1. Introduction
Severe storms pose a serious threat to electric distribution networks, generating great repair costs and disrupting quality of life for millions of Americans every year [
1]. Several increasingly sophisticated outage prediction models (OPMs) were developed and validated in recent years for hurricanes [
2,
3,
4,
5,
6,
7,
8], thunderstorms [
9,
10,
11,
12], rain and wind [
9,
10,
11], snow [
13] and ice storms [
13,
14]. Except for an isolated case [
7] that studied the dynamics of Hurricane Irene, all other studies focused on the prediction of storm total outages. A missing aspect of the literature is the prediction of outage dynamics during thunderstorms, which are the most common type of damaging storms in many areas of the world. In fact, as noted by several authors, the impacts of thunderstorms are particularly difficult to predict due to the small-scale dynamics, which are not well represented in both numerical weather prediction models and current OPMs.
Modeling the magnitude and timing of weather impact on the electric distribution network represents critical information for estimating the time to outage restoration [
4,
15,
16]. This type of impact modeling can also be used to evaluate the effectiveness of electric grid hardening activities such as tree trimming [
17]. Advancing outage prediction precision is therefore necessary for storm preparedness among power utilities. The most important factors responsible for the advancement in model accuracy and precision are the increasing temporal and spatial resolution of publicly available weather data [
18,
19], the incorporation of additional geographic datasets [
6,
20,
21,
22], and the proliferation of nonparametric [
8,
23], probabilistic [
24], and failure rate methods [
25,
26,
27].
Early methods for power outage prediction leveraged statistical approaches such as generalized linear models [
28] or generalized linear mixed models [
14] and focused only on a few storm types such as ice storms or hurricanes [
29]. Later, researchers explored hybrid models, such as stacking models together in an ensemble with binary models to predict whether at least one outage would occur followed by regression models that predict the count of outages [
5], and nonparametric decision tree ensembles that could be adapted and generalized to a variety of storm types [
9,
10,
11]. The models developed in these last three studies were employed by Eversource Energy to plan responses to damage caused by storms in New England since 2015.
All these prior studies summarize weather features from time series, rather than leveraging the dynamical information inherent in the raw data. While aggregated features are useful for some statistical and machine learning models that cannot directly use time series data, feature engineering is often time-consuming and the resultant features represent the source data with lower fidelity. Thus, most models do not account for weather-electric-grid interactions at fine time scales, and lose information in the feature engineering process.
Recent advancements in weather prediction methods and machine learning techniques make possible a new and more dynamic modeling framework for forecasting impacts from storms that change quickly in meteorological character and interact locally with power grid infrastructure. Our method represents atmospheric conditions and their impacts on the power grid at high temporal resolution. We leverage this data with a variety of statistical and machine learning models, including Poisson regression,
k-nearest neighbors (KNN), random forest, and a long short-term memory (LSTM) neural network model [
30,
31,
32,
33,
34] to forecast hourly dynamics of power outages over the course of a thunderstorm. We show validation results, including comparison to a baseline eventwise OPM [
9,
10,
11], demonstrating that utilities can use these predictions to plan the number of crews and timing of crew deployment.
Our study is outlined as follows.
Section 2 introduces the publicly available weather data source: High-Resolution Rapid Refresh (HRRR), and the outage data collected by the local electric utility (Eversource Energy-CT). Also described are the data processing steps used to inform a variety of temporally conscious models detailed in
Section 3. Finally, the model evaluation methodology is presented with the results of these dynamic OPMs and an eventwise OPM in
Section 4, followed by a discussion of model performance in
Section 5, and concluding remarks about the contributions of this study and future work in
Section 6.
2. Data Sources and Processing
2.1. Weather Data
We use historical High-Resolution Rapid Refresh (HRRR) atmospheric forecasts produced by NOAA and archived by the University of Utah [
35]. The Rapid Refresh (RAP) atmospheric model on which HRRR is updated hourly provides the temporal resolution our models use to correlate severe weather and outage occurrences over the course of a storm. HRRR, on top of RAP, incorporates radar observations every 15 min to reach a 3-km spatial resolution.
For the purpose of predicting outages caused by thunderstorms, we focus on reflectivity at 1000 m and six surface-level features: wind gust, atmospheric pressure, relative humidity, wind speed, convective available potential energy (CAPE), and convective inhibition (CIN). Sustained winds and wind gusts break branches and trees, causing damage to the grid. Relative humidity can help distinguish frontal from post-frontal showers. Atmospheric pressure, CAPE, and CIN are related to atmospheric instability, thunderstorm intensity, and the likelihood of gusts reaching the surface. For model training, we extract each of these features at zero-hour forecasts from the pixel containing the center of each town in the Eversource-CT service territory.
The HRRR archived dataset begins in mid-July of 2016. Only the months during which thunderstorms are likely to occur—April through September—are selected. Although incorporation of the other months of the year would more than double the size of this dataset, these months are very unlikely to harbor thunderstorm occurrences, their inclusion would violate assumptions of geospatial constancy inherent to the modeling framework (e.g., the presence of leaves on trees), and the selected HRRR features would include non-thunderstorm meteorological conditions. Thus, these months were excluded from the model. We also excluded 200 h during and after an outlier tornado in May 2018, which caused outages lasting more than a week unrelated to weather as the grid underwent repairs. In total, we have weather forecasts and corresponding outage counts (described in the
Section 2.2) for 10456 h. In addition to these observations, we imputed a total of 19 missing hours of HRRR archived forecasts linearly with respect to the last known hour and next known hour of forecasts.
2.2. Outage Data
The proprietary Eversource outage dataset consists of real-time customer-reported outage occurrences organized by its Outage Management System (OMS), which is also used to generate service tickets for directing repair crews. We define an outage as damage to a component of the power grid. OMS specialists use customer phone calls and limited sensor data to determine when outages occurred, and associate outage reports in the OMS database with the suspected geographic locations of the infrastructure assets at fault.
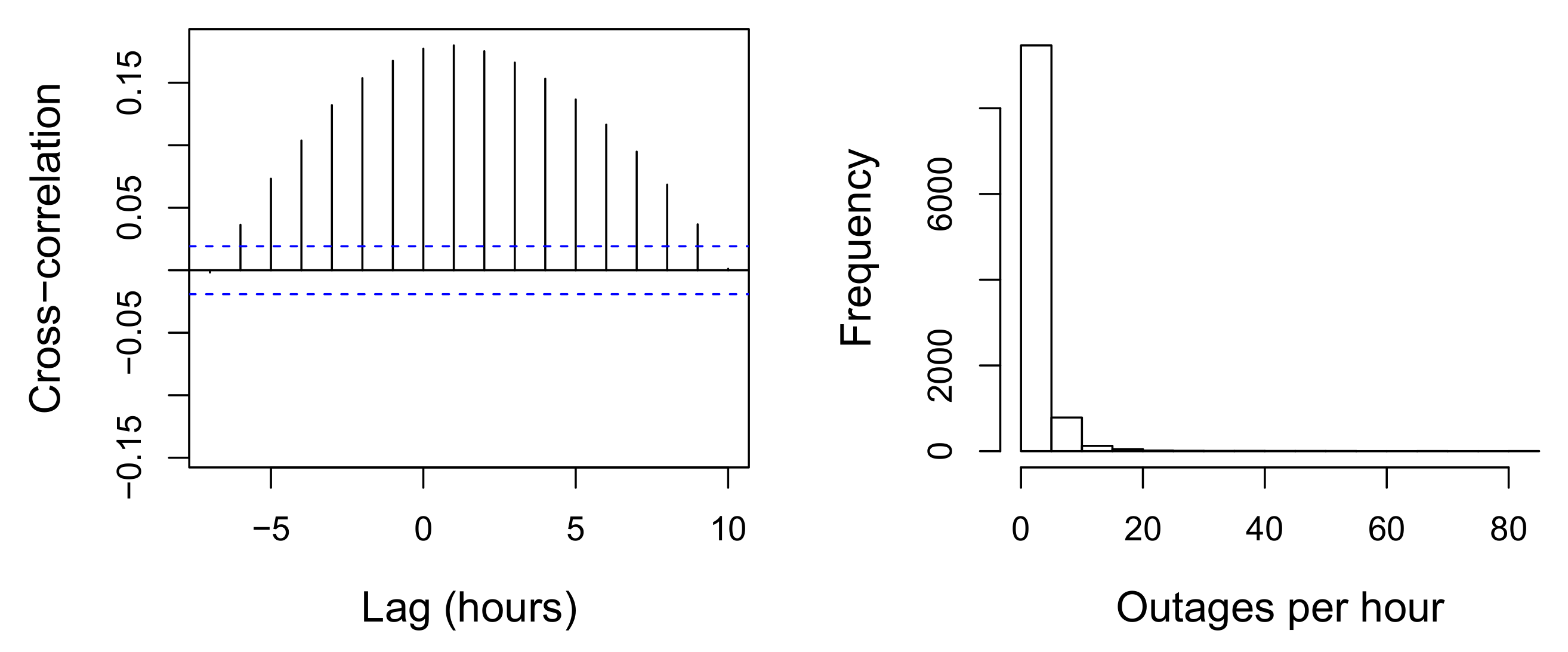
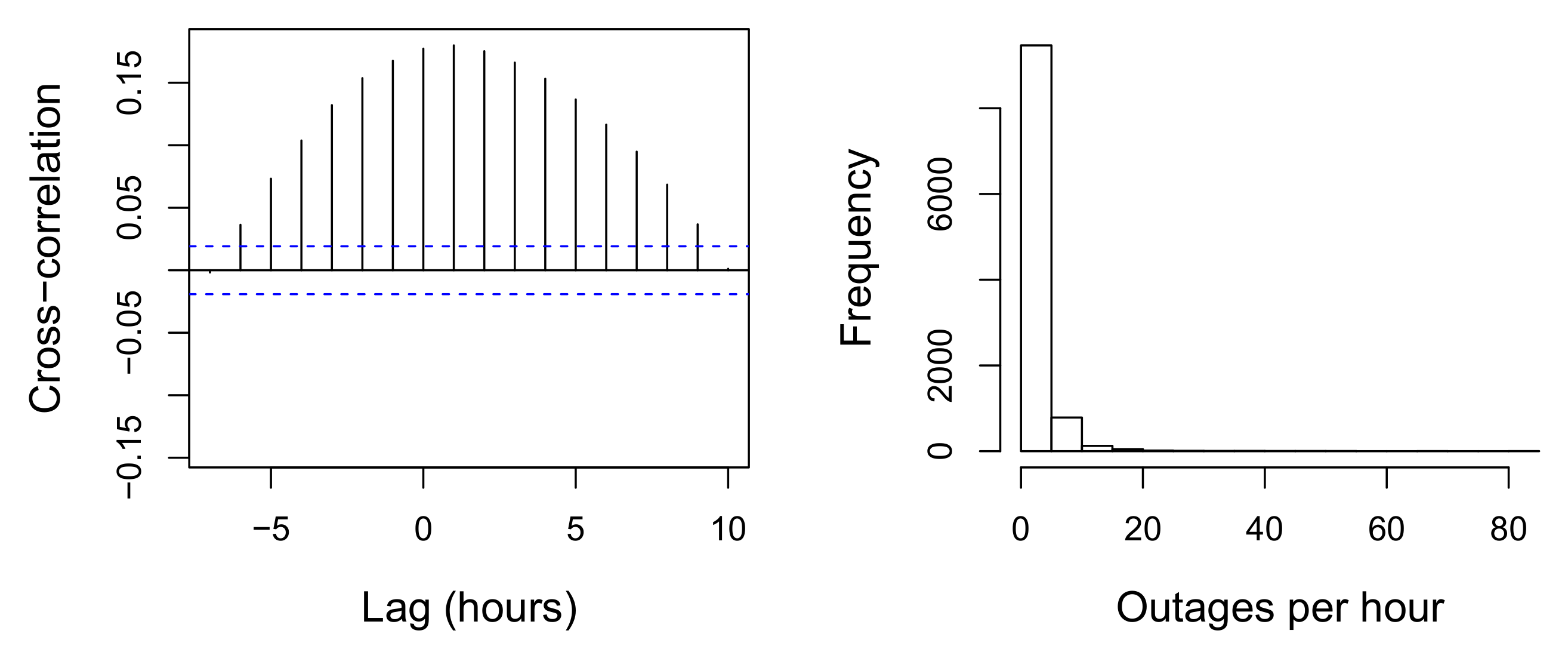
Since customers cannot be expected to immediately report outage occurrences, historical outage counts have an inherent lag behind severe weather, especially for storms that occur at night when customers are less likely to notice and report power outages. It can also be difficult for specialists to pinpoint assets at fault based only on current reports. Because of the networked nature of the grid, the damages most superficial in the network are perceptible. Damages deeper in the network can hide behind more superficial damages, and detecting them is very difficult until those superficial damages are repaired. Although Eversource has no means by which to record real-time outage occurrences, an analysis of the reported outage lag is shown in terms of wind speed in
Figure 1. The greatest cross-correlation is observed with an outage lag behind wind speed of 1 h. Even this cross-correlation is low, indicating the lag of reported outages behind winds is highly variable. To help compensate for this, we include the cyclically encoded hour consisting of two features:
and
, where
h is the hour of day, as features in our models, whose designs, described in
Section 3, are also relevant to addressing this issue.
For this study, 27 thunderstorm events were identified in CT between July 2016 (the start of the HRRR archive) and September 2018. These events caused both an elevated number of outages and were observed to have meteorological characteristics consistent with thunderstorms as reported by local METAR weather stations. Station data is downloaded and parsed from the Integrated Surface Dataset, hosted by NOAA’s National Centers for Environmental Information (NCEI). Observations of a short-lived peak in wind gusts, combined with intense precipitation, a sharp drop in air temperature, and/or reports of lightning or thunder were indicative of a thunderstorm event. Outages from previous hours are not included as features to predict the next hour’s outages—a live outage reporting system is thus unnecessary for the dynamic predictive framework that we present.
2.3. Feature Representation Framework
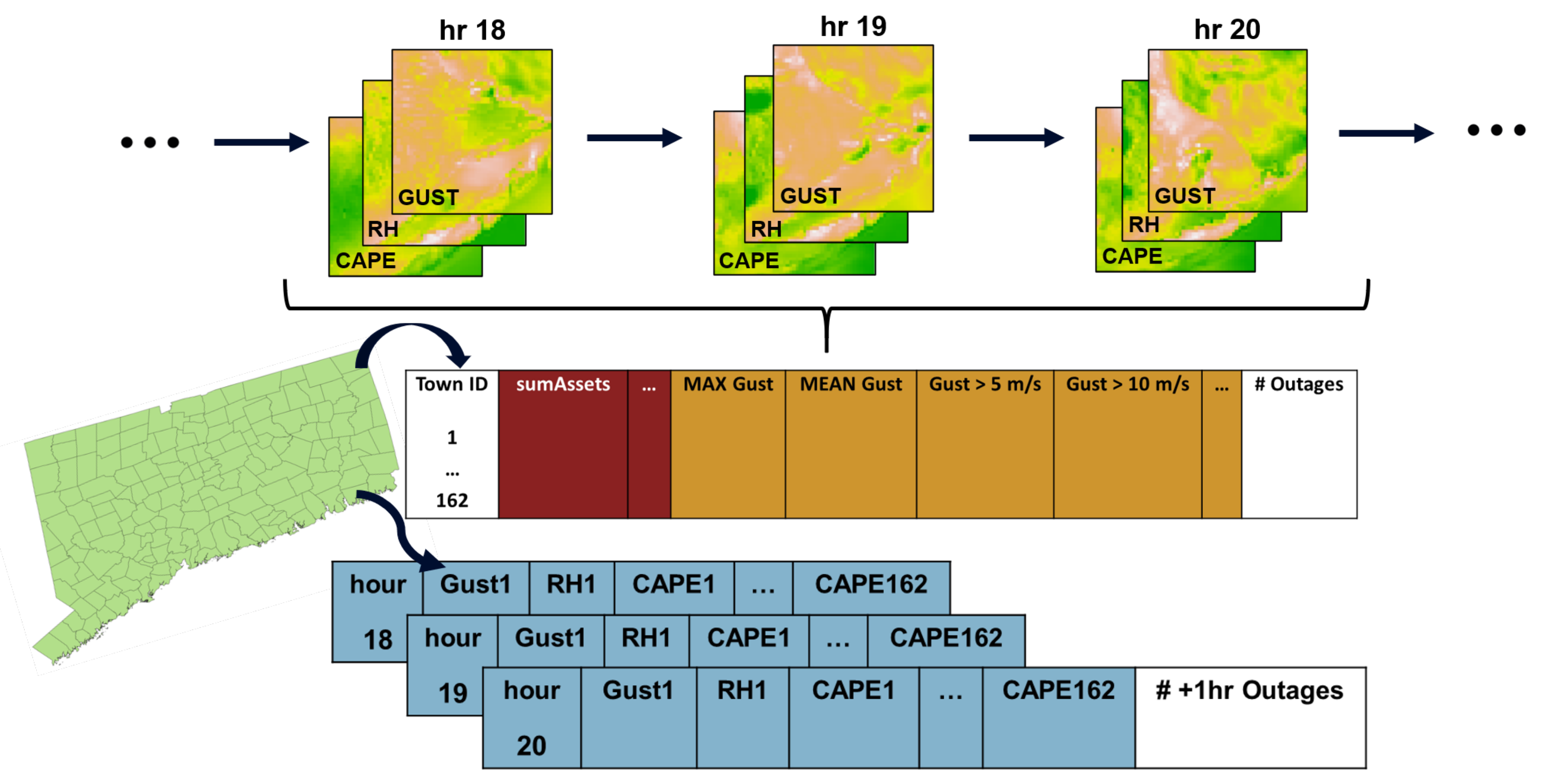
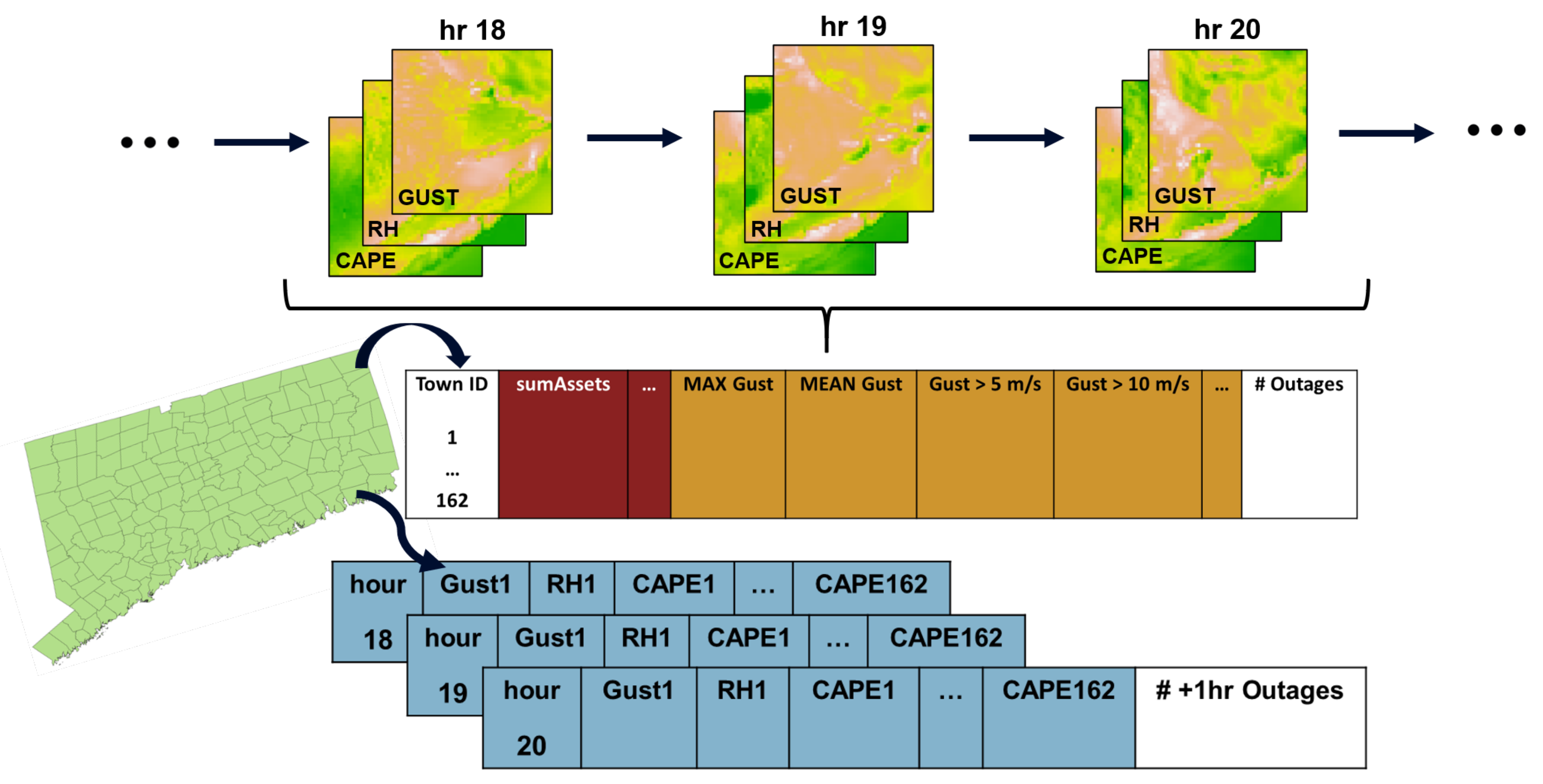
Under the time-indexed framework that was developed (
Figure 2), geospatial features (e.g., soil type, topography, land use) inherent to some eventwise models are eliminated. The framework also requires no information about the power system. Instead, weather variables are described for each town. The model is left to learn implicitly the characteristics of each town within the service territory, essentially producing an outage model for each town. This feature representation forgoes the intensive selection and processing of geospatial data, yielding intuitive models in which terrain and infrastructure conditions are assumed to remain static in the long term.
The issue of a limited training set is exacerbated by the large feature space created by this framework: with the extraction and geospatial tagging methodology, the set of selected weather features is generated for each town in the forecast domain. Doing so results in a total of 7 weather features × 162 towns = 1134 geospatial weather features. Principal components analysis (PCA) is applied across all time points in the training set of each iteration of the leave-one-storm-out (LOSO) cross-validation (described in
Section 4) to deal with this feature expansion. Using PCA, we reduce our 1134 features to a new set of 100 features with values at each time point. The PCA components consistently preserve about 95 percent of the variance of the original feature set. The small variance impact of such a drastic dimensional reduction can be explained by the high degree of spatial correlation between features describing the same weather variables across towns as well as the correlation between the atmospheric conditions themselves.
3. Dynamic OPMs
We applied a variety of standard statistical and machine learning models consisting of Poisson regression, KNN, random forest, and an LSTM to predict the outage count at each hour. Of the regression models we considered, Poisson regression, KNN, and random forest are not explicitly designed to work on sequences of features over time. Instead, to the zero-hour weather forecasts at each hour, we added the zero-hour features states from 0 to
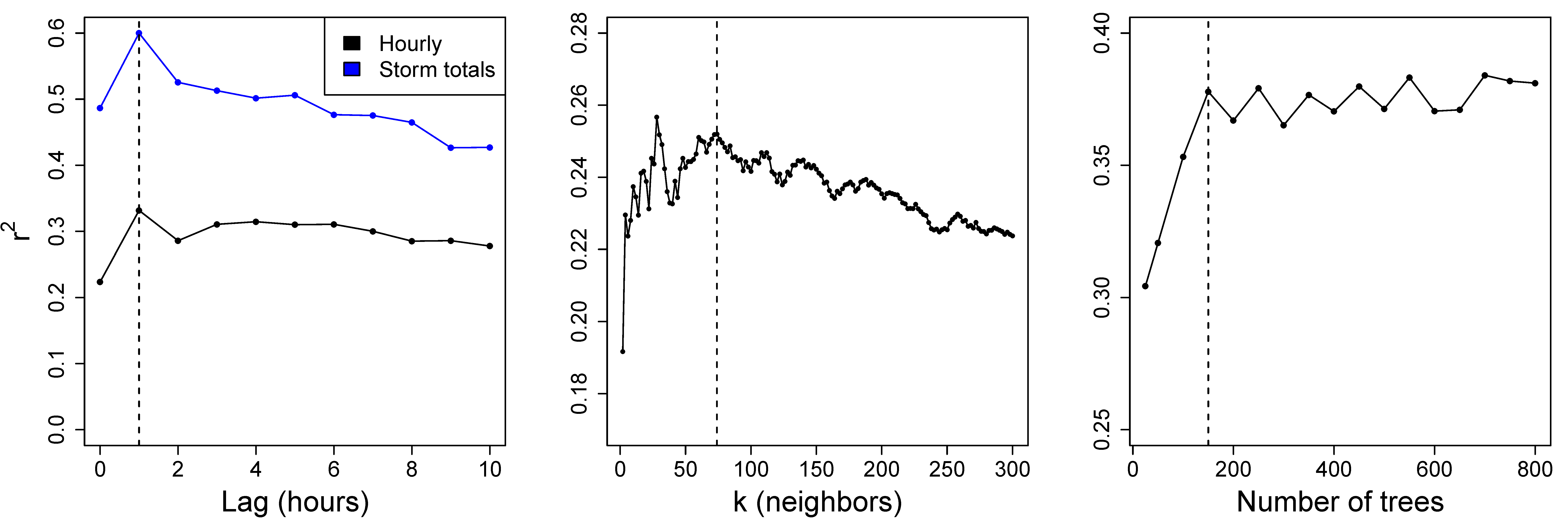
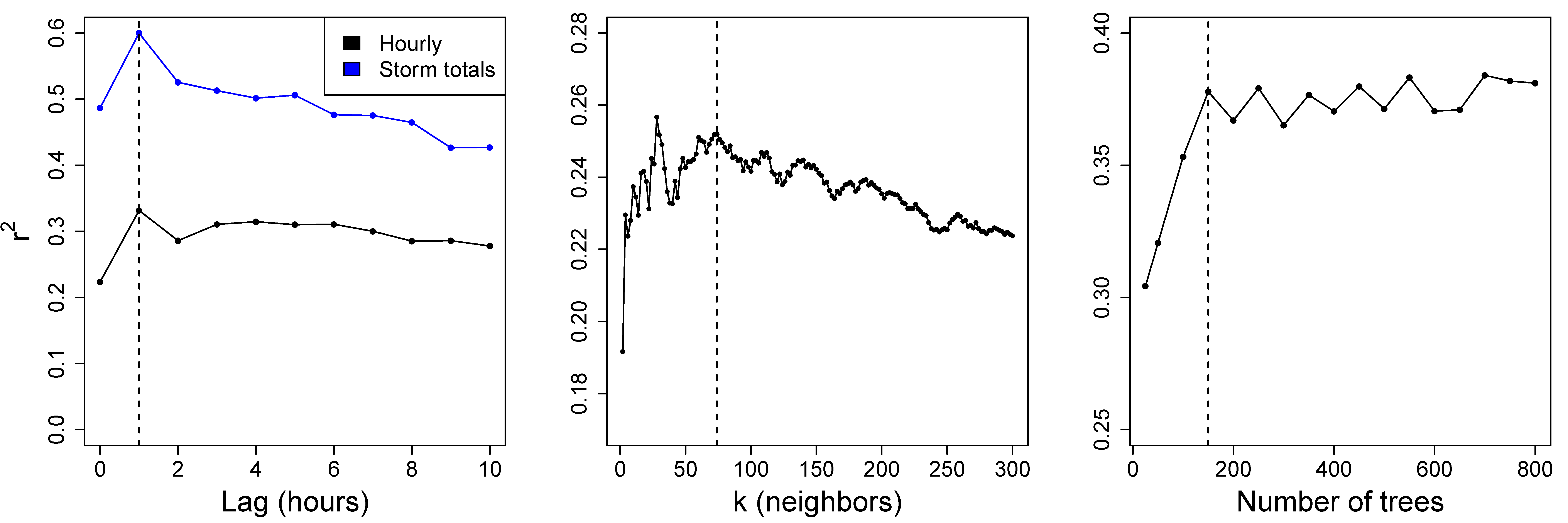
l hours in the past. We determined the optimal lag period to use for the proceeding analysis with these models by considering the LOSO cross-validated squared correlation (
) between actual and predicted hourly and storm-total outages across settings of
l between 0 and 10 (
Figure 3). Under the LOSO cross-validation scheme [
11], we define a storm window as an 18-hour period containing the thunderstorm. For each storm, the training set consists of all hours in our dataset excluding the storm window, and the test set consists of only those 18 h. A lag setting of
is optimal with respect to both correlation metrics in cross-validation, is consistent with the cross-correlation analysis between winds and outage reports (
Figure 1), and is statistically significant with respect to a zero-lag model (analysis of deviance test with
reference distribution;
). The setting
was thus used for the Poisson regression, KNN, and random forest models in the proceeding analyses.
In addition to the lag period, there are hyperparameters specific to KNN, random forest, and LSTM that should be tuned according to the reference data set. Before applying KNN, we must select the number of observations
k nearest the input data point whose outage counts are averaged to yield the prediction. We did so by performing a grid search over all even settings of
k between 2 and 300 with respect to LOSO cross-validated
between hourly actual and predicted outages; we thereby selected
(
Figure 3). This setting yields a model that is less variable with respect to the bias-variance tradeoff than models with lesser settings of
k that appear comparable or even superior in performance, and is therefore less prone to overfitting. We searched the number of trees in the random forest in the same manner, selecting 150 trees for the sake of parsimony despite marginal improvements in hourly outage correlation by forests with more trees.
LSTMs are capable of and intended for mapping time series of features to, for example, a scalar output such as outage counts. Under an LSTM design, each
l-hour weather feature window is batched as a single sample. The feature space can thus be described as sequences of
l weather time steps. These sequence samples are then associated with next-hour total outages across CT as the response. We chose
as the lookback period for the LSTM as there exists significant cross-correlation of actual outages with state-average wind for lags up to 9 h (
Figure 1). The weather forecasts for the lookback period, in addition to the weather forecasts for the current hour, are used to produce the LSTM predictions hereafter. We tuned the architecture of the LSTM, namely the number of hidden layers and the number of nodes per layer, according to a grid search over these parameters. As with the traditional statistical and machine learning models, we used the mean hourly
to evaluate performance. However, for tractability, we performed LOSO cross-validation on a total of three thunderstorms, with low (storm “a”), medium (storm “x”), and high (storm “p”) impacts. Based on this search (
Supplementary Data File 1), we selected an architecture consisting of 128 LSTM nodes followed by three hidden layers of 128, 64, and 16 regular fully connected nodes, respectively (
Supplementary Table S1). Because of the variability of fitting neural networks under different initial conditions, we use the average hourly predictions of five fittings of the LSTM in the results following. The operation of an LSTM unit within a neural network is described mathematically in a dedicated section of the
Supplementary Materials.
5. Discussion
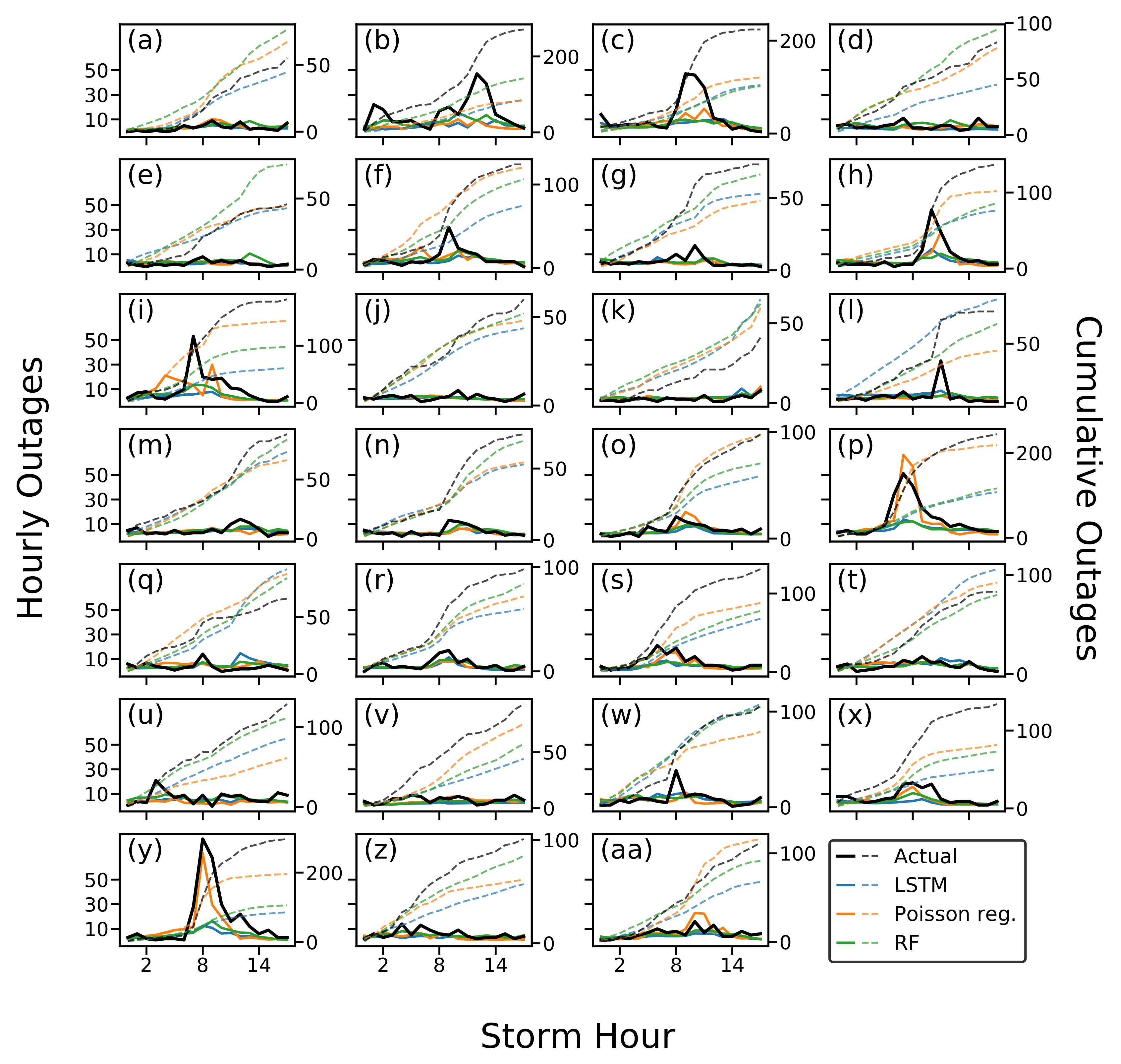
Across the full series of metrics of prediction accuracy, consisting of those related to the time series distribution of outage occurrences, marginal hourly outage occurrences, and storm totals, it appears that the temporally conscious perspective of dynamic OPMs can make substantial improvements over existing eventwise OPMs. The Poisson regression, KNN, random forest, and LSTM models all show substantial improvements relative to the baseline eventwise OPM in predicting the spread of the outage distribution, and often even in total storm outages.
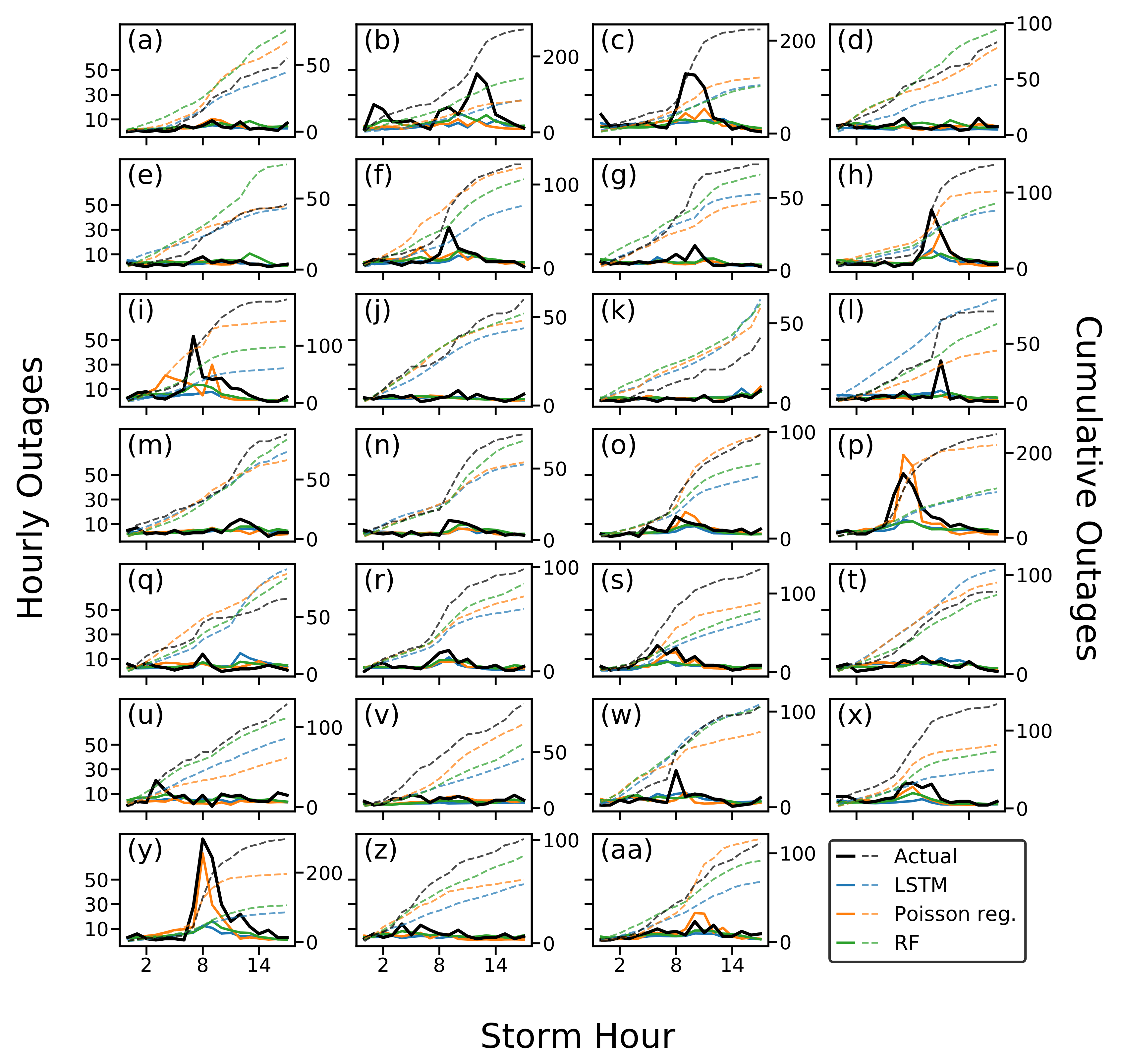
Of the dynamic OPMs, the Poisson regression demonstrates the best performance across most facets of outage prediction, especially total storm outages. It is also capable of capturing unusually large peaks in outages which the other models do not, particularly in storms “p” and “y” (
Figure 4). The dynamic OPMs that we developed and the baseline OPM that we tested represent a wide range of model complexity, from KNN regression to an LSTM neural network with thousands of parameters. That Poisson regression regularly outperforms this array of models suggests the assumption of log-linearity between weather features and outage occurrences is a good approximation to true weather-grid interactions. This finding is in agreement with those of a recent study on snow and ice OPMs, in which a Poisson regression model outperformed random forest and BART for a large class of storms [
13]. A forecasting error simulation on a well-predicted held out storm suggests that the predictions of the LSTM and random forest are robust to forecasting error (
Supplementary Figure S3), although these models may not be as suitable for extrapolation to relatively extreme weather events as linear models (
Figure 4). KNN appears largely invariant to perturbations in the features, which we surmise is due to the sparsity of observations in high-dimensional feature spaces such as ours. It is likely that the accuracy of more complex thunderstorm OPMs (e.g., the Event-OPM, LSTM, random forest) in predicting total outage outages will grow steadily as the number of training storms increases [
39].
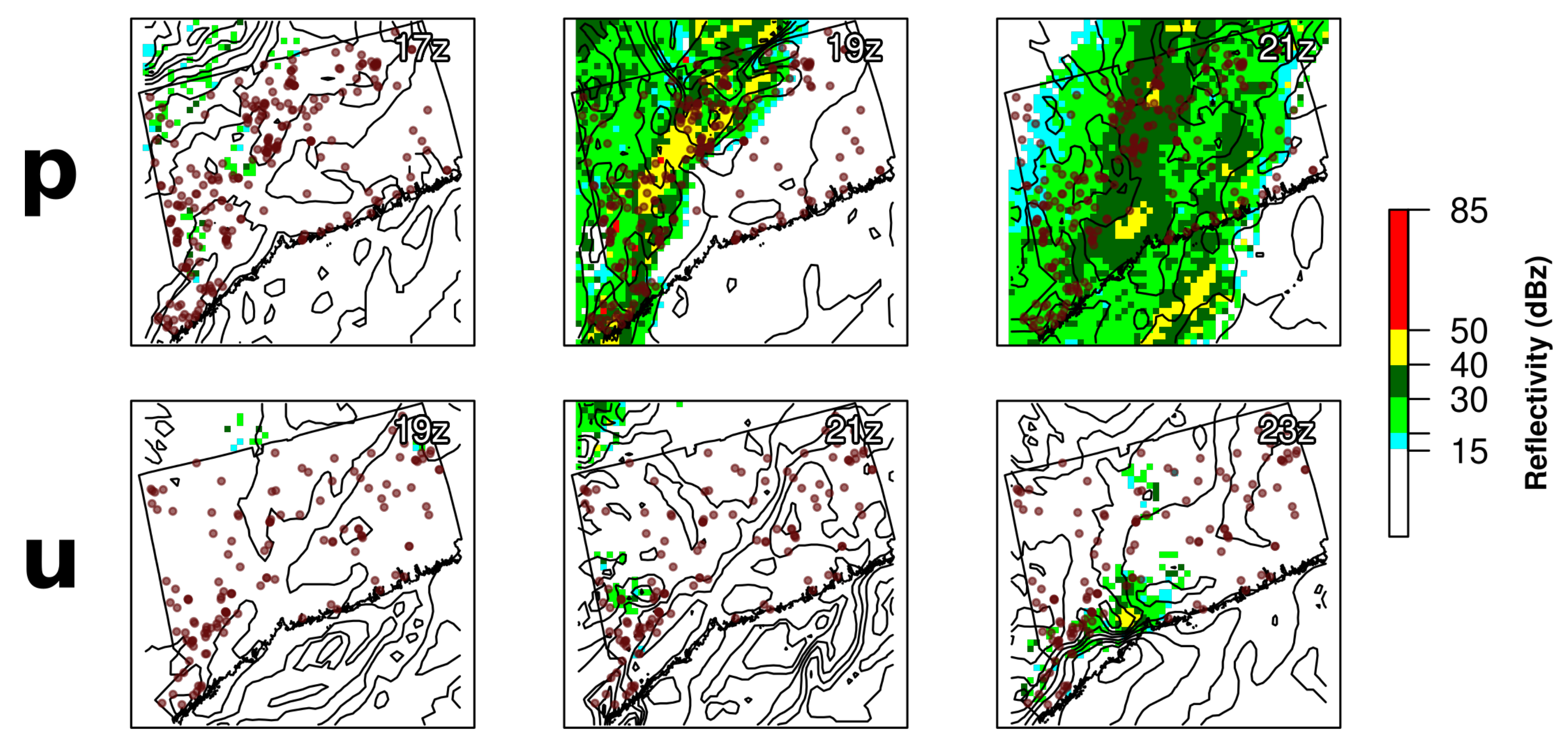
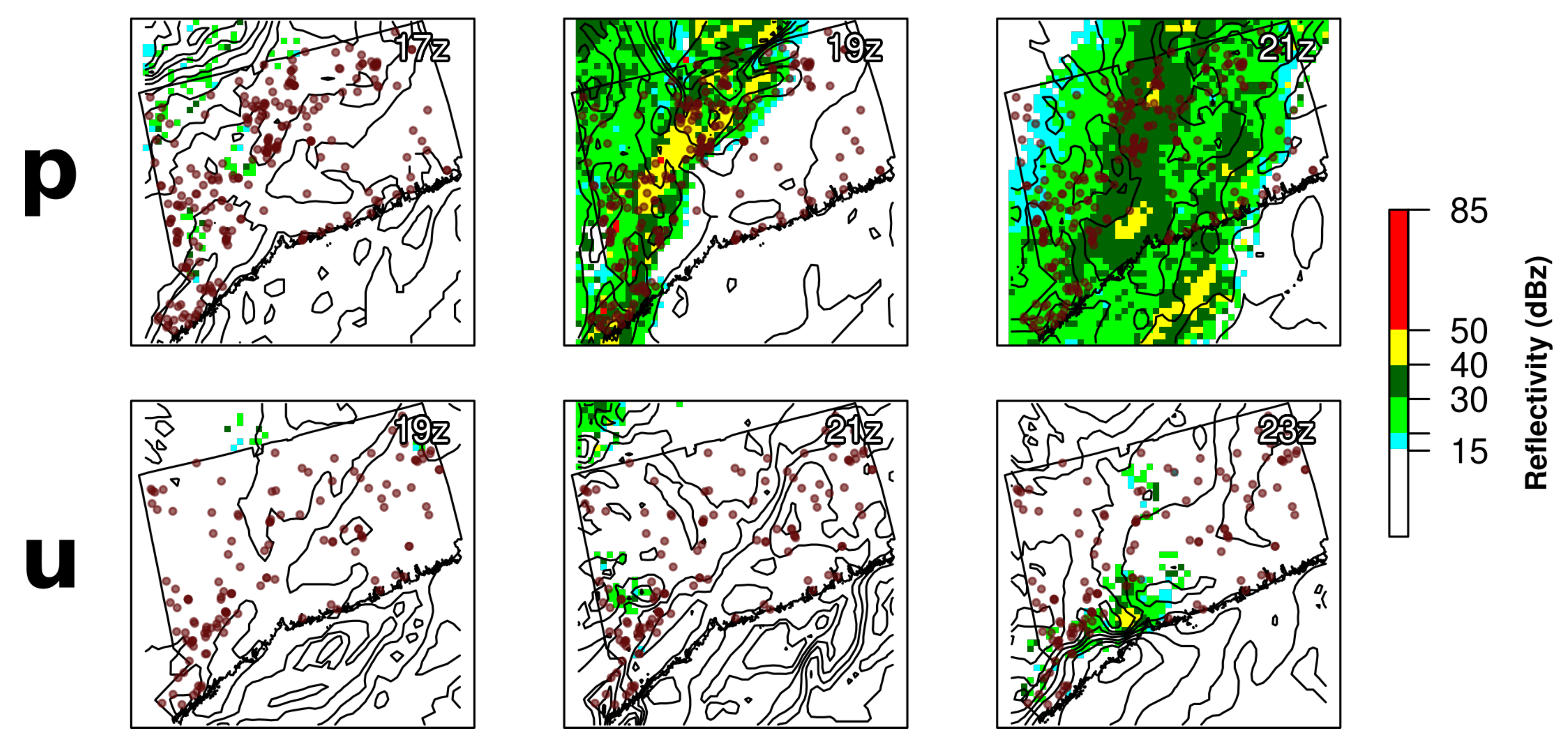
We sought to characterize the association between the meteorological properties and uncertainties of each storm in our dataset and the corresponding average performance of the dynamic OPMs we used to model them. Namely, those storms which are more organized, present a storm front with a strong and consistent gradient of wind gusts, and have cohesive reflectivity are generally better predicted by the dynamics OPMs, as opposed to storms that are isolated systems without distinctive fronts (
Figure 5,
Supplementary Figures S4 and S5). These storms may also exhibit spatial and temporal weather forecasting errors that propagate to outage prediction. For example, during storm “u” (
Figure 5), the outages occurred in the Danbury area, but the HRRR weather forecasts did not predict severe weather in that area, but rather near Litchfield, nearly fifty kilometers away, where there were not many outages.
6. Conclusions
A major contribution of this work has been the development of a framework to holistically and flexibly represent spatiotemporal weather features as they pertain to meteorological impacts. These techniques are adaptable to a variety of spatiotemporal, transient, and chaotic systems, where feature engineering is expensive, or where there is a desire to maintain the structure inherent to unengineered data. More specifically, this study demonstrates that it is possible to render moderately accurate temporal forecasts of thunderstorm outages not provided by eventwise OPMs. Using our approach, utilities are able to plan how many repair crews should be deployed, as well as when and for how long those crews should be deployed. All of the models we developed were built on a nationally available weather forecasting resource. The dynamic framework can be directly applied to any region in the US for which outage data at a reasonably fine temporal resolution exists. We suggest continuation of this work to include customer outages from non-utility sources as a way to demonstrate scalability of this framework beyond the US northeastern states.
We showed that dynamic OPMs can substantially outperform complex eventwise OPMs in terms of predicting total thunderstorm outages by comparing against a version of a state-of-the-art eventwise OPM modified for this noisy and data-limited problem. Our results indicate that complex machine models, some dynamic OPMs we developed among them, are not yet superior for high-resolution thunderstorm datasets such as the one used in this study, but that generalized linear models provide a good approximation of weather-grid interactions as these datasets grow. Simulation results suggest that linear models are particularly susceptible to forecast errors. Extensions of the dynamic framework may derive probabilistic estimates of outages that account for uncertainty in the weather inputs and modeling. Our meteorological analysis of poorly and well-predicted highlights the need to understand how spatial and temporal errors in weather forecasts of convective events propagate to OPMs.
We employed a leave-one-storm-out evaluation technique. There are two main sources of contamination from future periods in the training set: changes in power infrastructure and climatic trends. Climatic trends are by definition long-term and not prevalent in a dataset of only three years. Of greater concern are infrastructure conditions, which may be significantly impacted by tree trimming programs and other upgrades to grid resilience [
17,
22]. Future work with longer datasets may incorporate an objective date/time feature or employ evaluation procedures that maintain the chronological order of training and test data.
Future studies may attempt to increase the spatial resolution of dynamic thunderstorm OPMs. Although statewide outage predictions are valuable in operational settings for determining how many crews to stage, predictions on the town or division level can help utilities determine where to stage them. The main limitation for adopting this forecasting approach in this study was the small size of the dataset. This limitation is exacerbated by the large number of features created by associating each weather feature with each town in the service territory, but may be remedied in future work by computer vision approaches.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}