Automatic Grouping in Singular Spectrum Analysis



Abstract
:1. Introduction
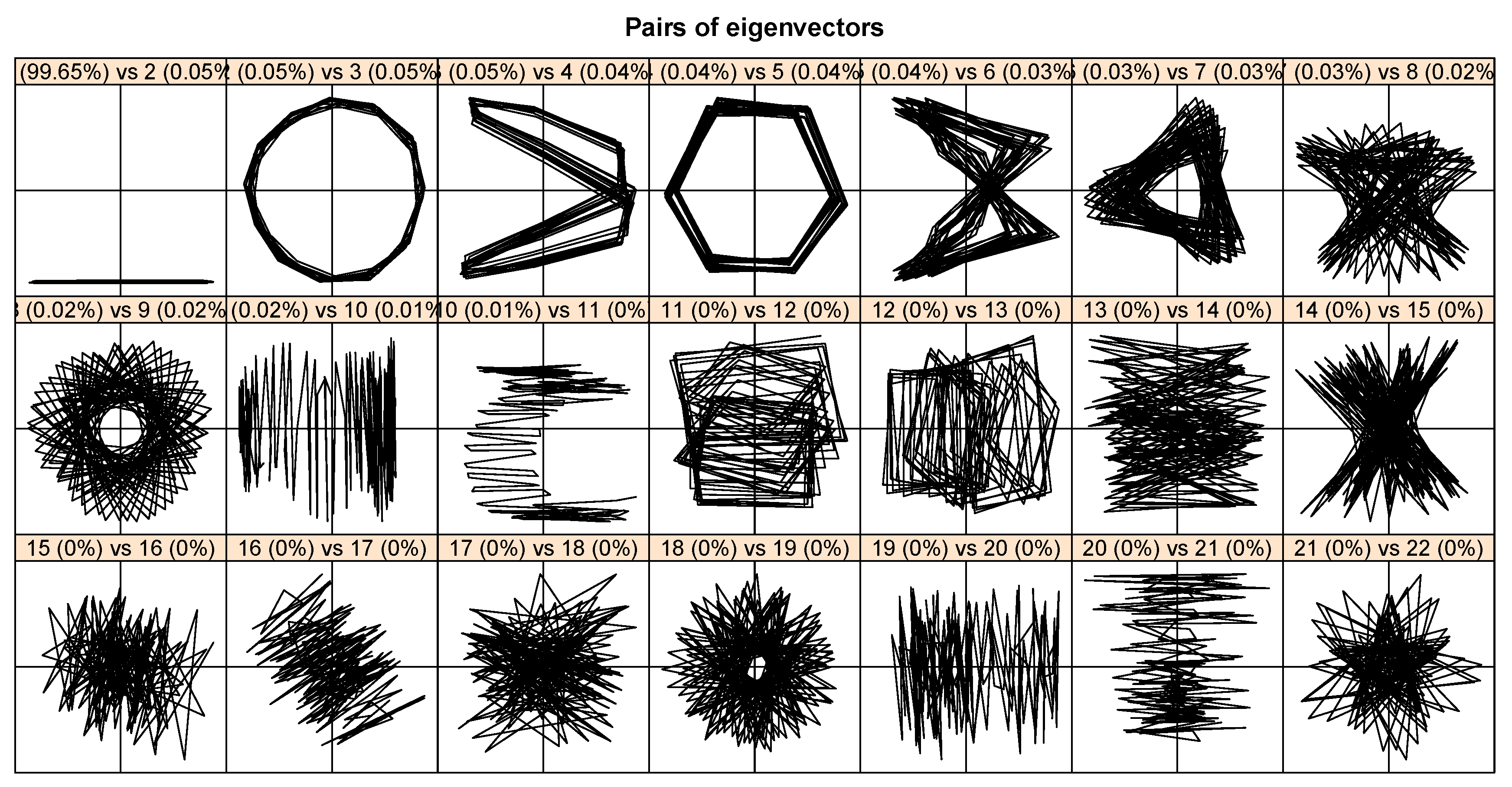
2. Review of SSA
3. Theoretical Background
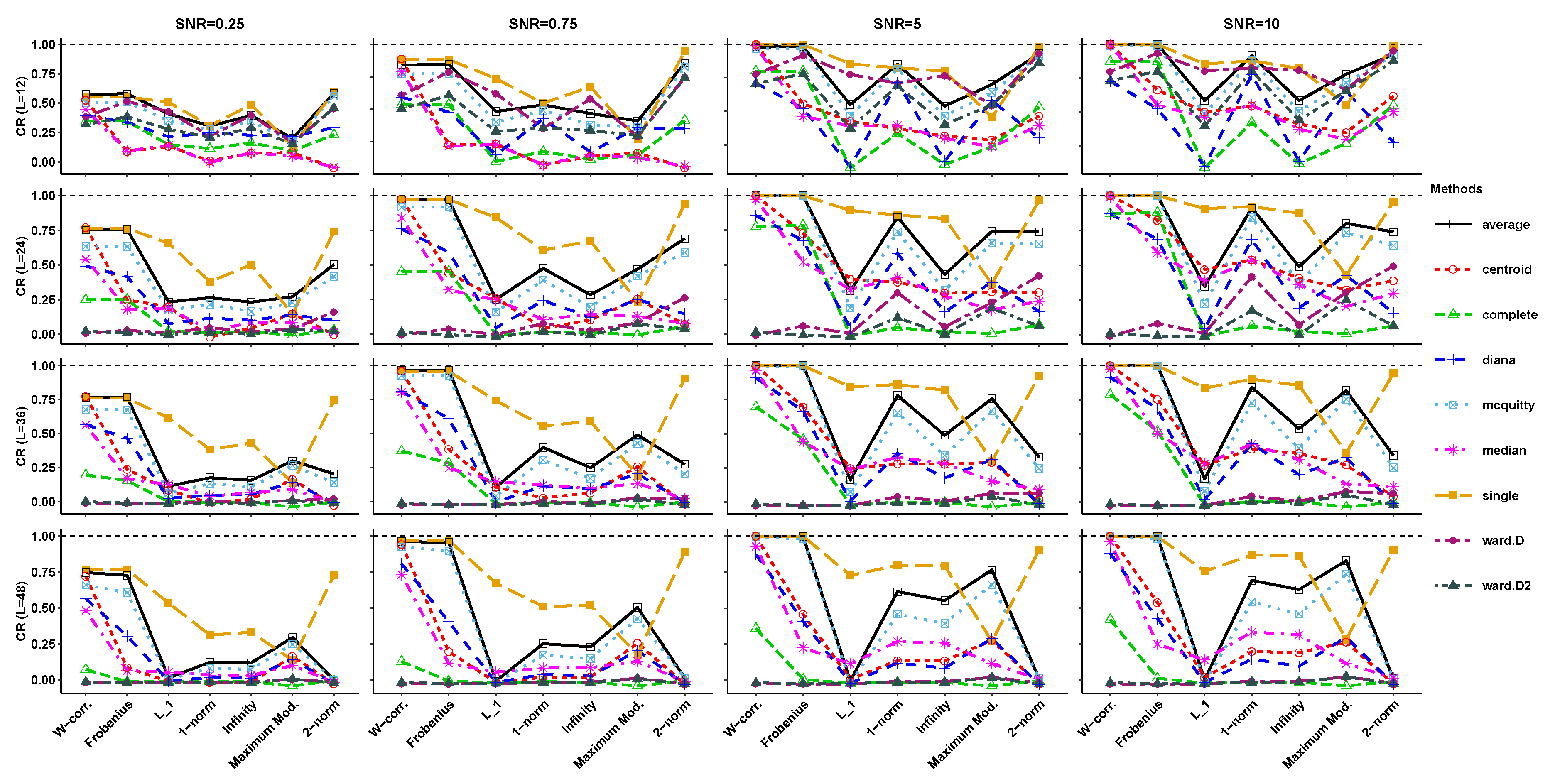
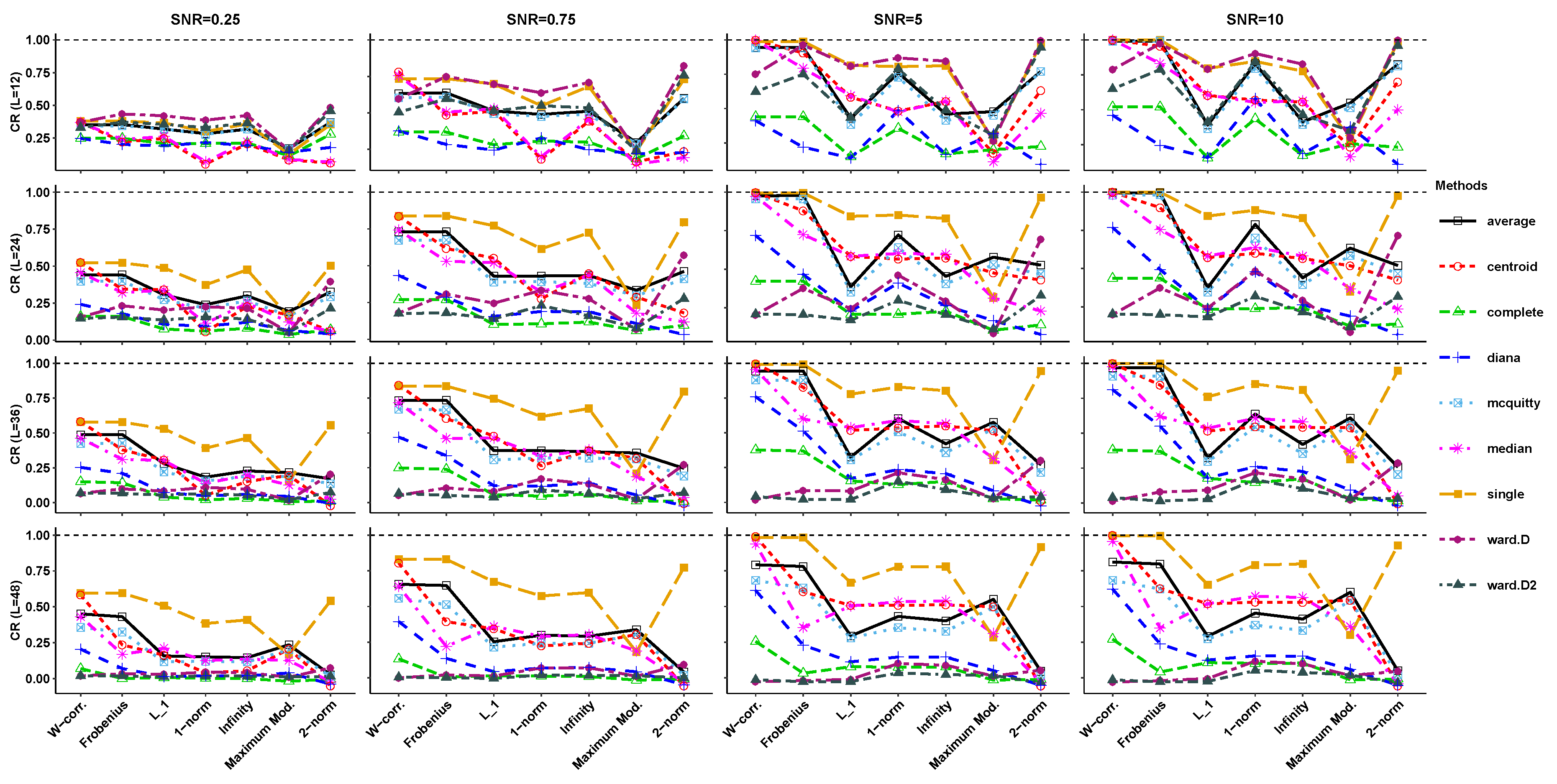
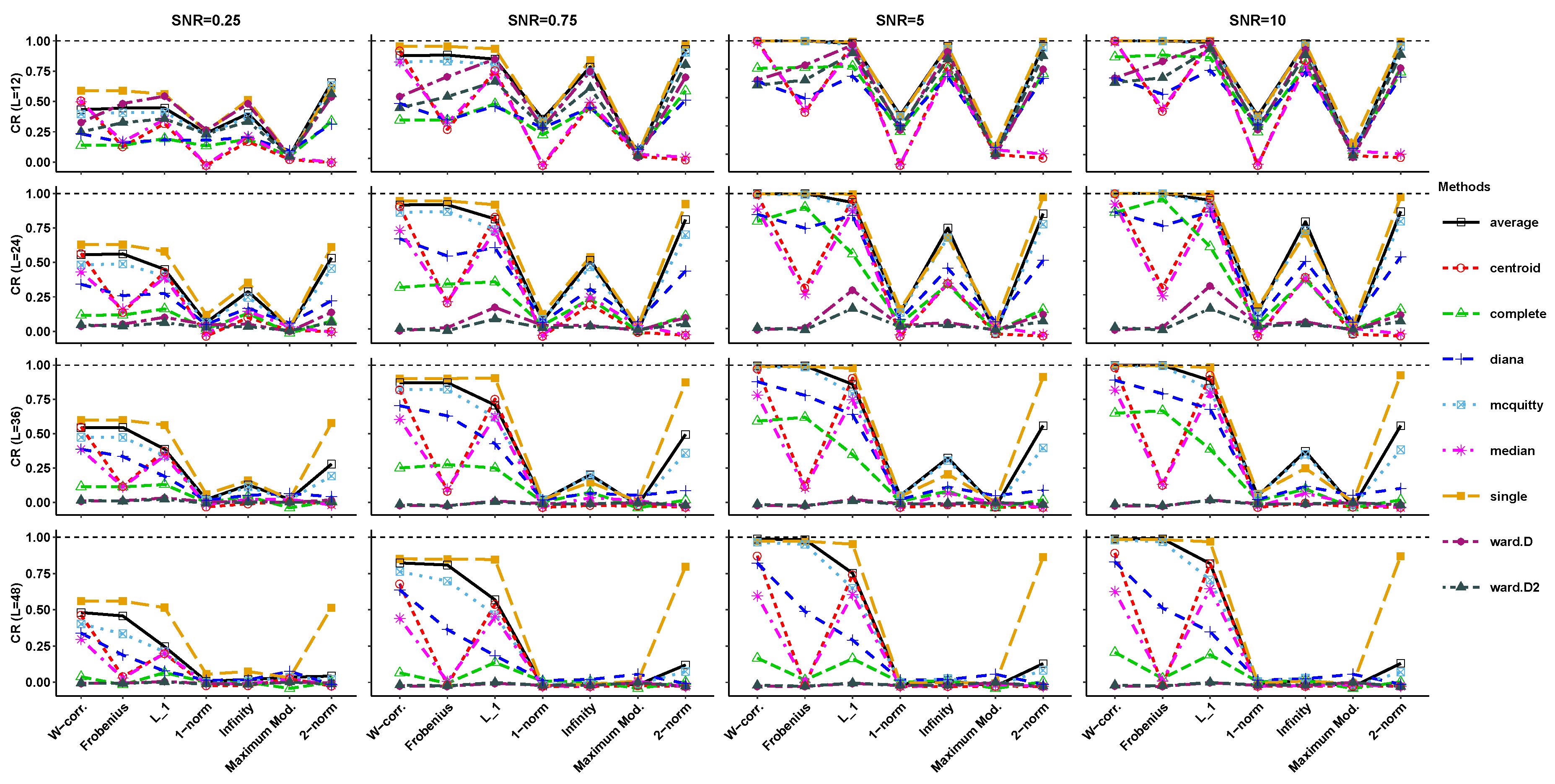
3.1. Distances Based on Matrix Norms
- The Frobenius normThe most frequently used matrix norm is the Frobenius norm defined as:
- The -normThe -norm of the matrix is defined as:
- The 1-normThe 1-norm of the matrix is the maximum of the absolute column sums, that is,
- The infinity normThe infinity norm of the matrix is the maximum of the absolute row sums, that is,
- The maximum modulus normIn this case, the maximum modulus of all the elements in the matrix is computed, that is,
- The 2-normThe spectral or 2-norm of the matrix is denoted by . It can be shown that
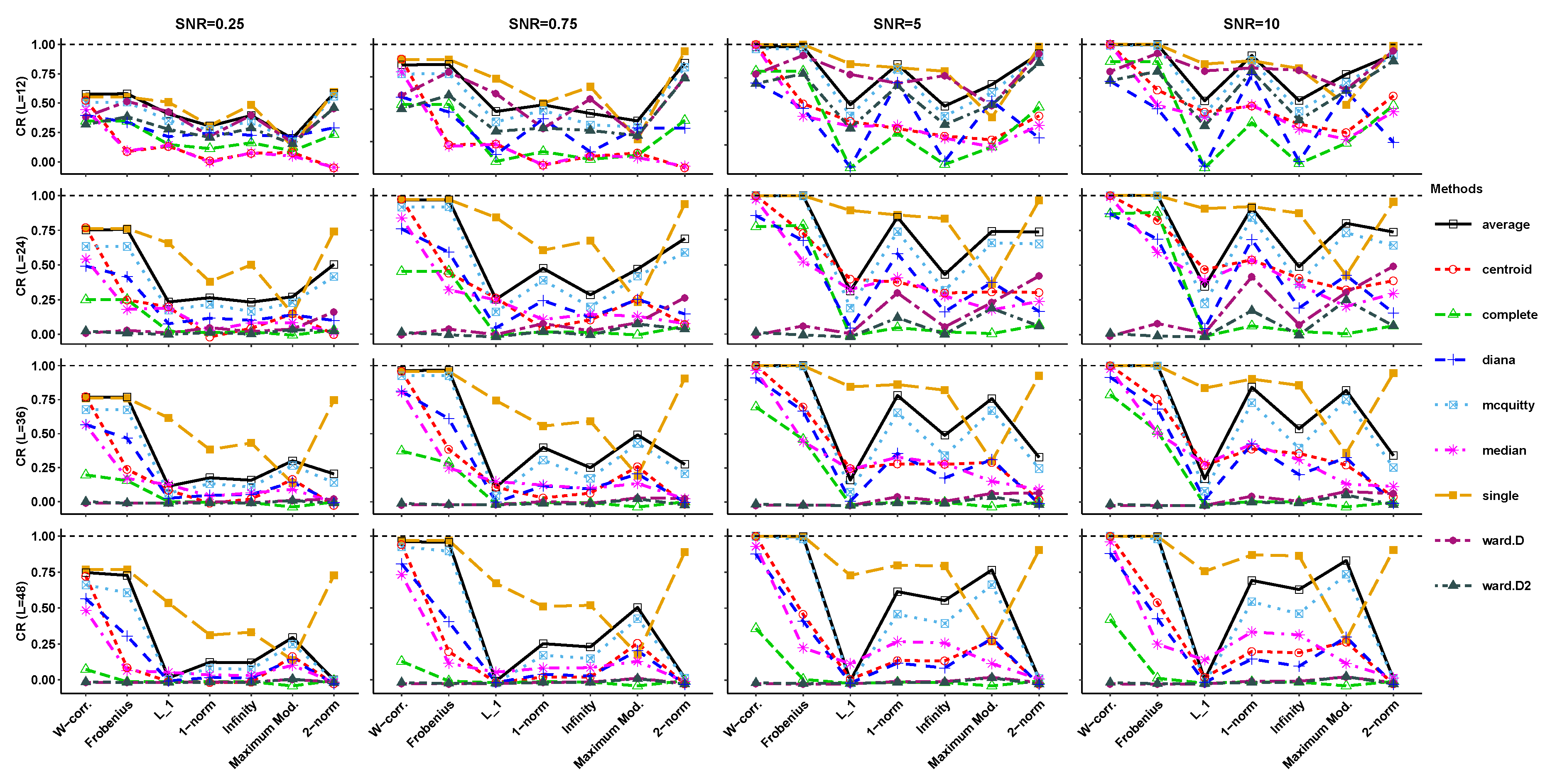
3.2. Hierarchical Clustering Methods
- Divisive: In this technique, an initial single cluster of objects is divided into two clusters such that the objects in one cluster are far from the objects in the other cluster. The procedure continues by splitting the clusters into smaller and smaller clusters until each object makes a separate cluster [41,42]. This method is implemented in our research via the function diana from the cluster package [43] of the freely available statistical R software [44].
- Agglomerative: In this method, the individual objects are initially treated as a cluster, and then the most similar clusters are merged according to their similarities. This process proceeds by successive fusions until all clusters are fused into a single cluster. [41,42]. The agglomerative hierarchical clustering methods that are applied in this research are as follows [45].
- Single: The distance between two clusters and () is the minimum distance between two points x and y, where and ; that is,
- Complete: The maximum distance between two points x and y is treated as the distance between two clusters and , where and ; that is,
- Average: is defined as the mean of the distances between the pair of points x and y, where and :where and are the number of elements in clusters and , respectively.
- McQuitty: is defined as the mean of the between-cluster dissimilarities:where cluster is formed from the aggregation of clusters and .
- Median: is defined as follows:where cluster is formed from the aggregation of clusters and .
- Centroid: is defined as the squared Euclidean distance between the centres of gravity of the two clusters; that is,where and are the mean vectors of the two clusters.
- Ward: This method is based on minimizing the total within-cluster variance. The pair of clusters with the minimum cluster distance is merged at each step of the analysis. This pair of clusters provides a minimum increase in the total within-cluster variance after merging [45]. There are two algorithms ward.D and ward.D2 for this method, which are available in R packages such as stats and NbClust [45]. By implementing the ward.D2 algorithm, the dissimilarities are squared before the cluster updates.
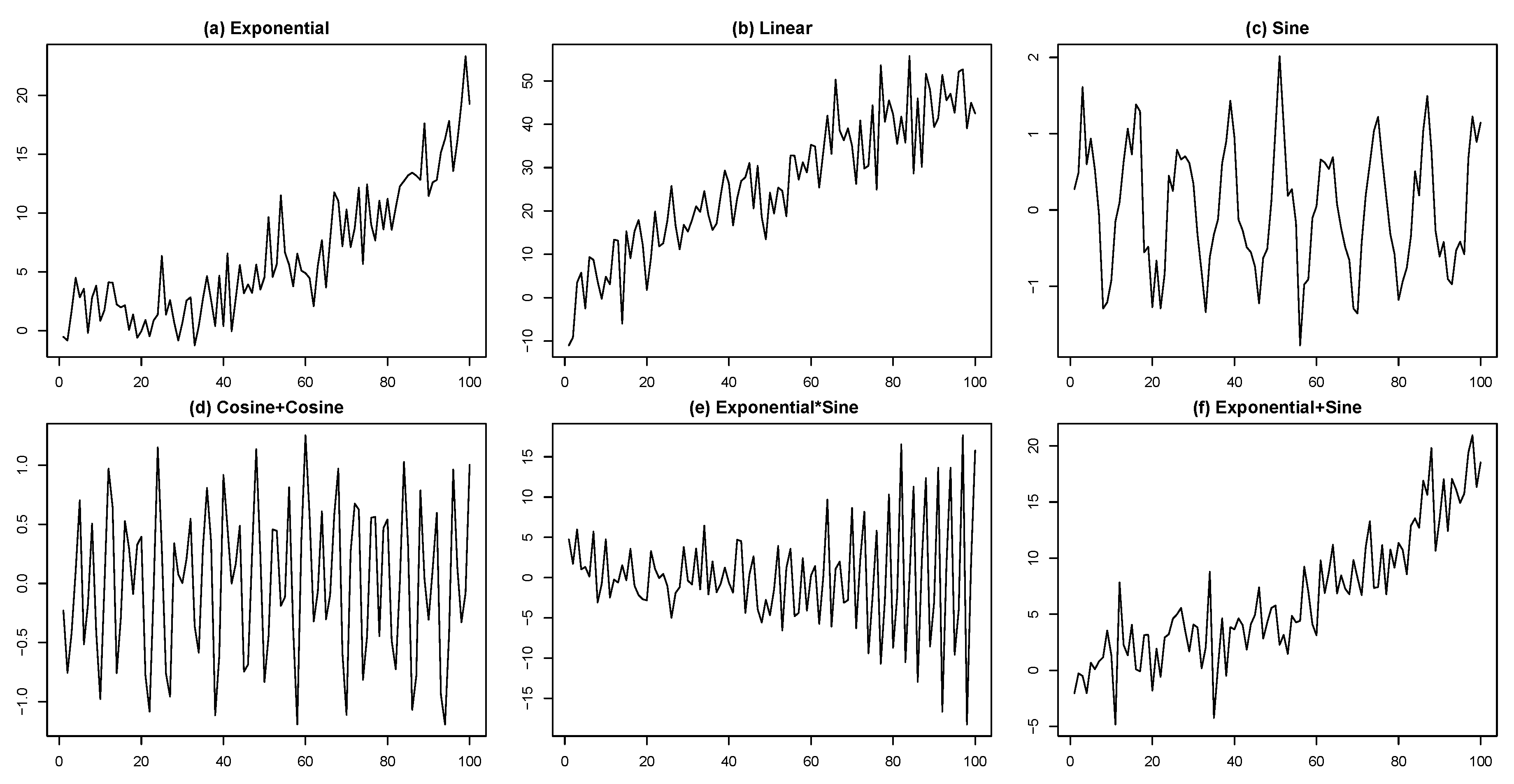
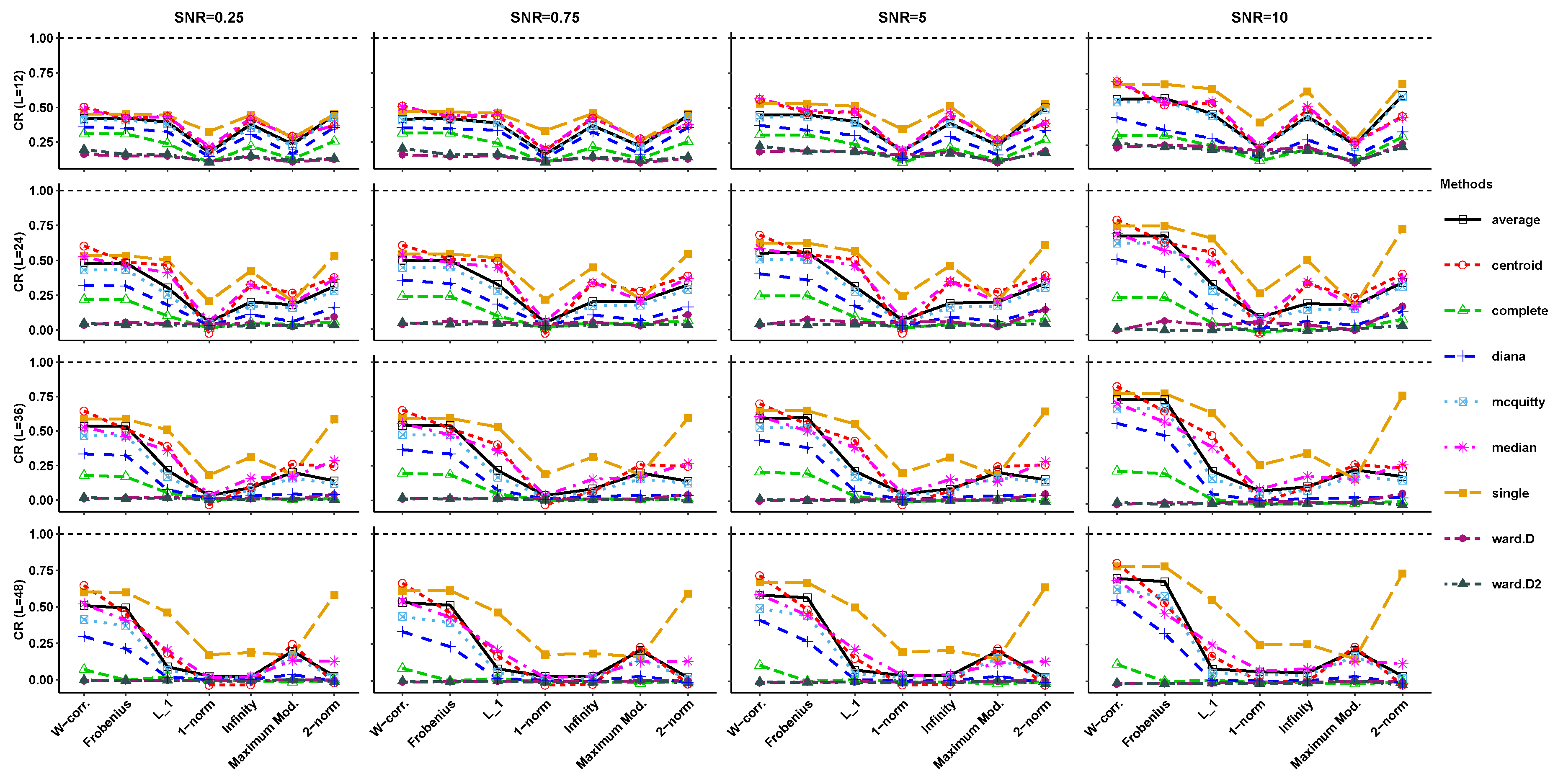
4. Simulation Results
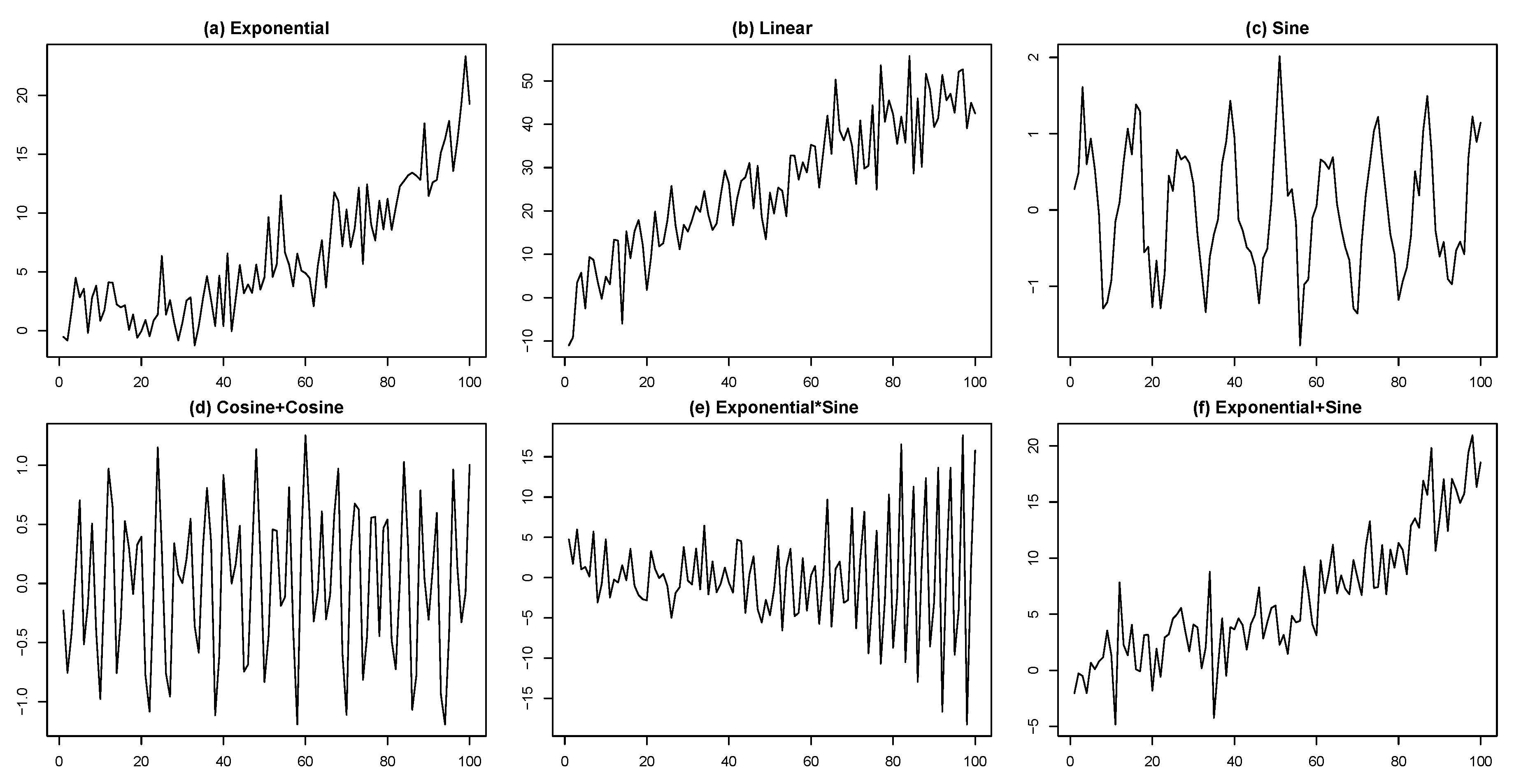
- (a)
- Exponential:.
- (b)
- Linear:.
- (c)
- Sine:.
- (d)
- Cosine+Cosine:.
- (e)
- Exponential×Sine:.
- (f)
- Exponential+Sine:.
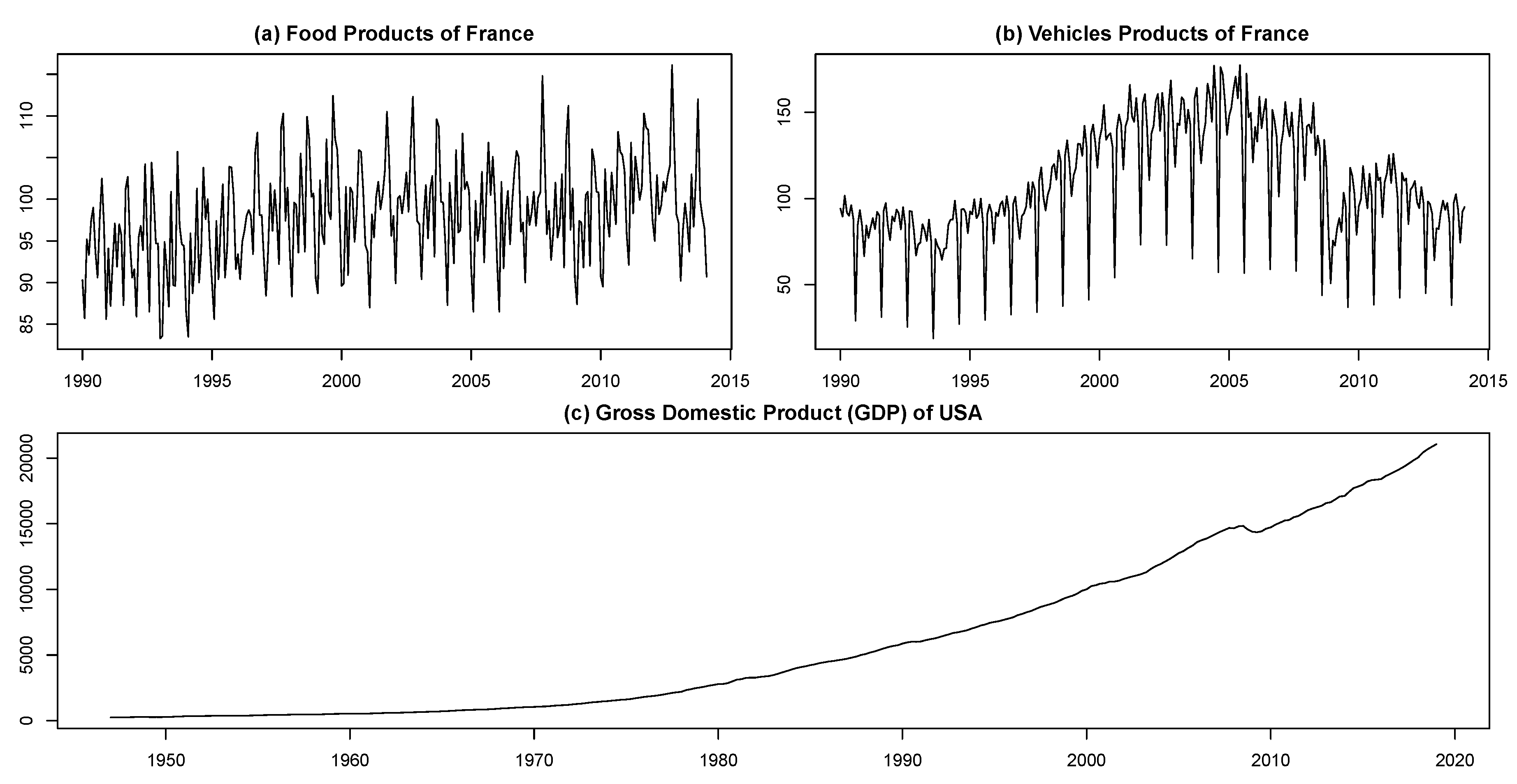
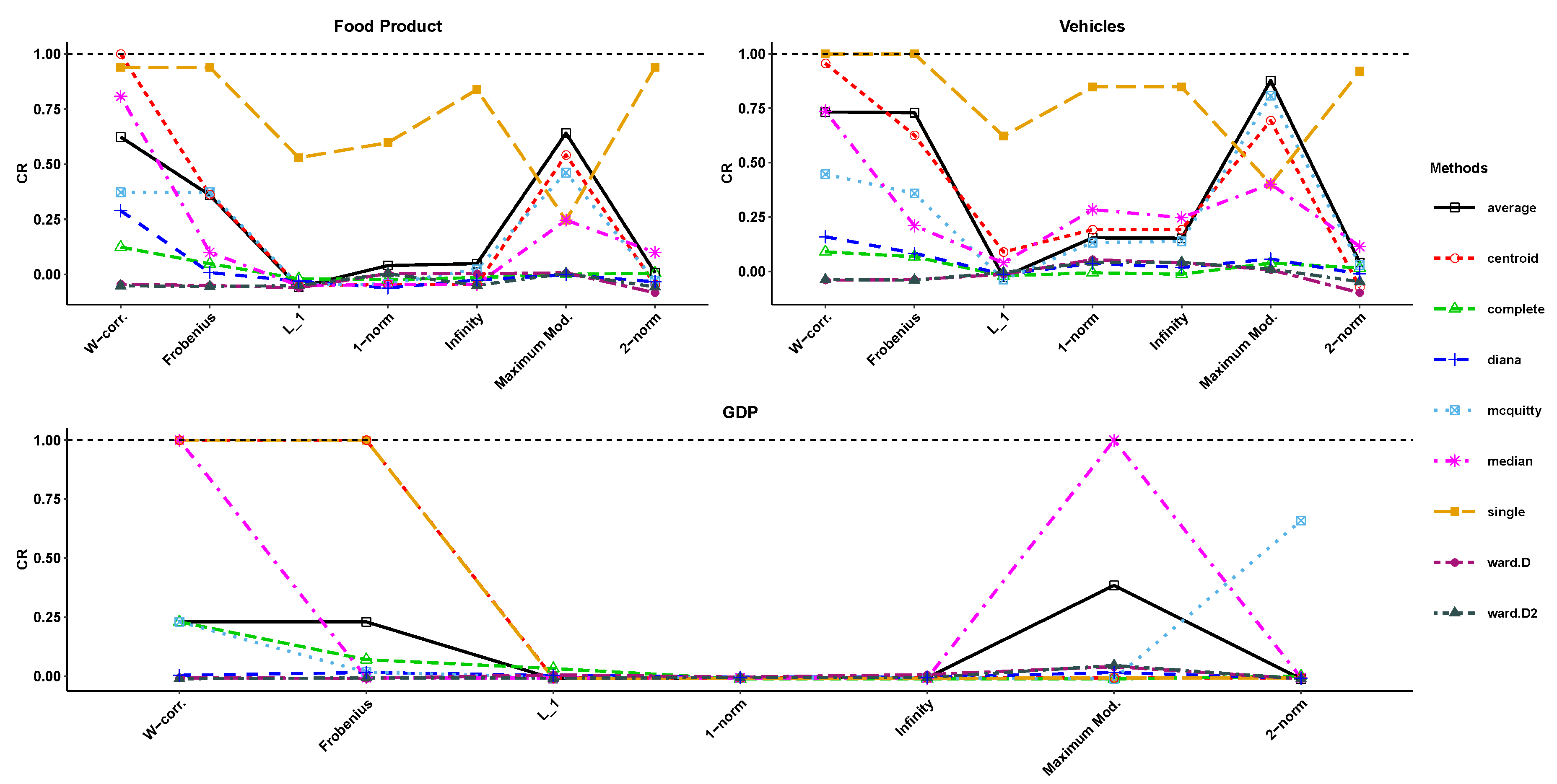
5. Real-World Data
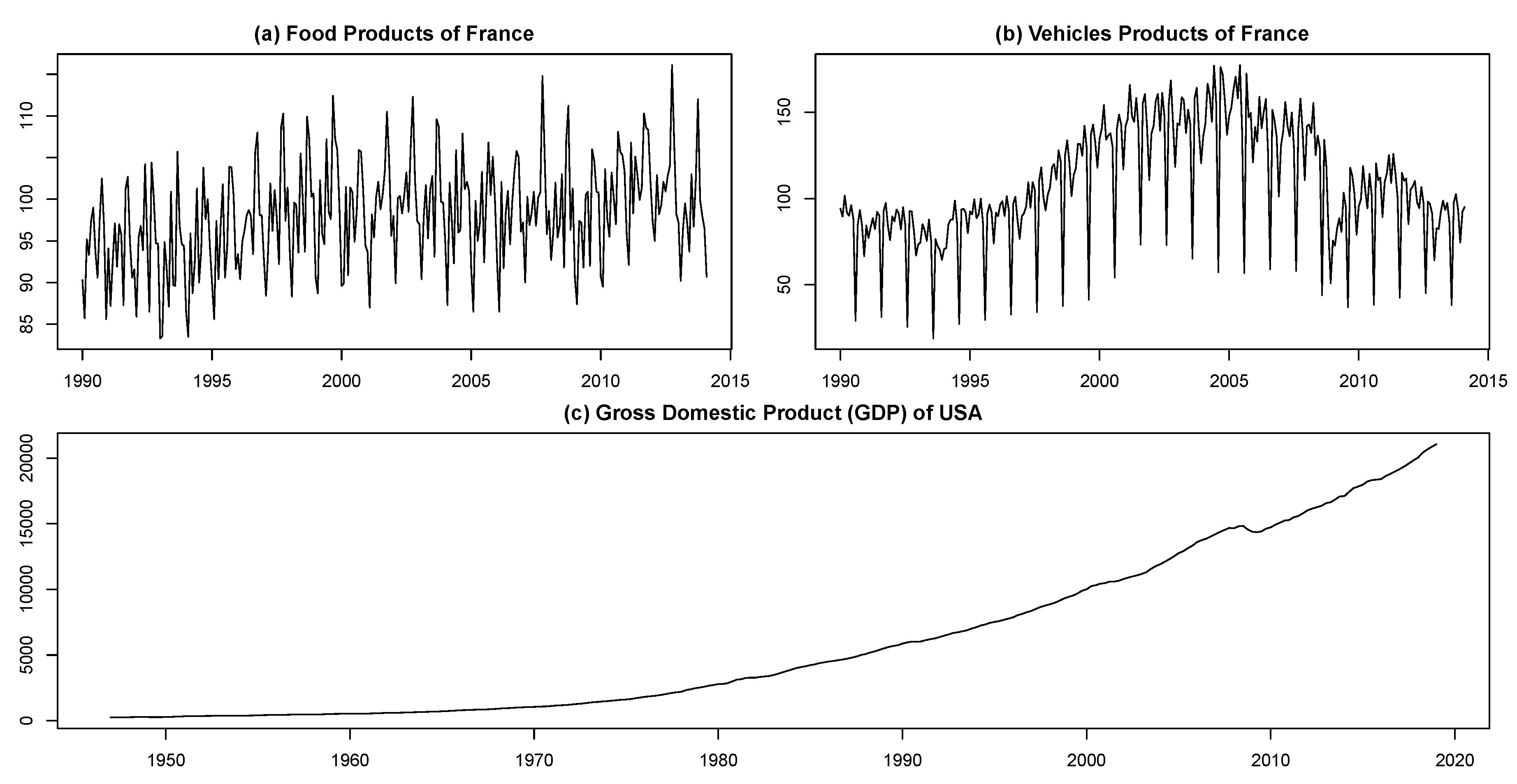
- Seasonally non-adjusted food and vehicle products of France from January 1990 to February 2014. These data are taken from INSEE (Institute National de la Statistique et des Etudes Economiques) including 290 observations. These series were previously used in [52,53,54]. Those interested in a summary of the data are referred to [52] instead of replicating this information here. The time series plots for these data, which are depicted in Figure 8, clearly show that they have a seasonal structure along with a non-linear trend.
- Gross domestic product (GDP) of the United States of America (USA) in billions of dollars from January 1947 to January 2019. This quarterly time series contains 289 observations that are taken from Federal Reserve Economic Data available at https://www.quandl.com/data/FRED/GDP. As shown in Figure 8, the GDP series is non-stationary with a non-linear trend that appears to increase exponentially over time.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Golyandina, N.; Zhigljavsky, A. Singular Spectrum Analysis for Time Series; Springer Briefs in Statistics; Springer: New York, NY, USA, 2013. [Google Scholar]
- Aydin, S.; Saraoglu, H.M.; Kara, S. Singular Spectrum Analysis of Sleep EEG in Insomnia. J. Med. Syst. 2011, 35, 457–461. [Google Scholar] [CrossRef]
- Sanei, S.; Hassani, H. Singular Spectrum Analysis of Biomedical Signals; Taylor & Francis/CRC: Boca Raton, FL, USA, 2016. [Google Scholar]
- Hassani, H.; Yeganegi, M.R.; Silva, E.S. A New Signal Processing Approach for Discrimination of EEG Recordings. Stats 2018, 1, 155–168. [Google Scholar] [CrossRef] [Green Version]
- Safi, S.M.M.; Pooyan, M.; Nasrabadi, A.M. Improving the performance of the SSVEP-based BCI system using optimized singular spectrum analysis (OSSA). Biomed. Signal Proces. Control 2018, 46, 46–58. [Google Scholar] [CrossRef]
- Ghodsi, Z.; Silva, E.S.; Hassani, H. Bicoid Signal Extraction with a Selection of Parametric and Nonparametric Signal Processing Techniques. Genom. Proteom. Bioinform. 2015, 13, 183–191. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Movahedifar, M.; Yarmohammadi, M.; Hassani, H. Bicoid signal extraction: Another powerful approach. Math. Biosci. 2018, 303, 52–61. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, M.; Rodrigues, P.C.; Rua, A. Tracking the US business cycle with a singular spectrum analysis. Econ. Lett. 2012, 114, 32–35. [Google Scholar] [CrossRef]
- Hassani, H.; Silva, E.S.; Gupta, R.; Segnon, M.K. Forecasting the price of gold. Appl. Econ. 2015, 47, 4141–4152. [Google Scholar] [CrossRef]
- Silva, E.S.; Ghodsi, Z.; Ghodsi, M.; Heravi, S.; Hassani, H. Cross country relations in European tourist arrivals. Ann. Tour. Res. 2017, 63, 151–168. [Google Scholar] [CrossRef]
- Arteche, J.; Garcia-Enriquez, J. Singular Spectrum Analysis for signal extraction in Stochastic Volatility models. Econom. Stat. 2017, 1, 85–98. [Google Scholar] [CrossRef]
- Groth, A.; Ghil, M. Synchronization of world economic activity. Chaos Interdiscip. J. Nonlinear Sci. 2017, 27, 127002. [Google Scholar] [CrossRef] [Green Version]
- Groth, A.; Ghil, M. Multivariate singular spectrum analysis and the road to phase synchronization. Phys. Rev. E 2011, 84, 036206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mahmoudvand, R.; Rodrigues, P.C. Predicting the Brexit Outcome Using Singular Spectrum Analysis. J. Comput. Stat. Model. 2018, 1, 9–15. [Google Scholar]
- Saayman, A.; Klerk, J. Forecasting tourist arrivals using multivariate singular spectrum analysis. Tour. Econ. 2019, 25, 330–354. [Google Scholar] [CrossRef]
- Hassani, H.; Rua, A.; Silva, E.S.; Thomakos, D. Monthly forecasting of GDP with mixed-frequency multivariate singular spectrum analysis. Int. J. Forecast. 2019, 35, 1263–1272. [Google Scholar] [CrossRef] [Green Version]
- Rocco S, C.M. Singular spectrum analysis and forecasting of failure time series. Reliab. Eng. Syst. Saf. 2013, 114, 126–136. [Google Scholar] [CrossRef]
- Muruganatham, B.; Sanjith, M.A.; Krishnakumar, B.; Satya Murty, S.A.V. Roller element bearing fault diagnosis using singular spectrum analysis. Mech. Syst. Signal Process. 2013, 35, 150–166. [Google Scholar] [CrossRef]
- Chen, Q.; Dam, T.V.; Sneeuw, N.; Collilieux, X.; Weigelt, M.; Rebischung, P. Singular spectrum analysis for modeling seasonal signals from GPS time series. J. Geodyn. 2013, 72, 25–35. [Google Scholar] [CrossRef]
- Hou, Z.; Wen, G.; Tang, P.; Cheng, G. Periodicity of Carbon Element Distribution Along Casting Direction in Continuous-Casting Billet by Using Singular Spectrum Analysis. Metall. Mater. Trans. B 2014, 45, 1817–1826. [Google Scholar] [CrossRef]
- Liu, K.; Law, S.S.; Xia, Y.; Zhu, X.Q. Singular spectrum analysis for enhancing the sensitivity in structural damage detection. J. Sound Vib. 2014, 333, 392–417. [Google Scholar] [CrossRef]
- Bail, K.L.; Gipson, J.M.; MacMillan, D.S. Quantifying the Correlation Between the MEI and LOD Variations by Decomposing LOD with Singular Spectrum Analysis. In Earth on the Edge: Science for a Sustainable Planet International Association of Geodesy Symposia; Springer: Berlin/Heidelberg, Germany, 2014; Volume 139, pp. 473–477. [Google Scholar]
- Chao, H.-S.; Loh, C.-H. Application of singular spectrum analysis to structural monitoring and damage diagnosis of bridges. Struct. Infrastruct. Eng. Maint. Manag. Life-Cycle Des. Perform. 2014, 10, 708–727. [Google Scholar] [CrossRef]
- Khan, M.A.R.; Poskitt, D.S. Forecasting stochastic processes using singular spectrum analysis: Aspects of the theory and application. Int. J. Forecast. 2017, 33, 199–213. [Google Scholar] [CrossRef]
- Lahmiri, S. Minute-ahead stock price forecasting based on singular spectrum analysis and support vector regression. Appl. Math. Comput. 2018, 320, 444–451. [Google Scholar] [CrossRef]
- Poskitt, D.S. On Singular Spectrum Analysis and Stepwise Time Series Reconstruction. J. Time Ser. Anal. 2019. [Google Scholar] [CrossRef]
- Golyandina, N.; Nekrutkin, V.; Zhigljavsky, A. Analysis of Time Series Structure: SSA and Related Techniques; Chapman & Hall/CRC: London, UK, 2001. [Google Scholar]
- Hassani, H.; Mahmoudvand, R. Singular Spectrum Analysis Using R; Palgrave Macmillan: Basingstoke, UK, 2018. [Google Scholar]
- Golyandina, N.; Korobeynikov, A.; Zhigljavsky, A. Singular Spectrum Analysis with R; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Golyandina, N. Particularities and commonalities of singular spectrum analysis as a method of time series analysis and signal processing. arXiv 2019, arXiv:1907.02579v1. [Google Scholar]
- Alexandrov, T.; Golyandina, N. Automatic extraction and forecast of time series cyclic components within the framework of SSA. In Proceedings of the 5th St.Petersburg Workshop on Simulation, Saint Petersburg, Russia, 26 June–2 July 2005; pp. 45–50. Available online: http://www.gistatgroup.com/gus/autossa2.pdf (accessed on 2 October 2019).
- Bilancia, M.; Campobasso, F. Airborne particulate matter and adverse health events: Robust estimation of timescale effects. In Classification as a Tool for Research; Locarek-Junge, H., Weihs, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 481–489. [Google Scholar]
- Hassani, H. Singular Spectrum Analysis: Methodology and Comparison. J. Data Sci. 2007, 5, 239–257. [Google Scholar]
- Broomhead, D.; King, G. Extracting qualitative dynamics from experimental data. Physica D 1986, 20, 217–236. [Google Scholar] [CrossRef]
- Broomhead, D.; King, G. On the qualitative analysis of experimental dynamical systems. In Nonlinear Phenomena and Chaos; Sarkar, S., Ed.; Adam Hilger: Bristol, UK, 1986; pp. 113–144. [Google Scholar]
- Proschan, M.A.; Shaw, P.A. Essential of Probability Theory for Statisticians; Chapman & Hall/CRC: London, UK, 2016. [Google Scholar]
- Golub, G.H.; Loan, C.F.V. Matrix Computations, 4th ed.; The John Hopkins University Press: Baltimore, UK, 2013. [Google Scholar]
- Korobeynikov, A. Computation- and space-efficient implementation of SSA. Stat. Its Interface 2010, 3, 257–368. [Google Scholar] [CrossRef]
- Golyandina, N.; Korobeynikov, A. Basic Singular Spectrum Analysis and forecasting with R. Comput. Stat. Data Anal. 2014, 71, 934–954. [Google Scholar] [CrossRef]
- Golyandina, N.; Korobeynikov, A.; Shlemov, A.; Usevich, K. Multivariate and 2D Extensions of Singular Spectrum Analysis with the Rssa Package. J. Stat. Softw. 2015, 67, 1–78. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; Wiley: New York, NY, USA, 1990. [Google Scholar]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 6th ed.; Pearson Education Limited: Harlow, UK, 2013. [Google Scholar]
- Maechler, M.; Rousseeuw, P.; Struyf, A.; Hubert, M.; Hornik, K. Cluster: Cluster Analysis Basics and Extensions; R Package Version 2.0.7-1; R Package Vignette: Madison, WI, USA, 2018. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: https://www.R-project.org/ (accessed on 2 October 2019).
- Charrad, M.; Ghazzali, N.; Boiteau, V.; Niknafs, A. NbClust: An R Package for Determining the Relevant Number of Clusters in a Data Set. J. Stat. Softw. 2014, 61, 1–36. [Google Scholar] [CrossRef]
- Contreras, P.; Murtagh, F. Hierarchical Clustering. In Handbook of Cluster Analysis; Henning, C., Meila, M., Murtagh, F., Rocci, R., Eds.; Chapman & Hall/CRC: London, UK, 2016; pp. 103–123. [Google Scholar]
- Gordon, A.D. Classification, 2nd ed.; Chapman and Hall: London, UK, 1999. [Google Scholar]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Gates, A.J.; Ahn, Y.Y. The impact of random models on clustering similarity. J. Mach. Learn. Res. 2017, 18, 1–28. [Google Scholar]
- Vinh, N.X.; Epps, J.; Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 2010, 11, 2837–2854. [Google Scholar]
- Hennig, C. fpc: Flexible Procedures for Clustering, R package version 2.1-11.1; R Package Vignette: Madison, WI, USA, 2018; Available online: https://CRAN.R-project.org/package=fpc (accessed on 2 October 2019).
- Silva, E.S.; Hassani, H.; Heravi, S. Modeling European industrial production with multivariate singular spectrum analysis: A cross-industry analysis. J. Forecast. 2018, 37, 371–384. [Google Scholar] [CrossRef]
- Hassani, H.; Heravi, H.; Zhigljavsky, A. Forecasting European industrial production with singular spectrum analysis. Int. J. Forecast. 2009, 25, 103–118. [Google Scholar] [CrossRef]
- Heravi, S.; Osborn, D.R.; Birchenhall, C.R. Linear versus neural network forecasts for European industrial production series. Int. J. Forecast. 2004, 20, 435–446. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulated Series | Correct Groups |
|---|---|
| Exponential | |
| Linear | |
| Sine | |
| Cosine+Cosine | |
| Exponential×Sine | |
| Exponential+Sine |
| Real Time Series | L | Groups |
|---|---|---|
| Food product | 144 | |
| Vehicles | 144 | |
| GDP | 144 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kalantari, M.; Hassani, H. Automatic Grouping in Singular Spectrum Analysis. Forecasting 2019, 1, 189-204. https://doi.org/10.3390/forecast1010013
Kalantari M, Hassani H. Automatic Grouping in Singular Spectrum Analysis. Forecasting. 2019; 1(1):189-204. https://doi.org/10.3390/forecast1010013
Chicago/Turabian StyleKalantari, Mahdi, and Hossein Hassani. 2019. "Automatic Grouping in Singular Spectrum Analysis" Forecasting 1, no. 1: 189-204. https://doi.org/10.3390/forecast1010013
APA StyleKalantari, M., & Hassani, H. (2019). Automatic Grouping in Singular Spectrum Analysis. Forecasting, 1(1), 189-204. https://doi.org/10.3390/forecast1010013