Symbols describing models for survival data involve are defined in
Table 1. Assume that the distribution of latent event time
for subject
j depends on covariates
. Let
represent the survival function
, and define the hazard function
. Furthermore, censoring times
are determined for each subject. Investigators observe the minimum of the censoring and event times,
, and an indicator
.
Cox proportional hazards regression models the hazard function for subject
j with covariates
as
where
corresponds to the baseline hazard function (i.e., when all covariates are zero),
is covariate
i for subject
j, and
is component
i of the fixed event parameter
, as in
Table 1.
Practitioners generally desire inference on
, often without inference on
. Generally, the partial likelihood is
where
is the set of subjects who have the event and
is the set of subjects at risk of having the event when subject
j has the event. This simulation produces a data set allowing the estimation of coverage probabilities.
Appendix A (Simulation Details) in the appendix provides implementation details that supplement the following overview. The computer code may be found at
https://github.com/dbaumg/Gaussian-Approx-Proportional-Hazards (accessed on 20 April 2025).
2.1. Assessment of Frequency Properties of Estimates via Simulation
As mentioned, simulations presented here are performed on two levels. We first describe the outer simulation, which is parameterized by inputs N, m, , , and . These govern the process that generates data sets indexed by i (running from 1 to N) that maintain time, status, and covariate values. A vector is constructed with m entries, where each entry is set to .
The
N covariate vectors
x were generated as independent
m-variate standard normal variables. Weibull latent event times were obtained using a sample of size
N from the uniform distribution; for subject
j, call this random quantity
. The latent times themselves were calculated as
The parameter vector
and the vector of covariates
have the same number of components, and their contributions were combined with a dot product. The censoring mechanism used a random sample of size
N from the exponential distribution (using
). These were each increased by
, and the obtained value is the censoring time
C. We compute the time for subject
j as
, we can define
so that it indicates censoring:
2.2. Evaluating and Comparing Standard Errors
This research is motivated by the observation that likelihood-based inference provides p-values that are systematically too small; this was noted in the introduction and is manifest in the simulation below. A first step in determining the source of this discrepancy is to evaluate the quality of various standard errors.
Fix some constant
k, and generate
k data sets as per
Section 2.1. For each simulated data set, several standard errors will be compared. These are as follows:
- 1.
The value calculated from the partial log-likelihood second derivative and referred to as the “naive” value;
- 2.
The value obtained from jackknifing and referred to as the “jackknife” value;
- 3.
The value obtained from the random-
x bootstrap ([
4]);
- 4.
The value determined from the expected second derivative of the log partial likelihood and referred to as the “information” value.
The computation of the first standard error value is relatively simple in standard Cox regression software as the second derivative of the partial likelihood evaluated at the parameter estimate. The next standard error is then given as a direct result of the jackknifing process.
The expectation (
2) in the equation for the ideal standard error cannot be performed in closed form. In order to calculate the Fisher information, the following process is repeated
K times. We wish to obtain the Fisher information, defined as in (
2). Hence, each iteration generates a new set of time and status data, with fixed covariates. These simulated data are used to compute the average Fisher information, which is given by the second derivative of the partial log-likelihood
. The square root of the inverse of this matrix is used as a standard error.
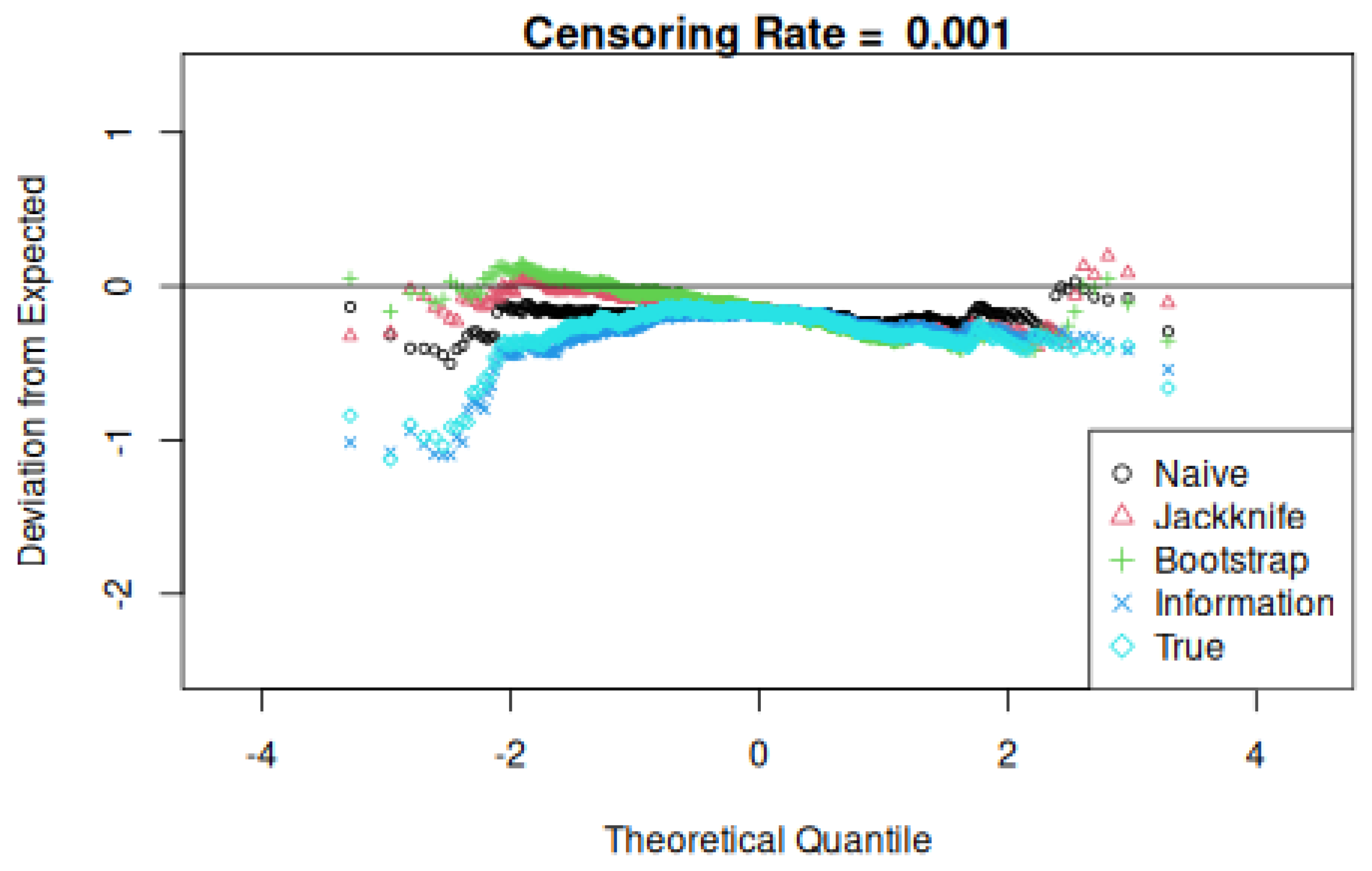
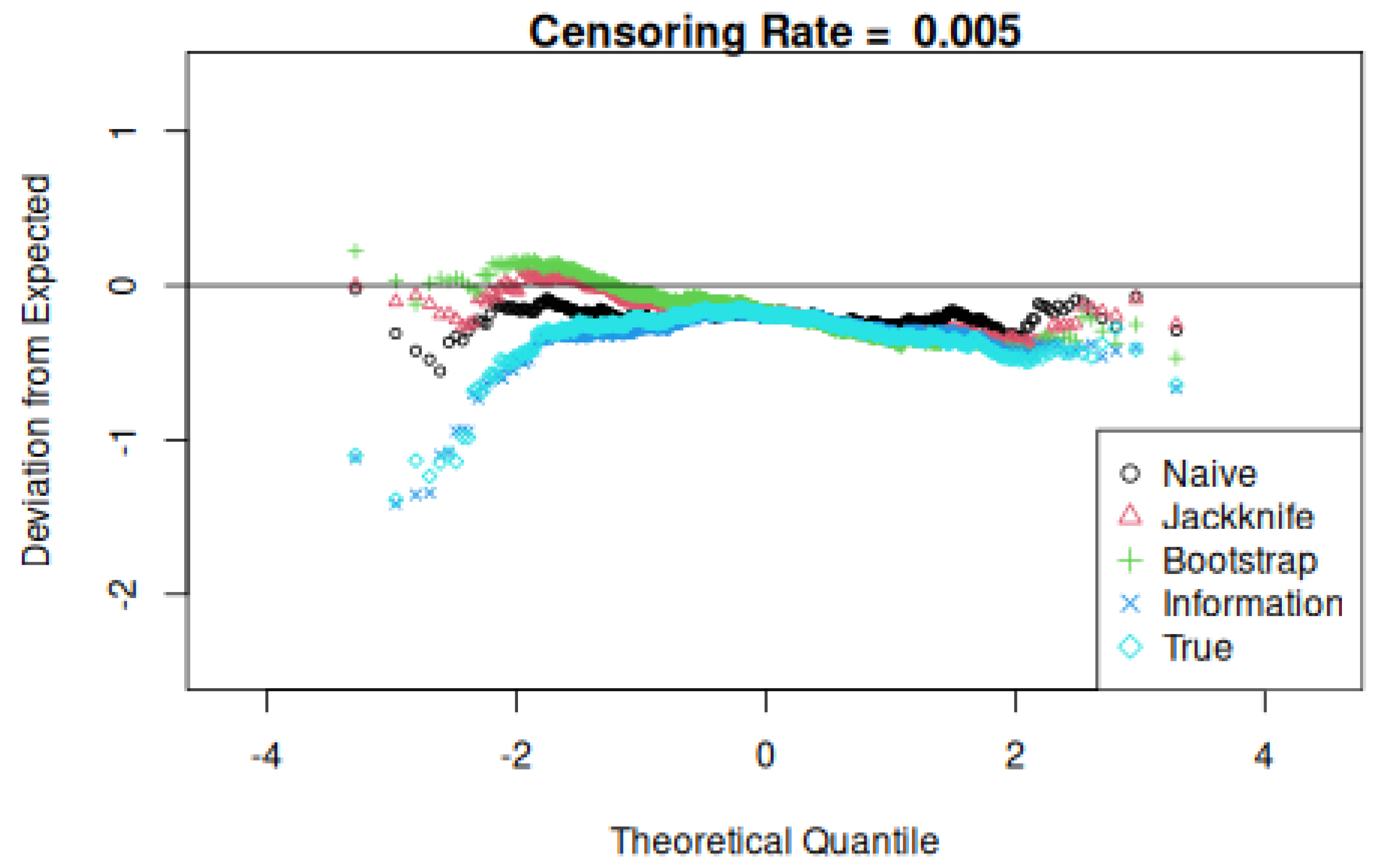
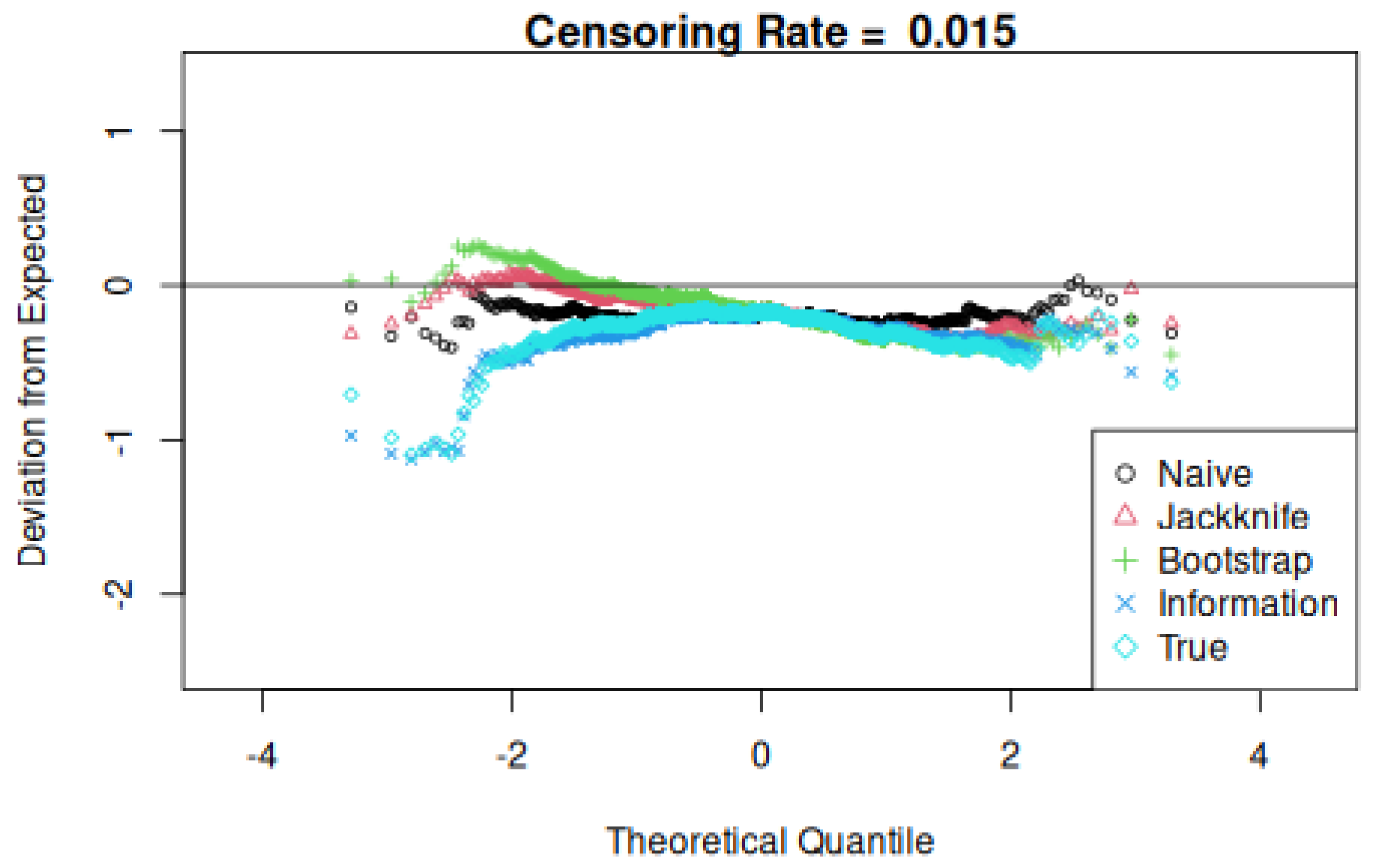
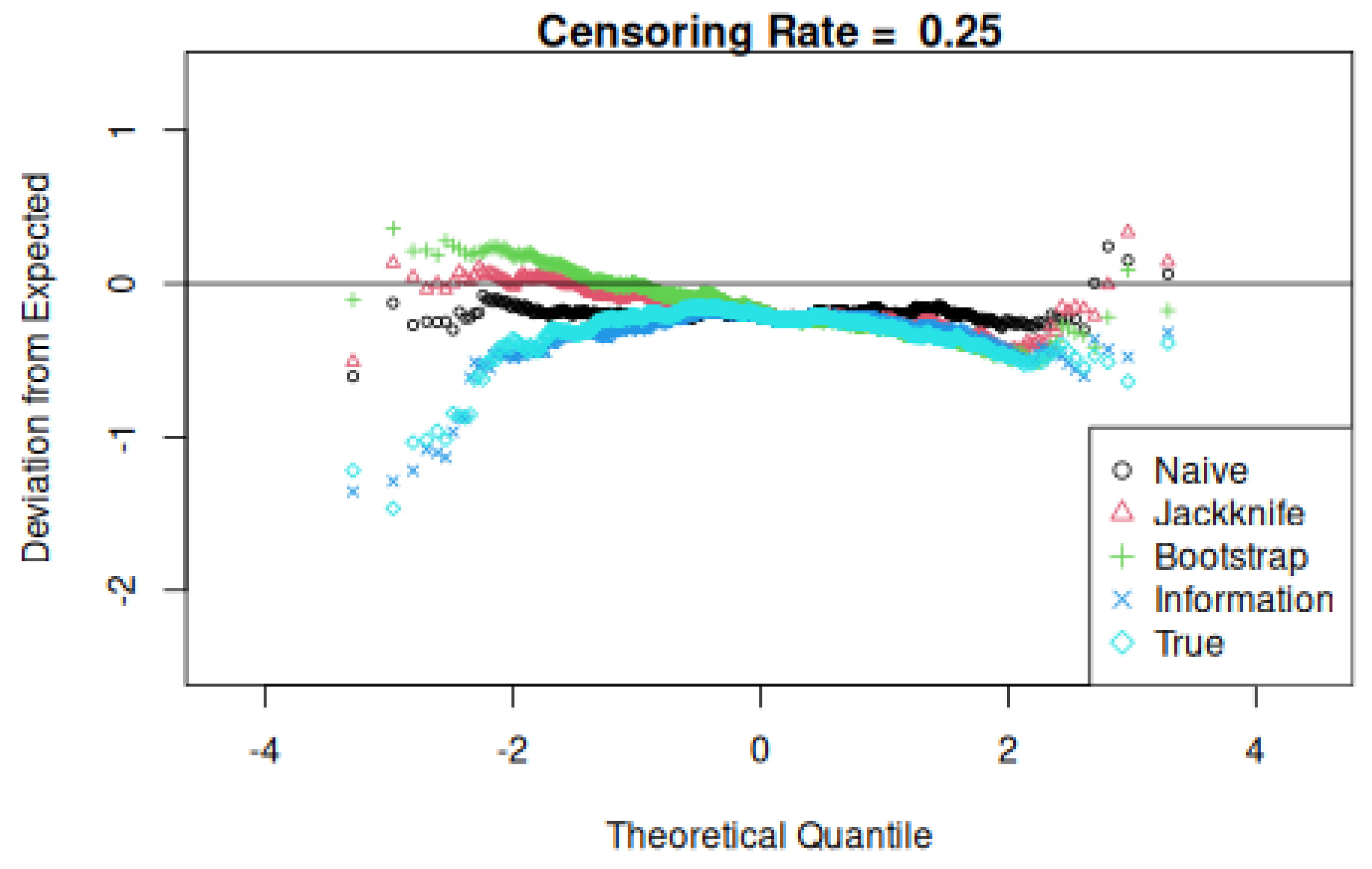
Three comparisons are then made, yielding tallied counts relative to the total k and counting the number of times that the true value exceeds naive, jackknife, and information values. Note that the true and information standard deviation value depend only on the covariate values and not on event and censoring times. Finally, plots of the difference between the theoretical and observed quantiles are made to assess their normality or lack thereof.
2.3. Considering the Continuity Correction
When a regressor in a Cox model takes integer values (for example, the covariates are indicator variables coding a categorical covariate), then potential values of the score statistic (i.e., the first derivative of the log partial likelihood associated with that covariate) have potential values in a discrete set, with values separated by one. That is, suppose that covariate
i from model (
2) takes on integer values, and let
be the components of the vector derivative used in (
1). Then, potential values of the partial score
are separated by one, and when using a normal approximation to calculate
to obtain
p-values, the profile likelihood ought to be modified by adjusting the data to reduce
by one-half unit. Specifically, the score statistic is adjusted by adding
before multiplying by the inverse of the second derivative to obtain the next iteration in the profile likelihood maximization. This moves the partial score closer to its null hypothesis expectation. One might see this as a regression towards the mean; it might more directly be seen as the requirement to increase a
p-value arising from a discrete distribution to include the entire probability atom reflecting the discrete observation.
This modification represents a continuity correction, and, to our knowledge, is newly presented in this manuscript in the context of proportional hazards regression.
As with more conventional regression models, if a sample of size
n consists of covariate patterns drawn at random from a superpopulation, then standard errors for
decrease at the rate of
. A one-sided test of size
of a point null hypothesis that a parameter
takes a value
vs. the alternative that
exceeds
for the score test statistic
is
, for
, the
quantile of a standard normal, and
I is given by (
2). Furthermore,
, for
i the Fisher information in a single observation, and hence the critical value for this one-sided test is
. When the continuity correction is employed, the critical value becomes
, and so the error in omitting the continuity correction is a multiple of
.
Because normal approximations to Wald and the signed root of the likelihood ratio statistic are built around an approximate normality of the score, the data should be modified before applying normal approximations to these statistics as well. The
p-values calculated for the Wald statistics are adjusted by comparing the root of (
1) with the score redefined by adding
to the score function. The resulting root is used in (
3) and compared to a standard normal distribution.
We considered the effect of continuity correction on the behavior of the
p-values. For the same
k, we repeat the process from
Section 2.1 a further
k times. In each iteration, two Cox proportional hazards regressions are made: one with and one without a continuity correction. While the regression with no continuity correction is attained by maximizing the profile likelihood, the continuity correction requires the additional step of determining the numerical value of the adjustment itself.
Among these k Monte Carlo iterations, we report the proportion of data sets for which the two Cox proportional hazards models yield p-values satisfying for . These results are tabulated in the next section.



{kind=link}
{kind=link}
{kind=link}
{kind=link}