1. Introduction
How do oil prices respond to financial and macroeconomic shocks? Is there a link between commodity prices, stock markets and monetary policy? Moreover, should this link exist? And which are the driving factors of oil price determination? Or, in other words, which are the variables that drive oil price evolution? Despite the vast research literature in the field, inferences on the relationship between macroeconomic variables, financial variables and oil prices is still an active issue of debate in the literature.
In one of the first attempts to describe the relationship between oil prices and macroeconomic variables, Ref. [
1] suggests the existence of a direct link between oil prices and the implemented monetary policy, claiming that oil prices are determined by interest rates. Despite the critique of the Nobel laureate Robert Solow on what is now known as the “Hotelling’s rule” [
2], the detailed survey of [
3] on the impact of Hotelling’s work on the literature reveals that the relationship between oil prices and interest rates is still subject to research debate. Another important milestone in the quest of the driving factors of oil prices is the work of [
4]. He detected a strong positive correlation between fluctuations of the business cycle and oil prices, suggesting an active link between economic conditions and oil prices. Nevertheless, his study included a period with a significant positive trend in economic output, leaving the area of oil prices during periods of economic downturn uncharted.
Under a different perspective, Ref. [
5] built a model that forecasts crude oil prices to pinpoint the variables that actually foresee oil price shocks. The scope of their study was to provide an empirical “rule of thumb” of what works and what does not, with direct policy implications for central bankers. Based on monthly exchange rates for the euro, the Canadian dollar and the Norwegian krona with the U.S. dollar and also economic activity and Brent oil prices, the authors built a Vector Autoregressive (VAR) model that studied the period January 1974—December 2011. Nevertheless, their empirical findings suggest that their model cannot outperform the Random Walk model in out-of-sample forecasting, supporting the efficiency of oil markets.
More recently, Ref. [
6] reviewed oil price shocks from the 1973–1974 oil crisis to the 2008 global financial crisis. Examining a variety of relations between oil prices and the economy, they conclude that oil prices are hard to forecast and that most oil price surges should be attributed to supply and demand shocks and not to a causal relationship with other variables. In an alternative approach based on models that are used in measuring risk in financial markets, Ref. [
7] studied the relationship between monthly spot Brent oil prices and future contracts for the period January 1999—December 2006. He concludes that forecasts of typical Ordinary Least Squares (OLS) models that are based on the future premium adhere more closely to spot oil prices than forecasts of the Random Walk (RW) model. Thus, spot prices are determined by the expectations of future prices. Ref. [
8] also studied the informational content of future contracts in forecasting real spot oil prices. Based on a daily sample of NYMEX futures and West Texas Intermediate (WTI) oil prices for the period 30 March1983 to 28 February 2007, they show that the variability of the future premium affects spot oil prices. Going a step further, they show that the variability of the future premium stems from changes in the macroeconomic environment, suggesting an indirect link between oil prices and the macroeconomy (The interested reader is referred to the excellent review of [
9] on the predictability of oil prices based on typical econometric approaches.).
Apart from the typical econometric approaches, there exists a vast number of studies that apply machine learning methodologies in forecasting oil prices. In a machine learning framework, Ref. [
10] show that
Google trend searches can forecast monthly crude oil prices over the period January 2004—June 2016 based on “extreme learning machines”, while the application of linear regression on the same sample yields a lower forecasting accuracy. Ref. [
11] combine deep learning with signal processing to forecast monthly WTI crude oil prices spanning the period January 1986 to May 2016, exploiting a pool of 193 potential variables. The key idea of their approach is not to select the most informative variables in terms of forecasting, however to assign a different weight to each variable in order to improve the overall forecasting accuracy. Based on a sample of monthly observations spanning the period January 1986 to May 2016, they show that machine learning applications outperform typical econometric methodologies.
In a similar vein, Ref. [
12] apply signal processing techniques as a pre-processing step to neural network models in forecasting daily WTI and Brent oil prices. For the period 1 January 1986 to 30 September 2006, they found that their autoregressive forecasting scheme outperforms econometric alternatives in out-of-sample forecasting of the last 968 observations. Their empirical findings also held for an updated sample from 03 January 2011 to 17 July 2013 [
13]. The authors found that their hybrid forecasting setup that combines signal processing to machine learning reaches a 62.2% directional accuracy in out-of-sample forecasting of WTI oil prices. Ref. [
14] combine supervised to unsupervised machine learning in forecasting WTI oil prices for the period January 1992 to June 2008. Their approach exploits the forecasting ability of the supervised learning methods and the merit of unsupervised learning in modelling the structure of the data. Using the last 100 observations for out-of-sample forecasting, they found that their autoregressive “semi-supervised” technique outperforms the RW model. Overall, the review of the literature suggests that machine learning methodologies produce a higher forecasting accuracy in comparison to the typical econometric ones and they typically outperform the RW model, while econometric approaches often fail to do so.
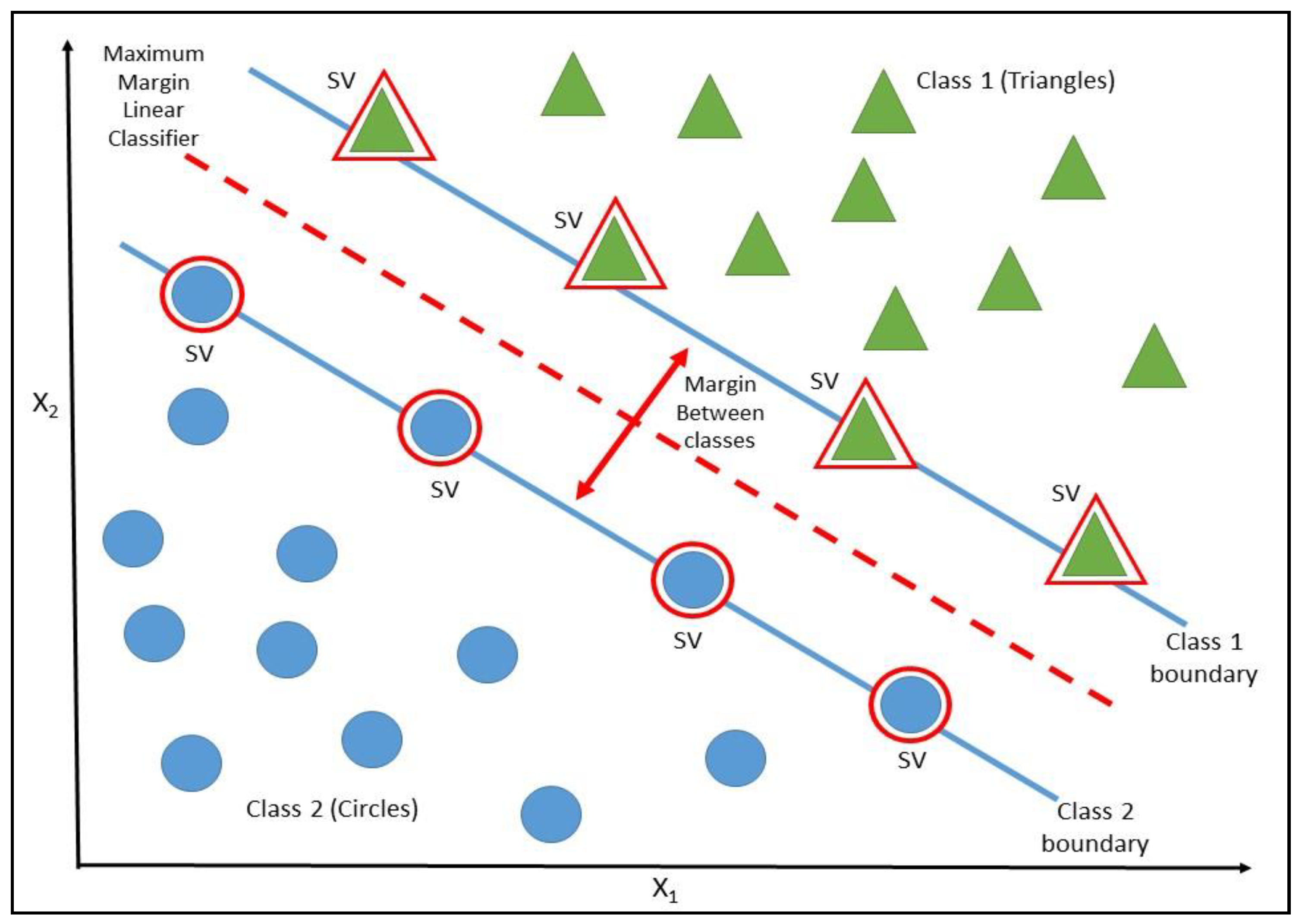
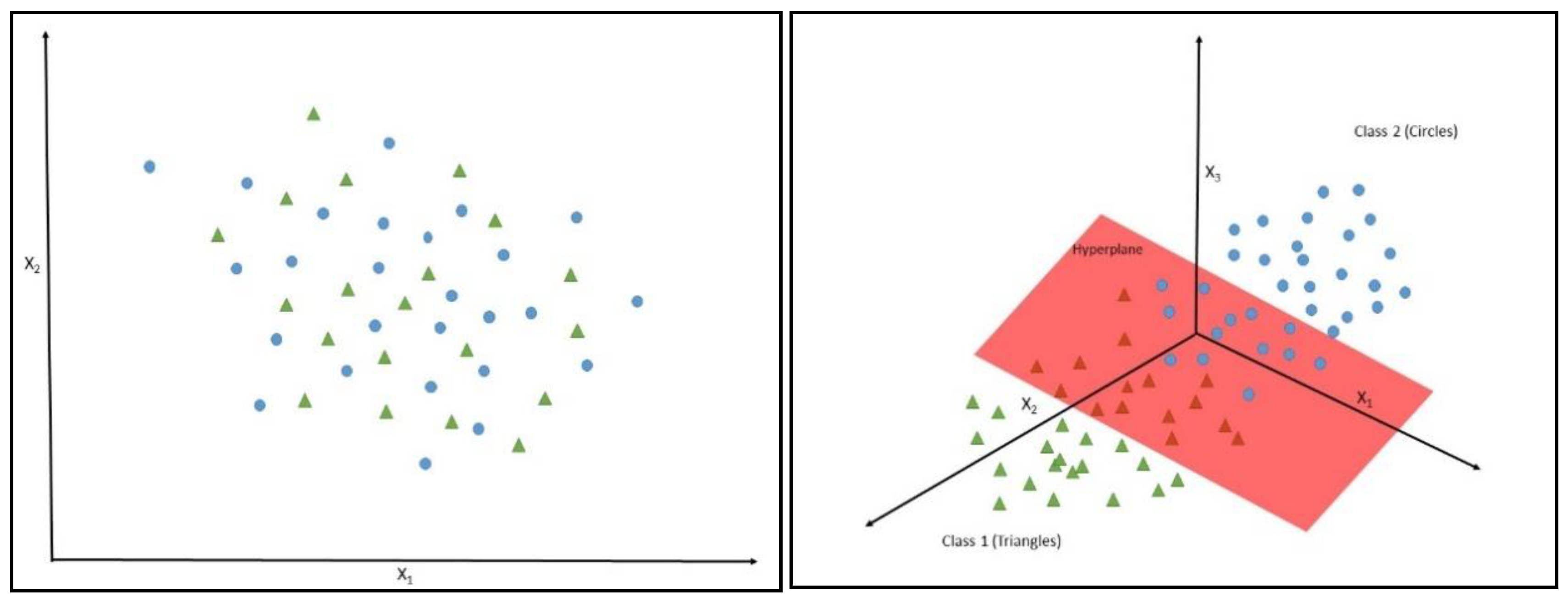
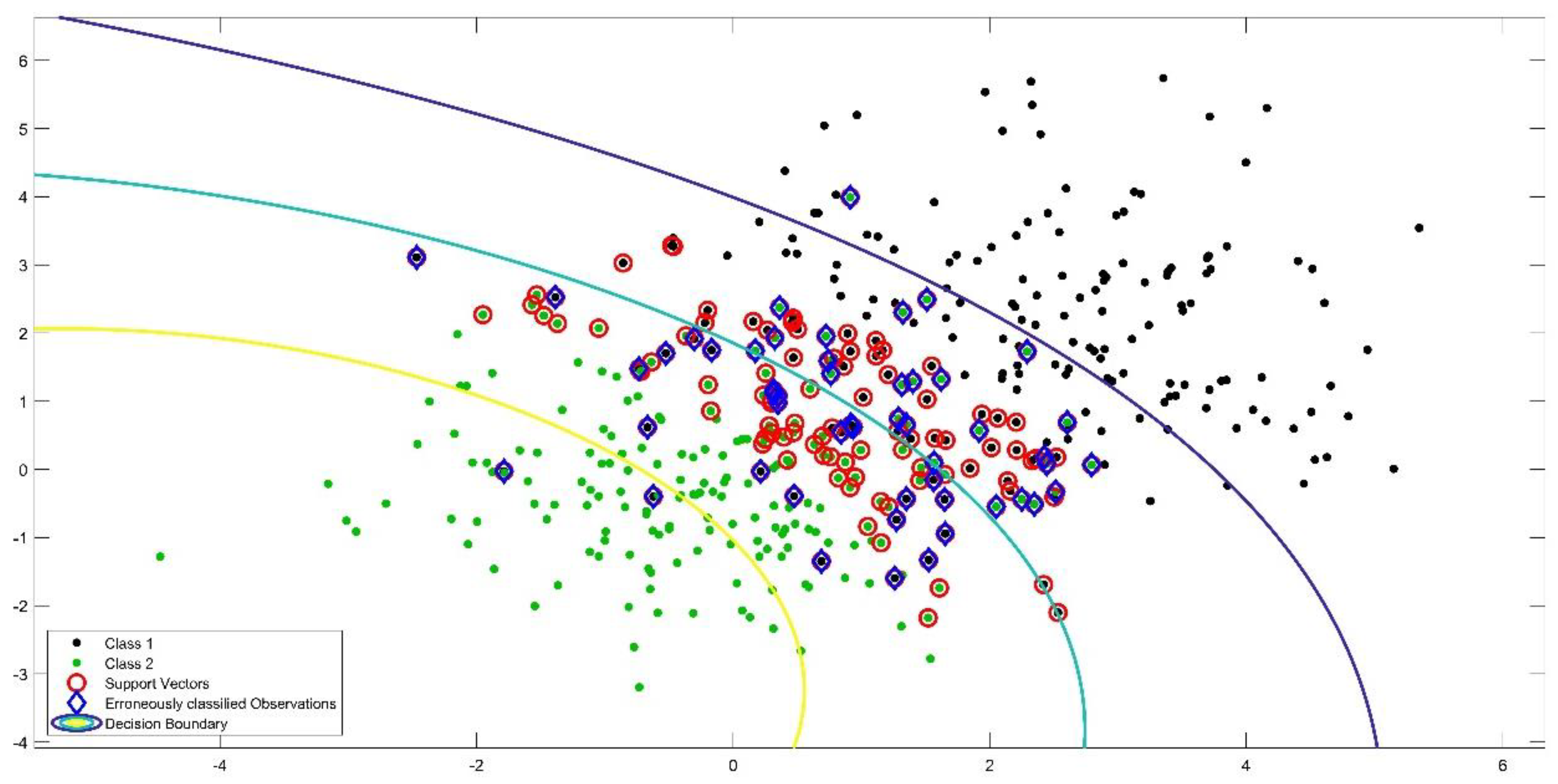
In this paper, we attempt to uncover the possible relationship between oil prices (namely WTI prices) and other economic variables by employing a machine learning framework on a monthly basis. Unlike previous machine learning approaches in forecasting oil prices that select variables atheoretically, we will compile a pool of 38 potential regressors based on economic theory and the literature reported herein, and will select the variables that are most relevant to oil prices forecasting. Based on a Support Vector Machines (SVM) model coupled with the linear kernel and the nonlinear Radial Basis Function (RBF) kernel, we examine the directional forecasting performance of our models in comparison to the typical econometric logistic regression methodology.
The selection of the SVM methodology is motivated by the superior forecasting ability of the methodology, which has been reported in the relevant literature, in forecasting economic and financial variables (see among others [
15,
16]). Thus, the innovation of our paper stems from the application of a state-of-the-art machine learning methodology and the empirical recognition of a causal relationship between variables reported in the literature and oil prices. We also specifically test the relationship between oil prices and interest rates as a possible empirical validation of Hotelling’s rule under a machine learning framework. To the best of our knowledge, this is the first attempt to do so. In
Section 2 of the paper, we will briefly describe the methodology and the data,
Section 3 presents our empirical findings, while
Section 4 concludes the paper.
3. Empirical Results
Given the scope of this paper, as reported in the introduction, we proceeded in three steps. The first step was to test for the best autoregressive (AR) model in directional forecasting of oil prices (rise and drop) based on the SVM and the logistic regression methodologies. A comparison of the AR model with the naïve RW model that is used as a benchmark where the best guess about the next period’s directional change is the current one, revealed whether we can reject the weak form efficiency in the oil market. Proposed by [
20], the Efficient Market Hypothesis (EMH) states that the evolution of prices in an efficient market follows a random walk and thus, it is impossible to create a forecasting model that achieves sustainable positive returns in the long-run. The EMH is usually presented in three forms; the weak, the semi-strong and the strong form of efficiency. An efficient market of the weak-form is observed when historic prices of the variable in question cannot forecast the future ones. Thus, autoregressive models have no forecasting power and the best forecast about the next period’s price is today’s price. Semi-strong efficiency imposes more strict assumptions in that all historic prices and all publicly available information is already reflected in current asset prices and thus, they cannot be used successfully in forecasting. Finally, the strong form of the EMH builds on the semi-strong case adding all private information and, thus, rendering it impossible to consistently forecast the future evolution of an asset’s price. Overall, outperforming the RW model is an indication of potential economic gains for a trader that follows an alternative trading strategy.
As a second step, we examined whether we can build structural forecasting models that are more accurate that the AR ones. These models were built on the best AR models by augmenting them with various relevant variables as potential regressors. In doing so, we tested all possible combinations of variables in order to detect the most accurate forecasting models. Both in the AR and the structural models, we used quarterly dummy variables to account for seasonal fluctuations in oil demand (EIA, 2018).
Finally, the third step was to focus explicitly on the interest rates and evaluate their ability to forecast oil prices. By doing so, we empirically tested Hotelling’s rule.
We started our analysis with the AR versions of all models. We split our sample into two parts; the sub-sample from June 2006 to September 2015 i.e., 112 months was used for training the models and the sub-sample from October 2015 to February 2018 i.e., 29 months was used to evaluate the out-of-sample forecasting accuracy on one-period-ahead forecasting.
In terms of the best AR models, our empirical findings suggest that the most accurate SVM model coupled with the linear kernel is the one that includes 11 lags of the WTI price (SVM-linear-11). The most accurate SVM model with the RBF kernel includes 5 lags of the WTI price (SVM-RBF-5) and the most accurate logistic regression AR model has 12 lags (All detailed results are available from the authors upon request).
After determining of the most accurate AR models, we augmented them with additional variables through an exhaustive search of all possible combinations. We kept the same subsamples for training and testing purposes. According to this scheme, the most accurate structural SVM-linear-11 model includes the dependent variable “Fuel oil, No. 2 NY gal”. The most accurate structural SVM-RBF-5 model includes the “Trade weighted U.S. dollar index” variable, while the most accurate structural Logit-12 model includes the variables “Fuel oil, No. 2 NY gal” and “Trade weighted U.S. dollar index”. The variable “Fuel oil, No. 2 NY gal” reports refined oil spot prices that were sold in the New York area, while the “Trade weighted U.S. dollar index” is a trade-weighted index of the U.S. dollar to a basket of foreign currencies that is based on the trading volumes of the U.S. economy with its trade partners. The directional accuracy of each model is reported in
Table 2.
As we observe from
Table 2, our best overall model both in in-sample and out-of-sample forecasting accuracy is the structural SVM coupled with the non-linear RBF kernel. The second most accurate model is the structural SVM model with the linear kernel, followed by the structural logistic regression model. Thus, our results corroborate with the relevant literature with respect to the forecasting superiority of the machine learning methodologies when compared to equivalent econometric methods. Moreover, we detect that certain variables are useful in forecasting oil prices as in [
11], however unlike their approach, we are able to specifically identify these variables. Another finding is that all AR models are less accurate than their respective structural versions.
Interestingly, all AR or structural SVM models outperformed the RW model in terms of out-of-sample forecasting accuracy. This finding suggests that the conclusion of [
6] that no model outperforms a RW may be attributed to the low forecasting ability of the econometric methodology that was applied in their study. In our dataset, the machine learning approach that we employed in this study clearly outperforms the RW model, rejecting their conclusion. Moreover, given that the AR SVM models outperform the RW model, this provides evidence against the EMH for the WTI oil market, even in its weak form. The reported directional forecasting accuracies are not common in the typical econometric literature and can be attributed to the superior forecasting ability of the machine learning approach in comparison to the probit/logit model that was used in forecasting (see [
9] for more details). On several occasions, the out-of-sample forecasting accuracy was higher than the in-sample one, however this was sample dependent since the “unknown” data that was used for the out-of-sample forecasting was not used during the training phase of the models.
Our atheoretical approach has not highlighted, however, the existence of a potential causal relationship (lead-lag relationship) between interest rates and WTI oil prices, given that they were not selected through the exhaustive search step as informative variables. In order to test for the hypothesis suggested by the Hotelling’s rule that interest rates determine oil prices, we built SVM and logistic regression models using the four interest rate variables in our sample as well as the spread between the 10-year and 5-year interest rates for the U.S. with the effective federal funds rate. The use of the term spread between long and short-term rates was motivated by the need to include the expectations about future economic conditions, which are captured by the term spread. To keep things tractable, we used the same sub-samples for training and testing the forecasting accuracy and we also used the seasonal dummy variables. Unlike our atheoretical approach, we did not include lags of the dependent variable in this empirical analysis. We tested alternative lag orders of interest rates, however the models with the highest forecasting accuracy are the ones that forecast next period’s (month) oil prices based on this period’s interest rates (We also tested models that included lags of the dependent variable as regressors, which are not reported given that they exhibit lower forecasting accuracy to the models reported in
Table 3. The results are available from the authors upon request.). In
Table 3, we report the out-of-sample forecasting accuracy of the interest rate models.
As we observe from
Table 3, all models outperform the out-of-sample accuracy of the RW model reported in
Table 2 (48.28%). No model outperforms the structural RBF-SVM model of our atheoretical approach that is reported in
Table 2 (67.86%), however in two cases, the forecasting accuracy reaches 64%. More specifically, the most accurate models are the SVM-RBF based on the “Effective Federal Funds Rate” and the “CBOE Interest Rate 10 Year minus Effective Federal Funds Rate”. Thus, the short-term federal funds rate seems to drive WTI oil prices and this effect is best captured by the non-linear RBF kernel, suggesting that oil market participants follow short-term interest rates closer than long-term ones.
Unlike the bulk of literature that rejects Hoteling’s rule [
3], our empirical findings provide evidence in favor of interest rates driving oil prices. Although the interest rates models do not achieve the highest forecasting accuracy (and thus, they are not selected during the atheoretical step), they outperform the RW model, suggesting that they are able to forecast oil prices’ evolution. In contrast, older studies fail to do so. This discrepancy with the existing literature should be attributed to the forecasting ability of the machine learning approach, while older studies are based on OLS regressions and logistic regressions. The use of our SVM methodology with the higher forecasting accuracy in comparison to typical econometric methodologies is able to unveil the relationship between interest rates and oil prices. We leave the issue open for further research.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}