained. Because the sample size is small in some cases, we account for parameter uncertainty. Ideally, we get the correct point-wise coverage at each interval and in total, as well as a small MSIS from (
6).
The forecast bands have the following form:
This is the standard forecast uncertainty for an autoregressive model with regressors, but here with an inflation factor
that depends on the frequency. The value of
is determined by withholding
H observations from the training data, and finding a value that combined reasonably good coverage at all forecast horizons with a low value of MSIS. The form of
is given in
Appendix B. The critical value
is from a Student-t distribution, with the degrees of freedom given below (
A7) in
Appendix B.
In addition, for , we average the forecast standard errors from calibration in logs with those from calibration applied to the levels.
8. Cardt and COVID-19
Cardt is a relatively simple forecasting device, based on some of the principles discussed here: robustness, trend dampening, averaging, limited number of parameters with limited range in the first stage, followed by a richer model in the final calibration.
Cardt is fast and performs well on both M3 and M4 data, suggesting that it can be a general purpose device to provide baseline forecasts for macro-economic data. Ref. [
17] shows in simulations that
Cardt can be useful to forecast conditioning variables in the presence of breaks. Ref. [
47] apply this to unemployment forecasting, showing that the conditional model has more accurate forecasts for 2019, but
Cardt for 2020.
One unresolved issue is that of the forecast horizon. Because of the calibration, and as an example, the third forecast for a horizon of three is not identical to the third for a horizon of four. Next is the use of logarithms. In M3 and M4 it was best (and easiest) to always use logs. But a default of testing using (
7) with
may be preferable in other settings.
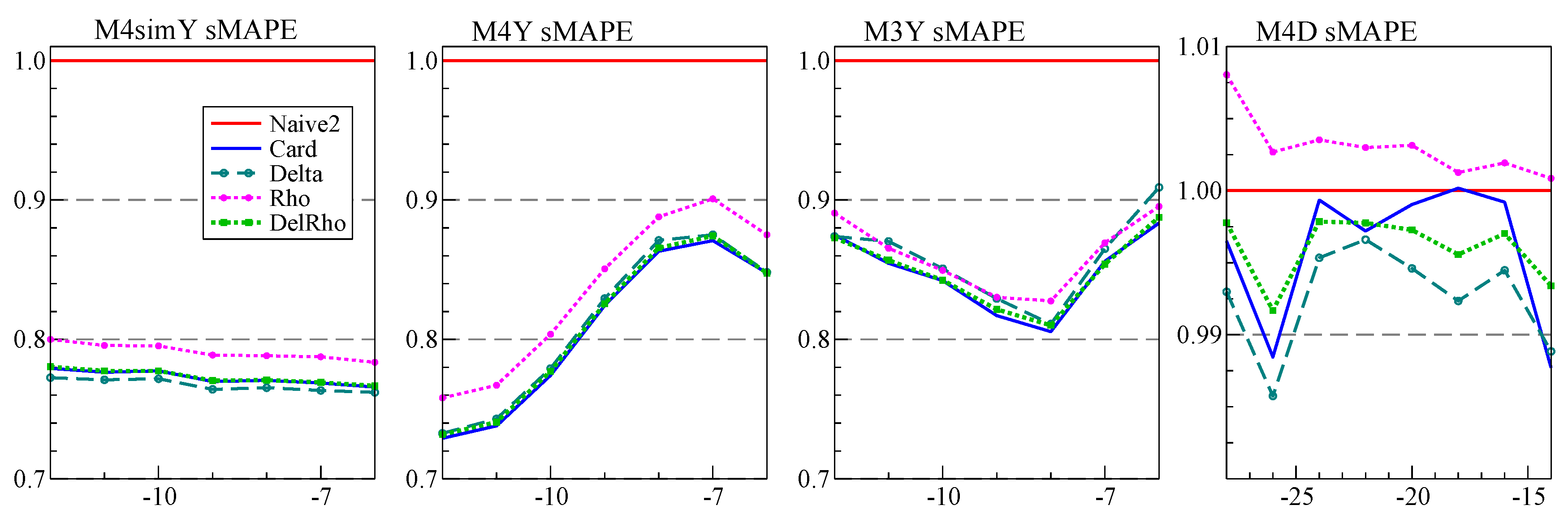
We performed some additional robustness checks on the performance of Cardt. The first set of experiments vary the parameters and sample size of the artificial DGP. The second is for a range of transformations of the M4 variables, including logs, differences, differences of logs, square roots, reversing each series, and cumulating each series. Cardt outperforms Naive2, Theta2, THIMA.log, Delta, and Rho in almost all cases. The one exception is for the cumulated M4 series, where Rho tends to perform badly. This will be caused by the suppression of the autoregressive parameter and the trend. In turn this affects Cardt, especially for monthly, weekly, daily and hourly data. The Delta method does surprisingly well for the cumulated data, suggesting a route for improvement.
While the cumulated M4 series do not look much like economic data, they have more in common with the cumulated counts of cases and deaths from COVID-19: this pandemic data shows periods of rapid growth followed by slowdowns, subjected to many shocks, including shifts in measurements and definitions with large ex post revisions. As documented in [
48], we use a novel trend-seasonal decomposition of cumulated counts. Forecasts of the estimated trend and remainder are then made with the
Cardt method. For the trend we can apply
Cardt to the differenced trend, and then cumulate the forecasts, say
Cardt-I(2). At the start of the pandemic, although data was still limited, this was found to overestimate the future growth. As a solution we adopted the average of
Cardt and
Cardt-I(2). Refs. [
48,
49] investigate the forecast performance of the adjusted
Cardt method for COVID-19, showing generally good performance.
9. Conclusions
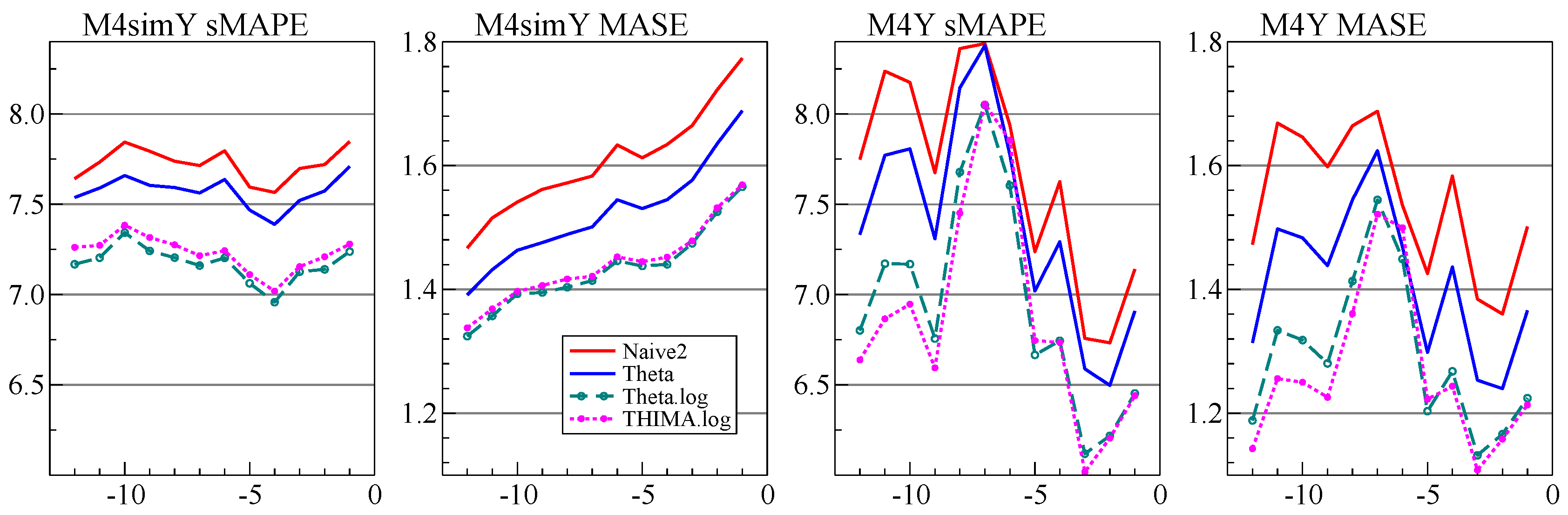
We established that the dominant features of M4 are mostly stationary growth rates that are subject to intermittent large shocks, combined with strong seasonality. This led us to propose a simple extension to the Theta method by adding a simple rule to take logarithms. We also introduced THIMA.log as a simple benchmark method that helps understanding the Theta method. Moreover, this improves on Theta(2) in both M3 and M4 forecasting at low frequencies. We added this to the forecast combination prior to calibration, which mainly improved performance at the yearly frequency.
Our experience with M4 supports most of the principles that were introduced in the introduction:
- (I)
dampen trends/growth rates;
This certainly holds for our methods and Theta-like methods. Both Delta and Rho explicitly squash the growth rates. Theta(2) halves the trend. The THIMA method that we introduced halves the mean of the differences, which has the same effect.
- (II)
average across forecasts from "non-poisonous" methods;
This principle, which goes back to [
16], is strongly supported by our results, as well as the successful methods in M4. There may be some scope for clever weighting schemes for the combination, as used in some M4 submissions that did well. It may be that a judicious few would be better than using very many.
A small amount of averaging also helped with forecast intervals, although the intervals from annual data in levels turned out to be ‘poisonous.’
- (III)
include forecasts from robust devices in that average;
We showed that short-horizon forecasts of Rho could be improved by overdifferencing when using levels. The differenced method already has some robustness, because it reintegrates from the last observation. This, in turn, could be an adjustment that is somewhat too large. The IMA model of the THIMA method effectively estimates an intercept correction, so has this robustness property (as does Theta(2), which estimates it by exponential smoothing).
- (IV)
select variables in forecasting models at a loose significance;
Some experimentation showed that the seasonality decisions work best at
, in line with this principle. Subsequent pruning of seasonal dummies in the calibration model does not seem to do much, probably because we already conditioned on the presence of seasonality. However, for forecast uncertainty, a stricter selection helps to avoid underestimating the residual variance. Ref. [
17] find support for this in a theoretical analysis.
- (V)
update estimates as data arrive, especially after forecast failure;
This aspect was only covered here by restricting estimation samples to say, 40 years for annual data given the many large shifts that occurred in earlier data. Recursive and moving windows forecasts are quite widely used in practical forecasting.
- (VI)
‘shrink’ estimates of autoregressive parameters in small samples;
As the forecast error variance can only be estimated from out-of-sample extrapolation, it is essential to avoid explosive behaviour, so constrain all .
- (VII)
adapt choice of predictors to data frequency;
For example, method 118 by [
50] had the best performance for yearly and monthly forecasting but
Card was best at forecasting the hourly data.
- (VIII)
address ‘special features’ like seasonality.
Appropriate handling of seasonality was important as described in
Section 2.3 and even transpired to be an important feature of forecasting COVID-19 cases and deaths as in [
49].
We derived a DGP that generates data similar to annual M4. This could be a useful complement to the actual data. It also confirmed the good performance of our Cardt method. Extending this to include the properties of the seasonal time series is left to a later date.
We believe that Cardt is useful as a baseline method for economic forecasting: it is fast, transparent, and performs well in a range of realistic and simulated settings. Most recently, it helped to provide useful short-run forecasts of COVID-19 cases and deaths.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











